
to Improve Efficiency in Identifying Opportunities HPC...
33
Identifying Opportunities to Improve Efficiency in HPC Clusters Jordi Blasco Co-founder & CTO HPC Advisory Council - Perth - August 2018
-
Upload
nguyenxuyen -
Category
Documents
-
view
214 -
download
0
Transcript of to Improve Efficiency in Identifying Opportunities HPC...

Identifying Opportunities to Improve Efficiency in
HPC Clusters
Jordi BlascoCo-founder & CTO
HPC Advisory Council - Perth - August 2018

Quick introduction to HPCNow!
Identifying Opportunities to Improve Efficiency in HPC Clusters - Jordi Blasco
● Global HPC consulting company● IT + scientific background● HPC services and solutions● User-oriented company● Hardware agnostic

System Administratorsand User Support
Top500 Supercomputer Users
Identifying Opportunities to Improve Efficiency in HPC Clusters - Jordi Blasco

Contributions to HPC Community
Identifying Opportunities to Improve Efficiency in HPC Clusters - Jordi Blasco

IISW

Public sector Private Companies
Identifying Opportunities to Improve Efficiency in HPC Clusters - Jordi Blasco

Identifying Opportunities to Improve Efficiency in HPC Clusters - Jordi Blasco
Motivation
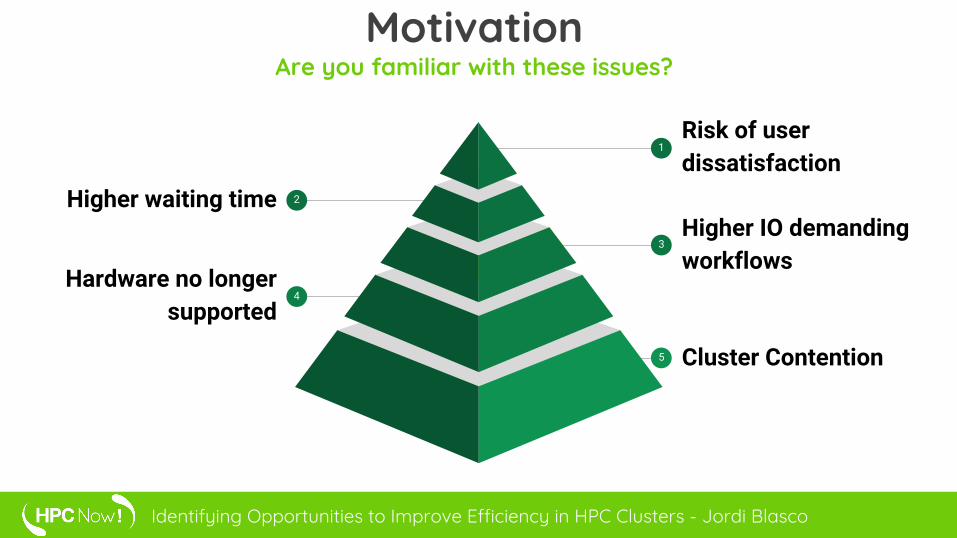
MotivationAre you familiar with these issues?
Identifying Opportunities to Improve Efficiency in HPC Clusters - Jordi Blasco
1Risk of user dissatisfaction
3Higher IO demanding workflows
5 Cluster Contention
2Higher waiting time
4Hardware no longer
supported

Identifying Opportunities to Improve Efficiency in HPC Clusters - Jordi Blasco
Buy a New Cluster
Large procurement usually involves long and complex RfP process.
MotivationPotential Solutions

Identifying Opportunities to Improve Efficiency in HPC Clusters - Jordi Blasco
Buy a New Cluster
Large procurement usually involves long and complex RfP process.
Use CloudExtend the current compute capacity by using cloud bursting to accommodate peaks of needs is definitely the best option. Unfortunately, ongoing and regular usage become expensive.
MotivationPotential Solutions

Use CloudCloud Bursting Capabilities - Hybrid Cloud
Identifying Opportunities to Improve Efficiency in HPC Clusters - Jordi Blasco

Identifying Opportunities to Improve Efficiency in HPC Clusters - Jordi Blasco
Buy a New Cluster
Large procurement usually involves long and complex RfP process.
Use CloudExtend the current compute capacity by using cloud bursting to accommodate peaks of needs is definitely the best option. Unfortunately, ongoing and regular usage become expensive.
Improve Efficiency
By improving the performance and efficiency, you are somehow creating more allocation for new jobs with zero investment in hardware capacity.
MotivationPotential Solutions

Improve Job EfficiencyImpact in Job Allocation and Resources Availability
Identifying Opportunities to Improve Efficiency in HPC Clusters - Jordi Blasco

Identifying Opportunities to Improve Efficiency in HPC Clusters - Jordi Blasco
How to identify tuning opportunities easily?

Job Efficiency Monitoring
Identifying Opportunities to Improve Efficiency in HPC Clusters - Jordi Blasco
Traditional tools like Ganglia are not capable of representing the metrics required to identify inefficient jobs.● based load monitoring● no link to user● no link to job● no link to other nodes allocated for the same job● no information regarding efficiency in the allocated
resources

Job Efficiency Monitoring Requirements
Identifying Opportunities to Improve Efficiency in HPC Clusters - Jordi Blasco
1
Review re
source
s
requested vs
used
Key fundamental m
etrics t
o understand
how well u
sed are th
e reso
urces
requested. 2
Real Tim
e Monito
ring
Enables proacti
ve jo
b profiling and also
enables the poss
ibility t
o trigger re
al
time acti
ons.3
30 Seconds R
esolutio
n
30 seco
nds reso
lution is
quite re
asonable
for the m
ajority of H
PC workl
oads.
The main goal is to identify opportunities to improve user workflows, user codes and applications, in addition to user mistakes.
Given the huge number of jobs and large number of nodes, the solution requires big data strategy.

Identifying Opportunities to Improve Efficiency in HPC Clusters - Jordi Blasco
Architecture

Architecture
Identifying Opportunities to Improve Efficiency in HPC Clusters - Jordi Blasco
Large number of events to analyse requires the use of Big Data technologies. Data is gathered using custom codes and aggregated into ElasticSearch, an open source search and analytics engine which has high reliability and proven scalability. Finally, the data is represented through Grafana and Kibana, which are leading tools for querying and visualizing large datasets and metrics.
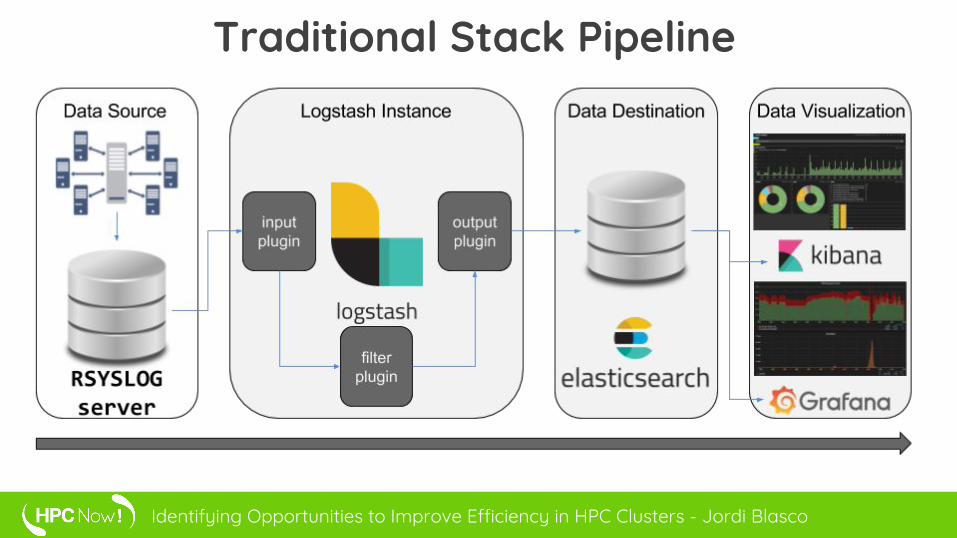
Traditional Stack Pipeline
Identifying Opportunities to Improve Efficiency in HPC Clusters - Jordi Blasco

Custom Monitoring Stack pipeline for HPC
Identifying Opportunities to Improve Efficiency in HPC Clusters - Jordi Blasco

Custom Monitoring Stack for HPC prototype
Identifying Opportunities to Improve Efficiency in HPC Clusters - Jordi Blasco

Standard vs Custom
Identifying Opportunities to Improve Efficiency in HPC Clusters - Jordi Blasco
Current statistics Standard Custom Prototype
Metrics per user (s) 8 8
Resolution 30 30
Avg. events/cycle 380 380
Avg. size per package (bytes) 2000 400
Avg. TB/year in ElasticSearch 1.80TB 0.17TB
Theoretical limit (events/s) 50k 260k

Standard vs Custom vs Prototype
Identifying Opportunities to Improve Efficiency in HPC Clusters - Jordi Blasco
Current statistics Standard Custom Prototype
Metrics per user (s) 8 8 318
Resolution 30 30 10
Avg. events/cycle 380 380 380
Avg. size per package (bytes) 2000 400 6800
Avg. TB/year in ElasticSearch 1.80TB 0.17TB 8.5
Theoretical limit (events/s) 50k 260k 15k
The prototype setup is based on LXD containers allocated across two bare metal nodes with 24 cores (Intel Haswell), 32GB of memory, 2TB of SSD disks and 1GB Ethernet.

Identifying Opportunities to Improve Efficiency in HPC Clusters - Jordi Blasco
● Going down to 10 seconds resolution● Job level usage● Task level usage● Allocated CPU usage● Memory usage● IPC● Disk IO● Network (Infiniband)● Cluster File System
Job Efficiency Monitoring (prototype)Additional Metrics and Features
● Read / Write calls● inodes updates● MB write / read● Open / Close requests● Walltime used / requested● Memory used / requested● Retention / purging policy● Alerts and event correlation● MPI stats (collectives)

Need to Scale Up?
Identifying Opportunities to Improve Efficiency in HPC Clusters - Jordi Blasco
Migrate to 10GB ethernet
Which could increase the number of events digested
to x10
Use buffersWhich could increase the number of events digested to x10
Add more elasticsearch nodesVirtually unlimited scalability
03
01 02

Identifying Opportunities to Improve Efficiency in HPC Clusters - Jordi Blasco
No performance penalty based on HPL resultsAdditional Metrics and Features

Custom Monitoring Stack for HPC prototype
Identifying Opportunities to Improve Efficiency in HPC Clusters - Jordi Blasco

Most Relevant Case Studies
Identifying Opportunities to Improve Efficiency in HPC Clusters - Jordi Blasco
Case Study CPUTime (h) Output
VASP user 4,265,883 Improved efficiency from 74% to 97.6%
ORCA user 2,300,033 Improved efficiency from 18% to 87% and IO.
R code user 1,670,402 Resilience issues (zombie tasks)
Fluent workflow user 1,401,825 Improved the efficiency 200%
Ansys Fluent user 1,391,951 x5 efficiency (100 vs 500 cores) + resilience
OMNeT++ user 1,253,462 Improved the efficiency from 6% to 96%
Custom CESM user 1,093,184 Improved the efficiency from 1% to 98%

Identifying Opportunities to Improve Efficiency in HPC Clusters - Jordi Blasco
Conclusions

Efficiency
Scalability
Performance
ConclusionsThanks to the job efficiency monitoring we have been able to improve
Identifying Opportunities to Improve Efficiency in HPC Clusters - Jordi Blasco

Efficiency
Scalability
Performance
ConclusionsThanks to the job efficiency monitoring we have also been able to
Detect user mistakes early
Avoid massive waste of CPU time
Improve user workflows
Accelerate research
Improve reliability
Improve user satisfaction
Identifying Opportunities to Improve Efficiency in HPC Clusters - Jordi Blasco

“The best way to predict the future is to invent it.” -- Alan Kay
Identifying Opportunities to Improve Efficiency in HPC Clusters - Jordi Blasco
www.hpcnow.com
Marie Curie, 8 - 08042 Barcelona (Spain)
34 Fernly Rise, 2019 Auckland (New Zealand)
Barcelona
Auckland


















