
Tibet 5.0 / CouchDB
45
TIBET 5.0 by William J. Edney and Team TIBET ™ TM 1 Confirm you have a full, un-minified of TSH/TDC up and running. Confirm network connectivity via wifi and/or personal hotspot.
-
Upload
bedney -
Category
Technology
-
view
445 -
download
1
Transcript of Tibet 5.0 / CouchDB
TIBET 5.0 by William J. Edney and Team TIBET ™
TM
1
Confirm you have a full, un-minified of TSH/TDC up and running.
Confirm network connectivity via wifi and/or personal hotspot.

Enterprise / XL App Focus
Enterprise Apps Have:
❖ Significant Screen Counts
❖ Transactional Worker Focus
❖ 10-Year Deployment Lifespans
❖ Legacy Integration Issues 0
100
200
300
400
500
Small Med Large XL
2
Two example applications which help show the scale TIBET is designed for:
!1997 "Large": 100 screens in 11 modules; One of 80 planned web apps.
2005 "XLarge": 500+ screens in 50+ modules; One of a set of planned apps.
!While TIBET can be used for applications of any size, it's just JavaScript after all, it's specifically intended for "desktop class" applications, applications that would previously have
been built in VB, Delphi, PowerBuilder, or similar tools.

The Hardest AJAX Problem
3
Scaling The Developer Pool: ❖ Support an Authoring Pyramid
❖ 70% Tags
❖ 20% Objects
❖ 10% Primitives
❖ Provide for Tooling & Training
❖ True "Framework"
❖ Convention-Driven
Hardest Ajax problem of all? Recruiting. -- Scott Deitzen former CTO of BEA, former CEO Zimbra. Circa 2006.
!NOTHING HAS CHANGED.
!TIBET focuses on solving the real problem in large-scale web development -- scaling the developer pool. We do this via a layered architecture whose primary development API is
the use of intelligent type-backed markup.
!We call this "The Authoring Pyramid" and it's central to TIBET's design.
!Tag-centric development is also the direction the web at large is heading as seen in the rise of tools like angular, polymer, and web components.

Single-Sourced Stack
4
A la Carte
angular.jsbackbone.js
jqueryclass.js + traits.js
underscorelog4javascript
? config ?require.js
grunt / bash /makejasmine + sinon + syn
livereload + ?
TIBET
Tag SystemTP.core.URI
TP.core.NodeTP.lang
TP PrimitivesTP.log.*
TP.sys.cfgTP.boot
tibet CLITP.test.*
TSH + Sherpa
XL applications need a broad range of functionality and a broad range of tools to maintain their quality over time. That's the reality of the problem to solve.
!You can build your own solution using an a la carte approach. If you choose the right modules and combine them effectively that can certainly solve the core technical issues.
Unfortunately it can actually make cultural issues such as ease-of-hiring, ease-of-onboarding, and ease-of-maintenance worse since you now have a custom framework and
custom class library to manage and maintain.
!TIBET is a fully-integrated application stack designed specifically to give you a common, vendor-supported solution focused on XL web applications.
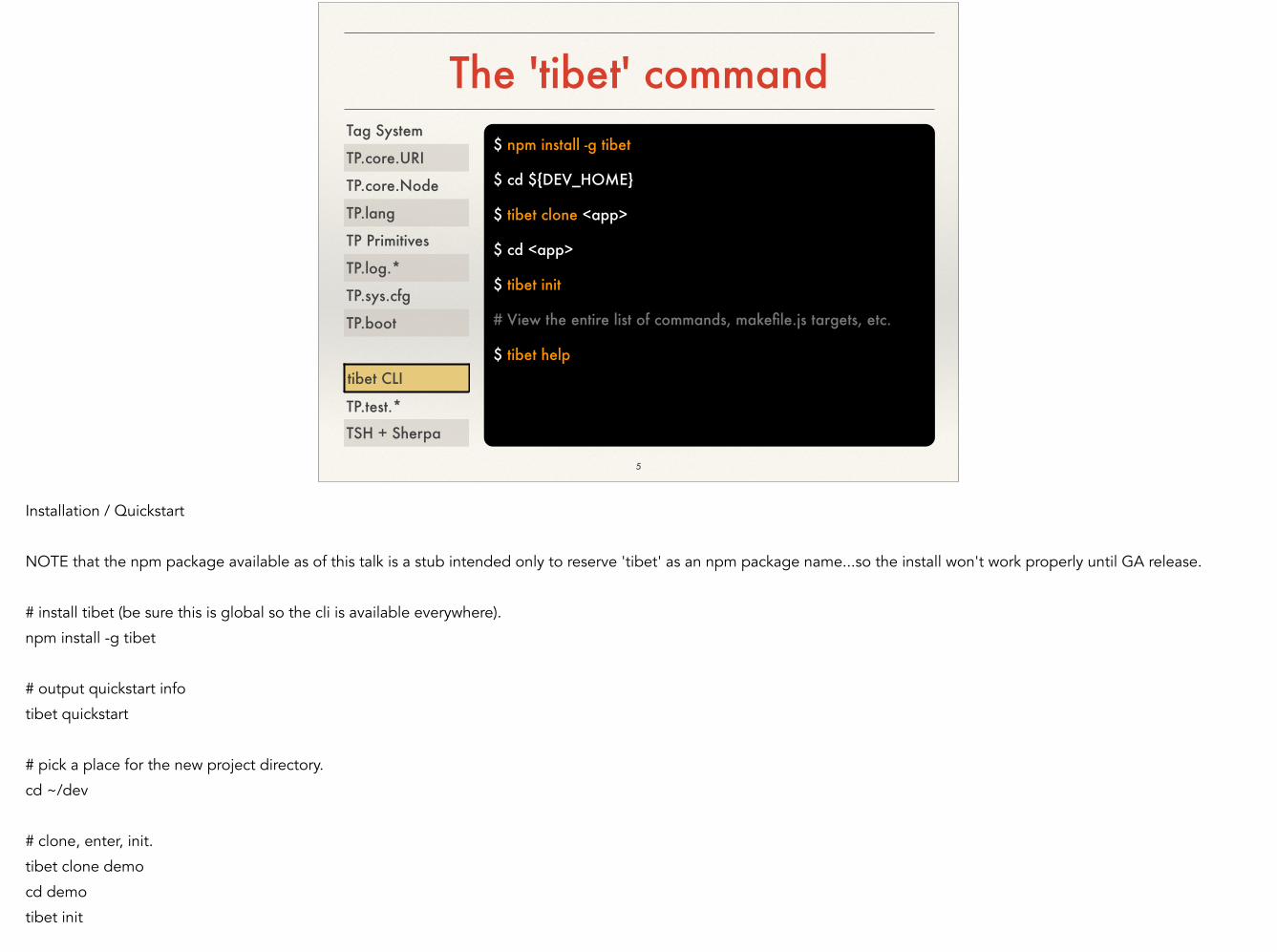
The 'tibet' command
5
Tag System
TP.core.URI
TP.core.Node
TP.lang
TP Primitives
TP.log.*
TP.sys.cfg
TP.boot
tibet CLI
TP.test.*
TSH + Sherpa
$ npm install -g tibet
$ cd ${DEV_HOME}
$ tibet clone <app>
$ cd <app>
$ tibet init
# View the entire list of commands, makefile.js targets, etc.
$ tibet help
Installation / Quickstart
!NOTE that the npm package available as of this talk is a stub intended only to reserve 'tibet' as an npm package name...so the install won't work properly until GA release.
!# install tibet (be sure this is global so the cli is available everywhere).
npm install -g tibet
!# output quickstart info
tibet quickstart
!# pick a place for the new project directory.
cd ~/dev
!# clone, enter, init.
tibet clone demo
cd demo
tibet init
!

TP.boot
6
Tag System
TP.core.URI
TP.core.Node
TP.lang
TP Primitives
TP.log.*
TP.sys.cfg
TP.boot
tibet CLI
TP.test.*
TSH + Sherpa
$ tibet start
$ open http://0.0.0.0:1407
# check out the package files which drive TIBET's tools
$ cd TIBET-INF/cfg
$ ls
app.xml
phantom.xml
...
# start the TIBET Development Server (TDS)
tibet start
!# launch the cloned application by opening the pre-defined index.html
open http://0.0.0.0:1407
!# EXTRA CREDIT :) launch the same application from the file system. MacOS shown here.
alias chrome='/Applications/Google\ Chrome.app/Contents/MacOS/Google\ Chrome --disable-web-security --allow-file-access-from-files'
!open file:///${HOME}/dev/demo/index.html # replace ${HOME}
!# check out the package files which drive the boot system and other tools.
cd ~/dev/demo/TIBET-INF/cfg
ls -1c

Welcome To TIBET!
7
Tag System
TP.core.URI
TP.core.Node
TP.lang
TP Primitives
TP.log.*
TP.sys.cfg
TP.boot
tibet CLI
TP.test.*
TSH + Sherpa
TIBET applications use a "code frame" to hold code and shared data and one or more "ui frames" to contain your UI screens. You can integrate any JS code you want in your UI
frames without impacting TIBET's shared library in any way. Your code-frame code should be TIBET-based code (which still allows for integration of third-party libraries in most
cases).
!# look at the tag template responsible for this page's content
vi src/tags/APP.demo.app.xhtml
!# check out the boot log in the now-hidden UIBOOT iframe.
Alt-Up
!# inspect the top-level DOM to see how index.html works in TIBET
UIROOT // all application UI
UIBOOT // TIBET boot UI and developer console UI

Two-Phased Booting
8
Tag System
TP.core.URI
TP.core.Node
TP.lang
TP Primitives
TP.log.*
TP.sys.cfg
TP.boot
tibet CLI
TP.test.*
TSH + Sherpa
# note the phases...
!TIBET code loads in phase one, typically from the application cache so there's no network overhead. For enterprise apps this often happens while users are entering a username/
password so it's invisible in terms of perceived load time.
!Your application-specific code loads in phase two, often only after successful login is done. APP code is much smaller so it happens much quicker, normally sub-second making
startup feel almost instantaneous.
!Two-phase booting lets you boot common code (e.g. a "shared lib") while the user is logging in or viewing a splash page and boot the application-specific code only when
needed.

TP.sys.[set]cfg
9
Tag System
TP.core.URI
TP.core.Node
TP.lang
TP Primitives
TP.log.*
TP.sys.cfg
TP.boot
tibet CLI
TP.test.*
TSH + Sherpa
$ tibet config [prop[=value]]
# supports TIBET's "virtual uris" based on ~
~, ~app, ~lib, ~app_*, ~lib_*
# manages local project settings via tibet.json
$ cat tibet.json
# url-based overrides via the URL fragment
http://..../#boot.level=1
# default values are in ~lib_cfg/tibet_cfg.js
TIBET integrates a configuration/settings layer which is used by the cli, the framework, the test harness, and your code. You can access this from the command line via the tibet
config command and override settings from the URL to dynamically configure the application.
!# list stuff...
tibet config
tibet config log
tibet config log.color
!# set stuff...
tibet config boot.level=1 // NO SPACES AROUND "=" !!!
cat tibet.json
!# see it change how the boot happens...now should log @ trace
open http://0.0.0.0:1407
!# EXTRA CREDIT :) Override it on the boot url (turn it all off)
open http://0.0.0.0:1407/#boot.level=off
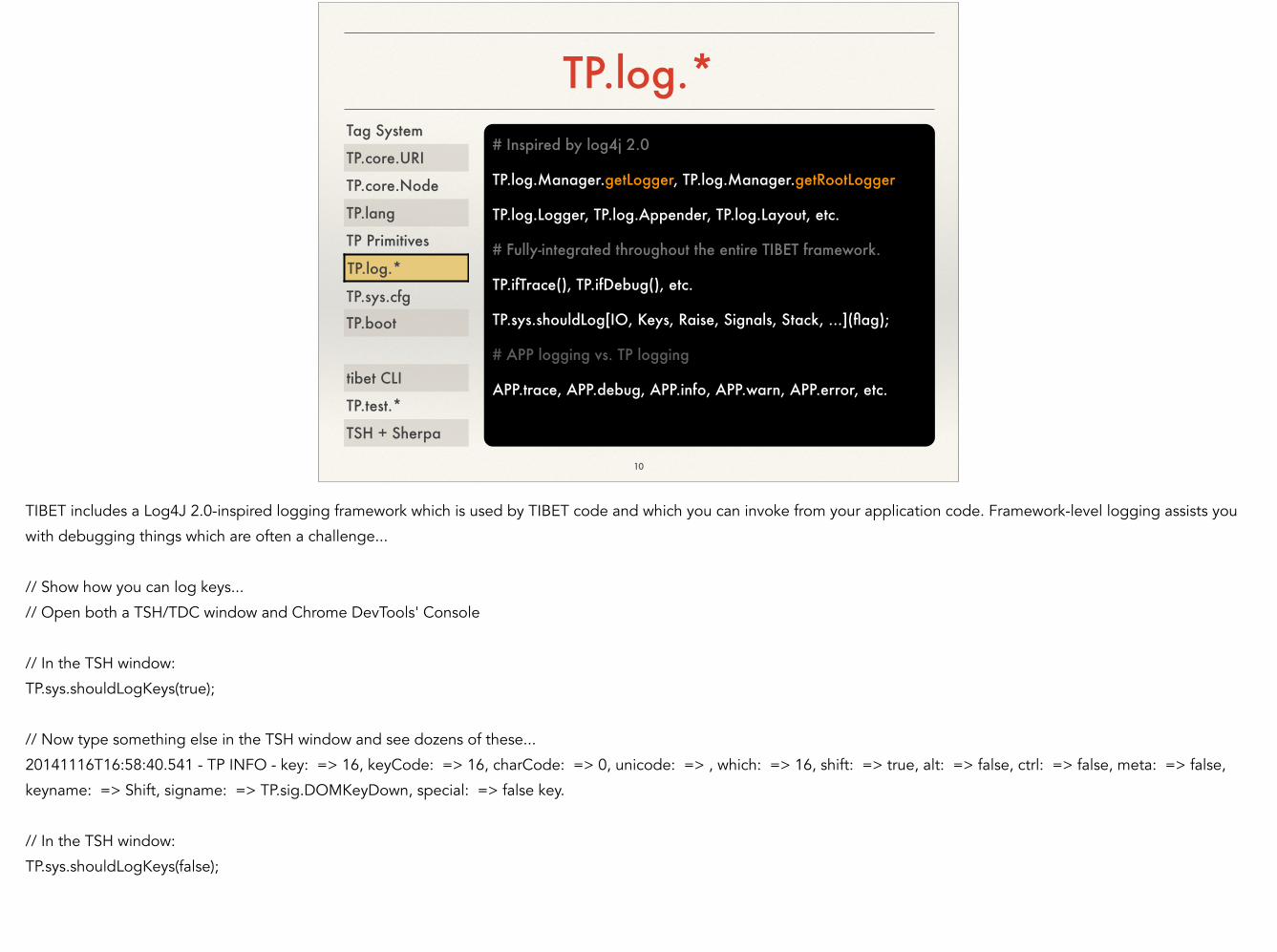
TP.log.*
10
Tag System
TP.core.URI
TP.core.Node
TP.lang
TP Primitives
TP.log.*
TP.sys.cfg
TP.boot
tibet CLI
TP.test.*
TSH + Sherpa
# Inspired by log4j 2.0
TP.log.Manager.getLogger, TP.log.Manager.getRootLogger
TP.log.Logger, TP.log.Appender, TP.log.Layout, etc.
# Fully-integrated throughout the entire TIBET framework.
TP.ifTrace(), TP.ifDebug(), etc.
TP.sys.shouldLog[IO, Keys, Raise, Signals, Stack, ...](flag);
# APP logging vs. TP logging
APP.trace, APP.debug, APP.info, APP.warn, APP.error, etc.
TIBET includes a Log4J 2.0-inspired logging framework which is used by TIBET code and which you can invoke from your application code. Framework-level logging assists you
with debugging things which are often a challenge...
!// Show how you can log keys...
// Open both a TSH/TDC window and Chrome DevTools' Console
!// In the TSH window:
TP.sys.shouldLogKeys(true);
!// Now type something else in the TSH window and see dozens of these...
20141116T16:58:40.541 - TP INFO - key: => 16, keyCode: => 16, charCode: => 0, unicode: => , which: => 16, shift: => true, alt: => false, ctrl: => false, meta: => false,
keyname: => Shift, signame: => TP.sig.DOMKeyDown, special: => false key.
!// In the TSH window:
TP.sys.shouldLogKeys(false);

TP "Primitives"
11
Tag System
TP.core.URI
TP.core.Node
TP.lang
TP Primitives
TP.log.*
TP.sys.cfg
TP.boot
tibet CLI
TP.test.*
TSH + Sherpa
~600 methods on TP.*
# Query Interfaces
TP.$, TP.by*, TP.uc, *
# Check Functions
TP.isValid, TP.notValid, TP.isKindOf, TP.isMemberOf, *
# Construction Helpers
TP.hc, TP.str, TP.elem, TP.doc, TP.node, TP.json, *
# DOM Utilities
TP.document*, TP.element*, TP.event*, TP.node*, etc.
The lowest layer of the TIBET platform is what we call the "Primitives", a set of hundreds of calls which provide a powerful cross-browser encapsulation layer tested over 15 years.
!By porting the primitives we've been able to migrate TIBET though over a decade of browser evolution from IE4/Nav4 to today's modern HTML5 browsers with effectively no
changes to TIBET's public development APIs and no impact on tag-level interfaces.
!// select and sort the primary set of primitives on TP.
Object.keys(TP).filter(
function(item) {
return item.startsWith('if') ||
item.startsWith('is') ||
item.startsWith('not') ||
item.startsWith('define') ||
item.startsWith('object') ||
item.startsWith('regex') ||
item.startsWith('element') ||
item.startsWith('document') ||
item.startsWith('window') ||
item.startsWith('attribute') ||

TP.lang - Type Definition
12
Tag System
TP.core.URI
TP.core.Node
TP.lang
TP Primitives
TP.log.*
TP.sys.cfg
TP.boot
tibet CLI
TP.test.*
TSH + Sherpa
TP.lang.Object.defineSubtype('APP.demo.Hello');
APP.demo.Hello.Inst.defineAttribute('msg');
APP.demo.Hello.Inst.defineMethod('init', function(str) {
this.$set('msg', str);
return this; });
APP.demo.Hello.Inst.defineMethod('greet', function() {
alert(this.get('msg'));
});
APP.demo.Hello.construct('Hello World!').greet();
TIBET includes OO functionality on the level of Smalltalk. Instances inherit. Types inherit. Everything can be overridden. Everything can call "super". All via definition methods
which support advanced run-time reflection capability.
!// define a simple type residing in the APP.demo namespace.
TP.lang.Object.defineSubtype('APP.demo.Hello');
!// define an attribute for instances of that type.
APP.demo.Hello.Inst.defineAttribute('msg');
!// define an instance initializer (called automatically by construct())
APP.demo.Hello.Inst.defineMethod('init', function(str) {
this.$set('msg', str);
return this;
});
!// define a useful method relying on our instance data/initializer.
APP.demo.Hello.Inst.defineMethod('greet', function() {
alert(this.get('msg'));

TP.lang - Trait Definition
13
Tag System
TP.core.URI
TP.core.Node
TP.lang
TP Primitives
TP.log.*
TP.sys.cfg
TP.boot
tibet CLI
TP.test.*
TSH + Sherpa
# Define a type and make it abstract (no instance creation).
TP.lang.Object.defineSubtype('log.Leveled');
TP.log.Leveled.isAbstract(true);
# Add to the Type or Inst prototypes as usual.
TP.log.Leveled.Inst.defineAttribute('level');
TP.log.Leveled.Inst.defineMethod('getLevel', function() {
return TP.ifInvalid(this.$get('level'), TP.log.ALL);
});
TIBET's OO subsystem fully integrates trait-based extension, providing a powerful form of multiple inheritance you can control to resolve conflicts while factoring code efficiently.
!The slide code is straight out of TIBETLogging.js which uses traits in multiple locations to share common code between loggers, appenders, and layouts.
!The isAbstract method for a type is the only "best practices" difference between a "trait" and a "type" in TIBET and it's not strictly required. Any type can be used as a trait with
respect to any other type.
!By design, TIBET traits are type-level constructs. While traits are typically used at an instance level such usage can impose performance overhead and does nothing to ensure
code stays organized. In TIBET we blended traits with our OO system to minimize issues.
!

TP.lang - Trait Application
14
Tag System
TP.core.URI
TP.core.Node
TP.lang
TP Primitives
TP.log.*
TP.sys.cfg
TP.boot
tibet CLI
TP.test.*
TSH + Sherpa
TP.log.Logger.addTraits(TP.log.Leveled);
// Loggers inherit so we need to preserve getters.
TP.log.Logger.Inst.resolveTraits(
TP.ac('getLevel', 'getFilters', 'getParent'),
TP.log.Logger);
// Define any additional attributes, methods, etc.
...
// Finalize traits now that definition is complete.
TP.log.Logger.finalizeTraits();
Applying a trait is straightforward. You add one or more traits to the target type via the addTraits() call common to all Type objects.
!The slide code is straight out of TIBETLogging.js where we are adding the concepts of leveling to a Logger. (Appenders also use this trait).
!Note that you can addTraits multiple times from multiple sources which allows you to mix/match shared functionality in any cross-cutting fashion you need.
!The resolveTraits method (and resolveTrait method) gives you the means to
define how traits should be resolved when they would otherwise conflict.
!Traits are resolved during processing of each type's 'initialize' method by default. Types which mix in traits must either implement 'initialize' or they can call finalizeTraits()
manually. This is typically done after all property definition has occurred.

TP.core.Node
15
Tag System
TP.core.URI
TP.core.Node
TP.lang
TP Primitives
TP.log.*
TP.sys.cfg
TP.boot
tibet CLI
TP.test.*
TSH + Sherpa
# A factory returning the right type to encapsulate the node.
var node = TP.core.Node.construct(someDOMNode);
# Returned by a number of methods including:
TP.$, TP.wrap, etc.
# Encapsulates the DOM-related primitives from TP:
TP.element*, TP.document*, TP.node*, etc.
# Major subtypes for the tag system include:
TP.core.UIElementNode, TP.core.TemplatedNode
One of the core types in TIBET is TP.core.Node. This type is the supertype for all DOM node types in TIBET. Immediate child types include TP.core.Element, TP.core.Document,
etc. Types also exist for HTML and SVG node types as well as many others. Custom tags matched to types is central to TIBET development.
!// List the subtype names (and note the reflection API here :)).
TP.core.Node.getSubtypeNames();
!// Query for elements/nodes/etc using one of several query methods...
elem = TP.byId('UIBOOT', top));
!// Convert native elements to TIBET tag instances using TP.wrap() as needed...
bootframe = TP.wrap(elem);
!// Ask it something :)
bootframe.getPageRect();

TP.core.URI
16
Tag System
TP.core.URI
TP.core.Node
TP.lang
TP Primitives
TP.log.*
TP.sys.cfg
TP.boot
tibet CLI
TP.test.*
TSH + Sherpa
# A factory returning a scheme-specific Type:
TP.uc('urn:tibet:TP'); // name any TIBET object or Type.
TP.uc('http://127.0.0.1:1407/index.html');
Custom TIBET schemes include jsonp:, localdb:, pouchdb:
# Can load, save, refresh, and otherwise manage content.
url.getResource();
url.setResource();
url.save();
# Heavily involved in TIBET's data binding subsystem.
Along with TP.core.Node the TP.core.URI type provides access to local and remote data. Using URIs is central to TIBET development since URIs serve as the "names" or "ids" for
objects in TIBET and provide caching, change notification, and other features which let them serve as universal models.
!// Access the index.html from the current app...
TP.uc('http://127.0.0.1:1407/index.html').getResource()
!// Access any Type via a TIBET URN:
TP.uc('urn:tibet:TP.log.Manager').getResource()
!// Create a "value holder" for some data...
TP.uc('urn:tibet:demoJSON').setResource('{"demo":"json"}');
!// Get it back and turn it into a TP.lang.Hash (without needing a var)
TP.json2js(TP.uc('urn:tibet:demoJSON').getResource())
!// Access football results from Google via a jsonp: url directly in the TSH/TDC
jsonp://ajax.googleapis.com/ajax/services/search/web?v=1.0&q=football&start=10

Tag System - Custom Tags
17
Tag System
TP.core.URI
TP.core.Node
TP.lang
TP Primitives
TP.log.*
TP.sys.cfg
TP.boot
tibet CLI
TP.test.*
TSH + Sherpa
<!-- This tag drives the entire system via UIROOT.xhtml -->
<tibet:root/>
<!-- Render the TIBET Shell console (also UIROOT.xhtml -->
<tsh:console ... />
<!-- Render your application's "root tag" by default -->
<{{appname}}:app />
<!-- Implement APP.{{appname}}.app to start development -->
~app/src/tags/APP.{{appname}}.app.js (and/or .xhtml).
TIBET's tag system uses custom subtypes of TP.core.Element, often bound to data from one or more TP.core.URI instances, to let you author in markup specific to your
application or shared across your entire enterprise. Tag libraries are reusable components.
!// The first two tags are taken from UIROOT.xhtml which is your "home page"
!// Rendering logic for <tibet:root/> drives the rest of the startup sequence...
!// IF TP.sys.cfg('tibet.apptag') is set, that is rendered...
// ELSE <tibet:app/> is rendered...which displays a default screen
!// Your application's root tag is named APP.{{appname}}.app by default.
vi ./src/tags/APP.demo.app.js
vi ./src/tags/APP.demo.app.xhtml (if templated)

Tag System - Compiled
18
Tag System
TP.core.URI
TP.core.Node
TP.lang
TP Primitives
TP.log.*
TP.sys.cfg
TP.boot
tibet CLI
TP.test.*
TSH + Sherpa
APP.demo.tag.defineSubtype('hello');
APP.demo.hello.Type.defineMethod('tagCompile,
function(aRequest){
var elem = aRequest.at('node');
var newElem = TP.xhtmlnode(
'<div tibet:tag="demo:hello">Hello World!</div>'
);
TP.elementReplaceWith(elem, newElem);
});
Tags which implement the 'tagCompile' method can use JavaScript to generate their UI representation. This method, along with several others, allow your types to respond to
framework calls from TIBET during rendering, awakening, and removal from the DOM.
!// create the demo:hello tag type
APP.demo.compiled.defineSubtype('hello');
!// define a method for compiling it to XHTML
APP.demo.hello.Type.defineMethod('tagCompile',
function(aRequest) {
var elem = aRequest.at('node');
var newElem = TP.xhtmlnode(
'<h1 tibet:tag="demo:hello">Hello!</h1>');
TP.elementReplaceWith(elem, newElem);
});

Tag System - Templated
19
Tag System
TP.core.URI
TP.core.Node
TP.lang
TP Primitives
TP.log.*
TP.sys.cfg
TP.boot
tibet CLI
TP.test.*
TSH + Sherpa
/* In APP.demo.templated.js */
APP.demo.templated.defineSubtype('demo:hello');
!
/* In APP.demo.templated.xhtml */
<h1 tibet:tag="demo:hello">
Hello World!
</h1>
Templated tags rely on a common supertype and use template files to contain their runtime markup. Currently TIBET supports an engine inspired by handlebars which uses
{{variable}} syntax. Support for pluggable templating engines will be appearing in a future update.
!// create the demo:hello tag type
APP.demo.templated.defineSubtype('hello');
!// create and edit an XHTML5 template for content
<h1 xmlns="http://www.w3.org/1999/xhtml" tibet:tag="demo:hello">
Hello World!
</h1>

Tag System - Binding
20
Tag System
TP.core.URI
TP.core.Node
TP.lang
TP Primitives
TP.log.*
TP.sys.cfg
TP.boot
tibet CLI
TP.test.*
TSH + Sherpa
<div bind:scope="urn:tibet:employeeData">
<input type="text" value="[[firstname]]">
<input type="text" value="[[lastname]]">
<div bind:repeat="addresses/address">
<input type="text" value="[[city]]">
<input type="text" value="[[state]]">
</div>
</div>
In some sense a data binding is a "persistent" substitution, one that is run any time data changes. As a result TIBET's binding syntax uses doubled square brackets in a form
similar to the curly bracket syntax of handlebars.
!Binds are always done to a TIBET URI. This approach allows URIs to work as "value holders" whose content may change (like "current employee") and for bind authoring to
remain consistent and to leverage the power of TIBET's URI and access path syntax.
!With TIBET URIs and access paths you can bind to leaves, collections, slices, even data that doesn't exist yet (using what XForms referred to as "lazy authoring" in which the bind
actually creates the data slot it targets on demand).

TP.test - Definition
21
Tag System
TP.core.URI
TP.core.Node
TP.lang
TP Primitives
TP.log.*
TP.sys.cfg
TP.boot
tibet CLI
TP.test.*
TSH + Sherpa
TP.log.Manager.Type.describe('a test suite', function() {
var driver = this.getDriver();
driver.setLocation(
TP.uc('~lib_tst/src/tibet/focusing/Focusing1.xhtml'));
this.it('can handle tab focusing', function() {
driver.startSequence().sendKeys('[Tab]').perform();
this.then(...);
});
});
TIBET includes a Promise-driven test harness which ties tests to the objects being tested. The syntax is inspired by Jasmine, but is actually message-based and fully extensible.
!In the slide example we're using the built-in 'describe' method to define a test for the TP.log.Manager.Type. This particular test uses TIBET's UI driver to set a location (load a
page) and then send a key sequence to that page. Promises are leveraged to ensure asynchronous test steps can be easily managed and can be chained as needed.
!NOTE that TIBET's approach to test definition means you can ask objects for their tests. This also implies you can ask the system to return lists of objects which have no tests,
giving you a simple reflection-driven approach to ensuring method-level test coverage.
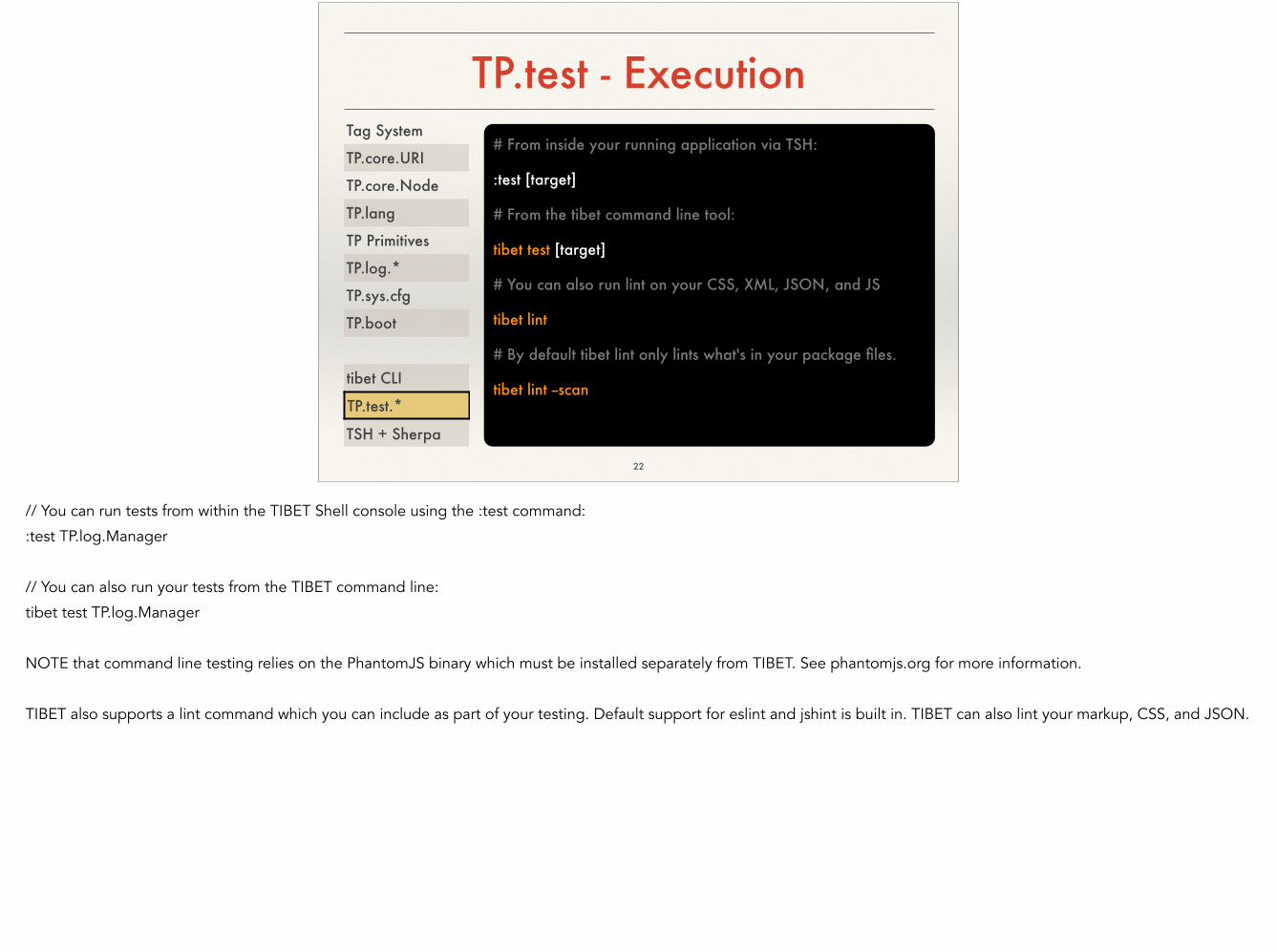
TP.test - Execution
22
Tag System
TP.core.URI
TP.core.Node
TP.lang
TP Primitives
TP.log.*
TP.sys.cfg
TP.boot
tibet CLI
TP.test.*
TSH + Sherpa
# From inside your running application via TSH:
:test [target]
# From the tibet command line tool:
tibet test [target]
# You can also run lint on your CSS, XML, JSON, and JS
tibet lint
# By default tibet lint only lints what's in your package files.
tibet lint --scan
// You can run tests from within the TIBET Shell console using the :test command:
:test TP.log.Manager
!// You can also run your tests from the TIBET command line:
tibet test TP.log.Manager
!NOTE that command line testing relies on the PhantomJS binary which must be installed separately from TIBET. See phantomjs.org for more information.
!TIBET also supports a lint command which you can include as part of your testing. Default support for eslint and jshint is built in. TIBET can also lint your markup, CSS, and JSON.
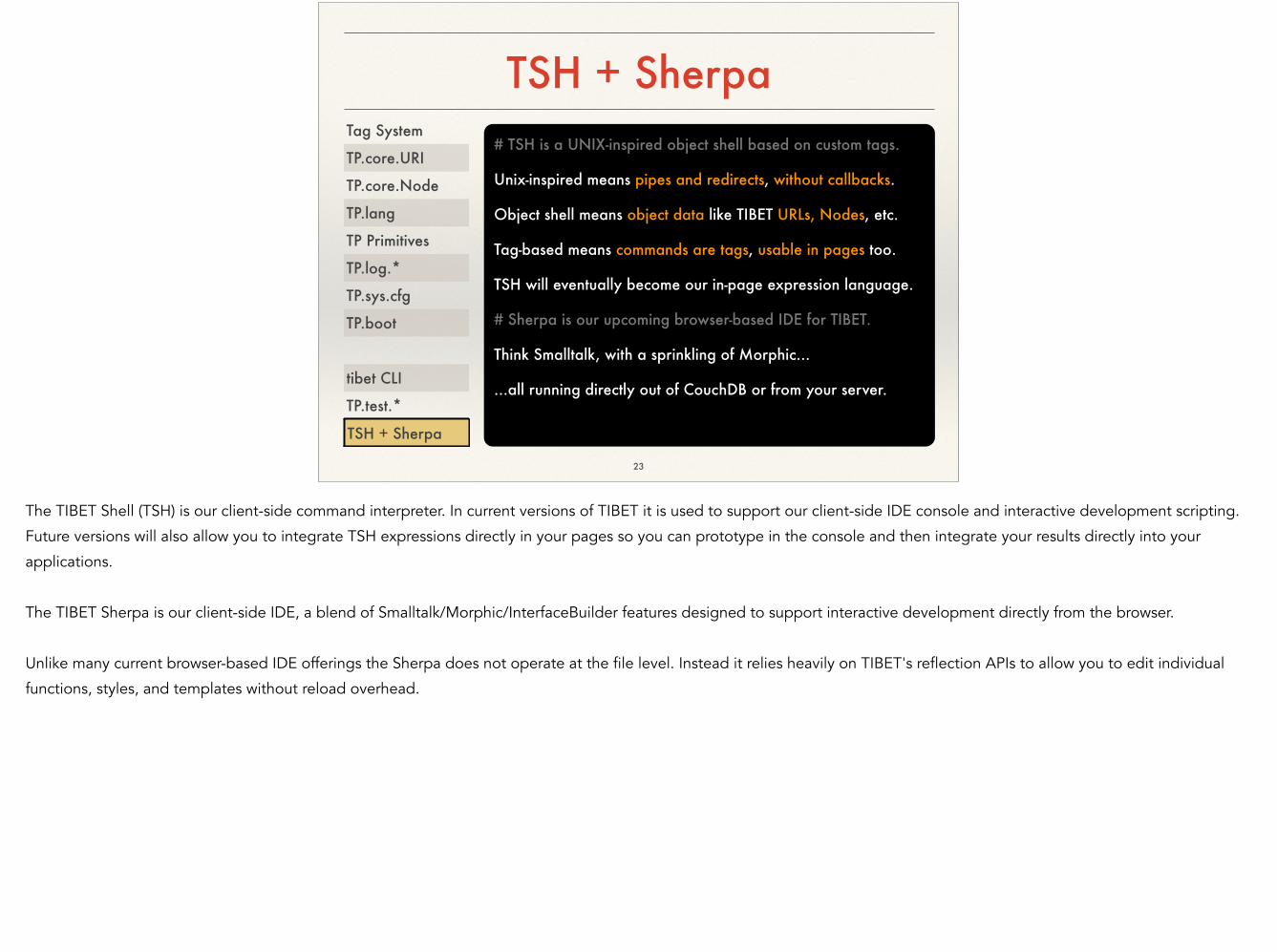
TSH + Sherpa
23
Tag System
TP.core.URI
TP.core.Node
TP.lang
TP Primitives
TP.log.*
TP.sys.cfg
TP.boot
tibet CLI
TP.test.*
TSH + Sherpa
# TSH is a UNIX-inspired object shell based on custom tags.
Unix-inspired means pipes and redirects, without callbacks.
Object shell means object data like TIBET URLs, Nodes, etc.
Tag-based means commands are tags, usable in pages too.
TSH will eventually become our in-page expression language.
# Sherpa is our upcoming browser-based IDE for TIBET.
Think Smalltalk, with a sprinkling of Morphic...
...all running directly out of CouchDB or from your server.
The TIBET Shell (TSH) is our client-side command interpreter. In current versions of TIBET it is used to support our client-side IDE console and interactive development scripting.
Future versions will also allow you to integrate TSH expressions directly in your pages so you can prototype in the console and then integrate your results directly into your
applications.
!The TIBET Sherpa is our client-side IDE, a blend of Smalltalk/Morphic/InterfaceBuilder features designed to support interactive development directly from the browser.
!Unlike many current browser-based IDE offerings the Sherpa does not operate at the file level. Instead it relies heavily on TIBET's reflection APIs to allow you to edit individual
functions, styles, and templates without reload overhead.

Questions?
24

Thank You! To get started with TIBET visit: www.technicalpursuit.com
25

CouchDB + TIBET by William J. Edney and Team TIBET ™
TM
26
Confirm you have a full, un-minified of TSH/TDC up and running.
Confirm you have CouchDB up and running, verify via Futon.
Confirm network connectivity via wifi and/or personal hotspot.
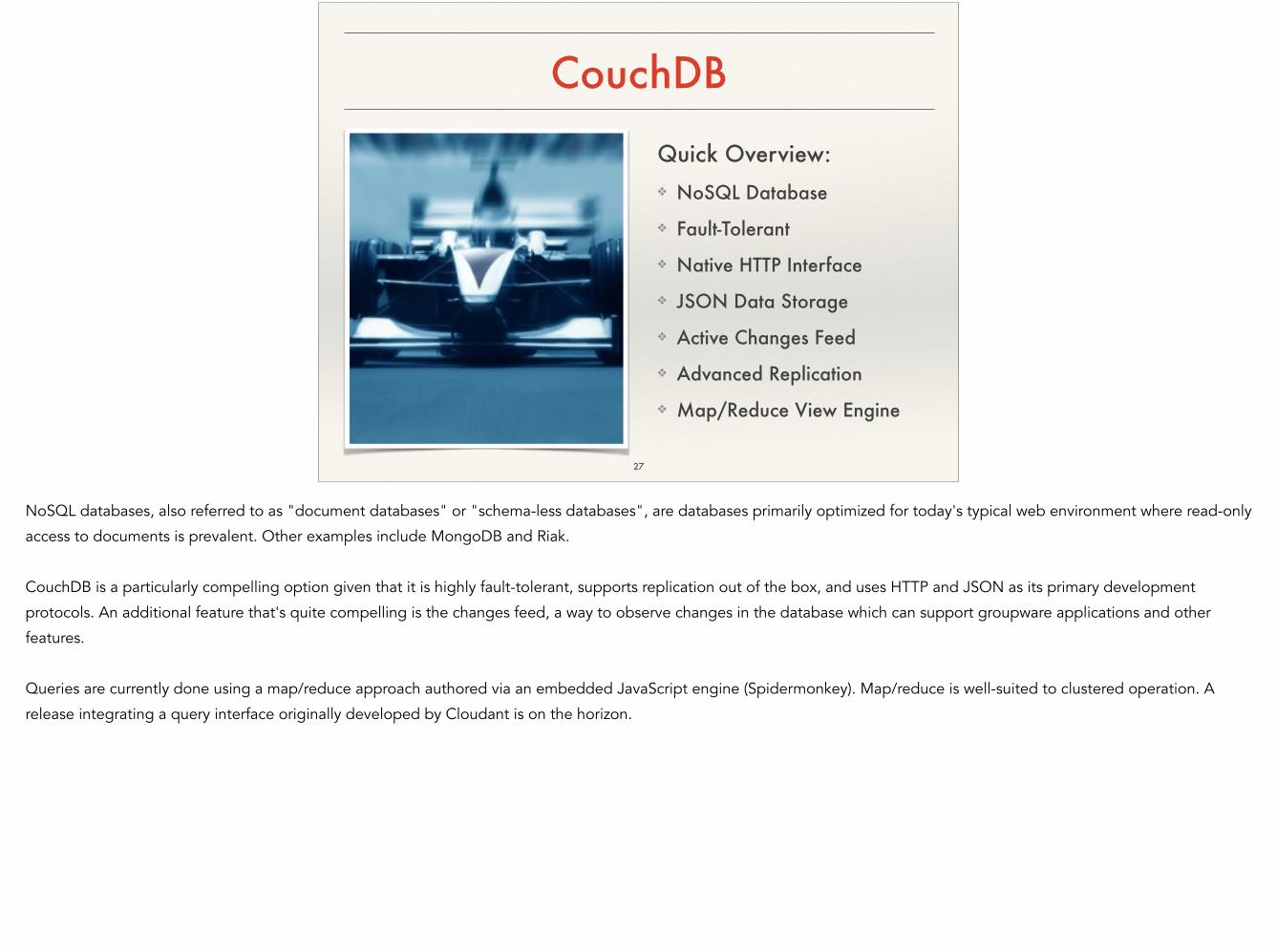
CouchDB
27
Quick Overview: ❖ NoSQL Database
❖ Fault-Tolerant
❖ Native HTTP Interface
❖ JSON Data Storage
❖ Active Changes Feed
❖ Advanced Replication
❖ Map/Reduce View Engine
NoSQL databases, also referred to as "document databases" or "schema-less databases", are databases primarily optimized for today's typical web environment where read-only
access to documents is prevalent. Other examples include MongoDB and Riak.
!CouchDB is a particularly compelling option given that it is highly fault-tolerant, supports replication out of the box, and uses HTTP and JSON as its primary development
protocols. An additional feature that's quite compelling is the changes feed, a way to observe changes in the database which can support groupware applications and other
features.
!Queries are currently done using a map/reduce approach authored via an embedded JavaScript engine (Spidermonkey). Map/reduce is well-suited to clustered operation. A
release integrating a query interface originally developed by Cloudant is on the horizon.

"Cluster Of Unreliable Commodity Hardware"
28
Fault Tolerance Through: ❖ Erlang ❖ Replication Protocol
❖ CouchDB ❖ PouchDB ❖ Couchbase Lite ❖ Cloudant Sync
COUCH is actually an acronym for Cluster of Unreliable Commodity Hardware. This focus on clustered, fault-tolerant operation is central to how CouchDB is designed.
!To help ensure both scalability and fault-tolerance CouchDB is written in Erlang, a language designed (by Ericsson) to support distributed, fault-tolerant, hot-swappable
applications.
!CouchDB's "secret sauce" is its replication protocol. This protocol has allowed the creation of client-side database layers such as pouchdb for web browers and node.js servers,
and Couchbase Lite and Cloudant Sync which target mobile devices. Applications integrating these technologies can run offline and sync when online, a compelling feature that's
"built in" thanks to CouchDB's replication protocol. There’s even a PHP script that implements the CouchDB replication protocol and keeps MySQL in sync with it!

Born Of The Web
29
Native HTTP Interface:
❖ Administration API
❖ create databases via PUT
❖ access metadata via GET
❖ Data Access API
❖ add ID'd documents via PUT
❖ or add documents via POST
❖ retrieve documents via GET
While other databases such as PostgreSQL provide HTTP access the HTTP interface is native to CouchDB, in fact it's essentially the only way to communicate with the database.
!Everything from administration to user-level data access is done via HTTP calls as we'll see in several of the slides we'll be going over shortly.
!The key thing to keep in mind is simply that you can do everything you need to do with CouchDB using nothing more than standard HTTP verbs.

HTTP-based Administration
30
// Verify the CouchDB server is running... curl -X GET http://127.0.0.1:5984 {"couchdb":"Welcome","uuid":"7fc1109a1e23ff100270f46ee4afb887","version":"1.6.0","vendor":{"version":"1.6.0","name":"The Apache Software Foundation"}} !// Create a new database from the command line. curl -X PUT http://127.0.0.1:5984/demo {"ok":true} !// List available databases curl -X GET http://127.0.0.1:5984/_all_dbs ["_replicator","_users","demo"]
By default CouchDB runs on port 5984, so we can use a curl command with the GET verb to query the server. If we get a valid response back it tells us the server is running.
!We can create new databases using PUT and a database name at the end of the URL:
curl -X PUT http://127.0.0.1:5984/demo
{"ok":true}
!Or we can list available databases by querying the special _all_dbs URL:
curl -X GET http://127.0.0.1:5984/_all_dbs
["_replicator","_users","demo"]

JSON in, JSON out
31
Everything Is JSON:
❖ PUT JSON Documents
❖ GET JSON Documents
CouchDB JSON Keys:
❖ _id - unique document ID
❖ _rev - unique revision
All input and output to CouchDB is in the form of JSON, from the admin APIs to user data APIs. As seen on the previous slide an HTTP response containing {"ok": true} is
idiomatic in CouchDB for "success".
!In addition to all input and output being JSON, all document storage in CouchDB is also JSON, where every document includes at least two special key fields: _id and _rev.
!_id is CouchDB's UUID field used to uniquely identify each document in the database.
!_rev is a revision field used to track unique document revisions.

Document IDs: _id
32
# All documents have a unique ID in the _id field (or "id" attribute in results): curl -X PUT http://127.0.0.1:5984/demo/tibet -d '{"name": "TIBET"}' {"ok":true,"id":"tibet","rev":"1-a89fbda1b216e948d4be140beb93f1f5"} !curl -X GET http://127.0.0.1:5984/demo/tibet {"_id":"tibet","_rev":"1-a89fbda1b216e948d4be140beb93f1f5","name":"TIBET"} !# You can get auto-generated IDs by using POST instead of PUT: curl -X POST http://127.0.0.1:5984/demo -d '{"name": "TEST"}' \ -H 'Content-Type: application/json' {"ok":true,"id":"b4d9ee1f263ef09d45fd5cf634000029", "_rev": ...}
CouchDB requires all documents to have a unique ID to identify them. You have a few options with respect to these IDs.
!First, you can specify an ID on the URL after the database name:
curl -X PUT http://127.0.0.1:5984/demo/{{id}} -d '{{json-content}}'
!You can use the same ID to retrieve the document via the URL:
curl -X GET http://127.0.0.1:5984/demo/{{id}}
!You can have CouchDB generate an ID for you by using POST:
curl -X POST http://127.0.0.1:5984/demo -d '{"name": "TEST"}' \
-H 'Content-Type: application/json'
{"ok":true,"id":"b4d9ee1f263ef09d45fd5cf634000029","rev":"..."}
!You can query CouchDB for one or more unused UUIDs for use:
curl -X GET http://127.0.0.1:5984/_uuids?count=3
{"uuids":["b4d9ee1f263ef09d45fd5cf634000512","b4d9ee1f263ef09d45fd5cf634000751","..."]}

Document Revisions: _rev
33
# Every document instance includes a revision as well as an id. Revision values are of the form {{N}}-{{uuid}} where N is a revision count beginning with 1: curl -X GET http://127.0.0.1:5984/demo/tibet {"_id":"tibet","_rev":"1-a89fbda1b216e948d4be140beb93f1f5","name":"TIBET"} !# Updating a document requires you to provide the id and the latest revision: curl -X PUT http://127.0.0.1:5984/demo/tibet -d '{"name": "TIBET", "version": "0.5.0", "_rev": "1-a89fbda1b216e948d4be140beb93f1f5"}' {"ok":true,"id":"tibet","rev":"2-c693f1bf97f23ada3e2bb1d8c8bae6c4"} !# Without the latest revision number update attempts cause CouchDB to return: {"error":"conflict","reason":"Document update conflict."}
In addition to an _id each document instance also includes a unique revision id stored in the _rev key of the document.
!During creation and query operations you don't need to concern yourself with the document revision, CouchDB manages this field internally during creation and will return the
latest document revision when you query the document ID without a revision.
!The combination of the _id and _rev fields is how CouchDB supports MVCC, which is the subject of our next slide....
!!

MVCC
Multi-Version Concurrency
❖ No "in-situ" updating
❖ No locking overhead
❖ Conflict Detection
❖ Eventual Consistency
❖ Database Compaction
34
CouchDB uses an MVCC (Multi-Version Concurrency Control) approach to manage data in a scalable and predictable way. MVCC offers several key features for a clustered
database:
!No "in place edits" of documents. CouchDB never updates or deletes a document, it simply creates a new revision of the document with new data, or marks it as deleted.
!Since documents are never directly updated there's no reason to ever "lock" one. This can dramatically improve performance in databases with a lot of commonly accessed data.
!To update or delete a document you must provide the _rev value of what you believe to be the latest version. If you do not have the latest version CouchDB will detect the
conflict and trigger an automatic conflict-resolution process, the key aspects of which include marking the conflicting versions with _conflicts: [rev, rev, ...] and picking a "winning
version" to default to for any queries which arrive before the conflict has been manually resolved.
!Through replication the latest revisions eventually make their way throughout the database cluster, ensuring that the latest data makes its way as close to each user as possible.
!Since documents are never edited in place but instead create versions the database can grow over time. To offset this CouchDB "compacts" the database periodically, removing
unnecessary revisions of each document.

The "Changes Feed"
35
Database changes since...
❖ HTTP-accessible (.../{{db}}/_changes)
❖ Sequentially indexed
❖ Multiple "modes":
❖ Continuous
❖ Continuous-since
❖ Filterable
One of the more interesting features of CouchDB is the "changes feed", a list of new document revisions which have occurred relative to some initial point in time.
!The list can be queried via HTTP as with all other CouchDB features.
curl -X GET http://127.0.0.1:5984/demo/_changes
!In recent versions of CouchDB this feed is observable via server-sent events, allowing you to connect the feed to a modern web browser. This opens the door to collaborative
applications which use the changes feed as a way of staying synchronized.
!The changes feed is sequentially indexed via an incremental value so asking what has changed since the last time the list was queried is very efficient. In fact, the replication
process makes use of this feature.
!There are a number of ways to filter the changes feed to meet your specific requirements. The CouchDB documentation is the best place to see what your options are.

Replication
CouchDB's secret sauce :) ❖ Essentially plays a source
database's changes feed against a target database.
❖ Can be filtered by filtering the changes feed being used.
❖ Supports bi-directional update (inverting source and target)
❖ Detects circular updates.
36
# Replication is yet another operation you can manage via an HTTP interface:
curl -X POST http://127.0.0.1:5984/_replicate \
-d '{"source":"db1", "target":"db2" }'
!Yeah, it's that easy.

Map / Reduce Views
JavaScript Views: ❖ Temporary (POST to...)
❖ <database>/_temp_view
❖ Permanent (PUT to...)
❖ <db>/_design/<name>
❖ Embedded JS Engine
❖ Currently SpiderMonkey
❖ V8 Experiments
37
Map/Reduce is a strategy for query processing which allows queries to work across shards in a database cluster by breaking the query resolution up into easily composed chunks.
While it takes a little getting used to it can be very performant and highly scalable.
!Map/reduce definitions in CouchDB are referred to as "views" which are somewhat analogous to a view in the SQL world in that they represent predefined queries.
!Temporary views rely on POST'ing a definition to the route ../{{db}}/_temp_view as follows:
curl -X POST http://127.0.0.1:5984/demo/_temp_view \
-d '{"map":"function(doc) { emit(null, doc);}"}' \
-H "Content-type: application/json"
!Persistent views are stored in what are known as "design documents" under a special _design path. Different design documents are distinguished by name and can have one or
more views associated with them. The individual views within each design document are found below the _views path. For example, a design document named "test" with a
persistent view named "query" in our demo database could be run using this URL:
!curl -X GET http://127.0.0.1:5984/demo/_design/test/_view/query
!CouchDB currently embeds the Spidermonkey JavaScript engine which allows you to author map and reduce functions using JavaScript. Experiments using a V8 view engine are
underway so a change to the view engine for more Node.js compatibility may be seen in future versions of CouchDB.

CouchApps
CouchDB Applications:
❖ Data in JSON in CouchDB
❖ "Stored Procedure" Views
❖ Client code in Documents
❖ Scalable via Replication
38
A "CouchApp" is a web application whose components are stored within a CouchDB database and which can be activated directly from CouchDB by querying for one or more
documents from within a web browser.
!The advantages of this approach are primarily the reduction of "moving parts" in the application and the ability to scale the application and its data via CouchDB replication. An
additional feature if client-side CouchDB-compatible databases such as pouchdb are used is that the application can also run offline and sync when online.

Futon / Fauxton
39
A built-in admin CouchApp
❖ Database management
❖ Document management
❖ View management
❖ User configuration
CouchDB ships with a perfect example of a "CouchApp", the Futon (or Fauxton in future versions) administration application.
!Futon is a CouchApp which launches directly from CouchDB and which allows you to manage your database, create/edit/delete documents, create/edit/delete views, and
perform any other tasks necessary to manage a CouchDB instance.
!

CouchDB + TIBET
40
A NoSQL Database...
❖ with HTTP APIs...
❖ that speaks in JSON...
❖ queries via JS functions...
❖ supports embedded apps...
❖ and scales via replication.
Hmmm....
All that technology got us thinking.... :)
!
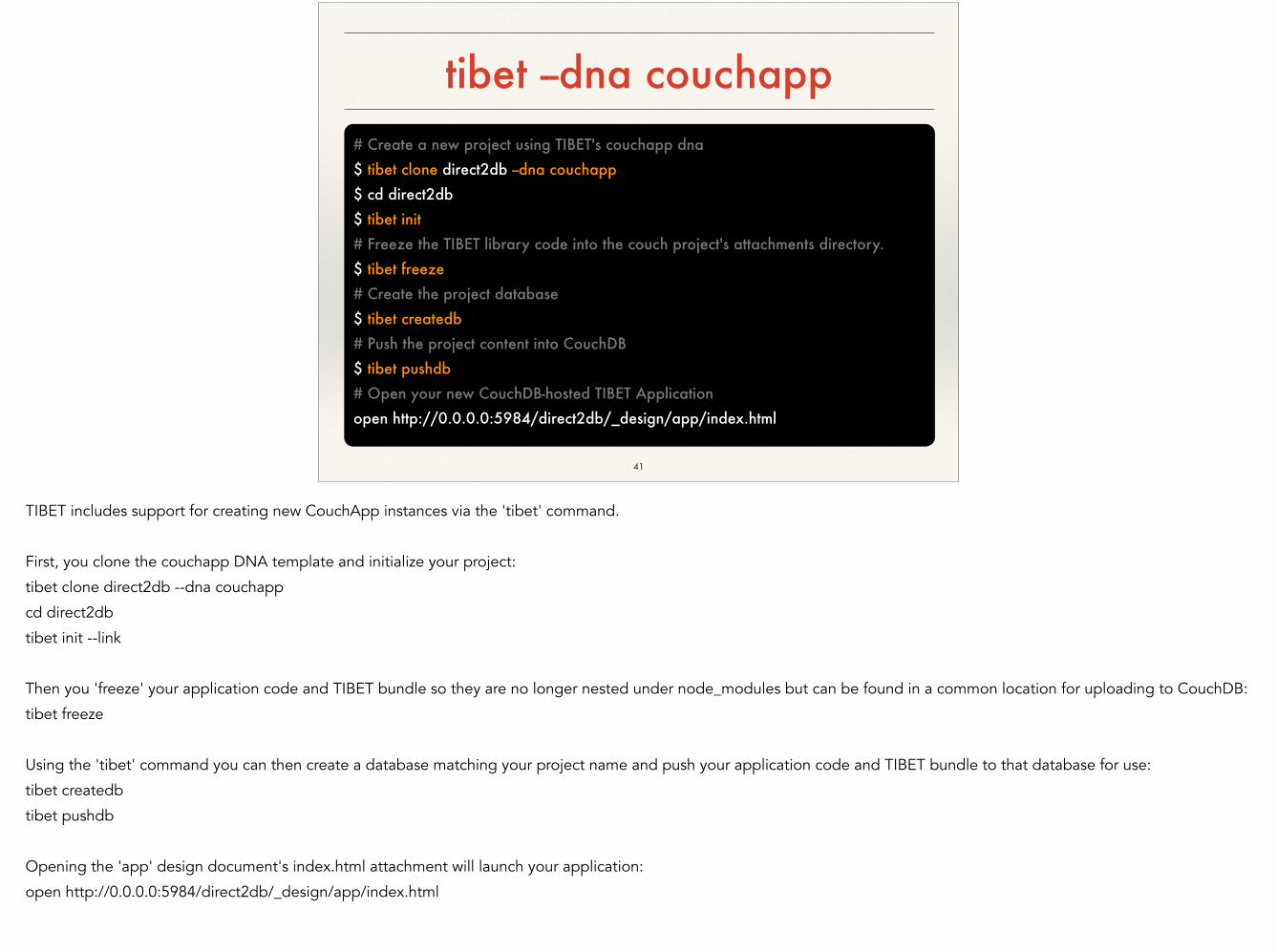
tibet --dna couchapp
41
# Create a new project using TIBET's couchapp dna $ tibet clone direct2db --dna couchapp $ cd direct2db $ tibet init # Freeze the TIBET library code into the couch project's attachments directory. $ tibet freeze # Create the project database $ tibet createdb # Push the project content into CouchDB $ tibet pushdb # Open your new CouchDB-hosted TIBET Application open http://0.0.0.0:5984/direct2db/_design/app/index.html
TIBET includes support for creating new CouchApp instances via the 'tibet' command.
!First, you clone the couchapp DNA template and initialize your project:
tibet clone direct2db --dna couchapp
cd direct2db
tibet init --link
!Then you 'freeze' your application code and TIBET bundle so they are no longer nested under node_modules but can be found in a common location for uploading to CouchDB:
tibet freeze
!Using the 'tibet' command you can then create a database matching your project name and push your application code and TIBET bundle to that database for use:
tibet createdb
tibet pushdb
!Opening the 'app' design document's index.html attachment will launch your application:
open http://0.0.0.0:5984/direct2db/_design/app/index.html

CouchDB Installation
42
Installation can be done:
❖ via platform binaries
❖ via Homebrew
❖ via MacPorts
❖ via apt-get or yum
Complete Instructions At:
http://couchdb.apache.org

CouchDB + CORS
43
// Enable CORS support by updating your ${COUCH}/etc/couchdb/local.ini // where ${COUCH} is the location of your CouchDB installation... !// In the '[httpd]' section enable_cors = true
// Add the '[cors]' section [cors] origins = * headers = pragma,cache-control,content-type,x-request-id,x-requested-with methods = GET,HEAD,POST,PUT,DELETE,TRACE,CONNECT,COPY,OPTIONS
If you need to access CouchDB using the CORS approach you can configure it via changes in the local.ini file.
!The example above allows CORS access from any inbound IP address and makes all the HTTP verbs available. YOU SHOULD RESTRICT THIS LIST FOR MOST USAGES.
!

Questions?
44

Thank You! To get started with TIBET visit: www.technicalpursuit.com
45
45:00


















