
Things Every Oracle DBA Needs to Know About the Hadoop Ecosystem (c17lv version)
70
Session ID: Prepared by: Things Every Oracle DBA Needs to Know about the Hadoop Ecosystem 690 Zohar Elkayam, Brillix @realmgic https://www.realdbamagic.com
-
Upload
zohar-elkayam -
Category
Technology
-
view
152 -
download
0
Transcript of Things Every Oracle DBA Needs to Know About the Hadoop Ecosystem (c17lv version)

Session ID:
Prepared by:
Things Every Oracle DBA Needs to Know about the Hadoop Ecosystem
690
Zohar Elkayam, Brillix
@realmgic
https://www.realdbamagic.com

April 2-6, 2017 in Las Vegas, NV USA #C17LV
Who am I?
• Zohar Elkayam, CTO at Brillix
• Programmer, DBA, team leader, database trainer, public speaker, and a senior consultant for over 19 years
• Oracle ACE Associate
• Member of ilOUG – Israel Oracle User Group
• Involved with Big Data projects since 2011
• Blogger – www.realdbamagic.com and www.ilDBA.co.il
2

April 2-6, 2017 in Las Vegas, NV USA #C17LV
About Brillix
• We offer complete, integrated end-to-end solutions based on best-of-breed innovations in database, security and big data technologies
• We provide complete end-to-end 24x7 expert remote database services
• We offer professional customized on-site trainings, delivered by our top-notch world recognized instructors
3

April 2-6, 2017 in Las Vegas, NV USA #C17LV
Some of Our Customers
4

April 2-6, 2017 in Las Vegas, NV USA #C17LV
Agenda
• What is the Big Data challenge?
• A Big Data Solution: Apache Hadoop• HDFS
• MapReduce and YARN
• Hadoop Ecosystem: HBase, Sqoop, Hive, Pig and other tools
• Another Big Data Solution: Apache Spark
• Where does the DBA fits in?
5

Please Complete Your Session Evaluation
Evaluate this session in your COLLABORATE app. Pull up this session and tap "Session Evaluation" to complete the survey.
Session ID: 670

The Challenge
7

April 2-6, 2017 in Las Vegas, NV USA #C17LV
The Big Data Challenge
8

April 2-6, 2017 in Las Vegas, NV USA #C17LV
Volume
• Big data comes in one size: Big.
• Size is measured in Terabyte (1012), Petabyte (1015), Exabyte (1018), Zettabyte (1021)
• The storing and handling of the data becomes an issue
• Producing value out of the data in a reasonable time is an issue
9

April 2-6, 2017 in Las Vegas, NV USA #C17LV
Variety
• Big Data extends beyond structured data, including semi-structured and unstructured information: logs, text, audio and videos
• Wide variety of rapidly evolving data types requires highly flexible stores and handling
10
Un-Structured Structured
Objects Tables
Flexible Columns and Rows
Structure Unknown Predefined Structure
Textual and Binary Mostly Textual

April 2-6, 2017 in Las Vegas, NV USA #C17LV
Velocity
• The speed in which data is being generated and collected
• Streaming data and large volume data movement
• High velocity of data capture – requires rapid ingestion
• Might cause a backlog problem
11

April 2-6, 2017 in Las Vegas, NV USA #C17LV
Value
Big data is not about the size of the data,
It’s about the value within the data
12

April 2-6, 2017 in Las Vegas, NV USA #C17LV
So, We Define Big Data Problem…
• When the data is too big or moves too fast to handle in a sensible amount of time
• When the data doesn’t fit any conventional database structure
• When we think that we can still produce value from that data and want to handle it
• When the technical solution to the business need becomes part of the problem
13

How to do Big Data
14

15

April 2-6, 2017 in Las Vegas, NV USA #C17LV
Big Data in Practice
• Big data is big: technological framework and infrastructure solutions are needed
• Big data is complicated: • We need developers to manage handling of the data
• We need devops to manage the clusters
• We need data analysts and data scientists to produce value
16

April 2-6, 2017 in Las Vegas, NV USA #C17LV
Possible Solutions: Scale Up
• Older solution: using a giant server with a lot of resources (scale up: more cores, faster processers, more memory) to handle the data• Process everything on a single server with hundreds
of CPU cores
• Use lots of memory (1+ TB)
• Have a huge data store on high end storage solutions
• Data needs to be copied to the processes in real time, so it’s no good for high amounts of data (Terabytes to Petabytes)
17

April 2-6, 2017 in Las Vegas, NV USA #C17LV
Distributed Solution
• A scale-out solution: let’s use distributed systems; use multiple machine for a single job/application
• More machines means more resources• CPU
• Memory
• Storage
• But the solution is still complicated: infrastructure and frameworks are needed
18

April 2-6, 2017 in Las Vegas, NV USA #C17LV
Infrastructure Challenges
• We need Infrastructure that is built for:• Large-scale• Linear scale out ability• Data-intensive jobs that spread the problem across
clusters of server nodes
• Storage: efficient and cost-effective enough to capture and store terabytes, if not petabytes, of data
• Network infrastructure that can quickly import large data sets and then replicate it to various nodes for processing
• High-end hardware is too expensive - we need a solution that uses cheaper hardware
19

April 2-6, 2017 in Las Vegas, NV USA #C17LV
Distributed System/Frameworks Challenges
• How do we distribute our workload across the system?
• Programming complexity – keeping the data in sync
• What to do with faults and redundancy?
• How do we handle security demands to protect highly-distributed infrastructure and data?
20

A Big Data Solution:Apache Hadoop
21

April 2-6, 2017 in Las Vegas, NV USA #C17LV
Apache Hadoop
• Open source project run by Apache Foundation (2006)
• Hadoop brings the ability to cheaply process large amounts of data, regardless of its structure
• It Is has been the driving force behind the growth of the big data industry
• Get the public release from:• http://hadoop.apache.org/core/
22

April 2-6, 2017 in Las Vegas, NV USA #C17LV
Original Hadoop Components
• HDFS (Hadoop Distributed File System) –distributed file system that runs in a clustered environment
• MapReduce – programming paradigm for running processes over a clustered environment
• Hadoop main idea: let’s distribute the data to many servers, and then bring the program to the data
23

April 2-6, 2017 in Las Vegas, NV USA #C17LV
Hadoop Benefits
• Designed for scale out
• Reliable solution based on unreliable hardware
• Load data first, structure later
• Designed for storing large files
• Designed to maximize throughput of large scans
• Designed to leverage parallelism
• Solution Ecosystem
24

April 2-6, 2017 in Las Vegas, NV USA #C17LV
What Hadoop Is Not?
• Hadoop is not a database – it is not a replacement for DW, or other relational databases
• Hadoop is not commonly used for OLTP/real-time systems
• Very good for large amounts, not so much for smaller sets
• Designed for clusters – there is no Hadoop monster server (single server)
25

April 2-6, 2017 in Las Vegas, NV USA #C17LV
Hadoop Limitations
• Hadoop is scalable but it’s not very fast
• Some assembly might be required
• Batteries are not included (DIY mindset) – some features needs to be developed if they’re not available
• Open source license limitations apply
• Technology is changing very rapidly
26

Hadoop under the Hood
27

April 2-6, 2017 in Las Vegas, NV USA #C17LV
Original Hadoop 1.0 Components
• HDFS (Hadoop Distributed File System) –distributed file system that runs in a clustered environment
• MapReduce – programming technique for running processes over a clustered environment
28

April 2-6, 2017 in Las Vegas, NV USA #C17LV
Hadoop 2.0
• Hadoop 2.0 changed the Hadoop conception and introduced a better resource management concept:• Hadoop Common
• HDFS
• YARN
• Multiple data processing frameworks including MapReduce, Spark and others
29

April 2-6, 2017 in Las Vegas, NV USA #C17LV
HDFS is...
• A distributed file system
• Designed to reliably store data using commodity hardware
• Designed to expect hardware failures and still stay resilient
• Intended for larger files
• Designed for batch inserts and appending data (no updates)
30

April 2-6, 2017 in Las Vegas, NV USA #C17LV
Files and Blocks
• Files are split into 128MB blocks (single unit of storage)• Managed by NameNode and stored on DataNodes
• Transparent to users
• Replicated across machines at load time• Same block is stored on multiple machines
• Good for fault-tolerance and access
• Default replication factor is 3
31

April 2-6, 2017 in Las Vegas, NV USA #C17LV
HDFS is Good for...
• Storing large files• Terabytes, Petabytes, etc...
• Millions rather than billions of files
• 128MB or more per file
• Streaming data• Write once and read-many times patterns
• Optimized for streaming reads rather than random reads
33

April 2-6, 2017 in Las Vegas, NV USA #C17LV
HDFS is Not So Good For...
• Low-latency reads / Real-time application• High-throughput rather than low latency for small
chunks of data• HBase addresses this issue
• Large amount of small files• Better for millions of large files instead of billions of
small files
• Multiple Writers• Single writer per file• Writes at the end of files, no-support for arbitrary
offset
34

April 2-6, 2017 in Las Vegas, NV USA #C17LV
Using HDFS in Command Line
35
April 2-6, 2017 in Las Vegas, NV USA #C17LV
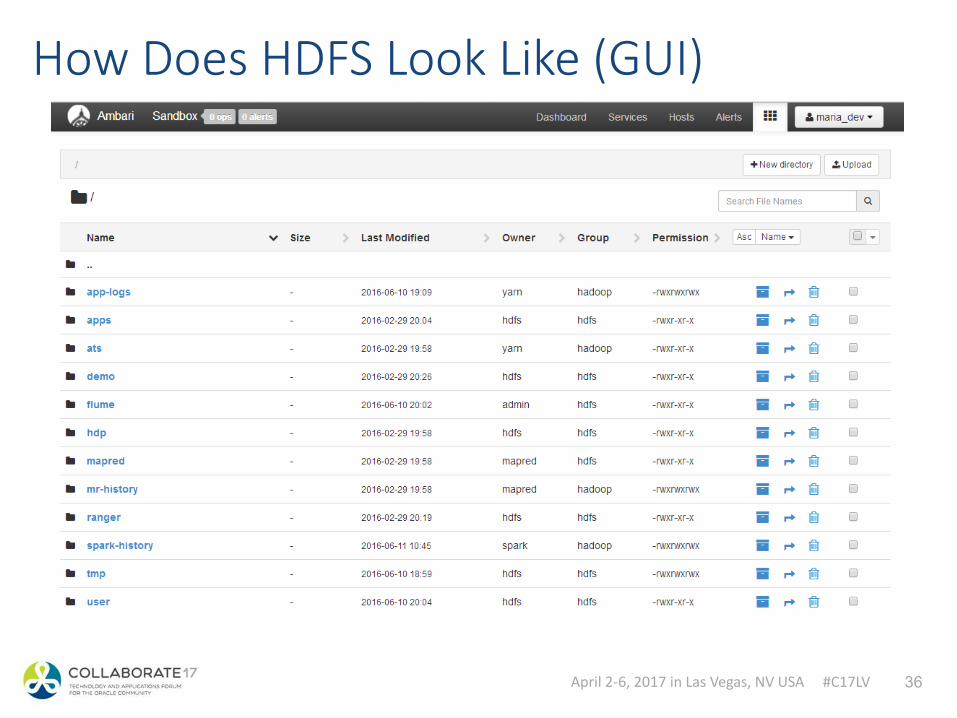
How Does HDFS Look Like (GUI)
36

April 2-6, 2017 in Las Vegas, NV USA #C17LV
Interfacing with HDFS
37

April 2-6, 2017 in Las Vegas, NV USA #C17LV
MapReduce is...
• A programming model for expressing distributed computations at a massive scale
• An execution framework for organizing and performing such computations
• MapReduce can be written in Java, Scala, C, Python, Ruby and others
• Concept: Bring the code to the data, not the data to the code
38

April 2-6, 2017 in Las Vegas, NV USA #C17LV
The MapReduce Paradigm
• Imposes key-value input/output
• We implement two main functions:• MAP - Takes a large problem and divides into sub problems
and performs the same function on all sub-problemsMap(k1, v1) -> list(k2, v2)
• REDUCE - Combine the output from all sub-problems (each key goes to the same reducer)Reduce(k2, list(v2)) -> list(v3)
• Framework handles everything else (almost)
39

April 2-6, 2017 in Las Vegas, NV USA #C17LV
MapReduce Word Count Process
40

April 2-6, 2017 in Las Vegas, NV USA #C17LV
YARN Features
• Takes care of distributed processing and coordination
• Scheduling• Jobs are broken down into smaller chunks called tasks
• These tasks are scheduled to run on data nodes
• Task Localization with Data• Framework strives to place tasks on the nodes that
host the segment of data to be processed by that specific task
• Code is moved to where the data is
41

April 2-6, 2017 in Las Vegas, NV USA #C17LV
YARN Features (2)
• Error Handling• Failures are an expected behavior so tasks are
automatically re-tried on other machines
• Data Synchronization• Shuffle and Sort barrier re-arranges and moves data
between machines
• Input and output are coordinated by the framework
42

April 2-6, 2017 in Las Vegas, NV USA #C17LV
YARN Framework Support
• With YARN, we can go beyond the Hadoop ecosystem
• Support different frameworks:• MapReduce v2
• Spark
• Giraph
• Co-Processors for Apache HBase
• More…
43

April 2-6, 2017 in Las Vegas, NV USA #C17LV
Submitting a Job
• Yarn script with a class argument command launches a JVM and executes the provided Job
44
$ yarn jar HadoopSamples.jar mr.wordcount.StartsWithCountJob \/user/sample/hamlet.txt \/user/sample/wordcount/

April 2-6, 2017 in Las Vegas, NV USA #C17LV
Resource Manage: UI
45

April 2-6, 2017 in Las Vegas, NV USA #C17LV
Application View
46

April 2-6, 2017 in Las Vegas, NV USA #C17LV
Hadoop Main Problems
• Hadoop MapReduce Framework (not MapReduce paradigm) had some major problems:• Developing MapReduce was complicated – there was
more than just business logics to develop
• Transferring data between stages requires the intermediate data to be written to disk (and than read by the next step)
• Multi-step needed orchestration and abstraction solutions
• Initial resource management was very painful –MapReduce framework was based on resource slots
47

Extending HadoopThe Hadoop Ecosystem

April 2-6, 2017 in Las Vegas, NV USA #C17LV
Improving Hadoop: Distributions
• Core Hadoop is complicated so some tools and solution frameworks were added to make things easier
• There are over 80 different Apache projects for big data solution which uses Hadoop (and growing!)
• Hadoop Distributions collects some of these tools and release them as a complete integrated package• Cloudera
• HortonWorks
• MapR
• Amazon EMR
49

April 2-6, 2017 in Las Vegas, NV USA #C17LV
Common HADOOP 2.0 Technology Eco System
50

April 2-6, 2017 in Las Vegas, NV USA #C17LV
Improving Programmability
• MapReduce code in Java is sometime tedious, so different solutions came to the rescue• Pig: Programming language that simplifies Hadoop
actions: loading, transforming and sorting data
• Hive: enables Hadoop to operate as data warehouse using SQL-like syntax
• Spark and other frameworks
51

April 2-6, 2017 in Las Vegas, NV USA #C17LV
Pig
• Pig is an abstraction on top of Hadoop• Provides high level programming language designed for
data processing
• Scripts converted into MapReduce code, and executed on the Hadoop Clusters
• Makes ETL/ELT processing and other simple MapReduce easier without writing MapReduce code
• Pig was widely accepted and used by Yahoo!, Twitter, Netflix, and others
• Often replaced by more up-to-date tools like Apache Spark
52

April 2-6, 2017 in Las Vegas, NV USA #C17LV
Hive
• Data Warehousing Solution built on top of Hadoop
• Provides SQL-like query language named HiveQL• Minimal learning curve for people with SQL expertise
• Data analysts are target audience
• Early Hive development work started at Facebook in 2007
• Hive is an Apache top level project under Hadoop• http://hive.apache.org
53

April 2-6, 2017 in Las Vegas, NV USA #C17LV
Hive Provides
• Ability to bring structure to various data formats
• Simple interface for ad hoc querying, analyzing and summarizing large amounts of data
• Access to files on various data stores such as HDFS and HBase
• Also see: Apache Impala (mainly in Cloudera)
54

April 2-6, 2017 in Las Vegas, NV USA #C17LV
Databases and DB Connectivity
• HBase: Online NoSQL Key/Value wide-column oriented datastore that is native to HDFS
• Sqoop: a tool designed to import data from and export data to relational databases (HDFS, Hbase, or Hive)
• Sqoop2: Sqoop centralized service (GUI, WebUI, REST)
55

April 2-6, 2017 in Las Vegas, NV USA #C17LV
HBase
• HBase is the closest thing we had to database in the early Hadoop days
• Distributed key/value with wide-column oriented NoSQL database, built on top of HDFS
• Providing Big Table-like capabilities
• Does not have a query language: only get, put, and scan commands
• Often compared with Cassandra (non-Hadoop native Apache project)
56

April 2-6, 2017 in Las Vegas, NV USA #C17LV
When Do We Use HBase?
• Huge volumes of randomly accessed data
• HBase is at its best when it’s accessed in a distributed fashion by many clients (high consistency)
• Consider HBase when we are loading data by key, searching data by key (or range), serving data by key, querying data by key or when storing data by row that doesn’t conform well to a schema.
57

April 2-6, 2017 in Las Vegas, NV USA #C17LV
When NOT To Use HBase
• HBase doesn’t use SQL, don’t have an optimizer, doesn’t support transactions or joins
• HBase doesn’t have data types
• See project Apache Phoenix for better data structure and query language when using HBase
58

April 2-6, 2017 in Las Vegas, NV USA #C17LV
Sqoop and Sqoop2
• Sqoop is a command line tool for moving datafrom RDBMS to Hadoop. Sqoop2 is a centralizedtool for running sqoop.
• Uses MapReduce load the data from relational database to HDFS
• Can also export data from HBase to RDBMS
• Comes with connectors to MySQL, PostgreSQL, Oracle, SQL Server and DB2.
59
$bin/sqoop import --connect 'jdbc:sqlserver://10.80.181.127;username=dbuser;password=dbpasswd;database=tpch' \
--table lineitem --hive-import
$bin/sqoop export --connect 'jdbc:sqlserver://10.80.181.127;username=dbuser;password=dbpasswd;database=tpch' \
--table lineitem --export-dir /data/lineitemData

April 2-6, 2017 in Las Vegas, NV USA #C17LV
Improving Hadoop – More Useful Tools
• For improving coordination: Zookeeper
• For improving scheduling/orchestration: Oozie
• Data Storing in memory: Apache Impala
• For Improving log collection: Flume
• Text Search and Data Discovery: Solr
• For Improving UI and Dashboards: Hue and Ambari
60

April 2-6, 2017 in Las Vegas, NV USA #C17LV
Improving Hadoop – More Useful Tools (2)
• Data serialization: Avro and Parquet (columns)
• Data governance: Atlas
• Security: Knox and Ranger
• Data Replication: Falcon
• Machine Learning: Mahout
• Performance Improvement: Tez
• And there are more…
61

62

April 2-6, 2017 in Las Vegas, NV USA #C17LV
Is Hadoop the Only Big Data Solution?
• No – There are other solutions:• Apache Spark and Apache Mesos frameworks
• NoSQL systems (Apache Cassandra, CouchBase, MongoDB and many others)
• Stream analysis (Apache Kafka, Apache Storm, Apache Flink)
• Machine learning (Apache Mahout, Spark MLlib)
• Some can be integrated with Hadoop, but some are independent
63

April 2-6, 2017 in Las Vegas, NV USA #C17LV
Another Big Data Solution: Apache Spark
• Apache Spark is a fast, general engine for large-scale data processing on a cluster
• Originally developed by UC Berkeley in 2009 as a research project, and is now an open source Apache top level project
• Main idea: use the memory resources of the cluster for better performance
• It is now one of the most fast-growing project today
64

April 2-6, 2017 in Las Vegas, NV USA #C17LV
The Spark Stack
65

April 2-6, 2017 in Las Vegas, NV USA #C17LV
Spark and Hadoop
• Spark and Hadoop are built to co-exist• Spark can use other storage systems (S3, local disks, NFS) but
works best when combined with HDFS• Uses Hadoop InputFormats and OutputFormats• Fully compatible with Avro and SequenceFiles as well of other types
of files
• Spark can use YARN for running jobs• Spark interacts with the Hadoop ecosystem:
• Flume• Sqoop (watch out for DDoS on the database…)• HBase• Hive
• Spark can also interact with tools outside the Hadoop ecosystem: Kafka, NoSQL, Cassandra, XAP, Relational databases, and more
66

April 2-6, 2017 in Las Vegas, NV USA #C17LV
Okay, So Where Does the DBA Fits In?
• Big Data solutions are not databases. Databases are probably not going to disappear, but we feel the change even today: DBA’s must be ready for the change
• DBA’s are the perfect candidates to transition into Big Data Experts:• Have system (OS, disk, memory, hardware) experience
• Can understand data easily
• DBA’s are used to work with developers and other data users
67

April 2-6, 2017 in Las Vegas, NV USA #C17LV
What DBAs Needs Now?
• DBA’s will need to know more programming: Java, Scala, Python, R or any other popular language in the Big Data world will do
• DBA’s needs to understand the position shifts, and the introduction of DevOps, Data Scientists, CDO etc.
• Big Data is changing daily: we need to learn, read, and be involved before we are left behind…
68

April 2-6, 2017 in Las Vegas, NV USA #C17LV
Summary
• Big Data is here – it’s complicated and RDBMS does not fit anymore
• Big Data solutions are evolving Hadoop is an example for such a solution
• Spark is very popular Big Data solution
• DBA’s need to be ready for the change: Big Data solutions are not databases and we make ourselves ready
69

Q&A

April 2-6, 2017 in Las Vegas, NV USA #C17LV
Thank You and
Don’t Forget To Evaluate (670)
Zohar Elkayamtwitter: @[email protected]
www.realdbamagic.com
71


















