
Business Statistics for Managerial Decision Inference for proportions.

The Planning-by-Inference view on decision
making and goal-directed behaviour
Marc Toussaint
Machine Learning & Robotics Lab – FU Berlin
Nov. 14, 2011
1/20

pigeons
2/20

pigeons
Wolfgang Kohler (1917)
Intelligenzprufungen am
Menschenaffen
The Mentality of Apes
2/20

Richard E. Bellman (1920-1984)Bellman’s principle of optimality
A
B
A opt ⇒ B opt
V (s) = maxa
[
R(a, s) + γ∑
s′P (s′ | a, s) V (s′)
]
π(s) = argmaxa
[
R(a, s) + γ∑
s′P (s′ | a, s) V (s′)
]
⇒ Dynamic Programming, recursing backward
Reinforcement Learning (Q-learning, etc)
the paradigm of goal-directed decision making nowadays
– value function over full state space → curse of dimensionality
– distinguished role of rewards
3/20

4/20

von Neumann
(1903-1957)
Morgenstern
(1902-1977)
Shachter
(Stanford)
Cooper
(Pittsburgh)
utility/reward/success
∼ just another state (random) variable
Shachter/Cooper/Peot (1988):
inference P (behavior |R = 1)
– I think: idea was sleeping for 15 years
– should have had great influence on thinking about behavior!
– a group of MLs independently rediscovered this recently5/20

Planning by Inference
things you know/
current state
things to do/
actions
things you want to
see in the future
X
ZY
A
We condition on goals/desired observations and infer actions/motion.
6/20

OBSERVATIONS
CONSTRAINTS
GOALS
CU
RR
EN
T S
TA
TE
ACTIONS
– assume permanent “relaxation process”
7/20

OBSERVATIONS
CONSTRAINTS
GOALS
CU
RR
EN
T S
TA
TE
ACTIONS
– assume permanent “relaxation process”
– “imagining a goal” means conditioning a variable → the
network relaxes into a new posterior, implying new actions
7/20

OBSERVATIONS
CONSTRAINTS
GOALS
CU
RR
EN
T S
TA
TE
ACTIONS
– assume permanent “relaxation process”
– “imagining a goal” means conditioning a variable → the
network relaxes into a new posterior, implying new actions
• works for networks of goals, constraints, observations, etc.
7/20
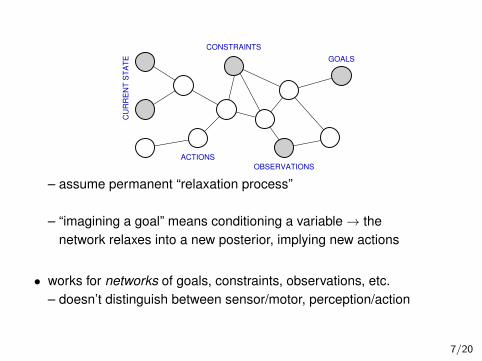
OBSERVATIONS
CONSTRAINTS
GOALS
CU
RR
EN
T S
TA
TE
ACTIONS
– assume permanent “relaxation process”
– “imagining a goal” means conditioning a variable → the
network relaxes into a new posterior, implying new actions
• works for networks of goals, constraints, observations, etc.
– doesn’t distinguish between sensor/motor, perception/action
7/20

OBSERVATIONS
CONSTRAINTS
GOALS
CU
RR
EN
T S
TA
TE
ACTIONS
– assume permanent “relaxation process”
– “imagining a goal” means conditioning a variable → the
network relaxes into a new posterior, implying new actions
• works for networks of goals, constraints, observations, etc.
– doesn’t distinguish between sensor/motor, perception/action
– we got rid of notion of state as one big variable
7/20

Markov Decision Processes
a0
s0
r0
a1
s1
r1
a2
s2
r2
Problem: Find argmaxπV π = E{
∑
∞
t=0 γt rt;π}, γ ∈ [0, 1]
8/20

Markov Decision Processes
a0
s0
r0
a1
s1
r1
a2
s2
r2
Problem: Find argmaxπV π = E{
∑
∞
t=0 γt rt;π}, γ ∈ [0, 1]
• Planning by Inference:
Define another stochastic process (mixture of finite-time MDPs) s.t.
Max. Likelihood Lπ = P (R = 1;π) in this process
⇐⇒
Max. Value V π in the MDP
(Toussaint & Storkey, ICML 2006)
8/20
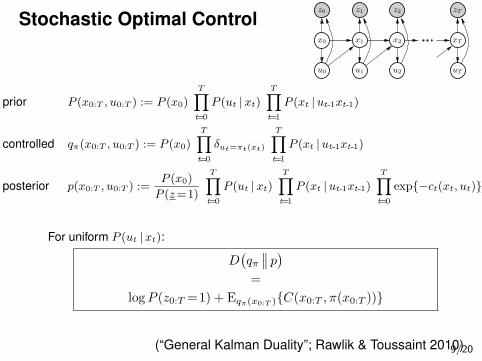
Stochastic Optimal Controlx2
u2
z2
x1
u1
z1
xT
uT
zT
x0
z0
u0
prior P (x0:T , u0:T ) := P (x0)
T∏
t=0
P (ut |xt)
T∏
t=1
P (xt |ut-1xt-1)
controlled qπ(x0:T , u0:T ) := P (x0)
T∏
t=0
δut=πt(xt)
T∏
t=1
P (xt |ut-1xt-1)
posterior p(x0:T , u0:T ) :=P (x0)
P (z=1)
T∏
t=0
P (ut |xt)
T∏
t=1
P (xt |ut-1xt-1)
T∏
t=0
exp{−ct(xt, ut)}
For uniform P (ut |xt):
D(
qπ∣
∣
∣
∣ p)
=
logP (z0:T =1) + Eqπ(x0:T ){C(x0:T , π(x0:T ))}
(“General Kalman Duality”; Rawlik & Toussaint 2010)9/20

MDPs
(Toussaint, Storkey, ICML 2006)
s
aT
xT
r
a0
a0 a1
a2a1a0
a0 a1 a2
r
r
r
s0
s0 s1
s1 s2s0
s0 s1 s2
Relational RL
(Lang, Toussaint, ICML 2009)
Network-Distributed POMDP
(Kumar, Toussaint, Zilberstein, IJCAI
2011)
hierarchical POMDP
(Charlin, Poupart, Toussaint, UAI 2008)n2
n1
n0
y
s s′
y′
a
n′0
e0
e1
n′2
n′1
10/20

Planning by Inference ...
• An alternative framework when
– exact Bellman is infeasible
– approximate inference can exploit structure
• Literature on reductions to Probabilistic Inference:
Toussaint & Storkey: Probabilistic inference for solving discrete and continuous stateMarkov Decision Processes (ICML 2006).
Todorov: General duality between optimal control and estimation (Decision and Control,2008)
Toussaint: Robot Trajectory Optimization using Approximate Inference (ICML 2009).
Kappen, Gomez & Opper: Optimal control as a graphical model inference problem(arXiv:0901.0633, 2009)
Rawlik, Toussaint & Vijayakumar: Approximate Inference and Stochastic Optimal Control(arXiv:1009.3958, 2010)
11/20

Random exploration:
Relational explore-exploit:
Planning:
Real-world:
12/20

Neural perspective
13/20

Neural perspective
Matthew Botvinick
(Princeton)
Goal-directed decision making in prefrontal cortex:
A computational framework (NIPS 2008)
“We take three empirically motivated points as found-
ing premises: (1) Neurons in dorsolateral prefrontal cor-
tex represent action policies, (2) Neurons in orbitofrontal
cortex represent rewards, and (3) Neural computation,
across domains, can be appropriately understood as per-
forming structured probabilistic inference. [...]”
... essentially proposes Planning by Inference
13/20

Karl Friston (UCL)
Karl J. Friston, Jean Daunizeau, James Kilner, Ste-
fan J. Kiebel: Action and behavior: a free-energy
formulation, Biol Cyb.
“minimize sensory prediction error (free-energy)
through action”
Expectation Maximization and Free Energy Minimization are
equivalent.
14/20

15/20

Inference in neural systems
Bayesian Brain: Probabilistic Approaches to Neural Coding. K. Doya,
S. Ishii, A. Pouget, RPN. Rao (editors), MIT Press (2007)
Hierarchical Bayesian Inference in Networks of Spiking Neurons.
Rajesh P. N. Rao (NIPS 2004)
The Neurodynamics of Belief Propagation on Binary Markov Random
Fields. T. Ott, R. Stoop (NIPS 2006)
current work by Wolfgang Maas ...
16/20

Johnson & Redish (J o Neuroscience, 2007): Neural ensembles in CA3
transiently encode paths forward of the animal at a decision point
17/20

Theories of thought
Rick Grush (Behavioral and Brain Sciences, 2004):
The emulation theory of representation: motor control, imagery, and
perception.
(20 pages + 46 pages commentary & response!)
Keywords: Kalman filters, overt & covert actions, imagery
18/20

Theories of thought
G. Hesslow (Trends in Cog Sciences, 2002):
Conscious thought as simulation of behaviour and perception.
A ‘simulation’ theory of cognitive function can be based on three
assumptions about brain function.
(1) First, behaviour can be simulated by activating motor structures,
as during an overt action but suppressing its execution.
(2) Second, perception can be simulated by internal activation of
sensory cortex, as during normal perception of external stimuli.
(3) Third, both overt and covert actions can elicit perceptual
simulation of their normal consequences.
A large body of evidence supports these assumptions. It is argued
that the simulation approach can explain the relations between
motor, sensory and cognitive functions and the appearance of an
inner world.
19/20

• Thanks to all collaborators:
– PhD students:
Tobias Lang, Nikolay Jetchev, Stanio Dragiev
– Pascal Poupart, Laurent Charlin (U Waterloo)
– Nikos Vlassis (U Crete)
– Michael Gienger, Christian Goerick (Honda, Offenbach)
– Klaus-Robert Muller, Manfred Opper (TU Berlin)
– Amos Storkey, Stefan Harmeling, Sethu Vijayakumar (U Edinburgh)
• thanks for your attention!
• Source code:
on my webpage: code for AICO, DDP/iLQG, EM-POMDP solver
on Tobias’ webpage: code for PRADA
20/20













![Grounding Natural Language Instructions to Semantic Goal ... · decision-making problem [Gopalan et al., 2017]. In parallel, performing a single inference to arrive at the inter-mediate](https://static.fdocuments.us/doc/165x107/5f57fcb11ebfc64d9b4a3488/grounding-natural-language-instructions-to-semantic-goal-decision-making-problem.jpg)


![Unsupervised gene network inference with decision trees ... · Unsupervised gene network inference with decision trees and Random forests ... (e.g. [6–13]), usually achieving competitive](https://static.fdocuments.us/doc/165x107/5ec8fd42a1b3d77468653010/unsupervised-gene-network-inference-with-decision-trees-unsupervised-gene-network.jpg)

