![ALEXANDER GNEDIN AND GRIGORI OLSHANSKI arXiv:1103… filearxiv:1103.1498v1 [math.pr] 8 mar 2011 the two-sided infinite extension of the mallows model for random permutations alexander](https://static.fdocuments.us/doc/165x107/5e1708839c74ff68200c9cc0/alexander-gnedin-and-grigori-olshanski-arxiv1103-11031498v1-mathpr-8-mar-2011.jpg)
The Kendall and Mallows Kernels for Permutations€¦ · Kendall and Mallows Kernels for...
25
Poster Session 6E Tonight! The Kendall and Mallows Kernels for Permutations Yunlong Jiao & Jean-Philippe Vert MINES ParisTech ICML Lille, July 8, 2015 1 / 25
Transcript of The Kendall and Mallows Kernels for Permutations€¦ · Kendall and Mallows Kernels for...

Poster Session 6E Tonight!
The Kendall and Mallows Kernels for Permutations
Yunlong Jiao & Jean-Philippe Vert
MINES ParisTech
ICML Lille, July 8, 2015
1 / 25

Introduction
Recommender system,e.g. CollaborativeFiltering.
Learn from converted rankings,e.g., gene expression dataanalysis for leukemiaclassification [Tan et al., 2005].
– Data: n × p matrix (p � n).
– Rule: if SPTAN1 ≥ CD33then ALL; else AML.
– Accuracy: 93.80% (LOOCV).
2 / 25

Introduction
Recommender system,e.g. CollaborativeFiltering.
Learn from converted rankings,e.g., gene expression dataanalysis for leukemiaclassification [Tan et al., 2005].
– Data: n × p matrix (p � n).
– Rule: if SPTAN1 ≥ CD33then ALL; else AML.
– Accuracy: 93.80% (LOOCV).
3 / 25

Outline
1 Data type
– Rankings and permutations.
2 Methods
– Computationally efficient kernels for total rankings, partialrankings and rankings converted from quantitative vectors.
3 Experiments
– High-dimensional classification in biomedical applications.
4 / 25

Total Rankings and Permutations
A total ranking is a strict ordering of n items {x1, x2, . . . , xn} ,
xi1 � xi2 � · · · � xin .
A permutation is a rearrangement of n indices,
σ : {1, 2, . . . , n} → {1, 2, . . . , n} such that σ(i) 6= σ(j) for i 6= j .
A total ranking is equivalently represented by a permutationif σ maps item index to item rank, e.g.,
x2 � x4 � x3 � x1
⇐⇒ σ =
(2 4 3 14 3 2 1
)— index— rank
⇐⇒ σ(1) = 1, σ(2) = 4, σ(3) = 2, σ(4) = 3 .
5 / 25

Total Rankings and Permutations
A total ranking is a strict ordering of n items {x1, x2, . . . , xn} ,
xi1 � xi2 � · · · � xin .
A permutation is a rearrangement of n indices,
σ : {1, 2, . . . , n} → {1, 2, . . . , n} such that σ(i) 6= σ(j) for i 6= j .
A total ranking is equivalently represented by a permutationif σ maps item index to item rank, e.g.,
x2 � x4 � x3 � x1
⇐⇒ σ =
(2 4 3 14 3 2 1
)— index— rank
⇐⇒ σ(1) = 1, σ(2) = 4, σ(3) = 2, σ(4) = 3 .
6 / 25

Kendall tau Distance for Permutations
Kendall tau distance [Kendall, 1938]counts the number of discordant pairsbetween permutations, i.e.,
nd(σ, σ′) =∑i<j
1σ(i)<σ(j)1σ′(i)>σ′(j)
+ 1σ(i)>σ(j)1σ′(i)<σ′(j) .
The number of concordant pairsbetween permutations is
nc(σ, σ′) =
(n
2
)− nd(σ, σ′) .
E.g.,
index e 1 2 3 4
rank σ 2 3 4 1rank σ′ 3 1 4 2
nd(σ, σ′) = 1 + 1 + 0 = 2
nc(σ, σ′) =4(4− 1)
2−2 = 4
7 / 25

Kendall tau Distance for Permutations
Kendall tau distance [Kendall, 1938]counts the number of discordant pairsbetween permutations, i.e.,
nd(σ, σ′) =∑i<j
1σ(i)<σ(j)1σ′(i)>σ′(j)
+ 1σ(i)>σ(j)1σ′(i)<σ′(j) .
The number of concordant pairsbetween permutations is
nc(σ, σ′) =
(n
2
)− nd(σ, σ′) .
E.g.,
index e 1 2 3 4
rank σ 2 3 4 1rank σ′ 3 1 4 2
nd(σ, σ′) = 1 + 1 + 0 = 2
nc(σ, σ′) =4(4− 1)
2−2 = 4
8 / 25

Kendall and Mallows Kernels for Permutations
The Kendall tau coefficient is definedas
Kτ (σ, σ′) =nc(σ, σ′)− nd(σ, σ′)(n
2
) .
The Mallows measure is defined forany λ ≥ 0 by
KλM(σ, σ′) = e−λnd (σ,σ′) .
E.g.,
index e 1 2 3 4
rank σ 2 3 4 1rank σ′ 3 1 4 2
Kτ (σ, σ′) =4− 2
6=
1
3
KλM(σ, σ′) = e−2λ, λ ≥ 0
Theorem (Main theorem)
These two similarity measures for permutations are positive definitekernels.
9 / 25

Kendall and Mallows Kernels for Permutations
The Kendall tau coefficient is definedas
Kτ (σ, σ′) =nc(σ, σ′)− nd(σ, σ′)(n
2
) .
The Mallows measure is defined forany λ ≥ 0 by
KλM(σ, σ′) = e−λnd (σ,σ′) .
E.g.,
index e 1 2 3 4
rank σ 2 3 4 1rank σ′ 3 1 4 2
Kτ (σ, σ′) =4− 2
6=
1
3
KλM(σ, σ′) = e−2λ, λ ≥ 0
Theorem (Main theorem)
These two similarity measures for permutations are positive definitekernels.
10 / 25

Kendall and Mallows Kernels for Permutations
The Kendall kernel is defined as
Kτ (σ, σ′) =nc(σ, σ′)− nd(σ, σ′)(n
2
) .
The Mallows kernel is defined for any λ ≥ 0 by
KλM(σ, σ′) = e−λnd (σ,σ′) .
Theorem (Main theorem)
These two kernels for permutations are positive definite.
Proof.
Consider the explicit kernel mapping
Φ : Sn → R(n2), σ 7→(
sgn(σ(i)− σ(j)))
1≤i<j≤n.
The Kendall and Mallows kernel correspond respectively to a linearand Gaussian kernel on a
(n2
)-dimensional embedding of Sn.
11 / 25

Kendall and Mallows Kernels for Permutations
The Kendall kernel is defined as
Kτ (σ, σ′) =nc(σ, σ′)− nd(σ, σ′)(n
2
) .
The Mallows kernel is defined for any λ ≥ 0 by
KλM(σ, σ′) = e−λnd (σ,σ′) .
Theorem (Main theorem)
These two kernels for permutations are positive definite.
Theorem ([Knight, 1966])
These two kernels for permutations can be evaluated in O(n log n)time.
12 / 25

Convolution Kendall Kernel for Partial Rankings
Two interesting types of partial rankings are interleavingpartial ranking
xi1 � xi2 � · · · � xik , k ≤ n.
and top-k partial ranking
xi1 � xi2 � · · · � xik � Xrest, k ≤ n.
Partial rankings can be uniquely represented by a set ofpermutations compatible with all the observed partial orders.
Theorem
For these two particular types of partial rankings, the convolutionkernel [Haussler, 1999] induced by Kendall kernel
K ?τ (R,R ′) =
1
|R||R ′|∑σ∈R
∑σ′∈R′
Kτ (σ, σ′)
can be evaluated in O(k log k) time.
13 / 25

Convolution Kendall Kernel for Partial Rankings
Two interesting types of partial rankings are interleavingpartial ranking
xi1 � xi2 � · · · � xik , k ≤ n.
and top-k partial ranking
xi1 � xi2 � · · · � xik � Xrest, k ≤ n.
Partial rankings can be uniquely represented by a set ofpermutations compatible with all the observed partial orders.
Theorem
For these two particular types of partial rankings, the convolutionkernel [Haussler, 1999] induced by Kendall kernel
K ?τ (R,R ′) =
1
|R||R ′|∑σ∈R
∑σ′∈R′
Kτ (σ, σ′)
can be evaluated in O(k log k) time.14 / 25

Stabilized Kendall Kernel for Quantitative Vectors
−3 −2 −1 0 1 2 3
−1.0
−0.5
0.0
0.5
1.0
xi − xj
ΦijΨij
Kendall mapping for quantitative vectors isdiscrete-valued and very sensitive to “almostties”, i.e.,
Φ : Rn → R(n2), x 7→(1xi>xj − 1xi<xj
)1≤i<j≤n
.
We propose a noise-corrupted kernel mapping instead(similarly to [Muandet et al., 2012])
Ψ(x) = EΦ(x + ε︸ ︷︷ ︸x
) =(P (xi > xj)− P (xi < xj)
)1≤i<j≤n
.
Kendall kernel stabilized alternative is given by
G(x, x′
)= Ψ(x)>Ψ(x′) = EKτ (x, x′) .
15 / 25

Mallows Kernel vs. Diffusion Kernel over Sn
Figure : Cayley graph of S4.
Diffusion kernel[Kondor and Lafferty, 2002] isdefined by
Kβdif(σ, σ
′) = [eβ∆]σ,σ′ ,
where ∆ is the graph laplacian.
Mallows kernel is written as
KλM(σ, σ′) = e−λnd (σ,σ′) ,
where nd(σ, σ′) = dG(σ, σ′) theshortest path distance on graph.
16 / 25

Gene Expression Data
Datasets
Dataset No. of features No. of samples (training/test)C1 C2
Breast Cancer 1 23624 44/7 (Non-relapse) 32/12 (Relapse)Breast Cancer 2 22283 142 (Non-relapse) 56 (Relapse)Breast Cancer 3 22283 71 (Poor Prognosis) 138 (Good Prognosis)
Colon Tumor 2000 40 (Tumor) 22 (Normal)Lung Cancer 1 7129 24 (Poor Prognosis) 62 (Good Prognosis)Lung Cancer 2 12533 16/134 (ADCA) 16/15 (MPM)
Medulloblastoma 7129 39 (Failure) 21 (Survivor)Ovarian Cancer 15154 162 (Cancer) 91 (Normal)
Prostate Cancer 1 12600 50/9 (Normal) 52/25 (Tumor)Prostate Cancer 2 12600 13 (Non-relapse) 8 (Relapse)
Methods
Kernel machines Support Vector Machines (SVM) and KernelFisher Discriminant (KFD) with Kendall kernel, linear kernel,Gaussian RBF kernel, polynomial kernel.
Top Scoring Pairs (TSP) classifiers [Tan et al., 2005].
Hybrid scheme of SVM + TSP feature selection algorithm.17 / 25
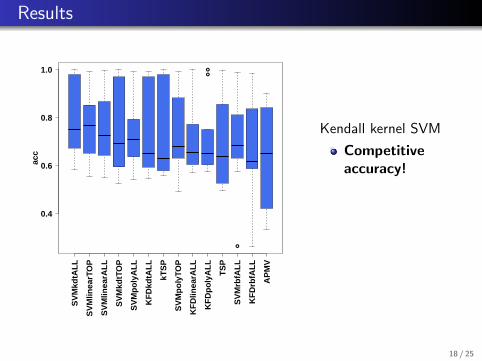
Results
●
●
●
SV
Mkd
tALL
SV
Mlin
earT
OP
SV
Mlin
earA
LL
SV
Mkd
tTO
P
SV
Mpo
lyA
LL
KF
Dkd
tALL
kTS
P
SV
Mpo
lyTO
P
KF
Dlin
earA
LL
KF
Dpo
lyA
LL TS
P
SV
Mrb
fALL
KF
Drb
fALL
AP
MV
0.4
0.6
0.8
1.0
acc
Kendall kernel SVM
Competitiveaccuracy!
Insensitive to Cparameter!
No featureselection!
18 / 25

Results
1e−02 1e+00 1e+02
0.3
0.4
0.5
0.6
0.7
0.8
0.9
BC1
C parameter
acc
●
SVMlinearALLSVMkdtALLSVMpolyALLSVMrbfALLKFDlinearALLKFDkdtALLKFDpolyALLKFDrbfALL
Kendall kernel SVM
Competitiveaccuracy!
Insensitive to Cparameter!
No featureselection!
19 / 25

Results
1 5 10 50 500 5000
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1.0
PC1
Number k of top gene pairs
acc
●
SVMlinearTOPSVMkdtTOPSVMpolyTOPkTSPSVMlinearALLSVMkdtALLSVMpolyALLTSPAPMV
Kendall kernel SVM
Competitiveaccuracy!
Insensitive to Cparameter!
No featureselection!
20 / 25

Results
●
● ●
●
●●
●
●
● ●
●
●
●
●
●
●
●
●●
●
1e+01 1e+02 1e+03 1e+04 1e+05
0.60
0.62
0.64
0.66
0.68
0.70
MB
Noise window size a
cvac
c
● SVMkdtALLalt−−exactSVMkdtALLalt−−MCapprox (D=1)SVMkdtALLalt−−MCapprox (D=3)SVMkdtALLalt−−MCapprox (D=5)SVMkdtALLalt−−MCapprox (D=7)SVMkdtALLalt−−MCapprox (D=9)SVMkdtALL
Kendall kernel SupportMeasure Machines[Muandet et al., 2012]
Improvedaccuracy!
−3 −2 −1 0 1 2 3
−1.0
−0.5
0.0
0.5
1.0
xi − xj
ΦijΨij
21 / 25

Conclusion
Poster Session 6E Tonight!
IF you are dealing with ranking-related problems,
IF your problem can be formulated in a way that some kernelmachine can cope with,
DO throw Kendall and Mallows kernel into that kernel machine!
22 / 25

Acknowledgments
This work was supported by theEuropean Union 7th FrameworkProgram through the Marie CurieITN MLPM grant No 316861, andby the European Research Councilgrant ERC-SMAC-280032.
23 / 25

References I
Haussler, D. (1999).
Convolution kernels on discrete structures.
Technical Report UCSC-CRL-99-10, UC Santa Cruz.
Kendall, M. G. (1938).
A new measure of rank correlation.
Biometrika, 30(1/2):81–93.
Knight, W. R. (1966).
A computer method for calculating Kendall’s tau with ungrouped data.
J. Am. Stat. Assoc., 61(314):436–439.
Kondor, I. R. and Lafferty, J. (2002).
Diffusion kernels on graphs and other discrete input spaces.
In Proceedings of the Nineteenth International Conference on MachineLearning, volume 2, pages 315–322, San Francisco, CA, USA. MorganKaufmann Publishers Inc.
24 / 25

References II
Muandet, K., Fukumizu, K., Dinuzzo, F., and Scholkopf, B. (2012).
Learning from distributions via support measure machines.
In Pereira, F., Burges, C. J. C., Bottou, L., and Weinberger, K. Q.,editors, Adv. Neural. Inform. Process Syst., volume 25, pages 10–18.Curran Associates, Inc.
Tan, A. C., Naiman, D. Q., Xu, L., Winslow, R. L., and Geman, D.(2005).
Simple decision rules for classifying human cancers from gene expressionprofiles.
Bioinformatics, 21(20):3896–3904.
25 / 25


















