
The Human Apolipoprotein C-I1 Gene Sequence Contains a ... · The minisatellite DNA sequence at...
7
THE JOURNAL OF BIOLOGICAL CHEMISTRY 0 1987 by The American Society of Biological Chemista, Inc. Vol . 262, No. 10, Issue of April 5, pp. 4787-4793,1987 Printed in U. S. A. The Human Apolipoprotein C-I1 Gene Sequence Contains a Novel Chromosome 19-specific Minisatellite in Its Third Intron* (Received for publication, May 19, 1986) Hriday K. DasS, Cynthia L. Jacksong, Dorothy A. MillerT, Todd LeffS, and Jan L. BreslowSII From $The Rockefeller University, New York, NewYork 10021, §Massachusetts Institute of Technology, Cambridge,Massachusetts 02139, and 7 Wayne State University, Detroit, Michigan 48201 The human apolipoprotein C-I1 gene was sequenced and found to contain four exons and three introns, with a major transcription initiation site located 26 base pairs downstream from a TATA sequence element. The third intron was found to be composed almost entirely of a novel 37-base pair minisatellite that is repeated six times. The minisatellite sequence was found to be present in approximately 60 different genomic loca- tions. The minisatellite DNA sequence at three of these loci were compared and found to be highly conserved. In situ hybridization indicated that the minisatellite loci were clustered in the q13.3 band of chromosome 19. This is the first example of a chromosome- and band-specific repetitive element in the mammalian ge- nome. Apolipoprotein C-I1 (apoC-11)’ is a major component of very low density lipoprotein anda minor component of high density lipoprotein (1, 2). ApoC-I1 plays an important role in lipoprotein metabolism as a cofactor for the enzyme lipopro- tein lipase (triacylglycerol acylhydrolase EC 3.1.1.3) (3-5). Previous work has defined the sequence of apoC-I1 cDNA clones and the chromosomal location of the gene (6-8). In the process of determining the nucleotide sequence of the apoC- I1 gene, we have identified a novel 37-bp element repeated six times in its third intron. This minisatellite appears to be present at approximately 60 locations in the genome. Se- quencing two additional locations revealed that the first con- tained one repeat and the second, approximately 22 repeats. All of these characterized loci were remarkably similar with high conservation of nucleotide sequence. In situ hybridiza- tion strongly suggested that this element occurs uniquely on the long arm of chromosome 19. MATERIALS AND METHODS Genomic Cloning and Sequencing-The apoC-I1 genomic clone in phage X charon 4A (X C-11) was isolated from a human genomic library constructed by Dr. Thomas Maniatis, Harvard University (9) using an apoC-I1 cDNA probe (6). A cosmid (COS CII) clone was isolated from a library made with DNA from a human B cell line JY Grants HL33714 and AG04727, March of Dimes Birth Defects Foun- *This research was supported by National Institutes of Health dation Grant 1-950, as well as general support from the Pew Trusts. The costs of publication of this article were defrayed in part by the payment of page charges. This article must therefore be hereby marked “advertisement” in accordance with 18 U.S.C. Section 1734 solely to indicate this fact. The nucleotide sequence(s) reported in this paper has been submitted to the GenBankTM/EMBL Data Bank with accession number(s) 502698. (1 Established Investigator of the American Heart Association. The abbreviations used are: apoC-11, apolipoprotein C-11; bp, base pair; kb, kilobase; IVS, intervening sequence. (from Dr. S. M. Weissman, Yale University) using a 300-bp probe from the 5’ flanking region of the X C-I1 genomic clone. Two additional cosmid clones were isolated, one from the JY cell library (COS 4C) using a probe specific for the 37-bp minisatellite sequence (the insert of PE670, described below) and the other from a cosmid library (10) using a probe isolated from the 5’ end of a cosmid clone containing the apoE and apoC-I genes (11). AluI restric- tion fragments from these cosmids were cloned into M13, and sub- clones hybridizing tothe PE670 insert probe were isolated and sequenced. Subclones in pUC18 were made using standard methods (12). DNA fragments were digested with appropriate restriction en- zymes, blunt ended with either T4 DNA polymerase or Escherichia coli DNA polymerase (Klenow), ligated to HincII cut M13 Mp8 vector, and transfected into JMlOlcells. Dideoxynucleotide sequencing was performed according to Sanger et al. (13). A 17-nucleotide-long uni- versal sequencing primer was used (New England Biolabs). Maxam and Gilbert (14) sequencing was performed as described. long primer with the sequence 5’-d[AGCTGGGAGGAGTCGTGT Primer Extension and SI Nuclease Mapping-A 24-nucleotide- GCCCATI-3’, complementary to the mRNA sequence coding for the first 8 amino acids of apoC-I1 (7), was labeled at the 5’ end with [y- 32P]ATP by polynucleotide kinase, hybridized to poly(A+) RNA iso- lated from HepG2 cells, and extended by reverse transcriptase (15). The products of the extension reaction were isolated by elution from polyacrylamide gels and sequenced according to Maxam and Gilbert (14). S1 nuclease mapping and RNA purification were carried out essentially as described (16). A 5’-end-labeled single-stranded DNA probe, complementary to the coding strand from -204 to +28 (relative to the start site of transcription), was hybridized to 10 pg of cyto- plasmic RNA purified from HepG2 cells. After treatment of the hybrids with S1 nuclease, the protected DNA fragments were electro- phoresed on 8% polyacrylamide-50%urea gels and autoradiographed. Chromosomal Mapping of the 37-bp Repeats-Metaphase chromo- some preparations were made from normal female leukocytes in short term culture (17). Slides were stained with quinacrine HC1, photo- graphed, and passed through a xylene and an alcohol series before storage under vacuum at room temperature. The probe for insitu hybridization was made from a plasmid (PE670) containing a 670-bp genomic PstI-EcoRI fragment that extends from the 3’ end of intron 2 to the 3’ untranslated region of exon 4. This region contains all the 37-bp repeats found in the IVS- 3 of the apoC-I1gene. The whole plasmid (500 ng) was nick translated with tritiated deoxynucleotides (Amersham Corp.) to a specific activ- ity of 3 X lo7 cpm/pg. Hybridization of the metaphase chromosome preparation to the 3H-labeled probe was carried out in buffer contain- ing 50% formamide-10% dextran sulfate at 37 “C for 17 h (18). The slides were washed at 39 “C, coated with Ilford K2 emulsion, and stored at 4 “C. The slides were developed at various times up to 21 days and restained with Giemsa, and the location of individual grains was recorded using prints of previously photographed cells. Southern Transfer Analysis-Human, monkey, mouse, and chicken DNA were digested with EcoRI and HindIII, electrophoresed on a 0.7% agarose gel, transferred to nitrocellulose filters, and hybridized to the nick translated PE670bp insert probe. Hybridization was carried out at 65 “C in 4 X SSC, 5% dextran sulfate, 2 X Denhart’s, 0.1% sodium dodecyl sulfate, 1 mM EDTA, and 25 pg/ml salmon sperm DNA. The filters were washed three times for 15 min with 0.1 X SSC and 0.1% sodium dodecyl sulfate at room temperature, and twice for 15 min at 55 “C. 4787
-
Upload
nguyenkhuong -
Category
Documents
-
view
215 -
download
0
Transcript of The Human Apolipoprotein C-I1 Gene Sequence Contains a ... · The minisatellite DNA sequence at...

THE JOURNAL OF BIOLOGICAL CHEMISTRY 0 1987 by The American Society of Biological Chemista, Inc.
Vol . 262, No. 10, Issue of April 5, pp. 4787-4793,1987 Printed in U. S. A.
The Human Apolipoprotein C-I1 Gene Sequence Contains a Novel Chromosome 19-specific Minisatellite in Its Third Intron*
(Received for publication, May 19, 1986)
Hriday K. DasS, Cynthia L. Jacksong, Dorothy A. MillerT, Todd LeffS, and Jan L. BreslowSII From $The Rockefeller University, New York, New York 10021, §Massachusetts Institute of Technology, Cambridge, Massachusetts 02139, and 7 Wayne State University, Detroit, Michigan 48201
The human apolipoprotein C-I1 gene was sequenced and found to contain four exons and three introns, with a major transcription initiation site located 26 base pairs downstream from a TATA sequence element. The third intron was found to be composed almost entirely of a novel 37-base pair minisatellite that is repeated six times. The minisatellite sequence was found to be present in approximately 60 different genomic loca- tions. The minisatellite DNA sequence at three of these loci were compared and found to be highly conserved. In situ hybridization indicated that the minisatellite loci were clustered in the q13.3 band of chromosome 19. This is the first example of a chromosome- and band-specific repetitive element in the mammalian ge- nome.
Apolipoprotein C-I1 (apoC-11)’ is a major component of very low density lipoprotein and a minor component of high density lipoprotein (1, 2). ApoC-I1 plays an important role in lipoprotein metabolism as a cofactor for the enzyme lipopro- tein lipase (triacylglycerol acylhydrolase EC 3.1.1.3) (3-5). Previous work has defined the sequence of apoC-I1 cDNA clones and the chromosomal location of the gene (6-8). In the process of determining the nucleotide sequence of the apoC- I1 gene, we have identified a novel 37-bp element repeated six times in its third intron. This minisatellite appears to be present at approximately 60 locations in the genome. Se- quencing two additional locations revealed that the first con- tained one repeat and the second, approximately 22 repeats. All of these characterized loci were remarkably similar with high conservation of nucleotide sequence. In situ hybridiza- tion strongly suggested that this element occurs uniquely on the long arm of chromosome 19.
MATERIALS AND METHODS
Genomic Cloning and Sequencing-The apoC-I1 genomic clone in phage X charon 4A ( X C-11) was isolated from a human genomic library constructed by Dr. Thomas Maniatis, Harvard University (9) using an apoC-I1 cDNA probe (6). A cosmid (COS CII) clone was isolated from a library made with DNA from a human B cell line JY
Grants HL33714 and AG04727, March of Dimes Birth Defects Foun- *This research was supported by National Institutes of Health
dation Grant 1-950, as well as general support from the Pew Trusts. The costs of publication of this article were defrayed in part by the payment of page charges. This article must therefore be hereby marked “advertisement” in accordance with 18 U.S.C. Section 1734 solely to indicate this fact.
The nucleotide sequence(s) reported in this paper has been submitted to the GenBankTM/EMBL Data Bank with accession number(s) 502698.
( 1 Established Investigator of the American Heart Association. The abbreviations used are: apoC-11, apolipoprotein C-11; bp, base
pair; kb, kilobase; IVS, intervening sequence.
(from Dr. S. M. Weissman, Yale University) using a 300-bp probe from the 5’ flanking region of the X C-I1 genomic clone.
Two additional cosmid clones were isolated, one from the JY cell library (COS 4C) using a probe specific for the 37-bp minisatellite sequence (the insert of PE670, described below) and the other from a cosmid library (10) using a probe isolated from the 5’ end of a cosmid clone containing the apoE and apoC-I genes (11). AluI restric- tion fragments from these cosmids were cloned into M13, and sub- clones hybridizing to the PE670 insert probe were isolated and sequenced. Subclones in pUC18 were made using standard methods (12).
DNA fragments were digested with appropriate restriction en- zymes, blunt ended with either T4 DNA polymerase or Escherichia coli DNA polymerase (Klenow), ligated to HincII cut M13 Mp8 vector, and transfected into JMlOl cells. Dideoxynucleotide sequencing was performed according to Sanger et al. (13). A 17-nucleotide-long uni- versal sequencing primer was used (New England Biolabs). Maxam and Gilbert (14) sequencing was performed as described.
long primer with the sequence 5’-d[AGCTGGGAGGAGTCGTGT Primer Extension and SI Nuclease Mapping-A 24-nucleotide-
GCCCATI-3’, complementary to the mRNA sequence coding for the first 8 amino acids of apoC-I1 (7), was labeled at the 5’ end with [y- 32P]ATP by polynucleotide kinase, hybridized to poly(A+) RNA iso- lated from HepG2 cells, and extended by reverse transcriptase (15). The products of the extension reaction were isolated by elution from polyacrylamide gels and sequenced according to Maxam and Gilbert (14). S1 nuclease mapping and RNA purification were carried out essentially as described (16). A 5’-end-labeled single-stranded DNA probe, complementary to the coding strand from -204 to +28 (relative to the start site of transcription), was hybridized to 10 pg of cyto- plasmic RNA purified from HepG2 cells. After treatment of the hybrids with S1 nuclease, the protected DNA fragments were electro- phoresed on 8% polyacrylamide-50% urea gels and autoradiographed.
Chromosomal Mapping of the 37-bp Repeats-Metaphase chromo- some preparations were made from normal female leukocytes in short term culture (17). Slides were stained with quinacrine HC1, photo- graphed, and passed through a xylene and an alcohol series before storage under vacuum at room temperature.
The probe for in situ hybridization was made from a plasmid (PE670) containing a 670-bp genomic PstI-EcoRI fragment that extends from the 3’ end of intron 2 to the 3’ untranslated region of exon 4. This region contains all the 37-bp repeats found in the IVS- 3 of the apoC-I1 gene. The whole plasmid (500 ng) was nick translated with tritiated deoxynucleotides (Amersham Corp.) to a specific activ- ity of 3 X lo7 cpm/pg. Hybridization of the metaphase chromosome preparation to the 3H-labeled probe was carried out in buffer contain- ing 50% formamide-10% dextran sulfate at 37 “C for 17 h (18). The slides were washed at 39 “C, coated with Ilford K2 emulsion, and stored at 4 “C. The slides were developed at various times up to 21 days and restained with Giemsa, and the location of individual grains was recorded using prints of previously photographed cells.
Southern Transfer Analysis-Human, monkey, mouse, and chicken DNA were digested with EcoRI and HindIII, electrophoresed on a 0.7% agarose gel, transferred to nitrocellulose filters, and hybridized to the nick translated PE670bp insert probe. Hybridization was carried out at 65 “C in 4 X SSC, 5% dextran sulfate, 2 X Denhart’s, 0.1% sodium dodecyl sulfate, 1 mM EDTA, and 25 pg/ml salmon sperm DNA. The filters were washed three times for 15 min with 0.1 X SSC and 0.1% sodium dodecyl sulfate at room temperature, and twice for 15 min at 55 “C.
4787

4788 ApoC-II Gene Contains a Chromosome-specific Minisatellite
RESULTS
Analysis of ApoC-ZI Gene Structure-The cDNA clone pCII-711 (6) was used as a probe to isolate the apoC-I1 genomic clone from a charon 4A human genomic library (9). One of the positive clones, X CII, was selected for further analysis. The results of restriction enzyme analysis of this clone are shown in Fig. 1. The X CII 5' terminal 300-bp EcoRI fragment, the internal 3.5-kb EcoRI fragment, and the over- lapping 4.8-kb BurnHI fragment were cloned in pUC18. Sub- clones were made in M13 mp8 and sequenced by the dideoxy technique. Some DNA fragments were sequenced directly by the chemical degradation method. The sequence is shown in Fig. 2.
Comparison of the genomic sequence with the published cDNA sequence and with the sequence of primer extension products on HepG2 mRNA revealed three introns. The first intron (2386 bp) is located in the 5' noncoding region, the second (167 bp) interrupts the codon specifying amino acid residue -4 of the signal peptide, and the third (296 bp) interrupts the codon specifying amino acid residue 50 of the mature protein. There are four Alu-type repetitive elements present in the first intron (Fig. 2). The first and second elements are incomplete and do not contain any direct repeats, while the third and fourth are each composed of two Alu-type repetitive elements fused together and flanked by two direct repeats. Another interesting feature of this intron is a GT dinucleotide sequence element that is repeated 22 times. The third intron was found to be composed almost entirely of a previously undescribed 37-bp repetitive element (minisatel- lite). This element is described in further detail below.
The 5' end of the apoC-I1 mRNA was located by primer extension and S1 nuclease mapping of apoC-I1 mRNA. A 24- nucleotide-long primer complementary t o the mRNA se- quence coding for the first 8 amino acids of the apoC-I1 signal peptide was hybridized to poly(A+) RNA isolated from HepG2 cells and extended with reverse transcriptase (Fig. 3A). The three extension products were eluted from the gel and se- quenced by the method of Maxam and Gilbert. The most abundant product (Fig. 3A, bund 2) corresponds to the major site of transcription initiation. This was confirmed by S1 nuclease mapping of HepG2 cytoplasmic RNA that revealed a major protected band that maps to the same site (Fig. 3B).
z=z - " w " - 4 "
" 7
- " "
"
c .-" +-.
."" *.". *.." .~. ." .", .-.
FIG. 1. Restriction map of the apoC-I1 gene and sequence analysis strategy. Panel A, schematic restriction map showing the 300-bp and 3.5-kb long EcoRI fragments and the 4.8-kb BamHI fragment. Panel B, detailed restriction map of the CII gene. Exons are indicated by dotted rectangles. Restriction sites are abbreviated as follows: RZ, EcoRI, B, BamHI, P, PstI, S, SacI, T, TuqI, Rs, RsaI, Hf, H i d , D, DdeI, A , AluI, H, HaeIII. Dashed arrows indicate common restriction sites used for DNA sequencing. They may occur
the gene insert and an arm of the X charon 4A vector. Solid horizontal more frequently than indicated. RZ(L) represents the junction between
determined by the dideoxy method (13). Dashed horizontal arrows arrows indicate the direction and extent of nucleotide sequences
indicate the direction and extent of sequences determined by the Maxam and Gilbert method (14).
70
140
210
28u
350
420
490
550
6%
7 w
770
840
910
9Bu
1050
l l z o
~
A C P A G I K C T T G T C T T G T G T f f i RllTK GTGTTCTTTCTCCG533lCffi 16K'
R T C T C A C C C T C T T T C T G C C G T A C T T C C T C A T C T C C T ~ T G T ~ T f f i T ~ l ~ T T G T G C C C ~ G T ~ T 6 T 17% : a: :
FIG. 2. The DNA sequence of the apoC-I1 gene and flanking regions. Exons are underlined and the amino acid sequence is shown above the translated regions. The Alu sequences are labeled and their direct terminal repeats are boxed. The TATA box is indicated by an ouerline and the major cap site by +I. Asterisks are placed over the termination codon. The polyadenylation signals (AATAAA) are in- dicated by an ouerline. The 37-bp repeats in 1%-3 are numbered.

ApoC-11 Gene Contains a
Sn Leu Ser Ser Tyr Trp 6111 Sn Ala Ly. Thr Ala Ala 6111 Ikn Leu Tyr
TCT CTC Ta: M TIY: Tffi W6 Tcll I AuI 6cc 6cc c116 RRC CT6 TIY: 3294
Thr Tyr Thr 61y Ile Phe Thr kp 61n Val Leu Ser Val Leu Ly. 61y 61u
~ T ~ A C A ~ A n l T l ~ ~ ~ 6 ~ ~ ~ 6 T 6 ~ I R W 6 3713
FIG. 2-Continued
Chromosome-specific Minisatellite 61u W
APOC I1 Extension I
-
"2
-3
4789
FIG. 3. Primer extension and S1 nuclease mapping of the apoC-II mRNA 5' end. Panel A, autoradiogram showing cDNA extension products. Extension was primed by a 32P-5'-end-labeled 24-base long primer (50 pmol) hybridized to human HepG2 poly(A+) mRNA (80 pg) as described under "Materials and Methods." Three products are visible: a major product (band 2) of 66 nucleotides, and two minor products (bands I and 3) of 87 and 48 nucleotides, respec- tively. The position of the primer (24mer) is also marked. Panel B, S1 nuclease mapping of the 5' end of the C-I1 mRNA. Cytoplasmic RNA was hybridized to a R2P-5'-end-labeled DNA probe (complemen- tary to sequences from -204 to +28, relative to the start of transcrip- tion), treated with S1 nuclease (as described under "Materials and Methods"), and analyzed on an 8% polyacrylamide-50% urea gel (lane SI). A parallel dideoxy sequencing reaction (first three lanes) was carried out using a 32P-5'-end-labeled primer complementary to C-I1 mRNA sequences from +28 (5' end) to +9 (3' end). Dots indicate primary sites of initiation of transcription, with the major site indi- cated as +1. Panel C, the nucleotide sequence of the apoC-I1 promoter region showing the locations of the 5' end points of the primer extension products shown in panel A (solid triangles) and the end points of the S1 nuclease analysis shown in panel B (dots). End- labeled DNA from each band was eluted from gel fragments and sequenced by the Maxam and Gilbert method. The exact location of the 5' end point of band 1 is an estimate based on the size of the extension product. The major transcription start site is indicated as +I. Sequences complementary to the 24-mer oligonucleotide primer are underlined. The TATA box sequence is overlined.

4790 ApoC-11 Gene Contains a Chromosome-specific Minisatellite
A canonical TATA sequence resides 26 bp upstream of this site. Both the primer extension and S1 nuclease mapping techniques revealed an additional transcription initiation site (Fig. 3A, band 1, and 3B) 21 bp upstream from the major start site. The smallest product of the primer extension reaction (Fig. 3A, band 3) could not be confirmed by S1 mapping as a bona fide transcription initiation site. The data are summa- rized in Fig. 3C.
The 3’ untranslated region of the gene contains three different polyadenylation signals, AATAAA. The apoC-I1 cDNA sequences, reported by this and other laboratories (6- 8), indicate that the majority of apoC-I1 mRNA is polyaden- ylated 10 bp downstream from the first of these polyadenyl- ation signals.
Characterization of the 37-bp Minisatellite-The 37-bp min- isatellite is present in the third intron as five almost perfect tandem repeats and a partial sixth copy of the sequence. A computer search of the GenBank failed to find sequences homologous to this repeat, suggesting that it represents a new class of repetitive element.
An estimation of the number of sites in the genome that contain minisatellite sequences was made using a method similar to that described by Heller et al. (19). The cosmid library from the B cell line, JY (see “Materials and Methods”), containing 200,000 clones (2.5 genomes worth) was divided into 40 aliquots. Total DNA from seven of these aliquots was digested with EcoRI, subjected to electrophoresis, and trans- ferred to nitrocellulose filters. These filters were then hybrid- ized to the minisatellite-specific probe (PE670) as described under “Materials and Methods.” A total of 27 bands hybrid- izing to PE670 were present in these seven aliquots. Together these seven aliquots represent slightly less than half a genome and, therefore, the complete genome must contain approxi- mately 60 EcoRI fragments that contain this minisatellite sequence.
To obtain an idea of the sequence diversity of the minisat- ellite a t different genomic locations, two of these loci were isolated from cosmid libraries (see “Materials and Methods”) using a minisatellite-specific probe. The sequence of the re- peats at these loci (Fig. 4) reveals strong sequence conserva- tion. There was, however, a large difference in the number of repeats at each locus. While the apoC-I1 gene contains five and one-half repeats the COS 20 locus contains less than one copy (28 bp) and the COS 4C locus contains approximately 22 copies.
To examine the phylogenetic distribution of this minisatel- lite, the PE670bp probe was hybridized to Southern blots containing EcoRI or HindIII digested human, monkey, mouse, and chicken DNA. As shown in Fig. 5, the probe hybridized to distinct fragments of the human, monkey, and mouse genomes. The pattern of hybridizing bands indicates that the repeat is present in low copy number in the human, monkey,
A c T T C A G C “ C C C C A G C C C - T c c T c c c T c A c A c c c A c c A G T C C A c G “ C C T C A G C C C - T c c T c c c T c A c A c c c A c c
A G T C C A C C - T C C C C A G A C C C T C C T C C C T C A C A C C C A C C A G T C C A G C - C C C C C A G C C C C T C C T C C C T C A C A C C C A C C
A G T C C A C c - C C C C C A G C C C C T c c . f c c c T c
A C T C A A C A - C C C C C A G C C C C T c c T c c c T c A c A c c c A c c A c T C A A C ~ A C C C C C A G C C C C T c c T c c c l c A c A c c c A c c A G T C A A C A A C C C C C A C C C C C T c c T c c c T c A c A c c c A c c
Ivs-3 A G T C C A G C - C C C C C A G C C C C T c c T c c c T c A c A c c c A c c
c o s 4 c A G T C A A C A C C C C C C A G C C C C T c c ~ c c c T c A c A c T c A T c A C T C C A C A - C C C C C A C C C C C T ~ ~ T ~ ~ ~ T ~ A ~ A ~ ~ ~ A ~ ~ A C T C C A C A - C C C C C A C C C C C T C C T C C C T C A C A C C C A C C A C T C C A C A - C C C C C A C C C C C T c c . f c c c T c A c A c c c A G c A C T C C A G G ” C C C C A - C C C C T C
cos 20 C c ” C C C - A C - C C C T C C T C C c T c A c A T c c A c c
FIG. 4. The nucleotide sequence of the minisatellites deter- mined from the IVS-3 of the apoC-I1 gene, COS 4C, and COS 20. The nucleotide sequence was determined by the dideoxy method (13).
1 2 3 4 5
23kb -
9.4kb - 6.5 kb -
6.5kb-
4.4kb- .. .-
4.4kb-
2 3 k b - 2kb -
e 2.3 kb -
2kb-
FIG. 5. Southern transfer analysis of restriction enzyme- digested human, monkey, mouse, and chicken genomic DNA hybridized to the 37-bp minisatellite probe (670 bp, PstI- EcoRI) as described under “Materials and Methods.”. Lanes I and 2, DNA (10 pg) from human B cell line J Y digested with EcoRI and HindIII, respectively. Lanes 3-5, DNA (IO pg) from monkey, mouse, and chicken, respectively, digested with EcoRI. The size markers on the left are HindIII-digested X DNA.
and rodent genomes but is not present in the chicken genome. The single band seen in the genomic blot may be due to the presence of an apoC-I1 related sequence in the chicken ge- nome.
The chromosomal distribution of the minisatellite DNA was investigated by in situ hybridization. Human metaphase chromosomes from female leukocytes were identified by band- ing with quinacrine HCl (Fig. 6A) and hybridized to the ‘H- labeled PE670 plasmid. The slides were exposed for up to 21 days prior to development and single grains were visualized (Fig. 6B). 622 grains were scored in 52 cells. 24% of the total grains were located in the region 19q13.3-qter. The distribu- tion of silver grains over the remaining chromosome regions appeared to be random and at background level (Fig. 7).
DISCUSSION
We have determined the sequence of the apoC-I1 gene and its flanking regions and mapped the transcription initiation sites of the apoC-I1 messenger RNA. The major initiation site is located 26 bp downstream from a canonical TATA se- quence, while a minor initiation site was located 21 bp up- stream from the major start site near the TATA box. The apoC-I1 gene has a four-exon, three-intron structure that strongly resembles those of the apoA-I, apoA-11, apoC-111, and apoE genes.
The third intron of the apoC-I1 gene is composed almost entirely of a 37-bp minisatellite element that is repeated six times. Homologous sequences were not revealed in a search of the GenBank data base and, therefore, this minisatellite represents a new class of repetitive element. This repeat was found to be present in approximately 60 different locations in the human genome. The sequence of the minisatellite at three of these loci suggested that the sequence was strongly con- served from one locus to the next (Fig. 4), while the number of repeats at any given locus varies substantially. While the
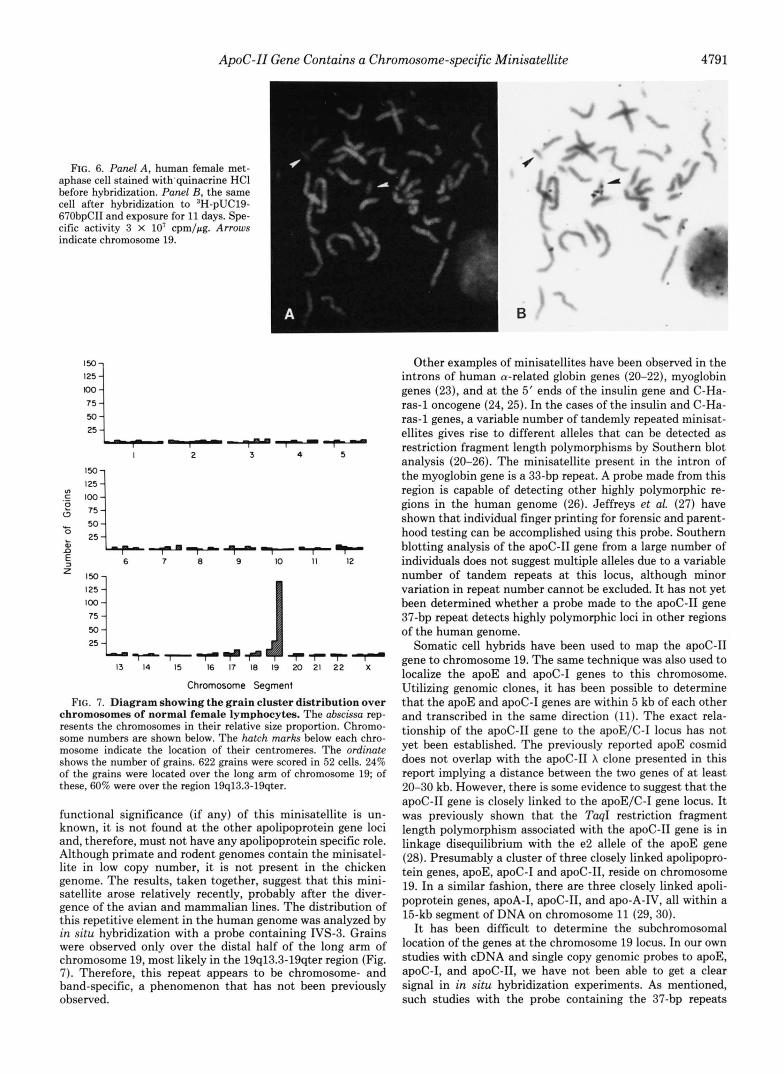
ApoC-11 Gene Contains a Chromosome-specific Minisatellite 4791
FIG. 6. Panel A , human female met- aphase cell stained with'quinacrine HCl before hybridization. Panel B, the same cell after hybridization to 3H-pUC19- 67ObpCII and exposure for 11 days. Spe- cific activity 3 X lo' cpm/pg. Arrows indicate chromosome 19.
'L 50 25 I 1"- 2 3 4 5
,E "i /:L 50 25 ?"+* 7 7 7 r
a 0
e c 50
n 8 25 +?""
E, 6 7 8 9 10 11 12
13 14 15 16 17 18 19 20 21 22 X
Chromosome Segment FIG. 7. Diagram showing the grain cluster distribution over
chromosomes of normal female lymphocytes. The abscissa rep- resents the chromosomes in their relative size proportion. Chromo- some numbers are shown below. The hatch marks below each chro- mosome indicate the location of their centromeres. The ordinate shows the number of grains. 622 grains were scored in 52 cells. 24% of the grains were located over the long arm of chromosome 19; of these, 60% were over the region 19q13.3-19qter.
functional significance (if any) of this minisatellite is un- known, it is not found at the other apolipoprotein gene loci and, therefore, must not have any apolipoprotein specific role. Although primate and rodent genomes contain the minisatel- lite in low copy number, it is not present in the chicken genome. The results, taken together, suggest that this mini- satellite arose relatively recently, probably after the diver- gence of the avian and mammalian lines. The distribution of this repetitive element in the human genome was analyzed by in situ hybridization with a probe containing IVS-3. Grains were observed only over the distal half of the long arm of chromosome 19, most likely in the 19q13.3-19qter region (Fig. 7). Therefore, this repeat appears to be chromosome- and band-specific, a phenomenon that has not been previously observed.
Other examples of minisatellites have been observed in the introns of human a-related globin genes (20-22), myoglobin genes (23), and at the 5' ends of the insulin gene and C-Ha- ras-1 oncogene (24,25). In the cases of the insulin and C-Ha- ras-1 genes, a variable number of tandemly repeated minisat- ellites gives rise to different alleles that can be detected as restriction fragment length polymorphisms by Southern blot analysis (20-26). The minisatellite present in the intron of the myoglobin gene is a 33-bp repeat. A probe made from this region is capable of detecting other highly polymorphic re- gions in the human genome (26). Jeffreys et al. (27) have shown that individual finger printing for forensic and parent- hood testing can be accomplished using this probe. Southern blotting analysis of the apoC-I1 gene from a large number of individuals does not suggest multiple alleles due to a variable number of tandem repeats at this locus, although minor variation in repeat number cannot be excluded. It has not yet been determined whether a probe made to the apoC-I1 gene 37-bp repeat detects highly polymorphic loci in other regions of the human genome.
Somatic cell hybrids have been used to map the apoC-I1 gene to chromosome 19. The same technique was also used to localize the apoE and apoC-I genes to this chromosome. Utilizing genomic clones, it has been possible to determine that the apoE and apoC-I genes are within 5 kb of each other and transcribed in the same direction (11). The exact rela- tionship of the apoC-I1 gene to the apoE/C-I locus has not yet been established. The previously reported apoE cosmid does not overlap with the apoC-I1 X clone presented in this report implying a distance between the two genes of at least 20-30 kb. However, there is some evidence to suggest that the apoC-I1 gene is closely linked to the apoE/C-I gene locus. It was previously shown that the TaqI restriction fragment length polymorphism associated with the apoC-I1 gene is in linkage disequilibrium with the e2 allele of the apoE gene (28). Presumably a cluster of three closely linked apolipopro- tein genes, apoE, apoC-I and apoC-11, reside on chromosome 19. In a similar fashion, there are three closely linked apoli- poprotein genes, apoA-I, apoC-11, and apo-A-IV, all within a 15-kb segment of DNA on chromosome 11 (29,30).
It has been difficult to determine the subchromosomal location of the genes at the chromosome 19 locus. In our own studies with cDNA and single copy genomic probes to apoE, apoC-I, and apoC-11, we have not been able to get a clear signal in in situ hybridization experiments. As mentioned, such studies with the probe containing the 37-bp repeats

4792 ApoC-II Gene Contains a Chromosome-specific Minisatellite TABLE I
Discrepancies in the nucleotide sequence of the apoC-ZZ gene between Wei, et al. and the current paper Numbers indicate nucleotide Dositions in Fia. 7 in Ref. 31 and in Fig. 2 in this paper, respectively.
Wei et al. Das et a1
Nucleotide position
1. 379 2.437 3. 522 4.632
6.662 7.685 8.702
5.646-652
9.726-730 10. 740-742 11.765-766 12.1140-1141 13.1235 14.1241 15. 1292 16.1303 17.1328
19.1451 20.1458 21.1521 22.1534 23.1614 24.1617 25. 1637 26.1666 27.166&1670 28.1934 29.1963-1964 30.1980 31. 1985 32. 2012 33.2048 34.2081 35.2137 36.2158 37.2267 38.2359 39.2468-2484 40.2489 41.2523
43.2610 44.2649 45.2684 46.2688-2690 47.2718 48.2725 49.2734 50.2739-2743 51.2748 52.2756 53.2816 54.2824
18.1400-1402
42.2549-2552
55.2859-2865 56.3131-3136 57.3364-3365 58.3400 59.3436
61.3543 62.3595 63.3879 64.3897 65. 3904
60.3476-3479
C G G
GAAGCGA 2 As
T GT, 8 times
AAGCT AG, 8 times
CCT T C AA 2 cs T 6 As G A TGA G C T A (TaqI site missing) C
C 13 As
A TAC 2 cs GC
G G (BgZI site missing)
G 4 cs G C T 2 Gs
TGGGTGGCATTGAGCCC 3 cs T 3 As ATCT T G A ATC 3 As GA T GATGC (HinfI site missing) 3 As A A A (SacI site missing) GGGGGCT CCCTTG AC 4 cs 4 cs CTCT C 4 cs C T C
1.360 2.418 3.503 4.612
6.643 7.666 8. 711 9. 733-737
10.747-750 11.773-775 12.1149-1150 13.1244 14. 1251 15.1301 16. 1313 17.1337 18. 1410-1412 19. 1461 20.1468 21.1531 22. 1544 23. 1625 24. 1628 25.1646 26.1675 27.1677-1678 28. 1942 29.1972
31.1994 32. 2021 33.2057 34.2086 35. 2145 36.2166 37.2275 38.2366
40.2496
42. 2557-2562 43.2620 44.2659
5.627-633
30.1988-1989
39.2476-2491
41.2530-2533
45.2694-2695 46.2699-2703 47. 2731 48.2739 49. 2747 50. 2752-2756 51.2761 52.2168 53.2828 54. 2836 55. 2871-2876 56.3143-3149 57. 3375 58.3410 59.3445 60.3484 61.3548 62.3600 63.3883 64.3901 65. 3908
Equivalent position
T C T 3 As AGAGGCA A GT, 22 times AG, 7 times AGTCT GCCC CTC TG 3 cs C
A 7 As
ATG 2 As
C T A GA (Confirmed Tag1 site) T 11 As A G T C 3 cs C GC (Confirmed EglI site) C C 3 cs A T G G 4 cs AGGTTGCAGTGAGCCG C GAGA CAAAAA G A AG GATTC 4 As A G GAATC (Confirmed HinfI site) 2 As G C T (Confirmed SacI site) GTGGGC GGGCTCT (No AC found) 3 cs 3 cs G T 3 cs G C G

ApoC-11 Gene Contains a Chromosome-specific Minisatellite 4793
suggest that this cluster maps to the 19q13.3-qter region. However, a recent study with somatic cell hybridization panels containing a rearranged chromosome 19 suggested apoC-I1 mapped to a more proximal location, 19cen-q13.2 (Human Gene Mapping 8). Thus, either the probe used in our in situ hybridization experiments is detecting repeat struc- tures that are mainly located distal to the apoC-I1 gene, or the somatic cell hybrid chromosome 19 rearrangement was complex and the apoC-I1 gene is not located in the 19cen- q13.2 region. We are currently trying to map these genes by in situ hybridization with a new set of probes that can give clear signals yet not contain the 37-bp repeat.
After the completion of this work, Wei et al. (31) published the structure of the human apoC-I1 gene. Comparison of these sequences reveals substantial differences (summarized in Ta- ble I). One of the more striking differences in these two sequences is in the number of GT dinucleotide repeats in the first intron. The Wei et al. sequence contains 8 GT repeats followed by 8 GA repeats, while in the sequence presented here, the GT repeat occurs 22 times followed by 7 GA repeats. This difference could be explained if the two sequences are of a different allele of the apoC-I1 gene. To investigate this possibility, we isolated an apoC-I1 cosmid clone from an independent human genomic library made from the B cell line JY. The sequence of this clone reveals 21 GT repeats followed by 7 GA repeats. Therefore, the apoC-I1 gene derived from the cosmid represents a different allele than the one derived from X CII. It is possible that the apoC-I1 gene sequenced by Wei et al. represents yet a third apoC-I1 allele. There are many other discrepancies between the sequence presented in Fig. 2 and that of Wei et al. and it is not clear whether these discrepancies are due to allelic differences or errors in sequencing.
Acknowledgments-We wish to thank Dr. Thomas Newman for his computer analyses of the data and Lorraine M. Duda for her help in preparing the manuscript.
REFERENCES 1. Breslow, J. L. (1985) Annu. Reu. Biochem. 54,699-727 2. Smith, L. C., Pownall, H. J., and Gotto, A. M., Jr. (1978) Annu.
Rev. Bwchem. 47, 751-777 3. Havel, R. J., Shore, V. G., Shore, B., and Bier, D. M. (1970) Circ.
Res. 33,595-600 4. LaRosa, J. C., Levy, R. I., Herbert, P., Lux, S. E., and Fredrickson,
D. S. (1970) Biochern. Biophys. Res. Commun. 41, 57-62 5. Nilsson-Ehle, P., Garfinkel, A. S., and Schotz, M. C. (1980) Annu.
Rev. Biochem. 49, 667-693 6. Jackson, C. J., Bruns, G. A. P., and Breslow, J. L. (1984) Proc.
Natl. Acad, Sci. U. S. A. 8 1 , 2945-2949 7. Sharpe, C. R., Sidoli, A., Shelley, C. S., Lucero, M. O., Shoulders,
C. C., and Baralle, E. F. (1984) Nucleic Acids. Res. 12, 3917- 3932
8. Myklebost, O., Williamson, B., Markham, A. F., Myklebost, S. R., Rogers, J., Woods, D. E., and Humphries, S. E. (1984) J. Biol. Chem. 259,4401-4404
9. Lawn, R. M., Fritsch, E. F., Parker, R. C., Blake, G., and Maniatis, T. (1978) Cell 15, 1157-1174
10. Lau, Y.-F., and Kan, Y. W. (1983) Proc. Natl. Acad. Sci. U. S. A.
11. Das, H. K., and Breslow, J. L. (1985) Arteriosclerosis 5, 503a 12. Maniatis, T., Fritsch; E. F., and Sambrook, J. (1982) in Molecular
Cloning, A Laboratory Manwl , Cold Spring Harbor Laboratory, Cold Spring Harbor, NY
13. Sanger, F., Nicklen, S., and Coulson, A. R. (1977) Proc. Natl. Acad. Sci. U. S. A. 74, 5463-5467
14. Maxam, A. M., and Gilbert, W. (1980) Methods Enzymol. 65,
15. Das, H. K., Biro, P. A., Cohen, S. N., Erlich, H. A., vonGabain, A., Lawrence, S. K., Lemaux, P. G., McDevitt, H. O., Peterlin, B. M., Schulz, M. F., Sood, A. K., and Weissman, S. M. (1983) Proc. Natl. Acad. Sci. U. S. A. 80, 1531-1535
80,5225-5229
499-560
16. Leff, T., and Chambon, P. (1986) Mol. Cell. Bid . 6, 201-208 17. Miller, D. A., Firschein, I. L., Dev, V. G., Tantravahi, R., and
18. Harper, M. E., and Saunders, G. F. (1981) Chromosoma (Berl.)
19. Heller, D., Jackson, M., and Leinwand, L. (1984) J. Mol. Biol.
20. Higgs, D. R., Goodbourn, S. E. Y., Waincoat, J . S., Clegg, J. B., and Weatherall, D. J. (1981) Nucleic Acids Res. 9,4213-4224
21. Proudfoot, N. J., Gil, A., and Maniatis, T. (1982) Cell 3 1 , 553- 563
22. Goodbourn, S. E. Y., Higgs, D. R., Clegg, J. B., and Weatherall, D. J. (1983) Proc. Natl. Acad. Sci. U. S. A. 80, 5022-5026
23. Weller, P., Jeffreys, A. J., Wilson, V., and Blanchetot, A. (1984)
24. Bell, G. I., Selby, M. J., and Rutter, W. J. (1982) Nature 295,
25. Capon, D. J., Chen, E. Y., Levinson, A. D., Seeburg, P. H., and
26. Jeffreys, A. J., Wilson, V., and Thein, S. L. (1985) Nature 314 ,
27. Jeffreys, A. J., Wilson, V., and Thein, S. L. (1985) Nature 316 ,
28. Humphries, S. E., Berg, K., Gill, L., Cumming, A. M., Robertson, F. W., Stalenhoef, A. F. H., Williamson, R., and Borresen, A. L. (1984) Clin. Genet. 26 , 389-396
29. Karathanasis, S. K. (1985) Proc. Natl. Acad. Sci. U. S. A. 8 2 ,
30. Elshourbagy, N. A., Walker, D. W., Boguski, M. S., Gordon, J. I., and Taylor, J. M. (1985) J. Biol. Chem. 2 6 1 , 1998-2002
31. Wei, C.-F., Tsao, Y.-K., Robberson, D. L., Gotto, A. M., Jr., Brown, K., and Chan, L. (1985) J. Bwl. Chem. 2 6 0 , 15211- 15221
Miller, 0. J. (1974) Cytogenet. Cell Genet. 13, 536-550
83,431-439
173,419-436
EMBO J. 3,439-446
31-35
Goeddel, D. V. (1983) Nature 302,33-37
67-73
76-79
6374-6378


















