
The evolution of data analytics
35
The Evolution of Data Analytics
-
Upload
natalino-busa -
Category
Data & Analytics
-
view
248 -
download
2
Transcript of The evolution of data analytics

The Evolution of Data Analytics

about:how to grok data with machinesand keep up with changing times

The origins (40s, 50s, 60s)
Operation Research during World War IIFirst Predictive Weather Model on ENIAC


The origins (40s, 50s, 60s)
● Operational Research● Collision loss vs Anti-Aircraft loss● Optimization (Statistical) problems● Scheduling and resource allocation


The origins (40s, 50s, 60s)
● ENIAC predicting weather● Barometric equations● 24 hours compute time (mostly manual work)

Analytics goes Mainstream (70s, 80s)
● The Relational Database is born!
1972: E.F. Codd relational database model, normalization: (free from insertion, deletion and update anomalies)
1978: Peter Chen, The entity-relationship model

● 1982: IBM DB2, Oracle v3, Sybase (SAP)● 1986: First standardized SQL
● 1987: Commercial use of Decision Support Systems: Texas Air Traffic Expert system
Analytics goes Mainstream (70s, 80s)

http://www-03.ibm.com/ibm/history/ibm100/us/en/icons/system360/impacts/

Exploratory Data Analysis
In 1977, Tukey published Exploratory Data Analysis, arguing that more emphasis needed to be placed on using data to suggest hypotheses to test and that Exploratory Data Analysis and Confirmatory Data Analysis “can—and should—proceed side by side.”
Analytics goes Mainstream (70s, 80s)

The Internet goes Global (90s)
● 1995: Amazon● 1995: eBay● 1996: HotMail● 1998: Google● 1998: Paypal

Knowledge Data in Databases (1996)

Knowledge Data in Databases (1996)
What is all the excitement about? This article provides an overview of this emerging field, clarifying how data mining and knowledge discovery in databases are related both to each other and to related fields, such as machine learning, statistics, and databases.
AI Magazine Volume 17 Number 3 (1996) (© AAAI)http://www.aaai.org/ojs/index.php/aimagazine/article/view/1230/1131

The Internet goes Global (90s)
● Analytics (OLAP): Long queries, aggregations, data mining, reporting, models
● Operations (OLTP):Fast transactions, ACID, consistent, available, fault-tolerant

Data warehouses and ETLs (90s)
● Building the Data Warehouse by William Inmon (John Wiley - QED, 1992)
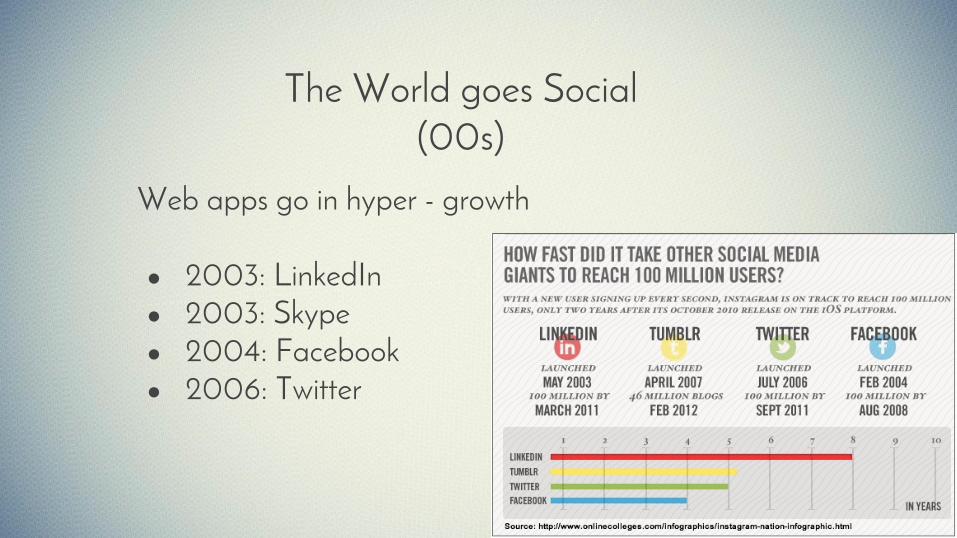
The World goes Social (00s)
Web apps go in hyper - growth
● 2003: LinkedIn● 2003: Skype● 2004: Facebook● 2006: Twitter

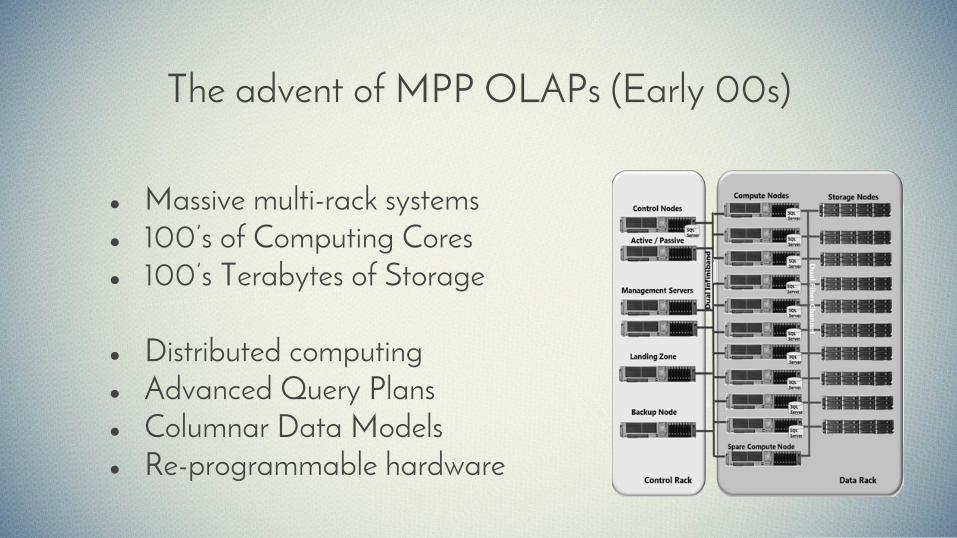
The advent of MPP OLAPs (Early 00s)
● Massive multi-rack systems● 100’s of Computing Cores● 100’s Terabytes of Storage
● Distributed computing● Advanced Query Plans● Columnar Data Models● Re-programmable hardware

● Vertica (HP)● Greenplum (Pivotal)● Netezza (IBM)● Exadata (Oracle)● Exasol (Exasol)
The advent of MPP OLAPs (Early 00s)

Map-Reduce and Hadoop (Early 00s)
● Simpler programming paradigm● Distributed, Replicated File System
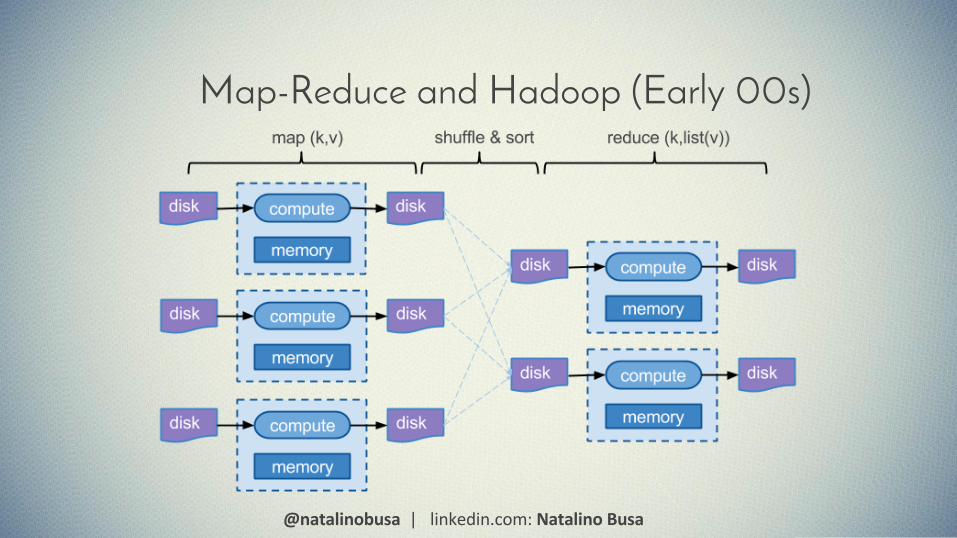
Map-Reduce and Hadoop (Early 00s)

Hadoop or MPPs or both?
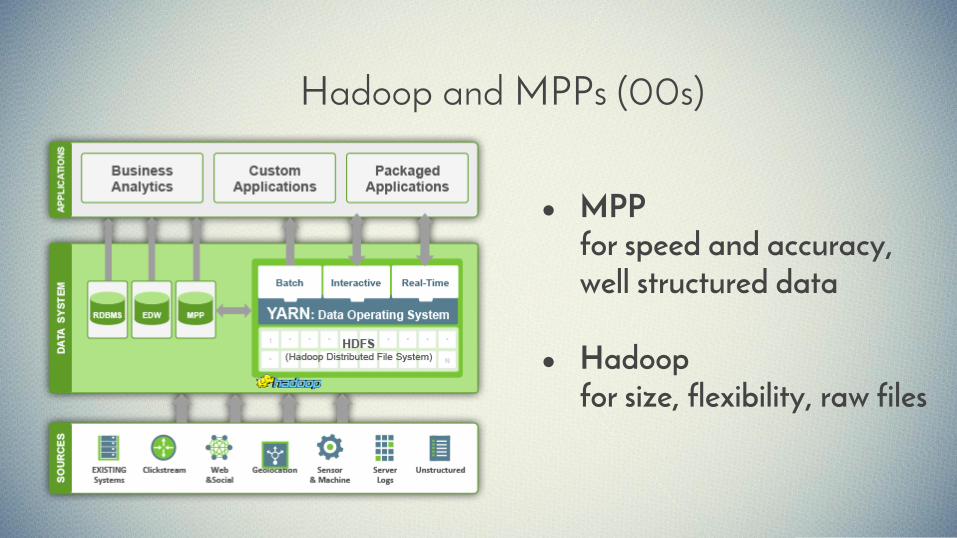
Hadoop and MPPs (00s)
● MPP for speed and accuracy, well structured data
● Hadoop for size, flexibility, raw files

http://flowingdata.com/2009/06/04/rise-of-the-data-scientist/http://medriscoll.com/post/4740157098/the-three-sexy-skills-of-data-geeks
The rise of the data scientist (late 00s)
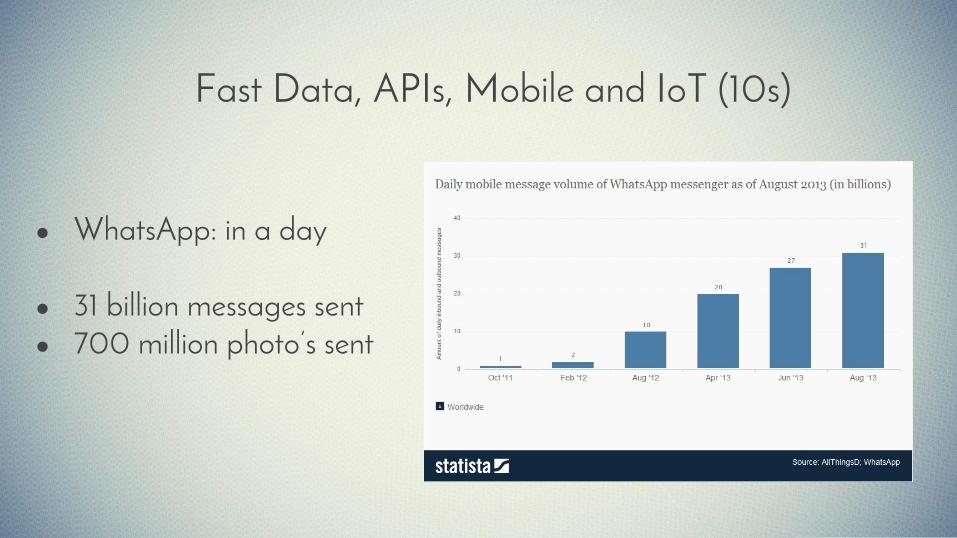
Fast Data, APIs, Mobile and IoT (10s)
● WhatsApp: in a day
● 31 billion messages sent● 700 million photo’s sent

Fast Data, APIs, Mobile and IoT (10s)
New Problems:
● Hadoop is too slow (File -> File)● Productivity of Data Science goes down
● SQL is not enough● Distributed Machine Learning algorithms?
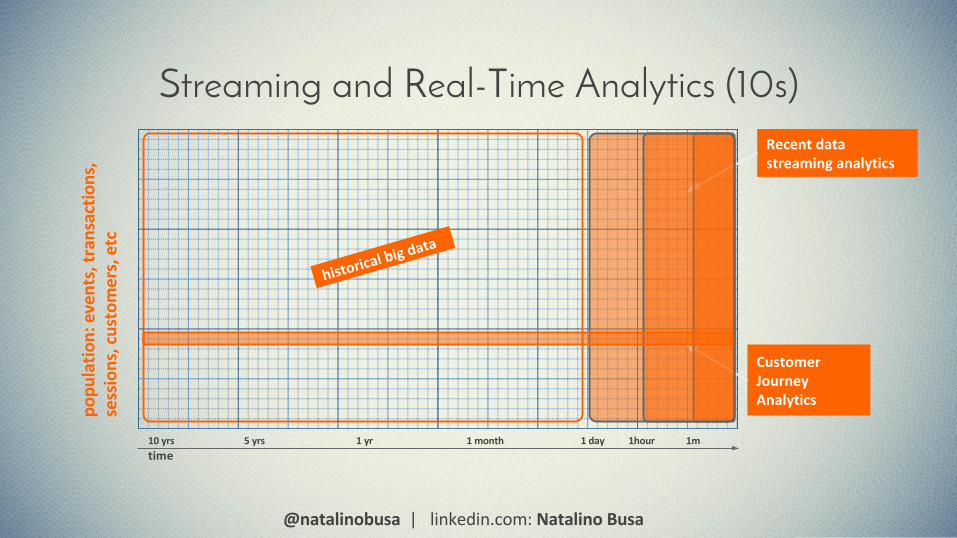
Streaming and Real-Time Analytics (10s)

The RAM is the new Disk (10s)
Spark is a new framework for in-memory computing
Unify in a Distributed Computing paradigm:SQL, Machine Learning, Map-Reduce, Graph Analytics

SparkGeneralityCombine SQL, streaming, and complex analytics.
Runs EverywhereSpark runs on Hadoop, Mesos, standalone, or in the cloud.
Multiple Data SourcesIt can access diverse data sources including HDFS, Cassandra, HBase, and S3.
https://spark.apache.org/

Popular Analytical Stacks (10s)
Hadoop Hive + MPP
Spark + Cassandra (no Hadoop!)
Spark + HDFS + Elastic(Search)

Future (10s, 20s)
Micro-Batch and Event Streaming Analytics
- Micro-Batch (Spark Streaming)- Log Oriented (Kafka, Samza)- NewSQL (VoldDB)

Takeaways
1) SQL is there to stay
2) Data Science must be easy to program
3) Memory is King
4) Spark is the new Hadoop



















