
Text Classification and Naïve Bayes - ecology labfaculty.cse.tamu.edu › ... ›...
45
Text Classification and Naïve Bayes The Task of Text Classification Many slides are adapted from slides by Dan Jurafsky
Transcript of Text Classification and Naïve Bayes - ecology labfaculty.cse.tamu.edu › ... ›...

TextClassificationandNaïveBayes
TheTaskofTextClassification
Many slides are adapted from slides by Dan Jurafsky
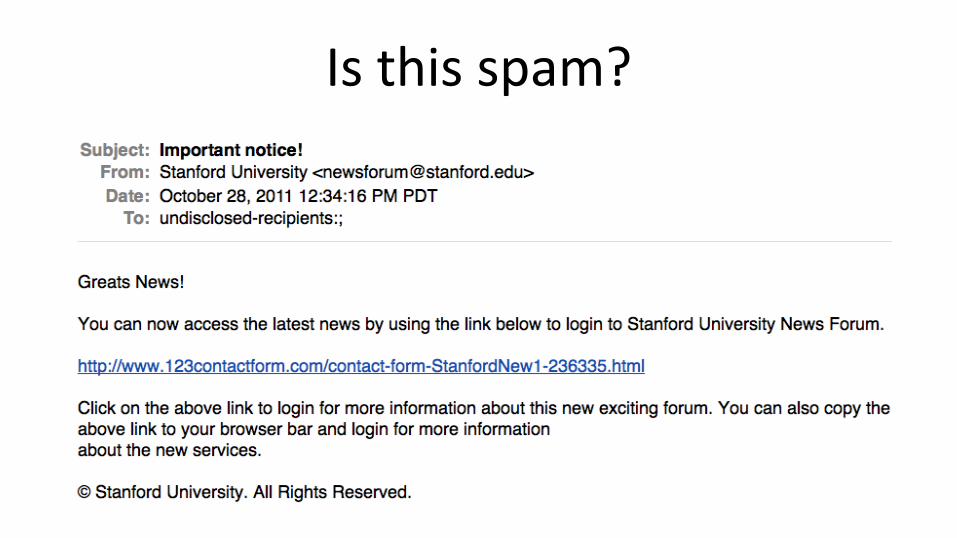
Isthisspam?

WhowrotewhichFederalistpapers?• 1787-8:anonymousessaystrytoconvinceNewYorktoratifyU.SConstitution: Jay,Madison,Hamilton.
• Authorshipof12ofthelettersindispute• 1963:solvedbyMosteller andWallaceusingBayesianmethods
JamesMadison AlexanderHamilton

Maleorfemaleauthor?1. By1925present-dayVietnamwasdividedintothreeparts
underFrenchcolonialrule.ThesouthernregionembracingSaigonandtheMekongdeltawasthecolonyofCochin-China;thecentralareawithitsimperialcapitalatHuewastheprotectorateofAnnam…
2. Claraneverfailedtobeastonishedbytheextraordinaryfelicityofherownname.Shefoundithardtotrustherselftothemercyoffate,whichhadmanagedovertheyearstoconverthergreatestshameintooneofhergreatestassets…
S.Argamon,M.Koppel,J.Fine,A.R.Shimoni,2003.“Gender,Genre,andWritingStyleinFormalWrittenTexts,”Text,volume23,number3,pp.321–346

Positiveornegativemoviereview?• unbelievablydisappointing• Fullofzanycharactersandrichlyappliedsatire,andsomegreatplottwists
• thisisthegreatestscrewballcomedyeverfilmed
• Itwaspathetic.Theworstpartaboutitwastheboxingscenes.
5

Whatisthesubjectofthisarticle?
• Antogonists andInhibitors
• BloodSupply• Chemistry• DrugTherapy• Embryology• Epidemiology• …
6
MeSH SubjectCategoryHierarchy
?
MEDLINE Article

TextClassification
• Assigningsubjectcategories,topics,orgenres• Spamdetection• Authorshipidentification• Age/genderidentification• LanguageIdentification• Sentimentanalysis• …

TextClassification:definition• Input:– adocumentd– afixedsetofclassesC= {c1,c2,…,cJ}
• Output:apredictedclassc Î C

ClassificationMethods:Hand-codedrules
• Rulesbasedoncombinationsofwordsorotherfeatures– spam:black-list-addressOR(“dollars”AND“have beenselected”)
• Accuracycanbehigh– Ifrulescarefullyrefinedbyexpert
• Butbuildingandmaintainingtheserulesisexpensive

ClassificationMethods:SupervisedMachineLearning
• Input:– adocumentd– afixedsetofclassesC= {c1,c2,…,cJ}– Atrainingsetofm hand-labeleddocuments(d1,c1),....,(dm,cm)
• Output:– alearnedclassifierγ:dà c
10

ClassificationMethods:SupervisedMachineLearning
• Anykindofclassifier– Naïve Bayes– Logisticregression,maxent– Support-vectormachines– k-NearestNeighbors
– …

TextClassificationandNaïveBayes
TheTaskofTextClassification

TextClassificationandNaïveBayes
TextClassification:Evaluation

The2-by-2contingencytable
correct notcorrectselected tp fp
notselected fn tn

Precisionandrecall• Precision:%ofselecteditemsthatarecorrectRecall:%ofcorrectitemsthatareselected
correct notcorrectselected tp fp
notselected fn tn

Acombinedmeasure:F• AcombinedmeasurethatassessestheP/RtradeoffisFmeasure(weightedharmonicmean):
• PeopleusuallyusebalancedF1measure– i.e.,withb =1(thatis,a =½): F =2PR/(P+R)
RPPR
RP
F+
+=
−+= 2
2 )1(1)1(1
1ββ
αα

Confusionmatrixc• Foreachpairofclasses<c1,c2>howmanydocumentsfromc1 wereincorrectlyassignedtoc2?– c3,2:90wheatdocumentsincorrectlyassignedtopoultry
17
Docsintestset AssignedUK
Assignedpoultry
Assignedwheat
Assignedcoffee
Assignedinterest
Assignedtrade
TrueUK 95 1 13 0 1 0
Truepoultry 0 1 0 0 0 0
Truewheat 10 90 0 1 0 0
Truecoffee 0 0 0 34 3 7
Trueinterest - 1 2 13 26 5
Truetrade 0 0 2 14 5 10

PerclassevaluationmeasuresRecall:Fractionofdocsinclassi classifiedcorrectly:
Precision:Fractionofdocsassignedclassi thatareactually
aboutclassi:
Accuracy:(1- errorrate)Fractionofdocsclassifiedcorrectly: 18
ciii∑
ciji∑
j∑
ciic ji
j∑
ciicij
j∑
Sec. 15.2.4

Micro- vs.Macro-Averaging– Ifwehavemorethanoneclass,howdowecombinemultipleperformancemeasuresintoonequantity?
• Macroaveraging:Computeperformanceforeachclass,thenaverage.Averageonclasses
• Microaveraging:Collectdecisionsforeachinstancefromallclasses,computecontingencytable,evaluate.Averageoninstances
19
Sec. 15.2.4

Micro- vs.Macro-Averaging:Example
Truth:yes
Truth:no
Classifier:yes 10 10
Classifier:no 10 970
Truth:yes
Truth:no
Classifier:yes 90 10
Classifier:no 10 890
Truth:yes
Truth:no
Classifier:yes 100 20
Classifier:no 20 1860
20
Class1 Class2 MicroAve.Table
Sec.15.2.4
• Macroaveraged precision:(0.5+0.9)/2=0.7• Microaveraged precision:100/120=.83• Microaveraged scoreisdominatedbyscoreoncommonclasses

DevelopmentTestSetsandCross-validation
• Metric:P/R/F1orAccuracy• Unseentestset– avoidoverfitting (‘tuningtothetestset’)– moreconservativeestimateofperformance
– Cross-validationovermultiplesplits• Handlesamplingerrorsfromdifferentdatasets
– Poolresultsovereachsplit– Computepooleddev setperformance
Trainingset Development Test Set TestSet
TestSet
TrainingSet
TrainingSetDev Test
TrainingSet
Dev Test
Dev Test

TextClassificationandNaïveBayes
TextClassification:Evaluation

TextClassificationandNaïveBayes
FormalizingtheNaïve BayesClassifier

NaïveBayesIntuition
• Simple(“naïve”)classificationmethodbasedonBayesrule
• Reliesonverysimplerepresentationofdocument– Bagofwords

Bayes’RuleAppliedtoDocumentsandClasses
•Foradocumentd andaclassc
P(c | d) = P(d | c)P(c)P(d)

Naïve BayesClassifier(I)
cMAP = argmaxc∈C
P(c | d)
= argmaxc∈C
P(d | c)P(c)P(d)
= argmaxc∈C
P(d | c)P(c)
MAP is “maximum a posteriori” = most likely class
Bayes Rule
Dropping the denominator

Naïve BayesClassifier(II)
cMAP = argmaxc∈C
P(d | c)P(c)
Document d represented as features x1..xn
= argmaxc∈C
P(x1, x2,…, xn | c)P(c)

Naïve BayesClassifier(III)
How often does this class occur?
cMAP = argmaxc∈C
P(x1, x2,…, xn | c)P(c)
O(|X|n•|C|)parameters
We can just count the relative frequencies in a corpus
Couldonlybeestimatedifavery,verylargenumberoftrainingexampleswasavailable.

ThebagofwordsrepresentationI love this movie! It's sweet, but with satirical humor. The dialogue is great and the adventure scenes are fun… It manages to be whimsical and romantic while laughing at the conventions of the fairy tale genre. I would recommend it to just about anyone. I've seen it several times, and I'm always happy to see it again whenever I have a friend who hasn't seen it yet.
γ(
)=c
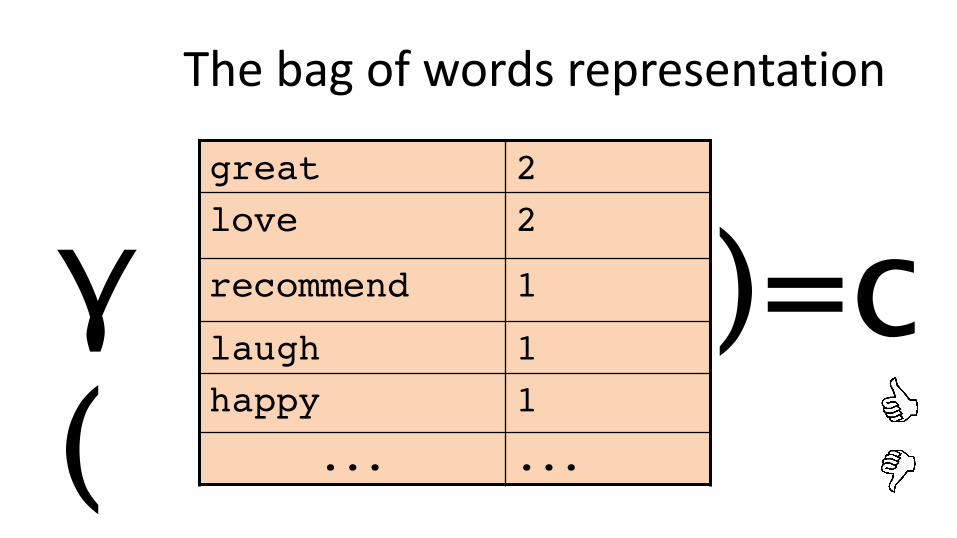
Thebagofwordsrepresentation
γ(
)=cgreat 2love 2
recommend 1
laugh 1happy 1
... ...

Planning GUIGarbageCollection
Machine Learning NLP
parsertagtrainingtranslationlanguage...
learningtrainingalgorithmshrinkagenetwork...
garbagecollectionmemoryoptimizationregion...
Test document
parserlanguagelabeltranslation…
Bagofwordsfordocumentclassification
...planningtemporalreasoningplanlanguage...
?

MultinomialNaïve BayesIndependenceAssumptions
• BagofWordsassumption:Assumepositiondoesn’tmatter
• ConditionalIndependence:AssumethefeatureprobabilitiesP(xi|cj)areindependentgiventheclassc.
P(x1, x2,…, xn | c)
P(x1,…, xn | c) = P(x1 | c)•P(x2 | c)•P(x3 | c)•...•P(xn | c)

ApplyingMultinomialNaiveBayesClassifierstoTextClassification
cNB = argmaxc j∈C
P(cj ) P(xi | cj )i∈positions∏
positions ¬ allwordpositionsintestdocument

TextClassificationandNaïveBayes
FormalizingtheNaïve BayesClassifier

TextClassificationandNaïveBayes
Naïve Bayes:Learning

LearningtheMultinomialNaïve BayesModel
• Firstattempt:maximumlikelihoodestimates– simplyusethefrequenciesinthedata
Sec.13.3
P̂(wi | cj ) =count(wi,cj )count(w,cj )
w∈V∑
P̂(cj ) =doccount(C = cj )
Ndoc

Parameterestimation
• Createmega-documentfortopicj byconcatenatingalldocsinthistopic– Usefrequencyofw inmega-document
fractionoftimeswordwi appearsamongallwordsindocumentsoftopiccj
P̂(wi | cj ) =count(wi,cj )count(w,cj )
w∈V∑

ProblemwithMaximumLikelihood• Whatifwehaveseennotrainingdocumentswiththewordfantastic and
classifiedinthetopicpositive (thumbs-up)?
• Zeroprobabilitiescannotbeconditionedaway,nomattertheotherevidence!
P̂("fantastic" positive) = count("fantastic", positive)count(w, positive
w∈V∑ )
= 0
cMAP = argmaxc P̂(c) P̂(xi | c)i∏
Sec.13.3

Laplace(add-1)smoothing:unknownwords
P̂(wu | c) = count(wu,c)+1
count(w,cw∈V∑ )
#
$%%
&
'(( + V +1
Addoneextrawordtothevocabulary,the“unknownword”wu
=1
count(w,cw∈V∑ )
#
$%%
&
'(( + V +1

UnderflowPrevention:logspace• Multiplyinglotsofprobabilitiescanresultinfloating-pointunderflow.• Sincelog(xy)=log(x)+log(y)
– Bettertosumlogsofprobabilitiesinsteadofmultiplyingprobabilities.• Classwithhighestun-normalizedlogprobabilityscoreisstillmost
probable.
• Modelisnowjustmaxofsumofweights
cNB = argmaxc j∈C
logP(cj )+ logP(xi | cj )i∈positions∑

TextClassificationandNaïve Bayes
Naïve Bayes:Learning

TextClassificationandNaïveBayes
MultinomialNaïve Bayes:AWorkedExample

Choosingaclass:P(c|d5)
P(j|d5) 1/4*(2/10)3 *2/10 *2/10≈0.00008
Doc Words Class
Training 1 Chinese BeijingChinese c
2 ChineseChineseShanghai c3 ChineseMacao c4 TokyoJapanChinese j
Test 5 ChineseChineseChineseTokyo Japan ?
43
ConditionalProbabilities:P(Chinese|c)=P(Tokyo|c)=P(Japan|c)=P(Chinese|j)=P(Tokyo|j)=P(Japan|j)=
Priors:P(c)=P(j)=
34 1
4
P̂(w | c) = count(w,c)+1count(c)+ |V |
P̂(c) = Nc
N
(5+1)/(8+7)=6/15(0+1)/(8+7)=1/15
(1+1)/(3+7)=2/10(0+1)/(8+7)=1/15
(1+1)/(3+7)=2/10(1+1)/(3+7)=2/10
3/4*(6/15)3 *1/15 *1/15≈0.0002
µ
µ
+1

Summary:NaiveBayesisNotSoNaive• RobusttoIrrelevantFeatures
IrrelevantFeaturescanceleachotherwithoutaffectingresults
• Verygoodindomainswithmanyequallyimportantfeatures
DecisionTreessufferfromfragmentation insuchcases– especiallyiflittledata
• Optimaliftheindependenceassumptionshold:Ifassumedindependenceiscorrect,thenitistheBayesOptimalClassifierforproblem
• Agooddependablebaselinefortextclassification– Butwewillseeotherclassifiersthatgivebetteraccuracy

TextClassificationandNaïveBayes
MultinomialNaïve Bayes:AWorkedExample


















