
Diagnóstico y tratamiento de las malformaciones vasculares ...

Tesis de Máster
Reconstrucción de escenarios virtuales y desarrollo de aplicaciones de realidad
aumentada para rehabilitación cognitiva
Ibai Diez Palacio
Donostia, Septiembre 2010
Universidad del País Vasco / Euskal Herriko Unibertsitatea Departamento de Ciencia de la Computación
e Inteligencia Artificial
Director: Xabier Basogain Olabe (UPV/EHU) Alejandro García-Alonso Montoya (UPV/EHU) Javier Arcas Ruiz-Ruano (Tecnalia)
http://www.ccia-kzaa.ehu.es/


iii
Resumen
Cada vez es más común el uso de la realidad virtual para mejorar/ampliar el proceso de la rehabilitación cognitiva. La rehabilitación cognitiva es el proceso a través del cual la gente con daño cerebral trabaja para remediar o aliviar los déficits cognitivos que surgen tras una afección neurológica.
Una de las principales afecciones neurológicas son los accidentes cerebro vasculares (ACV), que son la principal causa de discapacidad en adultos y la tercera causa de muerte en países desarrollados. Para la rehabilitación de estos pacientes es necesaria una terapia intensiva con el fin de recuperar la movilidad perdida y aprender de nuevo a realizar las tareas de la vida cotidiana. La rehabilitación comienza con un periodo inicial en el que se realizan ejercicios de rehabilitación mediante “juegos de mesa” o en su lugar, el mismo tipo de ejercicios simulados en ordenador. El siguiente paso en el proceso de rehabilitación consiste en acompañar al paciente a su hogar y realizar tareas de la vida cotidiana.
El objetivo que se persigue en este trabajo es el de sustituir estos ejercicios iniciales utilizados en la rehabilitación por ejercicios de la vida cotidiana simulados en un entorno virtual basado en su propio hogar. De esta manera, se puede mejorar el proceso de rehabilitación debido al efecto beneficioso que ejerce en la terapia la inclusión de entornos conocidos por el paciente. Para ello, mediante la captura de diferentes imágenes del entorno a reconstruir, ya sean fotografías o vídeos, se pretende generar automáticamente el entorno virtual para el entrenamiento del paciente.
Por otro lado, también se utilizará la realidad aumentada como sistema de aprendizaje para tareas en cadenas de montaje para personas con discapacidades cognitivas, con el propósito de una mayor integración social/laboral de este colectivo.
Por lo tanto, este proyecto se embarca en el uso de la realidad virtual y sistemas de realidad aumentada en el ámbito de la rehabilitación cognitiva analizando e implementando diferentes técnicas que se utilizan en la actualidad.


v
Índice
1. INTRODUCCIÓN............................................................................................................................ 1
2. ANTECEDENTES ........................................................................................................................... 5
2.1 NECESIDAD DEL PROYECTO ........................................................................................................... 5 2.2 ESTADO DE LA TECNOLOGÍA .......................................................................................................... 6
3. OBJETIVOS Y ALCANCE........................................................................................................... 13
4. DESARROLLO.............................................................................................................................. 17
4.1 INSTALACIÓN DEL PROYECTO....................................................................................................... 17 4.2 OPCIONES DE USO.................................................................................................................. 17
4.2.1 Procesamiento de imágenes ................................................................................................. 17 4.2.2 Uso de la WebCam .............................................................................................................. 18 4.2.3 Procesando un conjunto de imágenes ................................................................................... 20 4.2.4 Procesando videos ............................................................................................................... 21
4.3 PROCESAMIENTO DE IMAGEN............................................................................................. 23 4.3.1 Tipos de imágenes................................................................................................................ 23 4.3.2 Operación a nivel de píxel.................................................................................................... 25
4.3.2.1 Transformación de píxel ................................................................................................ 25 4.3.2.2 Transformación de color................................................................................................ 30 4.3.2.3 Compositing & matting ................................................................................................. 32 4.3.2.4 Histograma.................................................................................................................... 34
4.3.2.3.1 Ecualización de histograma.................................................................................... 34 4.3.3 Filtrado espacial.................................................................................................................. 36
4.3.3.1 Relleno (Padding).......................................................................................................... 39 4.3.3.2 Filtrado separable.......................................................................................................... 42 4.3.3.3 Filtrado dirigible y paso banda....................................................................................... 44 4.3.3.4 Filtrado no lineal ........................................................................................................... 54
4.3.4 Procesado morfológico ........................................................................................................ 54 4.3.4.1 Operadores morfológicos............................................................................................... 54 4.3.4.2 Transformada de distancia ............................................................................................. 56 4.3.4.3 Componentes conectados............................................................................................... 57
4.3.5 Transformada de Fourier..................................................................................................... 58 4.3.5.1 Filtro Wiener................................................................................................................. 63 4.3.5.2 Transformada discreta del coseno .................................................................................. 63
4.3.6 Pirámides ............................................................................................................................ 64 4.3.6.1 Interpolación ................................................................................................................. 64 4.3.6.2 Diezmado...................................................................................................................... 67 4.3.6.3 Multiresolución ............................................................................................................. 67
4.4 DETECCIÓN Y MATCHING DE FEATURES ........................................................................................ 68 4.4.1 Detectores de puntos de interés ............................................................................................ 69

vi
4.4.1.1 Operador Moravec ........................................................................................................ 72 4.4.1.2 Determinante de Hessian............................................................................................... 74 4.4.1.3 Algoritmo de Harris & Stephens/Plessey ....................................................................... 75 4.4.1.4 Detector de SUSAN (Smallest Univalue Segment Assimilating Nucleus)....................... 80 4.4.1.5 Operador Trajkovic ....................................................................................................... 83 4.4.1.6 Features from Accelerated Segment Test (FAST) .......................................................... 85 4.4.1.7 Invarianza en la escala................................................................................................... 89 4.4.1.8 LoG (Laplacian of a Gaussian) ...................................................................................... 89 4.4.1.9 DoG (Difference of a Gaussian) .................................................................................... 90 4.4.1.10 Fast Hessian................................................................................................................ 97 4.4.1.11 Harris-Laplace ...........................................................................................................100 4.4.1.12 Invarianza rotacional y estimación de la orientación....................................................101 4.4.1.13 Invarianza afin ...........................................................................................................102 4.4.1.14 Harris-Afinne.............................................................................................................102 4.4.1.15 Hessian-Afinne ..........................................................................................................105 4.4.1.16 EBR (Edge-based region detector)..............................................................................105 4.4.1.17 IBR (Intensity extrema-based region detector) ............................................................107 4.4.1.18 Salient Region............................................................................................................108 4.4.1.19 MSER........................................................................................................................108 4.4.1.20 Comparación de detectores.........................................................................................110
4.4.2 Descriptores .......................................................................................................................113 4.4.2.1 Descriptor SIFT (Scale-invariant feature transform)......................................................116 4.4.2.2 Descriptor PCA- SIFT..................................................................................................119 4.4.2.3 Descriptor GLOH (Gradient location-orientation histogram).........................................122 4.4.2.4 Descriptor SURF(Speeded Up Robust Feature).............................................................122 4.4.2.5 Comparación de descriptores........................................................................................125
4.4.3 Emparejamiento de features................................................................................................126 4.4.3.1 Estrategia de emparejamiento y ratios de error ..............................................................126 En la figura 4.4.33 se puede observar el resultado obtenido: ...........................................127 4.4.3.2 Estrategias eficientes de emparejamiento ......................................................................129 4.4.3.3 Verificación del emparejamiento de features.................................................................133
4.4.4 Tracking de features ...........................................................................................................134 4.5 CASO PRÁCTICO: APLICACIÓN DE REALIDAD AUMENTADA............................................................135
5. CONCLUSIONES.........................................................................................................................141
5.1 REALIDAD AUMENTADA .............................................................................................................141 5.2 RECONSTRUCCIÓN 3D.................................................................................................................145
6. LÍNEAS FUTURAS ....................................................................................................................149
7. BIBLIOGRAFÍA...........................................................................................................................151
ANEXO I: INSTALACIÓN Y CONFIGURACIÓN........................................................................153

INTRODUCCIÓN
1
1. INTRODUCCIÓN
En la sociedad de la tecnología en la que vivimos, el avance y los cambios en diferentes ámbitos impiden que ciertas personas puedan adaptarse con facilidad, creando un grupo de personas socialmente excluidas. Dentro de este colectivo se abarcan las personas que han nacido con alguna discapacidad, las personas que han sufrido algún tipo de accidente o personas que por la edad se vean incapacitadas para realizar ciertas tareas. El progresivo envejecimiento de la población hace que las cifras de discapacitados vayan aumentando exponencialmente. Teniendo en cuenta este hecho y con el objetivo de ayudar a la integración de este colectivo y contrarrestar las carencias de la sociedad actual, este proyecto nace con la idea de implementar la tecnología necesaria que sirva como base para una de las nuevas líneas de investigación dentro de la unidad Salud y Calidad de Vida de Tecnalia.
Esta nueva línea de investigación se centra en el uso de escenarios virtuales y aplicaciones de realidad aumentada en el ámbito de la rehabilitación cognitiva. El término rehabilitación implica el restablecimiento de los pacientes al nivel de funcionamiento más alto posible a nivel físico, psicológico y de adaptación social. Incluye poner todos los medios posibles para reducir el impacto de las condiciones que son discapacitantes y permitir a la gente discapacitada alcanzar un nivel óptimo de integración social (O.M.S., 1986). La rehabilitación cognitiva, Barbara Wilson (1989) la define como un "proceso a través del cual la gente con daño cerebral trabaja junto con profesionales del servicio de salud para remediar o aliviar los déficits cognitivos que surgen tras una afección neurológica". Con ello se pretenden implementar diferentes aplicaciones que puedan ayudar a personas con discapacidad cognitiva en las tareas cotidianas o en su rehabilitación.
Actualmente se está trabajando mucho en la rehabilitación de personas que han sufrido un accidente cerebrovascular (ACV). Los accidentes cerebro vasculares son la principal causa de discapacidad en adultos y la tercera causa de muerte en países desarrollados. El ACV es un tipo de enfermedad caracterizada por una brusca interrupción del flujo sanguíneo al cerebro que origina una serie de síntomas variables en función del área/hemisferio cerebral afectada. Los síntomas pueden variar desde los puramente sensoriales a los puramente motores, pasando por los síntomas sensitivo-motores. Los más frecuentemente diagnosticados son la pérdida de fuerza en un brazo o una pierna o parálisis en la cara, dificultad para expresarse o entender lo que se le dice, dificultad al caminar, pérdida de equilibrio o de coordinación…
El proceso de rehabilitación busca minimizar los déficits o discapacidades experimentadas por los pacientes que han sufrido el ACV, así como facilitar su reintegración social. Este es un

PROYECTO FIN DE MÁSTER
2
proceso activo que requiere la colaboración y capacidad de aprendizaje del paciente y de su familia. Como en muchos de los casos no se alcanza la recuperación completa del paciente, el objetivo fundamental es ayudar al paciente a adaptarse a sus déficits y no sólo a mitigarlos, ya que en la mayoría de los casos, la lesión neurológica se recupera en todo o en parte espontáneamente en un período de tiempo variable o puede que no se recupere nunca; todo depende de la gravedad del ACV.
En la actualidad, muchas clínicas, en colaboración con centros de investigación, están utilizando entornos virtuales o juegos con interfaces adaptados a las diferentes partes del cuerpo a rehabilitar (recuperar movimiento) para que los pacientes no se aburran con los ejercicios habituales, se sientan más motivados y que incluso puedan llegar a realizar parte de la terapia desde el hogar de manera remota. Diferentes estudios como los realizados por Holden en 1999 y 2005, Kizony en 2003, S.H You en 2005 y Meredith R. Golomb en 2009 han demostrado que la realidad virtual ayuda a los pacientes en su rehabilitación contribuyendo positivamente a la organización neural y a la recuperación de habilidades perdidas entre otros. Esta terapia facilita que, a medida que los pacientes van recuperando la movilidad, aprendan a realizar las tareas de su vida cotidiana, las labores del hogar, a orientarse en la calle etc.
Desde el centro de rehabilitación de Aita Menni se ha planteado para este proyecto que se aproveche más el potencial de la realidad virtual para crear escenarios más complejos, en lugar de utilizar los clásicos juegos (puzzles, laberintos…) que se utilizan hoy en día en la rehabilitación. Se plantea sustituir estos juegos por simulaciones de tareas cotidianas en un entorno virtual que estén basados en el propio entorno del paciente. Esto probablemente ayudaría al cerebro del paciente a ir asociando las tareas e ir familiarizándose con ellas y con su propio hogar antes de pasar al siguiente paso de la rehabilitación.
Teniendo en cuenta que los empleados del centro no tienen los conocimientos ni el tiempo necesarios para crear los escenarios virtuales, se plantea la generación automática del modelo tridimensional del hogar del paciente. Para ello, partiendo de un conjunto de imágenes capturadas del entorno del paciente (ya sean fotos o videos), mediante complejos algoritmos de visión artificial se intentará generar la estructura y el modelo de este entorno para que más adelante los pacientes puedan realizar la rehabilitación, inmersos en su entorno.
Partiendo de los vídeos o de los conjuntos de imágenes captadas del hogar del paciente a rehabilitar, este proyecto se adentra en los diferentes pasos necesarios para poder construir estos entornos virtuales, implementando las técnicas necesarias y analizando los resultados obtenidos.
Por lo tanto, y tal y como se ha mencionado anteriormente, el objetivo no es sólo la rehabilitación mediante la realidad virtual, sino también el uso de la realidad aumentada como soporte para el aprendizaje de personas con discapacidad. Poniendo como ejemplo Lantegi Batuak, que proporcionan empleo a personas con discapacidad, entre otras a personas con síndrome de Down. Una de las tareas que las personas con síndrome de Down realizan en Lantegi Batuak es el montaje de piezas en cadenas de montaje. Aunque estas personas necesitan más trabajo que el resto para el aprendizaje de ciertas tareas, una vez aprendidas

INTRODUCCIÓN
3
ejecutan el trabajo a la perfección. Por lo tanto, con el objetivo de ayudar en esas tareas de aprendizaje, ya sea para cuando tengan que montar nuevas piezas con las que no estén familiarizados o incluso para el aprendizaje de nuevas tareas, se plantea un sistema de realidad aumentada. En este sistema mediante visión artificial y el uso de gafas de realidad aumentada o teléfonos móviles, se pretende reconocer la tarea que está realizando la persona e ir guiándola hasta que la finalice, de forma que poco a poco el usuario vaya aprendiendo a realizarla.
Los pasos a seguir en la implementación de las aplicaciones de realidad aumentada están muy ligados a la construcción de escenarios tridimensionales. Por lo que a medida que se explican los pasos para generar estos entornos, se explicarán también qué pasos son necesarios para hacer funcionar este tipo de aplicaciones, implementando y comparando las diferentes técnicas que actualmente se utilizan.


ANTECEDENTES
5
2. ANTECEDENTES
2.1 NECESIDAD DEL PROYECTO
Este proyecto nace con la necesidad de facilitar ciertas tareas a los usuarios, mejorando su calidad de vida y ayudando a personas con discapacidad a integrarse en la sociedad actual. En los últimos años, se ha trabajado mucho en este sector haciendo uso de las nuevas tecnologías emergentes.
La tecnología ha ido evolucionando de tal manera que actualmente es raro ver a personas que no posean al menos un teléfono móvil. Hace pocos años estos terminales estaban al alcance de unos pocos y solo permitían la realización de llamadas y el envío de mensajes. En pocos años esta industria ha ido evolucionando y en la actualidad los móviles incorporan pantallas y cámaras con alta resolución, GPS, Wi-Fi, conexión 3G de datos, procesadores potentes… que permiten al usuario poder ejecutar diferentes tipos de aplicaciones que hasta hace pocos años eran impensables.
El fabricante de teléfonos móviles de Ericsson afirmó que en los últimos estudios se muestra como se ha triplicado en el último año el tráfico de datos móvil. Esto puede deberse al auge de los teléfonos inteligentes y a la banda ancha móvil, que está acelerando el crecimiento con la introducción de redes de alto rendimiento. Se ha llegado a un punto en el que los usuarios disponen de teléfonos móviles con altas prestaciones y una conexión de datos que les permite acceder a cualquier información de la red fácilmente.
Aunque el acceso a Internet esté presente en muchos de estos terminales, la búsqueda de información muchas veces es una tarea complicada. Hasta ahora se entraba en un buscador como Google y se intentaba describir la información que se desea buscar. Esta forma de interactuar para la búsqueda de información es poco natural. Por ello empresas como Google y diferentes grupos de investigación están trabajando en buscadores basados en imágenes, es decir que el buscador busque en Internet la información referente a una imagen. Esta manera de interactuar es más natural ya que no tenemos la necesidad de describir el objeto ni escribirlo en el terminal.
Las nuevas técnicas de procesado de imagen junto a la capacidad de procesado de los nuevos terminales móviles han hecho que empiecen a desarrollarse los primeros programas de realidad aumentada basados en visión. El objetivo de la realidad aumentada es añadir

PROYECTO FIN DE MÁSTER
6
información adicional al entorno real que nos rodea. De esta manera esta tecnología puede ser utilizada para ayudar a realizar tareas desconocidas a los usuarios, incluyendo en el mundo real la información necesaria para que el usuario pueda realizar la tarea.
La necesidad de ir aumentando nuestra calidad de vida e ir ayudando a las personas discapacitadas en su integración, hace que la realidad aumentada sea una de las tecnologías perfectas para esta labor. Ayudando a las personas a estar interconectadas con Internet con una interfaz muy sencilla, la imagen.
Por otro lado, tal y como se ha comentado en el apartado anterior, el centro de rehabilitación de Aita Menni remarcaba la importancia de poder ejecutar los ejercicios de rehabilitación en entornos virtuales basados en el hogar del paciente para mejorar su recuperación neural. Aunque se haya empezado a utilizar la realidad virtual en diferentes partes de la rehabilitación cognitiva, no se ha explotado todo el potencial de esta tecnología en este ámbito.
Gracias a que la capacidad de procesado de los ordenadores y de las tarjetas gráficas han aumentado considerablemente, surge la necesidad de implementar este tipo de entornos. El problema de generar estos entornos es que es una tarea muy complicada y que implica mucho trabajo. Además los terapeutas de los centros de rehabilitación no poseen los conocimientos necesarios, por lo que surge la necesidad de poder generar estos entornos virtuales de una manera sencilla, por ejemplo mediante la captura de imágenes de este entorno y el uso de la visión artificial.
2.2 ESTADO DE LA TECNOLOGÍA
El término Realidad aumentada se utilizó por primera vez en 1990 por Tom Caudell para describir una pantalla digital que utilizan los electricistas de aeronaves que mezcla gráficos virtuales con la realidad física. La realidad mixta puede mejorar la percepción de los usuarios y la interacción con el mundo real (Azuma et al., 2001), en particular mediante el uso de realidad aumentada. En la definición de un sistema de Realidad Aumentada por Azuma (1997), define que esta tiene que cumplir las siguientes características:
Combinar contenido real y virtual.
El sistema debe ser interactivo y ejecutarse en tiempo real.
El contenido virtual debe estar registrado con el mundo real.
Es decir, la realidad aumentada consiste en un conjunto de dispositivos que añaden información virtual a la información física ya existente. Entre estos dispositivos se utilizan gafas de realidad virtual, teléfonos móviles o consolas portátiles y pantallas de proyección.
Múltiples investigaciones demuestran que la Realidad Aumentada puede aplicarse en diferentes campos como la educación, medicina, ingeniería, militar y entretenimiento. Por ejemplo, los mapas virtuales pueden ser superpuestos al mundo real para ayudar a las

ANTECEDENTES
7
personas a orientarse, diferentes imágenes médicas pueden aparecer sobre el cuerpo del paciente y los arquitectos pueden observar edificios virtuales en el lugar indicado antes de construirlos.
La realidad aumentada es una tecnología relativamente novedosa y todavía no se han desarrollado muchas aplicaciones para la ayuda a discapacitados.
El Grupo de Autismo y Dificultades de Aprendizaje junto a la fundación Orange España están desarrollando la habitación de los pictogramas (Pictogram Room). Este proyecto pretende crear una herramienta educativa basada en tecnologías de realidad aumentada para personas con autismo. Los objetivos educativos están relacionados, entre otros, con la comprensión de los pictogramas, el desarrollo del concepto de uno mismo, el esquema corporal, la imitación y la comprensión de las relaciones causa-efecto de carácter social.
Figura 2.2.1. El usuario debe observar un pictograma y realizar la misma tarea que se muestra en la imagen.
El grupo de investigación Virtual Reality Therapy de la Universidad de Ulster ha desarrollado diferentes juegos con Realidad Aumentada para la rehabilitación de los miembros superiores para pacientes que han sufrido un accidente cerebro-vascular (figura 2.2.2). Con el objetivo de recuperar el movimiento de los brazos, los juegos plantean ejercicios en los que el paciente debe estirar los brazos para conseguir una buena puntuación. También se plantean diferentes ejercicios en los que el paciente debe agarrar objetos y moverlos al lugar indicado. Trabajando así la fuerza y la destreza.
Empresas como Indra también se encuentran trabajando en aplicaciones para la rehabilitación. En el congreso internacional World of Health IT 2010 han presentado el proyecto Tratamiento 2.0, para concebir nuevas formas de tratamiento rehabilitador a través del uso de la realidad aumentada y nuevas interfaces.
También existen proyectos en los que se ha utilizado los entornos virtuales con el objetivo de integrar socialmente a personas discapacitadas. El Grupo de Autismo y Necesidades Especiales de la Universidad de Valencia desarrolla diferentes aplicaciones para personas con autismo y dificultades de aprendizaje. Entre otros proyectos han desarrollado un supermercado virtual donde el usuario debe realizar las tareas típicas que se realizan en este lugar, un colegio virtual para personas con síndrome de Down… En este grupo también trabajan con

PROYECTO FIN DE MÁSTER
8
aplicaciones multimedia para el apoyo a la integración laboral de personas con Síndrome de Down.
Figura 2.2.2. En esta imagen se muestran diferentes ejemplos de aplicaciones desarrolladas por el grupo de investigación Virtual Reality Therapy de la Universidad de Ulster. En la imagen superior se puede observar uno de los ejercicios que tiene como objetivo que el paciente estire los brazos para ir recuperando la movilidad de los brazos. En la imagen posterior observamos un ejercicio que haciendo uso de marcadores encima de objetos cotidianos se plantea al usuario que mueva estos a diferentes lugares de la mesa.
Figura 2.2.3. En las dos imágenes se puede observar diferentes escenarios virtuales desarrollados por el grupo de Autismo y Necesidades Especiales de la Universidad de Valencia.
El uso de la realidad virtual para mejorar las habilidades sociales ha sido un tema que se ha centrado mucho en personas con autismo. La Universidad de Haifa ha creado un simulador con

ANTECEDENTES
9
realidad virtual que enseña a los niños autistas a cruzar la carretera. Esta aplicación permite que los niños autistas no sufran ningún peligro mientras aprenden tareas de la vida cotidiana como cruzar la carretera. El estudio se realizó con 6 niños autistas de 7 a 12 años que estuvieron practicando durante un mes en el simulador. Mientras la luz del semáforo virtual estaba roja los niños no cruzaban y cuando este se ponía en verde, tras mirar a la izquierda y a la derecha y ver que no venia ningún coche virtual, cruzaban la carretera. Se realizaron las simulaciones con diferentes condiciones: de día y de noche, con mucho tráfico etc. Finalmente los niños conseguían cruzar solos la carretera en la vida real.
Según apuntan diferentes estudios la realidad virtual es una herramienta que ha demostrado grandes avances en las terapias para mejorar las habilidades sociales y cognitivas de pacientes con autismo.
La universidad de Caen (Francia) junto a la Universidad de Lund (Suiza) implementaron un entorno virtual para tratar fobias sociales. Este sistema no solo trataba el miedo al habla en público, también trataba otro tipo de habilidades sociales. Con ayuda del terapeuta el paciente aprende a adaptarse a las situaciones simuladas reduciendo su ansiedad en las correspondientes situaciones en la vida real.
Una de las aplicaciones más prometedoras de la realidad aumentada consiste en mejorar la productividad del ensamblaje, mantenimiento de equipos y de los procedimientos de aprendizaje. Según un estudio realizado por la Universidad de Michigan los errores cometidos en tareas de ensamblaje se reducen un 82% utilizando sistemas de realidad aumentada. La mayoría de aplicaciones de realidad aumentada para operaciones de ensamblaje se centran en el mantenimiento y la reparación.
En 1992 Steven Feiner, Blair MacIntyre y Doree Seligmann publicaron el primer gran artículo sobre Realidad Aumentada que trataba sobre el sistema KARMA (Knowledge-based Augmented Reality for Maintenance Assistance). Este sistema era un prototipo que hacía uso de una pantalla óptica transparente para mostrar al usuario las instrucciones necesarias para realizar el mantenimiento de una impresora láser.
Figura 2.2.4. En la imagen podemos observar una captura de la pantalla óptica transparente del sistema KARMA donde se mostraba al usuario como sacar el papel de la impresora.

PROYECTO FIN DE MÁSTER
10
Años más tarde en 1998, el departamento de Visualización y Realidad Virtual de Darmstadt Germany creó una de las primeras aplicaciones de realidad Aumentada para el montaje de la cerradura de la puerta de un coche utilizando gafas de realidad virtual. En ellas se mostraba paso a paso las operaciones a realizar sobre la propia puerta del coche.
Figura 2.2.5. Sistema desarrollado por el departamento de Visualización y realidad virtual de Darmstadt Germany para el montaje de cerraduras de coche.
La Universidad de Cambridge, en esta línea, implementó un software que permitía ejecutar operaciones de ensamblaje mediante realidad aumentada. En este caso un usuario experto recibía la imagen del técnico y sobre ella iba insertando la información en tiempo real. De esta forma el usuario experto guiaba al técnico en los diferentes pasos de la reparación.
Figura 2.2.6. Sistema de operaciones de ensamblaje de la Universidad de Cambridge.
En 2009 la Universidad de Columbia presentó en IEEE International Symposium on Mixed and Augmented Reality un prototipo de realidad aumentada para el apoyo en el mantenimiento dentro de vehículos blindados militares (figura 2.2.7). Utilizando unas gafas ópticas trasparentes añaden texto, flechas y animaciones a la imagen real, para facilitar la ejecución, localización y comprensión de la tarea. Además de poder efectuar las tareas con estas gafas también se da la posibilidad de utilizar una pantalla en lugar de las gafas.
Tras realizar un experimento en el que los usuarios realizaban 18 tareas diferentes, se observó como el tiempo de realización de las tareas era inferior utilizando sistemas de Realidad Aumentada. Aunque la diferencia entre las gafas y la pantalla son muy pequeñas, en ciertas tareas con las gafas obtenían tiempos de ejecución inferiores.

ANTECEDENTES
11
Figura 2.2.7. Prototipo de realidad aumentada para el apoyo y mantenimiento dentro de vehículos blindados.
Con el objetivo de formar a sus técnicos para la reparación de sus coches la empresa BMW se está planteando la utilización de esta tecnología.
Figura 2.2.8. Sistema de realidad aumentada propuesto por BMW.
El técnico haciendo uso de unas gafas de realidad virtual observa las operaciones que tiene que realizar superpuestas a los elementos reales. De esta manera el técnico solo tendrá que imitar los pasos que se le muestran en las gafas.
Diferentes centros de investigación como el VTT de Finlandia han realizado diferentes aplicaciones en el ámbito del ensamblaje para empresas como Valtra PLC. Incluso han conseguido simular alguna de estas aplicaciones utilizando un teléfono móvil. Entre las aplicaciones de simulación de ensamblaje, en una de ellas se debe de construir un puzzle 3D con piezas de madera tal y como se va mostrando en el móvil.
Hoy en día varios proyectos como ARVIKA o ARTESAS impulsados por el ministerio de educación e investigación alemán entre otros, están utilizando la realidad aumentada para

PROYECTO FIN DE MÁSTER
12
desarrollar aplicaciones de ensamblaje en ámbitos como la automoción o industrias aeroespaciales.

OBJETIVOS Y ALCANCE
13
3. OBJETIVOS Y ALCANCE
En este apartado se exponen los pasos necesarios a seguir para poder realizar la construcción de entornos virtuales partiendo de un conjunto de imágenes. Como se ha mencionado anteriormente estos bloques también son utilizados para las aplicaciones de realidad aumentada.
En la figura 3.1 podemos observar el diagrama de bloques que describe el proceso de generación de un entorno virtual a partir de un conjunto de imágenes. Tal y como se observa en la parte inferior del diagrama de bloques, durante todo el proceso será necesario el uso de técnicas de procesado de imagen. Por ello en primer lugar se realizara una introducción a las funciones básicas de procesado de imagen que sirvan como base durante los diferentes bloques del proceso de reconstrucción.
Tal y como se muestra en la imagen los diferentes bloques del sistema son:
Detección de puntos de interés: Este bloque consiste en extraer un conjunto de
puntos en las imágenes. Estos puntos tienen que ser fácilmente reconocibles en otras imágenes donde aparezca el mismo objeto. De esta forma los puntos que expresen la misma posición en diferentes imágenes serán emparejados para la reconstrucción 3D. Estos puntos además de utilizarse para la reconstrucción de modelos 3D también se utilizan para reconocimiento de objetos.
Segmentación: La segmentación es uno de los apartados de procesado de imágenes más utilizados y consiste en encontrar grupos de píxeles que “van juntos”, es decir, que pertenecen a un mismo objeto, área etc. La segmentación es muy utilizada para reconocer la categoría de diferentes objetos o segmentos de la imagen.
Reconocimiento: El objetivo principal es reconocer diferentes objetos en una imagen. Si sabemos que objeto estamos buscando el problema puede simplificarse para buscar en la imagen donde puede ocurrir un emparejamiento del objeto que se busca. El área más difícil del reconocimiento es en general el reconocimiento de la categoría, que consiste en que el sistema pueda identificar objetos de diferentes categorías animales, alimentos… Para ello suele utilizarse los puntos de interés extraídos tanto como los resultados obtenidos segmentando la imagen.

PROYECTO FIN DE MÁSTER
14

OBJETIVOS Y ALCANCE
15
Alineación de puntos de interés: Una vez extraídos los puntos de interés de una imagen se realiza el emparejamiento con los puntos extraídos de otras imágenes. Un componente importante es verificar si los emparejamientos realizados son geométricamente consistentes, es decir, si el desplazamiento del punto de interés de una imagen a otra esta descrito por una transformación geométrica simple 2D o 3D. Este movimiento que ha sufrido el punto de interés puede utilizarse en aplicaciones como la realidad aumentada. Uno de los parámetros a calcular es la estimación de la pose que determina la posición relativa de la cámara respecto a un objeto 3D o escena. Con la información de estos puntos también es posible calcular los parámetros internos de calibración de la cámara.
Estructura en base al movimiento: El objetivo de este bloque consiste en estimar puntos 3D de la estructura partiendo de múltiples imágenes y las correspondencias entre sus puntos de interés. Este proceso que normalmente implica estimar la estructura 3D y la posición de la cámara (movimiento) se conoce como structure from motion.
Estimación del movimiento: Existen muchos algoritmos para la estimación del movimiento que se usan ampliamente para aplicaciones como estabilización de video, compresión, teledetección, imágenes medicas…
Alineación de imágenes: En ocasiones para construir la escena 3d necesitaremos unir varias imágenes para crear la textura que se desea asignar a un objeto. El proceso de alinear estas imágenes en base a sus correspondencias y unirlas se denomina stitching. Este algoritmo es muy utilizado para la creación de imágenes panorámicas, que permite generar fotografías que no pueden ser capturadas con una cámara.
Fotografía computacional: La fotografía computacional se utiliza para crear nuevas imágenes, que no pueden generar los sistemas de captura de imágenes tradicionales, mediante el análisis y procesado de imagen de una o más fotografías. Mediante la fotografía computacional puede aumentarse la resolución de la imagen fusionando múltiples imágenes o utilizando algoritmos sofisticados. También se utiliza mucho para cortar piezas de una imagen y pegarlas en otra pareciendo que son parte de esta escena. Otra de las aplicaciones más utilizadas es la generación de nuevas texturas desde muestras del mundo real para aplicaciones que por ejemplo necesitan tapar los huecos que quedan por falta de información en esa área.
Correspondencia estereo: Stereo matching es el proceso de coger dos o más imágenes y estimar el modelo 3D de la escena, encontrando los emparejamientos entre los píxeles de diferentes imágenes y convirtiendo sus posiciones 2D en intensidades en 3D (añadimos la profundidad). Después de haber calculado la pose de la cámara y la estructura en función del movimiento mediante el stereo matching se construye un modelo 3D más completo asignando profundidades a los píxeles de la imagen.
Modelo 3D: La técnica de stereo matching es solo una de diferentes formas que pueden utilizarse para estimar la forma a partir de un conjunto de imágenes. Otro tipo de información como las texturas, sombras y el enfocado pueden utilizarse para estimar la forma. Si se tiene control sobre las diferentes fuentes de luz y pueden encenderse y apagarse independientemente puede generarse un modelo detallado con la información de las sombras utilizando photmetric stereo.

PROYECTO FIN DE MÁSTER
16
El modelado 3D se hace más eficiente cuando sabemos qué tipo de objetos se tratan de reconstruir, si son caras, personas, edificios…
Uno de los pasos importantes en este bloque es la extracción de texturas de las imágenes para añadirlos a los modelos 3D para poder obtener un mayor realismo.
Entorno Virtual: En este bloque se mezcla la reconstrucción 3D de visión por computador con las técnicas de renderizado de gráficos por computador para generar escenarios virtuales que utilizan múltiples puntos de vista de la escena para crear experiencias foto-realistas.
Este proyecto además de crear las funciones básicas para el procesado de imágenes, que se podrán utilizar a lo largo de todo el diagrama de bloques, se centra en los diferentes métodos actualmente utilizados en el bloque de detección de puntos de interés. A lo largo del proyecto se analizarán diferentes técnicas implementando y comparando sus resultados.

DESARROLLO
17
4. DESARROLLO
En esta sección se explicarán los conceptos básicos de procesado de imagen necesarios para cumplir con los objetivos planteados. Además se explicará cómo hacer uso de las funciones implementadas, proporcionando los resultados obtenidos y comparando entre diferentes técnicas. De esta manera según las necesidades de la aplicación (aplicación en tiempo real, reconstrucción 3d…) se podrá decidir que técnicas proporcionan mejor resultado, o quizás un resultado peor pero con un coste computacional menor.
Se comenzará viendo los conceptos más básicos de procesado de imagen, partiendo de que el usuario no tiene experiencia en este ámbito y se continuará con los diferentes bloques necesarios para implementar las aplicaciones anteriormente mencionadas.
4.1 INSTALACIÓN DEL PROYECTO
Para poder hacer uso de las funciones implementadas, es necesario tener instalado el Java Media Framework para la capturar las imágenes de la WebCam y el reproductor QuickTime, utilizado para procesar los frames de los videos.
Para observar paso a paso como instalar estos complementos y como configurar el entorno Eclipse para utilizar estas funciones consultar el Anexo A.1.
4.2 OPCIONES DE USO
4.2.1 Procesamiento de imágenes
El uso de la librería para el procesamiento de imágenes es muy sencillo. En primer lugar se tendrá que leer una imagen de disco. La librería permite la lectura de los formatos TIFF, BMP, GIF, JPG, JPEG y PNG:
//Leemos imagen de disco: Imagen im=ImagenIO.getImagen("c:/imagenes/tucano.jpg");
Una vez leída la imagen del disco tenemos un objeto imagen que puede manipularse como se desee. Para visualizar en una ventana la imagen leída o la imagen tras aplicar un procesado es tan sencillo como:

PROYECTO FIN DE MÁSTER
18
new Ventana(im); //Se abrirá una ventana mostrando la imagen im new Ventana(im,"Tucano"); //Se abrirá una ventana mostrando la imagen im y con el título de la ventana como Tucano new Ventana(im,"Tucano",true); //Se abrirá una ventana mostrando la imagen im, con el título de la ventana como Tucano y si se pulsa en la x de la ventana el programa java finalizara por completo, cerrando el resto de ventanas que estén abiertas etc.
En la figura 4.2.1 podemos observar el resultado de aplicar el comando anterior.
Figura 4.2.1. En la imagen superior podemos observar la ventana en la que se muestra la imagen indicada. Como se ha comentado anteriormente en la parte superior de la ventana se muestra el título que se le pasa como parámetro a la clase Ventana.
Finalmente si se desea almacenar la imagen tras aplicar las modificaciones deseadas:
//Guardamos imagen en disco: ImagenIO.writeImagen(im,"bmp","c:/resultado.bmp");
El comando anterior almacena la imagen en formato bmp pero especificando el segundo parámetro del método podemos almacenar las imágenes en los formatos BMP, GIF, JPG, JPEG y PNG.
4.2.2 Uso de la WebCam
Es posible que la aplicación que se deseé desarrollar tenga como objetivo el procesado en tiempo real de las imágenes capturadas de la WebCam conectada al equipo. Si este es el caso crearemos una clase que extienda de la clase WebCam. Esta tendrá la siguiente estructura:
public class prueba extends WebCam { public void procesarImagenes(Imagen in,Imagen out){
//Escribir el procesamiento que se desee } public static void main (String [] args){

DESARROLLO
19
prueba p=new prueba();//Cremos una instancia de la clase que extiende de WebCam p.conectar(); } }
Como se puede observar en el código de la parte superior, en el main se creará la instancia a la clase que extienda de WebCam y una vez ejecutamos el método conectar el proceso de captura de imágenes de la WebCam comenzará. Por cada imagen capturada de la WebCam se procesara el código implementado en el método procesarImagenes. Donde in es la imagen capturada de la WebCam en ese instante y out es la imagen que se mostrará en pantalla.
Si se desea mostrar la misma imagen que se captura de la WebCam por pantalla el método procesarImagenes tendrá la siguiente forma:
public void procesarImagenes(Imagen in,Imagen out){ Imagen.copyIntColorArray(in, out);
}
Por defecto la aplicación funcionara con la imagen de la primera WebCam detectada, en el caso de poseer más de una conectada al equipo, y con una resolución de 320x240. Aunque estos parámetros pueden ser observados/modificados en función de la aplicación deseada.
public static void main (String [] args){ prueba p=new prueba(); //Numero de Webcams conectadas al equipo System.out.println("Numero WebCams: "+getNumDispositivos()); //Obtenemos formatos soportados por la WebCam conectada al ordenador p.imprimirFormatosDispositivos(); //Especificamos una resolución de 640x480. Observar en los formatos soportados el id del formato que se desea, este será el formato que hay que pasarle como parámetro a setFormato. p.setFormato(4); p.conectar(); }
Tal y como se muestra en la figura 4.2.2 en la ventana podemos observar como de rápido se ejecuta el algoritmo que se ha implementado en frames por segundo. Los frames por segundo indican el tiempo que se tarda en coger la última imagen capturada por la WebCam, procesarla y mostrar el resultado en pantalla.
En función del formato/resolución con la que se capture las imágenes desde la WebCam el algoritmo tardará más o menos en ejecutarse. Como es de suponer cuanto mayor resolución, mayor será el tiempo necesario para procesar la imagen y menor serán los frames procesados por segundo.
Durante el resto de la memoria se mostrarán diferentes tablas mostrando los tiempos de ejecución que se han obtenido con un Dell Optiplex 755, Intel(R) Core(TM) 2 Duo CPU, E8400 @ 3.00GHz, 1.97 GHz, 3,23GB de RAM.

PROYECTO FIN DE MÁSTER
20
Figura 4.2.2. En la imagen superior podemos observar la ventana en la que se muestra la imagen de la WebCam.
En la siguiente tabla se puede observar los tiempos de ejecución obtenidos con los diferentes formatos admitidos por la WebCam utilizada. En esta prueba se capturaba la imagen de la WebCam y se copiaba el array de los colores de esta imagen a la imagen a mostrar.
Formato Resolución FPS
0 320x240 1108
1 160x120 4335
2 176x144 3351
3 352x288 828
4 640x480 218
4.2.3 Procesando un conjunto de imágenes
Para ciertas aplicaciones puede ser necesario aplicar el mismo procesado aún conjunto amplio de imágenes. Este proceso puede realizarse de una forma sencilla haciendo que nuestra clase extienda de ProcesadoMultiple:

DESARROLLO
21
public class prueba extends ProcesadoMultiple { public void procesarImagenes(Imagen in){
//Escribir el procesamiento que se desee } public static void main (String [] args){ //Cremos una instancia de la clase que extiende de PrcesadoMultiple prueba p=new prueba(); //Definimos el directorio donde se encuentran las imágenes p.setPath("c:/imagenes/"); //Comienza el proceso p.process(); } }
El funcionamiento es muy similar al caso anterior. En primer lugar creamos una instancia de la clase ProcesadoMultiple. Una vez creada le indicaremos el directorio donde se encuentran las imágenes a procesar. Una vez comience el proceso, a cada imagen que se encuentre en el directorio especificado se le aplicará las funciones especificadas en el método procesarImagenes, donde in es cada una de las imágenes del directorio.
4.2.4 Procesando videos
En muchas ocasiones puede que el objetivo de la aplicación a desarrollar sea procesar la información disponible en videos. En nuestro caso por ejemplo, para la construcción de modelos 3D, se procesarán las imágenes obtenidas de una secuencia de video que contenga el objeto a construir.
Para acceder a los frames del video se ha utilizado la librería de java de QuickTime, ya que JMF no soportaba muchos formatos de video. Lo bueno de utilizar esta librería es que podemos procesar cualquier video que reproduzca QuickTime (avi, mov, mpeg…).
Normalmente la mayoría de videos en formato digital están comprimidos (para no ocupar tanto), la librería QuickTime puede reproducir los videos comprimidos con los siguientes códec:
QT_RGB * QT_YUV * QT_RLE * QT_BMP
QT_SORENSON3 QT_CINEPAK QT_JPG * QT_MJPG *
QT_MJPGB QT_H261 QT_H263 QT_DVCPAL
QT_SORENSON QT_MPEG4 QT_MJPGA QT_DVCNTSC
*Se recomienda procesar videos con este formato, los otros por la compresión que llevan puede que hayan perdido información que pueda sernos de interés.
Si se desea procesar todos los frames de un video:

PROYECTO FIN DE MÁSTER
22
public class pruebaVideo extends ProcesadoVideo { public void procesarImagenes(Imagen in){
//Escribir el procesamiento que se desee } public static void main (String [] args){ pruebaVideo pv=new pruebaVideo();//Creamos una instancia de la clase que extiende de ProcesadoVideo pv.processVideo("c:/video.mov");//Seleccionamos el video a procesar pv.setBarraProgreso(true);//Queremos ver el progreso de la ejecución en una barra de progreso pv.start();//Iniciamos el proceso } }
Tal y como se observa en el código del recuadro superior una vez se selecciona el video que se desea procesar, puede activarse la opción que muestra en una barra de progreso el porcentaje de video que se ha procesado. Esta opción es muy cómoda a la hora de estimar cuanto tiempo ha transcurrido y cuanto tiempo queda para que finalice de procesar el video pasado como parámetro.
Figura 4.2.3. En esta imagen podemos observar la interface que nos muestra el porcentaje de video procesado.
Si no deseamos que se procesen todos los frames del video porque son demasiados, podemos especificar que se ejecuten 1 de cada 100 frames por ejemplo, antes de ejecutar el start().
pv.setProcesFrames(100);//Se procesarán 1 de cada 100 frames pv.start();//Iniciamos el proceso
Si al contrario, se desea aplicar un procesamiento al video y modificar la imagen para generar un nuevo video modificado, el método a seguir es similar pero utilizando la clase ProcesadoVideoAFichero:
public class prueba extends ProcesadoVideoAFichero { public void procesarImagenes(Imagen in){
//Escribir el procesamiento que se desee } public static void main (String [] args){ prueba p=new prueba();//Creamos una instancia de la clase que extiende de ProcesadoVideoAFichero //Seleccionamos el formato de salida

DESARROLLO
23
p.setFormatoVideoSalida(0); //Seleccionamos el frame rate para exportar el video p.setFrameRate(24); //Seleccionamos la calidad del video p.setCalidadVideo(5); //Seleccionamos el video a procesar p.processVideo("c:/video.mov"); //Especificamos donde se almacenara el resultado p.setFicheroSalida("c:/resultado.mov"); //Queremos ver el progreso de la ejecución en una barra de progreso p.setBarraProgreso(true); //Iniciamos el proceso p.start(); } } Como puede observarse es necesario especificar el formato de salida y la calidad del video de salida. Para saber que formatos y calidades hay disponibles, podemos obtener la información ejecutando las siguientes funciones:
p.imprimirFormatoVideos();//Muestra los formatos permitidos p.imprimirCalidadVideos();//Muestra las diferentes calidades
4.3 PROCESAMIENTO DE IMAGEN
4.3.1 Tipos de imágenes
Una imagen está compuesta por muchos puntos (denominados píxeles) que toman diferentes colores y conjuntamente forman la imagen gráfica. Cuanto más píxeles tenga una imagen lógicamente mayor calidad tendrá. Para interactuar con los píxeles y procesar la imagen definiremos esta como una matriz donde sus diferentes valores representan el color en ese punto de la imagen.
Si pensamos en una imagen en escala de grises cada píxel tendrá un valor que varía desde 0 (negro) hasta 255 (blanco). Sin embargo las imágenes en color se componen mediante la mezcla de los tres colores básicos (rojo, verde y azul), cuya combinación puede generar cualquier color. Por lo que las imágenes en color (RGB) en lugar de poseer un valor que varía desde 0 a 255 poseerán 3 valores, uno por cada componente de color.
A continuación se muestra como se lee una imagen en color y como se accede a sus píxeles:
//1.Leemos imagen de disco. Imagen im=ImagenIO.getImagen("c:/imagenes/tucano.jpg"); //2.Accedemos a la componente roja del píxel de la fila 0 y columna 0 im.getComponente0(0,0); //3.Accedemos a la componente verde del píxel de la fila 1 y columna 0 im.getComponente1(1,0); //2.Accedemos a la componente azul del píxel de la fila 0 y columna 1 im.getComponente2(0,1);

PROYECTO FIN DE MÁSTER
24
Muchas de las operaciones de procesado de imagen en lugar de realizarse con los tres valores de color, que puede ralentizar muchos las operaciones, se realizan con su valor de luminancia. Para obtener el valor de luminancia de una imagen de color se aplica la siguiente fórmula:
BGRY 114.0587.0299.0601
Donde R es el componente rojo, G el componente verde y B el componente azul. Se debe tener en cuenta que si se usan imágenes con la nueva definición de color para HDTV en BT.709 la luminosidad se calculara con esta otra fórmula:
BGRY 0721.07154.02125.0709
Al calcular la luminancia de una imagen lo que se hace es pasar esta a escala de grises. La mayoría de algoritmos de procesado de imagen procesan las imágenes en blanco y negro. Para pasar una imagen de color a escala de grises:
//1.Leemos imagen de disco. Imagen im=ImagenIO.getImagen("c:/imagenes/tucano.jpg"); //2.Pasamos la imagen a una imagen en BN ImagenBN imBN=new ImagenBN(im);
A continuación se muestra como se lee una imagen de disco directamente en escala de grises y como se accede al valor de sus píxeles:
//1.Leemos imagen de disco en BN. ImagenBN imBN=ImagenIO.getImagenBN("c:/imagenes/tucano.jpg"); //2.Accedemos al píxel en la fila 0 columna 0 imBN.getIntensidad(0,0);
Además de imágenes en color y en escala de grises un recurso muy utilizado en el procesado de imagen son las imágenes binarias. Los valores de los píxeles de estas imágenes solo pueden tomar dos valores posibles o 0 o 1. Para convertir una imagen a imagen binaria es necesario definir un valor de thresholding (desde 0 a 255). Todo valor de intensidad que esté por debajo de este Threshold se convertirá en 0 y los superiores en 1.
//1.Leemos imagen de disco. Imagen im=ImagenIO.getImagen("c:/imagenes/leo.jpg"); //2.Convertimos la imagen en binaria convirtiendo todo los píxeles con luminancia menor que 125 a 0 y el resto a 1 ImagenBinaria imbin=new ImagenBinaria(im,125); //3.Mostramos resultado new Ventana(ir,"Imagen Binaria",true);
En la figura 4.3.1 se muestra el resultado de ejecutar este código.

DESARROLLO
25
Figura 4.3.1. En las imágenes superiores se muestran los tres tipos de imágenes con las que se trabajará. Imagen en color, en escala de grises e imagen binaria.
4.3.2 Operación a nivel de píxel
Las trasformaciones de procesado de imagen más sencillas son aquellas donde el valor del píxel de la imagen resultante solo depende del píxel de la imagen de entrada. Este tipo de trasformaciones se utilizan para mejorar la apariencia de la imagen. Un ejemplo de operación a nivel de píxel es la modificación del brillo, el contraste, la corrección de color…
4.3.2.1 Transformación de píxel
En general las transformaciones de píxel tienen la siguiente forma:
))(()( xfhxg ó )),((),( jifhjig
Donde la imagen de salida g depende una transformación h sobre la imagen original f.
Dos de las operaciones más comunes en las transformaciones de píxel son la multiplicación y la suma por una constante.
bxafxg )()(
En este caso a se denomina gain (debe ser mayor que 0) y b bias. En ocasiones se utilizan estos parámetros para modificar el contraste y el brillo de las imágenes. Para modificar el brillo y el contraste de una imagen utilizaremos la clase BrilloContraste:
//1.Leemos imagen de disco. Imagen im=ImagenIO.getImagen("c:/imagenes/tucano.jpg"); //2.Creamos una imagen del mismo tamaño que la imagen original para almacenar el resultado Imagen ir=new Imagen(im.getWidth(),im.getHeight()); //3.Creamos objeto de la clase BrilloContraste. BrilloContraste bc=new BrilloContraste(); //4.Añadimos 90 de brillo a im y se guarda el resultado en ir. bc.processBrillo(im,ir,90); //5.Actualizamos los valores de la imagen ir ir.update(); //6 mostramos la imagen resultante new Ventana(ir,"Brillo y contraste",true);

PROYECTO FIN DE MÁSTER
26
En la figura4.3.2 podemos observar el resultado de utilizar esta función, para aclarar y oscurecer imágenes.
Figura 4.3.2. La primera imagen muestra la imagen original, a su derecha se observa la misma imagen con un brillo de 90 y posteriormente la misma imagen con un brillo -90.
En este caso para modificar el brillo de la imagen se modifica el parámetro bias de la siguiente manera:
brilloxfb *)255/)(1(
Por lo que el valor del píxel de la salida se puede calcular con:
brilloxfxfxg *)255/)(1()()(
Para modificar el contraste de una imagen la metodología es muy parecida al caso anterior, en este caso se utilizará la función processContraste:
//Añadimos 2 de contraste bc.processContraste(im,ir,2f); ir.update();
En la figura 4.3.3 podemos observar el resultado de utilizar esta función.
Figura 4.3.3. La primera imagen muestra la imagen original, a su derecha se observa la misma imagen con un contraste de 2 y posteriormente la misma imagen con un contraste de 0.5.
Para modificar el contraste se modifica el gain calculando el valor del píxel de salida de la siguiente manera:
255*)5.0*)5.0255/)((()( contrastexfxg
Por lo que si queremos modificar simultáneamente el brillo y el tono:

DESARROLLO
27
brilloxfcontrastexfxg *)255/)(1(255*)5.0*)5.0255/)((()(
En lugar de tener que usar dos funciones para modificar el brillo y el contraste, podemos modificar estos valores con una sola función:
//Función que procesa el cambio de brillo y de tono bc.process (im,ir,-90,2f); ir.update();
Si no sabemos qué valor de brillo y contraste añadir a la imagen, en lugar de ir probando uno a uno los valores, se pueden probar diferentes valores fácilmente cargando la ventana BrilloContraste (figura 4.3.4) que te permite modificar estos con un slider y ver el resultado.
//Ventana Brillo Contraste new VentanaBrilloContraste(im,true);
Figura 4.3.4. Observamos la ventana que permite modificar los valores de brillo y contraste.
Otra de las operaciones, con dos entradas, más utilizada es la mezcla lineal (linear blend).
)()()1()( 10 xfxfxg
En este caso 0f y 1f son las dos imágenes de entrada y (de 0 a 1) especifica la cantidad de mezcla entre las imágenes. Esta operación se utiliza para efectos de video, donde modificando el valor de la imagen va desapareciendo, mientras se mezcla con la nueva imagen que aparece. Este operador también se utiliza en diferentes algoritmos de morphing.
Para realizar este efecto se dispone de la clase Mezcla. Hay que tener en cuenta que para realizar este efecto las imágenes deben de tener el mismo tamaño:

PROYECTO FIN DE MÁSTER
28
//1.Leemos las 2 imagenes de disco. Imagen im1=ImagenIO.getImagen("c:/imagenes/children.jpg"); Imagen im2=ImagenIO.getImagen("c:/imagenes/lago.jpg"); //2.Creamos una imagen del mismo tamaño que la imagen original para almacenar el resultado Imagen ir=new Imagen(im.getWidth(),im.getHeight()); //3.Creamos objeto de la clase Mezcla Mezcla m=new Mezcla(); //4.Mezclamos un 50% las imagenes. m.mezclar(im1,im2,0.5f,ir); //5.Actualizamos los valores de la imagen ir ir.update(); //6 mostramos la imagen resultante new Ventana(ir,"Mezcla",true);
En la figura 4.3.5 podemos observar el resultado de utilizar esta función.
Figura 4.3.5 La primera y segunda imaginen son las imágenes utilizadas como entrada. Mezclando estas con un valor de un 50% obtenemos la última imagen.
Al igual que en el caso anterior podemos observar el efecto de disolver la imagen moviendo el slider de la ventana mezcla en la figura 4.3.6:
//Ventana Brillo Contraste new VentanaMezcla(im1,im2,true);
Otra de las transformaciones (no lineales) más usadas antes de cualquier tipo de procesado es la corrección gamma (gamma correction). Esta transformación se utiliza con el objetivo de remover el mapeo no lineal entre la radiación y el valor cuantificado de los píxeles. La imagen debería ser directamente proporcional a la luz que incidió, durante el proceso de captación de la imagen. Teóricamente, la respuesta debería ser lineal, no obstante, se ha demostrado empíricamente que esta respuesta siempre es no lineal. Para corregir este efecto se introduce artificialmente una distorsión opuesta que se denomina corrección gamma.
gfxfxg /)]([)(
Donde:
f : Es el factor gamma de la cámara.
g : Es el factor gamma del receptor.

DESARROLLO
29
Figura 4.3.6. Observamos la ventana que permite modificar el porcentaje de mezcla entre dos imágenes.
Para una respuesta ideal f debería de ser 1, por lo que:
/1)]([)( xfxg
El valor necesario para obtener la corrección gamma se ha estandarizado en 45.0f ya que aplicando este factor de corrección se logra la linealidad del sistema. Esto implica que un valor de 2.2 es un valor razonable para la mayoría de cámaras digitales.
Para realizar una corrección gamma a una imagen:
//1.Leemos imagen del disco. Imagen im=ImagenIO.getImagen("c:/imagenes/habitacion.jpg"); //2.Creamos una imagen del mismo tamaño que la imagen original para almacenar el resultado Imagen ir=new Imagen(im.getWidth(),im.getHeight()); //3.Creamos objeto de la clase GammaCorrection GammaCorrection gc=new GammaCorrection(); //4.Aplicamos la corrección gamma para una gamma típica. gc.mezclar(im,i4); //5.Actualizamos los valores de la imagen ir ir.update(); //6 mostramos la imagen resultante new Ventana(ir,"Gamma Correction",true);
Podemos modificar el valor gamma que queremos aplicar:
//Cambiamos el valor gamma a aplicar gc.setGamma(1/2.8);
En la figura 4.3.7 se puede observar el efecto de aplicar la corrección gamma.

PROYECTO FIN DE MÁSTER
30
Figura 4.3.7. A la izquierda observamos la imagen original mientras que a la derecha obtenemos el resultado de aplicar una corrección gama de 2.2
4.3.2.2 Transformación de color
El procesamiento de color es un recurso muy utilizado en el ámbito del procesamiento de imágenes, por ejemplo para buscar objetos de cierto color. Muchos algoritmos de detección de caras se basan en buscar los píxeles que sean del color de la piel humana. Por ejemplo Peer en 2003 implemento un clasificador de piel donde todo píxel que cumpliese con las siguientes condiciones se consideraba perteneciente a un área con piel:
1. R>95 y G>40 y B>20.
2. La componente roja(R) debe ser mayor que las otras dos (G y B).
3. El máximo entre {R,G,B} menos el mínimo entre {R,G,B} debe ser mayor de 15.
4. |R-G|>15.
Para utilizar este algoritmo:
//1.Leemos imagen del disco. Imagen im=ImagenIO.getImagen("c:/imagenes/peli.jpg"); //2.Creamos una imagen del mismo tamaño que la imagen original para almacenar el resultado Imagen ir=new Imagen(im.getWidth(),im.getHeight()); //3.Creamos objeto de la clase DeteccionColorPiel DeteccionColorPiel dcp=new DeteccionColorPiel(); //4. Ejecutamos la búsqueda. dcp.process(im,ir); //5.Actualizamos los valores de la imagen ir ir.update(); //6 mostramos la imagen resultante new Ventana(ir,"Color piel",true);
En la figura 4.3.8 podemos observar el resultado de aplicar este algoritmo.

DESARROLLO
31
Figura 4.3.8. En la primera imagen podemos observar una imagen extraída de una película donde se ve un conjunto de gente. Tras aplicar el algoritmo de detección de color de piel obtenemos la segunda imagen donde podemos observar exclusivamente las áreas de la imagen con este color.
Al procesar imágenes de color tenemos que tener especial cuidado con el espacio RGB. A la hora de buscar un color concreto en una imagen el espacio RGB es muy poco robusto a cambios de iluminación por lo que sería una buena idea procesar las imágenes en otro tipo de espacio. Además si queremos aumentar la intensidad de cada píxel añadiendo una constante, esto puede afectar a parámetros como el matiz (hue) y la saturación (saturation). El matiz es el tipo de color (como rojo, azul o amarillo). Se representa como un grado de ángulo cuyos valores posibles van de 0 a 360° (aunque para algunas aplicaciones se normalizan del 0 al 100). Cada valor corresponde a un color. Ejemplos: 0 es rojo, 60 es amarillo y 120 es verde.
La saturación se representa como la distancia al eje de brillo negro-blanco. Cuanto menor sea la saturación de un color, mayor tonalidad grisácea habrá y más decolorado estará.
En el caso de querer aumentar la intensidad de los píxeles la mejor opción sería convertir la imagen RGB a coordenadas de cromaticidad o a ratios de color, computar el efecto deseado y volver a pasar la imagen a RGB. De esta manera los valores como hue y saturation no sufrirían modificaciones. Para este tipo de operaciones se dispone de la clase ModeloColor. Para pasar una imagen RGB a HSV(hue, saturation, value):
//1.Leemos imagen del disco. Imagen im=ImagenIO.getImagen("c:/imagenes/arana.jpg"); //2.Creamos una imagen del mismo tamaño que la imagen original para almacenar el resultado Imagen ir=new Imagen(im.getWidth(),im.getHeight()); //3.Creamos objeto de la clase ModeloColor ModeloColor mc=new ModeloColor(); //4. Pasamos imagen de rgb a hsv mc.rgbToHsv(im,ir); //5.Realizamos las operaciones deseadas sobre la imagen ir ... //6. Pasamos de hsv a rgb mc.rgbToHsv(ir,im); //7.Actualizamos los valores de la imagen ir

PROYECTO FIN DE MÁSTER
32
im.update(); //8. mostramos la imagen resultante new Ventana(im,"Procesamiento color",true);
Para poder modificar los valores del matiz, saturación y brillo puede utilizarse el interfaz gráfico VentanaHSV.
//Ventana HSV new VentanaHSV(im,true);
Figura 4.3.9. La ventana HSV nos permite modificar los valores de la tonalidad, saturación y brillo de la imagen.
4.3.2.3 Compositing & matting
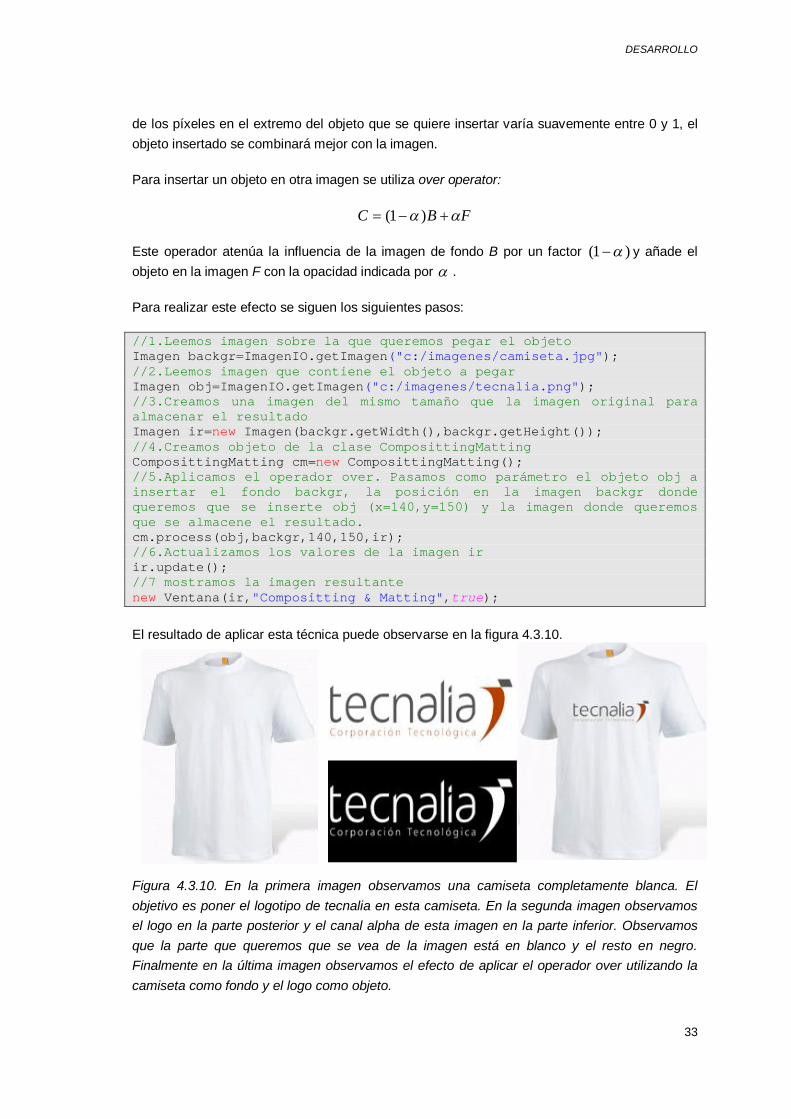
En muchas aplicaciones de edición de foto o de efectos especiales se desea cortar un objeto de una imagen y ponerlo sobre el fondo de otra. El proceso de extraer un objeto de una imagen se denomina matting mientras que el proceso de insertar este objeto en otra imagen se llama compositing.
La imagen que especifica que píxeles de una imagen pertenecen al objeto que se desea extraer se llama imagen alpha-matted. Hay cierto formato de imágenes como por ejemplo las imágenes PNG que además de los tres canales RGB utilizan un canal alpha que describe como de opaco ( 1 ) o transparente ( 0 ) son cada píxel de la imagen. Si el canal alpha
DESARROLLO
33
de los píxeles en el extremo del objeto que se quiere insertar varía suavemente entre 0 y 1, el objeto insertado se combinará mejor con la imagen.
Para insertar un objeto en otra imagen se utiliza over operator:
FBC )1(
Este operador atenúa la influencia de la imagen de fondo B por un factor )1( y añade el objeto en la imagen F con la opacidad indicada por .
Para realizar este efecto se siguen los siguientes pasos:
//1.Leemos imagen sobre la que queremos pegar el objeto Imagen backgr=ImagenIO.getImagen("c:/imagenes/camiseta.jpg"); //2.Leemos imagen que contiene el objeto a pegar Imagen obj=ImagenIO.getImagen("c:/imagenes/tecnalia.png"); //3.Creamos una imagen del mismo tamaño que la imagen original para almacenar el resultado Imagen ir=new Imagen(backgr.getWidth(),backgr.getHeight()); //4.Creamos objeto de la clase ComposittingMatting ComposittingMatting cm=new ComposittingMatting(); //5.Aplicamos el operador over. Pasamos como parámetro el objeto obj a insertar el fondo backgr, la posición en la imagen backgr donde queremos que se inserte obj (x=140,y=150) y la imagen donde queremos que se almacene el resultado. cm.process(obj,backgr,140,150,ir); //6.Actualizamos los valores de la imagen ir ir.update(); //7 mostramos la imagen resultante new Ventana(ir,"Compositting & Matting",true);
El resultado de aplicar esta técnica puede observarse en la figura 4.3.10.
Figura 4.3.10. En la primera imagen observamos una camiseta completamente blanca. El objetivo es poner el logotipo de tecnalia en esta camiseta. En la segunda imagen observamos el logo en la parte posterior y el canal alpha de esta imagen en la parte inferior. Observamos que la parte que queremos que se vea de la imagen está en blanco y el resto en negro. Finalmente en la última imagen observamos el efecto de aplicar el operador over utilizando la camiseta como fondo y el logo como objeto.

PROYECTO FIN DE MÁSTER
34
El operador mencionado no es el único que puede utilizarse para esta tarea, diferentes algoritmos han sido implementados para realizar el mismo efecto.
4.3.2.4 Histograma
Un histograma es una representación gráfica de la distribución de las intensidades de los píxeles de una imagen. Supongamos una imagen en escala de grises. Las intensidades de los píxeles de esta imagen variarán desde 0 (negro) a 255 (blanco). Un histograma nos mostraría para cada valor de intensidad (del 0 al 255) cuantos píxeles con esta intensidad hay en la imagen.
Para observar un histograma se utilizará la clase Histograma:
//1.Leemos la imagen de disco. Imagen im=ImagenIO.getImagen("c:/imagenes/peces.jpg"); //2 creamos el histograma new Histograma(im);
Si al histograma se le pasa una imagen en escala de grises solo se obtendrá el histograma de los niveles de grises. Si se le pasa una imagen en color se obtendrá un histograma por cada color RGB( Rojo, Verde y Azul), tal y como se muestra en la figura 4.3.11.
4.3.2.3.1 Ecualización de histograma
Como se ha mencionado anteriormente la ganancia y el brillo pueden utilizarse para mejorar la apariencia de la imagen. Pero en muchas ocasiones deseamos que este proceso se realice automáticamente. Una forma sencilla de hacerlo sería coger el valor más claro y el más oscuro de la imagen y estirar el histograma hasta el valor negro (0) y blanco (255). Otra posible solución es hallar el valor promedio de los píxeles de la imagen y mover este hasta el centro del histograma y expandir el resto de valores hasta los valores negro y blanco puro.
Una de las soluciones más populares es realizar la ecualización del histograma. Para ello a de encontrarse un función de mapeo de intensidad para que el histograma resultante sea plano. Esta función se calcula integrando la distribución h(I) (el histograma original) para obtener la distribución cumulativa c(I).
I
i
IhN
IcihN
Ic0
)(1)1()(1)(
Donde N es el número de píxeles de la imagen. Para cada valor de intensidad del histograma se ha calculado un nuevo valor de intensidad que será sustituido en la imagen obteniendo resultados como los de la figura 4.3.12 Para ecualizar una imagen:
//1.Leemos imagen del disco. ImagenBN im=ImagenIO.getImagenBN("c:/imagenes/oscuro.jpg"); //2.Creamos una imagen del mismo tamaño que la imagen original para almacenar el resultado ImagenBN ir=new ImagenBN(im.getWidth(),im.getHeight()); //3.Creamos objeto de la clase EcualizacionHistograma

DESARROLLO
35
EcualizacionHistograma eh=new EcualizacionHistograma(); //4.Aplicamos la ecualización. Acordarse de actualizar la imagen si es una imagen en color eh.ecualizar(im,ir); //6 mostramos la imagen resultante new Ventana(ir,"Imagen Ecualizada",true);
Figura 4.3.11. En la imagen se puede apreciar una imagen con diferentes colores y a su lado la misma imagen en escala de grises. Si se aplica el histograma a la imagen en escala de grises se obtendrá el histograma que nos define desde 0 a 255 cuantos píxeles hay de cada intensidad. Si se aplica el histograma a la imagen en Color se obtendrá el histograma del color rojo, verde y azul.
En ocasiones el resultado obtenido no suele variar mucho el contraste y el aspecto de la imagen es un poco “turbio”. Una forma de mejorar esto es compensando el histograma parcialmente, por ejemplo utilizando una mezcla de la distribución cumulativa con la transformada identidad.

PROYECTO FIN DE MÁSTER
36
IIcIf )1()()(
Figura 4.3.12. La primera fila muestra una imagen muy oscura, donde vemos que la intensidad de los píxeles concentrados en un rango del histograma de píxeles oscuros. Para conseguir un mayor contraste aplicamos la ecualización y obtenemos el resultado de la imagen de la segunda fila con su correspondiente histograma que se ha expandido a lo largo de las diferentes intensidades.
Otro problema con la ecualización de histogramas suele ser que el ruido en zonas oscuras puede ser amplificado.
Mientras que en ciertas imágenes la ecualización es de gran ayuda en otras puede ser preferible aplicar diferentes tipos de ecualización según la región de la imagen que se esté tratando.
Para conseguir una ecualización óptima existen otros métodos como por ejemplo la ecualización de histograma adaptativo o incluso la ecualización de histograma adaptativo limitado por el contraste, que reduce el ruido producido por la ecualización.
4.3.3 Filtrado espacial
Un filtro es el conjunto de técnicas englobadas dentro del pre-procesamiento de imágenes cuyo objetivo fundamental es obtener, a partir de una imagen origen, otra final cuyo resultado sea

DESARROLLO
37
más adecuado para una aplicación específica, mejorando ciertas características de la misma que posibilite efectuar operaciones del procesado sobre ella.
Los principales objetivos que se persiguen con la aplicación de filtros son:
Suavizar la imagen: reducir la cantidad de variaciones de intensidad entre píxeles vecinos.
Eliminar ruido: eliminar aquellos píxeles cuyo nivel de intensidad es muy diferente al de sus vecinos.
Realzar bordes: destacar los bordes que se localizan en una imagen.
Detectar bordes: detectar los píxeles donde se produce un cambio brusco en la función intensidad.
Por tanto, se consideran los filtros como operaciones que se aplican a los píxeles de una imagen digital para optimizarla, enfatizar cierta información o conseguir un efecto especial en ella.
El proceso de filtrado puede llevarse a cabo sobre los dominios de frecuencia y/o espacio. Los filtros de frecuencia procesan una imagen trabajando sobre el dominio de la frecuencia utilizando la Transformada de Fourier de la imagen (el proceso se muestra en la figura 4.3.13). Primero se debe pasar la imagen al dominio frecuencial mediante la transformada de Fourier. Una vez en el dominio de la frecuencia multiplicaremos la función frecuencial del filtro a la imagen en el dominio de la frecuencia y realizaremos la trasformada inversa de Fourier para obtener la imagen en el dominio espacial.
Figura 4.3.13. Funcionamiento del filtrado frecuencial.
En una imagen las componentes de alta frecuencia se ubican en los cambios bruscos de intensidad entre píxeles, es decir en los bordes. Por lo que si eliminaos componentes de baja frecuencia podremos acentuar los bordes. Por el otro lado las componentes de baja frecuencia se encuentran en las aéreas donde no hay cambios de intensidad, permanecen constantes. Si eliminamos altas frecuencias conseguiremos un efecto de suavizado, que eliminará el ruido pero también difuminara los bordes y puede que en posteriores procesos no se detecten.
Los filtros espaciales operan directamente sobre los píxeles de la imagen y también se les conoce como operaciones de vecindad. Su funcionamiento es muy sencillo y más rápido que los filtros frecuenciales.

PROYECTO FIN DE MÁSTER
38
Según el teorema de la convolución una multiplicación en el dominio frecuencial equivale a una convolución en el dominio espacial. Por lo que los filtros espaciales se basan en la convolución de la imagen con una mascara (función espacial del filtro).
Para realizar la convolución, en primer lugar se define un punto central y se realiza la operación con sus píxeles vecinos. Esta operación está representada por un kernel, una matriz que asigna el peso que se le da a cada píxel que toma parte en la operación. El valor resultante de esta operación se convierte en el píxel, del punto central que hemos definido en la nueva imagen. Esta operación se realiza para cada píxel de la imagen con sus vecinos tal y como muestra en la figura 4.3.14.
Figura 4.3.14. Funcionamiento del filtrado espacial.
Para suavizar las imágenes, con el objetivo de reducir el ruido de estas, una posibilidad es aplicar un filtro que realice el promedio de cada píxel con sus píxeles vecinos (no es la mejor forma de reducir el ruido pero para introducir el concepto de filtrado sirve). El resultado de este filtro será una imagen más borrosa, lo que elimina el ruido pero también puede dificultar la detección de bordes en posteriores procesos, por lo que se tendrá que tener cuidado. La imagen será más borrosa o menos según el tamaño del filtro, cuanto mayor sea el tamaño más borrosa y más ruido reducirá, pero se apreciarán menos detalles. Aplicaremos a la imagen de la figura 4.3.15 un filtro con una longitud y altura de 5 píxeles tal y como se muestra a continuación.
Para ello:

DESARROLLO
39
//1.Leemos imagen del disco. Imagen im=ImagenIO.getImagen("c:/imagenes/flor.jpg"); //2.Creamos una imagen del mismo tamaño que la imagen original para almacenar el resultado Imagen ir=new Imagen(im.getWidth(),im.getHeight()); //3.Creamos el filtro a aplicar. El kernel que hará el promedio float [] k=new float[25]; k[0]=1f/25; k[1]=1f/25; k[2]=1f/25; k[3]=1f/25; k[4]=1f/25; k[5]=1f/25; k[6]=1f/25; k[7]=1f/25; k[8]=1f/25; k[9]=1f/25; k[10]=1f/25; k[11]=1f/25; k[12]=1f/25; k[13]=1f/25; k[14]=1f/25; k[15]=1f/25; k[16]=1f/25; k[17]=1f/25; k[18]=1f/25; k[19]=1f/25; k[20]=1f/25; k[21]=1f/25; k[22]=1f/25; k[23]=1f/25; k[24]=1f/25; //3.Creamos objeto de la clase Convolución y le pasamos el kernel y su tamaño anchura, altura. Podemos crear el objeto convolución de dos maneras: Convolucion c=new Convolucion(k,5,5); //Convolucion Convolucion c=new Convolucion(k,5,5,true); //Si el resultado del píxel al realzar la convolución es menor que 0 este se pondrá a 0 y si es mayor que 255 se pondrá a 255 //4.Realizamos la convolución c.process(im,ir); ir.update(); new Ventana(ir,"Imagen Suavizada",true);
Los resultados pueden apreciarse en la figura 4.3.15.
Figura 4.3.15. Tras aplicar un kernel de tamaño 5x5 con una función promedio observamos como la imagen se suaviza pero además sale un borde negro alrededor de la imagen.
4.3.3.1 Relleno (Padding)
Podemos observar en la imagen anterior, que tras aplicar el filtro a una imagen obtenemos un borde negro alrededor de la imagen resultante. Esto es debido a que a los bordes de la imagen no se les aplica el filtro porque parte del kernel quedaría fuera de la imagen tal y como muestra la figura 4.3.16.

PROYECTO FIN DE MÁSTER
40
La solución de este problema se denomina relleno. Se rellenarán los bordes de las imágenes con diferentes valores (dependiendo del tipo de relleno escogido) para poder operar en todos los píxeles de la imagen.
Existen diferentes técnicas de relleno (padding):
Relleno cero: Se ponen todos los píxeles fuera de la imagen a 0 (buena opción en caso de recortes alpha-matted).
Relleno constante: Todos los píxeles fuera de la imagen tendrán el valor de la constante especificada.
Relleno replicado: Se repite el píxel del borde de la imagen indefinidamente.
Relleno cíclico: Gira en torno a la imagen en una configuración toroidal. (Este tipo de relleno no ha sido implementado en esta librería)
Relleno simétrico: Refleja los píxeles sobre el borde de la imagen. (Efecto espejo)
Relleno extendido: Esta versión resta al relleno replicado el relleno simétrico.
Figura 4.3.16. En la primera imagen podemos observar el problema del filtrado en las imágenes. En este caso al aplicar un kernel 3x3 observamos que a la primera línea entre otras no puede aplicarse el valor porque no hay acceso a los píxeles superiores. La solución se muestra en la segunda imagen en la que se ha puesto un relleno para que pueda realizarse las operaciones con estos píxeles también.
//1.Leemos imagen del disco. Imagen im=ImagenIO.getImagen("c:/imagenes/flor2.jpg"); //2.Creamos una imagen del mismo tamaño que la imagen original para almacenar el resultado Imagen ir=new Imagen(im.getWidth(),im.getHeight()); //3.Creamos el filtro a aplicar. El kernel que hará el promedio float [] kernel=new float[25]; for (int i=0;i<25;i++){ kernel[i]=1f/25; }

DESARROLLO
41
//4.Asignamos a la imagen un relleno cero, constante, replicado simétrico o extendido. Solo aplicar uno. Si la imagen ya tiene padding y se quiere eliminar im.setPaddig(null); im.setPadding("zero"); im.setPadding("constant",255); im.setPadding("replicate"); im.setPadding("symmetric"); im.setPadding("extend"); //5.Creamos objeto de la clase Convolucion y le pasamos el kernel y su tamaño anchura, altura Convolucion c=new Convolucion(k,5,5); //6.Realizamos la convolución c.process(im,ir); ir.update(); new Ventana(ir,"Imagen Suavizada",true);
Los rellenos que mejor resultado ofrecen son el simétrico y la réplica pero dependiendo para que aplicación puede ser interesante algún otro tipo de relleno. En la figura 4.3.17 puede observarse el efecto de los diferentes rellenos.
Figura 4.3.17. Si aplicamos a la primera imagen (imagen original) un kernel 5x5 de promedio sin relleno obtenemos la segunda imagen, en la que se puede apreciar el borde negro alrededor. En la tercera imagen se aprecia el efecto del relleno cero donde los bordes quedan oscurecidos y el resultado no es muy bueno. En la cuarta imagen observamos la imagen filtrada con un relleno constante de valor 255, con lo que el borde está aclarado. Las últimas dos imágenes son el efecto de filtrar la imagen original con un relleno replicado y uno simétrico. Como se puede apreciar ofrecen los mejores resultados.
Para probar el tiempo de procesado de la convolución se ha probado a aplicar un suavizado realizando el promedio a la imagen capturada de la WebCam con un kernel 3x3 y uno 5x5. Se

PROYECTO FIN DE MÁSTER
42
han realizado las pruebas con los dos formatos (320x240 y 640x480) admitidos por la WebCam.
Tipo Padding Imagen 320x240 Imagen 640x480
Sin relleno y Kernel 3x3 321fps 70fps
Sin relleno y Kernel 5x5 171fps 40fps
Con Relleno y Kernel 3x3
263fps 64fps
Con Relleno y Kernel 5x5
114fps 32fps
Obviamente las imágenes sin relleno se ejecutan mucho más rápido que con relleno. Independientemente del tipo de relleno la convolución requiere más o menos el mismo tiempo de procesado.
Otra alternativa al relleno es difuminar la imagen con relleno cero RGBA y a continuación dividirla por su valor alpha para eliminar el efecto de oscurecimiento.
4.3.3.2 Filtrado separable
El proceso de realizar una convolución requiere K2operaciones por píxel donde K es el tamaño (altura o anchura) del kernel utilizado. En ocasiones se puede acelerar el proceso de convolución realizando una convolución unidimensional horizontal y después vertical, lo que requiere 2K operaciones. Los kernel que pueden sustituirse por dos kernels unidimensionales para operar de forma más rápida se denominan filtros separables.
Para saber si un filtro es separable se tratará la imagen como una matriz K de 2 dimensiones y se realizará su SVD (Singular Value Decomposition).
i
Tiii vuK
Si el único valor singular diferente de cero es 0 entonces el filtro es separable y podemos obtener el kernel unidimensional horizontal y vertical fácilmente:
00 ulKHorizonta 00 vKVertical
El kernel original puede obtenerse de nuevo mediante la siguiente operación:
TlKHorizontaKVerticalK )(
Podemos obtener los kernels unidimensional horizontal y vertical de un kernel de la siguiente manera:

DESARROLLO
43
//1.Creamos el kernel a aplicar. Kernel 5x5 que hará el promedio float [] kernel=new float[25]; for (int i=0;i<25;i++){ kernel[i]=1f/25; } //2.Realizamos el Singular Value Decomposition. SVD c=new SVD(kernel,5,5); //3.Miramos si el filtro es separable if(c.isSeparable()){ System.out.println("Filtro separable"); //4.Obtenemos kernel unidimensional horizontal System.out.println(c.getHorizontalKernel()); //5.Obtenemos kernel unidimensional vertical System.out.println(c.getVerticalKernel()); }
En el código anterior se puede observar cómo se comprueba si un filtro promedio 5x5 es separable o no y cuáles serían sus kernel horizontal y vertical. Los filtros promedio, bilineales, gaussianas, Sobel… son separables. En la figura 4.3.17 podemos observar alguno de estos filtros con sus matrices de convolución bidimensionales y unidimensionales horizontal y vertical.
Figura 4.3.17. En la imagen superior podemos ver los kernel bidimensionales y horizontales y verticales de un filtro promedio (primera columna), un filtro bilineal (segunda columna), filtro de sobel (tercera columna) y un detector de esquinas (última columna).
Para procesar un filtro separable simplemente realizaremos la convolución horizontal de la imagen y después la vertical. En el siguiente ejemplo se realizará un suavizado mediante un kernel promedio 5x5 (al igual que en el caso anterior), pero en esta ocasión mediante filtrado separable.
//1.Leemos imagen del disco. Imagen im=ImagenIO.getImagen("c:/imagenes/flor2.jpg"); //2.Creamos una imagen del mismo tamaño que la imagen original para almacenar el resultado Imagen ir=new Imagen(im.getWidth(),im.getHeight()); //3.Creamos el filtro horizontal a aplicar float [] kernel=new float[5]; for (int i=0;i<5;i++){ kernel[i]=1f/5; } //4.Asignamos a la imagen un relleno cero, constante, replicado simétrico o extendido. Solo aplicar uno. Si la imagen ya tiene padding y se quiere eliminar im.setPaddig(null);

PROYECTO FIN DE MÁSTER
44
im.setPadding("zero"); im.setPadding("constant",255); im.setPadding("replicate"); im.setPadding("symmetric"); im.setPadding("extend"); //5.Creamos objeto de la clase Convolucion y le pasamos el kernel y su tamaño anchura,altura Convolucion c=new Convolucion(k,5,1); //6.Realizamos la convolución Separable. Como el kernel horizontal y vertical son el mismo pero traspuestos puede usarse esta función. c.convolucionHV(im,ir); ir.update(); new Ventana(ir,"Imagen Suavizada",true); //6.Si los kernels fueran diferentes en lugar de convolucionHV usaríamos primero la convolución horizontal y luego la vertical. Imagen aux=new Imagen(im.getWidth(),im.getHeight()); c.convolucionHorizontal(im,aux); aux.update(); c.setKernel(kernel2,1,5); c.convolucionVertical(aux,ir); ir.update(); new Ventana(ir,"Imagen Suavizada",true);
4.3.3.3 Filtrado dirigible y paso banda
Pueden crear kernels más sofisticados suavizando la imagen con un filtro Gaussiano de área unidad y después realizando la primera o segunda derivada. El filtro Sobel es una aproximación a un filtro direccional, que puede obtenerse suavizando la imagen con una Gaussiana y aplicando una derivada direccional. Estos filtros se conocen como filtros paso banda porque eliminan frecuencias bajas y altas.
Para generar una Gaussiana se utiliza la siguiente función:
2
22
222
1);,(
yx
eyxG
De acuerdo con la definición matemática de las derivadas una imagen digitalizada no puede derivarse ya que no es un una señal continua(es una señal discreta), por lo que existen diferentes técnicas que aproximan el resultado que daría la derivada de la imagen como señal continua. Normalmente el hecho de calcular las derivadas de una imagen producirá un aumento en el ruido de altas frecuencias, esa es la razón de aplicar una Gaussiana antes de realizar la derivada, para suavizar la imagen con el objetivo de eliminar este ruido.
Como una imagen es una función de dos o más variables es importante definir en qué dirección se toma la derivada. Para el caso de las imágenes de 2 dimensiones (filas y columnas), se utilizan la dirección horizontal y la vertical, aunque pueden utilizarse otras direcciones como combinación de estas dos:
][sin][cos][ yx hhh

DESARROLLO
45
Donde h representa un filtro de derivada con dirección y xh y yh representan sus respectivos filtros de derivada horizontal y vertical.
Es posible obtener el vector de derivada como el gradiente de la imagen:
iyfhixfhIIiyyfix
xff yxyx )*()*(
Para ello se realiza la convolución de la imagen con el kernel horizontal y el vertical y obtenemos la derivada horizontal y vertical de la imagen. Para obtener la magnitud y la dirección del gradiente, se utilizan:
)*()*( fhfhfadienteMagnitudGr yx
fhfh
fradienteDireccionGx
y
**
arctan)(
En los diferentes algoritmos desarrollados para calcular la magnitud del gradiente se ha utiliza la siguiente expresión, ya que realiza los cálculos con una mayor velocidad y el resultado es muy similar.
fhfhfadienteMagnitudGr yx **
El resultado del gradiente depende en gran medida del filtro horizontal xh y vertical yh que se aplique. Para seleccionar estos filtros hay diferentes posibilidades:
Filtros de derivadas básicos: Pueden ser de longitud 2 o 3 y tienen la siguiente forma:
Estos dos filtros difieren considerablemente en su magnitud y fase de Fourier. El segundo término realiza supresión de términos de alta frecuencia mientras que el primero realiza un cambio de fase.
Filtro Prewitt: Estos filtros son especificados por las siguientes matrices:

PROYECTO FIN DE MÁSTER
46
Donde xh y yh son separables. Sin nos fijamos bien lo que realiza este filtro es aplicar un filtro de derivada básico de tamaño 3 y otro filtro de suavizado de tamaño 3.
Filtro Sobel: Estos filtros son especificados por las siguientes matrices:
De nuevo xh y yh son separables. Sin nos fijamos bien lo que realiza este filtro es aplicar un filtro de derivada básico de tamaño 3 y otro filtro de suavizado triangular de tamaño 3.
Filtros alternativos: Se pueden utilizar diferentes técnicas de procesado de señal
unidimensional. Por ejemplo se puede utilizar el algoritmo del filtro Parks-McClellan para seleccionar las bandas de frecuencias donde se desea que se tomen las derivadas y en que frecuencias se desea suprimir el ruido.
Filtros Gaussianos: En los algoritmos actuales de procesado de imagen se suele
utilizar un filtro Gaussiano para realzar el suavizado y después una de las técnicas de derivada mencionadas. Realizar un filtrado gaussiano y después calcular su derivada es equivalente a filtrar la imagen con la derivada de la gaussiana. De esta última forma se calcula el resultado mucho más rápido. Si quisiésemos realizar el filtrado gaussiano en una sola dirección, partiremos de la formula de la gaussiana unidimensional:

DESARROLLO
47
2
2
222
1);(
x
exG
Su derivada tendrá la siguiente forma:
2
2
242
);(
x
exxxG
Por lo tanto la derivada bidimensional de la gaussiana:
2
22
242
);();(
yx
eyxyyG
xxGG
La segunda derivada de una imagen es conocida como el operador Laplaciano:
)*()*( 22222
2
2
22 fhfhII
yf
xff yxyx
Donde xh2 y yh2 son filtros de segunda derivada. Hay que tener en cuenta que la derivada produce dos respuestas por cada borde donde su signo especifica si este píxel esta en el lado claro u oscuro del borde. Al igual que con los filtros de primera derivada tenemos diferentes opciones para conseguir xh2 y yh2 :
Filtros de segunda derivada básicos: A continuación podemos observar el filtro bidimensional y los unidimensionales en el eje horizontal y en el vertical.
Filtro Gaussiano de segunda derivada: Esta es la extensión directa de la primera derivada del filtro Gaussiano descrito anteriormente y se puede aplicar de forma independiente en cada dimensión. En primer lugar, se aplica el suavizado Gaussiano con una sigma elegida sobre la base de la especificación del problema. A continuación, aplicamos la ecuación de derivada de segundo orden deseado. De la misma manera que para la derivada de primer orden, aplicar a una imagen un filtro Gaussiano y después el operador Laplaciano puede simplificarse realizando la convolución con la segunda derivada de la Gaussiana, es decir aplicando un filtro LoG (Laplacian of a Gaussian):
2
22
22
22
424
222 1
21):,()2();,(
yx
eyxyxGyxyxG
El filtro LoG puede ser simplificado tal que:

PROYECTO FIN DE MÁSTER
48
)()()()(),( 1221 ygxgygxgyxg
Donde:
,12
1)( 2
2
22
2
41
t
ettg
2
2
22 )(
t
etg
Si lo que se desea es aplicar el filtro LoG en una sola dimensión se utiliza la siguiente fórmula:
2
2
22
2
42 1
21);(
x
exxG
Filtros Laplacianos alternativos: Al igual que para los filtros de primera derivada, se pueden utilizar diferentes técnicas de procesado de señal unidimensional para conseguir la segunda derivada. Por ejemplo se puede utilizar el algoritmo del filtro Parks-McClellan para seleccionar las bandas de frecuencias donde se desea que se tomen la segunda derivada y en que frecuencias se desea suprimir el ruido.
Filtro SDGD (Second derivative in gradient direction): Este es un filtro muy útil para
detección de bordes y para obtener medidas de objetos. Este filtro utiliza las seis derivadas parciales:
2
2
xfI xx
yxfI xy
2
xfI x
2
2
yfI yy
yxfI yx
2
yfI y
Podemos observar cómo xyI e yxI dan el mismo resultado. El filtro SDGD combina las derivadas parciales de la siguiente manera:
22
22 2)(
yx
yyyyxxyxxx
IIIIIIIII
fSDGD
El gran número de derivadas parciales que se aplica en esta ecuación implica que el resultado puede amplificar mucho el ruido por lo que es muy recomendable usar una Gaussiana para disminuir el ruido. También es importante que al realizar la segunda derivada los filtros posean las mismas bandas de paso que las primeras derivadas. Esto significa que si para conseguir la primera derivada utilizamos el filtro [1 0 -1] entonces para la segunda derivada tendríamos que usar [1 0 -2 0 1], o simplemente

DESARROLLO
49
podemos derivar de nuevo el resultado de la primera derivada con el mismo filtro de derivada.
Para obtener las matrices de los diferentes filtros para realizar la derivada de la imagen se utiliza la clase FuncionesEspeciales:
//1.Creamos instancia de la clase FuncionesEspeciales FuncionesEspeciales fe=new FuncionesEspeciales(); //2.Funciones especiales float []g= fe.getGaussiana(3,1.0f); //Gaussiana de tamaño3 y sigma =1 //3.Para obtener los filtros primera derivada float []pdb=fe.getPrimeraDerivadaBasico(3); //Primera derivada tamaño3 float []pdp=fe.getPrewitt(); float []pds=fe.getSobel(); //4.Para obtener los filtros segunda derivada float []sdb=fe.getSegundaDerivadaBasico(); float []sdl=fe.getLoG(3,1.0f); //Laplacian of a gaussian de tamaño 3 y sigma =1
En la figura 4.3.19 se muestran los diferentes resultados obtenidos aplicando las diferentes técnicas de filtrado mencionadas.

PROYECTO FIN DE MÁSTER
50
Figura 4.3.19. En la primera fila podemos observar la imagen original a la que se le aplicará la derivada, la primera y la segunda derivada respectivamente. En este caso no se ha utilizado ningún técnica de suavizado antes de realizar la derivada. Con la primera derivada no se observa mucho ruido pero en el caso de la segunda ya se aprecia considerablemente por lo que filtros con alguna técnica de suavizado darían mejor resultado. En la segunda fila observamos el efecto del filtro Prewitt, Sobel y SDGD. Los operadores Prewitt y Sobel son operadores de primera derivada pero sus bordes son más anchos porque también suavizan la imagen. La única diferencia entre estos dos operadores radica en que Prewitt es suavizado con un filtro promedio y Sobel con uno triangular. El algoritmo SDGD obtiene el mejor resultado pero también es el que más operaciones precisa ya que hay que calcular todas las derivadas parciales. En la última fila podemos observar la imagen filtrada mediante Laplacian of a Gaussian de tamaño 3x3. En la primera imagen se ha tomado una sigma de valor 1 para calcular la gaussiana, lo que nos da una imagen con contornos muy finos y pocos detalles. Cuanto menor sea el valor de sigma más detalles tendremos como en la segunda imagen que se ha utilizado una sigma de 0.4. La sigma se podrá ajustar a la calidad deseada para extraer bordes y poco ruido. La última imagen posee una sigma de 0.7.
Si queremos filtrar la imagen con un filtro Gaussiano:
//1.Leemos imagen del disco. Imagen im=ImagenIO.getImagen("c:/imagenes/salon.jpg"); //2.Creamos una imagen del mismo tamaño que la imagen original para almacenar el resultado Imagen ir=new Imagen(im.getWidth(),im.getHeight()); //3.Creamos objeto de la clase FiltroGaussiano donde le especificamos el tamaño del kernel deseado y la sigma para generar la gaussiana. En este caso especificamos tamaño 3 y una sigma de 1.4 FiltroGaussiano fg=new FiltroGaussiano(3,1.4f); //4. Filtramos imagen y guardamos resultado en ir fg.process(im,ir); ir.update(); new Ventana(ir,"Imagen Suavizada",true);
Para aplicar un filtro LOG el funcionamiento es similar:
//1.Leemos imagen del disco. Imagen im=ImagenIO.getImagen("c:/imagenes/salon.jpg"); //2.Creamos una imagen del mismo tamaño que la imagen original para almacenar el resultado Imagen ir=new Imagen(im.getWidth(),im.getHeight()); //3.Creamos objeto de la clase FiltroLOG donde le especificamos el tamaño del kernel deseado y la sigma para generar la gaussiana. En este caso especificamos tamaño 3 y una sigma de 1.4 FiltroLOG fl=new FiltroLOG(3,1.4f); //4. Filtramos imagen y guardamos resultado en ir fl.process(im,ir); ir.update(); new Ventana(ir,"Imagen Suavizada",true);
Finalmente para usar un filtro SDGD:

DESARROLLO
51
//1.Leemos imagen del disco. Imagen im=ImagenIO.getImagen("c:/imagenes/salon.jpg"); //2.Creamos una imagen del mismo tamaño que la imagen original para almacenar el resultado Imagen ir=new Imagen(im.getWidth(),im.getHeight()); //3.Creamos objeto de la clase FiltroSDGD FiltroSDGD fs=new FiltroSDGD(); //4. Filtramos imagen y guardamos resultado en ir fs.process(im,ir); ir.update(); new Ventana(ir,"Imagen Suavizada",true);
Como se he expuesto en este tema, con las derivadas de las imágenes conseguimos extraer los bordes de las imágenes. Existen otros algoritmos más complejos para la extracción bordes con mejores resultados. En 1986 F. Canny desarrollo el algoritmo de Canny para detección de bordes que pretendía mejorar los fallos de los sistemas de detección de bordes anteriores. Para muchos el detector de bordes de Canny es el detector de bordes óptimo. Este algoritmo se basa en 3 criterios:
Buena detección: Se debe conseguir un ratio de error muy bajo, es decir, el algoritmo deberá de detectar la mayoría de los bordes posibles.
Buena localización: Los bordes deben estar lo más cerca posible de los bordes reales de la imagen.
Respuesta mínima: El borde de una imagen sólo debe ser marcado una vez, y siempre que sea posible el ruido de la imagen no debe crear falsos bordes.
Basándose en los criterios anteriores el algoritmo primero suaviza la imagen para eliminar el ruido. A continuación calcula el gradiente derivando la imagen y se eliminan los píxeles que no sean máximos locales. A continuación se reduce el gradiente mediante histéresis para quedarse solo con los bordes más significativos.
Para implementar este algoritmo:
1. Se elimina el ruido de la imagen. Para ello es recomendable el uso de una gaussiana para suavizarlo. Una de las gaussianas más utilizadas para el suavizado es de tamaño 5x5 y sigma 1.4:
El tamaño y la sigma aplicados a la imagen pueden afectar mucho al resultado del algoritmo. Los filtros pequeños causan menos suavizado por lo que permitirán la detección de bordes muy finos. Si se desea encontrar los bordes gruesos se aplicaran

PROYECTO FIN DE MÁSTER
52
gaussianas de tamaño mayor para que haya un mayor suavizado. También hay que tener en cuenta que cuanto mayor sea el tamaño de la ventana gaussiana el algoritmo tardará más en ejecutarse.
2. Calcular el gradiente de la imagen utilizando uno de los operadores mencionados anteriormente como el de Sobel por ejemplo. Será necesario el cálculo tanto de la magnitud como de la dirección del gradiente
22yx GGadienteMagnitudGr
2
2
arctanx
y
GG
radienteDireccionG
3. Una vez conocida la dirección del gradiente hay que traducir esta dirección a una
dirección que pueda seguirse en una imagen. Es decir, un píxel está rodeado por 8 píxeles vecinos por lo que solo podrá tener 4 direcciones posibles (horizontal 0º, diagonal positiva 45 º, vertical 90 º y diagonal negativa 135º). Para traducir la dirección obtenida a una de estas cuatro direcciones usaremos el siguiente criterio:
Horizontal: 0-22.5 y 157.5-180. Diagonal positiva: 22.5-67.5 Vertical: 67.5-112.5 Diagonal negativa: 112.5-157.5
4. Una vez se conoce la dirección del gradiente se aplica non maximum suppression. Es decir, se mira si el píxel en la dirección del gradiente es un máximo local (si su valor es el mayor entre los vecinos en la dirección del gradiente), si no es así este punto se eliminará ya que no pertenece al borde.
5. Para terminar se utiliza la histéresis con un umbral superior T1 y otro inferior T2. Se supone que los bordes importantes son continuos por lo que el uso de 2 umbrales permitirá descartar bordes no continuos. Se comienza buscando puntos que formen parte de un borde para a continuación realizar el seguimiento de ese borde. Cualquier píxel con una intensidad mayor que T1 se presupone que pertenece a un borde y en la dirección calculada anteriormente con una intensidad mayor a T2 se considerará que pertenece a ese mismo borde.

DESARROLLO
53
Para utilizar Canny:
//1.Leemos imagen del disco. Imagen im=ImagenIO.getImagen("c:/imagenes/ciudad.jpg"); //2.Creamos una imagen del mismo tamaño que la imagen original para almacenar el resultado Imagen ir=new Imagen(im.getWidth(),im.getHeight()); //3.Creamos objeto de Canny y definimos valor de threshold máximo y minimo en este caso 50 y 65 Canny c=new Canny(50,65); //4. Aplicamos Canny y guardamos resultado en ir fl.process(im,ir); ir.update(); new Ventana(ir,"Detector de bordes Canny",true);
Si no sabemos qué valor de Threshold nos puede dar mayor información sin introducir mucho ruido podemos utilizar VentanaCanny que nos permite modificar con un slider los valores del threshold observando el resultado optimo tal y como se muestra en la figura 4.3.20.
//1.Leemos imagen del disco. Imagen im=ImagenIO.getImagen("c:/imagenes/ciudad.jpg"); //2.Creamos la ventana Canny para generar la ventana new VentanaCanny(im,true);
Figura 4.3.20. VentanaCanny que permite modificar los valores del Threshold inferior y superior para observar los resultados.
Summed area tables (integral image)
Si una imagen va a ser repetidamente convolucionada por diferentes filtros promedio puede mejorarse su eficiencia mediante la pre-computación de summed area table, que no es más que la suma de todo los píxeles desde el origen:
i
k
j
llkfjis
0 0),(),(

PROYECTO FIN DE MÁSTER
54
Este método puede ser implementado eficientemente mediante un algoritmo recursivo:
),()1,1()1,(),1(),( jifjisjisjisjis
La imagen s(i,j) puede ser calculada usando dos adiciones por píxel si se utilizan las sumas de las filas de forma separada. Como desventajas hay que destacar que estas tablas requieren
)log()log( NM bits extra en la acumulación de la imagen, donde M y N son la anchura y altura de la imagen. En el área de la visión por computador esta técnica han sido utilizadas en la detección de caras y para hallar puntos de interés rápidamente tal y como se verá en puntos posteriores.
4.3.3.4 Filtrado no lineal
Los filtros que hemos visto hasta el momento son filtros lineales, aunque en ocasiones se obtienen mejores resultados utilizando filtros no lineales. Como por ejemplo filtros que calculan la mediana, filtros bilaterales u operaciones morfológicas.
4.3.4 Procesado morfológico
4.3.4.1 Operadores morfológicos
La morfología en el procesado de imagen se refiere a la representación de objetos en una imagen. El procesamiento morfológico puede realizarse a imágenes en escala de grises pero en este caso solo se utilizará para imágenes binarias. Como ya se ha mencionado en capítulos anteriores, las imágenes binarias solo tienen dos valores posibles 0 ó 1 y para convertir una imagen en imagen binaria pueden aplicarse diferentes técnicas de thresholding. Las operaciones morfológicas con imágenes binarias son muy utilizadas en algoritmos de reconocimiento de carácteres.
Las operaciones más comunes de las imágenes binarias son las operaciones morfológicas. Estas operaciones modifican la forma de los objetos representados en la imagen binaria. Para realizar estas operaciones debemos convolucionar la imagen binaria con un elemento estructurante y después seleccionar el valor de salida en función del resultado de la convolución. Los elementos estructurantes pueden ser de cualquier forma o tamaño, desde simples rectángulos 3x3 a estructuras de disco.
Los operadores morfológicos básicos son:
Erosión: La erosión elimina todos aquellos objetos que tengan un tamaño inferior al elemento estructurante y adelgaza el resto. Al realizar la convolución de un píxel con el elemento estructurante, si se encuentra algún píxel con valor 0 en el área de vecindad del píxel de la imagen que coincide con el elemento estructurante, el píxel resultante será cero.

DESARROLLO
55
Dilatación: La dilatación dilata los objetos de la imagen uniendo aquellas líneas rotas etc. Al realizar la convolución de un píxel con el elemento estructurante, si se encuentra algún píxel con valor 1 en el área de vecindad del píxel de la imagen que coincide con el elemento estructurante, el píxel resultante será 1.
Apertura: Como hemos visto anteriormente la erosión sirve para eliminar los objetos más pequeños que el elemento estructurante pero además de eliminar estos objetos también adelgaza el resto. Si queremos eliminar estos objetos sin que se adelgace el resto de la imagen se aplica la Apertura. La apertura consiste en aplicar la erosión para eliminar los elementos con un tamaño menor al elemento estructurante y después aplicar una dilatación para que los objetos adelgazados vuelvan a su tamaño original. La apertura suaviza el contorno rompiendo las líneas delgadas.
Cierre: Al igual que la apertura este operador suaviza el contorno pero en este caso uniendo las líneas rotas. El funciona es en orden inverso a la apertura, es decir, primero se aplica la dilatación para unir líneas rotas o pequeños puntos en los objetos y después se aplica la erosión para restaurar el tamaño original de los objetos.
Para usar estos operadores se utiliza la clase OperadorMorfologico:
//1.Leemos imagen del disco y la convertimos en binaria Imagen im=ImagenIO.getImagen("c:/imagenes/huella.jpg"); ImagenBinaria ib=new ImagenBinaria(im); //2.Creamos una imagen binaria del mismo tamaño que la imagen original para almacenar el resultado ImagenBinaria ibr=new ImagenBinaria(ib.getWidth(),ib.getHeight()); //3. Creamos elemento estructurante en este caso cuadrado de tamaño 3x3 float [] es=new float[9]; for (int i=0;i<9;i++){ es[i]=1f; } //4.Creamos instancia de la clase OperadorMorfologico y le pasamos el elemento estructurante y su tamaño anchura y altura OperadorMorfologico om=new OperadorMorfologico(es,3,3); //5.Aplicamos el operador deseado. om.erosion(ib,ibr); //Erosion. om.dilatacion(ib,ibr); //Dilatación. om.apertura(ib,ibr); //Apertura. om.cierre(ib,ibr); //Cierre.
Los operadores morfológicos, como hemos visto, sirven para modificar la forma de los objetos, recuperar su forma, eliminar objetos… En la figura 4.3.21 se puede observar un ejemplo de uso de estos operadores.

PROYECTO FIN DE MÁSTER
56
Figura 4.3.21. En la primera imagen se puede observar una imagen binaria de una huella dactilar con mucho ruido. Si aplicamos la erosión con un elemento estructurante cuadrado de tamaño 4x4 obtenemos la segunda imagen. En esta imagen observamos como efectivamente el ruido de la imagen se ha eliminado pero las trazas de la huella son mucho más delgadas y muchas de ellas se rompen perdiendo su continuidad. En la tercera imagen observamos el efecto de la dilatación respecto a la imagen original. En esta imagen podemos observar como efectivamente las pequeñas discontinuidades de las trazas se unen pero el ruido es amplificado y el espesor de todas las trazas. En la siguiente imagen observamos el efecto de aplicar la apertura donde conseguimos eliminar el ruido sin afectar al grueso de la traza, pero muchas de estas trazas se rompen. Si aplicamos el cierre conseguimos eliminar las trazas rotas pero el ruido no se elimina del todo. Finalmente la última imagen representa el resultado de realizar primero una apertura y después un cierre para unir las discontinuidades de la imagen.
4.3.4.2 Transformada de distancia
La transformada de distancia es muy útil para calcular rápidamente la distancia a una curva o a un conjunto de puntos usando un algoritmo de rastreo en dos pasos. Esta transformada tiene muchas aplicaciones como el calado en la mezcla de imágenes o para la unión de imágenes y para la alineación del punto más cercano entre otros. Conceptos que se verán más adelante.
Para la transformada de distancia existen diferentes métricas que permiten medir la distancia de forma diferente. Dos de las métricas más populares son:
Distancia euclidea: 22),( lklkd
Distancia Manhattan o city block: lklkd ),(
La trasformada de la distancia se define como:

DESARROLLO
57
),(min),(0),(:,
ljkidjiDlkblk
Utilizando la métrica de la distancia de Manhattan, la transformada de distancia puede implementarse fácilmente utilizando un algoritmo de paso hacia adelante y hacia atrás, tal y como se muestra en la figura 4.3.22. En algoritmo proporcionara la distancia mínima de cada píxel del objeto hasta la frontera de este.
Figura 4.3.22. Partimos de la primera imagen, una imagen binaria. Como se muestra en la segunda imagen al realizar el paso hacia adelante cada píxel diferente de 0 es sustituido por el valor mínimo entre (1+píxel izquierda) y (1+píxel encima). Una vez finalizado en la tercera imagen se puede observar el efecto del paso hacia atrás, esta vez el valor mínimo será entre el propio valor, (1+píxel derecha) y (1+píxel debajo). La última imagen muestra el resultado completo.
Implementar la transformada de la distancia utilizando la métrica de distancia euclidea es más complicado. En este caso se debe utilizar un vector distancia con las coordenadas x e y que definen la distancia hasta la frontera y se comparan utilizando la regla de la distancia cuadrada.
La “cresta” en la transformada de distancia forma el esqueleto del objeto donde se ha procesado la transformada. La cresta consiste en los píxeles cuya distancia es igual o mayor que 2.
A veces se desea saber la distancia de todos los píxeles de la imagen a la frontera del objeto, en lugar de saber solo la distancia de los píxeles dentro de este objeto. Para ello, después de calcular la transformada de distancia se realiza el complemento de la imagen y se vuelve a calcular esta, así conseguimos la distancia desde todos los puntos de la imagen. Esta transformada se denomina signed distance transform.
4.3.4.3 Componentes conectados
Otra de las operaciones morfológicas es encontrar los componentes conectados, es decir, las regiones de píxeles adyacentes con el mismo valor o etiqueta. Los píxeles adyacentes son píxeles encima, debajo, a la izquierda o a la derecha. Aquellos píxeles que estén diagonalmente no se consideran píxeles adyacentes. Esto se denomina vecindad N4, mientras que si se consideran también los píxeles diagonales se denominaría vecindad N8. El análisis de componentes conectados suele utilizarse para encontrar letras individuales en documentos escaneados o para encontrar objetos en imágenes binarias…

PROYECTO FIN DE MÁSTER
58
En la figura 4.3.23 puede observarse una imagen con 4 componentes conectados.
Figura 4.3.23. Partimos de la primera imagen para analizar sus componentes conectadas. En primer lugar dividimos la imagen en tramos horizontales y coloreamos los tramos con colores diferentes que representan etiquetas de diferentes tramos. Si el píxel de la izquierda o de la derecha tiene el mismo valor lo etiquetaremos con el mismo color. Si alguno de esos dos píxeles tiene otro valor ese píxel se etiquetara con otro color (componente diferente). Este proceso se observa en la segunda imagen en la que solo se han tenido en cuenta los píxeles horizontales (derecha e izquierda). En una segunda fase se miran tramos adyacentes verticalmente y se unen esas componentes tal y como se muestra en la última imagen.
Existen diferentes algoritmos para encontrar componentes conectados y mucho más sofisticados que este.
Estadísticas de componentes
Una vez segmentada una imagen en sus diferentes componentes conectadas suele aplicarse diferentes estadísticas a cada uno de estos. Las estadísticas más usadas son:
Área: número de píxeles en el componente.
Perímetro: Número de píxeles frontera.
Centroide: promedio de los valores x e y.
Segundo momento:
),( yxyyxx
yy
xxM
4.3.5 Transformada de Fourier
Una forma sencilla de saber el comportamiento de un filtro para una frecuencia dada, es aplicarle a la entrada del filtro una señal sinusoidal con esta frecuencia y ver cuanto se atenúa a la salida.
)sin()2sin()( ii wxfxxs

DESARROLLO
59
Donde la f es la frecuencia, la fase y w la frecuencia angular ( fw 2 ). Si filtramos una señal )(xs con un filtro con respuesta al impulso )(xh obtenemos una nueva señal )(xo con la misma frecuencia pero con diferente amplitud y fase.
)sin()(*)()( owxAxsxhxo
Los parámetros del filtro son la magnitud A, que se denomina ganancia o magnitud del filtro y la diferencia de la fase io .
Figura 4.24. En la imagen podemos observar el funcionamiento de un filtro donde al insertar una sinusoide en la salida obtenemos otra con diferente amplitud y fase.
Si utilizamos una sinusoide de valores complejos entonces:
wxjwxexs jwx sincos)(
Donde:
jwxAexsxhxo )(*)()(
Para poder analizar las características frecuenciales de los filtros se utiliza el análisis de Fourier. La transformada de Fourier en el dominio continuo tiene la siguiente forma:
dxexhwH jwx)()(
Para señales discretas como las imágenes digitales la transformada de Fourier tiene la siguiente forma:
1
0
2
)(1)(N
x
Nkxj
exhN
kH
Donde N es la longitud de la señal y 2/,2/ NNk . La transformación de Fourier en el dominio discreto se denomina DFT (Discrete Fourier Transform). La DFT requiere O(N2) operaciones que pueden ser reducidas a O(Nlog2N) si se utiliza la FFT (transformada rápida de Fourier).
Las señales en el dominio de la frecuencia tienen las siguientes propiedades:

PROYECTO FIN DE MÁSTER
60
Propiedad Espacio Frecuencia
Superposición )()( 21 xfxf )()( 21 wFwF
Desplazamiento )( 0xxf 0)( jwxewF
Inversa )( xf )(* wF
Convolución )(*)( xhxf )()( wHwF
Correlación )()( xhxf )()( * wHwF
Multiplicación )()( xhxf )(*)( wHwF
Derivada )(' xf )(wjwF
Escalado )(axf
awF
a1
Imágenes reales )()()()( * wFwFxfxf
Thm. Parseval’s x w
wFxf 22 )]([)]([
*Nota: )(* wF significa el conjugado complejo de la señal F(w).
En la siguiente tabla se pueden ver las transformadas de Fourier de alguno de los filtros más usados.

DESARROLLO
61
De la misma forma en la siguiente tabla se observan las transformadas de Fourier de kernels separables:

PROYECTO FIN DE MÁSTER
62
Para realizar la transformada de Fourier bidimensional en lugar de especificar una frecuencia horizontal o vertical, se crea una sinusoide orientada de frecuencia wx y wy.
)sin(),( ywxwyxs yx
La transformada bidimensional de Fourier en el dominio continuo tiene la siguiente forma:
dxdyeyxhwwH ywxwjyx
yx )(),(),(
Para señales discretas como las imágenes digitales la transformada de Fourier tiene la siguiente forma:
1
0
21
0),(1),(
N
y
MNykxk
jM
xyx
yx
eyxhMN
kkH

DESARROLLO
63
Donde M y N son el ancho y la altura de la imagen. Todas las propiedades mencionadas sobre las trasformadas de Fourier se pueden trasladar a las señales bidimensionales sustituyendo los valores escalares por los vectores ),(),,(),,(),,( 000 yxyx aaayxxwwwyxx
4.3.5.1 Filtro Wiener
El propósito del filtro de Wiener es reducir el ruido presente en una señal de entrada mediante métodos estadísticos, aproximándose lo más posible a la señal deseada (imagen sin ruido). Una imagen ruidosa será la suma de la imagen s sin ruido más el ruido n que corrompe a la imagen.
),(),(),( yxnyxsyxo
Debido a la linealidad de la transformada de Fourier:
),(),(),( yxyxyx wwNwwSwwO
Partiendo del teorema de Bayes puede calcularse la transformada del filtro óptimo de Wiener para eliminar el ruido de la imagen con un espectro de potencia ),( yxs wwP .
),(/11),( 2
yxsnyx wwP
wwW
Donde 2n es el espectro de potencia de ruido que se asume constante. Este filtro tiene una
ganancia de 1 para frecuencias donde el espectro de potencia de la imagen es mayor que la del ruido, mientras que para frecuencias altas atenúa el ruido con un factor 2/ nsP .
Más adelante se mostraran algoritmos más sofisticados para eliminar el ruido.
4.3.5.2 Transformada discreta del coseno
La transformada discreta del coseno (DCT) es una variante de la transformada de pero utilizando únicamente números reales. La DCT unidimensional tiene la siguiente forma:
1
0
)())21(cos()(
N
i
ifkiN
kF
Donde k es el coeficiente (frecuencia).
De la misma forma la DCT bidimensional tiene la siguiente forma:
1
0
1
0
),())21(cos())
21(cos(),(
N
i
N
jjiflj
Nki
NlkF

PROYECTO FIN DE MÁSTER
64
Al igual que la FFT la DCT puede ejecutarse en O(NlogN) y puede implementarse de forma separada realizando primero la DCT de cada línea y después de cada columna. La DCT se utiliza mucho en compresión de video e imagen.
4.3.6 Pirámides
En diferentes aplicaciones de procesado de imágenes es necesario cambiar la resolución de una imagen. Por ejemplo, se puede necesitar interpolar una pequeña imagen para igualar su resolución con la de la pantalla del ordenador o podemos querer reducir la imagen para acelerar la ejecución de algún algoritmo.
En ocasiones, como por ejemplo en aplicaciones de detección de caras, no sabemos a qué escala aparecerán las caras, por lo que puede ser interesante generar una pirámide con diferentes resoluciones de la imagen y escanear cada una de estas en busca de caras. Este proceso también sirve para acelerar algoritmos de búsqueda de objetos, donde primero se buscan donde están los objetos en imágenes con baja resolución y luego en la imagen con alta resolución solo se analiza la zona donde se sabe que está el objeto.
4.3.6.1 Interpolación
Se denomina interpolación a la construcción de nuevos puntos partiendo del conocimiento de un conjunto discreto de puntos. En el caso de procesamiento de imagen, para poder aumentar la resolución de una imagen es necesario seleccionar un kernel de interpolación por el que convolucionar esta.
lk
rljrkihlkfjig,
),(),(),(
Esta fórmula es muy parecida a la fórmula original de la convolución, pero en este caso el kernel utiliza un ratio de sobre-muestreo r.
Dependiendo de la relación entre calidad y tiempo de computación se elegirá un tipo de kernel u otro para la interpolación. Tipos de interpolación:
Nearest Neighbor: Esta técnica es la más rápida y sencilla, para generar los nuevos píxeles solo hace falta el valor del píxel más cercano. Realmente lo que se hace con esta técnica es agrandar el tamaño de los píxeles por lo que no suele dar muy buen resultado.
Interpolación bilineal: Esta técnica tiene en cuenta los 4 píxeles más cercanos al píxel a crear. Teniendo en cuenta la distancia del nuevo píxel a los cuatro píxeles vecinos, el valor del nuevo píxel será:
dxdyjifdxdyjifdydxjifdydxjifyxg
)1,1()1)()(1,()1)()(,1()1)(1)(,(),(
Donde dx es la distancia del nuevo píxel i al píxel horizontal más cercano y dy la distancia de este píxel al píxel vertical más cercano. Esta fórmula equivale a filtrar la imagen con el siguiente filtro:

DESARROLLO
65
(1-dx)(1-dy) (1-dy)dx
(1-dx)dy dxdy
El efecto de esta interpolaciónresulta más suave que en el caso anterior. Si se desea realizar esta operación más rápido podemos despreciar la distancia al píxel más cercano y suponer que la distancia siempre es igual haciendo la media ponderada de estos 4píxeles. Por lo tanto el kernel utilizado para obtener esta interpolación sería:
El resultado obtenido es peor que en el caso anterior y el algoritmo no es mucho más veloz. Para realizar esta técnica también puede utilizarse un kernel tent de tamaño 3x3 tal que:
Esta técnica es muy parecida a la anterior pero en lugar de tener en cuenta los 4 píxeles más cercanos, tiene en cuenta los 9 píxeles más cercanos dando más peso a los valores de los píxeles más cercanos.
Interpolación cúbica B-spline: Esta técnica de interpolación considera sus 16 píxeles vecinos para calcular el valor del nuevo píxel. Dependiendo de la distancia del píxel nuevo a sus vecinos se les da un peso u otro al hacer la ponderación. Este método genera imágenes más nítidas que las interpolaciones anteriores, pero requiere más tiempo de computación.
Por cada píxel a calcular realizaremos la convolución horizontal con la siguiente ventana:
Donde x es la distancia entre el píxel nuevo y el píxel de la ventana que se está tomando el valor par la ponderación. Después de realizar la convolución en horizontal será necesario realizarla verticalmente con la misma ventana.
Interpolación mediante filtro Lanczos: Este método es el más complejo y lento de los métodos de interpolación expuestos pero también debería de generar el mejor resultado. El proceso para el cálculo es muy similar al caso anterior, el único cambio reside en la ventana de convolución. En este caso el kernel de convolución tiene la siguiente forma:

PROYECTO FIN DE MÁSTER
66
La mayoría de tarjetas graficas utilizan la interpolación bilineal mientras que la mayoría de de paquetes de edición fotográfica utilizan la interpolación bicúbica. En la figura 4.3.25 se puede observar el efecto de la interpolación.
//1.Leemos imagen del disco. Imagen im=ImagenIO.getImagen("c:/imagenes/flor2.jpg"); //2.Creamos una imagen del tamaño deseado como salida. En este caso el doble Imagen ir=new Imagen(im.getWidth()*2,im.getHeight()*2); //3.Creamos objeto de Interpolación Interpolacion i=new Interpolacion(); //4. Aplicamos el método deseado i.nearestNeighbor(im,ir); //Vecino mas cercano i.bilineal(im,ir); //Bilineal i.bicubic(im,ir); //Bicúbica i.lanczos(im,ir); //Lanczos //5. Actualizamos y mostramos resultado ir.update(); new Ventana(ir,"Imagen interpolada x2",true);
Figura 4.3.25. En la primera imagen podemos observar la interpolación del vecino más cercano, que no da muy buen resultado. Se puede observar como la imagen se pixela. En la segunda imagen observamos la interpolación bilineal que suaviza la imagen dando un resultado notablemente superior. La tercera imagen muestra el resultado de la interpolación

DESARROLLO
67
bicúbica que podemos observar como genera una mayor nitidez. Por último se observa el efecto del uso del filtro Lanczos.
4.3.6.2 Diezmado
Para reducir la imagen el proceso es muy similar al anterior. Es importante suavizar la imagen antes de sub-muestrearla. Si sub-muestreamos la imagen sin antes haberla suavizado (algoritmo del vecino más cercano) podremos perder bastante información tal y como se muestra en la figura 4.3.26.
Figura 4.3.26.En la imagen superior se puede observar la perdida de información como resultado de submuestrear la imagen sin suavizarla antes.
El resto de los algoritmos vistos para la interpolación realizan un suavizado con los píxeles vecinos por lo que este efecto no sucederá. Se puede utilizar la clase Interpolación de la misma manera que en el caso anterior pero especificando que se desea una imagen con tamaño inferior.
4.3.6.3 Multiresolución
Las pirámides se suelen utilizar para acelerar algoritmos de búsqueda, buscar objetos o patrones a diferentes escalas y para realizar operaciones de mezclado de multi-resolución.
La pirámide más conocida y probablemente la más utilizada en visión por computador es la pirámide Laplaciana (1983) de Burt y Adelson. Para construir esta pirámide en primer lugar se suaviza y se sub-muestrea la imagen original por un factor de 2 y se almacena la imagen en el siguiente nivel de la pirámide. En el trabajo original de Burt y Adelson, propusieron un kernel de 5 posiciones para suavizar la imagen:
c b a b c
Donde b=1/4 y c=1/4 – a/2. En la práctica con a=3/8 se consigue el ya mencionado kernel binomial:

PROYECTO FIN DE MÁSTER
68
Al suavizar la imagen se va perdiendo nivel de detalle. La razón de llamar a la pirámide resultante pirámide de Gaussiana es porque repetidas convoluciones del kernel binomial convergen en una Gaussiana.
Para generar la pirámide Laplaciana, Burt y Adelson primero suavizaban la imagen para obtener la versión paso bajo de la imagen original. Después restaban esta a la imagen original para obtener la imagen Laplaciana, la banda de paso (que puede ser almacenada para futuros procesamientos). En base a la imagen Laplaciana y la Gaussiana de nivel base se puede reconstruir la imagen original tal y como se muestra en la figura 4.3.27. La pirámide Laplaciana está compuesta de los detalles que se pierden al realizar la interpolación en cada nivel.
Figura 4.3.27. En la figura podemos observar la imagen original G1 de Pikachu. A su derecha tenemos el resultado de suavizar la imagen con un filtro binomial. Si se restan estas dos imágenes obtenemos L1 la Laplaciana de la imagen original, es decir la información que se pierde de la imagen original a la imagen suavizada. Esta imagen puede servirnos para reconstruir desde la versión de baja resolución la imagen de mayor resolución. Después de la imagen suavizada se observa la imagen sub-muestreada G2 y el proceso se repite continuamente.
4.4 DETECCIÓN Y MATCHING DE FEATURES
No existe una definición exacta de feature y además su significado puede variar en función del tipo de aplicación. Una feature suele referirse a una parte “interesante” o a una característica de una imagen utilizada como punto de partida en muchos algoritmos de visión. Por ello gran parte de la calidad de estos algoritmos radicará en lo bueno que sea el algoritmo de detección de features. La característica más importante de un feature es la repetitividad, es decir que ese punto de interés de la imagen pueda ser detectado en imágenes consecutivas o en imágenes

DESARROLLO
69
que pertenezcan al mismo escenario independientemente de cambios en la iluminación, escala, rotación etc.
En ocasiones, cuando la detección de features es computacionalmente costosa y se tienen limitaciones de tiempo se suele utilizar un algoritmo de mayor nivel donde solo se buscan features en ciertas áreas de la imagen.
La detección y matching de features se utilizan para diferentes aplicaciones como por ejemplo, alinear y unir dos imágenes para componer una imagen panorámica, establecer un conjunto denso de puntos de correspondencias para poder construir un modelo 3D, reconocimiento de objetos etc.
Los features comúnmente suelen ser puntos, líneas regiones o bordes de interés que ayudan a detectar la misma característica en imágenes sucesivas.
4.4.1 Detectores de puntos de interés
Los puntos de interés son comúnmente utilizados para encontrar un conjunto de localizaciones en imágenes sucesivas, como paso previo a la detección de la pose de la cámara, para alinear diferentes imágenes o para realizar instancias de objetos o reconocimiento de su categoría. La ventaja de los puntos de interés frente a otro tipo de features es que permiten el matching en presencia de oclusión (ciertos puntos de interés no se ven por la cámara) o con cambios bruscos de escala o orientación
Para encontrar cuales son los puntos de interés y sus puntos correspondientes en imágenes sucesivas, existen dos técnicas diferentes.
1. Encontrar puntos en la imagen que puedan ser fácilmente seguidos (encontrados en otras imágenes). Para ello se utilizan técnicas de búsqueda locales como la correlación o la búsqueda de mínimos cuadrados. Esta técnica es la más adecuada para aplicaciones donde se quiere detectar la forma de la escena en base a una larga sucesión de imágenes (por ejemplo secuencias de video).
2. Detectar independientemente los puntos de interés en todas las imágenes a tratar y emparejar aquellos puntos según su apariencia. El objetivo es detectar el mismo punto en diferentes imágenes que pueden estar movidas, rotadas… Esta técnica se utiliza cuando se espera mucho movimiento en las imágenes o cambios de apariencia. Se utiliza en aplicaciones como creación de panoramas, establecer correspondencias en estéreo de base amplia o para reconocimiento de objetos.
La detección y matching de puntos de interés puede dividirse en 4 pasos diferentes.
1. Extracción de puntos de interés: Se buscan puntos en la imagen con altas posibilidades de poder ser detectados en imágenes sucesivas.
2. Descripción del punto de interés: La región alrededor del punto de interés se convierte en un descriptor más compacto y estable que permita reconocer el mismo punto en imágenes sucesivas.

PROYECTO FIN DE MÁSTER
70
3. Emparejamiento de los puntos de interés: Busca entre los puntos de interés de diferentes imágenes buscando candidatos a emparejar.
4. Seguimiento del punto de interés: Es una alternativa al paso anterior que solo busca el punto de interés en un punto cercano del que se encontraba anteriormente. Esta técnica se suele utilizar en secuencias de video donde de una imagen a otra el punto de interés no varía mucho su posición.
Un buen algoritmo de detección de puntos de interés debe cumplir con los siguientes criterios:
Debe detectar todas las esquinas.
No debe detectar falsos puntos.
Las esquinas tienen que estar bien localizadas.
El detector debe ser robusto frente al ruido.
El detector debe ser eficiente.
Los puntos de interés más fáciles de detectar se encuentran en las zonas con un largo contraste de cambios (al menos en dos direcciones), mientras que en las zonas sin cambios de intensidad es imposible su localización. Hay que tener especial cuidado con las zonas que incluyen líneas en una sola dirección, ya que sufren problemas de apertura tal y como se muestra en la figura 4.4.1 y en la figura 4.4.2.
Figura 4.4.1. En la imagen (a) podemos apreciar un punto detectado en una esquina. Al tener al menos dos direcciones de cambio es fácil detectar la localización exacta de este. En la segunda imagen observamos una imagen en una línea donde solo tiene una dirección de cambio, por lo que se sabe que el punto se encuentra en esa línea pero no a qué altura de esta. En la tercera imagen se muestra un punto en una zona donde no hay cambios de intensida. Como consecuencia el punto no puede ser localizado porque todos sus píxeles de alrededor poseen las mismas caracteristicas..
Para saber como de estable es el punto de interés seleccionado se utiliza la función de auto-correlación.
i
iiiAC xfuxfxwuE 2)()()()(

DESARROLLO
71
Esta función determina lo estable que es el punto de interés respecto a pequeñas variaciones en la posición u , comparando una zona de la imagen consigo misma, donde )(xw es una función de ponderación que varia espacialmente.
Figura 4.4.2. En la imagen podemos observar 3 features diferentes marcadas con una cruz roja en la imagen. La primera de ellas se encuentra en la parte de las flores donde hay mucho contraste, por lo que si observamos su auto-correlación (b) vemos un pico indicando que es un buen candidato a ser punto característico. Si se selecciona el feature del tejado se observa que la auto-correlación (c) es ambiguo ya que representa una dirección no un punto, por lo que sabremos que el feature estaría en esa dirección pero no en qué punto exactamente. Para finalizar, el último feature está situado en una nube con pocos cambios de intensidad por lo que su auto-correlación (d) no marca ningún punto que pueda ser distinguido, por lo que este punto no es un buen candidato para ser un feature.
Una de las características más importantes de un detector de feature es la repetitividad. Esta se define como la frecuencia en la que los puntos detectados en una imagen son encontrados

PROYECTO FIN DE MÁSTER
72
en una imagen transformada. Lo ideal es tener un detector que sea invariante, es decir, que pueda ser capaz de detectar el mismo punto independientemente de las rotaciones, cambios de escala, cambios de iluminación, cambios de punto de vista y con diferentes niveles de ruido.
4.4.1.1 Operador Moravec
Este operador, desarrollado por Hans P. Moravec en 1977, fue uno de los primeros algoritmos de detección de puntos de interés. Para encontrar esquinas o punto de interés parte de la teoría que indica que las esquinas poseen un valor muy bajo de auto-similitud. El algoritmo observa por cada píxel como de parecido es un patch centrado en ese píxel con un patch cercano que se solapa con el anterior. El parecido se mide mediante la suma de las diferencias cuadradas de los patch, cuanto menor sea este valor mayor similitud.
Si el píxel se encuentra en un área con intensidad uniforme los patch serán muy similares. Si el píxel se encuentra en un borde el patch en dirección paralela al borde tendrá un pequeño cambio mientras que el patch perpendicular al borde será muy diferente.
Si el píxel se encuentra en un punto con variación en todas las direcciones todos sus patch alrededor serán diferentes.
El corner response del punto de interés se define como el menor de las diferencias cuadradas entre el patch del píxel y los patch vecinos (horizontal, vertical y dos diagonales). Si este valor es un máximo local entonces este píxel es un punto de interés.
Este operador no es isotrópico, es decir, si se presenta un borde que no está en la dirección de los vecinos, este punto no se detectará como punto de interés.
Para implementar el algoritmo se siguen los siguientes pasos:
1. Por cada píxel (x,y) calcular la variación de intensidad respecto a un patch desplazado (u,v).
ba
vu yxIvyuxIbawyxV,
2, ),(),(),(),(
Los patch desplazados (u,v) serán: (1,0) ,(1,1),(0,1),(-1,-1),(-1,0),(0,-1),(1,-1),(-1,1)

DESARROLLO
73
2. Se construye el mapa de puntos de interés calculando el corner response C(x,y) por
cada píxel, es decir, el menor de las diferencias cuadradas entre el patch del píxel y los patch vecinos:
)),(min(),( , yxVyxC vu
3. Se eliminan todos aquellos puntos de interés del mapa que tengan un valor menor que
el umbral T.
4. Se realiza non-maximal supression para encontrar los máximos locales
Este algoritmo ha quedado prácticamente obsoleto ya que no es rotacionalmente invariante y detecta falsas esquinas en bordes diagonales, pero computacionalmente es muy ligero. Hoy en día que se posee mayor capacidad de procesado se utilizan otros algoritmos.
Para utilizar este operador:
//1.Leemos imagen del disco. Imagen im=ImagenIO.getImagen("c:/imagenes/salon.jpg"); //2.Creamos objeto Moravec con el constructor vacío o definiendo un threshold. Sino se define threshold por defecto 1000 Moravec m=new Moravec(); Moravec m=new Moravec(250); //Si queremos definir otro Threshold //3. Buscamos puntos de interés m.process(im); //4. Mostramos imagen y dibujamos los features Ventana v=new Ventana(im,"Moravec",true); List<Feature> features=m.getFeatures(); v.dibujarFeatures(features);
Este algoritmo encuentra muchos features muy cercanos unos de otros tal y como se muestra en la figura 4.4.3. Para evitar esto nos quedaremos solo con un feature en un radio r. Nos quedaremos con el feature con mayor corner response.
//1.Leemos imagen del disco. Imagen im=ImagenIO.getImagen("c:/imagenes/salon.jpg"); //2.Creamos objeto Moravec con el constructor vacío y definimos rmin a 10 Moravec m=new Moravec(); m.setRMin(15); //Por defecto se aplica RMI con 10 a no ser que se especifique otro valor //3. Buscamos puntos de interés m.process(im); //4. Mostramos imagen y dibujamos los features Ventana v=new Ventana(im,"Moravec",true); List<Feature> features=m.getFeatures(); v.dibujarFeatures(features);

PROYECTO FIN DE MÁSTER
74
Figura 4.4.3. En la primera imagen observamos el efecto de aplicar el operador de Moravec. Observamos cómo se obtienen demasiados features donde muchos de ellos están muy cerca uno del otro. En la segunda además de aplicar el operador se eliminan todos los features menos uno en un radio de 10 píxeles. El feature con el que nos quedamos es aquel que tenga un contraste mayor con los píxeles de alrededor.
4.4.1.2 Determinante de Hessian
En 1978 Beaudet propuso el uso del determinante Hessian, que utiliza las segundas derivadas parciales con el objetivo de buscar derivadas fuertes en dos direcciones ortogonales.
La matriz Hessian de dos dimensiones tiene la siguiente forma:
yyxy
xyxx
IIII
IHessian )(
Donde I(u) es la derivada de la imagen respecto a la dirección u. Una vez calculadas las segundas derivadas parciales de la imagen calcularemos el determinante de hessian para obtener el denominado corner response.
2))(det( xyyyxx IIIIHessian
El corner response de un píxel representa si este es un punto o no, cuanto más alto sea el valor de este más probabilidades de que sea un punto de interés. Para obtener los puntos de interés se realizará la supresión no máxima de los corner response, es decir se calculará el máximo local y si este está por encima de un umbral especificado se considerará un punto de interés y si no será descartado.
Para utilizar el detector Hessian:
//1.Leemos imagen del disco. Imagen im=ImagenIO.getImagen("c:/imagenes/salon.jpg"); //2.Creamos objeto Hessian Hessian h=new Hessian(); //3.Si lo deseamos podemos modificar los parámetros rmin y threshold. Si no modificamos por defecto rmin=10 y threshold=500

DESARROLLO
75
h.setThreshold(400); h.setRMin(15); //4. Buscamos puntos de interés h.process(im); //5. Mostramos imagen y dibujamos los features Ventana v=new Ventana(im,"Hessian",true); List<Feature> features=m.getFeatures(); v.dibujarFeatures(features);
4.4.1.3 Algoritmo de Harris & Stephens/Plessey
A diferencia del operador Moravec, este algoritmo también se basa en las derivadas de la imagen. Donde la matriz de auto-correlación tiene la siguiente forma:
Y:
En este caso la función suma de ponderación ha sido modificada por una convolución con un kernel ponderación.
La inversa de la matriz A proporciona un límite inferior sobre la incertidumbre en la localización de un punto para el emparejamiento, que sirve como un indicador para saber qué puntos pueden ser emparejados. La manera más sencilla de ver la incertidumbre es realizar un eigenvalues analysis de la matriz de auto-correlación, que produce dos valores ( 0 , 1 ) y dos direcciones tal y como se muestra en la figura 4.4.4.
Figura 4.4.4. Esta elipse representa un análisis de eigenvalues de la matriz de auto-correlación que representa la elipse de incertidumbre (en qué zona podría estar el feature).
Para calcular los eigenvalues:
0)det( IA
Donde I es la matriz identidad, de forma que el determinante queda de la siguiente manera:

PROYECTO FIN DE MÁSTER
76
0det 2
2
yyx
yxx
IIIIII
Basándose en la magnitud de los eigenvalues:
Si 00 y 01 : Ese píxel no posee punto de interés.
Si 00 y 1 es un valor positivo grande: Se ha encontrado un borde.
Si 0 y 1 tienen valores positivos grandes: Se ha encontrado una esquina.
El valor mínimo de eigenvalue no es el único valor que puede utilizarse para encontrar puntos de interés. Harris y Stephens (1988) propusieron el siguiente valor para detectar puntos de interés:
21010
2 )()()det( AtraceAMc
Se han conseguido buenos resultados utilizando un entre 0.04 y 0.15. Suele recomendarse el uso de 06.0 . Este valor no requiere calcular raíces cuadradas como con el método de eigenvalues y sigue siendo rotacionalmente invariante. Aun así, este algoritmo suele presentar problemas con el cambio de escala de las imágenes.
Shi y Tomashi demostraron que tomar el valor mínimo de los eigenvalues proporciona un mejor resultado que Mc para parches que van a sufrir una transformación afín.
Por otro lado Trigss propuso el uso del valor:
10
Donde 05.0 , que reduce las respuestas en bordes 1D, donde en ocasiones los errores
de aliasing inflan el valor del menor eigenvalue.
En 2005 Brown y otros propusieron usar la media armónica que es una función más suave en la región en que 10 :
10
10)det(
trA
A
Para implementar estos algoritmos de detección de puntos de interés se han seguido los siguientes pasos que se muestran en la figura 4.4.5:
1. Se calculan las derivadas horizontal xI y vertical yI convolucionando la imagen con
las derivadas de una Gaussiana.

DESARROLLO
77
2. Se calculan los valores de la matriz A ( 2xI , 2
yI , yx II ).
3. Se realiza la convolución de cada uno de estos valores con una Gaussiana mayor.
4. Se utiliza una de las medidas anteriores para encontrar los puntos de interés (Harris, Shi Tomashi, Trigss o la media armónica)
5. Para seleccionar los puntos de interés se busca el máximo local por encima de un threshold dado.
La mayoría de detectores buscan el máximo local en la función de interés pudiendo provocar una distribución irregular de puntos en la imagen (habrá más puntos en regiones con contraste elevado). Para mitigar este problema Brown y otros (2005) propusieron detectar los puntos de interés que sean máximos locales y que su valor de respuesta sea significante mayor (sobre un 10%) al resto de sus vecinos dentro de un radio r. También encontraron un método eficiente para asociar el radio de supresión con todos los máximos locales clasificando por su respuesta de intensidad y después creando una segunda lista más pequeña reduciendo el radio de supresión.
Schmid y otros (2000) tras analizar la entropía (información disponible de cada punto de interés) de un conjunto de descriptores rotacionalmente invariantes observaron que: la versión mejorada (utilizando derivadas Gaussianas) del operador Harris con 1d (escala de la derivada Gaussiana) y 2i (escala de la Gaussiana de integración) obtiene el mejor resultado.
Para utilizar el algoritmo de Harris:
//1.Leemos imagen del disco. Imagen im=ImagenIO.getImagen("c:/imagenes/salon.jpg"); //2.Creamos objeto Harris Harris h=new Harris(); //3.Si lo deseamos podemos modificar los parámetros rmin y threshold. Si no modificamos por defecto rmin=10 y threshold=100000 h.setThreshold(50000); h.setRMin(15); //4. Buscamos puntos de interés con un alpha=0.04 h.process(im,0.04); //5. Mostramos imagen y dibujamos los features Ventana v=new Ventana(im,"Harris",true); List<Feature> features=h.getFeatures(); v.dibujarFeatures(features);

PROYECTO FIN DE MÁSTER
78
Figura 4.4.5 La primera imagen muestra la imagen original de la cual se desea extraer los puntos de interés. En la segunda imagen podemos observar el valor de la luminancia suavizado con una gaussiana de sigma 1.4 en el eje x. Una vez suavizad la imagen se calculan sus derivadas. La tercera imagen muestra la derivada en el eje horizontal y la cuarta imagen en el eje vertical. Como se puede observar con la derivada en el eje horizontal obtenemos los bordes verticales y viceversa. Una vez que se obtienen los bordes se calculan los elementos de la matriz de correlación. La quinta imagen muestra el valor de la derivada horizontal al cuadrado que acentúa los valores de los bordes. Con IxIy conseguimos lo bordes diagonales. A continuación se suavizan de nuevo la imagen como se muestra en la sexta imagen. Tras calcular el Harris corner response obtenemos una gran cantidad de puntos tal y comos e muestra el la imagen 7. Finalmente aplicando non-maximal supresión obtenemos el conjunto de puntos de la imagen 8 que se muestran superpuestos a la imagen original en la última imagen.
Si deseamos utilizar los valores de Shi y Tomashi:
//1.Leemos imagen del disco. Imagen im=ImagenIO.getImagen("c:/imagenes/salon.jpg"); //2.Creamos objeto ShiTomashi ShiTomashi st=new ShiTomashi(); //3.Si lo deseamos podemos modificar los parámetros rmin y threshold. Si no modificamos por defecto rmin=10 y threshold=50 st.setThreshold(60); st.setRMin(15); //4. Buscamos puntos de interés st.process(im);

DESARROLLO
79
//5. Mostramos imagen y dibujamos los features Ventana v=new Ventana(im,"Shi y Tomashi",true); List<Feature> features=st.getFeatures(); v.dibujarFeatures(features);
Si en cambio deseamos utilizar los valores de Trigss:
//1.Leemos imagen del disco. Imagen im=ImagenIO.getImagen("c:/imagenes/salon.jpg"); //2.Creamos objeto Trigss Trigss t=new Trigss(); //3.Si lo deseamos podemos modificar los parámetros alpha, rmin y threshold. Si no modificamos por defecto rmin=10 y threshold=50 t.setAlpha(0.06f); t.setThreshold(60); t.setRMin(15); //4. Buscamos puntos de interés t.process(im); //5. Mostramos imagen y dibujamos los features Ventana v=new Ventana(im,"Trigss",true); List<Feature> features=t.getFeatures(); v.dibujarFeatures(features);
Por último si se desea utilizar los valores de la media armónica:
//1.Leemos imagen del disco. Imagen im=ImagenIO.getImagen("c:/imagenes/salon.jpg"); //2.Creamos objeto Trigss MediaArmonica ma=new MediaArmonica(); //3.Si lo deseamos podemos modificar los parámetros rmin y threshold. Si no modificamos por defecto rmin=10 y threshold=100 ma.setThreshold(120); ma.setRMin(15); //4. Buscamos puntos de interés ma.process(im); //5. Mostramos imagen y dibujamos los features Ventana v=new Ventana(im,"Media armonica",true); List<Feature> features=ma.getFeatures(); v.dibujarFeatures(features);
Puede ocurrir que debido a futuros procesamientos de la aplicación a realizar, el procesado de cada feature sea costoso y que en este paso se desee poder especificar cuantos features se deben detectar como máximo. De esta manera la aplicación podrá procesarse en un tiempo reducido con los features que tienen una respuesta más elevada. Para ello se recorren todos los features almacenados y nos quedamos solamente con aquellos que tengan la respuesta más elevada.
//1.Leemos imagen del disco. Imagen im=ImagenIO.getImagen("c:/imagenes/salon.jpg"); //2.Creamos objeto Harris Harris h=new Harris(); //3. Buscamos puntos de interés con un alpha=0.04 h.process(im,0.04); //4. Especificamos que solo queremos quedarnos con 50 features mas destacados

PROYECTO FIN DE MÁSTER
80
h.setMaxFeatures(50); //5. Mostramos imagen y dibujamos los features Ventana v=new Ventana(im,"Harris",true); List<Feature> features=h.getFeatures(); v.dibujarFeatures(features);
4.4.1.4 Detector de SUSAN (Smallest Univalue Segment Assimilating Nucleus)
Este algoritmo fue propuesto por Smith y Brady en 1995. A diferencia de los algoritmos anteriores este no requiere el uso de derivadas, se basa en que cada punto de una imagen tiene asociada un área local de brillo comparable.
La detección de puntos de interés se realiza a través de una máscara circular que recorre toda la imagen. Se define una área en la máscara donde los píxeles tiene el mismo valor (o parecido) de brillo que el núcleo, para ello se compara el brillo de todo los píxeles de la máscara con el brillo del núcleo de esta. Este área de la máscara se conoce como USAN (Univalue Segment Assimitaling Nucleuses) y es mínima en los bordes, obteniendo el mínimo local en las esquinas. En la figura 4.4.6 se puede observar el concepto en el que se basa el algoritmo para la detección de esquinas.
Figura 4.4.6. En la imagen se muestra un rectángulo oscuro sobre un fondo claro. Además se muestran 5 máscaras circulares en posiciones diferentes para comparar el funcionamiento. Dentro de cada mascará podemos observar la cantidad de área oscura y área clara y en base al área pueden detectarse las esquinas. La área de USAN es definida por el área oscura y es máxima en el rectángulo y mínima en los bordes, obteniendo el mínimo local en las esquinas. En el caso de la máscara a, esta puede considerarse una esquina ya que el área de USAN (área oscura) es menor que la mitad del área de la máscara. En las mascaras b, c y d al contrario la zona oscura es mayor que la clara por lo que no serán detectados como puntos de interés. Se dice que para encontrar un borde el área de USAN debe ser de la mitad del área de la ventana circular, mientras que para una esquina tendría que ser de un cuarto de esta área.
Para implementar el algoritmo se siguen los siguientes pasos:

DESARROLLO
81
1. Determinar una máscara circular, típicamente de 37 píxeles tal y como se muestra a
continuación:
1 1 1
1 1 1 1 1
1 1 1 1 1 1 1
1 1 1 1 1 1 1
1 1 1 1 1 1 1
1 1 1 1 1
1 1 1
2. Se calcula la diferencia de brillo entre cada píxel de la máscara y el núcleo de esta.
r: posición del píxel que se está analizando.
r0: posición del núcleo de la mascara
I: Intensidad del píxel.
t: Umbral que marca la mínima diferencia de brillo a detectar y su respuesta anti-ruido.
Esta fórmula no suele ser muy estable así que para obtener una mayor eficiencia suele utilizarse la siguiente función de comparación:
60 )()(
0 ),(
trIrI
errc
3. Se calcula el área de USAN.
)(
000
),()(rcr
rrcrn
4. Se compara n con el umbral geométrico g que se define como la mitad del máximo valor que podría tener n. Aunque suele utilizarse el 25% para detectar puntos de interés y el 50% para detectar bordes.
2/)max(ng

PROYECTO FIN DE MÁSTER
82
5. Si el área USAN es menor que la mitad del tamaño del área de la máscara y es un
mínimo local, este punto será una esquina donde intersectan 2 líneas.
El proceso mencionado anteriormente puede generar falsas esquinas. Para eliminar esos falsos positivos generados por bordes fuertes y el ruido se aplican 2 pasos adicionales.
6. Se busca el centroide (centro de gravedad) del área de SUSAN. Las esquinas tendrán el centroide alejado del núcleo. Para encontrar el centroide:
Por ello se eliminaran todos aquellos puntos de interés que tengan el centroide menor que una distancia dada, en este caso esa distancia se ha definido como 1.2. Y nos quedamos con los puntos alejados del centroide, es decir las esquinas.
7. En las imágenes con ruido los falsos positivos generados por estos se encuentran fuera de la línea recta que une el núcleo de la máscara con su centroide. Por lo que solo nos quedaremos con las esquinas que estén en la línea recta que une el núcleo de la máscara con el centroide de este y que a su vez pertenezca al área de USAN.
Para utilizar la primera versión que es menos estable pero más rápida (donde al calcular la diferencia de brillo el resultado solo es 0 o 1 dependiendo de un umbral):
//1.Leemos imagen del disco. Imagen im=ImagenIO.getImagen("c:/imagenes/salon.jpg"); //2.Creamos objeto SUSAN donde especificamos el umbral que se utiliza y la distancia de separación minima entre features. Al especificar en el ultimo parámetro true queremos decir que lo ejecute rápidamente aunque no sea muy preciso SUSAN s=new SUSAN(60,10, true); //3. Buscamos puntos de interés s.process(im); //4. Mostramos imagen y dibujamos los features Ventana v=new Ventana(im,"SUSAN",true); List<Feature> features=s.getFeatures(); v.dibujarFeatures(features);
Para la utilización del segundo método el proceso es igual pero en el constructor pasaremos el valor boolean false.

DESARROLLO
83
4.4.1.5 Operador Trajkovic
Este operador fue implementado por Trajkovic y Hedley en 1998 con el objetivo de obtener una tasa alta de repetitividad y localización con un coste computacional bajo. Compararon su operador con el algoritmo de Harris y aunque la repetitividad era algo inferior y la localización en uniones L era similar, la localización en el resto de uniones mejoraba. Demostraron empíricamente que el algoritmo era 5 veces más rápido que el algoritmo de Harris e incluso más rápido que el detector SUSAN. El tiempo de procesado mejoraba respecto a otros algoritmos porque en primer lugar utilizaban una imagen de baja resolución para hallar los puntos de interés. El objetivo de utilizar imágenes con diferentes resoluciones es descartar los puntos de interés encontrados por cambios de intensidad en texturas y quedarse exclusivamente con los puntos de interés encontrados por la geometría de los objetos de la imagen. Trajkovic creía que son más estables los puntos de interés debidos a la geometría que debido a las texturas.
El tiempo de ejecución del algoritmo lo hace idóneo para aplicaciones en tiempo real pero no es rotacionalmente invariante, es sensible al ruido y detecta todos los puntos de los bordes diagonales por lo que es preferible el uso del algoritmo de Harris.
1. Se calcula una resolución menor de la imagen. La resolución dependerá del tipo de aplicación. (Aplicaremos la mitad de la resolución de la imagen original) Cuanto menor sea la resolución más rápido será el algoritmo.
2. Por cada píxel de la imagen de baja resolución se calcula simple cornerness measure y nos quedamos con aquellos por encima de un umbral T1 como puntos de interés potenciales.
22 )),(),1(()),(),1(( yxIyxIyxIyxIra
22 )),()1,1(()),()1,1(( yxIyxIyxIyxIrb
22 )),()1,(()),()1,(( yxIyxIyxIyxIrd 22 )),()1,1(()),()1,1(( yxIyxIyxIyxIre
),,,min(),( edbaSIMPLE rrrryxC
1),( TyxCfeaturesPotential SIMPLE
3. Por cada punto de interés potencial encontrado en el punto anterior, se calcula de la misma manera el simple cornerness measure del punto equivalente en la imagen original (de alta resolución) y se comprueba si este valor es mayor a un segundo umbral T2. Si no es así el punto se descarta como feature.
4. Se calcula el interpixel approximation cornerness measure y se descartan como puntos de interés aquellos que tengan un valor inferior al umbral T2.

PROYECTO FIN DE MÁSTER
84
edba rrrrrrrr 4321 ,,,
)),(),1())(,1()1,1(()),(),1())(,1()1,1((1
yxIyxIyxIyxIyxIyxIyxIyxIB
)),()1,1())(1,1()1,(()),()1,1())(1,1()1,((2
yxIyxIyxIyxIyxIyxIyxIyxIB
)),()1,1())(1,()1,1(()),()1,1())(1,()1,1((3
yxIyxIyxIyxIyxIyxIyxIyxIB
)),()1,1())(1,1(),1(()),()1,1())(1,1(),1((4
yxIyxIyxIyxIyxIyxIyxIyxIB
11 2BrrA ab
22 2BrrA bd
33 2BrrA de
44 2BrrA ea 5. Realizar non-maximal suppression.
Para utilizar esta técnica:
//1.Leemos imagen del disco. Imagen im=ImagenIO.getImagen("c:/imagenes/salon.jpg"); //2.Creamos objeto Trajkovic Trajkovic t=new Trajkovic (); //3. Buscamos puntos de interés t.process(im); //4. Mostramos imagen y dibujamos los features Ventana v=new Ventana(im," Trajkovic",true); List<Feature> features=t.getFeatures(); v.dibujarFeatures(features);

DESARROLLO
85
4.4.1.6 Features from Accelerated Segment Test (FAST)
Este detector de puntos de interés opera considerando los píxel en un círculo de 16 píxeles alrededor del píxel candidato p tal y como se muestran en la figura 4.4.7. The segment test criterion considera que el píxel p es un punto de interés si:
Existen al menos n píxeles contiguos en el círculo que tengan una intensidad mayor que la intensidad del píxel candidato más un umbral t.
Existen al menos n píxeles contiguos en el círculo que tengan una intensidad menor que la intensidad del píxel candidato menos el umbral t.
Figura 4.4.7. Por cada píxel p de la imagen se observan los 16 píxeles que forman una circunferencia a su alrededor, tal y como se muestra en la imagen. Si al menos n (tamaño del feature a detectar) de los píxeles en esta circunferencia tienen una intensidad mucho mayor o menor que p, este punto se considera un punto de interés.
Diferentes pruebas han demostrado que 9 es un valor óptimo de n, este valor es el mínimo que permite que los bordes no sean detectados. También se utiliza una n de 12 o superior que permite realizar un primer test rápido para descartar puntos que no son esquinas. Con este test rápido se examinan solo 4 píxeles de la circunferencia. Por cada píxel p se examinan los píxeles en el norte, sur, este y oeste (1, 5, 9 y 13 de la figura 4.4.7). En este caso p será un candidato a punto de interés si:
Al menos 3 de estos píxeles tienen una intensidad mayor que la intensidad del píxel p más un umbral t.
Al menos 3 de estos píxeles tienen una intensidad menor que la intensidad del píxel p menos un umbral t.
Una vez realizado el test se dispone de un conjunto de posibles features donde se comprueba mediante The segment test criterion sobre los n valores de la circunferencia si ese punto realmente es un feature. Se debe de tener en cuenta que el test rápido no funciona

PROYECTO FIN DE MÁSTER
86
correctamente para n<12. Los puntos de interés conseguidos son muy estables. Pero se consiguen múltiples features adyacentes.
Figura 4.4.8.En la imagen de la derecha se puede observar los puntos de interés detectados sin utilizar el test rápido. Observamos que sin realizar este test muchos de los bordes (como en este caso los cuadros) obtienen muchos puntos. Además tal y como se ha mencionado se hayan muchos puntos adyacentes unos de otros. Si ejecutamos el test rápido y después eliminamos aquellos puntos de interés adyacentes a una distancia de 10 píxeles que sean inferiores a una respuesta del 10% del máximo en esa región, obtenemos un mejor resultado que puede observarse en la segunda imagen.
Para utilizar este algoritmo:
//1.Leemos imagen del disco. Imagen im=ImagenIO.getImagen("c:/imagenes/salon.jpg"); //2.Creamos objeto FAST. Donde especificamos una n=12, un umbral t=35 y una distancia de 10 para el adaptative non maximal supresión. FAST f=new FAST (12,35,10); //3. Buscamos puntos de interés f.process(im); //4. Mostramos imagen y dibujamos los features Ventana v=new Ventana(im," FAST",true); List<Feature> features=f.getFeatures(); v.dibujarFeatures(features);
Adicionalmente, para optimizar el orden en el que los píxel son testeados se utiliza el algoritmo ID3, dando como resultado el detector de puntos de interés computacionalmente más eficiente.
Este proceso se realiza mediante aprendizaje automático. El uso del algoritmo ID3 permite la búsqueda de hipótesis o reglas en un conjunto dado de ejemplos que permitan clasificar ante nuevas instancias. Para ello el algoritmo ID3 realiza esta labor mediante la construcción de un árbol de decisión. En este caso particular el objetivo será sacar las hipótesis necesarias para saber si un píxel es un punto de interés o no, de manera que ante nuevos píxeles pueda decidirse si este es un feature.
Con el objetivo de crear un detector de puntos de interés para una n dada, primero se detectarán con The segment test criterion los puntos de interés con esa n y un umbral t

DESARROLLO
87
adecuado en un conjunto de imágenes de entrenamiento. Este conjunto de imágenes preferiblemente serán del estilo al de las aplicaciones que se utilizarán con el detector. (Por cada píxel se analizarán los 16 píxeles de la circunferencia, no se utiliza el test rápido).
Por cada localización }16...1{x en el círculo alrededor del píxel en la posición p, podemos tener uno de los siguientes tres estados en cuanto a la diferencia de intensidad:
Eligiendo una x (una posición de la circunferencia) y calculando xpS de todos los píxeles Pp de todas las imágenes de entrenamiento obtenemos 3 conjuntos Pd,Ps.Pb , donde cada
píxel p es asignado a xpSP
.
También tendremos una variable boolean Kp que determinará si el píxel p pertenece a una esquina o no.
Llegados a este punto ya tenemos la información necesaria para nuestro sistema, ahora se utilizará el algoritmo ID3 para el aprendizaje. Los 16 valores de la circunferencia ( }16...1{x ) son las variables del árbol de decisión. En primer lugar hay que seleccionar que atributo (punto de la circunferencia x) es el que más información aporta a la hora de sacar una hipótesis para saber si p es un punto de interés. Para ello se calcula la entropía de P (conjunto de todos los píxeles de todas las imágenes):
ccccccccPH 222 loglog)(log)()(
Donde:
esquinasnodeNumerofalseisKpc
esquinasdeNumerotrueisKpc
p
p
|
|
Para calcular la ganancia de información de x:
)()()()( bsd PHPHPHPH
Una vez seleccionada la x que proporciona más información, el proceso se aplica recursivamente a los 3 subconjuntos Pd,Ps,Pb seleccionando la xb,xs,xb óptimas.
El proceso termina cuando la entropía del subconjunto es cero. Esto significa que todo p en el subconjunto tiene el mismo valor que Kp, todos los píxel o ninguno son puntos de interés. Esto está garantizado que pasará ya que la entropía es una función exacta de los datos aprendidos.

PROYECTO FIN DE MÁSTER
88
Este proceso crea un árbol de decisión que puede clasificar correctamente todos los puntos de interés de las imágenes de entrenamiento y aproximadamente los puntos de interés de nuevas imágenes. Este árbol de decisión se puede convertir en un conjunto de sentencias condicionales para su programación. En algunos casos 2 de los 3 sub-árboles puede que sean iguales, en ese caso eliminaremos el operador booleano que los separa para una ejecución más rápida. Para una mayor optimización, este proceso se ejecuta 2 veces, una para obtener el contorno de las imágenes de entrenamiento y una segunda vez permitiendo obtener los contornos en forma de arco para permitir la reordenación de la optimización.
Para optimizaciones adicionales forzamos a xb,xs,xd a ser iguales. En este caso, el segundo píxel testeado será siempre igual. Si este es el caso, el test del primer y segundo píxel puede realizarse conjuntamente. Esto permite realizar los primeros dos tests en paralelo para una zona de píxeles usando instrucciones de vectorización presentes en microprocesadores de alto rendimiento. Teniendo en cuenta que la mayoría de puntos son descartados tras realizar 2 test, esto incrementa notablemente la velocidad.
Hay que tener en cuenta que este detector está basado en el aprendizaje de un conjunto de datos por lo que el resultado dependerá mucho de los datos aprendidos y no siempre acertará.
Como en este caso no se calcula corner response no puede calcularse la supresión no máxima de los features obtenidos directamente. Para ello se calculará un valor v por cada punto de interés encontrado y se aplicará la supresión no máxima a este valor, eliminando los puntos de interés que tengan puntos de interés adyacentes con un valor más elevado de v. Pueden tomarse diferente valores de v:
1. El máximo valor de n para el que p sigue siendo un punto de interés.
2. El máximo valor de t para el que p sigue siendo un punto de interés.
3. La suma de la diferencia absoluta entre los píxeles en el arco contiguo y el píxel central.
Muchos píxeles comparten el mismo valor indicado en el punto 1 y 2 por lo que lo mejor será utilizar la tercera opción. Para mejorar el tiempo de computación se modifica ligeramente la definición de esta tercera opción:
Soscuroxxpp
Sclaroxpxp tIItIIV ,max
Para utilizar el árbol de decisión generado para n=9 por los creadores de este algoritmo:
//1.Leemos imagen del disco. Imagen im=ImagenIO.getImagen("c:/imagenes/salon.jpg"); //2.Creamos objeto FAST9. Le pasamos la distancia para el adaptative non maximal suppresion FAST9 f9=new FAST9(10); //3. Buscamos puntos de interés f9.process(im); //4. Mostramos imagen y dibujamos los features

DESARROLLO
89
Ventana v=new Ventana(im," FAST9",true); List<Feature> features=f9.getFeatures(); v.dibujarFeatures(features);
Teniendo en cuenta que se puede medir la repetitividad de los features encontrados, implementaron un nuevo detector que busca solo los features que tienen una alta repetitividad. Este detector se denomina FAST-ER.
4.4.1.7 Invarianza en la escala
Los detectores vistos hasta ahora no son invariantes en escala, por lo que ante cambios considerables en la escala no se detectan los mismos puntos. Además en ocasiones la detección de puntos en la escala más fina no suele ser apropiado, por ejemplo cuando se realiza el emparejamiento con imágenes con frecuencias altas (por ejemplo nubes), puede que no existan puntos de interés.
Una posible solución es extraer los puntos de interés en la imagen con diferentes escalas, por ejemplo realizando las mismas operaciones de detección con múltiples resoluciones en una pirámide y después asociando los puntos de interés al mismo nivel. Este método es apropiado cuando la imagen a emparejar no va a sufrir grandes cambios de escala.
Aun así, en la mayoría de aplicaciones de reconocimiento de objetos la escala del objeto en la imagen no es conocida. En lugar de extraer los puntos de intereses a diferentes escalas y emparejarlos es más eficiente extraer los puntos de interés que son estables en posición y escala.
Los detectores que se verán a continuación además de invarianza traslacional y rotacional, también son invariantes en escala.
4.4.1.8 LoG (Laplacian of a Gaussian)
Investigaciones previas por Lindeber (1993), propusieron por primera vez el uso de la función Laplacian of Gaussian (LoG) para detectar los puntos de interés. En su trabajo demostró que la función LoG normalizada con 2 :
2
22
22
22
222
211);,(
yx
eyxyxG
proporcionaba invarianza en la escala. Donde escogeremos la en función de:
2r
r es el radio de los puntos en los que la Laplaciana será máxima. El problema es que LoG genera muchos features muy cercas unos de otros tal y como se muestra en la figura 4.4.9. En

PROYECTO FIN DE MÁSTER
90
2002 Mikolajczyk descubrió que el máximo y el mínimo de esta función proporcionan los features más estables comparados con otros detectores como el gradiente, Hessian o Harris.
Figura 4.4.9. En la primera imagen podemos observar el resultado de filtrar la imagen con el operador LoG sin comprobar si estos features son máximos o no, por lo que se obtienen muchos puntos y muy cercanos. En la segunda imagen puede apreciarse los puntos detectados una vez comprobado si ese punto es máximo o no respecto a sus 27 vecinos.
Para utilizar este detector:
//1.Leemos imagen del disco. Imagen im=ImagenIO.getImagen("c:/imagenes/ciudad.jpg"); //2.Creamos el Detector LoG con una sigma para la gaussiana de 1.2f DetectorLoG dl=new DetectorLoG(1.2f); //3. Buscamos puntos de interés dl.process(im); //4. Mostramos imagen y dibujamos los features Ventana v=new Ventana(im,"Detector Log",true); List<Feature> features=dl.getFeatures(); v.dibujarFeatures(features);
Cuanto mayor sea la sigma aplicada para la gaussiana la localización de los features tendrá un mayor error. Esto es debido a que cuanto mayor es la gaussiana el suavizado sobre la imagen será mayor y los bordes detectados serán más gruesos.
4.4.1.9 DoG (Difference of a Gaussian)
Basándose en este trabajo en 2004 Lowe propuso realizar un conjunto de filtros sub-octave Difference of Gaussian, en busca del máximo 3D (espacio escala) en la estructura (figura 4.4.10).
El objetivo es buscar puntos de interés estables en las diferentes escalas posibles, utilizando una función continua conocida como scale space (Witkin,1983). Diferentes estudios apuntan a que el único kernel para el space scale es la función Gaussiana. La función Scale Space se define como la convolución de la imagen con una Gaussiana:

DESARROLLO
91
),(*),,(),,( yxIyxGyxL
Figura 4.4.10. En esta imagen se puede observar el proceso de generación de la pirámide DoG. En primer lugar se coge la imagen y se va suavizando con sigmas cada vez mayores. Si restamos las imágenes suavizadas sucesivamente obtenemos un conjunto de imágenes denominadas diferencias de gaussianas (DoG). Después de suavizar sucesivamente la imagen esta se reduce a la mitad y se realiza el mismo proceso. Cada vez que se reduce a la mitad estamos ante una nueva octava.
Lowe en 1999 propuso el uso de space scale en forma de diferencia de Gaussiana (DoG) convolucionada con la imagen. La diferencia de Gaussiana se obtiene restando dos escalas adyacentes separadas una por una factor constante k:
),,(),,(),(*)),,(),,((),,( yxLkyxLyxIyxGkyxGyxD
La diferencia de Gaussianas permite un cálculo más ágil que el cálculo de la Laplaciana. La función DoG es una aproximación al Laplaciano de una Gaussiana normalizado ( G22 ). Concretamente la relación entre estas funciones se define como:
GkyxGkyxG 22)1(),,(),,(
El factor (k-1) es una constante en las diferentes escalas y no afecta a la localización de extremos para hallar los puntos de interés. Aunque el error de aproximación se acerca a cero cuando k tiende a 1, en la practica la aproximación no tiene impacto en la estabilidad de la detección de extremos ni en la localización para diferencias en la escala de por ejemplo
2k .
Para construir la pirámide DoG la imagen inicial es convolucionada con una Gaussiana repetidas veces para generar imágenes separadas por una escala k. Se decidió dividir cada

PROYECTO FIN DE MÁSTER
92
octava de scale space en un número entero s de intervalos donde sk /12 . Además se deben de generar s+3 imágenes suavizadas por cada octava, para la correcta localización de extremos. Tras varios experimentos se observó que el número de escalas por octava que proporcionaba una tasa más elevada de repetitividad era 3. Finalmente para producir la pirámide DoG se restan las imágenes adyacentes de cada octava tal y como se muestra en la figura 4.4.11. Una vez procesada una octava, se sub-muestrea la imagen que haya sido convolucionada con una Gaussiana con el doble del valor de la inicial. Para submuestrear cogeremos los píxeles pares de la imagen tanto en x como en y.
Figura 4.4.11. En la imagen podemos observar como por cada octava se calculan 5 imágenes suavizadas mediante una gaussiana y restando estas obtenemos 4 escalas diferencia de gaussiana por octava.
Una vez generada la pirámide DoG hay que hallar los puntos de interés invariantes en escala para ello se realiza la detección de extremos locales. Por cada píxel de la imagen DoG se comparará si este es el menor o el mayor entre sus ocho vecinos en la imagen actual y con sus 9 vecinos de la imagen posterior y anterior, tal y como se muestra en la figura 4.4.12. Si este píxel es máximo o mínimo esto significa que se ha encontrado un punto de interés. La búsqueda de extremos tiene un coste computacional bajo ya que la mayoría de píxeles serán descartados sin necesidad de observar todos sus píxeles vecinos. Hay que tener en cuenta que los extremos hallados muy cercanos, son inestables respecto a pequeñas perturbaciones en la imagen.

DESARROLLO
93
Figura 4.4.12.En la escala del medio podemos observar el pixel que estamos analizando con una x. Para saber si este pixel x es un extremo se observa si es mayor o menor que sus 8 vecinos en la misma escala y de sus 9 vecinos en la escala superior e inferior. Si el píxel es un valor máximo respecto al resto o mínimo, será un punto de interés.
Una vez encontrado un feature, como x,y,n están cuantizadas no se conoce la posición exacta de este. Por lo que es necesario hallar la localización a nivel de subpixel. Brown en 2002 implemento un método para ajustar los puntos locales del muestreo en una función cuadrática para determinar la localización interpolada del máximo. Los diferentes experimentos demostraron que esta técnica mejoraba la estabilidad en el proceso de matching. Este método utiliza la expansión de Taylor de la función ),,( yxD desplazada para que el origen este en el punto de muestreo.
xxDxx
xDDxD
T
2
2
21)(
Donde D y sus derivadas son calculadas en el punto de muestreo y Tyxx ),,( es el Offset desde este punto. La localización del extremo x̂ , se calcula tomando la derivada de esta función respecto a x e igualándola a cero. Obteniendo como resultado:
xD
xDx
2
12
ˆ
Brown sugirió aproximar el Hessian y las derivadas de D usando diferencias con los píxeles vecinos. El sistema lineal 3x3 resultante puede ser resuelto con un coste mínimo. Si el offset x̂ es mayor que 0.5 en cualquier dimensión significa que el extremo pertenece a otro píxel. En este caso se modifica el píxel analizado a otro y se realiza la interpolación respecto a ese píxel. El offset final x̂ se añade a la localización del píxel al que pertenece para obtener la interpolación estimada del extremo.
El valor de la función en el extremo, )ˆ(xD , sirve para eliminar los extremos inestables con un contraste bajo.
xx
DDxDT
ˆ21)ˆ(

PROYECTO FIN DE MÁSTER
94
Lowe en sus experimentos descartaba todo los valores para los que )ˆ(xD es inferior a 0.03.
Para obtener una mayor estabilidad no es suficiente con eliminar los features con un contraste bajo. La función DoG tiene una respuesta fuerte a los bordes, por lo que tal y como se muestra en la figura 4.4.13 aparecerán muchos features en estos. Para eliminar la respuesta a estos bordes puede calcularse la curvatura principal usando la matriz Hessian 2x2.
yyxy
xyxx
DDDD
H
Para calcular si la relación de curvatura principal está debajo de un threshold r:
rr
HDetHTr 22 )1(
)()(
Donde:
2)()(
)(
xyyyxx
yyxx
DDDHDet
DDHTr
Lowe para sus experimentos utilizaba una r=10.
Figura 4.4.13. En la primera imagen se puede observar los extremos de la imagen tras aplicar la detección DoG. Se puede observar como la localización de estos extremos no es muy buena. Tras calcular la localización y eliminar los features con un contraste inferior a 0.025 obtenemos los features mostrados en la segunda imagen. Todavía se puede observar cómo se detectan muchos features en bordes como por ejemplo en el cuadro. Eliminando la respuesta a bordes obtenemos la última imagen.
Aunque a medida que aumenta, aumenta la repetitividad hay un coste asociado a utilizar valores elevados de en cuestión de la eficiencia, por lo que se decidió el uso de 6.1 . Antes de generar la pirámide DoG la imagen original debe estar suavizada con una gaussiana de al menos 5.0 . Se puede observar como disminuyendo la escala obtenemos menos puntos de interés ya que filtramos con una mayor. Los puntos que se eliminan son aquellos menores a la aplicada a esa imagen.

DESARROLLO
95
Por lo tanto para implementar el detector DoG:
1. Suavizamos la imagen con una Gaussiana con 1 .
2. Se genera pirámide DoG:
a. Primero calcularemos el número de octavas a calcular. Se ha definido un valor máximo para comenzar a procesar la imagen de 1024x1024 píxeles. Si la imagen tiene mayor dimensión que este umbral se irá reduciendo constantemente a la mitad hasta llegar a ser menor que este umbral. También se ha definido un umbral mínimo de 64x64pixels, de manera que el número de octavas quedará definido por cuantas veces podemos reducir la imagen a la mitad sin que su nueva dimensión sea inferior a 64x64 píxeles. Como máximo tendremos cinco octavas a procesar.
b. Una vez sabemos cuántas octavas deseamos generar calcularemos los kernels Gaussianos necesarios para calcular las diferentes escalas de cada octava. Para ello teniendo en cuenta que la primera imagen esta filtrada con una gaussiana de 6.1 , los otras cinco kernels podrán ser filtrados sobre
esta imagen con unas gaussianas con una 22/ )6.1()2*6.1( si donde i varia de 1 a 5 (s+2=5 kernels para 6 escalas).
c. Una vez se disponen de los kernel gaussianos con los que será filtrado cada escala de cada octava se empezará con el cálculo de estas. Hay que tener en cuenta que si la imagen es mayor que 1024x1024 píxeles hay que reducirla entre 2 recursivamente hasta obtener una dimensión menor a este umbral. En primer lugar se filtra la imagen con una gaussiana de 6.1 . Esta imagen filtrada será la primera escala de la primera octava. Para calcular el resto de las escalas, esta primera escala será filtrada con los 5 kernels calculados anteriormente. De esta manera ya hemos calculado las 6 escalas de la primera imagen.
d. A continuación se reducirá a la mitad del tamaño la escala que se ha calculado filtrando con la sigma que pertenecía a i=s. Para ello se cogerán los píxeles pares de esta imagen tanto en x como en y. Las siguientes 5 escalas de esta octava se calculan de la misma manera, filtrando la imagen reducida con los 5 kernels calculados. El proceso se continúa recursivamente hasta calcular todas las escalas de todas las octavas.
e. Para calcular la pirámide DoG por cada escala adyacente de cada octava:
)1(),,(),,(
kyxLkyxL
Donde:
2k
De esta manera se consiguen 5 imágenes DoG por cada octava (s+2).

PROYECTO FIN DE MÁSTER
96
3. Una vez se dispone de la pirámide DoG hay que hallar los puntos de interés de cada octava. Parar ello se busca por cada píxel si este es el máximo o el mínimo entre sus vecinos en la escala superior y en la inferior tal y como se muestra en la figura 4.4.12.
4. Una vez hallados los features se localizarán estos con una precisión de subpixel. Para ello en primer lugar calcularemos la matriz de Hessian 3x3.
Para calcular las derivadas se hará restando los píxeles vecinos, es decir:
),,(),,1(),,(),,1( nyxpnyxpnyxpnyxpDxx ),,(),1,(),,(),1,( nyxpnyxpnyxpnyxpDyy
),,()1,,(),,()1,,( nyxpnyxpnyxpnyxpDii
4/)),1,1(),1,1(),1,1(),1,1(( nyxpnyxpnyxpnyxpDxy 4/))1,,1()1,,1()1,,1()1,,1(( nyxpnyxpnyxpnyxpDxi 4/))1,1,()1,1,()1,1,()1,1,(( nyxpnyxpnyxpnyxpDyi
También es necesario calcular las derivadas de cada variable:
2/)),,1(),,1(( nyxpnyxpDx 2/)),1,(),1,(( nyxpnyxpDy 2/))1,,()1,,(( nyxpnyxpDxx
Para estimar la localización del Offset del extremo:
iyxx DHDHDHo )0,0()1,0()0,0( 111
iyxy DHDHDHo )0,1()1,1()0,1( 111
iyxi DHDHDHo )0,2()1,2()0,2( 111
222iyx ooooffs
Para que el feature analizado sea localizable la variable Offset debe ser menor a 2. Si este es el caso y los Offset de las tres variables iyx ooo ,, son menor que 0.5 la posición del feature será:
xn oxx yn oyy
Si alguno de estos valores es mayor que 0.5 entonces se cogerá el píxel ),( yx oyoxp .

DESARROLLO
97
5. Una vez localizados los features se eliminan aquellos features con un contraste menor que un umbral.
6. Finalmente se elimina la respuesta a los bordes de la matriz Hessian 2x2.
Donde:
2)()(
)(
xyyyxx
yyxx
DDDHDet
DDHTr
Para utilizar este detector:
//1.Leemos imagen del disco. Imagen im=ImagenIO.getImagen("c:/imagenes/ciudad.jpg"); //2.Creamos el Detector DoG con una sigma para la gaussiana de 1.4f,s=3, el tamaño minimo de la imagen a procesar 64x64 y maxmo 1024x1024 DetectorDoG d=new DetectorDoG(1.6f,3,64,1024); //3. Buscamos puntos de interés d.process(im); //4. Mostramos imagen y dibujamos los features Ventana v=new Ventana(im,"Detector DoG",true); List<Feature> features=d.getFeatures(); v.dibujarFeatures(features);
4.4.1.10 Fast Hessian
Este detector utiliza una aproximación de la matriz Hessiana debido a su buen rendimiento en cuanto a la velocidad de cálculo y precisión. Viola y Jones hicieron popular el uso de las imágenes integrales para conseguir reducir el tiempo de filtrado. Como ya hemos mencionado anteriormente dado un punto ),( yxp de la imagen I, la matriz Hessiana ),( pH en el punto p a la escala se define como:
,(,(,(),(
),(pLpLpLpL
pHyyxy
xyxx
Donde ),( pLxx es la convolución de la derivada parcial de segundo orden de la Gaussiana 22 /)( xg con la imagen I en el punto p. Ocurre lo mismo para ),( pLxy y ),( pLyy .
A pesar de que los filtros Gaussianos son óptimos para el análisis del espacio escala, debido a una serie de limitaciones de estos filtros (como la necesidad de ser discretizados, la no

PROYECTO FIN DE MÁSTER
98
prevención totalmente del efecto aliasing, la velocidad de procesado, etc.) se optó por otra alternativa, los filtros de caja.
Estos filtros calculan una aproximación de las derivadas parciales de segundo orden de las Gaussianas y pueden ser evaluados de manera muy rápida partiendo de la imagen integral, independientemente del tamaño de éstas. La imagen integral en una localización x, y contienen la suma de píxeles que están encima de él y a su izquierda:
yyxx
yxiyxii','
)','(),(
Tal y como se muestra en la figura 4.4.14, una vez calculada la imagen integral solo es necesario tres adiciones para el cálculo de las suma de intensidad sobre cualquier área rectangular.
Figura 4.4.14. Utilizando imágenes integrales solo es necesario el uso de 3 adiciones y 4 accesos a memoria para calcular la suma de las intensidades en un área rectangular.
Las aproximaciones de las derivadas parciales se denotan como xxD , xyD y yyD
y el determinante de la matriz Hessiana, queda definido de la siguiente manera:
2)9.0()det( xyyyxxaprox DDDH
Tal y como se ha visto en la implementación del detector DoG, los espacios de escala son a menudo implementados como pirámides de imágenes, en las que éstas son suavizadas repetidamente con un filtro Gaussiano y posteriormente submuestreadas para alcanzar un nivel más alto en la pirámide. Este detector, debido al uso de filtros de caja e imágenes integrales, no tiene que aplicar iterativamente el mismo filtro a la salida de una capa filtrada previamente, sino que se pueden aplicar dichos filtros de cualquier tamaño a la misma velocidad directamente en la imagen original. Este espacio escala es analizado por medio de ir elevando el tamaño del filtro, en vez de ir reduciendo el tamaño de la imagen. La escala inicial suele ser un filtro caja de 9x9, que corresponde a una derivada de segundo orden Gaussian con
2.1 . Las siguientes capas de la pirámide se obtienen como consecuencia de aplicar gradualmente filtros mayores. Como no es necesario reducir el tamaño de la imagen no se produce aliasing.

DESARROLLO
99
El espacio escala se divide en octavas. Una octava representa una serie de respuestas, a los filtros obtenidos convolucionando la imagen con un filtro que va aumentando de tamaño. En total una octava abarca un factor de escala de 2 (que implica que se ha superado en el doble el tamaño del filtro). Cada octava se divide en un número constante de niveles de escala. Dada la naturaleza de las imágenes integrales, la diferencia mínima entre escalas depende de la longitud de los lóbulos positivos o negativos de la derivada parcial de segundo orden en la dirección de la derivada (x o y), el cual se establece como un tercio del tamaño del filtro. En el caso del filtro 9x9, la longitud seria 3. Para dos niveles sucesivos, hay que incrementar el tamaño del filtro en 6.
Como ya se ha comentado, el espacio escala comienza con el filtrado de la imagen con un filtro de tamaño 9x9, que calcula las respuestas de los puntos con escalas más pequeñas. A continuación se calculan las diferentes escalas de la pirámide con los siguientes tamaños de filtro:
Octava inicial: 27272121151599666
xxxx
Segunda octava:
5151393927271515121212
xxxx
Tercera octava:
9999757551512727242424
xxxx
Y así sucesivamente.
Finalmente, para localizar los puntos de interés en la imagen y en todas las escalas se eliminan los puntos que no sean máximos en una región de vecindad 3x3x3. Entonces, el máximo determinante de la matriz Hessiana es interpolado en la escala y el espacio de la imagen.
Como se puede observar el proceso de implementación es muy similar al de DoG, aunque en este caso simplemente se usa la imagen integral para filtrar.
Para utilizar este detector:
//1.Leemos imagen del disco. Imagen im=ImagenIO.getImagen("c:/imagenes/salon.jpg"); //2.Creamos objeto FastHessian. Donde especificamos que se eliminen aquellos puntos de interés con un corner response menor que 0.004f. en este caso se especifica que se generen 3 octavas y 4 niveles en cada octava. El valor 1 hace referencia al submuestreo inicial, es decir q se utiliza la imagen entera y después decimos que el factor de incremento es 2 tal y como se ha visto en la teoría. FastHessian fh=new FastHessian(0.004f,3,4,1,2); //3. Buscamos puntos de interés fh.process(im); //4. Mostramos imagen y dibujamos los features Ventana v=new Ventana(im,"Fast Hessian",true); List<Feature> features=fh.getFeatures(); v.dibujarFeatures(features);

PROYECTO FIN DE MÁSTER
100
4.4.1.11 Harris-Laplace
Mientras que el método DoG funciona bien en la práctica, no se basa en los mismos fundamentos de la estabilidad espacial del máximo como los detectores basados en la auto-correlación.
Para añadir un mecanismo de selección de escala para el detector de esquinas de Harris, Mikolajczyk y Schmid (2004) calcularon la función Laplacian of a Gaussian en cada punto detectado por el algoritmo Harris (en una pirámide multi-escala) y se quedaron solo con los puntos para los que la Laplaciana es un extremo.
Para ello el operador Harris-Laplace utiliza la función de auto-correlación adaptada a la escala:
),(),(),(),(
*)( 2
22
DyDyx
DyxDxID xLxLL
xLLxLgA
Donde I es la escala de integración, D la escala de diferenciación y aL es la derivada en la dirección a. Las derivadas locales se calculan con kernels Gaussianos con un tamaño determinado por D . Después las derivadas son suavizadas con una gaussiana con I . Para localizar los puntos en la scale-space se sigue utilizando la misma fórmula que en el caso anterior pero en esta ocasión utilizando la nueva matriz de auto-correlación:
21010
2 )()()det( AtraceAMc
A continuación se calcula el punto para el cual el Laplaciano de la gaussiana alcanza un máximo en la escala:
),(),(),( 2nyynxxnn xLxLxLoG
xxL y yyL representan la segunda derivada en su respectiva dirección.
Mikolajczyk y Schmid en su artículo proponen dos algoritmos diferentes para implementar este operador:
Harris Laplace: más robusto pero más lento.
Harris Laplace simplificado: Más eficiente computacionalmente pero posee una menor precisión.
El algoritmo de Harris Laplace consiste en dos pasos principales: un detecto de puntos multi-escala y una selección iterativa de la escala y la localización. En primer lugar se construye una representación scale space con la función Harris para una serie de escalas 0 n
n seleccionadas, donde es el factor de escala entre niveles sucesivos (Lindeberg y Lowe utilizaban el valor 1.4). En cada nivel de la representación se extraen los puntos de interés detectando el máximo local en los 8 vecinos del punto x. Se utiliza un valor de threshold para eliminar los máximos de pequeñas esquinas, ya que son menos estables con variaciones en la

DESARROLLO
101
imagen. La matriz A es calculada con nI y una escala local nD s donde s es un valor constante que en los experimentos se fijo en 0.7.
Después por cada feature detectado se aplica un algoritmo iterativo que detecta simultáneamente la localización y la escala de este feature. Los extremos en la escala del LoG se utilizan para seleccionar la escala de los puntos de interés. Se eliminan los features para los que LoG no representa un extremo y no supera un umbral. Dado un punto inicial x con una escala I (k indica la iteración k-esima), los pasos iterativos son:
1. Encontrar los extremos locales para las diferentes escalas de LoG para los puntos )(kx , sino eliminar el punto. El rango de escalas para realizar el
análisis se limita a )()1( kI
kI t con ]4.1,...,7.0[t .
2. Detectar la localización espacial )1( kx de un máximo de la medida Harris más
cercano a )(kx para la )1( kI seleccionado.
3. Volveremos al paso 1 si )()1( kI
kI
o )()1( kk xx .
Los puntos iniciales son detectados con el detector Harris multi-escala con un cambio grande entre dos escalas sucesivas, por ejemplo 1.4. Un pequeño cambio de escala (1.1) se utiliza en el algoritmo iterativo y proporciona una mayor precisión para la localización de x y la escala
I . Dado los puntos iniciales detectados con el intervalo de escala 4.1 el algoritmo iterativo explora el rango de escalas It con 4.1,...,7.0t que corresponde al hueco entre dos niveles de vecinos en el punto inicial de la escala I del scale space. Hay que tener en cuenta que los puntos iniciales detectados en la misma estructura pero en diferentes escalas convergen a la misma localización y a la misma escala. Por ello, para representar la estructura es suficiente con quedarse con uno de estos.
Harris Laplace simplificado
El algoritmo de Harris-Laplace puede simplificarse para poder acelerar el proceso de detección de features. Como en el caso anterior, los puntos iniciales son detectados con el detector Harris multi-escala (se construye el scale-space con la función Harris y se detecta el máximo local en cada escala). A continuación por cada uno de los puntos iniciales que constituyen un máximo en LoG, en la escala del punto nos quedamos con aquellos que sean mayores que el mismo punto en la escala inferior y en la superior. Además se eliminaran los puntos para los que el Laplaciano no sea un extremo o su respuesta sea inferior a un umbral. Llegados a este punto hemos obtenido un conjunto de puntos asociados a una escala. El intervalo de la gaussiana entre dos niveles sucesivos de la escala debería ser pequeño (entorno a 1.2) para obtener la localización y la escala con precisión.
4.4.1.12 Invarianza rotacional y estimación de la orientación
La mayoría de algoritmos de emparejamiento y de reconocimiento de objetos además de ser invariantes a cambios de escala necesitan ser invariantes al menos a rotaciones en un plano.

PROYECTO FIN DE MÁSTER
102
Una forma de conseguir esta invarianza rotacional es diseñar un descriptor que sea rotacionalmente invariante, pero estos descriptores tienen una habilidad de discriminación muy mala.
Otro método mejor es estimar la orientación dominante en cada punto detectado y en función de esta orientación y su escala se extrae un parche escalado y orientado alrededor del punto de interés para usarlo como descriptor. Estos métodos serán analizados en el siguiente aparatado con los descriptores.
4.4.1.13 Invarianza afin
Mientras que para muchas aplicaciones lo deseable es poseer invarianza rotacional y escalar para otras aplicaciones como reconocimiento de localización o stereo matching es preferible un detector totalmente invariante afín. Los detectores con invarianza afín no responden solo a cambios de escala y orientación, también responden a deformaciones afines.
4.4.1.14 Harris-Afinne
En apartados anteriores se ha modifico el detector de Harris para que este sea invariante a la escala. Partiendo desde ese punto para convertir a este detector en un detector con invarianza afín, hay que modificar alguna de las formulas matemáticas. La matriz del segundo momento es definida de forma más general para regiones anisotrópicas:
)),(),((*)()det(),,( TDDIDDI
xLxLgx
donde ΣI y ΣD son las matrices de covarianza que definen la diferenciación y la integración de las escalas del kernel gaussiano. Los eigenvectors y eigenvalues de la matriz de covarianza definen la rotación y tamaño de un elipsoide. Este elipsoide permite definir una región elíptica afín en la cual se integrará o diferenciará.
Si consideramos un punto y un punto transformado , donde A es una transformación afín. Las matrices de segundo momento se relacionan de la siguiente manera:
AxAxRDRIR
TLDLIL ),,(),,(
,,,,
),,(,, LDLILL xM
),,(,, RDRIRR xM
AMAM RT
L
TLIRI
AA ,, y
TLDRD
AA ,,
Donde ΣI,b y ΣD,b son las matrices de covarianza para el frame de referencia b. Si continuamos con esta formulación:
1,
LILIM y
1,
LDLDM

DESARROLLO
103
1,
RIRIM y
1,
RDRDM
Donde σI y σD son los factores de escala.
Al requerir que la matriz de covarianza cumpla estas condiciones, conseguimos que la matriz tenga ciertas propiedades. Una de esas propiedades es que la raíz cuadrada de la matriz de segundo momento transformará la región anisotrópica original en una región isotropica que está relacionada con una simple matriz de rotación R. Estas nuevas regiones isotropitas pueden ser vistas como frames de referencia normalizados. Las siguientes ecuaciones formulan la relación entre los puntos normalizados y .
21
21
LR RMMA
RRR xMx 21
'
Y LLL xMx 21
'
donde RL Rxx ''
Al igual que se ha explicado para el detector Harris, los eigenvalues y eigenvectors de la matriz de segundo momento, caracterizan la curvatura y la forma de la intensidad del píxel. El eigenvector asociado con el mayor eigenvalue indica la dirección de los mayores cambios y el eigenvector asociado con el menor eigenvalue define la dirección. En el caso 2D, se define una elipse. Para una región isotrópica, la región debería de ser de forma circular y no elíptica. Este es el caso en el que los eigenvalues tienen la misma magnitud. La medida isotrópica alrededor de una región local se define como:
)()(
max
min
MMQ
Donde λ denota los eigenvalues. Esta medida está entre un rango de 0 y 1, donde 1 corresponde a una forma isotrópica perfecta.
Utilizando esta formulación matemática, el algoritmo de este detector descubre iterativamente la matriz del segundo momento que transforma la región anisotrópica en una región normalizada en la que la medida isotrópica es suficientemente cercana a 1. El algoritmo utiliza una matriz de adaptación de forma U, para transformar la imagen en un frame de referencia normalizado. En este espacio normalizado, los parámetros del punto de interés (localización espacial, escala de integración y escala de diferenciación) son refinados usando métodos similares a los de Harris-Laplace. La matriz de segundo momento es calculada en este frame de referencia normalizado y debería tener una medida isotrópica cercana a 1 al final de la iteración. En cada iteración k-esima, cada región de interés es definida por varios parámetros que el algoritmo debe de calcular: la matriz U(k), la posición , la escala de )(k
I integración y la escala de diferenciación )(k
D . Debido a que el detector calcula la matriz del segundo momento en el dominio transformado es conveniente denotar la posición transformada )(k
wx como donde )()()( kk
wk xxU .
Los pasos para la implementación se muestran a continuación:

PROYECTO FIN DE MÁSTER
104
1. El detector inicializa el espacio de búsqueda con puntos detectados por el detector Harris-Laplace.
U(0) =identidad y , )0(D y )0(
I se toman del detector Harris-Laplace.
2. Se aplica la matriz de adaptación de forma anterior U(k − 1) para generar el frame de
referencia normalizada, . Para la primera iteración se aplica U(0).
3. Se selecciona la escala de integración, , utilizando un método similar al de Harris-Laplace. La escala es seleccionada como aquella que maximice el valor del Laplaciano de la Gaussiana (LoG). El espacio de búsqueda de las escalas, son aquellas entre las 2 espacio escala de las iteraciones de escala anteriores.
4. Se selecciona la escala de diferenciación, )(kD . Para reducir el espacio de búsqueda
y los grados de libertad, se toma la escala de diferenciación para que este relacionada
con la escala de integración mediante un factor constante: )()( k
ik
D . Por razones
obvias, el factor constante debe ser menor que 1, pero un valor muy pequeño hará el suavizado de la integración más significante en comparación a la diferenciación. Comúnmente se selecciona un factor de 0,5 o 0,75. L escala seleccionada maximizará
la medida isotrópica )()(
max
min
MMQ
.
Donde ),,( )(D
kI
kwx es la matriz del segundo momento para el frame de referencia
normalizado.
5. Se halla la localización espacial. Para ello se selecciona el punto )(kwx que maximiza la
respuesta de la medida de Harris en una vecindad de 8 alrededor del punto previo
.

DESARROLLO
105
La ventana )( )1( k
wxW es el conjunto de los 8 vecinos más cercanos del punto de la iteración previa del frame de referencia. Como la localización espacial se realizó en el frame de referencia normalizado, el nuevo punto debe ser transformado de nuevo al frame de referencia original.
6. Tal y como se ha explicado anteriormente, la raíz cuadrada de la matriz del segundo momento define la matriz de transformación que genera el frame de referencia
normalizado. Esta matriz debe ser almacenada: .
La matriz de trasformación U es actualizada: . Para asegurar que la imagen sea muestreada correctamente y que estamos expandiendo la imagen en la dirección del menor eigenvalue, se fija el máximo eigenvalue: λmax(U(k)) = 1. Utilizando este método de actualización, la matriz U toma el siguiente valor:
7. Si no se cumple el criterio para parar, se continúa con el paso 2 en una siguiente
iteración. La condición que se debe cumplir para que el algoritmo se detenga es:
Donde un valor que da buen resultado es εC = 0.05.
4.4.1.15 Hessian-Afinne
El algoritmo Hessian-Affine es prácticamente idéntico a Harris-Affine. Ambos algoritmos fueron propuestos por Krystian Mikolajczyk y Cordelia Schmid en 2002. La única diferencia radica en que este algorimo en lugar de basarse en la matriz de segundo momento se basa en el determinante de Hessian.
4.4.1.16 EBR (Edge-based region detector)
Este algoritmo parte de un punto de interés p detectado mediante Harris y un borde cercano extraído mediante el detector Canny. Para incrementar la robustez respecto a los cambios de escala, estos puntos de interés se extraen a diferentes escalas. Dos puntos p1 y p2 se mueven fuera de la esquina en ambas direcciones a lo largo del eje, tal y como se muestra en la figura 4.4.15.

PROYECTO FIN DE MÁSTER
106
Figura 4.4.15. Basándose en los ejes cercanos al punto de interés se puede detectar una región con invarianza affin.
Su velocidad relativa es acoplada a través de la igualdad entre los parámetros invariantes afines relativos l1 y l2:
iiiiii dssppspabsl )()()1(
Donde is es un parámetro de curva arbitrario (en ambas direcciones), )()1(ii sp es la primera
derivada de )( ii sp respecto a is , abs() representa el valor absoluto y |…| el determinante. Esta condición implica que las áreas entre el punto <p,p1> y el borde y entre la unión <p,p2> y el borde permanezcan idénticas. Este es uno de los criterios de la invarianza afin. Desde ahora en adelante se usara l para referirse a l1=l2.
Por cada valor l, los dos puntos )(1 lp y )(2 lp junto a la esquina p definen un paralelogramo )(l : el paralelogramo atravesado por los vectores plp )(1 y plp )(2 . Se obtiene una
familia unidimensional de regiones con forma de paralelogramo como función de l. De esta familia 1D se selecciona un (o más) paralelogramo para el cual las siguientes cantidades fotométricas de la textura pasan a través de un extremo.
2)(||||
100
000
200
100
21
211
MMMM
pppppppp
absInv gg
2)(||||
100
000
200
100
212
MMMM
pppppqpp
absInv gg
Donde dxdyyxyxIM qpnnpq ),(
Donde npqM de orden n, (p+1)-esimo grado del momento calculado a través de la región )(l ,
el centro de gravedad de la región gp , ponderado con la intensidad I(x,y), y q la esquina del

DESARROLLO
107
paralelogramo opuesto a la esquina p. El segundo factor de la fórmula ha sido añadido para garantizar la invarianza bajo un Offset de la intensidad.
En caso de que los bordes sean rectos, este método no puede ser aplicado, ya que l=0 a lo largo de todo el eje. Desde que la intersección de los dos ejes ocurre con frecuencia, no se puede descuidar este caso. Para resolver este problema, las dos cantidades fotométricas dadas en las ecuaciones anteriores son combinadas y se toman aquellas localizaciones donde ambas funciones tienen un valor mínimo para poder fijar s1 y s2 a lo largo de la línea recta. Por otra parte, en lugar de apoyarse en la correcta detección de la esquina mediante Harris, puede utilizarse la intersección de las líneas rectas.
4.4.1.17 IBR (Intensity extrema-based region detector)
Este método permite detector regiones con invarianza afín partiendo de los extremos de intensidad detectados en múltiples escalas. Para ello explora la imagen de una forma radial trazando regiones de formas arbitrarias, que más adelante son sustituidas por elipses.
Dado un extremo de intensidad local, se estudia la función de intensidad a lo largo de los rayos emitidos por los extremos, tal y como se muestra en la figura 4.4.16.
Figura 4.4.16. Se estudia la intensidad emitida por un extremo local. Se selecciona el punto de cada rallo para el que la función )(tf I alcanza un máximo. Uniendo estos puntos se consiguen regiones con invarianza afín.
Por cada rallo se evalúa la siguiente función:
Donde t es un parámetro arbitrario a lo largo del rallo, I(t) es la intensidad en la posición t, I0 es el valor de la intensidad en el extremo y d un numero pequeño para evitar divisiones entre 0. El punto para el que esta función alcanza un extremo es invariante a las transformaciones afines y

PROYECTO FIN DE MÁSTER
108
fotométricas. Normalmente se alcanza un máximo en posiciones donde la intensidad crece o decrece repentinamente. La función )(tf I es por si invariante, aun así, se seleccionan los puntos para los que esta función alcanza un extremo para una mayor robustez. A continuación, todos los puntos que corresponden a un máximo de )(tf I a lo largo de los rayos originados por el mismo extremo local son unidos para formar la región invariante. Estas regiones irregulares son sustituidas por regiones elípticas que tengan la misma forma que los momentos de segundo orden.
4.4.1.18 Salient Region
Este detector se basa en los valores pdf de la intensidad respecto a una región elíptica. El proceso de detección se divide en dos partes:
En primer lugar, por cada píxel se evalúa la entropía con las tres familias de parámetros centrado en ese píxel. Se almacenan el conjunto de los extremos de la entropía a lo largo de las diferentes escalas y sus correspondientes parámetros de la elipse. Estos son los candidatos a ser regiones salientes.
A continuación, la región candidata es clasificada utilizando la magnitud de la derivada del pdf respecto a la escala. Las p regiones clasificadas son retenidas.
La región elíptica , centrada en el píxel x es parametrizado por su escala s, orientado en función de , y el ratio del eje de mayor a menor . El pdf de la intensidad )(Ip se calcula através de . Para calcular la entropía:
I
IpIpH )(log)(
El conjunto de extremos de las escalas en H se calcula para los parámetros ,,s por cada píxel de la imagen. Por cada extremo la derivada de pdf ),,;( sIp con s se calcula de la siguiente manera:
I ssIp
ssW ),,;(
12
2
Y el rasgo sobresaliente Y de la región elíptica se calcula como HWY . Las regiones son clasificadas en función de su rasgo sobresaliente.
4.4.1.19 MSER
Otro detector con invarianza afín es el detector MSER (Maximally Stable Extremal Region). Este detector calcula regiones binarias haciendo thresholding de la imagen con todos los posibles valores. Esta operación se puede realizar eficientemente clasificando todo los píxeles por su valor en escala de grises y después añadiendo píxeles a cada componente conectada gradualmente cuando el threshold es modificado. Cuando se modifica el valor del threshold se monitoriza el área de cada componente (región); las regiones donde el cambio de área respecto al threshold es mínimo se definen como máximamente estables. Estas regiones son invariantes a transformaciones geométricas afines y a transformaciones fotométricas.

DESARROLLO
109
En el thresholding todos los píxeles con una intensidad menor a un umbral son negros y todos aquellos con una intensidad mayor o igual son blancos. Si nos muestran una secuencia de imágenes tI , con el frame t correspondiente a realizar el thresholding con el umbral t, en primer lugar observaríamos una imagen blanca e irían apareciendo pequeños mínimos en negro que irían creciendo a medida que el umbral crece. Tal y como se muestra en la figura 4.4.17.
Figura 4.4.17. En primer lugar observamos la imagen original del simbolo K. Si vamos aplicando la binarización con los diferentes umbrales g obtenemos los resultados que se muestran en el resto de imágenes.
Estas manchas negras poco a poco irán juntándose hasta que la imagen completa sea negra. El conjunto de todos los componentes conectados de todos los frames es el conjunto de regiones máximas; las regiones mínimas pueden ser calculando invirtiendo la intensidad de I y realizando el mismo proceso.
En muchas imágenes, la binarización local es estable en ciertas regiones respecto a un rango de umbrales. Estas regiones son de interés ya que tienen las siguientes propiedades:
Invarianza a las transformaciones afines de las intensidades de las imágenes.
Covarianza para la preservación adyacente de la transformación.
Detección multi-escala: Debido a que no se utiliza el suavizado, se detectan tanto las estructuras más gruesas como más finas.
El set de todas las regiones extremas pueden ser enumeradas en )loglog( nnO , donde n es el número de píxeles en la imagen.
David Nistér y Henrik Stewénius propusieron una forma de implementer este algoritmo en un tiempo lineal sin necesidad de realizar la binarización de todos los niveles de gris.

PROYECTO FIN DE MÁSTER
110
4.4.1.20 Comparación de detectores
Hay que tener en cuenta que dependiendo del tipo de aplicación que se esté implementando la resolución de la imagen a tratar será diferente. Por ejemplo para aplicaciones de realidad aumentada la cámara Web suele trabajar a una resolución de 320x280 o 640x480. Pero si se quieren procesar las imágenes capturadas con una cámara de fotos para realizar la reconstrucción 3D del escenario las imágenes capturadas tendrán resoluciones altas (dependiendo del número de Megapixel de la cámara fotográfica). Las aplicaciones desarrolladas en Java por defecto pueden utilizar un máximo de 256MB de memoria y si se utiliza Eclipse para ejecutarlas, dependiendo de la versión utilizada, se limita la memoria de las aplicaciones a 128MB. En muchos de los detectores mencionados con el objetivo de que vayan más rápido se utiliza gran parte de esta memoria. Podría realizarse el proceso contrario, utilizar menos memoria pero los algoritmos serían más lentos. Debido a esto, si buscamos los features en imágenes con una resolución superior a 2500x1875 suele saltar un error de memoria insuficiente. Para solucionar este problema puede incrementarse la memoria permitida por Java para la aplicación. ¿Pero es realmente necesario procesar las imágenes a resoluciones tan altas? El procesar las imágenes a resoluciones muy altas además de incrementar sustancialmente el tiempo de procesado de las aplicaciones no aporta demasiada información nueva. Lo ideal seria bajar la resolución de la imagen a unos 1024 píxeles en horizontal o vertical como máximo e ir buscando puntos de interés en las diferentes escalas. Al bajar la resolución de la imagen perderemos los detalles más pequeños de la imagen y probablemente no se extraerán todos los puntos de los objetos que se encuentren lejos, por ello es recomendable al sacar las fotos hacerlo desde un punto cercano a los detalles que se deseen obtener.
Esto sumado a los detectores que varían ante cambios de escala hace que en imágenes con resoluciones muy altas se obtengan los detalles más pequeños de la imagen pero no los más grandes. En la figura 4.4.18 podemos ver un ejemplo de este efecto aplicando el detector de Harris.
Figura 4.4.18. A la izquierda observamos los puntos detectados por el algoritmo de Harris a la imagen con una resolución de 1632x1224. A la derecha tenemos la misma imagen pero procesada a 326x244.

DESARROLLO
111
Cuando se procesa la imagen a una resolución de 1632x1224 obtenemos los detalles más pequeños, como aquellos que definen los botones del mando de la televisión, los detalles de la revista de la mesa etc. Pero si nos fijamos bien no se obtienen puntos de interés que definan las esquinas del sofá, el cual sería un elemento importante a modelar. Al procesar la misma imagen con un tamaño de 326x244 podemos observar como ya se detectan las esquinas que definen la estructura del sofá. Por lo que es importante el uso de un detector que sea invariante a las escala y que busque los puntos en diferentes escalas para que puedan obtenerse tanto los detalles más finos como los más grandes que definen la estructura de los objetos principales. Por lo que para aplicaciones de reconstrucción descartamos cualquier detector que varíe con la escala.
A diferencia de los detectores basados en el gradiente como Harris y Hessian, los basados en la intensidad (Moravec, SUSAN, FAST) de la imagen son más estables a cambios de escala. Aunque cuando se va reduciendo el tamaño de la imagen se pierden los detalles más pequeños, se siguen captando los puntos más importantes de la escena y no solo aquellos puntos que tengan el mismo tamaño de la gaussiana aplicada como en el caso de los detectores basados en el gradiente.
Dependiendo del tipo de aplicación de realidad aumentada que se quiera implementar, quizás que el detector sea variante en escala no importe tanto como la velocidad de procesado. Por lo que en esos casos podría utilizarse uno de los algoritmos de detección de puntos que sea variante en escala. Normalmente en aplicaciones de realidad aumentada una de las características de la aplicación debería de ser poder ejecutar la aplicación en tiempo real. Por ello a continuación se muestra el número de veces que se consigue procesar cada algoritmo con la imagen capturada de la WebCam a una resolución de 320x240.
Detector Tiempo Moravec 157fps Hessian 157fps Harris 85fps Shi Tomashi 77fps Trigss 77fps Media armónica 83fps Trajkovic 366fps FAST 141fps LoG 108 fps DoG 13fps FastHessian 33fps
Según observamos en la tabla el algoritmo más rápido seria el de Trajkovic seguidos por Hessian, Moravec y FAST. Seguramente esto se debe a que el algoritmo de Trajkovic busca los puntos en una imagen con la mitad de resolución. Este método también puede aplicarse al resto de detectores. Por ejemplo si hacemos que el detector invariante a cambios de escala FastHessian parta de la imagen con la mitad de resolución, obtenemos una velocidad de

PROYECTO FIN DE MÁSTER
112
110fps, muy superior a la de la tabla. Aunque se supone que el árbol utilizado en el detector FAST es el algoritmo más rápido que existe en la actualidad, al implementar este árbol en Java se ha obtenido una velocidad de tan solo 39fps. Ademas los detectores de Shi Tomashi y Trigss que basados en el detector de Harris, tienen una velocidad inferior a este ya que para estos es necesario el cálculo de los eigenvalues, lo que hace que la velocidad baje.
Dependiendo del tipo de aplicación sería recomendable poder utilizar diferentes trucos para poder incrementar la velocidad. Por ejemplo en una aplicación de reconocimiento de objetos en lugar de procesar todos los frames podríamos procesar 5 o 10 por segundo, consiguiendo ejecutar detector más complejos y que detectan puntos más estables. A nuestra percepción no notaríamos gran diferencia en que un objeto sea detectado en 10ms o en 100 ms. Además, si por ejemplo solo se desea detectar un objeto, se buscará este objeto hasta encontrarlo y entonces se realizará el Tracking de este, que puede ejecutarse más rápido.
Mikolajczyk y otros compararon el funcionamiento de los 6 detectores con invarianza a transformaciones afines vistos en esta sección: Harris-affine, Hessian-affine, MSER, EBR, IBR y Salient region. Observaron que no había ningún detector que fuese superior para cualquier tipo de transformación o escena. Normalmente el mejor resultado lo obtenía el detector MSER seguido del detector Hessian-afin.
El detector MSER proporcionaba mejores resultados ante transformaciones de cambio de vista y de iluminación, aunque es el más sensible al difuminado. En cuanto a las transformaciones de cambio de escala y rotación en plano el detector Hessian-afín es el que mejor funciona, seguido por MSER.
Aunque MSER funciona muy bien en imágenes que contienen regiones homogéneas con límites distintivos, Hessian-afín y Harris-afín encuentran más regiones que el resto, lo que puede ser de gran ayuda para el matching en escenas con oclusión. Por otro lado el detector EBR funciona muy bien en escenas que tienen muchas intersecciones en los bordes. Por ultimo el detector basado en saliente region no obtenía muy buenos resultados pero en el contexto de reconocimiento de objetos funciona muy bien.
No hay un detector mejor que otro, en función de la aplicación que queramos realizar será conveniente el uso de un detector u otro. El detector MSER suele funcionar muy bien para edificios y cosas impresas mientras que Harris-laplace, Hessian-laplace y DoG funcionan mejor para categorías naturales.
Normalmente, si la aplicación lo permite, el mejor resultados se obtiene combinando varios detectores.
Para el caso de reconstrucción de entornos 3D se utilizará el detector MSER combinándolo con otro detector como Hessian-laplace, ya que el proceso no será en tiempo real. En el caso de la realidad aumentada se utilizará el detector Fast Hessian ya que es el detector con invarianza en escala más rápido, lo que nos permitirá detectar el objeto buscado en diferentes escalas.

DESARROLLO
113
4.4.2 Descriptores
Tras detectar los puntos de interés el siguiente paso es realizar el matching de estos, es decir, determinar que features corresponden al mismo punto en diferentes imágenes. Para ellos se utilizan los descriptores. Un descriptor es un vector que define una región alrededor del punto de interés. Un buen descriptor debe ser invariante a cambios de condiciones como la iluminación, punto de vista…
Alguno de los métodos más simples son:
Parche de imagen: La idea más simple consiste en crear un vector que contenga los valores de los píxeles de una ventana alrededor del punto de interés (un parche). Este método no es muy bueno ya que el vector requiere una dimensión alta para una descripción correcta y además sería muy sensible a cambios de condiciones de iluminación, punto de vista…
Histograma local: Una solución mejor reside en utilizar el histograma local, es decir, el histograma de la ventana alrededor del punto de interés. En este caso la dimensionalidad se reduce y es más robusto a cambios de condiciones como rotaciones. Aun así, este descriptor sigue siendo poco discriminante y muy sensible a cambios de iluminación.
Figura 4.4.19. De la ventana alrededor del punto de interés se extrae su histograma.
Transformada de censo: Otra técnica consiste en binarizar los píxeles de la ventana utilizando el valor del píxel central como umbral. Esta técnica se conoce como transformada de censo. El descriptor es la secuencia de bits obtenida por lectura secuencial de todos los píxeles. Este método es más robusto que los valores de intensidad y más detallado que el histograma.

PROYECTO FIN DE MÁSTER
114
Figura 4.4.20. La transformada de censo consiste en binarizar los píxeles de la ventana utilizando como umbral el valor del píxel central.
Momentos generalizados: Los momentos generalizados son otra forma para describir la ventana de un punto de interés. Para calcular los momentos generalizados de una ventana de la Imagen I.
dxdyyxIyxM aqpapq ],[
De orden p+q y grado a.
Para a=1 se obtienen los momentos espaciales.
101M y 1
10M son las coordenadas del centroide de la ventana.
120M , 1
11M y 102M son la covarianza (extensión espacial).
Y para p=q=0 se obtienen los momentos de intensidad. Aunque con valores bajos de orden y grado pueden calcularse de una manera sencilla un número suficiente de momentos. Para una discriminación suficiente es necesario el cálculo de un gran número de momentos. Además los momentos de orden y/o grado elevado son muy sensibles a cambios geométricos y de intensidad.
Contexto de forma: Este método propuesto por Belongie, Malik y Puzicha (2002) es aplicable a formas definidas por su contorno. Para un punto, se representa la posición relativa de todos los otros puntos en forma de histograma. Este histograma es el descriptor del punto. Se usa un histograma log-polar para representar la distancia y la dirección. De esa manera, el descriptor es más sensible a la posición de los vecinos más cercanos.
Este descriptor puede hacerse invariante a la escala normalizando las distancias por la distancia mediana entre todos los pares de puntos. El descriptor también puede convertirse en rotacionalmente invariante definiendo la dirección con respecto a la tangente local, en lugar de un eje fijo de la imagen. Sin embargo, así se pierde una parte de la información, lo que puede reducir la discriminación.

DESARROLLO
115
Figura 4.4.21. Se utiliza un histograma log-polar para representar la distancia y la dirección.
Regiones afín-invariantes e imágenes spin: Como hemos visto en detectores Harris y DoG obtenemos una razón entre eigenvalues, eigenvalores, que indica la diferencia de extensión entre los dos ejes principales. La región puede normalizarse aplicando una transformación afín que iguala los dos eigenvalues.
Figura 4.4.22. Utilizando las elipses calculadas con eigenvalues.
A continuación se divide la región normalizada en anillos y se calcula el histograma de intensidad para cada anillo. La concatenación de esos histogramas se llama imagen spin y es el descriptor de la región.
Figura 4.4.23.Se calcula la imagen spin.

PROYECTO FIN DE MÁSTER
116
Este descriptor es invariante a transformaciones afines y rotaciones. Además puede obtenerse una invarianza parcial a cambios de iluminación normalizando la intensidad de dentro de la región.
A continuación se verán los descriptores más utilizados y robustos en la actualidad.
4.4.2.1 Descriptor SIFT (Scale-invariant feature transform)
Este descriptor publicado por Lowe en 1999 se basa en la obtención de los histogramas de orientación del gradiente. Para ello tenemos que calcular la orientación por cada feature detectado. En este método se realiza una normalización en rotación que permite comparar puntos con varias orientaciones. Tomaremos la orientación de un punto como la orientación dominante del gradiente en su vecindad.
Ya conocemos la escala 0t del punto de interés, entonces trabajaremos con la imagen suavizada con una gaussiana con la escala más cercana ),,( 0tyxL . De esta forma los cálculos se realizan de una forma invariante a la escala. Por cada punto se calculará el gradiente de la magnitud ),( yxm y la orientación ),( yx en su vecindad.
22 ))1,()1,(()),1(),1((),( yxLyxLyxLyxLyxm
),1(),1()1,()1,(tan),( 1
yxLyxLyxLyxLyx
Se calcula el histograma formado por las orientaciones del gradiente en la vecindad del punto de interés. El histograma tendrá 36 posiciones con las que cubre los 360º. Cada muestra que se añade al histograma es ponderado por la magnitud del gradiente y por una gaussiana de
05.1 t .
Los picos en el histograma determinan la orientación principal del punto. Para refinar la estimación se interpola una parábola entre los 3 puntos más cercanos al máximo.
Figura 4.4.24. Una vez se dispone del histograma del gradiente del área extraída, se observa cual es la orientación máxima entre las 36 posiciones analizadas.

DESARROLLO
117
Una vez hallado el pico máximo del histograma, si existen otros picos mayores al 80 % del máximo, se genera un punto independiente para cada pico, con la orientación correspondiente.
Figura 4.4.25. En esta ocasión existen varias orientaciones dominantes para un punto de interés. Por cada orientación se almacenará un punto.
Para localizaciones con múltiples picos de magnitud similar, habrá múltiples puntos creados en la misma escala y posición pero con diferente orientación. Solo un 15% de los puntos suelen tener orientaciones múltiples, pero estos contribuyen significativamente a la estabilidad del matching. Al igual que con la orientación principal con los demás picos se interpola una parábola entre los 3 puntos más cercanos para una precisión mayor.
Una vez disponemos de la posición, escala y orientación de cada punto de interés se creará el descriptor de estos puntos. Para ello se segmenta la vecindad en 4x4 regiones de 4x4 píxeles y se genera un histograma de orientación de gradiente para cada región usando una ponderación Gaussiana de ancho 4 píxeles.
Figura 4.4.26. Se extrae el descriptor en una vecindad de 4x4 regiones de 4x4 píxeles y se genera un histograma de orientación del gradiente para cada región.

PROYECTO FIN DE MÁSTER
118
Con un pequeño desplazamiento espacial, la contribución de un píxel puede pasar de una casilla a otra, lo que provoca cambios repentinos del descriptor. También ocurre lo mismo con una pequeña rotación, donde la contribución puede pasar de una orientación a otra.
Figura 4.4.27.Ante pequeños cambios espaciales o rotaciones un punto puede cambiar de región, realizando un cambio repentino en el descriptor.
Para evitar este problema, un píxel contribuye a todos sus vecinos (incluso en orientación). Para ello se multiplica la contribución por un peso 1-d, donde d es la distancia al centro de la casilla obteniendo cierta tolerancia a la rotación.
Figura 4.4.28.Cada píxel contribuirá con un peso diferente a todos sus vecinos.
Se obtiene un histograma tridimensional de 4x4x8=128 casillas y se almacena en un vector el valor de todas las casillas. Los cambios de brillo (adición de una constante) son eliminados por el gradiente. Para eliminar los cambios de contraste y obtener una tolerancia a cambios de iluminación se normaliza la magnitud del vector a 1 (multiplicación por constante). Con el objetivo de disminuir el efecto de gradientes muy fuertes, se limita el valor de cada componente a 0.2 (así cuenta más la orientación que la magnitud). Luego se vuelve normalizar a una amplitud de 1.
Además como cada histograma abarca varios píxeles, se obtiene una cierta tolerancia a cambios de vista.
Para utilizar el detector DoG junto al descriptor SIFT:

DESARROLLO
119
//1.Leemos imagen del disco. Imagen im=ImagenIO.getImagen("c:/imagenes/sample.jpg"); //2.Creamos el objeto DoGSIFT con una sigma para la gaussiana de 1.4f,s=3, el tamaño minimo de la imagen a procesar 64x64 y maxmo 1024x1024. Y para el detector definimos 4 regiones y 8 para la orientación DoGSIFT d=new DoGSIFT (1.6f,3,64,1024,4,8); //3. Buscamos puntos de interés d.process(im); //4. Mostramos imagen y dibujamos los features y descriptores Ventana v=new Ventana(im,"Detector DoG",true); List<Feature> features=d.getFeatures(); v.dibujarDescriptores(features,4); //Pasamos ademas de los features el numero de regiones que hemos expecificado
En la figura 4.4.29 se puede observar el resultado obtenido:
Figura 4.4.29. En la imagen podemos observar como los puntos localizados se muestran como puntos rojos, la orientación del descriptor mediante una línea azul y la ventana que se ha utilizado para obtener el descriptor está definida por el interior del recuadro verde.
4.4.2.2 Descriptor PCA- SIFT
Con el objetivo de obtener un descriptor que sea tan distintivo y robusto como SIFT, pero con un vector de menos componentes, Ke y Sukthankar (2004) propusieron una modificación a SIFT. Esta modificación reduce la dimensionalidad mediante el uso de la técnica de Análisis de Componentes Principales (PCA).
Al igual que en SIFT, primero se determina la escala y la orientación del punto de interés. En este caso se trabajará con ventanas de 39x39 en la escala correspondiente. Esta ventana se gira según la orientación dominante y se forma un vector V concatenando los mapas de gradientes horizontales y verticales.

PROYECTO FIN DE MÁSTER
120
Figura 4.4.30. Por cada punto de interés se extrae una ventana 39x39 orientada para generar el descriptor.
El vector inicial es normalizado a una magnitud de 1 para reducir el efecto de la iluminación.
En total se obtiene un vector V de 2x39x39=3042 elementos, que son muchos más que en SIFT pero no toda la información es significativa. Muchas variaciones de los elementos se deben a ruido o cambio de punto de vista. Además, muchos elementos están correlacionados. Tenemos que convertir el vector a una representación que resalte los parámetros importantes (los que describen la región de manera más distintiva), para ello se utiliza el análisis de componentes principales (PCA), consiguiendo reducir la dimensión del vector V.
El análisis de componentes principales (PCA) construye una transformación lineal que escoge un nuevo sistema de coordenadas para el conjunto original de datos en el cual la varianza de mayor tamaño del conjunto de datos es capturada en el primer eje (llamado el Primer Componente Principal), la segunda varianza más grande es el segundo eje, y así sucesivamente. Una de las ventajas de PCA para reducir la dimensionalidad de un grupo de datos, es que retiene aquellas características del conjunto de datos que contribuyen más a su varianza. El objetivo es que esos componentes de bajo orden a veces contienen el aspecto "más importante" de esa información y los componentes más altos pueden ser descartados.
Para el análisis de componentes principales consideremos un vector bidimensional Tyx ),( . Cuando existe una correlación fuerte entre x e y (si x es grande entonces y es grande, si x es pequeño entonces y es pequeño) y las desviaciones estándares de x e y son grandes:

DESARROLLO
121
Entonces si giramos los ejes hasta una orientación más adaptada a los datos, x1 e y1 ya no están correlacionados (la matriz de covarianza es diagonal). En este caso sólo la varianza de x1 es grande e y1 casi no contribuye a la descripción y se puede eliminar por lo que hemos conseguido reducir los datos.
Para el cálculo de PCA-SIFT se recopila muchos ejemplos de puntos de interés y se calcula sus vectores V. Con estos valores se calcula la matriz de covarianza de los vectores V:
TVVVVC ))((
Donde <> es el promedio sobre todos los ejemplos y VV .
Una vez calculada la matriz C se diagonaliza esta y se organiza por eigenvalues decrecientes. Los primeros eigenvectors (que corresponden a los eigenvalues más altos) indican los ejes más adecuados.
Para cada nuevo punto de interés, se obtiene el vector inicial V y se convierte al sistema de ejes de los eigenvectors ie . Donde el componente según el eje ie se obtiene por proyección sobre ie .
Finalmente, el descriptor está constituido por las 36 primeras componentes, es decir las proyecciones sobre los 36 ejes más distintivos. Por lo que se a conseguido reducir la dimensionalidad a 36 respecto de los 3042 originales y de los 128 de SIFT. En algunas versiones en lugar de quedarse con las 36 primeras componentes solo se almacenan las 20 primeras, reduciendo aun más el tamaño y el tiempo de matching del descriptor.
* Nota: el cálculo de los eigenvectors se hace una sola vez, fuera de línea.

PROYECTO FIN DE MÁSTER
122
4.4.2.3 Descriptor GLOH (Gradient location-orientation histogram)
El descriptor GLOH es una variante de SIFT propuesta por Mikolajczyk y Schmid en 2005. Este descriptor en lugar de utilizar una cuadricula espacial cuadrada, utiliza una cuadricula espacial log-polar.
En lugar de utilizar 8 orientaciones de gradiente GLOH utiliza 16. Por lo que el histograma total ocupa 272 casillas (17x16). Si se aplica PCA el descriptor es el conjunto de las 128 primeras componentes.
4.4.2.4 Descriptor SURF(Speeded Up Robust Feature)
Este descriptor presentado por Herbet Bay et al. en 2006 mejora la velocidad de procesado de los detectores anteriores, con una gran robustez ante transformaciones en la imagen. Para conseguir una mayor rapidez este descriptor reduce la dimensión y la complejidad del descriptor respecto a los anteriores, pero lo hace de modo que éstos continúen siendo suficientemente característicos e igualmente repetitivos. De forma análoga al descriptor SIFT y sus variantes, este descriptor describe la distribución de intensidades en la vecindad del punto de interés. Pero para ello en lugar de utilizar la información del gradiente utiliza las respuestas de las wavelets haar en las direcciones x e y, por lo que el descriptor se ejecuta más rápidamente y solo posee un tamaño de 64.
El primer paso consiste en hallar la orientación del punto de interés partiendo de una región circular alrededor del punto de interés. Después se construye una región cuadrada alineada con la orientación y se extrae el descriptor de ahí.
Cálculo de la orientación
Antes de aplicar el descriptor es necesario el uso de un detector para la extracción de puntos de interés, en el caso de Herbet Bay utilizaban el detector Fast Hessian para hallar estos. Una vez se disponen de los features, el primer paso es la asignación de la orientación. Este paso permite que el descriptor sea invariante rotacionalmente, otorgando a cada punto de interés una orientación.
Para calcular la orientación en un punto se calcula la respuesta Haar en la dirección x e y, en un área circular de vecindad de radio 6s alrededor del punto de interés, donde s representa la escala del punto de interés detectado. En primer lugar se calcularán las respuestas ondulas mediante haar, donde la longitud de las ondas es de 4s. Una vez calculadas las respuestas onduladas, se ponderan con una Gaussiana de s5,2 centrada en el punto de interés. Para

DESARROLLO
123
calcular el ángulo de estas respuestas se realiza como de costumbre calculando el arco tangente de la respuesta en y dividida entre la respuesta en x.
Para obtener la orientación dominante, se hace uso de una ventana de orientación móvil cubriendo un ángulo de 3/ . Esta ventana se va desplazando 0,15 radianes a lo largo de los 2 radianes que cubre la circunferencia completa y en cada posición analiza un ángulo de
3/ radianes. De este rango de 3/ radianes calcula la suma de las respuestas respecto al eje x y al eje y. Una vez que calculadas las sumas de las respuestas en x y en y ( 22 )()( ysumxsum ), se observa cual es el valor máximo de estas sumas obtenidas alrededor de la circunferencia. La orientación resultante será el ángulo que definen el sumatorio en x y en y de la ventana que a proporcionado el valor máximo. Es decir:
)()(arctan
xsumysumnorientacio
Extracción del descriptor
Para la extracción del descriptor, lo primero que vamos a hacer es la construcción de una región cuadrada alrededor del punto de interés y orientada en relación a la orientación calculada en el paso anterior. El tamaño de la región cuadrada será de 20s y la región será reducida progresivamente en regiones más pequeñas 4x4.
Para cada nueva subregión, se calculan características en puntos de muestra separados por una región 5x5. La respuesta de Haar en la dirección horizontal es denominada dx, mientras que en la dirección verticales denomina dy (la dirección horizontal y vertical se definen en función de la orientación del punto de interés seleccionado).
Figura 4.4.31. Para construir el descriptor, tal y como se muestra en la imagen de la izquierda se toma una cuadricula orientada de 4x4 sub-regiones cuadradas sobre el punto de interés.
Para darle mayor robustez ante deformaciones geométricas y errores de posicionamiento, las respuestas dx y dy son ponderadas con una Gaussiana de s3,3
centrada en el punto de

PROYECTO FIN DE MÁSTER
124
interés. Una vez llegados a este punto las respuestas dx y dy se suman en cada subregión conformando un primer conjunto de entradas para el vector de características.
Además, para recoger información de la polaridad de los cambios de intensidad, se realiza la suma de los valores absolutos de las respuestas |dx| |dy|. De modo que cada subregión tiene como descriptor un vector v de dimensión 4 para describir su estructura de intensidad:
),,,( yxux ddddv
Por lo que obtenemos un descriptor para las 4x4 subregiones de longitud 64.
Para utilizar este el detector Fast Hessian junto a este descriptor:
//1.Leemos imagen del disco. Imagen im=ImagenIO.getImagen("c:/imagenes/orb2.jpg"); //2.Creamos objeto FastHessianSURF. Donde especificamos los mismos parámetros que especificábamos para FASTHESSIAN y además diremos si queremos que no procese la orientación con lo que iría mas rápido pero el resultado seria peor. En nuestro caso esta a false para que busque la orientación aunque tarde mas. FastHessianSURF fhs=new FastHessianSURF(0.004f,3,4,1,2, false); //3. Buscamos puntos de interés y descriptor fhs.process(im); //4. Mostramos imagen y dibujamos los features y descriptores Ventana v=new Ventana(im,"SURF",true); List<Feature> features=fhs.getFeatures(); v.dibujarDescriptores(features);
El resultado se muestra al igual que en el caso de SIFT:
Figura 4.4.32. Puntos de interés obtenidos para SURF, indicando la orientación y el parche analizado para la construcción del descriptor.

DESARROLLO
125
4.4.2.5 Comparación de descriptores
En 2005 Mikolajczyk realizó una comparación entre los descriptores mencionados, exceptuando el descriptor SURF que fue publicado al año siguiente. La comparación se realizó bajo la presencia de transformaciones geométricas y transformaciones fotométricas con el objetivo de realizar el matching o reconocimiento de un objeto o escena.
En la mayoría de las pruebas GLOH obtenía el mejor resultado, seguido muy de cerca por SIFT. El contexto de forma también daba buenos resultados, pero cuando la escena tenía muchas texturas o los bordes no eran exactos su rendimiento se veía reducido.
Para ciertas aplicaciones la dimensionalidad de SIFT o GLOH puede ser un problema. Frente a estos los mejores detectores de dimensionalidad reducida son los filtros direccionales y los momentos del gradiente. También se puede utilizar la correlación cruzada, aunque esta depende mucho de los puntos de interés localizados, lo que hace que su resultado sea muy inestable frente al resto de descriptores.
Los resultados obtenidos por los detectores aplicados a puntos de interés localizados mediante detectores basados en la matriz Hessiana proporcionan mejor resultado que los basados en Harris debido a su mayor precisión. Además los resultados mejoran si se utilizan detectores basados en regiones en lugar de en puntos.
Aunque el descriptor SURF no ha sido evaluado en este estudio, parece ser que tiene un rendimiento parecido al de SIFT, con una dimensionalidad inferior, por lo que se ejecuta con mayor rapidez. Por ello para las aplicaciones de realidad aumentada utilizaremos el descriptor SURF mientras que para las aplicaciones de reconstrucción 3D utilizaremos el descriptor GLOH.

PROYECTO FIN DE MÁSTER
126
4.4.3 Emparejamiento de features
Una vez extraídos los puntos de interés y sus descriptores de dos o más imágenes, el siguiente paso es realizar algún tipo de emparejamiento entre estos puntos para saber cómo se corresponden entre ellos. El emparejamiento (matching) de los puntos de interés puede dividirse en dos partes:
Estrategia de emparejamiento: En primer lugar se debe seleccionar una estrategia de emparejamiento que determine que correspondencias pasan al siguiente paso para procesados posteriores.
Rapidez en el emparejamiento: Hay que seleccionar estructuras de datos y algoritmos que permitan realizar el emparejamiento lo más rápido posible.
4.4.3.1 Estrategia de emparejamiento y ratios de error
A la hora de realizar el emparejamiento con los puntos de interés pueden darse diferentes situaciones. Si tenemos dos imágenes que prácticamente se superponen, sabemos que la mayoría de features de una imagen serán emparejadas con las de la otra imagen, aunque algunas no serán emparejadas debido a la oclusión o porque su apariencia a cambiado en exceso. Este sería el caso de aplicaciones de creación de panorama o seguimiento de objetos.
Si por otra parte lo que se desea es encontrar diferentes objetos conocidos aparecen en una escena, la mayoría de features no serán emparejados. En el caso de que se deseen buscar objetos conocidos se requerirán estrategias eficientes para el emparejamiento.
El emparejamiento entre features se basa en la similitud de los descriptores de este. Como los descriptores son vectores, la similitud puede calcularse con la distancia euclidea:
i
ii VVVVd 22121 ),(
Si tenemos la distancia euclidea, la estrategia de emparejamiento más sencilla consiste en seleccionar un umbral (distancia máxima para que sea emparejado) y devolver aquellos emparejamientos que no superen este. Si el valor del umbral es muy alto se conseguirán muchos falsos positivos, puntos que realmente están mal emparejados. De la forma contraria poniendo un umbral muy bajo resulta en muchos falsos negativos, no se emparejan puntos que realmente habría que emparejar.
El problema de utilizar la métrica de la distancia euclidea es que es difícil de dar un valor al umbral, ya que este puede variar según la región de la imagen. Para solucionar este problema se utiliza la métrica del vecino más cercano (nearest neighbor). Teniendo en cuenta que habrá features que no tendrán punto con el cual emparejarse, ya sea porque pertenecen al fondo o porque están ocluidos, se definirá un umbral para reducir los falsos positivos. Si se dispone de suficientes imágenes de entrenamiento, es posible aprender diferentes umbrales para diferentes features.

DESARROLLO
127
Para aplicaciones como creación de panorama o construcción de modelos 3D partiendo de un conjunto de imágenes, una heurística conveniente podría ser comparar la distancia del vecino más cercano con el segundo vecino más cercano. De forma que puede definirse el ratio de la distancia al vecino más cercano como:
CA
BA
DDDD
ddNNDR
2
1
Donde 1d y 2d son la distancia al primer y segundo vecino más cercano, AD es el descriptor del objetivo y BD y CD son sus dos vecinos más cercanos.
En el caso del descriptor SURF se almacena la información sobre el signo Laplaciano. Este signo especifica si el punto detectado es oscuro sobre un punto claro o viceversa. Por ello para agilizar el proceso de emparejamiento, en este caso se puede mirar si el signo coincide y solo calcular el vecino más cercano de aquellos puntos cuyos signos coincidan. Si queremos realizar el emparejamiento de los puntos de interés de dos imágenes que utilicen el algoritmo FastHessian para detectar los puntos de interés, SURF como descriptor y utilizando el vecino más cercano para el emparejamiento teniendo en cuenta el signo laplaciano:
//1.Leemos las dos imágenes a comparar. Imagen in1=ImagenIO.getImagen("c:/imagenes/col.jpg"); Imagen in2=ImagenIO.getImagen("c:/imagenes/col2.jpg"); //2.Creamos el objeto SURF. Donde especificamos los mismos parámetros que especificábamos para FASTHESSIAN y además diremos si queremos que no procese la orientación con lo que iría mas rápido pero el resultado seria peor. En nuestro caso esta a false para que busque la orientación aunque tarde mas. Los dos ultimos parámetros indican el tamaño del descriptor y si deseamos o no eliminar los matching incorrectos realizando el emparejamiento de la segunda imagen con la primera. SURF s=new FastHessianSURF(0.001f,4,4,1,2,false,64,true); //3. Realizamos el emparejamiento s.process(in1,in2); //4. Mostramos los puntos emparejados. En el constructor de la ventana despeus de pasar las dos imágenes se indica como se desea mostrar las dos imagenespara dibujar lso emparejamientos. Si alineadas verticalmente 0 o horizontalmente 1 VentanaMatching vm=new VentanaMatching(in1,in2,1,"Matching",true); v.dibujarEmparejamientos(s.getPuntosEmparejados());
En la figura 4.4.33 se puede observar el resultado obtenido:

PROYECTO FIN DE MÁSTER
128
Figura 4.4.33. Al realizar el matching entre las dos imágenes, se obtienen las líneas que definen que punto de una imagen ha sido emparejado con el mismo punto de otra imagen. Para ello en las diferentes imágenes deberá existir el mismo objeto para poder encontrarlo.
Si se desea realizar el matching en tiempo real con la imagen capturada de la Webcams en lugar de extender de la clase WebCam se utilizará la clase WebCamMatching. Donde se le pasara los objetos emparejados para que los compare. Un ejemplo de cómo utilizar esta clase se encuentra en el paquete Ejemplos.WebCam.Matching.
Figura 4.4.34. Podemos observar el interface utilizado para realizar el matching en tiempo real mediante la imagen capturada de la webCam.

DESARROLLO
129
4.4.3.2 Estrategias eficientes de emparejamiento
Una vez hemos decidido una estrategia de emparejamiento necesitamos una manera eficiente de buscar candidatos potenciales. La manera más simple consiste en comparar todos los features de una imagen con el resto, buscando emparejamientos potenciales. Este método es cuadrático respecto al número de puntos de interés extraídos, lo que lo hace inviable para la mayoría de aplicaciones.
Una manera más eficiente de buscar candidatos es diseñar una estructura indexada como un árbol de búsqueda multidimensional o una hash table, para poder buscar rápidamente los features parecidos a un feature dado. Esta estructura indexada puede ser creada para cada imagen independientemente (si queremos buscar un objeto particular) o parta todas las imágenes de la base de datos. Para bases de datos extremadamente grandes (de millones de imágenes o más), se necesitan estructuras aun más eficientes como por ejemplo árboles de vocabulario, que se verán en la sección de reconocimiento.
Árboles kd:
Uno de los métodos más utilizados para la búsqueda son los árboles kd (kd trees), que organiza los vectores que contienen la descripción del feature recursivamente, formando grupos cada vez menores y ordenando dimensión a dimensión. En la figura 4.4.31 vemos un ejemplo de un árbol kd de dos dimensiones.
En este ejemplo, tal y como se observa en la primera imagen, primero se selecciona un umbral en x. Para elegir este umbral se suele tomar el punto de la mediana como separador en este caso (x=7, definido por el punto 7,2). Una vez definido el umbral por cada una de las mitades resultantes, vuelve a aplicarse el mismo criterio pero respecto al eje y, de esta forma conseguimos la división que se observa mediante líneas azules en la segunda imagen. Se realiza el mismo proceso pero ahora respecto a x y así sucesivamente hasta que no haya más puntos. Como resultado obtenemos la segunda imagen. Finalmente tal y como se muestra en la tercera imagen se obtiene el árbol binario dibujando en orden los puntos que han sido tomados como umbral.
Figura 4.4.35.En la imagen se observa un ejemplo de construcción de un árbol kd de 2 dimensiones.

PROYECTO FIN DE MÁSTER
130
Por lo que el algoritmo para la creación del árbol sigue los siguientes pasos:
1. Se empieza el proceso con una dimensión d=1.
2. Se busca cual de las dimensiones d de los vectores (descriptores) es la mediana.
3. Formar un grupo de vectores que tiene su componente d menor que la mediana y otro grupo que la tenga mayor.
4. Incrementamos la dimensión d=d+1.
5. Para cada grupo que tenga más de un punto, se repetirán las etapas de la 2 a la 4.
Una vez construido el árbol, para buscar el emparejamiento de un punto de interés utilizaremos la métrica del vecino más cercano. Este proceso es fácil de entender mediante el ejemplo bidimensional anterior.
Figura 4.4.36. Una vez creado el árbol de decisión se busca el vecino más cercano en este.
En la figura 4.4.36 podemos observar el proceso. Imaginemos que el nuevo feature que se quiere emparejar es el marcado con una cruz verde en la primera imagen. Para hallar cual es el vecino más cercano, en primer lugar se recorre el árbol de arriba hacia abajo observando en que región de las que se subdivide está el nuevo vector (descriptor). En la segunda imagen

DESARROLLO
131
observamos en verde aquellas regiones donde se encuentra el nuevo vector y en azul aquellas donde no se encuentra. A medida que se observan en que grupos se encuentra el vector se va calculando la distancia respecto al punto que ha definido el umbral de grupo. Una vez disponemos de las distancias podemos saber qué puntos de estos es el más cercano. Hay que tener en cuenta que no hemos analizado todos los puntos del espacio solo los grupos en los que se encontraba este por lo que podría darse el caso en que hubiese algún otro punto más cercano. Para comprobar si es así, recorremos el resto de las ramas de abajo hacia arriba y se descartan aquellas regiones que tengan una distancia mayor a la calculada. Tal y como se muestra en la última imagen se añade el grupo definido por el punto (4,7) para ser analizado. Para finalizar examinaremos cual es la menor distancia de todas.
Este algoritmo permite que no se tengan que comparar todos los puntos, incrementando la velocidad del emparejamiento. La búsqueda del vecino más cercano se hace en tiempo O(log N), donde N es el número de vectores. Sin embargo, con D dimensiones, el tiempo es O(2D). En práctica, la técnica no es utilizable para vectores con dimensiones mayores a 20 y aunque existen muchas variantes de los árboles-kd, en dimensionalidad alta ningún algoritmo es capaz de encontrar el vecino más cercano de una forma más efectiva que con la búsqueda exhaustiva.
The Best Bin First:
El algoritmo Best Bin First, propuesto por Beis y Lowe en 1997 es una variante de los árboles kd. Este algoritmo realiza una búsqueda aproximada, es decir encuentra uno de los vecinos más cercanos, pero no tiene porque ser el más cercano. Las casillas en lugar de ser buscado por proximidad en el árbol, se buscan por proximidad espacial y además se impone un límite de puntos visitados.
En primer lugar se debe de construir el árbol. La construcción de este es muy parecida al caso anterior, pero en esta ocasión se particionará según la dimensión con mayor varianza para ser un punto.
Por lo que el algoritmo para la creación del árbol sigue los siguientes pasos:
1. Se selecciona la dimensión d que tenga una mayor varianza (la varianza es una medida de la dispersión de los puntos).
2. Se busca la mediana de los vectores (descriptores) en la dimensión respecto de la dimensión d.
3. Formar un grupo de vectores que tiene su componente d menor que la mediana y otro grupo que la tenga mayor.
4. Dentro de cada grupo calculamos cual es la dimensión con mayor varianza.
5. Para cada grupo que tenga más de un punto, se repetirán las etapas de la 2 a la 4.
En la figura 4.4.33 podemos ver un ejemplo del funcionamiento en 2 dimensiones.

PROYECTO FIN DE MÁSTER
132
Figura 4.4.37. Se muestra un ejemplo de construcción de un árbol mediante el algoritmo best bin first en 2 dimensiones.
Tal y como observamos en la figura 4.4.37 en primer lugar observamos que dimensión de las dos tiene una varianza mayor. Como el eje x tiene una dispersión mayor este será el que mayor varianza tenga, por lo que tenemos que dividir en función de este eje. Si buscamos la mediana respecto x obtenemos un valor de 3,5. Dividimos en dos grupos en función de la mediana. Si observamos en el grupo de la derecha los puntos siempre tienen más varianza respecto el eje x por lo que siempre serán divididos en función de esta dimensión. De forma similar se dividen los puntos en el grupo de la izquierda hasta que solo quede un punto en cada cuadricula. A medida que se va dividiendo en cuadriculas el espacio se va creando el árbol igual que en el caso anterior.
Una vez construido el árbol el siguiente paso es la búsqueda aproximada del vecino más cercano. Para entender mejor el proceso se explicará con el ejemplo anterior.
Figura 4.4.38. Una vez construido el árbol el siguiente paso es la búsqueda aproximada del vecino más cercano.
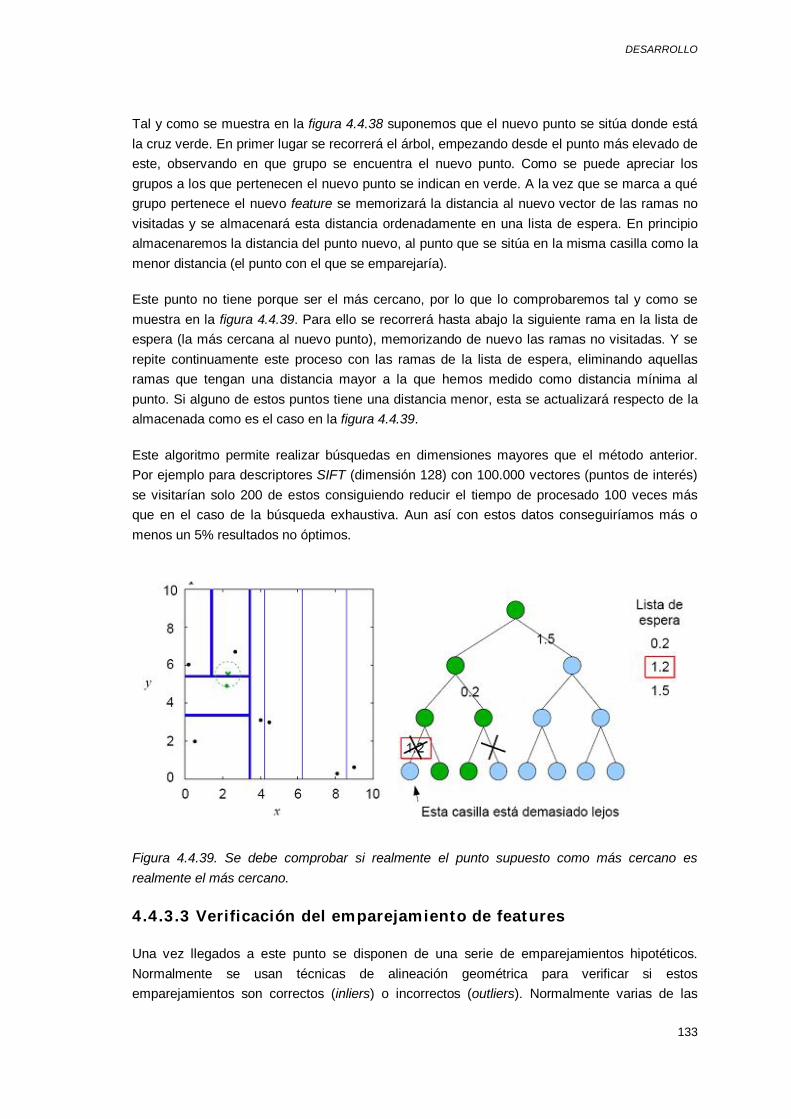
DESARROLLO
133
Tal y como se muestra en la figura 4.4.38 suponemos que el nuevo punto se sitúa donde está la cruz verde. En primer lugar se recorrerá el árbol, empezando desde el punto más elevado de este, observando en que grupo se encuentra el nuevo punto. Como se puede apreciar los grupos a los que pertenecen el nuevo punto se indican en verde. A la vez que se marca a qué grupo pertenece el nuevo feature se memorizará la distancia al nuevo vector de las ramas no visitadas y se almacenará esta distancia ordenadamente en una lista de espera. En principio almacenaremos la distancia del punto nuevo, al punto que se sitúa en la misma casilla como la menor distancia (el punto con el que se emparejaría).
Este punto no tiene porque ser el más cercano, por lo que lo comprobaremos tal y como se muestra en la figura 4.4.39. Para ello se recorrerá hasta abajo la siguiente rama en la lista de espera (la más cercana al nuevo punto), memorizando de nuevo las ramas no visitadas. Y se repite continuamente este proceso con las ramas de la lista de espera, eliminando aquellas ramas que tengan una distancia mayor a la que hemos medido como distancia mínima al punto. Si alguno de estos puntos tiene una distancia menor, esta se actualizará respecto de la almacenada como es el caso en la figura 4.4.39.
Este algoritmo permite realizar búsquedas en dimensiones mayores que el método anterior. Por ejemplo para descriptores SIFT (dimensión 128) con 100.000 vectores (puntos de interés) se visitarían solo 200 de estos consiguiendo reducir el tiempo de procesado 100 veces más que en el caso de la búsqueda exhaustiva. Aun así con estos datos conseguiríamos más o menos un 5% resultados no óptimos.
Figura 4.4.39. Se debe comprobar si realmente el punto supuesto como más cercano es realmente el más cercano.
4.4.3.3 Verificación del emparejamiento de features
Una vez llegados a este punto se disponen de una serie de emparejamientos hipotéticos. Normalmente se usan técnicas de alineación geométrica para verificar si estos emparejamientos son correctos (inliers) o incorrectos (outliers). Normalmente varias de las

PROYECTO FIN DE MÁSTER
134
correspondencias encontradas son outliers. Es necesario eliminar el mayor número posible de outliers, ya que para ciertas aplicaciones podrían ser muy perjudiciales.
Si por ejemplo, esperamos que la imagen que analizamos este trasladada o rotada, podemos estimar la transformación de los features y descartar aquellos que no sean parecidos a los esperados. El algoritmo de RANSAC (random sample consensus) en lugar de hacer la estimación con el número máximo de puntos y luego eliminar los outliers, estima el número mínimo de puntos y luego agrega más puntos.
4.4.4 Tracking de features
Quizás en ocasiones, por los requisitos de la aplicación, en lugar de buscar objetos en todos los frames de un video se prefiera buscar un objeto y una vez encontrado hacer el seguimiento de este (ya no nos interesa encontrar más objetos). Para ello una vez encontrado los features que describen al objeto en el video, en lugar de volver a buscarlos en el siguiente frame y así sucesivamente se hará un seguimiento de estos puntos denominado Tracking. Este tipo de aplicaciones de detección y seguimiento se realizan para el Tracking de video, donde se espera que el movimiento de un frame del video al otro sea pequeño.
El proceso de seleccionar buenos features para hacer el seguimiento está muy relacionado con la selección de buenos features para aplicaciones de reconocimiento. En los frames sucesivos funciona bastante bien buscar localizaciones donde el patch correspondiente tenga un valor bajo de diferencia de cuadrados. Aunque si las imágenes sufren de cambios de brillo, sería necesario aplicar compensaciones para estas variaciones, por lo que sería preferible aplicar la correlación cruzada normalizada. Si el rango de búsqueda es grande resulta más eficiente el uso de una estrategia de búsqueda jerárquica, que utilice emparejamientos en imágenes en menor resolución para obtener mejores estimaciones iniciales y por lo tanto acelerar la búsqueda. Otra alternativa implica el aprendizaje de la apariencia del patch del que se quiere hacer el seguimiento y después buscar este en la vecindad de la posición en la que se predice que estaría. Estos temas se tratan más en profundidad en secciones de predicción del movimiento.
Si el tracking de los features se realiza sobre secuencias de imágenes largas, su apariencia puede dar grandes cambios. En estos casos habrá que decidir si es mejor continuar con el emparejamiento en función de los features detectados originalmente o muestrear cada frame posterior en la localización del emparejamiento. La primera opción es propensa a fallar ya que el patch original puede sufrir modificaciones de apariencia como por ejemplo la reducción de la longitud del objeto según las reglas de la perspectiva. La última opción corre el riesgo de que el feature se halle movido a una localización diferente en la imagen.
Una solución mejor sería utilizar un modelo de movimiento afín para comparar el patch original con localizaciones de imágenes posteriores. Como se ha comentado anteriormente estos y mejores algoritmos se ven al estudiar la predicción de movimiento.

DESARROLLO
135
4.5 CASO PRÁCTICO: APLICACIÓN DE REALIDAD AUMENTADA
Mediante el uso de los diferentes bloques explicados, ya es posible implementar una aplicación de realidad aumentada. En nuestro caso se ha creado una aplicación que reconoce medicamentos. El funcionamiento es muy sencillo, el usuario se pone frente a la cámara Web mostrando la caja de un medicamento y en la pantalla aparecerá la información de este medicamento superpuesto a la imagen capturada por la cámara tal y como se muestra en la figura 4.5.1.
Figura 4.5.1. Se ha implementado una aplicación de reconocimiento de medicamentos para analizar el funcionamiento de los algoritmos mencionados en el ámbito de reconocimiento de objetos (reconocimiento de instancia).
Los diferentes pasos que se han seguido para implementar esta aplicación:
1. En primer lugar se deben de almacenar las características de los objetos que se desean reconocer (en nuestro caso medicamentos). Para ello se cogerá una imagen del objeto que se desea y se extraerán sus puntos de interés y los descriptores de estos. Por lo tanto por cada objeto a reconocer tendremos un conjunto de puntos de interés con sus descriptores. En el caso del detector FastHessian es importante definir un umbral que permita recoger un número suficiente de puntos de interés para poder comparar. Cuanto menor sea este umbral más puntos de interés se encontrarán tal y como se muestra en la figura 4.5.2.
Hay que tener en cuenta que cuantos más puntos se detecten el proceso será mucho más lento ya que será necesario extraer los descriptores de más puntos y comparar más puntos con aquellos que están en la base de datos. En nuestro caso utilizaremos un umbral de 0.001.

PROYECTO FIN DE MÁSTER
136
Figura 4.5.2. En la primera imagen podemos observar el efecto de detectar los puntos con un umbral de 0.004, con lo que solo obtenemos 40 puntos de interés. Sin embargo si aplicamos un umbral de 0.001 conseguimos 236 puntos de interés.
Una vez que tenemos los puntos de interés del objeto que queremos buscar, necesitaremos extraer su descriptor. Para ello en función de la escala en la que se ha encontrado el punto se calcula la orientación y se extrae un descriptor en esa dirección tal y como se muestra en la figura 4.5.3. Dependiendo de la capacidad de procesado del computador en el que se quiera realizar el reconocimiento, puede descartarse la información de la orientación y extraer el descriptor sin que este esté orientado. A la hora de realizar el matching el resultado puede empeorar, no emparejando bien dos puntos que realmente sean el mismo, pero como consecuencia se consigue aligerar la aplicación.

DESARROLLO
137
Figura 4.5.3. En la primera imagen podemos ver como los descriptores (definidos por los cuadrados verdes) están orientados en función de la orientación del punto (línea azul). En la segunda imagen observamos el descriptor que se usaría si no hiciésemos caso a la orientación de cada punto.
Es importante tener en cuenta la dimensión en la que se procesará la imagen. Es decir la mayoría de cámaras web capturan la imagen a una resolución de 320x240, por lo que los objetos que se encuentren al procesar esta imagen estarán a una escala inferior, por ello al extraer los puntos de interés para almacenar en la base de datos se realizará partiendo de imágenes en las mismas condiciones, es decir con una resolución inferior a 320x240. En el caso de que no se consiga ejecutar el algoritmo a la velocidad deseada, puede reducirse el tamaño de la imagen capturada por la cámara Web antes de buscar los puntos de interés, ganando muchos milisegundos en el procesado.
Normalmente a la hora de buscar los puntos de interés en las imágenes capturadas de la cámara, solo se procesa el algoritmo para un número limitado de escalas. Por lo que si el objeto aparece muy lejos de la cámara puede que no se detecte porque a esa escala ya no se encuentran puntos de interés. Por ello es interesante que se saquen fotos del medicamento a diferentes escalas, para almacenar los puntos en más escalas que en las que por defecto busca.
Otro factor importante a decidir, es si deseamos que el medicamento sea reconocido solo mediante la cara frontal o mediante cualquiera de sus caras. Si ese es el caso, al objeto se le tendrá que añadir los descriptores obtenidos de las fotos de todas las caras del medicamento.
Figura 4.5.4. Si se desea reconocer cualquier cara de la caja del medicamento se almacenarán las características almacenadas de todos las caras.
Hay que tener cuidado con el número de puntos que se insertan en la base de datos, ya que cuantos más puntos más lento será el matching.
Si se desean reconocer otros objetos como por ejemplo latas de bebida, en este caso si sería interesante sacar fotos desde diferentes puntos de vista para que cojas como cojas el objeto pueda reconocerlo correctamente.

PROYECTO FIN DE MÁSTER
138
Figura 4.5.5. En objetos circulares, si no sabemos que punto se enseñará a pantalla, cogeremos diferentes vistas.
2. Una vez que disponemos de una base de datos con los puntos que describen a cada objeto. Se procederá a buscar los puntos de interés de las imágenes capturadas de la cámara mediante el mismo algoritmo que se ha utilizado para almacenar los puntos de la base de datos(figura 4.5.6). Como es lógico también se utilizará el mismo umbral. En función de la capacidad de procesado del ordenador puede decidirse en cuantas octavas y escalas se desean buscar los puntos de interés. Cuanto mayor sea este número más lento será el algoritmo pero a la vez más probable de que encuentre más puntos.
Figura 4.5.6. Extraemos los puntos de interés de la imagen capturada de la Web Cam.
3. Una vez que disponemos de los puntos que definen la imagen capturada se extraerá el descriptor SURF. Si a la hora de extraer los puntos de interés de los objetos de la base de datos se utilizó el descriptor sin orientación aquí también deberá utilizarse sin orientación.

DESARROLLO
139
Figura 4.5.7. En la primera imagen observamos los descriptores orientados y en el segundo sin orientar.
4. Una vez tenemos los descriptores, compararemos estos con los de la base de datos para observar si pertenecen al mismo objeto.
Figura 4.5.8. Con los puntos detectados se procede a hacer el matching respecto de los puntos almacenados en la base de datos.
En primer lugar descartaremos aquellos puntos que no tengan el mismo signo Laplaciano, ya que este indica si es un punto oscuro sobre un fondo claro o al revés, y

PROYECTO FIN DE MÁSTER
140
el mismo objeto tendrá esta misma característica. Este paso ayuda a acelerar el proceso de búsqueda. Con el resto de puntos se busca los dos vecinos más cercanos y si el punto más cercano esta a una distancia inferior al de la distancia del segundo*0.5 consideraremos que este punto está emparejado.
5. Siempre y cuando se hayan encontrado como mínimo 3 emparejamientos entre la captura de la cámara y uno de los objetos de la base de datos, se considera que se ha encontrado este objeto. Dependiendo del tipo de aplicación habrá que decidir si una vez encontrado el objeto se desea seguir buscando más objetos o si es preferible realizar el Tracking del objeto detectado. Realizar el Tracking del objeto es computacionalmente menos costoso pero si apareciesen nuevos objetos en la escena no los detectaríamos.

CONCLUSIONES
141
5. CONCLUSIONES
Tras analizar los diferentes algoritmos para la detección, descripción y emparejamiento de puntos de interés, no se puede seleccionar uno de ellos como el que mejor resultado ofrece frente al resto. La elección del algoritmo a utilizar dependerá mucho de los requisitos de la aplicación a implementar.
En nuestro caso analizaremos dos tipos de aplicaciones diferentes, que ya han sido mencionadas en puntos anteriores. Por una parte se analizará cuál de estos es el idóneo para aplicaciones de reconstrucción 3D y por otra parte cuál de ellos es mejor para el reconocimiento de objetos en tiempo real.
5.1 REALIDAD AUMENTADA
Como ya se ha mencionado anteriormente, los algoritmos que se van a utilizar dependerán mucho del tipo de aplicación. Dentro del ámbito de la realidad aumentada existen aplicaciones con diferentes especificaciones por lo que nosotros partiremos de la aplicación de reconocimiento de medicamentos expuesta en el punto anterior.
La detección de objetos mediante puntos de interés ofrece muchas ventajas frente a los clásicos marcadores (figura 5.1.1) que se utilizan en realidad aumentada. Una de las diferencias más importantes radica en que a diferencia que los marcadores, los objetos detectados mediante los puntos de interés funcionan incluso con oclusión (parte del objeto no se ve en la vista de la cámara). Además aunque la detección de puntos sea computacionalmente más costosa, se elimina la necesidad de adaptar el entorno con marcadores, donde en muchas aplicaciones no sería viable.

PROYECTO FIN DE MÁSTER
142
Figura 5.1.1. En la primera imagen vemos los marcadores típicos que suelen utilizarse para aplicaciones de realidad aumentada. En la segunda imagen se puede apreciar como solo se está mostrando una pequeña parte del medicamento y aun así, reconoce perfectamente el medicamento.
Es necesario decidir que algoritmos van a utilizarse tanto para la detección, como para la descripción, como para el emparejamiento.
En nuestro caso es importante detectar el medicamento en diferentes escalas. Es decir independientemente de que el usuario sostenga el medicamento cerca o lejos de la cámara este se tendría que reconocer perfectamente. Por ello se escogerá un detector que sea invariante a cambios de escala. Puede que en ciertas aplicaciones el objeto siempre se vaya a encontrar a la misma distancia de la cámara por lo que no sería necesario el uso de un detector invariante en escala, con lo que se podría ejecutar el algoritmo en un tiempo inferior. Además, como los medicamentos se van a mostrar directamente a cámara no es necesario que tengamos en cuenta las transformaciones afines, con lo que descartamos la selección de un algoritmo que sea invariante a transformaciones afines ya que son más lentos. Teniendo en cuenta que para las aplicaciones de realidad aumentada un factor clave es la ejecución del algoritmo en tiempo real se escoge el detector FastHessian que es el más rápido de los detectores invariantes en escala.
En cuanto a los descriptores se selecciona el descriptor SURF ya que es uno de los descriptores más rápidos, que ocupa menos espacio y con un resultado comparable con los que mejor resultado proporcionan pero que son más lentos.
Como en este ejemplo no se están reconociendo una gran cantidad de objetos se está utilizando el signo laplaciano y la técnica del vecino más cercano para realizar el emparejamiento entre puntos de interés. A medida que añadiésemos más objetos a la base de datos (del orden de miles) sería interesante utilizar la técnica best bin first o incluso visual words.
Entre otras muchas cosas, hay que tener en cuenta que la calidad de las cámaras que se suelen utilizar no son muy buenas, por lo que en movimientos bruscos no detecta correctamente el objeto, ya que la imagen del medicamento aparece borrosa e incluso para la vista humana es difícil de reconocer.

CONCLUSIONES
143
Figura 5.1.2. Se muestra una captura de pantalla donde se observa que con movimientos bruscos la imagen del medicamento aparece borrosa, por lo que no se consigue identificar.
Tal y como se muestra en la figura 5.1.3, en ocasiones puede que el emparejamiento de dos puntos sea incorrecto.
Figura 5.1.3. En esta imagen podemos observar 13 emparejamientos de los cuales uno es incorrecto ya que empareja una parte del ordenado con la lata.
Para solucionar el problema de los puntos mal emparejados, suelen utilizarse técnicas como RANSAC o Robot Least Squares. En nuestro caso para eliminar estos puntos mal emparejados denominados outliers se ha procedido a realizar el matching al revés. Es decir si en primer lugar se comparaban los puntos de la imagen A con respecto a los de B, ahora se realizará al revés y se considerarán puntos bien emparejados aquellos que en las dos direcciones hayan sido emparejados de la misma forma.
En este caso tal y como se muestra en la figura 5.1.4 se elimina el outlier pero también se eliminan alguno de los emparejamientos que estaban bien realizados. Ahora en lugar de tener

PROYECTO FIN DE MÁSTER
144
13 emparejamientos tenemos 7. Como hemos definido que para reconocer un objeto con 3 es suficiente, no pasaría nada y se consideraría que habría reconocido la lata correctamente.
Figura 5.1.4. En esta ocasión obtenemos 7 emparejamientos, donde ninguno de ellos es un outlier.
En el caso de los medicamentes en ocasiones, el producto del interior suele tener el mismo logo que en la caja. Por ello mostrando el propio producto en la aplicación también reconoce correctamente el medicamento.
Figura 5.1.5. En este caso realiza el matching incluso con el producto del interior de la caja, reconociendo este correctamente. Podemos observar que hay un outlier con la O grande del frasco que la empareja con la o pequeña de la caja. Esto es debido a que son el mismo objeto (una letra o) en diferentes escalas.
Dependiendo del tipo de aplicación esto puede ser algo que interese o al contrario que no queramos que pase. Como posible solución podría definirse que no se ha identificado el medicamento a no ser que haya un mínimo más elevado de emparejamientos correctos o quizás comprobando mediante la transformada de Hough si el objeto es un rectángulo o no.

CONCLUSIONES
145
Si queremos optimizar el tiempo de ejecución dependiendo del tipo de aplicación pueden utilizarse diferentes técnicas. Por ejemplo en el caso de los medicamentos, si todas las cajas fuesen blancas podría binarizarse la imagen, buscar la caja y aplicar el procesado solo a la zona donde se ha detectado una caja. Otra posibilidad podría ser buscar formas dentro de la imagen y buscar cuadrados, una vez encontrados aplicar el detector solo a las zonas cuadradas.
En nuestro caso la búsqueda de objetos se está realizando en todos los frames capturados por la cámara Web, pero quizás fuese mejor procesarlo en 5 frames por segundo o 10, ya que para el ojo humano prácticamente no habría diferencia.
5.2 RECONSTRUCCIÓN 3D
Para aplicaciones de reconstrucción 3D, tal y como se ha mencionado anteriormente, la mejor opción es el uso del detector MSER, aunque como el tiempo no es un factor clave se utilizará combinado con algún otro detector. El detector MSER suele funcionar muy bien para edificios y cosas impresas mientras que Harris-laplace, Hessian-laplace y DoG funcionan mejor para categorías naturales. Por lo que combinaremos los resultados obtenidos del MSER con los obtenidos con el detector Hessian-Laplace ya que es más estable que Harris-Laplace.
A la hora de buscar puntos de interés y emparejarlos con los de otras imágenes para conseguir varias vistas de una imagen hay que tener en cuenta además de los outliers que pueden haber varias objetos iguales en la escena tal y como se muestra en la figura 5.2.1.

PROYECTO FIN DE MÁSTER
146
Figura 5.2.1. En la imagen puede observarse el resultado obtenido aplicando FastHessian y SURF. Cuando este implementado el método MSER y Hessian-Laplace se utilizarán estos métodos que proporcionan mejor resultado. Podemos observar en la imagen superior como empareja la silla de la izquierda con la silla derecha de la segunda imagen. Obviamente son iguales pero a la hora de reconstruir la imagen necesitaríamos que esta estuviese emparejada con la primera silla no con la segunda, ya que esto nos proporciona mala información.
En este caso al utilizar un detector que no es invariante a transformaciones afines, ante cambios bruscos de punto de vista de un objeto no se emparejan muchos puntos. En este caso prácticamente solo el cojín del centro del sofá. Cuantas más imágenes se posea mejor para poder asociar más objetos de la imagen y tener información de más puntos. Si realizamos las fotos sin cambios tan bruscos se emparejaran muchos más objetos.
Figura 5.2.2. En este caso sin un cambio de vista tan brusco el emparejamiento da mejores resultados.
Utilizando este detector el emparejamiento da mejores resultados si no se realizan cambios tan bruscos en el punto de vista de la imagen. Además aunque haya objetos iguales no pasa como en el caso anterior y no mezcla los puntos de estos en el emparejamiento.
Hay que tener en cuenta que para construir un modelo fiel a la realidad cuanto más puntos y detalles se consigan mejor, por ello es preferible sacar muchas fotos y que estas sean cercanas a los objetos y detalles a modelar.

CONCLUSIONES
147
Figura 5.2.3. En este caso tenemos muchos puntos emparejados.
A veces, puede que muchos de los puntos no nos proporcionarán información extra, ya que pertenecen a texturas. Para la reconstrucción son más interesantes los puntos que definen esquinas y formas en los objetos del entorno que los que definen las texturas.


LÍNEAS FUTURAS
149
6. LÍNEAS FUTURAS
La extracción de puntos de interés de una imagen es el primer paso de muchas aplicaciones en el ámbito de la visión artificial. En este proyecto se han expuesto dos de estas aplicaciones, la reconstrucción 3D y el reconocimiento de objetos en tiempo real para aplicaciones de realidad aumentada.
Para aplicaciones de realidad aumentada este proyecto podría ampliarse con diferentes líneas:
Utilizar visual words para reconocimiento de instancias (objetos). Realizar el reconocimiento de clases de objetos, es decir, poder identificar si lo que se
está viendo es un mueble, una persona, un animal, alimentos…
Intentar comprender que es lo que se está viendo en el entorno.
Utilizar la información de profundidad para poder interactuar con objetos tridimensionales.
Utilizar técnicas de tracking para hacer el seguimiento de objetos.
Búsqueda de objetos por su forma.
En cuanto a la reconstrucción 3D, todavía quedan de implementar los otros pasos expuestos en objetivos:
Estimar la posición de la cámara.
Estimar la estructura.
Calibración de la cámara.
Generación del modelo.
Para generar un entorno interactivo pueden combinarse técnicas de reconocimiento con técnicas de reconstrucción.


BIBLIOGRAFÍA
151
7. BIBLIOGRAFÍA
Gonzalez, R., Woods, R. (2009). Digital Image Processing. Prentice-Hall.
Pajares, G. (2007). Visión por computador, Imágenes digitales y aplicaciones. Ra-Ma.
Szeliski, R. (2010). Computer Vision: Algorithms and Applications. Springer.
Haller, M., Billinghurst, M., Thomas, B.H. (2007). Emerging Technologies of Augmented Reality: Interfaces and Design.
Trung Kien, D. (2005). A Review of 3D Reconstruction from Video Sequences. ISIS technical report series.
Harris, C. Stephens, M. (1988). A combined corner and edge detector. In Proceedings of The Fourth Alvey Vision Conference, pp. 147-151.
Stephens, M., Michael, J. (1997). International Journal of Computer Vision, vol. 23, pp.45-78.
Rosten, E., Porter, R., Drummond, T. (2008). Faster and better: a machine learning approach to corner detection. IEEE Transactions on Pattern Analysis and Machine Inteligence, vol. 32, pp. 105-119.
Mikolajczyk, K., Schmid, C. (2001). Indexing based on scale invariant interest points. In Proc. ICCV.
Mikolajczyk, K., Schmid, C. (2004). Scale & Affine Invariant Interest Point Detectors. International Journal of Computer Vision, vol. 60, pp. 63-86.
Lowe, D. (2004). Distictive Image Features from Scale-Invariant Keypoints. International Journal of Computer Vision, vol. 60, no. 2, pp. 91-110.
Ke, Y., Sukthankar, R. (2004). PCA-SIFT: A More Distinctive Representation for Local Image Descriptor. Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition.

PROYECTO FIN DE MÁSTER
152
Viola, P., Jones, M. (2001). Rapid Object Detection using Boosted Cascade of Simple Features. Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition.
Bay, H. Ess, A., Tuytelaars, T., Van Gol, L. (2008). SURF: Speeded Up Robust Features. Computer Vision and Imagen Understanding (CVIU), vol. 110, No.3, pp. 346-359.
Mikolajczyk, K., Schmid, C. (2005). A Performance Evaluation of Local Descriptors. IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 27, no. 10.
Tuytelaars, T., Van Gol, L. (2004). Matching Widely Separated Views Base don Affine Invariant Regions. International Journal of Computer Vision, vol. 59, pp. 61-85.
Kadir, T., Zisserman, A., Brady, M. (2004). An affine invariant salient region detector. Proceedings of the 8th European Conference on Computer Vision.
Matas, J., Chum, O., Urban, M., Pajdla, T. (2002). Robust Wide Baseline Stereo from Maximally Stable Extremal Regions. Image and Vision Computing, vol. 22, pp. 761-767.
Donoser, M., Bischof, H. (2006). Efficient Maximally Stable Extremal Region (MSER) Tracking. IEEE Conference on Computer Vision and Pattern Recognition, pp. 553-560.
Kristensen, F., McLean, W.J. (2007). Real-Time Extraction of Maximally Stable Extremal Regions on an FPGA. IEEE International Symposium on Circuits and Systems, pp. 165-168.
Nistér, D., Stewénius, H. (2008). Linear Time Maximally Stable Extremal Regions. Lecture Notes In Computer Science, vol. 5303, pp. 183-196.
Mikolajczyk, K., Tuytelaars, T., Schmid, C., Zisserman, A., Matas, J. et al. (2005). A Comparison of Affine Region Detectors. International Journal of Computer Vision, vol. 65, no. 1, pp. 43-72.

ANEXO I: INSTALACIÓN Y CONFIGURACIÓN
153
ANEXO I: INSTALACIÓN Y CONFIGURACIÓN
Las funciones de procesado de imagen implementadas se han programado utilizando el lenguaje de programación Java y el entorno de desarrollo de Eclipse, por lo que se explicará la integración del proyecto en este entrono.
En primer lugar, si no se dispone del jdk de Java para poder instalar y compilar las aplicaciones, procederemos a instalarlo desde la Web de Oracle:
http://www.oracle.com/technetwork/java/javase/downloads/jdk6-jsp-136632.html
Una vez instalado Java, es necesario descargarse el entorno Eclipse. Este entorno puede descargarse de la siguiente url:
http://www.eclipse.org/downloads/
Una vez en esta página descargaremos Eclipse IDE for Java Developers, tal y como se muestra en la figura A.1.
Figura A.1. En la página de eclipse elegiremos para la descarga Ecplise IDE for Java Developers.

PROYECTO FIN DE MÁSTER
154
Una vez descargado el archivo .rar lo descomprimimos en el directorio que deseemos. Ejecutando eclipse.exe accedemos al entorno de programación que utilizaremos. Después de instalar el entorno de programación a utilizar, instalaremos las librerías necesarias para que las diferentes funciones del proyecto puedan funcionar correctamente. Para poder acceder a las imágenes capturadas de la WebCam desde java es necesaria la instalación de Java Media Framework. Para descargar esta librería accederemos a la url: http://www.oracle.com/technetwork/java/javase/download-142937.html Antes de seguir adelante es necesaria la instalación del reproductor QuickTime. Ya que se utilizarán las librerías de este programa para el procesado de videos permitiendo acceder a los frames de videos en diferentes formatos. Podemos descargarnos QuickTime gratuitamente desde: http://www.apple.com/es/quicktime/download/ Una vez que tenemos todos los componentes necesarios instalados, procederemos con la configuración del proyecto en el Eclipse. Para ello se seguirán los siguientes pasos:
1. Copiamos el proyecto dentro del workspace, el sitio donde Eclipse almacena los proyectos por defecto. Si se desea almacenar en otro lugar, no hay inconveniente alguno.
2. Abrimos el Eclipse y pinchamos en File-> Import. Una vez hagamos click en esta opción se nos abrirá la siguiente ventana:
Figura A.2. Seleccionamos Existing Projects into Workspace.

ANEXO I: INSTALACIÓN Y CONFIGURACIÓN
155
En ella seleccionamos que deseamos importar un proyecto ya existente en el workspace, tal y como se muestra en la figura A.2. Despues se nos abrirá la siguiente ventana donde seleccionaremos la carpeta en la que esta almacenado nuestro proyecto en el workspace. Figura A.3. Seleccionamos el proyecto del workspace. Acto seguido se nos importará el proyecto con todas sus clases al entorno de trabajo. Pero tal y como se muestra en la figura A.4 el proyecto saldrá con una exclamación ya que le faltan las referencias a diferentes librerías. Figura A.4. Eclipse nos indica que el proyecto tiene errores.
3. Para referenciar nuestro proyecto con las librerías de QuikTime y JMF pulsaremos con
el segundo botón encima de nuestro proyecto y pulsaremos en propiedades. Dentro de propiedades seleccionaremos la pestaña Java Build Path.

PROYECTO FIN DE MÁSTER
156
Figura A.5. Dentro de las librerias debemos de añadir el path a jmf.jar. Tal y como observamos en la figura A.5 la referencia a la librería jmf da un error, por lo que a continuación deberemos de vincularlo con la librería jmf que nos hemos descargado. Para ello seleccionamos jmf.jar de la lista y pulsamos en el boton Edit. Se nos habrirá una ventana para que busquemos el archivo jmf.jar. Si no se ha modificado nada durante la instalación del Java Media Framework este archivo podremos encontrarlo en el directorio C:\Program Files\JMF2.1.1e\lib. Tal y como hemos mencionado anteriormente, tambien es necesaria la utilización de la librería de QuickTime, para incorporar esta pulsamos en la opción Add External JARs… y buscaremos el archivo QTJava.zip. Si no se a modificado nada en la instalación de QuickTime, este archivo se encontrará en la ruta: C:\Program Files\QuickTime\QTSystem.
A la hora de ejecutar el proyecto pueden surgir diferentes problemas. Aquí listamos alguno de estos y como se solucionan:
1. En ocasiones, sobre todo si los drivers de la WebCam a utilizar se han instalado
después del JMF puede que nos salga un error diciendo que no se encuentra el formato de video. Esto es debido a que JMF no tiene registrada la cámara Web. Para registrar la cámara en JMF ejecutaremos JMStudio que se ha instalado junto a la librería JMF. Una vez abierto el programa entraremos en File->Preferences. En la ventana emergente pincharemos en la sección Capture Devices y una vez aquí, tal y como muestra la figura A.6, pulsaremos en Detect Capture Devices.

ANEXO I: INSTALACIÓN Y CONFIGURACIÓN
157
Figura A.4. Dispositivos de captura de audio/video detectados por JMF. Esta búsqueda puede tardar un par de minutos. Una vez termine la búsqueda se nos añadirá a la lista un nuevo objeto, que representa a nuestra Web Cam. Seleccionamos nuestra WebCam y pulsamos en Commit. A partir de ahora JMF reconocerá nuestra cámara sin ningún problema. Si se esta realizando este proceso desde Windows Vista o Windows 7, leer siguiente punto.
2. Si se está realizando el proceso de registrar una cámara desde Windows Vista o
Windows 7 puede que siga sin reconocer la cámara debido a que no permite añadir la nueva cámara porque por restricciones de seguridad no se permite escribir el archivo de properties donde esta almacenada la información de los dispositivos registrados. Para solucionar este problema el archivo jmf.properties, tiene que ser creado en otro lado. Por ejemplo:
o Copiamos el directorio JMF2.1.1e al escritorio. o Ejecutamos bin/jmfregistry.exe y al igual que se explicaba en el caso anterior
se pulsa en detect capture device y una vez que este aparece se pulsa en Commit.
o Si no ha habido ningún problema en el jmf.properties de la carpeta lib de la carpeta pegada en el directorio, se habrá añadido la cámara correctamente.
o Sustituimos el jmf.properties de la ruta original por el creado en la carpeta del escritorio.


















