
Tamr | Biogen data unification imperative
19
THE DATA UNIFICATION IMPERATIVE ANDY PALMER | CO-FOUNDER, TAMR
-
Upload
tamrinc -
Category
Technology
-
view
88 -
download
1
Transcript of Tamr | Biogen data unification imperative

THE DATA UNIFICATION IMPERATIVEANDY PALMER | CO-FOUNDER, TAMR

BACKGROUND
Career is a mashup of:start-ups + enterprisecustomer + vendordata + applicationtechnical + business

HEALTHCARE INVESTMENTS

HUGE INVESTMENT IN ENTERPRISE IT & BIG DATA
Companies invested $3-4 Trillion in IT over last 20+ years
And now are investing billions in “Big Data” and Analytics 3.0...
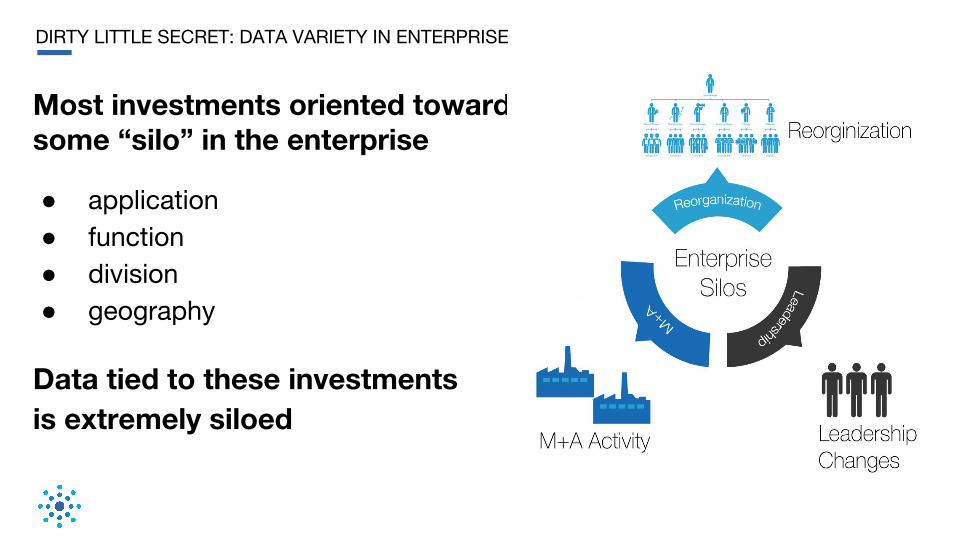
DIRTY LITTLE SECRET: DATA VARIETY IN ENTERPRISE
Most investments oriented towards some “silo” in the enterprise
● application● function● division● geography
Data tied to these investments is extremely siloed

BIG DATA & ANALYTICS NEED CLEAN + UNIFIED DATA
“Consider the more than $44 billion projected by Gartner to be spent on big data in
2014. The vast majority of it — $37.4 billion — is going to IT services. Enterprise software
only accounts for about a tenth. The disproportionate spending on services is a sign of
immaturity in how we manage data.” - Mahesh S. Kumar, Harvard Business Review

TACKLING THE ENTERPRISE DATA SILO PROBLEM
All are necessary but not sufficient to truly address next-gen challenges
● Democratized visualization and modeling - radical consumption heterogeneity● SemanticWeb/LinkedData - radical source heterogeneity● Provenance for data to improve reliability● Rapid iteration/change requires reproducability from source● Desire for longitudinal data across many entities● Need for automated data quality / assurance
Traditional approaches...
● Standardization - worth trying● Aggregation - yes - but actually makes the problem worse● Top-down modeling (MDM/ETL) - ok for app-specific or well-defined data

THE MYTH OF THE SINGLE TECH VENDOR SOLUTION
“Use my brand and data unification will just happen!”
REALLY?

HEALTHCARE/BIOPHARMA IS THE FRONT LINE
The diversity of data and decentralized nature of healthcare and specifically biopharmaceutical research make our industry the place where next gen data management will develop.
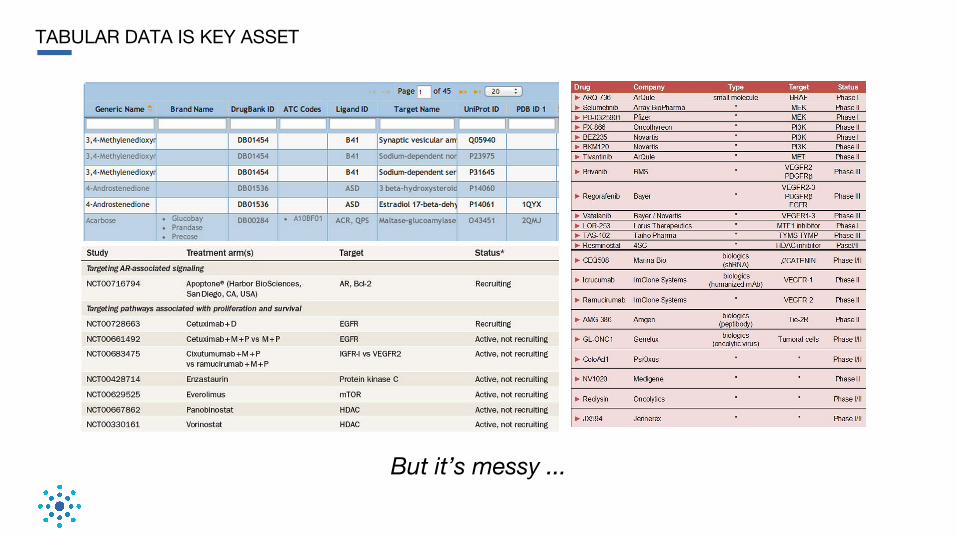
TABULAR DATA IS KEY ASSET
But it’s messy ...

CURATION AT SCALE
Hiring More Data Scientists Makes the Problem Worse
Reality Enterprise RealityGoal
• Manual data collection and preparation
• Long lead time to analyses
• Limited individual view on variety of data
• Extensive rework• No cohesive view of
data efforts• Expertise across
organization underutilized
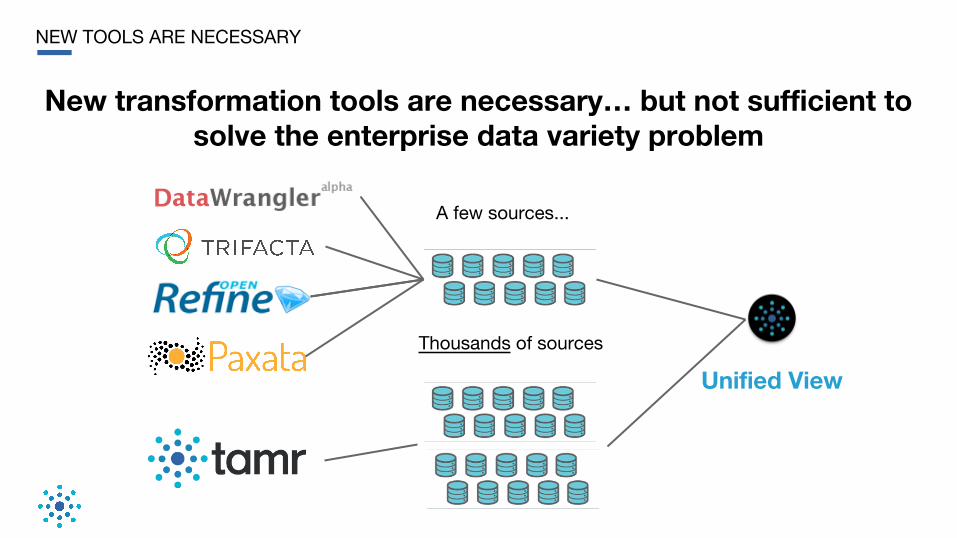
NEW TOOLS ARE NECESSARY
New transformation tools are necessary… but not sufficient to solve the enterprise data variety problem
Unified View
A few sources...
Thousands of sources
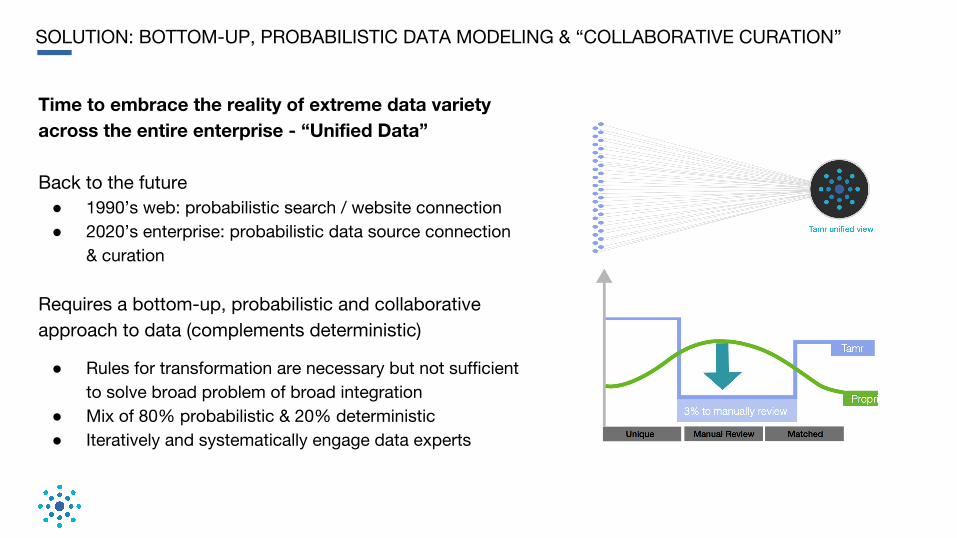
SOLUTION: BOTTOM-UP, PROBABILISTIC DATA MODELING & “COLLABORATIVE CURATION”
Time to embrace the reality of extreme data variety across the entire enterprise - “Unified Data”
Back to the future● 1990’s web: probabilistic search / website connection● 2020’s enterprise: probabilistic data source connection
& curation
Requires a bottom-up, probabilistic and collaborative approach to data (complements deterministic)
● Rules for transformation are necessary but not sufficient to solve broad problem of broad integration
● Mix of 80% probabilistic & 20% deterministic● Iteratively and systematically engage data experts
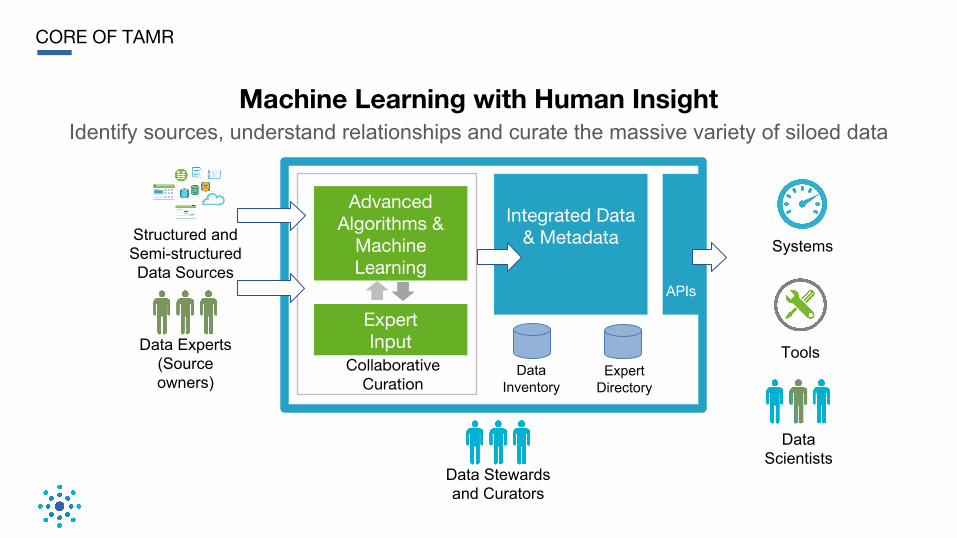
CORE OF TAMR
Machine Learning with Human InsightIdentify sources, understand relationships and curate the massive variety of siloed data
Structured and Semi-structured Data Sources
CollaborativeCuration
Data Experts(Source owners)
Data Stewardsand Curators
Data Inventory
APIs
Systems
Tools
Data Scientists
Advanced Algorithms &
MachineLearning
ExpertInput
Integrated Data & Metadata
Expert Directory
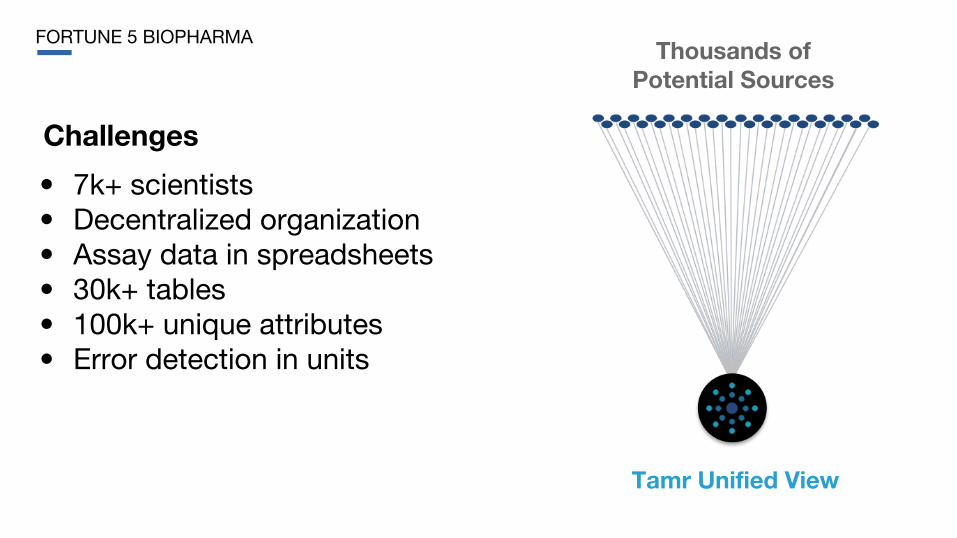
FORTUNE 5 BIOPHARMA
Challenges
• 7k+ scientists• Decentralized organization• Assay data in spreadsheets• 30k+ tables• 100k+ unique attributes• Error detection in units
Tamr Unified View
Thousands of Potential Sources

SOLUTION OVERVIEW: CDISC CONVERSION
The Problem• Clinical trial data reported in wide variety of
formats, ontologies and standards
• Underspecified attribute names, varying qualities of annotation, duplicate data, etc…
The Solution• A scalable, replicable way to automatically
unify and convert clinical trial data to CDISC format.
Benefit• Tamr technology solves common CDISC problems: schema mapping and expert sourcing• Faster way to aggregate and report ongoing trial data for regulatory filings• Simplified reporting for various agency ontologies
TAMR
TAMR

Thank You


















