
Taking Splunk to the Next Level - Architecture Breakout Session
44
Copyright © 2015 Splunk Inc. Take Splunk to the Next Level: Architecture
-
Upload
splunk -
Category
Technology
-
view
379 -
download
10
Transcript of Taking Splunk to the Next Level - Architecture Breakout Session

Copyright © 2015 Splunk Inc.
Take Splunk to the Next Level:Architecture

3
Splunk at the Next Level
Time to move beyond initial Splunk environment
• More use cases – how to tackle?
• More data – how do we scale?
• Splunk is mission critical == HA
• Global deployments
• Improving Splunk user experience Screenshot here

4
Growing your Splunk Deployment
Many customers start with a single use case…
• Ex: Monitor the web servers
• Help ensure up-time & response times
• Track usage, errors
• Provides business value

5
Growing your Splunk Deployment
Value statement for each overall service
Your services exist in a larger context than just one app, or one tier.
What is the value of the service as a whole?
What are CIO commitments for the service?
• The organization’s web site is one of the most critical parts of the business.
• Performance of the overall environment must be maintained at all times.
• Failures in any portion of the web site must be quickly identified, send
notification to the appropriate parties.
• Dependencies on external processes must be monitored as well.
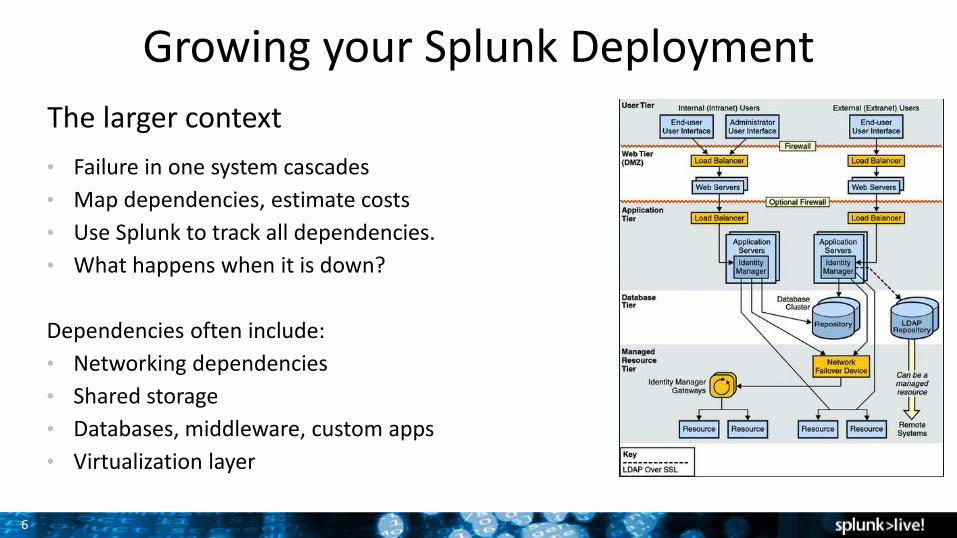
6
Growing your Splunk Deployment
The larger context
• Failure in one system cascades
• Map dependencies, estimate costs
• Use Splunk to track all dependencies.
• What happens when it is down?
Dependencies often include:
• Networking dependencies
• Shared storage
• Databases, middleware, custom apps
• Virtualization layer
Screenshot here

7
Scales to Hundreds of TBs/DayEnterprise-Class Scale, Resilience and Interoperability
Send data from thousands of servers using any combination of Splunk Forwarders
Auto load-balanced forwarding to Splunk Indexers
Offload search load to Splunk Search Heads
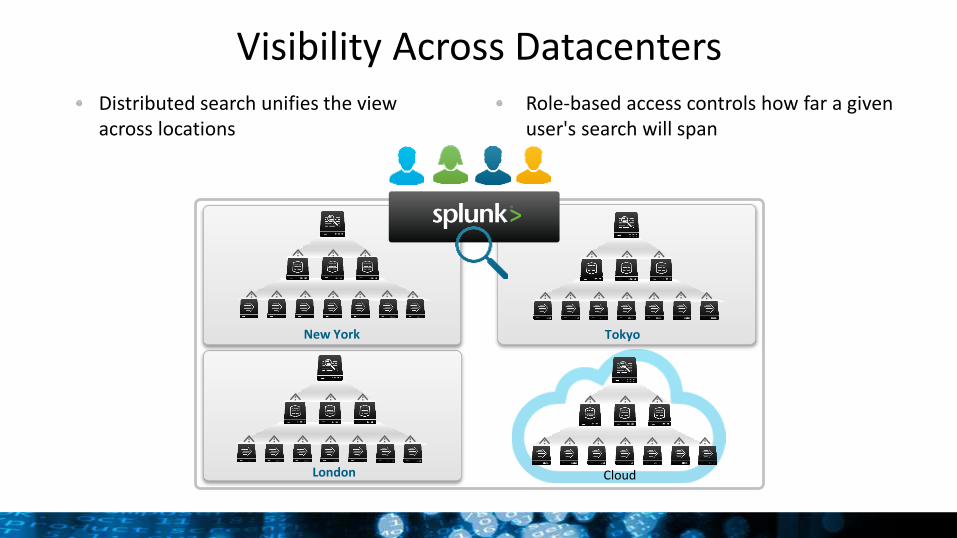
Visibility Across DatacentersDistributed search unifies the view across locations
Role-based access controls how far a given user's search will span
New York Tokyo
London Cloud
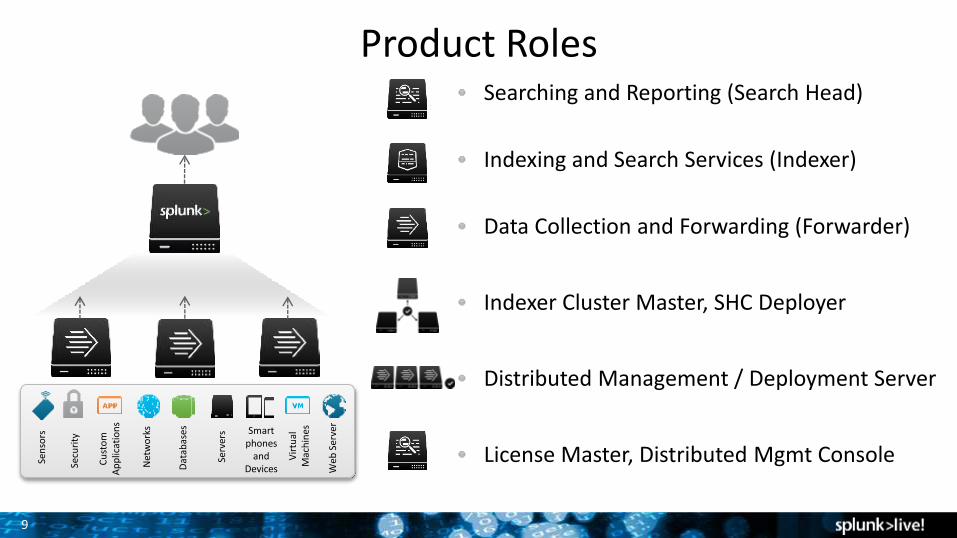
9
Product RolesSearching and Reporting (Search Head)
Indexing and Search Services (Indexer)
Data Collection and Forwarding (Forwarder)
Indexer Cluster Master, SHC Deployer
Distributed Management / Deployment Server
License Master, Distributed Mgmt Console
Dat
abas
es
Net
wo
rks
Serv
ers
Vir
tual
M
ach
inesSmart
phones and
Devices
Cu
sto
mA
pp
licat
ion
s
Secu
rity
Web
Serv
er
Sen
sors

Copyright © 2015 Splunk Inc.
Forwarders
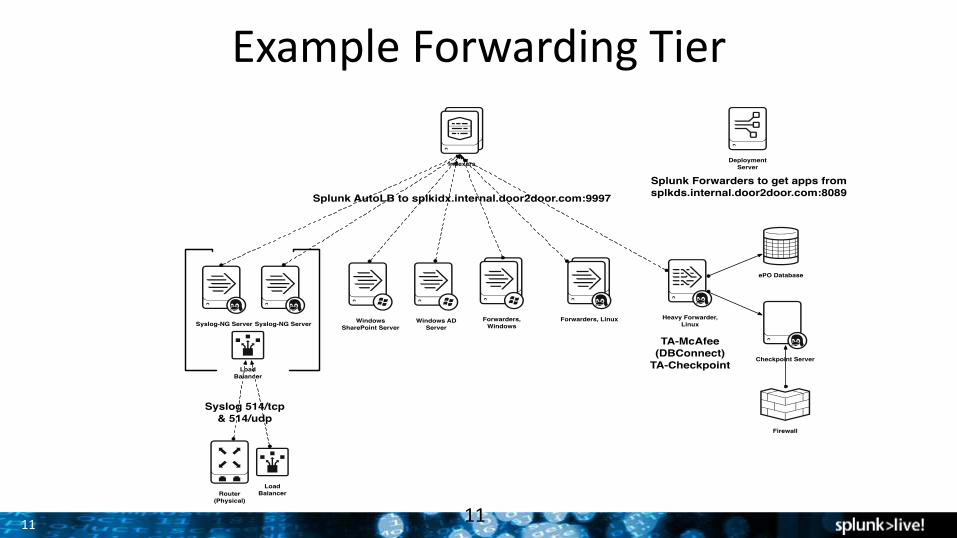
11
Example Forwarding Tier
11

12
Splunk Universal ForwarderWhy use the UF over other methods?
Collect syslog / event log / custom application logs
Collect configuration files, registry settings
Collect data NOT in log files: scripted inputs on current state
Collect wire data – Splunk Stream
Faster, Lower overhead than “agentless” polling
Centrally administered
… and
13
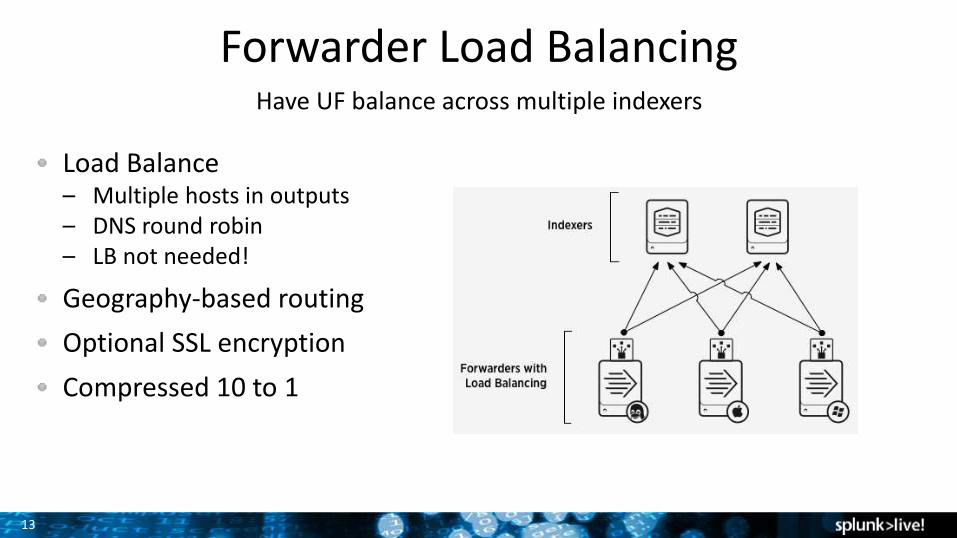
Forwarder Load BalancingHave UF balance across multiple indexers
Load Balance– Multiple hosts in outputs– DNS round robin– LB not needed!
Geography-based routing
Optional SSL encryption
Compressed 10 to 1

14
Deployment ServerCentral management of Splunk Forwarders
Deployment Server manages Apps, Configs
Select one or more classes for each host
Class defines apps & configs
Works by phone-home
Notes:
DS does not push forwarder binaries
Use Cluster Master to manage indexers in cluster, not DS

15
Forwarding Tier Design Best Practices
15
• Use a Syslog Server for Syslog data
• Deployment server (on a VM) for central management
• Let AutoLB distribute data across available indexers
• May need to increase UF throughput setting for high velocity sources– Enable forceTimebasedAutoLB (for more even distribution)– maxKBps (to adjust throttling)
Questions?

Copyright © 2015 Splunk Inc.
Indexers

17
IndexersDedicated indexers serve three primary roles:
Data Storage
Processing and parsing at index-time
Indexing
Data Management
Hot / warm / cold data rotation
Aging and removal
Data Retrieval
Perform search upon request, return data to search heads

18
Scaling - IndexersSizing for index performance
Indexers are usually storage-bound
Indexers: 150 to 250 GB per day, each. (With reference HW.)
Ref HW: 12 cores (2 GHz+), 12 GB RAM, 800+ IOPs
Optimal HW (normal disk): 16 CPU cores, 48 GB RAM
Optimal HW (SSD): 24 CPU cores, 132 GB RAM
Questions?

19
Tiered Storage
• Splunk supports tiered storage
• Hot / Warm buckets – put on fastest disk
• Size Hot/Warm for normal saved search durations. (7d, 30d)
• Use slower / cheaper storage (NAS?) for long term access
• Optional: Use Frozen to roll data to glacier, Hadoop, etc.

20
SSD Advantage
http://blogs.splunk.com/2012/05/10/quantifying-the-benefits-of-splunk-with-ssds/
• Low cost random seeks
• Writes are not that much faster – no great improvement with Indexing
• Significant improvements with Sparse/needle-haystack searches
• Dense searches become CPU bound
• Searches run faster allowing for more completed searches/min
• Use Enterprise-grade SSDs, not commercial-grade.

21
Scaling - StorageManual storage calculation
Raw data rate net compression of ~ 50% on disk.
Simple: rate * compression * retention / #indexers
Hot / warm requirements– 200 GB / day * 50% * 30 days = 3TB per indexer
Cold storage requirements– 200 GB / day * 50% * 335 days = 33.5TB per indexer
Clustering– Changes storage story completely

23
Scaling - StorageOne example of good local storage
A well configured indexer using local storage might look like:
• SSDs in RAID 5, sized for 14 days of storage
• SATA drives in RAID 5, sized for 6 months of storage
SSDs: RAID 5 provides decent performance
Spinning disks:
• Hot/Warm, RAID 1+0, 800 IOPS or faster
• Cold – RAID 5 with proper block / stripe sizing
24
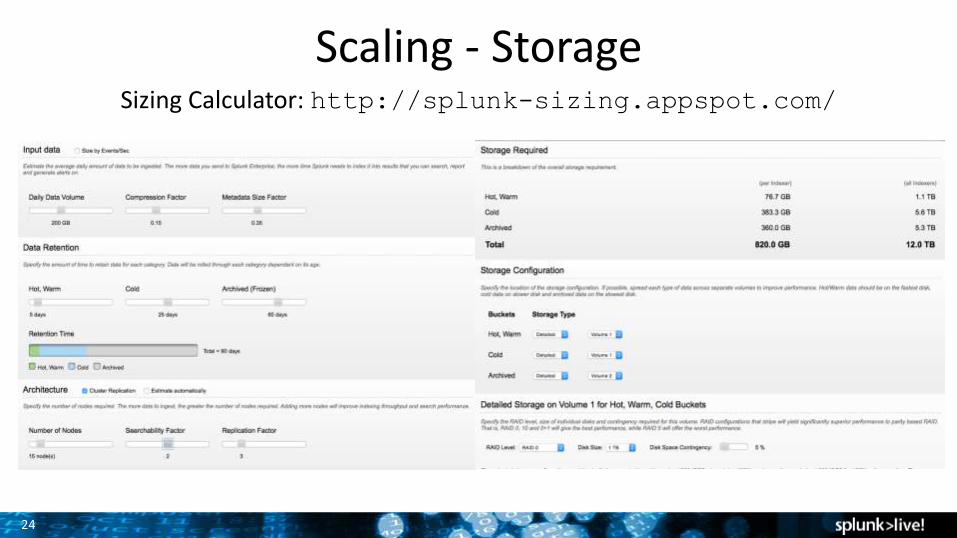
Scaling - StorageSizing Calculator: http://splunk-sizing.appspot.com/

Copyright © 2015 Splunk Inc.
Indexer Clustering

26
Delivers Mission-Critical Availability
• Data replication – maintain searchability even if servers go down
• Multi-site capable –maintain searchability even if a site goes down
• Search Affinity – optimized searches by fetching from the closest/fastest location
REPLICATION
PortlandDatacenter
New YorkDatacenter
Clustering
27
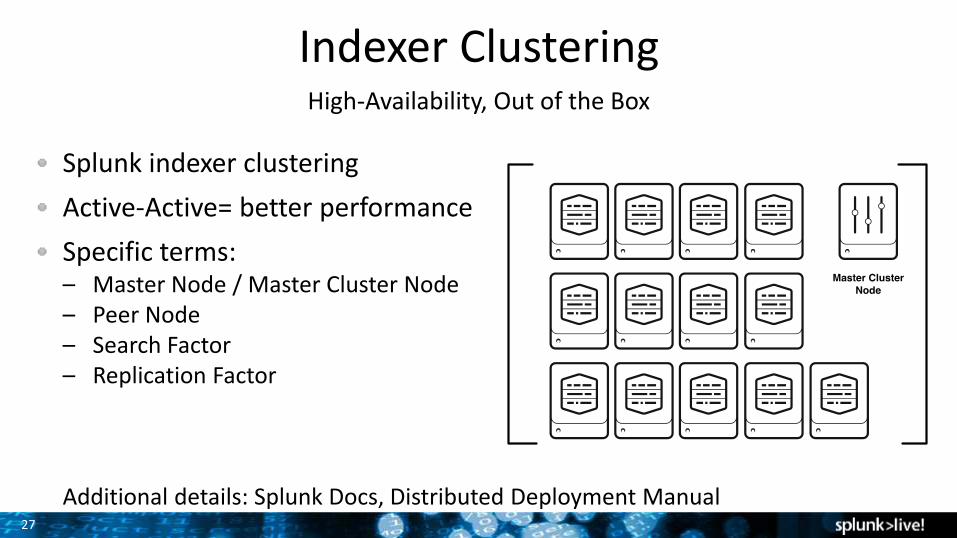
Indexer ClusteringHigh-Availability, Out of the Box
Splunk indexer clustering
Active-Active= better performance
Specific terms:– Master Node / Master Cluster Node– Peer Node– Search Factor– Replication Factor
Additional details: Splunk Docs, Distributed Deployment Manual
28
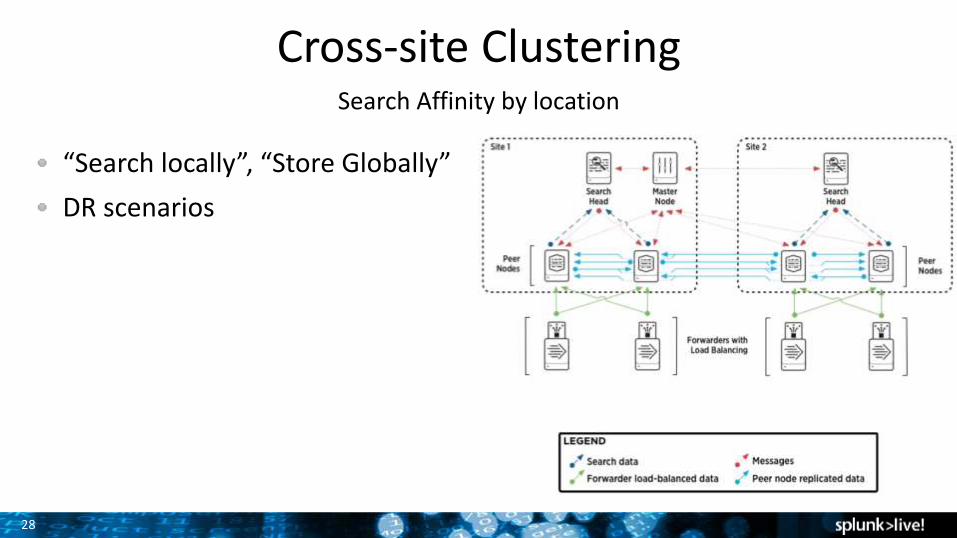
Cross-site ClusteringSearch Affinity by location
“Search locally”, “Store Globally”
DR scenarios

29
How Clustering Affects Sizing
• Increased storage:– 15% of raw usage for every replica copy– 35% MORE to make that searchable
• Increased processing– Incoming data to indexer is streamed to indexing peers to satisfy required
number of copies
• More hosts– Need “replication factor” + 2 (search head, cluster master)
29

30
Scaling - StorageSizing Calculator: http://splunk-sizing.appspot.com/

31
Downsides of Indexer Clustering
• Increased Storage
• Cluster master is required – use a VM.
• Increased bandwidth
Questions?
31

Copyright © 2015 Splunk Inc.
Search Heads

34
Scaling the Search HeadsSplunk Search is critical, too!
Scaling your search heads
Scale to handle # of concurrent queries
Dedicated Search heads for certain apps, scheduled alerts
Remember – Search heads virtualize well!

Copyright © 2015 Splunk Inc.
Search Head Clustering

36
SHP vs SHC
Search Head Clustering
Seach Head Pooling
• Available since v4.2
• Sharing configurations through NFS
• Single point of failure
• Performance issues
• No shared storage requirement
• Replication using local storage
• Commodity hardware
• OSes: Linux or Solaris
NFS

37
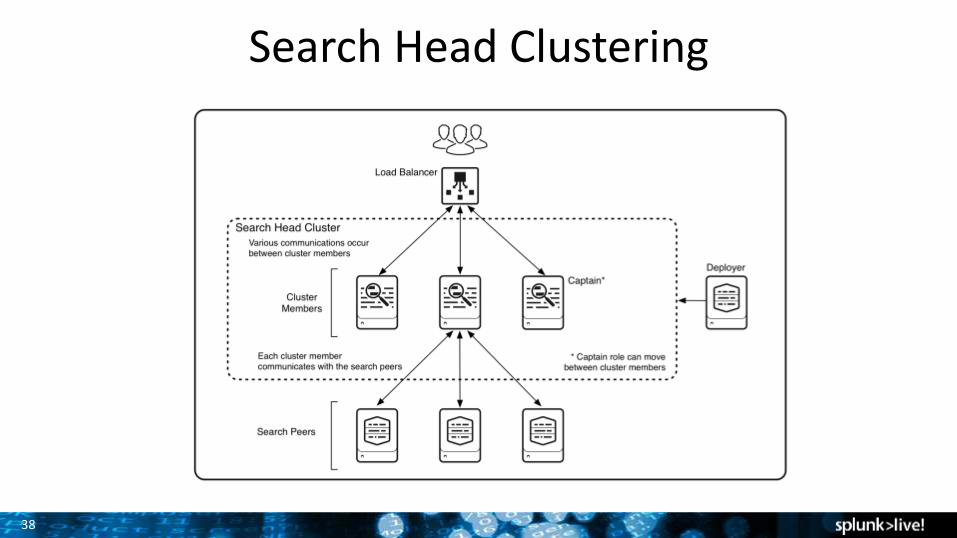
Search Head Clustering
1. Group search heads into a cluster2. A captain gets elected dynamically3. User created reports/dashboards automatically replicated
to other search heads
38
Search Head Clustering

39
Search Tier Design Best Practices
39
• Minimum 3 nodes required
• ES will still require a Separate Search Head or dedicated SHC
• Use LDAP/AD/SSO for user Authentication
• Load Balancer configured for sticky sessions
• Must use deployer to push apps to search heads
• Confirm your applications’ support for SHC!
Questions?

Copyright © 2015 Splunk Inc.
The Final Stretch
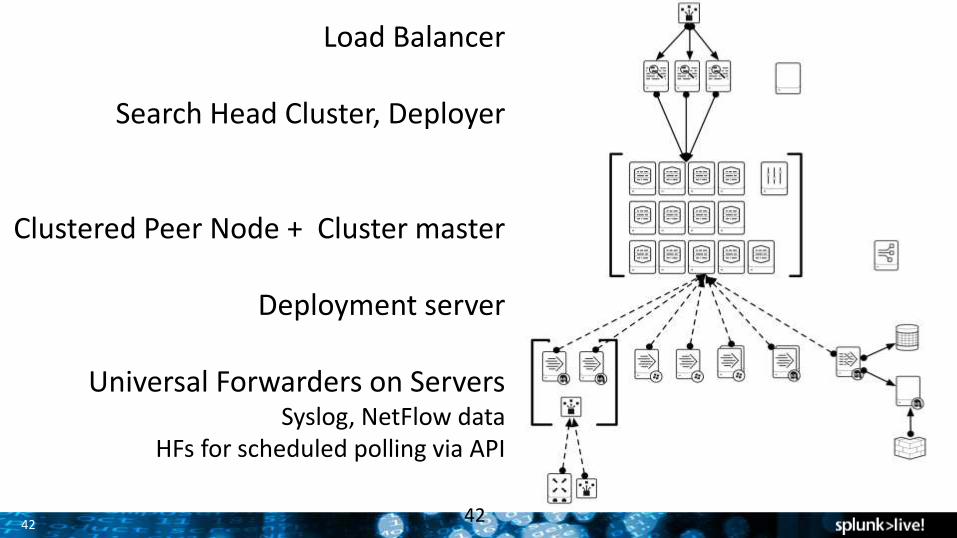
42
Load Balancer
Search Head Cluster, Deployer
Clustered Peer Node + Cluster master
Deployment server
Universal Forwarders on ServersSyslog, NetFlow data
HFs for scheduled polling via API
42
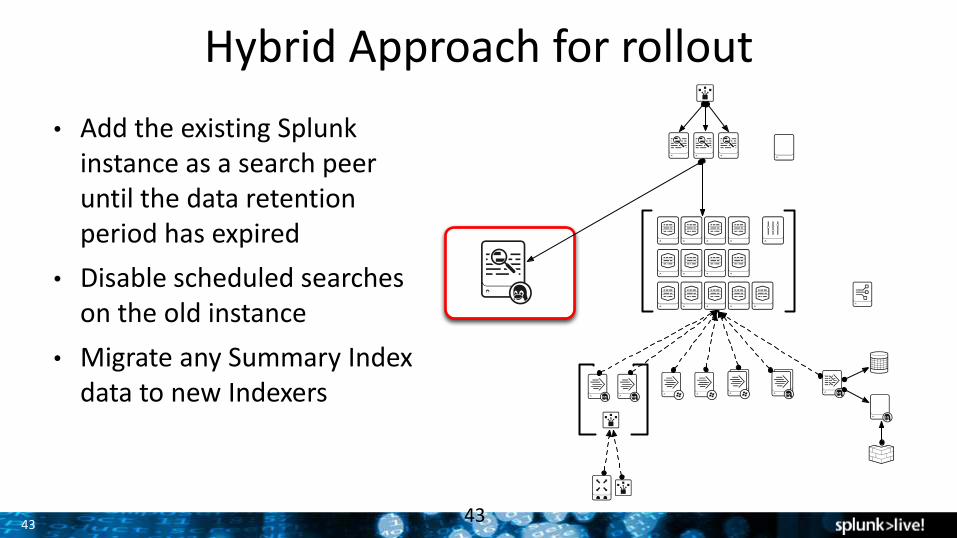
43
Hybrid Approach for rollout
43
• Add the existing Splunkinstance as a search peer until the data retention period has expired
• Disable scheduled searches on the old instance
• Migrate any Summary Index data to new Indexers

45
Distributed Management Console
Manage Splunk 6.2 environments
Replaces Deployment Monitor App
Incorporates SOS app prior to 6.2

46
Cloud & HybridScale without waiting for hardware

47
Suggested Reading
• Distributed Deployment Manual– http://docs.splunk.com/Documentation/Splunk/latest/Deploy/Distributedoverv
iew
• Highlights– Reference hardware specs– How searches affect performance
Dense / Rare / Sparse
– App considerations– Summary table
47

48
Top 5 things to Remember
48
• Indexers: Storage requirements, IOPS, RAID config
• Indexer clustering: HA, DR, and site affinity!
• SHC: Minimum buy-in for a SHC is 3
• When in doubt – add another Indexer
• Excellent VM candidates:– Master Cluster Node (Indexer clustering)– Deployer (Search head clustering)– Deployment Server (Central Forwarder management)– License Master– Distributed Management Console

Thank You


















