
Susceptible data classification and security reassurance ...
24
Susceptible data classification and security reassurance in cloud-IoT based computing environment SOUMYA RAY, KAMTA NATH MISHRA * and SANDIP DUTTA Department of Computer Science and Engineering, Birla Institute of Technology, Mesra, Ranchi, India e-mail: [email protected]; [email protected]; [email protected] MS received 1 October 2020; revised 10 August 2021; accepted 31 August 2021 Abstract. Susceptible data recognition has become a fundamental requirement in any network administration system. Though, in suitable sharing and usage, the susceptible data could wipe out the user’s privacy. So, susceptible data detection and its security re-assurance in a cloud-IoT (Internet of Things) integrated distributive communication network are mandatory. In this paper, the authors have anticipated novel susceptible data detection and re-assurance algorithms. The algorithms are capable to make out the identical attributes from diverse data sources which are pre ´cised by the domain expert. In the proposed method, the sensitivity scores of distinct attributes are measured as significant features for susceptible data identification and assurance. However, the distinctions of sensitivity scores will be able to distinguish the susceptible data from the non-susceptible data in a cloud-IoT integrated distributed computing environment. The authors have explicated various ways through which susceptible data may be exposed in the distributed system environment. Moreover, the authors have proposed novel algorithms for the security re-assurance of static/dynamic susceptible data. The decision tables are considered for each of the definite cases of security re-assurance in a cloud-IoT enabled distributive computing platform. These decision tables will facilitate the network managers to validate the legitimacy of the requests which are arriving from various extents of distributive internetworked systems. In this research work, the results of security re-assurance processes of static and dynamic susceptible data are authenticated through the two dimensional (2D) and three dimensional (3D) graphic representations. The two- and three-dimensional graphical representations designate that the requests initiated from inter/intra networks are being traced and the illegitimate requests are being leftover by the automated model in a cloud-IoT environment. This process will avert the attacks generated from identical internet protocol (IP) addresses. As a summing up it can be said that the research paper primarily emphasizes an innovative approach to recognizing the susceptible data in a cloud- IoT integrated distributive environment and the anticipated technique defends the susceptible data from unlawful admittance by the intruders. Keywords. Dynamic susceptible data; quasi identifier; static susceptible data; security assurance. 1. Introduction At present, the cloud-IoT-based computation technology is unavoidable to continue the enormous generation of storage and data on demand. Most of the organizations are imple- menting cloud for their IT services to trim down the charge of building their setup. The cloud model is entirely based on pay-per-usage representation. So, platform, software, and infrastructure can easily be obtainable to the different organizations based on their claim at a lesser cost. The benefits of cloud computing are applicable in academics as well as different knowledge-based systems. The most important benefit of cloud computing is that data can be mutually shared between different users, thus eventually leads the cloud as a worldwide recognition to the industries serving on the diverse domain [1–5]. Conversely, different cloud consumers are disinclined to obtain the benefits of the cloud due to security and privacy issues. Privacy protection is the most important downside of this technology. Big industries as well as various financial institutions maintain their service information along with the customer’s data in the cloud e.g., Federal Reserve Bank [5, 6]. Maximum data are produced through diverse IoT-based devices. These data are very confidential susceptible data. The security breaching of data due to the seepage of information can give out a gigantic monetary loss, leading to a negative impact on the consumer’s state of mind. Encryption of data can be the straight approach to maintain the security re- assurance of data. This way out is not valid always as the storage of data can be of different types. Most of the cloud- IoT-based applications are used to run with non-encrypted data sets only. Transferring and dealing out of encrypted *For correspondence Sådhanå (2021) 46:215 Ó Indian Academy of Sciences https://doi.org/10.1007/s12046-021-01740-y
Transcript of Susceptible data classification and security reassurance ...

Susceptible data classification and security reassurance in cloud-IoTbased computing environment
SOUMYA RAY, KAMTA NATH MISHRA* and SANDIP DUTTA
Department of Computer Science and Engineering, Birla Institute of Technology, Mesra, Ranchi, India
e-mail: [email protected]; [email protected]; [email protected]
MS received 1 October 2020; revised 10 August 2021; accepted 31 August 2021
Abstract. Susceptible data recognition has become a fundamental requirement in any network administration
system. Though, in suitable sharing and usage, the susceptible data could wipe out the user’s privacy. So,
susceptible data detection and its security re-assurance in a cloud-IoT (Internet of Things) integrated distributive
communication network are mandatory. In this paper, the authors have anticipated novel susceptible data
detection and re-assurance algorithms. The algorithms are capable to make out the identical attributes from
diverse data sources which are precised by the domain expert. In the proposed method, the sensitivity scores of
distinct attributes are measured as significant features for susceptible data identification and assurance. However,
the distinctions of sensitivity scores will be able to distinguish the susceptible data from the non-susceptible data
in a cloud-IoT integrated distributed computing environment. The authors have explicated various ways through
which susceptible data may be exposed in the distributed system environment. Moreover, the authors have
proposed novel algorithms for the security re-assurance of static/dynamic susceptible data. The decision
tables are considered for each of the definite cases of security re-assurance in a cloud-IoT enabled distributive
computing platform. These decision tables will facilitate the network managers to validate the legitimacy of the
requests which are arriving from various extents of distributive internetworked systems. In this research work,
the results of security re-assurance processes of static and dynamic susceptible data are authenticated through the
two dimensional (2D) and three dimensional (3D) graphic representations. The two- and three-dimensional
graphical representations designate that the requests initiated from inter/intra networks are being traced and the
illegitimate requests are being leftover by the automated model in a cloud-IoT environment. This process will
avert the attacks generated from identical internet protocol (IP) addresses. As a summing up it can be said that
the research paper primarily emphasizes an innovative approach to recognizing the susceptible data in a cloud-
IoT integrated distributive environment and the anticipated technique defends the susceptible data from unlawful
admittance by the intruders.
Keywords. Dynamic susceptible data; quasi identifier; static susceptible data; security assurance.
1. Introduction
At present, the cloud-IoT-based computation technology is
unavoidable to continue the enormous generation of storage
and data on demand. Most of the organizations are imple-
menting cloud for their IT services to trim down the charge
of building their setup. The cloud model is entirely based
on pay-per-usage representation. So, platform, software,
and infrastructure can easily be obtainable to the different
organizations based on their claim at a lesser cost. The
benefits of cloud computing are applicable in academics as
well as different knowledge-based systems. The most
important benefit of cloud computing is that data can be
mutually shared between different users, thus eventually
leads the cloud as a worldwide recognition to the industries
serving on the diverse domain [1–5]. Conversely, different
cloud consumers are disinclined to obtain the benefits of the
cloud due to security and privacy issues. Privacy protection
is the most important downside of this technology. Big
industries as well as various financial institutions maintain
their service information along with the customer’s data in
the cloud e.g., Federal Reserve Bank [5, 6]. Maximum data
are produced through diverse IoT-based devices. These data
are very confidential susceptible data. The security
breaching of data due to the seepage of information can
give out a gigantic monetary loss, leading to a negative
impact on the consumer’s state of mind. Encryption of data
can be the straight approach to maintain the security re-
assurance of data. This way out is not valid always as the
storage of data can be of different types. Most of the cloud-
IoT-based applications are used to run with non-encrypted
data sets only. Transferring and dealing out of encrypted*For correspondence
Sådhanå (2021) 46:215 � Indian Academy of Sciences
https://doi.org/10.1007/s12046-021-01740-ySadhana(0123456789().,-volV)FT3](0123456789().,-volV)

data through the network put away enormous bandwidth
and time. Susceptible data identification is a must to miti-
gate the dealing of the security reassurance process. Sus-
ceptible data detection can be achievable with the help of
the quasi-identifier technique [7, 8].
Quasi-identifiers (QIS) is represented as the grouping of
attributes that can exclusively make out persons by linking
peripheral data. Anonymity is associated with identifying a
person individually. In the absence of a person’s name, he/
she can be recognized by the SSN or Voter’s ID, etc.
[9–11]. A person can also be recognized by a blending of
attributes e.g., location, gender, and age. This is feasible
when the available data can be merged or joined with data
set listing definite information on these identities. For
instance, 84% of the inhabitants of the United States can
simply be recognized by the grouping of gender, zip code,
and Date of birth. So, erroneous publication of QIS will
direct to privacy seepage. Diverse privacy defending data
publishing methods eradicate the identifier attributes to
protect individual privacy, but attackers can easily get
susceptible information by concerning a few QIS collec-
tively [12–15].
The distributive approach to safeguard the privacy of
data is not prolific as the size of data in the cloud is
extremely large. Security re-assurance of susceptible data
(e.g., m-healthcare data) is also exigent in the cloud-IoT
model. The transient data through diverse networks pose
different security outbreaks and obliterate the whole justi-
fication of the data model [16, 17]. Appropriate imple-
mentation of data protection policy requirements must be
imposed by the cloud provider to endow with the security
of the susceptible data. Whenever a user will lay up sus-
ceptible data in the cloud, he should preserve the compli-
ance statement based on strategies set by the provider. The
user will supply the credentials linked to (log file, etc.) to
the provider and the process is termed as computer foren-
sics as e-discovery [18–20].
Notwithstanding numerous challenges to uphold the
security issues, proper susceptible data identification and
security re-assurance technique in cloud-IoT is essential.
The major contributions of the research paper are explained
below:
• A novel algorithm is designed to extract personal data
from the private data set.
• A novel susceptible data recognition algorithm using
quasi-identifiers is proposed and illustrates a compar-
ative analysis of the algorithm with the existing
algorithms. The architecture of the proposed model is
also presented as a part of the research paper.
• The decision tables are developed to provide the
security re-assurance of susceptible data over cloud
and IoT-based distributed domains.
• A comprehensive mathematical model of the suscep-
tible data identification and security re-assurance
technique is designed. This ultimately depicts the
complete flow of the identification and security re-
assurance process.
• The formal security analysis of the automated system
is also highlighted as a part of the research paper.
The remainder part of the paper is organized as follows.
The state of the art of the research is presented in section 2.
Susceptible data identification techniques are explained in
section 3. The mathematical model and architecture of the
proposed system are also explained in section 3. Security
re-assurance over susceptible data is highlighted in section
4. Section 5 depicts the results and analysis of the complete
research paper Finally, the authors conclude their research
work in section 6.
2. Related work
The objective of this section is to highlight the research in
the field of susceptible data identification and security re-
assurance in a cloud-IoT-based environment. Data is not
homogeneous in a distributed computing environment.
Data may be susceptible or non-susceptible. Susceptible
data recognition and its security assurance are mandatory
to protect the data from any vulnerable issues. The sus-
ceptible data may be transferred from one network to
another by using encryption technology. Most cloud
applications can easily decrypt the data. Traveling
encrypted data through the network path also consumes
huge bandwidth. The researchers [21, 22] face a challenge
to maintain the large heterogeneous dataset. In m-health-
care applications, diverse types of data are added to the
system and the size of data grows exponentially. The
map-educing technique may be the optimized solution in
this regard. Map-Reducing is a parallel processing
approach that is used to segregate the susceptible data
from non-susceptible data set easily.
In [23, 24] the K-anonymity model is suggested to pro-
vide the security re-assurance over the susceptible data set.
The model is not satisfactory as the type of data is not
identical in most of the cloud-IoT-based applications. The
moving data is more exposed to the intruders as compared
to data at rest. The researchers [25] have suggested that the
anonymization technique with the encryption of data can be
used to solve security issues. The destination end finds a
challenge in the de-anonymization process as it is more
time-consuming due to the size of the data.
To implement the security re-assurance over susceptible
data the researchers have provided different solutions. The
role of user and management people needs to be imple-
mented strictly. At the time of moving the client application
to the central cloud system, the user identities/authorization
should be set by the provider to prevent illegitimate access.
The existing algorithms must be integrated with security
protocols and complex network infrastructure to enhance
the susceptible data security mechanism [26, 27].
215 Page 2 of 24 Sådhanå (2021) 46:215

On other hand, Chen and Zhao [28] have analyzed the
user apprehension concerning the transition of data to the
cloud. As per the researcher’s opinion, various organiza-
tions are unwilling to shift their data into the central cloud
server due to network security issues. The authors have
presented the security re-assurance technique linked to the
cloud-IoT-based integrated environment. Cao et al [29]
have illustrated the various security threats that can oblit-
erate the confidentiality and secrecy of the client’s infor-
mation. Several security threats are reviewed and some
solutions are provided to overcome the attacks. The impact
of the security attacks over the cloud-IoT-based systems is
also analyzed and proposed optimal solutions to cope up
with the problem.
Lauter et al [30] have explicated the idea of ‘‘third party
privacy’’ where the system manager modifies its secure
database system on an un-trusted server at a fixed time
interval. This perception assumes that network clients and
an un-trusted server are not intelligent enough to break
through the security of the database without appropriate
authorization. The authors have anticipated a ‘‘server-side’’indexing technique that allows the network manager to
modify data/information efficiently and securely. Multiple
clients can be able to view the data using the outsourced
database.
Lee et al [31] have explained the various privacy pro-
tection schemes in a cloud-IoT-based environment to
maintain data confidentiality in the distributed networking
environment. The authors do not specify the correspond-
ing implementation details and privacy-preserving algo-
rithm. Xu et al [32] anticipated four-layer susceptible data
privacy-preserving approaches to minimize the security
threats in cloud-IoT architecture. The research does not
provide any data identification technique in advance. Lu
et al [33] have stated various attribute-based encryption
techniques to protect the susceptible data. The entire
process makes complete use of fog servers. The suscep-
tible data are identified and before transferring it to the
cloud server it will be encrypted by the fog server. The
efficiency of the scheme is not satisfactory as searching
for susceptible data from the distributed environment is
time-consuming. Duet al [34] have explained a privacy-
preserving framework to maintain the susceptible data
security between the different distributed network archi-
tecture. The framework modeling is completely based on
a public-private key cryptographic system to prevent
attacks that originated from the external network. The
entire process consumes huge network bandwidth. This
ultimately leads to the computational overhead in the
system architecture.
The security and privacy of susceptible data can also be
achieved using blockchain technology. Blockchain is used
to provide privacy and security in a decentralized envi-
ronment. Dorri et al [35] have explained the IoT security
assurance technique using blockchain-based smart home
concepts. The smart home contains an online high-end
resourceful device called ‘‘miner’’ which is responsible for
the privacy and security of blockchain along with control-
ling and communication across the smart home. Rehman
et al [36] have nicely presented the susceptible data sharing
in a secured way using blockchain technology. The
decentralized architecture helps to provide service authen-
tication at the integrated cloud-IoT-based service layer.
They have designed specific cloud nodes to identify the
valid edge server which uses proof of authority (POA) as an
agreement between service providers.
Several researchers are carried out their research to
establish the advantages of a decentralized IoT-based
model over the centralized architecture. Wang et al [37]
have stated that confidentiality and privacy of transactions
among multiple parties are secured in the blockchain-based
IoT model. They have designed hierarchical storage
‘‘Chain Splitter’’ where most of the blockchains are stored
in the cloud and frequently used ones are kept in different
layers of IoT network. This will optimize the space of the
resource constraint IoT devices. Sagirlar et al [38] have
observed the significant weakness of centralized IoT
architecture in terms of maintenance, cost, and support of
real-time applications. To overcome the specific issues,
they have designed hybrid blockchain architecture for the
cloud-IoT-based systems. The end-to-end integration and
validation of data in IoT can be achieved using blockchain
technology. Shenet al [39] have explained the modular
architecture with proof of work (POW) mechanism of
blockchain to serve the general IoT-based application
effectively.
3. Susceptible data identification using quasiidentifier technique
Detection of information attributes that might have sus-
ceptible data is vital before releasing it to a third party.
Once recognized typical anonymization or de-identification
procedures can be useful to avoid seepage of susceptible
information. Seepage of susceptible information to a third
party may direct economic losses, security gaps, and indi-
vidual confidentiality concerns. So, susceptible data needs
to be recognized appropriately from the data set, and after
that proper security, reassurance technique is to be imple-
mented. In this research paper, the authors have utilized the
quasi-identifier technique to recognize the susceptible data
from a private data set. The quasi-identifier can be defined
by the subset of attributes that can distinguish maximum
tuples in the traditional database management system
[40, 41].
The proposed susceptible data recognition technique
inspiration is based on the perception of cloud-IoT-based
technology. The research paper has recognized the limited
attributes of a patient at the time of admitting him to a
hospital. Various hospitals under the identical group make
use of diverse database technology. There is no option of
Sådhanå (2021) 46:215 Page 3 of 24 215

using a single homogeneous platform to collect all types of
patient data. The information transferring process in
between different network hospitals is not a very easy task.
Information is processed and composed in an IoT-based
distributive environment. The paper emphasizes the
assembling of data from diverse IoT devices and with the
help of API (Application Program Interface) the data hits
the central cloud server. The placing of the application
server in the central cloud system helps the authorized
persons to access data at any time as per their demand.
The authors have also considered that the encrypting of
susceptible data is inevitable before forwarding it to the
cloud storage or transferring it through the cloud-IoT
environment. Cloud service providers used to retain the
encryption/decryption key pair as per the prerequisite of the
user level. Cloud service providers are not always trust-
worthy. So, local level encryption is advantageous to dis-
pense further level of security as decryption is obligatory
before access to any susceptible data. This entire encryp-
tion/decryption procedure is based on a complex symmetric
key approach. Authorized users will obtain public and
private key pairs based on the exact identification number.
Data accessing is authorized after the successful authenti-
cation of the keys in the server. It is presumed that the
entire communication system does not sustain the network
cramming [42].
Figure 1 stipulates that the personal data of a patient is
specified as user input. The passing of input data through a
process/algorithm is used to extract the private data. The
susceptible data identification process using quasi-identi-
fiers is applied over the private data set. Data may not be
susceptible always. The passing of data between two dif-
ferent processes will generate the set of susceptible and
non-susceptible data. The two sets of data are stored/
archived for processing in the future.
3.1 Elimination of private data from personal data
The main purpose of this section is to do away with the
private data from personal data. The entire information
delimited in personal data cannot be considered his/her
private data always. The first name/last name of a person
can be his/her data, but it is not at all private data. The
credit card number/ bank account number of an individual
can be treated as his private data. The susceptible data and
private data are not always identical. Susceptible data is
defined by the domain expert. Consequently, to reveal the
susceptible data primarily we need to extract the private
data from the personal data. The recognition of private data
from any set of personal data is very exigent. The data is
not kept in a single place. It is always disseminated in
nature. The storage architecture of heterogeneous data is
also different [43, 44]. They can be accumulated in a
diverse relational database management system. The
recognition and identification of information are highly
reliant on the schema, attribute name, and data type of the
traditional database system. The primary key, unique key,
comments, and constraints declared in the diverse archi-
tectural systems play a key role to find out the private data
from the set of personal data.
The authors have noticed in many cases that attribute
tags are not indicative of the contents. The proposed
Algorithm 1 helps to identify the comments generated from
each database field. The novel algorithm extracts the
comments from each of the fields and produces the result
set after connecting the same with other linked attributes.
The authors have designed Algorithm 1 to remove the
private data from the personal data set. The schema of ’M’
sets of data is being considered as input and the schema of
non-private data ’D’ is produced as the output. The pro-
posed model reads each of the key attributes (like data type,
schema name, attribute name, unique key, primary key,
foreign key, constraint, and comments described in each
attribute) from the input data set and generates a schema of
non-private data set. All the attributes under SD are scanned
and compared with the primary key of the data set in steps
six to nine of the proposed Algorithm 1. Moreover, the non-
matching attributes are kept in temporary schema Ts. In the
subsequent phase, the scanning is executed in the tempo-
rary schema to read the comments declared in each of the
attributes. The comments which may not comprise names
are accumulated in the result set attribute Rs and the entire
information is sent back to the output data set.
The significance of the proposed Algorithm 1 is to
eradicate private data from personal data. A huge amount of
data related to patients is generated in the medical health-
care system or other business development systems. This
dataset is a combination of personal and private data of
patients/users. The recognition of susceptible data is prac-
tically not possible till the private data is filtered out from
the personal data using explicit data filtering methods. The
novel Algorithm 1 may scan the diverse data set andFigure 1. Process flow of Susceptible data identification.
215 Page 4 of 24 Sådhanå (2021) 46:215

efficiently screens the private data from the personal data.
Algorithm 1 of figure 2 uses the different variables. Table 1
defines the denotation of the variables.
3.2 Recognition of susceptible data from privatedata
The authors have anticipated Algorithm 1 of figure 2 to
recognize the private data from the personal data set. But
the private data is not always susceptible. The main
objective is to figure out susceptible data attributes defined
by the domain experts using the quasi-identifier technique.
Here the authors have considered broadly the patient his-
tory information in the medical healthcare system. This
information comprises of different attributes like Patient
ID, First Name, Last Name, Age, Date of Birth, Sex, Patient
Contact Number, Contact Person Mobile Number, Contact
Person Name, Address, Relationship, Patient city address,
Patient post office, Patient Police Station, Patient Medical
History, and Medical Insurance Claim Related Information.
The susceptible data attributes are predicted by the
domain expert. Domain experts are used to providing
attributes susceptibility scores also. A domain expert can be
considered as a skilled individual who has sufficient
knowledge in the functional area e.g., a well-known doctor
with eight or more years of experience in private / gov-
ernment hospitals with suitable bachelor’s, master’s, and
research degrees in medical science may be recognized as a
medical domain expert. The IoT-based intelligent medical
expert system architecture developed by highly skilled
professionals can also be considered as a domain expert.
Likewise, a management graduate (MBA in business
development) with five or more years of appropriate
involvement in several transactional activities such as
credit distribution, fund management, and debit/credit card
limit sanction can be treated as a domain expert in the
financial sector. The domain experts are utilized to perform
their specific tasks and this is completely guided by the
rules and regulations of the Information Technology
industry.
The Susceptible attributes are defined as follow:
Rule: A rule condition Rx= R1 R2 R2 is a condition with
R1e {schema name, data type, attribute name, primary key,
unique key, foreign key, constraint, comments}
R2 e U U l U a U w U £ U f U d U r and is an operator
in {=! =, \[, B, C, ! contains, contains}.The continuous
medical assessment is collecting data with Type-2 diabetes
for the following information from all of the institutes
linked with the patients: Patient RegNo, Initial Info, date of
initial diagnosis, Initial HgbA1c, HDL cholesterol level,
Comorbid condition, result date, serum creatinine level,
result date, and medical institute. R2 considers all these
attributes and as an example, the Jason format is considered
to fill this information. This is an instance of R2 considering
the medical field. In a changed domain, R2 varies with
different Jason formats.
Now, the information is composed of conjugations and
disjunctions of proposed conditions along with the rule
susceptibility score. The evaluation of susceptibility score
is ranged amid ‘‘re [1, 5]’’, of an attribute that utmost
satisfies the rule. The attribute susceptibility score is
designed based on the prearranged survey format. As an
example, the healthcare domain experts will put question-
naires that will be filled up by the patients/medical atten-
dants. The obtained medical data is to be sorted out based
Algorithm 1: Exclusion of private data from personal data
Input: Schema of ‘M’ sets of data
Output: Schema of non-privacy data ‘D’
1 Algorithm
Exclusion_of_Private_Data_From_Personal
_Data (Schema of M sets of Data)
2 {
3 for each key ki SM where i=1…n
4 Read schema name, attribute name,
datatype, unique key, primary key, foreign
key, constraint, comments
5 Add it to SD
6 For individual attribute Aj SD
7 # confidentiality condition (1)
8 if Ai! = Pk
9 Add it to Ts
10 for individual attribute Ak Ts
11 # confidentiality condition (2)
12 if comments do not comprise name [fname,
name, etc.]
13 Add it to Rs
14 Return Rs
15 }// end of Algorithm 1
Figure 2. Elimination of private data from personal data.
Table 1. Symbols and notations.
Notation Meaning
ki Attribute key
SM Schema of M sets of data
SD Schema of non-privacy data D
Aj Attribute name
Pk Primary key
Ts Temporary schema
Rs Result set attribute
Sådhanå (2021) 46:215 Page 5 of 24 215

on accurate diseases information because the susceptibility
score is not identical for all the diseases including critical
unending diseases. The incessant mathematical logic-based
inference formulates the scoring approach more accurately
for these critical diseases. Algorithm 2 is designed to rec-
ognize the susceptible data from the private data set. At this
time, a set of private data is passed as user input, and the
schema of susceptible data is retrieved as the output. The
proposed Algorithm 2 will scan the consequential set of
attributes obtained as an output from Algorithm 1 and
initially, the susceptibility score of individual attributes is
set to 1. Here, p’(xi) which is the initial pass of the certain
process p(x) checked with q (Ai), and the authors have
received the two possible outcomes of the ongoing process.
If the value is lesser than Aithen computation of xi?1= xi -
p(xi)/p’(xi) is prepared. Next, the difference of xi?1 -xi is
evaluated. If the evaluation outcome is smaller than the
threshold value u then the value of Axi is added by 1. The
control variable ’i’ will also be incremented till it will be
lower than the maximum number of pass N. But as soon as
the p’(xi) will be larger than the q(Ai) then it will filter out
the complete set of attributes from Rs whose susceptibility
score is larger than 5 and accumulate it in susceptible
schema set.
The significance of Algorithm 2 is to make out suscep-
tible data from the set of private data. The proposed algo-
rithm is designed based on susceptibility scores defined by
the domain expert/expert system. The proposed Algorithm-2 will extract only those attributes as susceptible whose
susceptibility score is larger than or identical to 5. Algo-
rithm-2 efficiently filters the susceptible attribute based on
the information given by the domain experts/expert
systems.
Let a process p(x), its initial pass p’(x), and initial esti-
mation to the susceptible score (’ss’) represented by ’x’.
The process considers a very small threshold value ’u’and
the highest number of passes are restricted to ’N’. The
susceptible data schema is represented by SSm. ‘q’ is
denoted by the quasi-identifier technique. The threshold
value can be defined as a checkpoint that halts the repetitive
process at a static point. The threshold value is computed
based on susceptible data attributes schemas by traversing
through various passes. The researchers have considered
healthcare data which may comprise of several schema
attributes and have a definite process to extract the sus-
ceptibility score for each of them. As per the proposed
Algorithm 2, the process requires several passes to produce
the susceptibility score. The parallel data processing tech-
nique is considered in the proposed scheme as the serial
data processing needs a longer time to process a single data
attribute. The researchers consider a threshold value and the
output of the two passes are compared using the parallel
processing technique. As soon as the threshold value is
attained the next schema attribute processing will be
initiated.
3.3 Projected mathematical model
The researchers have considered the susceptible data
recognition and security re-assurance (SDISA) technique
with the help of a mathematical model. The mathematical
structure is an imperceptible illustration of SDISA which
confirms the following:
a. The input collected and outputs obtained from every
stage of SDISA dispensation.
b. The connection between collected inputs, outputs, and
transitional phases.
c. The different states are produced from the primary to the
closing stages of dispensation.
d. The flow of data to the dissimilar processing states of
SDISA.
3.3.1 The assembly of SDISA components The
assembly of diverse components of the SDISA model can
be denoted by Eq. (1).
SDISA ¼ S;X
;R;Mf ;Nf ;
n oð1Þ
The symbolic depiction of Eq. (1) is explained as
follows.
S ! finite non-empty set of statesP! finite non-empty set of given input matrices pro-
vided to any components of SDISA
R ! finite non-empty set of receiving output matrices
obtained from any component of SDISA
Mf? State transformation function which takes SDISA
to the succeeding state. The succeeding state depends on
the preceding state.
Nf? The receiving output function depends on the input
elements and corresponding subsequent changes of states.
Each state can mainly be predictable as a distinct dis-
pensation unit whose legitimacy is exclusively reliant on
the collected input data from diverse IoT devices. The
receiving outputs from several states are kept in the cen-
tralized cloud platform. It may comprise non-susceptible
data also.
3.3.2 Interrelationship of SDISA components The
complete mathematical model of the SDISA based
components are explained as follows:
(i) Set of states (‘S’) The assumed inputs and receiving
outputs from the distinct states of SDISA are
recognized. The various in-between states processing
is reliant on the accepted inputs and outputs returned.
(ii) The input/ output sets (‘R’/ ‘R’) The given input
alphabet set R is the grouping of all those elements
which are considered as input to the projected model
at successive states. Therefore, it can be observed
that R= {y | y is an alphabet considered as given input
to the different states of the SDISA}
215 Page 6 of 24 Sådhanå (2021) 46:215

The component of R is the diverse types of susceptible
data in (either in the form of static or dynamic) the form of
matrices of order i 9 j 9 kThe element of R is matrices of order i 9 j 9 k.
X¼ fYj Yi�j�k is a matrix order of i� j� kg
Let P e R,
) P19191 is the easiest element in R, which is a real
number. If P e R then [P]=Pl;m;n = p(l, m, n) 8l;m; ne{Z?�0}. Here Pl;m;n is an element of the matrix where ’P’
belongs to the lth row, mth column, and nth layer. The fol-
lowing conditions are true for element ‘p’.
• 0\ pl;m;n• p e Z?
R is the output alphabet set of all the elements received
as output after processing of various states of SDISA. The
following can be valid for R
R ¼ fY jYi�j�k is a three - dimensional matrixg
if P eR, then the elements of matrix P can be denoted as
pi9j9k. Matrix P can be denoted as [P]
) P½ � ¼ pi�j�k 8i; j; k 2 fZþ � 0g:
where i, j, k represents a row, column, and plane
respectively.
The simplest element of R will be P1�1�1 which is a
single element of {Z?-0}.
3.3.3 The state transition function (Mf) In the state
transition function of SDISA, the flow control occurs in
between diverse states. It is observed that input flow from
one state to another state is obligatory and output is reliant
on the changes of different states due to interrelated
processing activities. The state transition function ’Mf ’can
be denoted by Eq. (2) as follows:
Mf :X�
�S ! S ð2Þ
In Eq. (2),P�
is the set of all processes produced by the
essentials of R.
3.3.4 The output function (Nf ) This function displays
the output attained from each state. The output function ’Nf’
denoted and explained by the following Eq. (3)
Nf :X�
�S ! R� ð3Þ
In Eq. (3) R* is the set of all processes received by the
elements of ‘R’
The processing tasks carried out in this model are iso-
lated into various algorithms where each of the algorithms
can be signified by the states of SDISA. The true values for
every tuple of the above-mentioned equations Eqs. (1) to
(3) can be represented by Eq. (4) as follows:
S ¼ s0;s1;s2;s3
� �X
¼ PED;PRD; SSD;DSD
� �
R ¼ PED;PRD; SSD;DSD
� �
Mf : S�� ! S and Nf : S�� ! R
ð4Þ
In Eq. (4) PED is the personal data of a patient and PRD is
the private data obtained from the personal data through the
data extraction process. SSD is the static susceptible data
and DSD is the dynamic susceptible data. Through the
SDISA all the data are interconnected and linked with the
system. The whole system can send and accept information
from each other and these can be kept in the cloud for
further processing.
Now, if ‘p’ eP2
and ‘s’e S then Mf (s, p) authorizes the
dispensation accomplished on ‘p’ eP2
at states e S. Here,
’s’ is representing an algorithm. Primarily Mf maps an
algorithm and an output in the symbol ofP2
which is
apparent to be executed. Likewise, the output function ’R’
links input and an algorithm to accept output. In this way,
each module of SDISA is interlinked with each other and
associated with the cloud-IoT-based system architecture.
3.4 Architecture of the proposed model
In this section, the authors have explained the four-layer
mobile healthcare architecture system. The architecture
supports collaborative and distributive data management
along with three major criteria. First, data transfer and
accessing will be more optimized for localized data.
Distributive and direct data processing at any stage of the
healthcare system provides low response time and the
workload between different nodes will be minimal. The
overall interfaces should be designed in such a way that
user-level experiences at the time of registering and
accessing the system are satisfactorily improved. The
architecture can be extended to manage healthcare data for
users fit in different healthcare services, e.g., private clinics
and government hospitals. The primary objective of the
proposed healthcare system is to collaborate with the dif-
ferent network entities for better data management. More
detailed architecture with the network entities is given as
follows.
3.4.1 User layer: The mobile healthcare system
provides various application software and a huge amount
of data is generated at the time of providing services to
different users. Users are also using different healthcare
service providers in their systems. The major purpose of
this layer is to collect healthcare data from different
heterogeneous wearable devices (e.g., smart gloves, smart
Sådhanå (2021) 46:215 Page 7 of 24 215

wriest devices) and sent it to the clinics, hospitals, and
any medical institution by authorized medical
professionals. These EMRs (Electronic Medical Records)
are stored in the respective institutions for immediate
treatment of critically ill patients. The data is further
uploaded to the central cloud system by the authorized
person so that it can be accessed from anywhere with a
valid identity. The healthcare data must be passed through
the secure data transmission medium with proper identity
authentication techniques. It is observed that data
accessing is prevented on time due to different attacks
in the system. The paper mainly focuses on the security
re-assurance of susceptible data while transferring through
the m-healthcare internetworking system architecture.
3.4.2 Faceless interaction layer: This layer is one of
the most important components of the m-healthcare system.
The layer supports accessing of data and responds to
patient’s requests through several channels irrespective of
the device or location. It provides necessary data to the
healthcare professionals that meet their needs. Patients can
get an improved experience with a self-service option to
access healthcare records by a simple interaction medium
in real-time. The entire communication between patients
and medical professionals is done through a multi-channel
integration networking system.
3.4.3 Application layer: The application layer controls
a large amount of healthcare data in a collaborative way
among the different network edges. This process is
beneficial for managing workloads among the different
nodes in the system. The application layer is useful to
reduce delay at the time of processing a bulk amount of
healthcare data. The fundamental functionalities of this
layer are given as follows.
3.4.3.a User registration The registration to the m-health
system is done in this layer. Users can register themselves
with valid identities. After the successful registration trus-
ted authority of the healthcare system will provide the
public/private key pair and digital signatures to them.
Thereafter users can access information from the remote
cloud system.
3.4.3.b Data storage The application layer stores raw
heterogeneous healthcare data in an encrypted format. The
past information related to data processing, storing, and
accessing is recorded in an ordered fashion. This process
will effectively reduce the information searching time from
the massive amount of data. The system also ensures to find
the leakage of information that happened due to security
attacks.
3.4.3.c Data processing and analysis of m-healthcaredata: Processing raw healthcare data is the most important
task after successful storing of data. Different formats of
data are stored in the healthcare domain. So, robust, com-
plex approaches related to cleaning, reduction, integrated
and normalized approaches are implemented. The appli-
cation layer also supports of non-revealing of susceptible
data to unauthorized users.
The healthcare service providers can process a large
amount of healthcare data dynamically. They support real-
time as well as the offline mode of processing based on
different scenarios. Data processing is done quickly for a
patient admitted to a critical care unit. The summarized
data analysis report is sent directly to the medical profes-
sionals for low latency response. Apart from the services
given to the critical care unit patient, the medical recom-
mendation to the patients and off-line analysis of data is the
important functionality of this layer.
3.4.4 Central layer: The central layer works as a top
security manager and is held responsible for the security
protection of different components of the m-healthcare
system. The entire data management operation is performed
in this layer. This layer stores and accesses all user-specific
information with its highest priority. The mapping
relationship among the different user’s data is also stored
in this layer. The central layer employs a global database to
maintain and update a large amount of healthcare
information. The major functionality of this layer is to
provide access control to the user based on the identity
authorization technique. Revocation of access control
operation is performed in special cases, e.g. if a user is
found doing malicious activity in the system and the
security of the system is compromised.
3.5 Data accessing technique
Mobile healthcare data is very susceptible data and it can be
static or dynamic. Whenever data is being accessed from
the inter/intra network then it will be validated by the
proposed algorithm. Decision tables are designed to iden-
tify the legitimate request and it is explained in section 5 of
the paper. The algorithms and the decision tables designed
in the paper indicate that only legitimate requests can
access susceptible data. Otherwise, data will be discarded
and saved the information in the database for further quick
identification of the request (figures 3, 4).
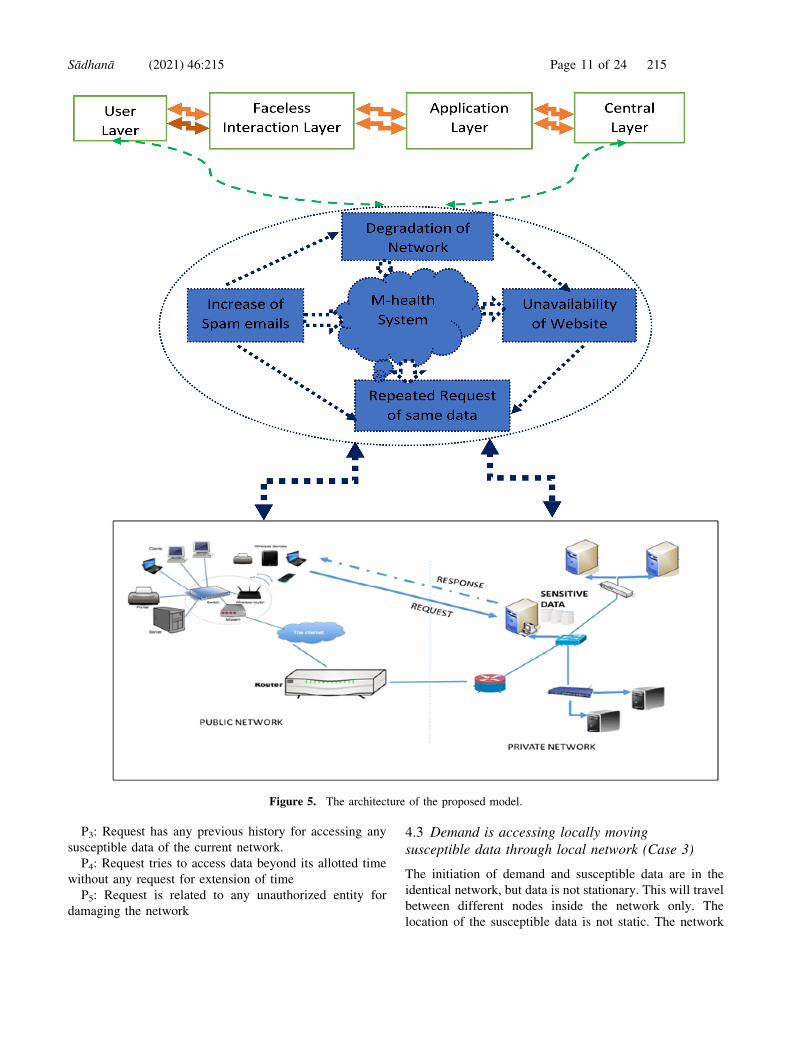
Figure 5 represents the architecture of the mobile
healthcare system. The function of the system solely
depends on the four layers. The layers are connected and
linked with the whole system also. The performance of
mobile healthcare is dependent on various factors like
repeated requests of the same data or increasing number
of spam emails etc. This ultimately slows down the
network. As a result, susceptible data accessing is halted
and request validation is stopped. The entire architecture
works in a decentralized environment. So, data accessing
and data storage issues are optimally handled as com-
pared to resource constraint IoT devices.
215 Page 8 of 24 Sådhanå (2021) 46:215

4. Security re-assurance over susceptible data
Currently susceptible data safety in a cloud-IoT computing
environment is the main inspiring research area. Threats/
requests can be initiated from the inside of the system or
they can originate from outside of the network. In both
cases, the security over susceptible data is in danger.
Seepage of data (e.g., credit card dealings) can generate
enormous financial loss as well as delivers a vast impres-
sion on the client’s mindset [45, 46]. In this proposed
research article, the authors have recognized diverse types
of requests over susceptible data to curtail the security
problems and examine them. For the recognition of dis-
similar cases initiation of requests is very significant. The
request may be originated from the identical network where
the susceptible data is extant. It can be initiated from a
dissimilar network. In this research article, the authors have
presented four different cases to analyze the problem.
Based on identified cases the authors have provided
approvals to access susceptible data by a legitimate request.
Diverse parameters are set to investigate the authorization
issues which eventually diminish the security gaps over
susceptible data.
The authors have explicated the security re-assurance
over susceptible data based on the parameters which are
attained from the expert/intelligent network architecture.
An expert/intelligent network arrangement is an entirely
automated system where no human involvement is
needed to choose the parameters for the safety of the
network. This arrangement supports controlling the net-
work and this leads to protect the susceptible data from
illegal access. The definite parameters are utilized to
detect the suspicious IP addresses and the equivalent
data is preserved in a database system. Therefore, sub-
sequent time whenever a request is initiated to access
the susceptible data then it will be inevitably authenti-
cated by the database system, and the reply is forwarded
to the distributed network system. The positive reply
will reject the request instantaneously. This procedure
will support averting supplementary attacks from these
distrusted IP addresses. If the reply is negative, then the
demand will be confirmed based on intelligent network
constraints. For the efficacious endorsement of the
demand, it will be able to access the susceptible data.
This complete process doesn’t involve human commu-
nication. Henceforth, authentication of requests and
movement of data inside the network system is less
time-consuming and effective. The permission-based
security re-assurance analysis over susceptible data is
explicated below.
{
"Patient": {
"PatientRegNo": "JH3924534",
"InitialInfo": {
"LastName": "Banerjee",
"FirstName": "Ujjal",
"Middle": "kumar",
"YearofBirth": "2002/05/17",
"Sex": "male",
“Height”: “5.2”,
“Weight”: “85”,
"ContactInfo": ["Phone": "9855555555","Email": "[email protected]"]
},
"IntakeCriteria": {
"DmDxDate": "2005/03/20",
"InitialHgbA1c": "6.5",
"CoMorbid": [ "Hypertension", "CAD”]
},
"Labs": {
"LDLCholestrol": {
"LDLLevel": "122.5",
"LDLResultDate": "2012/07/20"
},
"SerumCreatinine": {
"CreatinineLevel": "1.4",
"CreatinineResultDate": "20/07/20"
}
},
"MedicalInstitute": {
"InstituteName": "North Calcutta Polyclinic ",
"InstituteEmail": [email protected],
“PinCode”: 700055
}
}
Figure 3. Jason file format of patient information.
Sådhanå (2021) 46:215 Page 9 of 24 215

4.1 Demand is accessing stationary susceptibledata from local network (Case 1)
The demand is approaching from the network where sus-
ceptible data is extant. The network manager will preserve
the database internet protocol addresses from which any
damage or threat occurred already inside the network.
These are termed suspicious IP addresses. No demand is
acknowledged from these suspicious addresses. The
approval of demand is also a very significant consideration.
No demand is acknowledged to access susceptible data
without proper permission. The local request authentication
is done internally by the network manager. If the authen-
tication is successful, then the demand can access suscep-
tible data. Accessing susceptible data is a time-bound
process. Access rights will be revoked beyond the time
limit. The restrictions considered for the security re-assur-
ance over Case 1 are specified below.
P1: Request is approaching from the unauthenticated IP
address
P2: Request has any negative impact on the current
network.
P3: Request tries to access any susceptible data without
authorization
P4: Request tries to access data beyond its allotted time
P5: Request is related to any unauthorized entity for
damaging the network.
4.2 Demand is accessing stationary susceptibledata over the global network (Case 2)
The demand is initiated from a network where susceptible
data is not extant. In that situation, this will be very tough
for the network manager to authenticate the request
locally. The network manager will gather information
from adjacent networks to receive the suspicious IP
information. After receiving the information network
manager will consider the significance of the request. If
susceptible data is busy handling local requests till that
period global requests will not be entertained. The
importance of local demand is higher concerning global
requests for accessing susceptible data. After the valida-
tion of the whole history of the demand access write can
be provided over susceptible data. Accessing data is
restricted by a certain time limit. Access permission will
be withdrawn for the excess time limit. The network
manager will retain a close sight of the susceptible data.
Any anomalous state generates owing to accessing of data,
then access permission is revoked and the internet proto-
col addresses will be deposited in the suspicious database.
The restrictions considered for security re-assurance over
Case 2 are given below.
P1: Request is coming from the suspicious IP address
P2: Request has any negative impact on the adjacent
networks
Algorithm 2: Identification of Susceptible data from private data
Let a process p(x), its initial pass p'(x), and initial
estimation to the susceptible score ('ss') represented
by 'x'. The process considers a very small threshold
value ' highest number of passes are
restricted to 'N'. The susceptible data schema is
represented by . ‘q’ is denoted by the quasi-
identifier technique. The threshold value can be
defined as a checkpoint that halts the repetitive
process at a static point. The threshold value is
computed based on susceptible data attributes schemas by traversing through various passes. The
researchers have considered healthcare data which
may comprise of several schema attributes and have a
definite process to extract the susceptibility score for
each of them. As per the proposed Algorithm 2, the
process requires several passes to produce the
susceptibility score. The parallel data processing
technique is considered in the proposed scheme as
the serial data processing needs a longer time to
process a single data attribute. The researchers
consider a threshold value and the output of the two
passes are compared using the parallel processing
technique. As soon as the threshold value is attained
the next schema attribute processing will be initiated.
Input: A set of private data is passed in the process
Output: Schema of Susceptible data is generated
1 Algorithm Generation_Susceptible _Schema
_From _Private Data (Sets of Private Data)
2 {
3 i=1;
4 for each attribute Ai Rs
5 xAi=1 //sensitivity score
6 if p'(xi) < q(Ai)
7 {then go to step 11;}
8 else
9 {go to step 16 ;}
10 xi+1= xi -p(xi)/p'(xi);
11 if |xi+1 -xi|<12 Axi= Axi+1;
13 i=i+1;
14 if i ≤ N
15 {then go to step 6;}
16 else
17 {go to step 18;}
18 for each attribute Ai Rs
19 if xAi ≥ 5
20 Add Ai to ;
21 }// end of Algorithm 2
Figure 4. Identification of Susceptible data from private data.
215 Page 10 of 24 Sådhanå (2021) 46:215
P3: Request has any previous history for accessing any
susceptible data of the current network.
P4: Request tries to access data beyond its allotted time
without any request for extension of time
P5: Request is related to any unauthorized entity for
damaging the network
4.3 Demand is accessing locally movingsusceptible data through local network (Case 3)
The initiation of demand and susceptible data are in the
identical network, but data is not stationary. This will travel
between different nodes inside the network only. The
location of the susceptible data is not static. The network
Figure 5. The architecture of the proposed model.
Sådhanå (2021) 46:215 Page 11 of 24 215

manager will authenticate the status of the demand by
inspecting the suspicious IP records. The admittance right
of the node where susceptible data is kept at a specific point
of the period is also considered. The node may be engaged
with internal network activities, then the demand cannot be
acknowledged. If the demand is authentic by the network
manager, then it can be placed into the queue. During the
movement of data, the demand cannot be granted. While
the node is free from its internal actions then admittance
writes of the data for that specific node will be granted. If
the admittance right is confirmed appropriately then the
demand can be able to get the data for a fixed time.
Admittance rights will be revoked for the spare time limit.
The constraints considered for security re-assurance over
case 3 are specified below.
P1: Request is approaching from the suspicious IP
address to access moving susceptible data
P2: Susceptible data is busy with its internal activities
P3: Access right of the susceptible data for a particular
node
P4: Request tries to access data beyond its allotted time
without any request for the extension of time
P5: Request is related to any unauthorized entity for
damaging the network
4.4 Demand is accessing globally movingsusceptible data through the global network (Case4)
The demand initiates to access non-stationary susceptible
data from a dissimilar networking system. The position of
susceptible data is not fixed. It can travel between inter-
connected network architecture. Each time demand is try-
ing to contact susceptible data then it is the whole
obligation of the network manager to detect the location of
the data. As the networking systems are linked with each
other so they can simply forward their suspicious IP address
information. Consequently, the network manager will
modify the IP record. The global demand is not highly
significant concerning the local demand. So, if the data is
engaged in handling local demands till time no external
demand will be granted. Till that time demand must be kept
inside the queue. If the data is not engaged in any internal
processing, then access right for that data may be granted.
Identical data can have various access privileges based on
network architecture. Thus, the admittance write of the
node will be different as per the movement of data between
internetworking systems. After fruitful authentication by
the network manager demand can be permissible to access
data with a specified period. Access rights may be with-
drawn based on an excess time limit. The parameters
acknowledged for security re-assurance over Case 4 are
specified below.
P1: Request is coming from the suspicious IP address
P2: Susceptible data is busy with its internal activities
P3: Access right of the Susceptible data for a particular
node
P4: Request tries to access data beyond its allotted time
without any request for the extension of time
P5: Request is related to any unauthorized entity for
damaging the network
5. Analysis of outcomes and thoughts
The initial part of this section elucidates the study of the
susceptible data identification algorithms and compares
them with the prevailing algorithms. The next part signifies
the analysis of the security re-assurance over susceptible
data with the support of decision tables and graphical
illustration.
5.1 Investigation of the susceptible datarecognition algorithm
The objective of the algorithm is to classify the susceptible
data from the set of private data. The authors have con-
sidered patient health information attributes previously
explicated in section 3.2. Patient Name (First name, Last
Name) is the sharable data set. The credit card number of a
patient is his private data. Domain expert provides the
susceptible data attributes for a definite purpose. The
schema or the attributes do not match straight away with
the information given by the domain expert.
In India mostly, three categories of medical treatments
are offered i.e., Allopathic medicine, Homeopathic
medicine, and Ayurvedic medicine. The patient medical
data must be restricted within these three segments. The
specific attribute is saved in different databases along
with non-identical names. Finding a definite attribute
among diverse heterogeneous records/files is a major
problem [47]. The domain expert will provide some
‘‘attribute/comment’’ through which the identification of
data can be originated. The anticipated Algorithm 2 of
figure 4 is used to extract the identical attribute/com-
ment from the large dataset. As an example, the
recognition of gender information in the healthcare
domain is not a very easy process. Different databases
will save information as sex, Lingo, etc. The projected
algorithm will explore the identical attributes from the
heterogeneous databases. It is noticed that medical spe-
cialists used to write various coded symbols in their
prescriptions. As an example, 26S/42N/0.5m. The con-
notation of the symbol is 26 years female, 42years male,
and � year child. This category of information is
mostly ambiguous to a person not associated with the
medical profession [48]. So, domain experts will specify
a few comments/attributes to recognize this symbol from
diverse databases. Algorithm 2 of figure 4 matches the
alike code efficiently.
215 Page 12 of 24 Sådhanå (2021) 46:215

The susceptible value of the attributes is also considered
in the projected algorithm. Domain expert stipulates the
susceptibility score with a valid range. The proposed
algorithm checks the range and if the value is within the
susceptibility score then it will be added to a distinct list of
the susceptible attributes.
5.2 Evaluation of the projected susceptibilityalgorithm with the existing algorithm
At present, susceptible data recognition is a flourishing
research area. Various researchers from different domains
are continuing their research to explore a new dimension in
this field. The researchers have acknowledged diverse
constraints to clarify and rationalize their algorithm. In the
research paper, the authors have observed few parameters
from the existing papers like perception technique, De-
identifying methodology, basic practice, working model,
and extent of data set.
The identifying technique designates the category of
data. The data may not be always susceptible. The process
helps to extract the susceptible and non-susceptible data
individually. De-identifying of data is useful to maintain
the privacy of the susceptible data. The different data de-
identifying techniques include probabilistic de-identifica-
tion or screening using random sampling. Generalization
and substitution methodologies are used to ease the data
segregation process. The identification algorithm is fully
reliant on diverse computing rules. Rules can be framed
using the optimization algorithm technique which necessi-
tates several scans of the table. As per the architecture of
the distributed system, heterogeneous datasets are placed in
different locations. Accordingly, several scanning of
tables with the probabilistic method is apparent. The pre-
vailing algorithms primarily focus on the generic domain.
The working methodologies of the existing algorithms do
not show any optimal output for the change of execution
domain. Few of the prevailing algorithms execute in large
datasets but most of them are not able to provide an opti-
mized solution in this regard.
The authors have acknowledged susceptibility scores,
and a value of those scores is specified by the domain
expert. Attributes are screening from various sources and
the identical attributes specified by the domain experts
are recovered. If the attribute is within the scope of
susceptible score explicated by the domain experts, then
it can be considered as a susceptible attribute. This
anticipated Algorithm 2 of figure 4 cannot be restricted
to sole attributes and it may be executed well for unclean
data also. As the proposed algorithm filters data from
diverse sources, so cleaning is not feasible always. The
designing of Algorithms 1 & 2 has been experimented
with in the healthcare domain and approximations of
identical attributes retrieval are satisfactory. The proposed
algorithm’s execution works fine in the huge data set and
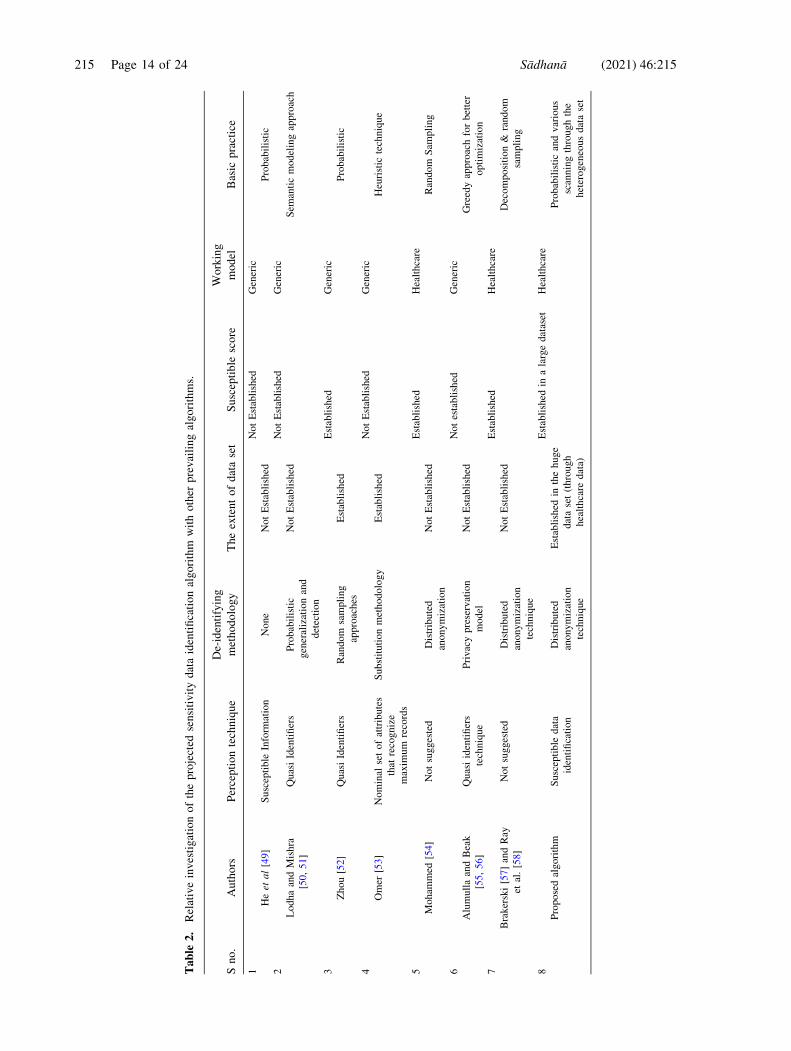
filtration of susceptible data is optimized. Table 2 anal-
yses the comparative study of the prevailing algorithms
with the proposed algorithm.
5.3 Analysis of security re-assuranceof susceptible data
Section 4 entirely depicts the diverse cases for security re-
assurance over susceptible data. The following section
designs the decision tables for each of the cases and based
on that network manager can simply validate the legitimacy
of the demand. The decision tables corresponding to the
algorithms are explained below.
5.3.1 Decision table for accessing stationarysusceptible data from the local networ In the first
case, the demand is arriving from the identical network
where the susceptible data is kept. The network manager
cannot directly permit the demand to access the susceptible
data till the demand is found to be genuine. The network
manager will set few parameters in the decision table to
validate the status of the demand (figures 6, 7, 8, 9). The
whole decision table is specified in Table 3. Figure 10
signifies a whole network where susceptible data is kept in
the server. Susceptible data is stationary. The system
arrangement linked to the local area network (LAN-2) is
providing a demand to access the secured data. The demand
cannot be approved promptly. This must be authorized
based on figure 6 of Algorithm 3 and table 3. If the
authentication is successful, then the demand will be
approved to access the data. Otherwise, it will be excluded,
and the demanded internet protocol address will be
transferred to the suspicious IP record file.
5.3.2 Decision table for accessing stationarysusceptible data from the global network The
demand and susceptible data are positioned in dissimilar
networks. The status of the demand is entirely unknown to
the network manager. Therefore, the network manager will
not directly permit the demand to get into the system. The
manager will validate the status of the demand from the
proposed decision table. The whole decision table along
with the parameters is explained in table 4.
Figure 11 illustrates a comprehensive network where
susceptible data is kept in the server. Susceptible data is
stationary. The server is linked to a local area network
(LAN-1). The demand is approaching from a different
network to access the susceptible data. The demand cannot
be approved instantaneously. This will be authenticated
based on figure 7 of Algorithm 4 and table 4. If the vali-
dation result is positive, then demand will be approved to
access the data. Else, it will be disallowed, and the
demanded IP information will be transferred to the suspi-
cious IP record file.
Sådhanå (2021) 46:215 Page 13 of 24 215
Table
2.
Rel
ativ
ein
ves
tig
atio
no
fth
ep
roje
cted
sen
siti
vit
yd
ata
iden
tifi
cati
on
alg
ori
thm
wit
ho
ther
pre
vai
lin
gal
go
rith
ms.
Sn
o.
Au
tho
rsP
erce
pti
on
tech
niq
ue
De-
iden
tify
ing
met
ho
do
log
yT
he
exte
nt
of
dat
ase
tS
usc
epti
ble
sco
re
Wo
rkin
g
mo
del
Bas
icp
ract
ice
1
Heet
al
[49]
Su
scep
tib
leIn
form
atio
nN
on
eN
ot
Est
abli
shed
No
tE
stab
lish
edG
ener
ic
Pro
bab
ilis
tic
2
Lo
dha
and
Mis
hra
[50
,5
1]
Qu
asi
Iden
tifi
ers
Pro
bab
ilis
tic
gen
eral
izat
ion
and
det
ecti
on
No
tE
stab
lish
ed
No
tE
stab
lish
edG
ener
ic
Sem
anti
cm
od
elin
gap
pro
ach
3
Zh
ou
[52]
Qu
asi
Iden
tifi
ers
Ran
do
msa
mpli
ng
app
roac
hes
Est
abli
shed
Est
abli
shed
Gen
eric
Pro
bab
ilis
tic
4
Om
er[5
3]
No
min
alse
to
fat
trib
ute
s
that
reco
gn
ize
max
imu
mre
cord
s
Su
bst
itu
tio
nm
eth
odo
log
yE
stab
lish
ed
No
tE
stab
lish
edG
ener
ic
Heu
rist
icte
chniq
ue
5
Mo
ham
med
[54]
No
tsu
gges
ted
Dis
trib
ute
d
ano
nym
izat
ion
No
tE
stab
lish
ed
Est
abli
shed
Hea
lthca
re
Ran
do
mS
amp
ling
6
Alu
mu
lla
and
Bea
k
[55
,5
6]
Qu
asi
iden
tifi
ers
tech
niq
ue
Pri
vac
yp
rese
rvat
ion
mo
del
No
tE
stab
lish
ed
No
tes
tab
lish
edG
ener
ic
Gre
edy
app
roac
hfo
rb
ette
r
op
tim
izat
ion
7
Bra
ker
ski
[57]
and
Ray
etal
.[5
8]
No
tsu
gges
ted
Dis
trib
ute
d
ano
nym
izat
ion
tech
niq
ue
No
tE
stab
lish
ed
Est
abli
shed
Hea
lthca
re
Dec
om
po
siti
on
&ra
nd
om
sam
pli
ng
8
Pro
po
sed
alg
ori
thm
Su
scep
tib
led
ata
iden
tifi
cati
on
Dis
trib
ute
d
ano
nym
izat
ion
tech
niq
ue
Est
abli
shed
inth
eh
ug
e
dat
ase
t(t
hro
ug
h
hea
lth
care
dat
a)
Est
abli
shed
ina
larg
edat
aset
Hea
lthca
re
Pro
bab
ilis
tic
and
var
iou
s
scan
nin
gth
roug
hth
e
het
ero
gen
eou
sd
ata
set
215 Page 14 of 24 Sådhanå (2021) 46:215

Algorithm 4: Algorithm for accessing stationary susceptible data from the global network
Inputs: Parameters passed; Output: Decision for
accessing the susceptible data
1 Algorithm Access_Satic_Susceptible_Data_Global_Net
(P1, P2, P3, P4, P5)
2 {
3 if ((P1==true) && (P5==true))
4 {printf (“Denial of service”);}
5 else if
6 ((P2==true) && (P5==true))
7 {printf (“Block the IP for sending
request”);}
8 else if
9 ((P2==true) && (P3==true))
10 {printf (“Report to network admin”);}
11 else if
12 ((P3==true) && (P4==true)
13 {printf (“Wait for the approval of access”);}
14 else
15 {printf (“Permitted to access”);}
16 } // end of Algorithm 4
Figure 7. Access to static susceptible data from the global
network.
Algorithm 5: Algorithm for accessing moving susceptible data from the local network
Inputs: Parameters passed; Output: Decision of
accessing the Susceptible data
1 Algorithm
Access_Moving_Susceptible_Data_Local_Net
(P1, P2, P3, P4, P5)
2 {
3 if ((P1==true) && (P5==true))
4 {printf (“Denial of service”);}
5 else if
6 ((P2==true) && (P5==true))
7 {printf (“Block the IP for sending request”);}
8 else if
9 ((P2==true) && (P3==true))
10 {printf (“Report to network admin”);}
11 else if
12 ((P3==true) && (P4==true)
13 {printf (“Wait for the approval of access”);}
14 else
15 {printf (“Permitted to access”);}
16 } // end of Algorithm 5
Figure 8. Access to moving Susceptible data from the local
network.
Algorithm 6: Algorithm for accessing moving susceptible data from the global network
Inputs: Parameters passed; Output: Decision of
accessing the susceptible data
1 Algorithm
Access_Moving_Susceptible_Data_Global_Net
(P1, P2, P3, P4, P5)
2 {
3 if ((P1==true) && (P5==true))
4 {printf (“Denial of service”);}
5 else if
6 ((P2==true) && (P5==true))
7 {printf (“Block the IP for sending request”);}
8 else if
9 ((P2==true) && (P3==true))
10 {printf (“Report to network admin”);}
11 else if
12 ((P3==true) && (P4==true)
13 {printf (“Wait for the approval of access”);}
14 else
15 {printf (“Permitted to access”);}
16 } // end of Algorithm 6
Figure 9. Access to moving Susceptible data from the global
network.
Algorithm 3: Algorithm for accessing stationary susceptible data from the local network
Inputs: Parameters passed; Output: Decision for
accessing the static susceptible data
1 Algorithm
Access_Satic_Susceptible_Data_Local_Net(P1, P2,
P3, P4, P5)
2 {
3 if ((P1==true) && (P2==true))
4 {printf (“Denial of Service for the request”);}
5 else if
6 ((P2==true) && (P5==true))
7 {printf (“Block the IP for sending request”);}
8 else if
9 ((P2==true) && (P3==true))
10 {printf (“Report to the network admin”);}
11 else if
12 ((P3==true) && (P4==true))
13 {printf (“Wait for the approval of access”);}
14 else
15 {printf (“permitted to access”);}
16 } // end of Algorithm 3
Figure 6. Access to static susceptible data from the local
network.
Sådhanå (2021) 46:215 Page 15 of 24 215

5.3.3 Decision table for accessing moving susceptibledata from the local network The susceptible data is not
always stationary. It can travel between different nodes in
the intra network system. The network manager will set the
system parameters to design the decision table. The demand
will be validated through the decision table and only
authorized requests will be allowed to access the
susceptible data. The final decision table with the
restrictions is explicated in table 5.
Figure12 depicts the whole system illustration where
susceptible data is not stationary. It is traveling inside the
intra network system. The demand is willing to get the
susceptible data from the identical network. The demand
cannot be approved immediately. This will be considered
based on the proposed rules outlined in figure 8 of Algo-
rithm 5 and the equivalent table 5. Successful validation of
requests will be entertained to access the susceptible data.
5.3.4 Decision table for globally moving susceptibledata from the global network The movement of
susceptible data cannot be limited to an intra network
only. It can travel to internetwork adjacent to the host
network. Demand can also be initiated from the different
networks where susceptible data is not located. So, the
network manager will not approve the demand
instantaneously. The demand will be authorized based on
figure 8 of Algorithm 6 and table 6. If the authentication is
efficacious then demand will be allowed to access the
Table 3. Request is accessing stationary susceptible data from the local network.
S. no Parameter name Action status(Y/N) Y: allow N: Deny
1. The request is coming from the unauthenticated IP address Y N Y N
2. The request has a negative impact on the current network. Y Y Y N
3. The request tries to access any Susceptible data without authorization N N Y Y
4. The request tries to access data beyond its allotted time N N N Y
5. The request is related to any unauthorized entity for damaging the
network
N Y N N
ACTION statements
1 Denial of Service Y N N N
2 Report to the Network admin N N Y N
3 Wait for approval of access N N N Y
4 Block the IP for sending the request N Y N N
Figure 10. Request to access static susceptible data from the local network.
215 Page 16 of 24 Sådhanå (2021) 46:215
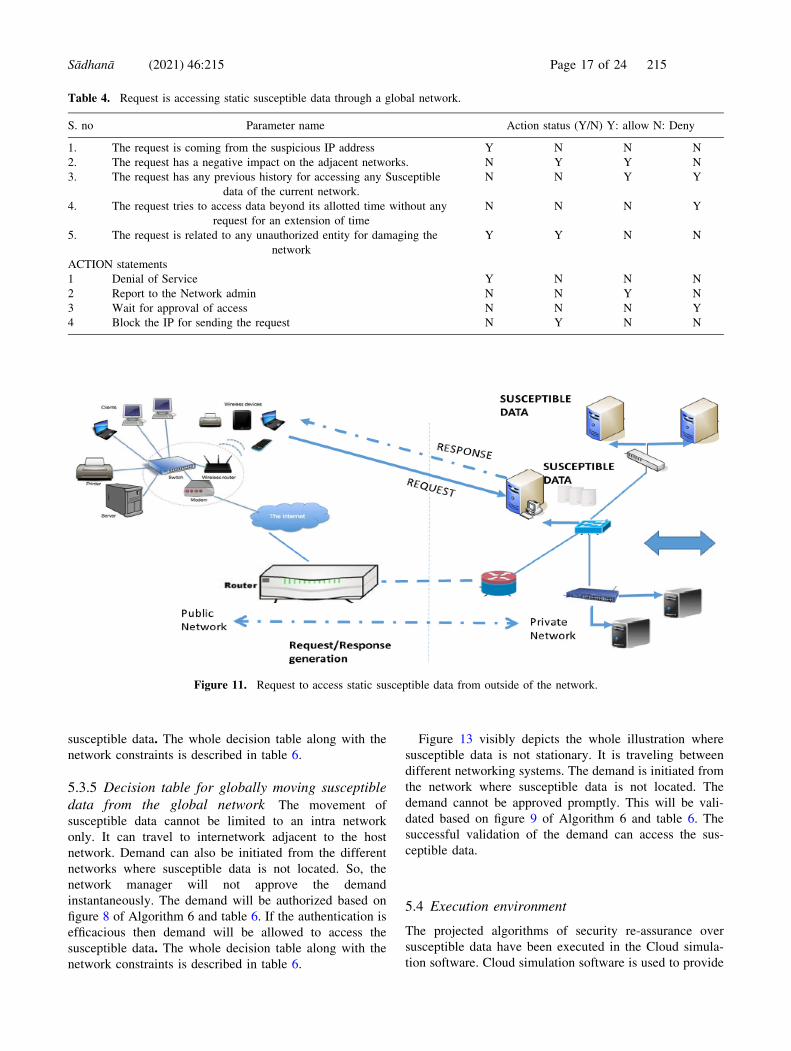
susceptible data. The whole decision table along with the
network constraints is described in table 6.
5.3.5 Decision table for globally moving susceptibledata from the global network The movement of
susceptible data cannot be limited to an intra network
only. It can travel to internetwork adjacent to the host
network. Demand can also be initiated from the different
networks where susceptible data is not located. So, the
network manager will not approve the demand
instantaneously. The demand will be authorized based on
figure 8 of Algorithm 6 and table 6. If the authentication is
efficacious then demand will be allowed to access the
susceptible data. The whole decision table along with the
network constraints is described in table 6.
Figure 13 visibly depicts the whole illustration where
susceptible data is not stationary. It is traveling between
different networking systems. The demand is initiated from
the network where susceptible data is not located. The
demand cannot be approved promptly. This will be vali-
dated based on figure 9 of Algorithm 6 and table 6. The
successful validation of the demand can access the sus-
ceptible data.
5.4 Execution environment
The projected algorithms of security re-assurance over
susceptible data have been executed in the Cloud simula-
tion software. Cloud simulation software is used to provide
Table 4. Request is accessing static susceptible data through a global network.
S. no Parameter name Action status (Y/N) Y: allow N: Deny
1. The request is coming from the suspicious IP address Y N N N
2. The request has a negative impact on the adjacent networks. N Y Y N
3. The request has any previous history for accessing any Susceptible
data of the current network.
N N Y Y
4. The request tries to access data beyond its allotted time without any
request for an extension of time
N N N Y
5. The request is related to any unauthorized entity for damaging the
network
Y Y N N
ACTION statements
1 Denial of Service Y N N N
2 Report to the Network admin N N Y N
3 Wait for approval of access N N N Y
4 Block the IP for sending the request N Y N N
Figure 11. Request to access static susceptible data from outside of the network.
Sådhanå (2021) 46:215 Page 17 of 24 215

test services in a repeatable and controllable environment.
Here the researchers have utilized the 105 VM (virtual
machine) and each VM memory is 1024 KB in the dual-
core machine. Six cloudlets used to run with six different
parameters and four different data sets/sources are being
considered for the execution environment. The entire
physical memory of the Celeron machine (with CPU Clock
Speed 1.2-2.8 GHz) is applied to load the cloud simulator
environment. The individual pass-run key is limited to 100,
200, and 300.
5.5 Implementation level study for stationarysusceptible data
In the preceding sections, tables 3 and 4 are representing
the rule to access stationary susceptible data based on the
local and global demand. After merging both the tables and
exclusive of the alike constraints the authors used to obtain
the subsequent parameters:
P1: Request is approaching from unauthenticated suspi-
cious IP addresses
P2: Request harms the present network.
P3: Request harms the adjacent networks.
P4: Request tries to access susceptible data without
approval
P5: Request tries to access susceptible data beyond its
fixed time
P6: Request is associated with the illegal entity for
destroying the network.
When demand comes to access stationary susceptible
data, the authors have analyzed the effect of the above-
mentioned constraints. The researchers have made the
experiment through the simulators and observed the vari-
ations of the state during the individual pass. The complete
situation is represented by 2-dimensional and
Table 5. Request is accessing locally moving susceptible data through local network.
S. no. Parameter name Action status (Y/N) Y: allow N: Deny
1. The request is coming from the suspicious IP address to access
dynamic Susceptible data
Y N N N
2. Susceptible data is busy with its internal activities N Y Y N
3. Access right of the Susceptible data for a particular node N N Y Y
4. The request tries to access data beyond its allotted time without any
request for the extension of time
N N N Y
5. The request is related to any unauthorized entity for damaging the
network
Y Y N N
Action statements
1 Denial of Service Y N N N
2 Report to the Network admin N N Y N
3 Wait for approval of access N N N Y
4 Block the IP for sending the request N Y N N
Figure 12. Request to access moving Susceptible data from the local network.
215 Page 18 of 24 Sådhanå (2021) 46:215

3-dimensional graphical representation. In this graph, the
’x’ axis symbolizes the demand parameters and the ’y’ axis
denotes the normalized throughput. Throughput is mea-
sured by the number of demands controlled by individual
cloudlets per unit of time.
In Pass 1, P3 and P4 are having the maximum number of
successes whereas P2 is having the lowermost number of
successes. If the number of passes is augmented in pass 2,
then P1 will have a higher number of hits concerning pass
1. Here, P5 and P6 are also varying as per the deviations of
pass. Further, in pass 3 the constraints are altering and it is
detected by the authors that P2 has the lowermost number
of successes. This varying scenario of the constraints
specifies that based on the demands the defined system
delivers control of accessing illicit data. Otherwise, an
alteration in parameters would not be possible. The various
changes of parameters during Pass 1, Pass 2 and Pass 3 are
represented in figure 14 using a 2-dimensional graphic
illustration.
Figure 15 signifies the 3-dimensional graph of stationary
data demand, which displays that the constraints are vary-
ing based on deviations of passes. The demand cannot be
approved promptly. The altering states of passes with the
normalized throughput confirms that the demand is being
identified and authorized by the automated system.
Only genuine demands can access the susceptible data
and illegitimate appeal information is kept to the internal
record file of the anticipated system to avert further
occurrences.
5.6 Implementation level study of non-stationarysusceptible data
In the preceding sections, tables 5 and 6 are demonstrating
the guidelines to access moving susceptible data based on
the local and global demands. After merging both the
tables and excluding the identical constraints the authors
acknowledged values linked to the resulting parameters:
P’1: Request is approaching from a suspicious IP address
in the state where the susceptible data is moving in the
network.
P’2: Susceptible data is busy with its internal activities
P’3: Demand has any approval to access susceptible data
P’4: Access right of the susceptible data for a specific
node
P’5: Request tries to access susceptible data beyond its
allotted time
P’6: Request is related to any unauthorized entity for
damaging the current/adjacent network
When demand comes to access non-stationary suscepti-
ble data from any internetworking system, the authors have
analyzed the effect of the above-mentioned constraints. The
researchers have implemented the execution in a simulated
environment.
and with an individual pass, they have observed the
variations of states. The complete situation is described in
figures 16, and 17 using a 2-dimensional and 3-dimensional
graphical representation. Next, it was detected in Pass 1
that the constraints P’3 and P’4 acknowledged the maxi-
mum number of successes whereas parameter P’2 received
the lowermost number of successes. The constraints P’1,
P’4, and P’5 received an average number of successes. If
the quantity of passes is being augmented, then in pass 2 the
constraint P’2 received a greater number of successes in
assessment to pass 1. Further, it is noticed by the authors
that the throughput of parameter P’1 is higher in pass 2 as
compared to P’1 in pass 1. The parameters P’5 and P’6
were also varying after the alteration of the pass. Moreover,
it is detected that in pass 3 the constraints were varying
where parameter P’2 acknowledged the lowermost number
Table 6. Request is accessing globally moving susceptible data
through a global network.
S. no. Parameter name
Action status (Y/N) Y: allow
N: Deny
1.
The request is coming
from the suspicious IP
address
Y
N
N
N
2.
Susceptible data is busy
with its internal
activities
N
Y
Y
N
3.
Access right of the
Susceptible data for a
particular node
N
N
Y
Y
4.
The request tries to access
data beyond its allotted
time without any
request for the
extension of time
N
N
N
Y
5.
The request is related to
any unauthorized entity
for damaging the
network
Y
Y
N
N
Action statements
1
Denial of Service Y
N
N
N
2
Report to the Network
admin
N
N
Y
N
3
Wait for the approval of
access
N
N
N
Y
4
Block the IP for sending
the request
N
Y
N
N
Sådhanå (2021) 46:215 Page 19 of 24 215
of successes in contrast to pass 2. This altering situation of
the network parameters specifies that based on demands
provided by the projected algorithms, illegitimate accessing
of data can be prevented in the distributed computing
environment. The 2-dimensional graphic illustration of
demands to access the non-stationary susceptible data is
depicted in figure 16.
Figure 17 indicates a 3-dimensional representation of
non-static susceptible data. The request parameters and the
corresponding throughputs are varying concerning the
change of passes from 100 to 300. The demands are
0
2
4
6
Pass 1 Pass 2 Pass 3
Nor
mal
ised
Th
roug
hput
Request Parameters
P1 P2 P3 P4 P5 P6
Figure 14. The 2-dimensional representation of static data
request.
Figure 15. The 3-dimensional representation of static data
request.
0
1
2
3
4
5
6
Pass 1 Pass 2 Pass 3Nor
mal
ised
Thr
ough
put
Request Parameters
P'1 P'2 P'3 P'4 P'5 P'6
Figure 16. The 2-dimensional representation of moving suscep-
tible data request.
P'1
P'4
0
2
4
6
Pass 1Pass 2
Pass 3
Requ
est P
aram
eter
s
Nor
mal
ised
Th
roug
hput
Figure 17. A 3-dimensional representation of moving data
request.
Figure 13. Request to access moving data from the global network.
215 Page 20 of 24 Sådhanå (2021) 46:215

observed and validated by the network parameters set by
the automated model. The comprehensive information
about the illegitimate demands is kept to the internal
database management system of the proposed automated
model.
5.7 The case study analysis of medical healthcaresystems
The researchers have anticipated algorithms and the
equivalent decision tables to deliver security over suscep-
tible data. Patient information is exceedingly susceptible in
any medical healthcare domain. The entire medical test
information led for a patient is susceptible data and it must
not be revealed to any individual without the consensus of a
patient. The efficacy of the anticipated algorithm can be
signified with the support of a case learning where hospi-
tals, patients, and doctors are denoted by Eqs. (5), (6), and
(7).
Hospitals ¼ H1;H2; . . .. . .;HNf g ð5Þ
where Hi is representing ith hospital.
Patients ¼ P11;P12. . .Pmnf g ð6Þ
where Pij is representing ith hospital’s jith patient.
Doctors ¼ D11;D12. . .. . .Dmnf g ð7Þ
where Dij is representing ith hospital’s jth doctor.
Now, the subsequent three cases may occur for a patient
who is staying in a hospital in the town:
Case 1: The Patient Pij has visited the hospital Hi. Every
test report was led by the hospital. The test information may
be treated as susceptible data. After viewing the test data,
the specialists of the hospital Hi observed that no expert
doctor was present for this explicit disease handling at the
hospital. Therefore, the patient must be transferred to dif-
ferent hospital Hij where Hi and Hj are belonging to dis-
similar groups of hospitals. In this condition, the
susceptible data (the patient’s medical information) is to be
shifted from a different group of hospitals. The specialists
of the hospital Hi may not trust the test information directed
by Hj because the medical reports (Susceptible data) may
be altered by the invaders at hospital Hi. Therefore, the
patient’s medical tests must be done once more at the
hospital Hj which leads to an extra monetary burden and
time consuming to the seriously ill patient. The anticipated
security re-assurance over the susceptible data algorithm
confirms that no invader will be able to change the data
while moving it to a different network.
Case 2: The patient Pij has visited the hospital Hi. Every
test report was led by the hospital, but it was observed that
the expert doctors of this disease are not available. There-
fore, the specialists Hi recommended that the doctor Dij of
hospital Hi is the expert for the dealing of this treatment.
Here, the researchers are considering Hi and Hj are the
hospitals of the identical network. Thus, the patient will
move to the hospital j physically but all the test information
will be passed HiHj through the intranet working commu-
nication channel. As soon as the susceptible data is passed
within the identical network, the projected algorithms will
competently deliver whole security to avert any malprac-
tices over the susceptible data.
Case 3: The seriously ailing patient Pij visited the hos-
pital Hi. The patient was not able to take admission to the
hospital Hi because no expert doctor was free then. Here,
the authors consider that the patient’s health status is very
serious. Therefore, the patient must be under treatment
immediately. The patient is transferred to Hospital Hj
where experts are accessible, but getting appointments is
difficult due to the busy schedule of the doctors. Now the
family members of the patient explore the specialists nearer
to his location. Next, the patient will take admission to the
hospital, and detail medical reports are given to the spe-
cialists. Consequently, the susceptible data is transferred
between different states/cities. There may be a possibility
of tampering with data inside the network. The projected
algorithm will bring complete security re-assurance to
deliver susceptible data to the destination safely.
5.8 Automated permission-based securityof the proposed system
The authors have designed the permission-based security
for the cases explained in the previous section (section 4).
The security system is completely automated and the exe-
cution is completely dependent on the cloudlet running in
the cloud-IoT environment. The permission is validated
automatically based on the algorithms designed and cor-
responding decision tables generated from the algorithms.
There is no concept of human intervention and response
will be done in a time-bound process. When a request tries
to access susceptible data then the system will identify the
nature of the request whether it is static or dynamic. The
origination of the request will also be considered. After
that, the request will be forwarded to the appropriate cases
it finds to be suitable. Before admitting the request to access
susceptible data it will be checked by the cloudlet to the
matching decision table. If the validation is successful then
the request will be able to access the data. Otherwise, it will
be discarded.
Now a day’s, network security attacks are very much
common in the digitized world. These attacks are con-
ducted for unauthorized access of corporate, private, or
governmental information technology assets, and to
destroy/modify/steal the susceptible data. Many servers
store critical data such as credit card numbers, usernames,
passwords, Aadhar Card information, or other personally
identified information. The attackers try to get these sus-
ceptible data using suspicious IP addresses. Whenever the
Sådhanå (2021) 46:215 Page 21 of 24 215

attacker sends a request through their IP addresses the
request cannot be granted instantly. It will be checked
automatically with the suspicious IP databases internally. If
the requested IP address information is not found in the
database, then it will be checked with the parameters
designed and developed from Algorithms 3 to 6 of our
proposed model. The activation status of the request is also
validated through the decision tables (tables 3 to 6) of the
proposed model. This IP address checking and validation
model is completely automated and hence no network
administrator involvement is needed to complete the vali-
dation of the request. Thus, further attacks from the same IP
addresses can be minimized. This model is trustable be-
cause it captures the unauthenticated requests originated
from the intra network or internetwork systems.
6. Conclusions
Presently, susceptible data recognition and security re-as-
surance in a centralized cloud-based system is the prime
research area. The major challenge of susceptible data
identification and security reassurance indicates that infor-
mation is being used and shared frequently in a cloud-IoT-
based distributed computing environment. The research
work initially presumes that susceptible data needs to be
protected from intruders to validate the network model. The
authors have designed novel algorithms to identify the
susceptible data from private data set and apply security re-
assurance mechanisms in this research work. To implement
the susceptible data security, the authors have analyzed
different cases of security re-assurance techniques in cloud-
IoT-based network architecture. The novel mathematical
model combines the different components of the internet-
working system to validate the input, processing, and out-
put of the system. The decision tables corresponding to the
novel algorithms authorize the access of susceptible data by
the request originated from inter/intra network. The secu-
rity model is completely automated and no human inter-
vention is needed to identify the illegitimate request.
The researchers have well thought-out the medical
healthcare data as a base to take out the whole research.
The supplementary susceptible data like debit / credit card
and other accounting data classification must be addressed
and joined / included with the accessible system architec-
ture. Additionally, the researchers may think about the
optimization of safety declaration techniques in distributed
surroundings as the forthcoming research direction.
References
[1] Patil R, Dudeja H and Modi C 2019 Designing an efficient
security framework for detecting intrusions in a virtual
network of cloud computing. Comput. Secur. 85: 402–422
[2] Ari A A A, Ngangmo O K, Titouna C, Thiare O,
Mohamadou A and Gueroui A M 2019 Enabling privacy
and security in Cloud of Things: Architecture, applications,
security & privacy challenges. Appl. Comput. Inform.,pp. 1–23
[3] Srinivas J, Mishra D and Mukhopadhyay S 2017 A mutual
authentication framework for wireless medical sensor net-
works. J. Med. Syst 41(5): 1–19
[4] Rabaninejad R, Attari M A, Asaar M R and Aref M R 2019
Comments on a lightweight cloud auditing scheme: security
analysis and improvement. J. Netw. Comput. Appl. 139:
49–56
[5] Chanal P M and Kakkasageri M S 2020 Security and privacy
in IoT: a survey. Wirel Personal Commun 115: 1668–1693
[6] Kelarestaghi K B, HeaslipK Fessmann V, Khalilikhah M and
Fuentes A 2018 Intelligenttransportationsystemsecurity:
Hackedmessage signs. SAE Int. J. Transp. CybersecurityPrivacy 1(2): 1–16
[7] Mo Y 2019 A data security storage method for IoT under
hadoop cloud computing platform. Int J Wirel Inf Netw 26:
152–157
[8] Kumar P and Chouhan L 2021 A secure authentication
scheme for IoT application in the smart home. Peer-to-PeerNetw. Appl 14: 420–438
[9] Khan M K, Chaturvedi A, Mishra D and Kumari S 2015 On
the security enhancement of integrated electronic patient
records information systems. Comput. Sci. Inf. Syst. 12(2):
857–872
[10] Shi W and Dustdar S 2016 The promise of edge computing.
Computer 49(5): 78–81
[11] Jordi C-R, Jordi H-J and Vicenc T 2015 A summary of
k-degree anonymous methods for privacy-preserving on
networks. Adv. Res. Data Privacy (567): 231–250
[12] Fatemeh A, Nasser Y, Shakery A and Chinaei A H 2016
Hierarchical anonymization algorithms against background
knowledge attack in data releasing. Knowl.-Based Syst. 101:
71–89
[13] Xu L and Wu F 2015 Cryptanalysis and improvement of a
user authentication scheme preserving uniqueness and
anonymity for connected health care. J. Med. Syst. 39(2):
1–9
[14] Sarkar M, Banerjee S, Badr Y and Sangaiah A K 2019
Configuring a trusted cloud service model for smart city
exploration using hybrid intelligence. Int J Ambient ComputIntell 8(3): 1–21
[15] Palanisamy B and Liu L 2015 Privacy-preserving data
publishing in the cloud: a multi-level utility controlled
approach. In: Proceedings of the IEEE 8th InternationalConference on Cloud Computing, USA, pp. 130–137
[16] Jin W, Yonghui Z, Youyuan W and Xiang G 2016 RPRep: a
robust and privacy-preserving reputation management
scheme for pseudonym-enabled VANETs. Int J Distrib SensNetw 12(3): 1–15
[17] Jiang Q, Ma J, Lu X and Tian Y 2015 An efficient two-factor
user authentication scheme with unlinkability for wireless
sensor networks. Peer Peer Netw. Appl. 8(6): 1070–
1081
[18] Hossain M M, Fotouhi M and Hasan R 2015 Towards an
analysis of security issues, challenges, and open problems in
the internet of things. in Services (SERVICES). In: IEEEWorld Congress on IEEE, pp. 21–28
215 Page 22 of 24 Sådhanå (2021) 46:215

[19] Dey N, Hassanien A E, Bhatt C, Ashour A S and Satapathy S
C 2018 Internet of things and big data analytics toward next-
generation intelligence Berlin: Springer, pp. 3–549
[20] Mohan A 2014 Cybersecurity for personal medical devices
internet of things. In: Distributed Computing in SensorSystems (DCOSS), IEEE International Conference on. IEEE,
pp. 372–374
[21] Yoon S, Park H and Yoo H S 2015 Security issues on smart
home in IoT environment. In: Computer Science and itsApplications. Springer, pp. 691–696
[22] Kang J, Huang X, Yu R, Zhang Y, and Gjessing S 2015
Hierarchical mobile cloud with social grouping for secure
pervasive healthcare. In: Proceedings of 17th InternationalConference E-Health Networking., Application and. Services(HealthCom), pp. 609–614
[23] Tawalbeh L A, Mehmood R, Benkhlifa E and Song H 2016
Mobile cloud computing model and big data analysis for
healthcare applications. IEEE Access 4: 6171–6180
[24] Xia Q, Sifah E B, Smahi A, Amofa S and Zhang X 2017
BBDS: Blockchain-based data sharing for electronic medical
records in cloud environments. Information 8(2): 1–16
[25] Shaikh R and Sasikumar M 2015 Data classification for
achieving security in cloud computing. Proc. Comput. Sci.45: 493–498
[26] Shuijing H 2014 Data security: the challenges of cloud
computing. In: IEEE Sixth International Conference onMeasuring Technology and Mechatronics Automation,
pp. 203–206
[27] Kumar V, Ahmad M and Kumari A 2019 A secure elliptic
curve cryptography based mutual authentication protocol for
cloud-assisted TMIS. Telematics Inform. 38: 100–117
[28] Chen D and Zhao H 2012 Data security and privacy
protection issues in cloud computing. In: IEEE InternationalConference on Computer Science and Electronics Engineer-ing, Vol. 1, pp. 647–651
[29] Cao N, Wang C, Li M, Ren K and Lou W 2014 Privacy-
preserving multi-keyword ranked search over encrypted
cloud data. IEEE Trans Parallel Distrib Syst 25(1): 222–233
[30] Lauter K, Lopez-Alt A and Naehrig M 2014 Private
computation on encrypted genomic data. Tech.Rep. MSR-
TR-2014-93, pp. 3–27
[31] Seungcheol L, Lee J, Hong S and Kim J-H 2020 Lightweight
end-to-end blockchain for IoT applications. KSII Trans.Internet Inf. Syst. 14(8): 3224–3242
[32] Xu C, Ren J, Zhang D and Zhang Y 2018 Distilling at the
edge: a local differential privacy obfuscation framework for
IoT data analytics. IEEE Commun. Mag. 56(8): 20–25
[33] Lu R, Heung K, Lashkari A H and Ghorbani A A 2017 A
lightweight privacy-preserving data aggregation scheme for
fog computing-enhanced IoT. IEEE Access 5: 3302–
3312
[34] Du M, Wang K, Liu X, Guo S and Zhang Y 2019 A
differential privacy-based query model for sustainable fog
data centers. IEEE Trans. Sustain. Comput. 4(2): 145–155
[35] Ali D, Kanhere S S, Jurdak R, Gauravaram P 2017
Blockchain for IoT security and privacy: the case study of
a smart home. In: 2017 IEEE International Conference onPervasive Computing and Communications Workshops(PerCom Workshops), pp. 618–623
[36] Mubariz R, Javaid N, Awais M, Imran M and Naseer N 2019
Cloud-based secure service providing for IoTs using
blockchain. In: IEEE Global Communications Conference(GLOBECOM), pp. 1–7
[37] Gang W, Shi Z, Nixon M and Han S 2019 Chainsplitter:
towards blockchain-based industrial IoT architecture for
supporting hierarchical storage. In: IEEE InternationalConference on Blockchain (Blockchain), pp. 166–175
[38] Gokhan S, Carminati B, Ferrari E, Sheehan J D and Ragnoli
E 2018 Hybrid-IoT: hybrid blockchain architecture for the
internet of things-pow sub-blockchains. In: 2018 IEEEInternational Conference on Internet of Things (iThings)and IEEE Green Computing and Communications (Green-Com) and IEEE Cyber, Physical and Social Computing(CPSCom), and IEEE Smart Data (SmartData),pp. 1007–1016
[39] Shen J, Shen J, Chen X, Huang X and Susilo W 2017 An
efficient public auditing protocol with novel dynamic
structure for cloud data. IEEE Trans. Inf. Forensics Secur12(10): 2402–2415
[40] Tari Z, Yi X, Premarathne U S, Bertok P and Khalil I 2015
Security and privacy in cloud computing: vision, trends, and
challenges. IEEE Cloud Comput 2(2): 30–38
[41] Singh A and Chatterjee K 2017 Cloud security issues and
challenges: a survey. J. Netw. Comput. Appl. pp. 88–115
[42] Zhou J, Lin X, Dong X and Cao Z 2015 Psmpa: patient self-
controllable and multi-level privacy-preserving cooperative
authentication in distributedm-healthcare cloud computing
system. IEEE Trans. Parallel Distrib. Syst. 26(6):
1693–1703
[43] Zhou L, Varadharajan V and Hitchens M 2013 Integrating
trust with cryptographic role-based access control for secure
cloud data storage. In Trust, Security and Privacy inComputing and Communications (TrustCom), 2013 12thIEEE International Conference on, pp. 560–569
[44] Sendor J, Lehmann Y, Serme G and Santana de Oliveira A
2014 Platform level support for authorization in cloud
services with oauth 2. In: Proceedings of the IEEE Interna-tional Conference on Cloud Engineering, IC2E, (Washing-ton, DC, USA), pp. 458–465
[45] Elhabob R, Zhao Y, Sella I and Xiong H 2019 An efficient
certificateless public key cryptography with authorized
equality test in IIoT. J. Ambient Intell. Humaniz. Comput.pp. 1–19
[46] Xu P, Jin H, Wu Q and Wang W 2012 Public-key encryption
with fuzzy keyword search: a provably secure scheme under
keyword guessing attack. IEEE Trans. Comput. 62(11):
2266–2277
[47] Wang Y, Hassan A, Duan X and Zhang X 2019 An efficient
multiple-user location-based query authentication approach
for social networking. J. Inform. Secur. Appl. 47: 284–294
[48] Khokhar R H, Fung B C, Iqbal F, Alhadidi D and Bentahar J
2016 Privacy-preserving data mashup model for trading
person-specific information. Electron. Commerce Res. Appl17: 19–37
[49] He D, Zeadally S, Xu B and Huang X 2015 An efficient
identity-based conditional privacy-preserving authentication
scheme for vehicular ad hoc networks. IEEE Trans. Inf.Forensics Secur. 10(12): 2681–2691
[50] Lodha S and Thomas D 2007 Probabilistic anonymity. In:
Privacy, Security, and Trust in KDD, First ACM SIGKDDInternational Workshop, PinKDD, San Jose, CA, USA,
pp. 56–79
Sådhanå (2021) 46:215 Page 23 of 24 215

[51] Mishra K N (2018) A novel mechanism for cloud data
management in distributed environment. In: Data-IntensiveComputing Applications for Big Data, pp. 267–291
[52] Zhou J, Cao Z, Dong X, Xiong N and Vasilakos A V 2015 A
secure and privacy-preserving key management scheme for
cloud-assisted wireless body area network in m-healthcare
social networks. Inf Sci 314: 255–276
[53] Omer A M and Mohamad M M B 2016 Simple and effective
method for selecting quasi-identifier. J Theor Appl InfTechnol 89(2): 512–517
[54] Mohammed N, Fung B C M, Hung P C K and Lee C 2010
Centralized and distributed anonymization for high-dimen-
sional healthcare data. ACM Trans. Knowl. Discovery Data4(4): 1–33
[55] Almulla S and Chon Y-Y 2010 Cloud computing security
management. In: 2nd International Conference On Engi-neering Systems Management and Its Applications, pp. 1–7
[56] Baek J, Vu Q, Liu J, Huang X and Xiang Y 2014 A secure
cloud computing-based framework for big data information
management of the smart grid. In: Cloud Computing, IEEETransactions, pp. 1–12
[57] Brakerski Z, Gentry C and Vaikuntanathan V 2012 Fully
homomorphic encryption without bootstrapping. In Innova-tions in Theoretical Computer Science, pp. 309–325
[58] Ray S, Mishra K N and Dutta S 2021 Sensitive data
identification and security assurance in cloud and IoT based
networks. Int J Comput Netw Inf Secur 13: 1–25
215 Page 24 of 24 Sådhanå (2021) 46:215















![Vol. 7, No. 2, 2016 Toward Information Diffusion Model for ......two: the susceptible-infected-removed model (SIR) [18] and the susceptible-infected-susceptible model (SIS) [19]. Another](https://static.fdocuments.us/doc/165x107/6063d91852afc16c8b6cac8b/vol-7-no-2-2016-toward-information-diffusion-model-for-two-the-susceptible-infected-removed.jpg)


