SUPERVISED CLASSIFICATION OF TEXT DOCUMENTS Ravi. N. Vivek Shenoy T Veer Prakash S.
57
SUPERVISED SUPERVISED CLASSIFICATION OF CLASSIFICATION OF TEXT DOCUMENTS TEXT DOCUMENTS Ravi. N. Vivek Shenoy T Veer Prakash S.
-
Upload
melvin-greer -
Category
Documents
-
view
218 -
download
1
Transcript of SUPERVISED CLASSIFICATION OF TEXT DOCUMENTS Ravi. N. Vivek Shenoy T Veer Prakash S.

SUPERVISED SUPERVISED CLASSIFICATION CLASSIFICATION
OF TEXT OF TEXT DOCUMENTSDOCUMENTSRavi. N.
Vivek Shenoy T
Veer Prakash S.

Contents
• Introduction
• Literature Review
• Document Representation
• Text Classifiers
• Implementation Aspects
• Results and Analysis
• Conclusion
• Future Enhancements
• References

INTRODUCTIONINTRODUCTION

• Current scenario of the Documents in the WEB.
• Structured data
• Unstructured data
• Information Retrieval (IR)• Deals with the representation, storage, organization and access to
information items.
• This representation of the information is used to manipulate the
unstructured data.
• Goal of IR• To provide users with those documents which satisfy their information
needs.

Objective of the project
• To classify the documents in the corpus. The documents thus
classified are then classified into various classes. A particular document
is assigned to a class if there is a relevance in the query and the
document.
• To provide a comparative study between two classifiers namely
- Centroid based classifier
- K- nearest Neighbour classifier

• Definition of Information Retrieval (IR) IR is finding material of an unstructured nature that satisfies an information
need from within large collections [28].
• Different fields of Information Retrieval (IR) There are 2 categories :
- General Applications of IR
- Domain Specific Applications
• IR Process The IR process is a 6 step process as shown in the next slide,

Problem recognition and acceptance
Query Formulation
Query Execution
Examination of the Result
Information Retrieval
Fig. Schematic representation of Information Retrieval

• Machine learning A system that can do autonomous acquisition, integration of knowledge
and is capable of learning from experience, analytical observation and other means,
resulting in a system that can continuously self-improve and thereby offer
increased efficiency and effectiveness [5].
•Types of Machine Learning :• Supervised Learning, in which the training data is labeled with the correct
answers, e.g.,“spam” .
• Unsupervised learning, in which user are given a collection of unlabeled
data, which have to be analyzed and patterns have to be discovered.
• Text Classification (Document Classification)• Classifying a set of documents into classes, this classification is based upon
the relevance of the document with the query given by the user [4].

•Types of Text Classification:•Supervised Learning : The training data is labeled with the correct
answers, e.g.,“spam”.
• Unsupervised Document Classification/ Document clustering
The classification must be done entirely without reference to
external information.
•Definition of Text Classification Let C = c1, c2, ... cm be a set of categories and D = d1, d2, ... dn a
set of documents. The task of the text classification consists in assigning to
each pair ( ci, dj ) of C x D (with 1 ≤ i ≤ m and 1 ≤ j ≤ n) a value of 0 or 1, i.e.
the value 0, if the document dj doesn't belong to ci. This mapping is done with
the help of a decision matrix [17].

LITERATURE LITERATURE REVIEWREVIEW

•Phases of IR Development : There are several phases in the development of IR :
•1st Phase, 1950s - 1960s, of IR is the research phase
•2nd Phase, 1970s, IR struggled for adoption
•3rd Phase, 1980s- 1990s, reached acceptance phase in terms of free-text
search systems.
• Now-a-days the influence of IR is such that it is moving towards projects
in sound and image retrieval, along with electronic provision [26].
•Defination of TC by H.P. Luhn H.P. Luhn gave a definition for TC in 1958, this made the start of the text
classification era [32], the definition is as follows :
“…utilize data-processing machines for auto-abstracting and auto-encoding of
documents and for creating interest profiles for each of the ‘action points’ in an
organization. Both incoming and internally generated documents are
automatically abstracted, characterized by a word pattern, and sent
automatically to appropriate action points.”

DOCUMENT DOCUMENT REPRESENTATIOREPRESENTATIO
NN

• Need for DR• The task of information retrieval is to extract relevant documents from
a large collection of documents in response to user queries. The
documents contain primarily unrestricted text.
Document representation basically involves generating a representation R of
a document such that for any text items D1 and D2, R(D1) ≈ R(D2)
where R is a function knows as relevance of the document which is obtained
by matching the key words in the query with document set.
In order to reduce the complexity of the documents and make them clear and
easier to handle we transform the document from its full text version to a
document vector which describes the contents of the document.
The terms that occur in a document are the parameters of the document
representation. The types of parameters determine the type of the document
representation.

• Different Types:• Binary Document Representation
• Term Frequency Representation (Frequency vector)
• Probabilistic representation
Documents Document content No. of Unique words
D0 Gold silver truck 3
D1 Shipment of gold damaged in a fire 4
D2 Delivery of silver arrived in a silver truck 4
D3 Shipment of gold arrived in a truck 4
Example Documents :

•Binary Document Representation: The Binary Independence Model (BIM) introduces some simple
assumptions, Here, the term “binary'' is equivalent to Boolean, documents and
queries are both represented as binary term incidence vectors. That is, a
document “d” is represented by the vector =(x1,…xM) where ‘xt=1’ if term
‘t’ is present in document ‘d’ and ‘xt=0’ if ‘t’ is not present in ‘d’ [22].
x
Doc id Arrived Damaged Delivery Fire Gold Shipment Silver Truck
D0 0 0 0 0 1 0 1 1
D1 0 1 0 1 1 1 0 0
D2 1 0 1 0 0 0 1 1
D3 1 0 0 0 1 1 0 1
• Drawback :
It does not take into account the frequency of a term within a
document. All the terms with in a document will be given equal weightage
irrespective of the number of their occurrence in the document.
• Representation of the Example Documents :

•Term Frequency Representation (Frequency vector) In this type of representation we assign to each term in a document a
weight, that depends on the number of occurrences of the term in the document.
Docid Arrived Damaged Delivery Fire Gold Shipment Silver Truck
D0 0 0 0 0 1 0 1 1
D1 0 1 0 1 1 1 0 0
D2 1 0 1 0 0 0 2 1
D3 1 0 0 0 1 1 0 1
• Drawback :
This approach does not weigh the terms in a document with respect
to other documents in the dataset.
• Representation of the Example Documents :

• Probabilistic representation In this scheme every component of the vector denotes the probability
of occurrence of the corresponding term with in the document. The probability
of a particular term is found by the following
Probability =Number of occurrences of the term ‘t’ in the document ‘d’
Total number of terms in the document ‘d'
Doc id Arrived Damaged Delivery Fire Gold Shipment Silver Truck
D0 0 0 0 0 1/3 0 1/3 1/3
D1 0 ¼ 0 1/4 1/4 ¼ 0 0
D2 1/4 0 1/4 0 0 0 2/4 1/4
D3 1/4 0 0 0 1/4 ¼ 0 1/4
• Representation of the Example Documents :

• tf-idf (term frequency – inverse document frequency)
representation
The main idea behind tf-idf is that the term occurring
infrequently should be given a higher weight than a term that occurs
frequently.
•Important definitions in tf-idf context :
t = number of distinct terms in the document collection.
tfij = number of occurrences of term tj in document Di.
This is also referred to as term frequency.
dfj = number of documents which contain tj.
idfj = log( d/dfj) where d is the total number of documents.
This is the inverse document frequency

The weighting factor for each term in the document is calculated
by taking the product of term-frequency and inverse-document frequency
related to the term by using the following,
dij = tfij * idfj
• Weighting Factor of each term :
• tf-idft,d assigns to term t a weight in document d that is
1. highest when t occurs many times within a small number of documents (thus
lending high discriminating power to those documents);
2. lower when the term occurs fewer times in a document, or occurs in many
documents (thus offering a less pronounced relevance signal);
3. lowest when the term occurs in virtually all documents. The values thus
computed are then filled into the document vectors,

Docid Arrived Damaged Delivery Fire Gold Shipment Silver Truck
D0 0 0 0 0 0.12 0 0.3 0.12
D1 0 0.3 0 0.6 0.12 0.3 0 0
D2 0.3 0 0.6 0 0 0 0.6 0.12
D3 0.3 0 0 0 0.12 0.3 0 0.12
• Representation of the Example Documents :

Text ClassifiersText Classifiers

TC is defined as the task of approximating the unknown target function
Φ: D×C →T,F
Where Φ is called as the classifier [29], where,
C=c1,...,c|C|…………………………a predefined set of categories
D …………………………..…………..a (possibly infinite) set of documents.
If Φ(dj ,ci)= T,
then dj is called a positive example (or a member) of ci,
If Φ(dj ,ci)= F
then dj is called a negative example (or not a member) of ci.
In order to build a classifier we need a set Ω documents such that the
value of Φ(dj ,ci) is known for every (dj ,ci) € Ω ×C, usually Ω is partitioned
into three disjoint sets Tr (the training set), Va (the validation set), and Te (the
test set) [31].
• Refined Definition of Text Classification (TC) :

• Training set: The training set is the set of documents observing which the
learner builds the classifier.
• Validation set: The validation set is the set of documents on which the
engineer fine tunes the classifier, e.g. choosing for a parameter p on which the
classifier depends, the value that has yielded the best effectiveness when
evaluated on Va.
• Test set : The test set is the set on which the effectiveness of the classifier is
finally evaluated.
“evaluating the effectiveness” means running the classifier on a set of
pre-classified documents (Va or Te) and checking the degree of correspondence
between the output of the classifier and the pre-assigned classes.

•Types of classifiers The following are some of the classifiers [37],
• Naïve-Bayesian classifier
• kNN classifier .
• Linear Classifiers
• C4.5
• Support Vector Machines etc.
In this project we mainly concentrate on only 2 classifiers.
• Centroid classifier
• kNN classifier.

• CENTROID CLASSIFIER
• This type of a classifier computes a centroid vector for every pre-defined
class using all the training documents belonging to the class.
• Next, the test document (which must be classified) is compared with all
these centroid vectors to compute the similarity coefficients.
• Finally a class is chosen whose centroid nearly matches with that of the
test document (i.e. selecting that class whose similarity coefficient score is
the highest)

• Pseudo code of Centroid Classifier
Step 1) The input documents (under pre-defined categories) are split into training
set and testing set respectively.
Step 2) Scan through the entire training set to identify all the unique words
across the entire collection .The total count of the unique words decides
the length of the document vector.
Step 3) For each of the unique terms (as identified in step 2) ,compute the
document frequency (i.e. total number of documents in which a particular
unique terms occurs).
Step 4) Represent every input training document as a vector.(here we shall
assume that we are using tf-idf weights to represent the input documents.
Any of the representation schemes explained earlier can also be used).

Thus a document vector is represented as
dtf = ( tf1 log (N/df1) ,tf2 log (N/df2), tf3 log (N/df3) , …tfm log (N/dfm) )
Step 5) For every pre-defined class compute a centroid vector. this is done using the
following formula
where S is the training set of the category/class for which the centroid vector is
being computed.
Thus, if there are “m” different classes, there will be “m” different
centroid vectors. The “m” centroid vectors are denoted as

3) Based on similarity coefficient score , assign document x to the class, with
whom ,the score is the highest. It can be mathematically represented as
Step 6: For every test document “d”
1)Use the document frequencies of the various terms computed from the
training set , to compute the tf – idf representation of d i.e
2) Compute the similarity coefficient between and all the k- centroid vectors
using the normalised cosine measure. The cosine measure is computed as
follows
where ,
Thus using the above discussed formula’s, the classification of the
document can be done.
is any centroid vector of a class.

• K Nearest Neighbor Classifier
• It is one of the instance learning algorithm which has been applied to text
categorization.
• This classifier first computes k nearest neighbor’s of a test document .Then
the similarities of the test document to the k-nearest neighbors are
aggregated according to the class of the neighbors, and the test document
is assigned to the most similar class (as measured by aggregate similarity)
[37].
• Drawbacks :
•one test document must be compared with all the test documents, so
as to decide the class of the test document. Thus it requires huge
amount of computation.
•It uses all the features equally in computing similarities. This may
lead to poor similarity measures and may lead to classification
errors.

• Pseudo code of KNN Classifier
Step 1) The input documents (under pre-defined categories) are split into training
set and testing set respectively.
Step 2) Scan through the entire training set to identify all the unique words across
the entire collection. The total count of the unique words decides the
length of the document vector.
Step 3) Fix a value for k. This value determines the number of nearest neighbors
which will be considered during document classification.
Step 4) For every test document , compute the similarity coefficient with each of
the training documents and record the similarity score in a hash table.
Step 5) Select the top “k” scores from the hash.

Step 6) Compute the aggregate score for each class. If several of the k-nearest
neighbor’s share a class, then the per- neighbor weights of that class are
added together and resulting weighted sum is used as likelihood score of
that class. Sort the scores of candidate classes and generate a ranked list.
The decision rule can be mathematically represented as
Where,
• “d” is the test document which is being classified and KNN (d) indicates the
set of k-nearest neighbors of document d.
• (dj, ci ) represents the classification for document dj with respect to class ci .
Step 7) Test document “d” should be assigned to the class that has the highest
weighted aggregate score.

Implementation Implementation AspectsAspects

• PERL
Perl stands for “Practical Extraction and Reporting Language”. It
was invented by Larry Wall. Perl is very powerful, versatile scripting language
and it is famously known as “Swiss Army chainsaw of programming
languages”.
• PDL “Perl Data Language” • PDL is an object oriented extension to perl that is designed for scientific and
bulk numeric data processing and display. It is a very powerful and at the same
time fast array-oriented language.
•The PDL concept gives standard Perl, the ability to compactly store and
speedily manipulate the large N-dimensional data setswhich are very essential
for scientific computing.
• PDL uses Perl `objects' to hold piddle data. An `object' is like a user-defined
data-type and is a very powerful feature of Perl, PDL creates it's own class of
`PDL' objects to store piddles.

• PDL’s over perl variables•It is impossible to manipulate Perl `arrays' arithmetically as we like.
i.e.
@y = @x * 2
•Perl lists are intrinsically one-dimensional and we can have `lists of
lists' but this is not the same thing as a pdl.
•Perl lists do not support the range of datatypes that piddles do (byte
arrays, integer arrays, single precision, double precision, etc.)
•Perl lists consume a lot of memory. At least 20 bytes per number, of
which only a few bytes are used for storing the actual value. This is because
Perl lists are flexible, and can contain text strings as well as numbers.
•Perl lists are scattered about memory. The list data structure means
consecutive numbers are not stored in a neat block of consecutive memory
addresses as in case C and other programming language.

• Advantages of using Perl Data Language
• Both Perl and PDL are easily available, free of cost under the open source
license.
• Since PDL is an extension of perl, a perl programmer has all the powerful
features of perl at his hands.Thus even in mainly numerically oriented
programming, it is often extremely handy if we have access to non-numeric
functionality.
• Since it is a package of perl ,it makes PDL extensible and interoperable.
• Syntax associated with PDL is very simple thus making it a user friendly
package
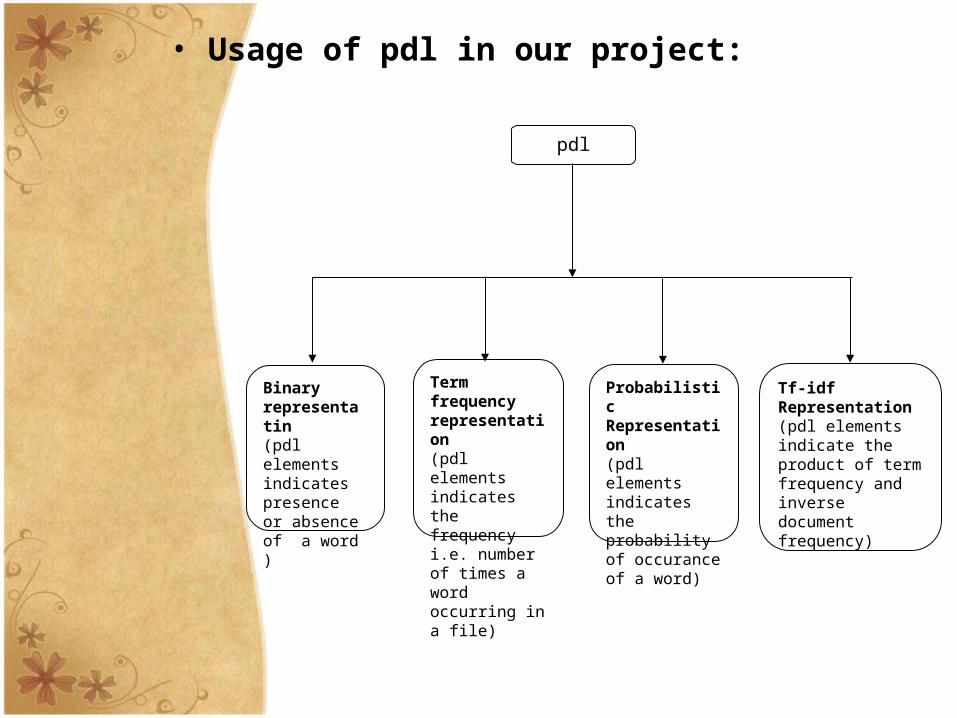
pdl
Binary representatin(pdl elements indicates presence or absence of a word )
Term frequency representation(pdl elements indicates the frequency i.e. number of times a word occurring in a file)
ProbabilisticRepresentation(pdl elements indicates the probability of occurance of a word)
Tf-idfRepresentation(pdl elements indicate the product of term frequency and inverse document frequency)
• Usage of pdl in our project:

• Organization of our code
Classifiers
Centroid KNN
Binary representation
Term frequency
representation
Probabilistic representation
Tf-idfrepresentation
Textfiles(contains all the training and testing documents)
Freq(contains the files representing training and testing documents which indicates the frequency of a word in a file)
String(contains all the scripts and the result of classification)
Actuals(contains predefined files which indicate the class to which each of the file belongs )

• Scripts of our project There are 6 different scripts.
1) init.pl
2) main.pl
3) script1.pl
4) script2.pl
5) script3.pl
6) script4.pl
1) init.pl
This is the initialization script. The main intention behind this
script is make all the necessary folders available for the smooth functioning
of the code. It deletes the selected folders (for example, freq, source
code/results etc which holds all the necessary data ) and recreates them
again

2) main.pl
This is the main script. This script invokes all the other scripts
sequentilally.
3) script1.pl
The main intention of this script is removal of stopwords and
other unwanted characters from the source file .
Note:- We are not actually modifying the actual source file.
4) script2 .pl
The main intention of this script is to calculate the document
frequency for each of the unique terms depicted in uniquefile.txt

5) script3.pl
This script mainly performs the task of document classification.
6) script4.pl
The main intention of this script, is to generate a input to an html
browser, so as to display the results to the user.

Results Results & &
Analysis Analysis

The following are the elements of our Project :
1) Pre-defined classes -7
2) Training documents - 651
3) Testing Documents - 47
1) Pre-defined classes :
The following are the 7 pre-defined classes, S.no. Class Name No. of Documents
1. Cricket 101
2. Formula-1 90
3. Hockey 109
4. Ice-Hockey 109
5. Movies 122
6. Politics 20
7. Religion 100
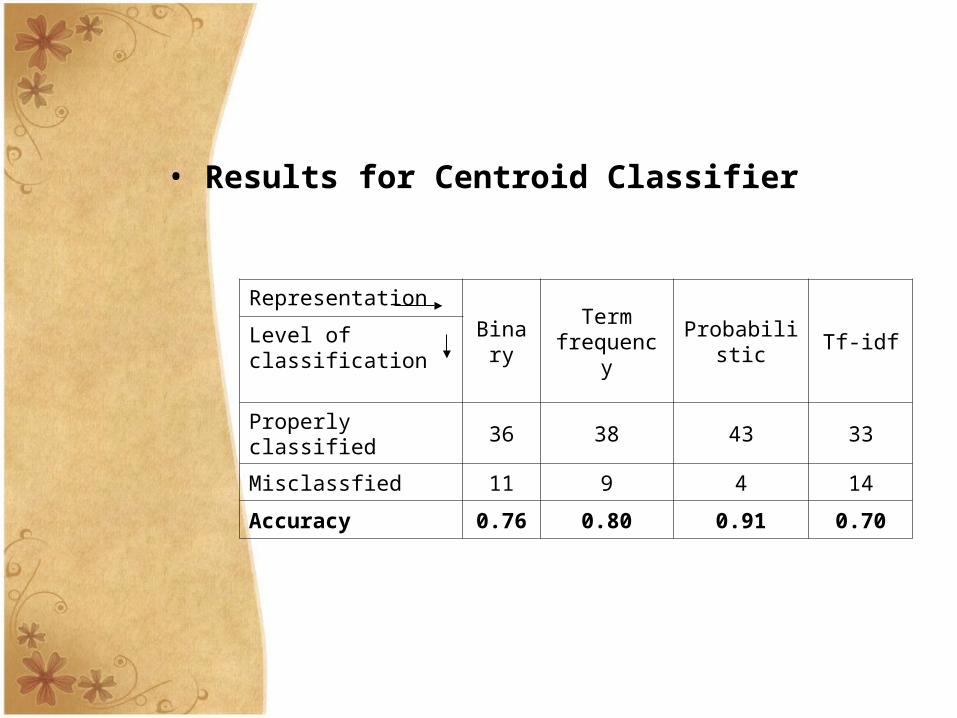
• Results for Centroid Classifier
Representation
BinaryTerm
frequencyProbabilistic Tf-idfLevel of classification
Properly classified 36 38 43 33
Misclassfied 11 9 4 14
Accuracy 0.76 0.80 0.91 0.70

Fig. 6.1.2 Accuracy obtained by the Centroid classifier in each Document Representation
0.760.8
0.91
0.7
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Binary Term Frequency Probabilistic Tf-idf
Document Representation Scheme
Acc
urac
y O
btai
ned
Accuracy
• Level of Accuracy Achieved

• Results for KNN Classifier
The following table shows the result of applying KNN classifier
on the document vectors when the value of k=2 is given by the user.
Representation
BinaryTerm
frequencyProbabilistic Tf-idfLevel of classification
Properly classified 39 41 42 37
Misclassfied 08 06 05 10
Accuracy 0.83 0.87 0.89 0.78

• Level of Accuracy Achieved
Fig. 6.2.2. Accuracy obtained by the KNN (k=2) classifier in each Document Representation.
0.83
0.87
0.89
0.78
0.72
0.74
0.76
0.78
0.8
0.82
0.84
0.86
0.88
0.9
Binary Term Frequency Probabilistic Tf-idf
Document Representation Scheme
Acc
urac
y O
bta
ined
Accuracy

The following table shows the result of applying KNN classifier on the
document vectors when the value of k=20 is given by the user.
Representation
BinaryTerm
frequencyProbabilistic Tf-idfLevel of classification
Properly classified 44 43 42 37
Misclassfied 3 4 5 10
Accuracy 0.94 0.91 0.89 0.78
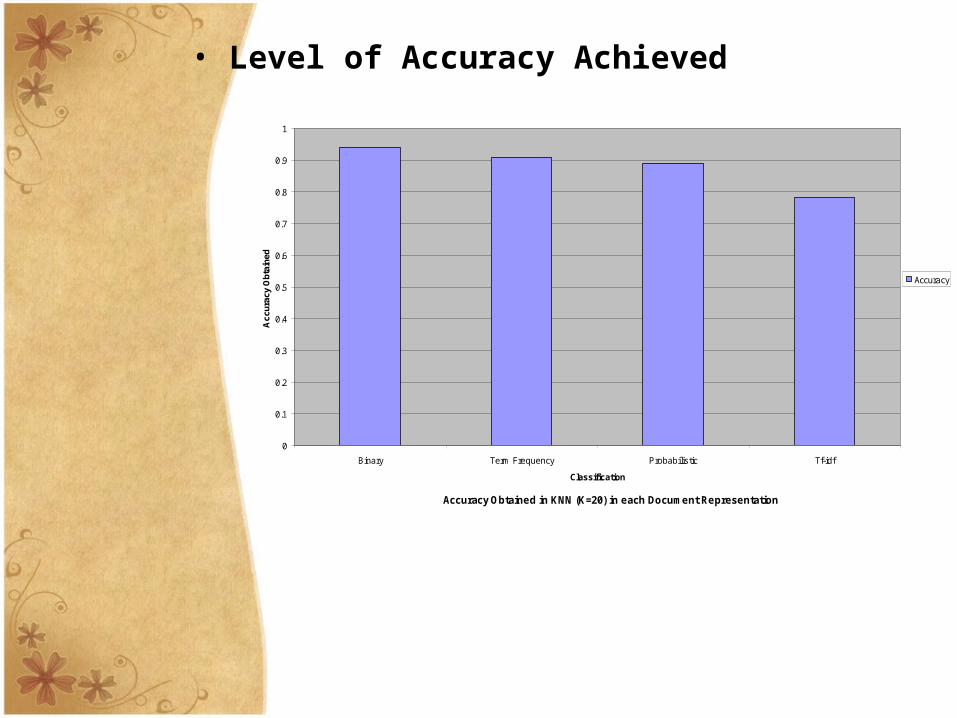
• Level of Accuracy Achieved
Accuracy Obtained in KNN (K=20) in each Document Representation
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Binary Term Frequency Probabilistic Tf-idf
Classification
Acc
urac
y O
btai
ned
Accuracy
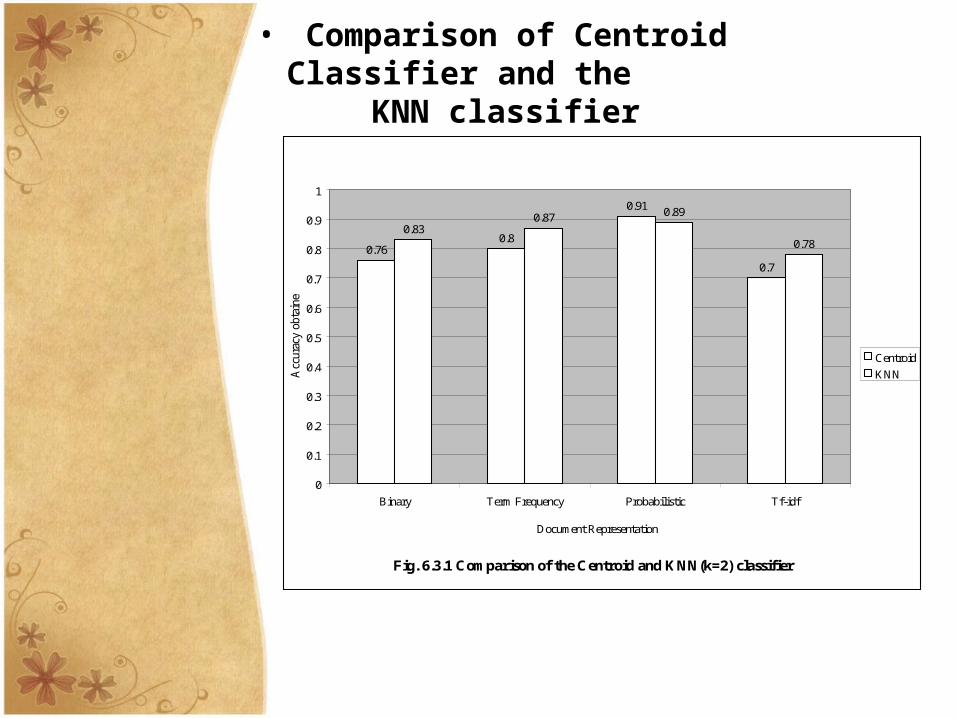
• Comparison of Centroid Classifier and the KNN classifier
Fig. 6.3.1 Comparison of the Centroid and KNN(k=2) classifier
0.760.8
0.91
0.7
0.830.87 0.89
0.78
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Binary Term Frequency Probabilistic Tf-idf
Document Representation
Acc
urac
y ob
tain
ed
Centroid
KNN

ConclusionConclusion

Drawbacks :
1) We cannot decide on the ideal value of K.
2) Requires huge amount of Computational Resources
3)Impracticle in case of very large Document Collections.
We find KNN Classifier provides the top notch results
in terms of classification accuracy.
About KNN Classifier

Advantages of Centroid Classifier over KNN
1) Does not require Huge amount of Computation.
2) Very quick to decide results of classification.
3) Ideally suited in case of very large input document
collection.
About Centroid Classifier
We also find that Centroid Classifier provides a
classification accuracy very near to that of KNN.

Thus we can conclude that
Centroid Classifier is better
than KNN Classifier.

• To increase the number of classes
• To build a suitable front end
• To integrate the classifiers built to the search engine to provide classification of
websites
• To enhance the centroid classifier by implementing weighted centroid classifier.
• To incorporate a stemming algorithm ex. Stemmer porter.
• To upgrade the implementation to incorporate the standard data collections,
such as, Reuters-21578, TREC-5, TREC-6 and OHSUMED collection, 20 news
group data set.
Future Future EnhancementsEnhancements

ReferencesReferences
[1].Ricardo Bayeza-yates, Berthier ribeiro Neto, “Modern Information Retrieval”, Addison-Wesley-
Longman Publishing co., 1999
[2].Spoerri, A, “Information Processing & Management”. Proceedings of the IEEE First International
Conference on Computer Vision. Volume 43, pp. 1044-1058, 2007
[3]. Forrester, “Coping with complex data”, The forrester Report, pp.2-4, April 1995.
[4]. W. Bruce, “intelligent Information Retrieval”, Croft Center for Intelligent Information Retrieval
Computer Science Department University of Massachusetts, Amherst Amherst, D-Lib Magazine,
November 1995
[5] Simon Colton, ”AI Bite”, The Society for the Study of Artificial Intelligence and Simulation of
Behaviour, pp.66-67,

Thank you.....

Any Questions???