
STUDIES ON TASK PARTITIONING STRATEGIES IN DISTRIBUTED ... fileDate:..\.1.r.ll.:.^j3 (Signature of...
125
STUDIES ON TASK PARTITIONING STRATEGIES IN DISTRIBUTED SYSTEM THESIS SUBMITTED FOR THE AWARD OF THE DEGREE OF Boctor of $|)tlo£(0p|)? rr COMPUTER SCIENCE ' Submitted By JAVEDALI « Under the Supervision of Dr. RAFIQUL ZAMAN KHAN (Associate Professor) DEPARTMENT OF COMPUTER SCIENCE ALIGARH MUSLIM UNIVERSITY ALIGARH (INDIA) 2013
Transcript of STUDIES ON TASK PARTITIONING STRATEGIES IN DISTRIBUTED ... fileDate:..\.1.r.ll.:.^j3 (Signature of...

STUDIES ON TASK PARTITIONING STRATEGIES IN DISTRIBUTED SYSTEM
THESIS SUBMITTED FOR THE AWARD OF THE DEGREE OF
Boctor of $|)tlo£(0p|)?
rr COMPUTER SCIENCE
' Submitted By
JAVEDALI
«
Under the Supervision of
Dr. RAFIQUL ZAMAN KHAN (Associate Professor)
DEPARTMENT OF COMPUTER SCIENCE ALIGARH MUSLIM UNIVERSITY
ALIGARH (INDIA) 2013

i-Htl i^W
T8753

dedicated/

CANDIDATE'S DECLARATION
I, JAVED„ALI, Dq>artment of Computer Science, certify that the work
embodied in this Ph.D. thesis is my own bonafide work carried out by me under the
supervision of T^]Rf..VJ^QJJL_ZAM^ Aligarfi Muslim University,
Aligarh. The matter embodied in this Ph.D. thesis has not been submitted for the
award of any other degree,
I declare that I have faithfiiUy acknowledged, given credit to and referred to
the research workers wherever their works have been cited in the text and the body of
the thesis. I fiuther certify that I have not willfully lifted up some other's work, para,
text, data, result, etc. reported in the journals, books, magazines, reports, dissertations,
theses, etc., or available at web-sites and included them in this Ph.D. thesis and cited
as my own work.
Date:.. .1! .T.'.'.r.?.^.'.? ( S ^ S n T o f ifee l^naidate) Sigiialare of ine Candu
Certificate from the Supervisor
This is to certify that the above statement made by the candidate is correct to the best of my knowledge.
Signature of the Supervisor: Name & Designation: DR. RAFIQUL ZAMAN KHAN
(ASSOCIATE PROFESSOR) Department: COMPUTER SCIENCE
(Signature of the Chairn^^M^^^«rDepartment with seal) - CHAIRMAN
Department of Computer Science A.M.U.. Aligarh

COPYRIGHT TRANSFER CERTIFICATE
Title of the Thesis: STUDIES ON TASK... PAJtTmQNING
STRATEGIES IN DISTRIBUTED SYSTEM
Candidate's Name: JAVED ALI
Copyright Transfer
The undersigned hereby assigns to the Aligaih Muslim University,
Aligarh, copyright that may exist in and for the above thesis submitted for the
award of Ph.D. degree.
^).I3> (Signature of the Candidate)

COURSE/ COMPREHENSIVE EXAMINATION/ PRE-SUBMISSION SEMINAR COMPLETION CERTIFICATE
This is to certify that MR JAVED ALI, Department of COMPUTER
SCIENCE has satisfactory completed the course work/comprehensive
examination and pre-submission seminar requirement which is part of his Ph.D.
programme.
Date:..\.1.r.ll.:.^j3 (Signature of the Chairman of the Deparmi nt)

ACKNOWLEDGEMENTS
First and foremost, I must bow in reverence to Almighty 'ALLAH', the cherisher and
the Sustainer to whom we entirely owe our all capabilities, strength, courage and
kriowledge, without His blessings nothing can be done. Words and lexicons cannot do
full justice in expressing a deep sense of gratitude and indebtedness which flows from
the core of my heart towards my esteemed supervisor Dr. RafiquI Zaman Khan,
(Associate Professor), Department of Computer Science. Under his benevolence and
able guidance, I learned and ventured to write. His inspiring benefaction bestowed
upon me so generously and his unsparing help and precious advice have gone into the
preparation of this thesis. He has been a beacon all long to enable me to present this
work. I shall never be able to repay for all that I have gained from him.
I wish to thank Mr. Suhail Mustajab (Chairman), Department of Computer Science,
for providing me various departmental facilities whenever it seems feasible. I also
avail this opportunity to express my thanks to all my teachers specially, Mr. S.
Maheshwari (Associate Professor), Mrs. Priti Bala (Associate Professor), Dr. M. U.
Bokhari (Associate Professor), Dr. Jamshed Siddiqui (Associate Professor), Dr. Asim
Zafar (Associate Professor), Mr. Shahid Masood (Assistant Professor), Mrs. Sehba
Masood (Assistant Professor) and Mr. Arman Rasool Faridi (Assistant Professor) for
their encouragement and inspiration.
Thanks are also due to all my colleagues especially Firoz Ali, Noor Adnan, Haider Al
Khalaf Jabbar, Shadab Alam, Sadaf Ahmad, Faheem Masoodi, Faraz Hasan, Shahab
Saquib Sohail, Zaki Ahmad Khan, Nazir Ahmad and Suby Khan who are always
giving me their valuable suggestions.
I wish to express my gratitude to all my office workers, Mr. Sharif Ahmad Khan, Mr.
Azimur Rehman, Mohd. frfan and Mr. Mazhar Moonis and several others who have
always stood beside me in my up and down.

At last but certainly the most, I am greatly indebted to my parents, Haji Idris Ahmad
(father), Mrs. Fahmida Khatoon (mother) for their continuous and constant
encouragement and above all for their moral support. I also avail this opportunity to
express my thanks to all my well wishers.
Finally, I owe a deep sense of gratitude to the authorities of Aligarh Muslim
University, my Ahna Mater, for providing me adequate research facilities.
JAVED ALI
Department of Computer Science,
Aligarh Muslim University, Aligarh

ABSTRACT
Parallel computing allows to indicate how different portions of the computation can
be executed concurrently in a heterogeneous computing environment. The high
performance of the existed systems may be achieved by a high degree of parallelism.
It supports parallel as well as sequential execution of processes and automatic inter
process communication and synchronization. Many scientific problems (Statistical
Mechanics, Computational Fluid Dynamics, Modeling of Human Organs and Bones,
Genetic Engineering, Global Weather and Environmental Modeling etc.) are so
complex that solving them via simulation requires extraordinary powerful computers.
Grand challenging scientific problems can be solved by using high performance
parallel computing architectures. Task partitioning of parallel applications is highly
critical for the prediction of the performance of distributed computing systems.
A well known representation of parallel applications is a DAG (Directed Acyclic
Graph) in which nodes represent application tasks. Directed arcs or edges represent
inter task dependencies. Execution time of any algorithm is known as schedule length
of that algorithm. The main problem in parallel computing is to find out the minimum
schedule length of DAG computations. Normalized Schedule Length (NSL) of an>
algorithm shows that, variation of communication cost depends upon the overhead of
the existing computing system. Minimization of inter-process communication cost
and selection of network architecture are notable parameters to decide the degree of
efficiency. Various list scheduling strategies (Task Duplication Based Scheduling
(TDB), Bounded Number of Processor Scheduling (BNP), Unbounded Number of
Cluster Scheduling (UNC) and Arbitrary Network Topology Scheduling (ANP) etc)
are discussed in the literature. All scheduling strategies have their pros and cons.
HEFT (Heterogeneous Earliest Finish Time), MCP (Modified Critical Path) and FPS
(Fast Preemptive Scheduling) algorithms are recent dynamic scheduling algorithms.
These algorithms depict the best speedup and efficiency amongst existing parallel
computing scheduHng algorithms.
We proposed task partitioning algorithms in heterogeneous parallel computing
systems. Proposed scheduling algorithms are NP-complete. An iterative list
scheduling algorithm has been proposed to improve the quality of the schedule in an

iterative fashion by using results from previous iterations. The results obtained by the
designed strategy shows significant improvement in inter process communication
cost. Proposed algorithm may simulate large number of complex applications in high
performance computing systems.
Most of the scheduhng algorithms do not provide a mechanism about communication
overhead. The second Proposed Optimal Task Partitioning Strategy vv'ith Duplication
(OTPSD) minimizes scheduling length as well as communication overhead. The
communication overhead of computing system has been reduced by duplication of
tasks. It's three phase algorithm in which first phase comprises of grainpackSubDAG
formation. The second phase is a priority assignment phase. In the third phase,
processors are grouped according to their processing capabilities. The proposed
algorithm (OTPSD) minimizes makespan and shows better performance in terms of
normalized schedule length and processor utilization over MCP and HEFT
algorithms. Calculated makespan of OTPSD by using Compute Unified Device
Architecture (CUDA) environment is (184.4 Sec) which is shorter than MCP (215.6
Sec) and HEFT (196.3 Sec) algorithms.
The third proposed algorithm is Minimal Task Partitioning Strategy with Minimum
Time (TPSMT). In the designed algorithm, communication cost improvement factor
has been introduced. This factor is accomplished to reduce the inter-process
communication cost in distributed computing systems. It's compared with two well
known HEFT and Critical Path Fast Duplication (CPFD) algorithms. TPSMT shows
lower complexity than compared algorithms. Communication to computation ratio
(CCR) is also taken into consideration to calculate the performance of the algorithms.
Average efficiency of TPSMT is 53.09% and 63.20% more than HEFT and CPFD
algorithm respectively. Sunulation results show that TPSMT gained speedup 17.36%
and 56.79% than HEFT and CPFD correspondingly.
The fourth proposed algorithm is Preemptive Task Partitioning Strategy (PTPS)
preemptive. It has been compared with preemptive MCP algorithm and FPS
algorithms. It increases CPU utilization by allowing recursive preemptions of
resources. In preemptive scheduling, idle time of processors decreases by assigning
jobs in a round robin system. The proposed algorithm assigns tasks in such a manner
that every participating processor engaged most of the time. PTPS is based on the

Earliest Start Time (EST) factor which provides optimum processing capability of the
existing machines. This algorithm contributes minimum finish time (minFT)
parameter which shows minimum Normalized Schedule Length (NSL). This result
predicts that if the communication cost amongst processes is large then scheduling of
these parallel applications is complex. On the basis of simulation results it has been
observed that running time of PTPS is 11.91 % less than running time of FPS.
j(TX

TABLE OF CONTENTS
List of Tables
List of Figures
List of Publications
CHAPTER-1 : INTRODUCTION 1-16
1.1 Parallel Computing Distributed System 2
1.2 Traditional Scheduling verses Parallel Computing Scheduling 2
1.2.1 Task partitioning small constraints in parallel computing 2
1.2.2 Optimization criteria for parallel computing scheduling 2
1.2.3 Data scheduling 3
1.2.4 Methodologies 3
1.3 Types ofParallel Computing Architectures 3
1.3.1 Flynn's taxonomy 3
1.3.1.1 SISD (Single Instruction stream/Single 3
Data stream)
1.3.1.2 SIMD (Single Instruction stream/ Multiple 3
Data stream)
1.3.1.3 MISD (Multiple Instruction /Single Data) 4
1.3.1.4 MIMD (Multiple Instructions and Multiple Data) 4
1.4 Important Laws in Parallel Computing 4
1.4.1 Amdahl's law 4
1.4.1.1 Limitationsof Amdahl's Law 4
1.4.2 Gustafson's law 6
1.5 Performance Parameters in Parallel Computing 7
1.5.1 Throughput 7
1.5.2 System utilization 7
1.5.3 Turnaround time 7
1.5.4 Waiting time 7
1.5.5 Response time 7
1.5.6 Reliability 7

1.6 Issues and Challenges in Parallel Computing 7
1.6.1 Role of server system 7
1.6.2 Allocation requirements 8
1.6.3 Resource management 9
1.6.4 Security 9
1.6.5 Reliability 9
1.6.6 Fault tolerance 9
1.7 NP Hard Scheduling 9
1.7.1 Classes P and NP in parallel computing 10
1.8 Thread in Parallel Processing Algorithms 10
1.8.1 Thread benefits 11
1.8.1.1 Responsiveness 11
1.8.1.2 Economy and resource sharing 11
1.8.1.3 Utilization of multiprocessor architectures 11
1.9 DAG in Different Scheduling Environments 11
Reference 15
CHAPTER-2 : COMPARATIVE STUDY OF PARALLEL 17-34
COMPUTING TOOLS
2.1 Introduction 18
2.2 PVM (Parallel Virtual Machine) 19
2.2.1 Evolution of PVM 20
2.2.2 Portability, interoperability and evolution of PVM 20
2.2.3 Computing model of PVM 22
2.3 MPI (Message Passing Interface) 23
2.3.1 Evolution of MPI 23
2.3.2 Portability, interoperability and fault tolerance of MPI 24
2.3.3 Implementation of MPI 25
2.4 BLACS 26
2.4.1 ID-Less communication in BLACS 26
2.5 ScaLAPACK 26
2.5.1 Portability and scalability of ScaLAPACK 27

2.5.2 Software component of ScaLAPACK 27
2.6 Parallel Virtual Message Passing Interface 27
2.7 Parallel MATLAB 28
2.8 Compute Unified Device Architecture 29
2.8.1 NVIDIA tesla GPU architecture 29
2.8.2 Thread organization and scheduling of CUDA 30
2.9 Comparison of parallel computing tools 30
Reference 32
CHAPTER 3 : CLASSIFICATION OF TASK PARTITIONING 35-49
STRATEGIES IN DISTRIBUTED PARALLEL
COMPUTING SYSTEMS
3.1 Introduction 36
3.2 Deterministic Task Partitioning Strategies 37
3.2.1 Papadimitriou and Yannakakis scheduling 38
3.2.2 Linear Clustering with Task Duplication Scheduling 38
3.2.3 Edge Zeroing Scheduling 38
3.2.4 Modified Critical Path Scheduhng 39
3.2.5 Earhest Time First Scheduling 39
3.3 Dynamic Task Partitioning Strategies 39
3.3.1 Evolutionary Task Scheduling 40
3.3.2 Dynamic Priority Scheduling 40
3.4 Preemptive Task Partitioning Strategies 40
3.4.1 Rate Monotonic-Decrease Utilization-Next Fit Scheduling 41
3.4.2 Optimal Preemptive Scheduling 41
3.4.3 Preemption Threshold Scheduling 41
3.4.4 Fixed Preemption Point Scheduhng 42
3.5 Non-Preemptive Partitioning Strategies 42
3.5.1 Multiple Strict Bound Constraints scheduling 42
3.5.2 Earliest Deadline First scheduling 42
Reference 46

CHAPTER-4 : OPTIMAL TASK PARTITIONING MODEL IN 50-63
DISTBUBUTED HETEROGENEOUS PARALLEL
COMPUTING ENVIRONMENT
4.1 Introduction 51
4.2 PRAM Model 52
4.3 Proposed Model for Task Partitioning in Distributed Environment 53
Scheduling
4.3.1 Proposed algorithm for inter-process communication 56
amongst tasks
4.3.2 Pseudo code for the proposed algorithin 56
4.3.3 Low communication overhead phase 57
4.3.4 Priority assignment and start time computing phase 57
4.3.5 Procedure for computing the ALAP 58
4.4 Experimental Phase 59
Reference 62
CHAPTER -5 : OPTIMAL TASK PARTITIONING STRATEGY 64-82
WITH DUPLICATION (OTPSD) IN PARALLEL
COMPUTING ENVIRONMENTS
5.1 Introduction 65
5.2 MCP Algorithm 66
5.2.1 Design of MCP algorithm 67
5.2.2 Efficiency of the algorithm 67
5.3 HEFT(Heterogeneous Earliest Finish Time algorithm) Algorithm 67
5.4 Performance Metric for Simulation 68
5.5 Proposed Model of Task Partitioning Strategies 69
5.5.1 Task and processors assignment phase 69
5.5.2 Pseudo Code for Grain Pack SubDAG 70
5.5.3 Pseudo code for proposed algorithm 73
5.6 OTPSD hnplementation Phase 74
Reference 80

CHAPTER-6 : TASK PARTITIONING STRATEGY WITH 83-92
MINIMUM TIME IN DISTRIBUTED PARALLEL
COMPUTING ENVIRONMENT
6.1 Introduction 84
6.2 Critical Path Fast Duplication (CPFD) algorithm 85
6.2.1 Pseudo code for CPFD algorithm 86
6.3 Proposed algorithm 87
6.3.1 Task assignment phase 87
6.3.2 Pseudo code for proposed algorithm 88
6.3.3 Simulation results 88
6.3.4 Computational analysis 90
Reference 92
CHAPTER-7 : PREEMPTIVE TASK PARTITIONING STRATEGY 93-102
WITH FAST PREEMPTION IN HETEROGENEOUS
DISTRIBUTED ENVIRONMENT
7.1 Introduction 94
7.2 Resource sharing 95
7.3 Proposed Algorithm for Preemptive Scheduling 96
7.3.1 Description of the scheduling algorithm 97
7.3.2 Experimental phase 100
Reference 101
CONCLUSION 103-104
PUBLICATION

Figure 1
Figure 2
Figure 3
Figure 4
Figure 5
Figure 6
Figure 7
Figure 8
Figure 9
Figure 10
LIST OF FIGURE
Speedup representation by Amdhal's Law 6
Protocol hierarchy of P VM in ATM network 21
PVM Architectural View 22
PVM Computational Model 23
Two Queues used in a typical MPI 25
Hierarchal view of different task partitioning strategies in 38
different platform
PRAM model for shared memory 52
Proposed dynamic task partitioning model 54
Iteration improvement analysis of proposed model 59
Speedup analysis of the algorithm upon the number of 60
processors
Figure 11 Serializability analysis of the algorithm upon the different 60
number of processors
Figure 12 Abstract model for task partitioning strategies 69
Figure 13 Makespan analysis of different algorithms 75
Figure 14 Analysis of NSL vs CCR 76
Figure 15 Efficiency vs CCR 77
Figure 16 DAG with communication costs 77
Figure 17 Average NSL vs DAG size 78
Figure 18 DAG with Communication Cost in TPSMT 89
Figure 19 Average SLR against CCR value 89
Figure 20 Average speed up against different number of processors 90
Figure 21 Average efficiency against different number of processors 90
Figure 22 Running time vs number of processors analyasis 98
Figure 23 CCR vs average normalized schedule length analysis at 4 98
processors
Figure 24 CCR vs average normalized schedule length analysis at 8 98
processors
Figure 25 CCR vs average normalized schedule length analysis at 16 99
processors

Figure 26 CCR vs average normalized schedule length analysis at 32 99
processors
Figure 27 CCR vs average normalized schedule length analysis at 64 99
processors
Figure 28 DAG example for similution 99

LIST OF TABLE
Table 1 Comparison of parallel computing tools 31
Table 2 Comparison of different task partitioning strategies 43
under various architectures
Table 3 Nomenclature for proposed task partitioning model 55
Table 4 Computational analysis of proposed model by using different 59
parameters
Table 5 Nomenclature for OTPSD Model 71
Table 6 Allocation of tasks upon different processors in OTPSD 75
model
Table 7 Average CPU utilization and makespan length of 78
compared algorithms
Table 8 Nomenclature for TPSMT model 87
Table 9 Nomenclature in PTPS model 98
Introduction
I IP

CHAPTER 1
INTRODUCTION
1.1 Parallel computing distributed system
Parallel computing is a form of computation in which many calculations are
carried out simultaneously. It operates on the principle that large problems can often
be divided into smaller ones, which can be solved concurrently. In a distributed
system, all processing elements are connected by a network. Parallel computing
becomes the dominant paradigm in computer architecture, mainly in the form of
multi-core processors. Data parallel programming is one which each process executes
the same action concurrently, but on different parts of shared data. While in task
parallel approach, every process performs a different step of computation on the same
data.
1.2 Traditional scheduling verses parallel computing scheduling
In traditional scheduling, scheduling is defined as the allocation of operations to
processing units. One of the primary differences between traditional and parallel
computing scheduling is that the parallel computing scheduler does not have full
control over parallel computmg systems. More specifically, local resources are not
controlled by the parallel computing scheduler, but by local scheduler. Another
difference is that parallel computing scheduler cannot assume that it has a global view
of parallel computing. The difference occurs mainly due to the dynamic nature of
resources and constraints in parallel computing environment. Issues on the basis of
which differences could be considered are as follows:
1.2.1 Task partitioning constraints in parallel computing: Scheduling constraints
can be hard or soft. Hard constraints are rigidly enforced. Soft constraints are those
that are desirable but not absolutely essential. Soft constraints are usually combined
into an objective function.
1.2.2 Optimization criteria for parallel computing scheduling: A variety of
optimization criteria for parallel computing scheduling is given below:
2 | P ,

1. Minimization of inter-process communication cost, sleek time (processor
utilization time) and NSL (Normalized Schedule Length).
2. Maximization of personal or general utility, resource utilization, fairness etc.
1.2.3 Data scheduling: A variety of data is necessary for a scheduler to describe the
jobs and resources [7] e.g. Job length, resource requirement estimation, time profiles,
uncertain estimation etc.
1.2.4 Methodologies: It is obvious that there is no deterministic scheduling method
which shows ideal results for parallel computing scheduling. But in conventional
scheduling many appropriate methods are available.
1.3 Types of parallel computing architectures
1.3.1 Flynn's taxonomy; Michael J. Flynn created one of the earliest classification
systems for parallel and sequential computers and programs. It's the best known
classification scheme for parallel computers. He classified programs and computers
for different data partitioning streams. A process is a sequence of instructions (the
instruction stream) that manipulates a sequence of operands (the data stream).
Computer hardware may support a single instniction stream or multiple instruction
streams for manipulating different data streams.
1.3.1.1 SISD (Single Instruction stream/Single Data stream): It's equivalent to an
entire sequential program. In SISD, virtual network machine fetches one sequence of
instruction, data and instruction's address from memory.
1.3.1.2 SIMD (Single Instruction stream/ Multiple Data stream): This category
refers to computers with a single instruction stream but multiple data streams. These
machines typically used by process arrays. A single processor fetches instructions and
broadcast these instructions to a number of data units. These data units fetch data and
perform operations on them. An appropriate programming language for such
machines has a single flow of control by operating an entire array rather than
individual array elements. It's analogous to doing the same operation repeatedly over
a large data set. This is commonly used in signal processing applications.
There are some special features of the SIMD.
3 | P a g e

1. All processors do the same thing or are idle.
2. It consists data partitioning and parallel processing phase.
3. It produces the best results for big and regular data sets.
Systolic array is the combination of SIMD and pipeline parallelism. It achieves
very high speed by circulating data among processor before returning to memory.
1.3.1.3 MISD (Multiple Instruction /Single Data): It's not totally clear that which
type of machine fits in this category. One kind of MISD machine can be design for
failing or safe operation. Several processors perform the same operation on the same
data and check each other to be sure that any failure will be caught. The main issues
in MISD are: branch prediction, instruction installation and flushing a pipeline.
Another proposed MISD machine is a systolic array processor. In this category,
stream of data are fetched from memory and passed to the array of processors. The
individual processor performs its operation on the stream of accepted data. But they
have no control over the fetching of data from memory. This combination is not very
useftil for practical implementations.
1.3.1.4 MIMD (Multiple Instructions and Multiple Data): In this stream several
processor fetches their own instructions. Multiple instructions are executed upon a
different set of data for computations of large tasks. To achieve maximum speed up,
the processors must communicate in synchronized manner. There are two types of
streams under this category which are as follows.
1. MIMD (Distributed Memory): In this stream unique memory is associated with
each processor of the distributed computing systems. So communication overhead
is high due to the exchange of data amongst the processors.
2. MIMD (Shared Memory): This structure shares a single physical memory
amongst the processors. Programs can share blocks of memory for the execution
of parallel programs. In this stream, shared memory concept causes the problems
of exclusive access, race condition, scalability and synchronization.
1.4 Important laws in parallel computing
1.4.1 Amdahl's law: This law had been generated by Gene Amdahl in 1967. It
provides an upper limit to the speedup which may be achieved by a number of parallel
processors to execute a particular task. Asymptotic speedup is increased as the
4 I P ii e e

number of processors increases in high performance computing systems [1]. If the
numbers of parallel processors in a parallel computing system are fixed then speedup
is usually an increasing function of the problem size. This effect is known as
Amdahl's effect.
Suppose/ be the sequential fraction of computations, where 0 < / < /. The
maximum speedup achieved by the parallel processing environment by using p
processors is as follows:
1 i{j <
( f+ ( i -Op)
1.4.1.1 Limitations of Amdahl's Law:
1. It does not provide overhead computation with the association of degree of
parallelism (DOP).
2. It assumes the problem size as a constant and depicts how increasing processors
can reduce computational overhead.
A small portion of the task which cannot be parallelized will limit the overall speedup
achieved by parallelization. Any large mathematical or engineering problem will
typically consist of several parallelizable parts and several sequential parts. This
relationship is given by the equation:
1
Where S is the speedup of the task (as a factor of its original sequential runtime)
and Pf is a parallelizable fraction.
5 I P a g e

Amdhal Law '*
3K
W
Ai
i \
y y y g ^ \
y\ VJ 1 1
fKI
1 1
1 1
T\^
~
to
!
1 2 3 4 5 6 7 8 9 10 1
Speed Lp J
Figure 1: Speedup represented by Amdhai's Law
If a sequential portion of a task is 10% of the runtime, we can't get more than lOx
speedup regardless of how many processors are added. This rule puts an upper limit to
add highest number of parallel execution units. When a task can't be partitioned due
to its sequential constraints then more efforts on this application has no effect on the
schedule. Bearing of a child takes nine months regardless of the matter of assignment
of a number of women [9]. Amdahl and Gustafson laws are related to each other
because both laws give a speedup performance after partitioning given tasks into sub-
tasks.
1.4.2 Gustafson's law: It's used to estimate the degree of parallelism over a serial
execution. It allows that the problem size being an increasing function of the number
of processors. Speedup predicted by this law is termed as scaled speedup. According
to Gustafson, maximum scaled speedup is given by,
S(P) = P - aiP- 1).
Where P, S and a denotes the number of processors, speedup and non-parallelizable
part of the process respectively. Gustafson law depends upon the sequential section of
the program. On the other hand, Amdhai's law does not depend upon the sequential
section of parallel applications. Communication overhead is also ignored by this
performance metric.
6 |P a go

1.5 Performance parameters in parallel computing
There are many performance parameters for parallel computing. Some of them
are listed as follows:
1.5.1 Throughput: It is measured in units of work accomplished per unit time. There
are many possible throughput metrics which depends upon the definition of a unit of
work. For a long process throughput may be one process per hour while for short
processes it might be twenty processes per seconds. This is totally depends upon the
underlying architecture and size of executing processes upon that architecture.
1.5.2 System utilization: It keeps the system as busy as possible. It may vary from
zero to 100 percent approximately.
1.5.3 Turnaround time: It is the time taken by the job from its submission to
completion. It's the sum of the periods spent waiting to get into memory, waiting in
ready queue, executing on the processor and spending time for input/output
operations.
1.5.4 Waiting time: It is the amount of time spent to wait by a particular job in ready
queue for getting a resource. In other words, waiting time for a job is estimated at the
time taken from the job from its submission to get system for execution. Waiting time
depends upon the parameters similar at turnaround time.
1.5.5 Response time: It is the amount of time to get first response but not the time
that the process takes to output that response. This time can be limited by the output
devices of computing system.
1.5.6 Reliability: It is the ability of a system to perform failure free operation under
stated conditions for a specified period of time.
1.6 Issues and challenges in parallel computing
Parallel computing is emerging as a viable option for high performance parallel
computing. Sharing of resources in parallel computing provides improved
performance at low cost. In parallel computing there are various issues such as;
1.6.1 Role of server system: Server system plays a major part in the parallel
computing heterogeneous system as today's server systems are relatively small and
7 I P a g e

they are connected to networks by the interfaces [14]. So these systems must be
supporting for high performance computing architectures.
1.6.2 Allocation requirements: Since parallel computing may be used as distributed
computing environment. Therefore, the following aspects play an important role in
the performance of allocated resources.
Services: It's considered that parallel computing is designed to address a single and
multiple issues like minimum turnaround time as well as real time with fault
tolerance.
Topology: Whether the job services are centralized or distributed or hierarchical in
nature? Selection of appropriate topology is a challenging task for the achievement of
better results.
Nature of the job: It can be predicted on the basis of load balancing and
communication overhead of the tasks over the parallel computing architectures [8].
The effect of existing load: Existing load may cause the poor results.
Load balancing: If the tasks are spread over the parallel computing systems then load
balancing strategy depends upon the nature and size of job and characteristics of
processing elements.
Parallelism: Parallelism of the jobs may be considered on the basis of fine grain level
or coarse grain level. After jobs submission or before inserting jobs this parameter
should be kept in mind.
Redundant resource selection: What should be the degree of redundancy in the form
of task replication or resource replication? In case of failure what should be the
criterion of node selection having task replica? How the system performance is
affected by allocating the resources properly?
Efficiency: Efficiency of scheduling algorithm is computed as:
T-./-jr • Scheduling Length of Uniprocessor System ^ „ „ Etiiciency = x 100 Scheduling Length on Multiprocessor SystemxNo. of Processors
Normalized Schedule Length: If makespan of an algorithm is the completion time of
that algorithm then Normalized Schedule Length (NSL) of scheduling algorithm is
defined as follows:
8 I P a g e

^,(-,, _ Makespan of Particular Algorithm Maximum of Sum of Computational Cost Alonga Critical Path
1.6.3 Resource management: Resource management is the key factor for target of
maximum throughput. In management of resources generally includes resource
inventories, fault isolation, resource monitoring, a variety of autonomic capabilities
and service-level management activities. The most interesting aspect of the resource
management area is the selection of the correct resource from the parallel computing
resource alternatives.
1.6.4 Security: Prediction of the heterogeneous nature of resources and security
policies is complicated and complex in a parallel computing environment. These
computing resources are hosted in different security areas. So middleware solutions
must address local security integration, secure identity mapping, secure
access/authentication and trust management.
1.6.5 Reliability: Reliability is the ability of a system to perfomi its required
flinctions under proposed conditions for a certain period of time. Heterogeneous
resources, different needs of the implemented applications and distribution of users at
the different places may generate insecure and unreliable circumstances. Due to these
problems it's not possible to generate ideal parallel computing architectures for the
execution of large and real tune parallel processing problems.
1.6.6 Fault tolerance: A fault is a physical distortion, imperfection or fatal mistake
that occurs within some hardware or software packages. An error is the deviation of
the results from the ideal outputs. So failures of the system means error and an error
generate some faults. Due to these limitations parallel computing system must be fault
tolerant. Therefore, if any type of problem is happening system must be capable to
generate proper results.
1.7 NP Hard scheduling
Most of scheduling problems can be considered as optimization problems as we
look for a schedule that optimizes a certain objective function. Computational
complexity provides a mathematical framework that is able to explain why some
problems are easier than others to solve. It is accepted that more computational
9 | P a g e

complexity means the problem is hard. Computational complexity depends upon the
input size and the constraints imposed on it.
Many scheduling algorithms contain the sorting of (n) jobs, which require at most
0 (nlogri) time. These types of problem can be solved by exact methods in
polynomial time. The class of all polynomial solvable problems is called class P.
Another class of optimization problems is known as NP-hard (A/Pcomplete)
problems. In NP-hard problems, no polynomial-time algorithms are known and it is
generally assumed that these problems carmot be solved in polynomial time.
Scheduling in a parallel computing environment is a WP-hard problem due to large
amount of resources and jobs are to be scheduled. Heterogeneity of resources and jobs
causes scheduling NP-hard.
1.7.1 Classes Pand NP in parallel computing: An algorithm is a step-by-step
procedure for solving a computational problem. For a given input, it generates the
correct output after a fmite number of steps. Time complexity or running time of an
algorithm expresses the total number of elementary operations such as additions,
multiphcations and comparisons etc. An algorithm is said to be a polynomial or a
polynomial-time algorithm, if it's running time is bounded by a polynomial in the
input size. For scheduhng problems, typical values of the running time are e.g.,
0 (n^) and 0 (nm).
1. A problem is called a decision problem if its output range is {yes, no}.
2. P is the class of decision problems which are polynomials solvable.
3. NP is the class of decision problems with the property that it's not solvable in
polynomial time fashion.
1.8 Threads in parallel processing algorithm
A program in execution is known as a process. Light weight processes are called
threads. The commonly used term thread is taking from thread of control which is just
a sequence of statements in a program. In shared memory architectures, a single
process may have multiple thread of control. Dynamic threads are used in shared
memory architectures. In dynamic threads, the master thread controls the collection of
workers threads. The master thread forks worker threads, these threads complete
10 I P a g e

assigned request and after termination it again joins a master thread. This facihty
makes the efficient use of system resources, because only at the time of running state
resources are used by threads. This phenomenon reduces idle time of the participating
processors. These facihties of threads maximize throughput and try to minimize the
communication overhead. Static threads are generated by the required setup which is
known in advance.
1.8.1 Threads benefits: Multiple threads programming have the following benefits.
1.8.1.1 Responsiveness: If some threads are damaged or blocked in multithreading
apphcations then it allows a program to run continuously. It facilitates user interaction
even if a process is loaded in another thread. So it increases the responsiveness of
users.
1.8.1.2 Economy and resource sharing: During the execution of the process it's
very costly to allocate memory in traditional parallel computing environments. In
multithreading, all threads of a process can share allocated resources. So the creation
and context switching of the threads of a process is economical. Because the creation
and allocation of a process are much more time consuming than threads. So thread
generates a very low overhead in the comparison of processes. Creating a process is
thirty time slower than creating a thread in Solaris (2) systems. Context switching is
5 times slower in processes than threads. The thread code sharing facility provides an
application to have several different threads of activities within the same address
space. These threads may share resources effectively and efficiently.
1.8.1.3 Utilization of multiprocessor architectures: Each thread of all processes
may run simultaneously upon different processors. Kernel level threads parallelization
increases the usage of processors. Kernel level threads are supported directly by the
operating systems without user thread interventions. While in traditional
multiprogramming, kernel level processes can't be generated by the operating
systems.
1.9 DAG in different scheduling environments
Any parallel program may be represented by DAG. In the execution of parallel
tasks more than one computing units required concurrently [21]. DAG scheduling has
been investigated on a set of homogeneous and heterogeneous environments. In
11 [ P a g e

heterogeneous systems, it has different speed and execution capabilities. The
computing environments are connected by the networks of different topologies. These
topologies (ring, star, mesh, hypercube etc.) may be partially or fully connected.
Minimization of the execution time is the main objective of DAG. It allocates the
tasks to the participating processors by preserving precedence constraints. Scheduling
length of a schedule (program) is the overall finish time of the program. This
scheduling length is termed as the mean flow time [2, 17] or earliest finish time in
many proposed algorithms.
In DAG a parallel program is represented by G = (V, E), where V is the set of
nodes (n) and E is the set of directed edges (e). A set of instructions which can be
sequentially on the same processor without preemption is known as a node on DAG.
Every edge (n;, rij) is the corresponding computation message amongst node by
preserving the precedence constraints. The communication cost of the nodes is
denoted by {ni,nj). Sink node is called child node and source node is called the
parent node of a DAG. A node without child node is known as an exit node while a
node without parent node is called an entry node. Precedence constraints mean that
child node can't be executed without the execution of parent node. If two nodes are
assigned on same processor then communication cost between them is assumed to be
zero.
The loop structure of the program can't be explicitly modeled in the DAG. Loop
separation techniques [4, 18] divide the loop into many tasks. All iterations of loop
started concurrently with the help of DAG. This model can be used for large matrix
multiplications and data flow problems. Fast Fourier Transformation (FFT) or
Gaussian Elimination (numerical applications) loop bound must be known at the time
of compilation. So many iterations of a loop can be encapsulated in a task. Message
passing primitives and memory access operations are means of calculation of node
weight and edge weight [15]. The granularity of tasks is also divided by the
programmer [16]. The scheduling algorithms [22] are used to refme the granularity of
DAG.
Preemptive and non-preemptive scheduling approaches investigated by [3] in
homogeneous computing architectures. They used independent tasks without having
precedence constraints. In DAG, condition of precedence constraints is inserted by
12 I P a g e

Chung and Ranka [6] for preemptive and non-preemptive scheduling. Earliest time
factor inserted by them in list scheduling strategies.
In preemptive scheduling, a partial portion of the task can be reallocated to the
different processors [11, 13, 19]. While in the case of no-preemptive scheduling,
allocated processors can't be re-allocated until it finishes assigned tasks. Flexibility
and resource utilization of the preemptive scheduling is more than non-preemptive
scheduling in a theoretical manner. Practically, re-assigning partial part of task causes
extra overhead. Preemptive scheduling shows polynomial time solutions while non-
preemptive are NP-complete [5, 10]. Scheduling with duplication upon different
processors is also NP-complete. Communication delay amongst preemptive tasks is
more due to preemptions of processors.
Problems of conditional branches may be analyses by DAG. Scheduling of
probabilistic branches reported in [20]. In this scheduhng, each branch is associated
with some non-zero probability having some precedence constraints. Towsley [20]
used two step methods to generate a schedule. In first step, he tries to minimize the
amount of indeterminism. While in second step, reduced DAG may be generated by
using pre-processor methods. Problem of conditional branches is also investigated in
[9] by merging schedules to generate a unified schedule.
With the above prospective the following objectives were attempt in this thesis:
In the first chapter of the thesis, basic concept and laws related to parallel computing
are discussed. DAG is a booming field in parallel computing, so a brief discussion
about DAG is also covered.
The selection of the tools for high performance computing is challenging problem.
Therefore a systematic and comparative study about parallel computing tools is
discussed in chapter second. With the help of this comparative analysis, a researcher
can choose appropriate tool for high performance parallel computing.
In the third chapter, a classification of parallel computing scheduling is given.
These scheduling techniques are used in static, dynamic, preemptive and non-
preemptive environments. The best task partifioning strategy can be choose with the
help of comparison table. Important parameters related to each scheduling may be
analyzed by using comparison table.
13 [ P a g e

In chapter four, an iterative task partitioning model has been proposed. Tiiis
model contribute low communication factor, which reduces communication cost
amongst the tasks.
In chapter five, we proposed an Optimal Task Partitioning Strategy with
Duplication (OTPSD) in parallel computing environment. Performance of the
proposed strategy has been composed with two well-known algorithms, MCP and
HEFT. Outperformance of proposed algorithm over compared algorithm has been
discussed in terms of experimental results.
A proposed Task Partitioning Strategy with Minimum Time (TPSMT) is
discussed in the chapter six. We compared this algorithm with HEFT and CPFD
algorithms. Efficiency and normalized schedule length of the proposed algorithm
shows better performance over HEFT and CPFD.
In the chapter seven, we proposed a Preemptive Task Partitioning Strategy
(PTPS) with fast preemptions. This algorithm is a preemptive class algorithm. PTPS
has been compared with preemptive MCP and FPS. We compute average NSL value
upon different processors. Calculated NSL value shows better result than preemptive
MCP and FPS.
14 I P a e c

REFERENCES
[1] G. M. Amdahl, "Validity of the Single-Processor Approach to Achieving
Large Scale Computing Capabilities," In AFIPS Conference Proceedings,
(1967), 480-481.
[2] J. Bruno, E. G. Coffman and R. Sethi, "Scheduling Independent Tasks to
Reduce Mean Finishing Time," Commun. ACM, 17, (1974), 380-390.
[3] J. Blazewicz, J. Weglarz and M. Drabowski, "Scheduhng Independent 2-
Processor Tasks to Minimize Schedule Length," Inf. Process. Lett., 18(5),
(1984), 267-273.
[4] M. Beck, K. Pingali and A. Nicolau, "Static Scheduling for Dynamic Dataflow
Machines," y. Parallel Distrib. Comput., 10, (1990), 275-291.
[5] E. G. Coffman and R. L. Graham, "Optimal Scheduling for Two-Processor
Systems,"/icto Inf, 1, (1972), 200-213.
[6] Y. C. Chung and S. Ranka, "Applications and Performance Analysis of a
Compile-Time Optimization Approach for List Scheduling Algorithm on
Distributed Memory Multiprocessors," In Proceedings of the 1992
Conferenceon Supercomputing (Supercomputing '92, Minneapolis, MN, Nov.
16-20), R. Werner, Ed. IEEE Computer Society Press, Los Alamitos, CA,
(1992), 515-525.
[7] R. Cheng, M. Gen and Y. Tsujimura, "A Tutorial Survey of Job-Shop
Scheduling Problems using Genetic Algorithms," Comput. Ind. Eng., 30 (4),
(1996), 983-997.
[8] A. W. David and D. H. Mark, "Cost-Effective Parallel Computing," IEEE
Computer, (1995), 67-11.
[9] El-Rewini and M. A. Hesham, "Static Scheduling of Conditional Branches in
Parallel Programs," J. Parallel Distrib. Comput., 24, (1995) 41-54.
[10] T. Gonzalez and S. Sahni, "Preemptive Scheduling of Uniform Processor
Systems," y. ACM, 25 (1), (1978), 92-101.
[11] Gustafson, J. L., "Reevaluating Amdahl's Law," Ames lab web link
http://www.scl.ameslab.gov/Publications/AmdahlsLaw/Amdahls.html, (1996).
15 I P a g e

[12] E. C. Horvath, S. Lam and R, "Sethi, A Level Algorithm for Preemptive
Scheduling," J. ACM. 24{\), (1977), 36-47.
[13] T. Haluk, H. Salim and Y. W. Min, "Performance-Effective and Low
Complexity Task Scheduling for Heterogeneous Computing," IEEE
Transactionson parallel and Distributed systems, 13(3), (2002), 262-279.
[14] H. Jiang, L. N. Bhuyan, and D. Ghosal, "Approximate Analysis of
Multiprocessing Task Graphs," In Proceedings of the International
Conference on Parallel Processing, (1990), 230-238.
[15] Y. K. Kwok and I. Ahmad, "Efficient Scheduling of Arbitrary Task Graphs to
Multiprocessors using a Parallel Genetic Algorithm," J. Parallel Distrih.
Comput., 47(1), (1991), 55-78.
[16] J. Y. T. Leung and G. H. Young, "Minimizing Schedule Length Subject to
Minimum Flow Time," SIAMJ. CompuL, 18(2), (1989), 310-333.
[17] B. Lee, A. R. Hurson and T. Y. Feng, "A Vertically Layered Allocation
Scheme for Data Flow Systems," J. Parallel Distrib. Comput., 77(3), (1991),
172-190.
[18] V. J. Rayward-Smith, "The Complexity of Preemptive Scheduling given
Interprocessor Communication Delays," Inf Process. Lett., 25(2), (1987),
120-128.
[19] D. Towsley, "Allocating Programs Containing Branches and Loops within a
Multiple Processor System," IEEE Trans. Softw. Eng. SE-12, 10, (1986),
1018-1024,
[20] Q. Wang, and K. H. Cheng, "List Scheduling of Parallel Tasks," Inf Process.
Lett., 37(5), {\99\),2%9-295.
[21] T. Yang and A. Gerasoulis, "PYRROS: Static Task Scheduling and Code
Generation for Message Passing Multiprocessors," In Proceedings of the 1992
international conference on Supercomputing (ICS '92, Washington, DC , K.
Kennedy and C. D. Polychronopoulos, Eds. ACM Press, New York, NY,
(1992), 428-437.
16 I P ag i

Comparative Study of (ParaOeC Computing IjooCs
1 7 | P a g

CHAPTER 2
COMPARATIVE STUDY OF PARALLEL COMPUTING
TOOLS
2.1 Introduction
In this chapter, perfonnance of ftequently utilized parallel processing tools are
discussed and compared. Each tool has its own feature which may be completely
different or have some resemblance to some extent with others. Evaluation and
prediction of parallel programming tools are very important because it is used to
identify the factors those influence application executions. Parallel computing without
efficient, flexible, portable and interoperable tool is not effective in high performance
distributed computing systems. Portability is a measure of the ease with which
software can be moved between heterogeneous computing platforms. Software which
can run on diverse platforms increases longevity because it can be migrated from
older to newer platforms. Software tools for a high performance computing
environment require the knowledge of internal architecture and components of the
distributed systems [22]. In case of distributed systems, different products are
combined with different strengths to achieve a combination which is better than any
of the individual components. Therefore over the last few years, a number of
applications are designed to solve message passing problems in distributed
environments. Inter-process communication amongst various processes during the
computation is the major factor for high speed computing. MPI is a standardized
interface for inter-process communication in high performance massively parallel
processing (MMPs) computer systems. It provides highly optimized and efficient
implementations than PVM. Message passing interface (MPI) [3] and parallel virtual
machine (PVM) [5] are the most popular tools for message passing. PVM and MPI
have different nature in terms of architectures [12]. ScaLAPACK internally
implements parallelism with the use of the BLACS. BLACS provides a message
passing interface that may be implemented efficiently and uniformly across a large
range of parallel computing and distributed system.
I S l P a c e

The BLACS are a message-passing tool designed for linear algebra which can be
used in ScaLAPACK. Message passing through BLACS is easy and convenient for
message passing environments. Portability issue is more important than performance
due to the two reasons: communication and fault tolerance. PVMPI uses non-MPI
functions to join separately started MPI jobs. PVMPI shows transparency and
flexibility amongst different types of distributed computing systems. It combines the
best features of PVM and MPI. PVM and MPI effectively harness the capability of a
distributed network of UNIX workstations as well as heterogeneous network of UNIX
and Windows NT workstations.
Parallel Computing Toolbox and MATLAB are server oriented software, which
are used to solve data-intensive problems. How can one compare these programming
environments? How are these programs easier than others? How do the portability and
interoperability play the important role in parallel computing distributed systems?
What are the advantages and disadvantages of the software? In this chapter, we shall
discuss each of these programming environments in detail.
2.2 PVM
PVM is specifically designed for heterogeneous networks of computers. It is de
facto for the message passing environment [11]. It offers good facilities for parallel
computing but poor scheduling facilities for distribution of workload. PVM supports
certain forms of error detection and recovery. It encapsulates the functions amongst
heterogeneous distributed computing system. PVM system has gained widespread
acceptance in high performance scientific computing community.
A virtual parallel machine may be constructed by using PVM due to its simplicity.
The virtual machine concept is the one, in which dynamic collection of heterogeneous
computational resources is managed as a single parallel computer. It has been strongly
supported by PVM. Dynamic process groups layer above the core of PVM routines.
The group member is uniquely numbered from zero to the number of group members
minus one.
Functions that logically deal with group of tasks are known as broadcast and
barrier functions. A process can link to multiple groups, and groups can change
dynamically at any time during computations [18]. PVM essentially consists of a
19 | P a g e

collection of protocol to implement reliable and sequential data transfer. Mutual
exclusion enables preemption of deadlock in several situations [11]. PVM facilitates
ability to utilize shared memory and high speed networks like ATM to move data
amongst the clusters of shared memory multiprocessors.
2.2.1 Evolution of PVM: The development of PVM started in 1989.VaidySunderam,
a professor at Emory University, visited Oak Ridge National Laboratory to do
research with AI Giest on distributed computing [25]. Research associate Bob
Manchek joined the team and implemented a portable version PVM 2.0 of PVM in
1991. PVM 2.0 becomes pubUcly available by the valuable efforts of Dongarra. On
the basis of the requirements of the users, some additional interfaces were designed by
the experts that allow third party debugging and resource management [4].
A PVM software framework for heterogeneous concurrent computing is available
in, different varieties of disciplines [18]. It supports dynamic process management
while in other systems the processes are statistically defined. Performance issue was
dealt primarily with communication overhead at the time of message passing. In the
dynamic PVM, task migration is possible within the system without affecting the
operation of user or application programs.
2.2.2 Portability, interoperability and evolution of PVM: The advancement of
technology has been improving the computing speed of the workstations rapidly.
Software with a high degree of portability is highly valuable because it can be used by
the various users. Great diversity of computer hardware and software poses a
fundamental threat to software portability. Computational enhancement through the
network may be achieved by PVM due to its portable capabilities [19]. PVM
provides the facility of language interoperability also i.e. A FORTRAN program can
send a message that is received by C program and vice-versa. A user defined
collection of serial, parallel and vector computers emulates a large distributed
memory computer under PVM. PVM facilitates automatically startup of tasks on the
virtual machine with message passing and synchronization. Multiple users can
configure overlapping virtual machines and each user can execute several PVM
apphcations simultaneously. PVM is highly remarkable in ATM [21].
20 I P a g e

Application
I P\'M Message Passing Interface
P^'M Internal
Socket Interface
UDP
IP
'^ Switch J ^ Cloud. ATM
ATM
AAL5
API
ATM
API 3/4 ATM
ATM
Switch
Figure 2: Protocol hierarchy of PVM in ATM network
A set of routines is given by the different standards of PVM. Tiiese routines
enable a user to add and delete hosts from the virtual machines. Synchronization may
be achieved by sending a Unix signal to other tasks, or by using barriers. To manage
and create the multiple send and receive buffers, some special routines have been
provided by the PVM for high speed computing over network [21]. Message buffers
are allocated dynamically to save the data temporarily by native machines [14]. PVM
provides the set of functions to enable applications to communicate directly with each
other via TCP sockets. The successfiil execution of large simulations without fault
space detection and recovery is not possible. Failure of any workstation in a large
simulation will cause unexpected results. Hence there are several types of applications
that explicitly require fault tolerance execution environment due to the safety level of
requirements. When the status of a virtual machine changes or a task falls under the
control of users, PVM gives special event message which contains information about
that particular event [17]. This message gives the opportunity to respond fault without
hanging or failing. The message due to fault tolerance is used to control the
21 i P a g e

computing resources. Many systems have been designed specifically for fault
tolerance purpose, which uses Condor at the top of PVM environment. Fault tolerance
facility of PVM boosts the performance of the message passing environment.
2.2.3 Computing model of PVM: Computing model of PVM provides the facility of
asynchronous blocking (send, receive) and non-blocking fiinctions. In point-to-point
communication functions, computing model supports multicast to a set of tasks and
broadcast to a user defined group of tasks. Tasks can communicate with each other
without the limitation of size and number of messages [18]. Figure (3) justifies the
PVM computing model as well as an architectural abstraction of the system.
• Inter Component Comm. and Synchronizations
Computer 1 C? Computer 2
Input and Partitioning
Output and Display Inter Instance Comm. and Synchronizations
Figure 3: PVM Architectural View
22 I P a g e

Cluster 1
^
Cluster 2
Bridge/Router
MPP \
VECTOR SC
^T
PVM Uniform View of Multi-programmed Virtual Machine
Figure 4: PVM Computational Model
2,3 Message Passing Interface
MPI designed by the MPI Forum (a diverse collection of implements, library
writers, and end users), is quite independent of any specific implementation. MPI [24]
specifications can be used for writing portable parallel programs. It would be a library
for writing application programs, not distributed operating system. A fixed set of
processes may be created at the time of program initialization. Each process knows
the rank of others. MPI would be modular to accelerate the development of portable
libraries.
MPI has more than one freely available quality implementations. The groups of
MPI are solid, efficient and deterministic. MPI (Message Passing Interface) defines
also a 3"^ party profiling mechanism. It provides over 40 routines related to groups,
communicators, and virtual typologies which are built upon MPI communicators and
groups. Support of MPI is not mandatory for UNIX features. Tasks will be assigned to
the processors according to the capability of systems.
2.3.1 Evolution of MPI: The processes use a library to exchange messages in parallel
computing. This message passing approach allows processes to run upon multiple
processors for the solution of large problems efficiently. A ftill MPI implementation
23 I P a u e

MPICH [16] is portable to all parallel machines and workstations running Chameleon,
p4 or PVM [2]. MPI interface is meant to provide essential virtual topology,
synchronization and communication flinctionality between a set of processes. The
applications of MPI-1 were not portable across a network of workstations because
there was no standard method to start MPI tasks on separate hosts. In 1995, MPI
committee started the eiforts to design the MPI-2 specifications to correct the problem
of portability and to add additional communication functions. After the evolution of
MPI-2, one sided communication and dynamic process management came into the
existence across a number of tasks. Key aspect of dynamic process management
feature is the ability of an MPI process to participate in the creation of new MPI
processes. This facility makes communication with MPI processes which have been
started separately.
MPl-1 and MPI-2 implementation show good results in overlapping and
computation. MPI also specifies thread safe interfaces which have cohesion and
coupling strategies. Multithreaded point-to-point MPI code is easier than other codes
supported by different implementations. MPI-2 defines three one sided
communication operations: put, get and accumulate to remote memory read and a
reduction operation on the same memory across a number of tasks. MPI-2 also defines
methods for the synchronization of the communication.
2.3.2 Portability, interoperability and fault tolerance of MPI: MPI is totally
portable. So compilation and implementation with virtual typologies and efficient
buffer management are the excellent features of MPI. It provides the portability of
efficient and flexible standards for message passing. The MPI specification does not
provide interoperability facilities because a program written in C can't communicate a
program written in FORTRAN, even if executing on the same architecture. Portability
plays an important role to reuse the software tools for communications [15].
Earlier version of MPI does not support fauh tolerance mechanism. In MPI-1, model
host and task are considered as static in terms of fault tolerance. MPI-2 includes a
specification for spawning new processes to expand the capabilities of the original
static MPI-1 [10]. Message passing across the tasks is very convenient because each
task already knows about the every other task and all communications can be made
24 1 P a e e

without the expUcit need of special daemon. In the fault tolerance mechanism
management of faults is discussed below:
(1) During restart of an entire application, the periodically intermediate results should
be saved by the programmer on the reliable media.
(2) The ftinction of MPI implementation may be augmented to return information
about faults and must accept communicator reconfiguration.
(3) A fully automatic fault detection and recovery facility of the MPI implementation
hides the fault from programmers and users.
2.3.3 Implementation of MPI: MPI specifications can be used for writing portable
and parallel programs [13]. The impetus for developing MPI, according to the
computing experts is that each Massively Parallel Processors (MPP) vendor creates
their own proprietary message passing. MPI is intended to be a standard message
passing specification that each MPP vendor would implement on their systems. The
model depicts the implementation issues on a socket for the communications.
Application Receive Request
MPI Library Received Message Queue. RMQ
/ 1 Runtime
*
*
1
Received Message Qu
—•!
->
;ue
- •
.RRQ
Kernel Received Message
Socket
Figure 5: Two Queues used in a typical MPI
MPI would be modular, to accelerate the development of portable parallel libraries.
MPI has more than one freely available quality implementations and fiill
asynchronous communications.
25 1 P a u e

2.4 BLACS
BLACS are message passing routines that communicate matrices amongst the
processes arranged in two dimensional virtual process topologies. It forms basic
communication layer for ScaLAPACK. MPI provides most suitable message passing
layer for the BLACS. Its wide availability has high level functionality to support
BLACS communication semantics. It has several advantages over other available
communication libraries like PVM [10]. Computational model of BLACS consists of
one or two dimensional process grid where each process stores pieces of the matrices
and vectors. BLACS permits a process to be a member of several overlapping or
disjoint process grids. BLACS goal was to implement a core set Of linear algebra
routines provided in LAPACK [4]. The package attempts to provide the same ease of
use and portability for distributed memory linear algebra communication such as the
BLAS provides for linear algebra computation in ScaLAPACK [20]. Portability of
the BLACS has recently been further increased by the development of a version that
uses MPI. A PVM version of the BLACS is also available.
2.4.1 ID-Less communication in BLACS: ID-less communication means that during
the communication no message ID carried out across the processes. In message
passing every message has its ID (msgid) for the unique identification of messages
during communication. However, the generation of these IDs may be problematic.
Non unique IDs which are used in any two sections of code not separated by an
explicit barrier can cause the same result. These kinds of programming mistakes can
lead to non-deterministic code which will give wrong results. In the point-to-point
communication scope, messages without IDs in the BLACS work properly while
messages need the ordering for the identification in the MPI. The BLACS users do
not need to give any msgid for broadcasts/combines.
2.5 ScaLAPACK
The ScaLAPACK library includes core factorization routines which allow
factorization and solution of a dense system of linear equation via LU, QR and
Cholesky. The scalable library for concurrent computers will be fully compatible with
the LAPACK library for vector and shared memory computers. ScaLAPACK also
26 j P a g e

makes use of block partitioning algorithms. It can be used to solve the grand
challenging problems on massively parallel distributed memory concurrent
computers. Heterogeneous ScaLAPACK is a software package which provides
optimized parallel linear algebra programs for heterogeneous computational clusters
(HCCs).
2.5.1 Portability and scalability of ScaLAPACK: Main goal of designing linear
algebra algorithms is to minimize the movement of the data between different levels
of memory of distributed computing systems. Block partition algorithms passes
through blocks instead of vectors which reduce startup costs due to few message
exchange [6]. Block-partitioned algorithm with adjustable block size use poly
algorithms (where the actual algorithm is selected at run time) to achieve the
granularity of computation. Standard basic message passing as well as higher-level
communication constructs (global summation, broadcast, etc.) is necessary to achieve
a higher degree of portability.
2.5.2 Software component of ScaLAPACK: ScaLAPACK is distributed memory
version of LAPACK. These libraries are used to provide portability, flexibility and
easy use of the software. ScaLAPACK can solve systems of linear equations, linear
least squares, eigenvalues and matrix factorizations. Building block of the
ScaLAPACK library consists of distributed-memory version of the BLAS or PBLAS
[26] and a set of the BLACS. High performance of LAPACK may be achieved by
using algorithms that do most of their work in call to BLAS [13], with the emphasis
of matrix-matrix multiplication and matrix factorization. BLAS (Basic Linear Algebra
Subprograms) is a de facto standard for solving the basic numerical linear algebra
problems. It is famous software which is used to solve many scientific and
engineering problems. BLAS library has the capability to implement upon many
supercomputers by which BLACS programs can be transplanted from one computer
to another computer. The computational model of BLACS consists of one or two
dimensional grid of process where each process store matrix and vectors [6].
2.6 Parallel Virtual Message Passing Interface
Parallel Virtual Message Passing Interface (PVMPI) is a software system that
allows independent MPI applications. It provides intercommunication even if they are
27 I P a i; c

running under different MPI implementations using different language bindings. It
allows interoperability of vendor's optimized MPI versions. Due to the lack of
interoperability of the different MPI implementations, vendors bear problems in
distributed computing across different vendor's machines. The use of PVMPI is
transparent to MPI applications and allows intercommunication via all MPI point-to-
point calls [7]. It provides the facility of protection from rogue message for the MPI
applications after enrolling in PVMPI. The second implementation of the PVMPI
system uses some features of the PVM 3.4. Under MPI-1, applications caimot
communicate with other processes outside their MPI-COMM-WORLD without using
some other entities. Groups of the processes which are registered in PVMPI improve
security and performance with locking attribute.
2.7 Parallel MATLAB
It started in the 1970s as an interactive interface with EISPACK [23], a set of
eigen value and a linear system solution routines. In 1995, the use of parallel
MATLAB in high performance parallel computing was negligible. Its small
interactive environment provides high performance parallel computing routines which
initiate drastic significant interest in the field of high performance computing.
Interpreted built in language of MATLAB which is sunilar to C and flexible matrix
indexing are the innovative features of matrix programming problems [9]. Strong
graphical capabilities of MATLAB make it good data analysis tool. It provides small
hooks to the Java programming language, making integration with compiled program
easy. With the help of parallel MATLAB, we can implement task-parallel and data-
parallel algorithms at a high level without programming for specific hardware and
network architectures. A job is any large operation that we need to perform in
MATLAB session. A job is broken into segments called tasks. We can divide our job
into identical tasks but tasks may not be identical. The MATLAB distributed
computing server performs the execution of jobs by evaluating each of its tasks and
returning the results to the client [12]. In file system based communication feature,
MATLAB-MPI [3] implements basic MPI fijnctions in parallel MATLAB using
cross-mounted directories. Parallelism may be achieved through polymorphism
property of parallel MATLAB [1].
28 I P a g e

2.8 Compute Unified Device Architecture
Inherently parallel computations may be achieved by Compute Unified Device
Architecture (CUDA) programming model. In high performance computing,
acceptance of parallelism increment is more than clock rate increment. High level
parallelism provides significant computational growths.
NVIDIA [28] developed a CUDA model with a forward extension of C/C++
languages. Tliis programming model improves scalability across the broad spectrum
of real parallel computations in distributed computing systems. Programmers are
guided by the CUDA model for the utilization of multiple threads to expose fine grain
parallelism [29]. It provides optimum abstraction of parallel computation. Two key
features of the CUDA programming model are:
• It dictates to the programmer how to craft needed parallel algorithms rather than
. grappling with the mechanics of not famiUar languages.
• High scalable parallel code may re-design which can run across thousands of
parallel threads with the help of processors cores.
2.8.1 NVIDIA Tesla GPU architecture: Tesla architecture executes CUDA
programs written in CUDA programming. It consists of multithread multiprocessors.
Its memory may be accessed by different type of instructions having integer as well as
data floating point data types. Tesla GPU architecture capacity is to execute up to
30,720 threads simultaneously. While its earlier versions were capable to execute
12,288 threads concurrently. Scheduling of threads consists very low overhead. The
cost of creating and destroying threads is also negligible. Chip level parallelism may
be achieved by modem Graphics Parallelism Units (CPUs) [27]. GPU provides a
large number of simple execution units which are capable to achieve several time
speedups. Unlike CPUs, GPUs lack sophisticated pipelines and speculation
mechanisms. So, GPUs are well-suited for data-parallel compute intensive tasks.
However, GPUs can offer very high memory bandwidth due to fast enough rate of
data. The architecture of GPUs is well-suited for single-program, multiple-data
(SPMD) parallel programming models.
A CUDA program can be partitioned into two parts. The first kind should be run
on device (GPU) and second one should be executed on the host (CPU). The compiler
29 I P a g e

(like NVIDIA's) separates these two kinds. There are many APIs available in CUDA
to write programs in high level languages like C and FORTRAN.
2.8.2 Thread organization and scheduling of CUDA: To utihze all available
resources on a GPU, one must create many threads. These threads are created by
specifying the dimensions of the parallel computing and the blocks before calling the
kernels. The coordinates of each lattice point in a parallel computing and a block
represent a unique id of the corresponding block and the corresponding thread,
respectively. Thread blocks are generated by the programmers for the execution of
large applications. Threads grouped mto warps (32-thread units) and these warps are
assigned to the streaming processors (SPs). During warp instructions, executing
scheduler selects the next warp to be executed. So, there is no overhead in selecting a
warp during a warp-swapping. There is no time required for saving context while
swapping a warp as each thread has already been allocated registers. Shared memory
is also shared among all threads in a block.
The scalar sequential program may be executed on a set of parallel threads of the
kernel. Entirely different codes can be strongly executed by different thread blocks or
different threads of a kernel. Task parallel kernel exposes less fine grain parallel
computations than data parallel kernels.
2.9 Comparison of parallel computing tools
Analysis of different features of tools is as follows:
30 I P a g e

<
u
<
O H
>
1
1
> O H
c/3
s es
P M
2^ y3
> •
t/5
u > •
> •
t/3 1)
>-
C/2 (U
>-
to
>-
o
3
15 iS u O
P-
—
V5
>-
<U
>
C/3
o
o D .
3
on
c
O
<N
V5 D
>-
> •
W5
>-
C/3
> •
y 5
"o
"o
o ex CL 3
1/3
1 O Urn
(
o
U5
>-
o
o
WD U
o a. u. 3
0 0
lt>
c iS o
13
3
>
^
1)
o 2
o & 3
g3 "o o H
l O
t/5
•a o o O
o o
O
<L>
O CL CX 3
t /3
D . 3 O
O W5 VI O U O U i
O H CJ
'a
Q
VO
Vi
Vi
'o
O o. & 3
0 0
"o "H o U
on VD OJ
o o
O H
t ^
> •
W5
VI
W
^
4->
o 2
'o Z
o ex o. 3
CO c
<u o
3 O VI O
oo
00
o 2
o
Vi
C/5 D O
cx 0 0
Z
ON
"o
z
4—1
o 2
4—• o Z
o Z
o Z
o Z
o Z
o cx 3
on c o •s o 'c 3
E E o U
o
VI U
o Z
o Z
>
o
z
o
z
o
z
o cx cx 3
tZl u bO ca
c «
o o
2
--
IZl
Vi U
VI
o
z
"o Z
<u 6 0 <A C
a
3 ,o ' • * - * u u O
U i-i ID
t 0 0
( N
VI
V
>
>
VI
o
o
z
o
z
o
z en
E
& o
0H
bO 3 O
^
E OT
"3
CL,
m
Z
C/3
z
'o Z
Z
o Z
o Z
CD (U
> •
g
_ 3
> w > N C3
Tj-
Vi
Vi
Vi
o Z
o Z
"o Z
ir-i
>
Vi 1)
O
Z
o Z
"o Z
o Z
"o Z
W5
U
>-
c u E c o
• >
e W 0 0
,c 'o
CO
H
\o
"o Z
>•
Vi U
Vi
<U
>-
o Z
en
>-
o Z
O to C S3
c o o u c c o
u c u G
t ^
>-
en
1/)
z
o
z
o
z
r. o cx D . 3
T 3 d
CJ
CQ
0 0
> •
en
'o
z
Vi
>-
o
z
z
15 CO
cx CO
u c
."& o
C/3
OS
en
o
z
en
en
o
z
o Z
tZ)
>-
S CO
I )
c«
o
cx,
o
§ OX)
e s a
o
I 3
H

REFERENCES
[1] C. Ron and E. Alan, "Parallel MATLAB: Doing it Right," Massachusetts
Institute of Technology, Cambridge, (2003), 2-8.
[2] Beguelin et al., "PVM 3 User's Guide's and Reference Manual," Technical
Report TM-12187.0ak Ridge National Laboratory, (1993).
[3] K. Jeremy, "Parallel Programming With MATLABMPI," High Performance
Embedded Computing HPEC, Workshop, (2001), 23-26.
[4] J. Choi et al., "CRPC Research into Linear Algebra Software for High
Performance Computers," International Journal of Super Computing
Applications, 8, (1994), 99-118.
[5] Beguelin, "PVM: Experiences Current Status and Future Directions,"
Technical Report CS/E 94-015. Oregon Graduate Institute CS, (1994).
[6] L.S. Blackford et al., "ScaLAPACK: A Portable Linear Algebra Library for
Distributed Memory Computers-Design Issues and Performance
Supercomputing," Proceedings of the ACM/IEEE Conference. 0-89791-854-1,
(1996), 5-5.
[7] E. F. Graham and D. J. Jack, "PVMPI: An Integration of the PVM and MPI
Systems," Department of Computer Science Technical Report CS 96 328,
Knoxville, (1996), 8-15.
[8] J. Choi et al., "The Design and Implementation of the ScaLAPACK LU, QR,
and Cholesky Factorization Routines," Technical Report ORNL/TM-12470,
Oak Ridge National Laboratory, (1994), 10-15.
[9] C. Stephane and B. M. Francois, "An Envu-onment for High Performance
MATLAB," In Languages, Compilers and Run-Time Systems for Scalable
Computers, (1998), 27-35.
[10] Geist et al., "PVM: A Users' Guide and Tutorial for Networked Parallel
Computing," MIT Press. (1994), 23-40.
[11] J. A. K. Geist and P. M. Papadopoulos, "PVM and MPI: A Comparison of
Features Calculate Parallel," 8(2), (1996), 20-26.
[12] C. Ron and E. Alan, "Parallel MATLAB survey,"
http://theory.lcs.mit.edu/cly/survey.html, (2001).
32 I P a t! c

[13] W. Gropp and E. Lusk, "PVM and MPI are Completely Different,"
Mathematics and Computer Science Division Argonne National Laboratory.
(1998), 1-4.
[14] C. L. Lowson et al., "Basic Linear Subprograms for FORTRAN Usage," ACM
Transactions on Mathematical Software, (1979), 308-323.
[15] J. Mooney et al., "Developing Portable Software. Information Technology:
Selected Tutorials," Springer Boston, ISBN 978-1-4020-8158-3, (2004), 55-
85.
[16] E. Nathan et al., "An Initial Implementation of MPI," Technical Report MCS-
P393-1193, Mathematics and Computer Science Division Argonne National
Laboratory, Argonne, IL 60439, (1993), 491-510.
[17] J. Pniyne and M. Liveny, "Providing Resource Management Services to
Parallel Applications," In Proceedings of the Second Workshop on
Environments and Tools for Parallel Scientific Computing, (1994).
[18] V. S. Sundarm et al., "The PVM Concunent Computing System: Evolution,
Experience and Trends," Compcon Spring., (1993), 21-29.
[19] L. C. Sheue et al., "Enhanced PVM Communications Over a High-Speed
LAN," IEEE Parallel and Distributed Technology, 3(3), (1995), 20-32.
[20] H. Salim et al., "A Problem Solving Environment for Network Computing,"
IEEE Computer Society, (1997), 22-28.
[21] Xuebin C, at. el., "Developing High performance Bias, Lapack and Scalapack
on Hitachi Sr 8000 in High Performance Computing in the Asia-Pacific
Region," The Fourth International Conference/Exhibition on, (2), (2000),
993-997.
[22] J. Ali and R. Z. Khan, "A Survey Paper on Task Partitioning Strategies in
Parallel and Distributed System," Globus-An International Journal of
Management & IT, 01, (2010), 5-9.
[23] T.S. Brian et al., "Matrix Eigen system Routines- EISPACK Guide," Springer-
Verlag, 2nd edition, 5-7, (1976), 124-135.
[24] Message Passing Interface Forum. "Document for a message passing
interface," Technical Report No: CS-93-214 1994. Available on netlib.
33 I F a e c

[25] V. S. Sundaram et al., "The PVM Concurrent Computing System: Evolution,
Experience and Trends," Parallel Computing, 20, (1994), 10-15.
[26] L. L. Charles et al, "Basic Linear Algebra Subprograms for Fortran Usage,"
ACM Trans. Math. Softw., 5(3), (1979), 308-323.
[27] P. Micikevicius, "3D Finite Difference Computation on CPUs Using CUDA,"
In: GPGPU-2: Proceedings of 2nd Workshop on General Purpose Processing
on Graphics Processing Units, New York, NY, USA, (2009), 79-84.
[28] NVIDIA: NVIDIA CUDA reference manual 3.1, (2010).
[29] S. Ryoo et al., "Optimization Principles and Application Performance
Evaluation of a Multithreaded GPU Using CUDA," In: ACM SIGPLAN
PPoPP., (2008), 2-3.
[30] K. Fatahalian et al., "Understanding the Efficiency of GPU Algorithms for
Matrix-Matrix Multiplication," In Proceedings of the ACM
SIGGRAPH/EUROGRAPHICS Conference on Graphics Hardware, (2004),
133-137.
[31] The Math Works, "Matlab Software Acknowledgements," Online,
http://www.mathworks.com/access/helpdesk/help/base/relnotes/software.html,
2006.
34 I P a e e

classification qf*Tas^
(Partitioning Strategies in
<I>istri6ute(f<ParaOeC
Computing Systems
35 I P

CHAPTER 3
CLASSIFICATION OF TASK PARTITIONING
STRATEGIES IN DISTRIBUTED PARALLEL
COMPUTING SYSTEMS
3.1 Introduction
Distribution of tasks amongst various computing nodes is a challenging problem
in high performance distributed computing systems. To choose the appropriate
strategy for required system is difficult without meaningful comparison of existing
task partitioning and load balancing strategies. Effectiveness of strategies depends
upon the number of factors including efficiency, interconnection topology,
communication mode, program structure, throughput and computing capabilities of
high performance computing structures. A number of task partitioning and load
balancing strategies have been proposed, each of which produces better results under
different circumstances. The main goal of this chapter is to unravel the mystery of
strategies and to classify when and where each strategy is appropriate. This chapter
provides a common terminology and classification mechanism. Scheduling is a
fiinction which is used to assign jobs to the different processors [6]. It's a two-step
process, processor allocation and assignment. A job is an autonomous program that
executes in its domain. Resource allocation is done by the scheduler over two
dimensions, time and space and at two level jobs and threads. In running state, job
constitutes threads to reduce overhead.
If a software package is used to execute parallel jobs instead of threads, it
increased load of parallel computing systems. Threads and communication between
them may be static or dynamic [10]. For example, in MIMD architecture [1], number
of threads and the communication pattem between the threads can change
dynamically during execution in the parallel computing systems. If multiple executing
entities are part of the same application, then we treat entities as threads and
applications as jobs [30]. A parallel job is the collection of tasks having some
precedence relationship. A task can be identified as an executable fragment that must
36 I P i! u e

be sequentially executed without partial parallel execution [2]. All parallel jobs cannot
be fiilly parallelized. Effective task partitioning and load balancing of large task is
required to achieve high performance in a parallel and distributed system. Increasing
demand of high performance computing systems amongst various fields of science
shows keen interest in the parallel computing. Selection of appropriate strategies for a
particular system is a deciding factor for successfiil execution of the tasks. In a
homogeneous architecture, serial fi'action of computation executes at the speed of any
of the identical processors. Sequential bottlenecks can be greatly reduced by
executing tasks on heterogeneous parallel computers by running critical tasks on
faster processors. Efficiency analysis of heterogeneity presented by [4, 5]. Processor
allocation in efficient manner deals with the determination of the number of
processors allocated to a job [7]. Time complexity analysis tool for task partitioning
has been developed by Pugh and Nirkhe [8]. It accurately estimates the execution time
of a general real time program employing on high level structures. Towsley and
Nelson [9] proposed an analytical model for partitioning independent tasks on
different processors. There is no ideal task partitioning strategy for all diverse
computing architectures. Under the different architectures some important task
partitioning strategies are as follows:
3.2 Deterministic task partitioning strategies
In deterministic task partitioning, characteristics of an application such as
communication cost, execution time, synchronization and data dependency are
known in advance [11]. Dynamic scheduling performs scheduling at runtime and the
allocation of the processes may change during the execution of tasks. Static
scheduling cannot support load balancing and fault tolerance while dynamic
scheduling support these parameters. Deterministic scheduling on a Network of
Workstation (NOW) is NP-complete in strong sense while nondeterministic is not
strongly NP-complete. Purely static task partitioning with OpenCL, determines the
best partitioning across processors in a system. It divides tasks into many chunks
based on the availability of processors [13].
37 I P a g e

Task Partitioning Strategies
Non-Determiiiistic{EKiiainic)
X Preemptive Non-Preemptive
Homogeneous
OFT iPT XIS3C
Heterogeneous
^
Homogeneous
rru /PSTS I L R F
PIS s i LRPT-FMS ^
LRPT-m O SRT OFSDFTO
Non-Homogeneous
Figure 6: Hierarchal view of different task partitioning strategies in different
platform
3.2.1 Papadimitriou and Yannakalds sciieduling: Papadimitriou and Yannakakis
[34] scheduling approximate absolute achievable lower bound start time of a node by
using e-value attribute. From the first node up to exit node e-value have been
computed recursively to assign the priority of the nodes. After calculating e-value of
the node, each node inserted into a cluster in such a way that ancestors have data
arrival time larger than e-value of the node.
3.2.2 Linear Clustering with Task Duplication Scheduling: LCTD (Linear
Clustering with Task Duplication) [35] scheduling identifies the edges among
clusters. These edges determine completion time after linear clustering of DAG. After
that it attempts to duplicate the parent nodes corresponding to these edges in order to
reduce start time of some nodes in the cluster.
3.2.3 Edge Zeroing Scheduling: Edge Zeroing (EZ) Scheduling [33] tries to select
computing environment by merging edge weights. This scheduling strategy finds
38 IP a u e

edges with the largest weight in every step. If merging does not decrease execution
time then two clusters are merged (zeroing the largest weight) for the reduction of
completion time. Ordering of the nodes is defined in the resulting cluster based upon
the static b-level of the nodes. DAG edges have been sorted in descending order of
edges weights.
3.2.4 Modified Critical Path Scheduling: Modified Critical Path (MCP) [31]
scheduling decides priorities of nodes on the basis of ALAP (As Last as Possible)
parameter. It computes ALAP of the existing node and constructs a list of nodes in
ascending order of ALAP times. MCP finds processors idle time slot for a given node.
It selects first node from the node list and insert it into the processor of earliest
execution time [15]. It cannot guarantee an optimal schedule for fork and join
structures.
3.2.5 Earliest Time First Scheduling: ETF (Earliest Time First) scheduling [32]
technique select the node of the smallest start time from the node of earliest start time
in ready queue at each step. Earliest start time is computed by examining start time of
the node on all processors exhaustively. When two nodes have same EST, then ETF
breaks the tie by selecting the node with higher static priority. The priorities are
assigned to the nodes by computing static b-level.
3.3 Dynamic task partitioning strategies
Position Scan Task Scheduling (PSTS) is pure dynamic load balancing. It can be
used in centralized and decentralized manner [14]. It is based on divide and conquers
principle in which higher grid of dimension k is divided into grids of dimension (k-1),
until the dimension is (1). Position Scan Load Balancing (PSLB) technique is two
phase technique. In the first phase, the system modeled as a hypercube only at one
time. In the second phase, load balancing is performed by obtaining necessary
information for each system node. On the basis of the prior information, PSLB
strategy calculates its fiiture load. After that load is migrate according to the
capabilities of the nodes. An important aspect of this strategy is that, in the case of
load migration, each node knows exactly where to send its extra work load.
Communication takes place only between neighboring nodes.
39 I P a e e

3.3.1 Evolutionary task scheduling: Evolutionary Task Scheduling [26] depends
upon previous scheduling stages. Use of heuristic in initialization phase and specific
mutation operator are two parameters, which provide beneficial results for effective
scheduling in a static environment. In consistent environment, tasks moves from
higher level processors to lower level processors. This can be achieved by using
"rebalancing" operator. But in the case of inconsistent environment less greedy
operators are used to provide the best results. In this scheduling, information collected
from the previous state is used to select the environment by the scheduler.
3.3.2 Dynamic Priority Scheduling: Dynamic Priority Scheduling (DPS) [27] assign
priorities to the tasks based upon difference of bottom level (b-level) and top level (t-
level). This technique tries to schedule minimum schedule length in Directed Acyclic
Graphs (DAGs) [3]. In Dynamic process assignment, the scheduler selects more
important tasks before less important ones. Mapping and scheduling of strategies
depend upon the processor scheduler, network architecture and the DAG structures
[28]. The t-level is the length of the longest path (execution cost + communication
cost) between the target and entry tasks of DAG. While b-level is the large path
between target and exit tasks. In this way, t-level determines earliest start time. This
start time consider as a critical path of GDA [12].
Dynamic Level Scheduhng (DLS) [29] uses Generalized Dynamic Level (GDL)
to determine dynamic priorities for all tasks in the ready queue. GDL gives priorities
to the processors according to their speeds. Many other factors are taken into account
due to different execution costs on each processor. It considers factors like median of
the execution cost over all processors, average execution cost and maximum or
minimum costs for the computation of schedule levels.
3.4 Preemptive tasks partitioning strategies
Preemptive Deterministic Scheduling (PDS) ensures repUca behavior while
preserving concurrency. Replication is achieved by the threads and there is no
communication between the threads. Performance improvement is achieved due to
multithreading by exploiting concurrency in thread execution. Multithreaded replica
shows non deterministic behavior. Only one physical thread can be scheduled at given
time, so it shows poor scalability and performance. PDS schedules multiple threads at

the same time, so it shows five times throughput than Nondeterministic Preemptive
Scheduhng (NDPS) [11]. Optimal preemptive schedule subject to release date has
been used to minimize the execution time on the homogeneous platforms. This
strategy performs two steps. In the first step, minimize maximum completion time on
the desired number of machines. In second step, it determine maximum lateness with
respect to due dates for the jobs [12] on arbitrary number of machines.
Fast Preemptive Scheduling (FPS) [17] strategy simulates preemptive task
execution at a very low overhead. It requires small runtime support in heterogeneous
and homogeneous parallel computing environment [22]. Preemptive Task Scheduling
(PTS) [18] strategy can also be used for homogeneous distributed memory systems.
3.4.1 Rate Monotonic-Decrease Utilization-Next Fit Scheduling: RM (Rate
Monotonic)-DU (Decrease Utilization)-NFS (Next Fit Scheduling) [19] strategy does
not suffer from execution time anomalies. It's a scheduling for periodically arriving
tasks in multiprocessor environment. If the following assumption does not hold; (1)
assume that a task meet its deadline if it does so when all tasks are executed at their
maximum execution time, or (2) assume that a task meets its deadline, if it does so
when all tasks arrive frequently, then this situation is known as scheduling anomalies.
RM-DU-NFS is the combination of DU and NFS which is based on high system
utilization bound.
3.4.2 Optimal Preemptive Sctieduling: Optimal Preemptive Scheduling [20] is used
to schedule different jobs on multiple parallel uniform machines. By assigning
shortest remaining processing time jobs to the fastest available machine. Flow time
has been minimized by serving jobs preemptions in increasing order of their
remaining processing time. Shortest Remaining Processing Time on Fastest Machine
(SRPT-FM) rule is also optimal for the discounted flow time criteria. Flow time is
minimized by scheduling jobs according to the shortest remaining processing time on
the fastest machine. Minimization of makespan has been achieved by using (LRPT-
FM rule) Longest Remaining Processing Time on Fastest Machine [21] scheduling.
3.4.3 Preemption Threshold Scheduling: Preemption Threshold Scheduhng (PTS)
[23] disables preemption up to a specific level, called preemption threshold. Regular
priority assignment to the arriving tasks is achieved by PTS. Tasks can preempt, only
if the priority of the arriving task is higher than the threshold of running task.
41 I P a g e

3.4.4 Fixed Preemption Point Scheduling: In Fixed Preemption Point (FPP)
scheduling [24] strategy, a task is assigned in a non-preemptive mode and a
preemption can take place at a specific point of the code, which is known as
preemption point. In this way, a task is divided into subtasks. If the highest priority
task arrives then preemption is postponed till the next preemption point. So the tasks
cooperate with each other by the preemption point.
3.5 Non-Preemptive Partitioning Strategies
Loose Synchronization Algorithms (LSA) uses non-preemptive deterministic
scheduler to maintain multithreaded replica consistency. Optimal Finish Time (OFT)
non preemptive strategy is known as NP complete with many uniform processors
[14]. Largest Processing Time First (LPT) scheduling is near optimal for non-
preemptive OFT.
3.5.1 Multiple Strict Bound Constraints scheduling: Multiple Strict Bound
Constraints (MSEC) scheduling is non-preemptive static strategy for heterogeneous
computing systems. It performs alternative task priority scheduhng instead of
Heterogeneous Earliest Finish Time (HEFT) scheme. It's also used to enhance the
performance of parallel computing applications on heterogeneous platforms due to
macro data flow graph implementation [16].
3.5.2 Earliest Deadline First scheduling: EDF (Earliest Deadline First) Strategy,
schedules periodic or sporadic tasks on single processor without preemption [25].
Periodic tasks are invoked after a certain time interval while sporadic tasks are
invoked in arbitrary time but within the limited time constraints. EDF is universal for
the set of periodic or sporadic tasks.
This chapter provides a suitable firamework for comparing past work in the area of
distributed parallel computing systems. Ideal performance of the strategy depends
upon the requirement used for distributed parallel processing systems. From the brief
discussion of scheduling strategies, it's clear that there is no ideal strategy for all
parallel computing systems. In this chapter, dynamic, preemptive and non-preemptive
task partitioning and load balancing strategies had been briefly discussed.
Advancement of the technology is a key factor for mapping heuristics of task
partitioning strategies. A researcher decides his direction of the research problem
42 I P a s e
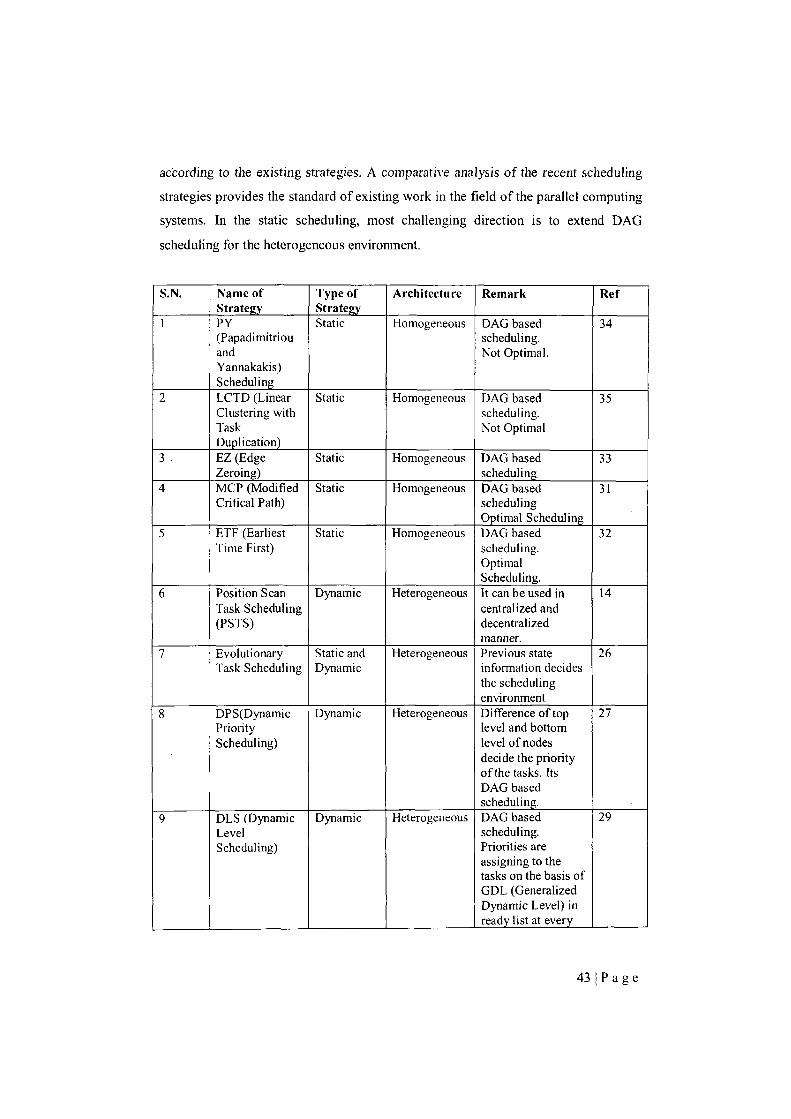
according to the existing strategies. A comparative analysis of the recent scheduhng
strategies provides the standard of existing work in the field of the parallel computing
systems. In the static scheduling, most challenging direction is to extend DAG
scheduling for the heterogeneous environment.
S.N.
1
2
3 .
4
5
6
7
8
9
Name of Strategy PY (Papadimitriou and Yannakakis) Scheduling LCTD (Linear Clustering with Task Duplication) EZ (Edge Zeroing) MCP (Modified Critical Path)
ETF (Earliest Time First)
Position Scan Task Scheduling (PSTS)
Evolutionary Task Scheduling
DPS(Dynamic Priority Scheduling)
DLS (Dynamic Level Scheduling)
Type of Strategy Static
Static
Static
Static
Static
Dynamic
Static and Dynamic
Dynamic
Dynamic
Architecture
Homogeneous
Homogeneous
Homogeneous
Homogeneous
Homogeneous
Heterogeneous
Heterogeneous
Heterogeneous
Heterogeneous
Remark
DAG based scheduling. Not Optimal.
DAG based scheduling. Not Optimal
DAG based scheduling DAG based scheduling Optimal Scheduling DAG based scheduling. Optimal Scheduling. It can be used in centralized and decentralized manner. Previous state information decides the scheduling environment Difference of top level and bottom level of nodes decide the priority of the tasks. Its DAG based scheduling. DAG based scheduling. Priorities are assigning to the tasks on the basis of GDL (Generalized Dynamic Level) in ready list at every
Ref
34
35
33
31
32
14
26
27
29
43 I P a g e

10
11
12
13
14
15
16
17
18
19
20
21
LMT( Level Min Time) Scheduling
FPS(Fast Preemptive Scheduling) PTS(Preemptive Task Scheduling) PDS(Preemptive Deterministic Scheduling)
Optimal Preemptive Scheduling subject to release date RM-DU-NFS Scheduling
Optimal Preemptive Scheduling with discount flow time objective SRPT-FM Scheduling LRPT-FM Scheduling PTS(Preemptive Threshold Scheduling) FPP(Fixed Preemption Point) Scheduling
LSA(Loose Synchronization Algorithm) Scheduling
Dynamic
Preemptive
Preemptive
Preemptive
Preemptive
Preemptive
Preemptive
Preemptive
Preemptive
Preemptive
Preemptive
Non-preemptive
Heterogeneous
Heterogeneous and Homogeneous Homogeneous
Heterogeneous
Homogeneous
Heterogeneous
Homogeneous
Homogeneous
Homogeneous
Real Time System
Real Time System
Heterogeneous
scheduling step. DAG based scheduling. During first phase level sorting has been used and in second phase greedy heuristic is applied for assigning priority. Scheduling cost is very low
Cannot be implemented in Heterogeneous Multiple threads and there is no inter replica communication Many step process
Free from scheduling anomalies SRPT-FM rule is also optimal for discounted flow time criteria
Minimize flow time
Minimize makespan
It's used to reduce unnecessary preemption Non preemptive task make preemptions with the help of preemption point in code of the job Its multithreaded replica strategy in which leader (thread) control to(follower) thread
30
17
18
11
12
19
20
21
21
23
13
44 I P a a e

•22
23
24
25
OFT(Optimal Finish Time) strategy LPTF(Largest Processing Time First) strategy MSBT(Multiple Strict Bound Constraints) strategy EDF(Earliest Deadline First) Scheduling
Non-preemptive
Non-preemptive
Non preemptive, static
Non-preemptive
Homogeneous
Homogeneous
Heterogeneous
Real Time System
by using mutex (locking/unlocking). NP-Complete
Its near optimal to non-preemptive OFT Its use macro data flow graph implementation
Universal for the set of periodic or sporadic tasks
14
15
16
25
Table 2: Comparison of different tasli partitioning strategies under various
arcliitectures
Comparative analysis of various task partitioning and scheduling strategies has been
discussed above in detail. This analysis is highly beneficial to choose the appropriate
strategy under the different requirements and architectures.
45 I P a g e

REFERENCES
[1] G. E. Christensen, "MIMD vs. SIMD Parallel Processing," A Case Study in
3D Medical Image Registration. Parallel Computing, 24 (9), (1998), 1369-
1383.
[2] D. G. Feitelson, "A Survey of Scheduling in Multi-programmed Parallel
Systems," Research Report RC 19790 (87657), IBM T.J. Watson Research
Center, (1997).
[3] X. Z. Jia and M. Z. Wei, "A DAG-Based Partitioning-Reconfiguring
Scheduling Algorithm in Network of Workstations," High Performance
Computing in the Asia-Pacific Region, 2000. Proceedings. The Fourth
International Conference/Exhibition, (1), (2000), 323-324.
[4] J. B. Andrews and C. D. Polychronopoulos, "An Analytical Approach to
Performance/ Cost Modeling of Parallel Computers," Journal of Parallel and
Distributed Computing, 12(4), (1991), 343-356.
[5] D. A. Menasce, D. Saha, Porto, S. C. D. S., V. A. F. Almeida and S. K.
Tripathi, "Static and Dynamic Processor Scheduling Disciplines in
Heterogeneous Parallel Architectures," J. Parallel Distrib. Comput., 28,
(1995), 3-6.
[6] D. Gajski and J. Peir, "Essential Issues in Multiprocessor," IEEE Computer,
18(6), (1985), 1-5.
[7] D. A. Menasce, S. C. Porto and S. K. Tripathi, "Static Heuristic Processor
Assignment in Heterogeneous Message Passing Architectures," Int. J. High
Speed Computing, (1994), 114-135.
[8] D. B. Shmoys, J. Wein and D.P. Williamson, "Scheduling Parallel Machines
On-line," SIAM Journal on Computing, (1995), 12-34.
[9] R. Nelson and D. Towsley, "Comparison of Threshold Scheduling Policies for
Multiple Server Systems," IBM, Research. Report, (1985), 45-57.
[10] D. G. Feitelson and L. Rudolph, "Parallel Job Scheduling: Issues and
Approaches," In IPPS'95 Workshop: Job Scheduling Strategies for Parallel
Processing, Springer-Verlag, Lecture Notes in Computer Science LNCS 949,
(1995), 1-3.
46 I I' a m

[11] Y. Kwok and I. Ahmad, "Static Scheduling Algorithms for Allocating
Directed Task Graphs to Multiprocessors," ACM Computing Surveys, 31(4),
(1999), 406-471.
[12] Y. Kwok and I. Ahmad, "Efficient Scheduhng of Arbitrary Task Graphs to
Multiprocessors Using a Parallel Genetic Algorithm," Journal of Parallel and
Distributed Computing, (1997), 1-3.
[13] D. Grewe and M. F. O'Boyle, "A Static Task Partitioning Approach for
Heterogeneous Systems Using OpenCL," In CC'll, (2011), 14-17.
[14] K. Savas and M. Tahar Kechadi, "Dynamic Task Scheduling in Computing
Cluster Environments," Proceedings of the ISPDC/Heterogeneous Parallel
Computing, IEEE conference, (2004), 121-154.
[15] S. Ali, H. J. Siegel, M. Maheswaran and D. Hensgen, "Task Execution Time
Modeling for Heterogeneous Computing System," Proceedings of
Heterogeneous Computing Workshop, (2000), 184-199.
[16] H. Chen, "On the Design of Task Scheduling in the Heterogeneous
Computing Envkonments," IEEE Pacific Rim Conference on
Communications, Computers and Signal Processing, (2005), 23-27.
[17] M. Ahmed, S. M. H. Chowdhury and M. Hasan, "Fast Preemptive Task
Scheduling Algorithm for Homogeneous and Heterogeneous Distributed
Memory Systems," In Ninth ACIS International Conference on Software
Engineering, Artificial Intelligence, Networking and Parallel/Distributed
Computing, (2008), 721-726.
[18] A. Radulescu and A. J. C. Gemund, "On Complexity of List Scheduling
Algorithms for Distributed Memory Systems," ACM Int'l Conf on
Supercomputing, Rhodes Greece, (1999), 45-57.
[19] B. Andersson and J. Jonsson, "Preemptive Multiprocessor Scheduling
Anomalies," Proceedmgs of IPDPS, (2002), 12-19.
[20] D. G. Pandelis, "Optimal Preemptive Scheduling on Uniform Machines with
Discounted Flow Time Objectives," European Journal of Operational
Research, 177(1), (2007), 630-637.
47 I P a g e

[21] T. Gonzalez, "Optimal Mean Finish Time Preemptive Schedules," Technical
Report 220, Computer Science Department, Pennsylvania State University,
(1977), 90-102.
[22] A. S. Renan and S. Romulo, "A Heterogeneous Preemptive and Non-
preemptive Scheduling Approach for Real-Rime Systems on
Multiprocessors," Second Brazilian Conference on Critical Embedded
Systems, (2012), 70-75.
[23] M. Desrochers, J. K. Lenstra, and M.W.P. Savelsbergh, "A Classification
Scheme for Vehicle Routing and Scheduling Problems," European Journal of
Operational Research, (1990), 320-331.
[24] A. Bums, "Preemptive Priority Based Scheduhng: An Appropriate
Engineering Approach," Technical Report YCS 214, University of York,
(1993), 12-18.
[25] K. Jeffay, D. F. Stanat and C.U. Martel, "On Non-Preemptive Scheduling of
Period and Sporadic Tasks. Real-Time Systems Symposium, Proceedings,"
Twelfth, (1991), 129-139.
[26] F. Zamfirache, D. Zaharie and C. Craciun, "Evolutionary Task Scheduling in
Static and Dynamic Environments," Computational Cybernetics and
Technical Informatics, International Joint Conference, (2010), 619-625.
[27] I. Ahmad, M. K. Dhodhi and R. Ul-Mustafa, "DPS: Dynamic Priority
Scheduling Heuristic for Heterogeneous Computing Systems," Computers
and Digital Techniques, IEEE Proceedings, 145(6), (1998), 411-418.
[28] Norman M. G. and Thanisch P, "Models of Machines and Computation for
Mapping in Multicomputers," ACM Comput. Survey, (1993), 263-302.
[29] G. C. Sih and E.A. Lee, "A Compile Time Scheduling Heuristic for
Interconnection-Constrained Heterogeneous Processor Architectures,"
Parallel and Distributed Systems, IEEE Transactions, 4(2), (1993), 175-187.
[30] M. Iverson, F. Ozgumer and G. Follen, "Parallelizing Existing Applications
in a Distributed Heterogeneous Environment," In Proceedings of the 4"
Heterogeneous Computing Workshop (HCW'95), (1995), 91-99.
48 I P a

[31] M.Y. Wu and D.D. Gajski, "Hypertool: A Programming Aid for Message-
Passing Systems," IEEE Transaction Parallel Distributed Systems, (1990),
331-344.
[32] J. J. Hwang, Y. C. Chow, F. D. Anger and C.Y. Lee, "Scheduling Precedence
Graphs in Systems with Inter-processor Communication Times," SIAM J.
Computer, (1989), 245-256.
[33] V. Sarkar, "Partitioning and Scheduling Parallel Programs for
Multiprocessors," MIT Press, Cambridge, M.A., (1989), 15-23.
[34] C. H. Papadimitriou and M. Yannakakis, "Towards an Architecture-
Independent Analysis of Parallel Algorithms," SIAM J. Computer, (1990),
324-327.
[35] H. Chen, B. Shirazi and J. Marquis, "Performance Evaluation of a Novel
Scheduling Method: Linear Clustering with Task Duplication," In
Proceedings of the 2" International Conference on Parallel and Distributed
Systems, (1993), 271-276.
49 I P a g e

Optma['Tas^<Partiticmin0 ModeCin <l>istn6ute(f<Par(UIeC
Computing Trnvironment
5 0 | ! \

CHAPTER 4
OPTIMAL TASK PARTITIONING MODEL IN
DISTRIBUTED PARALLEL COMPUTING
ENVIRONMENT
4.1 Introduction
Parallel computing systems compose task partitioning strategies in a true
multiprocessing manner. Such systems share the algorithm and processing unit as
computing resources to achieve higher inter process communications capabilities. A
large variety of experiments have been conducted on the proposed algorithm. Goal of
computational models is to provide a realistic representation of the costs of
programming.
This chapter represents optimal iterative task partitioning scheduling in distributed
heterogeneous environment. The main goal of the algorithm is to improve the
performance of the schedule in the form of iterations. This algorithm first uses fe-level
computation to calculate the initial schedule. Main characteristics of our method are
optimal scheduling and strong link between partitioning, scheduling and
communication. Some important models for task partitioning have also been
discussed in this chapter. The proposed algorithm improves inter process
co.mmunication between tasks by using recourses of the system in an efficient
manner.
Scheduling techniques might be used by an algorithm to optimize the code that
comes out from parallelizing algorithms. A researcher is always keen to construct a
parallel algorithm that runs in the shortest time. Another use of these techniques is the
designing of high-performance computing systems. Threads can be used for task
migration dynamically [1]. They are used to increase the efficiency of the algorithm.
Parallel computing systems have been implemented upon heterogeneous platforms
which comprise different kinds of units, such as CPUs, graphics co-processors, etc.
An algorithm has been constructed to solve the problem according to the processing
capabilities of the machines [10]. Communication factor is highly important feature to
51 I P a g e

solve the problem of task partitioning in the distributed systems. A conq)uter cluster is
a group of computers working together closely in such a manner that it's treated as a
single computer. The cluster is always used to improve the performance and
availability over that of a single computer. A cluster is used to improve the scientific
calculation capabilities of the distributed system [2]. Task partitioning has been
achieved by linking the computers closely to each other as a single implicit computer.
Large tasks partitioned into sub tasks by the algorithms to improve the productivity
and adaptability of the systems. Process division is a function that divides the process
into the number of processes or threads. Thread distribution distributes threads
proportionally among several machines in the cluster network [15]. A thread is a
function which executes on the different nodes independently, so the communication
cost problem is negligible [3]. Some important models [4] for task partitioning in a
parallel computing system are: PRAM, BSP etc.
4.2 PRAM model
It is a robust design paradigm provider. PRAM conqrased of P processors, each
with its own un-modifiable program. A single shared memory composed of a
sequence of words, each of which capable of containing an arbitrary integer [5].
PRAM model is an extension of the familiar RAM model and it's used in algorithm
analysis. It consists of a read-only input tape and a write-only ou^ut tape. Each
instruction in the instruction stream has been carried out by all processors
simultaneously. It requires unit time, reckless of the number of processors. Parallel
Random Access Machine (PRAM) model of computation consists of a number of
processors operatiag in lock step[13]. In this model each processor has a flag that
controls whether it is active in the execution of an instruction or not. Inactive
processors do not participate in the execution of instructions.
Shared Memory
Figure 7: PRAM model for shared memory
52 j P a g c

The processor ID can be used to distinguish processor behavior while executing
the common program. Synchronous PRAM produces results by multiple processors to
the same location in shared memory. Highest processing power of this model can be
used by using the Concurrent Read Concurrent Write (CRCW) operation. It's a
baseline model of concurrency and explicit model which specify operations at each
step [11]. It allows both concurrent read and concurrent write instructions to shared
memory locations. Many algorithms for other models (such as the network model)
can be derived directly from PRAM algorithms [12]. Classification of the PRAM
model is as follows:
1. In the Common CRCW PRAM, all the processors must write the same value.
2. In the Arbitrary CRCW PRAM, one of the processors arbitrarily succeeds in
writing.
3. In the Priority CRCW PRAM, processors have priorities associated with them
and the highest priority processor succeeds in writing.
4.3 Proposed model for task partitioning in distributed environment
scheduling
Task partitioning strategy in parallel computing system is the key factor to decide
the efficiency, speedup of the parallel computing systems. The process has been
partitioned into the subtasks where the size of the task is determined by the run time
performance of each server [9]. In this way assign a number of tasks will be
proportional to the performance of the server participated in the distributed computing
system. Inter-process communication cost amongst tasks is very important factor
which is used to improve the performance of the system [6]. Inter processes
communication cost estimation criteria is important for the enhancement of speed up
and turnaround time [8]. Call Procedure (C. P.) is used to dispatch the task according
to the capability of the machines. In this model server machine can be used for large
computations. Every processing element executes one task at a time and all tasks can
be assigned to any processing element. In the proposed model, subtasks communicate
to each other by sharing of data. So execution time is reduced due to sharing of data.
These subtasks assign to the server which dispatch the tasks to the different nodes.
53 I P a g e
•!•- t i

The proposed scheduling algorithm is used to compute the execution cost and
communication cost of the tasks. So the server is assumed by a system (P, [Pij], [Si],
[Til [Gil [Kij]) as mows:
a) P = [Pi,... P„] , vi4iere Pi denotes the processing elements on cluster
b) [Pij\ .uiiere NxN is processors topology
c) Si, 1 < i < N, specify the speed of processor Pi
d) Ti, 1 <i< N, specify the startup cost of initiating message on P,-
e) Gi ,1 < i < N, specify the startup cost of initiating process on P
J) Kij is the traosmission rate over the link connecting to adjacent processors Pj and
In the designing of the parallel algorithm, the main goal is to achieve large degree
of parallelism. For this purpose we used C.P. (Call Procedure).
Large Task
Sub Task Sub Task
Input Server Output Server
Inter Process Communication
C.P. C.P
Figure 8: Proposed dynamic task partitioning model
This model sphts both computation and data into small tasks [14]. The following
basic requirements have been fulfilled by the proposed model:
54 I P a g c
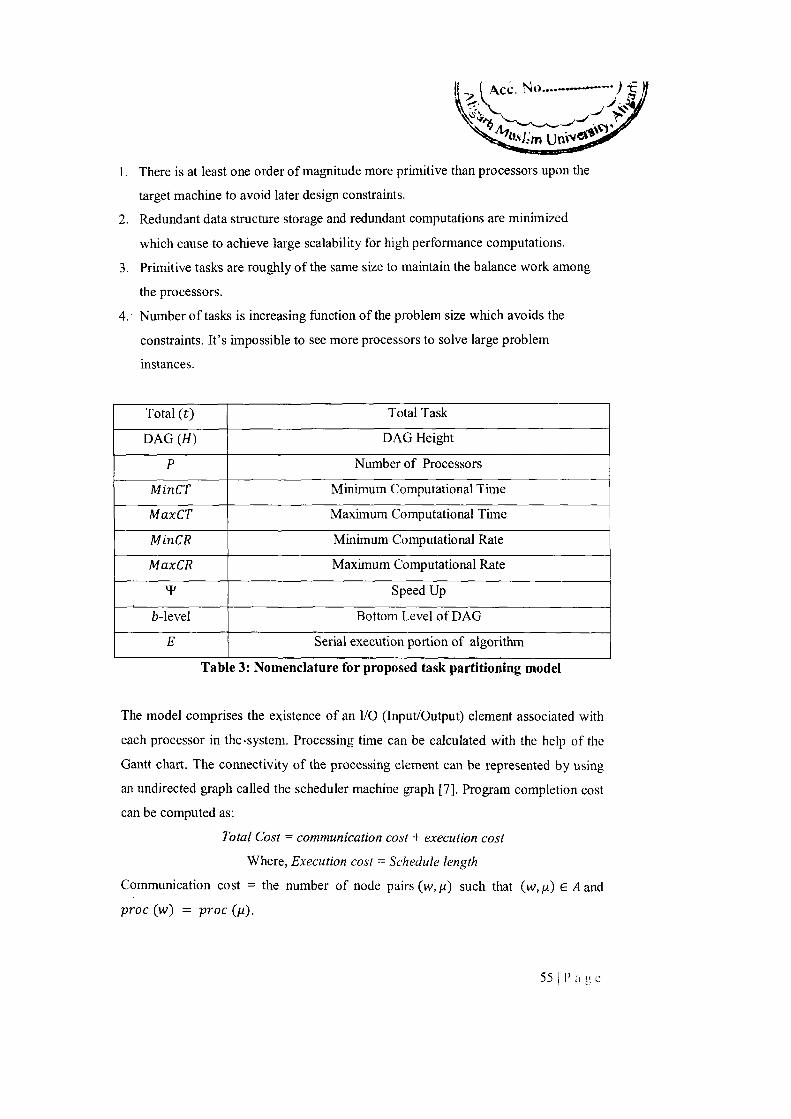
1. There is at least one order of magnitude more primitive than processors upon the
target machine to avoid later design constraints.
2. Redundant data structure storage and redundant computations are minimized
which cause to achieve large scalability for high performance computations.
3. Primitive tasks are roughly of the same size to maintain the balance work among
the processors.
4.- Number of tasks is increasing fiinction of the problem size which avoids the
constraints. It's impossible to see more processors to solve large problem
instances.
Total (t)
DAG (H)
P
MinCT
MaxCT
MinCR
MaxCR
T
fa-level
E
Total Task
DAG Height
Number of Processors
Minimum Computational Time
Maximum Computational Time
Minimum Computational Rate
Maximum Computational Rate
Speed Up
Bottom Level of DAG
Serial execution portion of algorithm
Table 3: Nomenclature for proposed task partitioning model
The model comprises the existence of an I/O (Input/Output) element associated with
each processor in the-system. Processing time can be calculated with the help of the
Gantt chart. The connectivity of the processing element can be represented by using
an undirected graph called the scheduler machine graph [7]. Program completion cost
can be computed as:
Total Cost = communication cost + execution cost
Where, Execution cost = Schedule length
Communication cost = the number of node pairs (w, ii) such that (w, n) E A and
proc (w) = proc {p.).
55 I P a ti e

4.3.1 The proposed algorithm for inter-process communication amongst tasks:
It's an optimal algorithm for scheduling interval ordered tasks on (m) processors. The
algorithm generates a schedule / that maps each task v 6 V to a processor P^ with a
starting time t^. Communication time between the processor P; and P, may be
defined as:
comm.(i,j) = [Ofori - j,otherwise 1]
task-ready (fi, i,f): the time when all the messages fi-om all task in N(v) have been
received by processor P,- in schedule / .
start time(fi, i, / ) : the earliest time at which task v can start execution on processor P;
in schedule / .
proc(^, / ) : the assigned processor to task n in schedule / .
start(//,/): the time in which task |a begins its actual execution in schedule / .
task(i,T,/): the task schedule on processor P, at time T in schedule / . If there is no
task schedule on processor P at time t in schedule / , then task(i, T,/)retums the
empty task <I). It's assumed that n2(0) < rizdi).
In this algorithm edge cut gain parameter is considered to calculate the
communication cost amongst the tasks [9].
gain(i,7) = €.gain edge cut + ( ] - € )
gain edge cut = edge cut actor / old edge cut
edge cut factor = old edge cut - new edge cut
Where € is used to set the percentage of gains from edge-cut and workload balance to
the total gain. Higher value of € contribute total gain of the communication cost.
4.3.2 Pseudo code for the proposed algorithm:
1. start 2. taskfi, T, j)*^0, for all positive integers i, where 1 < i <Pand x > 0 3. repeat 4. Let \i be the unmark task with highest priority 5. fori = 1 to P do 6. compute i-level for all tasks 7. schedule all tasks into non-increasing order of /?-level 8. compute ALAP, constructs a list of tasks in the ascending order of the ALAP
time 9. task_ready(ti, i, 0 <- max(start(n, f) -H comm(proc(^, 0, i) + 1) +
gain(i,j) for each |i 10. start_time(|i,i, f)<- minx, where task(i,x,0 *- <5and t > task_ready(n,i,0
56 I P a g e

11. endfor 12./(/i) «- (startjime(ii,i,f) if 13. start_time(n, i, 0 < (start_time(n,j,0, 1 < j < P,i = j or
start_time(pi,i,0 = (start_time(n,j,0 and n2(task(i, (start_time((i,i,0 - 1). f)^ n2(task(j,(start_time(n,j,0 - 1)./) 1 < j <P, i ^ j
14. mark task |i until all tasks marked \5.endif
4.3.3 Low communication overhead phase: Optimality of the algorithm over the
target machine can be achieved due to the following reasons:
Fact(l): comm(i, Ti,j,T2) where 1 < i,j < P
Swapping of the task by the task schedule on processor node (nj) at time (TI) with the
task schedule on node (rij) at time (T2). When the swapping of the task amongst the
different processor then
Fact (2/- total comm(i,7, T) where 1 < i,j < P
The effect of the above operation is to swap all the task schedule on node (n;) at time
Ti with the task schedule node (ny) at time T2, where T2 > T.
The following operation is equivalent to the more than one swap operations:
Fact (3): total comm(i,j,T)~ comm(i, r\,j, T2) V TI,T2 > T
4.3.4 Priority assignment and start time computing phase: Computation of the b-
level of DAG is used for the initial scheduhng. The following instructions have been
used to compute the initial scheduling cost of the task graph:
1. Construct a list of nodes in reverse order(Li) 2. for each node Oi ELI do 3. max = 0 4. for each child Oc of a, do 5. lfc{a\, Oc) + b-level(ac) >Mthen 6. M = c{a\, Oc) + b-level(ac) 7. endif 8. endfor 9. &-level(ai) = weight(ai) + M 10. endfor
In the scheduling process fo-level is usually constant until the node has been
scheduled. Procedure computes b-level and schedules a list in descending order The
quantitative behavior of the proposed strategy depends upon the topology used on the
57 I P a g e

target system. This observation might lead to the conclusion that fa-level perform best
results for all experiments. The algorithm employs the attribute ALAP (As Late as
Possible) start time which measure that how far the node's start time can be delayed
without increasing schedule length.
4.3.5 Procedure for computing the ALAP is as follows:
1. construct ready list in reverse topological order (A/;) 2. for each node Oj eMj do 3. min = k , where k is call procedure(C.P.) length 4. for each predecessor a^ of oi do 5. //•alap(ac) - c(ac, ai) < k then 6. k = alap(ac) - c(ac, a,) 7. endif 8. endfor 9. alap(ai) = k - wgt (a,) 10. endfor
According to priority of nodes, tasks allocated on the processors in distributed
computing environment. The ALAP time is computed and then constructs a list of
tasks in ascending order of ALAP time. Ties have been broken by considering ALAP
time of predecessors of tasks.
The following results from the above facts prove the optimality of the proposed
model:
1. The operation comm(i, T\,J, Xi) on the schedule f of the tasks preserves the
feasibility of the schedule of any task (w)
f(w) = (p, Ti) where pe [i,j} and T\ = T-1
2. Feasibility of the schedule f in the proposed model increased for any task schedule
f(w) = (p, Ti) where p G {i,j] and V T|
3. The operation conim(j, Ti,j, T2) and n2(total comm(J, ;, T)) > n2(task(i, TJ, / ))
shows optimality on the schedule of any task(w)
f(w) = (p, T3) where pg [i,j} and V T3
4. The operation comm(i,;, T) preserves feasibility of the schedule of any task(w)
f(w) = (p, Ti) where p e [i,j] and TI < x-l
5. The operation conim(i,;, T) also shows optimality of the schedule of any task(w)
f(w) = (p, Ti) where p^ [i,j} andVXi
58 j P a g e

4.4 Experimental phase
In experiments CCR increased as (0.1, 0.5, 1.0, 1.5, 1.75, 2.0, 5, 5.5, 7, 12) and
load factor varies from 0 to 12 with increment of 1.5. Tasks number ranging from {5,
10, 15,40, 70, 100, 130, 150}. In [16] percentage of improvement cases calculated as
70-75%. While in the proposed model percentage of unproved cases is up to 85%
with the increment of the iterations. Performance analysis of the algorithm based
upon the DAG example discussed in [16] with the assuming parameters:
No. of
Iterations
7
MaxCR
6
MinCR
1
MaxCT
150
MinCT
12
P
5
DAG(H)
13
Total(r)
150
Table 4: Computational analysis of proposed model by using different
parameters
Iteration Improvement Analysis
Average of Improvement Ratio
Figure 5: Iteration improvement analysis of proposed model
The result is shown in figure (20) in which simulation runs 100 times under each
case. The experimental computation predicted that when a smaller than the
percentage of improved cases is also small. This simulation result predicts that initial
schedule iteration contribute very low improvement in the computation of the
algorithms. When a is high then the percentage of improved cases reached at a critical
point, after that it becomes constant even if a increased.
59 I P a g e

Ratio of serial execution of program to parallel execution is known as Speedup. In
our experiment the results estimated upon the heterogeneous parallel computing
platform with 30 processors successively. When the number of the nodes is increased
then the speedup is increased up to an improved level after this level speedup factor is
not increased even if the number of processors increases.
40
30
20
10
0
Speedup Analysis
3 4 5
—^— Number of Processors
6 7
Speedup
Figure
S to
g 0.
o
2—€
10: Speedup analysis of the algorithm upon the number of processors
Serializabilty Analysis
^ -^a ^ ^ ^ . ^ ^ ^ ^ ^ ^ • F
2 3 4 5 6 7 8 9
Serial Exection Time -.^^m
Figure 11: Seriaiizability analysis of the algorithm upon the different number of
processors
Amdhal's Law and Gustafson Law ignore the communication overhead, so they can
overestimate speedup or scaled speedup. Serial fraction of the parallel computing
algorithm can be determined by the Karp-Flatt Metric which is defined as:
1 1 1
60 I P a g c

Serial fraction (e) is useful for the computation of the parallel overhead generated
by the execution of the algorithm over the distributed computing environment. Where
(y/) is the speedup factor and P are the number of processors using for the parallel
execution in distributed heterogeneous environments.
In this chapter, we proposed a new model for the estimation of communication
cost amongst various nodes at the time of the execution. The improvement ratio of
iterations has also been discussed. Our contribution gives cut edge inter-process
communication factor which is a highly important factor to assign the task to the
heterogeneous systems according to the processing capabilities of the processors on
the network. The model can also adapt the changing hardware constraints.
61 I Pa

REFERENCES
[1] N. Islam, A. Prodromidis and M. S. Squillante, "Dynamic Partitioning in
Different Distributed-Memory Environments," Proceedings of the 2nd
Workshop on Job Scheduling Strategies for Parallel Processing, (1996), 155-
170.
[2] D. J. Lilja, "Experiments with a Task Partitioning Model for Heterogeneous
Computing," University of Minnesota AHPCRC Preprint no. 92-142,
Minneapolis, MN, (1992), 15-19.
[3] L. G. Valiant, "A Bridging Model for Parallel Computation,"
Communications of the ACM, 33(8), (1990), 103-111.
[4] B. H. Juurlink and H. A. G. Wijshoff, "Communication primitives for BSP
Computers," Information Processing Letters, 58, (1996), 303-310.
[5] H. EI-Rewini and H. Ali, "The Scheduling Problem with Communication,"
Technical Report, University Of Nebraska at Omaha, (1993), 78-89.
[6] D. Menasce and V. Almeida, "Cost-Performance Analysis of Heterogeneity in
Supercomputer Architectures," Proc. Supercomputing, (1990), 169-177.
[7] T. L. Adam, K. M. Chandy and J. R. Dickson, "A Comparison of List
Schedules for Parallel Processing Systems," Comm. ACM, 17, (1974), 685-
689.
[8] L. G. Valiant, "A Bridging Model for Parallel Computation,"
Communications of the ACM, 33(8), (1990), 103-111.
[9] El-Rewini, T. G. Lewis, H. Ali, "Task Scheduling in Parallel and Distributed
Systems," Prentice Hall Series in Innovative Technology, (1994), 48-50.
[10] M. D. Ercegovac, "Heterogeneity in Supercomputer Architectures," Parallel
Computing, (7), (1987), 367-372.
[11] P. B. Gibbons, "A More Practical PRAM Model," In Proceedings of the
1989 Symposium on Parallel Algorithms and Architectures, Santa Fe,
NM,(1989), 158-168.
[12] Y. Aumann and M. O. Rabin, "Clock Construction in Fully Asynchronous
Parallel Systems and PRAM Simulation," In Proc. 33rd IEEE Symp. on
Foundations of Computer Science, (1992), 147-156.
62 j P a g e

[13] R. M. Karp and V. Ramachandran, "Parallel Algorithms for Shared-Memory
Machines," In J. van Leeuwen, editor. Handbook of Theoretical Computer
Science, (1990), 869-941.
[14] H. Topcuoglu, S. Hariri and M. Y. Wu, "Performance-Effective and Low-
Complexity Task Scheduling for Heterogeneous Computing," IEEE Trans.
Parallel and Distributed Systems, 13(3), (2002), 250-271.
[15] J. Ali and R. Z. Khan, "Dynamic Task Partitioning Model in Parallel
Computing Systems," Proceeding First International conference on Advanced
Information Technology (ICAIT), Coimbatore, Tamil Nadu, (2012), 7-10.
63 I P a ti e

Op1maC^as^(Partitdomng
Strategy witfi (DupGcation in <Para(le[ Computing
64

CHAPTER 5
OPTIMAL TASK PARTITIONING STRATEGY WITH
DUPLICATION IN PARALLEL COMPUTING
5.1 Introduction
Algorithms for scheduling tasks onto the heterogeneous processors must be
achievable of remarkable performance in terms of scheduUng length. Most of the
scheduling algorithms do not provide the mechanism about minimum communication
overhead. This chapter introduces Optimal Task Partitioning Strategy with
Duplication (OTPSD) that minimizes the scheduling length as well as communication
overhead. The proposed scheduling algorithm is NP-complete. Three phase algorithm
has been introduced in which the first phase comprises of grain_packSubDAG
formation. The second phase is a priority assignment phase. In the third phase,
processors are grouped according to their processing capabilities. The proposed
algorithm minimizes makespan and shows better performance in terms of normalized
schedule length and processor utilization over MCP and HEFT algorithms.
Mapping and scheduling of the dynamic tasks on multiprocessor architectures is a
challenging problem. Every participating processor has its own memory to execute
the segment of the executable code for the dynamic tasks. High level description of
the task partitioning applications is represented by DAG (Directed Acyclic Graph).
DAG [18] is a generic model of a parallel program consisting of a set of dependent
processes. In DAG, a set of tasks is connected by a set of direct edges. Outgoing
edges associated with computational tasks depict the control behavior of the task
graph at the associated executable task. Each process is represented by a task in the
graph. Each task may have one or more inputs/output tasks. The task is executed only
when all the inputs become available. A task without a parent is called an entry task
and a task without a child is called an exit task. The process execution time denoted
by Wi is called as the weight of task (t;). Communication between two tasks denoted
by Cij is equal to the message transfer time from task (tj) to task (tj). Obviously this
time becomes zero when two or more tasks are assigned to the same processor.
Communication and computation cost of the tasks is used to assign the priorities in
65 I P a g e

the DAG. High priority tasics are assigned prior to the low priority tasks. To estimate
the execution time of a task within a task graph during runtime is complex in parallel
computing architecture. Length of makespan is given by the exit task of DAG for a
given scheduling. A path from the entry task to the exit task for which communication
cost and computation cost is maximum is known as the critical path [10]. Goal of
scheduling algorithm is to minimize the schedule length. Task partitioning strategies
try to assign tasks on the appropriate processors. The execution order of the tasks is
the important factor for efficient task partitioning. If execution time and dependencies
are known in advance then it can be represented by static model. A number of task
partitioning strategies were proposed in the literature [5, 4, 6, 8, 10, 11, 14, 17]. These
task partitioning strategies are used for the set of homogeneous and heterogeneous
systems. Some of them show duplication and guided random behavior. In CBHD
algorithm, execution of the tasks started as soon as the dependent duplicated tasks are
finished [20]. In scheduling algorithms [10, 12], priorities are assigned to each task to
make ordering list. Scheduling algorithms [2, 6, 7, 10, 11, 16] are used in a
heterogeneous computing environment. Duplication of the tasks amongst different
processors is useful to reduce waiting time of ready tasks [1]. Duplication based
heuristics [10, 2,3] shows better efficiency for fine grain task graph. These duplication
based task graph algorithms are more effective for the network of high
communication latencies. Communication overhead and waiting time may be reduced
in duplication tasks partitioning strategies by redundant allocation of multiple
processing elements [10, 1]. Turnaround time of the tasks partially depends upon
waiting time.
A DAG may have many critical paths. We used DPS (Depth First Strategy) to find
the critical path in the different grain packs of DAG. In the proposed algorithm, ties
are broken on the basis of higher computation cost. Secondly, ties if any are broken
on the number of immediate predecessors of critical path tasks in the DAG.
5.2 MCP algorithm
MCP stands for the Modified Critical path algorithm. It is one of the six most
popular algorithms in the category of dynamic critical path algorithms e.g. MCP, ISH,
HLFET, DLS and ETF. MCP performed the best among these algorithms. MCP
66 I P a e e

algorithm is used for scheduling (DAG) Directed Acyclic Graph with communication
costs on to a bounded number of processors. The MCP algorithm possesses the
features that a DAG scheduling algorithm should have high quality and low
complexity.
5.2.1 Design of MCP algorithm: Design of MCP algorithm is based on as late as
possible (ALA?) start time to determine the task priority. This algorithin assigns
higher priorities to tasks which have smaller possible start times. ALA? start time of a
task is a measure of how far the task's start time can be delayed without increasing
scheduled length. The b-level stands for bottom level of a task. For a task say (t,), it is
the length of longest path from task (t;), to an exit task. The b-level is determined by
traversing the task graph (DAG) upward recursively from the exit task to the entry
task. The ALA? time of a task is computed by determining the length of the critical
path and then subtracting the b-level of task from it.
The MCP algorithm can be thus simply summarized in the following steps:
Step 1: Compute the ALAP start time for each task in the DAG.
Step 2: For each task in the graph, construct a Hst of ALAP start time of the task itself
and ALAP start times of all its children tasks in a descending order.
Step 3: Construct a list of tasks in an increasing lexicographical order of ALAP start
time.
Step 4: Remove first task from the list obtained in step 3 and schedule it to a
processor that allows the earliest execution by using insertion.
Step 5: Repeat step 4, until the task list obtained in step 3 becomes empty.
5.2.2 Efficiency of the algorithm
1. There is a better utilization of processors in MCP algorithm.
2. This algorithm can be implemented efficiently with a number of methods
including the extended ALAP time and ready time calculation.
3. Makespan of MCP increases with increase in the number of tasks as compared to
other algorithms.
5.3 Heterogeneous Earliest Finish Time algorithm
Heterogeneous EarHest Finish Time (HEFT) [3] is an application scheduling
algorithm for a bounded number of heterogeneous systems. It's a task selection phase
67 I P a g e

and processor selection phase based algorithm. It consists of two phases. In the first
phase; priorities are assigned to the tasks on the basis of their ranks [3]. The second
phase is a processor selection phase. This phase selects the processor which requires
minimum finish timing of tasks. Insertion base policy is used in HEFT, in which a
task inserted in earliest idle time between two scheduled tasks on a processor [19].
Communication cost is also calculated for heterogeneous computing processors. In
the first phase rank is calculated as follows:
rank^iti) = avgiwf) + maXt-esuccitoi^^aicij) + rank^{tj)) (5.1)
Where (w;) is an average computation of task (/) for all processors. Succ (t;) is the set
of child tasks of (ti). Avg (Qy), represent average computational cost between tasks
[ti) and (tj) for all pair of processors. Upward rank is the expected distance of any
task from the end of the computation. Highest priority task for which all child tasks
have finished is assigned to the processor which gives earhest finished time for that
task.
5.4 Performance metric for simulation
The performance of three algorithms is simulated on DAG. We generate ten graphs
having task size {30, 60, 90, 120, 150, 180, 210, 240, 270, 300}. Performance of
MCP, HEFT and OTPSD compared on the basis of NSL (Normalized Schedule
Length) and efficiency. Makespan of an algorithin is the completion time of that
algorithm. The average communication cost divided by the average computational
cost is ternned as CCR value [9].
68 I P a g e

r^»'.v Job Oin*M«
Figurel2: Abstract model for task partitioning strategies
5.5 Proposed model of task partitioning strategies
This model shows an abstract view of task partitioning in distributed computing.
Makespan of each algorithm is calculated by the schedule length count factor.
Minimum makespan shows optimality over other implemented algorithms. A total
conununication cost is given by the communication cost count factor. Sum of
communication cost and execution cost have been merged by aggregation phase. So
in task partitioning strategy phase, MCP algorithm assigns priorities to tasks on the
basis of b-level. In HEFT, upward rank is calculated by equation (5.1). The proposed
algorithm (OTPSD) clustered tasks into groups to make grain_packSubDAG. Rank in
each grain_packSubDAG is calculated according to the raiJi calculation in HEFT.
5.5.1 Task and processors assignment phase: Goal of this phase is to minimize total
execution time of the participating tasks running on heterogeneous environment. An
optimal partitioning of tasks is necessary to minimize the overall execution time.
Partitioning problem consists of partitioning a number of heterogeneous tasks among
data-parallel tasks in an optimal way. Mapping of the tasks onto the different
processing tasks is known to be NP-hard. Precedence constraints must be preserved
during the assignment of tasks in heterogeneous environments. Efficient resource
sharing is achieved by analyzing the mutual exclusion amongst different processors.
Selected tasks are assigned to the earliest available processors. A tie is breaking
amongst the tasks according to the processing capability of participating tasks.
Combining some task on DAG and assigning these grouped tasks onto processors
minimize communication overhead [15]. The processors of the similar capability are
grouped together. Due to this fact, heterogeneous computing environment becomes
69 [Pag c

similar to homogeneous. In the proposed algorithm, we sort the processors in
decreasing order of processing power.
5.5.2 Pseudo Code for Grain Pack SubDAG:
1. calculate comm_cost/or all tasks 2. sort tasks in decreasing order of comm_cost 3. for each task do 4. if comm._cost(ti) < comm_cost(ty) then 5. merg_tasks 6. endif 1. repeat step 3 to 5 8. endfor
According to the above steps, grain packs of tasks are fornied in the DAG. These
grouped tasks are mapped onto the grouped processors according to their ranks. If the
load of grouped tasks is more than processing capabilities of the grouped processors
then these grouped tasks are assigned to next grouped processors.
70 1 P a ti e

S.N.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
Symbol
DAG
9iPj
GpSD
Sp
ts
''US
tk9i
tr
9i
parity)
ft
ftSp
minschjengthgi
" 5
comm^cost(ti)
exec_cost{ti)
Uij
bij
Ct,
«( t i )
Kti)
Min_costGp
Description
Directed Acyclic Graph
i" grain_packSubDAG executing on processor P,
grain_packSubDAG
Selected Processor
Scheduled Task
Unscheduled Task
Key task on grain_packSubDAG
Task rank
i"' grain_packSubDAG
Parent key task
Finish time of mark task
Finish time on a selected processor
Minimum schedule length of ^j
Scheduled node
Communication cost of task(t,)
Execution cost of task(t()
start-time of a task {ti) on a processor {Pj)
fmish-time of a task (t;) on a processor (Pj)
Maximum cost successor task on critical path
Average execution of tasks on the set of processors
Successors communication cost
Group of minimum computational cost processors
Table 5: Nomenclature for OTPSD Model
71 I Page

Theorem 1://"fto, t^, t2,—,t.J are participating tasks of DAG and (CQ, C^, C 2 . . . C ^
are communication costs of edges (CQ, e^, 62,...,e^) respectively, then g^Pj, optimize
execution cost on the basis of max-min(maximum parallelism and minimum cost)
trade-off
Proof. According to Babb [13] "What qualifies as large grain processing will vary
somewhat depending upon the underplaying architecture?" In general, large grain
means that amount of processing a lowest-level program performed during an
execution is large [12], Grain packing is used to reduce communication overhead. It
reduces number of processors in comparison to list scheduling. Amount of
concurrency is reduced due to sequential execution of packed tasks. So, task size is
increased by merging many smaller tasks into one larger task. Parallelism is reduced
by increasing the size of grain in DAG. If grain size is too small then overhead is
increased due to context switching problem. The grain size must be related to max-
min (maximum parallelism and minimum cost) problem. It's a trade-off between
parallelism (fine-grain) and communication (large grain).
Definition 1: Combination of tasks and related edges which is assumed as
grain_packSubDAG Task Graph (GpSTG) is a directed acyclic graph DAG (V, E,
exec_cost, comm_cost) where:
1. E is the set of edges {(e,-, e^), C;, Cj € E] which represent the communication
from ei to ej.
2. Grain_packSubDAG (GySD) represent the set of grain packing, where (^,, gj) are
different grain_pack {gi, gj E DAG).
3. V represents the set of nodes, where every node (n,) represented by task (t;).
4. Positive level of each edge, represents communication cost (comm_cost) from
task(ti) to task (tj).
5. Associated weight of each edge depicts the execution cost of particular task (t;).
Definition 2: If there are muhiple edges amongst grain packs (gi, gj 6 DAG) where
\< i, j < n, then arithmetic mean (average value) of the communication cost of these
related edges is known as communication cost of two grain_pack of DAG.
In DAG, communication cost is associated with interrelated edges. There may be
muhiple edges between two grain packing. Because, every grain pack has many tasks
72 I P a e e

on the basis of computations and communications costs. So amongst different grain
packing communication cost is considered as a mean of communication costs
amongst the associated tasks (t;). We consider integer value of average
communication cost, partial values are neglected.
comm_cost (Si, gj) = [Q, Cj/n(Easso.)] (5.2)
where, n(Easso) ^re number of associated edges between two grain_packs.
Theorem 2: Highest priority task for all processors in subDAG, is a entry task of
critical path of Grain_packSubDAG (GpSD) and CTIJ is a maximum cost successor
task of critical path.
Proof. If task (rii) of subDAG has the highest value (priority) over all participating
processor, then its equal to highest rank value of (OTPSD) algorithm. So, task (nj)
selected as an entry task of at least one of the critical path of (OTPSD). Hence, each
critical path must have entry task (ni) which equal to highest priority task of DAG.
p
° ("i) = X *ii/P //Where p is the number of processors (5.3)
Communication cost (P) is the amount of cost which is required to transfer data to its
entire successor task in DAG. This communication cost may be computed as:
P(ni) = ZJ^i dij/AVherei < ; and for exit node p = 0 (5.4)
Where m is the number of tasks in unscheduled level of DAG. Rank of remaining
tasks can be calculated according to HEFT algorithm.
5.5 J Pseudo code for proposed algorithm:
1. construct Pj V Pi where 1 < i < n 2. while for t^j do 3. find t„gi, QiPj, tr 6 t^gi 4. if trh not unschjpar then 5. mark t € t^ 6. else mark t; e par(tr) 7. endif 8. compute /j e t^^Pi 9. find min/fSp 6 t^ 10. find minschjength gi 11. 5i -> min. costGP
73 I P a s e

12. update t € mark t^VgiPj 13. update comm_cost V giPj 14. update exe_cost ^giPj 15. update temp_zero_cost_edge(eg)giPj G min.costGP 16. update comm_costV giPj 17. endwhile
5.6 OTPSD implementation phase
The proposed algorithms are implemented in a CUDA environment with example
in figure (16). This environment allows using C language [21]. In the proposed
algorithm, DAG is derived into Sub DAG called grain_packSubDAG. After a cluster
of DAG theses grain pack sub DAG are assigned to the selected group of processors
to minimize workload [7]. All tasks inside grain_packSubDAG are also executes on a
group of selected processors. This type of allocation minimizes communication
overhead. In example (27), total tasks are grouped in four (GpSD). Tasks {t^, t2, t^,
U} are assigned to (P1P3). Grain_packSubDAG(5i2{t5, tg, tn}) and ig^it^oi 12})
are assigned to (P1P2) for minimization of sleek time. Because ('g2,g3y' have been
allocated to the group of (P1P2) so communication cost is also reduced. Task {tg} is
duplicated upon (P1P3), to execute dependent tasks{t7, tjo, tj2} as soon as possible.
Step ID
MHOTPSDOl
MHOTPSD02
MHOTPSD03
MHOTPSD04
MHOTPSD05
MHOTPSD06
MHOTPSD07
MHOTPSD08
MHOTPSD09
MHOTPSDIO
M H O T P S D l l
MCP
ts^Pi
t2 ^Pl
k^Ps
U-^PI
tj^p^
te^Pi
ts-^Ps
tio ^ PI
ts^Pi
t9 -*Pi
fn -^ P3
HEFT
h-'Pi
U^Pi
ti^Pz
ty^Pl
h^Pl
U^Pl
h-'Pj
tg -^Ps
t s ^ P i
tw ^ P2
til ^ Pi
OTPSD
h -^ P1P2
t2 ^ P1P2
h -* P1P2
ta -^ P1P2
ts ^ P2P3
tg ^ P2P3
t i l ^ P2P3
h -^ P3P1
t3 -^ P3P1
ts.ts-^PsPi
tio ^ P2P1
74 I P a g e

MH0TPSD12 t l 2 -^ P3
Execution
Time=215.6
t i2 -^ P3
Execution
Time=196.3
^12 ~* ^ 2 ^ 1
Execution
Time=184.4
Table 6: Allocation of tasks upon different processors in OTPSD model
P j
p.
Pi
t i i
ta
t i IS 33
t i •• •• « • • "
X™.
50
h 1 ts
sa
w. o™«p«"
l i s
i
u:
h t l 3
ts 15:
i
t9 US
t i l
195
tn 1
i i S i i 3 25S
MCPtExecutiortTirne
Pi
P2
p.
ta
t l
t i t;
^ tg
ts
tg
ty
hi
tiO
t, t,,
u : 155 15; 17:
HEFT ;Execu t ionTim»
US 2i-3 2J5 253
Pipj
PiPa
P2P3
t7
h
t i
ts 1
t2
ts
t j
t .
t i l
ts
ts
t jo t u
3S l i s Hi i s : i7S 13D OTPSD : Esecut icn Time
2iS 253 J53
Figure 13: Makespan analysis of different algorithms
There is a very low communication cost required amongst tasks in 5^. So, tiie total
computational cost reduces due to the reduction in communication costs amongst the
tasks of same GpSD. In simulation results, without duplication OTPS (Optimal Task
Partitioning Strategy) algorithm shows 78.6% CPU utilization. Average CPU
utilization in MCP, HEFT and OTPSD are 46.7%. 56.8% and 83% respectively. CPU
utilization increased due to allocation of grouped processors of similar capabilities.
These groups of processors minmiize heterogeneity in comparison to the random
allocation of processors. Total execution time of duplicated algorithm is (184.4)
instead of (189.1). So most of the time, all processors (Pj, P2, P3) are busy at the
time of execution of the proposed algorithm. Drawback of HEFT is that it can't
75 I P a g e

perform efficient CPU utilization amongst participating processors. Rank of each task
in g, is calculated on the basis of the equation (1). According to rank of tasks, tasks
are mapped onto processors. This approach also minimizes makespan. Calculated
makespan of OTPSD is (184.4) which is shorter than MCP (215.6) and HEFT (196.3)
algorithms. The average value of the NSL is plotted in figure (14) against the function
of the CCR. We calculate NSL value of MCP, HEFT and OTPSD at the CCR value
range (1, 1.5, 3.0, 4.5, 6.0, 7.5, 9.0). In figure (15) graph shows that, the behavior of
three algorithms is consistent in terms of values of CCR. The average NSL value
slightly increases up to the medium range of CCR. Above medium range of CCR,
OTPSD performs significant performance. At the maximum value of CCR proposed
algorithms outperform over compared algorithms. This result indicates that if
communication cost is large then task partitioning is difficult.
s
1
NSL v$ CCR
"T-t 1 J
CCR
Figure 14: Analysis of NSL vs CCR
761P a g e

|;,(^A^c,rV - i^i;
Effkieno- vs CCR
•A •A
i
0 J.1 i TJ SO
CCR
Figure 15: Analysis of Efficiency vs CCR
.JS
@
1 2 /
\ 3-J©
isX
X5) 8
(7" 4/ /
\ **^ sX
(Z
yi2 .
6 1
S>
© ^ ( &
Figure 16: DAG with communication costs
77 IP a g e

iS •
i •
15
5
NSL 'i
2 •
i J •
OJ •
c -
NSL vs DAG Size
^ >
__^a'^<^^^^
^^^^^^'^^ /
/t\ ^ U/ v—-^ /
3 : ; ; : ; 5 : : ; : 25c »-:
DAG Si2e(No. of Nodes)
-m-y^tr - * - 0 7 » »
j s :
Figure 17: Analysis of NSL vs DAG size
Algorithm
MCP
HEFT
OTPSD
Average CPU Utilization
46.7%,
56.8%
83%
Makespan Length
215.6
196.3
184.4
Table 7: Average CPU utilization and maliespan length of compared algorithms
Figure (17) shows simulation results for different size of graphs ranging from (30
to 300 nodes). Performance of MCP, HEFT and OTPSD shows that NSL value feebly
degrades if the number of nodes in the DAG is increased. In the range of (100-250)
NSL of proposed decreases in comparison of MCP and HEFT. After size 250 nodes
near to 300 nodes all three algorithm depicts average NSL (3.0-3.5). Because NSL is
normalized metric so each algorithm shows no large increment for a large number of
tasks.
In this chapter, we proposed a new task partitioning strategy (OTPSD) for
heterogeneous parallel computers. A number of experiments are conducted. The result
shows outperformance upon both MCP and HEFT in terms of efficiency and
78 IP a g c

makespan length. Proposed work demonstrates significant results in terms of better
CPU utilization. HEFT and MCP are not capable to minimize the professor's sleek
time.
79 I P a g e

REFERENCES:
[1] G, L. Park, B. Shirazi and J. Marquis, "A New Approach for Duplication
Based Scheduling for Distributed Memory Multiprocessor Systems," In: Proc.
11th Int'l Parallel Processing Symp., (1997), 153-162.
[2] R. Bajaj and D. P. Agrawal, "Improving Scheduling of Tasks in a
Heterogeneous Environment," In: IEEE Transactions on Parallel and
Distributed Systems, 15 (2), (2004), 110-111.
[3] H. Topcuoglu, S. Hariri and M.Y. Wu, "Performance-Effective and Low-
Complexity Task Scheduling for Heterogeneous Computing," In: IEEE
Transactions on Parallel and Distributed Systems, 13 (2), (2002), 25-35.
[4] O. Sinnen and L. Sousa, "List Scheduling: Extension for Contention
Awareness and Evaluation of Node Priorities for Heterogeneous Cluster
Architectures," In: Parallel Computing, (30), (2004), 75-95.
[5] G. L. Park, "Performance Evaluation of a List Scheduling Algorithm in
Distributed Memory Multiprocessor Systems," In: Future Generation
Computer Systems, (20), (2004), 230- 251.
[6] J. Barbosa, C. Morals, R. Nobrega and A. P. Monteiro, "Static Scheduling of
Dependent Parallel Tasks on Heterogeneous Clusters," In: Heteropar , IEEE
Computer Society, Los Alamitos, (2005), 1-8.
[7] Gerasoulis and T. Yang, "On the Granularity and Clustering of Directed
Acyclic Task Graphs" In: IEEE Transactions on Parallel and Distributed
Systems, (1993), 680-693.
[8] M. K. Aguilera, A. Merchant, M. Shah, A. V. Karamanolis and C. Sinfonia,
"A New Paradigm for Building Scalable Distributed Systems," In:
Proceedings of the 21st ACM symposium on operating systems principles,
New York: ACM Press, (2007), 159-174.
[9] D. Mohammad and K. Nawwaf, "A High Performance Algorithm for Static
Task Scheduling in Heterogeneous Distributed Computing Systems," In: J.
Parallel Distrib. Comput., (68), (2008), 403-405.
[10] Y. Kwok and I. Ahmad, "Dynamic Critical-Path Scheduling: An Effective
Technique for Allocating Task Graphs onto Multiprocessors," In: IEEE
Transactions on Parallel and Distributed Systems, 7 (5), (1996), 503-519.
80 j P a g e

[11] Y. Kwok and I. Ahmad, "On Multiprocessor Task Scheduling using Efficient
State Space Search Approaches," In: Journal of Parallel and Distributed
Computing, (65), (2005), 1510-1530.
[12] B. Kruatrachue and T.G. Lewis, "Grain Size Determination for Parallel
Processing," In: IEEE Software, (1988), 20-31.
[13] R. G. Babb, "Parallel Processing with Large Grain Data Flow Techniques," In:
Computer, (17), (1984), 50-59.
[14] J. K. Kim et al., "Dynamically Mapping Tasks with Priorities And Multiple
Deadlines in a Heterogeneous Environment," In: Journal of Parallel and
Distributed Computing, (67), (2007), 154-169.
[15] S. M. Alaoui, O. Frieder, T. A. EL-Ghazawi, "Parallel Genetic Algorithm for
Task Mapping on Parallel Machine," In: Proc. of the 13th International
Parallel Processing Symposium & 10th Symp. Parallel and Distributed
Processing IPPS/SPDP Workshops, (1999), 22-28.
[16] S. Wu, H. Yu, S. Jin, K. C. Lin and G. Schiavone, "An Incremental Genetic
Algorithm Approach to Multiprocessor Scheduling," In: IEEE Trans. Parallel
Distrib. Syst., (2004), 812-835.
[17] Radulescu and A. J. C. Van Gemund, "Low Cost Task Scheduling for
Distributed Memory Machines," In: IEEE Trans. Parallel Distrib. Syst., (13),
(2002), 640-642.
[18] S. Darba and D. P. Agrawal, "Optimal Scheduling Algorithm for Distributed
Memory Machines," In: IEEE Trans. Parallel and Distributed Systems, (1),
(1998), 85-93.
[19] X. Yuming, L. Kenli, T. K. Tung and Q. Meikang, "A Multiple Priority
Queuing Genetic Algorithm for Task Scheduling on Heterogeneous
Computing Systems," In: High Performance Computing and Communication
& 2012 IEEE 9th International Conference on Embedded Software and
Systems (HPCC-ICESS), 2012 IEEE Nth International Conference, (2012),
640-648.
[20] M. A. Doaa and O. Fatma., "Dynamic Task Scheduling Algorithm with Load
Balancing for Heterogeneous Computing System" In: Egyptian Informatics
Journal, Cairo University, (2012), 136-139.
81 i P a g e

[21] D. Javier, M. C. Camelia and N. Alfonso, "A Survey of Parallel Programming
Models and Tools in The Multi-Core Era," In: IEEE Transaction on Parallel
and Distributed Systems, 23 (8), (2012), 1369-1375.
82 I P a g e

^as^(PajtitUmw^ Strategy
witfi Minimum Ixme in (Distributed <Bara£[e[
Computing Environment
83 I P . ^ c

CHAPTER 6
TASK PARTITIONING STRATEGY WITH MINIMUM
TIME IN DISTRIBUTED PARALLEL COMPUTING
ENVIRONMENT
6.1 Introduction
Efficient task partitioning is necessary to achieve remarkable performance in
multiprocessing systems. When the number of processors is large then scheduling is
NP complete. Complexity of the systems depends upon the execution time [1]. The
objective flinction of any task partitioning strategy must consider computing factors.
A lot of parallel computing algorithms have been proposed which consider very small
factors concurrently. These tasks partitioning strategies are categories such as
preemptive verses non preemptive, adaptive versus non adaptive, dynamic versus
static, distributed versus centralized [2, 3]. In static task partitioning strategies runtime
overhead is negligible because the nature of every task is known prior to the
execution. If all performance factors are known in advance before the execution of the
tasks then static scheduling shows better results [4]. Practically to estimate all
communication factors prior to the execution of tasks is impossible. In round robin
systems every processor of the computing systems executes a same number of tasks.
The performance of the systems directly affected by dynamic tasks partitioning
strategies [6]. Centralized and distributed scheduling shows different behavior in
terms of overhead and complexities of scheduling algorithms. Scheduling information
is distributed amongst storage devices and related computing units in distributed
scheduling fashion. Dynamic scheduling balances the load by moving pointer from
compiler to processor. Source initiated scheduling offers the tasks from highly loaded
processors to low loaded processors [7]. While in sink initiated scheduling, tasks
transferred from low loaded CPUs to high loaded processors [5]. In symmetric
scheduling load may be transferred vice-versa. One or more processing units are used
to share the global information in centralized strategies. To access global information
contention is the major drawback for centralized scheduling algorithms. This
84 IJ' a g c

contention tends toward the minimization of existing resources. Some processors
which are used in centralized scheduling can't participate in the execution of tasks.
They are used only as storing devices. This is another serious drawback of centralized
scheduling architectures.
Dynamic scheduling plays an important role in the management of resources due
to run time interaction with under laying architectures [8]. In a large number of
application areas such as real time computing communication networks, query
processing, dynamic scheduling shows better performance than static scheduling.
A new list scheduling based strategy called Minimal Task Partitioning Strategy With
Minimum Time (TPSMT) has been proposed for heterogeneous computing
environments. This algorithm contributes average communication and computation
cost factor to assign the priorities to the critical path nodes.
6.2 Critical path fast duplication (CPFD) algorithm
Final schedule length of any algorithm is determined by the critical path of
implementing schedule. So, for the minimum schedule length critical path value of the
schedule must be optimum [2]. Due to the precedence constraint limitations, the finish
time of the (Critical Path) CP nodes is detemnined by the execution time of their
parent nodes. Therefore scheduling cost of the parent nodes of the critical path nodes
must be determined prior to the scheduling cost of CP nodes.
In CPFD, DAG is partitioned into three categories:
• Critical Path Node iCp„) of DAG
• In Branch Node (/bn) of DAG
• Out Branch Node (Ob„) of DAG
In branch nodes are those from where a path possess to the critical path nodes. Out
Branch are neither belongs to in branch or nor to critical paths. After partitioning the
problem, priorities are assigned to the critical path nodes. According to these priorities
total execution time is calculated by CPFD.
The start time of C^^ can be minimized by /ft„. So /{,„ are better than Oi,n- The
critical path of the DAG is constructed by the following procedure:
85 I P a g e

1. assignfirst node as a entry Cpjj. goto next node. Suppose Uy be the next Cp^-repeat
2. if all predecessor of Uy in queue then insert n^ in queue increment queue value. else
3. let n^ is predecessor of riy having maximum value of b-level which is not in queue.
4. tie broken by choosing predecessor with minimum t-level value. 5. If all the predecessor of n^ in queue then 6. include all parents of n^ in queue having more communication costs. 7. repeat all steps until all predecessors of Uy are in queue. 8. endif 9. make Uy to next C^^i 10. append all /bn to the queue in decreasing value of b-level.
Sequence generated by the above steps preserve constraints. C-p^ arranged in logical
maimer so that predecessor of Oj,n comes in front of successor of 0^^. All nodes of
the critical path are arranged in sequence (TXI, n^, 7x2, n^, n^, n^, n-,, HB, ng). This
ordering is on the basis of static level. CPFD generates the sequence of nodes
( « ! , n-2^. n-j, 71^,713, AZg, Wg, Uc,. n s ) .
First node of the DAG is (n^) which the first position node of critical path nodes
is. Second node (uz) has only one parent node so it's the second position node of the
sequence. After appended (712) to the critical path node, (Uy) inserted to the sequence.
After that (rig) has been considered. Both (n^) and (ng) have same b-level but (rig)
has smaller t-level. Only (n^) is the last node of the critical path.
6.2.1 Pseudo code for CPFD algorithm: Determine critical path and partitioned the
DAG into three categoriesCp^, /j,„, 0^^. Suppose key node be the entry node of Cp.^.
1. Let Pjetbe the processors set. 2. for every processor in P^et do
a. Determine key start time on P. b. Let (m) unscheduled node on Pjej. c. Assign (m) on idle processor. If assignment done than accept it as a new start
time for inserted node. d. i/"assignment can't be done then return control to examine another processors.
3. Allot processor to the ready node which gives earliest start time. 4. Perform all required duplications. 5. repeat procedure from step 2 to step 5 for each Ob„upon the set of processors
untill all Cpn nodes are assigned.
P a g e
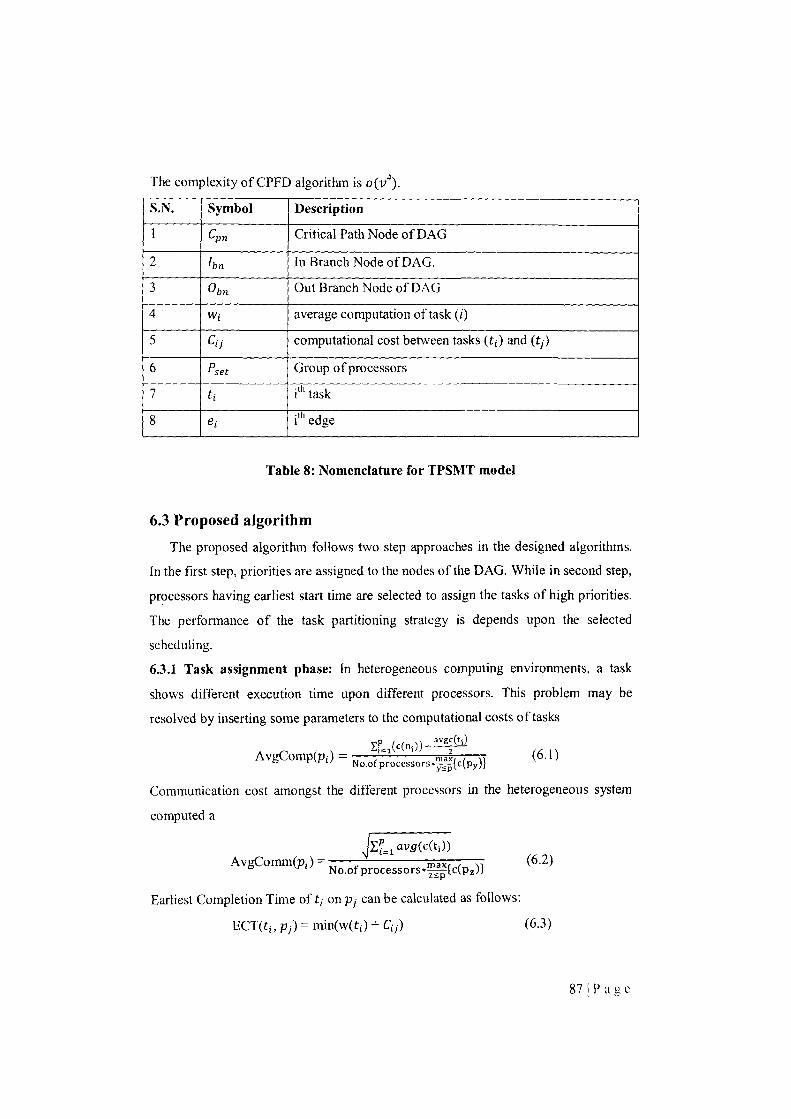
The complexity of CPFD algorithm is 0(17"*).
S.N.
I
2
3
4
5
6
7
8
Symbol
r
hn
Obn
Wi
Cii
Pset
ti
Si
Description
Critical Path Node of DAG
In Branch Node of DAG.
Out Branch Node of DAG
average computation of task (/)
computational cost between tasks (tj) and (ty)
Group of processors
1" task
i* edge
Table 8: Nomenclature for TPSMT model
6.3 Proposed algorithm
The proposed algorithm follows two step approaches in the designed algorithms.
In the first step, priorities are assigned to the nodes of the DAG. While in second step,
processors having earliest start time are selected to assign the tasks of high priorities.
The performance of the task partitioning strategy is depends upon the selected
scheduling.
6.3.1 Task assignment phase: In heterogeneous computing environments, a task
shows different execution time upon different processors. This problem may be
resolved by inserting some parameters to the computational costs of tasks
AvgCompCpi) Sf=i(c(ni))
avgc(ti)
(6.1) No.of processors»2^{c(py))
Communication cost amongst the different processors in the heterogeneous system
computed a
AvgComm(p,) = Jlf=iaps(c(ti))
No.ofprocessors*f^{c(Pz)} (6.2)
Earliest Completion Time oft, on py can be calculated as follows:
ECT(ti, py) = min(w(ti) + Qy) (6.3)
87 I P a a e

Earliest Finish Time of t; on pj can be calculated as follows;
EFT(ti, pj) = ECT(ti, pj) + w(ti) (6.4)
A critical path is a collection of nodes for those, sum of computational cost is
optimal. This CP is used to determine the lower bound of the task partitioning
strategies. So there must be an efficient scheduling strategy to assign the priorities to
the critical path node. When two tasks are assigned to the same processor then the
communication cost between them is zero. HEFT algorithms resolve this problem by
assigning the rank to the tasks. CPFD is static task partitioning strategy so it uses the
critical path method to assign the tasks to the processors.
In the proposed algorithm, a computational cost factor is inserted to compute the
priority of the tasks. This factor considers the average execution and computational
time along with communication and computational capabilities. Average
computational capability of the system processors may be computed as follows:
6.3.2 Pseudo code for proposed algorithm:
1. assign wgt(tj) <—AvgComp(p;) 2. assign wgt(ej) <— AvgComm(p,) 3. arrange tasks in descending order of ranks 4. while some tasks are not schedule do
begin select-first(ti) from priority queue for every processor in P^g^ do begin comput-ECT(ti,py); assign task (ti) to selected processor which minimize EFT;
end; end;
5. repeat steps 1 to 4 step until ranks assigned to all tasks.
6.3.3 Simulation results: Analysis of the proposed algorithm is implemented upon
the DAG in figure (18). Tasks associated with each others have different size and
communication costs.
P a g e

4 /
CjO ^ - " ^ /
CT
t-
r r^
'1 ([[
^ 1
(^ t;^
> /e 3 /
CuZ.
5
Cliil^ /s
/d>
Figure 18: DAG with Communication Cost in TPSMT
oc
40
35
30
&
I * .
25 -
20
15
10 1
Average SLR vs C'C'R
0.5 1.0
-TPSMT
-HEFT
-CPFD
Figure 19: Average SLR against CCR values
89 I P a g c

Number of Processors vs Avg Speedup
^ '
-IPSMT
-HFFT
- C W D
20 50 80 110 140 170 200 230 250
Numbrr of Procnsrx
Figure 20: Average speed up against different number of processors
Avg Eflicienc}- vs Number of Processors
3
J.. 2.5
I 2 E W 1.5
*< 0.5
0
-TPSMT
-HEFT
-CPU)
12 24 36 48
Number of ProcMMws
60
Figure 21: Average efficiency against different number of processors
6.3.4 Computational analysis: Average efficiency produced by TPSMT, HEFT and
CPFD with number of processors {12, 24, 36, 48, 60} represented in figure (21).
Plotted graph shows that average efficiency of the TPSMT is greater than HEFT and
CPFD by 53.09% and 63.20% respectively. While average efficiency of HEFT is
61.92 % greater than average efficiency of CPFD. These results show that
performance of TPSMT is better than the both compared algorithms. If efficiency of
the algorithm is large then it shows minimal execution time.
Figure (20) depicts the average speedup obtained from TPSMT, HEFT and CPFD
algorithms for the range of number of processors (20, 50, 80, 110, 140, 170, 200, 230,
250). From the graph it's clear that average speedup of all three scheduling algorithms
90 I P a g e

increased if the number of tasks increased. The proposed algorithm gained average
speedup value than HEFT and CPFD 17.36% and 56.79% respectively. For the real
world practical problems TPSMT algorithm outperforms HEFT and CPFD algorithms
CCR value for the three algorithms has been plotted against an average SLR value in
the figure (19). Plotted graphically expose that the performance of the compared
algorithms is consistence. If CCR value increased from smaller range to medium
range than average value slightly increased. When CCR becomes larger than the
average SLR value increases significantly. The average reduction in the NSL value of
the proposed algorithm with HEFT and CPFD are 8.08% and 28.40"/o respectively.
The average NSL value of HEFT is 25.30% less than NSL value of CPFD algorithm.
At largest value of CCR=10, the average NSL value of TPSMT is 7.69% and 26.92%
less than HEFT and CPFD respectively. These results indicate that if communication
cost is large then scheduling of the parallel applications is complex.
The performance of the proposed algorithm TPSMT compared with the best
existing algorithms HEFT and CPFD. In these algorithms one is best known dynamic
algorithm and another is a static algorithm (CPFD). TPSMT significantly outperform
compared algorithms in terms of NSL and average speedup values. Average SLR
valve of the proposed algorithm reduced 10.14% and 39.20% in comparison to HEFT
and CPFD respectively in the range of (2-10) CCR value. This factor shows that
TPSMT is also efficient for the high communication cost applications.
91 I P a g e

REFERENCES
[1] A. Bampis and J. C. Konig, "Scheduling Algorithms for Parallel Gaussian
Elimination with Communication Costs," IEEE Transactions on Parallel and
Distributed Systems, 9(7), (1998), 679-686.
[2] Y. Kwok and I. Ahmad, "Static Scheduling Algorithms for Allocating
Directed Task Graphs to Multiprocessors," ACM Computing Surveys, 31 (4),
(1999), 446^71.
[3] J. K. Kim, et al., "Dynamically Mapping Tasks with Priorities and Multiple
DeadUnes in a Heterogeneous Environment," Journal of Parallel and
Distributed Computing, 67, (2007), 154-169.
[4] J. Barbosa, C. Morals, R. Nobrega, A. P. Monteiro, "Static Scheduling of
Dependent Parallel Tasks on Heterogeneous Clusters," In: Heteropar. IEEE
Computer Society, Los Alamitos, (2005), 1-8.
[5] J. Bruno, E. G. Coffman and R. Sethi, "Scheduling Independent Tasks to
Reduce Mean Fmishing Time," Commun. ACM, 17, (1974), 380-390.
[6] M. Beck, K. Pingali and A. Nicolau, "Static Scheduling for Dynamic Dataflow
Machines," J. Parallel Distrib. Comput. 10, (1990), 275-291.
[7J E. G. Coffman and R. L. Graham, "Optimal Scheduling for Two-Processor
Systems," Acta Inf 1, (1972), 200-213.
[8] A. W. David and D. H. Mark, "Cost-Effective Parallel Computing," IEEE
Computer, (1995), 67-71.
92 |Pa zc

^eemptive q:askjPartitUming
StraUgy vnth (fast (Preemption in Ceterogeneous (DistriSuUd
Systems
93

CHAPTER 7
PREEMPTIVE TASK PARTITIONING STRATEGY
WITH FAST PREEMPTION IN HETEROGENEOUS
DISTRIBUTED SYSTEMS
7.1 Introduction
Non-preemptive scheduling strategies [1, 6, 9, 8, 3] have been discussed in
literature. Modified Critical Path (MCP), Highest Level First (HEFT) with estimated
time algorithm [10], Earliest Time First (EFT) [2] and Dynamic Level Scheduling
(DLS) are some well-known non-preemptive scheduling algorithms. Preemptive Task
Scheduling (PTS) algorithm shows low scheduling cost and better load balance than
the existing list scheduling algorithms. The time complexity of PTS is better than time
complexities of MCP, HLEFT, ETF, DLS algorithms. In these scheduling algorithms,
turnaround time and CPU utilization are the metrics to evaluate the performance of
the systems. FCFS scheduhng shows worst average job slow down than SJF [18].
Starvation problem may be occurring in FCFS because some long jobs having more
priority than short jobs may take very long execution time. This problem shows long
delays and very low throughput. Job fairness parameter shows better results in non-
preemptive scheduhng. It is clear that non-FCFS scheduling are less fair than FCFS
due to the starvation problems. Fairness of job may be calculated by the delay in time
due to delayed of a later arriving job. If the actual start time of a job is greater than its
fair start time then the job is treated as unfair. FCFS scheduling algorithms do not
shows always better results in terms of fairness than another scheduling algorithm
[10].
The complexities of the scheduling algorithms play an important role in the
execution of the processes. Low time complexities show good performance in all
performance metrics [5, 4, 7]. Scheduhng cost is proportional to the number of
processors used for the scheduling of a large number of tasks. This is a major problem
for iuturistic usage due to increasing number of processors. A scheduling algorithm
with fast preemptions can speed up the compilation process. Processes must be started
94 j P a g e

as soon as possible for minimization of execution time. If the waiting time is shorter
then turnaround time then it also affects the earliest short time of processing. Hence
throughput is increased if the earliest starting time is decreased. Preemptive
scheduling may be categories in the following categories:
a) Priority based preemptive scheduling: In these scheduling, tasks are allocated to
the processors according to their priorities.
b) Resource sharing: In this approach, all tasks have been allocated to the
processors simultaneously. Every task gets equal time quantum for the execution
of threads.
c) Implementation of the preemptive approaches by thread, shares low context
switching overhead.
7.2 Resource sharing
In the preemptive scheduling utilization of the resources increased due to the
following considerations. These considerations avoid deadlock due to regular
preemptions of the resources.
1. Designed algorithm must satisfy the requirement of parallel processing.
2. The algorithm should have a low Normalized Schedule Length (NSL) and
communication overhead.
3. The algorithm must achieve high performance efficiency and low response time in
multi-core systems.
4. At every instant of time, a resource should hold at most one task.
5. In resource scheduling algorithms deadlock condition must be avoided. To ensure
the absence of deadlock condition, at least one condition from the below must be
satisfied.
a) Allocation of the resources should be in non-sharable mode. Every
participating resource in the multiprocessing environment should not be
shared by multiple tasks.
b) If any resource allocated to a particular task then another task should wait until
it's released by allocating tasks.
95 I P a g e

c) The resources should not be allocated in the circular manner (First allocated
resource requested by last resource and second allocated resource must be
requested first resource and so on.)
d) No-preemption condition must be satisfied.
6. The proposed algorithm satisfies fixed priority preemptions and it's capable to
schedule the large number of tasks simultaneously.
In DAG based preemptive scheduhng, a partial portion of the task can be reallocated
to the different processors [12, 11, 17, 15], While in the case of no-preemptive
scheduling, allocated processors can't be re-allocated until it finishes assigned tasks.
Flexibility and resource utilization of the preemptive scheduhng is more than non-
preemptive scheduling in a theoretical manner. Practically, re-assigning the partial
part of the task causes extra overhead. Preemptive scheduling shows polynomial time
solutions while non-preemptive proved NP-complete [16]. Scheduling with
duplication upon different processors is also NP-complete. Communication delay
amongst the preemptive tasks is more due to preemptions of processors. Preemptive
and non-preemptive scheduhng approaches investigated by [14] in homogeneous
computing architectures. These approaches used independent tasks without having
precedence constraints. In DAG, condition of precedence constraints has been
inserted by Wang [13] for preemptive and non-preemptive scheduling. Earliest time
factor inserted by them to construct scheduling in list scheduling strategies.
7.3 Proposed algorithm for preemptive scheduling
1. Assign each tj -^ Pf 2. for all processors
generate priority queue(tj) -> Pj sort ascending EST(ti) -* P^ endfor
3. calculate A vgFT (tj for P^i / 4. while(ready-list not empty) do begin 5. Select task tj (highest priority) from priority queue; 6. Select the processor Pyfor task tjaccording to EST; 7. Assigned t; -» P,-; 8. Delete task tjfi-om the ready-queue; 9. Update ready-queue; 10. Compute FT all unscheduled tasks; 11. Schedule smallest FT tasks;
96 I P a g e

12. Move task t/ <-» P,-; 13. end while
7.3.1 Description of the scheduling algorithm: There are two phases in the proposed
scheduUng algorithm. In a first phase priorities are assigned to the tasks according to
their communication time and execution time. While in second phase, Earliest Start
Time (EST) has been calculated and tasks are scheduled upon the processors
according to their processing capabilities. Each task of the example is assigned on the
fastest processor. Nodes are sorted according to their ascending order Earliest Start
Time. First node having highest priority is numbered as (0). Next priority nodes are
numbered in the ascending order of natural numbers. After assigning the priorities
there is no dependency exist amongst the nodes. If dependency is found the new
group of the tasks are generated to remove the dependency of the nodes. In this
manner dependency from the tasks of DAG are removed and these tasks have been
assigned independently.
After calculating earliest starting time tasks are assigned to the selected
processors. When the task has been finished then it's removed fi-om the ready queue.
Ready queue is updated after the deletion of the tasks. Finish time of the remaining
tasks is calculated as follows:
FT=te;,ectime+ min ( ESTjy+FTi^) (7.1)
Smallest finish time tasks are assigned prior to the next smallest finish time. Due to
the preemptive nature of the tasks they can move amongst computing processors. So
the idle time of the processors decreases due to optimal and fast preemptions of tasks
upon the group of heterogeneous processors.
97 I P a li e

Symbol
ti
Pf
Ps
Pall
EST,;
^i,p
Definition
r Task
Fastest Processor
Selected Processor
All Processors
Earliest Staring Time of i"" task upon j*" processor
Finish Time of i* task upon j " " processor
Table 9: Nomenclature in FTPS model
^ 100
I 80 S 60
ot 40
1 ° S 0
Running Time vs Number of Processors
^ ^
mm*
mm
• Mcr
16 . , V , ^ 256 S12 1024 Number of Processors
Figure 22: Running time vs number of processors analyasis
CCR v» Average NSL at p=4
a 1.5 i 1 a 0.5 ^ 0
-FIW
0.2 0.5 1.5 2.5
CCR 10
Figure 23: CCR vs average normalized schedule length analysis at 4 processors
3.5 n
-^ 3
f 1.5 S 1
0 0.2
CCR vs Avg NSL at p=«
0.5 1 1.5 2.5 5 10
CCR
-«—MCP
- • - w s
-^—PIPS
Figure 24: CCR vs average normalized schedule length analysis at 8 processors
98 I P a g e

Figure 25: CCR vs average normalized sciiedule length analysis at 16 processors
J 2.5
£ OS •5 OH
,
• —
* - -0.2
CCR v» Avg NSL at p=32
—± 5—.—df- * *"
°^ ' d^R '' ' 10
—•—WCP
- • - I W
—*—FTPS
Figure 26: CCR vs average normalized schedule length analysis at 32 processors
2.5
S^ 2 ^
I 03 J < 0 -
- * = A-—
0.2
CCR vs Avg NSL at p=64
j ^ " * " * —
0 3 1 1.5 2.5 5 CCR
10
—•—MCP
- • - F P S
—*—PTFS
Figure 27: CCR vs average normalized schedule length analysis at 64 processors
Figure 28: DAG Example for Simulation
99 IP a g e

7.3.2 Experimental phase: Simulation based experiments have been conducted upon
the proposed algorithm against existing well known FPS (Fast Preemptive
Scheduling) and preemptive MCP (Minimum Critical Path) algorithms. In Figure
(22), running time (Sec) variation with the different number of processors has been
demonstrated. It can be observed that MCP shows very large running time for the
range of processors {4, 16, 64, 256, 512, 1024} in the comparison of FPS and PTPS
scheduling algorithms. While running time of PTPS is 11.91 % less than running time
of FPS.
Figure (23) shows the behavior of average (NSL) against a CCR range (0,2, 0.5, 1,
1.5, 2.5, 5, 10) values. When CCR values increases then the average NSL value is
also increased. At highest value CCR = 10 for p = 4, the NSL value of PTPS
decreases by FPS and MCP 11.41 % and 33.56 % respectively. This estimate that if
communication cost increases then the overhead is also increasing. The performance
of the proposed algorithm for the range (P=4, 8, 16, 32, 64) of processors have been
calculated. Figure (23-27) shows that optimal results have been obtained by PTPS
algorithm at the different number of processors. It may be observed that if the number
of processors increases then the average NSL value is continually going to decrease.
So, PTPS shows better performance upon the compared algorithms FPS and
preemptive MCP scheduling algorithms.
100|Pagi

REFERENCES
[1] L. George, N. Rivierre and M. Spuri, " Preemptive and Non-Preemptive Real-
Time Uni-Processor Scheduling, Institut National de Recherche in
Informatique et en Automatique," Tech. Rep., (1996), 45-50.
[2] R. Dobrin and G. Fohler., "Reducing The Number of Preemptions in Fixed
Priority Scheduling," Real-Time Systems, Proceedings 16th Euromicro
Conference On Ecrts, (2004), 144-152.
[3] C. L. Liu and J. W. Layland, "Scheduling Algorithms for Multiprogramming
in a Hard-Real-Time Environment," ToMr/vfl/ Of The ACM, 20 (1), (1973), 46-
61.
[4] A. Bastoni, "Cache-Related Preemption and Migration Delays: Empirical
approximation and Impact on Scheduling," In Sixth International Workshop
on Operating Systems Platforms for Embedded Real-Time Applications,
(2010), 33-34.
[5] R.H. Moring, A.S. Schulz and M. Uetz, "Approximation in Stochastic
Scheduling: The Power of LP-Based Priority Policies," ACM, (46), (1999),
924-942.
[6] C. G. Lee, J. Hahn, Y. M. Seo, S. L. Min, R. Ha, S. Hong, C. Y. Park, M. Lee
and C. S. Kim "Analysis of Cache-Related Preemption Delay in Fixed-
Priority Preemptive Scheduhng," IEEE Trans. Comput., 47(6), (1998), 700-
713.
[7] N. Megow, M. Uetz and T. Vredeveld, "Models And Algorithms for
Stochastic Online Scheduhn," Mathematics of Operations Research, (31),
(2006), 513-525.
[8] M. Bertogna and S. Baruah, "Limited Preemption of Scheduling of Sporadic
Task Systems," IEEE Transactions on Industrial Informatics, (2010), 45-49.
[9] S. Altmeyer, R. Davis and C. Maiza, "Cache Related Pre-Emption Delay
Aware Response Time Analysis for Fixed Priority Pre-Emptive Systems," In
Proc. 32nd IEEE Real-Time Syst. Symp. (RTSS.ll), Vienna,Austria, (2011),
23-28.
[10] M. Bertogna, O. Xhani, M. Marinoni, F. Esposito and G. Buttazzo, "Optimal
Selection of Preemption Points To Minimize Preemption Overhead," In Proc.
101 j P a g e

23rd Euromicro Conf. Real-Time Syst. (ECRTS'll), Porto, Portugal, (2011),
217-227.
[11] R. Cheng, M. Gen and Y. Tsujimura, "A Tutorial Survey of Job-Shop
Scheduling Problems Using Genetic Algorithms—I: Representation,"
Comput. Ind. Eng., 50(4), (1996), 983-997.
[12] M. J. Gonzalez, Jr., "Deterministic Processor Scheduling, " ACM Comput.
5wrv.,(3), (1977), 173-204.
[13] Y. C. Chung and S. Ranka, "Applications and Performance Analysis of a
Compile-Time Optimization Approach for List Scheduling Algorithin on
Distributed Memory Multiprocessors," In Proceedings Of The 1992
Conference on Supercomputing (Supercomputing '92, Minneapolis, MN), R.
Werner, Ed. IEEE Computer Society Press, Los Alamitos, CA, (1992), 515-
525.
[14] J. Blazewicz, J. Weglarz and M. Drabowski, " Scheduling Independent 2-
Processor Tasks To Minimize Schedule Length," Inf. Process. Lett., 18,
(1984), 267-273.
[15] V. J. Rayward-Smith , "The Complexity of Preemptive Scheduling Given
Interprocessor Communication Delays," Inf. Process. Lett., 25, (1987), 120-
128.
[16] E. G. Coffman and R. L. Graham, "Optimal Scheduling for Two-Processor
Systems," Acta Inf, 1, (1972), 200-213.
[17] E. C. Horvath, S. Lam and R Sethi," A Level Algorithm for Preemptive
Scheduling," J. ACM24 (1), (1977), 36-47.
[18] N. Guan, W. Yi, Q. Deng, Z. Gu, and G. Yu, "Schedulability Analysis for
Non-Preemptive Fixed-Priority Multiprocessor Scheduling," Journal Of
Systems Architecture, 57(5), (2011), 536 - 546.
102 I Pag
Conclusion
103

CONCLUSION
This thesis represents the results of the different task partitioning strategies cairied out
on distributed parallel computing architectures. Scheduhng in parallel computing is
highly important due to the efficient use of high performance computing systems.
Important laws related to parallel computing are also summarize.
To fulfill the objective of the thesis; we completed our study in two groups. The
first group has two parts: (1) Literature review about existing parallel computing
tools, (2) Comparison of existing task partitioning strategies in parallel computing
systems.
In the first part, we analyze the tools on the basis of comparative study. In this
comparison we found that PVM and MPI are the best parallel computing tools for
non-thread based parallel computing. While in thread based parallel computing,
CUDA is the best computing tool. It provides significant speedup and efficiency due
to strong thread background than other existing parallel computing tools.
, In second part, an important classification of the existed task partitioning
strategies has been presented. This comparative analysis summarize that there is no
ideal task partition strategy for all heterogeneous distributed computing systems.
Performances of the scheduling strategies depend upon the underlying architectures.
In the second group, we conducted experimental analysis of the proposed models and
algorithms. All experiments carried on the Directed Acyclic Graph (DAG). We
proposed an iterative task partitioning model and three algorithms. Out of three
algorithms, two algorithms are of dynamic nature. One proposed algorithm (OTPSD)
compared with MCP and HEFT algorithms. It shows lower execution time and NSL
value than the compared algorithms. The second dynamic proposed algorithm is
(TPSMT). This algorithm compared with HEFT and CPFD algorithms. Experimental
results show better performance in terms of average SLR versus CCR values. Average
efficiency shown by TPSMT is also better than HEFT and CPFD respectively. The
third proposed algorithm is preemptive. The algorithm (PTPS) is compared with
preemptive MCP and EPS algorithms. We observed that, its average NSL value upon
the number of different processors is less than compared algorithms. This result
shows that NSL value decreases proportionally if the number of processors increases.
The proposed problems in the thesis may give significant contribution in the field of
parallel computing. The proposed algorithms may be extended in temis of CPU
utilization analysis in heterogeneous architectures.
104 I Pa ue

LIST OF PUBLICATIONS
International Journal/Conference Publications:
1. Javed AH and Rafiqul Zaman Khan "A Survey Paper on Task Partitioning
Strategies in Parallel and Distributed System," Globus -An International Journal
of Management & IT, ISSN: 0975-721X, Vol.2, No-1, pp 1-12, (2010).
2. Rafiqul Zaman Khan and Javed All, Firoz All, "Performance Analysis of Parallel
Computing Tools: PVM, MPI, ScaLAPACK, BLACS and PVMPI," Proceedings
of International Conference on Advances in Mathematical & Computational
Methods (AMCM-2011), ISSN: 978-81-908497-6-0), Vol. 1, pp. 215-222, (2011).
3. Javed Ali and Rafiqul Zaman Khan, "Performance Analysis of Matrix
Multiplication Algorithms using MPI," International Journal of Computer
Science and Information Technologies (IJCIT), ISSN: 0975-9646, Vol. 3, No.l,
pp. 3103-3106,(2011).
4. Rafiqul Zaman Khan and Javed Ali, "A Practical Performance Analysis of
Modem Software used in High Performance Computing," International Journal of
Advanced Research in Computer Science and Software Engineering, ISSN: 2277-
1287, Vol. 2, No. 3, pp.15-19, (2011).
5. Javed Ali and Rafiqul Zaman Khan, "Dynamic Task Partitioning Model in
Parallel Computing," First International Conference on Advanced Information
Technology (ICAIT-2012), CoNeCo, WiMo, NLP, CRYPSIS ICAIT, ICDIP.
ITCSE, CS & IT 07, pp. 279-284, (2012).
6. Rafiqul Zaman Khan and Javed Ali, "Classification of Task Partitioning and Load
Balancing Strategies in Distributed Parallel Computing Systems," International
Journal of Computer Applications (IJCA), ISSN: 0123-4560, Vol. 60, pp. 34-41.
(2012).
7. Javed Ali and Rafiqul Zaman Khan, "Optimal Task Partitioning Model in
Distributed Heterogeneous Environment," International Journal of Advanced
Information Technology (IJAIT), ISSN: 2231-1920, Vol. 19, pp. 23-40, (2012).
8. Rafiqul Zaman Khan and Javed Ali, "Preemptive Task Partitioning Strategy
(PTPS) with Fast Preemption in Heterogeneous Distributed Environment."

International Journal of Applied Information Systems (IJAIS), ISSN: 2249-0868,
Vol. 6, No. 1, pp. 25-31,(2013).
9. Javed Ali and Rafiqul Zaman Khan, "Optimal Task Partitioning Strategy with
Duplication (OTPSD) in Parallel Computing Environments," International
Journal of Computers & Distributed Systems (IJCDS), Vol. 4, No. 1, pp.7-15,
(2013).
JO. Rafiqul Zaman Khan and Javed Ali, "Task Partitioning Strategy with Minimum
Time (TPSMT) in Distributed Parallel Computing Environment," International
Journal of Application or Innovation in Engineering & Management (IJAIEM),
ISSN: 2319 - 4847, Vol. 2, No. 7, pp. 522-528, (2013).


















