Spring 2013 EE457 Instructor: Gandhi Puvvada …...This mu lti-cycle datapath is similar to the 1st...
11
ee457_MT_Sp2013.fm April 4, 2013 6:30 am EE457 Midterm Exam - Spring 2013 Page - 1 / 11 C Copyright 2013 Gandhi Puvvada Spring 2013 EE457 Instructor: Gandhi Puvvada Midterm Exam (20%) Date: 4/5/2013, Friday Time: 09:15AM - 11:45AM in THH201 Name: Total points: 244 Perfect score: 220 / 244 1 ( pipeline 89 + single cycle 20 + multicycle 44 = 153 points) 100 min. Pipelining (Modified Lab 7 part 3 (further modified from Spring 2011 Midterm)): In the Spring 2011 midterm exam, we had two ADD4 units in the EX12 stage and also a branch if zero BZ instruction executing from the ID stage. There was no FU_BR or forwarding muxes in ID stage and we solved RAW dependency problems of the BZ instruction by simply stalling the BZ in ID stage. Given on the next page is the block diagram of the Spring 2011 question for your reference. Your friend says that an addition of FU_BR and a forwarding mux in ID stage could have avoided some of the stalls incurred by the BZ in the Spring 2011 design. True / False Explain: ________________________________________________________________________ _______________________________________________________________________________ _______________________________________________________________________________ _______________________________________________________________________________ Here, we added a MEM stage after the EX12 stage and added four new instructions, one load word instruction and three store word instructions as shown below. The JJJJ in BZ instruction as well as the JJJJ in the load word and store word instructions are the lower 16-bit field of the 32-bit instruction. It is obvious that the memory instructions use direct addressing mode. It is also obvious that the MEM stage shall be after the EX12 stage as SWP4 (store word plus 4) and SWP8 (store word plus 8) need the addition operation in the EX12 stage. Which of the instructions never provide help? (circle all right answers) None SW $X, JJJJ SWP4 $X, JJJJ SWP8 $X, JJJJ Which of the instructions never receive help? (circle all right answers) None SW $X, JJJJ SWP4 $X, JJJJ SWP8 $X, JJJJ 5 pts 10 pts 4 pts Instruction Operation NOP; MOV $R, $X; ($R) <= ($X) BZ $X, JJJJ; (PC) <= JJJJ if ($X) = 0 ADD4 $R, $X; ($R) <= ($X) + 4 ADD8 $R, $X; ($R) <= ($X) + 8 LW $R, JJJJ; ($R) <= M[JJJJ] SW $X, JJJJ; M[JJJJ] <= ($X) SWP4 $X, JJJJ; M[JJJJ] <= ($X) + 4 SWP8 $X, JJJJ; M[JJJJ] <= ($X) + 8 Which of the following junior instructions is/are dependent on LW $2 6780 ? (circle it/them) None, MOV $1, $2; MOV $2, $1; BZ $2, 1234; ADD4 $1, $2; ADD8 $1, $2; LW $2 8880; SW $2 8880; SWP4 $2 8880; SWP8 $2 8880; Which of the following junior instructions is/are dependent on SW $2 6780 ? (circle it/them) None, MOV $1, $2; MOV $2, $1; BZ $2, 1234; ADD4 $1, $2; ADD8 $1, $2; LW $2 8880; SW $2 8880; SWP4 $2 8880; SWP8 $2 8880; Any dependency requiring stalling or forwarding in each of the two pairs of instructions? In Pair#1 Yes / No . In Pair#2 Yes / No . Pair#1: Senior: LW $2 6780; Pair#2: Senior: SW $6 2380; Junior: SW $3 6780; Junior: LW $7 2380;
Transcript of Spring 2013 EE457 Instructor: Gandhi Puvvada …...This mu lti-cycle datapath is similar to the 1st...

ee457_MT_Sp2013.fm
April 4, 2013 6:30 am EE457 Midterm Exam - Spring 2013 Page - 1 / 11 C Copyright 2013 Gandhi Puvvada
Spring 2013 EE457 Instructor: Gandhi Puvvada Midterm Exam (20%) Date: 4/5/2013, Friday Time: 09:15AM - 11:45AM in THH201
Name: Total points: 244
Perfect score: 220 / 244
1 ( pipeline 89 + single cycle 20 + multicycle 44 = 153 points) 100 min.
Pipelining (Modified Lab 7 part 3 (further modified from Spring 2011 Midterm)):
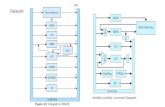
In the Spring 2011 midterm exam, we had two ADD4 units in the EX12 stage and also a branch if zero BZ instruction executing from the ID stage. There was no FU_BR or forwarding muxes in ID stage and we solved RAW dependency problems of the BZ instruction by simply stalling the BZ in ID stage. Given on the next page is the block diagram of the Spring 2011 question for your reference.
Your friend says that an addition of FU_BR and a forwarding mux in ID stage could have avoided some of the stalls incurred by the BZ in the Spring 2011 design. True / FalseExplain: ________________________________________________________________________ _______________________________________________________________________________ _______________________________________________________________________________ _______________________________________________________________________________ Here, we added a MEM stage after the EX12 stage and added four new instructions, one load word instruction and three store word instructions as shown below. The JJJJ in BZ instruction as well as the JJJJ in the load word and store word instructions are the lower 16-bit field of the 32-bit instruction. It is obvious that the memory instructions use direct addressing mode. It is also obvious that the MEM stage shall be after the EX12 stage as SWP4 (store word plus 4) and SWP8 (store word plus 8) need the addition operation in the EX12 stage. Which of the instructions never provide help? (circle all right answers) None SW $X, JJJJ SWP4 $X, JJJJ SWP8 $X, JJJJ
Which of the instructions never receive help? (circle all right answers) None SW $X, JJJJ SWP4 $X, JJJJ SWP8 $X, JJJJ
5pts
10pts
4pts
Instruction Operation
NOP;
MOV $R, $X; ($R) <= ($X)
BZ $X, JJJJ; (PC) <= JJJJ if ($X) = 0
ADD4 $R, $X; ($R) <= ($X) + 4
ADD8 $R, $X; ($R) <= ($X) + 8
LW $R, JJJJ; ($R) <= M[JJJJ]
SW $X, JJJJ; M[JJJJ] <= ($X)
SWP4 $X, JJJJ; M[JJJJ] <= ($X) + 4
SWP8 $X, JJJJ; M[JJJJ] <= ($X) + 8
Which of the following junior instructions is/are dependent on LW $2 6780 ? (circle it/them)
None, MOV $1, $2; MOV $2, $1; BZ $2, 1234; ADD4 $1, $2; ADD8 $1, $2; LW $2 8880; SW $2 8880; SWP4 $2 8880; SWP8 $2 8880;
Which of the following junior instructions is/are dependent on SW $2 6780 ? (circle it/them)
None, MOV $1, $2; MOV $2, $1; BZ $2, 1234; ADD4 $1, $2; ADD8 $1, $2; LW $2 8880; SW $2 8880; SWP4 $2 8880; SWP8 $2 8880;
Any dependency requiring stalling or forwarding in each of the twopairs of instructions? In Pair#1 Yes / No . In Pair#2 Yes / No . Pair#1: Senior: LW $2 6780; Pair#2: Senior: SW $6 2380;
Junior: SW $3 6780; Junior: LW $7 2380;

ee457_MT_Sp2013.fm
April 4, 2013 6:30 am
EE457 Midterm
Exam - Spring 2013 Page - 2 / 11
CC
opyright 2013 Gandhi Puvvada
PC
XA
Reg. File
XA
RA
RDR-Write
0
1
0
10
1
A
Cout
A
Cout
Comp Station in ID Stage
ID_XMEX12
P
IF ID EX12 WBComp Station in ID Stage
Q
ID_XA EX12_RA
P=Q
ID_XA Matched with EX12_RA
XD
HDU_BR
EN
XM
EX12
A+4 A+4
FU
EN
RD
Writ
e
RA
XD
RESET_BRESET_BRESET_B
1. Complete all missing connections to
2. Complete the STALL_ADD8 logic in EX12 and STALL_BR logic in ID stage.
4. Draw the logic to produce PCSource, IF_Flush, FORW, SKIP1, SKIP2 on this page itsef.
EX12_ADD4
EX12_ADD8
EX12_RA
WB_RA
WB_Write
WB_RDX1_MuxR1_Mux
R2_Mux
SKIP1
SKIP2
Modified LAB 7 Part 3 Block Diagram
I-M
EMEN
RESET_B
ADD4ADD4STALL_BR
EN
FORW
Q#2
ADD4
AD
D8
RAM
OV
ADD4
AD
D8
RA
MO
V
EX12_MOV
3. Complete all four enable (EN) controls on the pipeline registers (including PC).
ID_ADD4
ID_ADD8
ID_MOV
BZ
XD_ZERO
ID_BZ
+
D QCLKCLRCLK
RESET_B
1
0
1
JJJJ
BranchAddress
16
16 1616
ID_XMEX12
EX12
_Writ
e
PCSource
IF_Flush
STALL_ADD8
EX12_XMEX12
Spring 2011 Q#2 Block Diagram -- Just for reference

ee457_MT_Sp2013.fm
April 4, 2013 6:30 am
EE457 Midterm
Exam - Spring 2013 Page - 3 / 11
CC
opyright 2013 Gandhi Puvvada
PC
XA0
1
0
10
1
A
Cout
IF EX12 WB
A+4
FU_12EN
RD
Writ
e
RA
RESET_BRESET_B
WB_RA
WB_Write
WB_RD
XA
_Mux
R1_MuxR2_Mux
SKIP1
SKIP2
Modified LAB 7 Part 3 Block Diagram
I-M
EM
EN
RESET_B
ADD4ADD4EN
FORW_12A
Q#1
RA
BZ
+
D QCLKCLRCLK
RESET_B
1
0
1
JJJJ
16
16
16
16
PCSource
IF_Flush
STALL_12
A
Cout
A+4
Comp Station in ID Stage
ID_XMEX12 ID_XMMEM
P P QQ
ID_XA EX12_RA ID_XA MEM_RA
P=Q P=Q
ID_XMEX12= ID_XA Matched with EX12_RA
EN
XM
EX
12X
MM
EM
XD
RESET_BRA
Reg. File
XA
RA
RDR-Write
ID
XD
XD_ZERO
ID_BZ
BranchAddress
WB_RDWB_RA
WB_Write
0
1
FA_Mux
0
1
FB_Mux
HDU
FU_BR
FA_Sel
FB_Sel
ID_RA
Contr
ol
sig
nal
sO
ther
th
an B
Z
Co
ntr
ol
sign
als
Oth
er t
han
BZ
JJJJ
EN
XM
EX
12X
MM
EM
XD
RA
Co
ntr
ol
sig
nal
sO
ther
th
an B
ZJJ
JJ
0
1Din
Dout
1
0Address
FU_M
FORW_M
STALL_ID
Mem
ory
Add
ress
Mem
ory
Add
ress
IFRF
0
1
XB
_Mux
FORW_12B
FORW_12A
FORW_12B
MEM
_Reg
Writ
e
MD
1. Complete the 13 items marked as here on this page. Notes:These are 5 EN (enables) for the 5 registers, 5 forwarding paths for the 5 forwarding muxes,
ID_Bubble
PCSource, IF_Flush, and ID_Bubble.
.Produce the 8 items marked as on the next few pages.
Mem
toR
egMR MW
Mem
Rea
d
Mem
Wri
te
MEM
_Mem
toR
eg
Complete this
26pts

ee457_MT_Sp2013.fm
April 4, 2013 6:30 am EE457 Midterm Exam - Spring 2013 Page - 4 / 11 C Copyright 2013 Gandhi Puvvada
Given on the previous page is an incomplete design of the 5-stage pipeline. Browse through the same and also browse through the associated parts of the question below before starting answering. Use signal names with stage name as prefix in your design. For example the signal ID_XMMEM (meaning ID_XA matched with the MEM_RA), when carried to the EX12 stage (through the ID/EX12 stage register) bears the name EX12_XMMEM. The one-hot coded opcode provides the following control signals:MOV, BZ, ADD4, ADD8, LW, SW, SWP4, SWP8. When SW goes into EX12, it is called EX12_SW.
1.1 Consider the sequence of dependent instructions on the side. LW itself is not dependent on its seniors. Is it possible to execute this sequence without stalls? _____ Yes / No. If "No" how many stall are incurred and where and when? If "Yes" how the BZ is receiving help when his seniors themselves need to receive help? Why the VLSI engineer is concerned about a series of mux delays cascaded in our design and calls it a "snake path"?____________________________________________________________________________________________________________ _______________________________________________________________________________ _______________________________________________________________________________
1.2 Complete 13 items of the design on page 5. Complete 6 items of the design below.
1.2.1 HDU in ID stage contains stall logic to handle RAW dependencies of all instructions including BZ which can not be solved through forwarding.
1.2.2 FU_BR in ID stage to produce the two select signals for the two forwarding muxes in the ID stage. These muxes are properly ordered to implement priority in forwarding.
1.2.3 EX12_STALL_Logic
LW $2 8880; // in WB stageMOV $3, $2; // in MEM stageMOV $4, $3; // in EX12 stageBZ $4 1234; // in ID stage
WBMEMEX12ID
LWMOVMOVBZ
8pts
6pts STALL_ID
HDU
FA_Sel
FU_BR
FB_Sel
6pts
EX12_STALL_Logic
STALL_12D QCLKCLRCLK
RESET_B
6pts

ee457_MT_Sp2013.fm
April 4, 2013 6:30 am EE457 Midterm Exam - Spring 2013 Page - 5 / 11 C Copyright 2013 Gandhi Puvvada
1.2.4 EX12_other_Logic:The two forwarding muxes are properly ordered to implement priority in forwarding.
1.2.5 MEM stage Forwarding unit FU_M: Circle the instructions which can wait as late as MEM stage to receive forwarding help:MOV, BZ, ADD4, ADD8, LW, SW, SWP4, SWP8
1.2.6 MEM_other_Logic:
1.3 Complete the following "Single Cycle CPU" kind of a design for the 5-stage pipeline. Complete the control unit on the next page.
EX12_other_Logic
FORW_12A
FORW_12B
SKIP1
SKIP2
8pts
FORW_M
FU_M
4pts
MEM_other_Logic
MemWrite
MEM_MemtoReg
MEM_RegWrite
MemRead
6pts
12pts
LW
SWP4
SW
SWP8
PC
XA
Reg. File
XA
RA
RDR-Write
0
1
0
1A
Cout
XDA+4
RegWrite
R1_Mux R2_Mux
SKIP1
SKIP2
I-M
EM
PC_EN
RESET_B
ADD4
MOV
ADD4
RA
BZ
ADD8
+1
0
1
JJJJ
BranchAddress
16
16 1616
PCSource
XD
XD_ZERO
CU
BranchCond
Single Cycle CPU
A
Cout
A+4
ADD4
DinDout
Address
MD
MR MW
Mem
Rea
d
Mem
Wri
te
1
0
Mem
toR
eg
Show
the
desi
gn o
f thi
s C
ontro
l uni
t sep
arat
ely
?

ee457_MT_Sp2013.fm
April 4, 2013 6:30 am EE457 Midterm Exam - Spring 2013 Page - 6 / 11 C Copyright 2013 Gandhi Puvvada
1.3.1 Design the control unit for the single cycle CPU here.
1.4 Now let us try to build a multi-cycle version for the design. It is proposed that, we go for a single ALU, which can add a selected constant, (1 for PC and 4 for ADD4 or ADD8).ADD8 uses the ALU twice to add 4 two times. This multi-cycle datapath is similar to the 1st edition design except that here the ALU is built using dynamic logic (like in the 2nd edition). There is an ALUOut register like in the 2nd edition. You need to carefully decide when to take (tap) data from the upstream of the ALUOut register and when to take (tap) data from the downstream of the ALUOut register. We have an IR register (Instruction Register) to hold the instruction at the end of the first state(S0). IR is needed as PC is incremented using the ALU in the very first state. The memory has an output register MDR. We need to support a NOP instruction here besides MOV, BZ, ADD4, ADD8, LW, SW, SWP4, and SWP8.
1.4.1 Complete the datapath and the state diagram for control unit on the next two pages. To some extent, our state diagram resembles the 2nd edition state diagram reproduced below for your reference.We are doing a MOORE kind of state diagram and may be wasting a few clocks.
8pts
BranchCond
SKIP1
SKIP2
MemRed
MemWrit
MemtoReg
RegWriteJust for reference

ee457_MT_Sp2013.fm
April 4, 2013 6:30 am
EE457 Midterm
Exam - Spring 2013 Page - 7 / 11
CC
opyright 2013 Gandhi Puvvada
PC
XA
Reg. File
XA
RA
RDR-Write
B
Cout
XDA+B
RegWrite
I-M
EM
PC_EN
RESET_B
16-bit ALU
RA
0
1
JJJJ
BranchAddress
16
1616
PCSource
XD
XD_ZERO
CU
SKIP
IR
PCWritePCWriteCond
Multi Cycle CPU
0
1
In_Mux0
1
X_Mux
0
1
C_Mux
14
A
ONE/FOUR
IRWrite
ALU
Out
16
ASo
urce
[1]
ASo
urce
[0]
PCWrite
ASource[1:0]
PCWriteCond
ONE/FOUR
0
1
R_Mux
SKIP
CU
DinDout
Address
MD
MR MW
Mem
Rea
d
Mem
Wri
te
1
0
Mem
toR
eg
MemRead
Incremented PC
MD
R
MemWrite
MemReg
M_Mux
JJJJ
LW
SWP4
SW
SWP8
MOV
ADD4
BZ
ADD8
IRWrite
PCSource
Complete the 11 connections marked as
Data Path
The ALU
Out register _______
___________ (requires
/doesn’t require) a w
rite control.The M
DR
register __________________
(requires /
doesn’t require) a write control.
Reason for this is __________
______________________________________________________________________________________________________________________________________________________
6pts18pts

ee457_MT_Sp2013.fm
April 4, 2013 6:30 am
EE457 Midterm
Exam - Spring 2013 Page - 8 / 11
CC
opyright 2013 Gandhi Puvvada
S0 S1
PCSource=
ASource[1:0]=
ONE/FOUR =
RESET_B
NOP = MOV BZ ADD4 ADD8 LW SW SWP4 SWP8
No RTL needed.No signal list
Instruction FetchPC Incrementation Instruction Decode
Register Fetch
S2
S3
S4
S5
S6
S7S8
S9
S10
BZ
AD4ADD8
SW
SW4SWP8
ADD4ADD8
SWP4
SWP8
SWP8
ADD8
MOV
Add 2nd fourPerform simple SW
Perform SW Plus
LW Mem Read
LW Writeback R-Type completion MOV Completion
LW
Add 1st four
Branch execution
Multi Cycle CPUState Diagram
20pts

ee457_MT_Sp2013.fm
April 4, 2013 6:30 am EE457 Midterm Exam - Spring 2013 Page - 9 / 11 C Copyright 2013 Gandhi Puvvada
2 ( 43 points) 20 min.
Cache mapping techniques:
Fill-in all missing information in the table below based on information provided. In all four cases, it is the same amount of cache differently organized.
TAG RAM(s) and their size(s) and comparators to compare TAG(s) and their size.
In the case of Direct Mapping above, we use _______ (state a number) TAG RAM(s) of size ___________________ together with ________ (state a number) comparator(s) each of ______ -bit wide.
In the case of Set Associative Mapping with 2 Blocks/Set above, we use _______ (state a number) TAG RAM(s) of size ___________________ together with ________ (state a number) comparator(s) each of ______ -bit wide.
In the case of Set Associative Mapping with 8 Blocks/Set above, we use _______ (state a number) TAG RAM(s) of size ___________________ together with ________ (state a number) comparator(s) each of ______ -bit wide.
The Fully Associative Mapping is prohibitively expensive because you would need ___________state a number) comparator(s) each of ____________ -bit wide.
In the first case of direct mapping, the main memory shall be organized in a ________-way lower-order interleaving to facilitate efficient _________________________________________________The main memory organization is _______________ (same/different) in the above 4 cache organizations, because ____________________________________________________________________________________________________________________________________________
In general, a set can potentially have a set-associativity equal to any number (not necessarily a power of 2). The 2-way set-associative design was implemented and substantial silicon area was left out. The VLSI team estimated that they can increase the cache size to 5 time the original size easily. We the architects did not want to change the number of sets or the Block size. What else is there to change? What is the impact on TAG RAMs (size and number) and Data RAM segregations? _____________________________________________________________________________________________________________________________________________________________________________________________________________________________________________I
11pts
Direct
Fully
Set Associative2 Blocks/Set
MappingTechnique
AddrSpace
CacheSize
BlockSize
TAG FIELD BLOCK ORSET FIELD
WORDFIELD
____
-bit
Dat
a__
_-bi
t add
ress
Size
BYTEFIELD
(as appropriate)
___Words
(___Bytes)
____KB
byte
add
ress
able
Proc
esso
r
A4-A3 A2-A0(BE7-BE0)
A4-A3 A2-A0(BE7-BE0)
A4-A3 A2-A0(BE7-BE0)
A -
A - A
A - A
2
GBytes
A15 -
A -
use this
info.!
use thisinfo.!
use thisinfo.!
Associative
Set Associative8 Blocks/Set
A4-A3 A2-A0(BE7-BE0)
A - A A -
A A5
A5
A5
4pts
4pts
4pts
4pts
6pts
10pts

ee457_MT_Sp2013.fm
April 4, 2013 6:30 am EE457 Midterm Exam - Spring 2013 Page - 10 / 11 C Copyright 2013 Gandhi Puvvada
3 ( 48 points) 30 min.
Virtual Memory:
3.1 PTBR stands for _____________________________________________________________.It is initiated by _________________________ (hardware / operating system) and is utilized by ___________ (MMU / CCU) (i.e. memory management unit or cache control unit) to look up ______________________ (TLB / Page Table / Cache Tag RAM).
3.2 Page Table: Number of A,B,C,D Tables built by the OS:
PQRST on the side represents a 20-bit (5-digit hex) VPN in a 4-level page table with upper 4 bits (P) indexing the A-level table, next 8 bits (QR) indexing the B-level tables, next 4 bits (S) indexing the C-level tables, and the last 4 bits (T) indexing the D-level tables.
3.2.1 Suppose the first 8 distinct virtual pages accessed by the application program had the VPNs as stated in TABLE-I (in sorted order).How many tables of what size are built by OS by this time?A-level: _____________________________________________ B-level: _____________________________________________ C-level: _____________________________________________ D-level: _____________________________________________
3.2.2 Complete 8 distinct VPNs of your choice in TABLE-II such that the least number of A,B,C,D tables are built by OS. This least set consists of ____ of A-Table(s), ____ of B-Table(s), ____ of C-Table(s), ____ of D-Table(s).
3.2.3 Similarly, complete 8 distinct VPNs of your choice in TABLE-III such that the most number of A,B,C tables are built by OS. This most set consists of ____ of A-Table(s), ____ of B-Table(s), ____ of C-Table(s), ____ of D-Table(s).
3.3 The advantage of _______ (VIPT / PIPT) over ______ (VIPT / PIPT) comes from the fact that _______________________________________________________________________________ _______________________________________________________________________________ ______________________________________________________________________________________________________________________________________________________________ _______________________________________________________________________________
3.4 Memory addresses: In a 32-bit virtual address system using 16KB pages, state any two consecutive 32-bit word addresses (in hex) which do not fall in the same virtual page.______________________I am evicting a page containing the byte with virtual address 23456789h. What is its virtual page number (in hex)? __________. What is the range of byte addresses residing in that page (lowest virtual byte address to highest virtual byte address). ____________________________________
6pts
TABLE-II TABLE-IIIP Q R S T P Q R S T P Q R S T
TABLE-I
1 1 3 4 71 2 3 4 71 2 3 6 51 3 3 6 51 4 3 6 51 5 3 6 51 7 3 6 51 7 5 6 5
9pts
6pts
6pts
6pts
7pts

ee457_MT_Sp2013.fm
April 4, 2013 6:30 am EE457 Midterm Exam - Spring 2013 Page - 11 / 11 C Copyright 2013 Gandhi Puvvada
The physical page frame number in the main memory is 2 (just 2). What is the range of byte addresses residing in that page (lowest physical byte address to highest physical byte address). ___________________________________________________
3.5 Since we use write-back only for virtual memory, we need to maintain a dirty bit associated with ________________________________________________ (the entire TLB /the entire Page Table / each entry of the page table / each entry of the TLB / each entry in both TLB and Page Table).
3.6 Fully associative mapping may not be prohibitively expensive in the case of a _________________(TLB / L2 cache) because __________________________________________________________________________________________________________________________________________
4pts
4pts
The next few weeks are very important as we will be covering a lot of material in 4 weeks. Please, please do attend every lecture and discussion. And use our office hours. Thanks. -- The EE457 Teaching Team