
Spoken Language Processing Lab Who we are: Julia Hirschberg, Stefan Benus, Fadi Biadsy, Frank Enos,...
25
Spoken Language Processing Lab Who we are: Julia Hirschberg, Stefan Benus, Fadi Biadsy, Frank Enos, Agus Gravano, Jackson Liscombe, Sameer Maskey, Andrew Rosenberg Lab: The Speech Lab , CEPSR 7LW3-A
-
date post
20-Dec-2015 -
Category
Documents
-
view
216 -
download
1
Transcript of Spoken Language Processing Lab Who we are: Julia Hirschberg, Stefan Benus, Fadi Biadsy, Frank Enos,...

Spoken Language Processing Lab
Who we are:Julia Hirschberg, Stefan Benus, Fadi Biadsy, Frank Enos, Agus Gravano, Jackson Liscombe, Sameer Maskey, Andrew Rosenberg
Lab: The Speech Lab, CEPSR 7LW3-A

Prosody, Emotion and Speaker State
• A speaker’s emotional state represents important and useful information– To recognize (e.g. anger/frustration in IVR systems)– To generate (e.g. any emotion for games)– Many studies have shown that prosody helps to
convey/identify ‘classic emotions’ (anger, happiness,…) with some accuracy
• Can prosody also signal other types of speaker state?– In a tutoring domain (confidence vs. uncertainty)– Charisma– Deception

happysadangryconfidentfrustratedfriendlyinterested
anxiousboredencouraging
LDC Emotional Speech Corpus

Identifying Confidence vs. Uncertainty (Liscombe)
• The ITSpoke Corpus:
physics tutoring Collected at
U. Pittsburgh by Diane
Litman and students
– 17 students, 1 tutor
– 130 human/human dialogues
– ~7000 student turns (mean
length ≈ 2.5 sec)
– Hand labeled for confidence,
uncertainty, anger, frustration
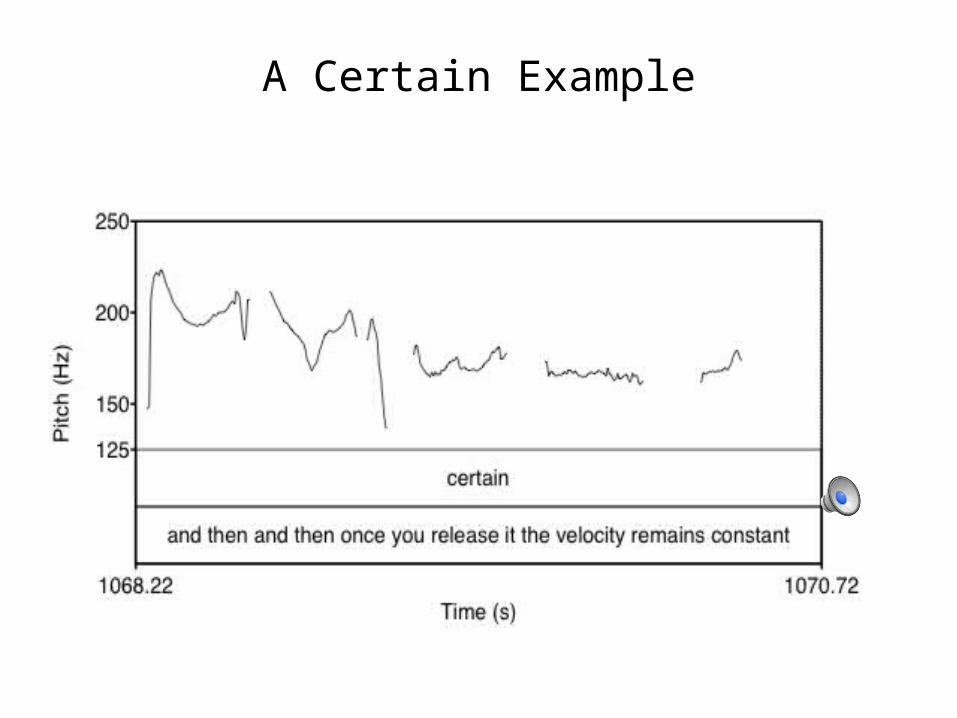
A Certain Example
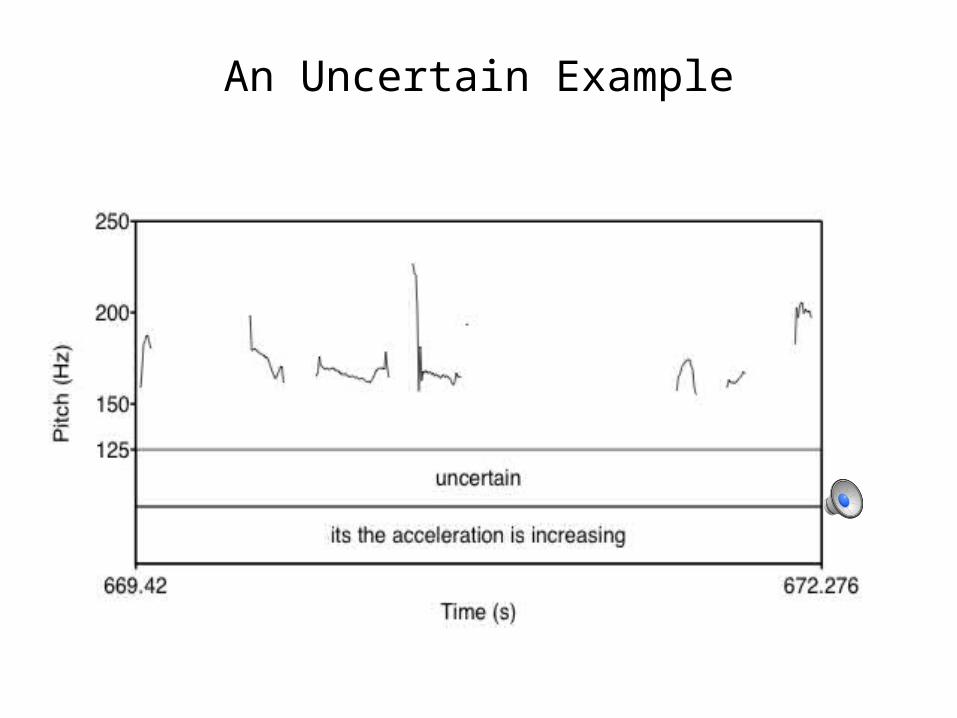
An Uncertain Example
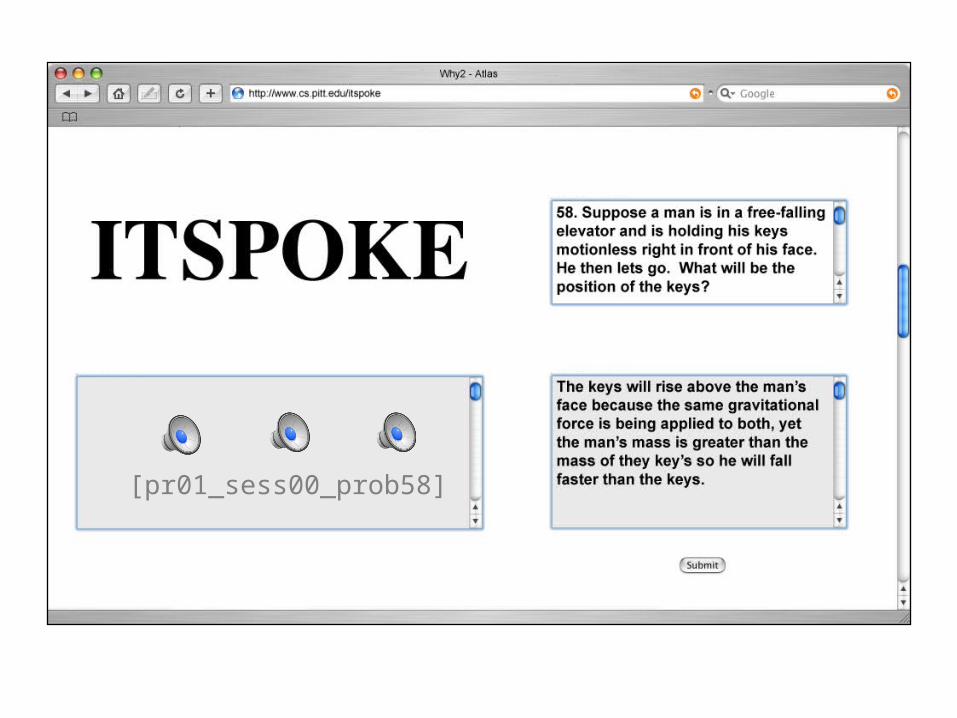
[pr01_sess00_prob58]

Direct Modeling of Prosodic Features
• Automatically extracted acoustic/prosodic
– Pitch, energy, speaking rate, unit duration (hand
labeled), pausal duration within and preceding unit
of analysis, filled pauses (hand labeled)
• Units
– Entire turns
– Breath groups
– Context: Same features from prior turn(s)
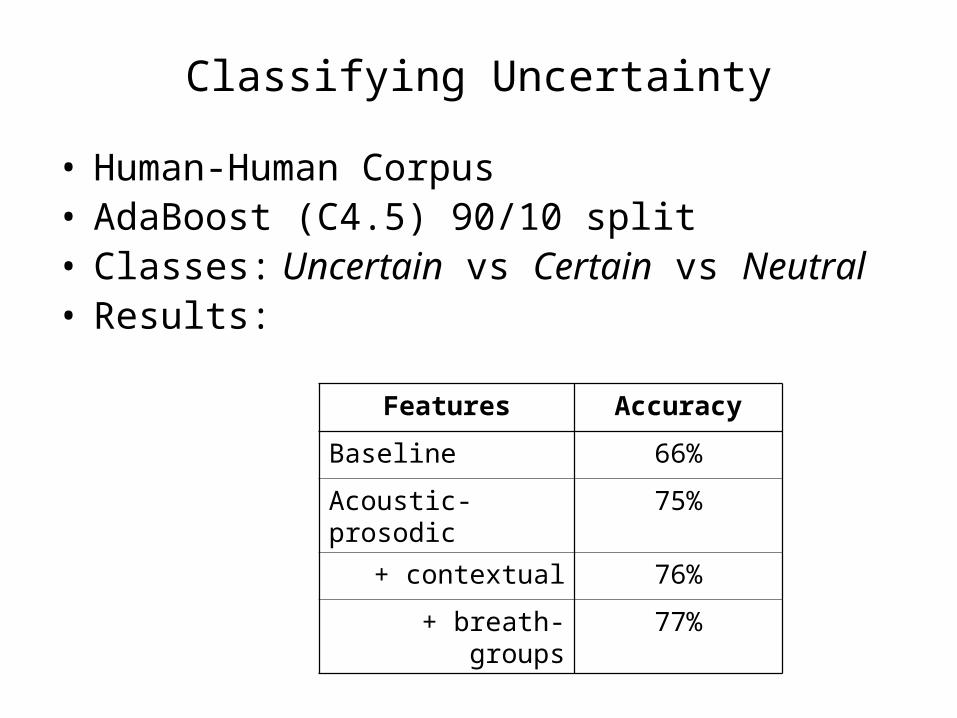
Classifying Uncertainty
• Human-Human Corpus• AdaBoost (C4.5) 90/10 split• Classes: Uncertain vs Certain vs Neutral• Results:
Features Accuracy
Baseline 66%
Acoustic-prosodic 75%
+ contextual 76%
+ breath-groups 77%

Charismatic Speech (Rosenberg, Biadsy)
• What is charisma?– The ability to attract, and retain followers by virtue
of personality as opposed to tradition or laws. (Weber ‘47)
• E.g. JFK, Hitler, Castro, Martin Luther King
• Why study it?– Identify new leaders early– Help people improve their public speaking– Produce more compelling TTS
• What makes leaders charismatic? • Can prosody help us identify charisma?


Method
• Data: 45 2-10s speech segments, 5 each from 9 candidates for Democratic nomination for president – 2 ‘charismatic’, 2 ‘not charismatic’– Topics: greeting, reasons for running, tax cuts,
postwar Iraq, healthcare
• 13 subjects rated each segment on a Likert scale (1-5) for 26 questions
• Correlation of lexical and acoustic/prosodic features with mean charisma ratings

Acoustic/Prosodic and Lexical Features
• Min, max, mean, stdev F0– Raw and normalized by
speaker
• Min, max, mean, stdev intensity
• Speaking rate (syls/sec)• Mean and stdev of
normalized F0 and intensity across phrases
• Duration (secs)• Length (words, syls)
• Number of intonational, intermediate, and internal phrases
• Mean words per intermediate and intonational phrase
• Mean syllables/word• 1st, 2nd, 3rd person
pronoun density• Function to content word
ratio

What makes speech charismatic?
• More content – Length in secs, words, syllables, and phrases
• Use of polysyllabic words– Lexical complexity (mean syllables per word)
• Use of more first person pronouns– First person pronoun density
• Higher and more dynamic raw F0– Min, max, mean, std. dev. of F0 over male speakers
• Greater intensity– Mean intensity

• Higher in a speaker’s pitch range– Mean normalized F0
• Faster speaking rate– Syllables per second
• Greater variation in F0 and intensity across phrases – Std. dev. of normalized phrase F0 and intensity
• But...what about cultural differences?– Next:
• Swedish ratings of American tokens• Palestinian Arabs of Arabic tokens

Acoustic/Prosodic and Lexical Cues to Deception (Enos)
• Deception evokes emotion in deceivers (Ekman ‘85-92)– Fear of discovery: higher
pitch, faster, louder, pauses, disfluencies, indirect speech
– Elation at successful deceiving ‘duping delight’: higher pitch, faster, louder, greater elaboration
• Detecting cues to these emotions may also identify deception
•Can prosody help us identify deceptive speakers?

Columbia/SRI/Colorado Corpus
• 15.2 hrs. of interviews; 7 hrs subject speech• Lexically transcribed & automatically aligned • Labeling conditions: Global / Local• Segmentation (LT/LL):
– slash units (5709/3782)– phrases (11,612/7108)– turns (2230/1573)
• Acoustic/prosodic features extracted from ASR output and lexical and discourse features extracted

Sample Features
• Duration features– Phone / Vowel / Syllable Durations– Normalized by Phone/Vowel Means, Speaker
• Speaking rate features (vowels/time)• Pause features (cf Benus et al 2006)
– Speech to pause ratio, number of long pauses– Maximum pause length
• Energy features (RMS energy)• Pitch features
– Pitch stylization (Sonmez et al.)– LTM model of F0 to estimate speaker range– Pitch ranges, slopes, locations of interest
• Spectral tilt features
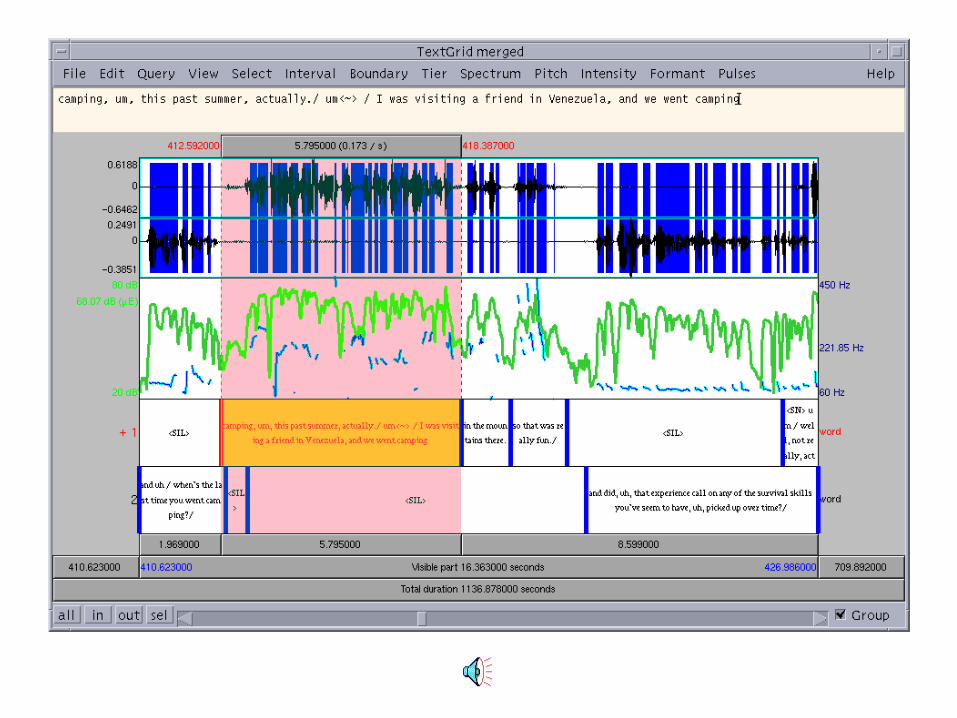

Speech summarization in Broadcast News
• Problem: How do we summarize text and speech documents together?
• Recognition Errors– Named Entities– Misrecognized rare terms
• Error propagation in the processing pipeline of ASR transcripts– Ex: Sentence boundary -> Turn boundary -> Speaker
Roles -> Summarization
• Solution: Combining lexical and acoustic information in one framework

Current Approach
• Use acoustic/prosodic features to compute acoustic significance of sentences
• Remove disfluencies from ASR transcripts• Compute ASR confidence for sentences• Cluster text and speech transcripts together
– Use acoustic scores as additional weights
• Word or Phrase level acoustic significance– Emphasized “George Bush” vs. non-emphasized “George Bush”
• Use Broadcast News structure in summarization– Headlines, Soundbites, Interviews, Weather report, Sports
section may be useful for certain questions – opinion, attribution, disaster

Spoken Dialogue Systems
• Discourse phenomena in dialogue– Turn-taking– Given/new information– Cue phrases– Entrainment
• The GAMES corpus– 12 sessions of dialogue– 12.2h– Annotations: orthographic, turns, cue phrases,
ToBI…, question form and function
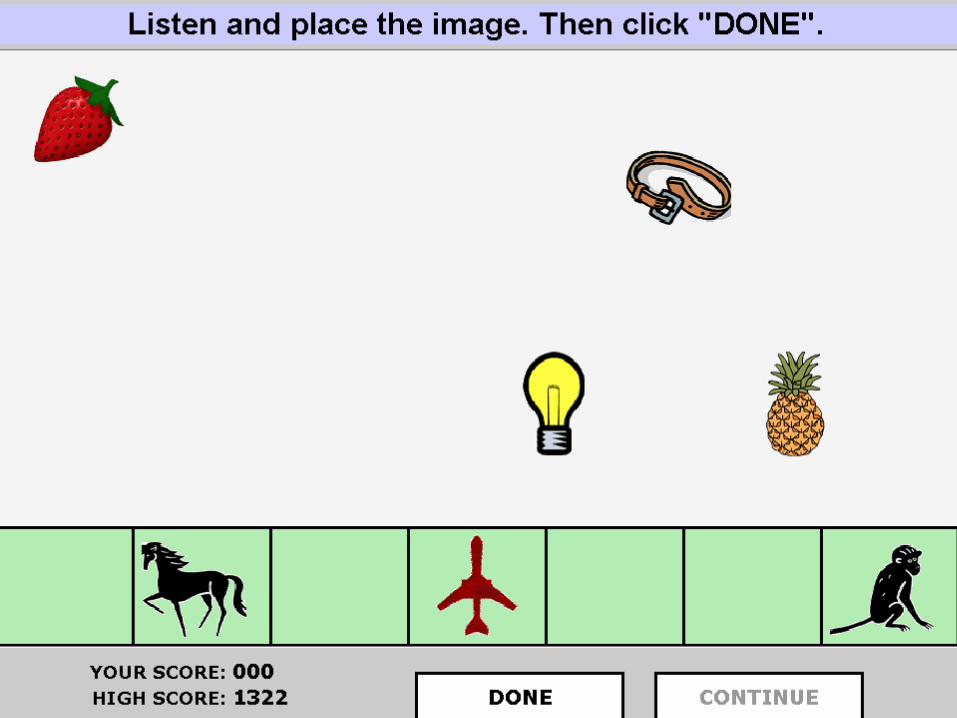
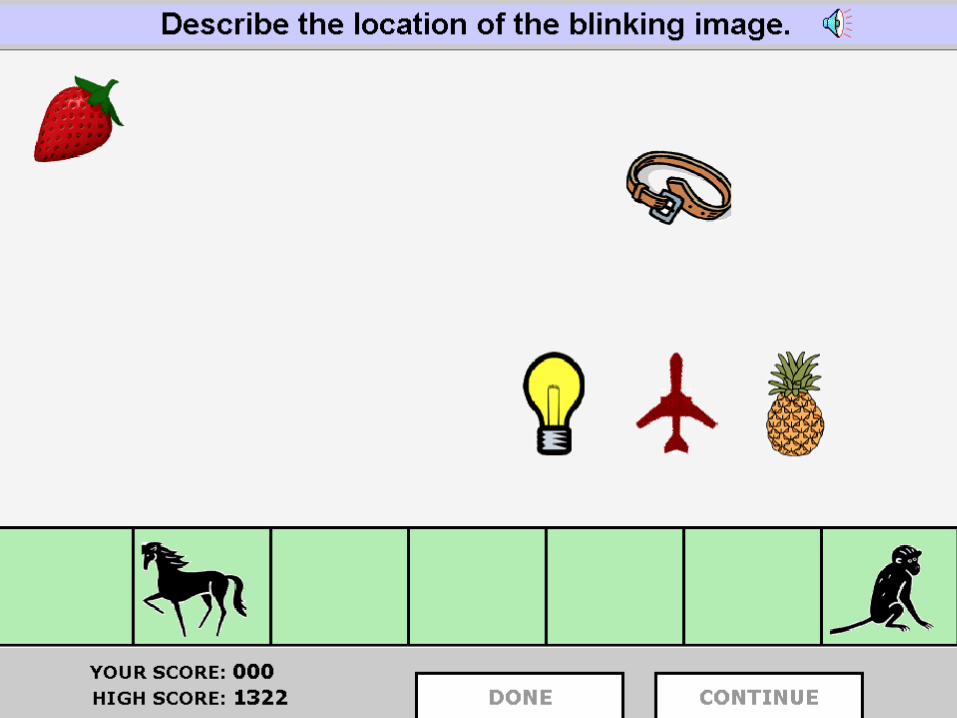

Translating Prosody: Mandarin/English (Rosenberg)
• Prosodic variation is the last thing we learn• How do speakers convey suprasegmental
information in different languages?• To translate, first identify
– Automatic Identification of Prosodic Events• Pitch Accents and Phrase Boundaries
• What are the correspondences?– Discourse structure– Intonational contours– Information status– Emotion













![Ocala Evening Star. (Ocala, Florida) 1902-06-30 [p ].ufdcimages.uflib.ufl.edu/UF/00/07/59/08/02377/00642.pdf · profile for-ward usedo relative right-he Benus since county SUITS overall](https://static.fdocuments.us/doc/165x107/5ffcfe730f3dd929b9506ae6/ocala-evening-star-ocala-florida-1902-06-30-p-profile-for-ward-usedo-relative.jpg)




