
(Spoiler: only Swift and Julia make the cut) - ARPA-E · 2018-07-06 · (Spoiler: only Swift and...
29
(Spoiler: only Swift and Julia make the cut) Alan Edelman (MIT & JC) Viral Shah (Julia Computing) Juan Pablo Vielma (MIT) Chris Rackauckas (UC Irvine) What Google knows about ML languages that you may not
Transcript of (Spoiler: only Swift and Julia make the cut) - ARPA-E · 2018-07-06 · (Spoiler: only Swift and...

(Spoiler: only Swift and Julia make the cut)
Alan Edelman (MIT & JC)Viral Shah (Julia Computing)
Juan Pablo Vielma (MIT)Chris Rackauckas (UC Irvine)
What Google knows about ML languages that you may not

Software Toolchain
Multiphysics (PDEs) Optimization Adjoint Methods Machine Surrogate Models(Backprop/Autodiff) Learning Dim Reduction
1 2 3 4 5 6 7
- 4
- 2
2
4
Composability Sensitivity Analysis Performance Uncertainty ScalableConfidence Intervals Nimble/Agile Quantification
?

Modern Software Development

Languages Studied by Google as Powerful for ML
https://github.com/tensorflow/swift/blob/master/docs/WhySwiftForTensorFlow.md

1. Filter on Technical Merits
Languages Studied by Google as Powerful for ML

1. Filter on Technical Merits
2. Filter on Usability
Languages Studied by Google as Powerful for ML

1. Filter on Technical Merits
2. Filter on Usability
Julia: Julia is … currently investing in machine learning techniques, and even have good interoperability with Python APIs. The Julia community shares many common values…
Languages Studied by Google as Powerful for ML

KNet

All languages areequally good.
… but I tune out any mention of
languages I don’t use
Psychology of Programming Languages

All languages areequally good.
… but I tune out any mention of
languages I don’t use
…at least until Google tells me to pay attention
Psychology of Programming Languages

Software Toolchain
Multiphysics (PDEs) Optimization Adjoint Methods Machine Surrogate Models(Backprop/Autodiff) Learning Dim Reduction
1 2 3 4 5 6 7
- 4
- 2
2
4
Composability Sensitivity Analysis Performance Uncertainty ScalableConfidence Intervals Nimble/Agile Quantification
?

Topology Optimization ---- 20 years ago what we did
Write Force Balance Law Finite Elements Linear System Solve Graph
Dense Matrices
Sparse Matrices

Now!
Write Force Balance Law Finite Elements Linear System Solve Graph
Dense Matrices
Sparse Matrices
Fancy Differential Equations Dimensionality Reduction
Topology Optimizaton
Compose many physical systems

Black Boxes vs White Boxes
visible code
Floating PointNumbers
Generic Types
Generic Types
Floating PointNumbers
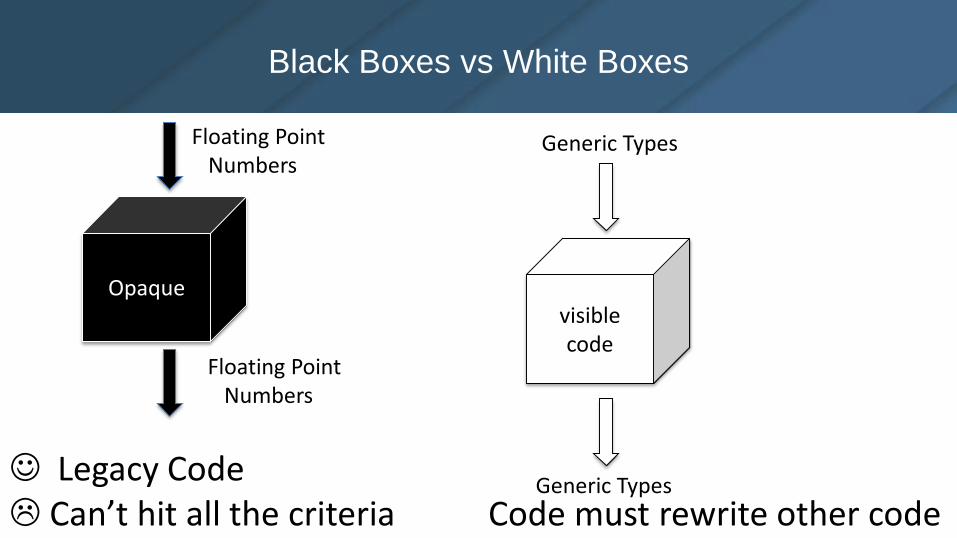
Black Boxes vs White Boxes
visible code
Opaque
Floating PointNumbers
Generic Types
Generic Types Legacy Code Can’t hit all the criteria Code must rewrite other code
Floating PointNumbers

An Idealized Modern Toolchain for Energy
(we can have this!)
True Physical Equations
PDEs, PDMPs, …
Surrogate Model
Neural Network, …
Optimization
floats in
floats in
floats in
floats out
floats out
floats out
Today (Fragmented) What could be with high level tools& generic types
adaptive data generationfor more accurate surrogates
specialized machine learningmodels for efficient optimization
optimal solutions withuncertainty estimates
trigger on demand, sensitivity analysis
needs programmable form


Retrofitting your software for machine learning, sensitivity analysis, scalability,
optimization
We would love to work with each and every one of you

• Support hardware accelerators (GPUs, TPUs, Nervana, New silicon)
• Parallelization (Multi-threading, Multi-GPU, Distributed)
• Optimization (Placement, Memory Use, Low overhead)
• Automatic Differentiation
• Ease of programming (Math notation, Debuggers, Libraries)
• Ease of deployment (Cloud, Phones, Embedded)
ML problems are really language problems
ML models are really programs

Models commonly need:
• Conditional branching
• Loops for recurrence
• Recursion over trees
In areas such as probabilistic programming
• Models need to reason about other programs (e.g. program generators and interpreters)
• Include non-differentiable components like Monte Carlo Tree Search.
New models have new demands
# Stanford TreeBank
def model(tree):
if isleaf(tree):
tree.value
else:
model(tree.left) + model(tree.right)

● We build a “computational graph” (essentially an AST)
● Which may contain control flow (tf.if, tf.while), variable scoping
● Cannot reuse existing libraries. Need new libraries for I/O and data processing.
TensorFlow is more like a language and
less like a library
Lazy (Eval) programming in JS
function add(a,b) {
return `${a}+${b}`;
}
x = 1; y = 2
z = add(‘x’, ‘y’) // ‘x+y’
eval(z) // 3
x = 4
eval(z) // 6
Abadi, M., Isard, M., Murray, D., A Computational Model for TensorFlow: An Introduction, 2018.

Mixed Integer Optimization and Julia
http://www.gurobi.com/company/example-customers
• Mixed Integer Optimization• Discrete + nonlinear• Theoretically hard• Routinely solved in practice
3/9 /16, 12:08 PMAcademic Page of Juan Pablo Vielma
Page 3 of 3ht tp:/ /www.mit .edu/~jvielma/
Jennifer ChallisE62-571, 100 Main Street,Cambridge, MA 02142(617) 324-4378jchallis at mit dot edu
Collaborators
Shabbir Ahmed, Daniel Bienstock, Daniel Dadush, Sanjeeb Dash, Santanu S. Dey, Iain Dunning, RodolfoCarvajal, Luis A. Cisternas, Miguel Constantino, Daniel Espinoza, Alexandre S. Freire, Marcos Goycoolea,Oktay Günlük, Joey Huchette, Nathalie E. Jamett, Ahmet B. Keha, Mustafa R. Kılınç, Guido Lagos, MilesLubin, Sajad Modaresi, Sina Modaresi, Eduardo Moreno, Diego Morán, Alan T. Murray, George L.Nemhauser, Luis Rademacher, David M. Ryan, Denis Saure, Alejandro Toriello, Andres Weintraub, SercanYıldız, Tauhid Zaman
Affiliations
Links
Back to top© 2013 Juan Pablo Vielma | Last updated: 02/29/2016 00:47:25 | Based on a template design by AndreasViklund
•• Optimization
modelling language and interphase
• Easy to use and advanced
• Integrated into Julia
3/9/16, 12:08 PMAcademic Page of Juan Pablo Vielma
Page 3 of 3ht tp:/ /www.mit .edu/~jvielma/
Jennifer ChallisE62-571, 100 Main Street,Cambridge, MA 02142(617) 324-4378jchallis at mit dot edu
Collaborators
Shabbir Ahmed, Daniel Bienstock, Daniel Dadush, Sanjeeb Dash, Santanu S. Dey, Iain Dunning, RodolfoCarvajal, Luis A. Cisternas, Miguel Constantino, Daniel Espinoza, Alexandre S. Freire, Marcos Goycoolea,Oktay Günlük, Joey Huchette, Nathalie E. Jamett, Ahmet B. Keha, Mustafa R. Kılınç, Guido Lagos, MilesLubin, Sajad Modaresi, Sina Modaresi, Eduardo Moreno, Diego Morán, Alan T. Murray, George L.Nemhauser, Luis Rademacher, David M. Ryan, Denis Saure, Alejandro Toriello, Andres Weintraub, SercanYıldız, Tauhid Zaman
Affiliations
Links
Back to top© 2013 Juan Pablo Vielma | Last updated: 02/29/2016 00:47:25 | Based on a template design by AndreasViklund

GPU computing in Julia
Native Array Libraries – CuArrays.jl, GPUArrays.jl, CLArrays.jl
CUDAnative.jl: 1,300 LOCPerformance difference between CUDA C++ and CUDAnative.jlimplementations of several benchmarks from the Rodiniabenchmark suite.
Besard. T., Foket, C., De Sutter, B., Effective Extensible Programming: Unleashing Julia on GPUs, 2017.

Julia ML at PetaScale to catalog the visible universe
650,000 cores. 1.3M threads. 60 TB of data.

Cori Phase II
Cori Phase II – 1.5 PetaFlop/s

Google TPU 3.0: 100 PetaFLOPS per Pod
Google TPU 3.0: 100 PetaFlop/s per Pod

It just works (Part I)
“We can teach our autodiffsystem to differentiate the svd” vs “It just works because of built in abstractions in language design”

It just works (Part II)
Machine learning with operators (not dense matrices, not sparse matrices)
Build Operatorssolve with“backslash”
Not Blackboard formulaimplementationdebugging

Software Toolchain
Multiphysics (PDEs) Optimization Adjoint Methods Machine Surrogate Models(Backprop/Autodiff) Learning Dim Reduction
1 2 3 4 5 6 7
- 4
- 2
2
4
Composability Sensitivity Analysis Performance Uncertainty ScalableConfidence Intervals Nimble/Agile Quantification
?


















