
Speech Summarization
70
Speech Summarization Sameer R. Maskey
description
Speech Summarization. Sameer R. Maskey. Summarization. ‘the process of distilling the most important information from a source (or sources) to produce an abridged version for a particular user (or users) and task (or tasks) [Mani and Maybury, 1999]. Indicative or Informative. Indicative - PowerPoint PPT Presentation
Transcript of Speech Summarization

Speech Summarization
Sameer R. Maskey

Summarization
‘the process of distilling the most important information from a source (or sources) to produce an abridged version for a particular user (or users) and task (or tasks) [Mani and Maybury, 1999]

Indicative or Informative
Indicative Suggests contents of the document Better suits for searchers
Informative Meant to represent the document Better suits users who want the overview

Speech Summarization
Speech summarization entails ‘summarizing’ speech Identify important information relevant to users and the
story Represent the important information Present the extracted/inferred information as an addition
or substitute to the story

Are Speech and Text Summarization similar?
Yes Identifying important
information Some lexical, discourse
features Extraction
NO! Speech Signal Prosodic features NLP tools? Segments – sentences? Generation? ASR transcripts Data size

Text vs. Speech Summarization (NEWS) Speech Signal
Speech Channels- phone, remote satellite, station
Transcripts- ASR, Close Captioned
Many Speakers- speaking styles
Prosodic Features-pitch, energy, duration
Structure-Anchor, Reporter Interaction
Commercials, Weather Report
Transcript- Manual
Some Lexical Features
Story presentationstyle
Error-free Text
Lexical Features
Segmentation-sentences
NLP tools

Speech Summarization (NEWS)Speech Signal
Speech Channels- phone, remote satellite, station
Transcripts- ASR, Close Captioned
Many Speakers- speaking styles
Prosodic Features-pitch, energy, duration
Structure-Anchor, Reporter Interaction
Commercials, Weather Report
Transcript- Manual
Some Lexical Features
Story presentationstyle
Error-free Text
Lexical Features
Segmentation-sentences
many NLP tools

Why speech summarization?
Multimedia production and size are increasing: need less time-consuming ways to archive, extract, use and browse speech data - speech summarization, a possible solution
Due to temporal nature of speech, difficult to scan like text
User-specific summaries of broadcast news is useful Summarizing voicemails can help us better organize
voicemails
Extraction Training w/ manual Summaries
Sentence ExtractionSimilarity Measures
Concept LevelExtract concepts units
Generate Words/Phrases
Use of Structured Data
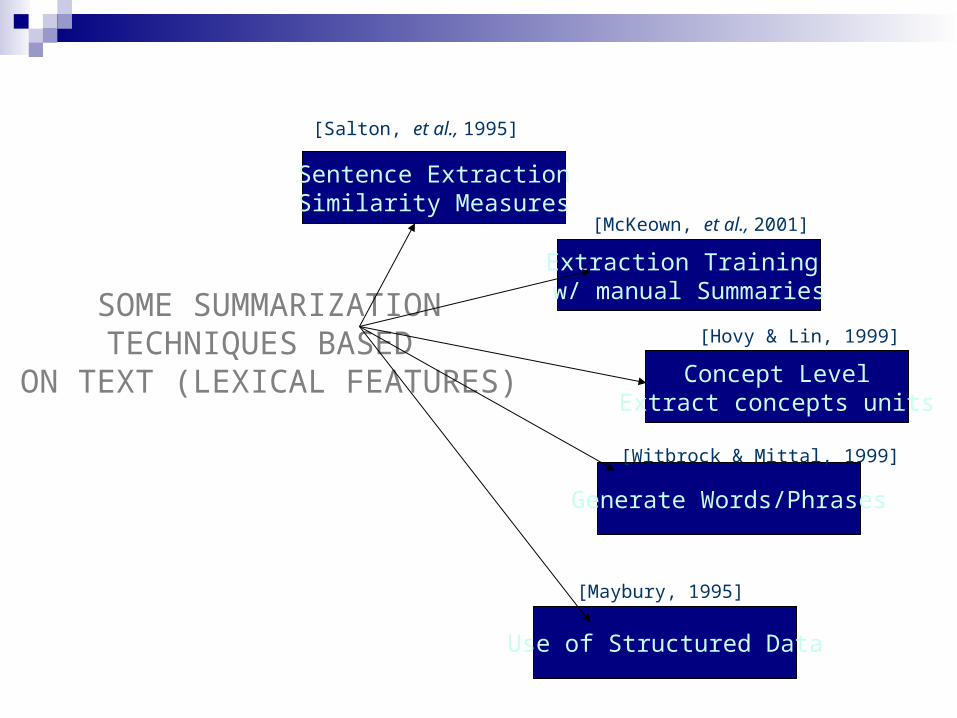
SOME SUMMARIZATIONTECHNIQUES BASED
ON TEXT (LEXICAL FEATURES)
[Salton, et al., 1995]
[McKeown, et al., 2001]
[Hovy & Lin, 1999]
[Witbrock & Mittal, 1999]
[Maybury, 1995]

Summarization by sentence extraction with similarity measures [Salton, et al., 1995]
Many present day techniques involve sentence extraction
Extract sentence by finding similar sentence to topic sentence or dissimilar sentences to already built summary (Maximal Marginal Relativity)
Find sentences similar to the topic sentence Various similarity measures [Salton, et al., 1995]
Cosine Measure Vocabulary Overlap Topic words overlap Content Signatures Overlap

“Automatic text structuring and summarization” [Salton, et al., 1995]
Uses hypertext link generation to summarize documents Builds intra-document hypertext links Coherent topic distinguished by separate chunk of links Remove the links that are not in close proximity Traverse along the nodes to select a path that defines a
summary Traverse order can be
Bushy Path: constructed out n most bushy nodes Depth first Path: Traverse the most bushy path after each node Segmented bushy path: construct bushy paths individually and
connect them on text level
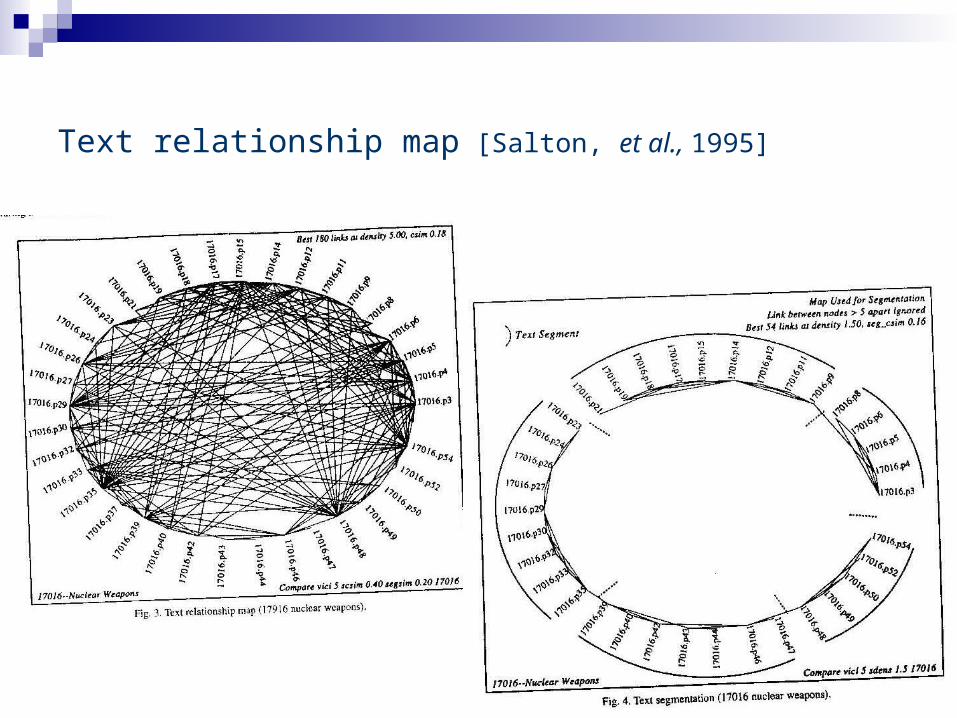
Text relationship map [Salton, et al., 1995]

Build manual summaries using available number of annotators Extract set of features from the manual summaries Train the statistical model with the given set of values for manual
summaries Use the trained model to score each sentence in the test data Extract ‘n’ highest scoring sentences Various statistical models/machine learning
Regression Models Various classifiers Bayes rules for computing probability for inclusion by counting [Kupiec, et al.,
1995]
Where S is summary given k features Fj and P(Fj) & P(Fj|s of S) can be computed by counting occurrences
k
jj
k
jj
k
FP
SsPSsFP
FFFSsP
1
1,21
)(
)()|(
)...,|(
Summarization by feature based statistical models [Kupiec, et al., 1995]

Summarization by concept/content level extraction
and generation [Hovy & Lin, 1999] , [Witbrock & Mittal, 1999]
Quite a few text summarizers based on extracting concept/content and presenting them as summary
Concept Words/Themes] Content Units [Hovy & Lin, 1999] Topic Identification
[Hovy & Lin, 1999] uses Concept Wavefront to build concept taxonomy
Builds concept signatures by finding relevant words in 30000 WSJ documents each categorized into different topics
Phrase concatenation of relevant concepts/content Sentence planning for generation

Summarization of Structured text database [Maybury,
1995]
Summarization of text represented in a structured form: database, templates Report generation of a medical history from a database is
such an example
Link analysis (semantic relations within the structure)
Domain dependent importance of events
events all of # Total
event E of soccurrence of # Eoffrequency Relative

Speech summarization: present
Speech Summarization seems to be mostly based on extractive summarization
Extraction of words, sentences, content units Some compression methods have also been proposed Generation as in some text-summarization techniques is
not available/feasible Mainly due to the nature of the content

Word scoringwith dependency structure
Sentence extraction withsimilarity measures
Classification
User access information
Weighted finite statetransducers
Removing disfluencies
SPEECH SUMMARIZATIONTECHNIQUES
[Christensen et al., 2004]
[Hori C. et al., 1999, 2002] , [Hori T. et al., 2003]
[Koumpis & Renals, 2004]
[He et al., 1999]
[Hori T. et al., 2003]
[Zechner, 2001]

Content/Context sentence level extraction for speech
summary [Christensen et al., 2004]
These are commonly used speech summarization
techniques: finding sentences similar to the lead topic sentences
Using position features to find the relevant nearby sentences after detecting the topic sentence
where Sim is a similarity measure between two sentences
)},({maxarg 1/
^
iEDs
k ssSimsSi
)},({maxarg/
^
iEDs
k sDSimsSi

Weighted finite state transducers for speech
summarization [Hori T. et al., 2003]
Speech Summarization includes speech recognition, paraphrasing, sentence compaction integrated into single Weighted Finite State Transducer
Enables decoder to employ all the knowledge sources in one-pass strategy Speech recognition using WFST
Where H is state network of triphone HMMs, C is triphone connection rules, L is pronunciation and G is trigram language model
Paraphrasing can be looked at as a kind of machine translation with translation probability P(W|T) where W is source language and T is the target language
If S is the WFST representing translation rules and D is the language model of the target language speech summarization can bee looked at as the following composition
GLCHR
DSGLCHZ
H C L G S DSpeech recognizer Translator
Speech Translator

User access information for finding salient parts [He et al., 1999]
Idea is to summarize lectures or shows extracting the parts that have been viewed the longest
Needs multiple users of the same show, meeting or lecture for a statistically significant training data
For summarizing lectures compute the time spent on each slide
Summarizer based on user access logs did as well as summarizers that used linguistic and acoustic features
Average score of 4.5 on a scale of 1 to 8 for the summarizer (subjective evaluation)

Word level extraction by scoring/classifying words [Hori C. et al., 1999, 2002]
Score each word in the sentence and extract a set of words to form a sentence whose total score is the product/sum of the scores of each word
Example: Word Significance score (topic words) Linguistic Score (bigram probability) Confidence Score (from ASR) Word Concatenation Score (dependency structure
grammar)
Where M is the number of words to be extracted, and I C T are weighting factors for balancing among L, I, C, and T r
)()()()...|({)( ,11
1 mmTmcm
M
mImm vvTrvCvIvvLVS

Assumptions
There are a few assumptions made in the previously mentioned methods Segmentation Information Extraction Automatic Speech Recognition Manual Transcripts Annotation

Speech Segmentation?
segmentation
speech
textExtraction
•Features•Techniques•Evaluation
•Sentences•Topics
•Text Retrieval Methods on ASR Transcripts
Segmentation Sentences Stories Topic Speaker

Information Extraction from Speech Data?
segmentation
speech
textExtraction
•Features•Techniques•Evaluation
•Sentences•Topics
•Text Retrieval Methods on ASR Transcripts
Information Extraction Named Entities Relevant Sentences and Topics Weather/Sports Information

Audio segmentation
Audio Segmentation
Topics Story
Commercials
Sentences
Weather
Speaker GenderSpeakerTypes

Audio segmentation methods
Can be roughly categorized in two different categories Language Models [Dharanipragada, et al., 1999] , [Gotoh &
Renals, 2000], [Maybury, 1998], [Shriberg, et al., 2000] Prosody Models [Gotoh & Renals, 2000], [Meinedo & Neto,
2003] , [Shriberg, et al., 2000] Different methods work better for different purposes and
different styles of data [Shriberg, et al., 2000] Discourse cues based method highly effective in broadcast
news segmentation [Maybury, 1998] Prosodic model outperforms most of the pure language
modeling methods [Shriberg, et al., 2000], [Gotoh & Renals, 2000]
Combined model of using NLP techniques on ASR transcripts and prosodic features seem to work the best

Overview of a few algorithms:statistical model [Gotoh & Renals, 2000]
Sentence Boundary Detection: Finite State Model that extracts boundary information from text and audio sources
Uses Language and Pause Duration Model Language Model: Represent boundary as two classes with “last word”
or “not last word” Pause Duration Model:
Prosodic features strongly affected by word Two models can be combined Prosody Model outperforms language model Combined model outperforms both

Segmentation using discourse cues [Maybury,
1998]
Discourse Cues Based Story Segmentation Sentence segmentation is not possible with this method Discourse Cues in CNN
Start of Broadcast Anchor to Reporter Handoff, Reporter to Anchor Handoff Cataphoric Segment (still ahead of this news) Broadcast End
Time Enhanced Finite State Machine to represent discourse states such as anchor, reporter, advertisement, etc
Other features used are named entities, part of speech, discourse shifts “>>” speaker change, “>>>” subject change
Source Precision Recall
ABC 90 94
CNN 95 75
Jim Lehrer Show 77 52

Speech Segmentation
Segmentation methods essential for any kind of extractive speech summarization
Sentence Segmentation in speech data is hard Prosody Model usually works better than Language
Model Different prosody features useful for different kinds of
speech data Pause features essential in broadcast news segmentation Phone duration essential in telephone speech
segmentation Combined linguistic and prosody model works the best

Information Extraction from Speech
Different types of information need to be extracted depending on the type of speech data
Broadcast News: Stories [Merlino, et al., 1997] Named Entities [Miller, et al., 1999] , [Gotoh & Renals,
2000] Weather information
Meetings Main points by a particular speaker Address Dates
Voicemail Phone Numbers [Whittaker, et al., 2002] Caller Names [Whittaker, et al., 2002]

Statistical model for extracting named entities [Miller, et al., 1999] , [Gotoh & Renals, 2000]
Statistical Framework: V denote vocabulary and C set of name classes,
Modeling class information as word attribute: Denote e=<c, w> and model using
In the above equation ‘e’ for two words with two different classes are considered different. This bring data sparsity problem
Maximum likelihood estimates by frequency counts Most probable sequence of class names by Viterbi algorithm
Precision and recall of 89% for manual transcript with explicit modeling
mi
iim eeepeep..1
111 ),...|(),...,(
),,...,,(... 11 maxarg..1
m
cc
m wcwcpccm

Named entity extraction results [Miller, et al., 1999]
BBN Named Entity Performance as a function of WER [Miller, et al., 1999]

Information Extraction from Speech
Information Extraction from speech data essential tool for speech summarization
Named Entities, phone number, speaker types are some frequently extracted entities
Named Entity tagging in speech is harder than in text because ASR transcript lacks punctuation, sentence boundaries, capitalization, etc
Statistical models perform reasonably well on named entity tagging

Speech Summarization at Columbia We make a few assumptions in segmentation and
extraction Some new techniques proposed 2-level summary
Headlines for each story Summary for each story
Summarization Client and Server model

Speech Summarization (NEWS)Speech Signal
Speech Channels- phone, remote satellite, station
Transcripts- ASR, Close Captioned
Many Speakers- speaking styles
Prosodic Features-pitch, energy, duration
Structure-Anchor, Reporter Interaction
Commercials, Weather Report
Transcript- Manual
Some Lexical Features
Story presentationstyle
Error-free Text
Lexical Features
Segmentation-sentences
many NLP tools
ACOUSTIC
LEXICAL
DISCOURSE
STRUCTURAL

Speech SummarizationINPUT:
TranscriptsTranscripts+
ACOUSTIC LEXICAL DISCOURSE STRUCTURAL
/Sentence Segmentation, Speaker Identification, Speaker Clustering, Manual Annotation,
2-Level Summary Headlines
Summary
StoryNamed Entity Detection, POS tagging

Corpus
Topic Detection and Tracking Corpus (TDT-2) We are using 20 “CNN Headline shows” for
summarization 216 stories in total 10 hours of speech data Using Manual transcripts, Dragon and BBN ASR
transcripts

Annotations - Entities
We want to detect – Headlines Greetings Signoff SoundByte SoundByte-Speaker Interviews
We annotated all of the above entities and the named entities (person, place, organization)

Annotations – by Whom and How?
We created a labeling manual following ACE standards
Annotated by 2 annotators over a course of a year 48 hours of CNN headlines news in total We built a labeling interface dLabel v2.5 that
went through 3 revisions for this purpose

Annotations - dLabel v2.5

Annotations – ‘Building Summaries’ 20 CNN shows annotated for extractive summary A Brief Labeling Manual No detailed instruction on what to choose and
what not to? We built a web-interface for this purpose, where
annotator can click on sentences to be included in the summary
Summaries stored in a MySQL database

Annotations – Web Interface

Annotations – Web Interface

Acoustic Features F0 features
max, min, mean, median, slope Change in pitch may be a topic shift
RMS energy feature max, min, mean
Higher amplitude probably means a stress on the phrases Duration
Length of sentence in seconds (endtime – starttime) Very short or a long sentence might not be important for summary
Speaker Rate how fast the speaker is speaking
Slower rate may mean more emphasis in a particular sentence

Acoustic Features – Problems in Extraction What should be the segment to extract these features –
sentences, turn, stories?
We do not have sentence boundaries.
A dynamic programming aligner to align manual sentence boundary with ASR transcripts
Feature values needs to be normalized by speaker: used Speaker Cluster ID available from BBN ASR

Acoustic Features – Praat: Extraction Tool

Lexical Features
Named Entities in a sentence Person People Organization Total count of named entities
Num. of words in a sentence Num. of words in previous and next sentence

Lexical Features - Issues
Using Manual Transcript Sentence boundary detection using Ratnaparkhi’s
mxterminator Named Entities annotated For ASR transcript:
Sentence boundaries aligned Automatic Named Entities detected using BBN’s Identifinder Many NLP tools fail when used with ASR transcript

Structural Features
Position Position of the sentence in the story and the turn Turn position in the show
Speaker Type Reporter or Not
Previous and Next Speaker Type Change in Speaker Type

Discourse Feature Given-New Feature Value Computed using the following equation
dt
s
d
niS ii
)(
Intuition: ‘newness’ ~ more new unique nouns in the sentence (ni/d) If many nouns already seen in the sentence ~ higher ‘givenness’
s_i/(t-d)
where n_i is the number of ‘new’ noun stems in sentence i, d is the total
number of unique nouns, s_i is the number of noun stems that have already
been seen, t is the total number of nouns

Experiments Sentence Extraction as a summary Binary Classification problem
‘0’ not in the summary ‘1’ in the summary
10 hours of CNN news shows 4 different sets of features – acoustic, lexical, structural, discourse 10 fold-cross validation 90/10 train and test 4 different classifiers WEKA and YALE learning tool Feature Selection Evaluation using F-Measure and ROUGE metrics

Feature Sets
We want to compare the various combination of our “4” feature sets Acoustic/Prosodic (A) Lexical (L) Structural (S) Discourse (D)
Combinations of feature sets, 15 in total L, A, …, L+A, L+S, … , L+A+S, … , L+S+D, … , L+A+S+D

Classifiers
Choice of available classifier may affect the comparison of feature sets
Compared 4 different classifiers by plotting threshold (ROC) curve and computing Area Under Curve (AOC)
Best Classifier has AOC of 1
Classifier AOC
Bayesian Network 0.771
C4.5 Decision Trees 0.647
Ripper 0.643
Support Vector Machines
0.535

ROC CurvesROC curves for some classifiers
0
100
200
300
400
500
600
700
800
-500 0 500 1000 1500 2000 2500 3000
False Positives (Specificity)
Tru
e P
osi
tive
s (S
ensi
tivi
ty)
bayesNet
decisiontable
decisiontreeJ48

Results – Best Combined Feature Set
We obtained best F-measure for 10 fold cross validation using all acoustic (A), lexical (L), discourse (D) and structural (S) feature.
Precision Recall F-Measure
Baseline 0.430 0.429 0.429
L+S+A+D 0.489 0.613 0.544
F-Measure is 11.5% higher than the baseline.

What is the Baseline?
Baseline is the first 23% of sentences in each story. In Average Model summaries were 23% in length
In summarization selecting first n% of sentences is pretty standard baseline For our purpose this is a very strict baseline, why?
Because stories are short. In average 18.2 sentences for each story
In broadcast news it is standard to summarize the story in the introduction
These sentences are likely to be in the summary
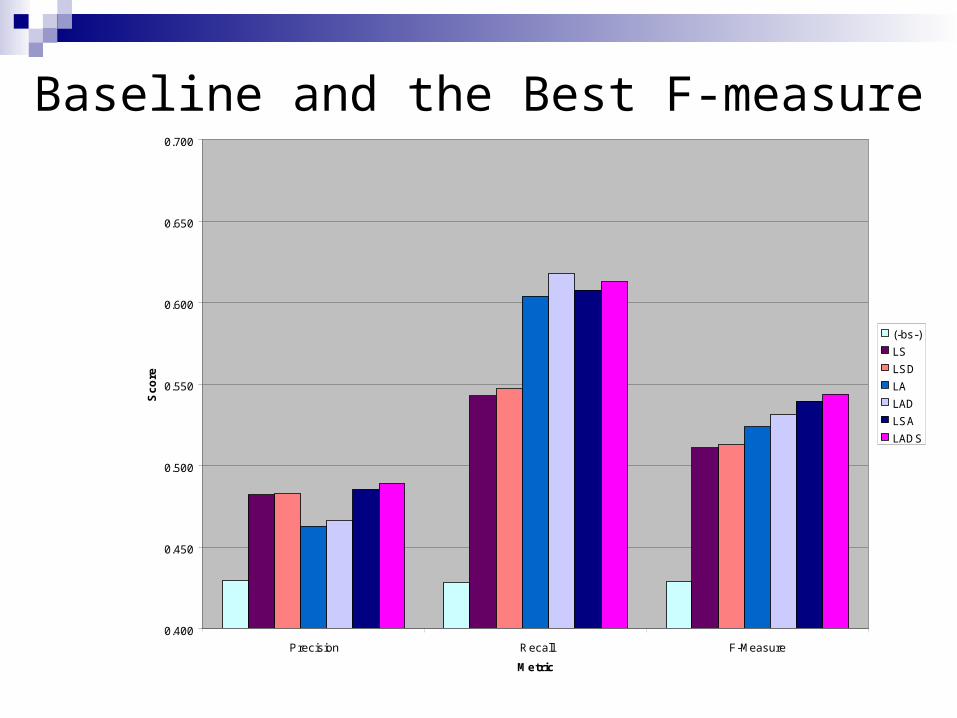
Baseline and the Best F-measure
0.400
0.450
0.500
0.550
0.600
0.650
0.700
Precision Recall F-Measure
Metric
Sc
ore
(-bs-)
LS
LSD
LA
LAD
LSA
LADS

0.679
0.5500.531
0.4300.443 0.447 0.443
0.481
0.455
0.483 0.482 0.4830.463 0.467
0.486 0.489
0.074
0.235
0.302
0.429
0.4950.512
0.542
0.505
0.542
0.511
0.543 0.547
0.6040.618
0.608 0.613
0.133
0.329
0.385
0.429
0.4680.478
0.487 0.493 0.495 0.4970.511 0.513
0.524 0.532 0.540 0.544
0.000
0.100
0.200
0.300
0.400
0.500
0.600
0.700
D S SD (-bs-) A AD L SA LD SAD LS LSD LA LAD LSA LADS
Feature Sets
Sc
ore
Precision
Recall
F-Measure
F-Measure for All 15 Feature Sets

Evaluation using ROUGE
F-measure is a too strict measure Predicted summary sentences has to match
exactly with the summary sentences What if we have a predicted sentence that is not
an exact but has a similar content? ROUGE takes account of this

ROUGE metric
Recall-Oriented Understudy for Gisting Evaluation (ROUGE) ROUGE-N (where N=1,2,3,4 grams) ROUGE-L (longest common subsequence) ROUGE-S (skip bigram) ROUGE-SU (skip bigram counting unigrams as well)

Evaluation using ROUGE metricROUGE-1
ROUGE-2
ROUGE-3
ROUGE-4
ROUGE-L
ROUGE-S
ROUGE-SU
Baseline 0.58 0.51 0.50 0.49 0.57 0.40 0.41
L+S+A+D 0.84 0.81 0.80 0.79 0.84 0.76 0.76
In average L+S+A+D is 30.3% higher than the baseline

Results - ROUGE
0.000
0.100
0.200
0.300
0.400
0.500
0.600
0.700
0.800
0.900
D S SD (-bs-) AD A LD L SA LSD LS SAD LAD LA LSA LADS
Feature Se ts
Sco
re
ROUGE-S*
ROUGE-SU*
ROUGE-4
ROUGE-3
ROUGE-2
ROUGE-L
ROUGE-1

Does importance of ‘what’ is said correlates with ‘how’ it is said? Hypothesis: “Speakers change their amplitude, pitch,
speaking rate to signify importance of words, phrases, sentences.”
If this is the case then the prediction labels for sentences predicted using acoustic features (A) should correlate with labels predicted using lexical features (L)
We found correlation of 0.74
This above correlation is a strong support for our hypothesis

Is It Possible to Build ‘good’ Automatic Speech Summarization Without Any Transcripts?
Feature Set F-Measure ROUGE-avg
L+S+A+D 0.54 0.80
L 0.49 0.70
S+A 0.49 0.68
A 0.47 0.63
Baseline 0.43 0.50
Just using A+S without any lexical features we get 6% higher F-measure and 18% higher ROUGE-avg than the baseline

Feature selection We used feature selection to find the best feature set among all the features in
the combined set 5 best features are shown in the table These 5 features consist of all 4 different feature sets Feature Selection also selected these 5 features as the optimal feature set F-measure using just 5 features is 0.53 which only 1% lower than using all
features
Rank Type Feature
1 A Time Length in seconds
2 L Num. of words
3 L Tot. Named Entities
4 S Normalized Sent. Pos
5 D Given-New Score

Problems and Future Work
We assume we have a good Sentence boundary detection Speaker IDs Named Entities
We obtain a very good speaker IDs and named entities from BBN but no sentence boundaries
We have to address the sentence boundary detection as a problem on its own.
Alternative solution: We can do a ‘breath group’ level segmentation and build a model based on such segmentation

More Current and Future Work
We annotated headlines, greetings, signoffs, interviews, soundbytes, soundbyte speakers, interviewees
We want to detect these entities (students involved for detecting some of these entities – Aaron
Roth, Irina Likhtina)
We want to present summary and these entities in a unified browsable frame work (student involved – Lauren Wilcox)
The browser is implemented in client/server framework

SPEECH
ASR
MANUAL
INPUT
SGML Parser
XML Parser
TranscriptAligner
SentenceParser
TextPreProcess
or
PRE-PROCESSINGFEATURE
EXTRACTION
ACOUSTIC
LEXICAL
STRUCTURE
DISCOURCE
SEGMENTATION/DETECTION
SEGMENTATION
Story
Headline
Interviews
Q&A
DETECTION
SoundBites
SoundBite-Speaker
Signon/off
Weather forecast
Named-Entity Tagger
SUMMARIZER
MINING
MODEL/PRESENTATION
SPEECH
MAN-UAL
ASR
CHUNKS
CC
Summarization Architecture

SENT27 a trial that pits the cattle industry against tv talk show host oprah winfrey is under way in amarillo , texas.
SENT28 jury selection began in the defamation lawsuit began this morning . SENT29 winfrey and a vegetarian activist are being sued over an exchange on her April 16, 1996 show . SENT30 texas cattle producers claim the activists suggested americans could get mad cow disease from
eating beef . SENT31 and winfrey quipped , this has stopped me cold from eating another burger SENT32 the plaintiffs say that hurt beef prices and they sued under a law banning false and disparaging
statements about agricultural products SENT33 what oprah has done is extremely smart and there's nothing wrong with it she has moved her
show to amarillo texas , for a while SENT34 people are lined up , trying to get tickets to her show so i'm not sure this hurts oprah . SENT35 incidentally oprah tried to move it out of amarillo . she's failed and now she has brought her
show to amarillo . SENT36 the key is , can the jurors be fair SENT37 when they're questioned by both sides, by the judge , they will be asked, can you be fair to both
sides SENT38 if they say , there's your jury panel SENT39 oprah winfrey's lawyers had tried to move the case from amarillo , saying they couldn't get an
impartial jury SENT40 however, the judge moved against them in that matter …
story summary
Generation or Extraction?

Conclusion
We talked about different techniques to build summarization systems
We described some speech-specific summarization algorithms
We showed feature comparison techniques for speech summarization A model using a combination of lexical, acoustic, discourse and
structural feature is one of the best model so far. Acoustic features correlate with the content of the sentences
We discussed possibilities of summarizing speech without any transcribed text


















