
Speech Coding Techniques (II) - SHARIF UNIVERSITY OF...
50
Speech Coding Techniques (II) Introduction Vector Quantization Coded Excitation Linear Prediction (CELP) System overview Long-term prediction Frequency weighting LPC Quantization Bit Allocation Variations of CELP Low-delay CELP (LD-CELP) Vector-Sum Excitation Linear Prediction (VSELP) Speech coding standards
Transcript of Speech Coding Techniques (II) - SHARIF UNIVERSITY OF...

Speech Coding Techniques (II)
Introduction Vector Quantization
Coded Excitation Linear Prediction (CELP) System overview Longterm prediction Frequency weighting LPC Quantization Bit Allocation
Variations of CELP Lowdelay CELP (LDCELP) VectorSum Excitation Linear Prediction (VSELP) Speech coding standards

Introduction to VQ
x Q x̂Scalar Quantization
Vector Quantization x1,…,xK Q x1,…,xK^ ^
Each sample is quantized independent of others
A block of samples are quantized simultaneously

Shannon’s RateDistortion TheoryD
R
SQ
VQ

Why VQ is Better? – A Toy Example in 2D
x1
x2
If we quantize x1 and x2 independently, it is impossible torecognize the two “point clouds” in the 2D space

Why VQ is Better? – A Geometric Perspective
Rectangular lattice in 2D Hexagonal lattice in 2D

Definition of VQ
f f 1s∈S
original vector
quantizationindex reconstructed
vector
x1,…,xK x1,…,xK^ ^
f: encoding function, f1: decoding function
S: codebook (collection of all codewords)
Bit rate= log2|S|/K bit per sample

VQ=Data Clustering
s1 s2
In pattern recognition, representative of each class is the centroid,which can be shown to be equivalent to the codeword in VQ thatminimizes the MSE within that class

How to Cluster Data? If we know the labeling for each vector, it is
straightforward to obtain the codebook For class k, find all vectors labeled by k and calculate
its centroid If we know the codeword (centroid) for each
class, it is straightforward to assign the label to each vector Go to the nearest neighbor (codeword)
The challenge is: we know neither except the observation data

The Power of Iteration
Update labelfor each vector
Update centroidfor each class
Randomly pickK centroids stop
Converged?No
Yes

KMeans (LBG) Algorithm

Example
>Help kmeans
X = [randn(20,2)+ones(20,2); randn(20,2)ones(20,2)];[cidx, ctrs] = kmeans(X, 2, 'dist','city', 'rep',5, 'disp','final');

Decoding = Table LookUP
snn
……
s22
s11
CodewordIndex
Each codeword is a vector in RK
x∈RKoriginalsequence
VQ encoding
Index sequence
VQ decoding
reconstructedsequencesI ∈RK
I

Issues With VQ Initialization (random is not always a good
choice) Trapped into local minimum Storage requirement on codebook Curse of dimensionality
Prohibitive computational complexity as K increases Feature extraction (in order to reduce dimensionality)
is nontrivial

An Example of Using VQ Optical Character Recognition (OCR)
Scenario I: input image is a binary LCD array Scenario II: input image is scanned document
x ∈{0,1}6x8 x ∈{0,…,255}?x?
Lots of uncertainty due to varying font size, style, orientation
little uncertainty due to fixedfont size, style, orientation

Speech Coding Techniques (II) Introduction
Vector Quantization Coded Excitation Linear Prediction (CELP)
System overview Longterm prediction Frequency weighting LPC Quantization Bit Allocation
Variations of CELP Lowdelay CELP (LDCELP) VectorSum Excitation Linear Prediction (VSELP) Speech coding standards

System Overview

ShortTerm Prediction (AR Modeling of Vocal Tract)
∑=
−=K
kk knxanx
1)()(ˆ
Recall LP Analysis (Autocorrelation Method)
∑=
−=K
knkn kiRaiR
1|)(|)(
∑=
−−== K
k
kk za
zHzHzEzX
11
1)(),()()(

Quantization of LPCs
Scalar Quantization
a1
a2
a3
a4a10
total
6bits5bits
4bits
3bits each
36 bits
a1a4
a5a10
12 bits (4096 codewords)
12 bits (4096 codewords)
Vector Quantization
total 24 bits
Bit rate savings=12bits/frame (600 bits per second)

Speech Example
Original speech Prediction residue

LongTerm Prediction
PLTLT azzHzHzEzR −−
==1
1)(),()()(
r(n)
e(n)
HLT(z)

Subframes
Nf =160 samples (20ms)
Nsf =40 samples (5ms)
Nsf Nsf Nsf Nsf
Each subframe is a vector in 40dimensional space

Random Vector Codebook
Nsf
x
1c
128c
7bit Codebook (e.g, >C=randn(128,40);)

Search the Best CodewordTarget vector to approximate
candidate vector in codebook
x
cd
||||,cos
cxcx
><=θθ
θsin|| x=d
Minimize d Minimize θ Maximize >< cx ,

Gain CalculationTarget vector to approximate
candidate vector in codebook
x
c
2||||min cx α−=D><><=
cccx
,,α
In CELP coding, x Prediction residue signal
c excitation codeword from the codebook

Putting Things Together (openloop)
ShorttermPrediction
longtermPrediction
CodewordSearch and gain
calculationinputframe
residuesignal
channel
LPC Pitch, gain Codeword, gain
intermediateresult

From Openloop to Closedloop Why?
Closest codeword in the codebook does not necessarily represent the optimal choice from the decoder perspective (recall the difference between openloop DPCM and closedloop DPCM)
How? AbyS: Do synthesis to reconstruct speech and
search the optimal codeword Key point: in closedloop, decoder is embedded in
encoder (and hence encoder has higher complexity than decoder)

Closedloop Search

Perceptual (Noise) Weighting Filter
∑
∑
=
−
=
−
−
−= K
k
kkk
K
k
kk
za
zazW
1
1
1
1)(
γ
suggested γ=0.8
In one word, MSE metric does not match human perceptionas well as weighted MSE metric (speech quality assessment)

The Complete Picture of CELP

Bit Allocation Example
30ms frame CELP coder at 4.8Kbps

CELP Summary A hybrid coder mixing waveform and modelbased
coders LP, VQ and AbyS all attempt to minimize MSE between
reconstructed speech and original speech LPC and excitation parameters are coarsely coded
Openloop and closeloop AbyS Openloop: LPC and pitch parameter Closeloop: gain and excitation codeword
Current state of the art in lowtomedium bit rate speech coding (48Kbps) Speech Quality: MOS>3 (4Kbps) MOS>3.5(8Kbps) Complexity: 210MIPS

Speech Coding Techniques (II) Introduction
Vector Quantization Coded Excitation Linear Prediction (CELP)
System overview Longterm prediction Frequency weighting LPC Quantization Bit Allocation
Variations of CELP Lowdelay CELP (LDCELP) VectorSum Excitation Linear Prediction (VSELP) Speech coding standards

LDCELP

LDCELP (Con’d) Sampling: fs = 8 kHz Bitrate:16 kbit/s Quality: comparable (or better) to 32 kbps Applications: Visual telephone Algorithm:
LPC predictor of 50th order with backward adaptation No Long Time Predictor (LTP) logarithmic differential quantization of the gain factor with 10th
order backward adaptive predictor frame size L =5 samples (i.e., 0.625 ms) 10bits per frame (7bits on excitation codeword, 3bits on gain and
sign) complexity around 20 MOPS ( MegaOperations per Second)

VSELP

VSELP (Con’d) Sampling: fs = 8 kHz Bitrate:8 kbit/s Quality: MOS=3.5 Applications: NorthAmerica CDMA Algorithm:
frame size L =160 samples (i.e., 20 ms) Subframe size = 40 samples (5ms) LPC parameters: 38bits/frame Pitch parameters: 7bits/subframe Codebook gain: 32bits/frame (8bits/subframe) Codeword: 56bits/frame (14bits/subframe) Frame energy: 5bits/frame In total: 160bits/frame

Overview of Speech Coding Standards ITUT (International Telecommunication
Union: Telecom Standardization) ETSI (European Telecommunications Standards
Institute) ISO (International Standardization Organization) TIA (Telecommunications Industry Association )

ITUT G.726: ADPCM Bitrate: 16, 24, 32, 40 kbps Quality: at 40kbps, quality comparable to
PCM (G.711) quality with 64 kbps Applications:
wireless digital telephone according to the DECT standard ( Digital Enhanced Cordless Telecommunication)
DCME (Digital Circuit Multiplication Equipment) Devices (e.g. transatlantic cables)
Algorithm: backward adaptive predictor with poles and zeros adaptation of the predictor with help of the sign LMS algorithm adaptive quantization of the predictor signal according to the AQB
procedure with w =2, 3, 4 or 5 quantization with fixed step size d for coding of modem signals

ITU G.728: LDCELP

ITUT G.729 ConjugateStructure Algebraic CELPCodec (CSACELP)

ITUT G.729 (Con’d) Bitrate: 8 kbps Quality:
comparable (or in part slightly worse than) to 32 kbit/s ADPCM inappropriate for music
Applications:visual telephone, multimedia Algorithm:
Code Excited Linear Prediction (CELP) LPCsynthesis filter of 10 th order Frame length TN=10ms, subframe length 1/2 TN=5ms filter parameters are vector quantized in form of LSF coefficients with 18 bit long time prediction (adaptive codebook) of the delayparameter N0 with so called openloop
presearch, closedloop postoptimization, and advanced timeresolution by interpolation with factor 3
coding of the delayparameter N0 for the first subframe with 8 bit, differential coding of the delayparameter for the second subframe with 5 bit
fixed algebraic codebook (ACELP) with effective 217 vectors of dimension 40 and 4 values different from zero
adaptive error weighting filter and depending on the current spectral envelopetwostage vector quantization of the gain factors ga and gs with 7 bit

ITUT G.723

ITUT G.723 Bitrate: 5.3 and 6.3 kbps Applications:
dual rate speech codec for multimedia communications Voice over Internet Protocol (VoIP) communications
Algorithm: Code Excited Linear Prediction (CELP) framelength TN=30ms, subframelength 7.5ms for every subframe a 10th order LPCfilter is calculated LPCfilter for the last subframe is quantized using a Predictive Split Vector Quantizer (PSVQ) the unquantized LPCcoefficients are used to form a shortterm formant perceptual weighting filter, that is
used to filter the whole frame to obtain the perceptually weighted speech signal for every two subframes (120 samples) the open loop pitch period is computed from this point on the speech is processed on a 60 samples per subframe basis using the estimated pitch period, a harmonic noise shaping filter is constructed combination of the LPC synthesis filter, the formant perceptual weighting filter and the harmonic noise
shaping filter yields an impulse response for further computations with help of the pitch period estimation and the impulse response a closed loop pitch predictor of 5th order
is computed the contribution of the pitch predictor is subtracted from the initial target vector the nonperiodic component of the excitation is approximated using MultiPulse Maximum Likelihood
Quantization (MPMLQ) for the high bit rate and an algebraiccodeexcitation (ACELP) for the low bit rate

Dual Rate Bit Allocation

ETSIGSM

ETSIGSM (Con’d) Bitrate: 13.0 kbps Quality:
limited telephone quality (speech) unsuitable for modem and music signals
Applications: mobile communication systems according to GSM standard voice over IP
Algorithm: predictive residual signal coding signal delay (algorithm) 20 ms complexity approx. 3.5 MOPS (Mega Operations Per Second) interpolation (extrapolation) of corrupted frames by frame repetition silence indication comfort noise
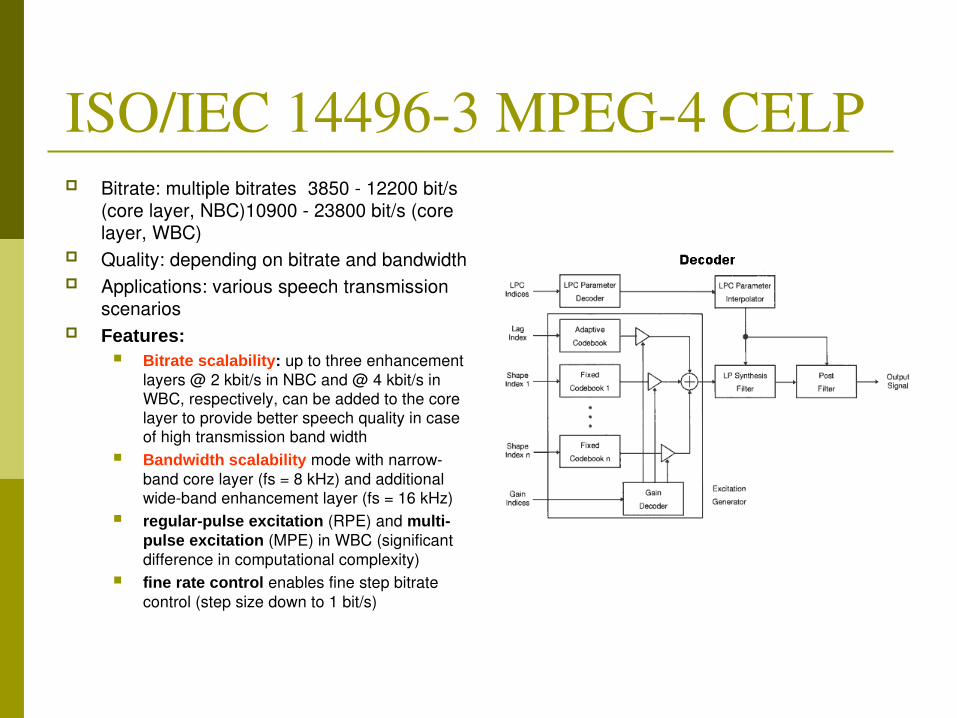
ISO/IEC 144963 MPEG4 CELP Bitrate: multiple bitrates 3850 12200 bit/s
(core layer, NBC)10900 23800 bit/s (core layer, WBC)
Quality: depending on bitrate and bandwidth Applications: various speech transmission
scenarios Features:
Bitrate scalability: up to three enhancement layers @ 2 kbit/s in NBC and @ 4 kbit/s in WBC, respectively, can be added to the core layer to provide better speech quality in case of high transmission band width
Bandwidth scalability mode with narrowband core layer (fs = 8 kHz) and additional wideband enhancement layer (fs = 16 kHz)
regularpulse excitation (RPE) and multipulse excitation (MPE) in WBC (significant difference in computational complexity)
fine rate control enables fine step bitrate control (step size down to 1 bit/s)

U.S. DOD Federal Standard 1016
Bitrate:4.8 kbit/s Quality: low qualityunsuitable for modem or music signals Applications:U.S. Department of Defense Standardtelecommunications Algorithm:
Code Excited Linear Prediction (CELP) Analog to digital conversion of radio voiceSTP incorporates a 10th order LP predictor frame rate TN = 30ms, 4 subframes of TN = 7.5ms LTP (adaptive codebook) containing 256 codewords fixed codebook of sparse, ternary values contains 512 codewords of 60 samples length

MELP MixedExcitation Linear Predictive Vocoder
Bitrate: 2.4 kbps Quality: comparable to the 8 kbit/s VSELP Applications:telecommunications Algorithm:
frame Size: 22.5mshigh pass filter: 4th order Chebychev type II
bandpass voicing analysis: 6th order Butterworth filters, 5 frequency bands
Linear Prediction Analysis: 10th Order error protection: unused coder parameters
during unvoiced mode are replaced with forward error correction
adaptive spectral enhancement filter: 10th order pole/zero with 1st order tilt compensation
linear prediction synthesis: direct form filter, coefficients correspond to interpolated LSF's
pulse dispersion: 65th order FIR filter derived from spectrally flattened triangle pulse

Towards the Fundamental Limit Currently, active research on low bit rate speech
coding (24Kbps) How does speaker’s intonation and stress affect
the speech waveforms? Maybe we should design a speakerdependent
speech coder Speech coding using Statistics
What are probabilistic models for pitch, LPC, and even residue signals?
http://wwwlns.tf.unikiel.de/demo/demo_speech.htm


















