

Sparkling Water Meetup 4.15.15
35
Building Machine Learning Applications with Sparkling Water 04/15/2015 Meetup Michal Malohlava and Alex Tellez and H2O.ai
-
Upload
sri-ambati -
Category
Spiritual
-
view
689 -
download
0
Transcript of Sparkling Water Meetup 4.15.15

Building Machine Learning Applications with Sparkling Water
04/15/2015 Meetup
Michal Malohlava and Alex Tellez and H2O.ai

Scalable Machine Learning
For Smarter Applications

Smarter Applications

Scalable Applications
Distributed
Able to process huge amount of data from different sources
Easy to develop and experiment
Powerful machine learning engine inside

BUT how to build
them?

Build an application with …
?

…with Spark and H2O
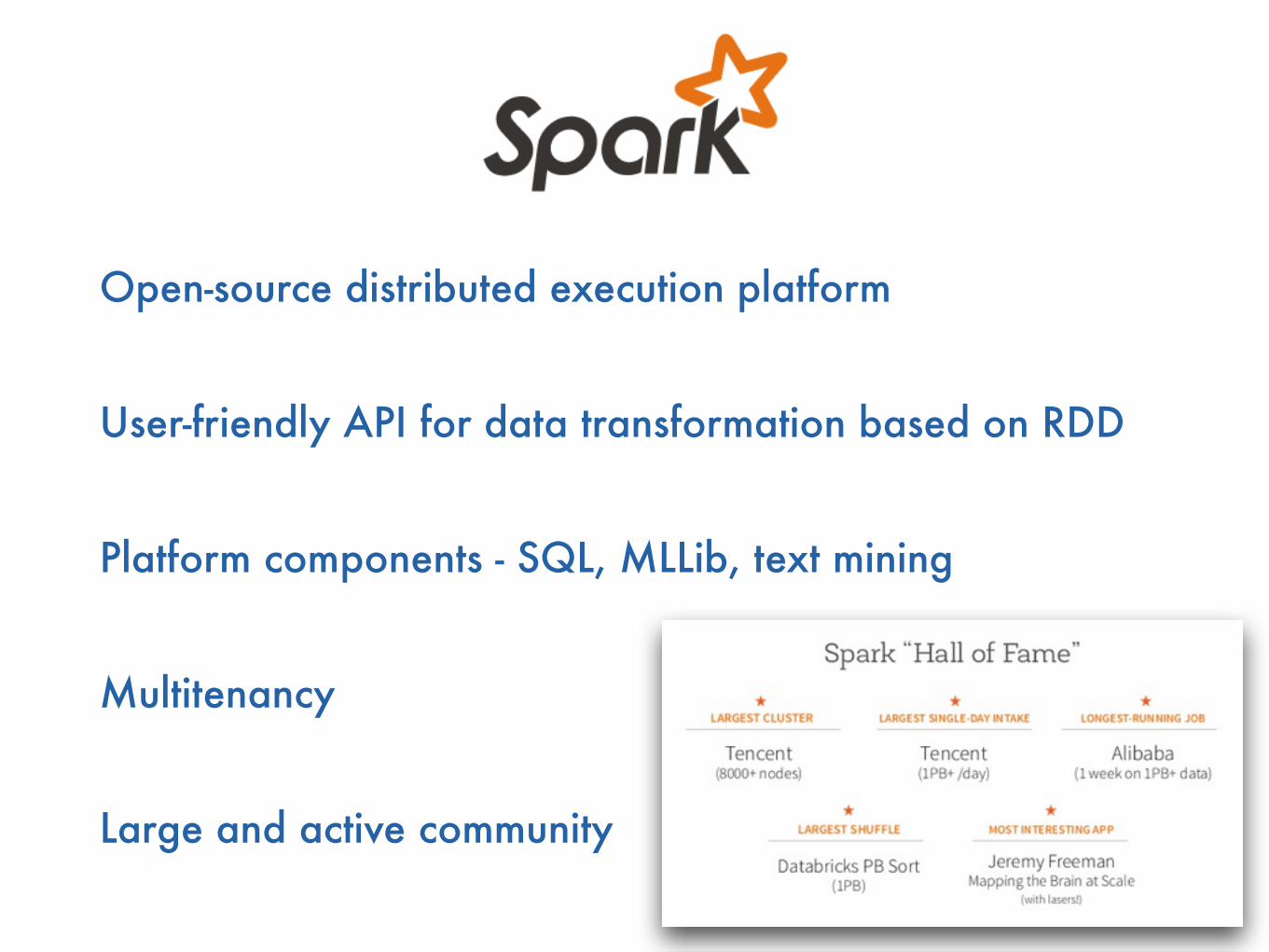
Open-source distributed execution platform
User-friendly API for data transformation based on RDD
Platform components - SQL, MLLib, text mining
Multitenancy
Large and active community

Open-source scalable machine learning platform
Tuned for efficient computation and memory use
Production ready machine learning algorithms
R, Python, Java, Scala APIs
Interactive UI, robust data parser

Ensembles
Deep Neural Networks
• Generalized Linear Models : Binomial, Gaussian, Gamma, Poisson and Tweedie
• Cox Proportional Hazards Models • Naïve Bayes • Distributed Random Forest : Classification or
regression models • Gradient Boosting Machine : Produces an
ensemble of decision trees with increasing refined approximations
• Deep learning : Create multi-layer feed forward neural networks starting with an input layer followed by multiple layers of nonlinear transformations
Statistical Analysis
Dimensionality Reduction
Anomaly Detection
• K-means : Partitions observations into k clusters/groups of the same spatial size
• Principal Component Analysis : Linearly transforms correlated variables to independent components
• Autoencoders: Find outliers using a nonlinear dimensionality reduction using deep learning
Clustering
Supe
rvis
ed L
earn
ing
Unsupervised Learning


Sparkling WaterProvides
Transparent integration of H2O with Spark ecosystem
Transparent use of H2O data structures and algorithms with Spark API
Excels in existing Spark workflows requiring advanced Machine Learning algorithms
Platform for building Smarter Applications

Sparkling Water Design
spark-submitSpark Master JVM
Spark Worker
JVM
Spark Worker
JVM
Spark Worker
JVM
Sparkling Water Cluster
Spark Executor JVM
H2O
Spark Executor JVM
H2O
Spark Executor JVM
H2O
Sparkling App
implements
?
Regular Spark applicationcontaining also Sparkling Water
classes

Data Distribution
H2O
H2O
H2O
Sparkling Water Cluster
Spark Executor JVMData
Source (e.g. HDFS)
H2O RDD
Spark Executor JVM
Spark Executor JVM
Spark RDD
RDDs and DataFramesshare same memory
space
toRDD
toH2OFrame

Lets build an application !

OR
Detect spam text messages

Data example
case class SMS(target: String, fv: Vector)
ham / spam feature vector

ML Workflow
1. Extract data
2. Transform, tokenize messages
3. Build Tf-IDF
4. Create and evaluate Deep Learning model
5. Score new messages
Goal: For a given text message identify if it is spam or not

Application environment
sparkling-shell

Lego #1: Data load
// Data loaddef load(dataFile: String): RDD[Array[String]] = { sc.textFile(dataFile).map(l => l.split(“\t")) .filter(r => !r(0).isEmpty)}
Produces [response,message]

Lego #2: Ad-hoc Tokenization
def tokenize(data: RDD[String]): RDD[Seq[String]] = { val ignoredWords = Seq("the", “a", …) val ignoredChars = Seq(',', ‘:’, …) val texts = data.map( r => { var smsText = r.toLowerCase for( c <- ignoredChars) { smsText = smsText.replace(c, ' ') } val words =smsText.split(" ").filter(w => !ignoredWords.contains(w) && w.length>2).distinct words.toSeq }) texts}
Message Bag of words

Lego #3: Tf-IDFdef buildIDFModel(tokens: RDD[Seq[String]], minDocFreq:Int = 4, hashSpaceSize:Int = 1 << 10): (HashingTF, IDFModel, RDD[Vector]) = { // Hash strings into the given space val hashingTF = new HashingTF(hashSpaceSize) val tf = hashingTF.transform(tokens) // Build term frequency-inverse document frequency val idfModel = new IDF(minDocFreq=minDocFreq).fit(tf) val expandedText = idfModel.transform(tf) (hashingTF, idfModel, expandedText)}
Hash words into large
space
Term freq scale
“Thank for the order…” […,0,3.5,0,1,0,0.3,0,1.3,0,0,…]
Thank Order
Bag of words
hashingfunctions
term freqmodel
Featurevectors representing text

Lego #4: Build a modeldef buildDLModel(train: Frame, valid: Frame, epochs: Int = 10, l1: Double = 0.001, l2: Double = 0.0, hidden: Array[Int] = Array[Int](200, 200)) (implicit h2oContext: H2OContext): DeepLearningModel = { import h2oContext._ // Build a model val dlParams = new DeepLearningParameters() dlParams._destination_key = Key.make("dlModel.hex").asInstanceOf[Key[Frame]] dlParams._train = train dlParams._valid = valid dlParams._response_column = 'target dlParams._epochs = epochs dlParams._l1 = l1 dlParams._hidden = hidden // Create a job val dl = new DeepLearning(dlParams) val dlModel = dl.trainModel.get // Compute metrics on both datasets dlModel.score(train).delete() dlModel.score(valid).delete() dlModel}
Deep Learning: Create multi-layer feed forward neural networks starting w i t h an i npu t l a ye r fo l lowed by mul t ip le l a y e r s o f n o n l i n e a r transformations
H2O model builder API
Do final scoring on train/test data

Assembly application// Data loadval data = load(DATAFILE)// Extract response spam or hamval hamSpam = data.map( r => r(0))val message = data.map( r => r(1))// Tokenize message contentval tokens = tokenize(message)// Build IDF modelvar (hashingTF, idfModel, tfidf) = buildIDFModel(tokens)// Merge response with extracted vectorsval resultRDD: SchemaRDD = hamSpam.zip(tfidf).map(v => SMS(v._1, v._2))val table:DataFrame = resultRDD// Split tableval keys = Array[String]("train.hex", "valid.hex") val ratios = Array[Double](0.8) val frs = split(table, keys, ratios)val (train, valid) = (frs(0), frs(1))table.delete()// Build a modelval dlModel = buildDLModel(train, valid)
Split dataset
Build model
Data munging

Data exploration

Model evaluationval trainMetrics = binomialMM(dlModel, train)val validMetrics = binomialMM(dlModel, valid)
Collect Model Metrics

Spam predictordef isSpam(msg: String, dlModel: DeepLearningModel, hashingTF: HashingTF, idfModel: IDFModel, hamThreshold: Double = 0.5):Boolean = { val msgRdd = sc.parallelize(Seq(msg)) val msgVector: SchemaRDD = idfModel.transform( hashingTF.transform ( tokenize (msgRdd))) .map(v => SMS("?", v)) val msgTable: DataFrame = msgVector msgTable.remove(0) // remove first column val prediction = dlModel.score(msgTable) prediction.vecs()(1).at(0) < hamThreshold}
Prepared models
Default decision threshold
Scoring

Predict spamisSpam("Michal, beer tonight in MV?")
isSpam("We tried to contact you re your reply to our offer of a Video Handset? 750 anytime any networks mins? UNLIMITED TEXT?")

Interactions with application from R
You need to install H2O’s R-package from:
http://h2o-release.s3.amazonaws.com/h2o-dev/master/1109/index.html#R

Use app from R
Collect Model Metrics

Where is the code?https://github.com/h2oai/sparkling-water/
blob/master/examples/scripts/

Sparkling Water Downloadhttp://h2o.ai/download/
http://h2o-release.s3.amazonaws.com/sparkling-water/master/93/index.html

Checkout H2O.ai Training Books
http://learn.h2o.ai/
Checkout H2O.ai Blog
http://h2o.ai/blog/
Checkout H2O.ai Youtube Channel
https://www.youtube.com/user/0xdata
Checkout GitHub
https://github.com/h2oai/sparkling-water
Meetups
https://meetup.com/
More info

Learn more at h2o.ai Follow us at @h2oai
Thank you!Sparkling Water is
open-source ML application platform
combining power of Spark and H2O


















