

Spark and MongoDB
59
-
Upload
norberto-leite -
Category
Software
-
view
2.802 -
download
0
Transcript of Spark and MongoDB


Spark in the Leaf



"BigDataSpain (2014) is great, hope I can make it next year too"
Wish making conference!

"BigDataSpain (2015) is great, hope I can win la Loteria"

7
Agenda Spark + MongoDB Connectors Use Cases Demo

By now, you should have heard about MongoDB
Unless you've been living under a rock for the last few years!

9
MongoDB
GENERAL PURPOSE DOCUMENT DATABASE OPEN-SOURCE

MongoDB is Fully Featured

11
Apache Spark

12
Spark is Taylor Swift of Big Data

13
Agenda Spark Taylor Swift + MongoDB Connectors Use Cases Demo

14
Apache Spark Taylor Swift

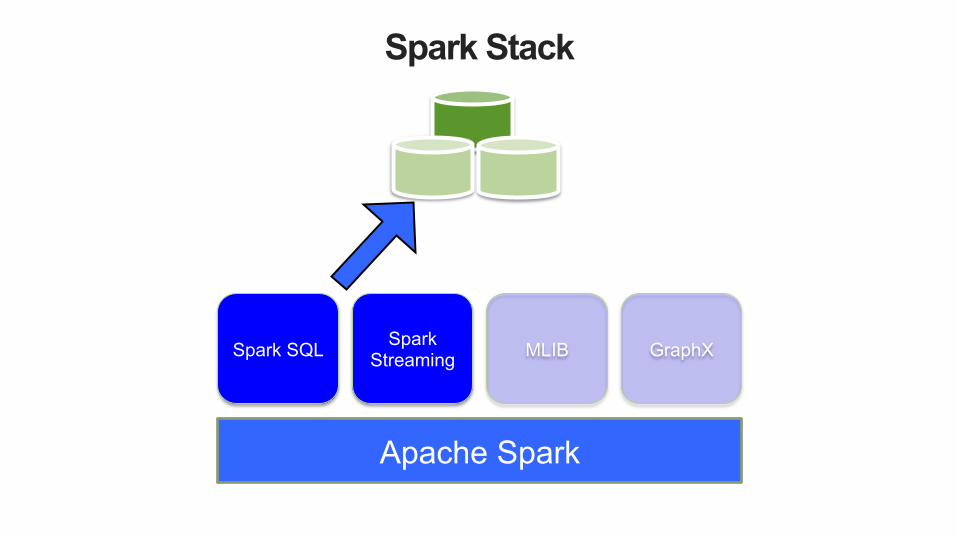
Spark Stack
Spark SQL Spark Streaming MLIB GraphX
Apache Spark
Seamless integration with SQL using
DataFrame API. Also supports HIVE SQL
Fast Feed data processing API. Designed for Fault Tolerance and
bridges streaming with batch processing MLib is Spark machine learning algorithms trick bag.
Spark graph library

Spark Stack
Spark SQL Spark Streaming MLIB GraphX
Apache Spark
Spark Stack
Spark SQL Spark Streaming MLIB GraphX
Apache Spark

Spark Stack
Spark SQL Spark Streaming MLIB GraphX
Apache Spark

Spark + MongoDB
20
Data Management
Offline Processing Analytics Data Warehousing
OLTP Applications Fine grained operations

The image cannot be displayed. Your computer 21
Delivering User Relevancy • Integrate data from many
sources • Fast-cycle analytics • Real-time • Reliable

Fraud Detection
I'm so in love!

Fraud Detection
I'm so in love!
Me, too<3
Now send me your CC number
?
Ok, XXXX-123-zzz
$$$

Fraud Detection

Workloads
Chat App
Login User Profile Contacts Messages …
Spark Fraud Detection Segmentation Recommendations
HDFS HDFS HDFS Archiving Data Crunching

26
Wearable Devices Embedded Systems Internet of Things Embedded medical devices

The image cannot be displayed. Your computer 27
Access complete patient history Avoid of conflicting prescriptions Clinical trials

High Speed Document Design

Time Series db.ticks.find(){ _id: 'MSFT_12', type: 'Open', date: ISODate("2015-07-12 10:00"), volume: 1699342, minutes: { "0": 12.9, "1": 14.4, ... "59": 15.8 }}
Resource
Type
When
Series

h1p://cdn.theatlan9c.com/sta9c/infocus/ngt051713/n10_00203194.jpg
WiredTiger

Very High Speed

> mongod --storageEngine wiredTiger

> mongod
On Upcoming 3.2

34
MongoDB Storage Engines
Content Repo
IoT Sensor Backend Ad Service Customer
Analytics Archive
MongoDB Query Language (MQL) + Native Drivers
MongoDB Document Data Model
MMAP V1 WT In-Memory ? ?
Supported in MongoDB 3.0 Future Possible Storage Engines
Man
agem
ent
Sec
urity
Experimental

Spark Streaming

36
Spark Streaming
Spark Twitter Feed

37
Spark Streaming
Twitter Feed
{ "statuses": [ { "coordinates": null, "favorited": false, "truncated": false, "created_at": "Mon Sep 24 03:35:21 +0000 2012", "id_str": "250075927172759552", "entities": { "urls": [
], "hashtags": [ { "text": "freebandnames", "indices": [ 20, 34 ] } ], "user_mentions": [] } }}

38
Spark Streaming
Spark
{ "statuses": [ { "coordinates": null, "favorited": false, "truncated": false, "created_at": "Mon Sep 24 03:35:21 +0000 2012", "id_str": "250075927172759552", "entities": { "urls": [
], "hashtags": [ { "text": "freebandnames", "indices": [ 20, 34 ] } ], "user_mentions": [] } }}
{ "time": "Mon Sep 24 03:35", "freebandnames": 1}
{ "statuses": [ { "coordinates": null, "favorited": false, "truncated": false, "created_at": "Mon Sep 24 03:35:21 +0000 2012", "id_str": "250075927172759552", "entities": { "urls": [
], "hashtags": [ { "text": "freebandnames", "indices": [ 20, 34 ] } ], "user_mentions": [] } }}
{ "statuses": [ { "coordinates": null, "favorited": false, "truncated": false, "created_at": "Mon Sep 24 03:35:21 +0000 2012", "id_str": "250075927172759552", "entities": { "urls": [
], "hashtags": [ { "text": "freebandnames", "indices": [ 20, 34 ] } ], "user_mentions": [] } }}
{ "statuses": [ { "coordinates": null, "favorited": false, "truncated": false, "created_at": "Mon Sep 24 03:35:21 +0000 2012", "id_str": "250075927172759552", "entities": { "urls": [
], "hashtags": [ { "text": "freebandnames", "indices": [ 20, 34 ] } ], "user_mentions": [] } }}
{ "time": "Mon Sep 24 03:35", "freebandnames": 4}

39
Capped Collection
Spark Streaming
{ "time": "Mon Sep 24 03:35", "freebandnames": 4}
{ "time": "Mon Sep 24 03:40", "bigdataspain": 400}
{ "time": "Mon Sep 24 03:50", "bigdataspain": 7556}
{ "time": "Mon Sep 24 03:50", "itshappending": 100}
Tailable Cursor

Spark SQL

MongoDB Hadoop Connector
Spark
HDFS HDFS HDFS
MongoDB Hadoop Connector
MongoDB Shard

MongoDB Hadoop Connector
Spark
HDFS HDFS HDFS
MongoDB Hadoop Connector
MongoDB Shard
YARN

43
MongoDB Hadoop Connector
Positive Not So Good
Battle Tested Not the fastest thing
Integrated with existing Hadoop components Not dedicated to Spark
Supports HIVE and PIG Dependent on HDFS
http://docs.mongodb.org/ecosystem/tutorial/getting-started-with-hadoop/

44
Stratio Spark-MongoDB http://spark-packages.org/?q=mongodb

45
Stratio Spark-MongoDB
https://github.com/Stratio/spark-mongodb
Spark
HDFS HDFS HDFS
MongoDB Shard
Stratio Spark-MongoDB

46
Stratio Spark-MongoDB
val mcInputBuilder = MongodbConfigBuilder(Map(Host -> List("localhost:27017"), Database -> "marketdata", Collection -> "minbars", SamplingRatio -> 1.0, WriteConcern -> MongodbWriteConcern.Normal))
val readConfig = mcInputBuilder.build()
Database
Collec9on
SamplingRa9o
WriteConcern

47
Stratio Spark-MongoDB
val sqlContext = new HiveContext(sc)val dfOneMin = sqlContext.fromMongoDB(readConfig)

48
Stratio Spark-MongoDB
val dfFiveMinForMonth = sqlContext.sql("""SELECT m.Symbol, m.OpenTime as Timestamp, m.Open, m.High, m.Low, m.CloseFROM...FROM minbars)as mWHERE unix_timestamp(m.CloseTime, 'yyyy-MM-dd HH:mm') - unix_timestamp(m.OpenTime, 'yyyy-MM-dd HH:mm') = 60*4""")

49
Stratio Spark-MongoDB
https://github.com/Stratio/spark-mongodb
Spark
HDFS HDFS HDFS
MongoDB Shard
Stratio Spark-MongoDB

50
DC West
DC West
DC West
Stratio Spark-MongoDB
https://github.com/Stratio/spark-mongodb
Spark
MongoDB Shard
Spark
Spark

Demo

52
Demo
Spark Stratio Spark-MongoDB

53
Feeling powerful ???

Future

55
What to expect
• We are working on a dedicated Spark Connector for MongoDB
• Stratio Connector is great but: – Some Operations are actually faster if performed using
Aggregation Framework • Better Integration with upcoming 3.2 Async Java Driver
– Specially for the Apache Streaming Support

MongoDB Days 2015 05 November, 2015 London
https://www.mongodb.com/events/mongodb-days-uk

57
Engineering
Sales&AccountManagement Finance&PeopleOpera9ons
Pre-SalesEngineering Marke9ng
JointheTeam
Viewalljobsandapply:h1p://grnh.se/pj10su



















