
Software Libraries and Middleware for Exascale Systems · • 24% improvement compared with an...
65
Programming Models and their Designs for Exascale Systems (Part II): Accelerators/Coprocessors, QoS and Fault Tolerance Dhabaleswar K. (DK) Panda The Ohio State University E-mail: [email protected] http://www.cse.ohio-state.edu/~panda Talk at HPC Advisory Council Lugano Conference (2013) by
Transcript of Software Libraries and Middleware for Exascale Systems · • 24% improvement compared with an...

Programming Models and their Designs for Exascale Systems (Part II): Accelerators/Coprocessors, QoS and
Fault Tolerance
Dhabaleswar K. (DK) Panda
The Ohio State University
E-mail: [email protected]
http://www.cse.ohio-state.edu/~panda
Talk at HPC Advisory Council Lugano Conference (2013)
by

• Scalability for million to billion processors – Support for highly-efficient inter-node and intra-node communication (both two-sided
and one-sided)
– Extremely minimum memory footprint
• Hybrid programming (MPI + OpenMP, MPI + UPC, MPI + OpenSHMEM, …)
• Balancing intra-node and inter-node communication for next generation multi-core (128-1024 cores/node)
– Multiple end-points per node
• Support for efficient multi-threading
• Support for GPGPUs and Accelerators
• Scalable Collective communication – Offload
– Non-blocking
– Topology-aware
– Power-aware
• Fault-tolerance/resiliency
• QoS support for communication and I/O
Recap from Yesterday’s Talk: Challenges in Designing (MPI+X) at Exascale
2 HPC Advisory Council Lugano Conference, Mar '13

• High Performance open-source MPI Library for InfiniBand, 10Gig/iWARP and
RDMA over Converged Enhanced Ethernet (RoCE)
– MVAPICH (MPI-1) ,MVAPICH2 (MPI-2.2 and initial MPI-3.0), Available since 2002
– MVAPICH2-X (MPI + PGAS), Available since 2012
– Used by more than 2,000 organizations (HPC Centers, Industry and Universities) in
70 countries
– More than 150,000 downloads from OSU site directly
– Empowering many TOP500 clusters
• 7th ranked 204,900-core cluster (Stampede) at TACC
• 14th ranked 125,980-core cluster (Pleiades) at NASA
• 17th ranked 73,278-core cluster (Tsubame 2.0) at Tokyo Institute of Technology
• and many others
– Available with software stacks of many IB, HSE and server vendors
including Linux Distros (RedHat and SuSE)
– http://mvapich.cse.ohio-state.edu
• Partner in the U.S. NSF-TACC Stampede (9 PFlop) System
3
Recap: MVAPICH2/MVAPICH2-X Software
HPC Advisory Council Lugano Conference, Mar '13

• Scalability for million to billion processors – Support for highly-efficient inter-node and intra-node communication (both two-sided
and one-sided)
– Extremely minimum memory footprint
• Scalable Collective communication – Multicore-aware and Hardware-multicast-based
– Topology-aware
– Offload and Non-blocking
– Power-aware
• Application Scalability
• Hybrid programming (MPI + OpenSHMEM, MPI + UPC, …)
• Support for Accelerators (GPGPUs)
• Support for Co-Processors (Intel MIC)
• QoS support for communication and I/O
• Fault-tolerance/resiliency
Challenges being Addressed by MVAPICH2 for Exascale
4 HPC Advisory Council Lugano Conference, Mar '13

• Support for Accelerators (GPGPUs) – High Performance MPI Communication to/from GPU-Buffer
– MPI Communication with GPU-Direct-RDMA
– OpenSHMEM Communication to/from GPU Buffer
– UPC Communication to/from GPU Buffer
• Support for Co-Processors (Intel MIC)
• QoS support for communication and I/O
• Fault-tolerance/resiliency
Challenges being Addressed by MVAPICH2 for Exascale
5 HPC Advisory Council Lugano Conference, Mar '13

• Many systems today want to use systems
that have both GPUs and high-speed
networks such as InfiniBand
• Problem: Lack of a common memory
registration mechanism
– Each device has to pin the host memory it will
use
– Many operating systems do not allow
multiple devices to register the same
memory pages
• Previous solution:
– Use different buffer for each device and copy
data HPC Advisory Council Lugano Conference, Mar '13 6
InfiniBand + GPU systems

• Collaboration between Mellanox and
NVIDIA to converge on one memory
registration technique
• Both devices register a common
host buffer
– GPU copies data to this buffer, and the network
adapter can directly read from this buffer (or
vice-versa)
• Note that GPU-Direct does not allow you to
bypass host memory
HPC Advisory Council Lugano Conference, Mar '13 7
GPU-Direct

PCIe
GPU
CPU
NIC
Switch
At Sender:
cudaMemcpy(sbuf, sdev, . . .);
MPI_Send(sbuf, size, . . .);
At Receiver:
MPI_Recv(rbuf, size, . . .);
cudaMemcpy(rdev, rbuf, . . .);
Sample Code - Without MPI integration
• Naïve implementation with standard MPI and CUDA
• High Productivity and Poor Performance
8 HPC Advisory Council Lugano Conference, Mar '13

PCIe
GPU
CPU
NIC
Switch
At Sender: for (j = 0; j < pipeline_len; j++)
cudaMemcpyAsync(sbuf + j * blk, sdev + j * blksz,. . .);
for (j = 0; j < pipeline_len; j++) {
while (result != cudaSucess) {
result = cudaStreamQuery(…);
if(j > 0) MPI_Test(…);
}
MPI_Isend(sbuf + j * block_sz, blksz . . .);
}
MPI_Waitall();
Sample Code – User Optimized Code
• Pipelining at user level with non-blocking MPI and CUDA interfaces
• Code at Sender side (and repeated at Receiver side)
• User-level copying may not match with internal MPI design
• High Performance and Poor Productivity
HPC Advisory Council Lugano Conference, Mar '13 9

Can this be done within MPI Library?
• Support GPU to GPU communication through standard MPI
interfaces
– e.g. enable MPI_Send, MPI_Recv from/to GPU memory
• Provide high performance without exposing low level details
to the programmer
– Pipelined data transfer which automatically provides optimizations
inside MPI library without user tuning
• A new Design incorporated in MVAPICH2 to support this
functionality
10 HPC Advisory Council Lugano Conference, Mar '13

At Sender:
At Receiver:
MPI_Recv(r_device, size, …);
inside MVAPICH2
Sample Code – MVAPICH2-GPU
• MVAPICH2-GPU: standard MPI interfaces used
• Takes advantage of Unified Virtual Addressing (>= CUDA 4.0)
• Overlaps data movement from GPU with RDMA transfers
• High Performance and High Productivity
11 HPC Advisory Council Lugano Conference, Mar '13
MPI_Send(s_device, size, …);

MPI-Level Two-sided Communication
• 45% improvement compared with a naïve user-level implementation
(Memcpy+Send), for 4MB messages
• 24% improvement compared with an advanced user-level implementation
(MemcpyAsync+Isend), for 4MB messages
0
500
1000
1500
2000
2500
3000
32K 64K 128K 256K 512K 1M 2M 4M
Tim
e (
us)
Message Size (bytes)
Memcpy+Send
MemcpyAsync+Isend
MVAPICH2-GPU
H. Wang, S. Potluri, M. Luo, A. Singh, S. Sur and D. K. Panda, MVAPICH2-GPU: Optimized GPU to GPU Communication for InfiniBand Clusters, ISC ‘11
12 HPC Advisory Council Lugano Conference, Mar '13

Other MPI Operations and Optimizations for GPU Buffers
• Overlap optimizations for
– One-sided Communication
– Collectives
– Communication with Datatypes
• Optimized Designs for multi-GPUs per node
– Use CUDA IPC (in CUDA 4.1), to avoid copy through host memory
13
• H. Wang, S. Potluri, M. Luo, A. Singh, X. Ouyang, S. Sur and D. K. Panda, Optimized Non-contiguous MPI Datatype Communication for GPU Clusters: Design, Implementation and Evaluation with MVAPICH2, IEEE Cluster '11, Sept. 2011
HPC Advisory Council Lugano Conference, Mar '13
• A. Singh, S. Potluri, H. Wang, K. Kandalla, S. Sur and D. K. Panda, MPI Alltoall Personalized Exchange on GPGPU Clusters: Design Alternatives and Benefits, Workshop on Parallel Programming on Accelerator Clusters (PPAC '11), held in conjunction with Cluster '11, Sept. 2011
• S. Potluri et al. Optimizing MPI Communication on Multi-GPU Systems using CUDA Inter-Process Communication, Workshop on Accelerators and Hybrid Exascale Systems(ASHES), to be held in conjunction with IPDPS 2012, May 2012

MVAPICH2 1.8 and 1.9 Series
• Support for MPI communication from NVIDIA GPU device memory
• High performance RDMA-based inter-node point-to-point communication (GPU-GPU, GPU-Host and Host-GPU)
• High performance intra-node point-to-point communication for multi-GPU adapters/node (GPU-GPU, GPU-Host and Host-GPU)
• Taking advantage of CUDA IPC (available since CUDA 4.1) in intra-node communication for multiple GPU adapters/node
• Optimized and tuned collectives for GPU device buffers
• MPI datatype support for point-to-point and collective communication from GPU device buffers
14 HPC Advisory Council Lugano Conference, Mar '13

OSU MPI Micro-Benchmarks (OMB) 3.5 – 3.9 Releases
• A comprehensive suite of benchmarks to compare performance
of different MPI stacks and networks
• Enhancements to measure MPI performance on GPU clusters
– Latency, Bandwidth, Bi-directional Bandwidth
• Flexible selection of data movement between CPU(H) and
GPU(D): D->D, D->H and H->D
• Support for OpenACC is added in 3.9 Release
• Available from http://mvapich.cse.ohio-state.edu/benchmarks
• Available in an integrated manner with MVAPICH2 stack
15 HPC Advisory Council Lugano Conference, Mar '13
• D. Bureddy, H. Wang, A. Venkatesh, S. Potluri and D. K. Panda, OMB-GPU: A Micro-benchmark suite for Evaluating MPI Libraries on GPU Clusters, EuroMPI 2012, September 2012.
HPC Advisory Council Lugano Conference, Mar '13 16
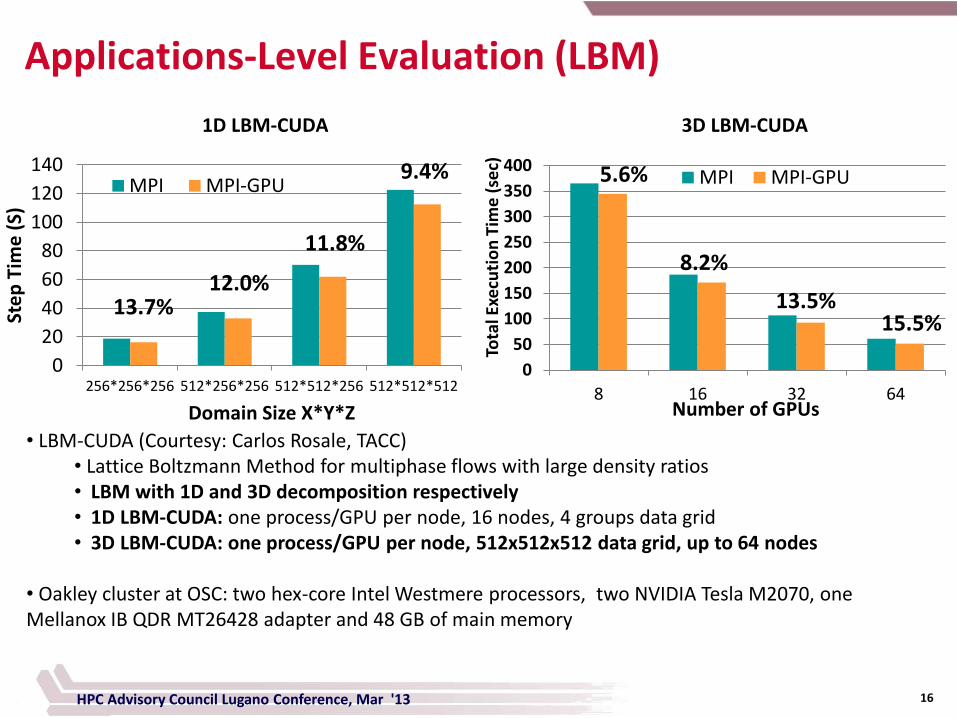
Applications-Level Evaluation (LBM)
• LBM-CUDA (Courtesy: Carlos Rosale, TACC) • Lattice Boltzmann Method for multiphase flows with large density ratios • LBM with 1D and 3D decomposition respectively • 1D LBM-CUDA: one process/GPU per node, 16 nodes, 4 groups data grid • 3D LBM-CUDA: one process/GPU per node, 512x512x512 data grid, up to 64 nodes
• Oakley cluster at OSC: two hex-core Intel Westmere processors, two NVIDIA Tesla M2070, one Mellanox IB QDR MT26428 adapter and 48 GB of main memory
0
20
40
60
80
100
120
140
256*256*256 512*256*256 512*512*256 512*512*512
Ste
p T
ime
(S)
Domain Size X*Y*Z
MPI MPI-GPU
13.7% 12.0%
11.8%
9.4%
1D LBM-CUDA
0
50
100
150
200
250
300
350
400
8 16 32 64
Tota
l Exe
cuti
on
Tim
e (
sec)
Number of GPUs
MPI MPI-GPU5.6%
8.2%
13.5% 15.5%
3D LBM-CUDA

HPC Advisory Council Lugano Conference, Mar '13 17
Applications-Level Evaluation (AWP-ODC)
•AWP-ODC (Courtesy: Yifeng Cui, SDSC) • A seismic modeling code, Gordon Bell Prize finalist at SC 2010 • 128x256x512 data grid per process, 8 nodes
• Oakley cluster at OSC: two hex-core Intel Westmere processors, two NVIDIA Tesla M2070, one Mellanox IB QDR MT26428 adapter and 48 GB of main memory
0102030405060708090
1 GPU/Proc per Node 2 GPUs/Procs per NodeTota
l Ex
ecu
tio
n T
ime
(se
c)
Configuration
AWP-ODC
MPI MPI-GPU
11.1% 7.9%

• Support for Accelerators (GPGPUs) – High Performance MPI Communication to/from GPU-Buffer
– MPI Communication with GPU-Direct-RDMA
– OpenSHMEM Communication to/from GPU Buffer
– UPC Communication to/from GPU Buffer
• Support for Co-Processors (Intel MIC)
• QoS support for communication and I/O
• Fault-tolerance/resiliency
Challenges being Addressed by MVAPICH2 for Exascale
18 HPC Advisory Council Lugano Conference, Mar '13

• Fastest possible communication
between GPU and other PCI-E
devices
• Network adapter can directly read
data from GPU device memory
• Avoids copies through the host
• Allows for better asynchronous
communication
• Preliminary driver is under work by
NVIDIA and Mellanox
HPC Advisory Council Lugano Conference, Mar '13 19
GPU-Direct RDMA with CUDA 5
InfiniBand
GPU
GPU Memory
CPU
Chip set
System Memory
HPC Advisory Council Lugano Conference, Mar '13 20
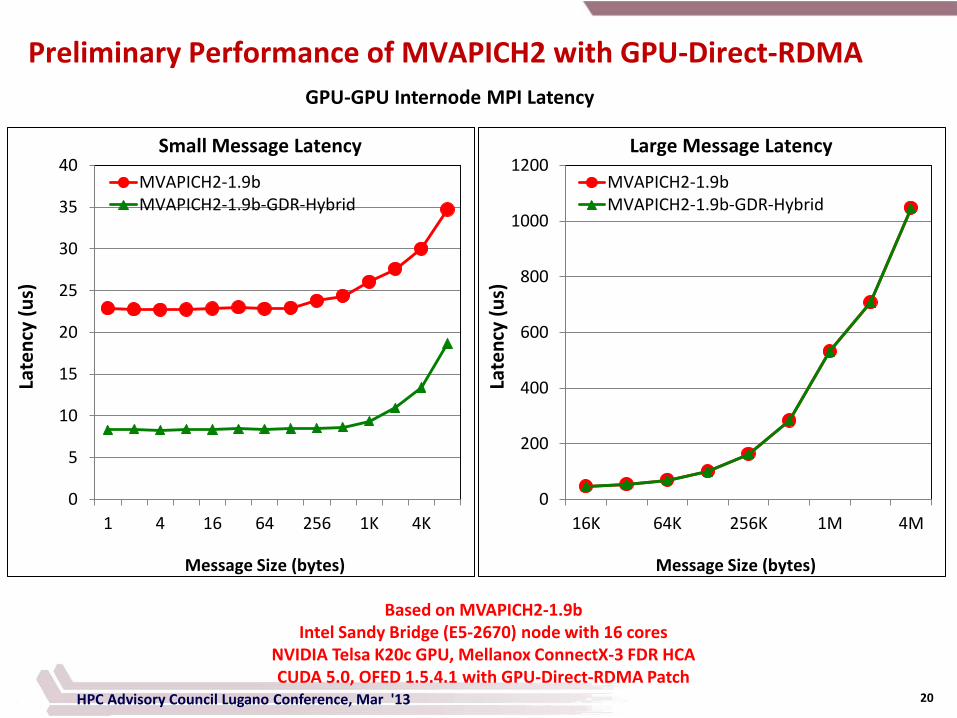
Preliminary Performance of MVAPICH2 with GPU-Direct-RDMA
Based on MVAPICH2-1.9b Intel Sandy Bridge (E5-2670) node with 16 cores
NVIDIA Telsa K20c GPU, Mellanox ConnectX-3 FDR HCA CUDA 5.0, OFED 1.5.4.1 with GPU-Direct-RDMA Patch
GPU-GPU Internode MPI Latency
0
5
10
15
20
25
30
35
40
1 4 16 64 256 1K 4K
MVAPICH2-1.9bMVAPICH2-1.9b-GDR-Hybrid
Small Message Latency
Message Size (bytes)
Late
ncy
(u
s)
0
200
400
600
800
1000
1200
16K 64K 256K 1M 4M
MVAPICH2-1.9bMVAPICH2-1.9b-GDR-Hybrid
Large Message Latency
Message Size (bytes)
Late
ncy
(u
s)

HPC Advisory Council Lugano Conference, Mar '13 21
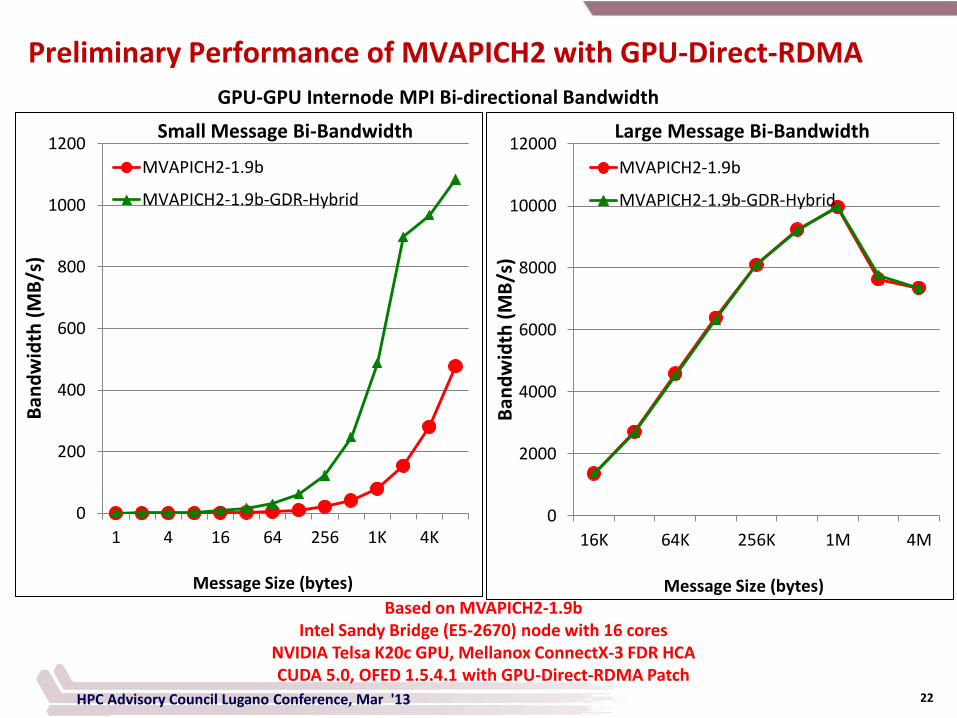
Preliminary Performance of MVAPICH2 with GPU-Direct-RDMA
Based on MVAPICH2-1.9b Intel Sandy Bridge (E5-2670) node with 16 cores
NVIDIA Telsa K20c GPU, Mellanox ConnectX-3 FDR HCA CUDA 5.0, OFED 1.5.4.1 with GPU-Direct-RDMA Patch
GPU-GPU Internode MPI Uni-directional Bandwidth
0
100
200
300
400
500
600
700
800
900
1 4 16 64 256 1K 4K
MVAPICH2-1.9b
MVAPICH2-1.9b-GDR-Hybrid
Message Size (bytes)
Ban
dw
idth
(M
B/s
)
Small Message Bandwidth
0
1000
2000
3000
4000
5000
6000
7000
16K 64K 256K 1M 4M
MVAPICH2-1.9b
MVAPICH2-1.9b-GDR-Hybrid
Message Size (bytes)
Ban
dw
idth
(M
B/s
)
Large Message Bandwidth
HPC Advisory Council Lugano Conference, Mar '13 22
Preliminary Performance of MVAPICH2 with GPU-Direct-RDMA
Based on MVAPICH2-1.9b Intel Sandy Bridge (E5-2670) node with 16 cores
NVIDIA Telsa K20c GPU, Mellanox ConnectX-3 FDR HCA CUDA 5.0, OFED 1.5.4.1 with GPU-Direct-RDMA Patch
GPU-GPU Internode MPI Bi-directional Bandwidth
0
200
400
600
800
1000
1200
1 4 16 64 256 1K 4K
MVAPICH2-1.9b
MVAPICH2-1.9b-GDR-Hybrid
Message Size (bytes)
Ban
dw
idth
(M
B/s
)
Small Message Bi-Bandwidth
0
2000
4000
6000
8000
10000
12000
16K 64K 256K 1M 4M
MVAPICH2-1.9b
MVAPICH2-1.9b-GDR-Hybrid
Message Size (bytes)
Ban
dw
idth
(M
B/s
)
Large Message Bi-Bandwidth

• Support for Accelerators (GPGPUs) – High Performance MPI Communication to/from GPU-Buffer
– MPI Communication with GPU-Direct-RDMA
– OpenSHMEM Communication to/from GPU Buffer
– UPC Communication to/from GPU Buffer
• Support for Co-Processors (Intel MIC)
• QoS support for communication and I/O
• Fault-tolerance/resiliency
Challenges being Addressed by MVAPICH2 for Exascale
23 HPC Advisory Council Lugano Conference, Mar '13

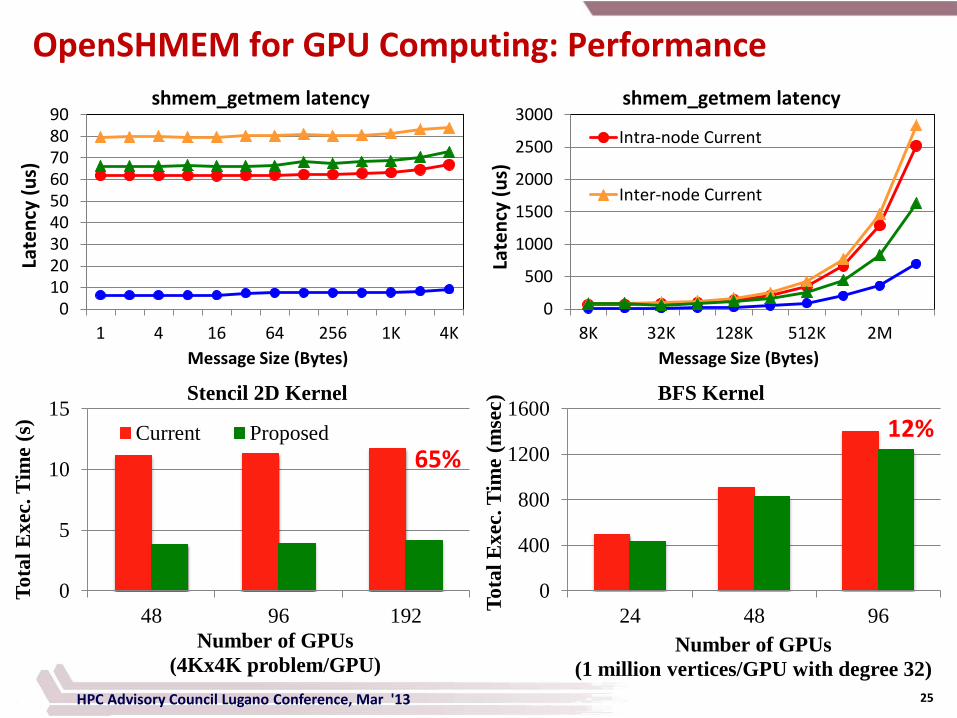
OpenSHMEM for GPU Computing
• OpenSHMEM can benefit programming on GPU clusters
- Better programmability (symmetric heap memory model)
- Low synchronization overheads (one-sided communication)
• Current model does not support communication from GPU memory
24 HPC Advisory Council Lugano Conference, Mar '13
PE 0 host_buf = shmalloc (size)
cudaMemcpy (host_buf, dev_buf, size,…) shmem_putmem (host_buf, host_buf, size, pe1) shmem_barrier ( . . . )
PE 1 host_buf = shmalloc (size)
shmem_barrier ( . . . ) cudaMemcpy (dev_buf, host_buf, size,…)
PE 0 map_ptr = shmap (dev_buf, size, MEMTYPE_CUDA )
shmem_putmem (map_ptr, map_ptr, size, pe1)
PE 1 map_ptr = shmap (dev_buf, size, MEMTYPE_CUDA )
– no more operations required –
Current Proposed Symmetric Map
S. Potluri, D. Bureddy, H. Wang, H. Subramoni and D. K. Panda - Extending OpenSHMEM for
GPU Computing , IPDPS 2013, Accepted to be presented.
OpenSHMEM for GPU Computing: Performance
HPC Advisory Council Lugano Conference, Mar '13 25
0102030405060708090
1 4 16 64 256 1K 4K
shmem_getmem latency
Message Size (Bytes)
Late
ncy
(u
s)
0
500
1000
1500
2000
2500
3000
8K 32K 128K 512K 2M
Intra-node Current
Inter-node Current
shmem_getmem latency
Message Size (Bytes)
Late
ncy
(u
s)
0
5
10
15
48 96 192
To
tal
Ex
ec. T
ime
(s)
Number of GPUs
(4Kx4K problem/GPU)
Stencil 2D Kernel
Current Proposed
0
400
800
1200
1600
24 48 96
To
tal
Ex
ec. T
ime
(mse
c)
Number of GPUs
(1 million vertices/GPU with degree 32)
BFS Kernel
65% 12%

• Existing UPC/CUDA programs:
– Complicated CUDA functions & temporary host buffer
– Explicit Synchronization
– Involvement of remote UPC thread: code & CPU
• GPU global address space with host and device memory
– Extended APIs: upc_ondevice/upc_offdevice
– Return true device memory through Unified Addressing (UVA)
• Communication over InfiniBand:
– RDMA fastpath for small/medium message
– Reduce larger buffer pin-down overhead
• Helper Thread for improved asynchronous access
– Helper threads complete memory access for busy UPC threads
HPC Advisory Council Lugano Conference, Mar '13 26
Multi-threaded UPC Runtime for GPU to GPU Communication over InfiniBand

0
100
200
300
400
500
N = 50 N = 100 N = 200 N = 300
Ave
rage
Tim
e (
us)
Matrix Size (N x N)
Matrix Multiplication on 4 GPU Nodes (Communication Time)
Naïve
Improved
Multi-threaded UPC Runtime for GPU to GPU Communication over InfiniBand (Pt-to-Pt and Application Performance)
27 HPC Advisory Council Lugano Conference, Mar '13
0
5
10
15
20
25
30
35
40
4 8 16 32 64 128 256 512
Tim
e (u
s)
Message Size (Bytes)
upc_memput latency (small message)
Naïve
Improved
0
20
40
60
80
100
1K 2K 4K 8K 16K 32K 64K
Tim
e (u
s)
Message Size (Bytes)
upc_memput latency (medium message)
Naïve
Improved
34%
47%
26%
38% M. Luo, H. Wang and D. K. Panda, Multi-Threaded UPC Runtime for GPU to GPU communication over InfiniBand, Int'l Conference on Partitioned Global Address Space Programming Models (PGAS '12), October 2012.
The latency of remote address access like upc_memput on GPU device memory can be reduced up to 47%.
Matrix Multiplication on 4 GPU nodes: communication happens between root and others before/after each iteration.
Improved design can achieve up to 38% improvement when matrix size is 50.

• Support for Accelerators (GPGPUs)
• Support for Co-Processors (Intel MIC)
– Programming Models for MIC
– MVAPICH2 Design for MPI-Level Communication
– Early Performance Evaluation
• Point-to-point
• Collectives
• Kernels and applications
– Continuing Work
• QoS support for communication and I/O
• Fault-tolerance/resiliency
Challenges being Addressed by MVAPICH2 for Exascale
28 HPC Advisory Council Lugano Conference, Mar '13

Many Integrated Core (MIC) Architecture
• Intel’s Many Integrated Core (MIC) architecture geared for HPC
• Critical part of Intel’s solution for exascale computing
• Many low-power processor cores, hardware threads and wide
vector units
• X86 compatibility - applications and libraries can run out-of-the-
box or with minor modifications
29 HPC Advisory Council Lugano Conference, Mar '13
Courtesy: Scott McMillan, Intel Corporation, Presentation at TACC-Intel Highly Parallel Computing Symposium` 12 (http://www.tacc.utexas.edu/documents/13601/d9d58515-5c0a-429d-8a3f-85014e9e4dab)
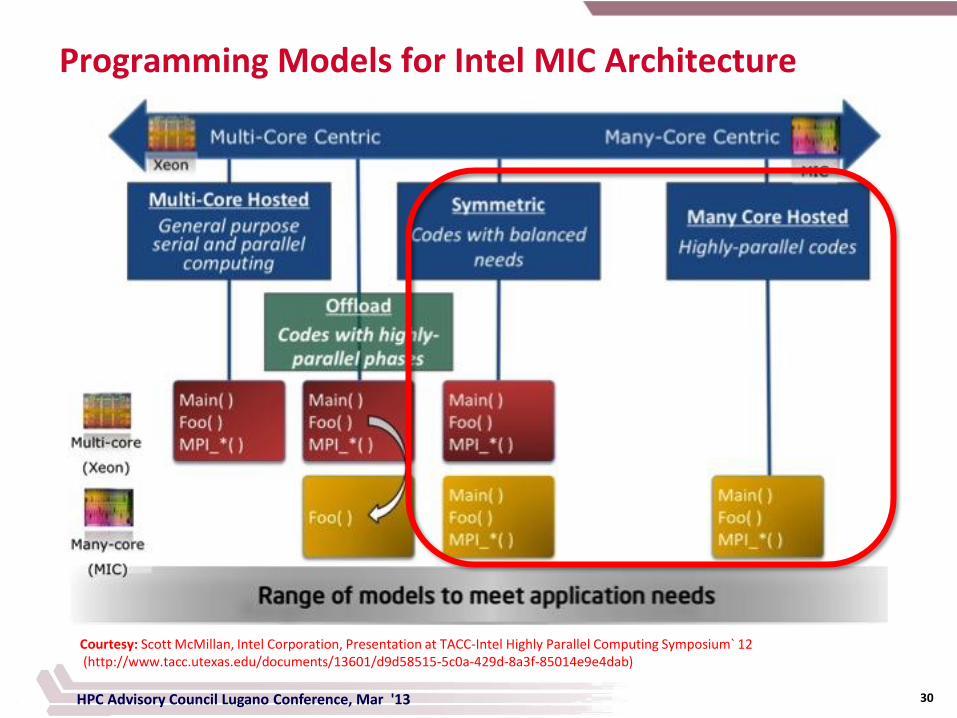
Programming Models for Intel MIC Architecture
30
Courtesy: Scott McMillan, Intel Corporation, Presentation at TACC-Intel Highly Parallel Computing Symposium` 12 (http://www.tacc.utexas.edu/documents/13601/d9d58515-5c0a-429d-8a3f-85014e9e4dab)
HPC Advisory Council Lugano Conference, Mar '13
31
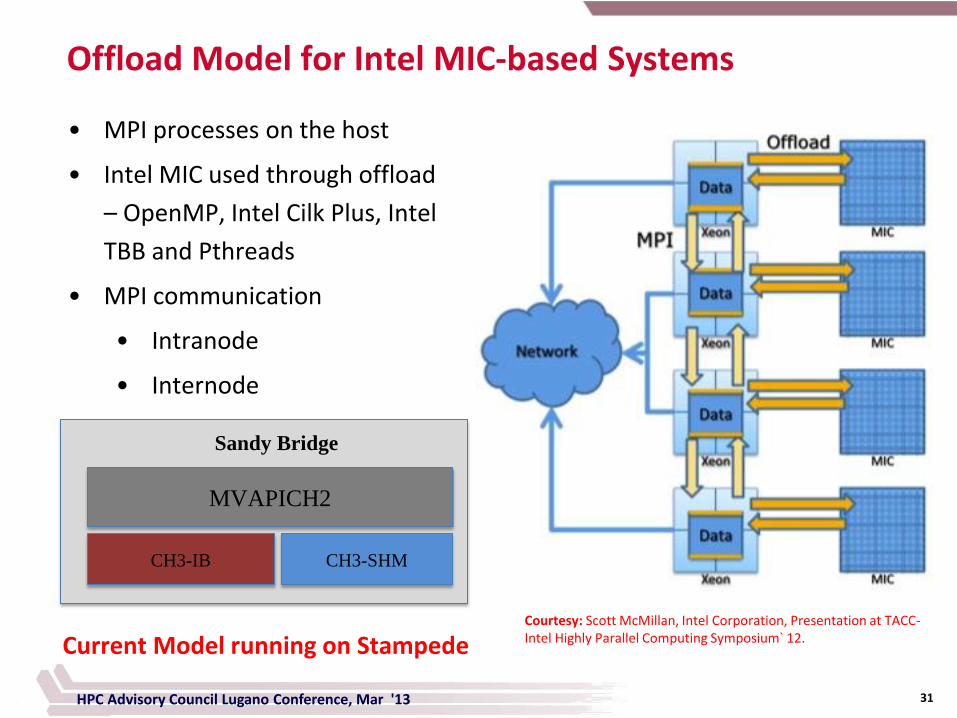
Offload Model for Intel MIC-based Systems
• MPI processes on the host
• Intel MIC used through offload
– OpenMP, Intel Cilk Plus, Intel
TBB and Pthreads
• MPI communication
• Intranode
• Internode
Courtesy: Scott McMillan, Intel Corporation, Presentation at TACC-Intel Highly Parallel Computing Symposium` 12.
MVAPICH2
CH3-IB
Sandy Bridge
CH3-SHM
HPC Advisory Council Lugano Conference, Mar '13
Current Model running on Stampede
32
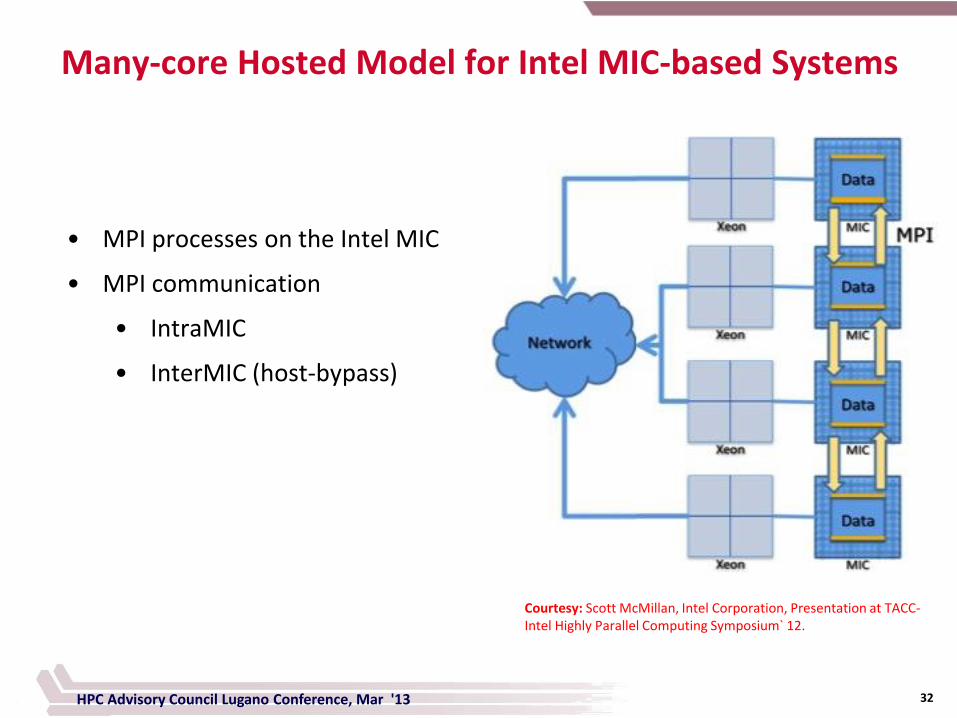
Many-core Hosted Model for Intel MIC-based Systems
• MPI processes on the Intel MIC
• MPI communication
• IntraMIC
• InterMIC (host-bypass)
Courtesy: Scott McMillan, Intel Corporation, Presentation at TACC-Intel Highly Parallel Computing Symposium` 12.
HPC Advisory Council Lugano Conference, Mar '13
33
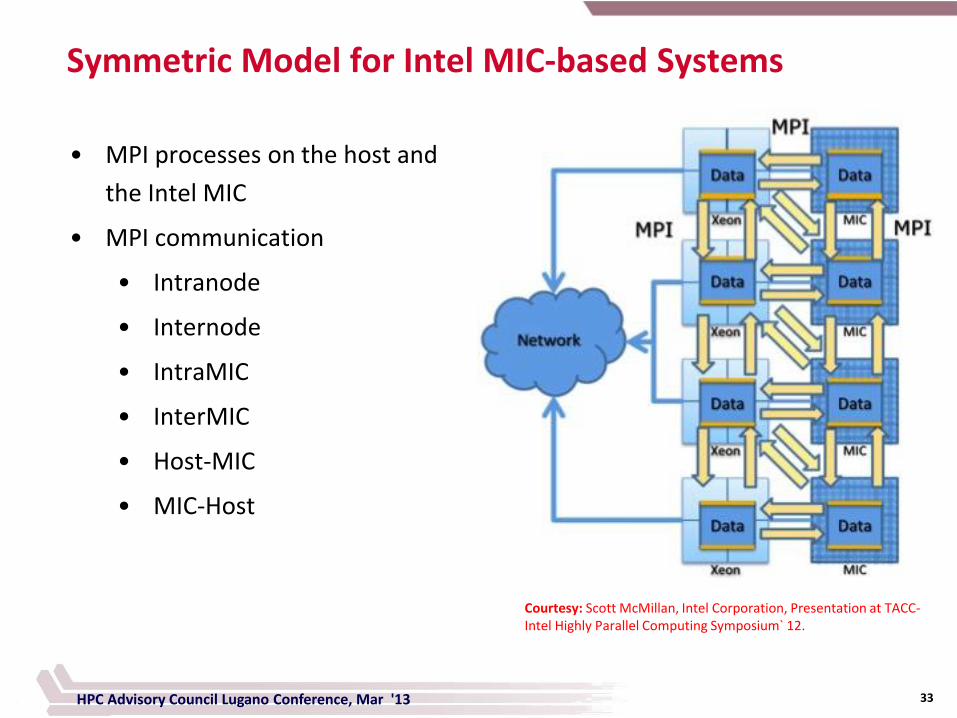
Symmetric Model for Intel MIC-based Systems
• MPI processes on the host and
the Intel MIC
• MPI communication
• Intranode
• Internode
• IntraMIC
• InterMIC
• Host-MIC
• MIC-Host
Courtesy: Scott McMillan, Intel Corporation, Presentation at TACC-Intel Highly Parallel Computing Symposium` 12.
HPC Advisory Council Lugano Conference, Mar '13
34
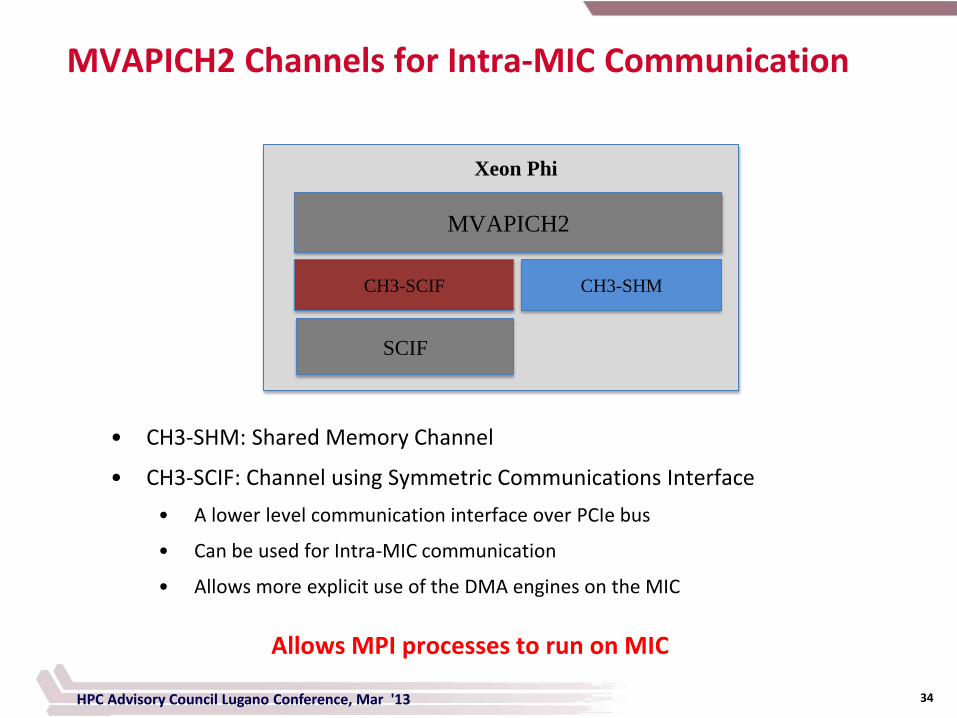
MVAPICH2 Channels for Intra-MIC Communication
MVAPICH2
CH3-SCIF
Xeon Phi
CH3-SHM
SCIF
• CH3-SHM: Shared Memory Channel
• CH3-SCIF: Channel using Symmetric Communications Interface
• A lower level communication interface over PCIe bus
• Can be used for Intra-MIC communication
• Allows more explicit use of the DMA engines on the MIC
HPC Advisory Council Lugano Conference, Mar '13
Allows MPI processes to run on MIC
35
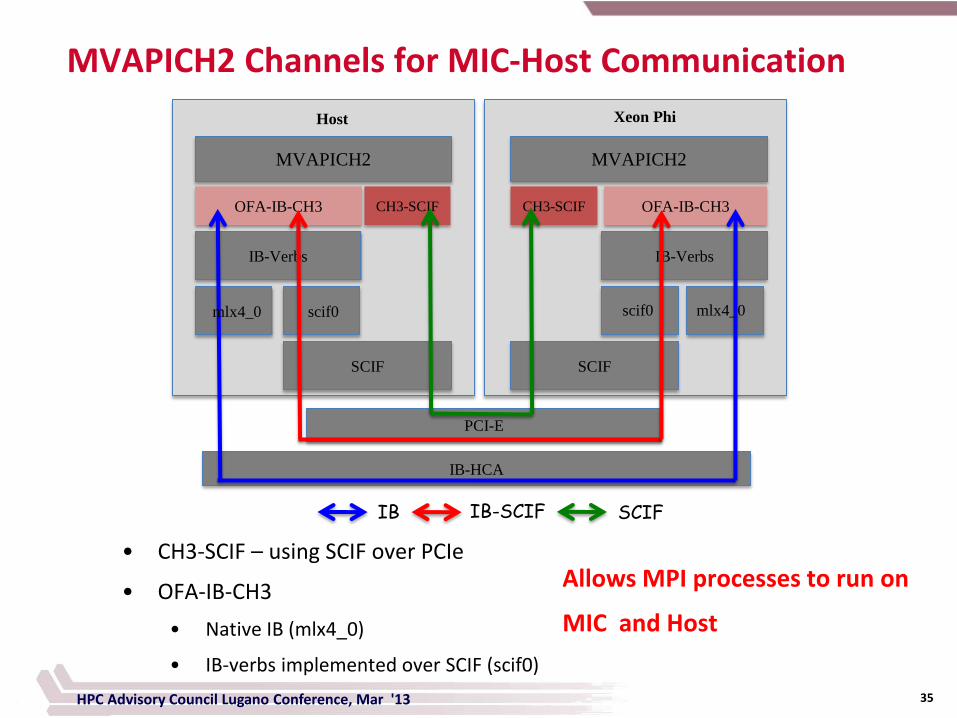
MVAPICH2 Channels for MIC-Host Communication
MVAPICH2
OFA-IB-CH3 CH3-SCIF
SCIF
IB-HCA
IB-Verbs
PCI-E
Xeon Phi
MVAPICH2
Host
OFA-IB-CH3
SCIF
IB-Verbs
CH3-SCIF
mlx4_0 scif0 scif0 mlx4_0
IB IB-SCIF SCIF
• CH3-SCIF – using SCIF over PCIe
• OFA-IB-CH3
• Native IB (mlx4_0)
• IB-verbs implemented over SCIF (scif0)
HPC Advisory Council Lugano Conference, Mar '13
Allows MPI processes to run on
MIC and Host

• Support for Accelerators (GPGPUs)
• Support for Co-Processors (Intel MIC)
– Programming Models for MIC
– MVAPICH2 Design for MPI-Level Communication
– Early Performance Evaluation
• Point-to-point
• Collectives
• Kernels and applications
– Continuing Work
• QoS support for communication and I/O
• Fault-tolerance/resiliency
Challenges being Addressed by MVAPICH2 for Exascale
36 HPC Advisory Council Lugano Conference, Mar '13

37
MVAPICH2-MIC (based on MVAPICH2 1.9a2) Intel Sandy Bridge (E5-2680) node with 16 cores, SE10P (B0-KNC),
MPSS 4346-16 (Gold), Composer_xe_2013.1.117, and IB FDR MT4099 HCA
MVAPICH2-MIC on TACC Stampede: Intra-node MPI Latency
0
1
2
3
4
5
6
7
8
9
10
0 8 32 128 512
Intra-Host
Intra-MIC
Host-MIC
MIC-Host
Small Message Latency
Message Size (Bytes)
Late
ncy
(u
s)
HPC Advisory Council Lugano Conference, Mar '13
0
200
400
600
800
1000
1200
1400
1600
2K 8K 32K 128K 512K 2M
Intra-Host
Intra-MIC
Host-MIC
MIC-Host
Large Message Latency
Message Size (Bytes)
Late
ncy
(u
s)

38
MVAPICH2-MIC on TACC Stampede: Intra-node MPI Bandwidth
0
2000
4000
6000
8000
10000
12000
1 16 256 4K 64K 1M
Intra-Host
Intra-MIC
Host-MIC
MIC-Host
Uni-directional Bandwidth
Message Size (Bytes)
Ban
dw
ith
(M
B/s
)
0
2000
4000
6000
8000
10000
12000
14000
1 16 256 4K 64K 1M
Intra-Host
Intra-MIC
Host-MIC
MIC-Host
Bi-directional Bandwidth
Message Size (Bytes)
Ban
dw
ith
(M
B/s
)
MVAPICH2-MIC (based on MVAPICH2 1.9a2) Intel Sandy Bridge (E5-2680) node with 16 cores, SE10P (B0-KNC),
MPSS 4346-16 (Gold), Composer_xe_2013.1.117, and IB FDR MT4099 HCA HPC Advisory Council Lugano Conference, Mar '13
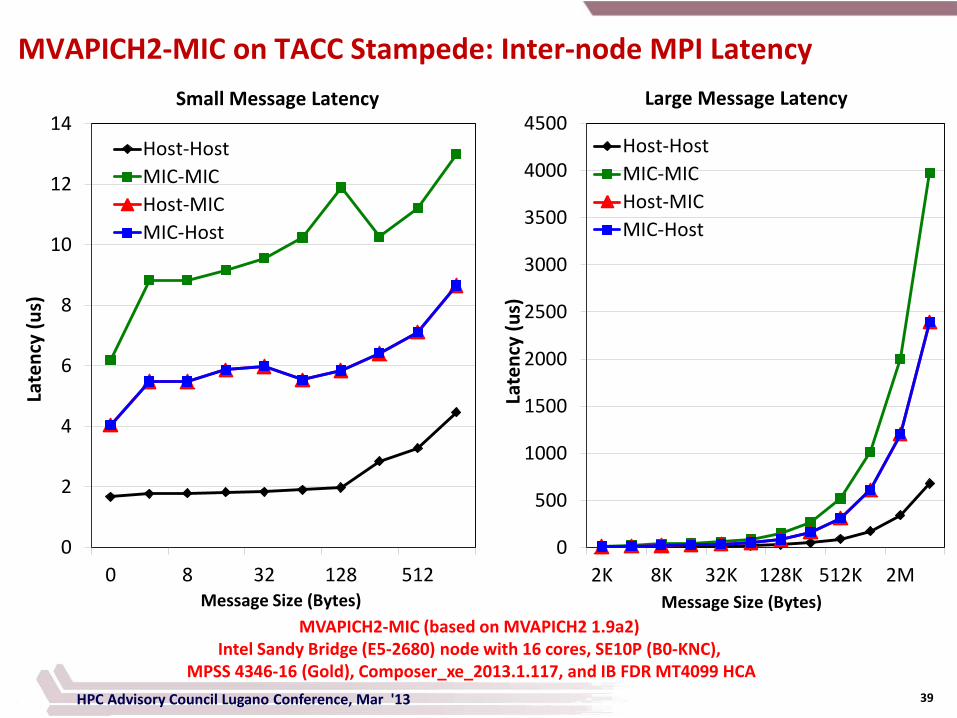
39
MVAPICH2-MIC on TACC Stampede: Inter-node MPI Latency
MVAPICH2-MIC (based on MVAPICH2 1.9a2) Intel Sandy Bridge (E5-2680) node with 16 cores, SE10P (B0-KNC),
MPSS 4346-16 (Gold), Composer_xe_2013.1.117, and IB FDR MT4099 HCA HPC Advisory Council Lugano Conference, Mar '13
0
2
4
6
8
10
12
14
0 8 32 128 512
Host-Host
MIC-MIC
Host-MIC
MIC-Host
Small Message Latency
Message Size (Bytes)
Late
ncy
(u
s)
0
500
1000
1500
2000
2500
3000
3500
4000
4500
2K 8K 32K 128K 512K 2M
Host-Host
MIC-MIC
Host-MIC
MIC-Host
Large Message Latency
Message Size (Bytes)
Late
ncy
(u
s)
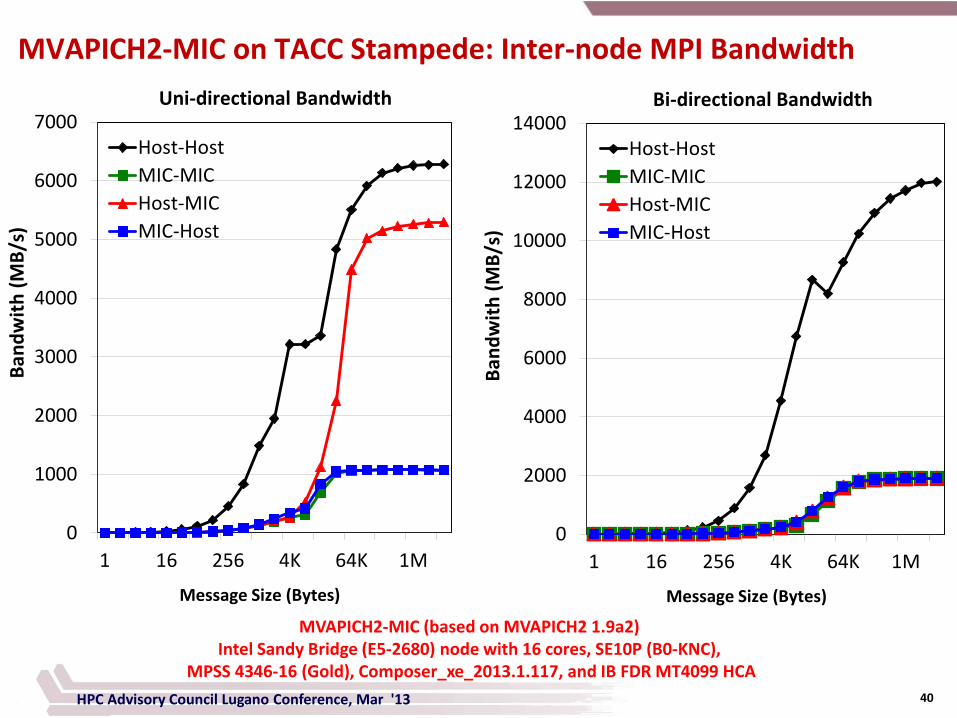
40
MVAPICH2-MIC on TACC Stampede: Inter-node MPI Bandwidth
MVAPICH2-MIC (based on MVAPICH2 1.9a2) Intel Sandy Bridge (E5-2680) node with 16 cores, SE10P (B0-KNC),
MPSS 4346-16 (Gold), Composer_xe_2013.1.117, and IB FDR MT4099 HCA HPC Advisory Council Lugano Conference, Mar '13
0
1000
2000
3000
4000
5000
6000
7000
1 16 256 4K 64K 1M
Host-Host
MIC-MIC
Host-MIC
MIC-Host
Uni-directional Bandwidth
Message Size (Bytes)
Ban
dw
ith
(M
B/s
)
0
2000
4000
6000
8000
10000
12000
14000
1 16 256 4K 64K 1M
Host-Host
MIC-MIC
Host-MIC
MIC-Host
Bi-directional Bandwidth
Message Size (Bytes)
Ban
dw
ith
(M
B/s
)

41
Performance of 16 processes MPI_Allgather operation
0
10
20
30
40
50
60
70
80
90
1001 2 4 8
16
32
64
12
8
25
6
51
2
16H
16M
8H-8M
4H-12M
12H-4M
0
5000
10000
15000
20000
25000
30000
35000
1K
4K
16
K
64
K
25
6K
1M
16H
16M
8H-8M
4H-12M
12H-4M
0
2
4
6
8
10
12
14
1 2 4 8
16
32
64
12
8
25
6
51
2
Normalized to 16H
16H
16M
8H-8M
4H-12M
12H-4M
0
10
20
30
40
50
60
70
1K
2K
4K
8K
16
K
32
K
64
K
12
8K
25
6K
51
2K
1M
Normalized to 16H
16H
16M
8H-8M
4H-12M
12H-4M
HPC Advisory Council Lugano Conference, Mar '13
Performance of heterogeneous mode falls in-between
Message Size (Bytes) Message Size (Bytes)
Message Size (Bytes) Message Size (Bytes)
Late
ncy
(u
s)
No
rmal
ize
d L
ate
ncy
N
orm
aliz
ed
Lat
en
cy
Late
ncy
(u
s)

42
Performance of 16 processes MPI_Bcast operation
0
2
4
6
8
10
12
141 2 4 8
16
32
64
12
8
25
6
51
2
16H
16M
8H-8M
4H-12M
12H-4M
0
1000
2000
3000
4000
5000
6000
7000
8000
1K
2K
4K
8K
16
K
32
K
64
K
12
8K
25
6K
51
2K
1M
16H
16M
8H-8M
4H-12M
12H-4M
0
5
10
15
20
25
30
35
40
1 2 4 8
16
32
64
12
8
25
6
51
2
Normalized to 16H
16H
16M
8H-8M
4H-12M
12H-4M
0
5
10
15
20
25
30
35
40
1K
2K
4K
8K
16
K
32
K
64
K
12
8K
25
6K
51
2K
1M
Normalized to 16H
16H
16M
8H-8M
4H-12M
12H-4M
HPC Advisory Council Lugano Conference, Mar '13
Heterogeneous mode performs worse with increasing number of MIC processes
Broadcast algorithm needs to be re-designed with heterogeneity in mind
Message Size (Bytes) Message Size (Bytes)
Message Size (Bytes) Message Size (Bytes)
No
rmal
ize
d L
ate
ncy
N
orm
aliz
e L
ate
ncy
Late
ncy
(u
s)
Late
ncy
(u
s)

43
P3DFFT Application using 16 MPI processes
0
0.02
0.04
0.06
0.08
0.1
0.12
0.14
0.16
0.18
128x128x128
Execution time
16H
16M
8H-8M
4H-12M
12H-4M0123456789
101112131415
128x28x128
Normalized execution time to 16H
16H
16M
8H-8M
4H-12M
12H-4M
0
0.2
0.4
0.6
0.8
1
1.2
1.4
256x256x256
Execution time
16H
16M
8H-8M
4H-12M
12H-4M
0123456789
1011
256x256x256
Normalized execution time to 16H
16H
16M
8H-8M
4H-12M
12H-4M
HPC Advisory Council Lugano Conference, Mar '13 Heterogeneous mode performs worse
Size = Size =
Size = Size =
No
rmal
ize
Tim
e
No
rmal
ize
Tim
e
Tim
e (
s)
Tim
e (
s)
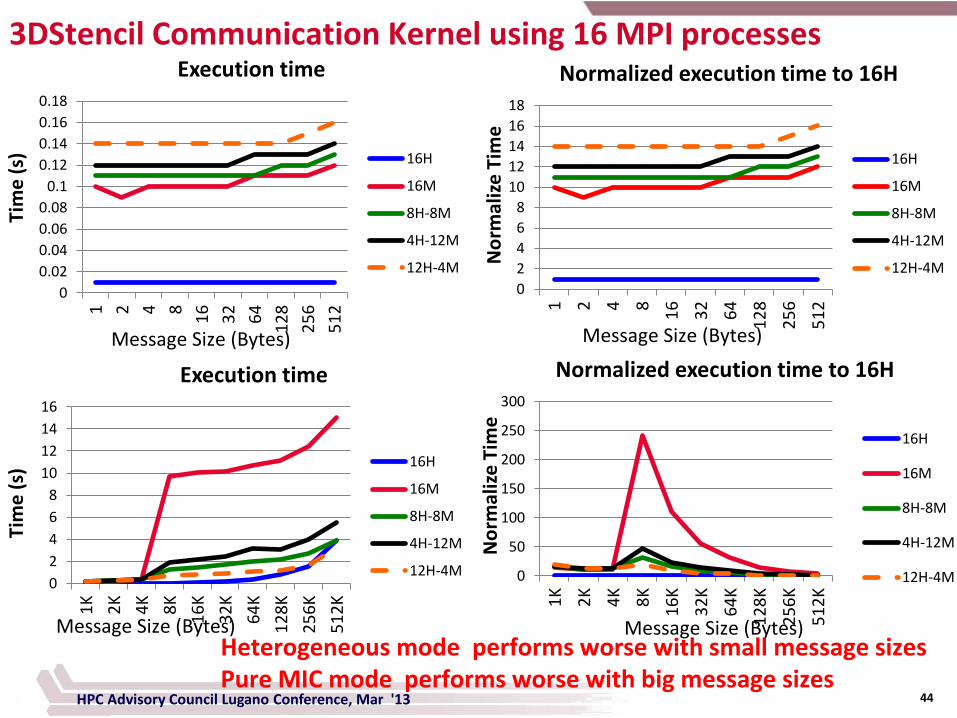
44
3DStencil Communication Kernel using 16 MPI processes
0
0.02
0.04
0.06
0.08
0.1
0.12
0.14
0.16
0.181 2 4 8
16
32
64
12
8
25
6
51
2
Execution time
16H
16M
8H-8M
4H-12M
12H-4M
0
2
4
6
8
10
12
14
16
1K
2K
4K
8K
16
K
32
K
64
K
12
8K
25
6K
51
2K
Execution time
16H
16M
8H-8M
4H-12M
12H-4M
0
2
4
6
8
10
12
14
16
18
1 2 4 8
16
32
64
12
8
25
6
51
2
Normalized execution time to 16H
16H
16M
8H-8M
4H-12M
12H-4M
0
50
100
150
200
250
300
1K
2K
4K
8K
16
K
32
K
64
K
12
8K
25
6K
51
2K
Normalized execution time to 16H
16H
16M
8H-8M
4H-12M
12H-4M
HPC Advisory Council Lugano Conference, Mar '13
Message Size (Bytes) Message Size (Bytes)
Message Size (Bytes) Message Size (Bytes) Heterogeneous mode performs worse with small message sizes Pure MIC mode performs worse with big message sizes
No
rmal
ize
Tim
e
No
rmal
ize
Tim
e
Tim
e (
s)
Tim
e (
s)
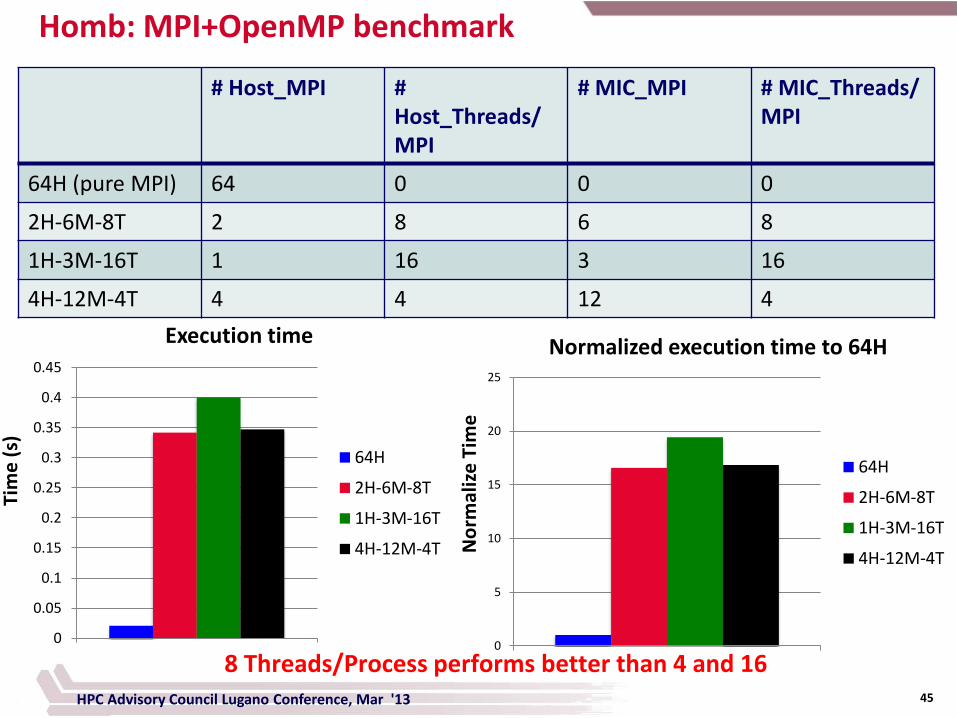
45
Homb: MPI+OpenMP benchmark
# Host_MPI # Host_Threads/ MPI
# MIC_MPI # MIC_Threads/ MPI
64H (pure MPI) 64 0 0 0
2H-6M-8T 2 8 6 8
1H-3M-16T 1 16 3 16
4H-12M-4T 4 4 12 4
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
Execution time
64H
2H-6M-8T
1H-3M-16T
4H-12M-4T
0
5
10
15
20
25
Normalized execution time to 64H
64H
2H-6M-8T
1H-3M-16T
4H-12M-4T
HPC Advisory Council Lugano Conference, Mar '13
8 Threads/Process performs better than 4 and 16
No
rmal
ize
Tim
e
Tim
e (
s)

• Support for Accelerators (GPGPUs)
• Support for Co-Processors (Intel MIC)
– Programming Models for MIC
– MVAPICH2 Design for MPI-Level Communication
– Early Performance Evaluation
• Point-to-point
• Collectives
• Kernels and applications
– Continuing Work
• QoS support for communication and I/O
• Fault-tolerance/resiliency
Challenges being Addressed by MVAPICH2 for Exascale
46 HPC Advisory Council Lugano Conference, Mar '13

47
Performance with Current State-of-the-art Approaches
MIC-to-Remote (Host/MIC) : Intra-IOH
Remote (Host/MIC)-to-MIC : Intra-IOH
MIC-to-Remote (Host/MIC) : Inter-IOH
Remote (Host/MIC)-to-MIC : Inter-IOH
370 MB/s
962.86 MB/s
5280 MB/s
1079 MB/s
HPC Advisory Council Lugano Conference, Mar '13
• Performance of IB reads from MIC is limited
• Communication Performance MIC-to-Remote
(Host/MIC) is limited

48
Performance with a Newer Approach (Proxy-based Design)
6977 MB/s
Host-to-Remote Host 6296 MB/s MIC-to-Host/Host-to-MIC
HPC Advisory Council Lugano Conference, Mar '13
• Proxy process on the hosts to rely the
communications
• MIC-to-Remote (Host/MIC) communications pass
through the proxies

• Support for Accelerators (GPGPUs)
• Support for Co-Processors (Intel MIC)
• QoS support for communication and I/O
• Fault-tolerance/resiliency
Challenges being Addressed by MVAPICH2 for Exascale
49 HPC Advisory Council Lugano Conference, Mar '13

• IB is capable of providing network
level differentiated service – QoS
• Uses Service Levels (SL) and
Virtual Lanes (VL) to classify traffic
0
1000
2000
3000
4000
1K 2K 4K 8K 16K 32K 64K
Po
int-
to-P
oin
t
Ban
dw
idth
(M
Bp
s)
Message Size (Bytes)
1-VL
8-VLs
13% Performance improvement over One VL case
50 HPC Advisory Council Lugano Conference, Mar '13
QoS in IB: MPI Performance with Multiple VLs & Inter-Job QoS
0
50
100
150
200
250
300
350
1K 2K 4K 8K 16K
Allt
oal
l La
ten
cy (
us)
Message Size (Bytes)
Inter-Job QoS
2 Alltoalls (No QoS)
2 Alltoalls (QoS)
1 Alltoall
0
0.2
0.4
0.6
0.8
1
Total Time Time in Alltoall
No
rmal
ize
d T
ime
for
CP
MD
Ap
plic
atio
n
1 VL 8 VLs
• Performance improvement over One VL case
• Alltoall – 20 %
• Application – 11%
• 12% performance improvement with Inter-Job QoS H. Subramoni, P. Lai, S. Sur and D. K. Panda, Improving Application Performance and Predictability using Multiple Virtual Lanes in Modern
Multi-Core InfiniBand Clusters , Int’l Conference on Parallel Processing (ICPP '10), Sept. 2010.

HPC Advisory Council Lugano Conference, Mar '13 51
Minimizing Network Contention w/ QoS-Aware Data-Staging
R. Rajachandrasekar, J. Jaswani, H. Subramoni and D. K. Panda, Minimizing Network Contention in InfiniBand Clusters
with a QoS-Aware Data-Staging Framework, IEEE Cluster, Sept. 2012
• Asynchronous I/O introduces contention for network-resources • How should data be orchestrated in a data-staging architecture to eliminate such contention? • Can the QoS capabilities provided by cutting-edge interconnect technologies be leveraged by parallel filesystems to minimize network contention?
• Reduces runtime overhead from 17.9% to 8% and from 32.8% to 9.31%, in case of AWP and NAS-CG applications respectively
MPI Message Latency
MPI Message Bandwidth
8%17.9%
0.9
0.95
1
1.05
1.1
1.15
1.2
default with I/O noise
I/O noise isolated
Anelastic Wave Propagation(64 MPI processes)
Normalized Runtime
32.8% 9.31%
0.9
1
1.1
1.2
1.3
1.4
default with I/O noise
I/O noise isolated
NAS Parallel BenchmarkConjugate Gradient Class D
(64 MPI processes)
Normalized Runtime

• Support for Accelerators (GPGPUs)
• Support for Co-Processors (Intel MIC)
• QoS support for communication and I/O
• Fault-tolerance/resiliency
Challenges being Addressed by MVAPICH2 for Exascale
52 HPC Advisory Council Lugano Conference, Mar '13

• Component failures are common in large-scale clusters
• Imposes need on reliability and fault tolerance
• Multiple challenges:
– Checkpoint-Restart vs. Process Migration
– Low-Overhead Failure Prediction with IPMI
– Benefits of SCR Support
HPC Advisory Council Lugano Conference, Mar '13 53
Fault Tolerance/Resiliency

HPC Advisory Council Lugano Conference, Mar '13 54
Checkpoint-Restart vs. Process Migration
X. Ouyang, R. Rajachandrasekar, X. Besseron, D. K. Panda, High Performance Pipelined Process Migration with RDMA,
CCGrid 2011
X. Ouyang, S. Marcarelli, R. Rajachandrasekar and D. K. Panda, RDMA-Based Job Migration Framework for MPI over
InfiniBand, Cluster 2010
10.7X
2.3X
4.3X
1
Time to migrate 8 MPI processes
• Job-wide Checkpoint/Restart is not scalable • Job-pause and Process Migration framework can deliver pro-active fault-tolerance • Also allows for cluster-wide load-balancing by means of job compaction • MVAPICH2 has support for both
0
5000
10000
15000
20000
25000
30000
Migrationw/o RDMA
CR (ext3) CR (PVFS)
Exe
cu
tio
n T
ime
(se
co
nd
s)
Job Stall
Checkpoint (Migration)
Resume
Restart
2.03x
4.49x
LU Class C Benchmark (64 Processes)
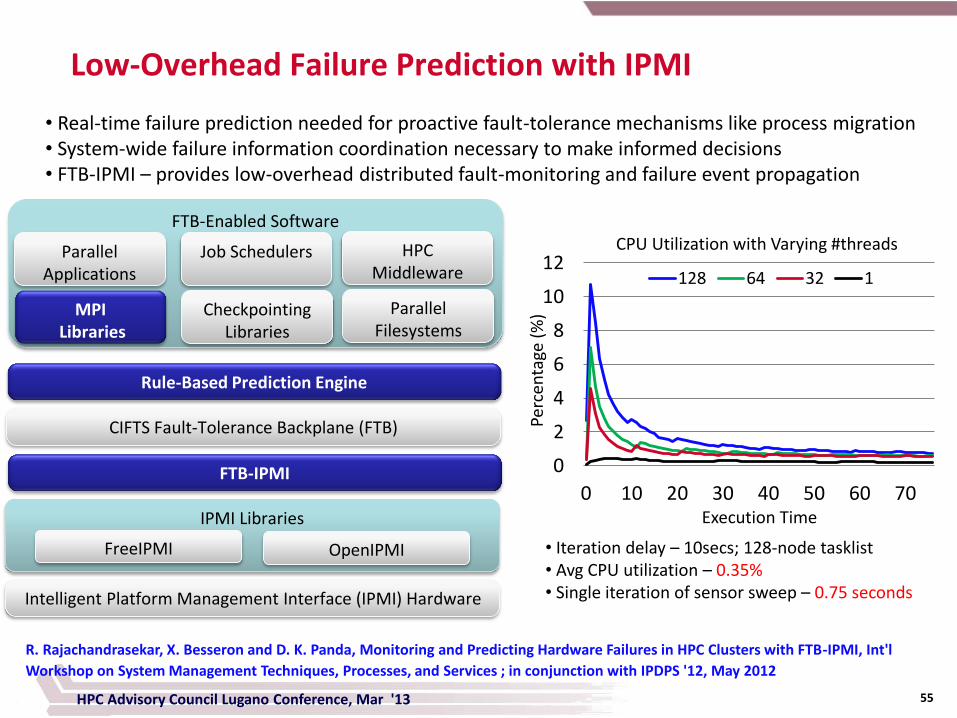
HPC Advisory Council Lugano Conference, Mar '13 55
Low-Overhead Failure Prediction with IPMI
Intelligent Platform Management Interface (IPMI) Hardware
IPMI Libraries
FreeIPMI OpenIPMI
FTB-IPMI
CIFTS Fault-Tolerance Backplane (FTB)
Rule-Based Prediction Engine
FTB-Enabled Software
Parallel Applications
Job Schedulers HPC Middleware
MPI Libraries
Checkpointing Libraries
Parallel Filesystems
• Real-time failure prediction needed for proactive fault-tolerance mechanisms like process migration • System-wide failure information coordination necessary to make informed decisions • FTB-IPMI – provides low-overhead distributed fault-monitoring and failure event propagation
• Iteration delay – 10secs; 128-node tasklist • Avg CPU utilization – 0.35% • Single iteration of sensor sweep – 0.75 seconds
R. Rajachandrasekar, X. Besseron and D. K. Panda, Monitoring and Predicting Hardware Failures in HPC Clusters with FTB-IPMI, Int'l
Workshop on System Management Techniques, Processes, and Services ; in conjunction with IPDPS '12, May 2012
0
2
4
6
8
10
12
0 10 20 30 40 50 60 70
Perc
enta
ge (
%)
Execution Time
CPU Utilization with Varying #threads
128 64 32 1
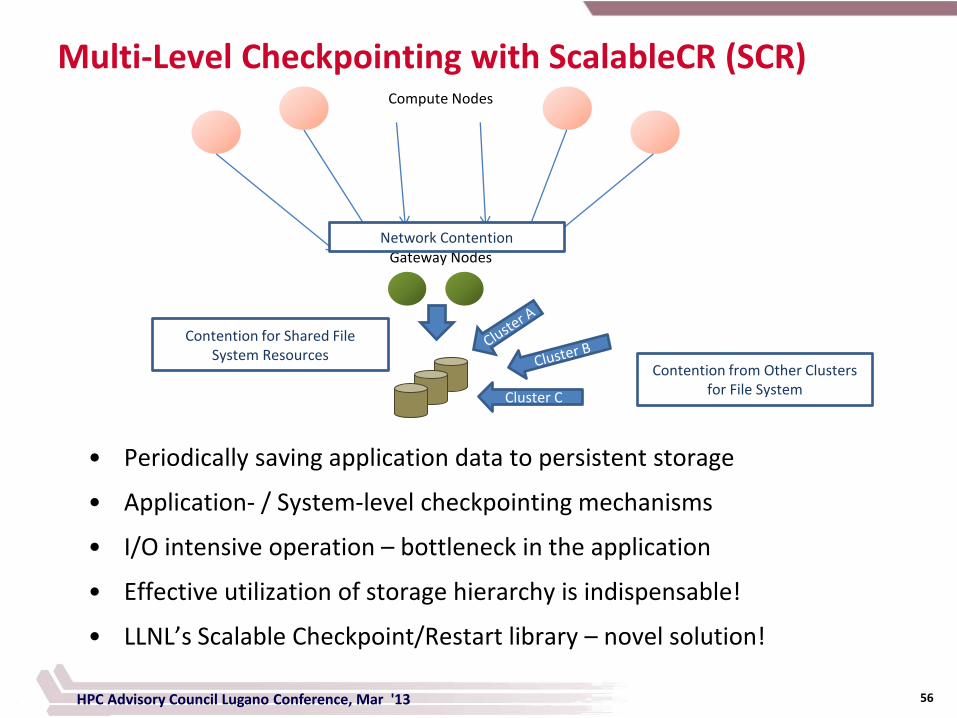
Multi-Level Checkpointing with ScalableCR (SCR)
56 HPC Advisory Council Lugano Conference, Mar '13
Cluster C
Gateway Nodes
Compute Nodes
Network Contention
Contention for Shared File System Resources
Contention from Other Clusters for File System
• Periodically saving application data to persistent storage
• Application- / System-level checkpointing mechanisms
• I/O intensive operation – bottleneck in the application
• Effective utilization of storage hierarchy is indispensable!
• LLNL’s Scalable Checkpoint/Restart library – novel solution!

Multi-Level Checkpointing with ScalableCR (SCR)
57 HPC Advisory Council Lugano Conference, Mar '13
Local: Store checkpoint data on node’s local storage, e.g. local disk, ramdisk
Partner: Write to local storage and on a partner node
XOR: Write file to local storage and small sets of nodes collectively compute and store parity redundancy data (RAID-5)
Stable Storage: Write to parallel file system
Ch
eckp
oin
t C
ost
an
d R
esili
ency
Low
High
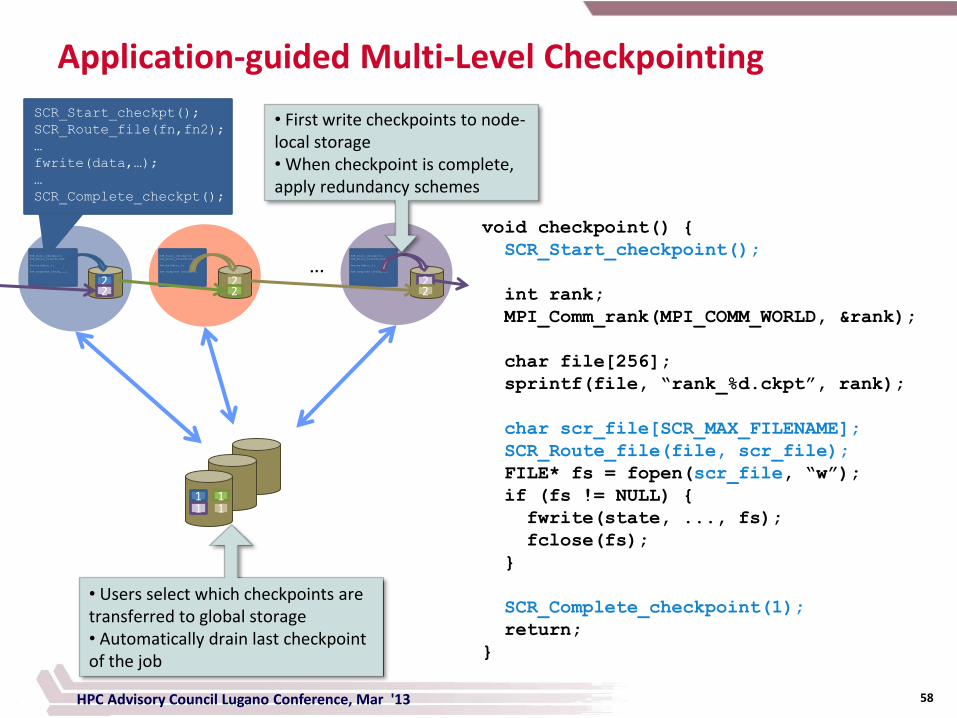
Application-guided Multi-Level Checkpointing
58 HPC Advisory Council Lugano Conference, Mar '13
void checkpoint() {
SCR_Start_checkpoint();
int rank;
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
char file[256];
sprintf(file, “rank_%d.ckpt”, rank);
char scr_file[SCR_MAX_FILENAME];
SCR_Route_file(file, scr_file);
FILE* fs = fopen(scr_file, “w”);
if (fs != NULL) {
fwrite(state, ..., fs);
fclose(fs);
}
SCR_Complete_checkpoint(1);
return;
}
…
SCR_Start_checkpt();
SCR_Route_file(fn,fn2);
…
fwrite(data,…);
…
SCR_Complete_checkpt();
SCR_Start_checkpt();
SCR_Route_file(fn,fn2);
…
fwrite(data,…);
…
SCR_Complete_checkpt();
2
SCR_Start_checkpt();
SCR_Route_file(fn,fn2);
…
fwrite(data,…);
…
SCR_Complete_checkpt();
2
SCR_Start_checkpt();
SCR_Route_file(fn,fn2);
…
fwrite(data,…);
…
SCR_Complete_checkpt();
2 2 2 2
1 1
1 1
• First write checkpoints to node-local storage • When checkpoint is complete, apply redundancy schemes
• Users select which checkpoints are transferred to global storage • Automatically drain last checkpoint of the job
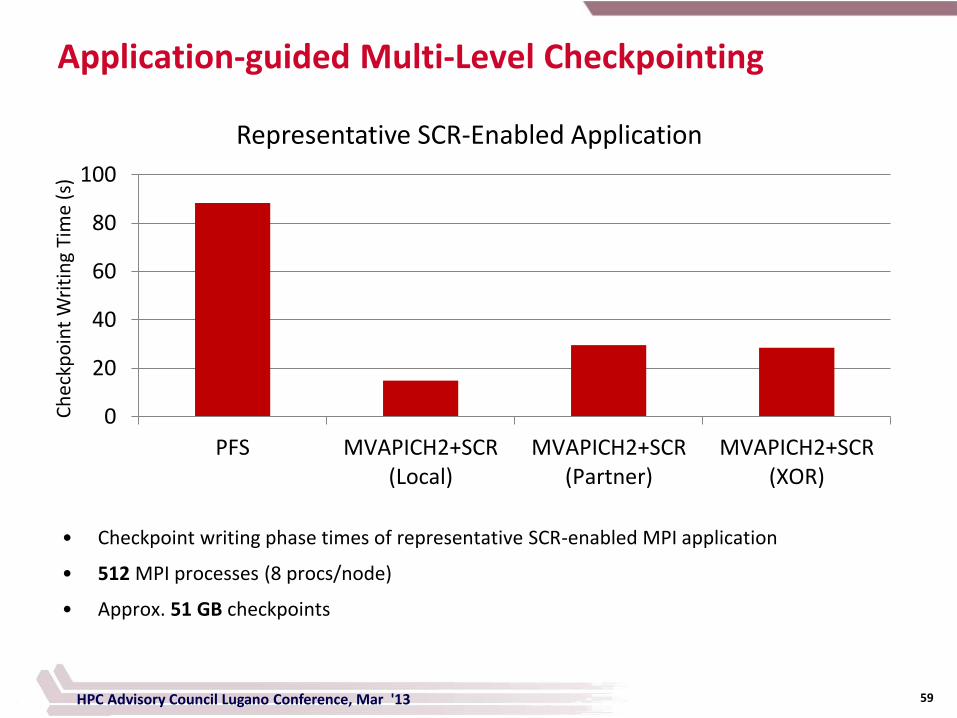
Application-guided Multi-Level Checkpointing
59 HPC Advisory Council Lugano Conference, Mar '13
0
20
40
60
80
100
PFS MVAPICH2+SCR(Local)
MVAPICH2+SCR(Partner)
MVAPICH2+SCR(XOR)
Ch
eckp
oin
t W
riti
ng
Tim
e (s
)
Representative SCR-Enabled Application
• Checkpoint writing phase times of representative SCR-enabled MPI application
• 512 MPI processes (8 procs/node)
• Approx. 51 GB checkpoints
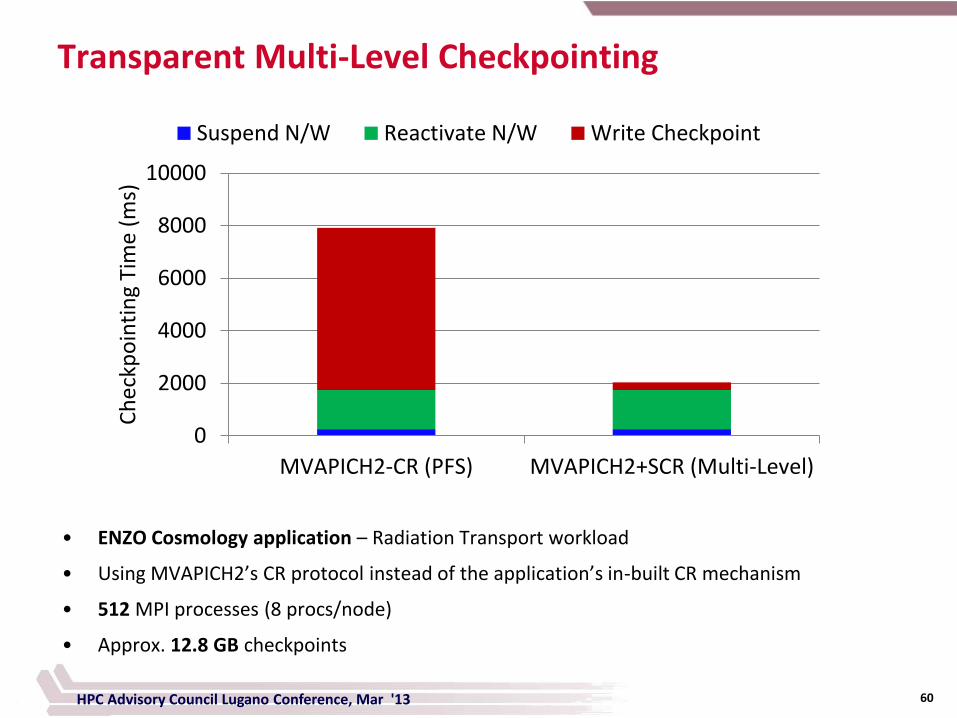
Transparent Multi-Level Checkpointing
60 HPC Advisory Council Lugano Conference, Mar '13
0
2000
4000
6000
8000
10000
MVAPICH2-CR (PFS) MVAPICH2+SCR (Multi-Level)
Ch
eckp
oin
tin
g Ti
me
(ms)
Suspend N/W Reactivate N/W Write Checkpoint
• ENZO Cosmology application – Radiation Transport workload
• Using MVAPICH2’s CR protocol instead of the application’s in-built CR mechanism
• 512 MPI processes (8 procs/node)
• Approx. 12.8 GB checkpoints

• Performance and Memory scalability toward 500K-1M cores – Dynamically Connected Transport (DCT) service with Connect-IB
• Hybrid programming (MPI + OpenSHMEM, MPI + UPC, MPI + CAF …) • Enhanced Optimization for GPU Support and Accelerators
– Extending the GPGPU support (GPU-Direct RDMA)
– Enhanced Support for Intel MIC (Symmetric Processing)
• Taking advantage of Collective Offload framework – Including support for non-blocking collectives (MPI 3.0)
• RMA support (as in MPI 3.0)
• Extended topology-aware collectives
• Power-aware collectives
• Support for MPI Tools Interface (as in MPI 3.0)
• Efficient Checkpoint-Restart and migration support with SCR
MVAPICH2 – Plans for Exascale
61 HPC Advisory Council Lugano Conference, Mar '13

• InfiniBand with RDMA feature is gaining momentum in HPC and
with best performance and greater usage
• As the HPC community moves to Exascale, new solutions are
needed for designing and implementing programming models
• Demonstrated how such solutions can be designed with
MVAPICH2 and MVAPICH2-X and their performance benefits
• Such designs will allow application scientists and engineers to
take advantage of upcoming exascale systems
62
Concluding Remarks
HPC Advisory Council Lugano Conference, Mar '13

HPC Advisory Council Lugano Conference, Mar '13
Funding Acknowledgments
Funding Support by
Equipment Support by
63
HPC Advisory Council Lugano Conference, Mar '13
Personnel Acknowledgments
Current Students
– N. Islam (Ph.D.)
– J. Jose (Ph.D.)
– K. Kandalla (Ph.D.)
– M. Li (Ph.D.)
– M. Luo (Ph.D.)
– S. Potluri (Ph.D.)
– R. Rajachandrasekhar (Ph.D.)
– M. Rahman (Ph.D.)
– H. Subramoni (Ph.D.)
– A. Venkatesh (Ph.D.)
Past Students
– P. Balaji (Ph.D.)
– D. Buntinas (Ph.D.)
– S. Bhagvat (M.S.)
– L. Chai (Ph.D.)
– B. Chandrasekharan (M.S.)
– N. Dandapanthula (M.S.)
– V. Dhanraj (M.S.)
– T. Gangadharappa (M.S.)
– K. Gopalakrishnan (M.S.)
– W. Huang (Ph.D.)
– W. Jiang (M.S.)
– S. Kini (M.S.)
– M. Koop (Ph.D.)
– R. Kumar (M.S.)
– S. Krishnamoorthy (M.S.)
– P. Lai (M.S.)
– J. Liu (Ph.D.)
– A. Mamidala (Ph.D.)
– G. Marsh (M.S.)
– V. Meshram (M.S.)
– S. Naravula (Ph.D.)
– R. Noronha (Ph.D.)
– X. Ouyang (Ph.D.)
– S. Pai (M.S.)
– G. Santhanaraman (Ph.D.)
– A. Singh (Ph.D.)
– J. Sridhar (M.S.)
– S. Sur (Ph.D.)
– K. Vaidyanathan (Ph.D.)
– A. Vishnu (Ph.D.)
– J. Wu (Ph.D.)
– W. Yu (Ph.D.)
64
Past Research Scientist – S. Sur
Current Post-Docs
– K. Hamidouche
– X. Lu
Current Programmers
– M. Arnold
– D. Bureddy
– J. Perkins
Past Post-Docs – X. Besseron
– H.-W. Jin
– E. Mancini
– S. Marcarelli
– J. Vienne
– H. Wang

HPC Advisory Council Lugano Conference, Mar '13
Web Pointers
http://www.cse.ohio-state.edu/~panda
http://nowlab.cse.ohio-state.edu
MVAPICH Web Page
http://mvapich.cse.ohio-state.edu
65


















