Soc architecture and design
24
wl 2015 10.1 SOC architecture and design • system-on-chip (SOC) – processors: become components in a system • SOC covers many topics – processor: pipelined, superscalar, VLIW, array, vector – storage: cache, embedded and external memory – interconnect: buses, network-on-chip – impact: time, area, power, reliability, configurability – customisability: specialized processors, reconfiguration – productivity/tools: model, explore, re-use, synthesise, verify – examples: crypto, graphics, media, network, comm, security – future: autonomous SOC, self-optimising/verifying design • our focus – overview, processor, memory
-
Upload
satya-harish -
Category
Devices & Hardware
-
view
355 -
download
0
Transcript of Soc architecture and design

wl 2015 10.1
SOC architecture and design
• system-on-chip (SOC) – processors: become components in a system
• SOC covers many topics – processor: pipelined, superscalar, VLIW, array, vector
– storage: cache, embedded and external memory
– interconnect: buses, network-on-chip
– impact: time, area, power, reliability, configurability
– customisability: specialized processors, reconfiguration
– productivity/tools: model, explore, re-use, synthesise, verify
– examples: crypto, graphics, media, network, comm, security
– future: autonomous SOC, self-optimising/verifying design
• our focus – overview, processor, memory

wl 2015 10.2
iPhone SOC
1 GHz ARM Cortex A8
I/O
I/O
I/O
Processor
Memory Source: UC Berkeley
wl 2015 10.3
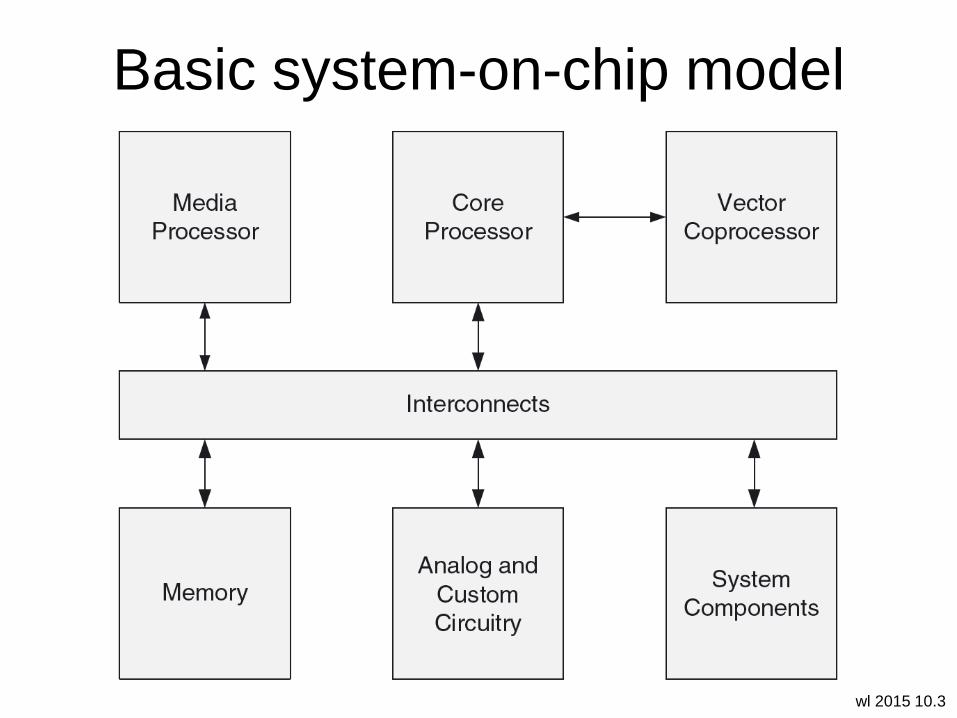
Basic system-on-chip model
wl 2015 10.4
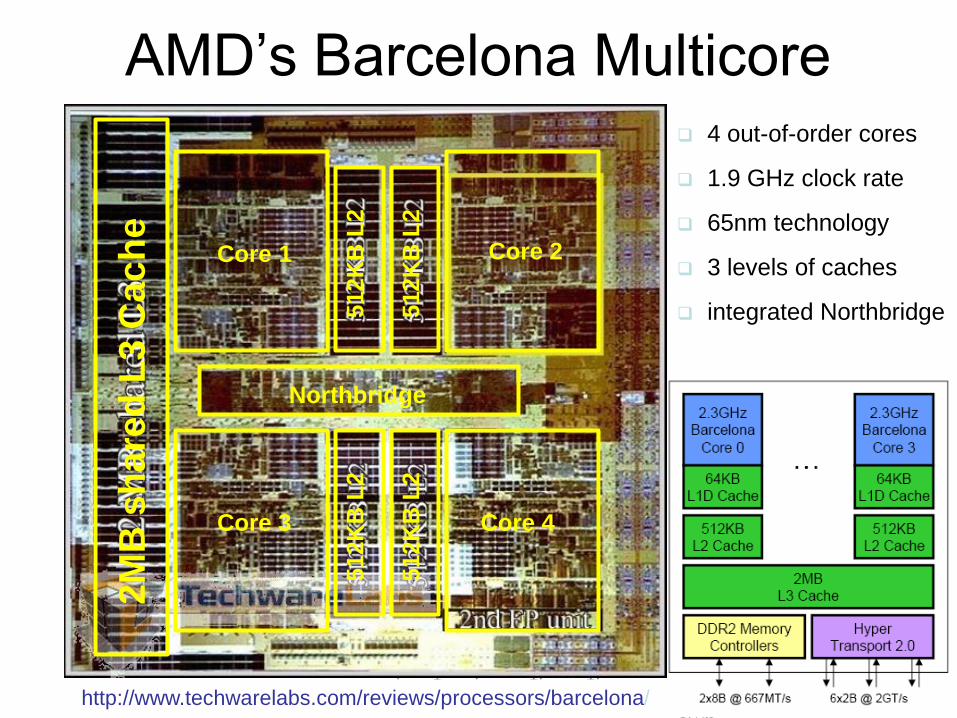
AMD’s Barcelona Multicore
Processor
Core 1 Core 2
Core 3 Core 4
Northbridge
512K
B L
2
512K
B L
2
512K
B L
2
512K
B L
2
2M
B s
hare
d L
3 C
ac
he
4 out-of-order cores
1.9 GHz clock rate
65nm technology
3 levels of caches
integrated Northbridge
http://www.techwarelabs.com/reviews/processors/barcelona/

wl 2015 10.5
SOC vs processors on chip
• with lots of transistors, designs move in 2 ways:
– complete system on a chip
– multi-core processors with lots of cache
System on chip Processors on chip
processor multiple, simple,
heterogeneous
few, complex,
homogeneous
cache one level, small 2-3 levels, extensive
memory embedded, on chip very large, off chip
functionality special purpose general purpose
interconnect wide, high bandwidth often through cache
power, cost both low both high
operation largely stand-alone need other chips

wl 2015 10.6
Processor types: overview
Processor type Architecture / Implementation approach
SIMD Single instruction applied to multiple
functional units
Vector Single instruction applied to multiple
pipelined registers
VLIW Multiple instructions issued each cycle
under compiler control
Superscalar Multiple instructions issued each cycle
under hardware control

wl 2015 10.7
Processors for SOCs
SOC Basic ISA Processor description
Freescale c600:
signal processing
PowerPC Superscalar with vector
extension
ClearSpeed
CSX600: general
Proprietary Array processor with 96
processing elements
PlayStation 2:
gaming
MIPS Pipelined with 2 vector
coprocessors
ARM VFP11:
general
ARM Configurable vector
coprocessor

wl 2015 10.8
Sequential and parallel machines
• basic single stream processors
– pipelined: overlap operations in basic sequential
– superscalar: transparent concurrency
– VLIW: compiler-generated concurrency
• multiple streams, multiple functional units
– array processors
– vector processors
• multiprocessors
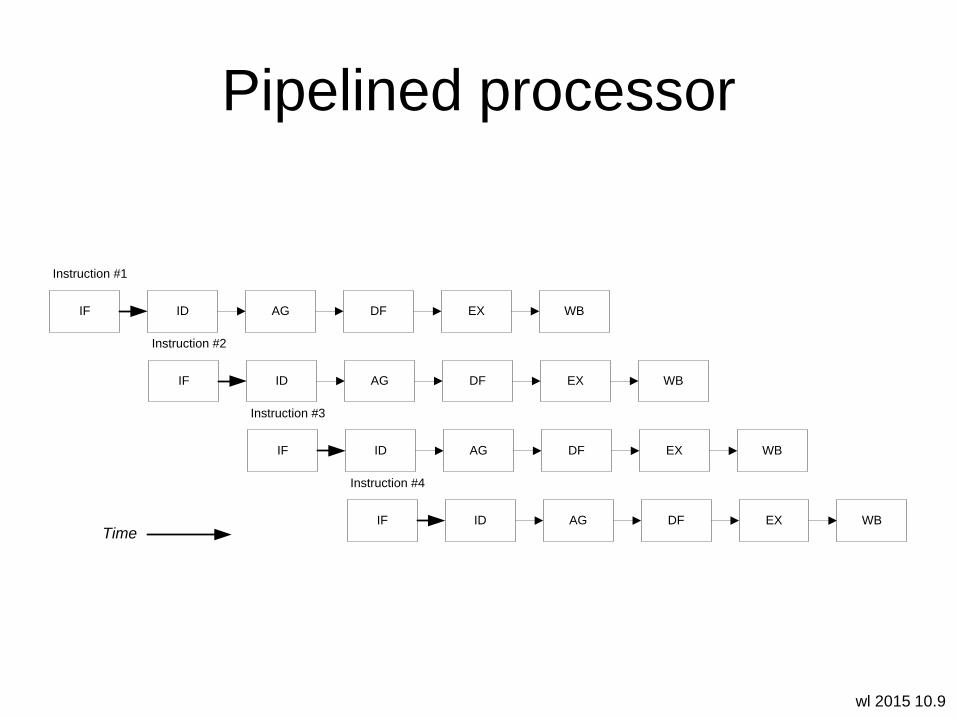
wl 2015 10.9
Pipelined processor
IF DFAGID WBEX
Instruction #1
IF DFAGID WBEX
Instruction #2
IF DFAGID WBEX
Instruction #3
IF DFAGID WBEX
Instruction #4
Time

wl 2015 10.10
Superscalar and VLIW processors
IF DFAGID WBEX
Instruction #2
IF DFAGID WBEX
Instruction #3
IF DFAGID WBEX
Instruction #5
IF DFAGID WBEX
Instruction #6
Time
IF DFAGID WBEX
IF DFAGID WBEX
Instruction #4
Instruction #1

wl 2015 10.11
Superscalar
VLIW
hardware for parallelism control
wl 2015 10.12
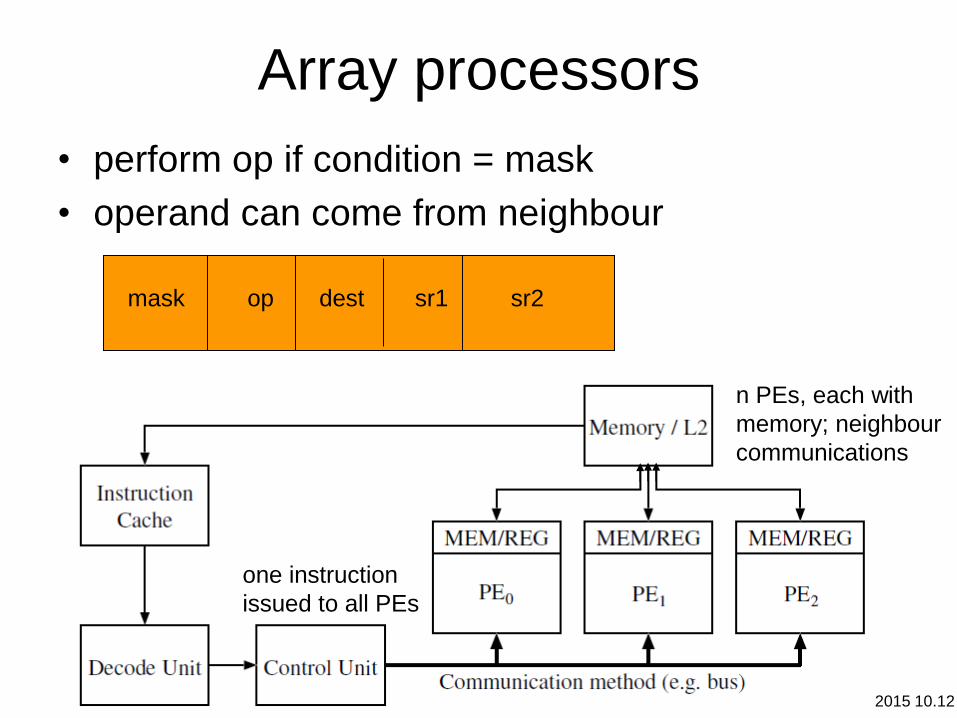
Array processors
• perform op if condition = mask
• operand can come from neighbour
mask op dest sr1 sr2
one instruction
issued to all PEs
n PEs, each with
memory; neighbour
communications

wl 2015 10.13
Vector processors
• vector registers, eg 8 sets x 64 elements x 64 bits
• vector instructions: VR3 = VR2 VOP VR1
wl 2015 10.14
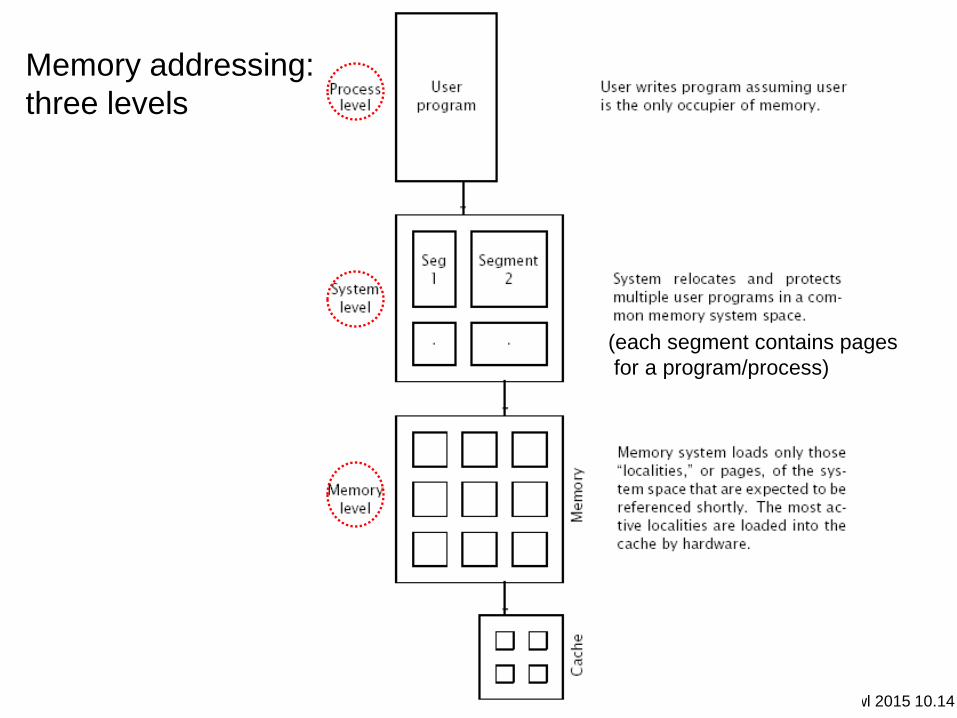
Memory addressing:
three levels
(each segment contains pages
for a program/process)

wl 2015 10.15
User view of memory: addressing
• a program: process address (offset + base + index)
– virtual address: from page address and process/user id
• segment table: process base and bound (for each process)
– system address: process base + page address
• pages: active localities in main/real memory
– virtual address: page table lookup to physical address
– page miss: virtual pages not in page table
• TLB (translation look-aside buffer): recent translations
– TLB entry: corresponding real and (virtual, id) address
• a few hashed virtual address bits address TLB entries
– if virtual, id = TLB (virtual, id) then use translation
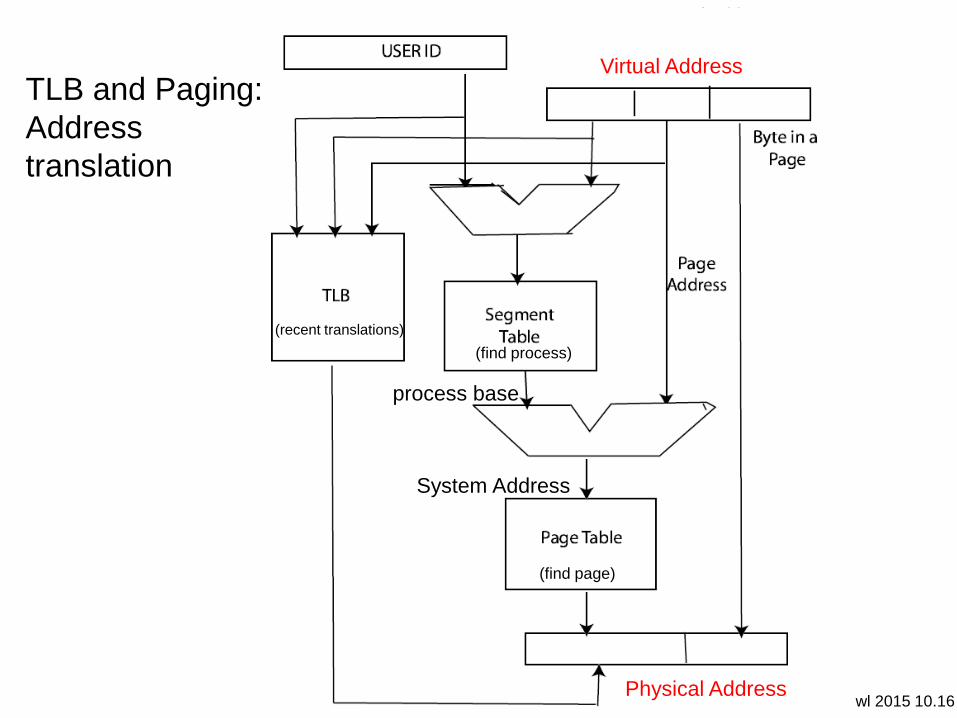
wl 2015 10.16
TLB and Paging:
Address
translation
process base
(find process)
(find page)
System Address
Physical Address
Virtual Address
(recent translations)

wl 2015 10.17
SOC interconnect
• interconnecting multiple active agents requires
– bandwidth: capacity to transmit information (bps)
– protocol: logic for non-interfering message transmission
• bus
– AMBA (Adv. Microcontroller Bus Architecture) from ARM,
widely used for SOC
– bus performance: can determine system performance
• network on chip
– array of switches
– statically switched: eg mesh
– dynamically switched: eg crossbar

wl 2015 10.18
Design cost: product economics
• increasingly product cost determined by
– design costs, including verification
– not marginal cost to produce
• manage complexity in die technology by
– engineering effort
– engineering cleverness
• design effort
– often dictated by
product volume
Basic
physical
tradeoffs
Design time
and effort
Balance point depends on
n, number of units
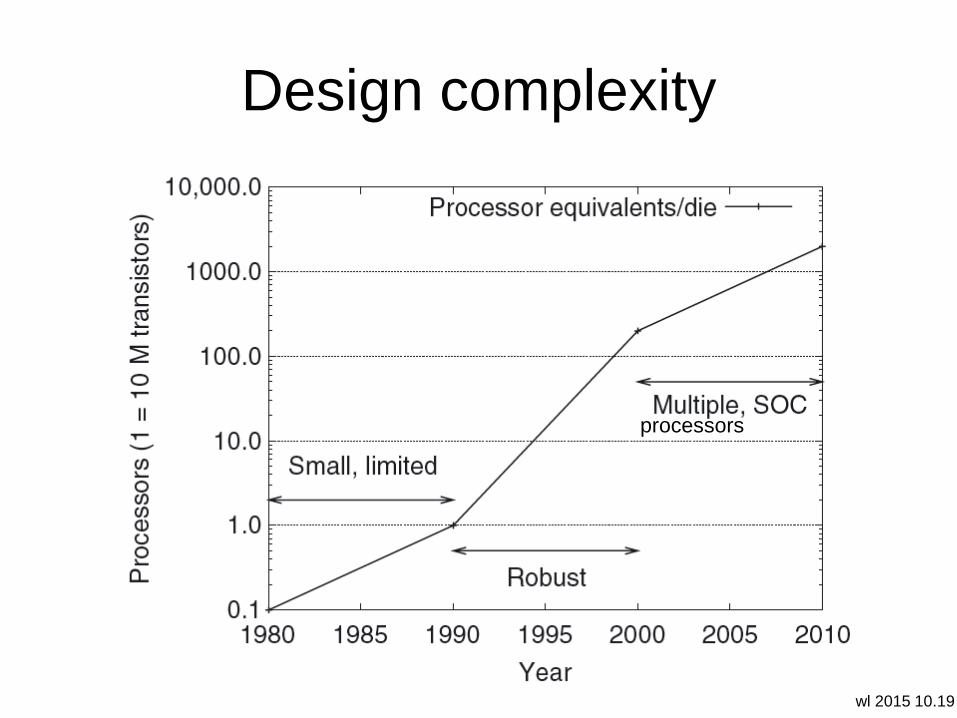
wl 2015 10.19
Design complexity
processors
wl 2015 10.20
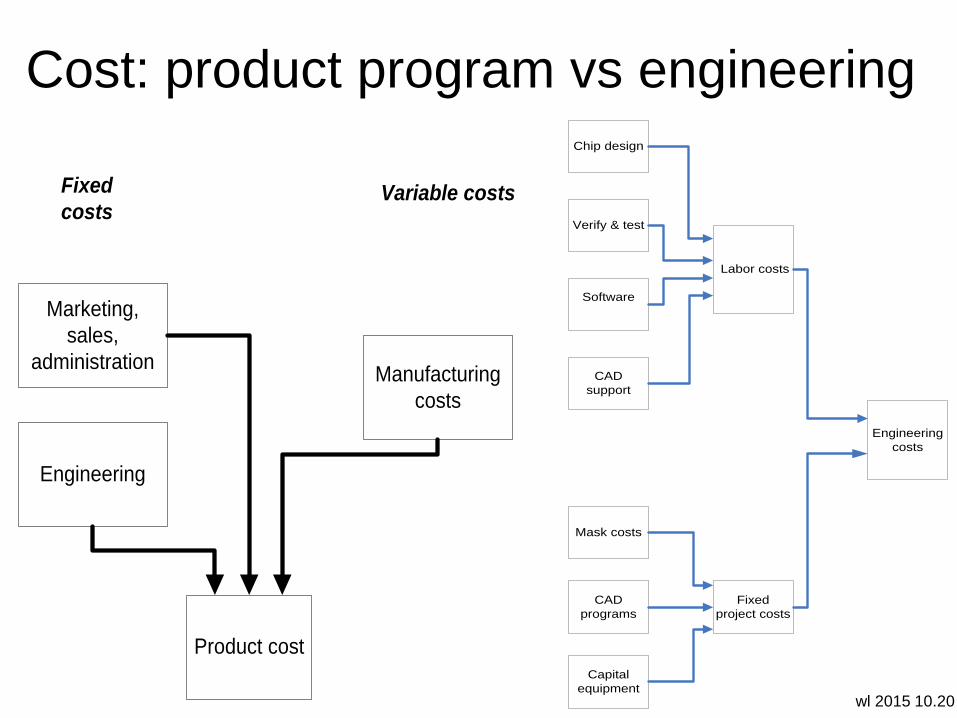
Cost: product program vs engineering
Product cost
Manufacturing
costs
Engineering
Marketing,
sales,
administration
Fixed
costsVariable costs
Chip design
CAD
support
Software
Verify & test
Mask costs
Capital
equipment
CAD
programs
Labor costs
Fixed
project costs
Engineering
costs

wl 2015 10.21
Example: two scenarios
• fixed costs Kf, support costs 0.1 x function(n), and variable costs Kv x n, so
• design gets more complex, while production costs decrease – Kf increases while Kv decreases
– if same price, requires higher volumes to break even
• when compared with 1995, in 2015 – Kf increased by 10 times
– Kv decreased by the same amount

wl 2015 10.22
More recent: higher NRE
2015
1995

wl 2015 10.23
IP: Intellectual Property

wl 2015 10.24
Answers to Unassessed Coursework 5
1. rdl1 R = snd [-]-1 ; R
rdln+1 R = snd aprn-1 ; rsh ; fst (rdln R) ; R
2. P0 = rdln Pcell; 1
<<s,x>, a> Pcell <sx+a, x>
3. rdln R = rown (Ri ; 2-1) ; 2
P1 = loop (rown Pcell1 ; fst mapn D) ; 1
<<s,x>, a> Pcell1 <a,<sx+a, x>>
4. loop (rown R) = (loop R)n
Proof: induction on n
(see www.doc.ic.ac.uk/~wl/papers/scp90.pdf)
P1 = P2 ; [D,D]-n
P2 = (loop (Pcell1 ; [D,[D,D]]))n