

#smxlondon Everything You Need to Know About How GraphSearch Works in 15-ish Minutes
73
Everything You Need to Know About How GraphSearch Works in 15-ish Minutes Kelvin Newman @kelvinnewman
-
Upload
kelvin-newman -
Category
Business
-
view
1.209 -
download
3
Transcript of #smxlondon Everything You Need to Know About How GraphSearch Works in 15-ish Minutes

Everything You Need to Know About How GraphSearch Works
in 15-ish MinutesKelvin Newman
@kelvinnewman

Or if this presentation has a sub-title...

Edges, Nodes and a Frickin’ Unicorn
http://www.escapefromcubiclenation.com/

Strategy DirectorSiteVisibility
A digital agency specialising in retail, travel and financial services

OrganiserBrightonSEO/Content
Marketing ShowTwo Free (and awesome) Conferences

Co-FounderClockwork Talent
Decent Digital Recruitment

Not here to convince you GraphSearch will
catch on but...

If the area of this slide represents all the
traffic on the internet

This much is Facebook
http://mashable.com/2010/11/19/facebook-traffic-stats/

And every thing in grey is the rest
of the internet

Google, YouTube, Wikipedia, The Daily Mail, etc.

your website, my website, her website etc.

we’re fighting over the scraps

If anyone can build a Google-Killer
it’s Facebook...

There’s a fundamental difference between Facebook & Google

is about...

documents and links
JD Hancock

is about...

things and relationships
JD Hancock

this difference is subtle but
huge

but I think it works better for the web
as we know it
JD Hancock

Facebook’s data has a far more
explicit structure than traditional
web text
D Hancock

it’s not that tricky for Google to parse “I Like Nerf Guns”
porkist

they could even have a go at “I was at Cattlegrid in Leeds for
Lunch Yesterday”**if you mark it up in the right way
R_Savvy

but has a much harder job understanding “Kelvin is
married to Carolyn”

Facebook knows that happened in 2007

And who attended the ceremony

And when we got engaged

etc.

On GraphSearch you’re not really making a
search.
You’re just filtering a structured database of all
the data Facebook has.

The Problem

But it’s a bloody big database
JD Hancock

1 Billion Users Every Month

240 Million Photo’s Per Day

2.7 Billion Likes Everyday

People share billions of pieces of content
everyday

One trillion connections of a thousand different
types
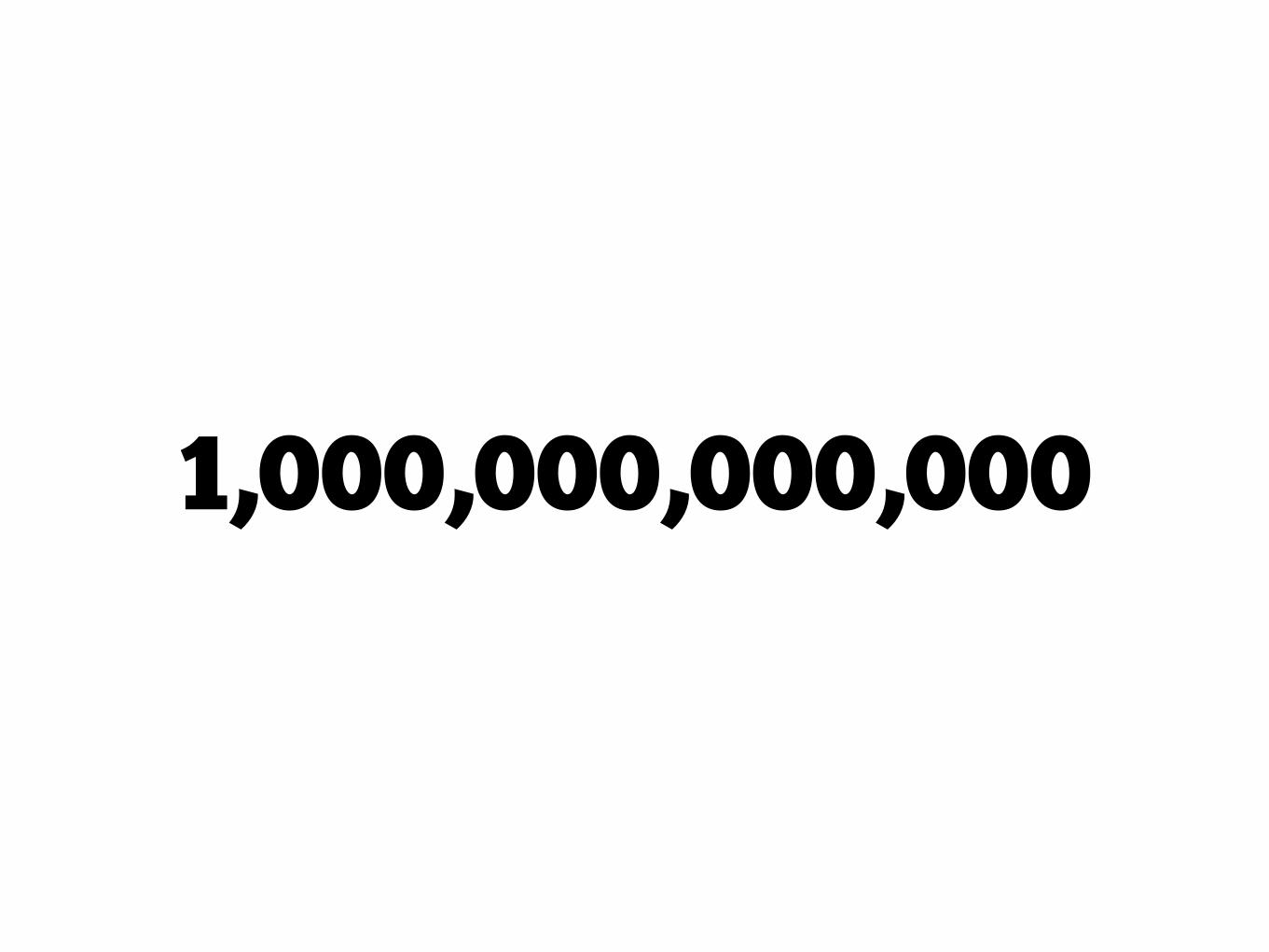
1,000,000,000,000

The Solution?

The Aforementioned Frickin’ Unicorn

But before we get into the unicorn,
let’s take a step back and define some terms

Edges & Nodes

Nodes are Nouns

Edges are Verbs

Every User, Page, Photo, Post & Place is a Node
JD Hancock

Every friendship, checkin, tag or like is an Edge
JD Hancock

Each Node has Meta-Data like description, this how
the old FB Search “worked”


GraphSearch Allows you search the Edges as well as the
Nodes
JD Hancock

Back the the Unicorn

Unicorn is and “inverted index system”

an inverted index (also referred to as postings file or inverted file) is an index data structure storing a mapping from content, such as words or numbers, to its locations in a database file, or in a document or a set of documents. The purpose of an inverted index is to allow fast full text searches, at a cost of increased processing when a document is added to the database.

The main components of Unicorn are:
■The index -- a many-to-many mapping from attributes (strings) to entities (fbids)
■A framework to build the index from other persistent data and incremental updates
■A framework to retrieve entities from the index based on various constraints on attributes

Suppose your friend has fbid 1234 and lives in New York and likes Downton Abbey. The index corresponding to your friend will include the mappings:
friend:10003 → 1234 lives-in:111 → 1234 like:222 → 1234
Here, we assume your fbid is 10003, and the fbid’s of New York and Downtown Abbey are 111 and 222 respectively.
In addition, friend:10003, lives-in:111, and like:222 may map to other users that share these attributes.

Unicorn makes it easy to find nodes that are connected to another node by searching for an edge-type combined with an input node.
E.g.:■Your friends: friend:10003■People who live in new york: lives-in:111■People who like downtown abbey: like:222

‘Facebook use query-independent signals to come up with a numeric value for importance.
This value is called the “static rank” of the entity.’
JD Hancock

What makes up static rank is still up for debate, but sensibly could be
informed by the elements of Edgerank
aka
the newsfeed algo


Affinity

Weight

Decay

But what do I do?

The value of legitimate likes from
well connected people just increased

You need an ‘Affinity
Acquisition Approach’

Constantly Build Affinity
subodh_chettri

Ask Questions
fontplaydotcom

Have a vote
ChodHound

Bait
Text
derekGavey

Tease

Get people to tag you

Do good Social Marketing

tl;dr
Graph Search is pretty awesome but works completely differently to Google rankings
rely exclusively on the connections between the user and the entity ranking, so you
need do ‘good’ Facebook marketing with a real focus on
building affinity.


















