
SMW Exhibit Thesis
63
Bachelorarbeit Integrating Semantic MediaWiki with Exhibit to Accelerate the Adoption of a Semantic Web Fabian Howahl
-
Upload
paolo-miozzo -
Category
Documents
-
view
224 -
download
0
Transcript of SMW Exhibit Thesis

8/3/2019 SMW Exhibit Thesis
http://slidepdf.com/reader/full/smw-exhibit-thesis 1/63
Bachelorarbeit
Integrating
Semantic MediaWiki with Exhibit
to Accelerate the Adoption
of a Semantic Web
Fabian Howahl

8/3/2019 SMW Exhibit Thesis
http://slidepdf.com/reader/full/smw-exhibit-thesis 2/63
Contents
Contents
1 Introduction 4
1.1 Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
1.1.1 Crossing the Boundaries . . . . . . . . . . . . . . . . . . . . 5
1.1.2 Increasing the Availability of Semantic Data . . . . . . . . . 6
1.2 Related Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
1.2.1 Data Exchange . . . . . . . . . . . . . . . . . . . . . . . . . 8
1.2.2 Attraction of Casual Users . . . . . . . . . . . . . . . . . . . 9
1.3 Structure of the Thesis . . . . . . . . . . . . . . . . . . . . . . . . . 10
2 An Overview of the Two Components 10
2.1 Semantic MediaWiki . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.1.1 Basic Concepts . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.1.2 Leveraging Semantics . . . . . . . . . . . . . . . . . . . . . . 14
2.2 Exhibit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2.2.1 Feeding Exhibit with Data . . . . . . . . . . . . . . . . . . . 18
2.2.2 Presentation . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
2.2.3 Wibbit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
3 Integration of Exhibit and Semantic MediaWiki 28
3.1 Integrating Exhibit as Result Printer . . . . . . . . . . . . . . . . . 29
3.1.1 Challenges and Goals . . . . . . . . . . . . . . . . . . . . . . 30
3.1.2 Structure of Result Printers . . . . . . . . . . . . . . . . . . 30
3.1.3 Wibbit as Basis of an Exhibit Result Printer . . . . . . . . . 33
3.1.4 Query Design . . . . . . . . . . . . . . . . . . . . . . . . . . 33
3.1.5 Implementation . . . . . . . . . . . . . . . . . . . . . . . . . 35
3.1.6 Advanced Features . . . . . . . . . . . . . . . . . . . . . . . 373.2 Enabling Exhibit to Fetch Data from Remote Wikis . . . . . . . . . 44
3.2.1 Architecture . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
3.2.2 Data Format . . . . . . . . . . . . . . . . . . . . . . . . . . 45
3.2.3 Data Model . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
3.2.4 Design of a JSON Exporter . . . . . . . . . . . . . . . . . . 49
1

8/3/2019 SMW Exhibit Thesis
http://slidepdf.com/reader/full/smw-exhibit-thesis 3/63
Contents
3.2.5 Implementation . . . . . . . . . . . . . . . . . . . . . . . . . 52
3.3 Using Exhibit to Enable Data Exchange Between Semantic Medi-
aWikis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 523.3.1 Design of Remote Queries . . . . . . . . . . . . . . . . . . . 53
3.3.2 Implementation . . . . . . . . . . . . . . . . . . . . . . . . . 53
3.3.3 Advanced Features . . . . . . . . . . . . . . . . . . . . . . . 54
4 Discussion and Outlook 55
4.1 Visualization of Query Results . . . . . . . . . . . . . . . . . . . . . 56
4.2 Use of Wiki Data in Other Web Applications . . . . . . . . . . . . . 56
4.3 Data Exchange . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
4.4 Outlook . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
2

8/3/2019 SMW Exhibit Thesis
http://slidepdf.com/reader/full/smw-exhibit-thesis 4/63
Contents
Abstract
This thesis promotes the integration of Semantic MediaWiki, a wiki engine for the
collaborative management of structured data, and Exhibit, a rich visualization
framework. The thesis argues that the integration of Semantic MediaWiki and
Exhibit makes a contribution to the mitigation of two known problems causing
the delayed adoption of a semantic web: the limited availability of semantic data
on the web and the fact that data is rarely shared and reused block the emergence
of a semantic web. The integration opposes these issues by attracting more casual
users to face up with semantic technologies and enabling a convenient method of
data exchange between two wikis.
The integration is organized into three steps. The first step establishes Exhibitas new interface for viewing query results in Semantic MediaWiki. Exhibit’s vi-
sualization widgets (e.g. maps and timelines) make wiki content more meaningful
and clear users from analytic tasks. With features such as faceted browsing, sort-
ing and aggregation of wiki content Exhibit helps subduing high information loads
wikis tend to show. Next the design and implementation of a JSON exporter for
Semantic MediaWiki is tackled to make data of a Semantic MediaWiki available
throughout the web. By this means wiki data finds its way into other web ap-
plications such as blogs or content management systems. Finally, the previousoutcomes are utilized to enable data exchange among Semantic MediaWikis.
3

8/3/2019 SMW Exhibit Thesis
http://slidepdf.com/reader/full/smw-exhibit-thesis 5/63
1 INTRODUCTION
1 Introduction
1.1 MotivationThe vision of a semantic web continues to keep researchers and practitioners busy.
As a cornerstone of this vision, Tim Berners-Lee, who is renowned for the invention
of the World Wide Web, has speculated on what a future semantic web could
look like in a journal article [1]. Even though the emergence of such ideas dates
back to the beginning of this century, essential elements of the vision remain
unimplemented [2]. The definition given by the World Wide Web Consortium
(W3C) [3] is a suitable point of reference for outlining Berners-Lee’s ideas and
related construction sites:
The Semantic Web provides a common framework that allows data to
be shared and reused across application, enterprise, and community
boundaries.
While analyzing this short definition, and also latest publications such as “Six
Challenges for the Semantic Web” [4], two urgent reasons for the delayed adoption
of the semantic web can be identified:
• The amount of available semantic data on the web is still limited
• Data is not shared and reused enough, particularly across boundaries
This thesis considers the integration of Semantic MediaWiki (SMW) and Exhibit
to be a part of the solution to these shortcomings. Semantic MediaWiki is a
wiki engine that enables users to create, manage and leverage structured content,
whereas Exhibit’s expertise lies in the visualization of structured content. The
integration of these components yields the following two contributions that help
mitigate the described shortcomings:
• It enables convenient data exchange among wikis to push reuse and sharing
of information
4

8/3/2019 SMW Exhibit Thesis
http://slidepdf.com/reader/full/smw-exhibit-thesis 6/63

8/3/2019 SMW Exhibit Thesis
http://slidepdf.com/reader/full/smw-exhibit-thesis 7/63
1 INTRODUCTION
1.1.2 Increasing the Availability of Semantic Data
Another challenge lies in the fact that the recently introduced semantic islands
are not yet populated by a wide range of web users. Casual users especially stay
away from these islands and thus should be highlighted. Casual users use the web
for recreational rather than professional activities. They take a proactive interest
in exploiting the web for their purposes, but they are limited in their actions
due to a lack of technical understanding. They were always a critical factor for
the advancement of the World Wide Web in the past development cycles. They
provided data through personal websites in early stages of the web [5]. Today
casual users spread their knowledge through wikis and blogs in an even higher
frequency. The entire Web 2.0 relies on the activity of casual users, since it is drivenby user-generated content [6]. The success of the semantic web also depends on
user contribution. Most of the data on the web has to be semantically enriched and
thus machine processable to form a semantic web with all its possible advantages.
The provision of such content is not a task only big publishers are expected to fulfill.
To create large semantic data amounts, casual users have to assist as well. That
is why it is necessary to get casual users onboard and encourage them to create
such data. Two basic requirements can be identified to attract casual users [7]:
• Participation has to be simple
• Results have to be visible and seizable immediately
The Status Quo of Wiki Usability
Semantic wikis, especially Semantic MediaWiki, already do a good job at simpli-
fying the participation in the semantic web. They promote the use of wikis as
foundation for the storage of semantic data. As this approach links advantages
of social software to the semantic web, a semantic wiki enables users to create
structured data easily in a community-oriented process. The community effect
does its part in speeding up the availability of new data. Although end users have
to be familiar with basic concepts of structuring data, this model can be consid-
ered successful, since it hides most of the complicated technologies of the semantic
web that tend to overburden users [5] and even researchers and practitioners [8].
The fast-growing number of personal, non-commercial wikis on the web as well
6

8/3/2019 SMW Exhibit Thesis
http://slidepdf.com/reader/full/smw-exhibit-thesis 8/63
1 INTRODUCTION
as a user study [9] suggest the easy learnability of wikitext, which is the markup
language for wiki articles. Wikitext is only plain text with certain mark-up inser-
tions. It aspires to simplifying HTML [10], but the language is still evolving andcontinuously develops new functions that exceed the capabilities of HTML.
Obviously, SMW is well-prepared for casual users. However, it is hard to con-
vince a casual user of the benefit of providing semantically enriched data instead
of ordinary textual data. In comparison, the creation of an HTML-file takes a few
minutes and the results can be reviewed in a web browser promptly. The creator
has control over the design of the page and can set free his creativity. But what
does the creator of structured data get? In the case of Semantic MediaWiki, a
couple of ways to leverage semantics exist [11]:
• Querying data
• Browsing data
• Data export (RDF, RSS ...)
It is questionable which of these features are appealing to casual users, though.
This thesis therefore aims at increasing the usability of these features for casual
users. The subsequent section depicts how Exhibit and its ecosystem make a
contribution here.
Exhibit’s contributions
Incontrovertibly, the possibility of querying stored knowledge is one of the most
valuable functionalities a semantic wiki has to offer. As it is arguable whether
casual users can handle queries [12], SMW relies on an easy query language based
on wikitext to give even inexperienced users an understanding of querying. Hence,
this feature has the potential to be more pitched to casual users. Exhibit can assist
here. It provides an incentive to create and query structured data for building
customizable visualizations users only know from big commercial websites such as
news or shopping sites. To put the user in the position to create and consume
these visualizations, this thesis pursues the integration of Exhibit as interface for
viewing query results.
At the same time Exhibit is able to improve the browsing experience of such
query results. As semantic data is prepared for the consumption by machines, it
7

8/3/2019 SMW Exhibit Thesis
http://slidepdf.com/reader/full/smw-exhibit-thesis 9/63
1 INTRODUCTION
is hardly consumable by human beings. As long as there are no agents on the
web acting as a proxy for doing human business, there have to be other ways to
consume the information. Albeit Semantic MediaWiki does its best at guidingthe user through the data volumes, there is space for improvements. Exhibit’s
features such as faceted browsing, sorting and aggregation of content enable a
clearly arranged presentation of structured data that puts the user in control of
large data volumes.
SMW’s current possibilities of exporting data only prove to be useful if there are
applications that process such data (e.g. XML/RDF). At the moment casual users
tend to refrain from using such applications (e.g. ontology editors), but there are
additional formats for structured data being more valuable to casual users. Oneof these formats is JSON, which attained success, because various web services
adopted it as input or output format (e.g. Google and Flickr). It makes sense
to add JSON to the formats SMW can handle and export. Casual users can feed
remote web pages that rely on Exhibit with data then. By this means they can
incorporate data of an SMW in blog entries or personal websites.
1.2 Related Work
This section gives a review of existing projects that target similar achievements.
Particularly, this section sets the achievements of this thesis apart from existing
solutions.
1.2.1 Data Exchange
In terms of data exchange among wikis, a couple of solutions already exist. Most of
them pursue a file-based approach as the export and import functions of SMW do.
The data of a wiki is exported as a file in a specific format and is imported to the
target wiki again. The author of [13] makes proposals on what a unified file format
for wiki data exports should look like. Nevertheless, manual file transfers make
data exchange tedious and slow. The goal of this thesis is to allow a convenient
exchange of data on the fly. Popular application programming interfaces such
8

8/3/2019 SMW Exhibit Thesis
http://slidepdf.com/reader/full/smw-exhibit-thesis 10/63
1 INTRODUCTION
as the Amazon1 or Google Maps2 API yet allow to query and reuse data easily
within other web applications without demanding the user to interfere. This thesis
attempts to make fetching data from SMWs as easy as getting data from GoogleMaps or Amazon.
1.2.2 Attraction of Casual Users
This section introduces other semantic repositories and elaborates on their attrac-
tion of casual users.
Wiki Systems
Semantic MediaWiki competes with further semantic wiki systems. The unique
selling point of other semantic wiki systems is the way structured data is authored.
ACEWiki [14] is able to interpret a subset of English. The semantics are extracted
from simple English sentences. The authors of IkeWiki [15] promote a WYSIWYG
(What You See Is What You Get) editor to create and edit content. The user study
“Are wikis usable” [9] suggests that wikitext can be learned quickly. Therefore this
thesis sticks with and even extends wikitext to prepare it for controlling Exhibit’s
visualizations and data exchange.
Some extensions to SMW also attempt to upgrade the usability. Halo3 is one ex-
ample. With features like auto completion and an ontology browser, the gardeningand browsing of data turns out to be more user-friendly. However, the extension
is not designed for casual users but intended for commercial use in a business en-
vironment. The Semantic Forms4 extension introduces a form-based way to edit
wiki articles and add semantics to them. Additionally, many other MediaWiki
extensions tackle the simplification of creating and editing data by applying the
WYSIWYG paradigm.
Other Repositories
In 2007 Metaweb launched an online database called Freebase5. The database
contains structured data, which can be contributed by any user. Freebase can be
1http://aws.amazon.com/2http://code.google.com/intl/en-en/apis/maps/3http://semanticweb.org/wiki/Project_Halo4http://www.mediawiki.org/wiki/Extension:Semantic_Forms5http://freebase.com
9

8/3/2019 SMW Exhibit Thesis
http://slidepdf.com/reader/full/smw-exhibit-thesis 11/63
2 AN OVERVIEW OF THE TWO COMPONENTS
thought of as a large Semantic MediaWiki that holds data of every kind. Inter-
estingly, the operators of freebase tweaked the browsing interface recently: With
Parallax6
it is possible to explore freebase with the aid of Exhibit. Another repos-itory of user-authored structured data is Many Eyes [16]. It allows users to upload
data tables and visualize this data right on the website. The visualizations Paral-
lax and Many Eyes create are tied to one repository and displayed on one single
website. The solution proposed in this thesis enables the visualization of data of
different SMW’s in different web applications (e.g. wikis, blogs and web sites).
1.3 Structure of the Thesis
The present thesis is structured by means of the essential steps to accomplish an
integration of Exhibit and Semantic MediaWiki. In Chapter 2 both components
are introduced before the integration is tackled. The integration itself just like the
third chapter about the integration is organized into three parts. The first part
describes how Exhibit can be used to visualize query results in SMW. The second
part presents how to enable Exhibit to fetch data from remote wikis. Finally, ways
of exchanging data between two SMWs are investigated. The thesis is closed by
an outlook summarizing effects of the integration and expectations for the future.
2 An Overview of the Two Components
This chapter introduces Semantic MediaWiki and Exhibit. Additionally, it gives
a sense of creating value with these applications.
2.1 Semantic MediaWiki
For many internet users Wikipedia is the one-stop resource for meeting their in-formation needs. People browse Wikipedia articles for useful information that is
pertinent to various daily situations. In most cases the retrieval of one article is
sufficient to receive a suitable answer. For instance, to spot the population fig-
ure of Boston, a reading of the first few lines of the article about Boston leads
6http://mqlx.com/˜david/parallax/
10

8/3/2019 SMW Exhibit Thesis
http://slidepdf.com/reader/full/smw-exhibit-thesis 12/63
2 AN OVERVIEW OF THE TWO COMPONENTS
to success. More complicated information needs may require a more ambitious
search for information that may be scattered across several articles. To find all
American cities with a population greater than 500,000 people, we have to checkevery article dealing with an American city for the population figure. Since such
a task is time-consuming, it is advisable to seek the assistance of computers here:
Processing large data quantities is a task computers are naturally good at. How-
ever, computers have trouble scanning human-authored texts for information, as
they are not able to process natural language on a semantic level. One approach
to give computers an understanding of the information a wiki article contains is
the attachment of semantic annotations. Annotations enhance wiki articles with
structured knowledge. Subsequently, annotated articles hold cues the computer is
capable to exploit. Semantic MediaWiki adopts this approach.
Semantic MediaWiki is an extension of the popular MediaWiki7 software, which
is famous for powering Wikipedia. It enables the enrichment of articles by adding
semantic annotations. Whereas MediaWiki yet offers a few concepts such as
namespaces and categories to describe and classify wiki pages to make it mean-
ingful to computers, SMW advances this approach and gives the wiki content
a new significance. It considers wiki pages as entities. Semantic annotations
set up relationships between these entities by using properties and the existing
category system. Semantic MediaWiki is licensed under the GPL and therefore
freely distributable. The home of the Semantic MediaWiki software is http:
//semantic-mediawiki.org . It hosts the main documentation, which is also,
along with “Semantic Wikipedia” [11], the source of the following information.
2.1.1 Basic Concepts
Before we can take advantage of semantically enriched content, we have to become
acquainted with SMW’s concepts and the annotation procedure. The following
sections introduce the syntax and the semantics of SMW’s basic constructs.
7http://www.mediawiki.org/
11

8/3/2019 SMW Exhibit Thesis
http://slidepdf.com/reader/full/smw-exhibit-thesis 13/63
2 AN OVERVIEW OF THE TWO COMPONENTS
Semantic Annotations
Instead of applying RDF/XML8 syntax, which tends to overburden most end users,
Semantic MediaWiki attempts to hide complicated knowledge representation fromusers as much as possible. A simple syntax is beneficial, because a complicated
syntax tends to stunt the quality of annotations [18]. The syntax used for annota-
tions in an SMW seamlessly fits the structure of wikitext. Thus a wiki author can
rely on his existing wikitext knowledge and the required adjustment is reduced to
a minimum.
The following example covers a wiki page about Boston as it could be found
on Wikipedia. Two semantic annotations are embedded in the continuous text,
though.
Boston is located in the [[located in::USA]].
It was settled in [[settled::1630]].
The expression [[located in::USA]], which resembles a usual wikitext
link, is such an annotation. It assigns the value “USA” to the Property “lo-
cated in”. Whereas a normal link in wikitext (e.g. [[USA]]) only establishes
a relationship between the articles Boston and USA, the typed link [[located
in::USA]] describes this relationship in more detail. As [[settled::1630]]indicates, the value of a Property is not necessarily a wiki article. Property values
can also be fixed values that are not represented by wiki pages.
The concept of setting up and describing a relationship between two entities is
often referred to as semantic glue [19]. While reading the text on the wiki page,
the user will not note the difference between a normal wiki link and a typed link.
The semantic enhancements are only revealed to the user by viewing the wikitext
of the page.
This annotation syntax offers an additional advantage. In most cases the anno-
tation of textual information causes redundant data and additional overhead [20].
For instance, an HTML file that is enriched with RDF contains the same informa-
tion twice. In the HTML part of the file the information is formatted for being
8RDF (Ressource Description Framework) is a common language to represent knowledge onthe web. RDF is often specified by using an XML (eXtended Markup Language) syntax. Forfurther information, please consult [17]
12

8/3/2019 SMW Exhibit Thesis
http://slidepdf.com/reader/full/smw-exhibit-thesis 14/63
2 AN OVERVIEW OF THE TWO COMPONENTS
consumed by human beings, whereas the RDF part makes the same information
available to machines. Besides, certain markup is required for specifying RDF. In
contrast SMW reduces the necessary overhead as well as redundant informationto a minimum. Links are an essential part of wiki pages for navigation purposes.
By adding a short description to the links, the overhead is minimal. The tra-
ditional two-step process of entering data and annotating information (see [21])
melts down to one step. Authoring and annotating of an article take place at the
same time. As a result, the overall time spent on the creation of annotations is
less compared to traditional ways. The uncomplicated and less time-consuming
way of annotating encourages even inexperienced (casual) users to refine entered
information.
Next we take a closer look at the description that is added to the common wiki
links. SMW calls this description Property, which will be the subject of the next
section.
Properties
We learned that Properties are the appropriate instrument to set up and describe
a relationship between two articles or an article and a fixed value. Properties, like
all core concepts of SMW, are represented by usual wiki pages. These wiki pages
reside in the namespace “Property”. Property pages include textual explanationsalong with special semantic annotations to characterize the Property.
The Property name can be arbitrarily chosen. Please note that SMW reserves
certain Property names for several purposes being introduced on occasion through-
out this thesis. The first special Property will be introduced instantaneously in
the next section.
Datatypes
We can add the special Property “has type” to Property pages to define the
datatype of a Property value. The default datatype is wiki page. The type wiki
page points towards the fact that the value is a further wiki article. Since the
value USA in our example is represented by an wiki article, the article “Prop-
erty:located in” is not expected to hold a “has type” annotation, since wiki page is
the default type. To declare a value as fixed, SMW comes up with various built-in
datatypes such as numbers, dates or strings to characterize a value. For instance,
13

8/3/2019 SMW Exhibit Thesis
http://slidepdf.com/reader/full/smw-exhibit-thesis 15/63
2 AN OVERVIEW OF THE TWO COMPONENTS
it makes sense to add [[has type::date]] to the article “Property:settled”,
since settled seems to describe a point in time. Information about datatypes is
fairly valuable to SMW, since datatypes have an effect on operations on values(e.g. sorting) and the appearance of values.
2.1.2 Leveraging Semantics
After having introduced the methods to create structured data, it is a fair question
how we can benefit from the invested time on adding annotations (albeit it was
little). Whereas the introduction only listed all important features to exploit
structured content, the following sections describe these features more explicit.
Browsing & Searching
In case the user sets a certain flag in the SMW configuration file, a so-called
Factbox (see Figure 1) appears at the bottom of every wiki article. The Factbox
summarizes the semantic annotations a page incorporates. Additionally, it features
numerous functions to browse the wiki content. When we click on a Property name,
we are directed to the corresponding page in the Property namespace. A click
on one of the magnifying glasses enables us to search for certain Property values.
Beside the Factbox, we can take advantage of various special pages, which facilitate
Figure 1: A Factbox as it would appear on a page about Boston
browsing of stored data. For instance, the “Special:Browse” page holds an interface
to traverse the wiki articles by means of their relationships. For data retrieval
purposes the two pages “Special:SearchByProperty” and “Special:PageProperty”
14

8/3/2019 SMW Exhibit Thesis
http://slidepdf.com/reader/full/smw-exhibit-thesis 16/63
2 AN OVERVIEW OF THE TWO COMPONENTS
can be considered helpful.
Queries
After having maintained a great number of semantic annotations, a remaining
issue is the retrieval of information we added to the wiki articles. As lists play
an important part here, the next paragraph illustrates the relevance of lists to the
wiki world.
The answer to a frequently occurring type of questions can be given by lists.
This special type of questions is characterized by the need of compiling information
from different wiki pages and comparing this information among themselves. This
includes questions like: What are the five biggest cities in the United States with
a female mayor? In exceptional cases the Wikipedia authors already maintain alist holding the answer to our question. Indeed, Wikipedia contains a list of cities
in the United States ordered by their population, but the requirement of having a
female mayor is not taken into account. One has to create a further list to meet
the demand of this extraordinary question. As one is expected to create such
lists manually, the compilation costs time. Therefore, only a few lists answering
generic questions are available on Wikipedia. Semantic MediaWiki can speed up
the creation of lists: it features the automatic generation of lists based on the data
collected from annotations. At a glance, the machinable compilation of lists yieldsthe following advantages:
• Lists gather information scattered across the wiki
• Automatically created lists ensure that the gathered data never gets outdated
• The user can influence how the information is arranged and displayed
The instrument to generate such lists and thus exploit the itemized advantages is
a query. SMW distinguishes between normal queries entered on the “Special:Ask”
page and inline queries that embed the query results in a wiki article. The “Spe-
cial:Ask” page enables a form-based specification of a query. Within this thesis
the concept of inline querying is preferred in most cases. So it is important to get
acquainted with the inline query syntax in advance. The following inline query
gathers all pages describing an entity, presumably cities, that is located in the
15

8/3/2019 SMW Exhibit Thesis
http://slidepdf.com/reader/full/smw-exhibit-thesis 17/63
2 AN OVERVIEW OF THE TWO COMPONENTS
United States on one wiki page. This query yields a list that is shown in Figure 2
(it is more a table than a list).
{{#ask: [[located in::USA]]
| ?state
| ?population
| ?settled
| mainlabel=City}}
Figure 2: Table of query results
As every function call in wikitext, the query string starts with the name of the
function (#ask:). The function name is followed by the parameters we want
to pass to the function. Multiple parameters are separated by pipes. The first
parameter indicates the wiki pages to be selected. Basically, we ask for wiki
pages with the given annotation. In order to expand the result set, comparators
(e.g. [[population>=500,000]]) as well as disjunctions (OR operator) are
permitted. We can refine the query with the help of further parameters to in-
fluence the output format. Parameters with a prepended question mark such as
?state are called print requests and tell the engine which additional Property
values of the selected wiki pages are required to be part of the result set. In the
example the Properties state, population and settled are selected and therefore
appear as columns in Figure 2. Additionally, we can define parameter-value pairs.
16

8/3/2019 SMW Exhibit Thesis
http://slidepdf.com/reader/full/smw-exhibit-thesis 18/63
2 AN OVERVIEW OF THE TWO COMPONENTS
Mainlabel=city defines the name of the first column of the table in Figure
2, for instance. Many of the accepted parameter-value pairs (e.g. limit, order or
sort) have counterparts in other query languages such as SQL or SPARQL. Oneparameter of particular interest is format. Format defines the result printer that
is used for output generation. The next paragraph explains the purpose of result
printers.
Semantic MediaWiki lets users influence the presentation of the query result
output to a certain extent. By adding a parameter to a query, we can define the
result format of the selected data:
{{#ask: [[located in::USA]]
| ...
| format=table}}
By default SMW already supports basic formats such as tables (see Figure 2) and
lists. The extension Semantic Result Formats9 brings even more sophisticated
formats (e.g. timelines and maps) to SMW. Result printers will play a dominant
part in the integration of SMW and Exhibit and will be therefore explained once
more in Section 3.1.2.
Data Import and ExportsSemantic MediaWiki is able to export the wiki content in different formats. The
most prominent format is OWL/RDF. Each Factbox holds a link that triggers the
RDF export of the semantic annotations on the page. Furthermore, we can use the
form on the “Special:ExportRDF” wiki page to export a collection of wiki pages.
With the help of a console-based dump script we even can export all annotations
in the wiki. On the other hand, the import of foreign vocabulary like FOAF10 is
feasible.
2.2 Exhibit
In its early stages, the World Wide Web was only a repository of plain HTML
pages. Today, most of the data on the web is still encoded in HTML, but with the
9http://semantic-mediawiki.org/wiki/SRF10http://www.foaf.org
17

8/3/2019 SMW Exhibit Thesis
http://slidepdf.com/reader/full/smw-exhibit-thesis 19/63
2 AN OVERVIEW OF THE TWO COMPONENTS
aid of technologies like PHP, CGI and JavaScript websites can adjust to the user’s
preferences and recreate the look-and-feel of desktop applications. As a matter of
fact, the content of the web is more dynamic and interactive today. To exploitthese advantages, one has to spend a great deal of time learning the handling of
these rapidly changing languages and frameworks. In the early years of the web,
the ability to run sophisticated, eye-catching websites was the exclusive province
of big publishers, who could afford to employ highly skilled web experts. Today,
lots of frameworks enable more inexperienced users to leverage possibilities latest
technologies offer. However, the entry hurdles have not completely disappeared
yet, although Exhibit lowers the entry barrier farther.
Exhibit is a JavaScript framework. It is part of the SIMILE (Semantic Interop-
erability of Metadata and Information in unLike Environments)11 tool suite and
was developed in the course of a doctoral thesis [7]. Most Exhibit-related docu-
mentation the following introduction is based on is compiled in the SIMILE wiki12.
Within this thesis, a webpage using Exhibit will be adressed as an exhibit in lower
case.
Exhibit creates rich data visualizations from structured data sources without
demanding deep knowledge of advanced web technologies like PHP or JavaScript.
A little HTML experience is sufficient. A complicated installation or setup-routine
is not necessary either. The purchase and usage of additional software is obsolete
as well (a simple text editor is adequate).
Exhibit, unlike HTML, separates the management of data from its presentation.
The thesis will describe Exhibit’s way to obtain input data for visualizations at
first. Thereafter the presentation features will be outlined.
2.2.1 Feeding Exhibit with Data
Natively Exhibit gets the data it is supposed to visualize from JSON files. Besides,
Exhibit is able to extract data from many other sources such as Google Spread-
sheets13 or BibTeX14 files. A web service15 for converting formats such as RDF
11http://simile.mit.edu12http://simile.mit.edu/exhibit13http://docs.google.com/14http://www.bibtex.org15http://simile.mit.edu/babel/
18

8/3/2019 SMW Exhibit Thesis
http://slidepdf.com/reader/full/smw-exhibit-thesis 20/63
2 AN OVERVIEW OF THE TWO COMPONENTS
or CSV (Comma-Separated Values) to JSON is available as well. The variety of
options to feed Exhibit with data yields the advantage that Exhibit does not force
the user to manage the data in a certain way or with a specific application. Theuser is at liberty to use a rudimentary text editor for creating a JSON file or a
more sophisticated application like a spreadsheet engine.
Within this work the focus lies on JSON as Exhibit uses it internally and as
basis of the mentioned ways to import data. Furthermore, it plays an important
part in the integration of SMW and Exhibit. To comprehend Exhibit’s own JSON
format, it is helpful to get a general idea of JSON at first.
Javascript Object Notation (JSON)
The JavaScript Object Notation (JSON) is a leightweight data exchange format. Itis based on a subset of the JavaScript language and serializes structured data. [22]
The detailed specification of JSON can be found in [23]. The fact that the
acronym JSON includes “JavaScript” does not indicate it just works in JavaScript
environments. A large number of programming languages evaluate JSON by map-
ping the JSON structures to the corresponding concepts such as arrays or objects.
Let us take a closer look at the JSON structures and their equivalents in other
programming languages.
JSON only knows two types of structures:
• ordered lists of values
• collections of name-value pairs
An ordered list is identical to an array. In JSON the different values of an array
are separated by commas and embraced by square brackets:
1 [value1,value2,...]
A collection can be regarded as an object. It is characterized by name-value pairs.In many programming languages an object is represented by an associative array
in which the name fills the role of an array key. A collection is embraced by
curly brackets. Names as well as values are quoted. Commas separate multiple
name-value pairs:
1 {
19

8/3/2019 SMW Exhibit Thesis
http://slidepdf.com/reader/full/smw-exhibit-thesis 21/63
2 AN OVERVIEW OF THE TWO COMPONENTS
2 "name1": "value1",
3 "name2": value2",
4 ...5 }
Throughout the thesis we shall address these two JSON structures as arrays and
objects. Of course, these structures can be nested. For instance, an array can have
objects as values.
Exhibit’s own JSON format
Exhibit expects a data source file to specify certain nested JSON arrays and ob-
jects. By means of Listing 1 we explore the required JSON structures.The JSON file defines an object that consists of three name-value pairs. The
first two pairs describe the schema of the data that is passed to Exhibit, whereas
the last name holds the data itself. As the first two names are not mandatory, the
following explanation starts with the latter name.
The value of the name items is an array (line 14-25). The array consists of
different objects that represent Items. Each Item is comparable to a single database
record or one row of a database table. An Item is represented by a JSON object
and therefore characterized by name-value pairs. In Exhibit’s terms the names of
an Item are called Properties. A Property can have multiple values which then are
enumerated in an array (cmp. the Property Borders in line 23 in Listing 1). The
Property label (line 16) is mandatory and can be considered the name or title
of an Item. To identify an Item unambiguously, it has an unique ID (line 17). In
case the ID is not set, the label is regarded as the unique ID.
Although the two names properties and types are optional, their speci-
fication is highly recommended to let Exhibit know what exactly it is about to
visualize. For example, a couple of Exhibit’s features relies on information about
datatypes. In terms of sorting it makes a difference whether a Property holds anumeric or textual value.
The value of types is an object that declares types an Item can have. By
adding the special Property type (see line 18) to an Item, it is possible to assign
these types. For instance, the Item Boston in the sample file is of the type City.
Since Exhibit displays the number of displayed Items it has to be aware of the
20

8/3/2019 SMW Exhibit Thesis
http://slidepdf.com/reader/full/smw-exhibit-thesis 22/63
2 AN OVERVIEW OF THE TWO COMPONENTS
1 {
2 types: {
3 ‘City’: {
4 pluralLabel: ‘Cities’
5 }
6 },
7 properties:{
8 "City" : { valueType: "item" },9 "Population" : { valueType: "number" },
10 "State" : { valueType: "item" },
11 "Settled" : { valueType: "number" },
12 "Geo" : { valueType: "item" }
13 },
14 items: [
15 {
16 "label": "Boston",
17 "ID": "Boston",
18 "type": "City",19 "Population": "590763",
20 "State": "Massachusetts",
21 "Settled": "1630",
22 "Geo": "1221,2121",
23 "Borders": ["Cambridge","Somerville"]
24 }
25 ]
26 }
Listing 1: An Exhibit JSON File
21

8/3/2019 SMW Exhibit Thesis
http://slidepdf.com/reader/full/smw-exhibit-thesis 23/63
2 AN OVERVIEW OF THE TWO COMPONENTS
plural of the type (line 4).
The object held by properties defines different Properties that may be used
for describing Items. The sample file describes a city by its population figure(Population), the state it is located in (State), when it was settled (Settled) and a
geographic coordinate (Geo). Similiar to Semantic MediaWiki, each value of these
Properties has a valueType (see line 8). Exhibit supports the types number,
url, text and date. Moreover, the value can be a further Item, which is also the
default type. The declaration of a Property with the valueType Item (see line
8) sets up a relationship between two different Items.
Navigation in the Data Modell
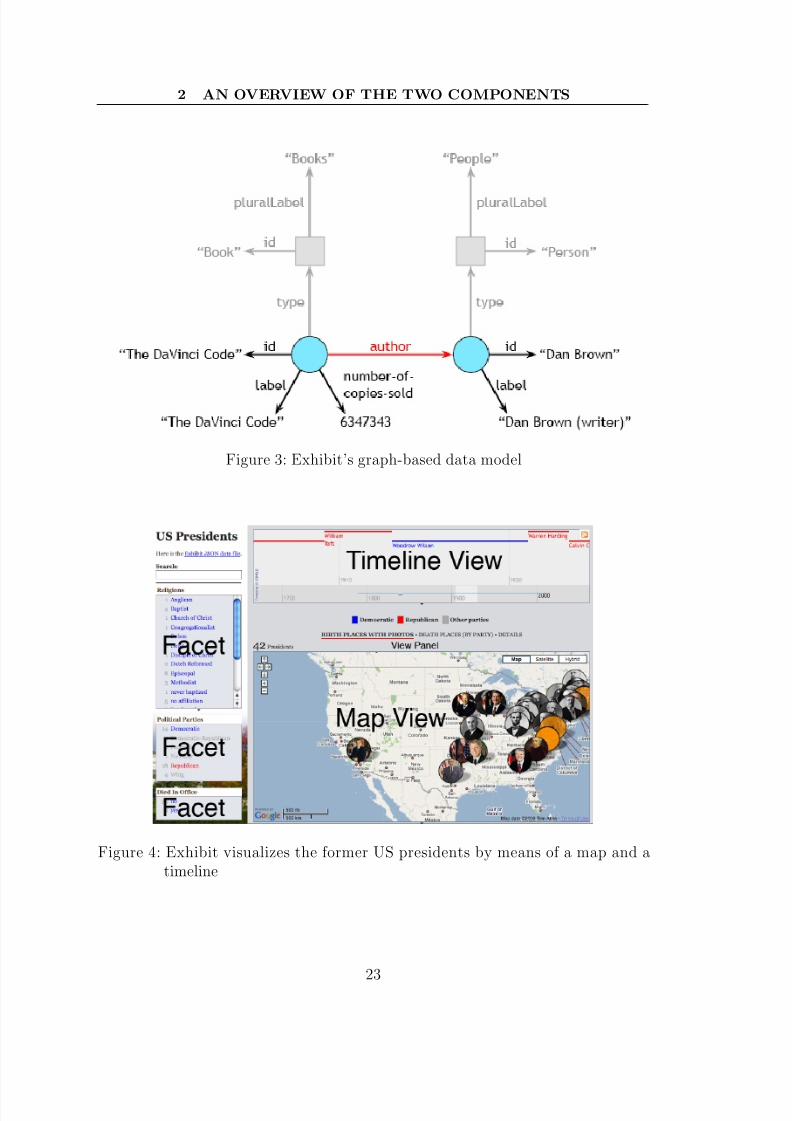
As the examined JSON file indicates, Exhibit relies on a graph-based data model.
Therefore it comes up with expressions to navigate through the nodes and edges
of the graph. These expressions are deployed for addressing Property values.
Throughout the thesis we shall address these expressions as Exhibit expressions.
We use Exhibit expressions to configure the presentation of the data in the next
section.
As shown in Figure 3, Items as well as values fill the role of nodes in the graph,
whereas Properties describe the edges.
To tell Exhibit to use values of a certain Property, the name of the Property
has to be prepended by a dot. To select the values of number-of-copies-sold of an
Item, we have to use the expression .number-of-copies-sold. To traverse
the graph vice versa an exclamation mark has to stand in front of the Property. It
is possible to concatenate the expressions by simply stringing them together (e.g.
!number-of-copies-sold.author.label ).
2.2.2 Presentation
Beside the introduced JSON file, an additional HTML file is required to configure
the presentation of the JSON data. This section gives a short review of HTML
constructs we can use to configure an exhibit. The list of configuration options is
not complete. The reader is encouraged to consult the SIMILE wiki for a complete
list of parameters. Figure 4 shows most HTML constructs in action.
22
8/3/2019 SMW Exhibit Thesis
http://slidepdf.com/reader/full/smw-exhibit-thesis 24/63
2 AN OVERVIEW OF THE TWO COMPONENTS
Figure 3: Exhibit’s graph-based data model
Figure 4: Exhibit visualizes the former US presidents by means of a map and atimeline
23

8/3/2019 SMW Exhibit Thesis
http://slidepdf.com/reader/full/smw-exhibit-thesis 25/63
2 AN OVERVIEW OF THE TWO COMPONENTS
Basics
To take advantage of Exhibit’s features we have to include the Exhibit Applica-
tion Programming Interface (API) in the web page we are about to create. Thefollowing code has to be added to the HTML header of the page:
1 <script
2 src="http://static.simile.mit.edu/exhibit/api-2.0/exhibit-
api.js?autoCreate=true"
3 type="text/javascript"/>
If we want to use special views or features such as maps and timelines, the
inclusion of further script tags may be necessary. In some cases we want to ap-
pend parameters to the URL pointing to the Exhibit API. For example, by adding
?autoCreate=false to the URL the default start-up procedure Exhibit per-
forms is deactivated. Since Exhibit is a javascript framework, rendering is done
on the client side. Server-side actions are not designated. The server is exclusively
expected to deliver the code of the referenced JavaScript files.
To supply Exhibit with data, we need to invoke a JSON source by adding a link
tag to the HTML header:
1 <link
2 href="cities.js"
3 type="application/json"
4 rel="exhibit/data" />
It is possible to include more than one data source. In this case Exhibit tries
to merge the data then. An use-case harnessing this functionality is illustrated in
Section 3.3.3.
Views
We can visualize data with the aid of views. The default view is the tiles view,
which is basically a list (see Figure 5). To make data more meaningful, we can
utilize advanced views such as timelines and maps. Who would realize that all
presidents of the United States except one were born in cities to the east of New
24

8/3/2019 SMW Exhibit Thesis
http://slidepdf.com/reader/full/smw-exhibit-thesis 26/63
2 AN OVERVIEW OF THE TWO COMPONENTS
Figure 5: Exhibit’s default view
Mexico, Wyoming and Montana by just analyzing the listed data? A view showing
the birth places by means of a map conveys this information at the first sight16.
1 <div
2 ex:role="view"
3 ex:viewClass="Tabular"
4 ex:columns=.label,.party,.religion
5 ex:sortColumn=.label/>
Listing 2: Tag adding a Table View
To activate a view we embed a marker (see Listing 2) in the section of the HTML
body where we want the view to appear. This marker is a div environment with
certain attributes. The ex:role attribute indicates the purpose of the marker:
it is a placeholder for a view. The ex:view attribute holds the name of thedesired view (e.g. Tabular, Timeline, Map). The remaining attributes are specific
to the different views. For instance, the tabular view expects Exhibit expressions
to constitute the arrangement of the columns (ex:columns on line 4) and the
16for a live experience visit http://simile.mit.edu/exhibit/examples/presidents/
presidents-2.html or see Figure 4 for a screenshot
25

8/3/2019 SMW Exhibit Thesis
http://slidepdf.com/reader/full/smw-exhibit-thesis 27/63
2 AN OVERVIEW OF THE TWO COMPONENTS
order of the table entries (ex:sortColumns in line 5).
We can place different views in various sections of the page. Furthermore, we
can insert a view panel to gather multiple views on a single spot. The view panelembeds controls to switch between the views. The exhibit in Figure 4 enables the
user to switch between different map views: one shows the president’s birth places,
whereas the other shows the death places.
Independent of the selected view, Items are clickable links. After clicking on an
Item a bubble with further information such as Properties and values appear (see
Figure 6).
Facets
Facets aggregate values by their occurrence [24]. The facets in Figure 4 filterthe presidents by their religion or political party. By clicking on one or multiple
values, only the presidents the selected values apply to are displayed, whereas
the remaining presidents vanish. The reduction of displayed Items lessens the
information load. Thus facets provide an effective way to filter out information
that is not of importance or out of scope. Casual users know faceted browsing from
commercial sites. For example, amazon employs facets for structuring product
categories to enhance the facility of inspection. To stick with the recent example
of presidents the following markup reserves space for a facet of the party Property:
1 <div ex:role="facet"
2 ex:expression=".party" />
To select which values a facet is supposed to aggregate, we have to assign an
Exhibit expression to the ex:expression attribute. Special facets for numeric
values are available as well. They embrace the values in customized intervals.
LensesThe user can gain control over the output beyond merely choosing a view. We
can influence the rendition of single Items with the aid of a lens. How a single
Item is rendered depends on the view. For instance, the tiles view (see Figure 5)
creates an uniform table of Property-value pairs for each Item. In the timeline
and map view a bubble (see Figure 6), which shows up when the user clicks on the
26

8/3/2019 SMW Exhibit Thesis
http://slidepdf.com/reader/full/smw-exhibit-thesis 28/63
2 AN OVERVIEW OF THE TWO COMPONENTS
Figure 6: This bubble shows up on click of a president’s head
Item, holds the rendition. A lens is an HTML template that replaces the default
rendition. We can specify a lens as follows:
1 <div ex:role="lens" ex:itemTypes="Presidents" >
2 <div ex:content=".label"></div>
3 <img ex:src-content=".imageURL" />
4 <a ex:href-subcontent="http://presidentswebsites.gov
/\{\{.label\}\}">link</a>
5 </div>
A div environment embraces the HTML snippet. To tell Exhibit where it is sup-
posed to fill in the Property values, we have to embed markers in the HTML
template. The ex:content attribute in line 2 causes Exhibit to insert the de-
fined Property values in the designated div environment. In this way the rendition
of each item includes the name of the president. Exhibit can also set the values of
HTML attributes. The ex:src-content attribute manipulates an image source
to display an image of the president (the property imageURL holds an URL toan image). Ex:subcontent joins hard-coded values with Exhibit’s content. By
this means the tag in line 4 yields a dynamic link target to a website about the
presidents.
With customized lenses Exhibit’s default views can be altered in an easy way
without touching the code of the API.
27

8/3/2019 SMW Exhibit Thesis
http://slidepdf.com/reader/full/smw-exhibit-thesis 29/63
3 INTEGRATION OF EXHIBIT AND SEMANTIC MEDIAWIKI
Collections
We can assign Items having a certain type to a collection. The collection incor-
porates all Items of the type specified by the ex:itemTypes attribute then.To constrain a view to only show Items of a certain collection, we can add the
ex:collectionID attribute to the view placeholder.
1 <div ex:role="collection" ex:itemTypes="typeA" />
2 <div ex:role="view" ex:viewClass="Timeline"
3 ex:collectionID="typeA-things" />
2.2.3 Wibbit
Wibbit is an extension of MediaWiki and allows the embedding of exhibits in wiki
articles. It extracts input data from tables within wiki articles instead from JSON
sources. As an advantage, we can edit the information source in a convenient way
by using a wiki table editor17. However, a simple table is not as expressive as a
JSON file. It does not contain metadata about values such as information about
datatypes, for instance. Hence, to configure the presentation, Wibbit requiresHTML code, which specifies the views, facets and lenses Exhibit is supposed to
use, in addition to the table .
3 Integration of Exhibit and Semantic MediaWiki
The integration of Exhibit and Semantic MediaWiki is organized into three stages.
As a first step, we design and implement a query result printer that uses Exhibitto format query results. Next we enable Exhibit to access content of SMWs as
new type of data source. Finally, we utilize this work to establish data exchange
among multiple wikis.
17for example the Simile Wiki Table Editor at http://simile.mit.edu/wiki/Wiki_
Table_Editor
28

8/3/2019 SMW Exhibit Thesis
http://slidepdf.com/reader/full/smw-exhibit-thesis 30/63
3 INTEGRATION OF EXHIBIT AND SEMANTIC MEDIAWIKI
Figure 7: Query results visualized by the Exhibit result printer
3.1 Integrating Exhibit as Result Printer
This section deals with the design and implementation of a new result printer
presenting query results with the aid of Exhibit. Figure 7 shows the desirable
output of such a result printer. To achieve this output, we have to come up
with a way to pass SMW content to Exhibit. Thereto, we explore result printers
from a technical point of view in Section 3.1.2. In Section 3.1.3 we combine the
existing table result printer and Wibbit to supply Exhibit’s visualizations with
input data. Since Exhibit needs information regarding the configuration of views,
facets and lenses, we introduce new parameters for inline queries in Section 3.1.4.
Section 3.1.5 describes the implementation of the new result printer. Indeed the
implemented result printer delivers an output as shown in Figure 7, but many of
Exhibit’s features remain unused. Therefore Section 3.1.6 discusses modifications
of the result printer with the objective of leveraging more advanced features of
Exhibit.
29

8/3/2019 SMW Exhibit Thesis
http://slidepdf.com/reader/full/smw-exhibit-thesis 31/63
3 INTEGRATION OF EXHIBIT AND SEMANTIC MEDIAWIKI
3.1.1 Challenges and Goals
Before designing a new result printer it is necessary to define the goals the im-
plementation is aiming at. Besides, it is useful to be aware of the accompanying
challenges.
Keeping querying simple
In comparison to other semantic repositories, querying in SMW is rather simple.
Thus one goal is to retain this simplicity as far as possible. The query syntax
has to be extended in a logical way so that users, who are already familiar with
the syntax, can adjust to the new query extensions easily. Whereas Exhibit needs
information to configure visualizations, the requirement of additional mandatory
parameters has to be reduced to a minimum to keep query strings as short and
clearly arranged as possible. A need for statements outside the query should
completely be avoided.
Reusing information SMW already contains
SMW already contains information that is meaningful to the presentation of wiki
content. It is advisable to pass this information to Exhibit to overcome redundant
data specification. For instance, information concerning datatypes is valuable, as
Exhibit is capable to adjust controls (e.g. facets) to different datatypes. The
more existing information can be harnessed, the more the need of additional query
parameters shrinks.
Aligning Exhibits to the traditional wiki user interface
Exhibits must seamlessly fit the wiki interface to create a comfortable look and
feel. Exhibits are not supposed to destroy the wiki layout by requiring horizontal
scrolling, for instance. On the other hand, they have to grapple with the limited
space wikis naturally offer due to fixed navigation bars, headers and footers.
3.1.2 Structure of Result Printers
Since the purpose of result printers has already been outlined in Section 2.1.2, this
section conducts a technical analysis of result printers. The analysis encompasses
descriptions of the query workflow, the composition of query results and details
regarding the implementation of result printers.
30

8/3/2019 SMW Exhibit Thesis
http://slidepdf.com/reader/full/smw-exhibit-thesis 32/63
3 INTEGRATION OF EXHIBIT AND SEMANTIC MEDIAWIKI
Figure 8: Simplified querying procedure
SMW processes queries in a certain order. Figure 8 sketches this workflow. The
query mechanism of SMW is based on a MediaWiki parser function. Whenever
MediaWiki registers an ask function call, a query parser disperses the function
parameters into different parts. The parser hands the various query elements to
the query processor. The query processor collects the requested data and stores it
in a result object of the type SMWQueryResult. From the content of the SMW-
QueryResult object, result printers generate outputs such as tables, timelines or
maps.
As the power of result printers depends on the accessible data, we investigate the
SMWQueryResult class now. The SMWQueryResult class constitutes the struc-
ture of the query results. Basically, this structure can be considered a table (see
Figure 9). Each row stands for one page that has been selected during query
evaluation. For each print request the table contains a column, which can be
adressed through an SMWPrintRequest object. This specific SMWPrintRequest
object holds, among other things, the Property name and its datatype. In contrast
to usual tables, the cells of the table are designed to contain multiple Property
values. These values are stored in an array-like data structure called SMWRe-
31

8/3/2019 SMW Exhibit Thesis
http://slidepdf.com/reader/full/smw-exhibit-thesis 33/63
3 INTEGRATION OF EXHIBIT AND SEMANTIC MEDIAWIKI
Figure 9: Structure of the SMWQueryResult object
sultArray. Additionally, result printers can access the query string as part of the
SMWQueryResult object.
Each result printer is implemented as a subclass of SMWResultPrinter in aseparate PHP file. The subclass implements a function getResultText() as
its most important part. This method creates a string that is either embedded
in the body of the output page or is released as detached file18. Even though
MediaWiki predetermines parts of the HTML output (navigation bars, headers and
footers), result printers are capable to manipulate other parts than the body of the
output page. For example, result printers influence the HTML head environment
by using the SMWOutput::RequireHeadItem() function to refer to scripts
or data sources. To provide a certain sense of how result printers work, the next
paragraph illustrates the proceeding of SMW’s built-in table result printer.
As many other result printers, the table result printer traverses the SMW-
QueryResult object row by row and adds format-dependent markup. The table
printer adds HTML tags such as table, th, td to the result data. First, the
18a detached file only contains the created string without navigation bars, headers and footers
32

8/3/2019 SMW Exhibit Thesis
http://slidepdf.com/reader/full/smw-exhibit-thesis 34/63
3 INTEGRATION OF EXHIBIT AND SEMANTIC MEDIAWIKI
printer sifts through the SMWPrintRequest object to create the headline of the
table. It puts each Property name in th tags, whereas the entire headline is put in
tr tags. The result rows of the SMWQueryResult object are embraced by tr tagsas well. Concrete values are clasped by td tags. Besides, the result printer invokes
a special JavaScript file in the header. The included JavaScript code enhances the
resulting HTML table with new functionality such as sorting (see Figure 2).
3.1.3 Wibbit as Basis of an Exhibit Result Printer
This section reveals that the table result printer can prepare data that is consumed
by Wibbit. As we can already embed exhibits in wiki pages with Wibbit (see
Section 3.1.3), it seems obvious to employ Wibbit as foundation for an Exhibitresult printer. Wibbit consists of JavaScript code that parses tables on wiki pages
and passes the table contents to Exhibit. Wibbit is able to process tables created
by the table result printer without restriction of any kind. The choice of Wibbit
holds two advantages:
• In the event the user’s browser does not support JavaScript a fallback is
initiated so that the user faces a normal table view
• There is no need for the creation of a detached JSON file (which would yield
an extra query processing)
Of course, a table is not as expressive as a complete JSON file. Information,
particularly about datatypes, gets lost in a table scheme, but Wibbit provides
workarounds here. However, these workarounds conflict with the goal of keeping
querying simple (see Section 3.1.1). The next section shows how to adjust these
workarounds in order that high usability is retained.
3.1.4 Query Design
Exhibit requires additional HTML markup for controlling the output (see Section
2.2.2). Wibbit requires users to place this HTML code in a modified shape in the
edit box of wiki articles. The mix of HTML and wikitext tends to confuse usual
wiki users, since they usually are not expected to use HTML for editing articles.
33

8/3/2019 SMW Exhibit Thesis
http://slidepdf.com/reader/full/smw-exhibit-thesis 35/63
3 INTEGRATION OF EXHIBIT AND SEMANTIC MEDIAWIKI
SMW’s query syntax is assumed to be known by users, though. Furthermore, the
query syntax is geared to the wikitext syntax and can therefore be adopted easily.
With the objective of avoiding user confusion, we provide information concerningExhibit’s output within the query string. Hence, the introduction of new query
parameters is necessary to eliminate the need of further HTML code:
{{#ask: [[located in::USA]]
| ...
| format=exhibit
| views=tiles,tabular,timeline,map
| facets=state,population
| start=settled
| latlng=geo}}
The views parameter specifies the different views the exhibit is going to show.
We can select multiple views by using a comma as limiter. As all views are defined
at the same position in the wikitext, a view panel manages the gathering of all
views on this spot (see Figure 7). At the moment possible parameter values are
tiles, tabular, timeline and map.
To add facets to the resulting exhibit, we assign the Properties, whose values
should be subject to a facet, to the new facets parameter (please note that the
user is not expected to provide Exhibit expressions but the plain Property name).
To add more than one facet, we separate multiple Properties by commas.
Furthermore, depending on the selected views additional parameters might be
mandatory. Particularly, the timeline and the map view demand more information
on how to deal with the input data they acquire. The map view requires the name
of the Property that contains the geographic coordinate to be displayed. We can
assign the name to the new latlng parameter. The start parameter conveys the
Property that contains a start date to the timeline. In Section 3.1.6 we shall see
that the specifications of these parameters can be bypassed. Exhibit processes fur-
ther parameters, which can be set through the query string. Since the specification
of such parameters happens analogously, a full explanation is omitted here.
34

8/3/2019 SMW Exhibit Thesis
http://slidepdf.com/reader/full/smw-exhibit-thesis 36/63
3 INTEGRATION OF EXHIBIT AND SEMANTIC MEDIAWIKI
3.1.5 Implementation
The implementation mainly consists of the creation of a new result printer. We
learned that result printers can influence the header as well as the body of the
HTML file that is delivered to the user’s web browser, when the user views a wiki
article containing a query. The next two sections present the exact changes of the
head and the body the result printer has to produce to let Exhibit take over the
visualization.
Head
To gain access to Exhibit’s functionality, the result printer adds a reference to
the API of Exhibit. Thereby, it disables Exhibit’s default start-up procedure byappending autoCreate=false to the link that is pointing to the Exhibit API. More-
over, the printer invokes a further JavaScript file called exhibit.js that provides
a replacement for the disabled start-up procedure. We shall examine the code of
exhibit.js subsequently. Additionally, the result printer declares three JavaScript
variables. These variables hold information we would normally expect to be part of
the HTML body. MediaWiki has a special engine, called Sanitizer, that prevents
the injection of malicious code. The Sanitizer relies on a white list that contains
HTML tags and attributes the author is permitted to use within wikitext. How-
ever, the majority of tag attributes Exhibit reads out to gain information about
the desired presentation format is not part of this list. That is why the result
printer stores information that is normally embodied by HTML tag attributes in
JavaScript variables in JSON notation. The next lines provide an impression on
what information is assigned to these variables and where the information comes
from.
1 var sources = {
2 source0: {
3 id: "querytable1" ,
4 columns: [item,number]
5 }
6 };
35

8/3/2019 SMW Exhibit Thesis
http://slidepdf.com/reader/full/smw-exhibit-thesis 37/63
3 INTEGRATION OF EXHIBIT AND SEMANTIC MEDIAWIKI
The sources variable holds a JSON object. This object contains further objects,
which describe the tables being the data source for the exhibit. Each of these
objects has an ID . This ID equals the HTML ID of the result table that the resultprinter will create in the body (see next section). The name columns defines the
datatypes of the values a table column holds. Since the SMWPrintRequest object
contains datatypes of Property values, the result printer reuses this information
here.
1 var facets = {
2 facet0: {
3 ex:expression=".state",
4 innerHTML: ’ex:role="facet" ’
5 }
6 };
The facets variable stores information about facets the resulting exhibit is ex-
pected to set up. Each facet is described by a JSON object. Ex:expression
defines the Property the facet will operate on. The name of this Property is de-
rived from the new query parameter facet . The name innerHTML holds further
HTML attributes describing the facet. These HTML attributes are extracted from
the query string as well.
1 var views = "ex:role=’view’ ex:viewClass=’Tabular’ ";
The view variable only contains HTML attributes. The value of the viewClass
attribute is extracted from the new views query parameter.
Before we find out about the exact purpose of these variables, let us take a look
at what the result printer embeds in the body of the output page.
BodyThe result printer creates an HTML table from the SMWQueryResult object in
the body. Since Section 2.1.2 described how the table result printer works, we omit
a further explanation. The resulting table is tagged with an ID corresponding to
the ID the sources variable holds.
Besides, the result printer adds a div tag with a special ID to the body:
36

8/3/2019 SMW Exhibit Thesis
http://slidepdf.com/reader/full/smw-exhibit-thesis 38/63
3 INTEGRATION OF EXHIBIT AND SEMANTIC MEDIAWIKI
1 <div id=\"exhibitLocation\" />
Listing 3: Placeholder
This new div tag can be regarded as marker. The function of this tag becomes
obvious, when we broach the issue of the invoked JavaScript file exhibit.js in the
next section.
The exhibit.js JavaScript file
The JavaScript code we are about to examine originates from Wibbit to a great
extent. The code implements a new start-up function for Exhibit. This function
can be divided into two parts.
The first part is dedicated to the procurement of input data. In place of
loading JSON data Exhibit’s Exhibit.HtmlTableImporter.loadTable()
function is used to scrape input data from an HTML table. Since the code we
are exploring at the moment can access the JavaScript variables in the head, the
JavaScript gets information about the ID of the table from the sources variable.
The second part deals with passing information regarding the presentation to
Exhibit. The variables sources, facets and views hold this data in JSON
notation. The code creates an HTML snippet containing all the usual tags Exhibit
processes from these variables. The resulting HTML snippet is inserted in the div
environment with the ID ”exhibitLocation”. Since the code creates and injects the
HTML on the client side, the Sanitizer cannot interfere here.
3.1.6 Advanced Features
The previous section covered the rudimentary implementation of an Exhibit re-
sult printer. The implementation exploited Exhibit’s basic features, whereupon
much potential remained unused. The features discussed in this section utilize
more sophisticated functionalities of Exhibit. The discussion points out further
capabilities as well as boundaries of Exhibit. Not every feature we consider in this
section can and will be implemented. The last section sums up which features find
their way into the final Exhibit printer by outlining their implementation.
37

8/3/2019 SMW Exhibit Thesis
http://slidepdf.com/reader/full/smw-exhibit-thesis 39/63
3 INTEGRATION OF EXHIBIT AND SEMANTIC MEDIAWIKI
Mechanisms to improve Usability
To accomplish high usability, the obligation of providing additional query param-
eters must be diminished as far as possible (see Section 3.1.1). The result printercan apply simple algorithms on the query results to retain non-bloated and well-
arranged query strings. These algorithms attempt to anticipate what the user
expects the exhibit to visualize. This section demonstrates two algorithms target-
ing the following achievements:
• Making parameters obsolete by reusing information about datatypes
• Calculating suitable numeric values for parameters by analyzing Property
values
As SMWs already contain information about datatypes, the Exhibit result
printer can exploit this information to forecast what the user plans to visual-
ize. To visualize data on a map, we have to convey a Property holding geographic
coordinates to Exhibit. The common way is assigning the Property name to the
latlng parameter in the ask query. To make this parameter dispensable, the result
printer can look out for Properties holding geographic coordinates, once the map
view is selected. We can do the same for the timeline view. A data set on the
timeline is characterized by a start and optionally an end date. We can pass in-
formation about which Property contains the start and which one the end date to
Exhibit by adding a start and an end parameter to the query. To make these dec-
larations obsolete, a small function can collect the first selected Properties holding
date values.
By now, the result printer just harnesses Property’s metadata. It is possible
to go farther and analyze the different Property values in a result set to derive
suitable configurations for facets. Section 2.2.2 mentioned numeric facets. In anumeric facet Exhibit groups values in several intervals. However, we have to set
the span of these intervals manually so far. By analyzing the set of numbers, a
simple algorithm can determine an appropriate interval span, though.
A description of the implementation of these features can be found at the end
of this section.
38

8/3/2019 SMW Exhibit Thesis
http://slidepdf.com/reader/full/smw-exhibit-thesis 40/63
3 INTEGRATION OF EXHIBIT AND SEMANTIC MEDIAWIKI
Browsing the data instead of just displaying it
Exhibit can be looked upon as a rich browsing interface for data. It competes with
projects like Tabulator [25] or mSpace [26]. At the moment the result printer doesnot take advantage of Exhibit’s browsing capabilities, since all resulting data is
presented in a flat list without any links. The lack of links gives the impression
that the wiki does not contain any related data. In most cases this is not true. To
overcome this impression, two approaches are imaginable:
• The result printer creates links to related wiki pages
• The result printer gathers data in advance and passes it to Exhibit
Data shown by Exhibit can be linked to the related wiki pages (if there are
any). We can use lenses (see Section 2.2.2) to alter the rendition of each result
entry and thus embed links. The customized lens design this thesis proposes is
not so different from the standard design (see Figure 10). In contrast to default
lenses, all text items are rendered as links, if SMW holds a page about them.
This applies to every Property name, since Properties are represented by articles
within SMW. Obviously, it makes sense to render values of the type wiki page as
links, too. For each ask query using the Exhibit result printer a new lens has to
be designed, because each query yields a different amount and different kinds of
Properties. As the result printer already creates HTML markup (for views, facets
etc.), an obvious approach is letting it create the code for a particular lens as
well. This feature is part of the implementation of the result printer (see Section
Implementation for details regarding the implementation).
Exhibit and SMW share a common data structure: they both rely on graph-
based data models. So far, this thesis pursued a query-oriented approach. This
approach yields that solely data gathered by queries is subject to the recently
described operations. However, constraining the data volume is a legitimate courseof action, since Exhibit is not designed to deal with large data volumes, as David
Huynh states in his doctoral thesis [7]. Despite of this fact, it is advisable to make
even some related data available to Exhibit.
Usual result printers only focus on tiny apertures of the graph-structure, since
the data provided by the SMWQueryResult object is limited. The result set is
39

8/3/2019 SMW Exhibit Thesis
http://slidepdf.com/reader/full/smw-exhibit-thesis 41/63
3 INTEGRATION OF EXHIBIT AND SEMANTIC MEDIAWIKI
Figure 10: Customized lens
just a flat list of pages (which correspond to Exhibit Items) and their Property
values. The fact, whether a Property value is represented by a further page, is
not taken into account. Hence, data from other articles is not part of the result
set. Subsequently, the bubbles Exhibit shows when an Item is clicked (see Section
2.2.2) stay blank. As workaround the solution proposed above embeds links to the
related pages and therefore prevents the bubbles from popping up. In consequence
we have to leave the exhibit behind, if we want to access further information. When
returning to the exhibit, it is back in default state and thus former changes (e.g.
view or facet selections) got lost. That is why it is worth it to push on with
taking advantage of Exhibit’s built-in browsing features on the whole. The next
paragraphs expand on achieving the exploitation of Exhibit’s browsing capabilities.
Exhibit copes with multiple data sources. It is possible to combine data from
tables with data from JSON sources. So far, the result printer only feeds Exhibit
through tables created from the result set. To open up information that resides on
other wiki pages, Exhibit can tap other sources: it can get the missing information
from JSON files, once it is available as JSON. One way to make the semantic data
of articles available as JSON is the establishment of a JSON exporter, which takes
the name of a wiki page as parameter in the URL and returns the content of the
Factbox on this page as JSON (SMW already offers this feature for RDF output).
To retrieve JSON, an URL of the following scheme can be called:
http://urltowiki/index.php/Special:JSONExport/pagename
40

8/3/2019 SMW Exhibit Thesis
http://slidepdf.com/reader/full/smw-exhibit-thesis 42/63
3 INTEGRATION OF EXHIBIT AND SEMANTIC MEDIAWIKI
For each wiki page value of the result table the result printer can create a link
to the corresponding URL in the header of the output page. Thus Exhibit gains
access to the data of related articles.In principle, Exhibit is able to traverse the whole data graph of an SMW, as
soon as it is available as JSON. Even though the export of the entire graph as
JSON is feasible, we run into performance issues here: Exhibit is not designed for
processing large amounts of data. However, Exhibit only fetches data during its
start-up procedure. Once the start-up function has been executed, we cannot ask
Exhibit to fetch additional data. The lack of an option to reload information on
demand forms an obstacle, since all data that might be requested by the user has to
be available in advance. So big parts of the data graph have to be prefetched. The
fetching procedure delays the construction phase of an exhibit tremendously. It is
much to be hoped that future releases of Exhibit provide an option to fetch data
on demand. As long as the construction phase of an exhibit is delayed significantly,
it is not advisable to add this feature to the Exhibit result printer. Therefore we
refrain from an implementation.
Multiple Exhibits as Obstacle and Opportunity
Articles in an SMW sometimes contain more than one query. We have not dealt
with the case of multiple queries using the Exhibit result printer on one page yet.There are two feasible approaches on how to tackle multiple queries:
• Merging the query results
• Separating different data sources by introducing collections
The query results can be mashed up. Exhibit merges data on the basis of
matching labels or IDs, respectively. Whereas it is not appropriate to merge data
describing different types of entities (e.g. cars vs. animals), it is apparent to
combine data sets that both contain entities of the same type. For instance,
we can let Exhibit unite cities located in the US and cities located in Germany.
However, the fact that we have to set parameters such as views and facets for each
query again and again leads to redundant or different query parameters. This is
not the only shortcoming the current query-oriented syntax yields. We shall face
an additional shortcoming in the next paragraph.
41

8/3/2019 SMW Exhibit Thesis
http://slidepdf.com/reader/full/smw-exhibit-thesis 43/63
3 INTEGRATION OF EXHIBIT AND SEMANTIC MEDIAWIKI
The second option is to populate the existing exhibit with a new view for each
data set. We can distinguish the various query results by using collections (see
Section2.2.2). With the help of the view panel, one can switch between the differentviews. Certainly, embedded in a normal wiki page an exhibit visualizing different
data sets in one view panel tends to confuse users. On usual wiki pages, the
information is structured by sections. Graphics are embedded at the position
where they are referred or match the context. The content of an article is browsed
by scrolling down the page. With different data sets, different information which
is not necessarily related to each other is presented on one single spot (remember
the cars vs. animals example). It becomes difficult to identify which section of the
text the exhibit refers to. The missing possibility to scatter different views across
a wiki article bares another shortcoming of the current query syntax.
Within this thesis data mash-up is considered to be the most advantageous
option of how to deal with multiple queries. We shall see that data mash-up is
useful in terms of remote querying in Section 3.3.
Information regarding Exhibit’s presentation can only be passed to Exhibit
through query parameters right now. As long as there is no way to place views on
different spots on a site, it is not advisable to implement the second option. We
have to come up with a new syntax for conveying information to Exhibit that is
independent of query strings.
Customizing Exhibits
In Section 3.1.6 Exhibit’s generic views were aligned to SMW’s infrastructure by
introducing a new lens template. However, this generic template is predetermined
and the user thus cannot influence the appearance of an exhibit beyond selecting
views and facets. As users might want to give exhibits a personal touch, the result
printer has to provide a way to define a lens. Assigning the HTML snippet of a
lens to a query parameter is not practical, because an HTML snippet bloats thequery string gratuitously. With the view to avoiding the need for special markup
outside the query string, other ways have to be investigated.
A closer look at MediaWiki’s template system pays off: in MediaWiki we can
define wikitext templates that are lodged on certain pages in the ”Template”
namespace. Let us consider a template called “City”. To define the template we
42

8/3/2019 SMW Exhibit Thesis
http://slidepdf.com/reader/full/smw-exhibit-thesis 44/63
3 INTEGRATION OF EXHIBIT AND SEMANTIC MEDIAWIKI
have to create the article Template:City that has the following content:
This is the city of {{{Name}}}.
It is located in {{{State}}}.
The template contains two markers (Name, State). If we want to paste this snippet
in an article, we have to place the following expression in the wikitext of the
corresponding article:
{{City | Name=Boston | State=Massachusetts}
The parameters after the template name assign values for the markers in the
template. MediaWiki’s template engine substitues the markers with the values.
The resulting replacement for the expression is:
This is the city of Boston.
It is located in Massachusetts.
For instance, info boxes many Wikipedia articles come along with are based on
templates. This concept is not fairly different from lenses. MediaWiki templates
as well as lenses describe renditions. So it seems obvious to employ MediaWiki’s
framework for specifying a template to define lenses for an Exhibit. To pass the
specification of a lens to Exhibit, we advise the result printer of the lens’ locationby setting a new query parameter called lens. The result printer fetches the lens
code from the corresponding page and converts the received wikitext to HTML.
The next section provides further details on the implementation.
Implementation
The recent sections discussed numerous features. In this section the implementa-
tion of these features is tackled.
Leveraging information to guess the values of query parameters To guess a
latlng parameter, the result printer loops through the SMWPrintRequest object.
As soon it finds a Property holding a geographic coordinate the loop breaks and
the Property name is passed to Exhibit. To anticipate start and end values for
timeline views, the result printer initiates the same loop, but it looks out for two
Properties holding date values. The first hit is assumed to be the start date,
43

8/3/2019 SMW Exhibit Thesis
http://slidepdf.com/reader/full/smw-exhibit-thesis 45/63
3 INTEGRATION OF EXHIBIT AND SEMANTIC MEDIAWIKI
whereas the second hit is considered to be the end date. If no second hit occurs,
the result printer only sets the start date.
Replacing Exhibit’s default lens to link related articles A new JavaScript vari-
able lens supplements the existing variables (sources, views, facets). The variable
holds HTML markup that describes the look of the lens. To create the HTML the
printer sifts through the print requests and utilizes the possibility to request an
HTML link to Property pages instead of getting only the pure title.
Enabling the user to define customized lenses The result printer derives the
name of the template from the lens parameter. Next it fetches the content from
the corresponding template page with the aid of basic MediaWiki library functions19. As the fetched content is formatted in wikitext, it must be converted to HTML
to be a lens for an exhibit. The call of MediaWiki’s wikitext parser to get HTML
turns out to be fairly simple. Since we cannot replace the markers with the code
Exhibit expects on the server side (the Sanitizer would filter certain tags, we have
to replace it with a further marker that passes the Sanitizer. Finally, new code in
the exhibit.js file replaces this markers with Exhibit’s way of addressing property
values. Please note that the names of the markers in the template have to match
the names of the Properties whose values Exhibit is supposed to fill in.
3.2 Enabling Exhibit to Fetch Data from Remote Wikis
Exhibit accesses various data sources and thus grants numerous options to create
and edit input data. A wide range of users employ Google Spreadsheets20 to
manage input data. However, using tables as a data source yields limitations.
For certain information, particularly metadata, a table scheme does not reserve
room. This section aims at arranging SMW as further alternative for creating
and managing input data. In contrary to Google Spreadsheets, SMW encourages
users to provide metadata that is valuable to Exhibit. Section 3.2.1 determines
the construction of data exchange between SMW and Exhibit. Next a decision
19http://www.organicdesign.co.nz/MediaWiki_code_snippets lists the most use-ful MediaWiki functions a contributor can resort to
20http://docs.google.com/
44

8/3/2019 SMW Exhibit Thesis
http://slidepdf.com/reader/full/smw-exhibit-thesis 46/63
3 INTEGRATION OF EXHIBIT AND SEMANTIC MEDIAWIKI
for the format of the exchanged data is made in Section 3.2.2. It turns out that
JSON is the most appropriate format. In consequence, we design (see Section
3.2.4) and implement (see Section 3.2.5) a JSON exporter for SMW. The outputof this exporter can feed exhibits throughout the web.
3.2.1 Architecture
While reviewing the collaboration of Exhibit and Google Spreadsheets, it is re-
vealed that data management and presentation are performed on separated servers.
Whereas the user creates and stores the input data on Google’s servers, Exhibit’s
presentation capabilities are leveraged on a different server. The use of SMW
instead of Google Spreadsheets does not change this scenario. The server thathosts SMW and the server the exhibit resides on do not necessarily have to be
the same. Therefore communication between a remote SMW and Exhibit across
server boundaries has to take place. This section outlines the main elements of
such a communication.
As it might not be desirable in all cases to export the entire wiki content to
Exhibit, we have to investigate ways to select certain parts of the data. Queries
are a helpful instrument here, since they select a subset of the entire data volume.
Thus a request for data Exhibit sends to SMW needs to include a query. Afterhaving received the request, SMW delivers the results in a certain format. The
choice of a format is the objective of the next section.
3.2.2 Data Format
This section substantiates that creating a JSON exporter for SMW is the best
method to feed an Exhibit with data across server boundaries. Both Seman-
tic MediaWiki and Exhibit offer an open infrastructure to build customized im-
porters and exporters. SMW’s existing exporters serialize data in XML (eXtendedMarkUp Language), whereas Exhibit prefers JSON as input format21. XML has
taken hold as a format for structured data on the web and is thus well-known by
web developers. In contrast, JSON is an emerging format which gains in impor-
tance and has not achieved such a wide adoption yet. JSON has a higher space
21Formats other than JSON have to run through a converter first
45

8/3/2019 SMW Exhibit Thesis
http://slidepdf.com/reader/full/smw-exhibit-thesis 47/63
3 INTEGRATION OF EXHIBIT AND SEMANTIC MEDIAWIKI
efficiency than XML, but the lean syntax of JSON affects the readability [27]. As
XML and JSON are not compatible, a conversion between these formats has to
occur at one point. It is arguable where this transformation process should besettled. Two options are conceivable:
• Enabling Exhibit to import XML data
• Enabling Semantic MediaWiki to export JSON
Since Exhibit is a JavaScript framework it internally handles data in JSON.
Within the scope of the first option, data is transformed to an arbitrary format
by SMW and then to JSON by Exhibit. The conversion to JSON happens on theclient side and slows down Exhibit’s rendering process. To save this transformation
step, SMW can directly deliver JSON.
Additionally, SMW benefits from a JSON exporter in other respects. Many web
services support JSON as input or output format (e.g. Freebase and many Google
services). A JSON exporter enables SMW to interact with these web services.
Since wikis tend to contain large data volumes, JSON’s space efficiency helps to
minimize the overhead of data transfers. Furthermore, an easy way to exchange
JSON across server-boundaries exists (see Section 3.2.4).Indeed JSON is identified as the format of choice, but a statement on how
SMW’s data model is encoded in JSON has not been made yet. We develop a
data model in the next section.
3.2.3 Data Model
This section argues for sticking with Exhibit’s JSON data representation (Exhibit’s
way to represent data in JSON will be referred to as Exhibit JSON from now on). A
format is not only characterized by its syntax but also by the underlying semantic
model and the resulting expressivity of this model. For example, it is possible to
serialize RDF in JSON. Proposals on how to represent RDF in JSON can be found
in [28]. The invention of a new way to represent SMW’s data in JSON can also
be anticipated, but we have to keep in mind that Exhibit is going to be the main
consumer of exported JSON data (for now).
46

8/3/2019 SMW Exhibit Thesis
http://slidepdf.com/reader/full/smw-exhibit-thesis 48/63
3 INTEGRATION OF EXHIBIT AND SEMANTIC MEDIAWIKI
Most web services have their own JSON format. The majority of these formats
does not significantly differ from Exhibit JSON and therefore only needs to be
slightly adjusted. If we want Exhibit to extract data from such a JSON source,we can pass the name of a javascript function that is taking care of the conversion
to Exhibit JSON. Listing 4 illustrates how to advise Exhibit of the JavaScript
function implementing a converter.
1 <link rel="exhibit/data" type="application/json"
2 href="..." ex:converter="JSONConverter" />
Listing 4: Specifying a Converter Function
However, the conversion, as the transformation from XML to JSON, requires
extra processor time. This extra processor time may not be underestimated, since
client-side rendering gets slower the larger the data volume is. To supersede this
conversion, the JSON exporter can output Exhibit JSON. Exhibit JSON excels
at good readability. It addresses the user’s eagerness to experiment with data.
These experiments include actions such as copying and pasting data manually
and reusing it for other exhibits. To be able to do that, the user must have an
understanding of the format. For instance, it can be doubted that a casual user
can cope with formats like these ones proposed in [28]. The next section shows
how SMW’s data structure can be encoded in Exhibit JSON.
Mapping to Exhibit JSON
Section 2.2.1 explained the structure of an Exhibit JSON file. Now we go over the
objects of an Exhibit JSON file once more to identify the corresponding informa-
tion SMW’s contain.
Item Types
Exhibit allows the user to specify the type of Items. When creating a query inSMW, it is not clear what type of entities will be returned. For example, when
asking for pages with the Property located in and the value United States, the
selected pages could deal with any entity that is located in the United States such
as a city, a state or a building.
Optionally, we can assign articles to categories. Categories can be construed
47

8/3/2019 SMW Exhibit Thesis
http://slidepdf.com/reader/full/smw-exhibit-thesis 49/63
3 INTEGRATION OF EXHIBIT AND SEMANTIC MEDIAWIKI
as classes. In certain cases the class matches the type of an entity (consider a
category City that contains articles about cities). In other cases the equality of
categories and types does not apply22
. Moreover, articles can belong to multipleor no categories. Due to these ambiguities the output of the JSON exporter we
implement in Section 3.2.5 does not encompass the types object.
Datatypes
Both SMW and Exhibit rely on datatypes to characterize Property values. Since
these datatypes are not utterly identical, we have to align them. The following
table proposes a mapping of the different datatypes.
Semantic MediaWiki Exhibit
Wiki Page Item
String Text
Number Number
Date Date
URL URL
The core piece of the two graph-based data models is a wiki page or an Item,
respectively. String and text as well as number and URL are a perfect match,
whereas SMW’s date datatype is more expressive and features a higher range.
SMW’s remaining built-in datatypes such as geographic coordinate do not have
counterparts in Exhibit, but these values can be treated as usual textual values.
Items
Each row of a query result set corresponds to one object of the Items array. Both
SMW and Exhibit rely on property-value pairs to describe an entity. The property
label is defined by the title of a selected article.
We saw that some of SMW’s valuable information (e.g. certain datatypes)does not find its way into Exhibit JSON. We can neglect this issue, since most
applications being capable to process JSON would not leverage this information
anyway. While reviewing various JSON formats of different web services it turns
out that most of these formats do not encompass metadata.
22for instance, a category USA could contain entities of different types (cities, states)
48

8/3/2019 SMW Exhibit Thesis
http://slidepdf.com/reader/full/smw-exhibit-thesis 50/63
3 INTEGRATION OF EXHIBIT AND SEMANTIC MEDIAWIKI
On the other hand, SMW does not provide information Exhibit JSON frequently
embodies (e.g. itemtypes). This information is not mandatory. Hence, we do not
run into problems here.
3.2.4 Design of a JSON Exporter
In Section 2.1.2 the Special:Ask page was introduced. The page hosts a form we
can use to define the different components of a query. Instead of being embedded
in an article, the query results are displayed on the special page itself then. Fur-
thermore, we can request plain results without the usual HTML markup for thewiki navigation. For instance, such plain results can be formatted as an RSS file.
To receive such a file, we pass the query to the PHP script that is implementing
the Special:Ask via GET parameters. SMW already features an RSS export. We
have to call the following URL to get a detached RSS file consisting of entities
that are located in the United States:
http://wikiurl/Special:Ask?title=Special%3AAsk&q=[[located+
in%3%3AUSA]]&po=&sort0=&order0=DESC&sc=1&eq=yes
To format these plain results and thus create the RSS file, Special:Ask relies on
result printers (see Section 2.1.2). Result printers detect whether they are expected
to deliver query results to be embedded in an article (if they are invoked by an
inline query) or a plain file (if they are called by Special:Ask).
Hence, it is essential to create a new result printer for formatting a (Exhibit)
JSON file. This result printer can be used for results of inline queries, too. Instead
of returning a plain file the result printer embeds a link to the JSON file in the
articles. The link points to the URL of Special:Ask and contains the encoded query
string then. Users can benefit from such a link, as they are able to copy and paste
the link location in an exhibit. There is only one obstacle: such an exhibit only
works properly if it is hosted on the same server the new result printer is running
on. The next section expands on reasons and workarounds for this obstacle.
49

8/3/2019 SMW Exhibit Thesis
http://slidepdf.com/reader/full/smw-exhibit-thesis 51/63
3 INTEGRATION OF EXHIBIT AND SEMANTIC MEDIAWIKI
JSON with Padding
Web browsers prevent cross-domain data fetching due to security issues (this policy
is often referred to as “Same Origin Policy”). Thus data from “foreign” resourcesoutside of the current domain is not fetched. At the first sight, it is not simple to
feed Exhibits with JSON files, which are located on remote servers, since a simple
link tag to the resource on the remote server does not have an effect.
Basically, two kinds of workarounds exist (apart from proprietary technologies
like Flash) to retrieve JSON from remote servers anyway:
One popular way to trick the browser is the setup of a PHP script on the server
that hosts the exhibit, which requests the JSON file from the remote server and
passes it to the browser. The browser is not aware of the fact that the JSON
file originated from a remote server, as it gets the JSON from the PHP script.
Such PHP scripts are called parrot scripts, since they just repeat the content of
the remote JSON file and twitter it to the browser. However, parrot scripts do
not work on every server. The PHP as well as Firewall configurations determine,
whether data fetching from remote servers is permitted. Additionally, an Exhibit
user cannot be expected to setup a PHP script.
JSON with Padding (JSONP) was introduced as a workaround that bypasses the
browser’s security arrangements. An initial blog post [29] triggered the circulation
of this idea in the blogosphere. In response to JSONP Yahoo published a similar
approach on the corporate website [30]. It is hard to come up with an universal
description on how JSONP works, since implementations vary. The following
paragraph encompasses the constitutive actions that all implementations perform.
In either case local JavaScript code dynamically generates a script tag that
points to a remote script. The remote script gets invoked, since script tags,
unlike link tags, are not subject to browser’s security limitations. In one of his
blog entries [31] Rick Strahl provides a sample on what such JavaScript code could
look like. The trick is that the invoked remote script contains more than only apure JSON string to make the JSON accessible to the local JavaScript. By putting
the JSON string in parentheses and prepending a function name, a function call
having the JSON string as parameter emerges:
1 callbackfunc({"foo":42});
50

8/3/2019 SMW Exhibit Thesis
http://slidepdf.com/reader/full/smw-exhibit-thesis 52/63
3 INTEGRATION OF EXHIBIT AND SEMANTIC MEDIAWIKI
The local JavaScript code implements the function that is called in the remote
script. Within the code of the function implementation the JSON string is acces-
sible via the passed parameter:
2 function callbackfunc(result)\{
3 alert(result.foo);
4 }
JSONP does not escape security issues. Using JSONP can lead to critical secu-
rity risks. The tapped data source has to be trustworthy and reliable, since it is
rather easy to inject malicious code by replying such code instead of the requested
JSONP. Furthermore, an error handling on the fetching side is fairly impossible, asthe incoming data comes “out of the dark” [32]. An encryption of the exchanged
data cannot take place either.
Currently, JSONP is offered as output format by many web services, including
Google Spreadsheets [33]. Exhibit utilizes Google Spreadsheet’s JSON export to
get data from spreadsheets. Similar to a normal link tag pointing to a JSON
data source, the following link tag taps a JSONP data source:
5 <link rel="exhibit/data" type="application/jsonp"
6 href="http://urltojsonp/exhibit.jsonp"
7 ex:jsonp-callback="editgridCallback"
8 />
In addition we can set the name of a particular callback function (ex:jsonp-callback)
in case the name of the function differs from the default name callback .
Query Adjustments
Certain applications desire JSON (because they are using a parrot script), whereas
others prefer JSONP. To stay flexible here, we have to signalize SMW what it is
expected to deliver. This is done through a new query parameter called callback .
Without adding this parameter to the query, regular JSON is exported. As soon
as a callback parameter is part of the query, SMW adds the obligatory callback
function to the JSON export. The name of this function is derived from the value
of the callback parameter. A sample JSONP query could look like the following:
51

8/3/2019 SMW Exhibit Thesis
http://slidepdf.com/reader/full/smw-exhibit-thesis 53/63
3 INTEGRATION OF EXHIBIT AND SEMANTIC MEDIAWIKI
{{ask: [[located in::Germany]]
| ?state
| format=JSON| callback=callback}}
3.2.5 Implementation
As the creation of a result printer has already been part of the first integration
step (see Section 3.1.2), the implementation of a JSON result printer is summarized
briefly. To format the properties object of the JSON output, the result printer
sifts through the print requests. For each print request the type of the Property
is read out and mapped to the corresponding Exhibit type. The mapping is hard-coded in an array. The items object is generated by going through the result
object row by row. The titles of the selected pages are assigned to the label
property. Furthermore, for each Item an URI property is created that holds an
URI to the wiki article that represents the Item. If a callback value is present, the
result printer puts the output in parentheses and prepends the callback function
name.
3.3 Using Exhibit to Enable Data Exchange Between SemanticMediaWikis
We encounter wikis in everyday situations. Wheras we might use one at work,
personal wikis become of interest more and more [34]. Along the way, we use
Wikipedia for knowledge procurement. As noted in the introduction, all these
wikis are separated islands without a stable connection. The lack of a convenient
method to exchange data among wikis fosters the generation of redundant data.
Textual data is copied and pasted to transfer data from one wiki to another. The
copied snippets get out of date quickly or evolve independent of the wiki they
are originating from. MediaWiki already supports a more sophisticated way of
exchanging data that is file-based. After having entered the names of pages to
be exported on the Special:Export page, the wiki system integrates the selected
pages in an XML file. In the target wiki, we must import these files with the aid
of another special page again. This best practice has the following shortcomings:
52

8/3/2019 SMW Exhibit Thesis
http://slidepdf.com/reader/full/smw-exhibit-thesis 54/63
3 INTEGRATION OF EXHIBIT AND SEMANTIC MEDIAWIKI
• Completion of several web forms and juggling with data files make the pro-
cedure rather tedious
• The problem regarding outdated information remains
• The selection of data to be exported is imprecise, since the selection process
is only page-based
In this section remote queries are introduced to help mitigate these shortcomings.
Section 3.3.1 describes the function of remote queries. The implementation of
remote queries is tackled in Section 3.3.2. Since the implementation leaves several
questions unanswered, Section 3.3.3 broaches the issue of possible improvements.
3.3.1 Design of Remote Queries
This section illustrates the procedure of remote queries. To request data from
remote wikis, we want to create an inline query containing a remote parameter
that indicates the wiki the query is meant for. The following query is supposed to
be executed on the data of http://semanticweb.org by the query processor of the
wiki running on this domain:
{{#ask: [[located in::USA]]
| ...
| format = exhibit
| remote=http://semanticweb.org}}
The query is passed to the remote wiki without being executed in the local wiki.
The remote wiki processes the query and delivers the query results as JSONP. We
use an exhibit in the local wiki to display the incoming JSONP data.
3.3.2 ImplementationThe two components being the ingredients of the implementation of remote queries
have already been designed and implemented:
1. JSON(P) Exporter
2. Exhibit result printer
53

8/3/2019 SMW Exhibit Thesis
http://slidepdf.com/reader/full/smw-exhibit-thesis 55/63
3 INTEGRATION OF EXHIBIT AND SEMANTIC MEDIAWIKI
These two components need to be combined to accomplish data exchange. To
add support for remote queries, we enhance the code of the Exhibit result printer.
Instead of creating a table from the result data to form a data source for Exhibit,the result printer creates a link pointing to a remote JSONP source. The link
location is defined by the remote query parameter. We have to extend this link
with a string that encodes the query we want to submit to the target wiki. The
SMWQueryResult object offers helpful methods to create this string.
3.3.3 Advanced Features
Indeed we enabled on the fly data exchange, but the current implementation shows
inadequacies that can only be solved by carrying out additional features. Thereforethe implementation can merely be regarded as proof of concept. The following
sections reveal needs for improvement.
Data Integration
One open issue is data integration. Even though data is requested and retrieved
from remote wikis, this data is exclusively displayed in the importing wiki. The
data is not mashed with the existing local data and thus does not become part
of the database of the local wiki. Of course, Exhibit cannot help to transfer data
into wiki databases, but it can merge multiple data sources in its views.The combination of the following two queries yields a data set which contains
US cities as well as German cities, although the set of German cities is picked up
from a remote wiki. The user is not be able to distinguish between data from the
local and the remote wiki while viewing the exhibit.
{{#ask: [[located in::USA]]
| ?geo
| format=exhibit
| views=map}}
{{#ask: [[located in::Germany]]
| ?geo
| format=exhibit
| views=map
54

8/3/2019 SMW Exhibit Thesis
http://slidepdf.com/reader/full/smw-exhibit-thesis 56/63
4 DISCUSSION AND OUTLOOK
| remote=http://localhost/˜fh/germanywiki}}
Different SMWs run on different ontologies. In the example, we assume that
properties and categories have the same name and semantics in both wikis. In
reality, the match of properties and categories is unlikely. It is necessary to come
up with a way to align properties originating from different wikis. For instance,
we can introduce new syntax constructs such as as statements to express that
properties with different names have the same semantics.
Multiple requests
To make thriving data exchange among wikis possible, the involved wikis have to
deal with multiple data requests at the same time. To contribute to an effectivehandling of data, wikis need to reduce the workload by caching the results to
avoid frequently-repeated execution of queries. We have to make up our mind
about caching strategies that speed up the availability but affect the currentness
of data as few as possible.
Confidential Data
Of course, not every wiki administrator wants to share the entire wiki data with
the public. We have to investigate mechanisms that protect confidential informa-
tion from being queried by remote wikis. Usual page-based restrictions are notsufficient, as they are not fine-grained enough.
Security Issues
Risks that are caused by technologies such as JSONP have to be averted. For
instance, we have to make sure users cannot query arbitrary resources. To prevent
that, we can only permit querying of trustworthy wikis that are part of a white
list.
4 Discussion and Outlook
The integration of Semantic MediaWiki and Exhibit covers the entire value chain
from creating to presenting structured data. SMW is in charge of creating and
managing structured data, whereas Exhibit displays the data. The following sec-
tions summarize the contributions of the integration and discuss their impact.
55

8/3/2019 SMW Exhibit Thesis
http://slidepdf.com/reader/full/smw-exhibit-thesis 57/63
4 DISCUSSION AND OUTLOOK
4.1 Visualization of Query Results
Due to Exhibit, SMW incorporates new visualization features and therefore pro-
vides further incentives for the annotation of wiki articles. Wiki data can be
consumed more easily. The user is cleared from analytic tasks, since new coher-
ences are promptly revealed through map and timeline views. High information
loads, wikis tend to have, are subdued by features such as faceted browsing, sorting
and aggregation of queried content.
4.2 Use of Wiki Data in Other Web Applications
By exploiting the JSON Exporter Exhibit can visualize data of SMWs at anyplace of the World Wide Web. So wiki data finds its way into personal websites
or blogs. Many web applications, including content management systems such as
Drupal23 or blog engines, allow the user to embed exhibits. The Wordpress plugin
datapress24 supports users in adding exhibits to blog entries. The user is instructed
by a wizard and is not supposed to write a single HTML line for setting up an
exhibit. He can configure data sources, views and facets with a few mouse clicks.
The barrier of building rich data-centric web applications is lowered again. With
the aid of tools such as Semantic Forms or datapress data management and pre-
sentation are facilitated. The user gets along with little knowledge of wikitext to
create rich web applications. In comparison, popular frameworks for building web
applications such as LAMP25 require the knowledge of a language for the appli-
cation logic (e.g. PHP), a language for presentation (e.g. HTML) and another
language for data querying and management (e.g. SQL).
4.3 Data Exchange
This thesis established remote queries as method for on the fly data exchange
among semantic wikis. The fact that data exchange can be enforced rather con-
23the following blog entry describes how to use Exhibit with Dru-pal without requiring a special plugin: http://joshhuckabee.com/
getting-started-exhibit-using-drupal-and-views-part-124http://projects.csail.mit.edu/datapress/25LAMP is a software bundle that consists of Linux, Apache, MySQL and PHP
56

8/3/2019 SMW Exhibit Thesis
http://slidepdf.com/reader/full/smw-exhibit-thesis 58/63
4 DISCUSSION AND OUTLOOK
venient and incoming data is mashed with the local data yields new opportunities
of meliorating wiki data. Wiki authors can fetch data from remote wikis without
taking over the responsibility of maintaining the imported information. So thedomain expert, who is maintaining the data, stays in charge of keeping the data
up-to-date. As soon as changes are applied, the data in the importing wiki is
contemporarily26 updated as well. By this means not only information is shared
and reused but also the related expertise. As a future step, other repositories can
be involved in data exchange. For instance, freebase contains lots of generic and
useful information that is valuable to wiki articles.
4.4 OutlookIt is much to be hoped that SMW takes further root as tool for personal and corpo-
rate knowledge management among casual users. With the aid of Exhibit, SMW
users, who conduct personal information management, publish this information
through blog entries or personal web pages, whereas users dealing with SMW in a
business context use wiki data as basis of reports or presentations. Even if all this
information flows into less structured mediums like blog entries, the semantic data
remains in the wiki. In the course of enabled data exchange, the various wikis
grow closer together. Thus a large pool of structured data emerges. This datais subject to all benefits of a semantic web such as semantic search or semantic
browsing and thus helps to form a semantic web.
26in terms of the shown implementation the data is updated immediately, caching procedureswould delay an update
57

8/3/2019 SMW Exhibit Thesis
http://slidepdf.com/reader/full/smw-exhibit-thesis 59/63
References
References
[1] Tim Berners-Lee, James Hendler, and Ora Lassila. Semantic web. Scientific
American , May, 2001.
[2] Nigel Shadbolt, Tim Berners-Lee, and Wendy Hall. The semantic web revis-
ited. IEEE Intelligent Systems, 21(3):96–101, May/Jun 2006.
[3] World Wide Web Consortium (W3C). W3C semantic web activities. http:
//www.w3.org/2001/sw/, last checked: 02/15/09.
[4] Richard Benjamins, Jesus Contreras, Oscar Corcho, and Asuncion Gomez-
Perez. Six challenges for the semantic web. In Proc. KR2002 Workshop on
Formal Ontology, Knowledge Representation and Intelligent Systems for the
Web, 2002.
[5] Anupriya Ankolekar, Markus Krotzsch, Thanh Tran, and Denny Vrandecic.
The two cultures - mashing up web 2.0 and the semantic web. Journal of Web
Semantics, 6, 2008.
[6] Tim O’Reilly. What is web 2.0? http://www.oreillynet.com/pub/
a/oreilly/tim/news/2005/09/30/what-is-web-20.html, last
checked: 01/18/09.
[7] David F. Huynh. User Interfaces Supporting Casual Data-Centric Interactions
on the Web. PhD thesis, Massachusetts Institute of Technology, 2007.
[8] Tom Heath, John Domingue, and Paul Shabajee. User interaction and uptake
challenges to successfully deploying semantic web technologies. In Proc. 3rd
International Semantic Web User Interaction , 2006.
[9] A. Desilets, S. Paquet, and N. G. Vinson. Are wikis usable. In Proc. 1st ACM
Wiki Symposium , 2005.
[10] Christoph Sauer. What you see is wiki - questioning wysiwyg in the internet
age. In Proc. Wikimania , 2006.
58

8/3/2019 SMW Exhibit Thesis
http://slidepdf.com/reader/full/smw-exhibit-thesis 60/63
References
[11] Markus Krotzsch, Denny Vrandecic, Rudi Studer, Max Volkel, and Heiko
Haller. Semantic Wikipedia. Journal of Web Semantics, 5, 2007.
[12] Abraham Bernstein, Esther Kaufmann, Anne Gohring, and Christoph Kiefer.
Querying ontologies: A controlled english interface for end-users. In Proc. 4th
International Semantic Web Conference (ISWC05), pages 112–126, 2005.
[13] Max Volkel and Eyal Oren. Towards a wiki interchange format (wif)–opening
semantic wiki content and metadata. In Proc. First Workshop on Semantic
Wikis - From Wiki To Semantics, 2006.
[14] Tobias Kuhn. AceWiki: A natural and expressive semantic wiki. In Proc. 3rd
Semantic Wiki Workshop, 2008.
[15] Sebastian Schaffert, Rupert Westenthaler, and Andreas Gruber. Ikewiki: A
user-friendly semantic wiki. In Proc. 3rd European Semantic Web Conference,
2006.
[16] Fernanda B. Viegas, Martin Wattenberg, Frank van Ham, Jesse Kriss, and
Matt McKeon. Many eyes: A site for visualization at internet scale. IEEE
Transactions on Visualizations and Computer Graphics, 13(6):1121–1129,
11/12 2007.
[17] Dave Beckett. Rdf/xml syntax specification. W3C Specification. Available
at: http://www.w3.org/TR/rdf-syntax-grammar/, last checked:
02/12/09, 2 2004.
[18] Petra S. Bayerl, Harald Lungen, Ulrike Gut, and Karsten I. Paul. Method-
ology for reliable schema development and evaluation of manual annotations.
In Proc. Workshop on Knowledge Markup and Semantic Annotation at the
Second International Conference on Knowledge Capture (KCAP), 2003.
[19] Malte Kiesel and Leo Sauermann. Towards semantic desktop wikis. UP-
GRADE , 6:30, 2005.
[20] Stefan Haustein and Joerg Pleumann. Is participation in the semantic web
too difficult? In Lecture Notes in Computer Science. Springer, 2002.
59

8/3/2019 SMW Exhibit Thesis
http://slidepdf.com/reader/full/smw-exhibit-thesis 61/63
References
[21] Aditya Kalyanpur, James Hendler, Bijan Parsia, and Jennifer Goldbeck.
Smore - semantic markup, ontology, and rdf editor. Available at: http:
//www.mindswap.org/papers/SMORE.pdf .
[22] Douglas Crockford. RFC 4627 application/json. Available at: http://www.
ietf.org/rfc/rfc4627.txt?number=4627 .
[23] JSON: The fat-free alternative to XML. http://www.json.org/xml.
html, last checked: 02/02/09.
[24] Marti A. Hearst. UIs for faceted navigation: Recent advances and remaining
open problems. In Proc. 2nd Workshop on Human-Computer Interaction and
Information Retrieval , 2008.
[25] Tim Berners-Lee, Yuhsin Chen, Lydia Chilton, Dan Connolly, Ruth Dha-
naraj, James Hollenbach, Adam Lerer, and David Sheets. Tabulator: Explor-
ing and analyzing linked data on the semantic web. In Proc. 3rd International
Semantic Web User Interaction Workshop, 2006.
[26] m.c. schraefel, Max Wilson, Alistair Russell, and Daniel A. Smith. mspace:
improving information access to multimedia domains with multimodal ex-
ploratory search. Communications of the ACM , 49(4):47–49, April 2006.
[27] Ramon Lawrence. The space efficiency of xml. Information and Software
Technology , 46(11):753–759, September 2004.
[28] Keith Alexander. RDF/JSON: A specification for serialising RDF in JSON.
In Proc. 4th Workshop on Scripting for the Semantic Web, 2008.
[29] Remote json - jsonp. http://bob.pythonmac.org/archives/2005/
12/05/remote-json-jsonp/, last checked: 02/01/09.
[30] Using JSON (JavaScript Object Notation) with Yahoo! Web Services. http:
//developer.yahoo.com/common/json.html , last checked 01/26/09.
[31] Rick Strahl. JSONP for cross-site callbacks. http://www.west-wind.
com/Weblog/posts/107136.aspx , last checked 01/10/09.
60

8/3/2019 SMW Exhibit Thesis
http://slidepdf.com/reader/full/smw-exhibit-thesis 62/63
References
[32] Remy Sharp. What is JSONP? http://remysharp.com/2007/10/08/
what-is-jsonp/, last checked 01/17/09.
[33] Google. Simple example of retrieving json feeds from spread-
sheets data api. http://code.google.com/apis/gdata/samples/
spreadsheet_sample.html , last checked 01/15/09.
[34] A. P. McAfee. Enterprise 2.0: The dawn of emergent collaboration. MIT
Sloan Management Review , 47(3):21–28, 2006.
61

8/3/2019 SMW Exhibit Thesis
http://slidepdf.com/reader/full/smw-exhibit-thesis 63/63
References
Ich versichere hiermit wahrheitsgemaß, die Arbeit bis auf die dem Aufgaben-
steller bereits bekannte Hilfe selbststandig angefertigt, alle benutzten Hilfsmittel
vollstandig und genau angegeben und alles kenntlich gemacht zu haben, was ausArbeiten anderer unverandert oder mit Abanderungen entnommen wurde.
(Ort, Datum) (Unterschrift)


















