![1 T2K Experiment - University of Rochestermamday/shortthesis.pdffor T2K [?]. Figure 1.3: The NA61 detector. NA61 uses 30 geV protons on a graphite target like T2K to give precise predictions](https://static.fdocuments.us/doc/165x107/5f705a97147bc57aee7cc1b7/1-t2k-experiment-university-of-mamdayshortthesispdf-for-t2k-figure-13.jpg)
slide - T2K Open Supercomputer
30
Report on Feasibility Study on Future HPC Infrastructure II -- Issues of Exascale Accelerated Computing -- Mitsuhisa Sato Director, Center for Computational Sciences, University of Tsukuba / Team Leader of Programming Environment Research Team, AICS, Riken IWSDHPC-2012@Tsukuba
Transcript of slide - T2K Open Supercomputer

Report on Feasibility Study on Future HPC Infrastructure II
-- Issues of Exascale Accelerated Computing --
Mitsuhisa Sato
Director, Center for Computational Sciences, University of Tsukuba / Team Leader of Programming Environment Research Team, AICS, Riken
IWSDHPC-2012@Tsukuba

Outline
Issues for Exascale computing Why Accelerated computing?
HA-PACS project HA-PACS (Highly Accelerated Parallel Advanced system for Computational
Sciences) “Advanced research and education on computational sciences driven by exascale
computing technology”, funded by MEXT, Apr. 2011 – Mar. 2014, 3-year TCA: Tightly Coupled Accelerator, Direct connection between accelerators (GPUs)
Programming issue XcalableMP and XMP-dev extension for GPU Clusters
HPCI-FS projects for Japanese post-petascale computing "Study on exascale heterogeneous systems with accelerators"

3
Background: "Post-petascale computing“, toward exascale computing
State of the art: Petascale computing infrastructure US: Titan(27PF, 2012),sequoia (>20PF,2012) Japan: The K computer (>10PF, 2011), Tsubame 2.0 EU: PRACE machines (>5 PF, 2012-2013)
#cores 10^6 power >10 MW
What's the next of "Petascale"? Projection (and prediction)by Top500

4
What's "post-petascale" computing
Post-petascale ⊃ "exaflops" Several Possibilities and Alternatives for the next of Petascale, on the road to
"exascale"
Exascale=Extreme Scale ≠ "exaflops" Embedded terascale (hand-held, 10-100W) Departmental petascale (1-2 racks, 10-100kW) (Inter)national exascale (100 racks, 25-50MW)
Challenges strong scaling = find 1000× more parallelism in applications fault tolerance = new algorithms + validation/verification energy efficiency = new programming model(s), eg minimise data movement,
intelligent powering Novel hardware and programming, algorithms = GPGPUs, heterogeneous chips massive (potentially corrupted) data and storage = new I/O models
5
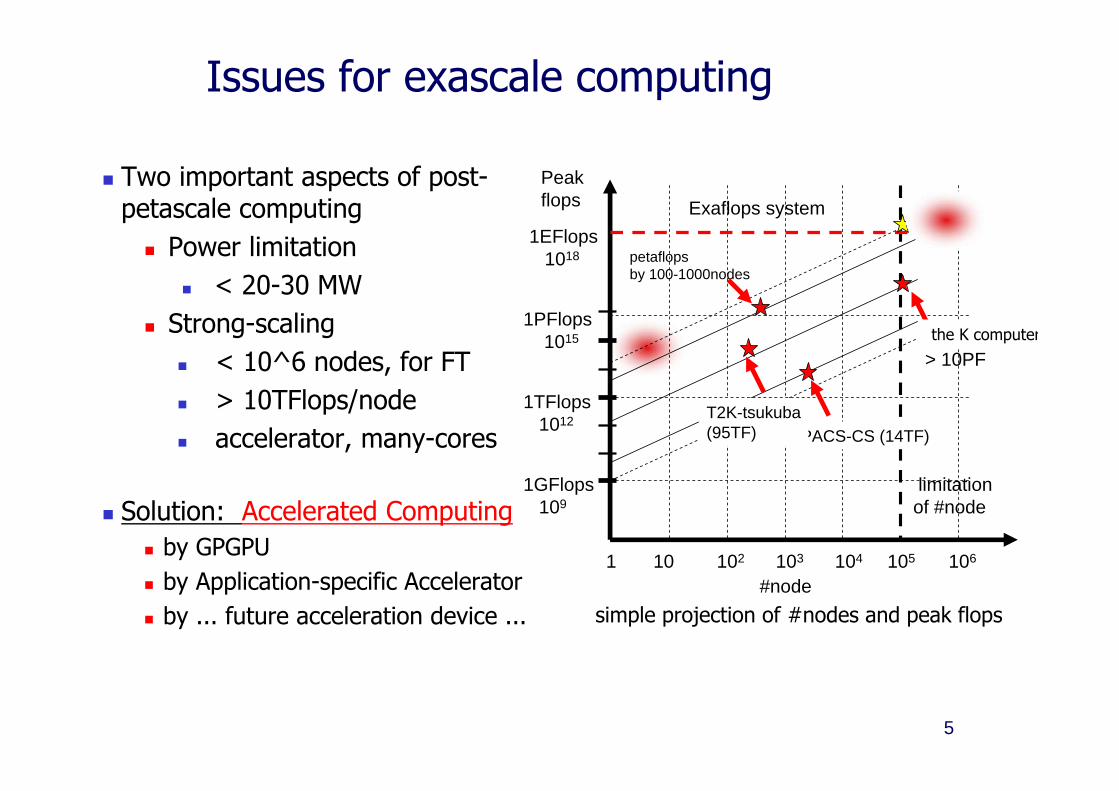
Issues for exascale computing
Two important aspects of post-petascale computing Power limitation
< 20-30 MW Strong-scaling
< 10^6 nodes, for FT > 10TFlops/node accelerator, many-cores
Solution: Accelerated Computing by GPGPU by Application-specific Accelerator by ... future acceleration device ...
1 10 102 103 104 105 106
1GFlops109
1TFlops1012
1PFlops1015
1EFlops1018
#node
Peakflops
limitationof #node
Exaflops system
PACS-CS (14TF)
petaflopsby 100-1000nodes
NGS> 10PF
T2K-tsukuba(95TF)
the K computer
simple projection of #nodes and peak flops

Outline
Issues for Exascale computing Why Accelerated computing?
HA-PACS project HA-PACS (Highly Accelerated Parallel Advanced system for Computational
Sciences) “Advanced research and education on computational sciences driven by exascale
computing technology”, funded by MEXT, Apr. 2011 – Mar. 2014, 3-year TCA: Tightly Coupled Accelerator, Direct connection between accelerators (GPUs)
Programming issue XcalableMP and XMP-dev extension for GPU Clusters
HPCI-FS projects for Japanese post-petascale computing "Study on exascale heterogeneous systems with accelerators"
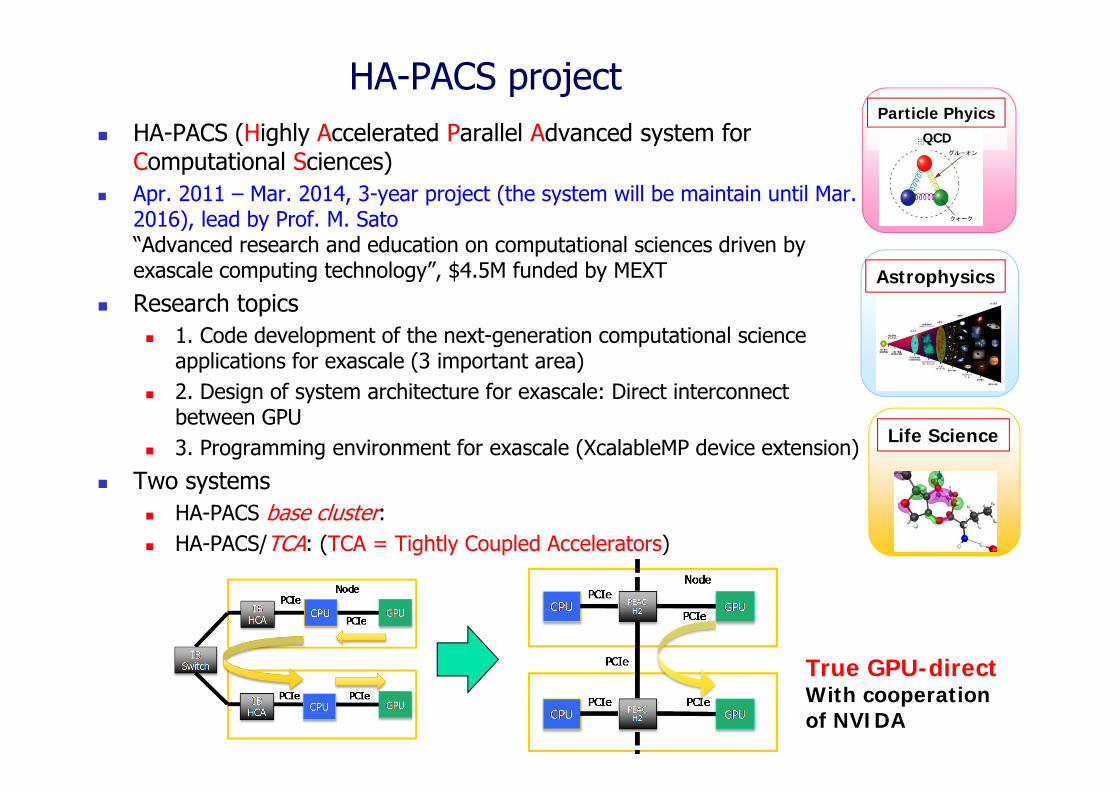
HA-PACS project HA-PACS (Highly Accelerated Parallel Advanced system for
Computational Sciences) Apr. 2011 – Mar. 2014, 3-year project (the system will be maintain until Mar.
2016), lead by Prof. M. Sato“Advanced research and education on computational sciences driven by exascale computing technology”, $4.5M funded by MEXT
Research topics 1. Code development of the next-generation computational science
applications for exascale (3 important area) 2. Design of system architecture for exascale: Direct interconnect
between GPU 3. Programming environment for exascale (XcalableMP device extension)
Two systems HA-PACS base cluster: HA-PACS/TCA: (TCA = Tightly Coupled Accelerators)
True GPU-directWith cooperation of NVIDA
QCD
Particle Phyics
Astrophysics
Life Science

HP-PACS system (base-cluster) System spec. 268 nodes CPU 89TFLOPS + GPU 713TFLOPS =
total 802TFLOPS Memory 34TByte、memory bandwidth
26TByte/sec Bi-section bandwidth 2.1TByte/秒 Storage 504TByte Power 408kW 26 ranks, Installed on Jan, 2012 Operation started from Feb, 2012
Spec of compute nodes CPU x2 + GPU x4/node
(4 GPU: 2660 GFLOPS + 2 CPU: 332 GFLOPS~ 3 TFLOPS / node)
Advanced CPU:Intel SandyBridge: high-peak performance enhandedby 256bit AVX instruction, and high memory bandwidth by 1600MHz DDR3(2.6GHz SandyBridge-EP (8 core) = 166.4 GFLOPS, 51.2GB/s memory bandwitdh, 128GB)
x40 lane for CPU direct I/O of PCIe Gen3
Advanced GPU:NVIDIA M2090: M2070 512core enhance version:peak performance 665GFLOPS
Interconnect network Infiniband QDR x 2 rail (trunk) Connected by PCIe Gen3 x8 lane

Issues of GPU Cluster
Problems of GPGPU for HPC Data I/O performance limitation
Ex) GPGPU: PCIe gen2 x16 Peak Performance: 8GB/s (I/O) ⇔ 665 GFLOPS (NVIDIA M2090)
Memory size limitation Ex) M2090: 6GByte vs CPU: 4 – 128 GByte
Communication between accelerators: no direct path (external)⇒ communication latency via CPU becomes large Ex) GPGPU:
GPU mem ⇒ CPU mem ⇒ (MPI) ⇒ CPU mem ⇒ GPU mem
Researches for direct communication between GPUs are required
9
Our another target is developing a direct communication system between external GPUs as a feasibility study for future accelerated computing

Block Diagram of TCA node Uniform view from CPU
Enable uniform access to GPU through PEACH2
Direct access to GPU memory by Kepler architecture + CUDA 5.0 “GPUDirect Support for RDMA”
Note: bad performance over QPI => GPU0, GPU1
Connecting other three nodes
10
CPU(Ivy-
Bridge)
CPU(Ivy-
Bridge)QPI
PCIe
GPU0
GPU2
GPU3
IBHCA
PEACH2
GPU1
G2 x8 G2
x16G2x16
G3x8
G2x16
G2x16
G2 x8
G2 x8
G2 x8 GPU: NVIDIA K20, K20X
(Kepler architecture)
Subcluster (8-16nodes) of nodes connected by TCA
Use infiniband between subclusters Two Level communication layer
Low latency/high bandwidth between near nodes
+ high bandwidth between subclusters
single PCIe address spacesingle PCIe address space
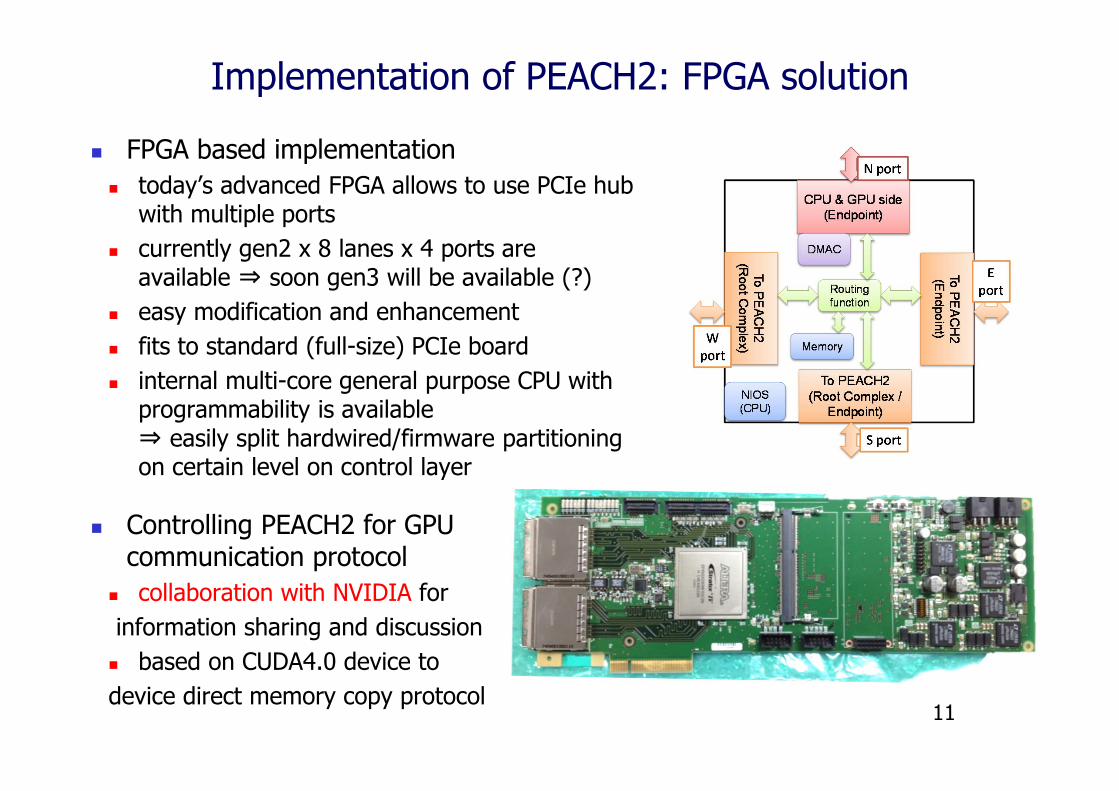
Implementation of PEACH2: FPGA solution
FPGA based implementation today’s advanced FPGA allows to use PCIe hub
with multiple ports currently gen2 x 8 lanes x 4 ports are
available ⇒ soon gen3 will be available (?) easy modification and enhancement fits to standard (full-size) PCIe board internal multi-core general purpose CPU with
programmability is available⇒ easily split hardwired/firmware partitioning on certain level on control layer
Controlling PEACH2 for GPU communication protocol
collaboration with NVIDIA forinformation sharing and discussion based on CUDA4.0 device to device direct memory copy protocol
11
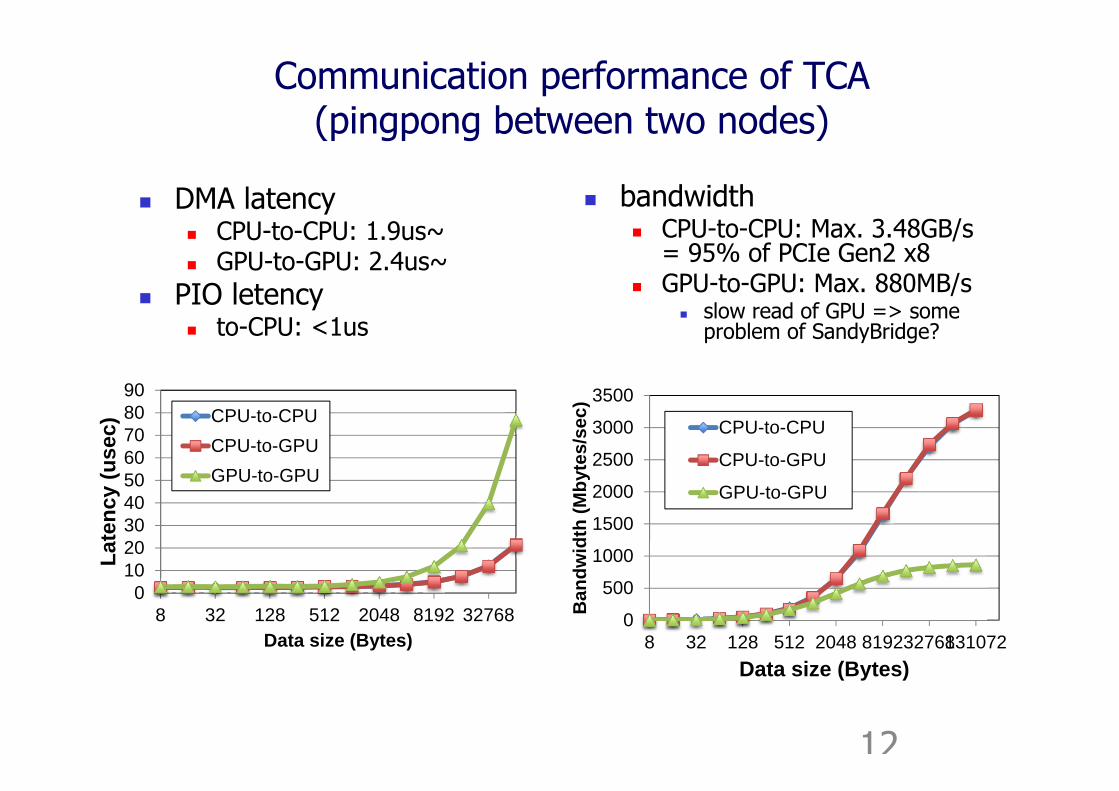
Communication performance of TCA(pingpong between two nodes)
DMA latency CPU-to-CPU: 1.9us~ GPU-to-GPU: 2.4us~
PIO letency to-CPU: <1us
bandwidth CPU-to-CPU: Max. 3.48GB/s
= 95% of PCIe Gen2 x8 GPU-to-GPU: Max. 880MB/s
slow read of GPU => some problem of SandyBridge?
12
0102030405060708090
8 32 128 512 2048 8192 32768
Late
ncy
(use
c)
Data size (Bytes)
CPU-to-CPUCPU-to-GPUGPU-to-GPU
0
500
1000
1500
2000
2500
3000
3500
8 32 128 512 2048 819232768131072
Ban
dwid
th (M
byte
s/se
c)
Data size (Bytes)
CPU-to-CPU
CPU-to-GPU
GPU-to-GPU
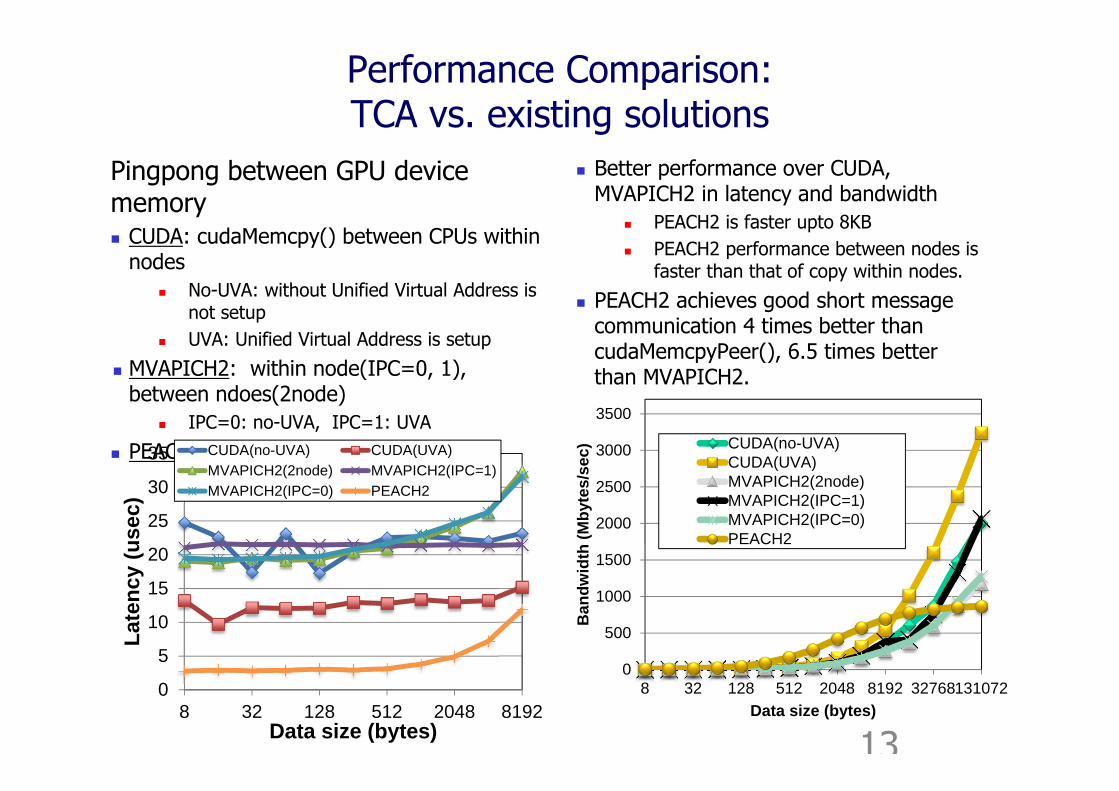
Performance Comparison:TCA vs. existing solutions
Pingpong between GPU device memory CUDA: cudaMemcpy() between CPUs within
nodes No-UVA: without Unified Virtual Address is
not setup UVA: Unified Virtual Address is setup
MVAPICH2: within node(IPC=0, 1), between ndoes(2node)
IPC=0: no-UVA, IPC=1: UVA
PEACH2: between nodes
Better performance over CUDA, MVAPICH2 in latency and bandwidth
PEACH2 is faster upto 8KB PEACH2 performance between nodes is
faster than that of copy within nodes.
PEACH2 achieves good short message communication 4 times better than cudaMemcpyPeer(), 6.5 times better than MVAPICH2.
13
0
5
10
15
20
25
30
35
8 32 128 512 2048 8192
Late
ncy
(use
c)
Data size (bytes)
CUDA(no-UVA) CUDA(UVA)MVAPICH2(2node) MVAPICH2(IPC=1)MVAPICH2(IPC=0) PEACH2
0
500
1000
1500
2000
2500
3000
3500
8 32 128 512 2048 8192 32768131072
Ban
dwid
th (M
byte
s/se
c)
Data size (bytes)
CUDA(no-UVA)CUDA(UVA)MVAPICH2(2node)MVAPICH2(IPC=1)MVAPICH2(IPC=0)PEACH2

Outline
Issues for Exascale computing Why Accelerated computing?
HA-PACS project HA-PACS (Highly Accelerated Parallel Advanced system for Computational
Sciences) “Advanced research and education on computational sciences driven by exascale
computing technology”, funded by MEXT, Apr. 2011 – Mar. 2014, 3-year TCA: Tightly Coupled Accelerator, Direct connection between accelerators (GPUs)
Programming issue XcalableMP and XMP-dev extension for GPU Clusters
HPCI-FS projects for Japanese post-petascale computing "Study on exascale heterogeneous systems with accelerators"

What’s XcalableMP?
XcalableMP (XMP for short) is: A programming model and language for distributed memory , proposed by XMP WG http://www.xcalablemp.org
XcalableMP Specification Working Group (XMP WG) XMP WG is a special interest group, which organized to make a draft on “petascale” parallel
language. Started from December 2007, the meeting is held about once in every month.
Mainly active in Japan, but open for everybody.
XMP WG Members (the list of initial members) Academia: M. Sato, T. Boku (compiler and system, U. Tsukuba), K. Nakajima (app. and
programming, U. Tokyo), Nanri (system, Kyusyu U.), Okabe (HPF, Kyoto U.) Research Lab.: Watanabe and Yokokawa (RIKEN), Sakagami (app. and HPF, NIFS), Matsuo
(app., JAXA), Uehara (app., JAMSTEC/ES) Industries: Iwashita and Hotta (HPF and XPFortran, Fujitsu), Murai and Seo (HPF, NEC),
Anzaki and Negishi (Hitachi), (many HPF developers!)
A prototype XMP compiler is being developed by U. of Tsukuba and RIKEN AICS. XMP is proposed for a programming language for the K computer, supported by the
programming environment research team. 15

16
A PGAS language. Directive-based language extensions for Fortran95 and C99 for the XMP PGAS model To reduce the cost of code-rewriting and education
Global view programming with global-view distributed data structures for data parallelism A set of threads are started as a logical task. Work mapping
constructs are used to map works and iteration with affinity to data explicitly.
Rich communication and sync directives such as “gmove” and “shadow”.
Many concepts are inherited from HPF
Co-array feature of CAF is adopted as a part of the language spec for local view programming (also defined in C).
directivesComm, sync and work-sharing
Duplicated execution
node0 node1 node2
XcalableMP : directive-based language eXtensionfor Scalable and performance-aware Parallel Programming
http://www.xcalablemp.org
int array[N];#pragma xmp nodes p(4)#pragma xmp template t(N)#pragma xmp distribute t(block) on p#pragma xmp align array[i][ with t(i)
#pragma xmp loop on t(i) reduction(+:res)for(i = 0; i < 10; i++)
array[i] = func(i,);res += …;
} }

17XMP project
Code Example (Fortran)
program xmp_exampleInteger array(XMAX,MAX)!$XMP nodes p(4)!$XMP template t(YMAX)!$XMP distribute t(block) onto p!$XMP align array(*,j) with t(j)
integer :: i, j, resres = 0
!$XMP loop on t(j) reduction(+:res)do j = 1, 10do I = 1, 10
array(I,j) = func(i, j)res += array(I,j)
enddoenddo
add to the serial code : incremental parallelization
data distribution
work mapping and data synchronization
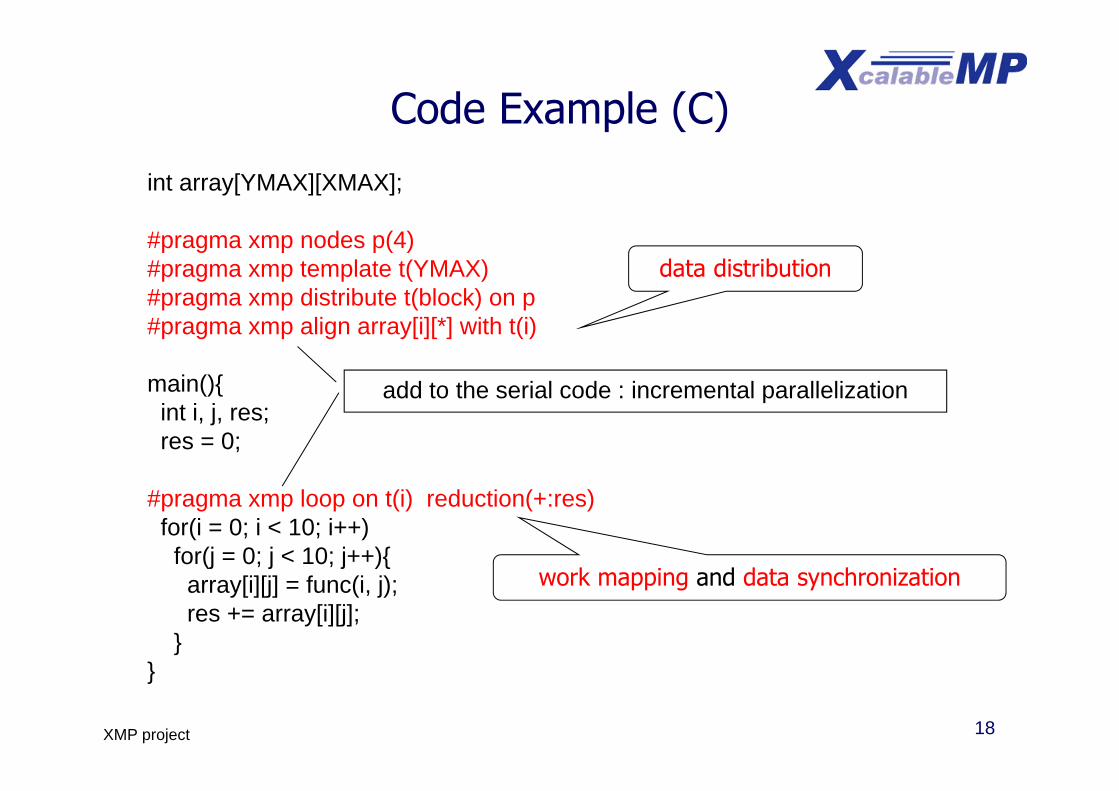
18XMP project
Code Example (C)
int array[YMAX][XMAX];
#pragma xmp nodes p(4)#pragma xmp template t(YMAX)#pragma xmp distribute t(block) on p#pragma xmp align array[i][*] with t(i)
main(){int i, j, res;res = 0;
#pragma xmp loop on t(i) reduction(+:res)for(i = 0; i < 10; i++)for(j = 0; j < 10; j++){
array[i][j] = func(i, j);res += array[i][j];
}}
add to the serial code : incremental parallelization
data distribution
work mapping and data synchronization

Programming for GPU clusters Programming for a single GPU
CUDA OpenCL OpenACC, ...
No framework to describe communication between GPUs GPU mem -> CPU mem -> MPI -> CPU mem -> GPU mem no operations to make use of TCA
Our solution: an extension of XcalableMP for acceleration device (GPUs), XMP-dev Extend XMP to offload a set of operations from CPUs to GPUs Similar to OpenACC idea in distributed memory environment
19XMP project

XMP-dev: XcalableMP acceleration device extension
Offloading a set of distributed array and operation to a cluster of GPU
20
CPU
GPU
CPU
GPU
CPU
GPU
CPU
GPU
CPU
GPU
CPU
GPU
CPU
GPU
CPU
GPU
CPU
GPU
CPU
GPU
CPU
GPU
CPU
GPU
CPU
GPU
CPU
GPU
CPU
GPU
CPU
GPU
#pragma xmp nodes p(4, 4)
#pragma xmp template t(0:99, 0:99)#pragma xmp distribute t(BLOCK, BLOCK) onto p
double b[100][100];#pragma xmp align b[i][j] with t(j, i)
double a[100][100];#pragma xmp align a[i][j] with t(j, i)#pragma xmp device allocate a
#pragma xmp (i, j) loop on t(j, i)for (i =0; i < 100; i++)for (j =0; j < 100; j++) ... = b[i][j];
#pragma xmp device (i, j) loop on t(j, i)for (i =0; i < 100; i++)for (j =0; j < 100; j++) a[i][j] = ...;
DEVICE (GPU)
HOST (CPU)
Template
Node
#pragma xmp gmoveb[:][:] = a[:][:];
#pragma xmp device replicate(u, uu){#pragma xmp device replicate_sync in (u)for (k = 0; k < ITER; k++) {
#pragma xmp device reflect (u)#pragma xmp device loop (x, y) on t(x, y) thre
for (y = 1; y < N-1; y++)for (x = 1; x < N-1; x++)uu[y][x] = (u[y-1][x] + u[y+1][x] +
u[y][x-1] + u[y][x+1]) / 4.0;#pragma xmp device loop (x, y) on t(x, y) thre
for (y = 1; y < N-1; y++)for (x = 1; x < N-1; x++)u[y][x] = uu[y][x];
}#pragma xmp device replicate_sync out (u)} // #pragma xmp device replicate
Hide complicated communication by reflect operation on distributed array allocated on GPUs
Laplace solver: 21.6 times speedup on Laplace 4GPU(Tesla C2050) in Laplace solver.

Outline
Issues for Exascale computing Why Accelerated computing?
HA-PACS project HA-PACS (Highly Accelerated Parallel Advanced system for Computational
Sciences) “Advanced research and education on computational sciences driven by exascale
computing technology”, funded by MEXT, Apr. 2011 – Mar. 2014, 3-year TCA: Tightly Coupled Accelerator, Direct connection between accelerators (GPUs)
Programming issue XcalableMP and XMP-dev extension for GPU Clusters
HPCI-FS projects for Japanese post-petascale computing "Study on exascale heterogeneous systems with accelerators"

The SDHPC white paper and Japanese “Feasibility Study" project
WGs ware orgainzed for drafting the white paper for Strategic Direction/Development of HPC in JAPAN by young Japanese researchers with advisers (seniors)
Contents Science roadmap until 2020 and List of application for 2020’s Four types of hardware architectures identified and performance projection in 2018
estimated from the present technology trend Necessity of further research and development to realize the science roadmap
For “Feasibility Study" project, 4 research teams were accepted Application study team leaded by RIKEN AICS (Tomita) System study team leaded by U Tokyo (Ishikawa)
Next-generation “General-Purpose” Supercomputer System study team leaded by U Tsukuba (Sato)
Study on exascale heterogeneous systems with accelerators System study team leaded by Tohoku U (Kobayashi)
Projects were started from July 2012 (1.5 year) …
22

System requirement analysis for Target sciences
System performance FLOPS: 800 – 2500PFLOPS Memory capacity: 10TB – 500PB Memory bandwidth: 0.001 – 1.0 B/F Example applications
Small capacity requirement MD, Climate, Space physics, …
Small BW requirement Quantum chemistry, …
High capacity/BW requirement Incompressibility fluid dynamics, …
Interconnection Network Not enough analysis has been carried out Some applications need >1us latency and large bisection BW
Storage There is not so big demand
23
1.0E-4
1.0E-3
1.0E-2
1.0E-1
1.0E+0
1.0E+1
1.0E-3 1.0E-2 1.0E-1 1.0E+0 1.0E+1 1.0E+2 1.0E+3R
equi
rem
ent o
f B
/FRequirement of Memory Capacity (PB)
Low BWMiddle capacity
High BWsmall capacity
High BWmiddle capacity
High BWHigh capacity
(From SDHPC white paper)
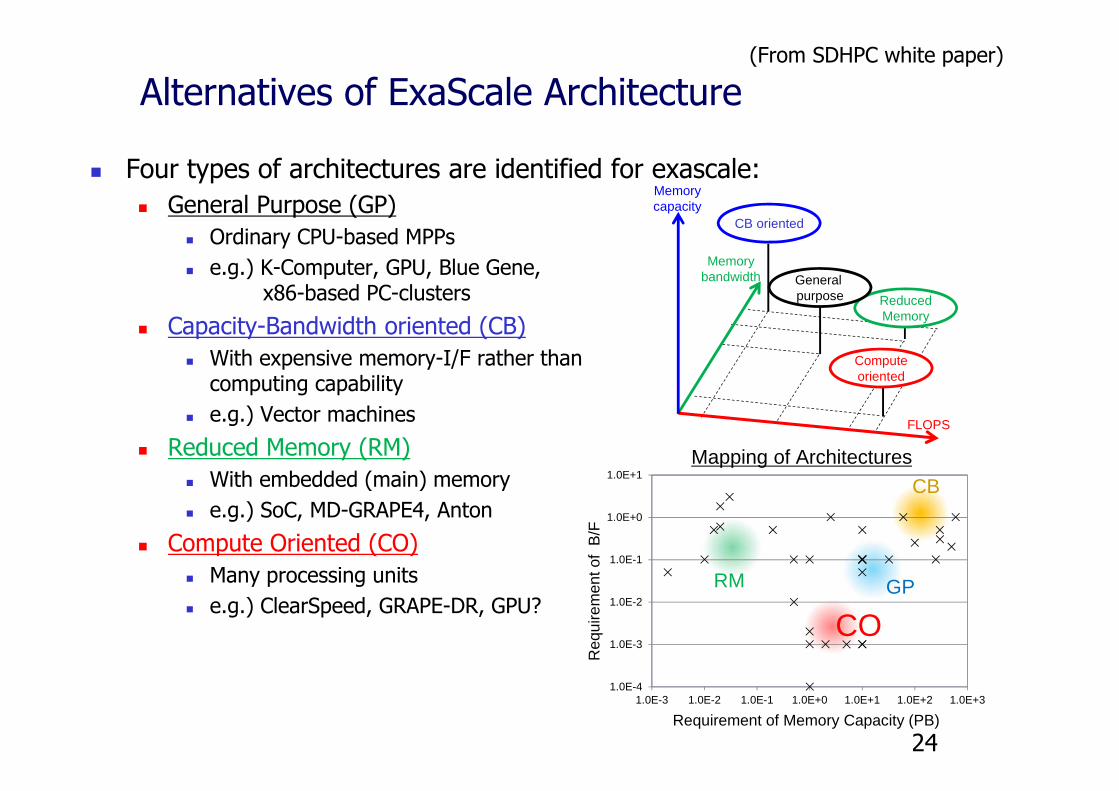
Alternatives of ExaScale Architecture
Four types of architectures are identified for exascale: General Purpose (GP)
Ordinary CPU-based MPPs e.g.) K-Computer, GPU, Blue Gene,
x86-based PC-clusters
Capacity-Bandwidth oriented (CB) With expensive memory-I/F rather than
computing capability e.g.) Vector machines
Reduced Memory (RM) With embedded (main) memory e.g.) SoC, MD-GRAPE4, Anton
Compute Oriented (CO) Many processing units e.g.) ClearSpeed, GRAPE-DR, GPU?
24
(From SDHPC white paper)
Memorybandwidth
Memorycapacity
FLOPS
CB oriented
Computeoriented
ReducedMemory
General purpose
CB
GP
CORM
1.0E-4
1.0E-3
1.0E-2
1.0E-1
1.0E+0
1.0E+1
1.0E-3 1.0E-2 1.0E-1 1.0E+0 1.0E+1 1.0E+2 1.0E+3
Req
uire
men
t of
B/F
Requirement of Memory Capacity (PB)
Mapping of Architectures

Study on exascale heterogeneous systems with accelerators (U Tsukuba proposal)
Two keys for exascale computing Power and strong-scaling
We study “exascale” heterogeneous systems with accelerators of many-cores. We are interested in: Architecture of accelerators, core and memory architecture Special-purpose functions Direct connection between accelerators in a group Power estimation and evaluation Programming model
and computational science applications
Requirement for general-purpose system
etc …
25

PACS-G: a straw man architecture SIMD architecture, for compute oriented apps (N-body, MD), and stencil apps. 4096 cores (64x64), 2FMA@1GHz, 4GFlops x 4096 = 16TFlops/chip 2D mesh (+ broardcast/reduction) on-chip network for stencil apps. We expect 14nm technology at the range of year 2018-2020,
Chip dai size: 20mm x 20mm Mainly working on on-chip memory (size 512 MB/chip, 128KB/core),
and, with module memory by3D-stack/wide IO DRAMmemory (via 2.5D TSV),bandwidth 1000GB/s, size 16-32GB/chip
No external memory (DIM/DDR)
250 W/chips expected 64K chips for 1 EFLOPS (at peak)
コントローラ
ホストプロセッサ
データメモリ
命令メモリ
通信バッファ
通信バッファ
通信バッファ
結果縮約ネットワーク
PE PE PE PE
PE PE PE PE
PE PE PE PE
PE PE PE PE通信バッファ
加速
機構間
ネットワーク
放送
メモリ
放送
メモリ
放送
メモリ
放送
メモリ
FSACCチップPACS-Gチップ
3D stack or Wide IO DRAM
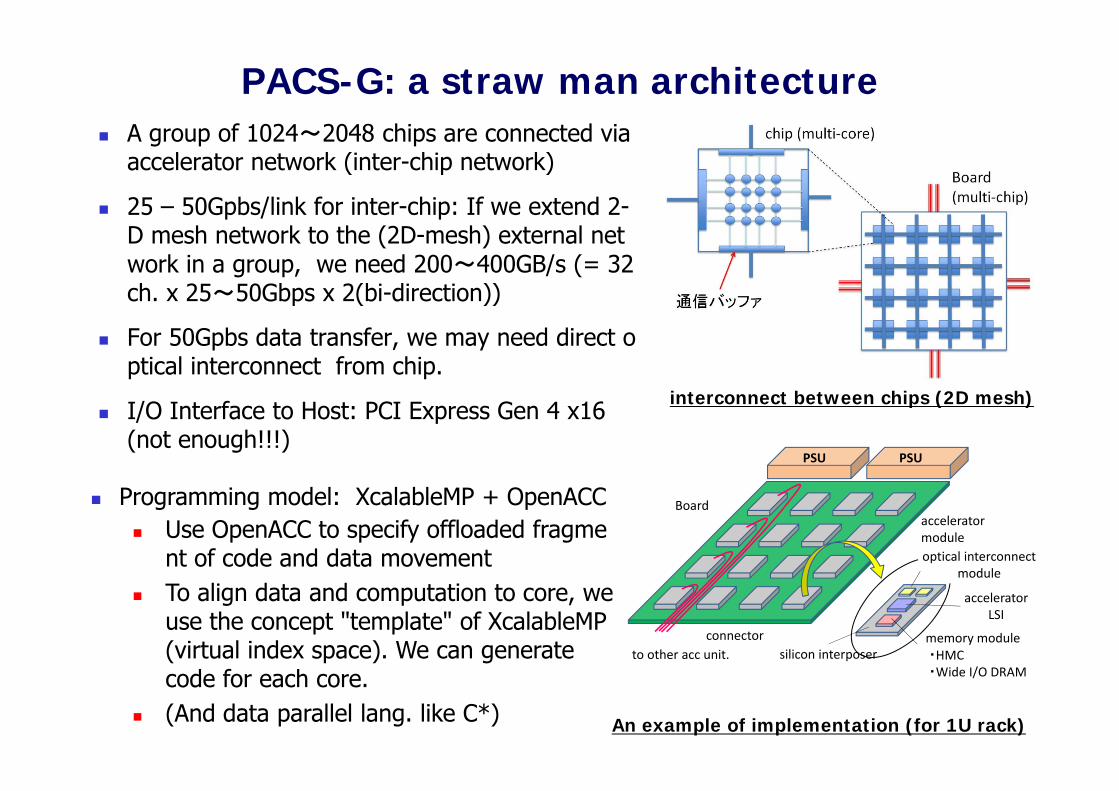
A group of 1024~2048 chips are connected via accelerator network (inter-chip network)
25 – 50Gpbs/link for inter-chip: If we extend 2-D mesh network to the (2D-mesh) external network in a group, we need 200~400GB/s (= 32ch. x 25~50Gbps x 2(bi-direction))
For 50Gpbs data transfer, we may need direct optical interconnect from chip.
I/O Interface to Host: PCI Express Gen 4 x16 (not enough!!!)
interconnect between chips (2D mesh)
Programming model: XcalableMP + OpenACC Use OpenACC to specify offloaded fragme
nt of code and data movement To align data and computation to core, we
use the concept "template" of XcalableMP (virtual index space). We can generate code for each core.
(And data parallel lang. like C*) An example of implementation (for 1U rack)
PACS-G: a straw man architecture
Board
acceleratorLSI
PSU
acceleratormodule
memory module・HMC・Wide I/O DRAM
optical interconnectmodule
connectorsilicon interposerto other acc unit.
PSU
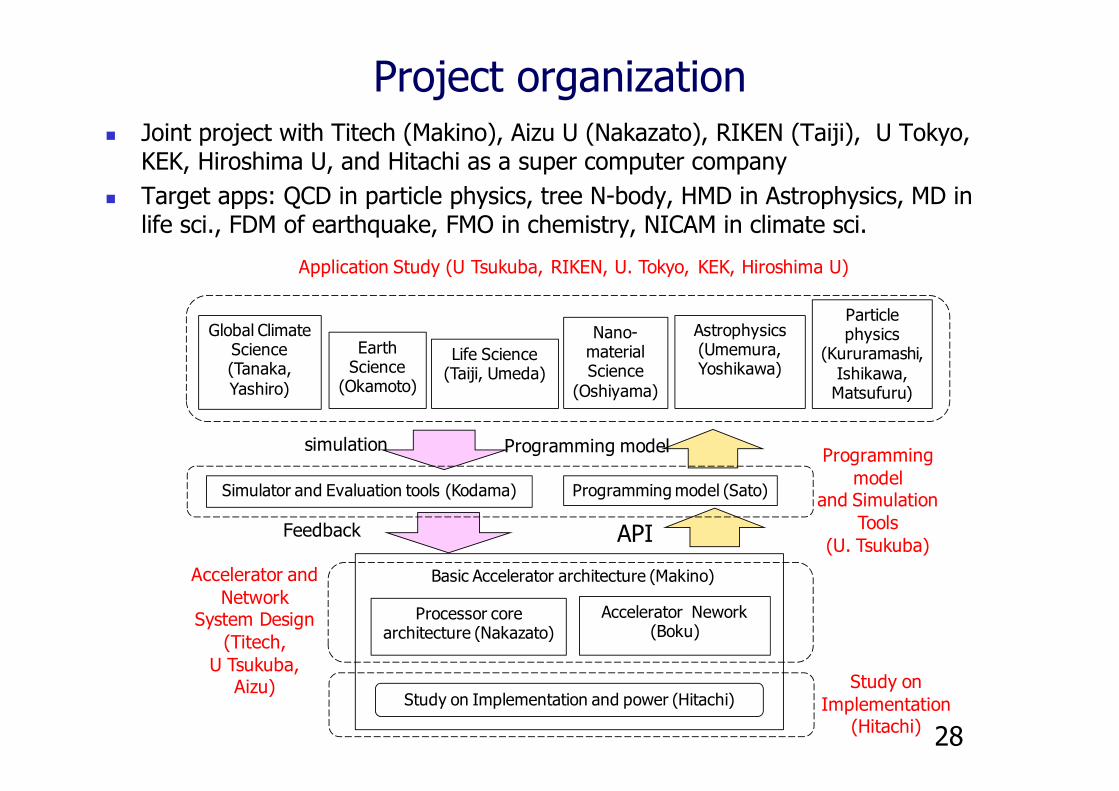
Project organization Joint project with Titech (Makino), Aizu U (Nakazato), RIKEN (Taiji), U Tokyo,
KEK, Hiroshima U, and Hitachi as a super computer company Target apps: QCD in particle physics, tree N-body, HMD in Astrophysics, MD in
life sci., FDM of earthquake, FMO in chemistry, NICAM in climate sci.
28
Simulator and Evaluation tools (Kodama) Programming model (Sato)
Study on Implementation and power (Hitachi)
Processor core architecture (Nakazato)
Accelerator Nework(Boku)
Basic Accelerator architecture (Makino)
Particle physics
(Kururamashi, Ishikawa,
Matsufuru)
Astrophysics (Umemura, Yoshikawa)
Nano-material Science
(Oshiyama)
Life Science (Taiji, Umeda)
Global Climate Science (Tanaka, Yashiro)
Earth Science
(Okamoto)
API
Programming modelsimulation
Feedback
Application Study (U Tsukuba, RIKEN, U. Tokyo, KEK, Hiroshima U)
Accelerator and Network
System Design(Titech,
U Tsukuba, Aizu)
Programming model
and Simulation Tools
(U. Tsukuba)
Study on Implementation
(Hitachi)

Current status and plan
We are now working on performance estimation by co-design process 2012 (done): QCD, N-body, MD, HMD 2013: earth quake sim, NICAM (climate), FMO (chemistry) When all data fits on on-chip memory, ratio B/F is 4 B/F, total mem size 1TB/group When data fits into module memory, ratio B/F is 0.05B/F, total mem size 32TB/group
Also, developing simulators (clock-level/instruction level) for more precious and quantitative performance evaluation
Compiler development (XMP and OpenACC) (Re-)Design and investigation of network topology
2D mesh is sufficient? or, other alternative?
Code development for apps using Host and Acc, including I/O Precious and more detail estimation of power consumptions

Summary and Final Remarks
Issues for exascale computing Power and Strong-scaling Solution: Accelerated Computing
Issues for Accelerated exascale computing HA-PACS project – A direct connection between Acc's XMP-dev prog. lang. – Programming for Massive Acc's HPCI FS on exascale heterogeneous systems with accelerators --
Acc (strawman) SIMD architecture in 2018-2020
I believe acceleration with SIMDs and on-chip memory is a first (and good) candidate for exascale computing in some scientific fields.


















