
SISTEMA INFORMÁTICO PARA CONSULTAS A …roa.ult.edu.cu/bitstream/123456789/1873/1/Yasser Moreno...
52
UNIVERSIDAD DE LAS TUNAS FACULTAD DE CIENCIAS TÉCNICAS DEPARTAMENTO DE INFORMÁTICA SISTEMA INFORMÁTICO PARA CONSULTAS A DATOS DE EPÍTOPES TRABAJO DE DIPLOMA EN OPCIÓN AL TÍTULO DE INGENIERO INFORMÁTICO AUTOR: YASSER MORENO RAD TUTOR: Ing. MANUEL ALEXANDER MOLINA ESPINOSA Las Tunas, junio de 2011
Transcript of SISTEMA INFORMÁTICO PARA CONSULTAS A …roa.ult.edu.cu/bitstream/123456789/1873/1/Yasser Moreno...

UNIVERSIDAD DE LAS TUNAS
FACULTAD DE CIENCIAS TÉCNICAS
DEPARTAMENTO DE INFORMÁTICA
SISTEMA INFORMÁTICO PARA CONSULTAS A DATOS DE EPÍTOPES
TRABAJO DE DIPLOMA EN OPCIÓN AL TÍTULO DE
INGENIERO INFORMÁTICO
AUTOR: YASSER MORENO RAD
TUTOR: Ing. MANUEL ALEXANDER MOLINA ESPINOSA
Las Tunas, junio de 2011

Dedicatoria
A mis padres, para que al fin vean
su sueño hecho realidad.

Agradecimientos
Primero que todo a Dios, por proporcionarme todo lo que necesité
para llegar a este momento.
A mi tutor, por ayudarme y dedicar parte de su preciado tiempo a
este trabajo.
A todos las personas que me ayudaron y apoyaron.
A la familia que me creó.
A la familia que yo he creado.
A todos mis amigos.

DECLARACIÓN DE AUTORÍA
Declaro que soy el único autor de este trabajo y autorizo a la Facultad de Ciencias
Técnicas así como al Departamento de Informática para que hagan el uso que
estimen pertinente con este trabajo.
Para que así conste firmo la presente a los 10 días del mes de junio de 2011.
______________ ______________
Firma del Autor Firma del Tutor

OPINIÓN DEL USUARIO DEL TRABAJO DE DIPLOMA
El Trabajo de Diploma, titulado SISTEMA INFORMÁTICO PARA CONSULTAS A
DATOS DE EPÍTOPES, fue realizado en la Universidad de Las Tunas. Esta entidad
considera que, en correspondencia con los objetivos trazados, el trabajo realizado le
satisface
Totalmente
Parcialmente en un ___ %
Los resultados de este Trabajo de Diploma le reportan a esta entidad los
beneficios siguientes:
Contar con una BD donde se reflejan los virus, proteínas,
componentes, epítopes y sus mutantes (actualmente solo HIV-1)
Seleccionar epítopes según el tipo de proteína y componente del que
forma parte
Visualizar y modificar los datos más importantes de los epítopes
Visualizar datos generales de epítopes
Visualizar datos de mutantes pertenecientes a un epítope dado
Y para que así conste, se firma la presente a los 10 días del mes de junio del
año 2011
Manuel A. Molina Espinosa Profesor
Representante de la entidad Cargo
___________ ___________
Firma cuño

RESUMEN
El presente trabajo muestra el desarrollo e implementación de un Sistema informático
para consultas a datos de epítopes, el cual permite explorar una base de datos con
información de los mismos. Se trata de una aplicación que brinda información acerca
de un epítope determinado y además, partiendo de este, posibilita al usuario conocer
otras informaciones, fundamentalmente de los mutantes y mutantes de escape
correspondientes, en caso de tenerlos, puesto que los últimos permiten a los virus
evadir la respuesta inmunológica del organismo. La realización de este trabajo está
determinada por la necesidad de analizar y estudiar las especificidades de estos
elementos, determinantes en el desarrollo bioinformático actual. Esta investigación y
la implementación en términos informáticos, determina su aplicación para el análisis
de las mutaciones en los virus y en base a estas, aspirar a una producción más
efectiva de las vacunas.

ÍNDICE
INTRODUCCIÓN ............................................................................................................................. 1
CAPÍTULO 1. Marco teórico conceptual ........................................................................................ 4
Introducción .................................................................................................................................. 4
1.1 Bioinformática ......................................................................................................................... 4
1.2 Algoritmos de distancia. ........................................................................................................ 6
1.2.1 Distancia de Levenshtein ............................................................................................... 7
1.3 Proceso de importación de los datos. .................................................................................. 8
1.4 Valoración de aplicaciones similares. ................................................................................ 11
1.5 Descripción de software, técnicas y metodologías utilizadas. ........................................ 12
Conclusiones .............................................................................................................................. 14
CAPÍTULO 2. Análisis y diseño del sistema ............................................................................... 15
Introducción ................................................................................................................................ 15
2.1 Modelo de Dominio. ............................................................................................................. 15
2.2 Modelo del Sistema. ............................................................................................................ 15
2.2.1 Objeto de automatización. ........................................................................................... 15
2.2.2 Captura de requisitos. .................................................................................................. 16
2.2.2.1 Requisitos funcionales. ............................................................................................. 16
2.2.2.2 Requisitos no funcionales ......................................................................................... 17
2.2.3 Casos de uso del sistema ............................................................................................ 18
2.2.4 Diagrama de casos de uso del sistema. ..................................................................... 18
2.2.5 Descripciones textuales de los casos de uso más importantes. .............................. 19
2.3 Modelo de Diseño ................................................................................................................ 23
2.3.1 Realización de los casos de usos. .............................................................................. 24
2.3.1.1 Diagrama de clases del diseño. ............................................................................... 24

2.3.1.2 Diagrama de secuencia. ........................................................................................... 27
2.3.2 Diagrama de clases persistentes. ............................................................................... 31
2.3.3 Modelo de Datos. .......................................................................................................... 32
2.3.4 Modelo de Despliegue. ................................................................................................. 33
2.4 Implementación. ................................................................................................................... 33
2.4.1 Modelo de Componentes. ............................................................................................ 33
2.4.1.1 Diagrama de la arquitectura del sistema. ................................................................ 33
2.4.1.2 Diagrama de componentes de los casos de uso críticos. ...................................... 34
Conclusiones .............................................................................................................................. 34
CAPÍTULO 3. Implementación del sistema ................................................................................. 35
3.1 Aspectos relativos a la implementación del sistema. ...................................................... 35
3.2 Diseño de la interfaz. ........................................................................................................... 35
3.3 Forma general y principios en que se basa el sistema de ayuda.................................... 36
3.4 Forma general y principios de la protección y seguridad. ................................................ 36
3.5 Forma general del tratamiento de errores. ........................................................................ 37
CONCLUSIONES .......................................................................................................................... 39
RECOMENDACIONES.................................................................................................................. 40
BIBLIOGRAFÍA............................................................................................................................... 41
REFERENCIAS BIBLIOGRÁFICAS ............................................................................................. 42
ANEXOS ......................................................................................................................................... 44

1
INTRODUCCIÓN
La existencia en nuestro país de numerosos complejos científicos, algunos de los
más relevantes son el Centro de Ingeniería Genética y el Centro de Investigaciones
de Medicina Tropical, ha permitido la concreción de importantes logros científicos.
Entre los más importantes obtenidos mediante la colaboración entre estos centros
científicos está la vacuna contra la meningo, que ha contribuido a salvar numerosas
vidas.
Un desarrollo adecuado en la preparación de vacunas es fundamental para mantener
protegida una población de individuos contra un agente patógeno, normalmente
externo. Nuestro sistema inmune reconoce múltiples fragmentos de las proteínas que
forman parte de este agente, denominados epítopes [HOFMEYR, 2000]. Una
adecuada elección de estos epítopes permitiría crear vacunas más efectivas contra
este invasor del organismo.
En la composición de las proteínas pueden aparecer hasta 20 tipos de aminoácidos
distintos. Un epítope al ser un fragmento de una proteína está compuesto también
por cualquier combinación de estos aminoácidos y una vez que se han obtenido los
mejores candidatos hay que probar las futuras vacunas contra estos y sus posibles
variantes.
Hoy en día, para crear una vacuna luego de seleccionar los epítopes candidatos se
realizan pruebas en laboratorio, y se analizan los resultados y la evolución de los
patógenos respecto a estos preparados, luego se determina el mejor para hacerle
frente a una infección real en un organismo.
El uso del método anterior implica que normalmente no se pueden probar todas las
variantes por diversas cuestiones (tiempo, dinero, tecnología) imposibilitando
obtener una vacuna más efectiva. La dificultad radica en el número tan elevado de
posibles mutaciones, puesto que cada aminoácido puede mutar a otro de los 19
existentes; esto genera una explosión combinatoria que imposibilita preparar
adecuadamente la vacuna contra todas, y más importante aún es que resulta
imposible predecir las variantes para evadir su acción preventiva.

2
Algunos autores han tratado este tema usando diversas técnicas para tratar de
predecir con mayor exactitud cuando se está en presencia de una variante de
escape. Entre las técnicas usadas están las comparaciones de estructuras
tridimensionales, el uso del factor IC50 (inhibitory concentration) para determinar la
posible afinidad entre el epítope y los anticuerpos.
Aunque existen varias aplicaciones, específicamente, bases de datos, de las cuales
se dispone para su uso en la producción de vacunas a nivel mundial, el autor
considera que las mismas, en los casos estudiados, profundizan bastante en el
aporte de información de los epítopes originales, no siendo así con los mutantes,
determinados por la variación que se produce en la cadena de aminoácidos que
forman el epítope original, o mutantes de escape, sobre los que no se produce
detección en el sistema inmunológico. El autor considera que la implementación de
un sistema que además de presentar información, permita el estudio de lo que a
mutantes respecta, constituiría una herramienta aún más eficiente y completa.
Disponer de una base de datos orientada a exponer las características de los
epítopes y sus mutantes para poder estudiar las relaciones que existan entre ellos,
constituye un valioso aporte.
Partiendo de lo antes expuesto podemos definir como problema científico: ¿Cómo
favorecer la gestión de los datos de epítopes presentes en las cadenas de los virus y
sus mutantes, para la producción de vacunas?
Dicho problema se circunscribe dentro del objeto de estudio: Gestión de datos
bioinformáticos del sistema inmunológico. Como campo de acción se define:
Gestión de datos de los epítopes y los mutantes.
Para dar solución al problema planteado se definió el siguiente objetivo: Elaborar
una aplicación que facilite la consulta de los datos tanto de epítopes como de sus
mutantes.
Por todo lo antes expuesto, este trabajo se basa en la siguiente idea a defender:

3
La elaboración de una aplicación para la consulta de datos de los epítopes y los
mutantes correspondientes, facilitará no solo el acceso a la información de estos,
sino que permitirá realizar estudios para determinar patrones de mutación de los
virus.
Objetivos Específicos
Definir conceptos vinculados a la bioinformática.
Explicar funcionamiento del sistema inmunológico.
Identificar las limitantes de los sistemas similares existentes.
Analizar los principales elementos que necesita el nuevo sistema.
Diseñar un sistema para la consulta de datos de epítopes y mutantes.
Implementar una aplicación de escritorio para la obtención de los datos.
Tareas Científicas
Estudio del funcionamiento del sistema inmunológico.
Estudio del estado del arte acerca de bases de datos de epítopes.
Análisis y diseño de una aplicación para la consulta de datos de epítopes y
mutantes.
Métodos de investigación
Histórico-lógico: Se hace un análisis y se caracterizan las bases de datos
existentes con el objetivo de apoyarnos en su experiencia y detectar
deficiencias.
Análisis-Síntesis: Se emplea principalmente para el desarrollo del marco
teórico ya que se analiza la bibliografía encontrada acerca del tema en general
y finalmente se sintetiza lo que interesa para este trabajo.

4
CAPÍTULO 1. Marco teórico conceptual
Introducción
En el presente capítulo se realiza un análisis para la comprensión de algunos temas
biológicos, teniendo en cuenta que de estos parte todo el asunto a tratar. Se explica
de manera general, el funcionamiento del sistema inmunológico para entender en
qué parte de este se manifiesta el proceso de formación de epítopes. Se definen
aspectos relacionados a los algoritmos para el cálculo de distancia, específicamente
la Distancia de Levenshtein; así como el bosquejo de algunas aplicaciones existentes
para la consulta de datos. Se describen las herramientas utilizadas para la
realización del software.
Las siguientes temáticas permiten comprender la caracterización y el diagnóstico del
problema presentado.
1.1 Bioinformática
En el mundo de hoy, las computadoras son tan usadas por biólogos como por
cualquier otro profesional altamente entrenado, ellos usan computadoras para
realizar tares comunes o para ocuparse de problemas que son muy específicos en la
biología. Estas tareas específicas, forman el campo de la bioinformática. Es decir,
podemos definir bioinformática como la rama computacional de la biología molecular.
[CLAVERIE, 2007].
1.1.1 La expresión genética y la síntesis de proteínas
El Ácido desoxirribonucleico (ADN) es el material genético de todos los organismos
celulares y la mayoría de los virus. El ADN transmite la información necesaria para la
síntesis de proteína y la replicación [PETTERSSON, 2005]. Las proteínas están
compuestas por 20 tipos de aminoácidos (fig.1 Anexo), generalmente compuestos de
carbono, hidrógeno, oxígeno, nitrógeno, y azufre; los que están unidos
secuencialmente como una cadena en un orden preciso determinando su identidad y
estructura.

5
1.1.2 Funcionamiento del Sistema inmunológico
El “propósito” del sistema inmunológico es proteger el cuerpo de amenazas
planteadas por agentes patógenos, y hacer eso de un modo que minimice daño para
el cuerpo y asegure su normal funcionamiento. El agente patógeno representa a
microorganismos hostiles, como bacterias, virus y otros, que constantemente asaltan
el cuerpo. Una vez que los agentes patógenos han sido detectados, el sistema
inmunológico los debe eliminar en alguna manera.
Figura 1. Tomada de An Interpretative Introduction to the Immune System.
Las defensas del sistema inmunológico son multicapas, comenzando por la piel, que
funciona como una barrera donde se eliminan parte de los agentes, luego las
condiciones fisiológicas, y seguido el sistema inmunológico innato, donde se produce
la fagocitosis. El estrato final es el sistema inmunológico adaptativo, lo cual consta de
células llamados linfocitos que se adaptan a la estructura de agentes patógenos para
eliminarlos eficazmente [HOFMEYR, 2000].
1.1.3 Reconocimiento específico del sistema inmunológico
Una detección o evento de reconocimiento ocurre en el sistema inmunológico cuando
los enlaces químicos son establecidos entre receptores en la superficie de una célula
inmune y epítopes, los cuales están localizados en la superficie de un agente
patógeno o fragmento de proteína.

6
Figura 2. Tomada de An Interpretative Introduction to the Immune System.
La similitud entre un receptor y un epítope es llamada afinidad. Los receptores son
estimados específicos porque amarran apretadamente sólo a algunas estructuras
similares del epítope. El comportamiento de linfocitos es fuertemente influenciado por
afinidades: Un linfocito sólo será activado (esto puede ser llamado un
“acontecimiento de detección”) cuando el número de receptores atados excede algún
límite. Así, un linfocito sólo será activado por agentes patógenos si sus receptores
tienen afinidades suficientemente altas para las estructuras particulares del epítope
en los agentes patógenos, y si los agentes patógenos existen en cantidades
suficientes alrededor del linfocito, o sea, cuando el número de patógenos detectados
es superior a un porciento significativo del total de receptores presentes en el linfocito
[HOFMEYR, 2000].
1.2 Algoritmos de distancia.
Aunque existe un conjunto de algoritmos basados en la distancia, como la Distancia
de Mahalanobis, establecida en las correlaciones entre los rasgos de dos vectores, la
Distancia de Manhattan, para medir la distancia más corta requerida para ir de un
punto a otro; o la Distancia de Minkousky como generalización de varias distancias

7
canónicas[HERTZ, 2006], por solo citar algunas; el autor considera la inefectividad
del empleo de las mismas para este trabajo, puesto que no funcionan
adecuadamente entre las cadenas de caracteres que componen a los epítopes; y la
utilidad que reportaría la Distancia de Levenshtein (específica para esto), dada sus
características, si se analiza su aplicación en la detección de las mutaciones en los
epítopes originales y en la implementación del cálculo de similitud entre los codones
que dan origen a un aminoácido entre un epítope original y un mutante,
determinando el valor probable de mutación que existe entre ellos.
1.2.1 Distancia de Levenshtein
La Distancia de Levenshtein(DL), distancia de edición, o distancia entre
palabras(descubierta por el científico ruso Vladimir Levenshtein en 1965), es una
medida de la similitud entre dos cadenas (string), a las cuales podemos referirnos
como cadena de origen (o) y cadena de destino (d). La distancia es el número de
supresiones, inserciones, o sustituciones necesarias para transformar o en d.
La Distancia de Levenshtein entre dos cadenas, s1 y s2, también puede ser definida
como el número mínimo de puntos de mutación necesarias para cambiar s1 en s2,
donde un punto de mutación puede estar determinado por cualquiera de las
transformaciones antes mencionadas, ofreciendo un indicador del grado de
“cercanía” entre una cadena y la otra. Por ejemplo:
Si o es “CASA” y d es “CASA”, entonces DL(o, d)=0; porque no es necesario
realizar transformaciones, las cadenas ya son idénticas.
Si o es “CASA” y d es “CAZA”, entonces DL(o, d)=1; porque una sustitución
(cambio de “S” a “Z”) es suficiente para transformar o en d.
Entre más grande sea el valor de la Distancia de Levenshtein, mayor será la
diferencia entre las cadenas. Los principales usos del algoritmo han sido para
revisión ortográfica, reconocimiento de idioma, detección de plagio y biología
molecular (análisis de ADN) [GUILLELAND, 2009].

8
1.3 Proceso de importación de los datos.
PDI (Pentaho Data Integration), originalmente nombrado Kettle, es una poderosa
solución del ETL (Extract, Transform, and Load) utilizada con disímiles propósitos.
[GET, 2010]. Para el caso particular de este trabajo, su principal uso está
determinado en la migración de los datos entre bases de datos y aplicaciones. PDI
permite crear dos tipos de documentos básicos: transformaciones y trabajos, los
primeros son usados para describir el flujo de los datos para ETL, como la lectura
desde una fuente, transformación y carga de datos dentro del lugar designado, y los
segundos para coordinar las actividades de definición del flujo y dependencias entre
diferentes trabajos y transformaciones, según el orden en que deben ejecutarse, o
preparar para la ejecución verificando precondiciones que deben cumplirse para una
ejecución satisfactoria.
Los pasos fundamentales realizados en el proceso de importación de los datos
bioinformáticos hacia las tablas del modelo relacional propuesto en PostgreSql
fueron:
1.-Selección de las fuentes disponibles, fundamentalmente la HIV Molecular
Immunology y la IEDB (Immune Epitope Database 2.0).
2.-Colección de los datos más relevantes en una base de datos en Access.
3.-Creación de una base de datos en PostgreSql como repositorio, con la finalidad de
almacenar las transformaciones a realizar.
4.-Creación de una base de datos con la finalidad de almacenar la información,
hacia los que van dirigidos los estudios mediante la aplicación visual.
5.-Creación y configuración de las transformaciones.
A continuación se muestra un fragmento del proceso de transformación realizado
para la importación de datos de los epítopes hacia la base de datos, con el empleo
de PDI.

9
La siguiente figura presenta cómo se define la entrada de los datos a partir de una
tabla en Access y la salida de los datos a una tabla en PostgreSql.
Figura 3. Definición de entrada y salida de los datos.
Haciendo doble click encima se definen los parámetros de la entrada de los datos.
Figura 4. Parámetros de entrada.

10
De igual manera se definen los parámetros para la salida de los datos.
Figura 5. Parámetros de salida.
El siguiente diagrama refleja el modelo conceptual aplicado en el proceso de ETL,
haciendo mayor énfasis en la parte de las transformaciones, como eslabón
fundamental al criterio del autor.
Figura 6. Modelo conceptual aplicado.

11
1.4 Valoración de aplicaciones similares.
Existe un vasto y siempre creciente volumen de información que ha sido acumulado
por décadas de análisis experimentales con inmunología. La única manera eficaz
para que esta información sea utilizada apropiadamente requiere el desarrollo de
bases de datos que la guardan y sistemas que lo usan. La creación, uso, y
manipulación de bases de datos que contienen la información biológicamente
importante son el rasgo más crucial de la bioinformática actual. Bases de datos
funcionales u orientados a epítopes son el más reciente desarrollo [PTOSELAND,
2010].
A continuación se hace un recuento de algunas de las bases de datos disponibles en
Internet, las que además de representar una poderosa herramienta para el desarrollo
biotecnológico a nivel mundial, sirven de punto de partida para el progreso de esta
investigación.
AntiJen es un sistema de base de datos enfocado en la integración de datos
cinéticos, termodinámicos, funcionales, y celulares dentro del contexto de
inmunología y la producción de vacunas. Comparado a su progenitor JenPep, oferta
una variedad más amplia de métodos de búsqueda. Aunque AntiJen v2.0 retiene un
enfoque hacia epítopes de células T y B, su mayor novedad es el archivado de datos
cuantitativos continuos en una variedad de interacciones moleculares inmunológicas.
Los usos de AntiJen incluyen el diseño de vacunas y diagnósticos. Constituye
además una ayuda al bioinformático o matemático en el modelado in silico del
sistema inmunológico [PTOSELAND, 2010].
La IEDB (Immune Epitope Database 2.0) proporciona un catálogo
experimentalmente caracterizado de epítopes de células B y T. La base de datos
representa las estructuras moleculares reconocidas por los receptores inmunes
adaptables y los contextos experimentales en que estas moléculas fueron
determinadas para ser epítopes inmunes. Los epítopes reconocidos en los
humanos, los primates, roedores, cerdos, gatos y todas las otras especies probadas
son incluidos. Se capturan los resultados experimentales positivos y negativos. Se

12
puede acceder a la información mediante la estructura del epítope, organismo, la
restricción de MHC, entre otros criterios. El propósito del IEDB es catalogar todo lo
derivado experimentalmente sobre los epítopes inmunes [SETTE, 2010].
ISED (Influenza Sequence and Epitope Database) fue diseñada para colectar,
almacenar y proveer información del virus de la influenza, incluyendo su resistencia a
los medicamentos. Las secuencias de virus en ISED son categorizadas dentro de
tablas de acuerdo a los países, en los cuales son categorizados por un conjunto de
atributos, como el tipo de virus, segmento de ARN (ácido ribonucleico), segmento de
aminoácidos, número de aminoácidos, entre otros [YANG, 2010].
El autor de este trabajo considera que, sin dudar del valor aportado por todas estas
aplicaciones, en ninguno de los casos conocidos (incluso los no mencionados), se
dispone de alguna que permita analizar los mutantes de los epítopes. Los ejemplos
citados anteriormente manifiestan un buen dominio de las técnicas para el desarrollo
y acceso a la información correspondiente a los epítopes, sin embargo no presentan
la solidez requerida al tratar los temas de sus variantes, entiéndase por estas, el
caso en que estos epítopes originales tengan mutantes y/o mutantes de escape, y lo
que estos últimos representan, al no producirse su detección en el organismo.
Aunque no se disponen de cifras exactas, la implementación, uso correcto y el
desarrollo de un sistema que resuelva las limitaciones antes mencionadas, tendría
una amplia repercusión económico-social, sobre todo, en el contexto actual, donde
nuestro país se proyecta en aras de sostener y desarrollar los resultados alcanzados
en el campo de la biotecnología, la industria del software, la bioinformática y la
nanotecnología [PLPES, 2010].
1.5 Descripción de software, técnicas y metodologías utilizadas.
En el diseño e implementación de nuestra aplicación, se han empleado diferentes
herramientas, metodologías y técnicas, las cuales se manifiestan a continuación

13
Java
Es un lenguaje de programación de alto nivel que ha ganado renombre en la
programación moderna. Permite la creación de poderosas aplicaciones, sitios web o
pequeños programas. Java es un lenguaje de programación completamente portable,
por lo que un programa escrito en Java podrá, teóricamente, correr en cualquier
computadora o sistema operativo, siempre y cuando tenga instalada su plataforma.
Se encuentra diseñado con el objetivo de brindar una plataforma de libre distribución
para la creación de aplicaciones.
PostgreSql
PostgreSql es un popular sistema de gestión de base de datos relacional orientada a
objetos. Es dirigido por una comunidad de desarrolladores y organizaciones
comerciales las cuales trabajan en su desarrollo, dicha comunidad es denominada el
PGDG (PostgreSql Global Development Group). Este potente gestor incorpora
características como la alta concurrencia, incorpora una amplia variedad de tipos de
datos e implementa ciertas características orientadas a objetos, además es
multiplataforma, muy seguro y robusto.
Pentaho Data Integration (PDI)
Es una herramienta que incluye facilidad de uso, diseño gráfico ambientado para
realizar trabajos y transformaciones, produciendo un desarrollo más rápido, con el
más bajo costo de mantenimiento, depuración interactiva, y desarrollo simple. PDI es
una herramienta sumamente flexible dirigida entre otros a la migración de datos entre
distintas bases de datos y aplicaciones. Es de fácil instalación y uso, con soporte
para plataformas Windows, Linux y Macintosh. Proporciona seguridad de
integración, planificación, y manejo robusto de contenido que incluye la completa
revisión para los trabajos y transformaciones [GET, 2010].

14
Metodología RUP (Rational Unified Process) con AM (Agile Modeling)
RUP es un proceso para describir el sistema, caracterizado por ser iterativo e
incremental, donde cada fase se desarrolla en iteraciones donde se involucran
actividades de todos los flujos de trabajo, centrado en la arquitectura que muestra la
visión común del sistema completo en la que el equipo de proyecto y los usuarios
deben estar de acuerdo; dirigido por caso de uso, ya que estos reflejan lo que los
usuarios futuros necesitan y desean. En tanto, AM no es un método ágil cerrado en
sí mismo, sino que constituye un complemento de otras metodologías (en nuestro
caso de RUP) para hacer más ligeros los procesos que se usan. Se le podría definir
como un proceso de software basado en prácticas cuyo objetivo es orientar el
modelado de una manera efectiva y ágil [AMBLER, 2002].
Lenguaje UML (Unified Modeling Language)
Es un lenguaje gráfico para visualizar, especificar y documentar cada una de las
partes que comprende el desarrollo de software, utilizado para la construcción de
aplicaciones basadas en conceptos orientados a objetos. Se usa para especificar
pues construye modelos sin ambigüedad y completos.UML tiene una sintaxis y
semántica bien definidas, permitiendo representar el modelado de sistemas mediante
el uso de una notación común. Se caracteriza por su flexibilidad, es extensible e
independiente de los diversos procesos del análisis y diseño orientado a objetos.
Conclusiones
Después de analizar el marco teórico correspondiente a este trabajo llegamos a la
siguiente conclusión.
Para dar solución al problema, es necesario la integración de los elementos
antes expuestos, en el diseño de una aplicación que además de presentar los
datos de los epítopes, permita realizar algunos estudios referentes a los
mismos.

15
CAPÍTULO 2. Análisis y diseño del sistema
Introducción
En el presente capítulo se muestra el proceso de modelado del sistema, teniendo en
cuenta la metodología a emplear. Se muestran los componentes vinculados al diseño
de la aplicación y sus requerimientos.
2.1 Modelo de Dominio.
El modelo de dominio o conceptual, representa los conceptos significativos en un
dominio del problema. Representa cosas del mundo real, no componentes del
software. A través de este se comunica cuáles son los términos importantes y cómo
se relacionan entre sí [LARMAN, 2004].
Virus ADN
1*
1*
Contiene
Codón
*
1
*
1
Estructurado-porProteína
*
1
*
1Compuesto-por
Aminoácido
1..*1 1..*1
generado-por
Epítope
* 1* 1
Fragmento-de
*1
*1
Compuesto-por
Mutante de escape
0..*
1
0..*
1
Puede-tener
Mutante
0..*
1
0..*
1Puede-tener
0..11 0..11
Puede-ser
Figura 7. Modelo de dominio.
2.2 Modelo del Sistema.
2.2.1 Objeto de automatización.
Se desea implementar una aplicación para la obtención y manipulación de
información en una base de datos de epítopes, de forma tal que el usuario pueda
acceder a la misma, y realizar los estudios que considere necesarios. La aplicación

16
debe permitir al usuario, entre otras cosas, estudiar la correlación existente entre las
variantes mutantes y mutantes de escape, dado un epítope original seleccionado de
una proteína.
2.2.2 Captura de requisitos.
Para el proceso de captura de requisitos se parte del objeto de automatización,
considerando que los requisitos funcionales son las capacidades o condiciones que
debe cumplir el sistema, es decir, las funcionalidades del software. Además, se
definen los requisitos no funcionales, dado por las propiedades o cualidades con que
debe contar el producto para su correcto empleo y aceptación.
2.2.2.1 Requisitos funcionales.
R1: Verificar validez del usuario.
R2: Mostrar organismo en estudio.
R3: Mostrar listado de subtipos.
R4: Permitir seleccionar un subtipo.
R5: Mostrar listado de proteínas del organismo.
R6: Permitir seleccionar la proteína.
R7: Mostrar listado de componentes de la proteína seleccionada.
R8: Permitir seleccionar un componente.
R9: Mostrar listado de epítopes.
R10: Permitir seleccionar un epítope.
R11: Mostrar detalles de un epítope.
R12: Mostrar listado de mutantes del epítope (en caso de tenerlos).
R13: Permitir seleccionar un mutante.

17
R14: Mostrar detalles de la mutación.
R15: Insertar un epítope.
R16: Modificar un epítope.
R17: Eliminar un epítope.
2.2.2.2 Requisitos no funcionales
Requerimientos de apariencia o interfaz externa.
El sistema es legible, fácil de usar y profesional. La interfaz es sencilla y fácil de
entender manteniendo una misma línea de principio a fin.
Requerimientos de Portabilidad.
El software permite ser usado en diferentes plataformas.
Requerimientos de Software.
Se debe disponer sistema operativo Windows NT o superior, Linux y Máquina Virtual
de Java (JVM).
Requerimientos de Hardware.
Se debe disponer de una máquina, con memoria RAM como mínimo de 512MB,
procesador Pentium 4 o superior.
Requerimientos de Seguridad.
Confidencialidad: La información manejada por el sistema está protegida de acceso
no autorizado y divulgación.
Integridad: La información manejada por el sistema es objeto de cuidadosa
protección contra la corrupción y estados inconsistentes, de la misma forma será
considerada igual a la fuente o autoridad de los datos.

18
Disponibilidad: Al usuario autorizado se le garantiza el acceso a la información y que
los dispositivos o mecanismos utilizados para lograr la seguridad no ocultarán o
retrasarán al mismo la obtención de los datos deseados en un momento dado.
2.2.3 Casos de uso del sistema
1. CUS Autenticarse.
2. CUS Obtener listado de componentes dada la proteína.
3. CUS Obtener listado de epítopes dado el componente.
4. CUS Obtener listado de mutantes dado el epítope.
5. CUS Obtener detalles de mutación.
6. CUS Gestionar datos del epítope.
El actor del sistema es para todos los CUS el usuario, puesto que la aplicación será
utilizada por una sola persona.
2.2.4 Diagrama de casos de uso del sistema.
En el siguiente diagrama se establecen las relaciones entre los casos de uso y el
actor que los inicia.

19
CUS Autenticarse
(from Casos de Uso del Sistema)
CUS Obtener listado de
componentes dada la proteína.
(from Casos de Uso del Sistema)
CUS Obtener listado de epítopes
dado el componente.
(from Casos de Uso del Sistema)
CUS Obtener listado de mutantes
dado el epítope.
(from Casos de Uso del Sistema)
CUS Obtener detalles de mutación.
(from Casos de Uso del Sistema)
Usuario
(f rom Actor)
CUS Gestionar datos del epítope.
(from Casos de Uso del Sistema)
Figura 8. Diagrama de casos de uso del sistema.
2.2.5 Descripciones textuales de los casos de uso más importantes.
Descripción del CUS Autenticarse
Nombre del CUS Autenticarse.
Actor Usuario.
Propósito Acceder al sistema.
Resumen El CUS se inicia cuando el usuario desea acceder al
sistema y termina luego que el sistema le permite el
acceso.
Referencias R1.
Pre-condiciones El usuario debe estar registrado.
Pos-condiciones (-).

20
Curso Normal de los Eventos
Acciones del Actor Respuesta del Sistema
1. El usuario introduce
usuario y contraseña.
1.1 El sistema verifica validez de los datos
y permite acceder al sistema.CA#1
Curso Alterno
CA#1 Paso 1 No pudo entrar al sistema, el
usuario y la contraseña no existen o los
insertó de manera incorrecta. Se emite un
mensaje de error.
Descripción del CUS Obtener listado de mutantes dado el epítope.
Nombre del CUS Obtener listado de mutantes dado el epítope.
Actor Usuario.
Propósito Conocer los mutantes de un epítope (si los tiene).
Resumen El CUS se inicia cuando el usuario desea conocer los
mutantes de un epítope, en caso de tenerlos y termina
luego que el sistema le muestra el resultado.
Referencias R10, R12.
Pre-condiciones El usuario debe acceder al sistema.
Pos-condiciones (-).
Curso Normal de los Eventos
Acciones del Actor Respuesta del Sistema
1. El usuario solicita al
sistema obtener el listado de
1.1 El sistema procesa la solicitud y

21
mutantes, dada la selección
de un epítope.
muestra el listado de mutantes.
Descripción del CUS Obtener detalles de mutación.
Nombre del CUS Obtener detalles de mutación.
Actor Usuario.
Propósito Conocer detalles de la mutación.
Resumen El CUS se inicia cuando el usuario desea conocer
aspectos relativos a la distancia (DL) entre el epítope y
el mutante, si es de escape, entre otros, y termina
luego que el sistema le muestra el resultado.
Referencias R13, R14.
Pre-condiciones El usuario debe acceder al sistema.
Pos-condiciones (-).
Curso Normal de los Eventos
Acciones del Actor Respuesta del Sistema
1. El usuario selecciona un
mutante.
1.1 Informa tipo de mutante (si es de
escape o con duda).
1.2 Muestra (para mutantes determinados)
otros datos respecto a la posición de la
mutación.
1.3 El sistema Realiza el cálculo de la
Distancia (DL) y muestra el resultado.
22
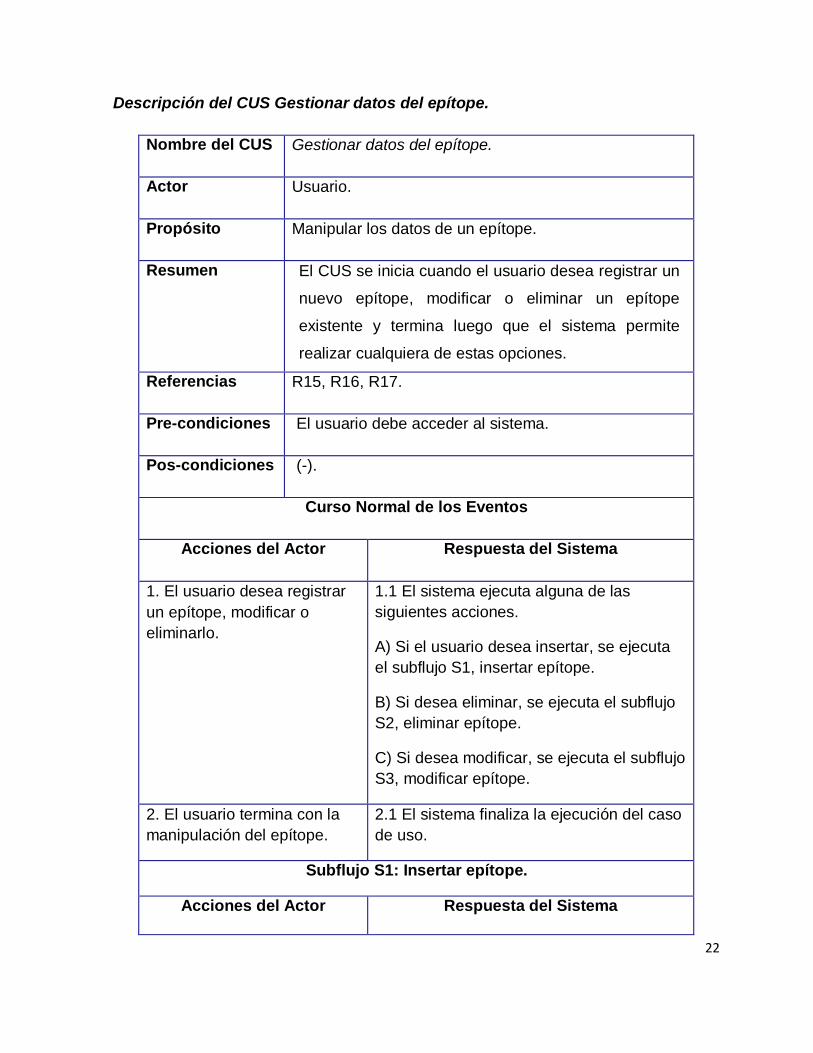
Descripción del CUS Gestionar datos del epítope.
Nombre del CUS Gestionar datos del epítope.
Actor Usuario.
Propósito Manipular los datos de un epítope.
Resumen El CUS se inicia cuando el usuario desea registrar un
nuevo epítope, modificar o eliminar un epítope
existente y termina luego que el sistema permite
realizar cualquiera de estas opciones.
Referencias R15, R16, R17.
Pre-condiciones El usuario debe acceder al sistema.
Pos-condiciones (-).
Curso Normal de los Eventos
Acciones del Actor Respuesta del Sistema
1. El usuario desea registrar
un epítope, modificar o
eliminarlo.
1.1 El sistema ejecuta alguna de las
siguientes acciones.
A) Si el usuario desea insertar, se ejecuta
el subflujo S1, insertar epítope.
B) Si desea eliminar, se ejecuta el subflujo
S2, eliminar epítope.
C) Si desea modificar, se ejecuta el subflujo
S3, modificar epítope.
2. El usuario termina con la
manipulación del epítope.
2.1 El sistema finaliza la ejecución del caso
de uso.
Subflujo S1: Insertar epítope.
Acciones del Actor Respuesta del Sistema

23
1. El usuario selecciona la
opción nuevo.
1.1 El sistema habilita los campos.
2. El usuario inserta los datos
del nuevo epítope y escoge la
opción insertar.
2.1 Inserta el nuevo epítope en la BD.
Subflujo S2: Eliminar epítope.
Acciones del Actor Respuesta del Sistema
1.1 El sistema muestra el listado de
epítopes.
2. El usuario selecciona el
epítope a eliminar y
selecciona la opción eliminar.
2.1 El sistema elimina el epítope y actualiza
la BD.
Subflujo S3: Modificar epítope.
Acciones del Actor Respuesta del Sistema
1.1 El sistema muestra el listado de
epítopes.
2. El usuario selecciona el
epítope a modificar y
selecciona la opción
modificar.
2.1 El sistema habilita los campos.
3. El usuario realiza los
cambios y selecciona la
opción guardar.
3.1El sistema guarda los cambios en la BD.
2.3 Modelo de Diseño
Se abordan los requerimientos en relación a lenguaje de programación, reutilización
de componentes, bases de datos, interfaces de usuarios, entre otros. Se deriva una
representación arquitectónica del sistema y se disminuye la distancia entre el
problema del mundo real y su solución computarizada.

24
2.3.1 Realización de los casos de usos.
Describe cómo se realiza un caso de uso específico, y como se ejecuta, en términos
de clases de diseño y sus objetos.
2.3.1.1 Diagrama de clases del diseño.
Los diagramas de clases muestran un conjunto de clases, interfaces y las relaciones
entre estas.
Diagrama de clases CUS Autenticarse.
Figura 9. Diagrama de clases CUS Autenticarse.
Diagrama de clases CUS Obtener listado de componentes dada la proteína.

25
Figura 10. Diagrama de clases CUS Obtener listado de componentes dada la
proteína.
Diagrama de clases CUS Obtener listado de epítopes dado el componente.
Figura 11. Diagrama de clases CUS Obtener listado de epítopes dado el
componente.

26
Diagrama de clases CUS Obtener listado de mutantes dado el epítope.
Figura 12. Diagrama de clases CUS Obtener listado de mutantes dado el epítope.
Diagrama de clases CUS Obtener detalles de mutación.
Figura 13. Diagrama de clases CUS Obtener detalles de mutación.

27
Diagrama de clases CUS Gestionar datos del epítope.
Figura 14. Diagrama de clases CUS Gestionar datos del epítope.
2.3.1.2 Diagrama de secuencia.
Muestran interacciones ordenadas en una secuencia de tiempo y los objetos que
participan.
Diagrama de secuencia CUS Autenticarse.
: Usuario : CI
Autentication
: CC Gestor : usuarios : CI Principal
Introducir datos(usuario,contrasenna).
Tasmitir datos(usuario, contrasenna).
if (V== true)
V =
if ( V== false)
Mostrar mensaje(" Datos no válidos")
Verifica datos(usuario, contrasenna):bool
Mostrar CI Principal().
Figura 15. Diagrama de secuencia CUS Autenticarse.

28
Diagrama de secuencia CUS Obtener listado de componentes dada la proteína.
: Usuario : CI Principal : CC Gestor : protein : component
Seleccionar una proteina(prot).
Trasmitir solicitud(prot).
Gestionar datos(prot).
Buscar componentes relacionados(prot).
Mostrar lista de componentes relacionados().
Figura 16. Diagrama de secuencia CUS Obtener listado de componentes dada la
proteína.
Diagrama de secuencia CUS Obtener listado de epítopes dado el componente.
: Usuario : CI Principal : CC Gestor : component : epitope
Seleccionar un componente(comp).
Trasmitir solicitud(comp).
Gestionar datos del componente(comp).
Buscar epítopes relacionados(comp).
Mostrar lista de epítopes relacionados().
Figura 17. Diagrama de secuencia CUS Obtener listado de epítopes dado el
componente.

29
Diagrama de secuencia CUS Obtener listado de mutantes dado el epítope.
: Usuario
: CI Principal : CC Gestor : epitope : mutant
Selecciona un epítope(epi).
Gestionar datos(epi).
Buscar mutantes relacionados(epi).
Trasmitir solicitud(epi).
Mostrar lista de mutantes relacionados().
Figura 18. Diagrama de secuencia CUS Obtener listado de mutantes dado el epítope.
Diagrama de secuencia CUS Obtener detalles de mutación.
: Usuario : CI Principal : CC Gestor : mutant : mutation : aminoacid
Seleccionar un mutante(mut).
Trasmitir solicitud(mut).
Gestionar datos del mutante(mut).
Gestinar datos de la mutación(mut).
Gestionar datos de los aminoácidos(mut).
Realizar cálculo de distanciaDL(epi,mut).
Mostrar resultados().
Figura 19. Diagrama de secuencia CUS Obtener detalles de mutación.

30
Diagrama de secuencia CUS Gestionar datos del epítope.
: Usuario : CI Principal : CC Gestor : epitope
Solicitar gestionar datos de epítope().
Insertar los datos(name, epitope,seq).
Seleccionar insertar().
Trasmitir solicitud().
Insertar datos del nuevo epitope(name, epítope_seq).
Seleccionar el epítope(epi).
Selecciona la opción eliminar().
Trasmitir solicitud().
Eliminar el epítope(epi).
Selecciona el epítope(epi).
Selecciona la opción modificar().
Trasmitir solicitud().
Realiza modificaciones(EPI).
Solicitar gardar(EPI).
Trasmitir solicitud().
Modificar el epítope(EPI).
Figura 20. Diagrama de secuencia CUS Gestionar datos del epítope.

31
2.3.2 Diagrama de clases persistentes.
Se representan las relaciones entre las clases que son capaces de mantener su
estado en el tiempo y en el espacio.
Figura 21. Diagrama de clases persistentes.

32
2.3.3 Modelo de Datos.
Figura 22. Modelo de datos.

33
2.3.4 Modelo de Despliegue.
El diagrama de despliegue muestra la configuración de los nodos participantes en la
ejecución de un sistema. Se modela la topología del hardware sobre la que se
ejecuta el sistema y la distribución física del mismo [JACOBSON, 2000].
Servidor de base
de datos de
epítopes.
Servidor de la
aplicación.
Cliente
Acceso del
usuario.
Servidor
<<TCP/IP>>
Figura 23. Diagrama de despliegue.
2.4 Implementación.
2.4.1 Modelo de Componentes.
2.4.1.1 Diagrama de la arquitectura del sistema.
El diagrama de componentes muestra un conjunto de componentes y sus relaciones.
Un componente es una parte física y reemplazable de un sistema que se conforma
con un conjunto de interfaces y proporciona la realización de dicho conjunto. Se usan
para modelar los elementos físicos que pueden hallarse en un nodo por lo que
empaquetan elementos como clases, colaboraciones e interfaces [JACOBSON,
2000].
SCDE.jar
Paquete visual Paquete de control Paquete de clases entidad
escape
Figura 24. Diagrama de componentes.

34
2.4.1.2 Diagrama de componentes de los casos de uso críticos.
CUS Obtener listado de mutantes dado el epítope.
Principal.java DBFactory.java
epitope.java mutant.java
escape
Figura 25. Diagrama de componentes CUS Obtener listado de mutantes dado el
epítope.
CUS Obtener detalles de mutación.
Principal.java DBFactory.java
mutation.java mutant.javaaminoacid.java
escape
Figura 26. Diagrama de componentes CUS Obtener detalles de mutación.
Conclusiones
Teniendo en consideración la metodología empleada, el autor de este trabajo
considera oportuno apoyarse en todos los elementos antes representados y pasar al
desarrollo de la aplicación.

35
CAPÍTULO 3. Implementación del sistema
3.1 Aspectos relativos a la implementación del sistema.
El sistema se desarrolló como un proyecto JPA (Java Persistence API) con
EclipseLink. El objetivo de EclipseLink es proveer un framework de persistencia que
sea comprensivo y universal, orientado en este caso para el estándar de persistencia
JPA, mediante el cual “el desarrollador Java” puede mapear, guardar, cargar y retirar
datos desde una base de datos relacional orientada a objetos y vice-versa, es decir,
permite el trabajo del desarrollador directamente con los objetos mapeados.
3.2 Diseño de la interfaz.
El diseño de la interfaz de usuario es la categoría de diseño que establece un medio
de comunicación entre el usuario y la computadora. Tiene como objetivo definir las
acciones de interfaz (y sus representaciones en pantalla) que posibilitan al usuario
explotar las opciones que brinda el sistema. Una interfaz bien diseñada mejora la
percepción del contenido y de los servicios que proporciona el sistema de software
[PRESSMAN, 2002]. Algunas de las características que están presentes en la
interfaz son la sencillez, claridad y facilidad de manipulación.
Figura 27. Interfaz principal.

36
3.3 Forma general y principios en que se basa el sistema de ayuda.
La ayuda de la aplicación es una opción que dota al usuario de una herramienta de
consulta sobre los conocimientos necesarios para la explotación del mismo.
Contempla toda la información concerniente a la aplicación, manipulación y servicios
que brinda el sistema. El usuario puede acceder a la ayuda seleccionando en el
menú.
Figura 28. Ayuda del SCDE.
3.4 Forma general y principios de la protección y seguridad.
Para que un sistema se pueda definir como seguro debe tener estas características:
• Integridad: la información que utiliza el sistema así como el origen de la misma
debe estar protegida contra la corrupción.
• Confidencialidad: la información sólo debe estar disponible para los usuarios
autorizados.
• Disponibilidad: cuando los usuarios soliciten alguna información, ésta debe estar
disponible y los mecanismos de seguridad empleados no deben demorar el proceso.

37
Teniendo en cuenta los aspectos anteriores se estableció que para acceder al
sistema se requiera la autenticación del usuario. Limitando el acceso a cualquier otra
persona.
Usuario: tiene acceso a todas las opciones que brinda el sistema.
3.5 Forma general del tratamiento de errores.
El sistema es capaz de reconocer y tratar los posibles errores producidos por una
mala manipulación o entradas de datos no válidas, dando una respuesta al usuario
en caso de que esto ocurra.
A continuación se muestran algunos ejemplos de posibles errores y la respuesta del
sistema para su tratamiento.
El usuario ha intentado insertar un nuevo epítope, sin introducir el dato para el
campo obligatorio secuencia.
Figura 29. Mensaje de error al dejar campos obligatorios sin llenar.

38
El usuario ha intentado insertar una secuencia con un caracter no válido.
Figura 30. Mensaje de error al intentar añadir caracteres no válidos.
El usuario ha intentado insertar una secuencia que ya existe.
Figura 31. Mensaje de error al intentar insertar una secuencia ya existente.

39
CONCLUSIONES
Al finalizar este trabajo se arribaron a las siguientes conclusiones:
El estudio de las bases de datos de epítopes reveló que existían deficiencias
en las mismas, relacionadas principalmente con la insuficiente información
referente a los mutantes.
Al realizar el análisis de la información disponible existente en las distintas
fuentes, se constató que es posible la integración de las mismas para realizar
un mejor estudio.
El sistema implementado permite realizar un mejor análisis de los datos,
manteniendo la utilización de herramientas informáticas que garantizan el
almacenamiento y procesamiento de la información.

40
RECOMENDACIONES
Como recomendaciones del presente trabajo se plantea:
Continuar la importación de los datos para el organismo en estudio (HIV) y
añadir datos para otros patógenos existentes.
Agrupar e integrar la mayoría de datos posibles, hasta obtener las
condiciones que sean propicias para realizar una minería de datos efectiva.
.

41
BIBLIOGRAFÍA
AMBLER, Scott. Agile Modeling and the Unified Process. 2002. Disponible en:
http://www.agilemodeling.com/essays/agileModelingRUP.htm
[consultado: 6/10/2010].
HOFMEYR, Steven A. An Immunological Model of Distributed Detection and Its
Application to Computer Security. 1999. p.7-11. Disponible en:
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.76.1335&rep=rep1&type=pdf
[consultado: 30/6/2010].
RANAWANA, Romesh. Intelligent Multi-Classifier Systems for Gene Recognition
in DNA Sequences. 2005. p.18-19. Disponible en:
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.85.1042&rep=rep1&type=pdf
[consultado: 30/6/2010].
YUSIM, Karina y cols. HIV Molecular Immunology. Nuevo México: Theoretical
Biology and Biophysics, 2009.

42
REFERENCIAS BIBLIOGRÁFICAS
[AMBLER, 2002]. AMBLER, Scott. Agile Modeling: Effective practices for Extreme
Programming and the Unified Process. John Wiley & Sons, 2002.Disponible en:
http://www.amazon.com/Agile-Modeling-Effective-Practices-Programming/dp/0471202827
[consultado: 6/10/2010].
[CLAVERIE, 2007]. CLAVERIE, Jean-Michel y NOTREDAME, Cedric.
Bioinformatics for Dummies. Wiley Publishing, 2007.p. 9-10.
[GET, 2010]. Getting started with Pentaho Data Integration. Orlando: Pentaho
Corporation, 2010. p. 4-5. Disponible en: http://www.pentaho.com
[consultado: 16/02/2011].
[GUILLELAND, 2009]. GUILLELAND, Michael. Levenshtein Distance, in Three
Flavors. Disponible en: http://www.merriampark.com/mgresume.htm
[consultado: 17/03/2011].
[HERTZ, 2006].HERTZ, Tomer. Learning distance functions: Algorithms and
Applications. Tesis por el grado de Doctor en Filosofía. Jerusalén: Universidad
Hebrea de Jerusalén, 2006.p.4.
[HOFMEYR, 2000]. HOFMEYR, Steven A. An Interpretative Introduction to the
Immune System.2000.p.1-6.Disponible en:
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.76.1335&rep=rep1&type=pdf
[consultado: 6/10/2010].
[JACOBSON, 2000]. JACOBSON, Ivar; BOOCH, Grady y RUMBAUGH, James. El
Proceso Unificado de Desarrollo de Software. Adison-Wesley. 2000.
[LARMAN, 2004]. LARMAN, Craig.UML y Patrones: Introducción al análisis y
diseño orientado a objetos. Editorial Félix Varela. 2004. p. 85-87.
[PETTERSSON, 2005]. PETTERSSON, Fredrik. A Multivariate Approach to
Computational Molecular Biology. 2005. p.13-17. Disponible en: http://umu.diva-
portal.org/smash/get/diva2:143974/FULLTEXT01
[consultado: 30/6/2010].
[PLPES, 2010]. Proyecto de lineamientos de la política económica y social. La
Habana, 2010. p. 18.

43
[PRESSMAN, 2002]. PRESSMAN, R. S. Ingeniería del software. Un enfoque
práctico. España, 2002.
[PTOSELAND, 2010].P. TOSELAND, Christopher y cols. AntiJen: a quantitative
immunology database integrating functional, thermodynamic, kinetic, biophysical,
and cellular data. Disponible en: http://creativecommons.org/licences/by/2.0
[consultado: 12/10/2010].
[SETTE, 2010]. SETTE, Alessandro y PETERS, Bjoern .La base de datos inmune
epítopo y análisis de los recursos: de la visión a Blueprint. Disponible en:
http://viaclinica.com/article.php?pmc_id=1065705
[consultado: 12/10/2010].
[YANG, 2010]. YANG, Seok y cols. Influenza sequence and epitope database.
Disponible en: http://creativecommons.org/licenses/by-nc/2.0/uk/
[consultado: 12/10/2010].

44
ANEXOS
Anexo 1


















