
Single-ISA Heterogeneous Multi-Core Architecture Zvika Guz [email protected] November, 2004.
48
Single-ISA Heterogeneous Multi-Core Architecture Zvika Guz Zvika Guz [email protected] [email protected] November, 2004 November, 2004
-
Upload
christopher-palmer -
Category
Documents
-
view
223 -
download
1
Transcript of Single-ISA Heterogeneous Multi-Core Architecture Zvika Guz [email protected] November, 2004.

Single-ISA Heterogeneous Multi-Core Architecture
Zvika GuzZvika Guz
[email protected]@tx.technion.ac.il
November, 2004November, 2004

2
Outline Motivation
Heterogeneous multi-core architecture
ToDo list and open questions Different Objective functions
SMT as building blocks
Phase detection
Summary

3
References
“Single-ISA Heterogeneous Multi-Core Architecture for Multithreaded Workload Performance”Rakesh Kumar, Dean M. Tullsen, Parthasarath Ranganathan, Norman P.Jouppi, Keith I. Farkas In Proceedings of the 31st International Symposium on Computer Architecture (ISCA’04),June, 2004
“Single-ISA Heterogeneous Multi-Core Architecture: The Potential for Processor Power Reduction”Rakesh Kumar, Keith I. Farkas, Norman P.Jouppi, Parthasarath Ranganathan, Dean M. Tullsen, In Proceedings of the 36st International Symposium on Microarchitecure, December 2003
“A Multi-Core Approach to Addressing the Energy-Complexity Problem In Microprocessor” Rakesh Kumar, Keith I. Farkas, Norman P.Jouppi, Parthasarath Ranganathan, Dean M. Tullsen, In Proceedings of the Workshop on Complexity-Effective Design (WCED), June 2003
“Processor Power Reduction Via Single-ISA Heterogeneous Multi-Core Architecture” Rakesh Kumar, Keith I. Farkas, Norman P.Jouppi, Parthasarath Ranganathan, Dean M. Tullsen, Computer Architecture Letters, Volume 2, Apr. 2003
Heterogeneous multi-core architectureHeterogeneous multi-core architecture

4
Diminishing performance return per chip area
The infamous power/performance ratio
The power wall
Chip area is bounded
Tomer’s assumptions:
perf area
VLSI sad facts of life:VLSI sad facts of life:
power area
Processor’s characteristics

5
Processor’s characteristics Few different generations of Alpha’s cores
All scaled to 0.10 micron
EV6+

6
ProcessorEV4EV5EV6EV8-
Issue-width246 (OOO)8 (OOO)
I-Cache8 KB, DM64 KB, 2-way64 KB, 2-way64 KB, 4-way
D-Cache8 KB, DM64 KB, 2-way64 KB, 2-way64 KB, 4-way
Branch Pred.2K gsharehybrid 2 levelhybrid 2 levelhybrid 2 level (2X EV6 size)
Threads1111
Area (mm2)2.875.0624.5236
Peak-power (Watt)
4.979.8317.8092.88
Typical Power (Watt)
3.736.8810.6846.44
Processor’s characteristics Few different generations of Alpha’s cores
All scaled to 0.10 micron
4.8x
1.5x

7
Processor’s characteristics
⇒ large number of small processors is better than small number of large processors
Processor are expected to supply competing objectives: High throughput for multi-thread environments
Good single thread performance
But what if TLP isn’t large enough ?

8
workloads characteristics
Different amount of ILP
Different TLP Among different applications
Among different workloads
Vary with time
Legacy code
Many applications under-utilize the hardware Suffer little performance loss when run on a less aggressive processor
Great diversity among different applicationsGreat diversity among different applications

9
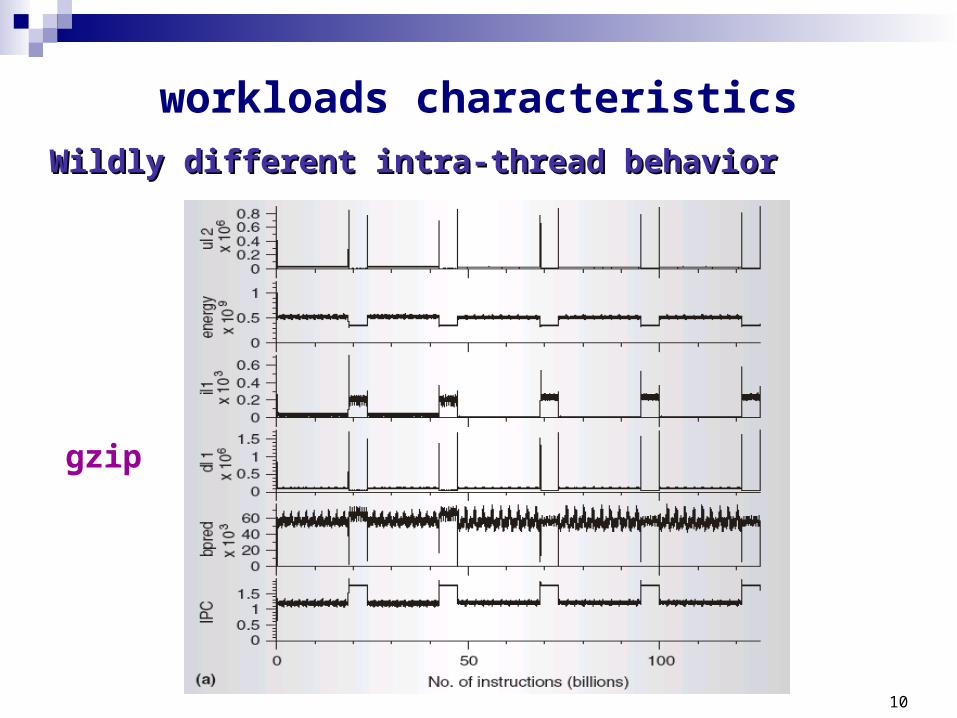
workloads characteristicsWildly different intra-thread behaviorWildly different intra-thread behavior
Programs fall into phases, each phase presents different behavior Variation in resources demands
Memory/computation bound
Branch mispredictions
Cache misses
During many phases the processor is under-utilized
10
workloads characteristicsWildly different intra-thread behaviorWildly different intra-thread behavior
gzip

11
workloads characteristicsWildly different intra-thread behaviorWildly different intra-thread behavior
gcc

12
Main IdeaMain Idea A multiprocessor composed of asymmetric cores
Better area-efficient coverage of the different workloads demands:
Single thread performance (legacy code)
Elevated throughput for high TLP
Single-ISA heterogeneous Multi-Core

13
Main IdeaMain Idea A multiprocessor composed of asymmetric cores
Better area-efficient coverage of the different workloads demands:
Single thread performance (legacy code)
Elevated throughput for high TLP
Use a smart dynamic task-to-core assignment Assign each application to the core best suite to meet its performance demands
Exploit the variations in resource demands between different application's phases
Single-ISA heterogeneous Multi-Core

14
Main IdeaMain Idea A multiprocessor composed of asymmetric cores
Better area-efficient coverage of the different workloads demands:
Single thread performance (legacy code)
Elevated throughput for high TLP
Use a smart dynamic task-to-core assignment Assign each application to the core best suite to meet its performance demands
Exploit the variations in resource demands between different application's phases
Use of-the-shelf cores Amortize design and verification effort
Single-ISA heterogeneous Multi-Core

15
The Potential of Heterogeneity

16
Architecture Model 3 different multi-core systems were compared:
4 EV6 cores (homogeneous MP)
20 EV5 cores (homogeneous MP)
3 EV6 and 5 EV5 cores (heterogeneous MP)
Each core has its own L1 caches
All cores share an on chip 4 MB L2 cache
Chip area of all 3 configurations is roughly the same Using the correct power model, so is the total power…

17
Scheduling issues OS scheduler is responsible for thread scheduling and assignment
Core-switch at OS timeslice intervals. (10-100msec)
The core-switch overhead is piggybacked with OS context switch
Application phase length are typically large, hence suite this timeslices

18
Scheduling issues OS scheduler is responsible for thread scheduling and assignment
Core-switch at OS timeslice intervals. (10-100msec)
The core-switch overhead is piggybacked with OS context switch
Application phase length are typically large, hence suite this timeslices
Sampling-based : During the Sampling phase
Thread migrate between different cores
Statistics is gathered for every allocation
During the Steady Phase:
The most beneficial allocation is used

19
Evaluation Metric: weighted speedup
Maximizing average performance gain over all applications
The jobs assigned to the EV5 are those that are least affected by its inferior capabilities
( _ )( _ )
i
i
IPC current coreIPC baseline core
all runningi threads
ws
Scheduling issues
Objective functionObjective function

20
Scheduling issues
sample-one: run each thread on each core once
sample-avg: run each thread on each core at least twice
sample-sched: constrained to choose only assignment that were actually sampled
Sampling StrategySampling Strategy

21
Simulation Results Static scheduling
22
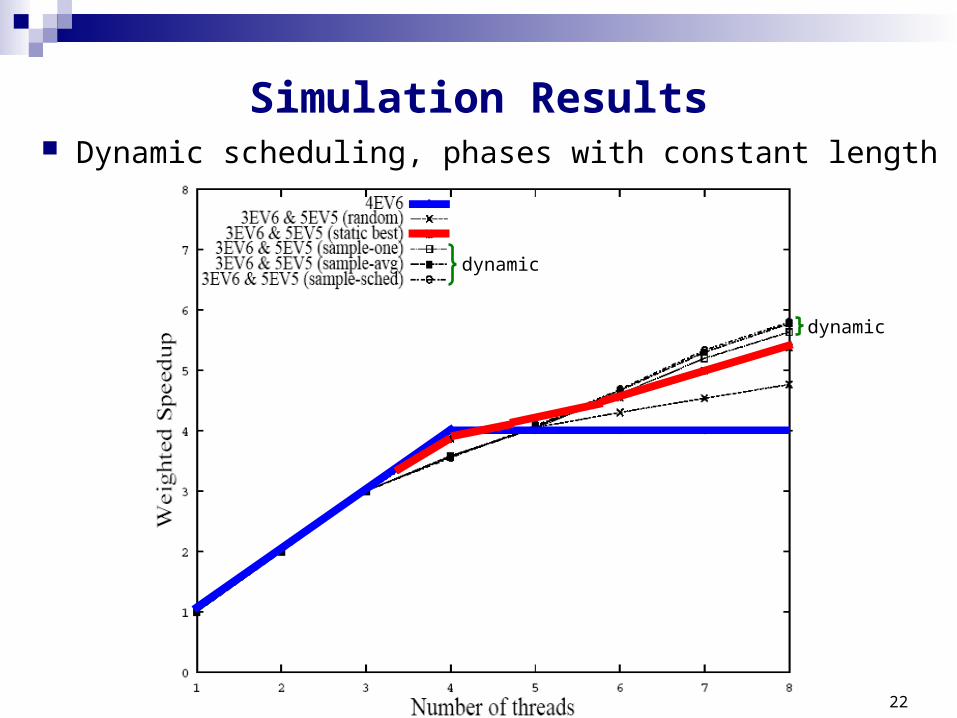
Simulation Results Dynamic scheduling, phases with constant length
dynamic
dynamic

23
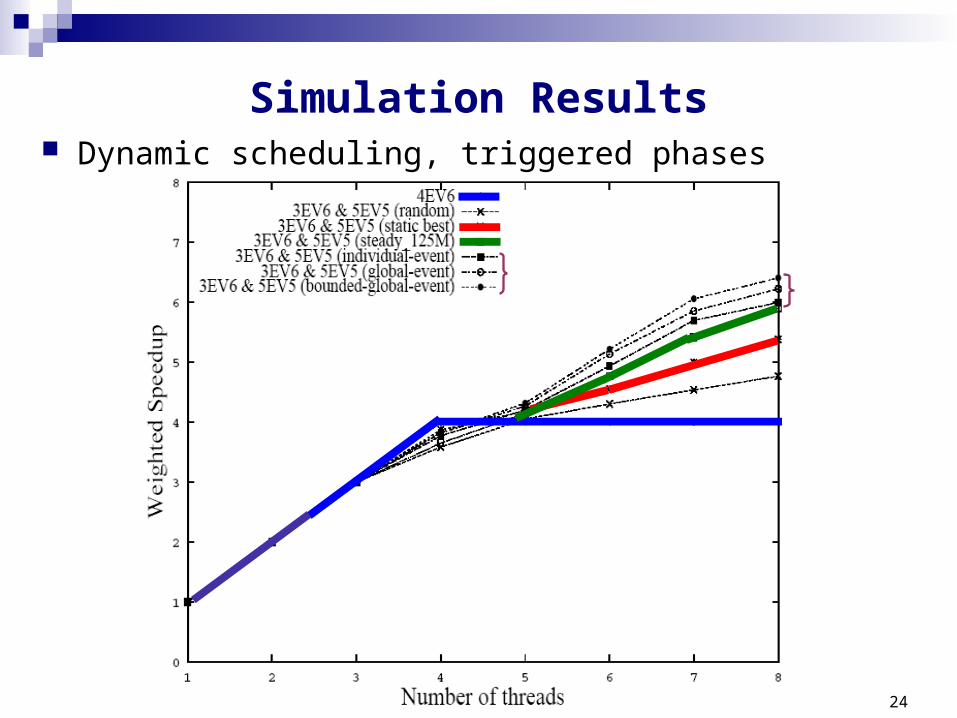
Scheduling issues
individual-event: whenever a thread’s IPC changes by more than 50%
global-event: whenever the total change in IPC for all threads exceeds 100%
bounded-global-event: the same as the global-event with minimum and maximum thresholds
Trigger MechanismTrigger Mechanism
24
Simulation Results Dynamic scheduling, triggered phases

25
Priorities among different threads Heterogeneous architecture ideally suite these task
Exploring different objective functionsExploring different objective functions
( _ )( _ )
i
i
IPC current corei IPC baseline core
all runningi threads
ws w
Todo list (open questions)

26
Priorities among different threads. Heterogeneous architecture ideally suite these task.
Minimize energy consumption
Use performance threshold
Exploring different objective functionsExploring different objective functions
( _ )( _ )
i
i
IPC current corei IPC baseline core
all runningi threads
ws w
Todo list (open questions)
*
( _ )
( _ )i
i
energy per instr baseline core
enrgy per instr current coreall runningi threads
ws

27
Priorities among different threads. Heterogeneous architecture ideally suite these task.
Minimize energy consumption.
Use performance threshold
Minimize the energy-delay product
Exploring different objective functionsExploring different objective functions
( _ )( _ )
i
i
IPC current corei IPC baseline core
all runningi threads
ws w
Todo list (open questions)
*
( _ )
( _ )i
i
energy per instr baseline core
enrgy per instr current coreall runningi threads
ws
2
2
_
_
i
i
i
i
IPScurrent core
Watt
IPSbaseline coreall runningi Wattthreads
ws

28
Energy-delay product during Energy-delay product during appluapplu life-time life-time
0
0.04
0.08
0.12
0.16
0.2
1 201 401 601 801
Committed instructions(in millions)
IPS
^2
/W
R4700EV4EV5EV6EV8-
1
enrgy delay
Todo list (open questions)

29
Great potential for energy saving: Pervious work, considering only one thread at a time, achieved more
than 30% of energy saving
Idle cores can be shut down
Objective function may change on the fly according to changing power conditions
Todo list (open questions)Exploring different objective functionsExploring different objective functions

30
Using SMT Cores
Enlarge flexibility and throughput with only modest area and power penalty
MotivationMotivation
No free lunches:No free lunches:
Interaction between threads can no longer be ignored Thread compete for virtually all processor resources
Only sampled assignments can be used
Permutations space of potential assignments is huge Can not sample all the assignments
The sampling space must be pruned
The sampling strategy is much more important

31
Simulation Results (SMT) Heterogeneous system with SMT cores

32
References
“Symbiotic Jobscheduling for a Simultaneous Multithreading Processor”Allan Snavely, Dean M. Tullsen, In the Proceedings of the 9th International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS IX),Novemeber, 2000
“Symbiotic Jobscheduling with Priorities for a Simultaneous Multithreading Processor”Allan Snavely, Dean M. Tullsen, In proceedisng of the 9th International Conference on Measurement and Modeling of Computer Systems (Sigmetrics 02), June, 2002
SOS (Sample, Optimize, Symbios)SOS (Sample, Optimize, Symbios)

33
SOS - (Sample, Optimize, Symbios) A first attempt to take into account threads interaction in SMT
symbiosis – the effectiveness with which multiple jobs achieve speedup when coexcecuted on multithreaded machines Throughput may actually go down
Plundered from Uri’s slides.

34
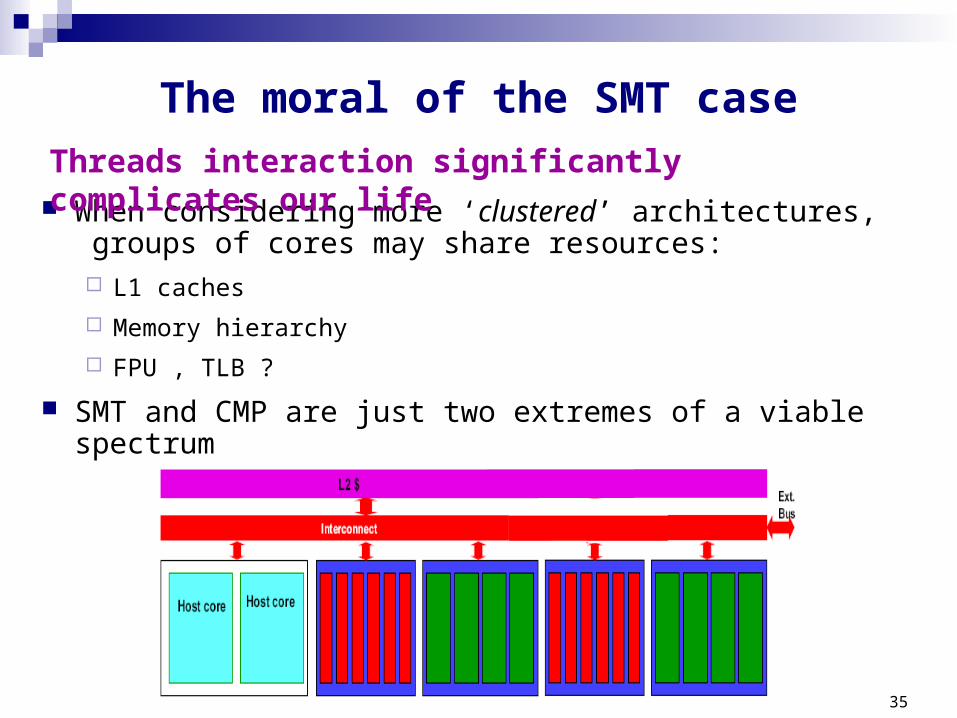
SOS - (Sample, Optimize, Symbios) Using sampling phases to profile execution
Choose combination that maximize overall weighted speedup
Which predictor to use ?
Extremely architecture dependent Encapsulation of hardware details from software
IPC and Dcache are inconsistent performers
35
The moral of the SMT case
When considering more ‘clustered’ architectures, groups of cores may share resources: L1 caches
Memory hierarchy
FPU , TLB ?
SMT and CMP are just two extremes of a viable spectrum
Threads interaction significantly complicates our life

36
The moral of the SMT case
A scheduler has 2 tasks: Define a running set – jobs to be executed during the upcoming
timeslice
Assign jobs from the running set to the different cores
We have overlooked the first task and simplified the second
We’ll have to tackle both
If only memory is to be shared our life may be easier Not by that much, though
Threads interaction significantly complicates our life

37
References
“Phase Tracking and Prediciton” Timothy Sherwood, Suleyman Sair, Brad Calder, Proceedings of the 30th annual international symposium on Computer architecture, IEEE CS Press, 2003, pp.336-349
“Discovering and Exploiting Program Phases” Timothy Sherwood, Erez Perelman, Greg Hamerly, Suleyman Sair, Brad Calder, IEEE Micro : Micro's Top Picks from Computer Architecture Conferences, Nov./Dec. 2003
Phase trackingPhase tracking

38
It is Profitable to accurately identify program phases React quickly to phase changes
Spare samplings overheads
IPC is not necessarily the most appropriate representative
Smart phase detectionSmart phase detection
Todo list (open questions)

39
Phases are a direct function of the way program traverse its code during execution Use basic blocks ratios to identify phases
Architectural independent
Basic Block Vector One dimension array with an index for every basic block in the
program
Each element represent the execution frequencies of the basic blocks weighted by instruction count, normalized
Phase TrackingMain IdeaMain Idea

40
Phase TrackingMain IdeaMain Idea
Basic Block Vector One dimension array with an index for every basic block in the
program
Each element represent the execution frequencies of the basic blocks weighted by instruction count, normalized
41
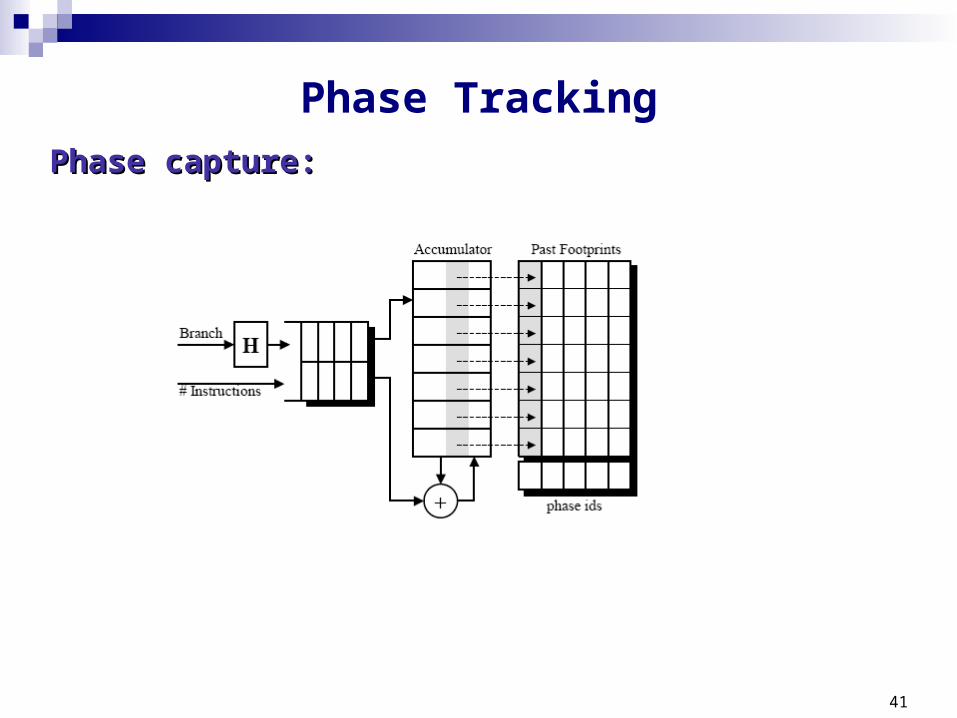
Phase TrackingPhase capture:Phase capture:

42
Work’s Innovation Using heterogeneous muti-cores to gain superior performance
Previous works targeted only power consumption
First real simulation results
General-purpose processors Previous works concentrated on SoC with known workloads
Dynamic task scheduling and task-to-core assignment Most of the works use static scheduling and a full knowledge of the
application characteristic

43
Summary Heterogeneous multi-core architecture can
provide significantly higher performance Covers a wide spectrum of workloads Dynamic core assignments policy exploit
intra-thread and inter-thread diversity Open issues:
Optimize energy consumption Thread interactions Phase detection A lot more…
Any questions ?

44
References of the day “Single-ISA Heterogeneous Multi-Core Architecture for Multithreaded Workload
Performance”Rakesh Kumar, Dean M. Tullsen, Parthasarath Ranganathan, Norman P.Jouppi, Keith I. Farkas In Proceedings of the 31st International Symposium on Computer Architecture (ISCA’04), June, 2004
“Single-ISA Heterogeneous Multi-Core Architecture: The Potential for Processor Power Reduction”Rakesh Kumar, Keith I. Farkas, Norman P.Jouppi, Parthasarath Ranganathan, Dean M. Tullsen, In Proceedings of the 36st International Symposium on Microarchitecure, December 2003
“A Multi-Core Approach to Addressing the Energy-Complexity Problem In Microprocessor” Rakesh Kumar, Keith I. Farkas, Norman P.Jouppi, Parthasarath Ranganathan, Dean M. Tullsen, In Proceedings of the Workshop on Complexity-Effective Design (WCED), June 2003
“Processor Power Reduction Via Single-ISA Heterogeneous Multi-Core Architecture” Rakesh Kumar, Keith I. Farkas, Norman P.Jouppi, Parthasarath Ranganathan, Dean M. Tullsen, Computer Architecture Letters, Volume 2, Apr. 2003
“Phase Tracking and Prediciton” Timothy Sherwood, Suleyman Sair, Brad Calder, Proceedings of the 30th annual international symposium on Computer architecture, IEEE CS Press, 2003,
“Discovering and Exploiting Program Phases” Timothy Sherwood, Erez Perelman, Greg Hamerly, Suleyman Sair, Brad Calder, IEEE Micro : Micro's Top Picks from Computer Architecture Conferences, Nov./Dec. 2003
“Symbiotic Jobscheduling for a Simultaneous Multithreading Processor”Allan Snavely, Dean M. Tullsen, In the Proceedings of the 9th International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS IX), Novemeber, 2000

45
References of the day “Symbiotic Jobscheduling with Priorities for a Simultaneous Multithreading Processor”
Allan Snavely, Dean M. Tullsen, In proceedisng of the 9th International Conference on Measurement and Modeling of Computer Systems (Sigmetrics 02), June, 2002
“Conjoind-core Chip Multiprocessing”Rakesh Kumar, Norman P.Jouppi, Dean M. Tullsen, In Proceedings of the 37st International Symposium on Microarchitecure, December 2004

46
Backup

47
Sample 2n configuration for n threads workload.
Pruning strategies: pref-EV6 : assumes it is best to run 2 thread on each EV6 before using
EV5
pref-EV5 : assumes it’s best to run on EV5 rather than put 2 threads on EV6
pref-nigther : sample random schedule
pref-similar: sampling is biased toward a configuration similar to the current one used.
Sampling strategiesSampling strategies
Using Multithreaded Cores

48
Workload construction 8 benchmarks from spec2000 Thread number vary up to the maximum number of available
processor contexts. Various compositions are simulated.
Large memory footprint
int
fp


















