
Similarity Search in High Dimensions via Hashing Aristides Gionis, Protr Indyk and Rajeev Motwani...
22
Similarity Search in High Dimensions via Hashing Aristides Gionis, Protr Indyk and Rajeev Motwani Department of Computer Science Stanford University presented by Jiyun Byun Vision Research Lab in ECE at UCSB
-
date post
21-Dec-2015 -
Category
Documents
-
view
218 -
download
0
Transcript of Similarity Search in High Dimensions via Hashing Aristides Gionis, Protr Indyk and Rajeev Motwani...

Similarity Search in High Dimensions
via Hashing
Aristides Gionis, Protr Indyk and Rajeev Motwani
Department of Computer Science
Stanford University
presented by Jiyun Byun
Vision Research Lab in ECE at UCSB

Outline
Introduction Locality Sensitive Hashing Analysis Experiments Concluding Remarks

Introduction
Nearest neighbor search (NNS) The curse of dimensionality
experimental approach : use heuristic analytical approach
Approximate approach
ε-Nearest Neighbor Search (ε-NNS) Goal : for any given query q Rd, returns the points p P
where d(q,P) is the distance of q to the its closest points in P
right answers are much closer than irrelevant ones
time/quality trade off
)P,q(d)+1(≤)p,q(d
∈

Locality Sensitive Hashing (LSH)
Collision probability depends on distance between points higher collision probability for close objects small collision probability for those that far apart
Given a query point, hash it using a set of hash functions inspect the entries in each bucket
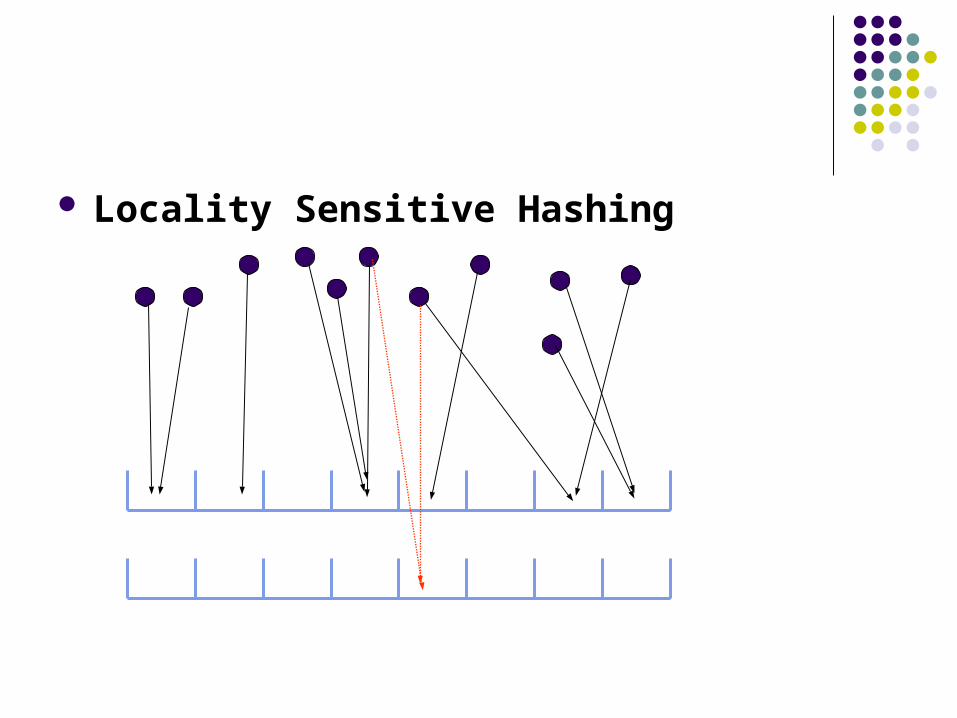
Locality Sensitive Hashing

Locality Sensitive Hashing (LSH)
Setting
C : the largest coordinate among all points in the given dataset P of dimension d (Rd)
Embed P into the Hamming cube {0,1}d’
dimension d’ = Cd v(p) = UnaryC(x1)…UnaryC(xd)
use the unary code for each point along each dimension
P)1,2(p ∈ 110100=)v(p
2R 3=C,2=dwhere}1,0.{e.iH 66
isometric embedding d1(p,q) = dH(v(p),v(q)) embedding preserves the distance between points

Locality Sensitive Hashing (LSH)
Hash functions(1/2)
Build a hash function on Hamming cube in d’ dimensions
Choose L subsets of the dimensions: I1,I2, ..IL
Ij consists of k elements from {1,…,d’} found by sampling uniformly at random with replacement
Project each point on each Ij.
gj(p) = projection of p on Ij obtained by concatenating the bit values of p for dimensions Ij
Store p in buckets gj(p), j = 1.. L

Locality Sensitive Hashing (LSH)
Hash functions(2/2)
Two levels of hashing LSH function
maps a point p to bucket gj(p)
standard hash function maps the contents of buckets into a hash table of size M
B : bucket capacity : memory utilization parameter
B
n=M

Query processing
Search buckets gj(q) until CL points are found or all L indices are searched.
Approximate K-NNS output the K points closest to q fewer if less than K points are found
-neighbor with parameter r

Analysis
where r1 < r2 and P1>P2
Family of single projections in Hamming cube Hd’ is (r, r(1+ ), 1-r/d’, 1- r(1+ )/d’) sensitive if dH(q,p) = r (r bits on which p and q differ)
Pr[ h(q) h(p)] = r/d’
S∈qp, all if
sensitive-)P,P,r,(risU}→{0,1}={h=HFamily 2121d
[ ][ ]
2H2
1H1
P≤)p(h=)q(hPrthenr>q-pif
P≥)p(h=)q(hPrthenr≤q-pif
≠

LSH solve(r+ ) Neighbor problem
Determine if there exists a point within distance r of query point q or whether all points are at least a distance r(1+ ) away from q
In the former case, return a point within distance r(1+ ) of q.
Repeat construction to boost the probability.

ε-NN problem
For a given query point q, return a point p from the dataset P
multiple instances of (r, )-neighbor solution. (r0, )-neighbor, (r0(1+ ), )-neighbor, (r0(1+ )2, )-
neighbor, …,rmax neighbor
)P,q(d)+1(≤)p,q(d

Experiments(1/3)
Datasets color histograms (Corel Draw)
n = 20,000; d= 8,…,64
texture features (Aerial photos) n = 270,000; d = 60
Query sets
Disk
second level bucket is directly mapped to a disk block
index/bytesn•d•2,block/ptsd
8192block/KB8 ⇒
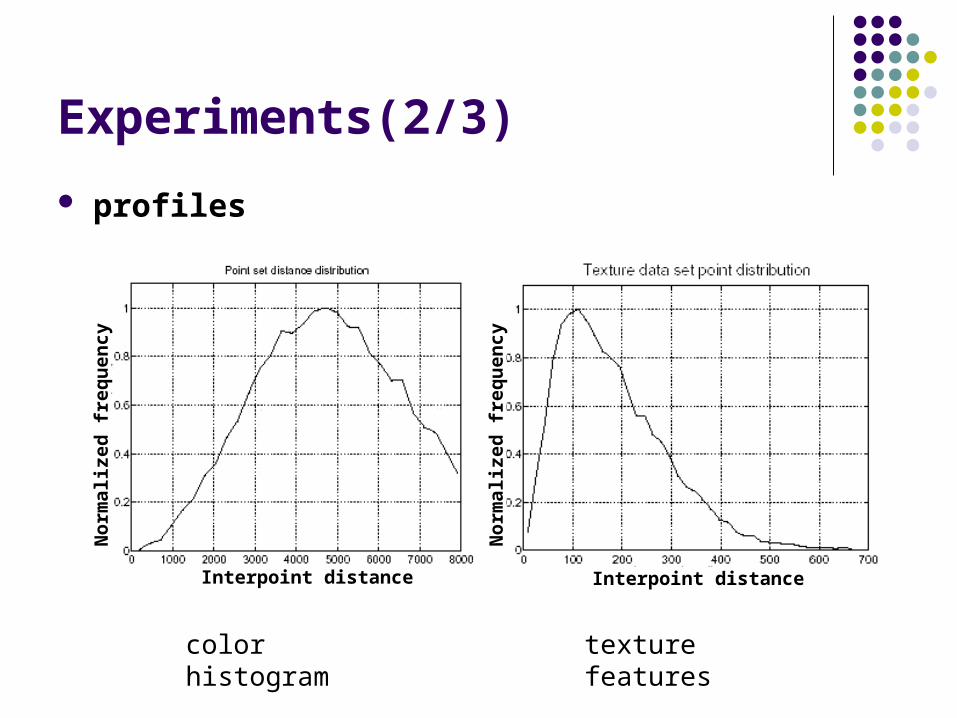
Experiments(2/3)
profiles
color histogram texture features
Interpoint distanceInterpoint distance
No
rmal
ized
fre
qu
ency
No
rmal
ized
fre
qu
ency

Experiments(3/3)
Performance speed : average number of blocks accessed effective error
dLSH : LSH NN distance(q) , d* : NN distance(q)
miss ratio the fraction of queries for which no answer was found
∑Q∈qquery
LSH
*d
d
Q
1=E
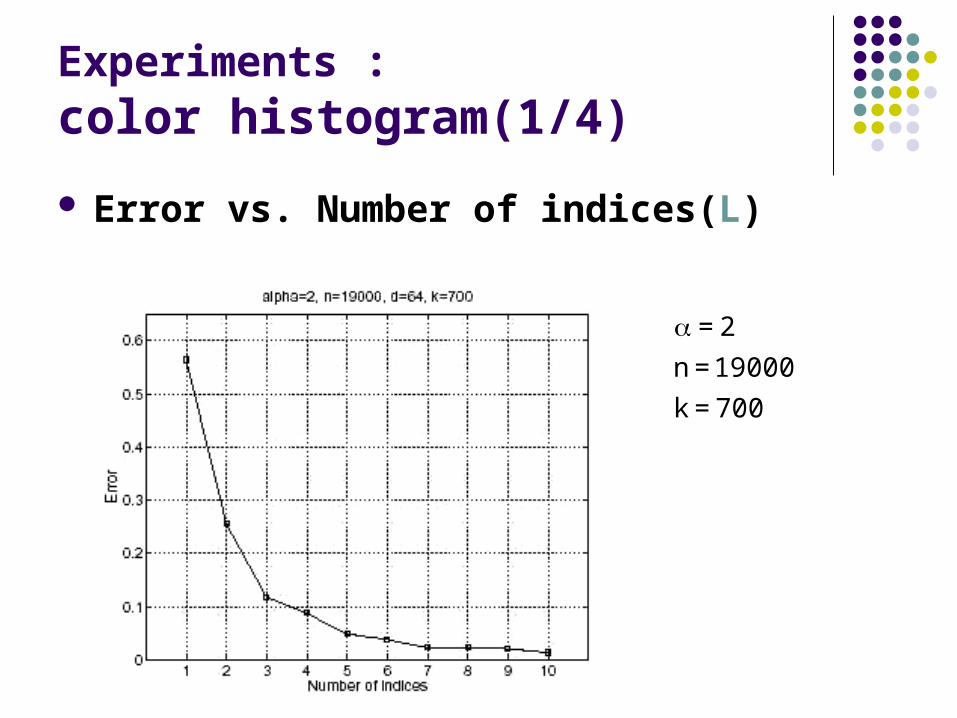
Experiments : color histogram(1/4)
Error vs. Number of indices(L)
700=k
19000=n
2=
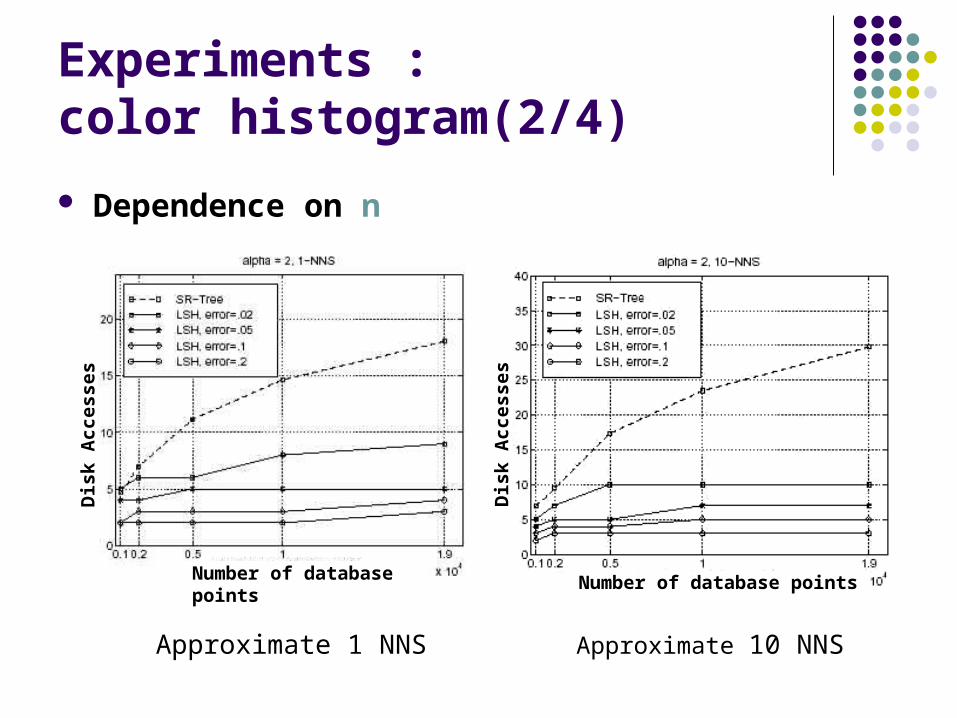
Experiments : color histogram(2/4)
Dependence on n
Approximate 1 NNS Approximate 10 NNS
Number of database pointsNumber of database points
Dis
k A
cces
ses
Dis
k A
cces
ses
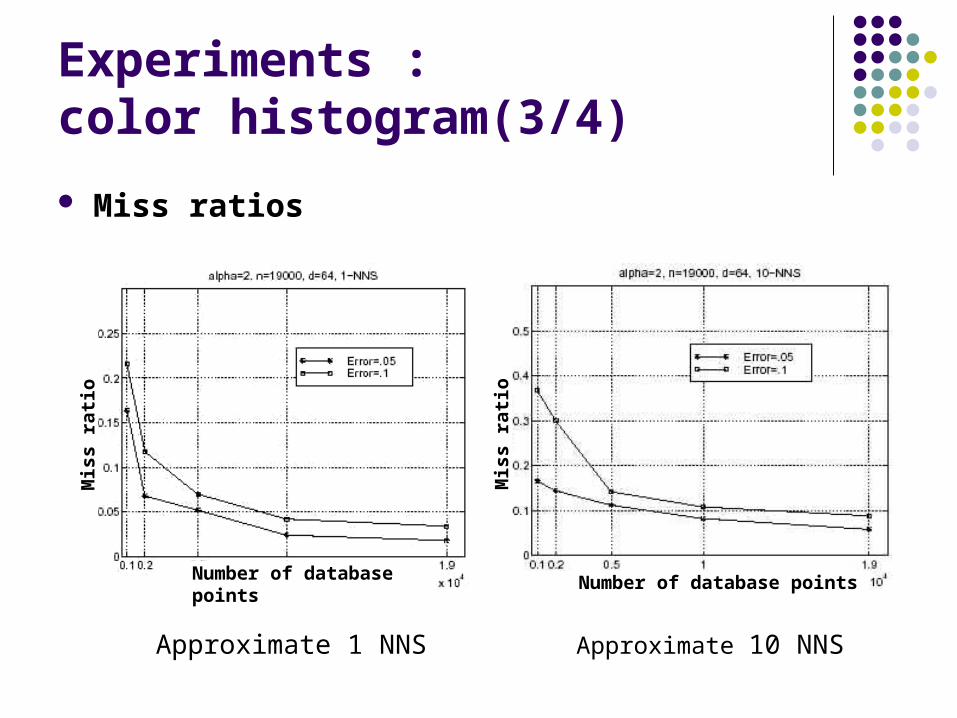
Experiments : color histogram(3/4)
Miss ratios
Approximate 1 NNS Approximate 10 NNS
Number of database pointsNumber of database points
Mis
s ra
tio
Mis
s ra
tio
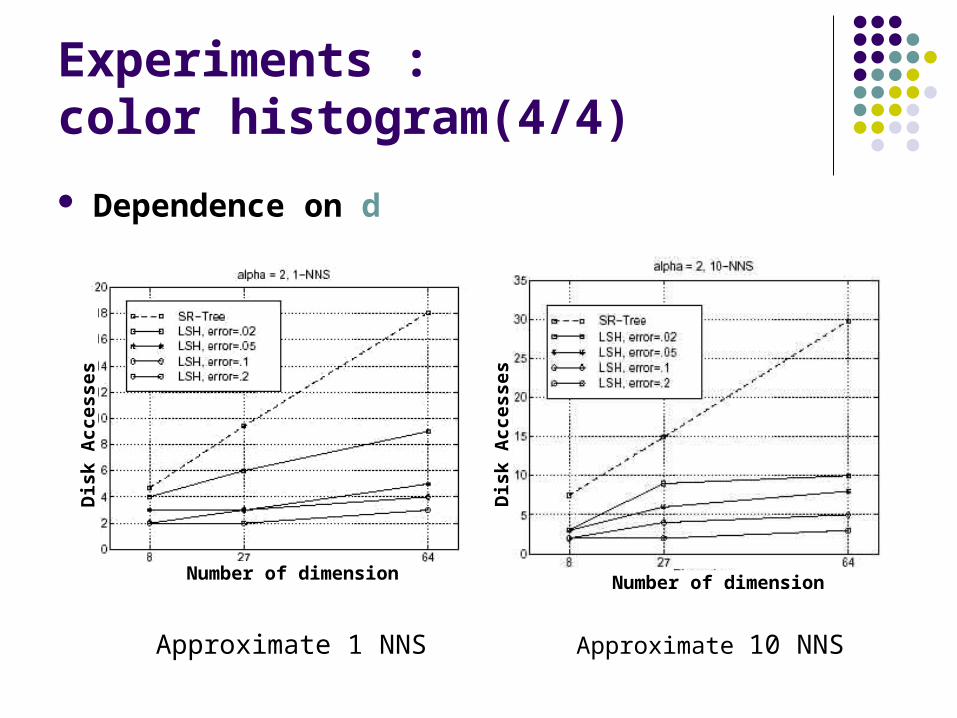
Experiments : color histogram(4/4)
Dependence on d
Approximate 1 NNS Approximate 10 NNS
Number of dimensionNumber of dimension
Dis
k A
cces
ses
Dis
k A
cces
ses
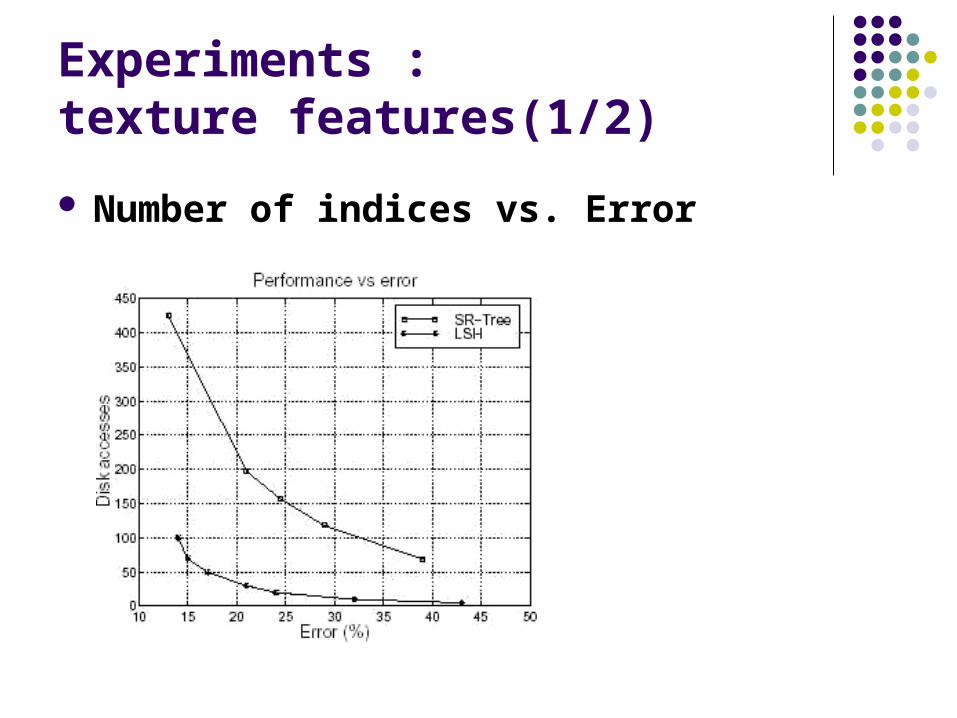
Experiments : texture features(1/2)
Number of indices vs. Error
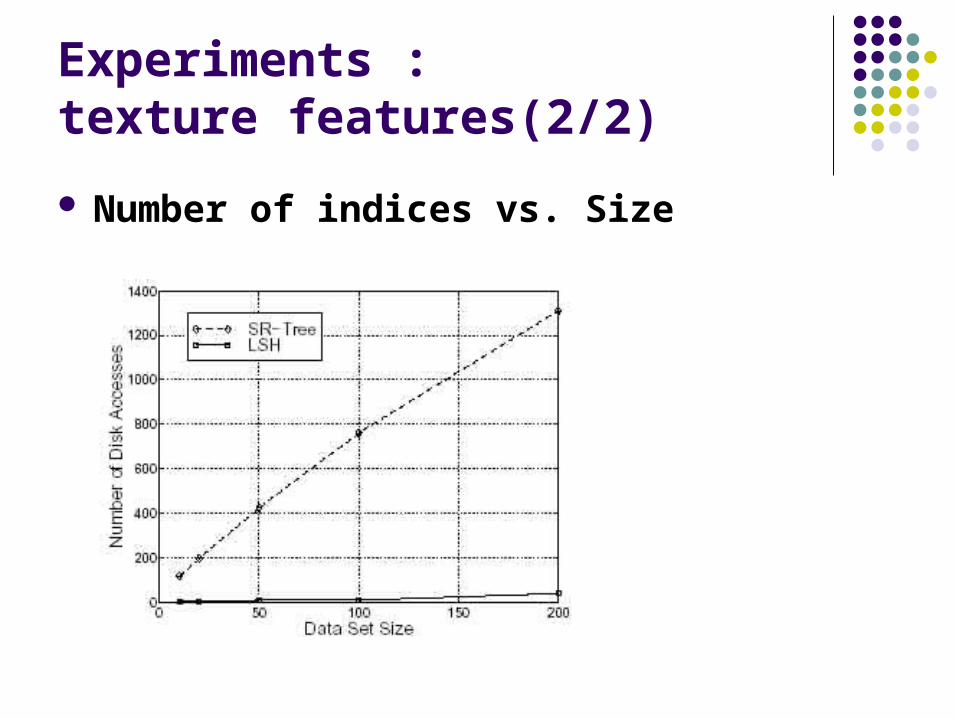
Experiments : texture features(2/2)
Number of indices vs. Size

Concluding remarks
Locality Sensitive Hashing fast approximation dynamic/join version
Future work hybrid techniques : tree-based and hashing-based


















