
semantic text doc clustering
53
Semantic Text Document Clustering 2015 2 C HAPTER : 1 INTRODUCTION TO SEMANTIC SIMILARITY
-
Upload
souvik-roy -
Category
Documents
-
view
152 -
download
0
Transcript of semantic text doc clustering

Semantic Text Document Clustering 2015
2
CHAPTER : 1
INTRODUCTION TO SEMA NTIC SIMILARITY

Semantic Text Document Clustering 2015
3
1.1 Introduction
Semantic similarity is a metric defined over a set of documents or terms, where
the idea of distance between them is based on the likeness of their meaning or
semantic content as opposed to similarity which can be estimated regarding
their syntactical representation (e.g. their string format). These are mathematical
tools used to estimate the strength of the semantic relationship between units of
language, concepts or instances, through a numerical description obtained
according to the comparison of information supporting their meaning or describing
their nature.
1.2 Similarity Measures
There are different measures for estimating the semantic similarity between units of
languages.
Some of them are as follows :
Path-based Measures:
The main idea of path-based measures is that the similarity between two
concepts/words is a function of the length of the path linking the concepts and
the position of the concepts in the taxonomy.
Introduction to Semantic Similarity

Semantic Text Document Clustering 2015
4
The Shortest Path based Measure:
The measure only takes len(c1,c2) into considerate. It assumes that the sim (c1,
c2) depend on how close of the two concepts are in the taxonomy.
Simpath(c1,c2)= 2*deep_max-len(c1,c2)
Wu & Palmer’s Measure :
Wu and Palmer introduced a scaled measure . This similarity measure takes
the position of concepts c1 and c2 in the taxonomy relatively to the position of
the most specific common concept lso(c1,c2) into account. It assumes that the
similarity between two concepts is the function of path length and depth in
path-based measures.
SimWP (c1,c2)=(2* depth(lso(c1,c2))) / (len(c1,c2)+2* depth(lso(c1,c2))
The following is the code in Java to implement Wu Palmer:
int N1 = depthFinder.getShortestDepth(synset1 );
int N2 = depthFinder.getShortestDepth( synset2 );
double score = 0;
if (N1>0 && N2 >0)
{ score = (double)( 2 * N ) / (double)( N1 + N2);}
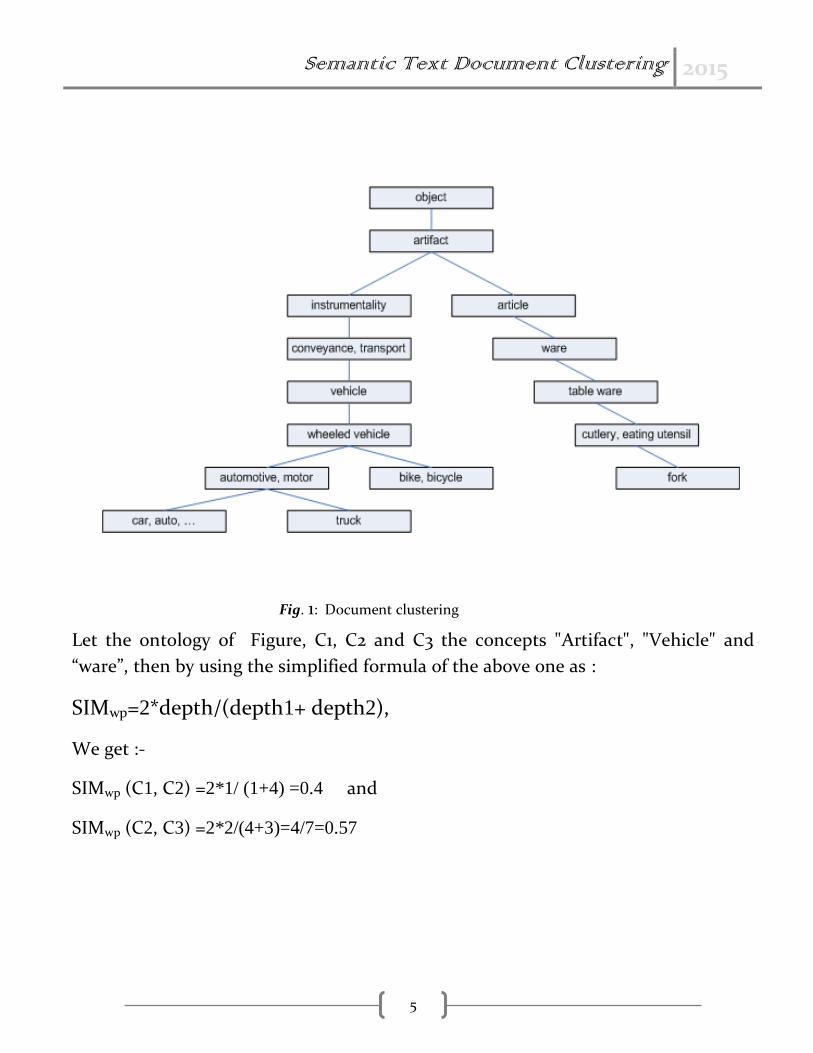
Semantic Text Document Clustering 2015
5
Let the ontology of Figure, C1, C2 and C3 the concepts "Artifact", "Vehicle" and
“ware”, then by using the simplified formula of the above one as :
SIMwp=2*depth/(depth1+ depth2),
We get :-
SIMwp (C1, C2) =2*1/ (1+4) =0.4 and
SIMwp (C2, C3) =2*2/(4+3)=4/7=0.57
Fig. 1: Document clustering
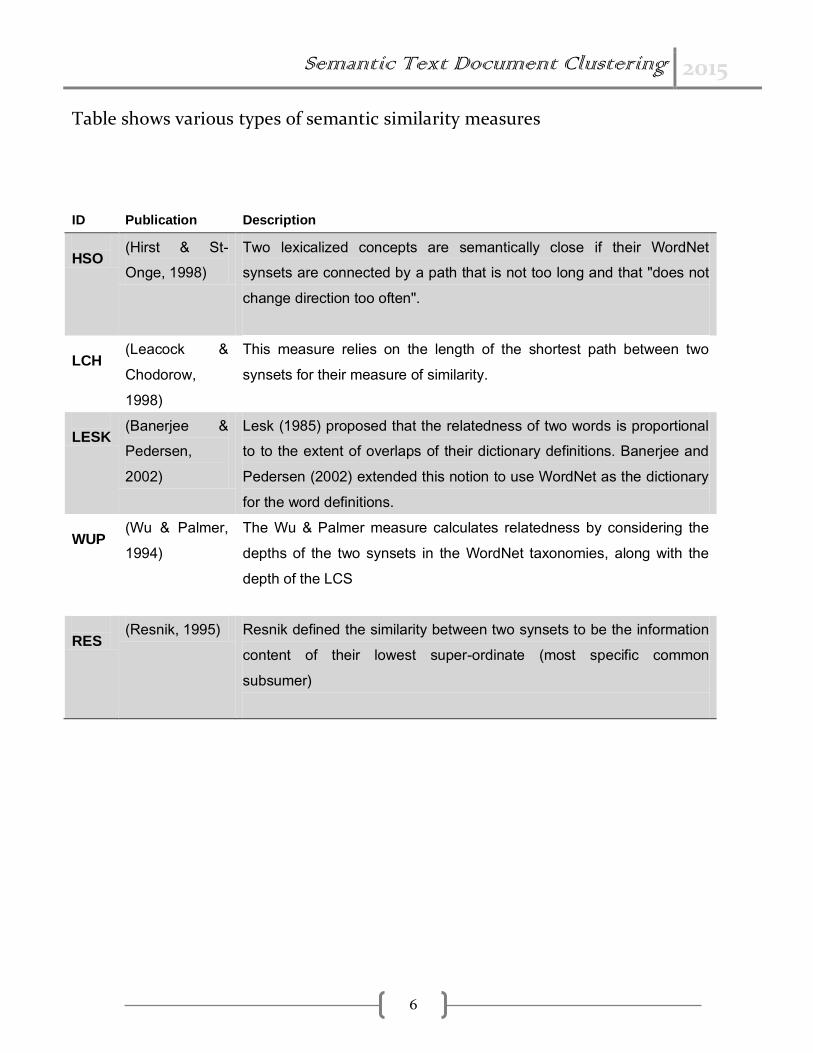
Semantic Text Document Clustering 2015
6
Table shows various types of semantic similarity measures
ID Publication Description
HSO
(Hirst & St-
Onge, 1998)
Two lexicalized concepts are semantically close if their WordNet
synsets are connected by a path that is not too long and that "does not
change direction too often".
LCH
(Leacock &
Chodorow,
1998)
This measure relies on the length of the shortest path between two
synsets for their measure of similarity.
LESK
(Banerjee &
Pedersen,
2002)
Lesk (1985) proposed that the relatedness of two words is proportional
to to the extent of overlaps of their dictionary definitions. Banerjee and
Pedersen (2002) extended this notion to use WordNet as the dictionary
for the word definitions.
WUP
(Wu & Palmer,
1994)
The Wu & Palmer measure calculates relatedness by considering the
depths of the two synsets in the WordNet taxonomies, along with the
depth of the LCS
RES
(Resnik, 1995) Resnik defined the similarity between two synsets to be the information
content of their lowest super-ordinate (most specific common
subsumer)

Semantic Text Document Clustering 2015
7
Wordnet
WordNet is a lexical database for the English language. It groups English words into
sets of synonyms called synsets, provides short definitions and usage examples, and
records a number of relations among these synonym sets or their members.
WordNet can thus be seen as a combination of dictionary and thesaurus. While it is
accessible to human users via a web browser, its primary use is in automatic text
analysis and artificial intelligence applications. The database and software tools have
been released under aBSD style license and are freely available for download from
the WordNet website. Both the lexicographic data (lexicographer files) and the
compiler (called grind) for producing the distributed database are available.
WordNet has been used for a number of different purposes in information systems,
including word sense disambiguation, information retrieval, automatic text
classification,automatic text summarization, machine translation and even
automatic crossword puzzle generation.

Semantic Text Document Clustering 2015
8
CHAPTER : 2
INTRODUCTION TO DOCUMEN T CLUSTERING

Semantic Text Document Clustering 2015
9
2.1 Introduction
Document clustering based on semantic similarity approach aims to
automatically divide documents into groups based on similarities of their content
(words). Each group (or cluster) consists of documents that are similar within the
group (have high intra-cluster similarity) and dissimilar to documents of other
groups (have low inter-cluster similarity). Clustering documents can be considered
an unsupervised task that attempts to classify documents by discovering underlying
patterns, i.e., the learning process is unsupervised, which means that there is no
need to define the correct output (i.e., the actual cluster into which the input should
be mapped to) for an input.
Documents Cluster
Low Inter-Cluster Similarity
Documents Cluster
Documents Cluster High intra-cluster Similarity
Clustering
Fig. 1: Document clustering
Introduction to Document Clustering
Documents

Semantic Text Document Clustering 2015
10
2.2 Document Pre-Processing
Document pre-processing is the process of introducing a new document to the
information retrieval system in which each document introduced is represented by a
vector of semantic similarity values. The goal of document pre-processing is to
represent the documents in such a way that their storage in the system and retrieval
from the system are very efficient.
Document Representation Document representation is a key process in the document processing and
information retrieval systems. To extract the relevant documents from the large
collection of the documents, it is very important to transform the full text version of
the documents to vector form. A such transformed document describes the contents
of the original documents based on the constituent terms called index terms. These
terms are used in indexing, the relevant ranking of the keywords for optimized
search results, information filtering and information retrieval. The vector space
model, also called vector model, is the popular algebraic model to represent textual
documents as vectors.
Document pre-processing includes the following stages:
2.2.1 Tokenization
Tokenization is the process of chopping up a given stream of text or character
sequence into words, phrases, symbols, or other meaningful elements called tokens
which are grouped together as a semantic unit and used as input for further
processing.

Semantic Text Document Clustering 2015
11
Usually, tokenization occurs in a word level but the definition of the “word” varies
accordingly to the context. So, the series of experimentation based on following
basic consideration is carried for more accurate output:
All alphabetic characters in the strings in close proximity are part of one
token; likewise with numbers.
Whitespace characters like space or line break or punctuation characters
separate the tokens.
The resulting list of tokens may or may not contain punctuation and
whitespace
In languages such as English (and most programming languages) where words are
delimited by whitespace, this approach is straightforward. Tokenization is a useful
process in the fields of both Natural language processing and data security. It is used
as a form of text segmentation in Natural Language processing and as a unique
symbol representation for the sensitive data in the data security without
compromising its security importance.
2.2.2 Stop word removal
Sometimes a very common word, which would appear to be of little significance in
helping to select documents matching user’s need, is completely excluded from the
vocabulary. These words are called “stop words” and the technique is called “stop
word removal”.

Semantic Text Document Clustering 2015
12
The general strategy for determining a “stop list” is to sort the terms by collection
frequency and then to make the most frequently used terms, as a stop list, the
members of which are discarded during indexing.
Some of the examples of stop-word are: a, an, the, and, are, as, at, be, for, from, has,
he, in, is, it, its, of, on, that, the, to, was, were, will, with etc.
2.2.3 Lemmatization
Lemmatisation (or lemmatization) in linguistics, is the process of reducing the
inflected forms or sometimes the derived forms of a word to its base form so that
they can be analysed as a single term.
In computational linguistic, lemmatisation is the algorithmic process of getting the
normalized or base form of a word, which is called lemma, using vocabulary and
morphological analysis of a given word. It is a difficult task to implement a
lemmatizer for a new language as the process involves complex tasks such
as full morphological analysis of the word, that is, understanding the context and
determining the role of a word in a sentence (requiring, for example, the
grammatical use of the word).
2.2.4 Information Extraction
Information Extraction (IE) is an important process in the field of Natural Language
Processing (NLP) in which factual structured data is obtained from an unstructured
natural language document. Often this involves defining the general form of the
information that we are interested in as one or more templates, which are then used
to guide the further extraction process.

Semantic Text Document Clustering 2015
13
IE systems rely heavily on the data generated by NLP systems. Tasks that IE systems
can perform include:
Term analysis: This identifies one or more words called terms, appearing in the
documents. This can be helpful in extracting information from the large documents
like research papers which contain complex multi –word terms.
Named-entity recognition: This identifies the textual information in a document
relating the names of people, places, organizations, products and so on.
Fact extraction: This identifies and extracts complex facts from documents .Such
facts could be relationships between entities or events.
2.3 Clustering Techniques
There are various methods of clustering. Like
• Hierarchical Clustering technique (K-means,K-medoids,etc. )
• Agglomerative Clustering technique
• Categorical Clustering technique ( ROCK, CACTUS, STIRR,etc.)

Semantic Text Document Clustering 2015
14
K-means is one of the most efficient hierarchical clustering techniques.
From the given set of n data, k different clusters; each cluster characterized
with a unique centroid (mean) is partitioned using the K-means algorithm. The
elements belonging to one cluster are close to the centroid of that particular cluster
and dissimilar to the elements belonging to the other cluster.
2.3.1 How it works ?
The letter “k” in the K-means algorithm refers to the number of groups we want to
assign in the given dataset. If “n” objects have to be grouped into “k” clusters, k
clusters centers have to be initialized. Each object is then assigned to its closest
cluster center and the center of the cluster is updated until the state of no change in
each cluster center is reached.
From these centers, we can define a clustering by grouping objects according to
which center each object is assigned to.
After the construction of the document vector, the process of clustering is carried
out. The K-means clustering algorithm is used to meet the purpose of this project.

Semantic Text Document Clustering 2015
15
The basic algorithm of K-means used for the project is as following: K-means Algorithm
Input:
k: the number of clusters,
Output:
A set of k clusters.
Method:
Step 1: Choose k numbers of clusters to be determined.
Step 2: Choose Ck centroids randomly as the initial centers of the clusters.
Step 3: Repeat.
3.1: Assign each object to their closest cluster center using Euclidean distance.
3.2: Compute new cluster center by calculating mean points.
Step 4: Until
4.1: No change in cluster center OR
4.2: No object changes its clusters.

Semantic Text Document Clustering 2015
16
CHAPTER : 3
REQUIREMENT ANALYSIS

Semantic Text Document Clustering 2015
17
3.1 Problem Statement
A person who is reading particular text content in one directory may also be
interested in reading similar text documents to find more about the topic. The
problem here is finding the file that covers the similar texts. The usual approach is
to visit each likely files/directories and then manually look for the similar texts in
them to find whether the content the person is looking for is present or not. This is
a problematic, time-consuming and tedious task. This even reduces the user’s
interest in reading that particular document as well as his enthusiasm to acquire
more information on that topic. On the other hand, people are so much into smart
technologies these days that they always look for the technology that can satisfy
their interest without having them to put in much effort and time.
The solution purposed here is based on the idea of text mining and clustering. The
basic idea is to create clusters of similar texts. This clustered information will then
be displayed using a GUI created where a reader can find all similar texts with the
corresponding links in a single directory which solves the issues of going through
each and every directories and looking for the required text document in them.
Requirement Analysis

Semantic Text Document Clustering 2015
18
3.2 Objectives
The objectives of this research work are:
To provide a single platform to place the clusters of similar texts.
To reduce the complexity of accessing random files.
3.3 Data Collection
In order to carry out the study, the text documents are collected from the random
sources. Those collected files are stored in a certain directory for preprocessing. The
directory is then fed to the system by referencing its location in the local machine
where each text files in that directory is represented as vectors after calculating the
semantic similarity of the units of each texts. The vector are stored in the form of a
matrix in a separate text file.
3.4 Functional Requirements
A functional requirement is something the system must do and includes various
functions performed by specific screen, outlines of work-flows performed by the
system and other business or compliance requirements the system has to meet.
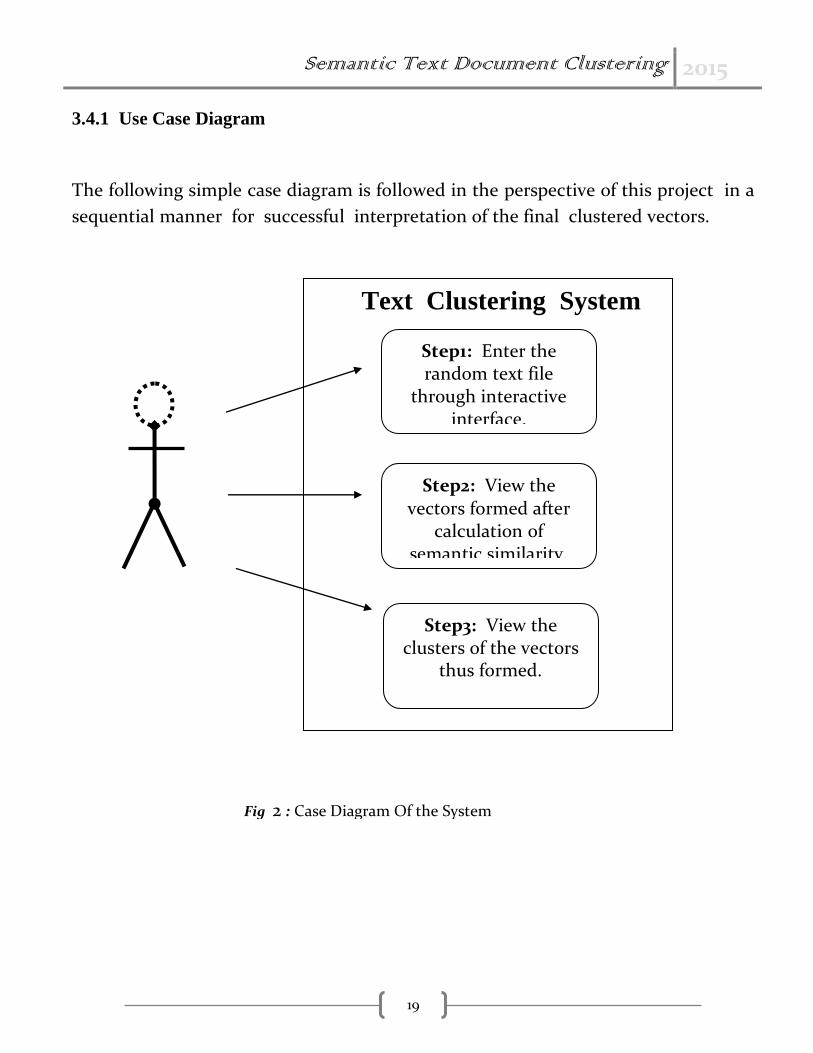
Semantic Text Document Clustering 2015
19
3.4.1 Use Case Diagram
The following simple case diagram is followed in the perspective of this project in a
sequential manner for successful interpretation of the final clustered vectors.
Text Clustering System
Step1: Enter the random text file
through interactive interface.
Step2: View the vectors formed after
calculation of semantic similarity.
Step3: View the clusters of the vectors
thus formed.
Fig 2 : Case Diagram Of the System

Semantic Text Document Clustering 2015
20
3.5 Non-Functional Requirements
The non-functional requirements represent requirements that should work to assist
the project to accomplish its goal. The non-functional requirements for the current
system are:
Interface The project constructed is interactive. The semantic similarity vectors are stored in
a separate file. The output cluster of vectors is displayed on a data matrix format .
Performance
The developed system must be able to group the text file vectors into clusters based
on the K means algorithm.
Scalability
The system must provide as many options like changing text files in the directory
and then the changes occur in the clusters as well.
3.6 Resource Requirements
Java-jdk-7u17-windows-i586
Java-7u17-windows-i586.exe is part of a product called known as Java(TM)
Platform SE 7 U17 and it is developed by Oracle Corporation .

Semantic Text Document Clustering 2015
21
Netbeans IDE-7.3-windows
NetBeans IDE 7.3 empowers developers to create and debug rich web and mobile
applications using the latest HTML5, JavaScript, and CSS3 standards. Developers
can expect state of the art rich web development experience with a page inspector
and CSS style editor, completely revamped JavaScript editor, new JavaScript
debugger, and more. Additional highlights available in 7.3 include continued
enhancements to the IDE's support for Groovy, PHP, JavaFX and C/C++. NetBeans
IDE 7.3 is available in English, Brazilian Portuguese, Japanese, Russian, and
Simplified Chinese.
In this project jframe is used for making exchange of documents
and to tokenize for further calculation of semantic similarity between each words in
text files for creation of vectors of each random text files, interactive and also
storing the each vectors in a separate file in matrix format.
Matlab 7.3
MATLAB (matrix laboratory is a multi-paradigm numerical computing environment
and fourth-generation programming language. Developed by MathWorks, MATLAB
allows matrix manipulations, plotting of functions and data, implementation
of algorithms, creation of user interfaces, and interfacing with programs written in
other languages, including C, C++, Java,Fortran and Python.

Semantic Text Document Clustering 2015
22
Although MATLAB is intended primarily for numerical computing, an optional toolbox uses the MuPAD symbolic engine, allowing access to symbolic computing capabilities.
An additional package, Simulink, adds graphical multi-domain simulation and model-based design for dynamic and embedded systems.
In this paper MathWorks is used for successful interpretation of the clusters after
processing the vector in .mat matrix format for performing K-means algorithm.
Notepad
Notepad is a common text-only (plain text) editor. The resulting files—typically
saved with the .txt extension—have no format tags or styles, making the program
suitable for editing system files to use in a DOS environment and, occasionally,
source code for later compilation or execution, usually through a command prompt.
It is also useful for its negligible use of system resources; making for quick load time
and processing time, especially on under-powered hardware. Notepad supports both
left-to-right and right-to-left based languages.

Semantic Text Document Clustering 2015
23
CHAPTER : 4
FEASIBILITY ANALYSIS AND SYSTEM PLANNING

Semantic Text Document Clustering 2015
24
4.1 Feasibility Analysis
The feasibility study is an important issue while developing a system. It deals with
all the specifications and requirements regarding the project and gives the complete
report for project sustainability. The feasibility studies necessary for the system
development are mentioned below :
Economic feasibility It is the study to determine whether a system is economically acceptable. This
development looks at the financial aspects of the project. It determines whether the
project is economically feasible or not. The system designed is an interactive
application which needs Netbeans IDE and Matlab and all other hardware
requirements for it so that the start-up investment is not a big issue.
Technical feasibility The system is developed for general purpose use. Technical feasibility is concerned
with determining how feasible a system is from a technical perspective. Technical
feasibility ensures that the system will be able to work
Feasibility Analysis and System Planning

Semantic Text Document Clustering 2015
25
in the existing infrastructure. In order to run the application, the user only needs to
have both Netbeans IDE and Matlab installed and to be able to edit
the random text files from various sources. These all requirements can be easily
satisfied.
Operational feasibility Operation feasibility is concerned with how easy the system is to operate. As it is a
interactive application, it is quite easy to handle with normal Netbeans IDE and
Matlab for showing clustered vector results skills. For the efficient operation of the
system, the user needs a general computer. The GUI is a jframe, so it does not
require any special skill to view and click the links. The proposed system is
operationally feasible.
4.2 System Planning
Needs Identification
The success of a system depends largely on how accurately a problem is
defined, thoroughly investigated and properly carried out through the
choice of solution.
It is concerned with what the user needs rather than what he/she wants.
Determining the User’s Information Requirements
It is difficult to determine user requirements because of the following reasons:
System requirements change and user requirements must be modified.
Articulation of requirements is difficult.

Semantic Text Document Clustering 2015
26
Heavy user involvement and motivation are difficult.
The pattern of interaction between users and analysts in designing information requirements is complex.
Getting Information from the existing information system
Data Analysis
Determining Information from existing system. It simply asks the user what information is currently received and what other information is required.
Ideal for Structured Decisions.
Decision Analysis
In this problem is broken down into parts, so that user can focus separately on the critical issues.
It is used for Unstructured Decisions.
Fact Finding
After obtaining the background knowledge, the analyst begins to collect data
on the existing system’s outputs, inputs and costs.
The tools used in gathering knowledge about the system under development
are:
Review of written documents
On site observations
Semantic Text Document Clustering 2015
27
Interviews
Questionnaires
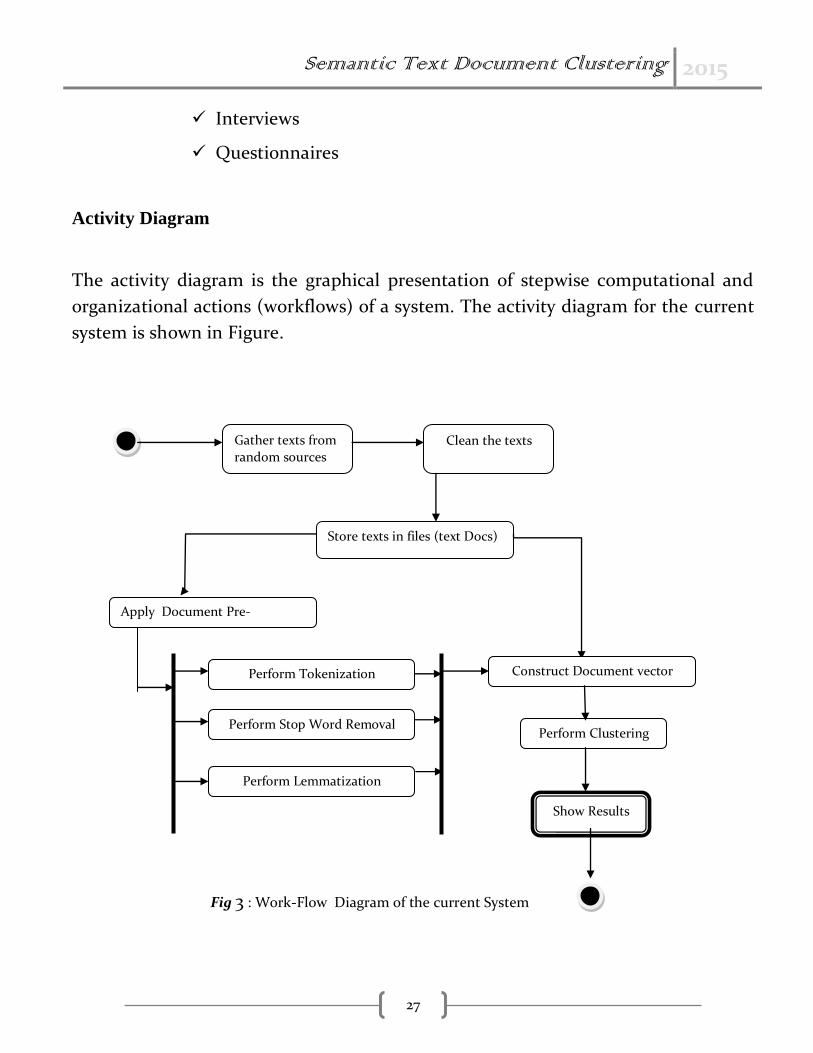
Activity Diagram
The activity diagram is the graphical presentation of stepwise computational and
organizational actions (workflows) of a system. The activity diagram for the current
system is shown in Figure.
Gather texts from
random sources Clean the texts
Store texts in files (text Docs)
Apply Document Pre-
processing
Construct Document vector Perform Tokenization
Perform Stop Word Removal
Perform Lemmatization
Perform Clustering
Show Results
Fig 3 : Work-Flow Diagram of the current System

Semantic Text Document Clustering 2015
28
CHAPTER : 5
IMPLEMENTATION

Semantic Text Document Clustering 2015
29
5.1 Introduction
Implementation is the process of executing a plan or design to achieve some output.
In this project, the implementation encompasses the extraction of semantic text
values of the texts in the documents, by calculating their respective semantic
relatedness with associated words through a certain semantic relatedness measuring
formula, and then fetching them in the system to go through the pre-processing
techniques, forwarding the pre-processed data to the clustering system and
obtaining clusters of similar-valued texts as a final output.
The model of implementation and the processes involved during implementation
phase are described with the help of flowcharts, which are the diagrammatic
representation of those processes.
Implementation
Semantic Text Document Clustering 2015
30
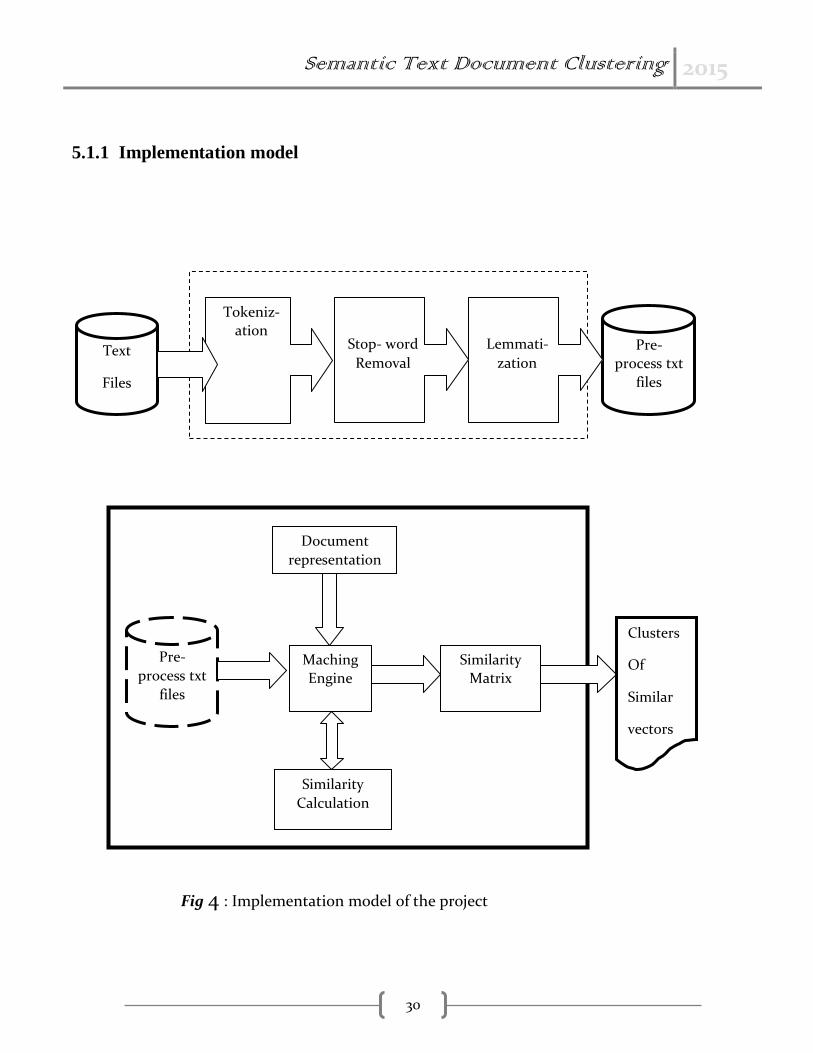
5.1.1 Implementation model
Text
Files
Pre-
process txt
files
Tokeniz-
ation
Lemmati-
zation
Stop- word
Removal
Pre-
process txt
files
Maching
Engine
Document
representation
Similarity
Calculation
Similarity
Matrix
Clusters
Of
Similar
vectors
Fig 4 : Implementation model of the project

Semantic Text Document Clustering 2015
31
5.1.2 Flowchart for Document Pre-processing
Start
Input text File
Documents
Tokenize the Docs
Remove Stop words from files
Lemmatization to find
normalized words
Pre-processed
document
Fig : Flowchart for document preprocessing
Semantic Text Document Clustering 2015
32
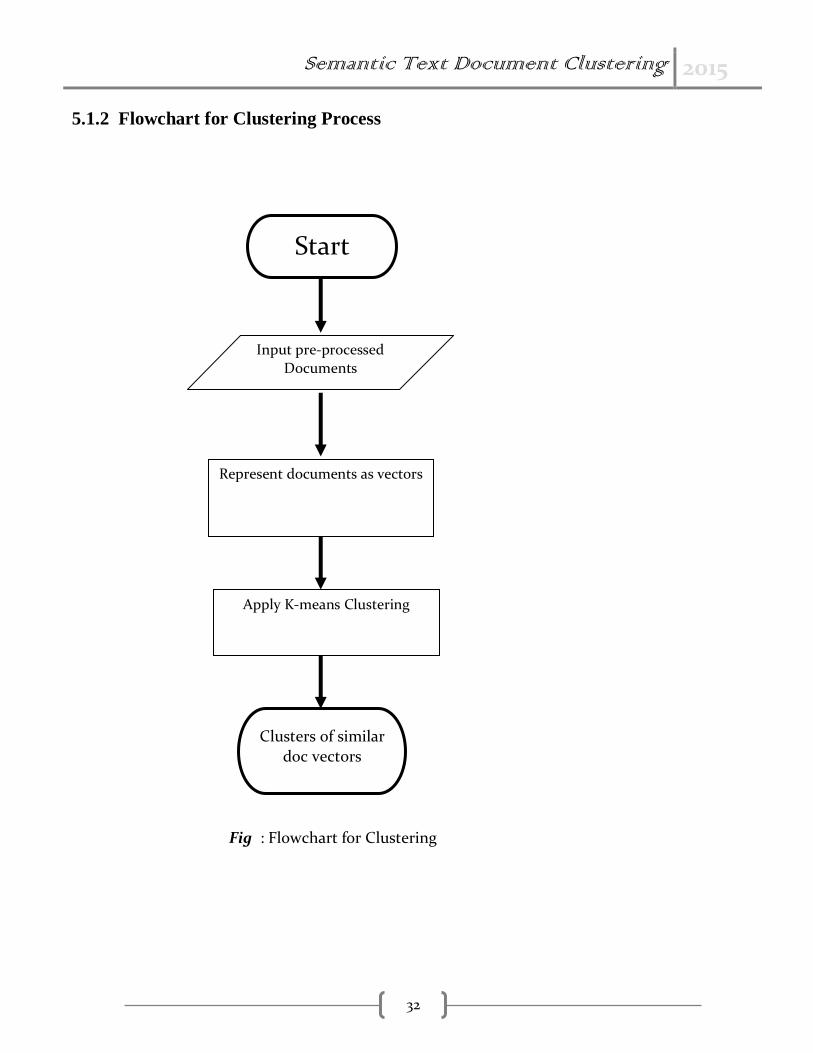
5.1.2 Flowchart for Clustering Process
Start
Input pre-processed
Documents
Represent documents as vectors
Clusters of similar
doc vectors
Apply K-means Clustering
Fig : Flowchart for Clustering
Semantic Text Document Clustering 2015
33
5.2 Input Text Files and finally generate clusters
Here the files are inserted one-by-one, where after inserting each files, the text files
are pre-processed by performing certain operation like :
Tokenization
Stop Word Removal
Lemmatization, etc.
Semantic Text Document Clustering 2015
34
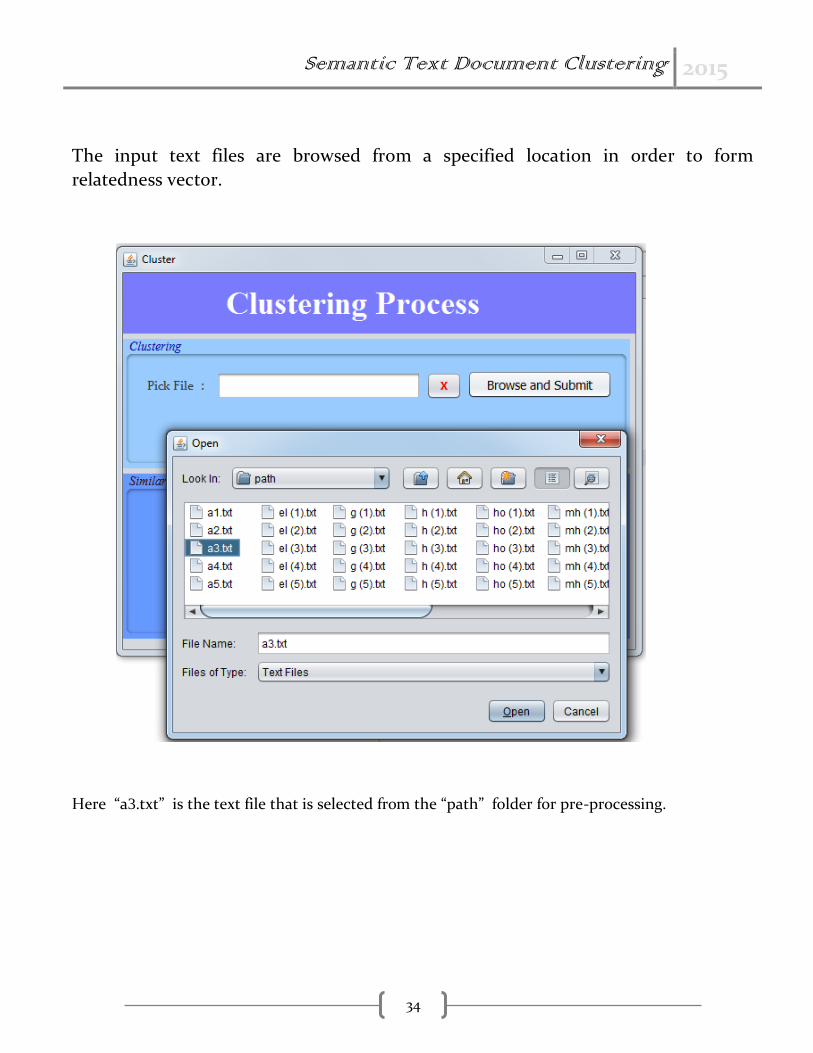
The input text files are browsed from a specified location in order to form
relatedness vector.
Here “a3.txt” is the text file that is selected from the “path” folder for pre-processing.

Semantic Text Document Clustering 2015
35
5.2.1 Java Code for pre-processing
package semantic;
import edu.cmu.lti.lexical_db.ILexicalDatabase;
import edu.cmu.lti.lexical_db.NictWordNet;
import edu.cmu.lti.ws4j.impl.WuPalmer;
import edu.cmu.lti.ws4j.util.WS4JConfiguration;
import java.io.BufferedInputStream;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.DataInputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileWriter;
import java.io.IOException;
import java.io.InputStreamReader;
import java.text.DecimalFormat;
import java.util.HashSet;
import java.util.Scanner;
import java.util.Set;
import java.util.StringTokenizer;
import java.util.logging.Level;
import java.util.logging.Logger;
import javax.swing.JFileChooser;
import javax.swing.JFrame;
import javax.swing.JOptionPane;
/**
*
* @author souvik
*/
public class Sel_txt extends javax.swing.JFrame {
private static ILexicalDatabase db = new NictWordNet();
private static double compute(String word1, String word2) {
WS4JConfiguration.getInstance().setMFS(true);
double s = new WuPalmer(db).calcRelatednessOfWords(word1, word2);
return s;
}
public Sel_txt() {
initComponents();
}

Semantic Text Document Clustering 2015
36
@SuppressWarnings("unchecked")
// <editor-fold defaultstate="collapsed" desc="Generated Code">
private void initComponents() {
jPanel1 = new javax.swing.JPanel();
jLabel1 = new javax.swing.JLabel();
jPanel2 = new javax.swing.JPanel();
jLabel2 = new javax.swing.JLabel();
browse_path = new javax.swing.JTextField();
clear = new javax.swing.JButton();
browse = new javax.swing.JButton();
jPanel3 = new javax.swing.JPanel();
jPanel4 = new javax.swing.JPanel();
jLabel3 = new javax.swing.JLabel();
jLabel4 = new javax.swing.JLabel();
word1 = new javax.swing.JTextField();
word2 = new javax.swing.JTextField();
jLabel5 = new javax.swing.JLabel();
sim = new javax.swing.JTextField();
sub = new javax.swing.JButton();
clr = new javax.swing.JButton();
setDefaultCloseOperation(javax.swing.WindowConstants.EXIT_ON_CLOSE);
setTitle("Cluster");
jPanel1.setBackground(new java.awt.Color(123, 123, 255));
jPanel1.setForeground(new java.awt.Color(51, 51, 51));
jLabel1.setFont(new java.awt.Font("Times New Roman", 1, 36)); // NOI18N
jLabel1.setForeground(new java.awt.Color(255, 255, 255));
jLabel1.setHorizontalAlignment(javax.swing.SwingConstants.CENTER);
jLabel1.setText("Clustering Process");
javax.swing.GroupLayout jPanel1Layout = new javax.swing.GroupLayout(jPanel1);
jPanel1.setLayout(jPanel1Layout);
jPanel1Layout.setHorizontalGroup(
jPanel1Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.LEADING)
.addGroup(jPanel1Layout.createSequentialGroup()
.addGap(67, 67, 67)
.addComponent(jLabel1, javax.swing.GroupLayout.PREFERRED_SIZE, 381,
javax.swing.GroupLayout.PREFERRED_SIZE)
.addContainerGap(javax.swing.GroupLayout.DEFAULT_SIZE, Short.MAX_VALUE))
);
jPanel1Layout.setVerticalGroup(
jPanel1Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.LEADING)
.addGroup(javax.swing.GroupLayout.Alignment.TRAILING, jPanel1Layout.createSequentialGroup()
.addContainerGap()
.addComponent(jLabel1, javax.swing.GroupLayout.DEFAULT_SIZE, 56, Short.MAX_VALUE)
.addContainerGap())
);

Semantic Text Document Clustering 2015
37
jPanel2.setBackground(new java.awt.Color(153, 204, 255));
jPanel2.setBorder(javax.swing.BorderFactory.createTitledBorder(null, "Clustering",
javax.swing.border.TitledBorder.DEFAULT_JUSTIFICATION, javax.swing.border.TitledBorder.DEFAULT_POSITION, new
java.awt.Font("Times New Roman", 2, 14), new java.awt.Color(0, 0, 153))); // NOI18N
jLabel2.setFont(new java.awt.Font("Constantia", 0, 14)); // NOI18N
jLabel2.setForeground(new java.awt.Color(51, 51, 51));
jLabel2.setHorizontalAlignment(javax.swing.SwingConstants.CENTER);
jLabel2.setText("Pick File :");
browse_path.setFocusable(false);
clear.setFont(new java.awt.Font("Tahoma", 1, 12)); // NOI18N
clear.setForeground(new java.awt.Color(255, 0, 0));
clear.setText("X");
clear.addActionListener(new java.awt.event.ActionListener() {
public void actionPerformed(java.awt.event.ActionEvent evt) {
clearActionPerformed(evt);
}
});
browse.setFont(new java.awt.Font("Tahoma", 0, 14)); // NOI18N
browse.setText("Browse and Submit");
browse.addActionListener(new java.awt.event.ActionListener() {
public void actionPerformed(java.awt.event.ActionEvent evt) {
browseActionPerformed(evt);
}
});
javax.swing.GroupLayout jPanel2Layout = new javax.swing.GroupLayout(jPanel2);
jPanel2.setLayout(jPanel2Layout);
jPanel2Layout.setHorizontalGroup(
jPanel2Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.LEADING)
.addGroup(jPanel2Layout.createSequentialGroup()
.addContainerGap()
.addComponent(jLabel2, javax.swing.GroupLayout.PREFERRED_SIZE, 79,
javax.swing.GroupLayout.PREFERRED_SIZE)
.addPreferredGap(javax.swing.LayoutStyle.ComponentPlacement.RELATED)
.addComponent(browse_path, javax.swing.GroupLayout.PREFERRED_SIZE, 228,
javax.swing.GroupLayout.PREFERRED_SIZE)
.addPreferredGap(javax.swing.LayoutStyle.ComponentPlacement.RELATED)
.addComponent(clear, javax.swing.GroupLayout.PREFERRED_SIZE, 40,
javax.swing.GroupLayout.PREFERRED_SIZE)
.addPreferredGap(javax.swing.LayoutStyle.ComponentPlacement.RELATED)
.addComponent(browse, javax.swing.GroupLayout.PREFERRED_SIZE, 162,
javax.swing.GroupLayout.PREFERRED_SIZE)
.addContainerGap(javax.swing.GroupLayout.DEFAULT_SIZE, Short.MAX_VALUE))
);
jPanel2Layout.setVerticalGroup(
jPanel2Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.LEADING)

Semantic Text Document Clustering 2015
38
.addGroup(javax.swing.GroupLayout.Alignment.TRAILING, jPanel2Layout.createSequentialGroup()
.addContainerGap()
.addGroup(jPanel2Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.BASELINE)
.addComponent(browse_path, javax.swing.GroupLayout.PREFERRED_SIZE, 31,
javax.swing.GroupLayout.PREFERRED_SIZE)
.addComponent(jLabel2, javax.swing.GroupLayout.PREFERRED_SIZE, 34,
javax.swing.GroupLayout.PREFERRED_SIZE)
.addComponent(clear, javax.swing.GroupLayout.PREFERRED_SIZE, 31,
javax.swing.GroupLayout.PREFERRED_SIZE)
.addComponent(browse, javax.swing.GroupLayout.PREFERRED_SIZE, 32,
javax.swing.GroupLayout.PREFERRED_SIZE))
.addContainerGap(61, Short.MAX_VALUE))
);
javax.swing.GroupLayout jPanel3Layout = new javax.swing.GroupLayout(jPanel3);
jPanel3.setLayout(jPanel3Layout);
jPanel3Layout.setHorizontalGroup(
jPanel3Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.LEADING)
.addGap(0, 0, Short.MAX_VALUE)
);
jPanel3Layout.setVerticalGroup(
jPanel3Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.LEADING)
.addGap(0, 0, Short.MAX_VALUE)
);
jPanel4.setBackground(new java.awt.Color(102, 153, 255));
jPanel4.setBorder(javax.swing.BorderFactory.createTitledBorder(javax.swing.BorderFactory.createTitledBorder(null,
"Similarity Calculation", javax.swing.border.TitledBorder.DEFAULT_JUSTIFICATION,
javax.swing.border.TitledBorder.DEFAULT_POSITION, new java.awt.Font("Times New Roman", 2, 14), new
java.awt.Color(51, 0, 0)))); // NOI18N
jLabel3.setFont(new java.awt.Font("Times New Roman", 1, 14)); // NOI18N
jLabel3.setForeground(new java.awt.Color(255, 255, 255));
jLabel3.setHorizontalAlignment(javax.swing.SwingConstants.CENTER);
jLabel3.setText("Word 1 :");
jLabel4.setFont(new java.awt.Font("Times New Roman", 1, 14)); // NOI18N
jLabel4.setForeground(new java.awt.Color(255, 255, 255));
jLabel4.setHorizontalAlignment(javax.swing.SwingConstants.CENTER);
jLabel4.setText("Word 2 :");
word1.addActionListener(new java.awt.event.ActionListener() {
public void actionPerformed(java.awt.event.ActionEvent evt) {
word1ActionPerformed(evt);
}
});
word2.addActionListener(new java.awt.event.ActionListener() {
public void actionPerformed(java.awt.event.ActionEvent evt) {
word2ActionPerformed(evt);

Semantic Text Document Clustering 2015
39
}
});
jLabel5.setFont(new java.awt.Font("Times New Roman", 1, 14)); // NOI18N
jLabel5.setForeground(new java.awt.Color(255, 255, 255));
jLabel5.setHorizontalAlignment(javax.swing.SwingConstants.CENTER);
jLabel5.setText("Similarity :");
sim.addActionListener(new java.awt.event.ActionListener() {
public void actionPerformed(java.awt.event.ActionEvent evt) {
simActionPerformed(evt);
}
});
sub.setText("Submit");
sub.addActionListener(new java.awt.event.ActionListener() {
public void actionPerformed(java.awt.event.ActionEvent evt) {
subActionPerformed(evt);
}
});
clr.setText("Clear");
clr.addActionListener(new java.awt.event.ActionListener() {
public void actionPerformed(java.awt.event.ActionEvent evt) {
clrActionPerformed(evt);
}
});
javax.swing.GroupLayout jPanel4Layout = new javax.swing.GroupLayout(jPanel4);
jPanel4.setLayout(jPanel4Layout);
jPanel4Layout.setHorizontalGroup(
jPanel4Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.LEADING)
.addGroup(jPanel4Layout.createSequentialGroup()
.addGap(22, 22, 22)
.addGroup(jPanel4Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.TRAILING)
.addComponent(jLabel4, javax.swing.GroupLayout.PREFERRED_SIZE, 79,
javax.swing.GroupLayout.PREFERRED_SIZE)
.addComponent(jLabel3, javax.swing.GroupLayout.PREFERRED_SIZE, 79,
javax.swing.GroupLayout.PREFERRED_SIZE))
.addPreferredGap(javax.swing.LayoutStyle.ComponentPlacement.RELATED)
.addGroup(jPanel4Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.LEADING)
.addGroup(jPanel4Layout.createSequentialGroup()
.addComponent(word1, javax.swing.GroupLayout.PREFERRED_SIZE, 110,
javax.swing.GroupLayout.PREFERRED_SIZE)
.addPreferredGap(javax.swing.LayoutStyle.ComponentPlacement.UNRELATED)
.addComponent(jLabel5, javax.swing.GroupLayout.PREFERRED_SIZE, 79,
javax.swing.GroupLayout.PREFERRED_SIZE))
.addComponent(word2, javax.swing.GroupLayout.PREFERRED_SIZE, 110,
javax.swing.GroupLayout.PREFERRED_SIZE))
.addPreferredGap(javax.swing.LayoutStyle.ComponentPlacement.RELATED)

Semantic Text Document Clustering 2015
40
.addGroup(jPanel4Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.LEADING)
.addGroup(jPanel4Layout.createSequentialGroup()
.addComponent(sub)
.addGap(18, 18, 18)
.addComponent(clr))
.addComponent(sim, javax.swing.GroupLayout.PREFERRED_SIZE, 110,
javax.swing.GroupLayout.PREFERRED_SIZE))
.addContainerGap(javax.swing.GroupLayout.DEFAULT_SIZE, Short.MAX_VALUE))
);
jPanel4Layout.setVerticalGroup(
jPanel4Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.LEADING)
.addGroup(jPanel4Layout.createSequentialGroup()
.addGroup(jPanel4Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.LEADING)
.addGroup(jPanel4Layout.createSequentialGroup()
.addGap(21, 21, 21)
.addGroup(jPanel4Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.BASELINE)
.addComponent(jLabel3, javax.swing.GroupLayout.PREFERRED_SIZE, 34,
javax.swing.GroupLayout.PREFERRED_SIZE)
.addComponent(word1, javax.swing.GroupLayout.PREFERRED_SIZE,
javax.swing.GroupLayout.DEFAULT_SIZE, javax.swing.GroupLayout.PREFERRED_SIZE))
.addGap(18, 18, 18)
.addGroup(jPanel4Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.BASELINE)
.addComponent(jLabel4, javax.swing.GroupLayout.PREFERRED_SIZE, 34,
javax.swing.GroupLayout.PREFERRED_SIZE)
.addComponent(word2, javax.swing.GroupLayout.PREFERRED_SIZE,
javax.swing.GroupLayout.DEFAULT_SIZE, javax.swing.GroupLayout.PREFERRED_SIZE)))
.addGroup(jPanel4Layout.createSequentialGroup()
.addGap(46, 46, 46)
.addGroup(jPanel4Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.BASELINE)
.addComponent(jLabel5, javax.swing.GroupLayout.PREFERRED_SIZE, 34,
javax.swing.GroupLayout.PREFERRED_SIZE)
.addComponent(sim, javax.swing.GroupLayout.PREFERRED_SIZE,
javax.swing.GroupLayout.DEFAULT_SIZE, javax.swing.GroupLayout.PREFERRED_SIZE))
.addPreferredGap(javax.swing.LayoutStyle.ComponentPlacement.UNRELATED)
.addGroup(jPanel4Layout.createParallelGroup(javax.swing.GroupLayout.Alignment.BASELINE)
.addComponent(sub)
.addComponent(clr))))
.addContainerGap(22, Short.MAX_VALUE))
);
javax.swing.GroupLayout layout = new javax.swing.GroupLayout(getContentPane());
getContentPane().setLayout(layout);
layout.setHorizontalGroup(
layout.createParallelGroup(javax.swing.GroupLayout.Alignment.LEADING)
.addComponent(jPanel1, javax.swing.GroupLayout.DEFAULT_SIZE, javax.swing.GroupLayout.DEFAULT_SIZE,
Short.MAX_VALUE)
.addGroup(layout.createSequentialGroup()
.addGroup(layout.createParallelGroup(javax.swing.GroupLayout.Alignment.LEADING)

Semantic Text Document Clustering 2015
41
.addComponent(jPanel2, javax.swing.GroupLayout.DEFAULT_SIZE,
javax.swing.GroupLayout.DEFAULT_SIZE, Short.MAX_VALUE)
.addComponent(jPanel4, javax.swing.GroupLayout.DEFAULT_SIZE,
javax.swing.GroupLayout.DEFAULT_SIZE, Short.MAX_VALUE))
.addPreferredGap(javax.swing.LayoutStyle.ComponentPlacement.RELATED)
.addComponent(jPanel3, javax.swing.GroupLayout.DEFAULT_SIZE, javax.swing.GroupLayout.DEFAULT_SIZE,
Short.MAX_VALUE))
);
layout.setVerticalGroup(
layout.createParallelGroup(javax.swing.GroupLayout.Alignment.LEADING)
.addGroup(layout.createSequentialGroup()
.addComponent(jPanel1, javax.swing.GroupLayout.PREFERRED_SIZE,
javax.swing.GroupLayout.DEFAULT_SIZE, javax.swing.GroupLayout.PREFERRED_SIZE)
.addPreferredGap(javax.swing.LayoutStyle.ComponentPlacement.RELATED)
.addComponent(jPanel2, javax.swing.GroupLayout.PREFERRED_SIZE,
javax.swing.GroupLayout.DEFAULT_SIZE, javax.swing.GroupLayout.PREFERRED_SIZE)
.addPreferredGap(javax.swing.LayoutStyle.ComponentPlacement.RELATED)
.addComponent(jPanel4, javax.swing.GroupLayout.DEFAULT_SIZE, javax.swing.GroupLayout.DEFAULT_SIZE,
Short.MAX_VALUE)
.addPreferredGap(javax.swing.LayoutStyle.ComponentPlacement.RELATED)
.addComponent(jPanel3, javax.swing.GroupLayout.DEFAULT_SIZE, javax.swing.GroupLayout.DEFAULT_SIZE,
Short.MAX_VALUE)
.addContainerGap())
);
pack();
}// </editor-fold>
@SuppressWarnings("empty-statement")
private void browseActionPerformed(java.awt.event.ActionEvent evt) {
// TODO add your handling code here:
File log=new File("E:\\pro.txt");
FileWriter bw = null;
try {
bw = new FileWriter(log,true);
} catch (IOException ex) {
Logger.getLogger(Sel_txt.class.getName()).log(Level.SEVERE, null, ex);
}
JFileChooser chooser = new JFileChooser();
chooser.setCurrentDirectory(new File("."));
chooser.setFileFilter(new javax.swing.filechooser.FileFilter() {
public boolean accept(File f) {
return f.getName().toLowerCase().endsWith(".txt")
|| f.isDirectory();
}

Semantic Text Document Clustering 2015
42
public String getDescription() {
return "Text Files";
}
});
int r = chooser.showOpenDialog(new JFrame());
if (r == JFileChooser.APPROVE_OPTION) {
String name = chooser.getSelectedFile().getPath();
String message = "\"Data inserted successfully\"\n";
JOptionPane.showMessageDialog(new JFrame(), message, "Success",JOptionPane.PLAIN_MESSAGE);
System.out.println(name);
browse_path.setText(name);
Set<String> words=new HashSet<String>();
String input="";
File dir = new File("E:\\path");
int fil=0;
for (String fn : dir.list()) {
try{
fil++;
File file = new File(dir+"/"+fn);
BufferedInputStream filereader1 = new BufferedInputStream(
new DataInputStream(new FileInputStream(file)));
byte[] data = new byte[(int) file.length()];
filereader1.read(data);
filereader1.close();
input = new String(data,"UTF-8");
Scanner inp=new Scanner(input);
while(inp.hasNext()){
StringTokenizer st = new StringTokenizer(inp.next(), " ,.;:\"-'?/()/|~`=!।1234567890@@#$%^&*<>{}[]+-_");
while(st.hasMoreTokens()){
String tmp = st.nextToken().toLowerCase();
if(!words.contains(tmp)){
words.add(tmp);}}}
}
catch(Exception e){}
}
String[] d;
d=words.toArray(new String[words.size()]);
System.out.println("Length is: "+d.length+"\n\n");
for(int i=0;i<d.length;i++)
{System.out.print(" "+d[i]+" ");}
System.out.print("\n");

Semantic Text Document Clustering 2015
43
String x;
int s;
double min;
double max;
double[] b=new double[1000];
double a=0;
DecimalFormat df = new DecimalFormat("#.####");
Set<String> wor=new HashSet<String>();
String files = null;
//System.out.println("Enter the path correctly:");
files=name;
Scanner inpt = null;
try {
inpt = new Scanner(new File(files), "UTF-8");
} catch (FileNotFoundException ex) {
Logger.getLogger(Sel_txt.class.getName()).log(Level.SEVERE, null, ex);
}
while(inpt.hasNext()){
StringTokenizer st = new StringTokenizer(inpt.next()," ,.;:\"-'?/()/|~`=!।1234567890@@#$%^&*<>{}[]+-_");
while(st.hasMoreTokens()){
String tmp = st.nextToken().toLowerCase();
if(!wor.contains(tmp)){
wor.add(tmp)
try {
bw.append(System.getProperty("line.separator"));
//append(System.getProperty("line.separator"));
} catch (IOException ex) {
Logger.getLogger(Sel_txt.class.getName()).log(Level.SEVERE, null, ex);
}
String[] w=wor.toArray(new String[wor.size()]);
System.out.println("Length is: "+w.length+"\n\n");
for(int i=0; i<w.length-1; i++){
for(int j=i+1; j<w.length; j++){
double distance =compute(w[i] , w[j]);
//System.out.println("\n"+w[i] +" - " + w[j] + " = " + distance);
a=a+distance;
}

Semantic Text Document Clustering 2015
44
b[i]=a;
}
max=b[0];
min=b[0];
//System.out.println(b[0]);
for(int i=1; i<w.length-1; i++){
if(b[i]>max)
max=b[i];
if(b[i]<min)
min=b[i];
}
for(int k=0; k<d.length; k++)
{
x="0";
for(int i=0; i<w.length; i++)
{
if(d[k].equals(w[i]))
{
x=w[i];
if(min==max)
{b[i]=0.5000;}
else
{ b[i]=Math.abs((b[i]-min)/(max-min)); }
//x=String.valueOf(df.format(b[i]));
//System.out.print(" "+a);
System.out.print(" ");
System.out.print(" "+df.format(b[i])+" ");
try {
bw.write(df.format(b[i])+" ");
//bw.append(System.getProperty("line.separator"));
} catch (IOException ex) {
Logger.getLogger(Sel_txt.class.getName()).log(Level.SEVERE, null, ex);
}
}
}
if(d[k] == null ? x != null : !d[k].equals(x))
{

Semantic Text Document Clustering 2015
45
System.out.print(" "+x+" ");
try {
bw.write(x+" ");
} catch (IOException ex) {
Logger.getLogger(Sel_txt.class.getName()).log(Level.SEVERE, null, ex)
System.out.println("\n");
try {
bw.close();
} catch (IOException ex) {
Logger.getLogger(Sel_txt.class.getName()).log(Level.SEVERE, null, ex);
}
}
private void clearActionPerformed(java.awt.event.ActionEvent evt) {
// TODO add your handling code here:
browse_path.setText("");
}
private void word1ActionPerformed(java.awt.event.ActionEvent evt) {
// TODO add your handling code here:
}
private void word2ActionPerformed(java.awt.event.ActionEvent evt) {
// TODO add your handling code here:
}
private void simActionPerformed(java.awt.event.ActionEvent evt) {
//
TODO add your handling code here:
}
private void subActionPerformed(java.awt.event.ActionEvent evt) {
// TODO add your handling code here:
if(word1.getText().isEmpty()||word2.getText().isEmpty())
{
String message = "\"Error!.. Enter data\"\n";
JOptionPane.showMessageDialog(new JFrame(), message, "Dialog",JOptionPane.ERROR_MESSAGE);
}
else{
String w1=word1.getText().toLowerCase(),w2=word2.getText().toLowerCase();
System.out.print(w1+" and " +w2);

Semantic Text Document Clustering 2015
46
//List<String> a=linkToSynsets(w1);
double dist=compute(w1,w2);
sim.setText(String.valueOf(dist));
}
}
private void clrActionPerformed(java.awt.event.ActionEvent evt) {
// TODO add your handling code here:
word1.setText("");
word2.setText("");
sim.setText("");
word1.requestFocus();
}
/**
* @param args the command line arguments
*/
public static void main(String args[]) {
/* Set the Nimbus look and feel */
//<editor-fold defaultstate="collapsed" desc=" Look and feel setting code (optional) ">
/* If Nimbus (introduced in Java SE 6) is not available, stay with the default look and feel.
* For details see http://download.oracle.com/javase/tutorial/uiswing/lookandfeel/plaf.html
*/
try {
for (javax.swing.UIManager.LookAndFeelInfo info : javax.swing.UIManager.getInstalledLookAndFeels()) {
if ("Nimbus".equals(info.getName())) {
javax.swing.UIManager.setLookAndFeel(info.getClassName());
break;
}
}
} catch (ClassNotFoundException ex) {
java.util.logging.Logger.getLogger(Sel_txt.class.getName()).log(java.util.logging.Level.SEVERE, null, ex);
} catch (InstantiationException ex) {
java.util.logging.Logger.getLogger(Sel_txt.class.getName()).log(java.util.logging.Level.SEVERE, null, ex);
} catch (IllegalAccessException ex) {
java.util.logging.Logger.getLogger(Sel_txt.class.getName()).log(java.util.logging.Level.SEVERE, null, ex);
} catch (javax.swing.UnsupportedLookAndFeelException ex) {
java.util.logging.Logger.getLogger(Sel_txt.class.getName()).log(java.util.logging.Level.SEVERE, null, ex);
}
//</editor-fold>
/* Create and display the form */
java.awt.EventQueue.invokeLater(new Runnable() {

Semantic Text Document Clustering 2015
47
public void run() {
new Sel_txt().setVisible(true);
}
});
}
// Variables declaration - do not modify
private javax.swing.JButton browse;
private javax.swing.JTextField browse_path;
private javax.swing.JButton clear;
private javax.swing.JButton clr;
private javax.swing.JLabel jLabel1;
private javax.swing.JLabel jLabel2;
private javax.swing.JLabel jLabel3;
private javax.swing.JLabel jLabel4;
private javax.swing.JLabel jLabel5;
private javax.swing.JPanel jPanel1;
private javax.swing.JPanel jPanel2;
private javax.swing.JPanel jPanel3;
private javax.swing.JPanel jPanel4;
private javax.swing.JTextField sim;
private javax.swing.JButton sub;
private javax.swing.JTextField word1;
private javax.swing.JTextField word2;
// End of variables declaration
private BufferedWriter FileWriter(String fl_nam) {
throw new UnsupportedOperationException("Not supported yet."); //To change body of generated methods, choose Tools |
Templates.
}}
5.2.2 Notepad Storing vectors
Each line/row of the notepad represents a vector. The whole notepad is a collection
of vectors in matrix format.

Semantic Text Document Clustering 2015
48
5.2.2 Matlab K-means Clustering
K-means Code
function [label, centroid,Initial_clusters] = fkmeans(X, k, options)
n = size(X,1);
% option defaults
weight = 0; % uniform unit weighting
careful = 0;% random initialization
if nargin == 3
if isfield(options, 'weight')
weight = options.weight;
end
if isfield(options,'careful') careful = options.careful;
end
end
% If initial centroids not supplied, choose them
if isscalar(k)
% centroids not specified
if careful
k = spreadseeds(X, k);
else
k = X(randsample(size(X,1),k),:);
%assignin(ws, 'Initial Cluster', k); Initial_clusters=k;
end
end
% generate initial labeling of points
[~,label] = max(bsxfun(@minus,k*X',0.5*sum(k.^2,2)));
k = size(k,1);
last = 0;
if ~weight
% code defactoring for speed
while any(label ~= last)
% remove empty clusters
[~,~,label] = unique(label); % transform label into indicator matrix
ind = sparse(label,1:n,1,k,n,n);
% compute centroid of each cluster
centroid = (spdiags(1./sum(ind,2),0,k,k)*ind)*X;
% compute distance of every point to each centroid
distances = bsxfun(@minus,centroid*X',0.5*sum(centroid.^2,2));
% assign points to their nearest centroid
last = label;
[~,label] = max(distances);
end
dis = ind*(sum(X.^2,2) - 2*max(distances)'); else
while any(label ~= last)

Semantic Text Document Clustering 2015
49
% remove empty clusters
[~,~,label] = unique(label);
% transform label into indicator matrix ind = sparse(label,1:n,weight,k,n,n);
% compute centroid of each cluster
centroid = (spdiags(1./sum(ind,2),0,k,k)*ind)*X;
% compute distance of every point to each centroid
distances = bsxfun(@minus,centroid*X',0.5*sum(centroid.^2,2));
% assign points to their nearest centroid
last = label;
[~,label] = max(distances);
end
dis = ind*(sum(X.^2,2) - 2*max(distances)');
end label = label';
function D = sqrdistance(A, B)
n1 = size(A,1); n2 = size(B,2);
m = (sum(A,1)+sum(B,1))/(n1+n2);
A = bsxfun(@minus,A,m);
B = bsxfun(@minus,B,m);
D = full((-2)*(A*B'));
D = bsxfun(@plus,D,full(sum(B.^2,2))');
D = bsxfun(@plus,D,full(sum(A.^2,2)))';
end
function [S, idx] = spreadseeds(X, k)
% X: n x d data matrix % k: number of seeds
% reference: k-means++: the advantages of careful seeding.
% by David Arthur and Sergei Vassilvitskii
% Adapted from softseeds written by Mo Chen ([email protected]),
% March 2009.
[n,d] = size(X);
idx = zeros(k,1);
S = zeros(k,d);
D = inf(n,1);
idx(1) = ceil(n.*rand);
S(1,:) = X(idx(1),:); for i = 2:k
D = min(D,sqrdistance(S(i-1,:),X));
idx(i) = find(cumsum(D)/sum(D)>rand,1);
S(i,:) = X(idx(i),:);
end
end
end

Semantic Text Document Clustering 2015
50
Work-space values in Matlab
The following workspace shows the initial assignments of cluster vectors (Here 10 clusters are taken
into consideration).
The following workspace shows the final centroids of the 10 cluster vectors.
The elapsed time of the algorithm is:
Semantic Text Document Clustering 2015
51
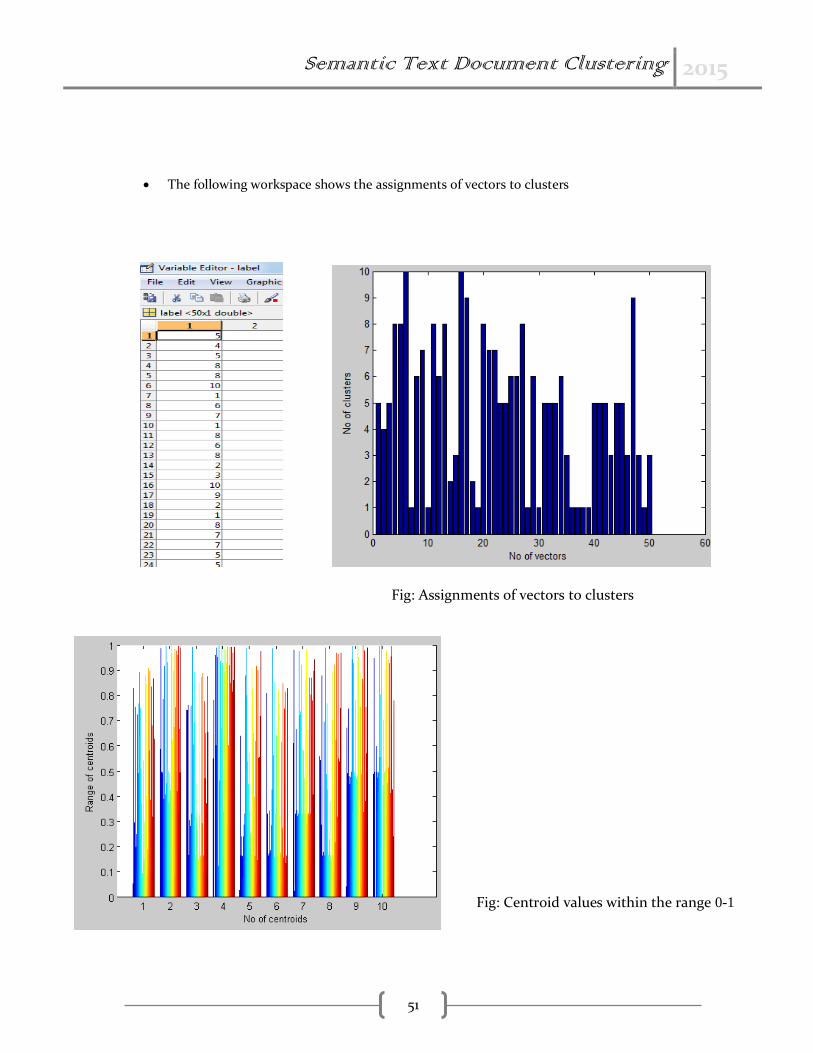
The following workspace shows the assignments of vectors to clusters
Fig: Assignments of vectors to clusters
Fig: Centroid values within the range 0-1

Semantic Text Document Clustering 2015
52
Fig: Inter-Cluster Distance
Fig: Average intra-Cluster distance

Semantic Text Document Clustering 2015
53
CONCLUSION AND FUTUR E SCOPE
Conclusion
The first goal of the current study was to use text mining techniques on text files.
The project study involved the great deal of work on various areas of information
retrieval and text mining and focused on the various methods for document pre-
processing and document clustering.
Text mining and clustering techniques are really powerful. This project study was
completely based on these techniques. The system was created for finding the
similarities among the text files/documents. Various techniques were applied for
preparing the pre-processed document vectors. Lastly, the k-means clustering
algorithm was used for creating the clusters of similar document vectors.
The real world application of the project study would help people to find the similar
text documents on a single platform from different sources. This would not have
been possible without the use of text mining and clustering techniques.
Future Scope
In its future scope, many advanced clustering techniques like: Categorical Clustering
(ROCK, STIRR, CACTUS,etc.) can be implemented for getting even better results of
clusters. Moreover, higher information retrieval techniques like: genetic algorithm
can also be used.

Semantic Text Document Clustering 2015
54
REFERENCES
Z. Wu and M. Palmer. “Verb semantics and lexical selection”. In Proceedings of the 32nd Annual
Meeting of the Associations for Computational Linguistics, pp 133-138. 1994.
T. Slimani, B. Ben Yaghlane, and K. Mellouli, “A New Similarity Measure based on Edge Counting”
World Academy of Science, Engineering and Technology, PP 34-38. 2006.] C.
X. Ji, W. Xu. Document clustering with prior knowledge. ACM
SIGIR Conference, 2006.
C. Aggarwal, Y. Zhao, P. S. Yu. On Text Clustering with Side
Information, ICDE Conference, 2012.
Huang, C., Simon, P., Hsieh, S. & Prevot, L. 2007. “Rethinking Chinese Word Segmentation: Tokenization,
Character Classification, or Word break Identification”. Retrieved September 2, 2013 from:
http://delivery.acm.org/10.1145/1560000/1557791/p69-
huang.pdf?ip=86.50.66.20&id=1557791&acc=OPEN&key=BF13D071DEA4D3F3B0AA4BA89B4BCA5B&CFID=38
9226789&CFTOKEN=39573449&__acm__=1387138322_f651d65355dcc035ef1e98e656194624
P. Anick, S. Vaithyanathan. Exploiting Clustering and Phrases for Context-Based Information
Retrieval. ACM SIGIR Conference, 1997.

















![Semantic Suffix Net Clustering for Search Results · web clustering engines [7]. Most search results clustering algorithms are a combination between search engines and text ... STC](https://static.fdocuments.us/doc/165x107/5f78a07dc76845036c372ea6/semantic-suffix-net-clustering-for-search-results-web-clustering-engines-7-most.jpg)
