

Searching over the past, present and future
37
Searching over the past, present and future Roi Blanco ([email protected]) http://labs.yahoo.com/Yahoo_Labs_Barcelona
-
Upload
roi-blanco -
Category
Technology
-
view
100 -
download
2
Transcript of Searching over the past, present and future

Searching over the past, present and future
Roi Blanco ([email protected]) http://labs.yahoo.com/Yahoo_Labs_Barcelona

Yahoo! Research BarcelonaEstablished January, 2006Led by Ricardo Baeza-YatesResearch areas
• Web Mining • Social Media• Distributed Web retrieval • Geo information retrieval• NLP and Semantics

Agenda• Natural Language retrieval• Time and search engines
• Searching over web archives• Searching on real time information
• Caching!
• Time-based exploratory search• Searching over future events
• Future directions

Natural Language Retrieval• How to exploit the structure and meaning of
natural language text to improve search• Current search engines perform only limited NLP
(tokenization, stemming)• Automated tools exist for deeper analysis
• Applications to diversity-aware search• Source, Location, Time, Language, Opinion, Ranking…
• Search over semi-structured data, semantic search• Roll-out user experiences that use higher layers of
the NLP stack• In this talk, focus on the time dimension


High-level Architecture of WSEs
Parser/Tokenizer
Index
terms
CacheQueryEngine
queries
Indexing pipeline
Runtime system
results
WWW WWW

Web Search and time
• Information freshness adds constraints/tensions in every layer of WSE
• Architecture • Crawling• Indexing• Caching• Serving system
• Modeling• Time-dependent user intent• UI (how to let the user take control)
7

Adding the time dimension• Some solutions don’t scale up anymore
Review your architectureReview your algorithmsAdd more machines (~$$$)
• Some solutions don’t apply anymoreCaching
8

Evolution• 1999
• Index updated ~once per month• Disk-based updates/indexing
• 2001• In-memory indexes• Changes the whole-game!
• 2007• Indexing time < 1 minute• Accept updates while serving
• Now• Focused crawling, delayed transactions, etc.• Batch Updates -> Incremental processing
9

Some landmarks
• Reliable distributed storage• Some models/processes require millions of accesses
• Massive parallelization• Map/Reduce – Hadoop
• Semi-structured storage systems• Asynchronous item updates
10

What’s going on “right now”?
11

Query temporal profiles
• Modeling• Time-dependent user intent• Implicitly time-qualified search queries
• SIGIR
• Dream theater barcelona
• Barcelona vs Madrid
• ….
12

Caching for Real-Time Indexes
• Queries are redundant (heavy-tail) and bursty• Caching search results saves up executing ~30/60% of the queries
• Tens of machines do the work of 1000s
• Dilemma: Freshness versus Computation• Extreme #1: do not cache at all – evaluate all queries
• 100% fresh results, lots of redundant evaluations• Extreme #2: never invalidate the cache
• A majority of stale results – results refreshed only due to cache replacement, no redundant work
• Middle ground: invalidate periodically (TTL)• A time-to-live parameter is applied to each cached entry
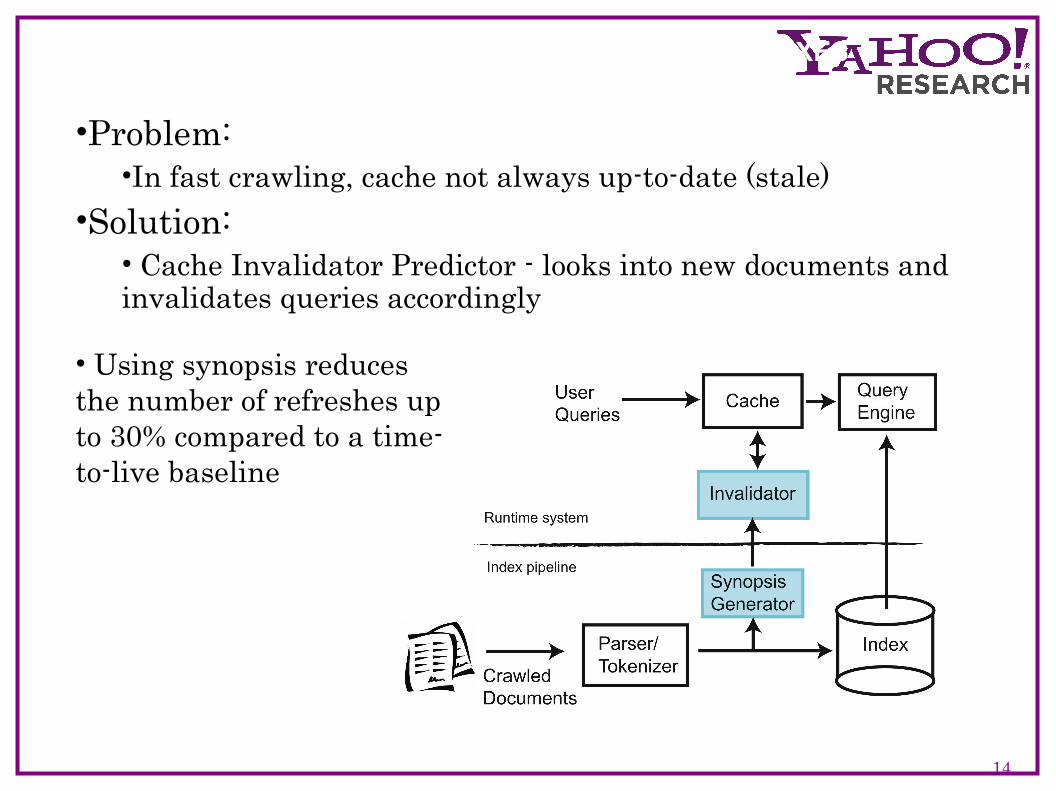
•Problem:•In fast crawling, cache not always up-to-date (stale)
•Solution: • Cache Invalidator Predictor - looks into new documents and invalidates queries accordingly
• Using synopsis reduces the number of refreshes up to 30% compared to a time-to-live baseline
14
CACHING FOR INCREMENTAL INDEXES

Time(ly) opportunitiesCan we create new user experiences based on a deeper
analysis and exploration of the time dimension?
Goals:Build an application that helps users to explore, interact
and ultimately understand existing information about the past and the future.
Help the user cope with the information overload and eventually find/learn about what she’s looking for

Original IdeaR. Baeza-Yates, Searching the Future, MF/IR 2005
On December 1st 2003, on Google News, there were more than 100K references to 2004 and beyond.
E.g. 2034: The ownership of Dolphin Square in London must revert to an
insurance company.Voyager 2 should run out of fuel.Long-term care facilities may have to house 2.1 million people
in the USA.A human base in the moon would be in operation.

17
Time Explorer
• Public demo since August 2010
• For exploring news through time and into the future
• Using a 1.8M news articles from New York Times Annotated Corpus
• Try it at http://fbmya01.barcelonamedia.org:8080/future/

Time Explorer

19
Time Explorer - Motivation Time is important to search Recency, particularly in news is highly related to
relevancy But, what about evolution over time?
How has a topic evolved over time? How did the entities (people, place, etc) evolve with respect to the
topic over time? How will this topic continue to evolve over the future? How does bias and sentiment in blogs and news change over time?
Google Trends, Yahoo! Clues, RecordedFuture … Great research playground

20
Time Explorer

21
Collections New York Times (1.8 million document)
Well structured manual annotations publically available but, not diverse
Web Crawl Collection (100 news source and 500 blogs sites)
Great for diversity Challenge because of format, languages, structure, etc
Custom Collections Yahoo! News

22
Analysis Pipeline Tokenization, Sentence Splitting, Part-of-speech
tagging, chunking with OpenNLP Entity extraction with SuperSense tagger Time expressions extracted with TimeML
Explicit dates (August 23rd, 2008) Relative dates (Next year, resolved with Pub Date)
Sentiment Analysis with LivingKnowledge Ontology matching with Yago Image Analysis – sentiment and face detection

23
Indexing/Search
• Lucene/Solr search platform to index and search– Sentence level– Document level
• Facets for entity types• Index publication date and content date –extracted dates if
they exists or publication date• Solr Faceting allows aggregation over query entity ranking
and allowing for aggregating counts over time• Content date allows searching into the future
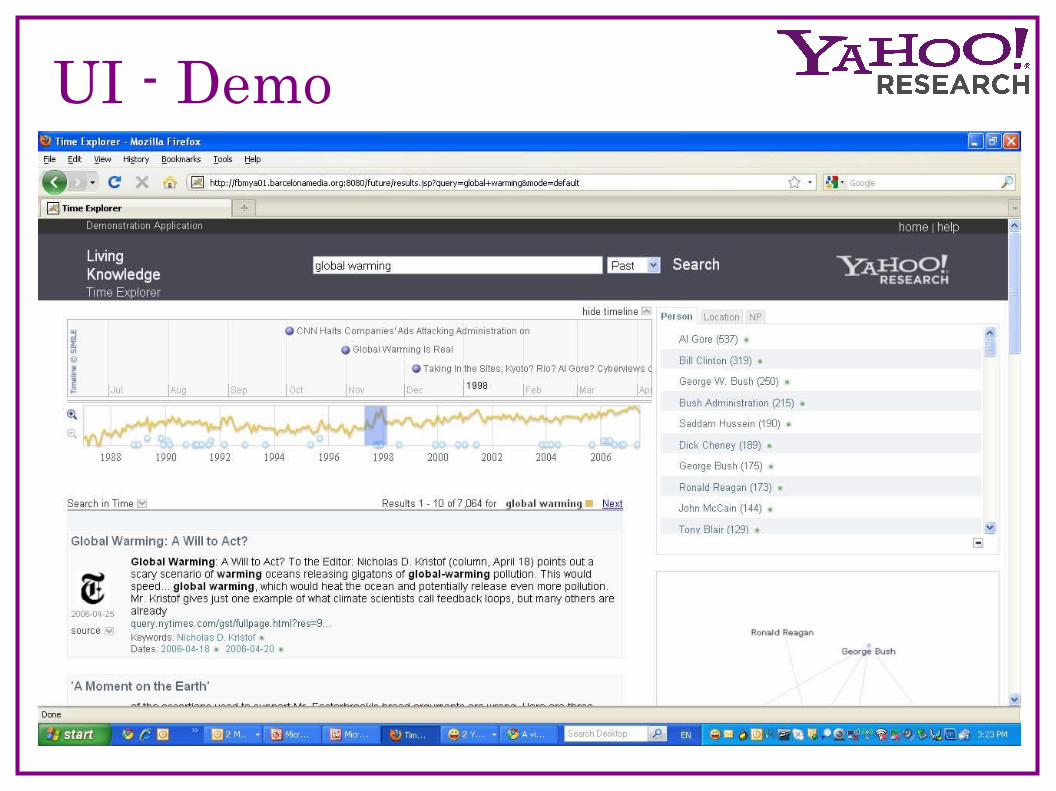
UI - Demo

Timeline

Timeline - Document

Facets
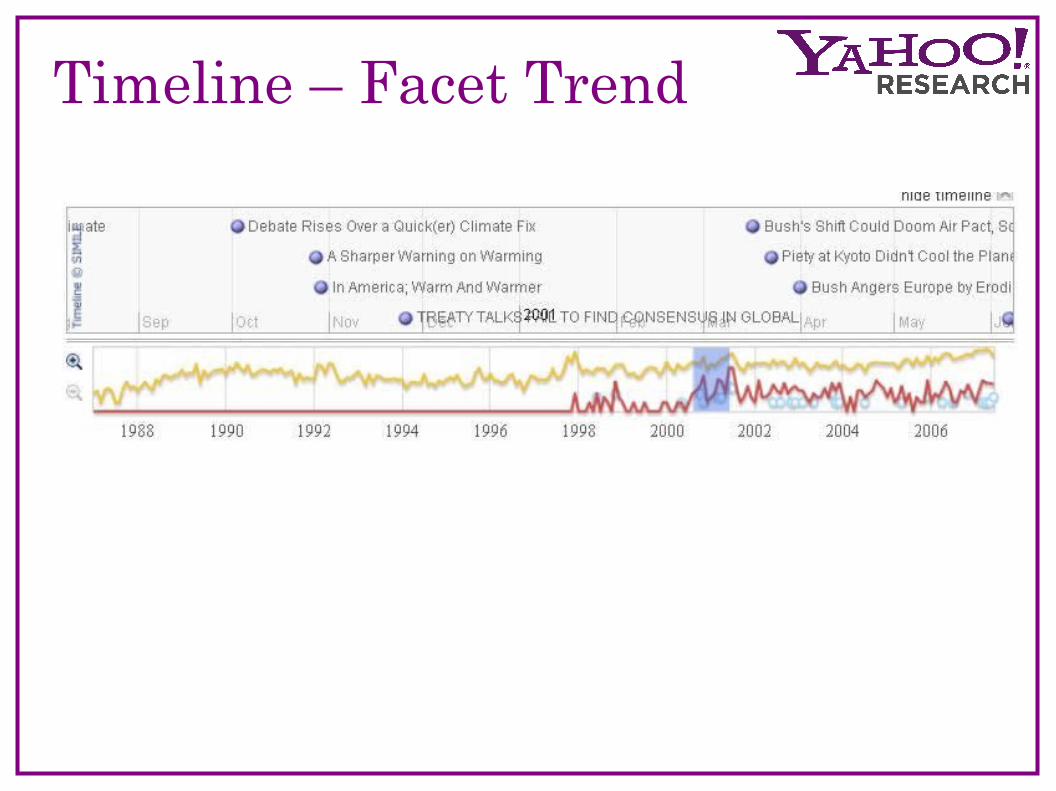
Timeline – Facet Trend

Timeline – Future

Timeline – Oil Spill

Oil Spill – Gulf of Mexico

Oil Spill – Predictions 2011
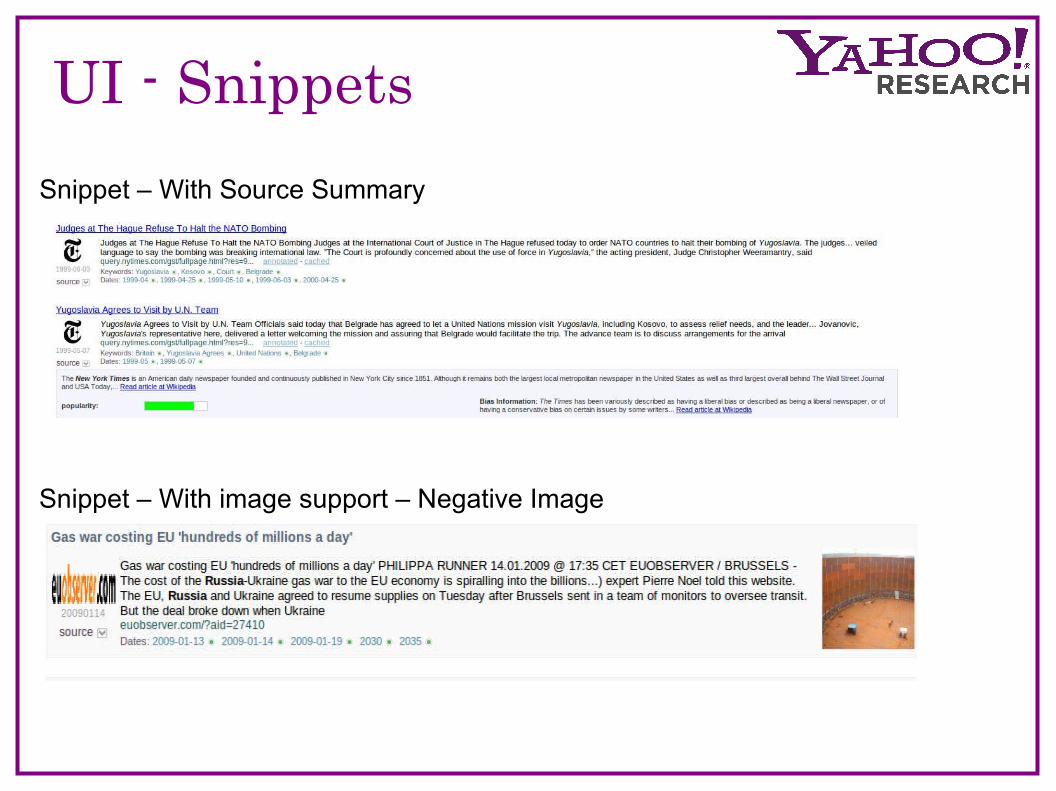
UI - Snippets
Snippet – With image support – Negative Image
Snippet – With Source Summary

Ongoing Work• Better Sentiment Detection– How has sentiment towards a particular topic changed
over time• Better Bias Detection– How does Fox News differ from NYT on presenting global
warming• Future Mentions to Future Prediction– Which opinions to trust?– How to aggregate?
• Move to web dataset– Domain shift – news to blogs– Noisy data – boilerplate, more date format, etc
• Integrating multimedia data

36
Any Questions?
Thanks for your attention
Joint work with Mike Matthews, Peter Mika, Jordi Atserias, Hugo Zaragoza and many others

References
37
•Caching Search Engine Results over Incremental Indices Roi Blanco; Edward Bortnikov; Flavio Junqueira; Ronny Lempel; Luca Telloli; Hugo Zaragoza, SIGIR'2010,
•Searching through time in the New York Times Michael Matthews; Pancho Tolchinsky; Roi Blanco; Jordi Atserias; Peter Mika; Hugo Zaragoza, HCIR 2010, 2010
•Ranking Related News Predictions Nattiya Kanhabua; Roi Blanco; Michael Matthews, SIGIR, 2011
•Searching the future. Ricardo Baeza-Yates, MF/IR workshop 2005


















