
Search on the fly: how to lighten your Big Data - Simona Russo, Auro Rolle - Codemotion Milan 2016
41
Search on the fly: how to lighten your Big Data Simona Russo Auro Rolle MILAN 25-26 NOVEMBER 2016
-
Upload
codemotion -
Category
Technology
-
view
123 -
download
0
Transcript of Search on the fly: how to lighten your Big Data - Simona Russo, Auro Rolle - Codemotion Milan 2016

Search on the fly: how to lighten your Big Data
Simona Russo Auro Rolle
MILAN 25-26 NOVEMBER 2016

Who am I?
Head of R&D FacilityLive
4yearsMajor Italian Software houses
+20years
Software products
(developed!)
4sw products
Finance
3years
Payroll
3years
Logistic
+10years
Search
4years
… so I’m
+20years old
Simona Russo ... some numbers

Who Am I ?
LINUX – WINDOWS ADMIN
SOFTWARE AUTOMATION
ENGINEER
PERFORMANCE ENGINEER
TEST AUTOMATION ENGINEER
1996
2016

AGENDA• Use cases
• Business needs• Analysis
• Architectural overview• Some components
• Ram indexes• Cache management• Push data from server to client• Optimize http data serialization
• Scale out• Stress test and performance test• Future improvements
Search on the fly: how to lighten your Big Data

Prerequisite: Lucene
Lucene is the de facto standardfor search library.
Initially developed by Doug Cutting in 1999 (also author of Hadoop in 2003), it joined Apache software foundation in 2001. See https://en.wikipedia.org/wiki/Apache_Lucene
Apache Lucene is an open source full-featured search engine library written entirely in JAVA:
• many powerful query types: phrase queries, wildcard queries, range queries• fielded searching (i.e. title, author, contents)• synonyms, stopwords options• … and more. See http://lucene.apache.org/ for further information

Use cases: Business needs
“I want constantly updated data”
“I want excellent search response time”
“I want to search all the available data I have (even from different data sources)”
“I don’t want to duplicate my data”

Use cases: Business needs
If you can’t resolve a problem
It’s because you’re playing by the rules
Paul Arden

Search Platform
Use cases: Conceptual high level layer overview
External Data Services
DB
FilesCSV, XLS, …
External Services
…
…
How to follow business
needs
Presentation Layer: search results
Data layeri.e. CustomersView
Lucene Indexes
i.e. InvoicesView
i.e. ProductsView
…

Use cases: Business needs
Data Sources
Analysis: how to integrate different data sources and search on them?
Simple! We can create one or many Lucene Indexes integrating different data sources (schema-less feature).• Joining data sources• Transforming data values• Enriching , cleansing and indexing data values
Can we use data virtualization/federation middleware from others vendors?• Yes, we can, but we have double data integrations:
1. from Data Source to Data Virtualization Middleware2. from Data Virtualization to Lucene Indexes.
Data Virtualization/Federations middleware
Data LayerLucene Indexes
It may add latency/consistency/poor flexibility and revenues issues in a search driven platform.
So we decided not to use it but instead to integrate data into Lucene Indexes directly.
“I want to search all the available data I have (even from different data sources)”

Use cases: Business needs
Analysis: How to avoid data sources duplications?
We have been indexing with Lucene only the metadata, the data that the user wants to search.
All others data (i.e. pdf, html page, …) can reside on the source system and can be accessed on demand.
So we significantly reduce data duplication
“I don’t want duplicate my data”

Use cases: Business needs
Analysis: how to get constantly updated data?
Constantly updated data must constantly call external services to retrieve updated data!
Issues:• Overload external data services
• Worst search time (before every search call service, create indexes and then search it!)
• Not feasible if I have to index ALL business data (Big Data) at search time or very small time interval

Use cases: Business needs
Analysis: how do I get constantly updated data?
We need to define the scope to verify that the business needs are
satisfied
We need to define a path

Use cases: Constraints
Consider the example of a Call Center use case where the Operator has a set of keywords to identify the caller (for example: phone number, fiscal code, customer id, …) and needs to find all the related business information.
The data is retrieved and indexed once the customer is identified and then the operator refines the search to find specific customer information related to the call.
If the operator does not interact with the system for a predefined time interval (for example 1 minute) the indexed data can be discarded and the next operator interaction will produce updated data.

Use cases: Constraints
The use-case is applicable to the single entity nature of the data (for example the customer of a call center) and the fact that the data is found using known specific key.
The technique is described as on-the-fly because the data is retrieved and indexed in realtime.
The application uses the data to enable the user to find the specific information required for the business transaction without recontacting the source systems.
“I want constantly updated data”
“I don’t want to duplicate my data”

Use cases: Business needs
Analysis: How to get excellent response time?
With the previous use case contraints we are indexing only the data correlated to the single entity searched:
• So we could create in memory Lucene Index (RAM) because we have a smaller data set. RAM Indexes have best performances than on disk indexes, but they must be evicted after a prefixed time (CACHE with eviction policy).
How to prevent one external data service from delaying the search response time?
• Push the data from single services to the Browser as soon as they are available (SSE).
“I want excellent search response time”

Architectural overview: Components
• Lucene RAM Indexes• Improve response time • Reduce data duplications
• Cache • Improve response time of refined search• Reduce data duplications (eviction policy)
• Push data when the data are available• Improve total response time

Lucene RAM Index
A memory resident implementation of Lucene Index.
WARNING! Lucene RAMDirectory implementation is not intended to work with huge indexes Everything beyond several hundred megabytes will waste resources (GC cycles), because it uses an internal buffer size of 1024 bytes, producing millions of byte[1024] arrays. This class is optimized for small memory-resident indexes. It also has bad concurrency on multithreaded environments.
Seehttps://lucene.apache.org/core/6_3_0/core/org/apache/lucene/store/RAMDirectory.html
• Limited environment in terms of data (single entity) and concurrent users

Lucene RAM Indexes
How we use RAM Indexes?
RAM index are indentified by:• UserId• Name (Logical Name of the data set), it depends on the user customization i.e.
customer, product, invoices• Context Id (alphanumeric value), a new context id is attributed to it when there
are empty results from the search.
So the first search has a new context id, the refined search has the same context id.The same search from different user leads to the creation of new indexes.

Lucene RAM Index
In a cluster environment the RAM Indexes related to a user search resides always on a dedicated node (load balancer with stickyness by user).
If this node fails the, the refined search will redirect to another node, so the RAM index will be created again.
User B
Node 1 RAM
(A) (A) (A)
Node 2 RAM
(B) (B)
LoadBalancer
User A
(A) (A)
(B)
(A)

Why Cache?Because we use RAM Indexes and we want to access Lucene Indexes when the user wants to refine the previous search.
Why not ConcurrentHashMap?Don’t reinvent the wheel! Because if we use cache we don’t have to build a lot of built-in functions among which eviction policies!
Eviction policies:Every cache needs to remove values using different criteria: by time, size, weight.
By Time (expiration), remove elements that have reached:• idle time, span of time when no operation is performed with the
given key (get/put key);• total lived time, maximum span of time an element can spend in the
cache.

Caches benchmarkJMH Microbenchmark: put/get (4 threads + 4 threads) 1000 alphanumeric key per iteration pre-inserted (plus 1000 with put operation) -i 10 -wi 2 -r 2s –f 5
Cache2k Guava EhCache Infinispan0
10000000
20000000
30000000
40000000
50000000
60000000
Put (ops/sec)Get (ops/sec)
MacBookPro Intel Core I7 CPU 2.5 GHz 4 core (2 threads per core) 16GB RAM • Cache2K 0.28-BETA• Guava version 20.0 (conc. 100)• Infinispan 8.2.4.Final (conc. 100)• EhCache 3.1.3
We tested and selected the libs in 2015 (jdk 1.7)
This benchmarks are updated with the last libs versions (jdk 1.8)
Cache2K Status“ … We use every cache2k release within production environments. However, some of the basic features are still evolving and there may be API breaking changes until we reach version 1.0.”
https://cache2k.org/
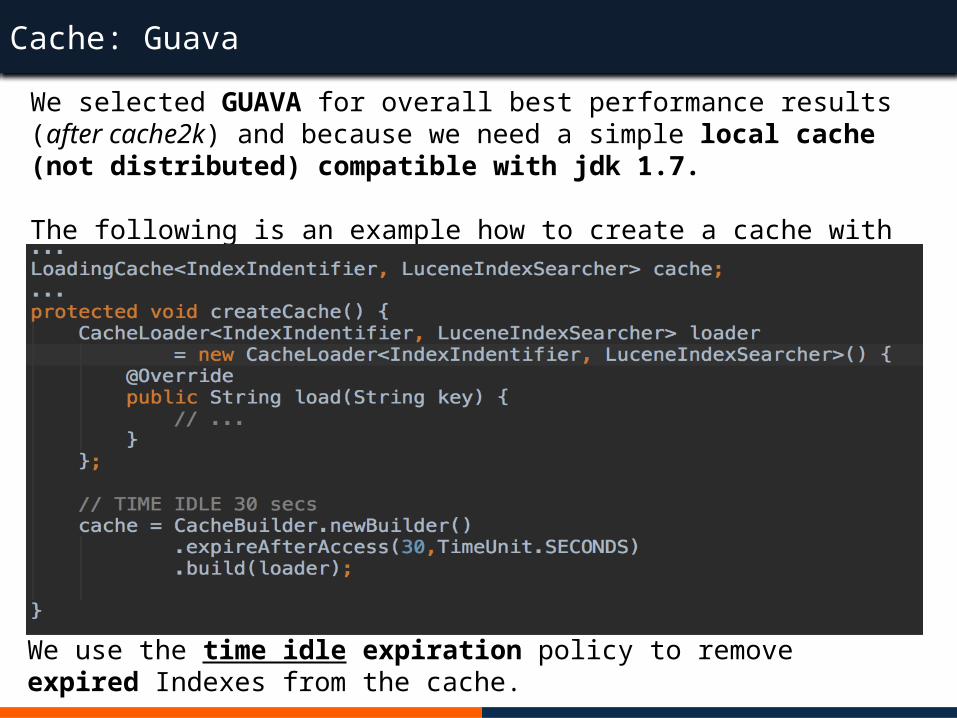
Cache: GuavaWe selected GUAVA for overall best performance results (after cache2k) and because we need a simple local cache (not distributed) compatible with jdk 1.7.
The following is an example how to create a cache with time idle expiration policy:
We use the time idle expiration policy to remove expired Indexes from the cache.

Cache: Guava
Expired elements
• Logical removedWhen an element expires, it is not automatically removed from the cacheExpired entries will never be visible to read or write operations.
Cache.size() counts also expired entries.
• Physical removed• Trying to write/access to expired entry• Calling Cache.cleanUp() (force eviction)
CleanUp is an expensive operation, so it is not automatically performed by GUAVA but the developer has to do it.

HOW to push data to browser?
Push data from server to browser

Polling
Client repeatedly sends new requests to a server. If the server has the response data it sends the response, otherwise it sends an empty response.
Push data from server to client
REQUEST
RESPONSE (with data or empty)
REQUEST
RESPONSE (with data or empty)

Long Polling
Client sends request to a server: if the server has no data it holds the connection and waits until data is available and then sends the data back to the client.
Push data from server to client
REQUEST
RESPONSE (with data)
REQUEST
RESPONSE (with data)

Server Sent EventsSimilar to long-polling, when the client sends a request to a server that waits until data is available and then sends the data back to the client as one or more events.The client processes the data without closing the connection until the server sends the last event.
Push data from server to client
REQUEST
EVENT (with data)
EVENT (with data)
EVENT (close connection)

Server Sent Events (SSE)
• The server transmits data to browser as a continuos stream with event-stream content-type, over a connection which is left open
• Transported over HTTP it can be poly-filled with javascript to backport SSE to browsers that do not support it yet.
• JAVA EE8 JSR370 (JAX RS 2.1) Proposed specification “SSE is a new technology defined as part of the HTML5 set of recommendations for a client (e.g., a browser) to automatically get updates from a server via HTTP. It is commonly employed for one-way streaming data transmissions in which a server updates a client periodically or every time an event takes place”
• Java Library to manage client/server SSE connection:• https://jersey.java.net/documentation/latest/sse.html
• WebSocket?
Push data from server to client

We use KRYO, a Java framework for fast and efficient object serialization, to reduce the size of object for the data being serialized in a http connection.We reduce http service response time up to 50%!
Optimize http data serialization
https://github.com/EsotericSoftware/kryoBenchmark:https://github.com/eishay/jvm-serializers/wiki

Search Manager
Architectural high level overview
External data
Services
…
Presentation Layer: search results
v1 v2 v3 v4 v5
4.HTTP Rest Access by Keyword(1 per service)
2. Search result “Context” Indexes
searchSearch
1. Search by “keyword”
3. No Results! Access by keywordASYNC
SSE GUAVA Cache
RAM Indexes
RAM Indexes
RAM Indexes
Service Mapper
Service Mapper
Service Mapper
Service Mapper
6. Send Response (1 per service)
5. Create RAM Indexes
Send event resp v1 Send event resp v2 Send event resp vx1. Refine Search
Kryo serializer

Scale out
Presentation Layer: search results
Search Manager
GUAVA Cache
RAM Indexes
RAM Indexes
RAM Indexes
Service Mapper
Service Mapper
Service Mapper
Service Mapper
Cluster
Load Balancer(stickiness by user)
Presentation Layer: search resultsPresentation Layer: search resultsLoad Balancer
(stickiness by user)
Search Layer
Cluster
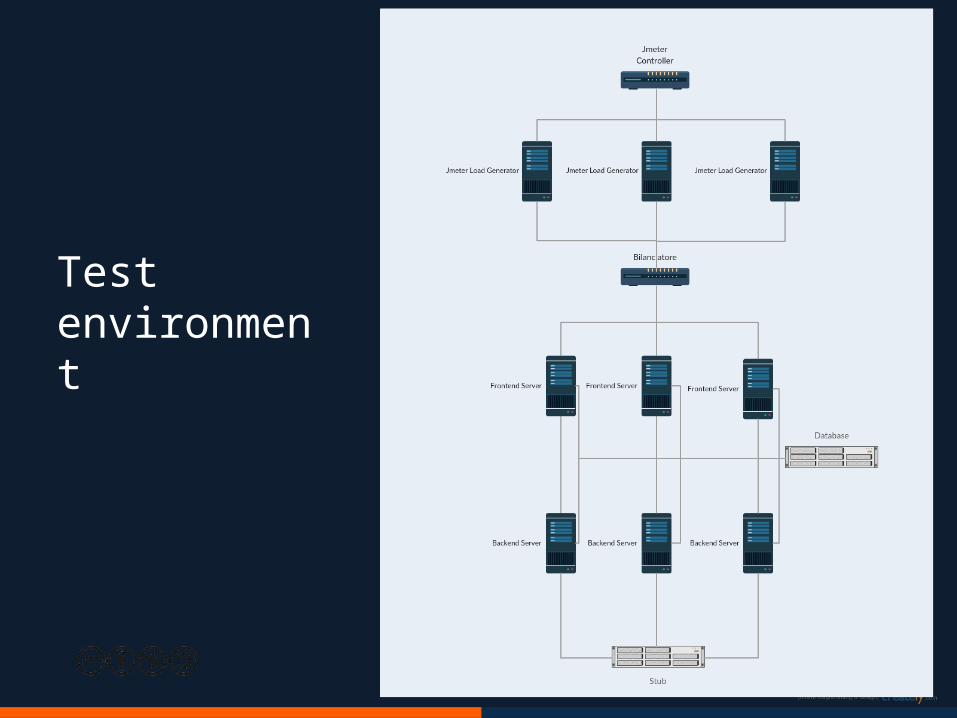
Test environment

Complete system test with 600 Vuser
27 [Tr/s]
9 [Tr/s] / 200 Vuser per chain FE-BE

32 GB RAM – 8 Core – Heap 20 GB
Phase 1Incremental tests to find the max transaction frequency• 400 Vuser• 800 Vuser
Phase 2Environment minimization and direct load on the search engine

Phase 1Test 400 Vuser
18 [Tr/s] – Linear gain

Phase 1Test 800 Vuser
24 [Tr/s] – Sub linear gain – Max found

Phase 2
Direct load injection on a single BE via API
Search and indexing transactions with the same document weight used in phase 1:
19 binary Add document on 19 Lucene indexes. Average size 20k per Add 1 Search with 24 results

Phase 2Test 200 Vuser13 [Tr/s] Clean UP 70s

Phase 2Test 200 Vuser43 [Tr/s] Clean UP 15s
Samples Average response time [ms] Errors % Transactions per second
TOTAL 1107087 66 0.00% 860.0

Future improvements
• We are migrating to a microservices architecture:• For example: Service Mapper and Searcher Manager are
easily converting to Microservices and scale out independently
• We are testing the benefits/drawback to migrate to HTTP2 • Header compression• Server push• Binary protocols

Search on the fly: how to lighten your Big Data
Simona Russo & Auro Rolle
MILAN 25-26 NOVEMBER 2016
Thank you for coming
It always seems impossible
until is doneNelson Mandela


















