Scott Sirowy Department of Computer Science and Engineering University of California, Riverside This...
41
Scott Sirowy Department of Computer Science and Engineering University of California, Riverside This work was supported in part by the National Science Foundation and the Office of Naval Research Emulation of SystemC Applications for Portable FPGA Binaries Advisor: Frank Vahid
-
Upload
johnathan-stevenson -
Category
Documents
-
view
215 -
download
0
Transcript of Scott Sirowy Department of Computer Science and Engineering University of California, Riverside This...

Scott Sirowy
Department of Computer Science and Engineering
University of California, RiversideThis work was supported in part by the National
Science Foundation and the Office of Naval Research
Emulation of SystemC Applications for Portable FPGA
Binaries
Advisor: Frank Vahid

2/37
FPGAs – Potential for tremendous speedups
0
10
20
30
40
50
60
Prewitt FIR
Wav
elet
Max
Blend
Antial
ias
Bright
en
Rober
ts
Sobel
Embo
ss
Sharp
en Blur
Gauss
ian
Burt-A
delso
n
Med
ian
Kuwah
ara
Avera
ge
Speedup
0
5
10
15
20
25
30
Placem
ent
Vehicl
e ro
utin
g
Cluste
ring
Genet
ic pr
ogra
mm
ing
Sortin
g
Fourie
r tra
nsfo
rm
Prote
in m
otif d
etec
tion
FPT
Seism
ic m
igrat
ion
Simula
ted
anne
aling
Avera
ge
Speedup
Intl Symp. on FPGAs, FCCM, FPL, CODES/ISSS, ICS, MICRO, CASES, DAC, DATE, ICCAD, RAW, …
Why? FPGAs implement circuits
for i in 0 to 9 loop a = a + c[i]*M[i]end loop;
M0 M1 M9
…
c0 c1 c9
a
***
+ +
+
10s to 100s of cycles
1-5 cycles
uP Implementation
FPGA Implementation500 200

3/37
FPGAs – Potential for tremendous speedups
0
10
20
30
40
50
60
Prewitt FIR
Wav
elet
Max
Blend
Antial
ias
Bright
en
Rober
ts
Sobel
Embo
ss
Sharp
en Blur
Gauss
ian
Burt-A
delso
n
Med
ian
Kuwah
ara
Avera
ge
Speedup
Xilinx Virtex II Pro. Source: Xilinx
SGI Altix supercomputer (UCR: 64 Itaniums plus 2 FPGA RASCs)
0
5
10
15
20
25
30
Placem
ent
Vehicl
e ro
utin
g
Cluste
ring
Genet
ic pr
ogra
mm
ing
Sortin
g
Fourie
r tra
nsfo
rm
Prote
in m
otif d
etec
tion
FPT
Seism
ic m
igrat
ion
Simula
ted
anne
aling
Avera
ge
Speedup
Intl Symp. on FPGAs, FCCM, FPL, CODES/ISSS, ICS, MICRO, CASES, DAC, DATE, ICCAD, RAW, …
FPGAs beginning to enter mainstream
AMD Opteron, Intel QuickAssist, Cray, SGI, IBM Cell, etc.

4/37
Problem #1: Highly specialized design process
“Standard” Microprocessor Design Flow
#include <stdio.h>int main(){…}
FPGA Design Flow
Compiler
Linker
Loader
FPGA
+** +
MEM
Entity circuit isPort( …. );
Proc.
Synthesis
Translation
Mapping
Place and Route
Capture in C, C++, Java, etc.
Capture in a hardware description
language
Pentium
C-based Synthesis Tools

5/37
Problem #2: FPGA binaries are not portable
#include <stdio.h>int main(){…}
FPGA
+** +
MEMOpteron Dual Core
Entity circuit isPort( …. );
Proc.
Pentium
x86 Binary
FPGA
+ +Proc.
FPGA
Proc.
Proc.FPGA
Entity circuitA isPort( …. );
Entity circuitB isPort( …. );
Entity circuitC isPort( …. );
FPGA Bitstream
1
FPGA Bitstream
2
FPGA Bitstream
3
Either can run “as-is”, or is dynamically translated
(Transmeta)
Such a binary is portable

6/37
Goal: Portable Circuit Distribution Format
FPGA
+** +
MEM
Entity circuit isPort( …. );
Proc.
Pentium
FPGA
+ +Proc.
FPGA
Proc.
Proc.FPGA
Entity circuitA isPort( …. );
Entity circuitB isPort( …. );
Entity circuitC isPort( …. );
FPGA Bitstream
1
FPGA Bitstream
2
FPGA Bitstream
3
With FPGAs increasing presence, portable format desirable, and needed
Current distribution methods Bitstreams
Tightly coupled to specific devices
RTL Requires resynthesis/remapping May not use FPGA resources most effectively
Higher Abstraction? C code (or any sequential language)?
Can yield more effective resource usage Could even run on platforms with no FPGA But also requires resynthesis/mapping
XXX
XXX
X
?

7/37
~~~~~~~~~
~~~~~~~~~
Problem: Many FPGA Applications Captured “Spatially” as Circuits, not C
Designer captures spatial algorithm as custom circuit for max performance
N unsorted
Split
1 sorted 1 sorted
SplitMerge
MergeSplit
2 sorted2 sorted
4 sorted 4 sorted
…
~~~~~~~~~
~~~~~~~~~
…
Circuits in FCCM Year
3D Vector Normalization 2001Regular Expression 2001RC4 2002Gaussian Noise Gen. 2003Molecular Dynamics 2004Particle Graphics 2005
Shortest Path 2006
~~~~~~~~~
~~~~~~~~~
~~~~~~~~~
~~~~~~~~~
~~~~~~~~~
~~~~~~~~~
~~~~~~~~~
~~~~~~~~~
~~~~~~~~~
~~~~~~~~~
~~~~~~~~~
~~~~~~~~~
~~~~~~~~~
~~~~~~~~~
~~~~~~~~~
~~~~~~~~~
~~~~~~~~~
~~~~~~~~~
~~~~~~~~~
~~~~~~~~~
~~~~~~~~~
~~~~~~~~~
~~~~~~~~~
~~~~~~~~~
~~~~~~~~~
~~~~~~~~~
~~~~~~~~~
~~~~~~~~~~~~
~~~~~~
~~~~~~~~~
70 custom circuits in FCCM’01-’06 alone

8/37
Queue 1_1, 1_2, 2_1, 2_2, 4_s, 4_us;Split(16_u.dequeue, 16_u.dequeue, 1_1, 1_2);stage1 = Merge(1_1.dequeue, 1_2.dequeue);Split(16_u.dequeue, 16_u.dequeue);stage1 += Merge(1_1.dequeue, 1_2.dequeue);Split(stage1, 2_1, 2_2);stage2 = Merge(2_1, 2_2);Split(16_u.dequeue, 16_u.dequeue);stage1 = Merge(1_1.dequeue, 1_2.dequeue);Split(16_u.dequeue, 16_u.dequeue);stage1 += Merge(1_1.dequeue, 1_2.dequeue);Split(stage1);stage2 += Merge(2_1, 2_2);Split(stage2, 4_1, 4_2);…
Capturing Circuit Level Designs in
N unsorted
Split
1 sorted 1 sorted
SplitMerge
MergeSplit
2 sorted2 sorted
4 sorted 4 sorted
…
Can designers’ circuits be reverse-engineered to some form of C code?
From which original circuit will be synthesized by “standard” synthesis tools
Synthesis
Designer captures spatial algorithm as custom circuit for max performance

9/37
Is C really for Circuits? Year ApplicationType2001 3D Vec. Normalization Spatial2001 Efficient CAM --2001 Automated Sensor Temporal2001 Regular Expression Spatial2002 Hyperspectral Image Spatial2002 Machine VisionSpatial2002 RC4 Temporal2002 Set Covering Spatial2002 Template Matching Spatial2002 Triangle Mesh Spatial2003 Congruential Sieves Temporal2003 Content Scanning Temporal2003 F.P and Square Root Spatial2003 Gaussian NoiseSpatial2003 TRNG --2004 3D FDTD Method Spatial2004 Deep Packet Filter --2004 Online Floating Point --2004 Molecular Dynamics Spatial2004 Pattern Matching Spatial2004 Seismic Migration Spatial2004 Software Deceleration --2004 V.M Window --2005 Data Mining Spatial2005 Cell Automata Temporal2005 Particle Graphics Spatial2005 Radiosity Temporal2005 Transient Waves Spatial2005 Road Traffic Temporal2006 All Pairs Shortest Path Spatial2006 Apriori Data Mining Spatial2006 Molecular Dynamics Spatial2006 Gaussian Elimination Spatial2006 Radiation DoseTemporal2006 Random Variates Spatial
FCCM 2001-2006 70 papers describing fast
application on FPGA Examined 35 in depth (every
other one) 6 used device-specific
features 9 represented expected
synthesized circuit from the obvious sequential algorithm
20 were spatially-oriented applications
e.g like the earlier Merge Sort

10/37
Portable Spatial Applications? Current portable microprocessor binaries –
sequential Extensions for threads, processes, ...
Must support spatial constructs Ports, connections, timing model
www.systemc.org
Adds libraries and macros, still standard C++
Sequential and spatial constructs Compiling links in the simulation kernel
Self-executing simulation Intended for SoC simulation
11/37
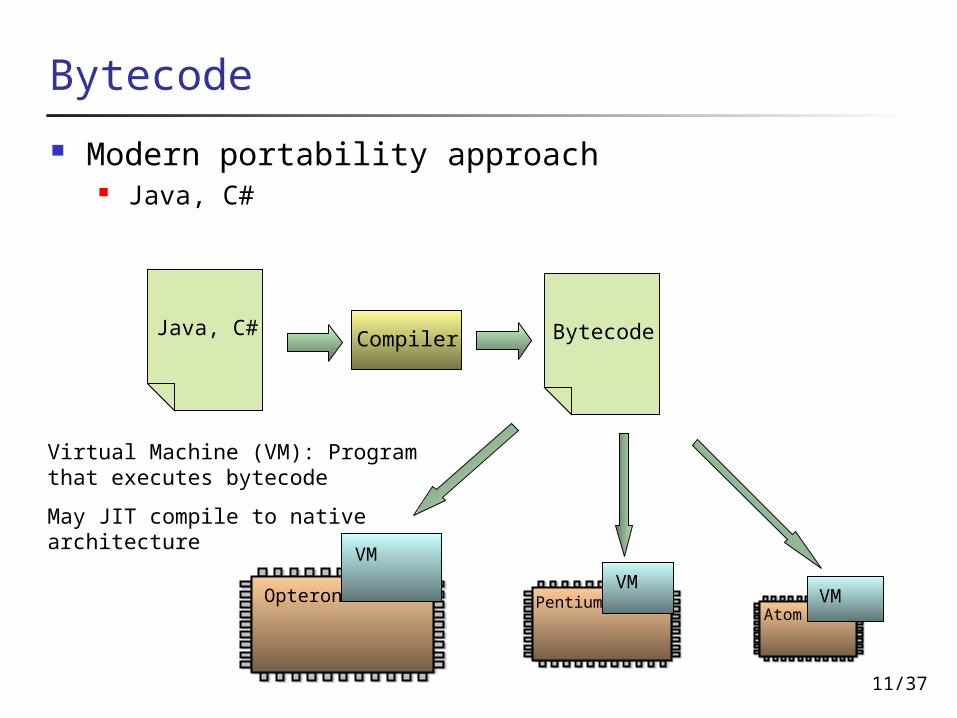
Bytecode
Modern portability approach Java, C#
Virtual Machine (VM): Program that executes bytecode
May JIT compile to native architecture
PentiumOpteronAtom
Compiler
VM
VMVM
BytecodeJava, C#

12/37
SystemC Bytecode?
Pentium FPGA
Compiler
VM VM
BytecodeSystemCSystemC
Opteron + FPGA
VM

13/37
Portable SystemC-on-a-Chip
SystemC Bytecode Compiler
SystemC Bytecode
SystemC Description
Processor
FPGA
Processor Processor
Processor
Emulation
Engine
Emulation
AcceleratorsSystemC bytecode can run on any platform that supports the SystemC emulation engine, without the need for recompilation or synthesis
Task: Create a custom circuit to detect edges in an image
Emulation Engine
Emulation Engine

14/37
SystemC Bytecode Compilerclass EDGE_DETECTOR : public sc_module {//signal declarations…EDGE_DETECTOR() { SC_method(mainComp); sensitive << dataReady;
SC_method(getPixel); sensitive << clock.pos();
}
SystemC Description
SystemC Bytecode
Pinapa Front End (Moy, EMSOFT’05)
Extracts architectural features and behavior of each process
Uses modified versions of GCC and the SystemC kernel
Bytecode Back End Flattens original SystemC circuit Generates SystemC bytecode that
preserves architecture and behavioral information
Output is a human-readable text file
Pinapa Front End
ELAB
ASTLink
Bytecode Back End
RegisterAllocation
Code Generation
SystemC Bytecode Compiler

15/37
SystemC Bytecode
Sequential Instructions Based on the RISC MIPS
instruction set Efficient emulation (Davis
2003) Spatial Instructions
Includes meta instructions for defining architectural features, bit width specific computations, and reading and writing signals
--headersignal clock : 1signal reset : 1signal memory_in : 32signal fb_data : 32signal leds : 4
process(clock)READ $1 memory_inADD $2 $0 3ADD $3 $2 $1WRITE $3 s1ADDI $1 $0 1WRITE $1 dataReadyEND
process(dataReady)READ $5 val6 SW $5 24($0) READ $5 val7 …ADDI $10 $0 0 ADDI $7 $0 0ADDI $13 $0 8 …END
SystemC Bytecode
MIPS-like sequential instructions
Spatial Constructs

16/37
SystemC Emulation Engine
USB Download Interface
Emulation Engine
Input Memory
Output Memory
UART
Buttons
LEDs
Read Signal Memory
Write Signal Memory
Instruction Memory
I/O Peripherals Emulation EngineKernel and Support Peripherals
USB Interface
Real I/O Peripherals Representative of many
systems Emulation Engine
Kernel Virtual Machine Discrete Event Kernel Peripheral Access and
Hooks Optional USB Download
Interface
Main Processor

17/37
SystemC-on-a-Chip Implementation
Xilinx Spartan 3E
Virtex4 Ml403 Virtex5 VLX110T
Main Processor
Bus Platform
Main Memory
Platform
Microblaze (50 MHz)
PowerPC(50 MHz)
Microblaze(100 MHz)
OPB
PLB PLB
BRAM SRAM SRAM+BRAM
Fully implemented 3 SystemC-on-a-Chip Prototypes*Demo

18/37
Limits to SystemC Emulation
Emulation Engine
Input Memory
Output Memory
UART
Buttons
LEDs
Read Signal Memory
Write Signal Memory
Instruction Memory
Ok for some settings Education Early Prototyping
Can be slow Orders of magnitude
slower than SystemC simulation
Slow Processor Speed Virtual Machine Execution Maintenance of
correctness of spatial application on sequential platform
Main Processor
SystemC Description

19/37
SystemC Emulation Performance
Emulation Engine
Input Memory
Output Memory
UART
Buttons
LEDs
Read Signal Memory
Write Signal Memory
Instruction Memory
Main Processor
SystemC Description
73%
15%
5%7%
Virtual Machine Execution
Signal Queue Maintenance
Event Queue Maintenance
Read and Write Signal Updates
10s to 100s of cycles to interpret one SystemC bytecode instruction

20/37
Just-in-Time Compilation on Soft-Core Architecture
Emulation Engine
Input Memory
Output Memory
UART
Buttons
LEDs
Read Signal Memory
Write Signal Memory
Instruction Memory
Main Processor
SystemC Description Just-in-Time Compilation
Straightforward translation of SystemC bytecode instructions to native processor instructions
Fast, one-time process performed when SystemC circuit is loaded
Softcore architecture lends well to “JIT Aware” architectural optimizations
73%
15%
5%7%
Emulation Execution Time

21/37
Just-in-Time Compilation on Soft-Core Architecture
Emulation Engine
Input Memory
Output Memory
UART
Buttons
LEDs
Read Signal Memory
Write Signal Memory
Instruction Memory
Main Processor
Soft-core Xilinx Microblaze or Altera Nios
JITMemory
73%
15%
5%7%
Compared to emulation instruction memory, JIT memory is built using small and fast single cycle access on-chip block memories
Emulation Execution Time

22/37
Just-in-Time Compilation on Soft-Core Architecture
Emulation Engine
Input Memory
Output Memory
UART
Buttons
LEDs
Read Signal Memory
Write Signal Memory
Instruction Memory
Main Processor
JITMemory
73%
15%
5%7%
27% of execution still on parallel maintenance Emulation Execution Time
Signal
Queu
e
Emulation Memory
Controller
Single cycle access signal queue
Can maintain signal queue much more efficiently than base emulator
Emulation controller can hide latency cost of maintaining signal memories under signal queue maintenance
JIT Aware Resources

23/37
Just-in-Time Compilation with JIT Aware Resources
0
10
20
30
40
50
60
70
80
90
EdgeDetection
Digital Timer MatrixMultiply
ElectronicLock
A5/1 Cipher Sequencer Average
No JIT Aware Resources With JIT Aware Resources Native Software
JIT Compilation with JIT Aware Resources achieves up to 10X performance compared to base SystemC emulation, and about 5X on average
Within 4X of Native SW Execution
Computationally expensive examples achieved orders of magnitude speedup
Execu
tion T
ime
(norm
aliz
ed t
o m
icro
pro
cess
or-
only
so
luti
on)

24/37
Limits of JIT Compilation
Emulation Engine
Input Memory
Output Memory
UART
Buttons
LEDs
Read Signal Memory
Write Signal Memory
Instruction Memory
Main ProcessorMemory Controller
s1 s2 s3 s4 s6 s7 s8 s9
go
--
MIN
+
255
dataaddress
Edge Detector
+ + + + +
+
+
+ + +
+
+
Execution Time
Base Emulation
JIT Compiled Emulation
…
…
JIT Compilation is faster, but still executes spatial circuit sequentially, and is not reminiscent of actual circuit behavior

25/37
Limits of JIT Compilation
Emulation Engine
Input Memory
Output Memory
UART
Buttons
LEDs
Read Signal Memory
Write Signal Memory
Instruction Memory
Main ProcessorMemory Controller
s1 s2 s3 s4 s6 s7 s8 s9
go
--
MIN
+
255
dataaddress
Edge Detector
+ + + + +
+
+
+ + +
+
+
Execution Time
Base Emulation
JIT Compiled Emulation
Parallel Emulation
…
…
More reflective of actual circuit behavior
Potentially faster too

26/37
SystemC bytecode
Spatial Emulation Engine Acceleration
Input Memory
Output Memory
UART
Buttons
LEDs
Read Signal Memory
Write Signal Memory
Main Processor
Instruction Memory
USB Interface
Accelerator 1
Accelerator 2
Accelerator 3FPGA
Accelerators can potentially speedup emulation by orders of magnitude
If available, use platform FPGA to create bytecode accelerators
Execute SystemC bytecode natively
Emulation Engine
Multiple accelerators can co-exist, enabling spatial emulation

27/37
SystemC bytecode
SystemC Bytecode Accelerators
UART
Buttons
LEDs
Read Signal Memory
Write Signal Memory
USB Interface
Accelerator 1
Accelerator 2
Accelerator 3FPGA
MIPS-like multicycle RISC datapath
Communicates to core emulator via memory-mapped registers
# of accelerators limited to # of masters allowed on bus
Accelerator
RISC Datapath
Register File
Local Mem
Bus, start,load logic
Emulation Engine
Main Processor
Input Memory
Output Memory Instruction
Memory

28/37
How to best utilize finite number of accelerators?
UART
Buttons
LEDs
USB Interface
Accelerator 1
Accelerator 2
Accelerator 3FPGA
Emulation Engine
Process Queue
Edge Blur EdgeEdgeBlur …
Image Processing System
? Emulate on
microprocessor, or accelerate using on a bytecode accelerator?
Available Accelerators Accelerator Loading
OverheadTota
l Execu
tion T
ime
Dynamically Manage Accelerators
Accelerate Every Process
Emulate every process on microprocessor
Communication and Loading Overhead
Main Processor
Read Signal Memory
Write Signal Memory
Instruction Memory
Input Memory
Output Memory

29/37
How to best utilize finite number of accelerators?
UART
Buttons
LEDs
USB Interface
Accelerator 1
Accelerator 2
Accelerator 3FPGA
Emulation Engine
Process Queue
Blur EdgeEdgeBlur …
Image Processing System
? Edge
Main Processor
Read Signal Memory
Write Signal Memory
Instruction Memory
Input Memory
Output Memory
Emulation platforms have dynamically changing inputs
Compared to simulation platforms
Prevents a static analysis of system to improve performance

30/37
Emulation Engine Acceleration Management
UART
Buttons
LEDs
USB Interface
Accelerator 1
Accelerator 2
Accelerator 3FPGA
Emulation Engine
Process Queue
Blur EdgeEdgeBlur …
Image Processing System
?Online Decision
Accelerate
Edge
Main Processor
Read Signal Memory
Write Signal Memory
Instruction Memory
Input Memory
Output Memory
Process # of uses
Edge
Emboss
Mean
Blur
Radial
History Table
8
4
3
5
2
Yes
No
No
Yes
No
Currently on Accelerator
(decision based only on past and current inputs)
Online algorithm also considers accelerator loading time, and communication overhead
Algorithm collectively known as Aggregate Gain (AG), first developed by Huang [DAC 2009]

31/37
Bypassing the Emulation Kernel
Core Acceleration Engine
Bus, Start, Load Logic
RISC Datapath
Register File
Local Memory
Core Acceleration Engine
Bus, Start, Load Logic
RISC Datapath
Register File
Local Memory
System Bus
Acceleration Engine Acceleration Engine
Kernel Bypass Configuration Kernel Bypass Configuration
The direct connections between the core acceleration engine and the adjacent signal cache
allow the two acceleration engines to communicate without using a shared bus memory
Signals to the main datapath to communicate with the signal cache and not the system bus when
configured properlyFor a limited number of signals, allows single-cycle
reading and writing of signals
Signal CacheSignal Cache

32/37
Experiments and Results
(a) Virtex 4 Ml403: 1 Accelerator
Microprocessor-Only Greedy Infinite Accelerators
Statically Preloaded
AG
0
500
1000
1500
2000
2500
3000
(b) Virtex 5 vlx110t: 3 Accelerators
Greedy slower than microprocessor-only emulation because of high reconfiguration cost
AG performs 9X better than microprocessor-only emulation
Static preloading gives 1.5X improvement
Execu
tion T
ime (
ms)

33/37
Kernel Bypass- Experiments and Results
Without Kernel Bypass
Heavy one-way communication results in larger kernel bypass speedups
0
2
4
6
8
10
12
14
16
Sobel Blur Sharpen Sobel2 Lung Radiosity
With Kernel Bypass
Kernel Bypass improves Online Emulation by 11-12% on average
Execu
tion T
ime (
ms)
Base platform is running AG Heuristic with 3 accelerators

34/37
Publications C is for Circuits: Capturing FPGA Circuits as
Sequential Code for Portability. Scott Sirowy, Greg Stitt, and Frank Vahid. FPGA 2008
Portable SystemC-on-a-Chip. Scott Sirowy, Bailey Miller, and Frank Vahid. CODES-ISSS 2009
Dynamic Acceleration Management for SystemC Emulation. Scott Sirowy, Chen Huang, and Frank Vahid. APRES 2009
Online SystemC Emulation Acceleration. Scott Sirowy, Chen Huang, and Frank Vahid. DAC 2010.
You’re Just-in-Time SystemC! Scott Sirowy, Andrew Becker, and Frank Vahid. CODES-ISSS 2010. In Review.

35/37
Main Contributions
Demonstrated the feasibility of a portable and spatial distribution format for FPGA binaries Based on the concept of SystemC bytecode Can run both on an FPGA and a standard
microprocessor, increasing portability Developed a fully working framework that
executes portable FPGA binaries Can run FPGA binaries without resynthesis or
remapping Performs several dynamic optimizations that take
advantage of available FPGA resources

36/37
Other Contributions – Just-in-Time Synthesis
Emulator
Input Memory
Output Memory
UART
Buttons
LEDs
Read Signal Memory
Write Signal Memory
Main Processor
Instruction Memory
Accelerator 1
Accelerator 2
Accelerator 3FPGA
SystemC bytecode
Send SystemC bytecode to synthesis server
FPGA Specific Bitstream
Dynamically reconfiguresome or all of the FPGA
1
10
100
1000
10000
100000Ju
st-in
-Tim
eC
ompi
latio
n
Onl
ine
Acc
eler
atio
n
PC
Sim
ulat
ion
Just
-in-T
ime
Syn
thes
is
Sp
eed
up
30X faster than PC Simulation

37/37
Other Contributions…
Controlling Time using SystemC for Digital Mockup Execution
SystemC-on-a-Chip in the Classroom
Traditional Instruction Granularity Debugging BNE $1 $2 5ADDI $4 $0 83ADDI $1 $0 1J 44ADDI $2 $0 1BNE $1 $2 5ADDI $4 $0 99ADDI $1 $0 2J 44
BNE $1 $2 5ADDI $4 $0 83ADDI $1 $0 1J 44ADDI $2 $0 1BNE $1 $2 5ADDI $4 $0 99ADDI $1 $0 2J 44
Set Break Step Step Step
Set Break
Start
No explicit concept of time, and not immediately useful for digital mockup execution
Time Granularity Debugging
Time
Step Set Break
Step Step
Lung Pressure
Lung Volume
Lung Flow
…
Explicit concept of time, and useful for discovering subtle changes and relationships in digital mockup system variables
2ms
4ms
6ms
8ms
Network

38/37
Further Performance Improvements: Bypassing the Emulation Kernel
Accelerator 1
Accelerator 2
Accelerator 3
FPGA
…Accelerator n
UART
Buttons
LEDs
USB Interface
Emulation Engine
Main Processor
Read Signal Memory
Write Signal Memory
Instruction Memory
Input Memory
Output Memory
p1
p2
Sample Application
p3
p6
p4 p5
p2
p1

39/37
Accelerator 1
Accelerator 2
Accelerator 3
FPGA
…Accelerator n
UART
Buttons
LEDs
USB Interface
Emulation Engine
Main Processor
Read Signal Memory
Write Signal Memory
Instruction Memory
Input Memory
Output Memory
p1
p2
p3
p6
p4 p5
p2
p1
Further Performance Improvements: Bypassing the Emulation Kernel
Sample Application

40/37
Accelerator 1
Accelerator 2
Accelerator 3
FPGA
…Accelerator n
UART
Buttons
LEDs
USB Interface
Emulation Engine
Main Processor
Read Signal Memory
Write Signal Memory
Instruction Memory
Input Memory
Output Memory
p1
p2
p3
p6
p4 p5
p2
p1
Further Performance Improvements: Bypassing the Emulation Kernel
Sample Application

41/37
Accelerator 1
Accelerator 2
Accelerator 3
FPGA
…Accelerator n
UART
Buttons
LEDs
USB Interface
Emulation Engine
Main Processor
Read Signal Memory
Write Signal Memory
Instruction Memory
Input Memory
Output Memory
p1
p2
p3
p6
p4 p5
p2
p1
3 costly bus accesses for just one signal! The effect is exacerbated with more
complex examples
Further Performance Improvements: Bypassing the Emulation Kernel
Sample Application