
Harnessing the Power of HTML5 Web Sockets to Create Scalable Real-Time Applications Presentation
Upload
trinhquynhCategory
view
221download
2
Scalable Information Management – Key to Scalable SOA
Qiming ChenHP Labs12/2006
2
HP Labs Worldwide
Bristol
JapanIsrael
Palo Alto
India
China

3
Scalable Information Management Research in
HP Labs China
• Directions– Parallel database system technology– Scalable information management solution

4
Why SOA ? – The Mass
ScreenScrape
ScreenScrape
ScreenScrape
ScreenScrape
MessageQueue
MessageQueue
MessageQueue
DownloadFile
DownloadFile
DownloadFile
TransactionFile
TransactionFile
TransactionFile
ORB
ORB
CICS Gateway
CICS Gateway
APPC
APPCRPC
RPC
TransactionFile
Sockets
Sockets
Message
Message
Application
Application
Application
Application
Application
Application
Application
Application
Application
Application
5
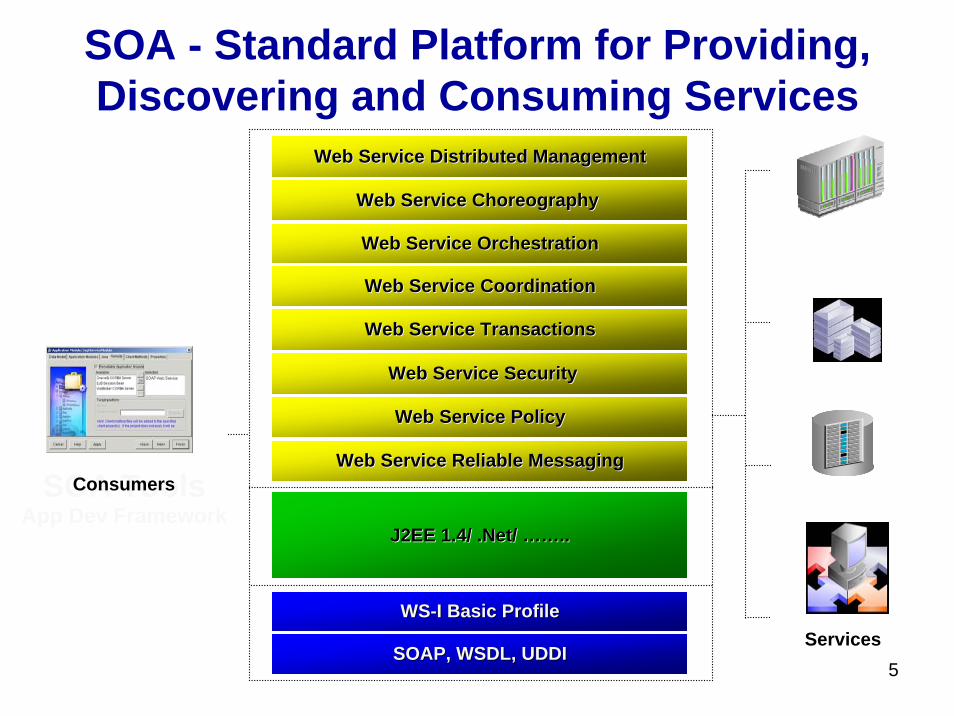
SOA - Standard Platform for Providing, Discovering and Consuming Services
SOA ToolsApp Dev Framework
SOAP, WSDL, UDDISOAP, WSDL, UDDI
WSWS--I Basic ProfileI Basic Profile
Web Service PolicyWeb Service Policy
Web Service TransactionsWeb Service Transactions
Web Service Reliable MessagingWeb Service Reliable Messaging
J2EE 1.4/ .Net/ J2EE 1.4/ .Net/ …………....
Web Service SecurityWeb Service Security
Web Service OrchestrationWeb Service Orchestration
Web Service Distributed ManagementWeb Service Distributed Management
Web Service CoordinationWeb Service Coordination
Web Service Choreography Web Service Choreography
Services
Consumers

6
• Modularize application functions and present them as services
• Provide IT architecture for synchronous and asynchronous service invocation
• Make services loosely coupled– Service interface is independent of
implementation – flexibility of change• In some sense, SOA is a wrapper
SOA also Addresses …

7
Integrated Functionality:Automation,
SOA,Security,
Info MgmtEvolution of Mgm
t Capabilities
BSMBusiness Service Mgmt
ITSMIT Service Mgmt
Performance/Availability
Performance/Availability
Both Element + Cross-Systems Management
Manageability of Infrastructure ElementsServers Data Other Elements
Configuration/Change Mgmt/Provisioning
Systems
Applications
Services
Networks
Systems Other Elements
Applications
Networks
Monitoring/Metering/Capacity MgmtInfrastructure
Overla
ppin
g Mgm
t Dom
ains
Behind SOA …is Service Management

8
Scalable Data Management – Key to SOAOtherwise …
ScreenScrape
ScreenScrape
ScreenScrape
ScreenScrape
MessageQueue
MessageQueue
MessageQueue
DownloadFile
DownloadFile
DownloadFile
TransactionFile
TransactionFile
TransactionFile
ORB
ORB
CICS Gateway
CICS Gateway
APPC
APPCRPC
RPC
TransactionFile
Sockets
Sockets
Message
Message
Application
Application
Application
Application
Application
Application
Application
Application
Application
Application
Service ConsumersService Consumers
Service Interface
Service Implementation

9
Examples• Data integration / consolidation• Scale data warehouse to infinity• Generate and maintain information from
collected data– Hydroinformatic system– Mash-up

10
Example 1Pain Point of Telco – Computation Everywhere,
Data Everywhere
Product Management
CRM
Order Process Management
Billing
System
Information Collection Platform
Service Provision & Activation
Resources &
Worksheet management
System M
anagement
Statistic Report
Integrated Access
Customer Interface
Sales Interface
System management Interface
Business Management Interface
Partner Interface
External Interface
Interface Portal
Data Data Data
Data Data Data Data
Difficulty in sync, sharing, complex query over distributed data sources, service extension

11
Convergent BSS need Centrally Shared Data
-- Ease sync, sharing, service extension-- Sharing consolidation throughput - reliability
Product Management
Customer Information
Order Process Management
Billing
System
Information Collection Platform
Service Provision & Activation
Resources &
Worksheet management
System M
anagement
Statistic Report
Integrated Access
Data Store
LocalData
LocalData
LocalData
LocalData
LocalData
LocalData
Local Data
EAI/BMP
Customer Interface
Sales Interface
System management
Interface
Business Management
Interface
Partner Interface
External Interface
Interface Portal

12
Data Consolidation – Challenge to Scalability
Integrated BillIntegrated Bill
Hot Billing Integrated Accounting
BillGeneration
OnlineCollection
PHSFix-line
Broadband
Area A
3G
PHSFix-line
Broadband
Area B
3G
PHSFix-line
Broadband
Area B
3G
OnlineCollection
OnlineCollection
SCP
Online Charging
GGSN/CCGISMP
CRM
Billing domain
OLTP ODS EDW80M users 10ms respmultiple reqper call
13
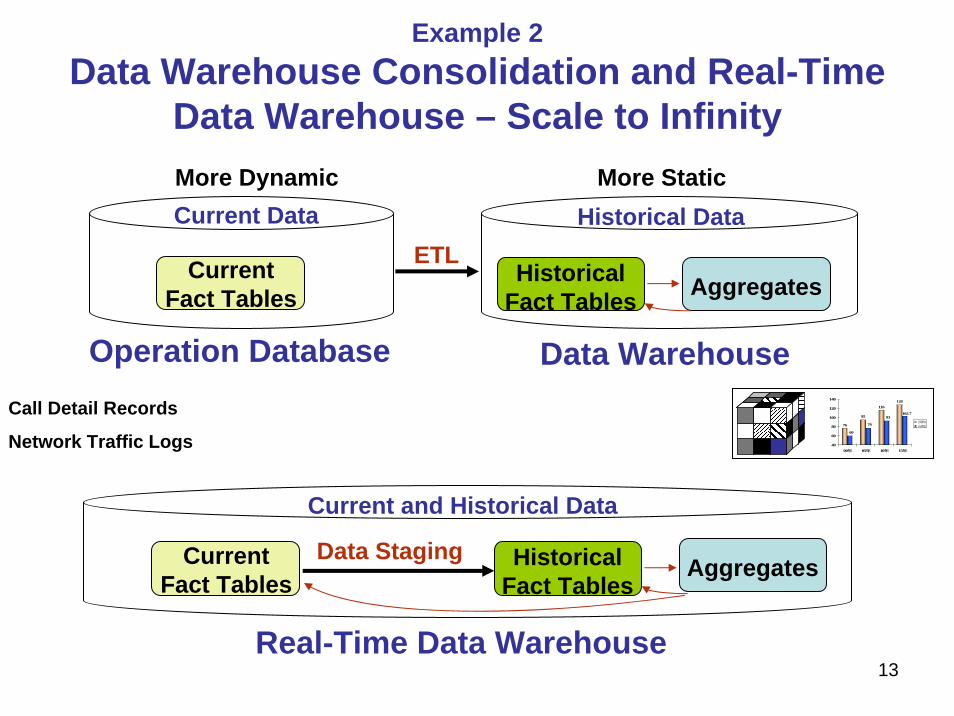
Example 2Data Warehouse Consolidation and Real-Time
Data Warehouse – Scale to Infinity
Operation Database
Historical DataCurrent Data
Data Warehouse
More Static
AggregatesCurrent Fact Tables
Historical Fact Tables
More Dynamic
AggregatesHistorical Fact Tables
Current Fact Tables
Current and Historical Data
Real-Time Data Warehouse
ETL
76
95
116128
60
76
93102.7
40
60
80
100
120
140
00年 05年 10年 15年
预测1
预测2
Data Staging
Call Detail Records
Network Traffic Logs

14
Rainfall & Snow
Example 3
Large Scale Multi-modal Hydro Information Management
Map
Remote sensing
Meteorology
Soil water
Precipitation
Evaporation
Hydrography
Hydrology
Services
Info Pipe
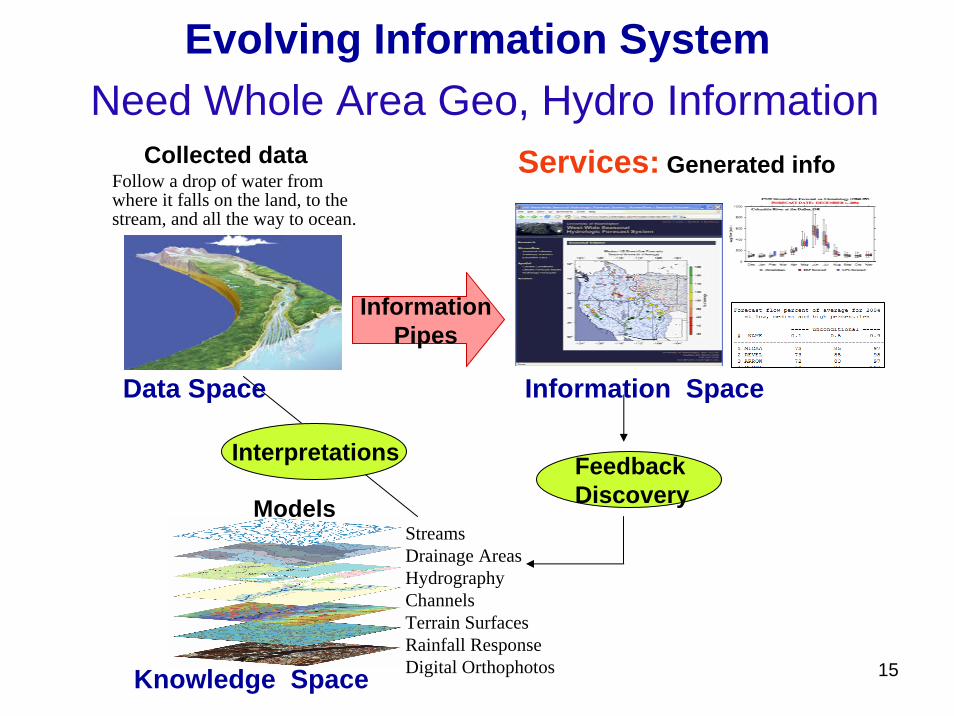
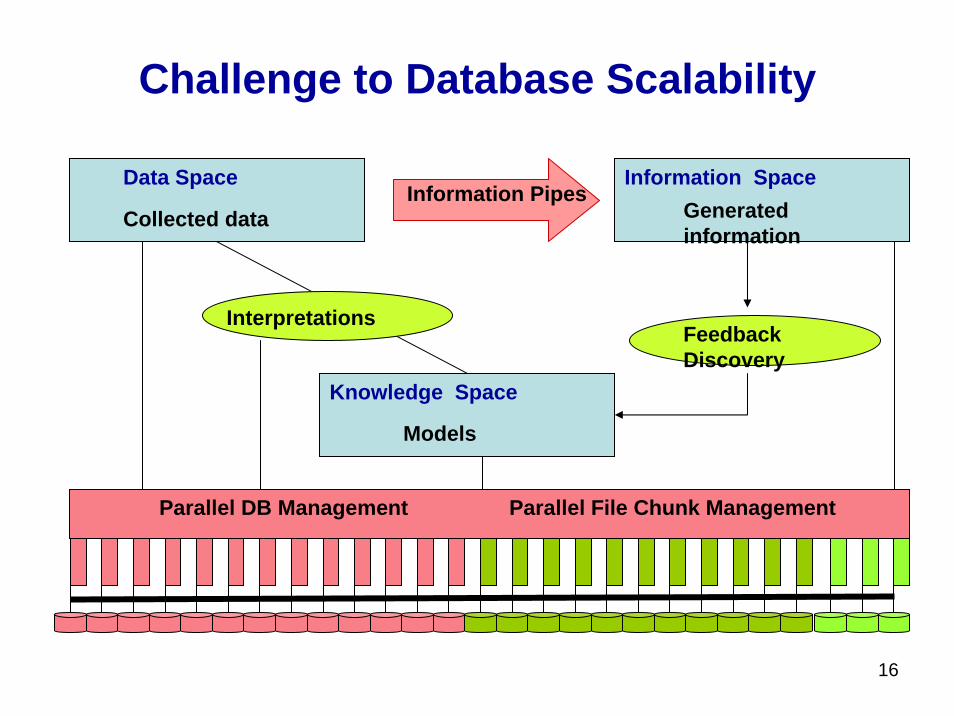
15Knowledge Space
Models
Data Space Information Space
Services: Generated info
Interpretations Feedback Discovery
Information Pipes
Collected dataFollow a drop of water from where it falls on the land, to the stream, and all the way to ocean.
StreamsDrainage AreasHydrographyChannelsTerrain SurfacesRainfall ResponseDigital Orthophotos
Evolving Information SystemNeed Whole Area Geo, Hydro Information
16
Knowledge Space
Models
Data Space
Collected data
Information SpaceGenerated information
InterpretationsFeedback Discovery
Information Pipes
Parallel DB Management Parallel File Chunk Management
Challenge to Database Scalability
17
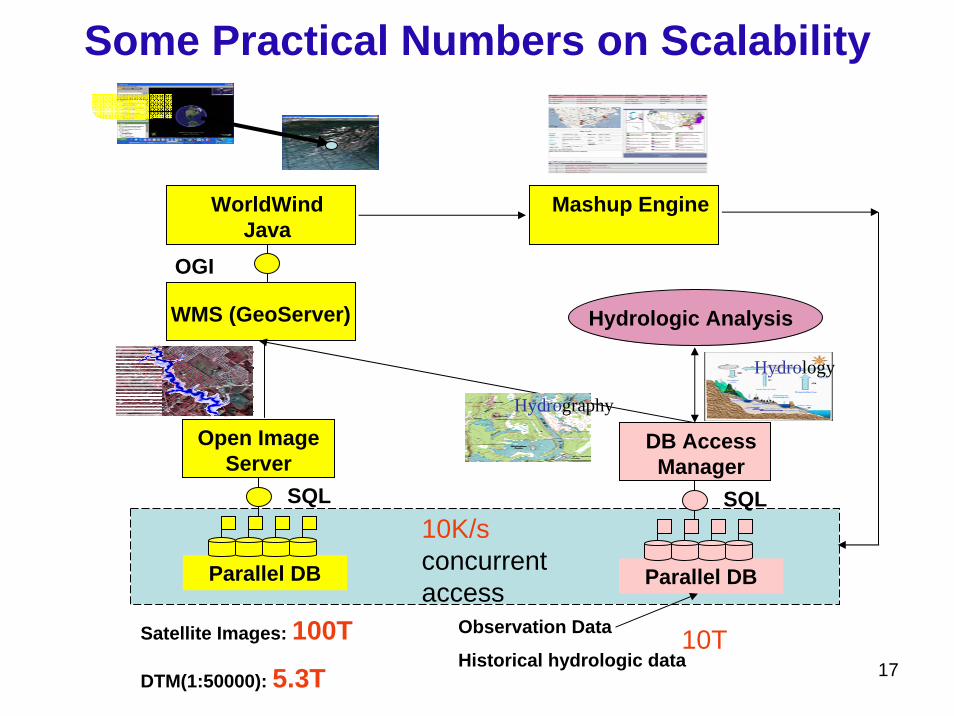
WorldWindJava
WMS (GeoServer)
OGI
Open Image Server
Parallel DB
SQL
Hydrologic Analysis
DB Access Manager
Parallel DB
SQL
Mashup Engine
Hydrography
Hydrology
Observation Data
Historical hydrologic dataSatellite Images: 100T
DTM(1:50000): 5.3T10T
Some Practical Numbers on Scalability
10K/s concurrent access
18
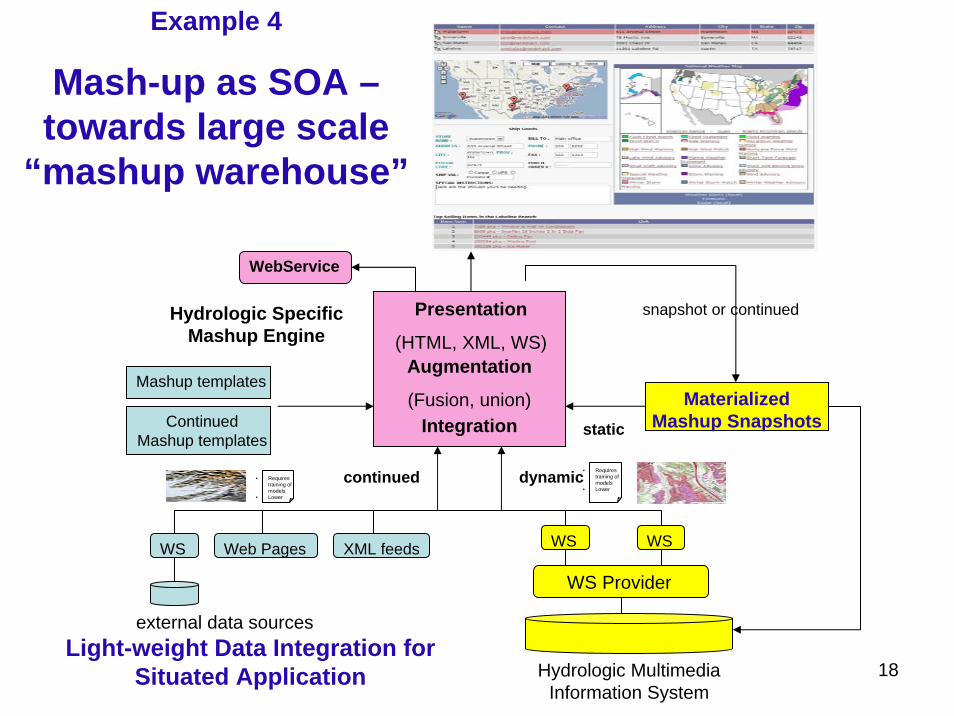
WS Web Pages
external data sources
Hydrologic Multimedia Information System
WS Provider
WS WS
Hydrologic Specific Mashup Engine
Materialized Mashup Snapshots static
dynamiccontinued
Continued Mashup templates
Mashup templates
XML feeds
Integration
Augmentation
(Fusion, union)
Presentation
(HTML, XML, WS)
• Requires training of models
• Lower
• Requires training of models
• Lower
WebService
snapshot or continued
Example 4
Mash-up as SOA –towards large scale
“mashup warehouse”
Light-weight Data Integration for Situated Application

19
Throughput! Not Size
• Bandwidth – transactions per second: 10K
• Latency - data rate: bytes per second (e.g1G bps)

20
Scale-up and Speed-up
• To scale-up, need overcome disk I/O bottleneck in terms of divide-and-conquer – partition data for share-nothing parallel processing
• To speed-up, need fill the gap between fast CPU and slow disk/memory access, by balancing the workload of computation and memory access, also by parallel processing

21
Some Solutions on Scalability
• Table partition• Reduce disk I/O
– Balance disk I/O and CPU workload• Automatic Life-Cycle based Storage
Adjustment • Parallel file system• Parallel DB system

22
Data Partition: Divide and Conquer
• Avoid a table or index to grow into a single large unmanageable glob, by breaking it into many smaller, more manageable chunks
• While partitions can be viewed and managed as a whole
• In Oracle, tables can be partitioned into up to 64,000 separate partitions
• But always tradeoff between load-balance (favorite small chunks) and communication cost (favorite large chunks)

23
Partition Types
• RANGE of data values• LIST of specified data values• HASH (pseudo-random distribution of data
values)• Composite RANGE-HASH• Composite RANGE-LIST

24
R/W Conflict in Partitioned Tables
• The issue: in DW, how to update (append) the most current partition only (small lock granularity), while allow the whole table to be queried
• The solution: – Separate partition from whole table when update– Allow query to go to both– Combine partition into the whole table by playing
with logical data description rather than physical data movement

25
Exchange Partition (Oracle)• EXCHANGE PARTITION can be transparent to in-
flight queries– Avoid updating big table
• Similar mechanisms of changing semantics but keep content ……
P1 P2 P3 P4 P5 P6 P7 P8
Tmp

2622-Feb2004
23-Feb2004
24-Feb2004
(empty) 25-Feb2004
Composite-partitionedtable TXN
Hash-partitionedtable TXN_TEMP
2. BulkLoads
5. EXCHANGE PARTITION
4. IndexCreates
3. Analyze
Exchange Partition (range-hash partition)
27
Limitation of Data Partition in Single DB Environment
• Memory bandwidth is still the bottleneck
DBMS

28
Some Solutions on Scalability
• Table partition• Reduce disk I/O
– Balance disk I/O and CPU workload• Automatic Life-Cycle based Storage
Adjustment • Parallel file system• Parallel DB system

29
How to Balance Workload of Disk I/O and CPU
• Load only required data– Column-based data structure
• Compression – decrease workload of I/O by R/W less– Increase workload of CPU by compress/decompress
• Parallel DB– decrease workload of I/O by R/W less in each
partition– Increase workload of CPU by passing data among
nodes

30
Memory Hierarchy
1-2 cycles
6-20 cycles
100-400 cycles

31
Faster Improvement of CPU/Cache than Disk I/O
What means to DBMS
• Disk I/O is a bottleneck, CPU wait for disk I/O, resulting < 50% usage in all DBMSs– Extremely fast of CPU means extremely hungry of
disk I/O– Which cannot be fully avoided…
• Main memory access bottleneck as well– DBMS tuple-at-a-time operations prohibit compiler to
put more data in cache, resulting in high cache-miss penalty
– algorithms and data-structures must be re-developed to reduce memory traffic

32
Column-based Storage Model• Reduce storage size for attributes not required• Vertically fragments tables on disk can save
bandwidth in case not all columns are requested for queries
• Disadvantage is increased update cost: a single row modification results in one I/O per each influenced column
• Monet/DB X100 solution is treating modifications as in-memory delta structures, periodically updating the chunks
• C-Store solution is providing separate but periodically synchronized read set and write set

33
Lightweight Compression
• Compression introduced not to reduce storage space but to increase disk bandwidth:– C-Store
• Data specific (VLDB 2006)– MonetDB/X100
• Decompress in cache rather than in RAM (SIGMOD 2006)
– Oracle• Reduce block size

34
Oracle Table Compression• Storing repeated data values once in each block
– A symbol table of distinct data values created in each block• The symbol table is stored as another table in the block
– Each column in a row in a block references back to an entry in the symbol table in the block
Header & Tailer
Table & Column Map
ITL
Symbol table
Free
Row data

35
Some Solutions on Scalability
• Table partition• Reduce disk I/O
– Balance disk I/O and CPU workload• Automatic Life-Cycle based Storage
Adjustment• Parallel file system• Parallel DB system
36
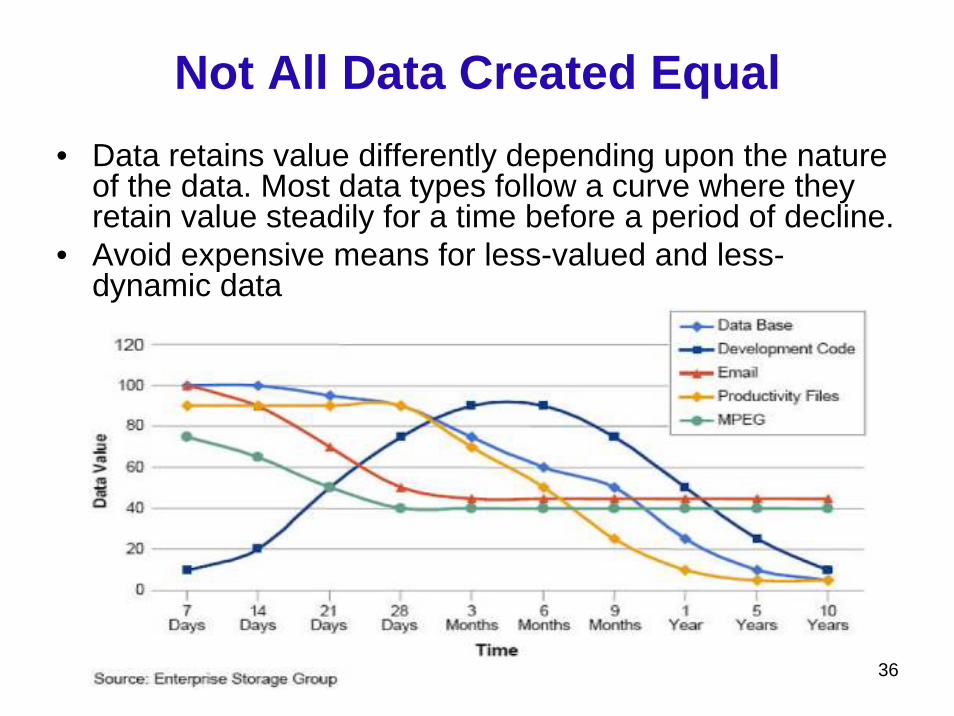
Not All Data Created Equal• Data retains value differently depending upon the nature
of the data. Most data types follow a curve where they retain value steadily for a time before a period of decline.
• Avoid expensive means for less-valued and less-dynamic data

37
Not All Disk Created Equal
• Fast disks for R/W most current data, but volumes small
• Large volume, slow disks for read-only historical data– Most-expensive (i.e. SSD – Solid State Disk)
small, fast– Very expensive (i.e. SAN)– Less expensive (i.e. JBOD/HDD, NAS,
SAMFS, etc) large, slow

38
READ ONLY Table Spaces (Oracle)• Partition by a datetime value allows time-variant
data of the same table to be separated• Within the same table, different partitions can exist
in different tablespaces• Different tablespaces can reside on different types
of storage media• Set tablespaces to READ ONLY as soon as
possible– Over time, majority of data in DW can be READ
ONLY (no locking ever needed)

39
• Moved from faster, more-expensive storage to slower, less-expensive storage– Without interrupting operations
• OS-level copy of data-files can proceed without interruption
• Only way to scale to large from a storage perspective
Move Data from more-expensive to less-expensive Storage Automatically
HP StorageWorks Solution
Move Data from more-expensive to less-expensive Storage Automatically
HP StorageWorks Solution
40
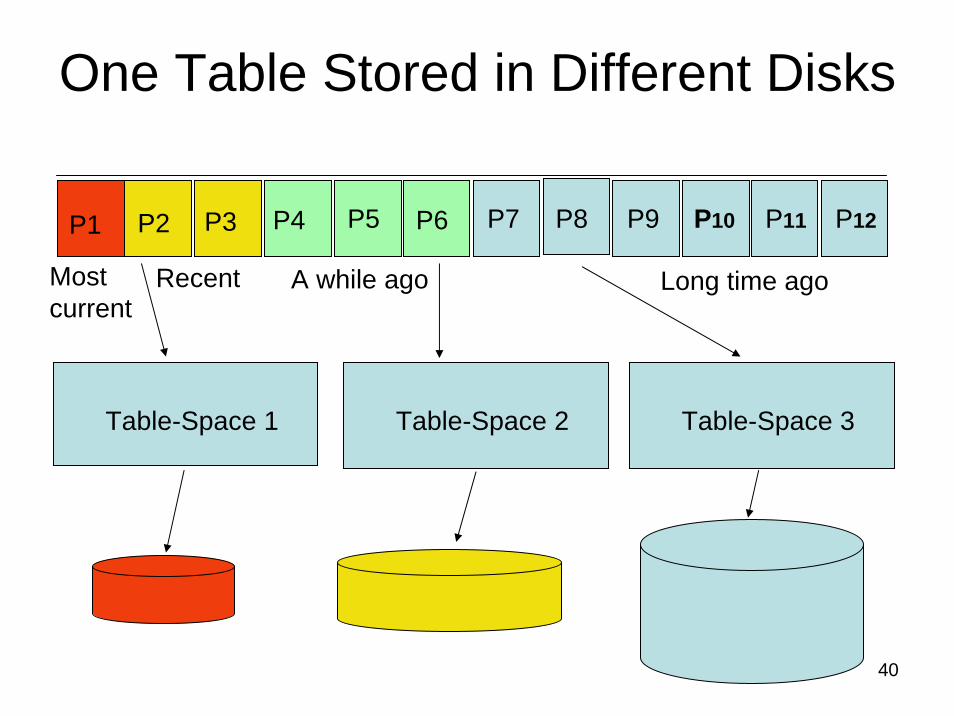
One Table Stored in Different Disks
Most current
Recent Long time ago
P1 P2 P3 P4 P5 P6 P7 P8 P9 P10 P11 P12
Table-Space 1
A while ago
Table-Space 2 Table-Space 3

41
Some Solutions on Scalability
• Table partition• Reduce disk I/O
– Balance disk I/O and CPU workload• Automatic Life-Cycle based Storage
Adjustment • Parallel file system• Parallel DB system

42
Google File System (GFS)• Single master, multiple chunk-servers• File - broken into multiple 64 MB chunks, each
with a handle (64 bit checksum)• Incremental scalability• Metadata – in-memory at master, at chunk-
servers (64 bytes per chunk)• Reliability through replication (3X)
227 chunk servers
Master server
180T disk 737K files
21G metadata per chunk
60G metadata

43
GFSDistributed File Servers with Central Control
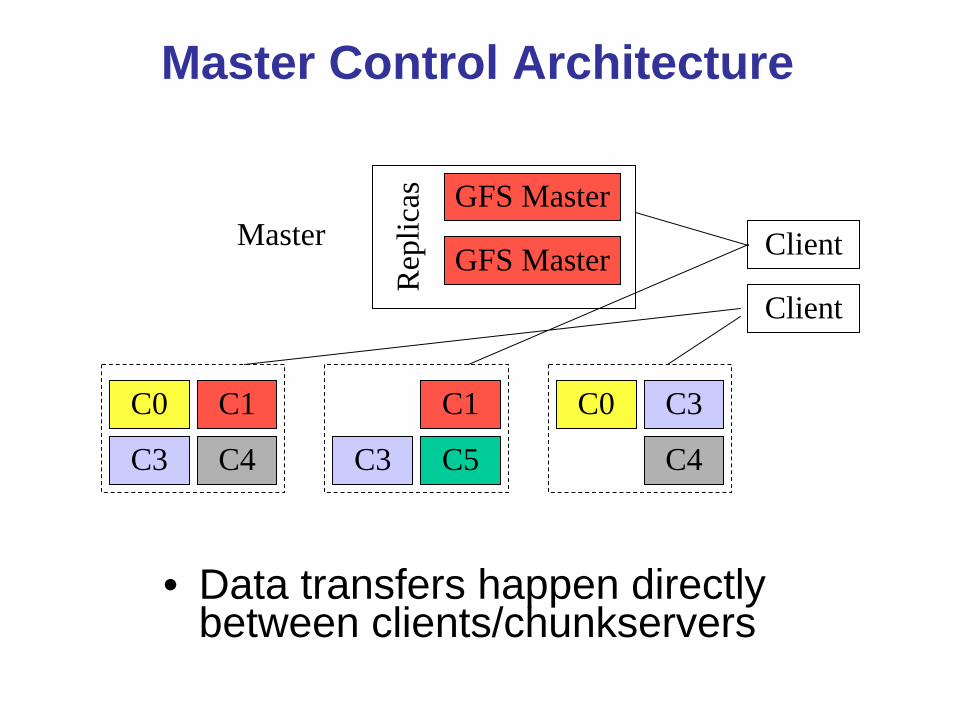
Master Control Architecture
• Data transfers happen directly between clients/chunkservers
Rep
licas
MasterGFS Master
GFS Master Client
Client
C1C0 C0
C3 C3C4
C1
C5
C3
C4

45
Good in Google Apps but Limitations in Others
• Most file modifications are appends– Random writes practically non-existent– Once written… sequential reads– Caching not terribly important
• Mutation of files – append rather than overwrite• Sustained bandwidth is considered more
important than latency– Batch processing of LOTS of data, but response time
for individual read/write not emphasized

46
Some Solutions on Scalability
• Table partition• Reduce disk I/O
– Balance disk I/O and CPU workload• Automatic Life-Cycle based Storage
Adjustment • Parallel file system• Parallel DB system

47
Parallel Database Architecture
• Share Everything Architecture (SEA)• Share Disk Architecture (SDA)• Share Nothing Architecture (SNA)
48
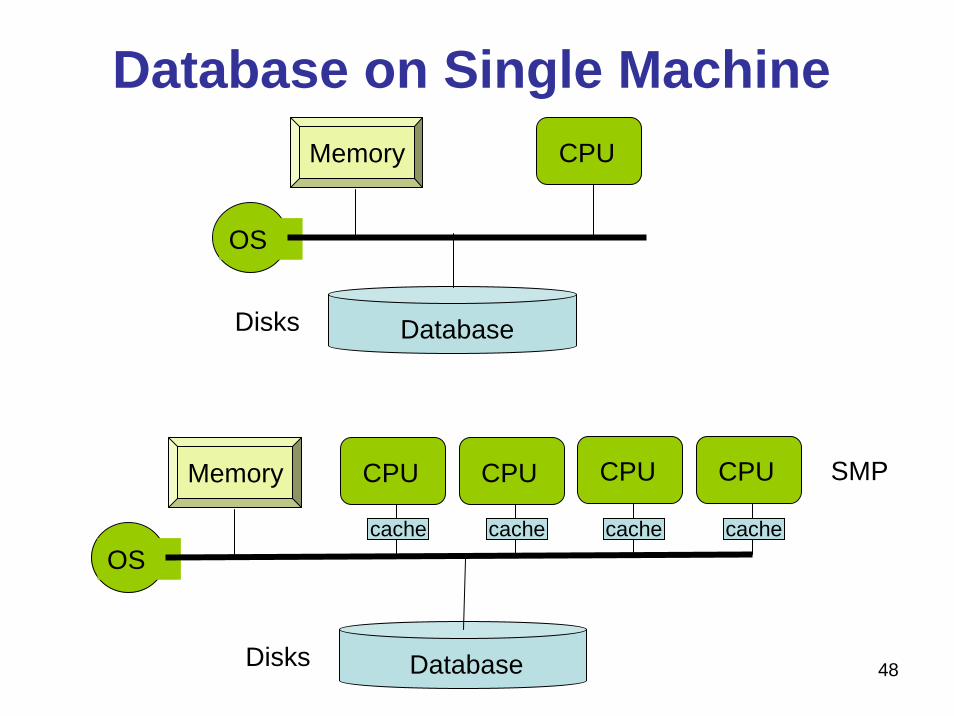
Database on Single Machine
DatabaseDisks
OS
Memory CPU
DatabaseDisks
OS
Memory CPU CPU CPU CPU
cache cache cache cache
SMP

49
Share Everything Architecturesync memory and share disk
e.g. Oracle RAC
OS
Memory CPUs
OS
Memory CPUs
sync
DatabaseDisks
Memory, disk bottleneckNot linear scalable

50
Share Disk Architecture
DatabaseDisks
OS
Memory CPUs
OS
Memory CPUs
MultistageSwitch Net
Memory, disk bottleneckNot linear scalable

51
Share Nothing ArchitectureHP SQL/MX, NCR Teradata, IBM DB2-PE
• Horizontally partitioned table (e.g. hash partition)
• Linear scalable without memory, disk bottleneck
Database partition
CPU, memory, OS, local disk
CPU, memory, OS, local disk
Database partition
Server net

52
HP SQL/MX
16 – 128 SQL
Processing Elements2 - 1.6Ghz Itanium2
8GB memory
8 - 128 Disk ArraysFiber channel attached
Duplexed JBOD
Server Area NetworkServer Area Network
Dual SwitchedDual Switched
ServerNet FabricServerNet Fabric
ETL EngineSMP
53
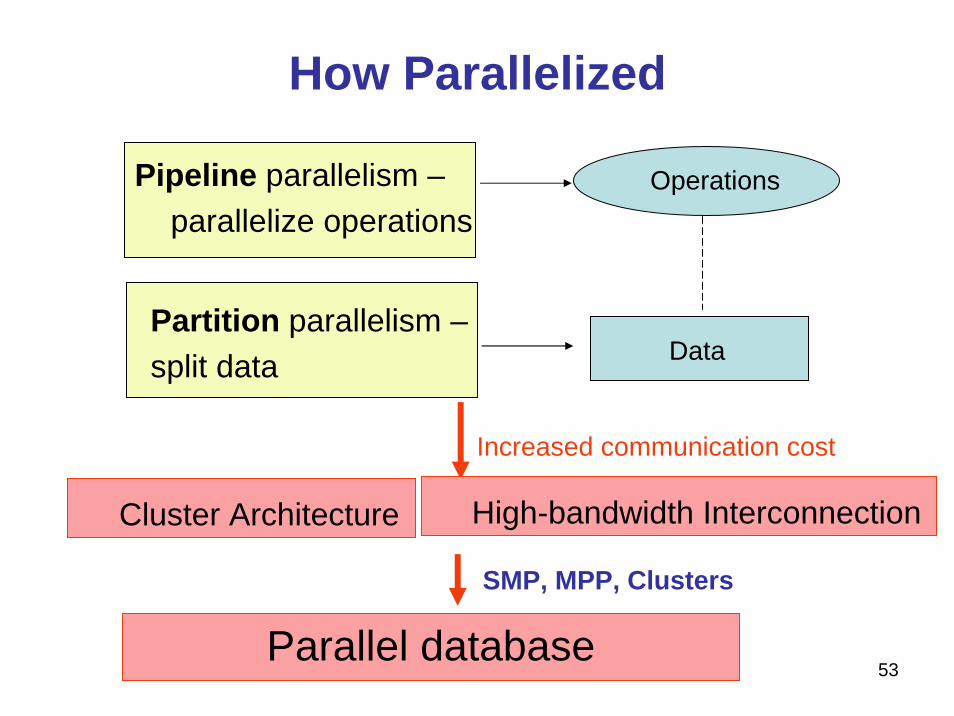
How Parallelized
Partition parallelism –split data
Parallel database
Operations
Data
Pipeline parallelism –parallelize operations
High-bandwidth InterconnectionCluster Architecture
Increased communication cost
SMP, MPP, Clusters

54
Scalability of Parallel Databases• Storage – Terabytes, Petabytes (2005 Winter
Corp honors HP MPP database at Sprint as world's largest and most heavily used database: 2,847,553 rows)
• Throughput – transactions per second: 10K• Data transfer rate (latency) – bytes per second
(bps) – 10-20G bps available (e.g. InfiniHost III Lx MHES14-XT HCA; SilverStorm 9xx0 Multi-Protocol Fabric Directors)
• Balance of load-balance (favorite small chunks) and communication cost (favorite large chunks)

55
Data Partition
• List partition – by individual values• Range partition – by range• Hash partition – by hash function

56
Hash Partition
Primary Index for a row
Hash function
Row Hash
Hash Map
Table Partitions

57
Secondary Index PartitionHash on PIPI
base-table
2-SE operationHash on USIUSI
base-table
USI-table
NUSI
base-table
NUSI-table
ALL-SE operation
Ref Teradata

58
Two Kinds of Parallel Databases Access
• Inter-query parallelism (fit OLTP)– Many small, independent queries/transactions – Each assigned to “next” available CPU – Require CPU bandwidth and load balance
• Intra-query parallelism (fit OLAP, DSS)– Single, large, complex query– Decompose query for multiple CPUs to
process in parallel– Require capability of split tasks and partition
data

59
for OLTP Performance
• Normalize tables – few tables and rows affected by an update
• High-selectivity – small result set, perhaps only one row
• Indexes – point to the row fast• CPU bandwidth – multiple CPUs with one
for each query simultaneously• Load balance – No CPU is idle

60
for DW Performance• A Low selectivity, large result, data load and
go– advantage of indexing does not apply to
sequential blocks, instead, indexing itself may become overhead
– advantage of normalization does not apply to rarely changed historical data, but increases join cost

61
Architecture Alternative: Super-Clusters since no One-size-fit-all
OLTP ODS EDW

62
Summary• SOA greatly simplified and scaled service
provisioning, discovery and invocation due to the separation of interface and implementation, standard platforms, etc.
• But SOA did not eliminate the complexity of service management
• And, SOA requires support from scalable data management

63


















