
Research on the Use of Intelligent Agents in Training Systems at Texas A&M
44
Research on the Use of Intelligent Agents in Training Systems at Texas A&M Thomas R. Ioerger Associate Professor Department of Computer Science Texas A&M University
-
Upload
amanda-beasley -
Category
Documents
-
view
19 -
download
0
description
Research on the Use of Intelligent Agents in Training Systems at Texas A&M. Thomas R. Ioerger Associate Professor Department of Computer Science Texas A&M University. Our Approach Historical Context of Projects TRL - an agent architecture Modeling Teamwork - PowerPoint PPT Presentation
Transcript of Research on the Use of Intelligent Agents in Training Systems at Texas A&M

Research on the Use of Intelligent Agents in Training Systems
at Texas A&M
Thomas R. IoergerAssociate Professor
Department of Computer ScienceTexas A&M University

Outline• Our Approach
• Historical Context of Projects
• TRL - an agent architecture
• Modeling Teamwork
• CAST - a multi-agent architecture
• Advanced Team Behaviors
• User Modeling in a Team Context
• Cognitive Modeling of Command and Control

Our Approach• Develop programmable agents that can be
hooked up with simulators
• Embed algorithms for interpreting collaborative activity to automatically produce appropriate interactions– they should be able to infer when to act or
communicate, like humans
• Simulating human behavior is useful for training...

Historical Context
• University XXI - DoD funding (1999-2000)– developed TRL for modeling info flow in Bn TOCs
• MURI - AFOSR funding (2001-2005)– worked with cognitive scientists to develop theories of
how to use agents in training, e.g. for AWACS
• Army Research Lab, Aberdeen (2001-2002)– HBR modeling of teams in sims like OneSAF, JVB
• NASA (current) – SATS: future ATC with aircraft self-separation
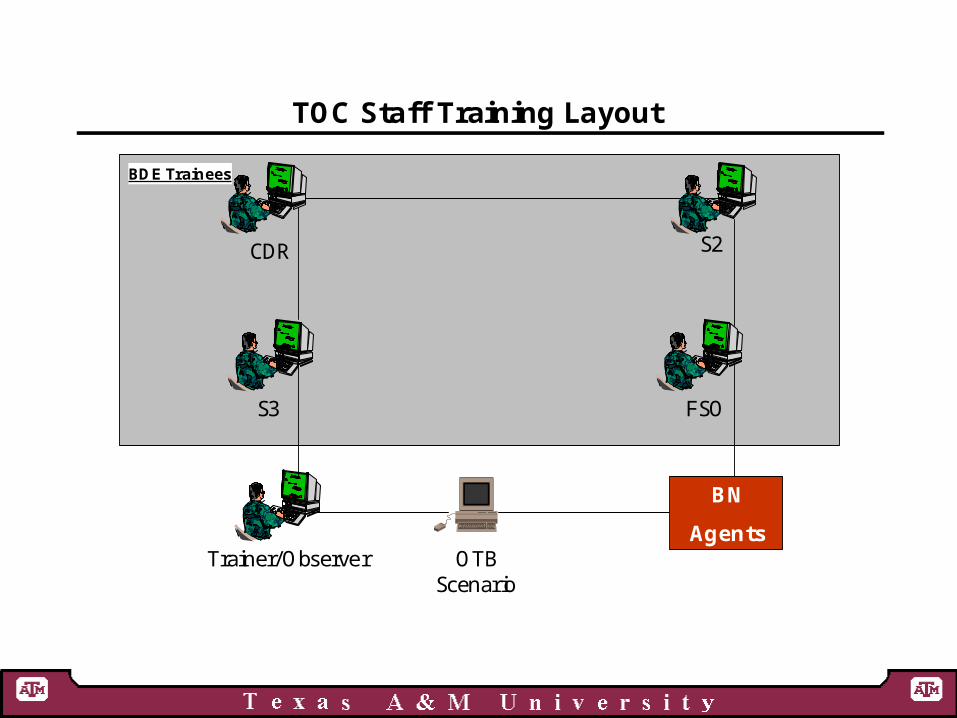
TOC Staff Training Layout
S2
S3 FSO
Trainer/Observer OTBScenario
CDR
BDE Trainees
BN
Agents

TRL Agent Architecture
• Declarative and procedural knowledge bases• TRL Knowledge Representation Language
- For Capturing Procedural Knowledge (Tasks & Methods)
• APTE Method Selection-Algorithm- responsible for building, maintaining, and
repairing task-decomposition trees• Inference Engine JARE
- Java Automated Reasoning Engine- Knowledge Base with Facts and Horn Clauses- back-chaining (like Prolog)- Updating World With Facts- now OpenSource at http://jare.sourceforge.net
• Written in Java

TaskableAgents
TRL Agent Architecture Diagram
sensingmessage
s
JARE KB: facts &Horn-
clauses
OTB(simulation)
operators
results
assert, query,retract
messages
APTEAlgorith
m
TRL TaskDecomposition
Hierarchy
ProcessNets
Other Agent
s
TRL KB:tasks &methods

JARE Knowledge Base• First-order Horn-clauses (rules with variables)• Similar to PROLOG• Make inferences by back-chaining
consequent antecedents
((threat ?a ?b)(enemy ?a)(friendly ?b)
(in-contact ?a ?b)(larger ?a ?b)
(intent ?a aggression))
>(query (threat ?x task-force-122))
solution 1: ?x = regiment-52
solution 2: ?x = regiment-54

Task Representation Language (TRL)
• Provides descriptors for: goals, tasks, methods, and operators• Tasks: “what to do”
– Can associate alternative methods, with priorities or preference conditions
– Can have termination conditions• Methods: “how to do it”
– Can define preference conditions for alternatives– Process Net
- Procedural language for specifying how to do things- While loops, if conditionals, sequential, parallel constructs- Can invoke sub-tasks or operators
• Operators: lowest-level actions that can be directly executed in the simulation environment, e.g. move unit, send message, fire on enemy– Each descriptor is a schema with arguments and variables– Conditions are evaluated as queries to JARE

Example TRL Knowledge
(:Task Monitor (?unit) (:Term-cond (destroyed ?unit)) (:Method (Track-with-UAV ?unit) (:Pref-cond (not (weather cloudy)))) (:Method (Follow-with-scouts ?unit) (:Pref-cond (ground-cover dense)))) (:Method Track-with-UAV (?unit) (:Pre-cond (have-assets UAV)) (:Process (:seq (:if(:cond(not(launched UAV)))(launch UAV)) (:let((x y)(loc ?unit ?x ?y))(fly UAV ?x ?y)) (circle UAV ?x ?y))))

Task-Decomposition Hierarchy
T1 M1
T2 T5
T3 T4
M7 M12 M92 M60
T15 T18 T40 T45 T40 C T45
T2
level 1 level 2 level 3 level 4 level 5
Tx =Task Mx = MethodC = Condition Process Nets
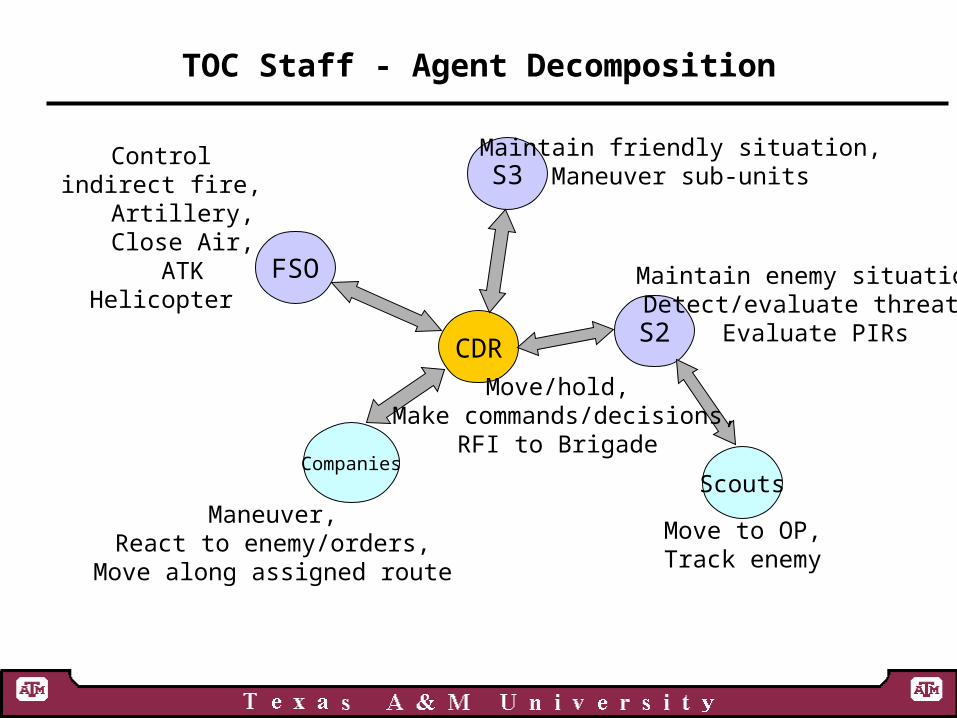
TOC Staff - Agent Decomposition
CDR
FSO
S3
S2
CompaniesScouts
Control indirect fire,
Artillery, Close Air,
ATK Helicopter Maintain enemy situation,Detect/evaluate threats,
Evaluate PIRs
Maintain friendly situation,Maneuver sub-units
Maneuver,React to enemy/orders,
Move along assigned route
Move to OP,Track enemy
Move/hold, Make commands/decisions,
RFI to Brigade

Modeling Teamwork• Team Psychology Research: Salas, Cannon-Bowers,
Serfaty, Ilgen, Hollenbeck, Koslowski, etc.
– “two or more individuals working together, interdependently, toward a common goal”
– members often play distinct roles– types of control: centralized (hierarchical) vs.
distributed (consensus-oriented)– process measures vs. outcome measures– communication, adaptiveness– shared mental models

Computational Models of Teamwork• Commitment to shared goals
– Joint Intentions (Cohen & Levesque; Tambe)
– Cooperation, non-interference
– Backup roles, helping behavior
• Mutual awareness– goals of teammates; achievement status
– information needs
• Coordination, synchronization• Distributed decision making
– consensus formation (voting), conflict resolution

CAST: Collaborative AgentArchitecture for Simulating Teamwork• developed at Texas A&M; part of MURI grant from
DoD/AFOSR• multi-agent system implemented in Java• components:
– MALLET: a high-level language for describing team structure and processes
– JARE: logical inference, knowledge base– Petri Net representation of team plan– special algorithms for: belief reasoning, situation
assessment, information exchange, etc.

CAST Architecture
MALLETknowledge base(definition of roles,tasks, etc.)
JARE knowledge base (domain rules)
Agent
expand team tasksinto Petri nets keep track of
who is doingeach step
make queriesto evaluateconditions,assert/retractinformation
models of otheragents’ beliefs
agent teammates
human teammates
simulation
messages
events, actionsstate data

MALLET
(role sam scout) (role bill S2) (role joe FSO)
(responsibility S2 monitor-threats)
(capability UAV-operator maneuver-UAV)
(team-plan indirect-fire (?target)
(select-role (scout ?s)
(in-visibility-range ?s ?target))
(process
(do S3 (verify-no-friendly-units-in-area ?target))
(while (not (destroyed ?target))
(do FSO (enter-CFF ?target))
(do ?s (perform-BDA ?target))
(if (not (hit ?target))
(do ?s (report-accuracy-of-aim FSO))
(do FSO (adjust-coordinates ?target))))))
evaluated by queries to JAREknowledge base
descriptions of team structure
descriptions of team process

Dynamic Role Selection(role al holder) (role dan holder)...
(team-plan kick-field-goal ()
(select-role (?c (center ?c))
(?h (holder ?h) (not (injured ?h)))
(?k (kicker ?k)))
(process (seq (hike-ball ?c)
(catch-ball ?h) (hold-ball ?h)
(kick-ball ?k))))
• When there is ambiguity, agents automatically communicate (send messages) to decide who will do what
• Key points:– coordination does not have to be explicit in plan– defer task assignments to see who is best

Proactive Information Exchange• Information sharing is a key to efficient teamwork • Want to capture information flow in team, including
proactive distribution of information• Agent A should send message I to Agent B iff:
– A believes I is true– A believes B does not already believe I (non-redundant)– I is relevant to one of B’s goals, i.e. pre-condition of current goal
that B is responsible for in plan• DIARG Algorithm (built into CAST):
1. check for transitions which other agents are responsible for that can fire (pre-conds satisfied)
2. infer whether other agent might not believe pre-conds are true (currently, beliefs based on post-conditions of executed steps, i.e. tokens in output places)
3. send proactive message with information

AWACS - DDD (Aptima, Inc.)

Approaches to Team Training• How to use agents in training?
– How to improve team performance?
• Classic approach: shared mental models
• Impact of individual cognition on teamwork– Collab. with Wayne Shebilske (Wright State)
– attention management, workload, automaticity, reserve capacity to help/share
• Many possible roles for agents:– user modeling, coaching, feedback, AAR, dynamic
scenarios, role players, partners, enemies, low-cost highly-available practice...

Complex Tasks, and the Needfor new Training Methods
• Complex tasks (e.g. operating machinery)– multiple cognitive components (memory, perceptual,
motor, reasoning/inference...)– novices feel over-whelmed– limitations of part-task training– automaticity vs. attention management
• Role for intelligent agents? – can place agents in simulation environments– need guiding principles to promote learning

Previous Work: Partner-Based Training
• AIM (Active Interlocked Modeling; Shebilske, 1992)– trainees work in pairs (AIM-Dyad)– each trainee does part of the task together
• importance of context (integration of responses)• can produce equal training, 100% efficiency gain• co-presence/social variables not required
– trainees placed in separate rooms• correlation with intelligence of partner
– Bandura, 1986: “modeling”

Automating the Partner with an Intelligent Agent
• Hypothesis: Would the training be as effective if the partner were played by an intelligent agent?
• Important pre-requisite: a CTA (cognitive task analysis)– a hierarchical task-decomposition allows
functions to be divided in a “natural” way between human and agent partners

Space Fortress: Laboratory Task• Representative of complex tasks
– has similar perceptual, motor, attention, memory, and decision-making demands as flying a fighter jet
– continuous control: navigation with joystick, 2nd-order thrust control
– discrete events: firing missles, making bonus selections with mouse
– must learn rules for when to fire, boundaries...
• Large body of previous studies/data– Multiple Emphasis on Components (MEC) protocol
– transfers to operational setting (attention mgmt)

PNTS CNTRL VLCTY VLNER IFF INTRVL SPEED SHOTS 200 100 119 0 W 90 70
$A MINE
THE FORTRESS
SHIP
BONUS AVAILABLE
P M I
MOUSE BUTTONS JOYSTICK
MISSLE

Implementation of a Partner Agent
• Implemented decision-making procedures for automating mouse and joystick
• Added if-then-else rules in C source code– emulate Decision-Making with rules
• Agent simple, but satisfies criteria: – situated, goal-oriented, autonomous
• First version of agent played too “perfectly”• Make it play “realistically” by adding some delays
and imprecision (e.g. in aiming)

Experiment 1• Hypothesis: Training with agent improves final scores
• Protocol: – 10 sessions of 10 3-minute trials each (over 4 days)– each session 1/2 hour: 8 practice trials, 2 test trials
• Groups: – Control (standard instructions+practice)– Partner Agent: (instructions+practice, alternate mouse
and joystick between trainee and agent)
• Participants: – 40 male undegrads at WSU– <20 hrs/wk playing video games

Results of Expt 1
*Difference in final scores was significant at p<0.05 level by paired T-test (with dof=38): t=2.33>2.04

Effect of Level of Simulated Expertise of Agent?
• Results of Expt 1 raises follow-up question: What is the effect of the level of expertise simulated by the agent?
• Can make the agent more or less accurate.• Recall: correlation with partner’s intelligence• Is it better to train with an expert? or perhaps with
a partner of matching skill-level?...– novices might have trouble comprehending experts
strategies since struggling to keep up

Results of Expt 2
0500
10001500200025003000350040004500
Final Scores inSpace Fortress
Conclusion: Training with an expert partner agent is best.

Lessons Learned for Future Applications• Principled approach to using agents in training systems: as
partners - cognitive benefits• Works best if there is a high degree of de-coupling among
sub-tasks– if greater interaction, agent might have to “cooperate” with human
by interpreting and responding to apparent strategies
• Desiderata for Partner Agents:1. Correctness
2. Consistency (necessary for modeling)
3. Realism (how to simulate human “errors”?)
4. Exploration (errors lead to unusual situations)

• Should also consider effect of workload, skill, and attention (user modeling)
• Working hypothesis:– effective teamwork requires sufficient reserve
capacity and attention management to be able to monitor activities of teammates of offer help or information
• Design of a team training protocol– look at impact of attention training on frequency
of interactions and helping behaviors within team
Application to Team Training

The more Traditional Approach: Agent-Based Coaching
• Agents can track trainees’ actions using team plan, offer hints (either online or via AAR)
• Standard approach: plan recognition
• Team context increases complexity of explaining actions and mistakes– failed because lack domain knowledge,
situational information, or “it’s not my responsibility”?

Modeling Command and Control• What’s missing from teamwork simulations?
– we have roles, proactive information sharing– special teams: Tactical Decision Making (TDM)
• C2 is what many teams are “doing” in many application areas (civilian as well as military)– distributed actions– distributed sensors, uncertainty– adversarial environment, ambiguity of enemy intent
• How to “practice” doing C2 better as a team?– it’s all about gathering and fusing information...

Cognitive Aspects of C2• many field studies of TDM teams...
• Naturalistic Decision Making (Klein)
• Situation Awareness (Endsley)
• Recognition-Primed Decision Making (RPD)
while (situation not clear)
choose feature unknown
initiate find-out procedure
trigger response action

Basic Activities to Integrate
missionobjectives
information gathering,situation assessment
implicit goals: maintain security maintain communications maintain supplies
emergency procedures,handling threats
tacticaldecisionmaking

Overview of Approach
• Implement RPD loop in TRL
• represent situations, features, weights in JARE
• find-out procedures– e.g. use radar, UAV, scouts, RFI to Bde, phone,
email, web site, lab test...
• challenges:– information management (selection, tracking,
uncertainty, timeouts)– priority management among activities

• C2/CAST: declarative and procedural KB’s (rules and plans)

Model of Situation Assessment• situations: S1...Sn
e.g. being flanked, ambushed, bypassed, diverted, enveloped, suppressed, directly assaulted
• features associated with each sit.: Fi1...Fim
• RPD predicts DM looks for these features
• weights: based on relevance of feature (+/-)
• evidence(Si)=j=1..m wij . Fij > i
• unknowns: assume most probable value: Fi=true if P[Fi=true]>0.5, else Fi=false

Situation Awareness Algorithm• (see ICCRTS’03 paper for details)
• basic loop:while situation is not determined (i.e. no situation
has evidence>threshold),
pick a relevant feature whose value is unknown
select a find-out procedure, initiate it
• information management issues– ask most informative question first (cost? time?)– asynchronous, remember answers pending– some information may go stale over time (revert to
unknown, re-invoke find-out)

PrioritiesModel: current “alert” level suspends lower-level activities
5 - handling high-level threats
4 - situation awareness
3 - handling low-level threats
2 - maintenance tasks for implicit goals
1 - pursuing targets of opportunity
0 - executing the missionhigh-levelthreat occurs,suspend mission
resume missionwhen threathandled

Current Work on C2• Extending RPD to model to team as a
“shared plan”– agents have shared model of common situations
and relevant information– work together to disambiguate and derive
consesus on identity of situation– infer what local information is relevant to the
group and sychronize views (resolve conflicts)
• Knowledge acquisition of air combat situations for modeling AWACS WD’s

Collaborators
• Wayne Shebilske (Wright State, Psych)
• Richard Volz (Texas A&M, Comp. Sci.)
• John Yen (Penn State, IST)


















