
Research Article Multiple Memory Structure Bit Reversal...
13
Research Article Multiple Memory Structure Bit Reversal Algorithm Based on Recursive Patterns of Bit Reversal Permutation K. K. L. B. Adikaram, 1,2,3 M. A. Hussein, 1 M. Effenberger, 2 and T. Becker 1 1 Group of Bio-Process Analysis Technology, Technische Universit¨ at M¨ unchen, Weihenstephaner Steig 20, 85354 Freising, Germany 2 Institut f¨ ur Landtechnik und Tierhaltung, V¨ ottinger Straße 36, 85354 Freising, Germany 3 Computer Unit, Faculty of Agriculture, University of Ruhuna, Mapalana, 81100 Kamburupitiya, Sri Lanka Correspondence should be addressed to K. K. L. B. Adikaram; [email protected] Received 6 April 2014; Revised 4 June 2014; Accepted 5 June 2014; Published 17 July 2014 Academic Editor: Ker-Wei Yu Copyright © 2014 K. K. L. B. Adikaram et al. is is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. With the increasing demand for online/inline data processing efficient Fourier analysis becomes more and more relevant. Due to the fact that the bit reversal process requires considerable processing time of the Fast Fourier Transform (FFT) algorithm, it is vital to optimize the bit reversal algorithm (BRA). is paper is to introduce an efficient BRA with multiple memory structures. In 2009, Elster showed the relation between the first and the second halves of the bit reversal permutation (BRP) and stated that it may cause serious impact on cache performance of the computer, if implemented. We found exceptions, especially when the said index mapping was implemented with multiple one-dimensional memory structures instead of multidimensional or one-dimensional memory structure. Also we found a new index mapping, even aſter the recursive splitting of BRP into equal sized slots. e four- array and the four-vector versions of BRA with new index mapping reported 34% and 16% improvement in performance in relation to similar versions of Linear BRA of Elster which uses single one-dimensional memory structure. 1. Introduction e efficiency of a bit reversal algorithm (BRA) plays a critical role in the Fast Fourier Transform (FFT) process because it contributes 10% to 50% of total FFT process time [1]. erefore, it is vital to optimize the BRA to achieve an efficient FFT algorithm. In 2009, Elster showed the relation between the first and the second halves of the BRP [2], but did not implement it. Elster stated that implementation of this relation may cause serious impact on cache perfor- mance of modern computers. As Elster stated, use of a two- dimensional memory structure to implement this relation reduced the efficiency of the bit reversal permutation (BRP). In contrast, the efficiency of the BRA increased when a one- dimensional memory structure was used for index mapping. When two equal sided one-dimensional memory structures were used, the performance was even much better than with single one-dimensional memory structure. Also, it was found out that bit reversal permutation can be further split into equal size blocks recursively, up to maximum of log 2 (n) times, where is the number of samples and =2 ; ∈ + . ese two findings motivate us to introduce a BRA which is capable of using 2 ( = 2,3,..., log 2()) equal-sized (/2 ) one- dimensional memory structures. In 1965 Cooley and Tukey introduced the FFT algorithm, which is an efficient algorithm to compute the Discrete Fourier Transformation (DFT) and its inverse [3]. FFT is a fast algorithm that has replaced the process of DFT, which had been used frequently in the fields of signal and image processing [4–7]. e structure of the FFT algorithm published by Cooley and Tukey known as radix-2 algorithm [3] is the most popular one [5]. ere are several other algorithm structures as radix-4, radix-8, radix-16, mixed- radix, and split-radix [8]. To apply FFT to a certain signal, there are basically two major requirements. e first requirement is = , where is the number of samples of the signal, ∈ + , and is the selected radix structure, for example, =2, 4, 8, and 16 for radix-2, radix-4, radix-8, and radix-16, respectively. e second requirement is that the input (or output) samples Hindawi Publishing Corporation Mathematical Problems in Engineering Volume 2014, Article ID 827509, 12 pages http://dx.doi.org/10.1155/2014/827509
Transcript of Research Article Multiple Memory Structure Bit Reversal...

Research ArticleMultiple Memory Structure Bit Reversal Algorithm Based onRecursive Patterns of Bit Reversal Permutation
K K L B Adikaram123 M A Hussein1 M Effenberger2 and T Becker1
1 Group of Bio-Process Analysis Technology Technische Universitat Munchen Weihenstephaner Steig 20 85354 Freising Germany2 Institut fur Landtechnik und Tierhaltung Vottinger Straszlige 36 85354 Freising Germany3 Computer Unit Faculty of Agriculture University of Ruhuna Mapalana 81100 Kamburupitiya Sri Lanka
Correspondence should be addressed to K K L B Adikaram lasanthadaad-alumnide
Received 6 April 2014 Revised 4 June 2014 Accepted 5 June 2014 Published 17 July 2014
Academic Editor Ker-Wei Yu
Copyright copy 2014 K K L B Adikaram et al This is an open access article distributed under the Creative Commons AttributionLicense which permits unrestricted use distribution and reproduction in any medium provided the original work is properlycited
With the increasing demand for onlineinline data processing efficient Fourier analysis becomes more and more relevant Due tothe fact that the bit reversal process requires considerable processing time of the Fast Fourier Transform (FFT) algorithm it is vitalto optimize the bit reversal algorithm (BRA)This paper is to introduce an efficient BRAwith multiple memory structures In 2009Elster showed the relation between the first and the second halves of the bit reversal permutation (BRP) and stated that it maycause serious impact on cache performance of the computer if implemented We found exceptions especially when the said indexmapping was implemented with multiple one-dimensional memory structures instead of multidimensional or one-dimensionalmemory structure Also we found a new index mapping even after the recursive splitting of BRP into equal sized slots The four-array and the four-vector versions of BRAwith new indexmapping reported 34 and 16 improvement in performance in relationto similar versions of Linear BRA of Elster which uses single one-dimensional memory structure
1 Introduction
The efficiency of a bit reversal algorithm (BRA) plays acritical role in the Fast Fourier Transform (FFT) processbecause it contributes 10 to 50 of total FFT process time[1] Therefore it is vital to optimize the BRA to achieve anefficient FFT algorithm In 2009 Elster showed the relationbetween the first and the second halves of the BRP [2]but did not implement it Elster stated that implementationof this relation may cause serious impact on cache perfor-mance of modern computers As Elster stated use of a two-dimensional memory structure to implement this relationreduced the efficiency of the bit reversal permutation (BRP)In contrast the efficiency of the BRA increased when a one-dimensional memory structure was used for index mappingWhen two equal sided one-dimensional memory structureswere used the performance was even much better than withsingle one-dimensional memory structure Also it was foundout that bit reversal permutation can be further split intoequal size blocks recursively up tomaximumof log
2(n) times
where 119899 is the number of samples and 119899 = 2119896 119896 isin 119885+ These
two findings motivate us to introduce a BRAwhich is capableof using 2119896 (119896 = 2 3 log 2(119899)) equal-sized (1198992119896) one-dimensional memory structures
In 1965 Cooley and Tukey introduced the FFT algorithmwhich is an efficient algorithm to compute the DiscreteFourier Transformation (DFT) and its inverse [3] FFT isa fast algorithm that has replaced the process of DFTwhich had been used frequently in the fields of signal andimage processing [4ndash7] The structure of the FFT algorithmpublished by Cooley and Tukey known as radix-2 algorithm[3] is the most popular one [5] There are several otheralgorithm structures as radix-4 radix-8 radix-16 mixed-radix and split-radix [8]
To apply FFT to a certain signal there are basically twomajor requirements The first requirement is 119899 = 119887
119873 where119899 is the number of samples of the signal 119873 isin 119885
+ and 119887 isthe selected radix structure for example 119887 = 2 4 8 and16 for radix-2 radix-4 radix-8 and radix-16 respectivelyThe second requirement is that the input (or output) samples
Hindawi Publishing CorporationMathematical Problems in EngineeringVolume 2014 Article ID 827509 12 pageshttpdxdoiorg1011552014827509
2 Mathematical Problems in Engineering
must be arranged according to a certain order to obtain thecorrect output [3 5 8 9]The BRA is used to create the orderof input or output permutation according to the requiredorder The BRA used in most FFT algorithms including theoriginal Cooley-Tukey algorithm [3] is known as bit reversalmethod (BRM)TheBRM is an operation for exchanging twoelements 119909(119896) and 119909(119896) of an array of length 119898 as shown in(1) and (2) respectively where 119886
119895are either 0 or 1 and 119887 is the
relevant base 2 4 8 or 16 depending on the selected radixstructure
119896 =
119898minus1
sum
119895=0
119886119895119887119895 (1)
119896 =
119898minus1
sum
119895=0
119886119895119887119898minus1minus119895
(2)
All the later algorithms for creating BRP were named as BRA(bit reversal algorithm) though they used other techniqueslike patterns of BRP instead of bit reversing techniques
During the last decades many publications addressednew BRAs [10] by improving the already existing originalBRA (BRM) or using totally different approaches In 1996Karp compared the performance of 30 different algorithms[10] against uniprocessor systems (computer system with asingle central processing unit) with different memory sys-tems Karp found that the performance of a BRA dependedon the memory architecture of the machine and the wayof accessing the memory Karp stated two hardware factsthat influence the BRA namely the memory architectureand the cache size of the machine According to Karp amachine with hierarchical memory is slower than a machinewith vector memory (computers with vector processor) andalgorithms do not perform well when array size is largerthan the cache size Also Karp pointed out four featuresof an algorithm that influence the BRA namely memoryaccess technique data reading sequence size of the indexof memory and type of arithmetic operations Accordingto Karp an algorithm that uses efficient memory accesstechniques is the fastest among algorithms with exactly thesame number of arithmetic operations Algorithms are fasterif (i) they require only a single pass over the data (ii) they useshort indexes and (iii) they operate with addition instead ofmultiplication
Karp especially mentioned that the algorithm publishedby Elster [11] in 1989 was different from other algorithmsbecause it used a pattern of BRP rather than improving deci-mal to binary and binary to decimal conversion According tothe findings of Karp Elsterrsquos ldquoLinear Bit Reversal Algorithmrdquo(LBRA) performs much better in most of the cases Thepublication of Elster (1989) [11] consists of two algorithmsto achieve BRP One algorithm used a pattern of BRP andthe other one used bit shifting operations Both algorithmsare interesting because they eliminate the conventional bitreversingmechanism which needmore computing timeThealgorithm by Rubio et al (BRA-Ru) of 2002 [12] is anotherapproach that uses an existing pattern of BRP However thepattern described in Rubiorsquos algorithm is different from the
pattern described in Elsterrsquos [11] In 2009 Elster and Meyerpublished an improved version of ldquoLinear Register-Level BitReversalrdquo which was published in 1989 [11] as ldquoElsterrsquos BitReversalrdquo (EBR) algorithm Elster mentioned it is possible togenerate the second half of the BRP by incrementing the rel-evant element of the first half by one Also Elster mentionedthere can be a serious impact on cache performance of thecomputer if the said pattern (Figure 1) is used
Programming languages provide different data structures[13] which handle memory in different ways In additionthe performance of the memory depends on machine archi-tecture and operating system [14] Therefore the efficiencyof the memory is the resultant output of the performancesof hardware operating system programming language andselected data structure
Based on the physical arrangement of memory elementsthere are two common ways of allocating memory for aseries of variables ldquoslot of continuousmemory elementsrdquo andldquocollection of noncontinuous memory elementsrdquo commonlyknown as ldquostackrdquo and ldquoheaprdquo [15] In most programminglanguages the term array is used to refer to a ldquoslot ofcontinuous memory elementsrdquo Arrays are the simplest andmost common type of data structure [16 17] and due tocontinuous physical arrangement of memory elements pro-vide faster access than ldquocollection of noncontinuous memoryelementsrdquo memory types However with the development ofprogramming languages different types of data structureswere introduced with very similar names to the standardnames like array stack and heap The names of new datastructures sometimes did not agree with the commonlyaccepted meaning ldquoStackrdquo ldquoArrayrdquo and ldquoArrayListrdquo providedby Microsoft Visual C++ (VC++) [18 19] are good examplesAccording to the commonly accepted meaning they shouldbe a ldquoslot of continuousmemory elementsrdquo but they are in facta ldquocollection of noncontinuousmemory elementsrdquoThereforeit is not a good practice to determine the performance of acertain data structure just by looking at its name To overcomethis ambiguous situation we use ldquoslot of continuous memoryelementsrdquo to refer to ldquoprimitive arrayrdquo (or array) typememorystructures
Due to the very flexible nature vector is the mostcommon one among the different types of data structures[14] Vector was introduced with C++ which is one of themost common and powerful programming languages whichhas been used since 1984 [20] However as most of otherdata structures the term ldquovectorrdquo is used to refer to memoryin computers with processor architecture called ldquovectorprocessorrdquo In this paper the term vector is used to refer tothe vector data structure that is used in the C++ interface
Indexmapping is a technique that can be used to improvethe efficiency of an algorithm by reducing the arithmetic loadof the algorithm [8] If 119899 [0119873 minus 1] and 119873 is not prime 119873can be defined as 119873 = prod
119899119894minus1
119894=0119873119894 where 119899
119894 [0119873
119894minus 1] lt
119873 This allows the usage of small ranges of 119899119894instead of large
range of 119899 andmaps a function119891(119899) into amultidimensionalfunction 1198911015840(119899
1 1198992 119899
119894)
There are two common methods of implementing indexmapping one-dimensional or multidimensional memory
Mathematical Problems in Engineering 3
Normal order
Reverse order Pattern
Dec Bin Bin Dec
0 0000 0000 0
1 0001 1000 8
2 0010 0100 4
3 0011 1100 12
4 0100 0010 2
5 0101 1010 10
6 0110 0110 6
7 0111 1110 14
8 1000 0001 1 0 + 1
9 1001 1000 9 8 + 110 1010 0101 5 4 + 1
11 1011 1101 13 12 + 1
12 1100 0011 3 2 + 1
13 1101 1011 11 10 + 1
14 1110 0111 7 6 + 1
15 1111 1111 15 14 + 1
Bloc
k1
ndash8el
emen
tsBl
ock2
ndash8el
emen
tsFigure 1 Relation between first and second halves of the BRP for 119899 = 16
structures In addition it is also possible to implement theindex mapping using several equal size one-dimensionalmemory structures However this option is not popular asit is uncomfortable for programming The performance ofmodern computers is highly dependent on the effectivenessof the cache memory of the CPU [4] To achieve the best per-formance of a series of memory elements the best practice istomaintain sequential access [4] Otherwise the effectivenessof the cache memory of the central processing unit (CPU)will be reduced Index mapping with multidimensional datastructures violates sequential access due to switching betweencolumnsrows and thus reduces the effectiveness of thecache memory Therefore it is generally accepted that theuse of a multidimensional data structure reduces computerperformance [4]
In this paper an efficient BRA is introduced to createthe BRP based on multiple memory structures and recursivepatterns of BRPThe findings of this paper show that the com-bination of multiple one-dimensional memory structuresindex mapping and the recessive pattern of BRP can be usedto improve the efficiency of BRA These findings are veryimportant to the field of signal processing as well as any fieldthat is involved in index mapping techniques
2 Material and Methods
21 New Algorithm (BRA-Split) Elster stated that it is pos-sible to generate the second half of the BRP by increment-ing items in the first half by one [2] (Figure 1) withoutchanging the order and the total number of calculations of
the algorithm Due to the recursive pattern of BRP it canbe further divided into equal size blocks by splitting eachblock recursively (Maximum log
2N times) After splitting 119904
times BRP is divided into 2119904 equal blocks each containing1198992119904 elements The relation between the elements in blocks is
given as follows
119861 (2119898+ 119895) [119894] = 119861 (119895) [119894] + 2
119878minus119898minus1 (3)
where 119861(2119898 + 119895)[119894] is 119894th element of block 119861(2119898 + 119895) and119898 =
0 1 119904 minus 1 119895 = 1 2119898Table 1 shows the relationship between elements in blocks
according to the index mapping shown in (3) after splittingBRP one time and two times for 119899 = 16 Depending on therequirement the number of splitting can be increased
22 Evaluation Process of New Algorithm To evaluate algo-rithms we used Windows 7 and Visual C++ 2012 on a PCwith multicore CPU (4 cores 8 logical processors) and 12GBmemory Detailed specifications of the PC and the softwareare given in Table 2 To eliminate limits of memory andaddress space related to the selected platform the compileroption ldquoLARGEADDRESSAWARErdquo was set [21] and plat-form was set to ldquox64rdquo All other options of the operatingsystem and the compiler were kept unchanged
The new algorithm was implemented using single one-dimensionalmemory structure and themost commonmulti-dimensional memory structure Furthermore the new BRAwas implemented using several equal size one-dimensionalmemory structures (multiple memory structure)
4 Mathematical Problems in Engineering
Table1Re
lationbetweenelem
entsof
16-elementB
RP(119899=16)for
split
=1and
split
=2
Normal
order
Reverse
order
Split
(119878)=1
Split
(119878=2)
Blocks
(12119904)
Index
ofthe
block119894
Reverseo
rder
calculation
Calculationmetho
d119898=0119904minus1(119898=0)
119895=12119898
119898=0119895=1
119894=11198992119904minus1
119894=17
Blocks
(12119904)
Indexof
the
block119894
Reverseo
rder
calculation
Calculationmetho
d119898=0119904minus1(119898=01)
119895=12119898
119898=0119895=1119898=1119895=12
119894=11198992119904minus1
119894=123
00
1
00
Initialized
00
Initialized
18
18=8+0
Use
Elste
rrsquosLinear
BitR
eversalm
etho
d
11
8=8+0
Use
Elste
rrsquosLinear
BitR
eversalm
etho
d2
42
4=4+0
24=4+0
312
312
=12
+0
312
=12
+0
42
42=2+0
02
Initialized
510
510
=10
+0
21
10=8+2
119861(2119898+119895)[119894]=119861(119895)[119894]+2119904minus119898minus1
66
66=6+0
26=4+2
For119898
=0119895=1119894=123
119861(20+1)[119894]=119861(1)[119894]+22minus0minus1
714
714
=14
+0
314
=12
+2
119861(2)[119894]=119861(1)[119894]+2
81
2
01
Initialized
01
Initialized
99
19=8+1
119861(2119898+119895)[119894]=119861(119895)[119894]+2119904minus119898minus1
For119898
=0119895=1119894=17
119861(20+1)[119894]=119861(1)[119894]+22minus0minus1
119861(2)[119894]=119861(1)[119894]+1
31
9=8+1
119861(2119898+119895)[119894]=119861(119895)[119894]+2119904minus119898minus1
105
25=4+1
25=4+1
For119898
=1119895=1119894=123
119861(21+1)[119894]=119861(1)[119894]+22minus1minus1
1113
313
=12
+1
313
=12
+1
119861(3)[119894]=119861(1)[119894]+1
123
43=2+1
03
Initialized
1311
511=10
+1
41
11=10
+1
119861(2119898+119895)[119894]=119861(119895)[119894]+2119904minus119898minus1
147
67=6+1
27=6+1
For119898
=1119895=2119894=123
119861(21+2)[119894]=119861(2)[119894]+22minus1minus1
1515
715
=14
+1
315
=14
+1
119861(4)[119894]=119861(2)[119894]+2
Mathematical Problems in Engineering 5
Table 2 Hardware and software specifications of the PC
Specifications
Processor Intel Core i7 CPU 870 293GHz (4 cores8 threads)
RAM 12GB DDR3-1333 2 channelsMemory bandwidth 21GBsL1 L2 and L3 cache 4 times 64KB 4 times 256KB and 8MB sharedL1 L2 and L3 cacheline size 64 bit
Brand and type Fujitsu CelsiusBIOS settings Default (hyper threading enabled)OS and service pack Windows 7 professional with service pack 1System type 64 bit operating systemOS settings DefaultVisual Studio 2012 Version 110507271 RTMRELNET Framework Version 4550709
Thenext taskwas to identify a suitable data structure fromdifferent types of available data structures We consideredseveral common techniques as summarized in Table 3 Datastructure 1 mentioned in Table 3 is not supporting dynamicmemory allocation (need to mention the size of the arraywhen array is being declared) For general bit reversalalgorithm it is a must to have dynamic memory allocation tocater different sizes of samples Even after setting the compileroption ldquoLARGEADDRESSAWARErdquo [21] data structures 3and 4 mentioned in Table 3 were not supported for accessingmemory greater than 2GB Therefore structures 1 3 and 4were rejected and memory structures 2 (array) and 5 (vector)were used to create all one-dimensional memory structuresThe same versions of array and vector were used to createmultidimensional memory structures
The new algorithm mentioned in Section 21 was imple-mented usingC++ in 24 types ofmemory structures as shownin Table 4 The performance of these algorithms was evalu-ated considering the ldquoclocks per elementrdquo (CPE) consumedbyeach algorithm To retrieve this value first average CPE foreach sample size of 2119899 where 119899 [21 31] (11 sample sizes) werecalculated after executing each algorithm 100 timesThis gave11 CPE representing each sample size Finally the combinedaverageof CPEwas calculated for each algorithmby averagingthose 11 values along with ldquocombined standard deviationrdquoThe combined average of CPE was considered as the CPEfor each algorithm The built-in ldquoclockrdquo function of C++ wasused to calculate the clocks Combined standard deviationwas calculated using the following
120590119888= (
sum119896
119904=1(1198991199041205902
119904+ 119899119904(119883119904minus 119883119888)
2
)
sum119896
119904=1119899119904
)
12
(4)
where119883119888= sum119896
119904=1119899119904119883119904sum119896
119904=1119899119904 119904 is the number of samples 119899
119904
is number of samples in each sample and 120590119904is the standard
deviation of each sample
Algorithms 1 2 and 3 illustrate the implementation ofnew BRA with single one-dimensional memory structuremultidimensional memory structure and multiple mem-ory structures respectively The algorithm illustrated inAlgorithm 1 (BRA Split 1 1A) was implemented using prim-itive array for split = 1 The algorithm BRM Split 2 4A(Algorithm 2) was implemented using vectors for split =2 The algorithm BRM Split 2 4A (Algorithm 3) was imple-mented using primitive array for split = 2 A sample per-mutation filling sequence of algorithms with single one-dimensional memory structures is illustrated in Figure 2Figure 3 illustrates a sample permutation filling sequence ofboth multidimensional and multiple memory structures
Secondly arithmetic operations per element (OPPE)werecalculated for each algorithm Arithmetic operations withineach algorithm were located in three regions of the codeinner FOR loop outer FOR loop and outside of the loopsThen the total number of operations (OP) can be defined as
OP = 1198701lowast 1198621+ 1198702lowast 1198622+ 1198623 (5)
where 1198621 1198622 and 119862
3are the number of operations in inner
FOR loop outer FOR loop and outside of the loops 1198701and
1198702are the number of iterations of outer loop and inner loop
Equation (5) can be represented as
OP =log2(NS)minus119904minus1
sum
119905=0
2119905lowast 1198621+
log2(NS)minus119904minus1
sum
119905=0
1198622+ 1198623 (6)
where NS is the number of samples and 119904 is the number ofsplits
The main contribution to calculations comes from theinner loop Comparing with the contribution of operationsin the inner loop the contribution of operations in rest ofthe code is very small For example consider the algorithmBRA Split 1 1A shown in Algorithm 1 As sample size is 2311198701lowast 1198621asymp 215 lowast 10
9lowast 1198621and 119870
2lowast 1198622+ 1198623asymp 1000 where
1198621gt 1 Therefore only the operations of inner loop were
considered for evaluation Then (6) can be simplified as
OP =log2(NS)minus119904minus1
sum
119905=0
2119905lowast 1198621 (7)
The ldquooperations per elementrdquo (OPPE) can be defined as
OPPE =(sum
log2(NS)minus119904minus1
119905=02119905lowast 1198621)
NS
(8)
For FFT always NS = 2119896 119896 isin 119885+Then from (7)
OPPE =(sum119896minus119904minus1
119905=02119905lowast 1198621)
2119896
(9)
119896
sum
119905=0
2119905+ 1 = 2
119896+1 (10)
6 Mathematical Problems in Engineering
Table 3 Common memory allocating methods that are used in Visual C++
Number Name Syntax Nature of memory layout1 Array int BRP[1000] Slot of continuous memory elements2 Array intlowast BRP = new int[119899] Slot of continuous memory elements3 Array array⟨int⟩andBRP = gcnew array⟨int⟩(119899) Collection of noncontinuous memory elements4 ArrayList ArrayList andBRP = gcnew ArrayList() Collection of noncontinuous memory elements5 Vector stdvector⟨int⟩ BRP(119899) Collection of noncontinuous memory elements
Table 4 Different versions of new BRA implemented with different data structures
Split (s) Data structure type AlgorithmSingle memory structure Multidimensional memory structure Multiple memory structure
1 Array (A) BRA Split 1 1A BRA Split 1 2DA BRA Split 1 2A1 Vector (V) BRA Split 1 1V BRA Split 1 2DV BRA Split 1 2V2 Array (A) BRA Split 2 1A BRA Split 2 4DA BRA Split 2 4A2 Vector (V) BRA Split 2 1V BRA Split 2 4DV BRA Split 2 4V3 Array (A) BRA Split 3 1A BRA Split 3 8DA BRA Split 3 8A3 Vector (V) BRA Split 3 1V BRA Split 3 8DV BRA Split 3 8V4 Array (A) BRA Split 4 1A BRA Split 4 16DA BRA Split 4 16A4 Vector (V) BRA Split 4 1V BRA Split 4 16DV BRA Split 4 16VNaming convention for algorithms ldquoBRA Splitrdquo + ltNumber of splitsgt + ltnature of memory structuregt xA xV x number of arrays and x number of vectorsxDA xDV single x-dimensional array and single x-dimensional vector
void mf BRM Split 1 1A (unsigned int ui NS int ui log2NS)
unsigned int ui Nunsigned int ui EBunsigned int ui tunsigned int ui Lunsigned int ui DL
ui N = ui NS Number of samplesui t = ui log2NS minus 1ui EB = ui N2ui L = 1unsigned intlowast BRP = new unsigned int[ui N]BRP[0] = 0BRP[ui EB] = 1for (unsigned int q = 0 q lt ui t q++)
ui DL = ui L + ui Lui N = ui N2for (unsigned int j = ui L j lt ui DL j++)
BRP[j] = BRP[j minus ui L] + ui NBRP[ui EB + j] = BRP[j] + 1
ui L = ui L + ui L
delete[] BRP
Algorithm 1 C++ implementation of new BRA with single array for split = 1 (BRA Split 1 1A)
Mathematical Problems in Engineering 7
Void mf BRM Split 2 4DV (unsigned int ui NS int ui log2NS)
unsigned int ui Nunsigned int ui EBunsigned int ui tunsigned int ui Lunsigned int ui DLui N = ui NS Number of samplesui t = ui log2NS minus 2ui EB = ui N4ui L = 1stdvectorltstdvectorltunsigned intgtgt BRP(4
stdvectorltunsigned intgt(ui EB))BRP[0][0] = 0BRP[1][0] = 2BRP[2][0] = 1BRP[3][0] = 3for (unsigned int q = 0 q lt ui t q++)
ui DL = ui L + ui Lui N = ui N2for (unsigned int j = ui L j lt ui DL j++)
BRP[0][j] = BRP[0][j minus ui L] + ui NBRP[1][j] = BRP[0][j] + 2BRP[2][j] = BRP[0][j] + 1BRP[3][j] = BRP[1][j] + 1
ui L = ui L + ui L
Algorithm 2 C++ implementation of new BRA with four arrays for split = 2 (BRM Split 2 4A)
0 8 4 12 2 10 6 14 1 9 5 13 3 11 7 15
Initialization
First iteration Seventh (last) iteration
Figure 2 Permutation filling sequence of new BRA with single memory structure for 119899 = 16 and split =1 (BRA Split 1 1A)
For large 119896 2119896 + 1 asymp 2119896 Then
119896
sum
119905=0
2119905= 2119896+1
(11)
Because the considered sample size is 221 to 231 the value 119896can be considered as large Then from (9)
OPPE =1198621lowast (2119896minus119904)
2119896
(12)
OPPE = 1198621
2119904 (13)
According to (13) OPPE is 119891(1198621 119904) The value 119862
1(oper-
ations in inner loop) and the value 119904 (number of splits) are aconstant for a certain algorithm
To evaluate the performance of new BRA we selectedthree algorithms (LBRA EBR and BRA-Ru) which used apattern instead of conventional bit reversing method Theperformance of vector and array versions of the best version
Table 5 The number of operations in the inner loop (1198621) of each
algorithm for different splits (119904) (The total number of operations ineach algorithm asymp 119862
1)
Memory structure type Value of 1198621
119904 = 1 119904 = 2 119904 = 3 119904 = 4
Single one-dimension (array and vector) 8 15 30 61Multidimension (array and vector) 7 11 19 35Multiple one-dimension (array and vector) 7 11 19 35
of new BRA was compared with the relevant versions ofselected algorithms
3 Results and Discussion
Our objective was to introduce BRA using recursive patternof the BRP that we identified We used multiple memorystructures which is a feasible yet unpopular technique toimplement index mapping According to Table 5 the num-bers of operations in all the array and vector versions of both
8 Mathematical Problems in Engineering
Void mf BRM Split 2 4A (unsigned int ui NS int ui log2NS)
unsigned int ui Nunsigned int ui EBunsigned int ui tunsigned int ui Lunsigned int ui DL
ui N = ui NS Number of samplesui t = ui log2NS minus 2ui EB = ui N4ui L = 1unsigned intlowast BRP1 = new unsigned int[ui EB]unsigned intlowast BRP2 = new unsigned int[ui EB]unsigned intlowast BRP3 = new unsigned int[ui EB]unsigned intlowast BRP4 = new unsigned int[ui EB]
BRP1[0] = 0BRP2[0] = 2BRP3[0] = 1BRP4[0] = 3for (unsigned int q = 0 q lt ui t q++)
ui DL = ui L + ui Lui N = ui N2for (unsigned int j = ui L j lt ui DL j++)
BRP1[j] = BRP1[j minus ui L]+ ui NBRP2[j] = BRP1[j] + 2BRP3[j] = BRP1[j] + 1BRP4[j] = BRP2[j] + 1
ui L = ui L + ui L
delete[] BRO1delete[] BRO2delete[] BRO3delete[] BRO4
Algorithm 3 C++ implementation of new BRA with four one-dimensional arrays for split = 2 (BRM Split 2 4A)
0 8 4 12
2 10 6 14
1 9 5 13
3 11 7 15
Initi
aliz
atio
n
Third
(las
t) ite
ratio
n
First iteration
Figure 3 Permutation filling sequence of 4 individual and single 4-dimensional memory structure for 119899 = 16
multidimensional and multiple memory structures are thesame Also Figure 5 shows continuous decrement of OPPEwhen the number of splits increases Then the algorithmwith the highest number of splits and the lowest number ofoperations is the one which is expected to be most efficient
However results in relation with CPE (Figure 5) show thatthe new algorithm with four memory structures of array isthe fastest and most consistent in the selected range Twofour eight and sixteen multiple array implementations ofnew BRA reported 25 34 33 and 18 higher efficiency
Mathematical Problems in Engineering 9
0
1
2
3
4
5
6
Refalgorithms
Ope
ratio
ns p
er el
emen
t (O
PPE)
Split = 1 Split = 2 Split = 3 Split = 4
Corresponds to both array and vector versions of algorithm of rudioCorresponds to both array and vector versions of ldquolinear bit reversalrdquo algorithmCorresponds to both array and vector versions of ldquoelsterrsquos bit reversalrdquo algorithmCorresponds to both array and vector versions of the new algorithm in
Corresponds to both array and vector versions of the new algorithm in
Corresponds to both array and vector versions of the new algorithm in
signal one-dimensional memory structure
signal multi-dimensional memory structure
signal multiple one-dimensional memory structure
Figure 4 Operations per element versus reference algorithms and new algorithm with different s (splits) where dashed column correspondsto both array and vector versions of algorithm of Rudio cross lines column corresponds to both array and vector versions of ldquoLinear BitReversalrdquo algorithm dotted column corresponds to both array and vector versions of ldquoElsterrsquos Bit Reversalrdquo algorithm vertical lines columncorresponds to both array and vector versions of the new algorithm in single one-dimensional memory structure inclined lines columncorresponds to both array and vector versions of the new algorithm in single multidimensional memory structure and horizontal linescolumn corresponds to both array and vector versions of the new algorithm in multiple one-dimensional memory structures
respectively in relation to the array version of LBRA Thealgorithm with eight memory structures has nearly the sameCPE as the four-array and four-vector versions but is lessconsistent On the other hand the four-vector implementa-tion of the new algorithm is the fastest and most consistentamong all vector versions Two four eight and sixteenmultiple vector implementations of new BRA reported 1316 and 16 higher and 23 lower efficiency respectively inrelation to the vector version of LBRAThis result proves thatat a certain point multiple memory structure gives the bestperformances in the considered domain Also usage of mul-tiple memory structures of primitive array is a good optionfor implementing index mapping of BRP compared to multi-dimensional or single one-dimensional memory structures
Due to the flexible nature of the vector it is commonlyused for implementing algorithms According to Figure 4there is no difference in OPPE between array and vectorversionsHowever our results in Figure 5 show that the vectorversions of BRA always required more CPE (44ndash142)than the array version The structure of vector gives priorityto generality and flexibility rather than to execution speedmemory economy cache efficiency and code size [22]There-fore vector is not a good option with respect to efficiency
The results in Table 5 and Figure 4 show that there is nodifference between the number of calculations and OPPEfor equal versions of algorithms with multidimensional andmultiple memory structure Structure and type of calcula-tions are the same for both types The only difference is thenature of the memory structure multidimension or multipleone-dimension When CPE is considered it shows 19ndash79
performance efficiency from algorithms with multiple one-dimension memory structures The reason for that observa-tion is that the memory access of multidimensional memorystructure is less efficient than one-dimensional memorystructure [22]
We agree with the statement of Elster about indexmapping of BRP [2] and the generally accepted fact (theusage of multidimensional memory structures reduces theperformance of a computer) [4] only with respect to multi-dimensional memory structures of vector Our results showthat even with multidimensional arrays there are situationswhere the new BRA performs better than the same typeof one-dimensional memory structure The four eight andsixteen dimensional array versions of new BRA perform 810 and 2 in relation to one-dimensional array version ofnew BRA Some results in relation to single one-dimensionalmemory structure implementation of new BRA are also notin agreement with the general accepted idea For examplesample size = 231 the two-dimensional vector version of newBRA (BRA Split 1 2DV) reported 542119864 minus 05 CPE which is389 higher in relation to average CPE of sample size rangeof 221 to 230 Also the inconsistency was very highThereforewe excluded values related to sample size = 231 for the two-dimensional vector version
We observed very high memory utilization with the two-dimensional vector version especially with sample size =231 Windows task manager showed that the memory uti-lization of all the considered algorithms was nearly thesame for all sample sizes except for multidimension versionsof vector The multidimensional version of vector initially
10 Mathematical Problems in Engineering
Cloc
ks p
er el
emen
t (CP
E)
000E + 00
500E minus 06
100E minus 05
150E minus 05
200E minus 05
250E minus 05
300E minus 05
BRM
split
01x
BRM
split
12x
BRM
split
24x
BRM
split
38x
BRM
split
416x
lowastBR
Msp
lit12
Dx
BRM
split
24
Dx
BRM
split
38
Dx
BRM
split
416
Dx
BRM
split
11x
BRM
split
21x
BRM
split
31x
BRM
split
41x
x-A or V (array or vector)Algorithms
Refe
renc
e alg
orith
m o
ne-
dim
ensio
nal s
ingl
e mem
ory
struc
ture
of s
izen
Multiple memorystructures
1
1
2
k
k
k
k = 2s
n sample size
Multidimensionalmemory structure
One-dimensionalmemory structure
nknk
nk
middotmiddotmiddot
middotmiddotmiddot
(s = 1 2 3 4)
Corresponds to array version of the algorithmCorresponds to vector version of the algorithmCorresponds to minimum reported CPE of the category
Figure 5 Clocks per element (combined average) versus algorithm for the sample size range from 221 to 231 where blue dotted columncorresponds to array version of the algorithm green column corresponds to vector version of the algorithm and red rhombus corresponds tominimum reported CPE of the category lowastFor vector version sample size 231 was excluded because at sample size 231 it showed huge deviationdue to memory limitation of the machine
utilizes highermemory and drops down to normal valueTheresults in relation to sample size = 2
30 showed that the extramemory requirement of two dimension vector was higherthan that of the four-dimensional vector Based upon that itcan be predicted that BRA Split 1 2DV needs an extra 3GB(total 13 GB) for normal execution at sample size = 2
31 butthe total memory barrier of 12GB of the machine slows theprocess down The most likely reason for this observation isthe influence ofmemory poolingmechanismWhen defininga memory structure it is possible to allocate the requiredamount of memory This is known as memory pooling [23]In all the memory structures used in algorithms discussedin this paper we used memory pooling Memory poolingallocates the required memory at startup and divides thisblock into small chunks If there is no memory poolingmemory will get fragmented Accessing fragmented memoryis inefficient When the existing memory is not enough forallocating then it switches to use fragmented memory forallocating memory elements In the considered situation theexisting memory (12GB) is not sufficient for allocating therequired amount (13GB) which switches to use fragmentedmemory
The total cache size of the machine is 825MB whichis less than the minimum memory utilization of consideredalgorithms (16MB to 8GB) in relation to the sample sizerange from 222 to 231 Only the sample size 221 occupies 8MBmemory which is less than the total cache memory ExceptBRA Split 4 1V structure all algorithms reported constantCPE in relation to the entire sample size range The bestalgorithms of each category especially reported very steady
behaviour This observation is in disagreement with thestatement of Karp ldquothat a machine with hierarchical memorydoes not performwell when array size is larger than the cachesizerdquo [10]
Comparison (Figure 6) of best reported version in theconsidered domain (four memory structure version) andthe selected algorithms shows that the array version ofEBR performs the best The four-array version of new BRAreported 1 lower performance than the array version ofEBR However the four-array version of new BRA reported34 and 23 higher performances than array versions ofLBRA and BRA-Ru Also the four-vector version of newBRA is reported to have the best performance among all thevector versions It reported 16 10 and 22 performancescompared to vector versions of LBRA EBR and BRA-Rurespectively
4 Conclusion and Outlook
Themain finding of this paper is the recursive pattern of BPRand the implementationmethod of it using multiple memorystructures With multiple memory structures especiallythe newly identified index mapping performs much betterthan multidimensional or single one-dimensional memorystructure Furthermore findings of this paper show that theperformance of primitive array is higher than vector typeThe result is in disagreement with the statement of Karp ldquothata machine with hierarchical memory does not perform wellwhen array size is larger than the cache sizerdquo Almost all thesample sizes we used were higher than the total cache size
Mathematical Problems in Engineering 11
120E ndash 05
100E minus 05
800E minus 06
600E minus 06
400E minus 06
200E ndash 06
000E + 00
Cloc
ks p
er el
emen
t (CP
E)
BRM
split
24x
(the b
est v
ersio
nof
the n
ewal
gorit
hm)
Line
ar b
it-re
vers
al1x
Elste
rrsquos b
it-
Rubi
o1x
reve
rsal
1x
x-A or V (array or vector)Algorithms
Corresponds to array version of the algorithmCorresponds to vector version of the algorithm
Figure 6 Clocks per element versus best version of new algorithm and selected algorithms where blue dotted column corresponds to arrayversion and green column corresponds to vector version of the algorithm
1
1
1
1
1
0
1
0
1
0
1
0
Process 1
Process 2
Process 5
Process 6Process 3
Process 4
Process 7
4 parallel processes
2 parallel processes
Single process
Tota
l sig
nal i
s div
ided
into
equa
l fou
r ind
epen
dent
mem
ory
struc
ture
s usin
g ne
w al
gorit
hm (B
RMsp
lit24x
)
x(0)
x(4)
x(2)
x(6)
x(1)
x(5)
x(3)
x(7)
minus1
w04
w14
w24
w34
w04
w14
w24
w34
A(0)
A(1)
A(2)
A(3)
B(0)
B(1)
B(2)
B(3)
x(0)
x(1)
x(2)
x(3)
x(4)
x(5)
x(6)
x(7)
minus1
minus1
minus1
Figure 7 Four-memory-structure version of algorithm and the parallel processes for sample size = 16
of the computer However multiple memory structure andthe multidimensional memory structure versions showedreasonable steady performancewith those samples In generalthese results show the effects of data structures and memoryallocation techniques and open a new window of creatingefficient algorithms with multiple memory structures inmany other fields where index mapping is involved
The new bit reversal algorithm with 2119904 independent
memory structures splits the total signal into 119904 independentportions and the total FFT process into 119904 + 1 levels Thenthese 119904 signal portions can be processed independently bymeans of 119904 independent processes on the first level Onthe next level the results from the previous level stored inindependent memory structures can be processed with 1199042
12 Mathematical Problems in Engineering
processes and so on until the last level Therefore we suggestusing the concept of multiple memory structures in total FFTprocess along with the new algorithm with multiple memorystructures and suitable parallel processing technique Weexpect that it is possible to achieve higher performance fromFFT process with proper combination of parallel processingtechnique and new algorithm compared to using the newalgorithm only to create bit reversal permutation Figure 7shows such approach with four (when 119904 = 2) independentmemory structures for sample size = 16
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
Acknowledgment
This publication is financially supported by the UniversityGrants Commission Sri Lanka
References
[1] C S Burrus ldquoUnscrambling for fast DFT algorithmsrdquo IEEETransactions on Acoustics Speech and Signal Processing vol 36no 7 pp 1086ndash1087 1988
[2] A C Elster and J C Meyer ldquoA super-efficient adaptable bit-reversal algorithm for multithreaded architecturesrdquo in Pro-ceedings of the IEEE International Symposium on Parallel ampDistributed Processing (IPDPS 09) vol 1ndash5 pp 1ndash8 Rome ItalyMay 2009
[3] J W Cooley and J W Tukey ldquoAn algorithm for the machinecalculation of complex Fourier seriesrdquoMathematics of Compu-tation vol 19 no 90 pp 297ndash301 1965
[4] M L Massar R Bhagavatula M Fickus and J KovacevicldquoLocal histograms and image occlusion modelsrdquo Applied andComputational Harmonic Analysis vol 34 no 3 pp 469ndash4872013
[5] R G Lyons Understanding Digital Signal Processing PrenticeHall PTR 2004
[6] C Deyun L Zhiqiang G Ming W Lili and Y XiaoyangldquoA superresolution image reconstruction algorithm based onlandweber in electrical capacitance tomographyrdquoMathematicalProblems in Engineering vol 2013 Article ID 128172 8 pages2013
[7] Q Yang and D An ldquoEMD and wavelet transform based faultdiagnosis for wind turbine gear boxrdquo Advances in MechanicalEngineering vol 2013 Article ID 212836 9 pages 2013
[8] C S Burrus Fast Fourier Transforms Rice University HoustonTex USA 2008
[9] C van Loan Computational Frameworks for the Fast FourierTransform vol 10 of Frontiers in Applied Mathematics Societyfor Industrial and Applied Mathematics (SIAM) PhiladelphiaPa USA 1992
[10] A H Karp ldquoBit reversal on uniprocessorsrdquo SIAM Review vol38 no 1 pp 1ndash26 1996
[11] A C Elster ldquoFast bit-reversal algorithmsrdquo in Proceedings ofthe International Conference on Acoustics Speech and SignalProcessing pp 1099ndash1102 IEEE Press Glasgow UK May 1989
[12] M Rubio P Gomez and K Drouiche ldquoA new superfast bitreversal algorithmrdquo International Journal of Adaptive Controland Signal Processing vol 16 no 10 pp 703ndash707 2002
[13] B Stroustrup Programming Principles and Practice Using C++Addison-Wesley 2009
[14] B Stroustrup ldquoSoftware development for infrastructurerdquo IEEEComputer Society vol 45 no 1 Article ID 6081841 pp 47ndash582012
[15] B Stroustrup The C++ Programming Language ATampT Labs3rd edition 1997
[16] S DonovanC++ by Example ldquoUnderCrdquo Learning Edition QUECorporation 2002
[17] S Mcconnell Code Complete Microsoft Press 2nd edition2004
[18] Microsoft STL Containers Microsoft New York NY USA2012 httpmsdnmicrosoftcomen-uslibrary1fe2x6ktaspx
[19] Microsoft Arrays (C++ Component Extensions) MicrosoftNew York NY USA 2012 httpmsdnmicrosoftcomen-uslibraryvstudiots4c4dw6(v=vs110)aspx
[20] B Stroustrup ldquoEvolving a language in and for the real worldC++ 1991ndash2006rdquo in Proceedings of the 3rd ACM SIGPLANHistory of Programming Languages Conference (HOPL-III rsquo07)June 2007
[21] Microsoft Memory Limits for Windows Releases MicrosoftNew York NY USA 2012 httpmsdnmicrosoftcomen-uslibraryaa36677828VS8529aspxmemory limits
[22] A Fog ldquoOptimizing software in C++rdquo 2014 httpwwwagnerorgoptimize
[23] Code Project ldquoC++ Memory Poolrdquo 2014 httpwwwcodepro-jectcomArticles15527C-Memory-Pool
Submit your manuscripts athttpwwwhindawicom
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical Problems in Engineering
Hindawi Publishing Corporationhttpwwwhindawicom
Differential EquationsInternational Journal of
Volume 2014
Applied MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Probability and StatisticsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
OptimizationJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
CombinatoricsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Operations ResearchAdvances in
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Function Spaces
Abstract and Applied AnalysisHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of Mathematics and Mathematical Sciences
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Algebra
Discrete Dynamics in Nature and Society
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Decision SciencesAdvances in
Discrete MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom
Volume 2014 Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Stochastic AnalysisInternational Journal of

2 Mathematical Problems in Engineering
must be arranged according to a certain order to obtain thecorrect output [3 5 8 9]The BRA is used to create the orderof input or output permutation according to the requiredorder The BRA used in most FFT algorithms including theoriginal Cooley-Tukey algorithm [3] is known as bit reversalmethod (BRM)TheBRM is an operation for exchanging twoelements 119909(119896) and 119909(119896) of an array of length 119898 as shown in(1) and (2) respectively where 119886
119895are either 0 or 1 and 119887 is the
relevant base 2 4 8 or 16 depending on the selected radixstructure
119896 =
119898minus1
sum
119895=0
119886119895119887119895 (1)
119896 =
119898minus1
sum
119895=0
119886119895119887119898minus1minus119895
(2)
All the later algorithms for creating BRP were named as BRA(bit reversal algorithm) though they used other techniqueslike patterns of BRP instead of bit reversing techniques
During the last decades many publications addressednew BRAs [10] by improving the already existing originalBRA (BRM) or using totally different approaches In 1996Karp compared the performance of 30 different algorithms[10] against uniprocessor systems (computer system with asingle central processing unit) with different memory sys-tems Karp found that the performance of a BRA dependedon the memory architecture of the machine and the wayof accessing the memory Karp stated two hardware factsthat influence the BRA namely the memory architectureand the cache size of the machine According to Karp amachine with hierarchical memory is slower than a machinewith vector memory (computers with vector processor) andalgorithms do not perform well when array size is largerthan the cache size Also Karp pointed out four featuresof an algorithm that influence the BRA namely memoryaccess technique data reading sequence size of the indexof memory and type of arithmetic operations Accordingto Karp an algorithm that uses efficient memory accesstechniques is the fastest among algorithms with exactly thesame number of arithmetic operations Algorithms are fasterif (i) they require only a single pass over the data (ii) they useshort indexes and (iii) they operate with addition instead ofmultiplication
Karp especially mentioned that the algorithm publishedby Elster [11] in 1989 was different from other algorithmsbecause it used a pattern of BRP rather than improving deci-mal to binary and binary to decimal conversion According tothe findings of Karp Elsterrsquos ldquoLinear Bit Reversal Algorithmrdquo(LBRA) performs much better in most of the cases Thepublication of Elster (1989) [11] consists of two algorithmsto achieve BRP One algorithm used a pattern of BRP andthe other one used bit shifting operations Both algorithmsare interesting because they eliminate the conventional bitreversingmechanism which needmore computing timeThealgorithm by Rubio et al (BRA-Ru) of 2002 [12] is anotherapproach that uses an existing pattern of BRP However thepattern described in Rubiorsquos algorithm is different from the
pattern described in Elsterrsquos [11] In 2009 Elster and Meyerpublished an improved version of ldquoLinear Register-Level BitReversalrdquo which was published in 1989 [11] as ldquoElsterrsquos BitReversalrdquo (EBR) algorithm Elster mentioned it is possible togenerate the second half of the BRP by incrementing the rel-evant element of the first half by one Also Elster mentionedthere can be a serious impact on cache performance of thecomputer if the said pattern (Figure 1) is used
Programming languages provide different data structures[13] which handle memory in different ways In additionthe performance of the memory depends on machine archi-tecture and operating system [14] Therefore the efficiencyof the memory is the resultant output of the performancesof hardware operating system programming language andselected data structure
Based on the physical arrangement of memory elementsthere are two common ways of allocating memory for aseries of variables ldquoslot of continuousmemory elementsrdquo andldquocollection of noncontinuous memory elementsrdquo commonlyknown as ldquostackrdquo and ldquoheaprdquo [15] In most programminglanguages the term array is used to refer to a ldquoslot ofcontinuous memory elementsrdquo Arrays are the simplest andmost common type of data structure [16 17] and due tocontinuous physical arrangement of memory elements pro-vide faster access than ldquocollection of noncontinuous memoryelementsrdquo memory types However with the development ofprogramming languages different types of data structureswere introduced with very similar names to the standardnames like array stack and heap The names of new datastructures sometimes did not agree with the commonlyaccepted meaning ldquoStackrdquo ldquoArrayrdquo and ldquoArrayListrdquo providedby Microsoft Visual C++ (VC++) [18 19] are good examplesAccording to the commonly accepted meaning they shouldbe a ldquoslot of continuousmemory elementsrdquo but they are in facta ldquocollection of noncontinuousmemory elementsrdquoThereforeit is not a good practice to determine the performance of acertain data structure just by looking at its name To overcomethis ambiguous situation we use ldquoslot of continuous memoryelementsrdquo to refer to ldquoprimitive arrayrdquo (or array) typememorystructures
Due to the very flexible nature vector is the mostcommon one among the different types of data structures[14] Vector was introduced with C++ which is one of themost common and powerful programming languages whichhas been used since 1984 [20] However as most of otherdata structures the term ldquovectorrdquo is used to refer to memoryin computers with processor architecture called ldquovectorprocessorrdquo In this paper the term vector is used to refer tothe vector data structure that is used in the C++ interface
Indexmapping is a technique that can be used to improvethe efficiency of an algorithm by reducing the arithmetic loadof the algorithm [8] If 119899 [0119873 minus 1] and 119873 is not prime 119873can be defined as 119873 = prod
119899119894minus1
119894=0119873119894 where 119899
119894 [0119873
119894minus 1] lt
119873 This allows the usage of small ranges of 119899119894instead of large
range of 119899 andmaps a function119891(119899) into amultidimensionalfunction 1198911015840(119899
1 1198992 119899
119894)
There are two common methods of implementing indexmapping one-dimensional or multidimensional memory
Mathematical Problems in Engineering 3
Normal order
Reverse order Pattern
Dec Bin Bin Dec
0 0000 0000 0
1 0001 1000 8
2 0010 0100 4
3 0011 1100 12
4 0100 0010 2
5 0101 1010 10
6 0110 0110 6
7 0111 1110 14
8 1000 0001 1 0 + 1
9 1001 1000 9 8 + 110 1010 0101 5 4 + 1
11 1011 1101 13 12 + 1
12 1100 0011 3 2 + 1
13 1101 1011 11 10 + 1
14 1110 0111 7 6 + 1
15 1111 1111 15 14 + 1
Bloc
k1
ndash8el
emen
tsBl
ock2
ndash8el
emen
tsFigure 1 Relation between first and second halves of the BRP for 119899 = 16
structures In addition it is also possible to implement theindex mapping using several equal size one-dimensionalmemory structures However this option is not popular asit is uncomfortable for programming The performance ofmodern computers is highly dependent on the effectivenessof the cache memory of the CPU [4] To achieve the best per-formance of a series of memory elements the best practice istomaintain sequential access [4] Otherwise the effectivenessof the cache memory of the central processing unit (CPU)will be reduced Index mapping with multidimensional datastructures violates sequential access due to switching betweencolumnsrows and thus reduces the effectiveness of thecache memory Therefore it is generally accepted that theuse of a multidimensional data structure reduces computerperformance [4]
In this paper an efficient BRA is introduced to createthe BRP based on multiple memory structures and recursivepatterns of BRPThe findings of this paper show that the com-bination of multiple one-dimensional memory structuresindex mapping and the recessive pattern of BRP can be usedto improve the efficiency of BRA These findings are veryimportant to the field of signal processing as well as any fieldthat is involved in index mapping techniques
2 Material and Methods
21 New Algorithm (BRA-Split) Elster stated that it is pos-sible to generate the second half of the BRP by increment-ing items in the first half by one [2] (Figure 1) withoutchanging the order and the total number of calculations of
the algorithm Due to the recursive pattern of BRP it canbe further divided into equal size blocks by splitting eachblock recursively (Maximum log
2N times) After splitting 119904
times BRP is divided into 2119904 equal blocks each containing1198992119904 elements The relation between the elements in blocks is
given as follows
119861 (2119898+ 119895) [119894] = 119861 (119895) [119894] + 2
119878minus119898minus1 (3)
where 119861(2119898 + 119895)[119894] is 119894th element of block 119861(2119898 + 119895) and119898 =
0 1 119904 minus 1 119895 = 1 2119898Table 1 shows the relationship between elements in blocks
according to the index mapping shown in (3) after splittingBRP one time and two times for 119899 = 16 Depending on therequirement the number of splitting can be increased
22 Evaluation Process of New Algorithm To evaluate algo-rithms we used Windows 7 and Visual C++ 2012 on a PCwith multicore CPU (4 cores 8 logical processors) and 12GBmemory Detailed specifications of the PC and the softwareare given in Table 2 To eliminate limits of memory andaddress space related to the selected platform the compileroption ldquoLARGEADDRESSAWARErdquo was set [21] and plat-form was set to ldquox64rdquo All other options of the operatingsystem and the compiler were kept unchanged
The new algorithm was implemented using single one-dimensionalmemory structure and themost commonmulti-dimensional memory structure Furthermore the new BRAwas implemented using several equal size one-dimensionalmemory structures (multiple memory structure)
4 Mathematical Problems in Engineering
Table1Re
lationbetweenelem
entsof
16-elementB
RP(119899=16)for
split
=1and
split
=2
Normal
order
Reverse
order
Split
(119878)=1
Split
(119878=2)
Blocks
(12119904)
Index
ofthe
block119894
Reverseo
rder
calculation
Calculationmetho
d119898=0119904minus1(119898=0)
119895=12119898
119898=0119895=1
119894=11198992119904minus1
119894=17
Blocks
(12119904)
Indexof
the
block119894
Reverseo
rder
calculation
Calculationmetho
d119898=0119904minus1(119898=01)
119895=12119898
119898=0119895=1119898=1119895=12
119894=11198992119904minus1
119894=123
00
1
00
Initialized
00
Initialized
18
18=8+0
Use
Elste
rrsquosLinear
BitR
eversalm
etho
d
11
8=8+0
Use
Elste
rrsquosLinear
BitR
eversalm
etho
d2
42
4=4+0
24=4+0
312
312
=12
+0
312
=12
+0
42
42=2+0
02
Initialized
510
510
=10
+0
21
10=8+2
119861(2119898+119895)[119894]=119861(119895)[119894]+2119904minus119898minus1
66
66=6+0
26=4+2
For119898
=0119895=1119894=123
119861(20+1)[119894]=119861(1)[119894]+22minus0minus1
714
714
=14
+0
314
=12
+2
119861(2)[119894]=119861(1)[119894]+2
81
2
01
Initialized
01
Initialized
99
19=8+1
119861(2119898+119895)[119894]=119861(119895)[119894]+2119904minus119898minus1
For119898
=0119895=1119894=17
119861(20+1)[119894]=119861(1)[119894]+22minus0minus1
119861(2)[119894]=119861(1)[119894]+1
31
9=8+1
119861(2119898+119895)[119894]=119861(119895)[119894]+2119904minus119898minus1
105
25=4+1
25=4+1
For119898
=1119895=1119894=123
119861(21+1)[119894]=119861(1)[119894]+22minus1minus1
1113
313
=12
+1
313
=12
+1
119861(3)[119894]=119861(1)[119894]+1
123
43=2+1
03
Initialized
1311
511=10
+1
41
11=10
+1
119861(2119898+119895)[119894]=119861(119895)[119894]+2119904minus119898minus1
147
67=6+1
27=6+1
For119898
=1119895=2119894=123
119861(21+2)[119894]=119861(2)[119894]+22minus1minus1
1515
715
=14
+1
315
=14
+1
119861(4)[119894]=119861(2)[119894]+2
Mathematical Problems in Engineering 5
Table 2 Hardware and software specifications of the PC
Specifications
Processor Intel Core i7 CPU 870 293GHz (4 cores8 threads)
RAM 12GB DDR3-1333 2 channelsMemory bandwidth 21GBsL1 L2 and L3 cache 4 times 64KB 4 times 256KB and 8MB sharedL1 L2 and L3 cacheline size 64 bit
Brand and type Fujitsu CelsiusBIOS settings Default (hyper threading enabled)OS and service pack Windows 7 professional with service pack 1System type 64 bit operating systemOS settings DefaultVisual Studio 2012 Version 110507271 RTMRELNET Framework Version 4550709
Thenext taskwas to identify a suitable data structure fromdifferent types of available data structures We consideredseveral common techniques as summarized in Table 3 Datastructure 1 mentioned in Table 3 is not supporting dynamicmemory allocation (need to mention the size of the arraywhen array is being declared) For general bit reversalalgorithm it is a must to have dynamic memory allocation tocater different sizes of samples Even after setting the compileroption ldquoLARGEADDRESSAWARErdquo [21] data structures 3and 4 mentioned in Table 3 were not supported for accessingmemory greater than 2GB Therefore structures 1 3 and 4were rejected and memory structures 2 (array) and 5 (vector)were used to create all one-dimensional memory structuresThe same versions of array and vector were used to createmultidimensional memory structures
The new algorithm mentioned in Section 21 was imple-mented usingC++ in 24 types ofmemory structures as shownin Table 4 The performance of these algorithms was evalu-ated considering the ldquoclocks per elementrdquo (CPE) consumedbyeach algorithm To retrieve this value first average CPE foreach sample size of 2119899 where 119899 [21 31] (11 sample sizes) werecalculated after executing each algorithm 100 timesThis gave11 CPE representing each sample size Finally the combinedaverageof CPEwas calculated for each algorithmby averagingthose 11 values along with ldquocombined standard deviationrdquoThe combined average of CPE was considered as the CPEfor each algorithm The built-in ldquoclockrdquo function of C++ wasused to calculate the clocks Combined standard deviationwas calculated using the following
120590119888= (
sum119896
119904=1(1198991199041205902
119904+ 119899119904(119883119904minus 119883119888)
2
)
sum119896
119904=1119899119904
)
12
(4)
where119883119888= sum119896
119904=1119899119904119883119904sum119896
119904=1119899119904 119904 is the number of samples 119899
119904
is number of samples in each sample and 120590119904is the standard
deviation of each sample
Algorithms 1 2 and 3 illustrate the implementation ofnew BRA with single one-dimensional memory structuremultidimensional memory structure and multiple mem-ory structures respectively The algorithm illustrated inAlgorithm 1 (BRA Split 1 1A) was implemented using prim-itive array for split = 1 The algorithm BRM Split 2 4A(Algorithm 2) was implemented using vectors for split =2 The algorithm BRM Split 2 4A (Algorithm 3) was imple-mented using primitive array for split = 2 A sample per-mutation filling sequence of algorithms with single one-dimensional memory structures is illustrated in Figure 2Figure 3 illustrates a sample permutation filling sequence ofboth multidimensional and multiple memory structures
Secondly arithmetic operations per element (OPPE)werecalculated for each algorithm Arithmetic operations withineach algorithm were located in three regions of the codeinner FOR loop outer FOR loop and outside of the loopsThen the total number of operations (OP) can be defined as
OP = 1198701lowast 1198621+ 1198702lowast 1198622+ 1198623 (5)
where 1198621 1198622 and 119862
3are the number of operations in inner
FOR loop outer FOR loop and outside of the loops 1198701and
1198702are the number of iterations of outer loop and inner loop
Equation (5) can be represented as
OP =log2(NS)minus119904minus1
sum
119905=0
2119905lowast 1198621+
log2(NS)minus119904minus1
sum
119905=0
1198622+ 1198623 (6)
where NS is the number of samples and 119904 is the number ofsplits
The main contribution to calculations comes from theinner loop Comparing with the contribution of operationsin the inner loop the contribution of operations in rest ofthe code is very small For example consider the algorithmBRA Split 1 1A shown in Algorithm 1 As sample size is 2311198701lowast 1198621asymp 215 lowast 10
9lowast 1198621and 119870
2lowast 1198622+ 1198623asymp 1000 where
1198621gt 1 Therefore only the operations of inner loop were
considered for evaluation Then (6) can be simplified as
OP =log2(NS)minus119904minus1
sum
119905=0
2119905lowast 1198621 (7)
The ldquooperations per elementrdquo (OPPE) can be defined as
OPPE =(sum
log2(NS)minus119904minus1
119905=02119905lowast 1198621)
NS
(8)
For FFT always NS = 2119896 119896 isin 119885+Then from (7)
OPPE =(sum119896minus119904minus1
119905=02119905lowast 1198621)
2119896
(9)
119896
sum
119905=0
2119905+ 1 = 2
119896+1 (10)
6 Mathematical Problems in Engineering
Table 3 Common memory allocating methods that are used in Visual C++
Number Name Syntax Nature of memory layout1 Array int BRP[1000] Slot of continuous memory elements2 Array intlowast BRP = new int[119899] Slot of continuous memory elements3 Array array⟨int⟩andBRP = gcnew array⟨int⟩(119899) Collection of noncontinuous memory elements4 ArrayList ArrayList andBRP = gcnew ArrayList() Collection of noncontinuous memory elements5 Vector stdvector⟨int⟩ BRP(119899) Collection of noncontinuous memory elements
Table 4 Different versions of new BRA implemented with different data structures
Split (s) Data structure type AlgorithmSingle memory structure Multidimensional memory structure Multiple memory structure
1 Array (A) BRA Split 1 1A BRA Split 1 2DA BRA Split 1 2A1 Vector (V) BRA Split 1 1V BRA Split 1 2DV BRA Split 1 2V2 Array (A) BRA Split 2 1A BRA Split 2 4DA BRA Split 2 4A2 Vector (V) BRA Split 2 1V BRA Split 2 4DV BRA Split 2 4V3 Array (A) BRA Split 3 1A BRA Split 3 8DA BRA Split 3 8A3 Vector (V) BRA Split 3 1V BRA Split 3 8DV BRA Split 3 8V4 Array (A) BRA Split 4 1A BRA Split 4 16DA BRA Split 4 16A4 Vector (V) BRA Split 4 1V BRA Split 4 16DV BRA Split 4 16VNaming convention for algorithms ldquoBRA Splitrdquo + ltNumber of splitsgt + ltnature of memory structuregt xA xV x number of arrays and x number of vectorsxDA xDV single x-dimensional array and single x-dimensional vector
void mf BRM Split 1 1A (unsigned int ui NS int ui log2NS)
unsigned int ui Nunsigned int ui EBunsigned int ui tunsigned int ui Lunsigned int ui DL
ui N = ui NS Number of samplesui t = ui log2NS minus 1ui EB = ui N2ui L = 1unsigned intlowast BRP = new unsigned int[ui N]BRP[0] = 0BRP[ui EB] = 1for (unsigned int q = 0 q lt ui t q++)
ui DL = ui L + ui Lui N = ui N2for (unsigned int j = ui L j lt ui DL j++)
BRP[j] = BRP[j minus ui L] + ui NBRP[ui EB + j] = BRP[j] + 1
ui L = ui L + ui L
delete[] BRP
Algorithm 1 C++ implementation of new BRA with single array for split = 1 (BRA Split 1 1A)
Mathematical Problems in Engineering 7
Void mf BRM Split 2 4DV (unsigned int ui NS int ui log2NS)
unsigned int ui Nunsigned int ui EBunsigned int ui tunsigned int ui Lunsigned int ui DLui N = ui NS Number of samplesui t = ui log2NS minus 2ui EB = ui N4ui L = 1stdvectorltstdvectorltunsigned intgtgt BRP(4
stdvectorltunsigned intgt(ui EB))BRP[0][0] = 0BRP[1][0] = 2BRP[2][0] = 1BRP[3][0] = 3for (unsigned int q = 0 q lt ui t q++)
ui DL = ui L + ui Lui N = ui N2for (unsigned int j = ui L j lt ui DL j++)
BRP[0][j] = BRP[0][j minus ui L] + ui NBRP[1][j] = BRP[0][j] + 2BRP[2][j] = BRP[0][j] + 1BRP[3][j] = BRP[1][j] + 1
ui L = ui L + ui L
Algorithm 2 C++ implementation of new BRA with four arrays for split = 2 (BRM Split 2 4A)
0 8 4 12 2 10 6 14 1 9 5 13 3 11 7 15
Initialization
First iteration Seventh (last) iteration
Figure 2 Permutation filling sequence of new BRA with single memory structure for 119899 = 16 and split =1 (BRA Split 1 1A)
For large 119896 2119896 + 1 asymp 2119896 Then
119896
sum
119905=0
2119905= 2119896+1
(11)
Because the considered sample size is 221 to 231 the value 119896can be considered as large Then from (9)
OPPE =1198621lowast (2119896minus119904)
2119896
(12)
OPPE = 1198621
2119904 (13)
According to (13) OPPE is 119891(1198621 119904) The value 119862
1(oper-
ations in inner loop) and the value 119904 (number of splits) are aconstant for a certain algorithm
To evaluate the performance of new BRA we selectedthree algorithms (LBRA EBR and BRA-Ru) which used apattern instead of conventional bit reversing method Theperformance of vector and array versions of the best version
Table 5 The number of operations in the inner loop (1198621) of each
algorithm for different splits (119904) (The total number of operations ineach algorithm asymp 119862
1)
Memory structure type Value of 1198621
119904 = 1 119904 = 2 119904 = 3 119904 = 4
Single one-dimension (array and vector) 8 15 30 61Multidimension (array and vector) 7 11 19 35Multiple one-dimension (array and vector) 7 11 19 35
of new BRA was compared with the relevant versions ofselected algorithms
3 Results and Discussion
Our objective was to introduce BRA using recursive patternof the BRP that we identified We used multiple memorystructures which is a feasible yet unpopular technique toimplement index mapping According to Table 5 the num-bers of operations in all the array and vector versions of both
8 Mathematical Problems in Engineering
Void mf BRM Split 2 4A (unsigned int ui NS int ui log2NS)
unsigned int ui Nunsigned int ui EBunsigned int ui tunsigned int ui Lunsigned int ui DL
ui N = ui NS Number of samplesui t = ui log2NS minus 2ui EB = ui N4ui L = 1unsigned intlowast BRP1 = new unsigned int[ui EB]unsigned intlowast BRP2 = new unsigned int[ui EB]unsigned intlowast BRP3 = new unsigned int[ui EB]unsigned intlowast BRP4 = new unsigned int[ui EB]
BRP1[0] = 0BRP2[0] = 2BRP3[0] = 1BRP4[0] = 3for (unsigned int q = 0 q lt ui t q++)
ui DL = ui L + ui Lui N = ui N2for (unsigned int j = ui L j lt ui DL j++)
BRP1[j] = BRP1[j minus ui L]+ ui NBRP2[j] = BRP1[j] + 2BRP3[j] = BRP1[j] + 1BRP4[j] = BRP2[j] + 1
ui L = ui L + ui L
delete[] BRO1delete[] BRO2delete[] BRO3delete[] BRO4
Algorithm 3 C++ implementation of new BRA with four one-dimensional arrays for split = 2 (BRM Split 2 4A)
0 8 4 12
2 10 6 14
1 9 5 13
3 11 7 15
Initi
aliz
atio
n
Third
(las
t) ite
ratio
n
First iteration
Figure 3 Permutation filling sequence of 4 individual and single 4-dimensional memory structure for 119899 = 16
multidimensional and multiple memory structures are thesame Also Figure 5 shows continuous decrement of OPPEwhen the number of splits increases Then the algorithmwith the highest number of splits and the lowest number ofoperations is the one which is expected to be most efficient
However results in relation with CPE (Figure 5) show thatthe new algorithm with four memory structures of array isthe fastest and most consistent in the selected range Twofour eight and sixteen multiple array implementations ofnew BRA reported 25 34 33 and 18 higher efficiency
Mathematical Problems in Engineering 9
0
1
2
3
4
5
6
Refalgorithms
Ope
ratio
ns p
er el
emen
t (O
PPE)
Split = 1 Split = 2 Split = 3 Split = 4
Corresponds to both array and vector versions of algorithm of rudioCorresponds to both array and vector versions of ldquolinear bit reversalrdquo algorithmCorresponds to both array and vector versions of ldquoelsterrsquos bit reversalrdquo algorithmCorresponds to both array and vector versions of the new algorithm in
Corresponds to both array and vector versions of the new algorithm in
Corresponds to both array and vector versions of the new algorithm in
signal one-dimensional memory structure
signal multi-dimensional memory structure
signal multiple one-dimensional memory structure
Figure 4 Operations per element versus reference algorithms and new algorithm with different s (splits) where dashed column correspondsto both array and vector versions of algorithm of Rudio cross lines column corresponds to both array and vector versions of ldquoLinear BitReversalrdquo algorithm dotted column corresponds to both array and vector versions of ldquoElsterrsquos Bit Reversalrdquo algorithm vertical lines columncorresponds to both array and vector versions of the new algorithm in single one-dimensional memory structure inclined lines columncorresponds to both array and vector versions of the new algorithm in single multidimensional memory structure and horizontal linescolumn corresponds to both array and vector versions of the new algorithm in multiple one-dimensional memory structures
respectively in relation to the array version of LBRA Thealgorithm with eight memory structures has nearly the sameCPE as the four-array and four-vector versions but is lessconsistent On the other hand the four-vector implementa-tion of the new algorithm is the fastest and most consistentamong all vector versions Two four eight and sixteenmultiple vector implementations of new BRA reported 1316 and 16 higher and 23 lower efficiency respectively inrelation to the vector version of LBRAThis result proves thatat a certain point multiple memory structure gives the bestperformances in the considered domain Also usage of mul-tiple memory structures of primitive array is a good optionfor implementing index mapping of BRP compared to multi-dimensional or single one-dimensional memory structures
Due to the flexible nature of the vector it is commonlyused for implementing algorithms According to Figure 4there is no difference in OPPE between array and vectorversionsHowever our results in Figure 5 show that the vectorversions of BRA always required more CPE (44ndash142)than the array version The structure of vector gives priorityto generality and flexibility rather than to execution speedmemory economy cache efficiency and code size [22]There-fore vector is not a good option with respect to efficiency
The results in Table 5 and Figure 4 show that there is nodifference between the number of calculations and OPPEfor equal versions of algorithms with multidimensional andmultiple memory structure Structure and type of calcula-tions are the same for both types The only difference is thenature of the memory structure multidimension or multipleone-dimension When CPE is considered it shows 19ndash79
performance efficiency from algorithms with multiple one-dimension memory structures The reason for that observa-tion is that the memory access of multidimensional memorystructure is less efficient than one-dimensional memorystructure [22]
We agree with the statement of Elster about indexmapping of BRP [2] and the generally accepted fact (theusage of multidimensional memory structures reduces theperformance of a computer) [4] only with respect to multi-dimensional memory structures of vector Our results showthat even with multidimensional arrays there are situationswhere the new BRA performs better than the same typeof one-dimensional memory structure The four eight andsixteen dimensional array versions of new BRA perform 810 and 2 in relation to one-dimensional array version ofnew BRA Some results in relation to single one-dimensionalmemory structure implementation of new BRA are also notin agreement with the general accepted idea For examplesample size = 231 the two-dimensional vector version of newBRA (BRA Split 1 2DV) reported 542119864 minus 05 CPE which is389 higher in relation to average CPE of sample size rangeof 221 to 230 Also the inconsistency was very highThereforewe excluded values related to sample size = 231 for the two-dimensional vector version
We observed very high memory utilization with the two-dimensional vector version especially with sample size =231 Windows task manager showed that the memory uti-lization of all the considered algorithms was nearly thesame for all sample sizes except for multidimension versionsof vector The multidimensional version of vector initially
10 Mathematical Problems in Engineering
Cloc
ks p
er el
emen
t (CP
E)
000E + 00
500E minus 06
100E minus 05
150E minus 05
200E minus 05
250E minus 05
300E minus 05
BRM
split
01x
BRM
split
12x
BRM
split
24x
BRM
split
38x
BRM
split
416x
lowastBR
Msp
lit12
Dx
BRM
split
24
Dx
BRM
split
38
Dx
BRM
split
416
Dx
BRM
split
11x
BRM
split
21x
BRM
split
31x
BRM
split
41x
x-A or V (array or vector)Algorithms
Refe
renc
e alg
orith
m o
ne-
dim
ensio
nal s
ingl
e mem
ory
struc
ture
of s
izen
Multiple memorystructures
1
1
2
k
k
k
k = 2s
n sample size
Multidimensionalmemory structure
One-dimensionalmemory structure
nknk
nk
middotmiddotmiddot
middotmiddotmiddot
(s = 1 2 3 4)
Corresponds to array version of the algorithmCorresponds to vector version of the algorithmCorresponds to minimum reported CPE of the category
Figure 5 Clocks per element (combined average) versus algorithm for the sample size range from 221 to 231 where blue dotted columncorresponds to array version of the algorithm green column corresponds to vector version of the algorithm and red rhombus corresponds tominimum reported CPE of the category lowastFor vector version sample size 231 was excluded because at sample size 231 it showed huge deviationdue to memory limitation of the machine
utilizes highermemory and drops down to normal valueTheresults in relation to sample size = 2
30 showed that the extramemory requirement of two dimension vector was higherthan that of the four-dimensional vector Based upon that itcan be predicted that BRA Split 1 2DV needs an extra 3GB(total 13 GB) for normal execution at sample size = 2
31 butthe total memory barrier of 12GB of the machine slows theprocess down The most likely reason for this observation isthe influence ofmemory poolingmechanismWhen defininga memory structure it is possible to allocate the requiredamount of memory This is known as memory pooling [23]In all the memory structures used in algorithms discussedin this paper we used memory pooling Memory poolingallocates the required memory at startup and divides thisblock into small chunks If there is no memory poolingmemory will get fragmented Accessing fragmented memoryis inefficient When the existing memory is not enough forallocating then it switches to use fragmented memory forallocating memory elements In the considered situation theexisting memory (12GB) is not sufficient for allocating therequired amount (13GB) which switches to use fragmentedmemory
The total cache size of the machine is 825MB whichis less than the minimum memory utilization of consideredalgorithms (16MB to 8GB) in relation to the sample sizerange from 222 to 231 Only the sample size 221 occupies 8MBmemory which is less than the total cache memory ExceptBRA Split 4 1V structure all algorithms reported constantCPE in relation to the entire sample size range The bestalgorithms of each category especially reported very steady
behaviour This observation is in disagreement with thestatement of Karp ldquothat a machine with hierarchical memorydoes not performwell when array size is larger than the cachesizerdquo [10]
Comparison (Figure 6) of best reported version in theconsidered domain (four memory structure version) andthe selected algorithms shows that the array version ofEBR performs the best The four-array version of new BRAreported 1 lower performance than the array version ofEBR However the four-array version of new BRA reported34 and 23 higher performances than array versions ofLBRA and BRA-Ru Also the four-vector version of newBRA is reported to have the best performance among all thevector versions It reported 16 10 and 22 performancescompared to vector versions of LBRA EBR and BRA-Rurespectively
4 Conclusion and Outlook
Themain finding of this paper is the recursive pattern of BPRand the implementationmethod of it using multiple memorystructures With multiple memory structures especiallythe newly identified index mapping performs much betterthan multidimensional or single one-dimensional memorystructure Furthermore findings of this paper show that theperformance of primitive array is higher than vector typeThe result is in disagreement with the statement of Karp ldquothata machine with hierarchical memory does not perform wellwhen array size is larger than the cache sizerdquo Almost all thesample sizes we used were higher than the total cache size
Mathematical Problems in Engineering 11
120E ndash 05
100E minus 05
800E minus 06
600E minus 06
400E minus 06
200E ndash 06
000E + 00
Cloc
ks p
er el
emen
t (CP
E)
BRM
split
24x
(the b
est v
ersio
nof
the n
ewal
gorit
hm)
Line
ar b
it-re
vers
al1x
Elste
rrsquos b
it-
Rubi
o1x
reve
rsal
1x
x-A or V (array or vector)Algorithms
Corresponds to array version of the algorithmCorresponds to vector version of the algorithm
Figure 6 Clocks per element versus best version of new algorithm and selected algorithms where blue dotted column corresponds to arrayversion and green column corresponds to vector version of the algorithm
1
1
1
1
1
0
1
0
1
0
1
0
Process 1
Process 2
Process 5
Process 6Process 3
Process 4
Process 7
4 parallel processes
2 parallel processes
Single process
Tota
l sig
nal i
s div
ided
into
equa
l fou
r ind
epen
dent
mem
ory
struc
ture
s usin
g ne
w al
gorit
hm (B
RMsp
lit24x
)
x(0)
x(4)
x(2)
x(6)
x(1)
x(5)
x(3)
x(7)
minus1
w04
w14
w24
w34
w04
w14
w24
w34
A(0)
A(1)
A(2)
A(3)
B(0)
B(1)
B(2)
B(3)
x(0)
x(1)
x(2)
x(3)
x(4)
x(5)
x(6)
x(7)
minus1
minus1
minus1
Figure 7 Four-memory-structure version of algorithm and the parallel processes for sample size = 16
of the computer However multiple memory structure andthe multidimensional memory structure versions showedreasonable steady performancewith those samples In generalthese results show the effects of data structures and memoryallocation techniques and open a new window of creatingefficient algorithms with multiple memory structures inmany other fields where index mapping is involved
The new bit reversal algorithm with 2119904 independent
memory structures splits the total signal into 119904 independentportions and the total FFT process into 119904 + 1 levels Thenthese 119904 signal portions can be processed independently bymeans of 119904 independent processes on the first level Onthe next level the results from the previous level stored inindependent memory structures can be processed with 1199042
12 Mathematical Problems in Engineering
processes and so on until the last level Therefore we suggestusing the concept of multiple memory structures in total FFTprocess along with the new algorithm with multiple memorystructures and suitable parallel processing technique Weexpect that it is possible to achieve higher performance fromFFT process with proper combination of parallel processingtechnique and new algorithm compared to using the newalgorithm only to create bit reversal permutation Figure 7shows such approach with four (when 119904 = 2) independentmemory structures for sample size = 16
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
Acknowledgment
This publication is financially supported by the UniversityGrants Commission Sri Lanka
References
[1] C S Burrus ldquoUnscrambling for fast DFT algorithmsrdquo IEEETransactions on Acoustics Speech and Signal Processing vol 36no 7 pp 1086ndash1087 1988
[2] A C Elster and J C Meyer ldquoA super-efficient adaptable bit-reversal algorithm for multithreaded architecturesrdquo in Pro-ceedings of the IEEE International Symposium on Parallel ampDistributed Processing (IPDPS 09) vol 1ndash5 pp 1ndash8 Rome ItalyMay 2009
[3] J W Cooley and J W Tukey ldquoAn algorithm for the machinecalculation of complex Fourier seriesrdquoMathematics of Compu-tation vol 19 no 90 pp 297ndash301 1965
[4] M L Massar R Bhagavatula M Fickus and J KovacevicldquoLocal histograms and image occlusion modelsrdquo Applied andComputational Harmonic Analysis vol 34 no 3 pp 469ndash4872013
[5] R G Lyons Understanding Digital Signal Processing PrenticeHall PTR 2004
[6] C Deyun L Zhiqiang G Ming W Lili and Y XiaoyangldquoA superresolution image reconstruction algorithm based onlandweber in electrical capacitance tomographyrdquoMathematicalProblems in Engineering vol 2013 Article ID 128172 8 pages2013
[7] Q Yang and D An ldquoEMD and wavelet transform based faultdiagnosis for wind turbine gear boxrdquo Advances in MechanicalEngineering vol 2013 Article ID 212836 9 pages 2013
[8] C S Burrus Fast Fourier Transforms Rice University HoustonTex USA 2008
[9] C van Loan Computational Frameworks for the Fast FourierTransform vol 10 of Frontiers in Applied Mathematics Societyfor Industrial and Applied Mathematics (SIAM) PhiladelphiaPa USA 1992
[10] A H Karp ldquoBit reversal on uniprocessorsrdquo SIAM Review vol38 no 1 pp 1ndash26 1996
[11] A C Elster ldquoFast bit-reversal algorithmsrdquo in Proceedings ofthe International Conference on Acoustics Speech and SignalProcessing pp 1099ndash1102 IEEE Press Glasgow UK May 1989
[12] M Rubio P Gomez and K Drouiche ldquoA new superfast bitreversal algorithmrdquo International Journal of Adaptive Controland Signal Processing vol 16 no 10 pp 703ndash707 2002
[13] B Stroustrup Programming Principles and Practice Using C++Addison-Wesley 2009
[14] B Stroustrup ldquoSoftware development for infrastructurerdquo IEEEComputer Society vol 45 no 1 Article ID 6081841 pp 47ndash582012
[15] B Stroustrup The C++ Programming Language ATampT Labs3rd edition 1997
[16] S DonovanC++ by Example ldquoUnderCrdquo Learning Edition QUECorporation 2002
[17] S Mcconnell Code Complete Microsoft Press 2nd edition2004
[18] Microsoft STL Containers Microsoft New York NY USA2012 httpmsdnmicrosoftcomen-uslibrary1fe2x6ktaspx
[19] Microsoft Arrays (C++ Component Extensions) MicrosoftNew York NY USA 2012 httpmsdnmicrosoftcomen-uslibraryvstudiots4c4dw6(v=vs110)aspx
[20] B Stroustrup ldquoEvolving a language in and for the real worldC++ 1991ndash2006rdquo in Proceedings of the 3rd ACM SIGPLANHistory of Programming Languages Conference (HOPL-III rsquo07)June 2007
[21] Microsoft Memory Limits for Windows Releases MicrosoftNew York NY USA 2012 httpmsdnmicrosoftcomen-uslibraryaa36677828VS8529aspxmemory limits
[22] A Fog ldquoOptimizing software in C++rdquo 2014 httpwwwagnerorgoptimize
[23] Code Project ldquoC++ Memory Poolrdquo 2014 httpwwwcodepro-jectcomArticles15527C-Memory-Pool
Submit your manuscripts athttpwwwhindawicom
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical Problems in Engineering
Hindawi Publishing Corporationhttpwwwhindawicom
Differential EquationsInternational Journal of
Volume 2014
Applied MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Probability and StatisticsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
OptimizationJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
CombinatoricsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Operations ResearchAdvances in
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Function Spaces
Abstract and Applied AnalysisHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of Mathematics and Mathematical Sciences
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Algebra
Discrete Dynamics in Nature and Society
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Decision SciencesAdvances in
Discrete MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom
Volume 2014 Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Stochastic AnalysisInternational Journal of

Mathematical Problems in Engineering 3
Normal order
Reverse order Pattern
Dec Bin Bin Dec
0 0000 0000 0
1 0001 1000 8
2 0010 0100 4
3 0011 1100 12
4 0100 0010 2
5 0101 1010 10
6 0110 0110 6
7 0111 1110 14
8 1000 0001 1 0 + 1
9 1001 1000 9 8 + 110 1010 0101 5 4 + 1
11 1011 1101 13 12 + 1
12 1100 0011 3 2 + 1
13 1101 1011 11 10 + 1
14 1110 0111 7 6 + 1
15 1111 1111 15 14 + 1
Bloc
k1
ndash8el
emen
tsBl
ock2
ndash8el
emen
tsFigure 1 Relation between first and second halves of the BRP for 119899 = 16
structures In addition it is also possible to implement theindex mapping using several equal size one-dimensionalmemory structures However this option is not popular asit is uncomfortable for programming The performance ofmodern computers is highly dependent on the effectivenessof the cache memory of the CPU [4] To achieve the best per-formance of a series of memory elements the best practice istomaintain sequential access [4] Otherwise the effectivenessof the cache memory of the central processing unit (CPU)will be reduced Index mapping with multidimensional datastructures violates sequential access due to switching betweencolumnsrows and thus reduces the effectiveness of thecache memory Therefore it is generally accepted that theuse of a multidimensional data structure reduces computerperformance [4]
In this paper an efficient BRA is introduced to createthe BRP based on multiple memory structures and recursivepatterns of BRPThe findings of this paper show that the com-bination of multiple one-dimensional memory structuresindex mapping and the recessive pattern of BRP can be usedto improve the efficiency of BRA These findings are veryimportant to the field of signal processing as well as any fieldthat is involved in index mapping techniques
2 Material and Methods
21 New Algorithm (BRA-Split) Elster stated that it is pos-sible to generate the second half of the BRP by increment-ing items in the first half by one [2] (Figure 1) withoutchanging the order and the total number of calculations of
the algorithm Due to the recursive pattern of BRP it canbe further divided into equal size blocks by splitting eachblock recursively (Maximum log
2N times) After splitting 119904
times BRP is divided into 2119904 equal blocks each containing1198992119904 elements The relation between the elements in blocks is
given as follows
119861 (2119898+ 119895) [119894] = 119861 (119895) [119894] + 2
119878minus119898minus1 (3)
where 119861(2119898 + 119895)[119894] is 119894th element of block 119861(2119898 + 119895) and119898 =
0 1 119904 minus 1 119895 = 1 2119898Table 1 shows the relationship between elements in blocks
according to the index mapping shown in (3) after splittingBRP one time and two times for 119899 = 16 Depending on therequirement the number of splitting can be increased
22 Evaluation Process of New Algorithm To evaluate algo-rithms we used Windows 7 and Visual C++ 2012 on a PCwith multicore CPU (4 cores 8 logical processors) and 12GBmemory Detailed specifications of the PC and the softwareare given in Table 2 To eliminate limits of memory andaddress space related to the selected platform the compileroption ldquoLARGEADDRESSAWARErdquo was set [21] and plat-form was set to ldquox64rdquo All other options of the operatingsystem and the compiler were kept unchanged
The new algorithm was implemented using single one-dimensionalmemory structure and themost commonmulti-dimensional memory structure Furthermore the new BRAwas implemented using several equal size one-dimensionalmemory structures (multiple memory structure)
4 Mathematical Problems in Engineering
Table1Re
lationbetweenelem
entsof
16-elementB
RP(119899=16)for
split
=1and
split
=2
Normal
order
Reverse
order
Split
(119878)=1
Split
(119878=2)
Blocks
(12119904)
Index
ofthe
block119894
Reverseo
rder
calculation
Calculationmetho
d119898=0119904minus1(119898=0)
119895=12119898
119898=0119895=1
119894=11198992119904minus1
119894=17
Blocks
(12119904)
Indexof
the
block119894
Reverseo
rder
calculation
Calculationmetho
d119898=0119904minus1(119898=01)
119895=12119898
119898=0119895=1119898=1119895=12
119894=11198992119904minus1
119894=123
00
1
00
Initialized
00
Initialized
18
18=8+0
Use
Elste
rrsquosLinear
BitR
eversalm
etho
d
11
8=8+0
Use
Elste
rrsquosLinear
BitR
eversalm
etho
d2
42
4=4+0
24=4+0
312
312
=12
+0
312
=12
+0
42
42=2+0
02
Initialized
510
510
=10
+0
21
10=8+2
119861(2119898+119895)[119894]=119861(119895)[119894]+2119904minus119898minus1
66
66=6+0
26=4+2
For119898
=0119895=1119894=123
119861(20+1)[119894]=119861(1)[119894]+22minus0minus1
714
714
=14
+0
314
=12
+2
119861(2)[119894]=119861(1)[119894]+2
81
2
01
Initialized
01
Initialized
99
19=8+1
119861(2119898+119895)[119894]=119861(119895)[119894]+2119904minus119898minus1
For119898
=0119895=1119894=17
119861(20+1)[119894]=119861(1)[119894]+22minus0minus1
119861(2)[119894]=119861(1)[119894]+1
31
9=8+1
119861(2119898+119895)[119894]=119861(119895)[119894]+2119904minus119898minus1
105
25=4+1
25=4+1
For119898
=1119895=1119894=123
119861(21+1)[119894]=119861(1)[119894]+22minus1minus1
1113
313
=12
+1
313
=12
+1
119861(3)[119894]=119861(1)[119894]+1
123
43=2+1
03
Initialized
1311
511=10
+1
41
11=10
+1
119861(2119898+119895)[119894]=119861(119895)[119894]+2119904minus119898minus1
147
67=6+1
27=6+1
For119898
=1119895=2119894=123
119861(21+2)[119894]=119861(2)[119894]+22minus1minus1
1515
715
=14
+1
315
=14
+1
119861(4)[119894]=119861(2)[119894]+2
Mathematical Problems in Engineering 5
Table 2 Hardware and software specifications of the PC
Specifications
Processor Intel Core i7 CPU 870 293GHz (4 cores8 threads)
RAM 12GB DDR3-1333 2 channelsMemory bandwidth 21GBsL1 L2 and L3 cache 4 times 64KB 4 times 256KB and 8MB sharedL1 L2 and L3 cacheline size 64 bit
Brand and type Fujitsu CelsiusBIOS settings Default (hyper threading enabled)OS and service pack Windows 7 professional with service pack 1System type 64 bit operating systemOS settings DefaultVisual Studio 2012 Version 110507271 RTMRELNET Framework Version 4550709
Thenext taskwas to identify a suitable data structure fromdifferent types of available data structures We consideredseveral common techniques as summarized in Table 3 Datastructure 1 mentioned in Table 3 is not supporting dynamicmemory allocation (need to mention the size of the arraywhen array is being declared) For general bit reversalalgorithm it is a must to have dynamic memory allocation tocater different sizes of samples Even after setting the compileroption ldquoLARGEADDRESSAWARErdquo [21] data structures 3and 4 mentioned in Table 3 were not supported for accessingmemory greater than 2GB Therefore structures 1 3 and 4were rejected and memory structures 2 (array) and 5 (vector)were used to create all one-dimensional memory structuresThe same versions of array and vector were used to createmultidimensional memory structures
The new algorithm mentioned in Section 21 was imple-mented usingC++ in 24 types ofmemory structures as shownin Table 4 The performance of these algorithms was evalu-ated considering the ldquoclocks per elementrdquo (CPE) consumedbyeach algorithm To retrieve this value first average CPE foreach sample size of 2119899 where 119899 [21 31] (11 sample sizes) werecalculated after executing each algorithm 100 timesThis gave11 CPE representing each sample size Finally the combinedaverageof CPEwas calculated for each algorithmby averagingthose 11 values along with ldquocombined standard deviationrdquoThe combined average of CPE was considered as the CPEfor each algorithm The built-in ldquoclockrdquo function of C++ wasused to calculate the clocks Combined standard deviationwas calculated using the following
120590119888= (
sum119896
119904=1(1198991199041205902
119904+ 119899119904(119883119904minus 119883119888)
2
)
sum119896
119904=1119899119904
)
12
(4)
where119883119888= sum119896
119904=1119899119904119883119904sum119896
119904=1119899119904 119904 is the number of samples 119899
119904
is number of samples in each sample and 120590119904is the standard
deviation of each sample
Algorithms 1 2 and 3 illustrate the implementation ofnew BRA with single one-dimensional memory structuremultidimensional memory structure and multiple mem-ory structures respectively The algorithm illustrated inAlgorithm 1 (BRA Split 1 1A) was implemented using prim-itive array for split = 1 The algorithm BRM Split 2 4A(Algorithm 2) was implemented using vectors for split =2 The algorithm BRM Split 2 4A (Algorithm 3) was imple-mented using primitive array for split = 2 A sample per-mutation filling sequence of algorithms with single one-dimensional memory structures is illustrated in Figure 2Figure 3 illustrates a sample permutation filling sequence ofboth multidimensional and multiple memory structures
Secondly arithmetic operations per element (OPPE)werecalculated for each algorithm Arithmetic operations withineach algorithm were located in three regions of the codeinner FOR loop outer FOR loop and outside of the loopsThen the total number of operations (OP) can be defined as
OP = 1198701lowast 1198621+ 1198702lowast 1198622+ 1198623 (5)
where 1198621 1198622 and 119862
3are the number of operations in inner
FOR loop outer FOR loop and outside of the loops 1198701and
1198702are the number of iterations of outer loop and inner loop
Equation (5) can be represented as
OP =log2(NS)minus119904minus1
sum
119905=0
2119905lowast 1198621+
log2(NS)minus119904minus1
sum
119905=0
1198622+ 1198623 (6)
where NS is the number of samples and 119904 is the number ofsplits
The main contribution to calculations comes from theinner loop Comparing with the contribution of operationsin the inner loop the contribution of operations in rest ofthe code is very small For example consider the algorithmBRA Split 1 1A shown in Algorithm 1 As sample size is 2311198701lowast 1198621asymp 215 lowast 10
9lowast 1198621and 119870
2lowast 1198622+ 1198623asymp 1000 where
1198621gt 1 Therefore only the operations of inner loop were
considered for evaluation Then (6) can be simplified as
OP =log2(NS)minus119904minus1
sum
119905=0
2119905lowast 1198621 (7)
The ldquooperations per elementrdquo (OPPE) can be defined as
OPPE =(sum
log2(NS)minus119904minus1
119905=02119905lowast 1198621)
NS
(8)
For FFT always NS = 2119896 119896 isin 119885+Then from (7)
OPPE =(sum119896minus119904minus1
119905=02119905lowast 1198621)
2119896
(9)
119896
sum
119905=0
2119905+ 1 = 2
119896+1 (10)
6 Mathematical Problems in Engineering
Table 3 Common memory allocating methods that are used in Visual C++
Number Name Syntax Nature of memory layout1 Array int BRP[1000] Slot of continuous memory elements2 Array intlowast BRP = new int[119899] Slot of continuous memory elements3 Array array⟨int⟩andBRP = gcnew array⟨int⟩(119899) Collection of noncontinuous memory elements4 ArrayList ArrayList andBRP = gcnew ArrayList() Collection of noncontinuous memory elements5 Vector stdvector⟨int⟩ BRP(119899) Collection of noncontinuous memory elements
Table 4 Different versions of new BRA implemented with different data structures
Split (s) Data structure type AlgorithmSingle memory structure Multidimensional memory structure Multiple memory structure
1 Array (A) BRA Split 1 1A BRA Split 1 2DA BRA Split 1 2A1 Vector (V) BRA Split 1 1V BRA Split 1 2DV BRA Split 1 2V2 Array (A) BRA Split 2 1A BRA Split 2 4DA BRA Split 2 4A2 Vector (V) BRA Split 2 1V BRA Split 2 4DV BRA Split 2 4V3 Array (A) BRA Split 3 1A BRA Split 3 8DA BRA Split 3 8A3 Vector (V) BRA Split 3 1V BRA Split 3 8DV BRA Split 3 8V4 Array (A) BRA Split 4 1A BRA Split 4 16DA BRA Split 4 16A4 Vector (V) BRA Split 4 1V BRA Split 4 16DV BRA Split 4 16VNaming convention for algorithms ldquoBRA Splitrdquo + ltNumber of splitsgt + ltnature of memory structuregt xA xV x number of arrays and x number of vectorsxDA xDV single x-dimensional array and single x-dimensional vector
void mf BRM Split 1 1A (unsigned int ui NS int ui log2NS)
unsigned int ui Nunsigned int ui EBunsigned int ui tunsigned int ui Lunsigned int ui DL
ui N = ui NS Number of samplesui t = ui log2NS minus 1ui EB = ui N2ui L = 1unsigned intlowast BRP = new unsigned int[ui N]BRP[0] = 0BRP[ui EB] = 1for (unsigned int q = 0 q lt ui t q++)
ui DL = ui L + ui Lui N = ui N2for (unsigned int j = ui L j lt ui DL j++)
BRP[j] = BRP[j minus ui L] + ui NBRP[ui EB + j] = BRP[j] + 1
ui L = ui L + ui L
delete[] BRP
Algorithm 1 C++ implementation of new BRA with single array for split = 1 (BRA Split 1 1A)
Mathematical Problems in Engineering 7
Void mf BRM Split 2 4DV (unsigned int ui NS int ui log2NS)
unsigned int ui Nunsigned int ui EBunsigned int ui tunsigned int ui Lunsigned int ui DLui N = ui NS Number of samplesui t = ui log2NS minus 2ui EB = ui N4ui L = 1stdvectorltstdvectorltunsigned intgtgt BRP(4
stdvectorltunsigned intgt(ui EB))BRP[0][0] = 0BRP[1][0] = 2BRP[2][0] = 1BRP[3][0] = 3for (unsigned int q = 0 q lt ui t q++)
ui DL = ui L + ui Lui N = ui N2for (unsigned int j = ui L j lt ui DL j++)
BRP[0][j] = BRP[0][j minus ui L] + ui NBRP[1][j] = BRP[0][j] + 2BRP[2][j] = BRP[0][j] + 1BRP[3][j] = BRP[1][j] + 1
ui L = ui L + ui L
Algorithm 2 C++ implementation of new BRA with four arrays for split = 2 (BRM Split 2 4A)
0 8 4 12 2 10 6 14 1 9 5 13 3 11 7 15
Initialization
First iteration Seventh (last) iteration
Figure 2 Permutation filling sequence of new BRA with single memory structure for 119899 = 16 and split =1 (BRA Split 1 1A)
For large 119896 2119896 + 1 asymp 2119896 Then
119896
sum
119905=0
2119905= 2119896+1
(11)
Because the considered sample size is 221 to 231 the value 119896can be considered as large Then from (9)
OPPE =1198621lowast (2119896minus119904)
2119896
(12)
OPPE = 1198621
2119904 (13)
According to (13) OPPE is 119891(1198621 119904) The value 119862
1(oper-
ations in inner loop) and the value 119904 (number of splits) are aconstant for a certain algorithm
To evaluate the performance of new BRA we selectedthree algorithms (LBRA EBR and BRA-Ru) which used apattern instead of conventional bit reversing method Theperformance of vector and array versions of the best version
Table 5 The number of operations in the inner loop (1198621) of each
algorithm for different splits (119904) (The total number of operations ineach algorithm asymp 119862
1)
Memory structure type Value of 1198621
119904 = 1 119904 = 2 119904 = 3 119904 = 4
Single one-dimension (array and vector) 8 15 30 61Multidimension (array and vector) 7 11 19 35Multiple one-dimension (array and vector) 7 11 19 35
of new BRA was compared with the relevant versions ofselected algorithms
3 Results and Discussion
Our objective was to introduce BRA using recursive patternof the BRP that we identified We used multiple memorystructures which is a feasible yet unpopular technique toimplement index mapping According to Table 5 the num-bers of operations in all the array and vector versions of both
8 Mathematical Problems in Engineering
Void mf BRM Split 2 4A (unsigned int ui NS int ui log2NS)
unsigned int ui Nunsigned int ui EBunsigned int ui tunsigned int ui Lunsigned int ui DL
ui N = ui NS Number of samplesui t = ui log2NS minus 2ui EB = ui N4ui L = 1unsigned intlowast BRP1 = new unsigned int[ui EB]unsigned intlowast BRP2 = new unsigned int[ui EB]unsigned intlowast BRP3 = new unsigned int[ui EB]unsigned intlowast BRP4 = new unsigned int[ui EB]
BRP1[0] = 0BRP2[0] = 2BRP3[0] = 1BRP4[0] = 3for (unsigned int q = 0 q lt ui t q++)
ui DL = ui L + ui Lui N = ui N2for (unsigned int j = ui L j lt ui DL j++)
BRP1[j] = BRP1[j minus ui L]+ ui NBRP2[j] = BRP1[j] + 2BRP3[j] = BRP1[j] + 1BRP4[j] = BRP2[j] + 1
ui L = ui L + ui L
delete[] BRO1delete[] BRO2delete[] BRO3delete[] BRO4
Algorithm 3 C++ implementation of new BRA with four one-dimensional arrays for split = 2 (BRM Split 2 4A)
0 8 4 12
2 10 6 14
1 9 5 13
3 11 7 15
Initi
aliz
atio
n
Third
(las
t) ite
ratio
n
First iteration
Figure 3 Permutation filling sequence of 4 individual and single 4-dimensional memory structure for 119899 = 16
multidimensional and multiple memory structures are thesame Also Figure 5 shows continuous decrement of OPPEwhen the number of splits increases Then the algorithmwith the highest number of splits and the lowest number ofoperations is the one which is expected to be most efficient
However results in relation with CPE (Figure 5) show thatthe new algorithm with four memory structures of array isthe fastest and most consistent in the selected range Twofour eight and sixteen multiple array implementations ofnew BRA reported 25 34 33 and 18 higher efficiency
Mathematical Problems in Engineering 9
0
1
2
3
4
5
6
Refalgorithms
Ope
ratio
ns p
er el
emen
t (O
PPE)
Split = 1 Split = 2 Split = 3 Split = 4
Corresponds to both array and vector versions of algorithm of rudioCorresponds to both array and vector versions of ldquolinear bit reversalrdquo algorithmCorresponds to both array and vector versions of ldquoelsterrsquos bit reversalrdquo algorithmCorresponds to both array and vector versions of the new algorithm in
Corresponds to both array and vector versions of the new algorithm in
Corresponds to both array and vector versions of the new algorithm in
signal one-dimensional memory structure
signal multi-dimensional memory structure
signal multiple one-dimensional memory structure
Figure 4 Operations per element versus reference algorithms and new algorithm with different s (splits) where dashed column correspondsto both array and vector versions of algorithm of Rudio cross lines column corresponds to both array and vector versions of ldquoLinear BitReversalrdquo algorithm dotted column corresponds to both array and vector versions of ldquoElsterrsquos Bit Reversalrdquo algorithm vertical lines columncorresponds to both array and vector versions of the new algorithm in single one-dimensional memory structure inclined lines columncorresponds to both array and vector versions of the new algorithm in single multidimensional memory structure and horizontal linescolumn corresponds to both array and vector versions of the new algorithm in multiple one-dimensional memory structures
respectively in relation to the array version of LBRA Thealgorithm with eight memory structures has nearly the sameCPE as the four-array and four-vector versions but is lessconsistent On the other hand the four-vector implementa-tion of the new algorithm is the fastest and most consistentamong all vector versions Two four eight and sixteenmultiple vector implementations of new BRA reported 1316 and 16 higher and 23 lower efficiency respectively inrelation to the vector version of LBRAThis result proves thatat a certain point multiple memory structure gives the bestperformances in the considered domain Also usage of mul-tiple memory structures of primitive array is a good optionfor implementing index mapping of BRP compared to multi-dimensional or single one-dimensional memory structures
Due to the flexible nature of the vector it is commonlyused for implementing algorithms According to Figure 4there is no difference in OPPE between array and vectorversionsHowever our results in Figure 5 show that the vectorversions of BRA always required more CPE (44ndash142)than the array version The structure of vector gives priorityto generality and flexibility rather than to execution speedmemory economy cache efficiency and code size [22]There-fore vector is not a good option with respect to efficiency
The results in Table 5 and Figure 4 show that there is nodifference between the number of calculations and OPPEfor equal versions of algorithms with multidimensional andmultiple memory structure Structure and type of calcula-tions are the same for both types The only difference is thenature of the memory structure multidimension or multipleone-dimension When CPE is considered it shows 19ndash79
performance efficiency from algorithms with multiple one-dimension memory structures The reason for that observa-tion is that the memory access of multidimensional memorystructure is less efficient than one-dimensional memorystructure [22]
We agree with the statement of Elster about indexmapping of BRP [2] and the generally accepted fact (theusage of multidimensional memory structures reduces theperformance of a computer) [4] only with respect to multi-dimensional memory structures of vector Our results showthat even with multidimensional arrays there are situationswhere the new BRA performs better than the same typeof one-dimensional memory structure The four eight andsixteen dimensional array versions of new BRA perform 810 and 2 in relation to one-dimensional array version ofnew BRA Some results in relation to single one-dimensionalmemory structure implementation of new BRA are also notin agreement with the general accepted idea For examplesample size = 231 the two-dimensional vector version of newBRA (BRA Split 1 2DV) reported 542119864 minus 05 CPE which is389 higher in relation to average CPE of sample size rangeof 221 to 230 Also the inconsistency was very highThereforewe excluded values related to sample size = 231 for the two-dimensional vector version
We observed very high memory utilization with the two-dimensional vector version especially with sample size =231 Windows task manager showed that the memory uti-lization of all the considered algorithms was nearly thesame for all sample sizes except for multidimension versionsof vector The multidimensional version of vector initially
10 Mathematical Problems in Engineering
Cloc
ks p
er el
emen
t (CP
E)
000E + 00
500E minus 06
100E minus 05
150E minus 05
200E minus 05
250E minus 05
300E minus 05
BRM
split
01x
BRM
split
12x
BRM
split
24x
BRM
split
38x
BRM
split
416x
lowastBR
Msp
lit12
Dx
BRM
split
24
Dx
BRM
split
38
Dx
BRM
split
416
Dx
BRM
split
11x
BRM
split
21x
BRM
split
31x
BRM
split
41x
x-A or V (array or vector)Algorithms
Refe
renc
e alg
orith
m o
ne-
dim
ensio
nal s
ingl
e mem
ory
struc
ture
of s
izen
Multiple memorystructures
1
1
2
k
k
k
k = 2s
n sample size
Multidimensionalmemory structure
One-dimensionalmemory structure
nknk
nk
middotmiddotmiddot
middotmiddotmiddot
(s = 1 2 3 4)
Corresponds to array version of the algorithmCorresponds to vector version of the algorithmCorresponds to minimum reported CPE of the category
Figure 5 Clocks per element (combined average) versus algorithm for the sample size range from 221 to 231 where blue dotted columncorresponds to array version of the algorithm green column corresponds to vector version of the algorithm and red rhombus corresponds tominimum reported CPE of the category lowastFor vector version sample size 231 was excluded because at sample size 231 it showed huge deviationdue to memory limitation of the machine
utilizes highermemory and drops down to normal valueTheresults in relation to sample size = 2
30 showed that the extramemory requirement of two dimension vector was higherthan that of the four-dimensional vector Based upon that itcan be predicted that BRA Split 1 2DV needs an extra 3GB(total 13 GB) for normal execution at sample size = 2
31 butthe total memory barrier of 12GB of the machine slows theprocess down The most likely reason for this observation isthe influence ofmemory poolingmechanismWhen defininga memory structure it is possible to allocate the requiredamount of memory This is known as memory pooling [23]In all the memory structures used in algorithms discussedin this paper we used memory pooling Memory poolingallocates the required memory at startup and divides thisblock into small chunks If there is no memory poolingmemory will get fragmented Accessing fragmented memoryis inefficient When the existing memory is not enough forallocating then it switches to use fragmented memory forallocating memory elements In the considered situation theexisting memory (12GB) is not sufficient for allocating therequired amount (13GB) which switches to use fragmentedmemory
The total cache size of the machine is 825MB whichis less than the minimum memory utilization of consideredalgorithms (16MB to 8GB) in relation to the sample sizerange from 222 to 231 Only the sample size 221 occupies 8MBmemory which is less than the total cache memory ExceptBRA Split 4 1V structure all algorithms reported constantCPE in relation to the entire sample size range The bestalgorithms of each category especially reported very steady
behaviour This observation is in disagreement with thestatement of Karp ldquothat a machine with hierarchical memorydoes not performwell when array size is larger than the cachesizerdquo [10]
Comparison (Figure 6) of best reported version in theconsidered domain (four memory structure version) andthe selected algorithms shows that the array version ofEBR performs the best The four-array version of new BRAreported 1 lower performance than the array version ofEBR However the four-array version of new BRA reported34 and 23 higher performances than array versions ofLBRA and BRA-Ru Also the four-vector version of newBRA is reported to have the best performance among all thevector versions It reported 16 10 and 22 performancescompared to vector versions of LBRA EBR and BRA-Rurespectively
4 Conclusion and Outlook
Themain finding of this paper is the recursive pattern of BPRand the implementationmethod of it using multiple memorystructures With multiple memory structures especiallythe newly identified index mapping performs much betterthan multidimensional or single one-dimensional memorystructure Furthermore findings of this paper show that theperformance of primitive array is higher than vector typeThe result is in disagreement with the statement of Karp ldquothata machine with hierarchical memory does not perform wellwhen array size is larger than the cache sizerdquo Almost all thesample sizes we used were higher than the total cache size
Mathematical Problems in Engineering 11
120E ndash 05
100E minus 05
800E minus 06
600E minus 06
400E minus 06
200E ndash 06
000E + 00
Cloc
ks p
er el
emen
t (CP
E)
BRM
split
24x
(the b
est v
ersio
nof
the n
ewal
gorit
hm)
Line
ar b
it-re
vers
al1x
Elste
rrsquos b
it-
Rubi
o1x
reve
rsal
1x
x-A or V (array or vector)Algorithms
Corresponds to array version of the algorithmCorresponds to vector version of the algorithm
Figure 6 Clocks per element versus best version of new algorithm and selected algorithms where blue dotted column corresponds to arrayversion and green column corresponds to vector version of the algorithm
1
1
1
1
1
0
1
0
1
0
1
0
Process 1
Process 2
Process 5
Process 6Process 3
Process 4
Process 7
4 parallel processes
2 parallel processes
Single process
Tota
l sig
nal i
s div
ided
into
equa
l fou
r ind
epen
dent
mem
ory
struc
ture
s usin
g ne
w al
gorit
hm (B
RMsp
lit24x
)
x(0)
x(4)
x(2)
x(6)
x(1)
x(5)
x(3)
x(7)
minus1
w04
w14
w24
w34
w04
w14
w24
w34
A(0)
A(1)
A(2)
A(3)
B(0)
B(1)
B(2)
B(3)
x(0)
x(1)
x(2)
x(3)
x(4)
x(5)
x(6)
x(7)
minus1
minus1
minus1
Figure 7 Four-memory-structure version of algorithm and the parallel processes for sample size = 16
of the computer However multiple memory structure andthe multidimensional memory structure versions showedreasonable steady performancewith those samples In generalthese results show the effects of data structures and memoryallocation techniques and open a new window of creatingefficient algorithms with multiple memory structures inmany other fields where index mapping is involved
The new bit reversal algorithm with 2119904 independent
memory structures splits the total signal into 119904 independentportions and the total FFT process into 119904 + 1 levels Thenthese 119904 signal portions can be processed independently bymeans of 119904 independent processes on the first level Onthe next level the results from the previous level stored inindependent memory structures can be processed with 1199042
12 Mathematical Problems in Engineering
processes and so on until the last level Therefore we suggestusing the concept of multiple memory structures in total FFTprocess along with the new algorithm with multiple memorystructures and suitable parallel processing technique Weexpect that it is possible to achieve higher performance fromFFT process with proper combination of parallel processingtechnique and new algorithm compared to using the newalgorithm only to create bit reversal permutation Figure 7shows such approach with four (when 119904 = 2) independentmemory structures for sample size = 16
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
Acknowledgment
This publication is financially supported by the UniversityGrants Commission Sri Lanka
References
[1] C S Burrus ldquoUnscrambling for fast DFT algorithmsrdquo IEEETransactions on Acoustics Speech and Signal Processing vol 36no 7 pp 1086ndash1087 1988
[2] A C Elster and J C Meyer ldquoA super-efficient adaptable bit-reversal algorithm for multithreaded architecturesrdquo in Pro-ceedings of the IEEE International Symposium on Parallel ampDistributed Processing (IPDPS 09) vol 1ndash5 pp 1ndash8 Rome ItalyMay 2009
[3] J W Cooley and J W Tukey ldquoAn algorithm for the machinecalculation of complex Fourier seriesrdquoMathematics of Compu-tation vol 19 no 90 pp 297ndash301 1965
[4] M L Massar R Bhagavatula M Fickus and J KovacevicldquoLocal histograms and image occlusion modelsrdquo Applied andComputational Harmonic Analysis vol 34 no 3 pp 469ndash4872013
[5] R G Lyons Understanding Digital Signal Processing PrenticeHall PTR 2004
[6] C Deyun L Zhiqiang G Ming W Lili and Y XiaoyangldquoA superresolution image reconstruction algorithm based onlandweber in electrical capacitance tomographyrdquoMathematicalProblems in Engineering vol 2013 Article ID 128172 8 pages2013
[7] Q Yang and D An ldquoEMD and wavelet transform based faultdiagnosis for wind turbine gear boxrdquo Advances in MechanicalEngineering vol 2013 Article ID 212836 9 pages 2013
[8] C S Burrus Fast Fourier Transforms Rice University HoustonTex USA 2008
[9] C van Loan Computational Frameworks for the Fast FourierTransform vol 10 of Frontiers in Applied Mathematics Societyfor Industrial and Applied Mathematics (SIAM) PhiladelphiaPa USA 1992
[10] A H Karp ldquoBit reversal on uniprocessorsrdquo SIAM Review vol38 no 1 pp 1ndash26 1996
[11] A C Elster ldquoFast bit-reversal algorithmsrdquo in Proceedings ofthe International Conference on Acoustics Speech and SignalProcessing pp 1099ndash1102 IEEE Press Glasgow UK May 1989
[12] M Rubio P Gomez and K Drouiche ldquoA new superfast bitreversal algorithmrdquo International Journal of Adaptive Controland Signal Processing vol 16 no 10 pp 703ndash707 2002
[13] B Stroustrup Programming Principles and Practice Using C++Addison-Wesley 2009
[14] B Stroustrup ldquoSoftware development for infrastructurerdquo IEEEComputer Society vol 45 no 1 Article ID 6081841 pp 47ndash582012
[15] B Stroustrup The C++ Programming Language ATampT Labs3rd edition 1997
[16] S DonovanC++ by Example ldquoUnderCrdquo Learning Edition QUECorporation 2002
[17] S Mcconnell Code Complete Microsoft Press 2nd edition2004
[18] Microsoft STL Containers Microsoft New York NY USA2012 httpmsdnmicrosoftcomen-uslibrary1fe2x6ktaspx
[19] Microsoft Arrays (C++ Component Extensions) MicrosoftNew York NY USA 2012 httpmsdnmicrosoftcomen-uslibraryvstudiots4c4dw6(v=vs110)aspx
[20] B Stroustrup ldquoEvolving a language in and for the real worldC++ 1991ndash2006rdquo in Proceedings of the 3rd ACM SIGPLANHistory of Programming Languages Conference (HOPL-III rsquo07)June 2007
[21] Microsoft Memory Limits for Windows Releases MicrosoftNew York NY USA 2012 httpmsdnmicrosoftcomen-uslibraryaa36677828VS8529aspxmemory limits
[22] A Fog ldquoOptimizing software in C++rdquo 2014 httpwwwagnerorgoptimize
[23] Code Project ldquoC++ Memory Poolrdquo 2014 httpwwwcodepro-jectcomArticles15527C-Memory-Pool
Submit your manuscripts athttpwwwhindawicom
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical Problems in Engineering
Hindawi Publishing Corporationhttpwwwhindawicom
Differential EquationsInternational Journal of
Volume 2014
Applied MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Probability and StatisticsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
OptimizationJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
CombinatoricsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Operations ResearchAdvances in
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Function Spaces
Abstract and Applied AnalysisHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of Mathematics and Mathematical Sciences
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Algebra
Discrete Dynamics in Nature and Society
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Decision SciencesAdvances in
Discrete MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom
Volume 2014 Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Stochastic AnalysisInternational Journal of

4 Mathematical Problems in Engineering
Table1Re
lationbetweenelem
entsof
16-elementB
RP(119899=16)for
split
=1and
split
=2
Normal
order
Reverse
order
Split
(119878)=1
Split
(119878=2)
Blocks
(12119904)
Index
ofthe
block119894
Reverseo
rder
calculation
Calculationmetho
d119898=0119904minus1(119898=0)
119895=12119898
119898=0119895=1
119894=11198992119904minus1
119894=17
Blocks
(12119904)
Indexof
the
block119894
Reverseo
rder
calculation
Calculationmetho
d119898=0119904minus1(119898=01)
119895=12119898
119898=0119895=1119898=1119895=12
119894=11198992119904minus1
119894=123
00
1
00
Initialized
00
Initialized
18
18=8+0
Use
Elste
rrsquosLinear
BitR
eversalm
etho
d
11
8=8+0
Use
Elste
rrsquosLinear
BitR
eversalm
etho
d2
42
4=4+0
24=4+0
312
312
=12
+0
312
=12
+0
42
42=2+0
02
Initialized
510
510
=10
+0
21
10=8+2
119861(2119898+119895)[119894]=119861(119895)[119894]+2119904minus119898minus1
66
66=6+0
26=4+2
For119898
=0119895=1119894=123
119861(20+1)[119894]=119861(1)[119894]+22minus0minus1
714
714
=14
+0
314
=12
+2
119861(2)[119894]=119861(1)[119894]+2
81
2
01
Initialized
01
Initialized
99
19=8+1
119861(2119898+119895)[119894]=119861(119895)[119894]+2119904minus119898minus1
For119898
=0119895=1119894=17
119861(20+1)[119894]=119861(1)[119894]+22minus0minus1
119861(2)[119894]=119861(1)[119894]+1
31
9=8+1
119861(2119898+119895)[119894]=119861(119895)[119894]+2119904minus119898minus1
105
25=4+1
25=4+1
For119898
=1119895=1119894=123
119861(21+1)[119894]=119861(1)[119894]+22minus1minus1
1113
313
=12
+1
313
=12
+1
119861(3)[119894]=119861(1)[119894]+1
123
43=2+1
03
Initialized
1311
511=10
+1
41
11=10
+1
119861(2119898+119895)[119894]=119861(119895)[119894]+2119904minus119898minus1
147
67=6+1
27=6+1
For119898
=1119895=2119894=123
119861(21+2)[119894]=119861(2)[119894]+22minus1minus1
1515
715
=14
+1
315
=14
+1
119861(4)[119894]=119861(2)[119894]+2
Mathematical Problems in Engineering 5
Table 2 Hardware and software specifications of the PC
Specifications
Processor Intel Core i7 CPU 870 293GHz (4 cores8 threads)
RAM 12GB DDR3-1333 2 channelsMemory bandwidth 21GBsL1 L2 and L3 cache 4 times 64KB 4 times 256KB and 8MB sharedL1 L2 and L3 cacheline size 64 bit
Brand and type Fujitsu CelsiusBIOS settings Default (hyper threading enabled)OS and service pack Windows 7 professional with service pack 1System type 64 bit operating systemOS settings DefaultVisual Studio 2012 Version 110507271 RTMRELNET Framework Version 4550709
Thenext taskwas to identify a suitable data structure fromdifferent types of available data structures We consideredseveral common techniques as summarized in Table 3 Datastructure 1 mentioned in Table 3 is not supporting dynamicmemory allocation (need to mention the size of the arraywhen array is being declared) For general bit reversalalgorithm it is a must to have dynamic memory allocation tocater different sizes of samples Even after setting the compileroption ldquoLARGEADDRESSAWARErdquo [21] data structures 3and 4 mentioned in Table 3 were not supported for accessingmemory greater than 2GB Therefore structures 1 3 and 4were rejected and memory structures 2 (array) and 5 (vector)were used to create all one-dimensional memory structuresThe same versions of array and vector were used to createmultidimensional memory structures
The new algorithm mentioned in Section 21 was imple-mented usingC++ in 24 types ofmemory structures as shownin Table 4 The performance of these algorithms was evalu-ated considering the ldquoclocks per elementrdquo (CPE) consumedbyeach algorithm To retrieve this value first average CPE foreach sample size of 2119899 where 119899 [21 31] (11 sample sizes) werecalculated after executing each algorithm 100 timesThis gave11 CPE representing each sample size Finally the combinedaverageof CPEwas calculated for each algorithmby averagingthose 11 values along with ldquocombined standard deviationrdquoThe combined average of CPE was considered as the CPEfor each algorithm The built-in ldquoclockrdquo function of C++ wasused to calculate the clocks Combined standard deviationwas calculated using the following
120590119888= (
sum119896
119904=1(1198991199041205902
119904+ 119899119904(119883119904minus 119883119888)
2
)
sum119896
119904=1119899119904
)
12
(4)
where119883119888= sum119896
119904=1119899119904119883119904sum119896
119904=1119899119904 119904 is the number of samples 119899
119904
is number of samples in each sample and 120590119904is the standard
deviation of each sample
Algorithms 1 2 and 3 illustrate the implementation ofnew BRA with single one-dimensional memory structuremultidimensional memory structure and multiple mem-ory structures respectively The algorithm illustrated inAlgorithm 1 (BRA Split 1 1A) was implemented using prim-itive array for split = 1 The algorithm BRM Split 2 4A(Algorithm 2) was implemented using vectors for split =2 The algorithm BRM Split 2 4A (Algorithm 3) was imple-mented using primitive array for split = 2 A sample per-mutation filling sequence of algorithms with single one-dimensional memory structures is illustrated in Figure 2Figure 3 illustrates a sample permutation filling sequence ofboth multidimensional and multiple memory structures
Secondly arithmetic operations per element (OPPE)werecalculated for each algorithm Arithmetic operations withineach algorithm were located in three regions of the codeinner FOR loop outer FOR loop and outside of the loopsThen the total number of operations (OP) can be defined as
OP = 1198701lowast 1198621+ 1198702lowast 1198622+ 1198623 (5)
where 1198621 1198622 and 119862
3are the number of operations in inner
FOR loop outer FOR loop and outside of the loops 1198701and
1198702are the number of iterations of outer loop and inner loop
Equation (5) can be represented as
OP =log2(NS)minus119904minus1
sum
119905=0
2119905lowast 1198621+
log2(NS)minus119904minus1
sum
119905=0
1198622+ 1198623 (6)
where NS is the number of samples and 119904 is the number ofsplits
The main contribution to calculations comes from theinner loop Comparing with the contribution of operationsin the inner loop the contribution of operations in rest ofthe code is very small For example consider the algorithmBRA Split 1 1A shown in Algorithm 1 As sample size is 2311198701lowast 1198621asymp 215 lowast 10
9lowast 1198621and 119870
2lowast 1198622+ 1198623asymp 1000 where
1198621gt 1 Therefore only the operations of inner loop were
considered for evaluation Then (6) can be simplified as
OP =log2(NS)minus119904minus1
sum
119905=0
2119905lowast 1198621 (7)
The ldquooperations per elementrdquo (OPPE) can be defined as
OPPE =(sum
log2(NS)minus119904minus1
119905=02119905lowast 1198621)
NS
(8)
For FFT always NS = 2119896 119896 isin 119885+Then from (7)
OPPE =(sum119896minus119904minus1
119905=02119905lowast 1198621)
2119896
(9)
119896
sum
119905=0
2119905+ 1 = 2
119896+1 (10)
6 Mathematical Problems in Engineering
Table 3 Common memory allocating methods that are used in Visual C++
Number Name Syntax Nature of memory layout1 Array int BRP[1000] Slot of continuous memory elements2 Array intlowast BRP = new int[119899] Slot of continuous memory elements3 Array array⟨int⟩andBRP = gcnew array⟨int⟩(119899) Collection of noncontinuous memory elements4 ArrayList ArrayList andBRP = gcnew ArrayList() Collection of noncontinuous memory elements5 Vector stdvector⟨int⟩ BRP(119899) Collection of noncontinuous memory elements
Table 4 Different versions of new BRA implemented with different data structures
Split (s) Data structure type AlgorithmSingle memory structure Multidimensional memory structure Multiple memory structure
1 Array (A) BRA Split 1 1A BRA Split 1 2DA BRA Split 1 2A1 Vector (V) BRA Split 1 1V BRA Split 1 2DV BRA Split 1 2V2 Array (A) BRA Split 2 1A BRA Split 2 4DA BRA Split 2 4A2 Vector (V) BRA Split 2 1V BRA Split 2 4DV BRA Split 2 4V3 Array (A) BRA Split 3 1A BRA Split 3 8DA BRA Split 3 8A3 Vector (V) BRA Split 3 1V BRA Split 3 8DV BRA Split 3 8V4 Array (A) BRA Split 4 1A BRA Split 4 16DA BRA Split 4 16A4 Vector (V) BRA Split 4 1V BRA Split 4 16DV BRA Split 4 16VNaming convention for algorithms ldquoBRA Splitrdquo + ltNumber of splitsgt + ltnature of memory structuregt xA xV x number of arrays and x number of vectorsxDA xDV single x-dimensional array and single x-dimensional vector
void mf BRM Split 1 1A (unsigned int ui NS int ui log2NS)
unsigned int ui Nunsigned int ui EBunsigned int ui tunsigned int ui Lunsigned int ui DL
ui N = ui NS Number of samplesui t = ui log2NS minus 1ui EB = ui N2ui L = 1unsigned intlowast BRP = new unsigned int[ui N]BRP[0] = 0BRP[ui EB] = 1for (unsigned int q = 0 q lt ui t q++)
ui DL = ui L + ui Lui N = ui N2for (unsigned int j = ui L j lt ui DL j++)
BRP[j] = BRP[j minus ui L] + ui NBRP[ui EB + j] = BRP[j] + 1
ui L = ui L + ui L
delete[] BRP
Algorithm 1 C++ implementation of new BRA with single array for split = 1 (BRA Split 1 1A)
Mathematical Problems in Engineering 7
Void mf BRM Split 2 4DV (unsigned int ui NS int ui log2NS)
unsigned int ui Nunsigned int ui EBunsigned int ui tunsigned int ui Lunsigned int ui DLui N = ui NS Number of samplesui t = ui log2NS minus 2ui EB = ui N4ui L = 1stdvectorltstdvectorltunsigned intgtgt BRP(4
stdvectorltunsigned intgt(ui EB))BRP[0][0] = 0BRP[1][0] = 2BRP[2][0] = 1BRP[3][0] = 3for (unsigned int q = 0 q lt ui t q++)
ui DL = ui L + ui Lui N = ui N2for (unsigned int j = ui L j lt ui DL j++)
BRP[0][j] = BRP[0][j minus ui L] + ui NBRP[1][j] = BRP[0][j] + 2BRP[2][j] = BRP[0][j] + 1BRP[3][j] = BRP[1][j] + 1
ui L = ui L + ui L
Algorithm 2 C++ implementation of new BRA with four arrays for split = 2 (BRM Split 2 4A)
0 8 4 12 2 10 6 14 1 9 5 13 3 11 7 15
Initialization
First iteration Seventh (last) iteration
Figure 2 Permutation filling sequence of new BRA with single memory structure for 119899 = 16 and split =1 (BRA Split 1 1A)
For large 119896 2119896 + 1 asymp 2119896 Then
119896
sum
119905=0
2119905= 2119896+1
(11)
Because the considered sample size is 221 to 231 the value 119896can be considered as large Then from (9)
OPPE =1198621lowast (2119896minus119904)
2119896
(12)
OPPE = 1198621
2119904 (13)
According to (13) OPPE is 119891(1198621 119904) The value 119862
1(oper-
ations in inner loop) and the value 119904 (number of splits) are aconstant for a certain algorithm
To evaluate the performance of new BRA we selectedthree algorithms (LBRA EBR and BRA-Ru) which used apattern instead of conventional bit reversing method Theperformance of vector and array versions of the best version
Table 5 The number of operations in the inner loop (1198621) of each
algorithm for different splits (119904) (The total number of operations ineach algorithm asymp 119862
1)
Memory structure type Value of 1198621
119904 = 1 119904 = 2 119904 = 3 119904 = 4
Single one-dimension (array and vector) 8 15 30 61Multidimension (array and vector) 7 11 19 35Multiple one-dimension (array and vector) 7 11 19 35
of new BRA was compared with the relevant versions ofselected algorithms
3 Results and Discussion
Our objective was to introduce BRA using recursive patternof the BRP that we identified We used multiple memorystructures which is a feasible yet unpopular technique toimplement index mapping According to Table 5 the num-bers of operations in all the array and vector versions of both
8 Mathematical Problems in Engineering
Void mf BRM Split 2 4A (unsigned int ui NS int ui log2NS)
unsigned int ui Nunsigned int ui EBunsigned int ui tunsigned int ui Lunsigned int ui DL
ui N = ui NS Number of samplesui t = ui log2NS minus 2ui EB = ui N4ui L = 1unsigned intlowast BRP1 = new unsigned int[ui EB]unsigned intlowast BRP2 = new unsigned int[ui EB]unsigned intlowast BRP3 = new unsigned int[ui EB]unsigned intlowast BRP4 = new unsigned int[ui EB]
BRP1[0] = 0BRP2[0] = 2BRP3[0] = 1BRP4[0] = 3for (unsigned int q = 0 q lt ui t q++)
ui DL = ui L + ui Lui N = ui N2for (unsigned int j = ui L j lt ui DL j++)
BRP1[j] = BRP1[j minus ui L]+ ui NBRP2[j] = BRP1[j] + 2BRP3[j] = BRP1[j] + 1BRP4[j] = BRP2[j] + 1
ui L = ui L + ui L
delete[] BRO1delete[] BRO2delete[] BRO3delete[] BRO4
Algorithm 3 C++ implementation of new BRA with four one-dimensional arrays for split = 2 (BRM Split 2 4A)
0 8 4 12
2 10 6 14
1 9 5 13
3 11 7 15
Initi
aliz
atio
n
Third
(las
t) ite
ratio
n
First iteration
Figure 3 Permutation filling sequence of 4 individual and single 4-dimensional memory structure for 119899 = 16
multidimensional and multiple memory structures are thesame Also Figure 5 shows continuous decrement of OPPEwhen the number of splits increases Then the algorithmwith the highest number of splits and the lowest number ofoperations is the one which is expected to be most efficient
However results in relation with CPE (Figure 5) show thatthe new algorithm with four memory structures of array isthe fastest and most consistent in the selected range Twofour eight and sixteen multiple array implementations ofnew BRA reported 25 34 33 and 18 higher efficiency
Mathematical Problems in Engineering 9
0
1
2
3
4
5
6
Refalgorithms
Ope
ratio
ns p
er el
emen
t (O
PPE)
Split = 1 Split = 2 Split = 3 Split = 4
Corresponds to both array and vector versions of algorithm of rudioCorresponds to both array and vector versions of ldquolinear bit reversalrdquo algorithmCorresponds to both array and vector versions of ldquoelsterrsquos bit reversalrdquo algorithmCorresponds to both array and vector versions of the new algorithm in
Corresponds to both array and vector versions of the new algorithm in
Corresponds to both array and vector versions of the new algorithm in
signal one-dimensional memory structure
signal multi-dimensional memory structure
signal multiple one-dimensional memory structure
Figure 4 Operations per element versus reference algorithms and new algorithm with different s (splits) where dashed column correspondsto both array and vector versions of algorithm of Rudio cross lines column corresponds to both array and vector versions of ldquoLinear BitReversalrdquo algorithm dotted column corresponds to both array and vector versions of ldquoElsterrsquos Bit Reversalrdquo algorithm vertical lines columncorresponds to both array and vector versions of the new algorithm in single one-dimensional memory structure inclined lines columncorresponds to both array and vector versions of the new algorithm in single multidimensional memory structure and horizontal linescolumn corresponds to both array and vector versions of the new algorithm in multiple one-dimensional memory structures
respectively in relation to the array version of LBRA Thealgorithm with eight memory structures has nearly the sameCPE as the four-array and four-vector versions but is lessconsistent On the other hand the four-vector implementa-tion of the new algorithm is the fastest and most consistentamong all vector versions Two four eight and sixteenmultiple vector implementations of new BRA reported 1316 and 16 higher and 23 lower efficiency respectively inrelation to the vector version of LBRAThis result proves thatat a certain point multiple memory structure gives the bestperformances in the considered domain Also usage of mul-tiple memory structures of primitive array is a good optionfor implementing index mapping of BRP compared to multi-dimensional or single one-dimensional memory structures
Due to the flexible nature of the vector it is commonlyused for implementing algorithms According to Figure 4there is no difference in OPPE between array and vectorversionsHowever our results in Figure 5 show that the vectorversions of BRA always required more CPE (44ndash142)than the array version The structure of vector gives priorityto generality and flexibility rather than to execution speedmemory economy cache efficiency and code size [22]There-fore vector is not a good option with respect to efficiency
The results in Table 5 and Figure 4 show that there is nodifference between the number of calculations and OPPEfor equal versions of algorithms with multidimensional andmultiple memory structure Structure and type of calcula-tions are the same for both types The only difference is thenature of the memory structure multidimension or multipleone-dimension When CPE is considered it shows 19ndash79
performance efficiency from algorithms with multiple one-dimension memory structures The reason for that observa-tion is that the memory access of multidimensional memorystructure is less efficient than one-dimensional memorystructure [22]
We agree with the statement of Elster about indexmapping of BRP [2] and the generally accepted fact (theusage of multidimensional memory structures reduces theperformance of a computer) [4] only with respect to multi-dimensional memory structures of vector Our results showthat even with multidimensional arrays there are situationswhere the new BRA performs better than the same typeof one-dimensional memory structure The four eight andsixteen dimensional array versions of new BRA perform 810 and 2 in relation to one-dimensional array version ofnew BRA Some results in relation to single one-dimensionalmemory structure implementation of new BRA are also notin agreement with the general accepted idea For examplesample size = 231 the two-dimensional vector version of newBRA (BRA Split 1 2DV) reported 542119864 minus 05 CPE which is389 higher in relation to average CPE of sample size rangeof 221 to 230 Also the inconsistency was very highThereforewe excluded values related to sample size = 231 for the two-dimensional vector version
We observed very high memory utilization with the two-dimensional vector version especially with sample size =231 Windows task manager showed that the memory uti-lization of all the considered algorithms was nearly thesame for all sample sizes except for multidimension versionsof vector The multidimensional version of vector initially
10 Mathematical Problems in Engineering
Cloc
ks p
er el
emen
t (CP
E)
000E + 00
500E minus 06
100E minus 05
150E minus 05
200E minus 05
250E minus 05
300E minus 05
BRM
split
01x
BRM
split
12x
BRM
split
24x
BRM
split
38x
BRM
split
416x
lowastBR
Msp
lit12
Dx
BRM
split
24
Dx
BRM
split
38
Dx
BRM
split
416
Dx
BRM
split
11x
BRM
split
21x
BRM
split
31x
BRM
split
41x
x-A or V (array or vector)Algorithms
Refe
renc
e alg
orith
m o
ne-
dim
ensio
nal s
ingl
e mem
ory
struc
ture
of s
izen
Multiple memorystructures
1
1
2
k
k
k
k = 2s
n sample size
Multidimensionalmemory structure
One-dimensionalmemory structure
nknk
nk
middotmiddotmiddot
middotmiddotmiddot
(s = 1 2 3 4)
Corresponds to array version of the algorithmCorresponds to vector version of the algorithmCorresponds to minimum reported CPE of the category
Figure 5 Clocks per element (combined average) versus algorithm for the sample size range from 221 to 231 where blue dotted columncorresponds to array version of the algorithm green column corresponds to vector version of the algorithm and red rhombus corresponds tominimum reported CPE of the category lowastFor vector version sample size 231 was excluded because at sample size 231 it showed huge deviationdue to memory limitation of the machine
utilizes highermemory and drops down to normal valueTheresults in relation to sample size = 2
30 showed that the extramemory requirement of two dimension vector was higherthan that of the four-dimensional vector Based upon that itcan be predicted that BRA Split 1 2DV needs an extra 3GB(total 13 GB) for normal execution at sample size = 2
31 butthe total memory barrier of 12GB of the machine slows theprocess down The most likely reason for this observation isthe influence ofmemory poolingmechanismWhen defininga memory structure it is possible to allocate the requiredamount of memory This is known as memory pooling [23]In all the memory structures used in algorithms discussedin this paper we used memory pooling Memory poolingallocates the required memory at startup and divides thisblock into small chunks If there is no memory poolingmemory will get fragmented Accessing fragmented memoryis inefficient When the existing memory is not enough forallocating then it switches to use fragmented memory forallocating memory elements In the considered situation theexisting memory (12GB) is not sufficient for allocating therequired amount (13GB) which switches to use fragmentedmemory
The total cache size of the machine is 825MB whichis less than the minimum memory utilization of consideredalgorithms (16MB to 8GB) in relation to the sample sizerange from 222 to 231 Only the sample size 221 occupies 8MBmemory which is less than the total cache memory ExceptBRA Split 4 1V structure all algorithms reported constantCPE in relation to the entire sample size range The bestalgorithms of each category especially reported very steady
behaviour This observation is in disagreement with thestatement of Karp ldquothat a machine with hierarchical memorydoes not performwell when array size is larger than the cachesizerdquo [10]
Comparison (Figure 6) of best reported version in theconsidered domain (four memory structure version) andthe selected algorithms shows that the array version ofEBR performs the best The four-array version of new BRAreported 1 lower performance than the array version ofEBR However the four-array version of new BRA reported34 and 23 higher performances than array versions ofLBRA and BRA-Ru Also the four-vector version of newBRA is reported to have the best performance among all thevector versions It reported 16 10 and 22 performancescompared to vector versions of LBRA EBR and BRA-Rurespectively
4 Conclusion and Outlook
Themain finding of this paper is the recursive pattern of BPRand the implementationmethod of it using multiple memorystructures With multiple memory structures especiallythe newly identified index mapping performs much betterthan multidimensional or single one-dimensional memorystructure Furthermore findings of this paper show that theperformance of primitive array is higher than vector typeThe result is in disagreement with the statement of Karp ldquothata machine with hierarchical memory does not perform wellwhen array size is larger than the cache sizerdquo Almost all thesample sizes we used were higher than the total cache size
Mathematical Problems in Engineering 11
120E ndash 05
100E minus 05
800E minus 06
600E minus 06
400E minus 06
200E ndash 06
000E + 00
Cloc
ks p
er el
emen
t (CP
E)
BRM
split
24x
(the b
est v
ersio
nof
the n
ewal
gorit
hm)
Line
ar b
it-re
vers
al1x
Elste
rrsquos b
it-
Rubi
o1x
reve
rsal
1x
x-A or V (array or vector)Algorithms
Corresponds to array version of the algorithmCorresponds to vector version of the algorithm
Figure 6 Clocks per element versus best version of new algorithm and selected algorithms where blue dotted column corresponds to arrayversion and green column corresponds to vector version of the algorithm
1
1
1
1
1
0
1
0
1
0
1
0
Process 1
Process 2
Process 5
Process 6Process 3
Process 4
Process 7
4 parallel processes
2 parallel processes
Single process
Tota
l sig
nal i
s div
ided
into
equa
l fou
r ind
epen
dent
mem
ory
struc
ture
s usin
g ne
w al
gorit
hm (B
RMsp
lit24x
)
x(0)
x(4)
x(2)
x(6)
x(1)
x(5)
x(3)
x(7)
minus1
w04
w14
w24
w34
w04
w14
w24
w34
A(0)
A(1)
A(2)
A(3)
B(0)
B(1)
B(2)
B(3)
x(0)
x(1)
x(2)
x(3)
x(4)
x(5)
x(6)
x(7)
minus1
minus1
minus1
Figure 7 Four-memory-structure version of algorithm and the parallel processes for sample size = 16
of the computer However multiple memory structure andthe multidimensional memory structure versions showedreasonable steady performancewith those samples In generalthese results show the effects of data structures and memoryallocation techniques and open a new window of creatingefficient algorithms with multiple memory structures inmany other fields where index mapping is involved
The new bit reversal algorithm with 2119904 independent
memory structures splits the total signal into 119904 independentportions and the total FFT process into 119904 + 1 levels Thenthese 119904 signal portions can be processed independently bymeans of 119904 independent processes on the first level Onthe next level the results from the previous level stored inindependent memory structures can be processed with 1199042
12 Mathematical Problems in Engineering
processes and so on until the last level Therefore we suggestusing the concept of multiple memory structures in total FFTprocess along with the new algorithm with multiple memorystructures and suitable parallel processing technique Weexpect that it is possible to achieve higher performance fromFFT process with proper combination of parallel processingtechnique and new algorithm compared to using the newalgorithm only to create bit reversal permutation Figure 7shows such approach with four (when 119904 = 2) independentmemory structures for sample size = 16
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
Acknowledgment
This publication is financially supported by the UniversityGrants Commission Sri Lanka
References
[1] C S Burrus ldquoUnscrambling for fast DFT algorithmsrdquo IEEETransactions on Acoustics Speech and Signal Processing vol 36no 7 pp 1086ndash1087 1988
[2] A C Elster and J C Meyer ldquoA super-efficient adaptable bit-reversal algorithm for multithreaded architecturesrdquo in Pro-ceedings of the IEEE International Symposium on Parallel ampDistributed Processing (IPDPS 09) vol 1ndash5 pp 1ndash8 Rome ItalyMay 2009
[3] J W Cooley and J W Tukey ldquoAn algorithm for the machinecalculation of complex Fourier seriesrdquoMathematics of Compu-tation vol 19 no 90 pp 297ndash301 1965
[4] M L Massar R Bhagavatula M Fickus and J KovacevicldquoLocal histograms and image occlusion modelsrdquo Applied andComputational Harmonic Analysis vol 34 no 3 pp 469ndash4872013
[5] R G Lyons Understanding Digital Signal Processing PrenticeHall PTR 2004
[6] C Deyun L Zhiqiang G Ming W Lili and Y XiaoyangldquoA superresolution image reconstruction algorithm based onlandweber in electrical capacitance tomographyrdquoMathematicalProblems in Engineering vol 2013 Article ID 128172 8 pages2013
[7] Q Yang and D An ldquoEMD and wavelet transform based faultdiagnosis for wind turbine gear boxrdquo Advances in MechanicalEngineering vol 2013 Article ID 212836 9 pages 2013
[8] C S Burrus Fast Fourier Transforms Rice University HoustonTex USA 2008
[9] C van Loan Computational Frameworks for the Fast FourierTransform vol 10 of Frontiers in Applied Mathematics Societyfor Industrial and Applied Mathematics (SIAM) PhiladelphiaPa USA 1992
[10] A H Karp ldquoBit reversal on uniprocessorsrdquo SIAM Review vol38 no 1 pp 1ndash26 1996
[11] A C Elster ldquoFast bit-reversal algorithmsrdquo in Proceedings ofthe International Conference on Acoustics Speech and SignalProcessing pp 1099ndash1102 IEEE Press Glasgow UK May 1989
[12] M Rubio P Gomez and K Drouiche ldquoA new superfast bitreversal algorithmrdquo International Journal of Adaptive Controland Signal Processing vol 16 no 10 pp 703ndash707 2002
[13] B Stroustrup Programming Principles and Practice Using C++Addison-Wesley 2009
[14] B Stroustrup ldquoSoftware development for infrastructurerdquo IEEEComputer Society vol 45 no 1 Article ID 6081841 pp 47ndash582012
[15] B Stroustrup The C++ Programming Language ATampT Labs3rd edition 1997
[16] S DonovanC++ by Example ldquoUnderCrdquo Learning Edition QUECorporation 2002
[17] S Mcconnell Code Complete Microsoft Press 2nd edition2004
[18] Microsoft STL Containers Microsoft New York NY USA2012 httpmsdnmicrosoftcomen-uslibrary1fe2x6ktaspx
[19] Microsoft Arrays (C++ Component Extensions) MicrosoftNew York NY USA 2012 httpmsdnmicrosoftcomen-uslibraryvstudiots4c4dw6(v=vs110)aspx
[20] B Stroustrup ldquoEvolving a language in and for the real worldC++ 1991ndash2006rdquo in Proceedings of the 3rd ACM SIGPLANHistory of Programming Languages Conference (HOPL-III rsquo07)June 2007
[21] Microsoft Memory Limits for Windows Releases MicrosoftNew York NY USA 2012 httpmsdnmicrosoftcomen-uslibraryaa36677828VS8529aspxmemory limits
[22] A Fog ldquoOptimizing software in C++rdquo 2014 httpwwwagnerorgoptimize
[23] Code Project ldquoC++ Memory Poolrdquo 2014 httpwwwcodepro-jectcomArticles15527C-Memory-Pool
Submit your manuscripts athttpwwwhindawicom
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical Problems in Engineering
Hindawi Publishing Corporationhttpwwwhindawicom
Differential EquationsInternational Journal of
Volume 2014
Applied MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Probability and StatisticsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
OptimizationJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
CombinatoricsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Operations ResearchAdvances in
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Function Spaces
Abstract and Applied AnalysisHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of Mathematics and Mathematical Sciences
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Algebra
Discrete Dynamics in Nature and Society
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Decision SciencesAdvances in
Discrete MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom
Volume 2014 Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Stochastic AnalysisInternational Journal of

Mathematical Problems in Engineering 5
Table 2 Hardware and software specifications of the PC
Specifications
Processor Intel Core i7 CPU 870 293GHz (4 cores8 threads)
RAM 12GB DDR3-1333 2 channelsMemory bandwidth 21GBsL1 L2 and L3 cache 4 times 64KB 4 times 256KB and 8MB sharedL1 L2 and L3 cacheline size 64 bit
Brand and type Fujitsu CelsiusBIOS settings Default (hyper threading enabled)OS and service pack Windows 7 professional with service pack 1System type 64 bit operating systemOS settings DefaultVisual Studio 2012 Version 110507271 RTMRELNET Framework Version 4550709
Thenext taskwas to identify a suitable data structure fromdifferent types of available data structures We consideredseveral common techniques as summarized in Table 3 Datastructure 1 mentioned in Table 3 is not supporting dynamicmemory allocation (need to mention the size of the arraywhen array is being declared) For general bit reversalalgorithm it is a must to have dynamic memory allocation tocater different sizes of samples Even after setting the compileroption ldquoLARGEADDRESSAWARErdquo [21] data structures 3and 4 mentioned in Table 3 were not supported for accessingmemory greater than 2GB Therefore structures 1 3 and 4were rejected and memory structures 2 (array) and 5 (vector)were used to create all one-dimensional memory structuresThe same versions of array and vector were used to createmultidimensional memory structures
The new algorithm mentioned in Section 21 was imple-mented usingC++ in 24 types ofmemory structures as shownin Table 4 The performance of these algorithms was evalu-ated considering the ldquoclocks per elementrdquo (CPE) consumedbyeach algorithm To retrieve this value first average CPE foreach sample size of 2119899 where 119899 [21 31] (11 sample sizes) werecalculated after executing each algorithm 100 timesThis gave11 CPE representing each sample size Finally the combinedaverageof CPEwas calculated for each algorithmby averagingthose 11 values along with ldquocombined standard deviationrdquoThe combined average of CPE was considered as the CPEfor each algorithm The built-in ldquoclockrdquo function of C++ wasused to calculate the clocks Combined standard deviationwas calculated using the following
120590119888= (
sum119896
119904=1(1198991199041205902
119904+ 119899119904(119883119904minus 119883119888)
2
)
sum119896
119904=1119899119904
)
12
(4)
where119883119888= sum119896
119904=1119899119904119883119904sum119896
119904=1119899119904 119904 is the number of samples 119899
119904
is number of samples in each sample and 120590119904is the standard
deviation of each sample
Algorithms 1 2 and 3 illustrate the implementation ofnew BRA with single one-dimensional memory structuremultidimensional memory structure and multiple mem-ory structures respectively The algorithm illustrated inAlgorithm 1 (BRA Split 1 1A) was implemented using prim-itive array for split = 1 The algorithm BRM Split 2 4A(Algorithm 2) was implemented using vectors for split =2 The algorithm BRM Split 2 4A (Algorithm 3) was imple-mented using primitive array for split = 2 A sample per-mutation filling sequence of algorithms with single one-dimensional memory structures is illustrated in Figure 2Figure 3 illustrates a sample permutation filling sequence ofboth multidimensional and multiple memory structures
Secondly arithmetic operations per element (OPPE)werecalculated for each algorithm Arithmetic operations withineach algorithm were located in three regions of the codeinner FOR loop outer FOR loop and outside of the loopsThen the total number of operations (OP) can be defined as
OP = 1198701lowast 1198621+ 1198702lowast 1198622+ 1198623 (5)
where 1198621 1198622 and 119862
3are the number of operations in inner
FOR loop outer FOR loop and outside of the loops 1198701and
1198702are the number of iterations of outer loop and inner loop
Equation (5) can be represented as
OP =log2(NS)minus119904minus1
sum
119905=0
2119905lowast 1198621+
log2(NS)minus119904minus1
sum
119905=0
1198622+ 1198623 (6)
where NS is the number of samples and 119904 is the number ofsplits
The main contribution to calculations comes from theinner loop Comparing with the contribution of operationsin the inner loop the contribution of operations in rest ofthe code is very small For example consider the algorithmBRA Split 1 1A shown in Algorithm 1 As sample size is 2311198701lowast 1198621asymp 215 lowast 10
9lowast 1198621and 119870
2lowast 1198622+ 1198623asymp 1000 where
1198621gt 1 Therefore only the operations of inner loop were
considered for evaluation Then (6) can be simplified as
OP =log2(NS)minus119904minus1
sum
119905=0
2119905lowast 1198621 (7)
The ldquooperations per elementrdquo (OPPE) can be defined as
OPPE =(sum
log2(NS)minus119904minus1
119905=02119905lowast 1198621)
NS
(8)
For FFT always NS = 2119896 119896 isin 119885+Then from (7)
OPPE =(sum119896minus119904minus1
119905=02119905lowast 1198621)
2119896
(9)
119896
sum
119905=0
2119905+ 1 = 2
119896+1 (10)
6 Mathematical Problems in Engineering
Table 3 Common memory allocating methods that are used in Visual C++
Number Name Syntax Nature of memory layout1 Array int BRP[1000] Slot of continuous memory elements2 Array intlowast BRP = new int[119899] Slot of continuous memory elements3 Array array⟨int⟩andBRP = gcnew array⟨int⟩(119899) Collection of noncontinuous memory elements4 ArrayList ArrayList andBRP = gcnew ArrayList() Collection of noncontinuous memory elements5 Vector stdvector⟨int⟩ BRP(119899) Collection of noncontinuous memory elements
Table 4 Different versions of new BRA implemented with different data structures
Split (s) Data structure type AlgorithmSingle memory structure Multidimensional memory structure Multiple memory structure
1 Array (A) BRA Split 1 1A BRA Split 1 2DA BRA Split 1 2A1 Vector (V) BRA Split 1 1V BRA Split 1 2DV BRA Split 1 2V2 Array (A) BRA Split 2 1A BRA Split 2 4DA BRA Split 2 4A2 Vector (V) BRA Split 2 1V BRA Split 2 4DV BRA Split 2 4V3 Array (A) BRA Split 3 1A BRA Split 3 8DA BRA Split 3 8A3 Vector (V) BRA Split 3 1V BRA Split 3 8DV BRA Split 3 8V4 Array (A) BRA Split 4 1A BRA Split 4 16DA BRA Split 4 16A4 Vector (V) BRA Split 4 1V BRA Split 4 16DV BRA Split 4 16VNaming convention for algorithms ldquoBRA Splitrdquo + ltNumber of splitsgt + ltnature of memory structuregt xA xV x number of arrays and x number of vectorsxDA xDV single x-dimensional array and single x-dimensional vector
void mf BRM Split 1 1A (unsigned int ui NS int ui log2NS)
unsigned int ui Nunsigned int ui EBunsigned int ui tunsigned int ui Lunsigned int ui DL
ui N = ui NS Number of samplesui t = ui log2NS minus 1ui EB = ui N2ui L = 1unsigned intlowast BRP = new unsigned int[ui N]BRP[0] = 0BRP[ui EB] = 1for (unsigned int q = 0 q lt ui t q++)
ui DL = ui L + ui Lui N = ui N2for (unsigned int j = ui L j lt ui DL j++)
BRP[j] = BRP[j minus ui L] + ui NBRP[ui EB + j] = BRP[j] + 1
ui L = ui L + ui L
delete[] BRP
Algorithm 1 C++ implementation of new BRA with single array for split = 1 (BRA Split 1 1A)
Mathematical Problems in Engineering 7
Void mf BRM Split 2 4DV (unsigned int ui NS int ui log2NS)
unsigned int ui Nunsigned int ui EBunsigned int ui tunsigned int ui Lunsigned int ui DLui N = ui NS Number of samplesui t = ui log2NS minus 2ui EB = ui N4ui L = 1stdvectorltstdvectorltunsigned intgtgt BRP(4
stdvectorltunsigned intgt(ui EB))BRP[0][0] = 0BRP[1][0] = 2BRP[2][0] = 1BRP[3][0] = 3for (unsigned int q = 0 q lt ui t q++)
ui DL = ui L + ui Lui N = ui N2for (unsigned int j = ui L j lt ui DL j++)
BRP[0][j] = BRP[0][j minus ui L] + ui NBRP[1][j] = BRP[0][j] + 2BRP[2][j] = BRP[0][j] + 1BRP[3][j] = BRP[1][j] + 1
ui L = ui L + ui L
Algorithm 2 C++ implementation of new BRA with four arrays for split = 2 (BRM Split 2 4A)
0 8 4 12 2 10 6 14 1 9 5 13 3 11 7 15
Initialization
First iteration Seventh (last) iteration
Figure 2 Permutation filling sequence of new BRA with single memory structure for 119899 = 16 and split =1 (BRA Split 1 1A)
For large 119896 2119896 + 1 asymp 2119896 Then
119896
sum
119905=0
2119905= 2119896+1
(11)
Because the considered sample size is 221 to 231 the value 119896can be considered as large Then from (9)
OPPE =1198621lowast (2119896minus119904)
2119896
(12)
OPPE = 1198621
2119904 (13)
According to (13) OPPE is 119891(1198621 119904) The value 119862
1(oper-
ations in inner loop) and the value 119904 (number of splits) are aconstant for a certain algorithm
To evaluate the performance of new BRA we selectedthree algorithms (LBRA EBR and BRA-Ru) which used apattern instead of conventional bit reversing method Theperformance of vector and array versions of the best version
Table 5 The number of operations in the inner loop (1198621) of each
algorithm for different splits (119904) (The total number of operations ineach algorithm asymp 119862
1)
Memory structure type Value of 1198621
119904 = 1 119904 = 2 119904 = 3 119904 = 4
Single one-dimension (array and vector) 8 15 30 61Multidimension (array and vector) 7 11 19 35Multiple one-dimension (array and vector) 7 11 19 35
of new BRA was compared with the relevant versions ofselected algorithms
3 Results and Discussion
Our objective was to introduce BRA using recursive patternof the BRP that we identified We used multiple memorystructures which is a feasible yet unpopular technique toimplement index mapping According to Table 5 the num-bers of operations in all the array and vector versions of both
8 Mathematical Problems in Engineering
Void mf BRM Split 2 4A (unsigned int ui NS int ui log2NS)
unsigned int ui Nunsigned int ui EBunsigned int ui tunsigned int ui Lunsigned int ui DL
ui N = ui NS Number of samplesui t = ui log2NS minus 2ui EB = ui N4ui L = 1unsigned intlowast BRP1 = new unsigned int[ui EB]unsigned intlowast BRP2 = new unsigned int[ui EB]unsigned intlowast BRP3 = new unsigned int[ui EB]unsigned intlowast BRP4 = new unsigned int[ui EB]
BRP1[0] = 0BRP2[0] = 2BRP3[0] = 1BRP4[0] = 3for (unsigned int q = 0 q lt ui t q++)
ui DL = ui L + ui Lui N = ui N2for (unsigned int j = ui L j lt ui DL j++)
BRP1[j] = BRP1[j minus ui L]+ ui NBRP2[j] = BRP1[j] + 2BRP3[j] = BRP1[j] + 1BRP4[j] = BRP2[j] + 1
ui L = ui L + ui L
delete[] BRO1delete[] BRO2delete[] BRO3delete[] BRO4
Algorithm 3 C++ implementation of new BRA with four one-dimensional arrays for split = 2 (BRM Split 2 4A)
0 8 4 12
2 10 6 14
1 9 5 13
3 11 7 15
Initi
aliz
atio
n
Third
(las
t) ite
ratio
n
First iteration
Figure 3 Permutation filling sequence of 4 individual and single 4-dimensional memory structure for 119899 = 16
multidimensional and multiple memory structures are thesame Also Figure 5 shows continuous decrement of OPPEwhen the number of splits increases Then the algorithmwith the highest number of splits and the lowest number ofoperations is the one which is expected to be most efficient
However results in relation with CPE (Figure 5) show thatthe new algorithm with four memory structures of array isthe fastest and most consistent in the selected range Twofour eight and sixteen multiple array implementations ofnew BRA reported 25 34 33 and 18 higher efficiency
Mathematical Problems in Engineering 9
0
1
2
3
4
5
6
Refalgorithms
Ope
ratio
ns p
er el
emen
t (O
PPE)
Split = 1 Split = 2 Split = 3 Split = 4
Corresponds to both array and vector versions of algorithm of rudioCorresponds to both array and vector versions of ldquolinear bit reversalrdquo algorithmCorresponds to both array and vector versions of ldquoelsterrsquos bit reversalrdquo algorithmCorresponds to both array and vector versions of the new algorithm in
Corresponds to both array and vector versions of the new algorithm in
Corresponds to both array and vector versions of the new algorithm in
signal one-dimensional memory structure
signal multi-dimensional memory structure
signal multiple one-dimensional memory structure
Figure 4 Operations per element versus reference algorithms and new algorithm with different s (splits) where dashed column correspondsto both array and vector versions of algorithm of Rudio cross lines column corresponds to both array and vector versions of ldquoLinear BitReversalrdquo algorithm dotted column corresponds to both array and vector versions of ldquoElsterrsquos Bit Reversalrdquo algorithm vertical lines columncorresponds to both array and vector versions of the new algorithm in single one-dimensional memory structure inclined lines columncorresponds to both array and vector versions of the new algorithm in single multidimensional memory structure and horizontal linescolumn corresponds to both array and vector versions of the new algorithm in multiple one-dimensional memory structures
respectively in relation to the array version of LBRA Thealgorithm with eight memory structures has nearly the sameCPE as the four-array and four-vector versions but is lessconsistent On the other hand the four-vector implementa-tion of the new algorithm is the fastest and most consistentamong all vector versions Two four eight and sixteenmultiple vector implementations of new BRA reported 1316 and 16 higher and 23 lower efficiency respectively inrelation to the vector version of LBRAThis result proves thatat a certain point multiple memory structure gives the bestperformances in the considered domain Also usage of mul-tiple memory structures of primitive array is a good optionfor implementing index mapping of BRP compared to multi-dimensional or single one-dimensional memory structures
Due to the flexible nature of the vector it is commonlyused for implementing algorithms According to Figure 4there is no difference in OPPE between array and vectorversionsHowever our results in Figure 5 show that the vectorversions of BRA always required more CPE (44ndash142)than the array version The structure of vector gives priorityto generality and flexibility rather than to execution speedmemory economy cache efficiency and code size [22]There-fore vector is not a good option with respect to efficiency
The results in Table 5 and Figure 4 show that there is nodifference between the number of calculations and OPPEfor equal versions of algorithms with multidimensional andmultiple memory structure Structure and type of calcula-tions are the same for both types The only difference is thenature of the memory structure multidimension or multipleone-dimension When CPE is considered it shows 19ndash79
performance efficiency from algorithms with multiple one-dimension memory structures The reason for that observa-tion is that the memory access of multidimensional memorystructure is less efficient than one-dimensional memorystructure [22]
We agree with the statement of Elster about indexmapping of BRP [2] and the generally accepted fact (theusage of multidimensional memory structures reduces theperformance of a computer) [4] only with respect to multi-dimensional memory structures of vector Our results showthat even with multidimensional arrays there are situationswhere the new BRA performs better than the same typeof one-dimensional memory structure The four eight andsixteen dimensional array versions of new BRA perform 810 and 2 in relation to one-dimensional array version ofnew BRA Some results in relation to single one-dimensionalmemory structure implementation of new BRA are also notin agreement with the general accepted idea For examplesample size = 231 the two-dimensional vector version of newBRA (BRA Split 1 2DV) reported 542119864 minus 05 CPE which is389 higher in relation to average CPE of sample size rangeof 221 to 230 Also the inconsistency was very highThereforewe excluded values related to sample size = 231 for the two-dimensional vector version
We observed very high memory utilization with the two-dimensional vector version especially with sample size =231 Windows task manager showed that the memory uti-lization of all the considered algorithms was nearly thesame for all sample sizes except for multidimension versionsof vector The multidimensional version of vector initially
10 Mathematical Problems in Engineering
Cloc
ks p
er el
emen
t (CP
E)
000E + 00
500E minus 06
100E minus 05
150E minus 05
200E minus 05
250E minus 05
300E minus 05
BRM
split
01x
BRM
split
12x
BRM
split
24x
BRM
split
38x
BRM
split
416x
lowastBR
Msp
lit12
Dx
BRM
split
24
Dx
BRM
split
38
Dx
BRM
split
416
Dx
BRM
split
11x
BRM
split
21x
BRM
split
31x
BRM
split
41x
x-A or V (array or vector)Algorithms
Refe
renc
e alg
orith
m o
ne-
dim
ensio
nal s
ingl
e mem
ory
struc
ture
of s
izen
Multiple memorystructures
1
1
2
k
k
k
k = 2s
n sample size
Multidimensionalmemory structure
One-dimensionalmemory structure
nknk
nk
middotmiddotmiddot
middotmiddotmiddot
(s = 1 2 3 4)
Corresponds to array version of the algorithmCorresponds to vector version of the algorithmCorresponds to minimum reported CPE of the category
Figure 5 Clocks per element (combined average) versus algorithm for the sample size range from 221 to 231 where blue dotted columncorresponds to array version of the algorithm green column corresponds to vector version of the algorithm and red rhombus corresponds tominimum reported CPE of the category lowastFor vector version sample size 231 was excluded because at sample size 231 it showed huge deviationdue to memory limitation of the machine
utilizes highermemory and drops down to normal valueTheresults in relation to sample size = 2
30 showed that the extramemory requirement of two dimension vector was higherthan that of the four-dimensional vector Based upon that itcan be predicted that BRA Split 1 2DV needs an extra 3GB(total 13 GB) for normal execution at sample size = 2
31 butthe total memory barrier of 12GB of the machine slows theprocess down The most likely reason for this observation isthe influence ofmemory poolingmechanismWhen defininga memory structure it is possible to allocate the requiredamount of memory This is known as memory pooling [23]In all the memory structures used in algorithms discussedin this paper we used memory pooling Memory poolingallocates the required memory at startup and divides thisblock into small chunks If there is no memory poolingmemory will get fragmented Accessing fragmented memoryis inefficient When the existing memory is not enough forallocating then it switches to use fragmented memory forallocating memory elements In the considered situation theexisting memory (12GB) is not sufficient for allocating therequired amount (13GB) which switches to use fragmentedmemory
The total cache size of the machine is 825MB whichis less than the minimum memory utilization of consideredalgorithms (16MB to 8GB) in relation to the sample sizerange from 222 to 231 Only the sample size 221 occupies 8MBmemory which is less than the total cache memory ExceptBRA Split 4 1V structure all algorithms reported constantCPE in relation to the entire sample size range The bestalgorithms of each category especially reported very steady
behaviour This observation is in disagreement with thestatement of Karp ldquothat a machine with hierarchical memorydoes not performwell when array size is larger than the cachesizerdquo [10]
Comparison (Figure 6) of best reported version in theconsidered domain (four memory structure version) andthe selected algorithms shows that the array version ofEBR performs the best The four-array version of new BRAreported 1 lower performance than the array version ofEBR However the four-array version of new BRA reported34 and 23 higher performances than array versions ofLBRA and BRA-Ru Also the four-vector version of newBRA is reported to have the best performance among all thevector versions It reported 16 10 and 22 performancescompared to vector versions of LBRA EBR and BRA-Rurespectively
4 Conclusion and Outlook
Themain finding of this paper is the recursive pattern of BPRand the implementationmethod of it using multiple memorystructures With multiple memory structures especiallythe newly identified index mapping performs much betterthan multidimensional or single one-dimensional memorystructure Furthermore findings of this paper show that theperformance of primitive array is higher than vector typeThe result is in disagreement with the statement of Karp ldquothata machine with hierarchical memory does not perform wellwhen array size is larger than the cache sizerdquo Almost all thesample sizes we used were higher than the total cache size
Mathematical Problems in Engineering 11
120E ndash 05
100E minus 05
800E minus 06
600E minus 06
400E minus 06
200E ndash 06
000E + 00
Cloc
ks p
er el
emen
t (CP
E)
BRM
split
24x
(the b
est v
ersio
nof
the n
ewal
gorit
hm)
Line
ar b
it-re
vers
al1x
Elste
rrsquos b
it-
Rubi
o1x
reve
rsal
1x
x-A or V (array or vector)Algorithms
Corresponds to array version of the algorithmCorresponds to vector version of the algorithm
Figure 6 Clocks per element versus best version of new algorithm and selected algorithms where blue dotted column corresponds to arrayversion and green column corresponds to vector version of the algorithm
1
1
1
1
1
0
1
0
1
0
1
0
Process 1
Process 2
Process 5
Process 6Process 3
Process 4
Process 7
4 parallel processes
2 parallel processes
Single process
Tota
l sig
nal i
s div
ided
into
equa
l fou
r ind
epen
dent
mem
ory
struc
ture
s usin
g ne
w al
gorit
hm (B
RMsp
lit24x
)
x(0)
x(4)
x(2)
x(6)
x(1)
x(5)
x(3)
x(7)
minus1
w04
w14
w24
w34
w04
w14
w24
w34
A(0)
A(1)
A(2)
A(3)
B(0)
B(1)
B(2)
B(3)
x(0)
x(1)
x(2)
x(3)
x(4)
x(5)
x(6)
x(7)
minus1
minus1
minus1
Figure 7 Four-memory-structure version of algorithm and the parallel processes for sample size = 16
of the computer However multiple memory structure andthe multidimensional memory structure versions showedreasonable steady performancewith those samples In generalthese results show the effects of data structures and memoryallocation techniques and open a new window of creatingefficient algorithms with multiple memory structures inmany other fields where index mapping is involved
The new bit reversal algorithm with 2119904 independent
memory structures splits the total signal into 119904 independentportions and the total FFT process into 119904 + 1 levels Thenthese 119904 signal portions can be processed independently bymeans of 119904 independent processes on the first level Onthe next level the results from the previous level stored inindependent memory structures can be processed with 1199042
12 Mathematical Problems in Engineering
processes and so on until the last level Therefore we suggestusing the concept of multiple memory structures in total FFTprocess along with the new algorithm with multiple memorystructures and suitable parallel processing technique Weexpect that it is possible to achieve higher performance fromFFT process with proper combination of parallel processingtechnique and new algorithm compared to using the newalgorithm only to create bit reversal permutation Figure 7shows such approach with four (when 119904 = 2) independentmemory structures for sample size = 16
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
Acknowledgment
This publication is financially supported by the UniversityGrants Commission Sri Lanka
References
[1] C S Burrus ldquoUnscrambling for fast DFT algorithmsrdquo IEEETransactions on Acoustics Speech and Signal Processing vol 36no 7 pp 1086ndash1087 1988
[2] A C Elster and J C Meyer ldquoA super-efficient adaptable bit-reversal algorithm for multithreaded architecturesrdquo in Pro-ceedings of the IEEE International Symposium on Parallel ampDistributed Processing (IPDPS 09) vol 1ndash5 pp 1ndash8 Rome ItalyMay 2009
[3] J W Cooley and J W Tukey ldquoAn algorithm for the machinecalculation of complex Fourier seriesrdquoMathematics of Compu-tation vol 19 no 90 pp 297ndash301 1965
[4] M L Massar R Bhagavatula M Fickus and J KovacevicldquoLocal histograms and image occlusion modelsrdquo Applied andComputational Harmonic Analysis vol 34 no 3 pp 469ndash4872013
[5] R G Lyons Understanding Digital Signal Processing PrenticeHall PTR 2004
[6] C Deyun L Zhiqiang G Ming W Lili and Y XiaoyangldquoA superresolution image reconstruction algorithm based onlandweber in electrical capacitance tomographyrdquoMathematicalProblems in Engineering vol 2013 Article ID 128172 8 pages2013
[7] Q Yang and D An ldquoEMD and wavelet transform based faultdiagnosis for wind turbine gear boxrdquo Advances in MechanicalEngineering vol 2013 Article ID 212836 9 pages 2013
[8] C S Burrus Fast Fourier Transforms Rice University HoustonTex USA 2008
[9] C van Loan Computational Frameworks for the Fast FourierTransform vol 10 of Frontiers in Applied Mathematics Societyfor Industrial and Applied Mathematics (SIAM) PhiladelphiaPa USA 1992
[10] A H Karp ldquoBit reversal on uniprocessorsrdquo SIAM Review vol38 no 1 pp 1ndash26 1996
[11] A C Elster ldquoFast bit-reversal algorithmsrdquo in Proceedings ofthe International Conference on Acoustics Speech and SignalProcessing pp 1099ndash1102 IEEE Press Glasgow UK May 1989
[12] M Rubio P Gomez and K Drouiche ldquoA new superfast bitreversal algorithmrdquo International Journal of Adaptive Controland Signal Processing vol 16 no 10 pp 703ndash707 2002
[13] B Stroustrup Programming Principles and Practice Using C++Addison-Wesley 2009
[14] B Stroustrup ldquoSoftware development for infrastructurerdquo IEEEComputer Society vol 45 no 1 Article ID 6081841 pp 47ndash582012
[15] B Stroustrup The C++ Programming Language ATampT Labs3rd edition 1997
[16] S DonovanC++ by Example ldquoUnderCrdquo Learning Edition QUECorporation 2002
[17] S Mcconnell Code Complete Microsoft Press 2nd edition2004
[18] Microsoft STL Containers Microsoft New York NY USA2012 httpmsdnmicrosoftcomen-uslibrary1fe2x6ktaspx
[19] Microsoft Arrays (C++ Component Extensions) MicrosoftNew York NY USA 2012 httpmsdnmicrosoftcomen-uslibraryvstudiots4c4dw6(v=vs110)aspx
[20] B Stroustrup ldquoEvolving a language in and for the real worldC++ 1991ndash2006rdquo in Proceedings of the 3rd ACM SIGPLANHistory of Programming Languages Conference (HOPL-III rsquo07)June 2007
[21] Microsoft Memory Limits for Windows Releases MicrosoftNew York NY USA 2012 httpmsdnmicrosoftcomen-uslibraryaa36677828VS8529aspxmemory limits
[22] A Fog ldquoOptimizing software in C++rdquo 2014 httpwwwagnerorgoptimize
[23] Code Project ldquoC++ Memory Poolrdquo 2014 httpwwwcodepro-jectcomArticles15527C-Memory-Pool
Submit your manuscripts athttpwwwhindawicom
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical Problems in Engineering
Hindawi Publishing Corporationhttpwwwhindawicom
Differential EquationsInternational Journal of
Volume 2014
Applied MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Probability and StatisticsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
OptimizationJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
CombinatoricsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Operations ResearchAdvances in
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Function Spaces
Abstract and Applied AnalysisHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of Mathematics and Mathematical Sciences
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Algebra
Discrete Dynamics in Nature and Society
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Decision SciencesAdvances in
Discrete MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom
Volume 2014 Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Stochastic AnalysisInternational Journal of

6 Mathematical Problems in Engineering
Table 3 Common memory allocating methods that are used in Visual C++
Number Name Syntax Nature of memory layout1 Array int BRP[1000] Slot of continuous memory elements2 Array intlowast BRP = new int[119899] Slot of continuous memory elements3 Array array⟨int⟩andBRP = gcnew array⟨int⟩(119899) Collection of noncontinuous memory elements4 ArrayList ArrayList andBRP = gcnew ArrayList() Collection of noncontinuous memory elements5 Vector stdvector⟨int⟩ BRP(119899) Collection of noncontinuous memory elements
Table 4 Different versions of new BRA implemented with different data structures
Split (s) Data structure type AlgorithmSingle memory structure Multidimensional memory structure Multiple memory structure
1 Array (A) BRA Split 1 1A BRA Split 1 2DA BRA Split 1 2A1 Vector (V) BRA Split 1 1V BRA Split 1 2DV BRA Split 1 2V2 Array (A) BRA Split 2 1A BRA Split 2 4DA BRA Split 2 4A2 Vector (V) BRA Split 2 1V BRA Split 2 4DV BRA Split 2 4V3 Array (A) BRA Split 3 1A BRA Split 3 8DA BRA Split 3 8A3 Vector (V) BRA Split 3 1V BRA Split 3 8DV BRA Split 3 8V4 Array (A) BRA Split 4 1A BRA Split 4 16DA BRA Split 4 16A4 Vector (V) BRA Split 4 1V BRA Split 4 16DV BRA Split 4 16VNaming convention for algorithms ldquoBRA Splitrdquo + ltNumber of splitsgt + ltnature of memory structuregt xA xV x number of arrays and x number of vectorsxDA xDV single x-dimensional array and single x-dimensional vector
void mf BRM Split 1 1A (unsigned int ui NS int ui log2NS)
unsigned int ui Nunsigned int ui EBunsigned int ui tunsigned int ui Lunsigned int ui DL
ui N = ui NS Number of samplesui t = ui log2NS minus 1ui EB = ui N2ui L = 1unsigned intlowast BRP = new unsigned int[ui N]BRP[0] = 0BRP[ui EB] = 1for (unsigned int q = 0 q lt ui t q++)
ui DL = ui L + ui Lui N = ui N2for (unsigned int j = ui L j lt ui DL j++)
BRP[j] = BRP[j minus ui L] + ui NBRP[ui EB + j] = BRP[j] + 1
ui L = ui L + ui L
delete[] BRP
Algorithm 1 C++ implementation of new BRA with single array for split = 1 (BRA Split 1 1A)
Mathematical Problems in Engineering 7
Void mf BRM Split 2 4DV (unsigned int ui NS int ui log2NS)
unsigned int ui Nunsigned int ui EBunsigned int ui tunsigned int ui Lunsigned int ui DLui N = ui NS Number of samplesui t = ui log2NS minus 2ui EB = ui N4ui L = 1stdvectorltstdvectorltunsigned intgtgt BRP(4
stdvectorltunsigned intgt(ui EB))BRP[0][0] = 0BRP[1][0] = 2BRP[2][0] = 1BRP[3][0] = 3for (unsigned int q = 0 q lt ui t q++)
ui DL = ui L + ui Lui N = ui N2for (unsigned int j = ui L j lt ui DL j++)
BRP[0][j] = BRP[0][j minus ui L] + ui NBRP[1][j] = BRP[0][j] + 2BRP[2][j] = BRP[0][j] + 1BRP[3][j] = BRP[1][j] + 1
ui L = ui L + ui L
Algorithm 2 C++ implementation of new BRA with four arrays for split = 2 (BRM Split 2 4A)
0 8 4 12 2 10 6 14 1 9 5 13 3 11 7 15
Initialization
First iteration Seventh (last) iteration
Figure 2 Permutation filling sequence of new BRA with single memory structure for 119899 = 16 and split =1 (BRA Split 1 1A)
For large 119896 2119896 + 1 asymp 2119896 Then
119896
sum
119905=0
2119905= 2119896+1
(11)
Because the considered sample size is 221 to 231 the value 119896can be considered as large Then from (9)
OPPE =1198621lowast (2119896minus119904)
2119896
(12)
OPPE = 1198621
2119904 (13)
According to (13) OPPE is 119891(1198621 119904) The value 119862
1(oper-
ations in inner loop) and the value 119904 (number of splits) are aconstant for a certain algorithm
To evaluate the performance of new BRA we selectedthree algorithms (LBRA EBR and BRA-Ru) which used apattern instead of conventional bit reversing method Theperformance of vector and array versions of the best version
Table 5 The number of operations in the inner loop (1198621) of each
algorithm for different splits (119904) (The total number of operations ineach algorithm asymp 119862
1)
Memory structure type Value of 1198621
119904 = 1 119904 = 2 119904 = 3 119904 = 4
Single one-dimension (array and vector) 8 15 30 61Multidimension (array and vector) 7 11 19 35Multiple one-dimension (array and vector) 7 11 19 35
of new BRA was compared with the relevant versions ofselected algorithms
3 Results and Discussion
Our objective was to introduce BRA using recursive patternof the BRP that we identified We used multiple memorystructures which is a feasible yet unpopular technique toimplement index mapping According to Table 5 the num-bers of operations in all the array and vector versions of both
8 Mathematical Problems in Engineering
Void mf BRM Split 2 4A (unsigned int ui NS int ui log2NS)
unsigned int ui Nunsigned int ui EBunsigned int ui tunsigned int ui Lunsigned int ui DL
ui N = ui NS Number of samplesui t = ui log2NS minus 2ui EB = ui N4ui L = 1unsigned intlowast BRP1 = new unsigned int[ui EB]unsigned intlowast BRP2 = new unsigned int[ui EB]unsigned intlowast BRP3 = new unsigned int[ui EB]unsigned intlowast BRP4 = new unsigned int[ui EB]
BRP1[0] = 0BRP2[0] = 2BRP3[0] = 1BRP4[0] = 3for (unsigned int q = 0 q lt ui t q++)
ui DL = ui L + ui Lui N = ui N2for (unsigned int j = ui L j lt ui DL j++)
BRP1[j] = BRP1[j minus ui L]+ ui NBRP2[j] = BRP1[j] + 2BRP3[j] = BRP1[j] + 1BRP4[j] = BRP2[j] + 1
ui L = ui L + ui L
delete[] BRO1delete[] BRO2delete[] BRO3delete[] BRO4
Algorithm 3 C++ implementation of new BRA with four one-dimensional arrays for split = 2 (BRM Split 2 4A)
0 8 4 12
2 10 6 14
1 9 5 13
3 11 7 15
Initi
aliz
atio
n
Third
(las
t) ite
ratio
n
First iteration
Figure 3 Permutation filling sequence of 4 individual and single 4-dimensional memory structure for 119899 = 16
multidimensional and multiple memory structures are thesame Also Figure 5 shows continuous decrement of OPPEwhen the number of splits increases Then the algorithmwith the highest number of splits and the lowest number ofoperations is the one which is expected to be most efficient
However results in relation with CPE (Figure 5) show thatthe new algorithm with four memory structures of array isthe fastest and most consistent in the selected range Twofour eight and sixteen multiple array implementations ofnew BRA reported 25 34 33 and 18 higher efficiency
Mathematical Problems in Engineering 9
0
1
2
3
4
5
6
Refalgorithms
Ope
ratio
ns p
er el
emen
t (O
PPE)
Split = 1 Split = 2 Split = 3 Split = 4
Corresponds to both array and vector versions of algorithm of rudioCorresponds to both array and vector versions of ldquolinear bit reversalrdquo algorithmCorresponds to both array and vector versions of ldquoelsterrsquos bit reversalrdquo algorithmCorresponds to both array and vector versions of the new algorithm in
Corresponds to both array and vector versions of the new algorithm in
Corresponds to both array and vector versions of the new algorithm in
signal one-dimensional memory structure
signal multi-dimensional memory structure
signal multiple one-dimensional memory structure
Figure 4 Operations per element versus reference algorithms and new algorithm with different s (splits) where dashed column correspondsto both array and vector versions of algorithm of Rudio cross lines column corresponds to both array and vector versions of ldquoLinear BitReversalrdquo algorithm dotted column corresponds to both array and vector versions of ldquoElsterrsquos Bit Reversalrdquo algorithm vertical lines columncorresponds to both array and vector versions of the new algorithm in single one-dimensional memory structure inclined lines columncorresponds to both array and vector versions of the new algorithm in single multidimensional memory structure and horizontal linescolumn corresponds to both array and vector versions of the new algorithm in multiple one-dimensional memory structures
respectively in relation to the array version of LBRA Thealgorithm with eight memory structures has nearly the sameCPE as the four-array and four-vector versions but is lessconsistent On the other hand the four-vector implementa-tion of the new algorithm is the fastest and most consistentamong all vector versions Two four eight and sixteenmultiple vector implementations of new BRA reported 1316 and 16 higher and 23 lower efficiency respectively inrelation to the vector version of LBRAThis result proves thatat a certain point multiple memory structure gives the bestperformances in the considered domain Also usage of mul-tiple memory structures of primitive array is a good optionfor implementing index mapping of BRP compared to multi-dimensional or single one-dimensional memory structures
Due to the flexible nature of the vector it is commonlyused for implementing algorithms According to Figure 4there is no difference in OPPE between array and vectorversionsHowever our results in Figure 5 show that the vectorversions of BRA always required more CPE (44ndash142)than the array version The structure of vector gives priorityto generality and flexibility rather than to execution speedmemory economy cache efficiency and code size [22]There-fore vector is not a good option with respect to efficiency
The results in Table 5 and Figure 4 show that there is nodifference between the number of calculations and OPPEfor equal versions of algorithms with multidimensional andmultiple memory structure Structure and type of calcula-tions are the same for both types The only difference is thenature of the memory structure multidimension or multipleone-dimension When CPE is considered it shows 19ndash79
performance efficiency from algorithms with multiple one-dimension memory structures The reason for that observa-tion is that the memory access of multidimensional memorystructure is less efficient than one-dimensional memorystructure [22]
We agree with the statement of Elster about indexmapping of BRP [2] and the generally accepted fact (theusage of multidimensional memory structures reduces theperformance of a computer) [4] only with respect to multi-dimensional memory structures of vector Our results showthat even with multidimensional arrays there are situationswhere the new BRA performs better than the same typeof one-dimensional memory structure The four eight andsixteen dimensional array versions of new BRA perform 810 and 2 in relation to one-dimensional array version ofnew BRA Some results in relation to single one-dimensionalmemory structure implementation of new BRA are also notin agreement with the general accepted idea For examplesample size = 231 the two-dimensional vector version of newBRA (BRA Split 1 2DV) reported 542119864 minus 05 CPE which is389 higher in relation to average CPE of sample size rangeof 221 to 230 Also the inconsistency was very highThereforewe excluded values related to sample size = 231 for the two-dimensional vector version
We observed very high memory utilization with the two-dimensional vector version especially with sample size =231 Windows task manager showed that the memory uti-lization of all the considered algorithms was nearly thesame for all sample sizes except for multidimension versionsof vector The multidimensional version of vector initially
10 Mathematical Problems in Engineering
Cloc
ks p
er el
emen
t (CP
E)
000E + 00
500E minus 06
100E minus 05
150E minus 05
200E minus 05
250E minus 05
300E minus 05
BRM
split
01x
BRM
split
12x
BRM
split
24x
BRM
split
38x
BRM
split
416x
lowastBR
Msp
lit12
Dx
BRM
split
24
Dx
BRM
split
38
Dx
BRM
split
416
Dx
BRM
split
11x
BRM
split
21x
BRM
split
31x
BRM
split
41x
x-A or V (array or vector)Algorithms
Refe
renc
e alg
orith
m o
ne-
dim
ensio
nal s
ingl
e mem
ory
struc
ture
of s
izen
Multiple memorystructures
1
1
2
k
k
k
k = 2s
n sample size
Multidimensionalmemory structure
One-dimensionalmemory structure
nknk
nk
middotmiddotmiddot
middotmiddotmiddot
(s = 1 2 3 4)
Corresponds to array version of the algorithmCorresponds to vector version of the algorithmCorresponds to minimum reported CPE of the category
Figure 5 Clocks per element (combined average) versus algorithm for the sample size range from 221 to 231 where blue dotted columncorresponds to array version of the algorithm green column corresponds to vector version of the algorithm and red rhombus corresponds tominimum reported CPE of the category lowastFor vector version sample size 231 was excluded because at sample size 231 it showed huge deviationdue to memory limitation of the machine
utilizes highermemory and drops down to normal valueTheresults in relation to sample size = 2
30 showed that the extramemory requirement of two dimension vector was higherthan that of the four-dimensional vector Based upon that itcan be predicted that BRA Split 1 2DV needs an extra 3GB(total 13 GB) for normal execution at sample size = 2
31 butthe total memory barrier of 12GB of the machine slows theprocess down The most likely reason for this observation isthe influence ofmemory poolingmechanismWhen defininga memory structure it is possible to allocate the requiredamount of memory This is known as memory pooling [23]In all the memory structures used in algorithms discussedin this paper we used memory pooling Memory poolingallocates the required memory at startup and divides thisblock into small chunks If there is no memory poolingmemory will get fragmented Accessing fragmented memoryis inefficient When the existing memory is not enough forallocating then it switches to use fragmented memory forallocating memory elements In the considered situation theexisting memory (12GB) is not sufficient for allocating therequired amount (13GB) which switches to use fragmentedmemory
The total cache size of the machine is 825MB whichis less than the minimum memory utilization of consideredalgorithms (16MB to 8GB) in relation to the sample sizerange from 222 to 231 Only the sample size 221 occupies 8MBmemory which is less than the total cache memory ExceptBRA Split 4 1V structure all algorithms reported constantCPE in relation to the entire sample size range The bestalgorithms of each category especially reported very steady
behaviour This observation is in disagreement with thestatement of Karp ldquothat a machine with hierarchical memorydoes not performwell when array size is larger than the cachesizerdquo [10]
Comparison (Figure 6) of best reported version in theconsidered domain (four memory structure version) andthe selected algorithms shows that the array version ofEBR performs the best The four-array version of new BRAreported 1 lower performance than the array version ofEBR However the four-array version of new BRA reported34 and 23 higher performances than array versions ofLBRA and BRA-Ru Also the four-vector version of newBRA is reported to have the best performance among all thevector versions It reported 16 10 and 22 performancescompared to vector versions of LBRA EBR and BRA-Rurespectively
4 Conclusion and Outlook
Themain finding of this paper is the recursive pattern of BPRand the implementationmethod of it using multiple memorystructures With multiple memory structures especiallythe newly identified index mapping performs much betterthan multidimensional or single one-dimensional memorystructure Furthermore findings of this paper show that theperformance of primitive array is higher than vector typeThe result is in disagreement with the statement of Karp ldquothata machine with hierarchical memory does not perform wellwhen array size is larger than the cache sizerdquo Almost all thesample sizes we used were higher than the total cache size
Mathematical Problems in Engineering 11
120E ndash 05
100E minus 05
800E minus 06
600E minus 06
400E minus 06
200E ndash 06
000E + 00
Cloc
ks p
er el
emen
t (CP
E)
BRM
split
24x
(the b
est v
ersio
nof
the n
ewal
gorit
hm)
Line
ar b
it-re
vers
al1x
Elste
rrsquos b
it-
Rubi
o1x
reve
rsal
1x
x-A or V (array or vector)Algorithms
Corresponds to array version of the algorithmCorresponds to vector version of the algorithm
Figure 6 Clocks per element versus best version of new algorithm and selected algorithms where blue dotted column corresponds to arrayversion and green column corresponds to vector version of the algorithm
1
1
1
1
1
0
1
0
1
0
1
0
Process 1
Process 2
Process 5
Process 6Process 3
Process 4
Process 7
4 parallel processes
2 parallel processes
Single process
Tota
l sig
nal i
s div
ided
into
equa
l fou
r ind
epen
dent
mem
ory
struc
ture
s usin
g ne
w al
gorit
hm (B
RMsp
lit24x
)
x(0)
x(4)
x(2)
x(6)
x(1)
x(5)
x(3)
x(7)
minus1
w04
w14
w24
w34
w04
w14
w24
w34
A(0)
A(1)
A(2)
A(3)
B(0)
B(1)
B(2)
B(3)
x(0)
x(1)
x(2)
x(3)
x(4)
x(5)
x(6)
x(7)
minus1
minus1
minus1
Figure 7 Four-memory-structure version of algorithm and the parallel processes for sample size = 16
of the computer However multiple memory structure andthe multidimensional memory structure versions showedreasonable steady performancewith those samples In generalthese results show the effects of data structures and memoryallocation techniques and open a new window of creatingefficient algorithms with multiple memory structures inmany other fields where index mapping is involved
The new bit reversal algorithm with 2119904 independent
memory structures splits the total signal into 119904 independentportions and the total FFT process into 119904 + 1 levels Thenthese 119904 signal portions can be processed independently bymeans of 119904 independent processes on the first level Onthe next level the results from the previous level stored inindependent memory structures can be processed with 1199042
12 Mathematical Problems in Engineering
processes and so on until the last level Therefore we suggestusing the concept of multiple memory structures in total FFTprocess along with the new algorithm with multiple memorystructures and suitable parallel processing technique Weexpect that it is possible to achieve higher performance fromFFT process with proper combination of parallel processingtechnique and new algorithm compared to using the newalgorithm only to create bit reversal permutation Figure 7shows such approach with four (when 119904 = 2) independentmemory structures for sample size = 16
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
Acknowledgment
This publication is financially supported by the UniversityGrants Commission Sri Lanka
References
[1] C S Burrus ldquoUnscrambling for fast DFT algorithmsrdquo IEEETransactions on Acoustics Speech and Signal Processing vol 36no 7 pp 1086ndash1087 1988
[2] A C Elster and J C Meyer ldquoA super-efficient adaptable bit-reversal algorithm for multithreaded architecturesrdquo in Pro-ceedings of the IEEE International Symposium on Parallel ampDistributed Processing (IPDPS 09) vol 1ndash5 pp 1ndash8 Rome ItalyMay 2009
[3] J W Cooley and J W Tukey ldquoAn algorithm for the machinecalculation of complex Fourier seriesrdquoMathematics of Compu-tation vol 19 no 90 pp 297ndash301 1965
[4] M L Massar R Bhagavatula M Fickus and J KovacevicldquoLocal histograms and image occlusion modelsrdquo Applied andComputational Harmonic Analysis vol 34 no 3 pp 469ndash4872013
[5] R G Lyons Understanding Digital Signal Processing PrenticeHall PTR 2004
[6] C Deyun L Zhiqiang G Ming W Lili and Y XiaoyangldquoA superresolution image reconstruction algorithm based onlandweber in electrical capacitance tomographyrdquoMathematicalProblems in Engineering vol 2013 Article ID 128172 8 pages2013
[7] Q Yang and D An ldquoEMD and wavelet transform based faultdiagnosis for wind turbine gear boxrdquo Advances in MechanicalEngineering vol 2013 Article ID 212836 9 pages 2013
[8] C S Burrus Fast Fourier Transforms Rice University HoustonTex USA 2008
[9] C van Loan Computational Frameworks for the Fast FourierTransform vol 10 of Frontiers in Applied Mathematics Societyfor Industrial and Applied Mathematics (SIAM) PhiladelphiaPa USA 1992
[10] A H Karp ldquoBit reversal on uniprocessorsrdquo SIAM Review vol38 no 1 pp 1ndash26 1996
[11] A C Elster ldquoFast bit-reversal algorithmsrdquo in Proceedings ofthe International Conference on Acoustics Speech and SignalProcessing pp 1099ndash1102 IEEE Press Glasgow UK May 1989
[12] M Rubio P Gomez and K Drouiche ldquoA new superfast bitreversal algorithmrdquo International Journal of Adaptive Controland Signal Processing vol 16 no 10 pp 703ndash707 2002
[13] B Stroustrup Programming Principles and Practice Using C++Addison-Wesley 2009
[14] B Stroustrup ldquoSoftware development for infrastructurerdquo IEEEComputer Society vol 45 no 1 Article ID 6081841 pp 47ndash582012
[15] B Stroustrup The C++ Programming Language ATampT Labs3rd edition 1997
[16] S DonovanC++ by Example ldquoUnderCrdquo Learning Edition QUECorporation 2002
[17] S Mcconnell Code Complete Microsoft Press 2nd edition2004
[18] Microsoft STL Containers Microsoft New York NY USA2012 httpmsdnmicrosoftcomen-uslibrary1fe2x6ktaspx
[19] Microsoft Arrays (C++ Component Extensions) MicrosoftNew York NY USA 2012 httpmsdnmicrosoftcomen-uslibraryvstudiots4c4dw6(v=vs110)aspx
[20] B Stroustrup ldquoEvolving a language in and for the real worldC++ 1991ndash2006rdquo in Proceedings of the 3rd ACM SIGPLANHistory of Programming Languages Conference (HOPL-III rsquo07)June 2007
[21] Microsoft Memory Limits for Windows Releases MicrosoftNew York NY USA 2012 httpmsdnmicrosoftcomen-uslibraryaa36677828VS8529aspxmemory limits
[22] A Fog ldquoOptimizing software in C++rdquo 2014 httpwwwagnerorgoptimize
[23] Code Project ldquoC++ Memory Poolrdquo 2014 httpwwwcodepro-jectcomArticles15527C-Memory-Pool
Submit your manuscripts athttpwwwhindawicom
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical Problems in Engineering
Hindawi Publishing Corporationhttpwwwhindawicom
Differential EquationsInternational Journal of
Volume 2014
Applied MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Probability and StatisticsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
OptimizationJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
CombinatoricsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Operations ResearchAdvances in
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Function Spaces
Abstract and Applied AnalysisHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of Mathematics and Mathematical Sciences
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Algebra
Discrete Dynamics in Nature and Society
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Decision SciencesAdvances in
Discrete MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom
Volume 2014 Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Stochastic AnalysisInternational Journal of

Mathematical Problems in Engineering 7
Void mf BRM Split 2 4DV (unsigned int ui NS int ui log2NS)
unsigned int ui Nunsigned int ui EBunsigned int ui tunsigned int ui Lunsigned int ui DLui N = ui NS Number of samplesui t = ui log2NS minus 2ui EB = ui N4ui L = 1stdvectorltstdvectorltunsigned intgtgt BRP(4
stdvectorltunsigned intgt(ui EB))BRP[0][0] = 0BRP[1][0] = 2BRP[2][0] = 1BRP[3][0] = 3for (unsigned int q = 0 q lt ui t q++)
ui DL = ui L + ui Lui N = ui N2for (unsigned int j = ui L j lt ui DL j++)
BRP[0][j] = BRP[0][j minus ui L] + ui NBRP[1][j] = BRP[0][j] + 2BRP[2][j] = BRP[0][j] + 1BRP[3][j] = BRP[1][j] + 1
ui L = ui L + ui L
Algorithm 2 C++ implementation of new BRA with four arrays for split = 2 (BRM Split 2 4A)
0 8 4 12 2 10 6 14 1 9 5 13 3 11 7 15
Initialization
First iteration Seventh (last) iteration
Figure 2 Permutation filling sequence of new BRA with single memory structure for 119899 = 16 and split =1 (BRA Split 1 1A)
For large 119896 2119896 + 1 asymp 2119896 Then
119896
sum
119905=0
2119905= 2119896+1
(11)
Because the considered sample size is 221 to 231 the value 119896can be considered as large Then from (9)
OPPE =1198621lowast (2119896minus119904)
2119896
(12)
OPPE = 1198621
2119904 (13)
According to (13) OPPE is 119891(1198621 119904) The value 119862
1(oper-
ations in inner loop) and the value 119904 (number of splits) are aconstant for a certain algorithm
To evaluate the performance of new BRA we selectedthree algorithms (LBRA EBR and BRA-Ru) which used apattern instead of conventional bit reversing method Theperformance of vector and array versions of the best version
Table 5 The number of operations in the inner loop (1198621) of each
algorithm for different splits (119904) (The total number of operations ineach algorithm asymp 119862
1)
Memory structure type Value of 1198621
119904 = 1 119904 = 2 119904 = 3 119904 = 4
Single one-dimension (array and vector) 8 15 30 61Multidimension (array and vector) 7 11 19 35Multiple one-dimension (array and vector) 7 11 19 35
of new BRA was compared with the relevant versions ofselected algorithms
3 Results and Discussion
Our objective was to introduce BRA using recursive patternof the BRP that we identified We used multiple memorystructures which is a feasible yet unpopular technique toimplement index mapping According to Table 5 the num-bers of operations in all the array and vector versions of both
8 Mathematical Problems in Engineering
Void mf BRM Split 2 4A (unsigned int ui NS int ui log2NS)
unsigned int ui Nunsigned int ui EBunsigned int ui tunsigned int ui Lunsigned int ui DL
ui N = ui NS Number of samplesui t = ui log2NS minus 2ui EB = ui N4ui L = 1unsigned intlowast BRP1 = new unsigned int[ui EB]unsigned intlowast BRP2 = new unsigned int[ui EB]unsigned intlowast BRP3 = new unsigned int[ui EB]unsigned intlowast BRP4 = new unsigned int[ui EB]
BRP1[0] = 0BRP2[0] = 2BRP3[0] = 1BRP4[0] = 3for (unsigned int q = 0 q lt ui t q++)
ui DL = ui L + ui Lui N = ui N2for (unsigned int j = ui L j lt ui DL j++)
BRP1[j] = BRP1[j minus ui L]+ ui NBRP2[j] = BRP1[j] + 2BRP3[j] = BRP1[j] + 1BRP4[j] = BRP2[j] + 1
ui L = ui L + ui L
delete[] BRO1delete[] BRO2delete[] BRO3delete[] BRO4
Algorithm 3 C++ implementation of new BRA with four one-dimensional arrays for split = 2 (BRM Split 2 4A)
0 8 4 12
2 10 6 14
1 9 5 13
3 11 7 15
Initi
aliz
atio
n
Third
(las
t) ite
ratio
n
First iteration
Figure 3 Permutation filling sequence of 4 individual and single 4-dimensional memory structure for 119899 = 16
multidimensional and multiple memory structures are thesame Also Figure 5 shows continuous decrement of OPPEwhen the number of splits increases Then the algorithmwith the highest number of splits and the lowest number ofoperations is the one which is expected to be most efficient
However results in relation with CPE (Figure 5) show thatthe new algorithm with four memory structures of array isthe fastest and most consistent in the selected range Twofour eight and sixteen multiple array implementations ofnew BRA reported 25 34 33 and 18 higher efficiency
Mathematical Problems in Engineering 9
0
1
2
3
4
5
6
Refalgorithms
Ope
ratio
ns p
er el
emen
t (O
PPE)
Split = 1 Split = 2 Split = 3 Split = 4
Corresponds to both array and vector versions of algorithm of rudioCorresponds to both array and vector versions of ldquolinear bit reversalrdquo algorithmCorresponds to both array and vector versions of ldquoelsterrsquos bit reversalrdquo algorithmCorresponds to both array and vector versions of the new algorithm in
Corresponds to both array and vector versions of the new algorithm in
Corresponds to both array and vector versions of the new algorithm in
signal one-dimensional memory structure
signal multi-dimensional memory structure
signal multiple one-dimensional memory structure
Figure 4 Operations per element versus reference algorithms and new algorithm with different s (splits) where dashed column correspondsto both array and vector versions of algorithm of Rudio cross lines column corresponds to both array and vector versions of ldquoLinear BitReversalrdquo algorithm dotted column corresponds to both array and vector versions of ldquoElsterrsquos Bit Reversalrdquo algorithm vertical lines columncorresponds to both array and vector versions of the new algorithm in single one-dimensional memory structure inclined lines columncorresponds to both array and vector versions of the new algorithm in single multidimensional memory structure and horizontal linescolumn corresponds to both array and vector versions of the new algorithm in multiple one-dimensional memory structures
respectively in relation to the array version of LBRA Thealgorithm with eight memory structures has nearly the sameCPE as the four-array and four-vector versions but is lessconsistent On the other hand the four-vector implementa-tion of the new algorithm is the fastest and most consistentamong all vector versions Two four eight and sixteenmultiple vector implementations of new BRA reported 1316 and 16 higher and 23 lower efficiency respectively inrelation to the vector version of LBRAThis result proves thatat a certain point multiple memory structure gives the bestperformances in the considered domain Also usage of mul-tiple memory structures of primitive array is a good optionfor implementing index mapping of BRP compared to multi-dimensional or single one-dimensional memory structures
Due to the flexible nature of the vector it is commonlyused for implementing algorithms According to Figure 4there is no difference in OPPE between array and vectorversionsHowever our results in Figure 5 show that the vectorversions of BRA always required more CPE (44ndash142)than the array version The structure of vector gives priorityto generality and flexibility rather than to execution speedmemory economy cache efficiency and code size [22]There-fore vector is not a good option with respect to efficiency
The results in Table 5 and Figure 4 show that there is nodifference between the number of calculations and OPPEfor equal versions of algorithms with multidimensional andmultiple memory structure Structure and type of calcula-tions are the same for both types The only difference is thenature of the memory structure multidimension or multipleone-dimension When CPE is considered it shows 19ndash79
performance efficiency from algorithms with multiple one-dimension memory structures The reason for that observa-tion is that the memory access of multidimensional memorystructure is less efficient than one-dimensional memorystructure [22]
We agree with the statement of Elster about indexmapping of BRP [2] and the generally accepted fact (theusage of multidimensional memory structures reduces theperformance of a computer) [4] only with respect to multi-dimensional memory structures of vector Our results showthat even with multidimensional arrays there are situationswhere the new BRA performs better than the same typeof one-dimensional memory structure The four eight andsixteen dimensional array versions of new BRA perform 810 and 2 in relation to one-dimensional array version ofnew BRA Some results in relation to single one-dimensionalmemory structure implementation of new BRA are also notin agreement with the general accepted idea For examplesample size = 231 the two-dimensional vector version of newBRA (BRA Split 1 2DV) reported 542119864 minus 05 CPE which is389 higher in relation to average CPE of sample size rangeof 221 to 230 Also the inconsistency was very highThereforewe excluded values related to sample size = 231 for the two-dimensional vector version
We observed very high memory utilization with the two-dimensional vector version especially with sample size =231 Windows task manager showed that the memory uti-lization of all the considered algorithms was nearly thesame for all sample sizes except for multidimension versionsof vector The multidimensional version of vector initially
10 Mathematical Problems in Engineering
Cloc
ks p
er el
emen
t (CP
E)
000E + 00
500E minus 06
100E minus 05
150E minus 05
200E minus 05
250E minus 05
300E minus 05
BRM
split
01x
BRM
split
12x
BRM
split
24x
BRM
split
38x
BRM
split
416x
lowastBR
Msp
lit12
Dx
BRM
split
24
Dx
BRM
split
38
Dx
BRM
split
416
Dx
BRM
split
11x
BRM
split
21x
BRM
split
31x
BRM
split
41x
x-A or V (array or vector)Algorithms
Refe
renc
e alg
orith
m o
ne-
dim
ensio
nal s
ingl
e mem
ory
struc
ture
of s
izen
Multiple memorystructures
1
1
2
k
k
k
k = 2s
n sample size
Multidimensionalmemory structure
One-dimensionalmemory structure
nknk
nk
middotmiddotmiddot
middotmiddotmiddot
(s = 1 2 3 4)
Corresponds to array version of the algorithmCorresponds to vector version of the algorithmCorresponds to minimum reported CPE of the category
Figure 5 Clocks per element (combined average) versus algorithm for the sample size range from 221 to 231 where blue dotted columncorresponds to array version of the algorithm green column corresponds to vector version of the algorithm and red rhombus corresponds tominimum reported CPE of the category lowastFor vector version sample size 231 was excluded because at sample size 231 it showed huge deviationdue to memory limitation of the machine
utilizes highermemory and drops down to normal valueTheresults in relation to sample size = 2
30 showed that the extramemory requirement of two dimension vector was higherthan that of the four-dimensional vector Based upon that itcan be predicted that BRA Split 1 2DV needs an extra 3GB(total 13 GB) for normal execution at sample size = 2
31 butthe total memory barrier of 12GB of the machine slows theprocess down The most likely reason for this observation isthe influence ofmemory poolingmechanismWhen defininga memory structure it is possible to allocate the requiredamount of memory This is known as memory pooling [23]In all the memory structures used in algorithms discussedin this paper we used memory pooling Memory poolingallocates the required memory at startup and divides thisblock into small chunks If there is no memory poolingmemory will get fragmented Accessing fragmented memoryis inefficient When the existing memory is not enough forallocating then it switches to use fragmented memory forallocating memory elements In the considered situation theexisting memory (12GB) is not sufficient for allocating therequired amount (13GB) which switches to use fragmentedmemory
The total cache size of the machine is 825MB whichis less than the minimum memory utilization of consideredalgorithms (16MB to 8GB) in relation to the sample sizerange from 222 to 231 Only the sample size 221 occupies 8MBmemory which is less than the total cache memory ExceptBRA Split 4 1V structure all algorithms reported constantCPE in relation to the entire sample size range The bestalgorithms of each category especially reported very steady
behaviour This observation is in disagreement with thestatement of Karp ldquothat a machine with hierarchical memorydoes not performwell when array size is larger than the cachesizerdquo [10]
Comparison (Figure 6) of best reported version in theconsidered domain (four memory structure version) andthe selected algorithms shows that the array version ofEBR performs the best The four-array version of new BRAreported 1 lower performance than the array version ofEBR However the four-array version of new BRA reported34 and 23 higher performances than array versions ofLBRA and BRA-Ru Also the four-vector version of newBRA is reported to have the best performance among all thevector versions It reported 16 10 and 22 performancescompared to vector versions of LBRA EBR and BRA-Rurespectively
4 Conclusion and Outlook
Themain finding of this paper is the recursive pattern of BPRand the implementationmethod of it using multiple memorystructures With multiple memory structures especiallythe newly identified index mapping performs much betterthan multidimensional or single one-dimensional memorystructure Furthermore findings of this paper show that theperformance of primitive array is higher than vector typeThe result is in disagreement with the statement of Karp ldquothata machine with hierarchical memory does not perform wellwhen array size is larger than the cache sizerdquo Almost all thesample sizes we used were higher than the total cache size
Mathematical Problems in Engineering 11
120E ndash 05
100E minus 05
800E minus 06
600E minus 06
400E minus 06
200E ndash 06
000E + 00
Cloc
ks p
er el
emen
t (CP
E)
BRM
split
24x
(the b
est v
ersio
nof
the n
ewal
gorit
hm)
Line
ar b
it-re
vers
al1x
Elste
rrsquos b
it-
Rubi
o1x
reve
rsal
1x
x-A or V (array or vector)Algorithms
Corresponds to array version of the algorithmCorresponds to vector version of the algorithm
Figure 6 Clocks per element versus best version of new algorithm and selected algorithms where blue dotted column corresponds to arrayversion and green column corresponds to vector version of the algorithm
1
1
1
1
1
0
1
0
1
0
1
0
Process 1
Process 2
Process 5
Process 6Process 3
Process 4
Process 7
4 parallel processes
2 parallel processes
Single process
Tota
l sig
nal i
s div
ided
into
equa
l fou
r ind
epen
dent
mem
ory
struc
ture
s usin
g ne
w al
gorit
hm (B
RMsp
lit24x
)
x(0)
x(4)
x(2)
x(6)
x(1)
x(5)
x(3)
x(7)
minus1
w04
w14
w24
w34
w04
w14
w24
w34
A(0)
A(1)
A(2)
A(3)
B(0)
B(1)
B(2)
B(3)
x(0)
x(1)
x(2)
x(3)
x(4)
x(5)
x(6)
x(7)
minus1
minus1
minus1
Figure 7 Four-memory-structure version of algorithm and the parallel processes for sample size = 16
of the computer However multiple memory structure andthe multidimensional memory structure versions showedreasonable steady performancewith those samples In generalthese results show the effects of data structures and memoryallocation techniques and open a new window of creatingefficient algorithms with multiple memory structures inmany other fields where index mapping is involved
The new bit reversal algorithm with 2119904 independent
memory structures splits the total signal into 119904 independentportions and the total FFT process into 119904 + 1 levels Thenthese 119904 signal portions can be processed independently bymeans of 119904 independent processes on the first level Onthe next level the results from the previous level stored inindependent memory structures can be processed with 1199042
12 Mathematical Problems in Engineering
processes and so on until the last level Therefore we suggestusing the concept of multiple memory structures in total FFTprocess along with the new algorithm with multiple memorystructures and suitable parallel processing technique Weexpect that it is possible to achieve higher performance fromFFT process with proper combination of parallel processingtechnique and new algorithm compared to using the newalgorithm only to create bit reversal permutation Figure 7shows such approach with four (when 119904 = 2) independentmemory structures for sample size = 16
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
Acknowledgment
This publication is financially supported by the UniversityGrants Commission Sri Lanka
References
[1] C S Burrus ldquoUnscrambling for fast DFT algorithmsrdquo IEEETransactions on Acoustics Speech and Signal Processing vol 36no 7 pp 1086ndash1087 1988
[2] A C Elster and J C Meyer ldquoA super-efficient adaptable bit-reversal algorithm for multithreaded architecturesrdquo in Pro-ceedings of the IEEE International Symposium on Parallel ampDistributed Processing (IPDPS 09) vol 1ndash5 pp 1ndash8 Rome ItalyMay 2009
[3] J W Cooley and J W Tukey ldquoAn algorithm for the machinecalculation of complex Fourier seriesrdquoMathematics of Compu-tation vol 19 no 90 pp 297ndash301 1965
[4] M L Massar R Bhagavatula M Fickus and J KovacevicldquoLocal histograms and image occlusion modelsrdquo Applied andComputational Harmonic Analysis vol 34 no 3 pp 469ndash4872013
[5] R G Lyons Understanding Digital Signal Processing PrenticeHall PTR 2004
[6] C Deyun L Zhiqiang G Ming W Lili and Y XiaoyangldquoA superresolution image reconstruction algorithm based onlandweber in electrical capacitance tomographyrdquoMathematicalProblems in Engineering vol 2013 Article ID 128172 8 pages2013
[7] Q Yang and D An ldquoEMD and wavelet transform based faultdiagnosis for wind turbine gear boxrdquo Advances in MechanicalEngineering vol 2013 Article ID 212836 9 pages 2013
[8] C S Burrus Fast Fourier Transforms Rice University HoustonTex USA 2008
[9] C van Loan Computational Frameworks for the Fast FourierTransform vol 10 of Frontiers in Applied Mathematics Societyfor Industrial and Applied Mathematics (SIAM) PhiladelphiaPa USA 1992
[10] A H Karp ldquoBit reversal on uniprocessorsrdquo SIAM Review vol38 no 1 pp 1ndash26 1996
[11] A C Elster ldquoFast bit-reversal algorithmsrdquo in Proceedings ofthe International Conference on Acoustics Speech and SignalProcessing pp 1099ndash1102 IEEE Press Glasgow UK May 1989
[12] M Rubio P Gomez and K Drouiche ldquoA new superfast bitreversal algorithmrdquo International Journal of Adaptive Controland Signal Processing vol 16 no 10 pp 703ndash707 2002
[13] B Stroustrup Programming Principles and Practice Using C++Addison-Wesley 2009
[14] B Stroustrup ldquoSoftware development for infrastructurerdquo IEEEComputer Society vol 45 no 1 Article ID 6081841 pp 47ndash582012
[15] B Stroustrup The C++ Programming Language ATampT Labs3rd edition 1997
[16] S DonovanC++ by Example ldquoUnderCrdquo Learning Edition QUECorporation 2002
[17] S Mcconnell Code Complete Microsoft Press 2nd edition2004
[18] Microsoft STL Containers Microsoft New York NY USA2012 httpmsdnmicrosoftcomen-uslibrary1fe2x6ktaspx
[19] Microsoft Arrays (C++ Component Extensions) MicrosoftNew York NY USA 2012 httpmsdnmicrosoftcomen-uslibraryvstudiots4c4dw6(v=vs110)aspx
[20] B Stroustrup ldquoEvolving a language in and for the real worldC++ 1991ndash2006rdquo in Proceedings of the 3rd ACM SIGPLANHistory of Programming Languages Conference (HOPL-III rsquo07)June 2007
[21] Microsoft Memory Limits for Windows Releases MicrosoftNew York NY USA 2012 httpmsdnmicrosoftcomen-uslibraryaa36677828VS8529aspxmemory limits
[22] A Fog ldquoOptimizing software in C++rdquo 2014 httpwwwagnerorgoptimize
[23] Code Project ldquoC++ Memory Poolrdquo 2014 httpwwwcodepro-jectcomArticles15527C-Memory-Pool
Submit your manuscripts athttpwwwhindawicom
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical Problems in Engineering
Hindawi Publishing Corporationhttpwwwhindawicom
Differential EquationsInternational Journal of
Volume 2014
Applied MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Probability and StatisticsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
OptimizationJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
CombinatoricsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Operations ResearchAdvances in
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Function Spaces
Abstract and Applied AnalysisHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of Mathematics and Mathematical Sciences
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Algebra
Discrete Dynamics in Nature and Society
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Decision SciencesAdvances in
Discrete MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom
Volume 2014 Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Stochastic AnalysisInternational Journal of

8 Mathematical Problems in Engineering
Void mf BRM Split 2 4A (unsigned int ui NS int ui log2NS)
unsigned int ui Nunsigned int ui EBunsigned int ui tunsigned int ui Lunsigned int ui DL
ui N = ui NS Number of samplesui t = ui log2NS minus 2ui EB = ui N4ui L = 1unsigned intlowast BRP1 = new unsigned int[ui EB]unsigned intlowast BRP2 = new unsigned int[ui EB]unsigned intlowast BRP3 = new unsigned int[ui EB]unsigned intlowast BRP4 = new unsigned int[ui EB]
BRP1[0] = 0BRP2[0] = 2BRP3[0] = 1BRP4[0] = 3for (unsigned int q = 0 q lt ui t q++)
ui DL = ui L + ui Lui N = ui N2for (unsigned int j = ui L j lt ui DL j++)
BRP1[j] = BRP1[j minus ui L]+ ui NBRP2[j] = BRP1[j] + 2BRP3[j] = BRP1[j] + 1BRP4[j] = BRP2[j] + 1
ui L = ui L + ui L
delete[] BRO1delete[] BRO2delete[] BRO3delete[] BRO4
Algorithm 3 C++ implementation of new BRA with four one-dimensional arrays for split = 2 (BRM Split 2 4A)
0 8 4 12
2 10 6 14
1 9 5 13
3 11 7 15
Initi
aliz
atio
n
Third
(las
t) ite
ratio
n
First iteration
Figure 3 Permutation filling sequence of 4 individual and single 4-dimensional memory structure for 119899 = 16
multidimensional and multiple memory structures are thesame Also Figure 5 shows continuous decrement of OPPEwhen the number of splits increases Then the algorithmwith the highest number of splits and the lowest number ofoperations is the one which is expected to be most efficient
However results in relation with CPE (Figure 5) show thatthe new algorithm with four memory structures of array isthe fastest and most consistent in the selected range Twofour eight and sixteen multiple array implementations ofnew BRA reported 25 34 33 and 18 higher efficiency
Mathematical Problems in Engineering 9
0
1
2
3
4
5
6
Refalgorithms
Ope
ratio
ns p
er el
emen
t (O
PPE)
Split = 1 Split = 2 Split = 3 Split = 4
Corresponds to both array and vector versions of algorithm of rudioCorresponds to both array and vector versions of ldquolinear bit reversalrdquo algorithmCorresponds to both array and vector versions of ldquoelsterrsquos bit reversalrdquo algorithmCorresponds to both array and vector versions of the new algorithm in
Corresponds to both array and vector versions of the new algorithm in
Corresponds to both array and vector versions of the new algorithm in
signal one-dimensional memory structure
signal multi-dimensional memory structure
signal multiple one-dimensional memory structure
Figure 4 Operations per element versus reference algorithms and new algorithm with different s (splits) where dashed column correspondsto both array and vector versions of algorithm of Rudio cross lines column corresponds to both array and vector versions of ldquoLinear BitReversalrdquo algorithm dotted column corresponds to both array and vector versions of ldquoElsterrsquos Bit Reversalrdquo algorithm vertical lines columncorresponds to both array and vector versions of the new algorithm in single one-dimensional memory structure inclined lines columncorresponds to both array and vector versions of the new algorithm in single multidimensional memory structure and horizontal linescolumn corresponds to both array and vector versions of the new algorithm in multiple one-dimensional memory structures
respectively in relation to the array version of LBRA Thealgorithm with eight memory structures has nearly the sameCPE as the four-array and four-vector versions but is lessconsistent On the other hand the four-vector implementa-tion of the new algorithm is the fastest and most consistentamong all vector versions Two four eight and sixteenmultiple vector implementations of new BRA reported 1316 and 16 higher and 23 lower efficiency respectively inrelation to the vector version of LBRAThis result proves thatat a certain point multiple memory structure gives the bestperformances in the considered domain Also usage of mul-tiple memory structures of primitive array is a good optionfor implementing index mapping of BRP compared to multi-dimensional or single one-dimensional memory structures
Due to the flexible nature of the vector it is commonlyused for implementing algorithms According to Figure 4there is no difference in OPPE between array and vectorversionsHowever our results in Figure 5 show that the vectorversions of BRA always required more CPE (44ndash142)than the array version The structure of vector gives priorityto generality and flexibility rather than to execution speedmemory economy cache efficiency and code size [22]There-fore vector is not a good option with respect to efficiency
The results in Table 5 and Figure 4 show that there is nodifference between the number of calculations and OPPEfor equal versions of algorithms with multidimensional andmultiple memory structure Structure and type of calcula-tions are the same for both types The only difference is thenature of the memory structure multidimension or multipleone-dimension When CPE is considered it shows 19ndash79
performance efficiency from algorithms with multiple one-dimension memory structures The reason for that observa-tion is that the memory access of multidimensional memorystructure is less efficient than one-dimensional memorystructure [22]
We agree with the statement of Elster about indexmapping of BRP [2] and the generally accepted fact (theusage of multidimensional memory structures reduces theperformance of a computer) [4] only with respect to multi-dimensional memory structures of vector Our results showthat even with multidimensional arrays there are situationswhere the new BRA performs better than the same typeof one-dimensional memory structure The four eight andsixteen dimensional array versions of new BRA perform 810 and 2 in relation to one-dimensional array version ofnew BRA Some results in relation to single one-dimensionalmemory structure implementation of new BRA are also notin agreement with the general accepted idea For examplesample size = 231 the two-dimensional vector version of newBRA (BRA Split 1 2DV) reported 542119864 minus 05 CPE which is389 higher in relation to average CPE of sample size rangeof 221 to 230 Also the inconsistency was very highThereforewe excluded values related to sample size = 231 for the two-dimensional vector version
We observed very high memory utilization with the two-dimensional vector version especially with sample size =231 Windows task manager showed that the memory uti-lization of all the considered algorithms was nearly thesame for all sample sizes except for multidimension versionsof vector The multidimensional version of vector initially
10 Mathematical Problems in Engineering
Cloc
ks p
er el
emen
t (CP
E)
000E + 00
500E minus 06
100E minus 05
150E minus 05
200E minus 05
250E minus 05
300E minus 05
BRM
split
01x
BRM
split
12x
BRM
split
24x
BRM
split
38x
BRM
split
416x
lowastBR
Msp
lit12
Dx
BRM
split
24
Dx
BRM
split
38
Dx
BRM
split
416
Dx
BRM
split
11x
BRM
split
21x
BRM
split
31x
BRM
split
41x
x-A or V (array or vector)Algorithms
Refe
renc
e alg
orith
m o
ne-
dim
ensio
nal s
ingl
e mem
ory
struc
ture
of s
izen
Multiple memorystructures
1
1
2
k
k
k
k = 2s
n sample size
Multidimensionalmemory structure
One-dimensionalmemory structure
nknk
nk
middotmiddotmiddot
middotmiddotmiddot
(s = 1 2 3 4)
Corresponds to array version of the algorithmCorresponds to vector version of the algorithmCorresponds to minimum reported CPE of the category
Figure 5 Clocks per element (combined average) versus algorithm for the sample size range from 221 to 231 where blue dotted columncorresponds to array version of the algorithm green column corresponds to vector version of the algorithm and red rhombus corresponds tominimum reported CPE of the category lowastFor vector version sample size 231 was excluded because at sample size 231 it showed huge deviationdue to memory limitation of the machine
utilizes highermemory and drops down to normal valueTheresults in relation to sample size = 2
30 showed that the extramemory requirement of two dimension vector was higherthan that of the four-dimensional vector Based upon that itcan be predicted that BRA Split 1 2DV needs an extra 3GB(total 13 GB) for normal execution at sample size = 2
31 butthe total memory barrier of 12GB of the machine slows theprocess down The most likely reason for this observation isthe influence ofmemory poolingmechanismWhen defininga memory structure it is possible to allocate the requiredamount of memory This is known as memory pooling [23]In all the memory structures used in algorithms discussedin this paper we used memory pooling Memory poolingallocates the required memory at startup and divides thisblock into small chunks If there is no memory poolingmemory will get fragmented Accessing fragmented memoryis inefficient When the existing memory is not enough forallocating then it switches to use fragmented memory forallocating memory elements In the considered situation theexisting memory (12GB) is not sufficient for allocating therequired amount (13GB) which switches to use fragmentedmemory
The total cache size of the machine is 825MB whichis less than the minimum memory utilization of consideredalgorithms (16MB to 8GB) in relation to the sample sizerange from 222 to 231 Only the sample size 221 occupies 8MBmemory which is less than the total cache memory ExceptBRA Split 4 1V structure all algorithms reported constantCPE in relation to the entire sample size range The bestalgorithms of each category especially reported very steady
behaviour This observation is in disagreement with thestatement of Karp ldquothat a machine with hierarchical memorydoes not performwell when array size is larger than the cachesizerdquo [10]
Comparison (Figure 6) of best reported version in theconsidered domain (four memory structure version) andthe selected algorithms shows that the array version ofEBR performs the best The four-array version of new BRAreported 1 lower performance than the array version ofEBR However the four-array version of new BRA reported34 and 23 higher performances than array versions ofLBRA and BRA-Ru Also the four-vector version of newBRA is reported to have the best performance among all thevector versions It reported 16 10 and 22 performancescompared to vector versions of LBRA EBR and BRA-Rurespectively
4 Conclusion and Outlook
Themain finding of this paper is the recursive pattern of BPRand the implementationmethod of it using multiple memorystructures With multiple memory structures especiallythe newly identified index mapping performs much betterthan multidimensional or single one-dimensional memorystructure Furthermore findings of this paper show that theperformance of primitive array is higher than vector typeThe result is in disagreement with the statement of Karp ldquothata machine with hierarchical memory does not perform wellwhen array size is larger than the cache sizerdquo Almost all thesample sizes we used were higher than the total cache size
Mathematical Problems in Engineering 11
120E ndash 05
100E minus 05
800E minus 06
600E minus 06
400E minus 06
200E ndash 06
000E + 00
Cloc
ks p
er el
emen
t (CP
E)
BRM
split
24x
(the b
est v
ersio
nof
the n
ewal
gorit
hm)
Line
ar b
it-re
vers
al1x
Elste
rrsquos b
it-
Rubi
o1x
reve
rsal
1x
x-A or V (array or vector)Algorithms
Corresponds to array version of the algorithmCorresponds to vector version of the algorithm
Figure 6 Clocks per element versus best version of new algorithm and selected algorithms where blue dotted column corresponds to arrayversion and green column corresponds to vector version of the algorithm
1
1
1
1
1
0
1
0
1
0
1
0
Process 1
Process 2
Process 5
Process 6Process 3
Process 4
Process 7
4 parallel processes
2 parallel processes
Single process
Tota
l sig
nal i
s div
ided
into
equa
l fou
r ind
epen
dent
mem
ory
struc
ture
s usin
g ne
w al
gorit
hm (B
RMsp
lit24x
)
x(0)
x(4)
x(2)
x(6)
x(1)
x(5)
x(3)
x(7)
minus1
w04
w14
w24
w34
w04
w14
w24
w34
A(0)
A(1)
A(2)
A(3)
B(0)
B(1)
B(2)
B(3)
x(0)
x(1)
x(2)
x(3)
x(4)
x(5)
x(6)
x(7)
minus1
minus1
minus1
Figure 7 Four-memory-structure version of algorithm and the parallel processes for sample size = 16
of the computer However multiple memory structure andthe multidimensional memory structure versions showedreasonable steady performancewith those samples In generalthese results show the effects of data structures and memoryallocation techniques and open a new window of creatingefficient algorithms with multiple memory structures inmany other fields where index mapping is involved
The new bit reversal algorithm with 2119904 independent
memory structures splits the total signal into 119904 independentportions and the total FFT process into 119904 + 1 levels Thenthese 119904 signal portions can be processed independently bymeans of 119904 independent processes on the first level Onthe next level the results from the previous level stored inindependent memory structures can be processed with 1199042
12 Mathematical Problems in Engineering
processes and so on until the last level Therefore we suggestusing the concept of multiple memory structures in total FFTprocess along with the new algorithm with multiple memorystructures and suitable parallel processing technique Weexpect that it is possible to achieve higher performance fromFFT process with proper combination of parallel processingtechnique and new algorithm compared to using the newalgorithm only to create bit reversal permutation Figure 7shows such approach with four (when 119904 = 2) independentmemory structures for sample size = 16
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
Acknowledgment
This publication is financially supported by the UniversityGrants Commission Sri Lanka
References
[1] C S Burrus ldquoUnscrambling for fast DFT algorithmsrdquo IEEETransactions on Acoustics Speech and Signal Processing vol 36no 7 pp 1086ndash1087 1988
[2] A C Elster and J C Meyer ldquoA super-efficient adaptable bit-reversal algorithm for multithreaded architecturesrdquo in Pro-ceedings of the IEEE International Symposium on Parallel ampDistributed Processing (IPDPS 09) vol 1ndash5 pp 1ndash8 Rome ItalyMay 2009
[3] J W Cooley and J W Tukey ldquoAn algorithm for the machinecalculation of complex Fourier seriesrdquoMathematics of Compu-tation vol 19 no 90 pp 297ndash301 1965
[4] M L Massar R Bhagavatula M Fickus and J KovacevicldquoLocal histograms and image occlusion modelsrdquo Applied andComputational Harmonic Analysis vol 34 no 3 pp 469ndash4872013
[5] R G Lyons Understanding Digital Signal Processing PrenticeHall PTR 2004
[6] C Deyun L Zhiqiang G Ming W Lili and Y XiaoyangldquoA superresolution image reconstruction algorithm based onlandweber in electrical capacitance tomographyrdquoMathematicalProblems in Engineering vol 2013 Article ID 128172 8 pages2013
[7] Q Yang and D An ldquoEMD and wavelet transform based faultdiagnosis for wind turbine gear boxrdquo Advances in MechanicalEngineering vol 2013 Article ID 212836 9 pages 2013
[8] C S Burrus Fast Fourier Transforms Rice University HoustonTex USA 2008
[9] C van Loan Computational Frameworks for the Fast FourierTransform vol 10 of Frontiers in Applied Mathematics Societyfor Industrial and Applied Mathematics (SIAM) PhiladelphiaPa USA 1992
[10] A H Karp ldquoBit reversal on uniprocessorsrdquo SIAM Review vol38 no 1 pp 1ndash26 1996
[11] A C Elster ldquoFast bit-reversal algorithmsrdquo in Proceedings ofthe International Conference on Acoustics Speech and SignalProcessing pp 1099ndash1102 IEEE Press Glasgow UK May 1989
[12] M Rubio P Gomez and K Drouiche ldquoA new superfast bitreversal algorithmrdquo International Journal of Adaptive Controland Signal Processing vol 16 no 10 pp 703ndash707 2002
[13] B Stroustrup Programming Principles and Practice Using C++Addison-Wesley 2009
[14] B Stroustrup ldquoSoftware development for infrastructurerdquo IEEEComputer Society vol 45 no 1 Article ID 6081841 pp 47ndash582012
[15] B Stroustrup The C++ Programming Language ATampT Labs3rd edition 1997
[16] S DonovanC++ by Example ldquoUnderCrdquo Learning Edition QUECorporation 2002
[17] S Mcconnell Code Complete Microsoft Press 2nd edition2004
[18] Microsoft STL Containers Microsoft New York NY USA2012 httpmsdnmicrosoftcomen-uslibrary1fe2x6ktaspx
[19] Microsoft Arrays (C++ Component Extensions) MicrosoftNew York NY USA 2012 httpmsdnmicrosoftcomen-uslibraryvstudiots4c4dw6(v=vs110)aspx
[20] B Stroustrup ldquoEvolving a language in and for the real worldC++ 1991ndash2006rdquo in Proceedings of the 3rd ACM SIGPLANHistory of Programming Languages Conference (HOPL-III rsquo07)June 2007
[21] Microsoft Memory Limits for Windows Releases MicrosoftNew York NY USA 2012 httpmsdnmicrosoftcomen-uslibraryaa36677828VS8529aspxmemory limits
[22] A Fog ldquoOptimizing software in C++rdquo 2014 httpwwwagnerorgoptimize
[23] Code Project ldquoC++ Memory Poolrdquo 2014 httpwwwcodepro-jectcomArticles15527C-Memory-Pool
Submit your manuscripts athttpwwwhindawicom
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical Problems in Engineering
Hindawi Publishing Corporationhttpwwwhindawicom
Differential EquationsInternational Journal of
Volume 2014
Applied MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Probability and StatisticsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
OptimizationJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
CombinatoricsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Operations ResearchAdvances in
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Function Spaces
Abstract and Applied AnalysisHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of Mathematics and Mathematical Sciences
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Algebra
Discrete Dynamics in Nature and Society
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Decision SciencesAdvances in
Discrete MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom
Volume 2014 Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Stochastic AnalysisInternational Journal of

Mathematical Problems in Engineering 9
0
1
2
3
4
5
6
Refalgorithms
Ope
ratio
ns p
er el
emen
t (O
PPE)
Split = 1 Split = 2 Split = 3 Split = 4
Corresponds to both array and vector versions of algorithm of rudioCorresponds to both array and vector versions of ldquolinear bit reversalrdquo algorithmCorresponds to both array and vector versions of ldquoelsterrsquos bit reversalrdquo algorithmCorresponds to both array and vector versions of the new algorithm in
Corresponds to both array and vector versions of the new algorithm in
Corresponds to both array and vector versions of the new algorithm in
signal one-dimensional memory structure
signal multi-dimensional memory structure
signal multiple one-dimensional memory structure
Figure 4 Operations per element versus reference algorithms and new algorithm with different s (splits) where dashed column correspondsto both array and vector versions of algorithm of Rudio cross lines column corresponds to both array and vector versions of ldquoLinear BitReversalrdquo algorithm dotted column corresponds to both array and vector versions of ldquoElsterrsquos Bit Reversalrdquo algorithm vertical lines columncorresponds to both array and vector versions of the new algorithm in single one-dimensional memory structure inclined lines columncorresponds to both array and vector versions of the new algorithm in single multidimensional memory structure and horizontal linescolumn corresponds to both array and vector versions of the new algorithm in multiple one-dimensional memory structures
respectively in relation to the array version of LBRA Thealgorithm with eight memory structures has nearly the sameCPE as the four-array and four-vector versions but is lessconsistent On the other hand the four-vector implementa-tion of the new algorithm is the fastest and most consistentamong all vector versions Two four eight and sixteenmultiple vector implementations of new BRA reported 1316 and 16 higher and 23 lower efficiency respectively inrelation to the vector version of LBRAThis result proves thatat a certain point multiple memory structure gives the bestperformances in the considered domain Also usage of mul-tiple memory structures of primitive array is a good optionfor implementing index mapping of BRP compared to multi-dimensional or single one-dimensional memory structures
Due to the flexible nature of the vector it is commonlyused for implementing algorithms According to Figure 4there is no difference in OPPE between array and vectorversionsHowever our results in Figure 5 show that the vectorversions of BRA always required more CPE (44ndash142)than the array version The structure of vector gives priorityto generality and flexibility rather than to execution speedmemory economy cache efficiency and code size [22]There-fore vector is not a good option with respect to efficiency
The results in Table 5 and Figure 4 show that there is nodifference between the number of calculations and OPPEfor equal versions of algorithms with multidimensional andmultiple memory structure Structure and type of calcula-tions are the same for both types The only difference is thenature of the memory structure multidimension or multipleone-dimension When CPE is considered it shows 19ndash79
performance efficiency from algorithms with multiple one-dimension memory structures The reason for that observa-tion is that the memory access of multidimensional memorystructure is less efficient than one-dimensional memorystructure [22]
We agree with the statement of Elster about indexmapping of BRP [2] and the generally accepted fact (theusage of multidimensional memory structures reduces theperformance of a computer) [4] only with respect to multi-dimensional memory structures of vector Our results showthat even with multidimensional arrays there are situationswhere the new BRA performs better than the same typeof one-dimensional memory structure The four eight andsixteen dimensional array versions of new BRA perform 810 and 2 in relation to one-dimensional array version ofnew BRA Some results in relation to single one-dimensionalmemory structure implementation of new BRA are also notin agreement with the general accepted idea For examplesample size = 231 the two-dimensional vector version of newBRA (BRA Split 1 2DV) reported 542119864 minus 05 CPE which is389 higher in relation to average CPE of sample size rangeof 221 to 230 Also the inconsistency was very highThereforewe excluded values related to sample size = 231 for the two-dimensional vector version
We observed very high memory utilization with the two-dimensional vector version especially with sample size =231 Windows task manager showed that the memory uti-lization of all the considered algorithms was nearly thesame for all sample sizes except for multidimension versionsof vector The multidimensional version of vector initially
10 Mathematical Problems in Engineering
Cloc
ks p
er el
emen
t (CP
E)
000E + 00
500E minus 06
100E minus 05
150E minus 05
200E minus 05
250E minus 05
300E minus 05
BRM
split
01x
BRM
split
12x
BRM
split
24x
BRM
split
38x
BRM
split
416x
lowastBR
Msp
lit12
Dx
BRM
split
24
Dx
BRM
split
38
Dx
BRM
split
416
Dx
BRM
split
11x
BRM
split
21x
BRM
split
31x
BRM
split
41x
x-A or V (array or vector)Algorithms
Refe
renc
e alg
orith
m o
ne-
dim
ensio
nal s
ingl
e mem
ory
struc
ture
of s
izen
Multiple memorystructures
1
1
2
k
k
k
k = 2s
n sample size
Multidimensionalmemory structure
One-dimensionalmemory structure
nknk
nk
middotmiddotmiddot
middotmiddotmiddot
(s = 1 2 3 4)
Corresponds to array version of the algorithmCorresponds to vector version of the algorithmCorresponds to minimum reported CPE of the category
Figure 5 Clocks per element (combined average) versus algorithm for the sample size range from 221 to 231 where blue dotted columncorresponds to array version of the algorithm green column corresponds to vector version of the algorithm and red rhombus corresponds tominimum reported CPE of the category lowastFor vector version sample size 231 was excluded because at sample size 231 it showed huge deviationdue to memory limitation of the machine
utilizes highermemory and drops down to normal valueTheresults in relation to sample size = 2
30 showed that the extramemory requirement of two dimension vector was higherthan that of the four-dimensional vector Based upon that itcan be predicted that BRA Split 1 2DV needs an extra 3GB(total 13 GB) for normal execution at sample size = 2
31 butthe total memory barrier of 12GB of the machine slows theprocess down The most likely reason for this observation isthe influence ofmemory poolingmechanismWhen defininga memory structure it is possible to allocate the requiredamount of memory This is known as memory pooling [23]In all the memory structures used in algorithms discussedin this paper we used memory pooling Memory poolingallocates the required memory at startup and divides thisblock into small chunks If there is no memory poolingmemory will get fragmented Accessing fragmented memoryis inefficient When the existing memory is not enough forallocating then it switches to use fragmented memory forallocating memory elements In the considered situation theexisting memory (12GB) is not sufficient for allocating therequired amount (13GB) which switches to use fragmentedmemory
The total cache size of the machine is 825MB whichis less than the minimum memory utilization of consideredalgorithms (16MB to 8GB) in relation to the sample sizerange from 222 to 231 Only the sample size 221 occupies 8MBmemory which is less than the total cache memory ExceptBRA Split 4 1V structure all algorithms reported constantCPE in relation to the entire sample size range The bestalgorithms of each category especially reported very steady
behaviour This observation is in disagreement with thestatement of Karp ldquothat a machine with hierarchical memorydoes not performwell when array size is larger than the cachesizerdquo [10]
Comparison (Figure 6) of best reported version in theconsidered domain (four memory structure version) andthe selected algorithms shows that the array version ofEBR performs the best The four-array version of new BRAreported 1 lower performance than the array version ofEBR However the four-array version of new BRA reported34 and 23 higher performances than array versions ofLBRA and BRA-Ru Also the four-vector version of newBRA is reported to have the best performance among all thevector versions It reported 16 10 and 22 performancescompared to vector versions of LBRA EBR and BRA-Rurespectively
4 Conclusion and Outlook
Themain finding of this paper is the recursive pattern of BPRand the implementationmethod of it using multiple memorystructures With multiple memory structures especiallythe newly identified index mapping performs much betterthan multidimensional or single one-dimensional memorystructure Furthermore findings of this paper show that theperformance of primitive array is higher than vector typeThe result is in disagreement with the statement of Karp ldquothata machine with hierarchical memory does not perform wellwhen array size is larger than the cache sizerdquo Almost all thesample sizes we used were higher than the total cache size
Mathematical Problems in Engineering 11
120E ndash 05
100E minus 05
800E minus 06
600E minus 06
400E minus 06
200E ndash 06
000E + 00
Cloc
ks p
er el
emen
t (CP
E)
BRM
split
24x
(the b
est v
ersio
nof
the n
ewal
gorit
hm)
Line
ar b
it-re
vers
al1x
Elste
rrsquos b
it-
Rubi
o1x
reve
rsal
1x
x-A or V (array or vector)Algorithms
Corresponds to array version of the algorithmCorresponds to vector version of the algorithm
Figure 6 Clocks per element versus best version of new algorithm and selected algorithms where blue dotted column corresponds to arrayversion and green column corresponds to vector version of the algorithm
1
1
1
1
1
0
1
0
1
0
1
0
Process 1
Process 2
Process 5
Process 6Process 3
Process 4
Process 7
4 parallel processes
2 parallel processes
Single process
Tota
l sig
nal i
s div
ided
into
equa
l fou
r ind
epen
dent
mem
ory
struc
ture
s usin
g ne
w al
gorit
hm (B
RMsp
lit24x
)
x(0)
x(4)
x(2)
x(6)
x(1)
x(5)
x(3)
x(7)
minus1
w04
w14
w24
w34
w04
w14
w24
w34
A(0)
A(1)
A(2)
A(3)
B(0)
B(1)
B(2)
B(3)
x(0)
x(1)
x(2)
x(3)
x(4)
x(5)
x(6)
x(7)
minus1
minus1
minus1
Figure 7 Four-memory-structure version of algorithm and the parallel processes for sample size = 16
of the computer However multiple memory structure andthe multidimensional memory structure versions showedreasonable steady performancewith those samples In generalthese results show the effects of data structures and memoryallocation techniques and open a new window of creatingefficient algorithms with multiple memory structures inmany other fields where index mapping is involved
The new bit reversal algorithm with 2119904 independent
memory structures splits the total signal into 119904 independentportions and the total FFT process into 119904 + 1 levels Thenthese 119904 signal portions can be processed independently bymeans of 119904 independent processes on the first level Onthe next level the results from the previous level stored inindependent memory structures can be processed with 1199042
12 Mathematical Problems in Engineering
processes and so on until the last level Therefore we suggestusing the concept of multiple memory structures in total FFTprocess along with the new algorithm with multiple memorystructures and suitable parallel processing technique Weexpect that it is possible to achieve higher performance fromFFT process with proper combination of parallel processingtechnique and new algorithm compared to using the newalgorithm only to create bit reversal permutation Figure 7shows such approach with four (when 119904 = 2) independentmemory structures for sample size = 16
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
Acknowledgment
This publication is financially supported by the UniversityGrants Commission Sri Lanka
References
[1] C S Burrus ldquoUnscrambling for fast DFT algorithmsrdquo IEEETransactions on Acoustics Speech and Signal Processing vol 36no 7 pp 1086ndash1087 1988
[2] A C Elster and J C Meyer ldquoA super-efficient adaptable bit-reversal algorithm for multithreaded architecturesrdquo in Pro-ceedings of the IEEE International Symposium on Parallel ampDistributed Processing (IPDPS 09) vol 1ndash5 pp 1ndash8 Rome ItalyMay 2009
[3] J W Cooley and J W Tukey ldquoAn algorithm for the machinecalculation of complex Fourier seriesrdquoMathematics of Compu-tation vol 19 no 90 pp 297ndash301 1965
[4] M L Massar R Bhagavatula M Fickus and J KovacevicldquoLocal histograms and image occlusion modelsrdquo Applied andComputational Harmonic Analysis vol 34 no 3 pp 469ndash4872013
[5] R G Lyons Understanding Digital Signal Processing PrenticeHall PTR 2004
[6] C Deyun L Zhiqiang G Ming W Lili and Y XiaoyangldquoA superresolution image reconstruction algorithm based onlandweber in electrical capacitance tomographyrdquoMathematicalProblems in Engineering vol 2013 Article ID 128172 8 pages2013
[7] Q Yang and D An ldquoEMD and wavelet transform based faultdiagnosis for wind turbine gear boxrdquo Advances in MechanicalEngineering vol 2013 Article ID 212836 9 pages 2013
[8] C S Burrus Fast Fourier Transforms Rice University HoustonTex USA 2008
[9] C van Loan Computational Frameworks for the Fast FourierTransform vol 10 of Frontiers in Applied Mathematics Societyfor Industrial and Applied Mathematics (SIAM) PhiladelphiaPa USA 1992
[10] A H Karp ldquoBit reversal on uniprocessorsrdquo SIAM Review vol38 no 1 pp 1ndash26 1996
[11] A C Elster ldquoFast bit-reversal algorithmsrdquo in Proceedings ofthe International Conference on Acoustics Speech and SignalProcessing pp 1099ndash1102 IEEE Press Glasgow UK May 1989
[12] M Rubio P Gomez and K Drouiche ldquoA new superfast bitreversal algorithmrdquo International Journal of Adaptive Controland Signal Processing vol 16 no 10 pp 703ndash707 2002
[13] B Stroustrup Programming Principles and Practice Using C++Addison-Wesley 2009
[14] B Stroustrup ldquoSoftware development for infrastructurerdquo IEEEComputer Society vol 45 no 1 Article ID 6081841 pp 47ndash582012
[15] B Stroustrup The C++ Programming Language ATampT Labs3rd edition 1997
[16] S DonovanC++ by Example ldquoUnderCrdquo Learning Edition QUECorporation 2002
[17] S Mcconnell Code Complete Microsoft Press 2nd edition2004
[18] Microsoft STL Containers Microsoft New York NY USA2012 httpmsdnmicrosoftcomen-uslibrary1fe2x6ktaspx
[19] Microsoft Arrays (C++ Component Extensions) MicrosoftNew York NY USA 2012 httpmsdnmicrosoftcomen-uslibraryvstudiots4c4dw6(v=vs110)aspx
[20] B Stroustrup ldquoEvolving a language in and for the real worldC++ 1991ndash2006rdquo in Proceedings of the 3rd ACM SIGPLANHistory of Programming Languages Conference (HOPL-III rsquo07)June 2007
[21] Microsoft Memory Limits for Windows Releases MicrosoftNew York NY USA 2012 httpmsdnmicrosoftcomen-uslibraryaa36677828VS8529aspxmemory limits
[22] A Fog ldquoOptimizing software in C++rdquo 2014 httpwwwagnerorgoptimize
[23] Code Project ldquoC++ Memory Poolrdquo 2014 httpwwwcodepro-jectcomArticles15527C-Memory-Pool
Submit your manuscripts athttpwwwhindawicom
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical Problems in Engineering
Hindawi Publishing Corporationhttpwwwhindawicom
Differential EquationsInternational Journal of
Volume 2014
Applied MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Probability and StatisticsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
OptimizationJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
CombinatoricsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Operations ResearchAdvances in
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Function Spaces
Abstract and Applied AnalysisHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of Mathematics and Mathematical Sciences
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Algebra
Discrete Dynamics in Nature and Society
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Decision SciencesAdvances in
Discrete MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom
Volume 2014 Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Stochastic AnalysisInternational Journal of

10 Mathematical Problems in Engineering
Cloc
ks p
er el
emen
t (CP
E)
000E + 00
500E minus 06
100E minus 05
150E minus 05
200E minus 05
250E minus 05
300E minus 05
BRM
split
01x
BRM
split
12x
BRM
split
24x
BRM
split
38x
BRM
split
416x
lowastBR
Msp
lit12
Dx
BRM
split
24
Dx
BRM
split
38
Dx
BRM
split
416
Dx
BRM
split
11x
BRM
split
21x
BRM
split
31x
BRM
split
41x
x-A or V (array or vector)Algorithms
Refe
renc
e alg
orith
m o
ne-
dim
ensio
nal s
ingl
e mem
ory
struc
ture
of s
izen
Multiple memorystructures
1
1
2
k
k
k
k = 2s
n sample size
Multidimensionalmemory structure
One-dimensionalmemory structure
nknk
nk
middotmiddotmiddot
middotmiddotmiddot
(s = 1 2 3 4)
Corresponds to array version of the algorithmCorresponds to vector version of the algorithmCorresponds to minimum reported CPE of the category
Figure 5 Clocks per element (combined average) versus algorithm for the sample size range from 221 to 231 where blue dotted columncorresponds to array version of the algorithm green column corresponds to vector version of the algorithm and red rhombus corresponds tominimum reported CPE of the category lowastFor vector version sample size 231 was excluded because at sample size 231 it showed huge deviationdue to memory limitation of the machine
utilizes highermemory and drops down to normal valueTheresults in relation to sample size = 2
30 showed that the extramemory requirement of two dimension vector was higherthan that of the four-dimensional vector Based upon that itcan be predicted that BRA Split 1 2DV needs an extra 3GB(total 13 GB) for normal execution at sample size = 2
31 butthe total memory barrier of 12GB of the machine slows theprocess down The most likely reason for this observation isthe influence ofmemory poolingmechanismWhen defininga memory structure it is possible to allocate the requiredamount of memory This is known as memory pooling [23]In all the memory structures used in algorithms discussedin this paper we used memory pooling Memory poolingallocates the required memory at startup and divides thisblock into small chunks If there is no memory poolingmemory will get fragmented Accessing fragmented memoryis inefficient When the existing memory is not enough forallocating then it switches to use fragmented memory forallocating memory elements In the considered situation theexisting memory (12GB) is not sufficient for allocating therequired amount (13GB) which switches to use fragmentedmemory
The total cache size of the machine is 825MB whichis less than the minimum memory utilization of consideredalgorithms (16MB to 8GB) in relation to the sample sizerange from 222 to 231 Only the sample size 221 occupies 8MBmemory which is less than the total cache memory ExceptBRA Split 4 1V structure all algorithms reported constantCPE in relation to the entire sample size range The bestalgorithms of each category especially reported very steady
behaviour This observation is in disagreement with thestatement of Karp ldquothat a machine with hierarchical memorydoes not performwell when array size is larger than the cachesizerdquo [10]
Comparison (Figure 6) of best reported version in theconsidered domain (four memory structure version) andthe selected algorithms shows that the array version ofEBR performs the best The four-array version of new BRAreported 1 lower performance than the array version ofEBR However the four-array version of new BRA reported34 and 23 higher performances than array versions ofLBRA and BRA-Ru Also the four-vector version of newBRA is reported to have the best performance among all thevector versions It reported 16 10 and 22 performancescompared to vector versions of LBRA EBR and BRA-Rurespectively
4 Conclusion and Outlook
Themain finding of this paper is the recursive pattern of BPRand the implementationmethod of it using multiple memorystructures With multiple memory structures especiallythe newly identified index mapping performs much betterthan multidimensional or single one-dimensional memorystructure Furthermore findings of this paper show that theperformance of primitive array is higher than vector typeThe result is in disagreement with the statement of Karp ldquothata machine with hierarchical memory does not perform wellwhen array size is larger than the cache sizerdquo Almost all thesample sizes we used were higher than the total cache size
Mathematical Problems in Engineering 11
120E ndash 05
100E minus 05
800E minus 06
600E minus 06
400E minus 06
200E ndash 06
000E + 00
Cloc
ks p
er el
emen
t (CP
E)
BRM
split
24x
(the b
est v
ersio
nof
the n
ewal
gorit
hm)
Line
ar b
it-re
vers
al1x
Elste
rrsquos b
it-
Rubi
o1x
reve
rsal
1x
x-A or V (array or vector)Algorithms
Corresponds to array version of the algorithmCorresponds to vector version of the algorithm
Figure 6 Clocks per element versus best version of new algorithm and selected algorithms where blue dotted column corresponds to arrayversion and green column corresponds to vector version of the algorithm
1
1
1
1
1
0
1
0
1
0
1
0
Process 1
Process 2
Process 5
Process 6Process 3
Process 4
Process 7
4 parallel processes
2 parallel processes
Single process
Tota
l sig
nal i
s div
ided
into
equa
l fou
r ind
epen
dent
mem
ory
struc
ture
s usin
g ne
w al
gorit
hm (B
RMsp
lit24x
)
x(0)
x(4)
x(2)
x(6)
x(1)
x(5)
x(3)
x(7)
minus1
w04
w14
w24
w34
w04
w14
w24
w34
A(0)
A(1)
A(2)
A(3)
B(0)
B(1)
B(2)
B(3)
x(0)
x(1)
x(2)
x(3)
x(4)
x(5)
x(6)
x(7)
minus1
minus1
minus1
Figure 7 Four-memory-structure version of algorithm and the parallel processes for sample size = 16
of the computer However multiple memory structure andthe multidimensional memory structure versions showedreasonable steady performancewith those samples In generalthese results show the effects of data structures and memoryallocation techniques and open a new window of creatingefficient algorithms with multiple memory structures inmany other fields where index mapping is involved
The new bit reversal algorithm with 2119904 independent
memory structures splits the total signal into 119904 independentportions and the total FFT process into 119904 + 1 levels Thenthese 119904 signal portions can be processed independently bymeans of 119904 independent processes on the first level Onthe next level the results from the previous level stored inindependent memory structures can be processed with 1199042
12 Mathematical Problems in Engineering
processes and so on until the last level Therefore we suggestusing the concept of multiple memory structures in total FFTprocess along with the new algorithm with multiple memorystructures and suitable parallel processing technique Weexpect that it is possible to achieve higher performance fromFFT process with proper combination of parallel processingtechnique and new algorithm compared to using the newalgorithm only to create bit reversal permutation Figure 7shows such approach with four (when 119904 = 2) independentmemory structures for sample size = 16
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
Acknowledgment
This publication is financially supported by the UniversityGrants Commission Sri Lanka
References
[1] C S Burrus ldquoUnscrambling for fast DFT algorithmsrdquo IEEETransactions on Acoustics Speech and Signal Processing vol 36no 7 pp 1086ndash1087 1988
[2] A C Elster and J C Meyer ldquoA super-efficient adaptable bit-reversal algorithm for multithreaded architecturesrdquo in Pro-ceedings of the IEEE International Symposium on Parallel ampDistributed Processing (IPDPS 09) vol 1ndash5 pp 1ndash8 Rome ItalyMay 2009
[3] J W Cooley and J W Tukey ldquoAn algorithm for the machinecalculation of complex Fourier seriesrdquoMathematics of Compu-tation vol 19 no 90 pp 297ndash301 1965
[4] M L Massar R Bhagavatula M Fickus and J KovacevicldquoLocal histograms and image occlusion modelsrdquo Applied andComputational Harmonic Analysis vol 34 no 3 pp 469ndash4872013
[5] R G Lyons Understanding Digital Signal Processing PrenticeHall PTR 2004
[6] C Deyun L Zhiqiang G Ming W Lili and Y XiaoyangldquoA superresolution image reconstruction algorithm based onlandweber in electrical capacitance tomographyrdquoMathematicalProblems in Engineering vol 2013 Article ID 128172 8 pages2013
[7] Q Yang and D An ldquoEMD and wavelet transform based faultdiagnosis for wind turbine gear boxrdquo Advances in MechanicalEngineering vol 2013 Article ID 212836 9 pages 2013
[8] C S Burrus Fast Fourier Transforms Rice University HoustonTex USA 2008
[9] C van Loan Computational Frameworks for the Fast FourierTransform vol 10 of Frontiers in Applied Mathematics Societyfor Industrial and Applied Mathematics (SIAM) PhiladelphiaPa USA 1992
[10] A H Karp ldquoBit reversal on uniprocessorsrdquo SIAM Review vol38 no 1 pp 1ndash26 1996
[11] A C Elster ldquoFast bit-reversal algorithmsrdquo in Proceedings ofthe International Conference on Acoustics Speech and SignalProcessing pp 1099ndash1102 IEEE Press Glasgow UK May 1989
[12] M Rubio P Gomez and K Drouiche ldquoA new superfast bitreversal algorithmrdquo International Journal of Adaptive Controland Signal Processing vol 16 no 10 pp 703ndash707 2002
[13] B Stroustrup Programming Principles and Practice Using C++Addison-Wesley 2009
[14] B Stroustrup ldquoSoftware development for infrastructurerdquo IEEEComputer Society vol 45 no 1 Article ID 6081841 pp 47ndash582012
[15] B Stroustrup The C++ Programming Language ATampT Labs3rd edition 1997
[16] S DonovanC++ by Example ldquoUnderCrdquo Learning Edition QUECorporation 2002
[17] S Mcconnell Code Complete Microsoft Press 2nd edition2004
[18] Microsoft STL Containers Microsoft New York NY USA2012 httpmsdnmicrosoftcomen-uslibrary1fe2x6ktaspx
[19] Microsoft Arrays (C++ Component Extensions) MicrosoftNew York NY USA 2012 httpmsdnmicrosoftcomen-uslibraryvstudiots4c4dw6(v=vs110)aspx
[20] B Stroustrup ldquoEvolving a language in and for the real worldC++ 1991ndash2006rdquo in Proceedings of the 3rd ACM SIGPLANHistory of Programming Languages Conference (HOPL-III rsquo07)June 2007
[21] Microsoft Memory Limits for Windows Releases MicrosoftNew York NY USA 2012 httpmsdnmicrosoftcomen-uslibraryaa36677828VS8529aspxmemory limits
[22] A Fog ldquoOptimizing software in C++rdquo 2014 httpwwwagnerorgoptimize
[23] Code Project ldquoC++ Memory Poolrdquo 2014 httpwwwcodepro-jectcomArticles15527C-Memory-Pool
Submit your manuscripts athttpwwwhindawicom
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical Problems in Engineering
Hindawi Publishing Corporationhttpwwwhindawicom
Differential EquationsInternational Journal of
Volume 2014
Applied MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Probability and StatisticsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
OptimizationJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
CombinatoricsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Operations ResearchAdvances in
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Function Spaces
Abstract and Applied AnalysisHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of Mathematics and Mathematical Sciences
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Algebra
Discrete Dynamics in Nature and Society
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Decision SciencesAdvances in
Discrete MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom
Volume 2014 Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Stochastic AnalysisInternational Journal of
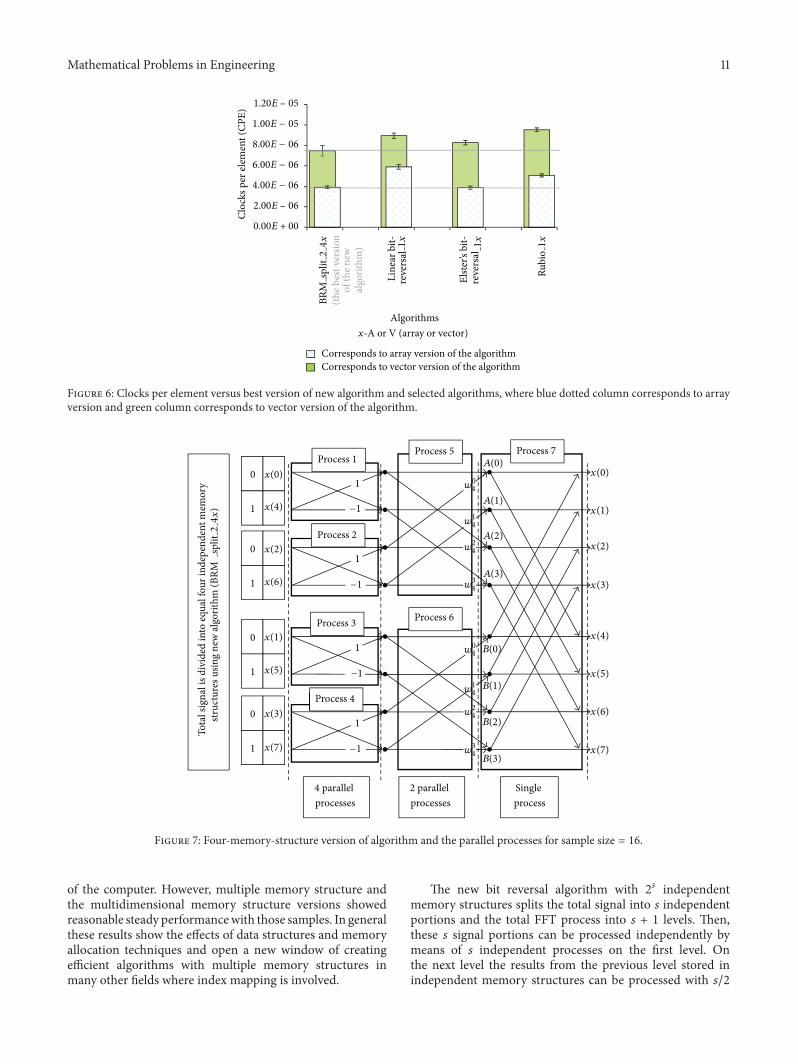
Mathematical Problems in Engineering 11
120E ndash 05
100E minus 05
800E minus 06
600E minus 06
400E minus 06
200E ndash 06
000E + 00
Cloc
ks p
er el
emen
t (CP
E)
BRM
split
24x
(the b
est v
ersio
nof
the n
ewal
gorit
hm)
Line
ar b
it-re
vers
al1x
Elste
rrsquos b
it-
Rubi
o1x
reve
rsal
1x
x-A or V (array or vector)Algorithms
Corresponds to array version of the algorithmCorresponds to vector version of the algorithm
Figure 6 Clocks per element versus best version of new algorithm and selected algorithms where blue dotted column corresponds to arrayversion and green column corresponds to vector version of the algorithm
1
1
1
1
1
0
1
0
1
0
1
0
Process 1
Process 2
Process 5
Process 6Process 3
Process 4
Process 7
4 parallel processes
2 parallel processes
Single process
Tota
l sig
nal i
s div
ided
into
equa
l fou
r ind
epen
dent
mem
ory
struc
ture
s usin
g ne
w al
gorit
hm (B
RMsp
lit24x
)
x(0)
x(4)
x(2)
x(6)
x(1)
x(5)
x(3)
x(7)
minus1
w04
w14
w24
w34
w04
w14
w24
w34
A(0)
A(1)
A(2)
A(3)
B(0)
B(1)
B(2)
B(3)
x(0)
x(1)
x(2)
x(3)
x(4)
x(5)
x(6)
x(7)
minus1
minus1
minus1
Figure 7 Four-memory-structure version of algorithm and the parallel processes for sample size = 16
of the computer However multiple memory structure andthe multidimensional memory structure versions showedreasonable steady performancewith those samples In generalthese results show the effects of data structures and memoryallocation techniques and open a new window of creatingefficient algorithms with multiple memory structures inmany other fields where index mapping is involved
The new bit reversal algorithm with 2119904 independent
memory structures splits the total signal into 119904 independentportions and the total FFT process into 119904 + 1 levels Thenthese 119904 signal portions can be processed independently bymeans of 119904 independent processes on the first level Onthe next level the results from the previous level stored inindependent memory structures can be processed with 1199042
12 Mathematical Problems in Engineering
processes and so on until the last level Therefore we suggestusing the concept of multiple memory structures in total FFTprocess along with the new algorithm with multiple memorystructures and suitable parallel processing technique Weexpect that it is possible to achieve higher performance fromFFT process with proper combination of parallel processingtechnique and new algorithm compared to using the newalgorithm only to create bit reversal permutation Figure 7shows such approach with four (when 119904 = 2) independentmemory structures for sample size = 16
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
Acknowledgment
This publication is financially supported by the UniversityGrants Commission Sri Lanka
References
[1] C S Burrus ldquoUnscrambling for fast DFT algorithmsrdquo IEEETransactions on Acoustics Speech and Signal Processing vol 36no 7 pp 1086ndash1087 1988
[2] A C Elster and J C Meyer ldquoA super-efficient adaptable bit-reversal algorithm for multithreaded architecturesrdquo in Pro-ceedings of the IEEE International Symposium on Parallel ampDistributed Processing (IPDPS 09) vol 1ndash5 pp 1ndash8 Rome ItalyMay 2009
[3] J W Cooley and J W Tukey ldquoAn algorithm for the machinecalculation of complex Fourier seriesrdquoMathematics of Compu-tation vol 19 no 90 pp 297ndash301 1965
[4] M L Massar R Bhagavatula M Fickus and J KovacevicldquoLocal histograms and image occlusion modelsrdquo Applied andComputational Harmonic Analysis vol 34 no 3 pp 469ndash4872013
[5] R G Lyons Understanding Digital Signal Processing PrenticeHall PTR 2004
[6] C Deyun L Zhiqiang G Ming W Lili and Y XiaoyangldquoA superresolution image reconstruction algorithm based onlandweber in electrical capacitance tomographyrdquoMathematicalProblems in Engineering vol 2013 Article ID 128172 8 pages2013
[7] Q Yang and D An ldquoEMD and wavelet transform based faultdiagnosis for wind turbine gear boxrdquo Advances in MechanicalEngineering vol 2013 Article ID 212836 9 pages 2013
[8] C S Burrus Fast Fourier Transforms Rice University HoustonTex USA 2008
[9] C van Loan Computational Frameworks for the Fast FourierTransform vol 10 of Frontiers in Applied Mathematics Societyfor Industrial and Applied Mathematics (SIAM) PhiladelphiaPa USA 1992
[10] A H Karp ldquoBit reversal on uniprocessorsrdquo SIAM Review vol38 no 1 pp 1ndash26 1996
[11] A C Elster ldquoFast bit-reversal algorithmsrdquo in Proceedings ofthe International Conference on Acoustics Speech and SignalProcessing pp 1099ndash1102 IEEE Press Glasgow UK May 1989
[12] M Rubio P Gomez and K Drouiche ldquoA new superfast bitreversal algorithmrdquo International Journal of Adaptive Controland Signal Processing vol 16 no 10 pp 703ndash707 2002
[13] B Stroustrup Programming Principles and Practice Using C++Addison-Wesley 2009
[14] B Stroustrup ldquoSoftware development for infrastructurerdquo IEEEComputer Society vol 45 no 1 Article ID 6081841 pp 47ndash582012
[15] B Stroustrup The C++ Programming Language ATampT Labs3rd edition 1997
[16] S DonovanC++ by Example ldquoUnderCrdquo Learning Edition QUECorporation 2002
[17] S Mcconnell Code Complete Microsoft Press 2nd edition2004
[18] Microsoft STL Containers Microsoft New York NY USA2012 httpmsdnmicrosoftcomen-uslibrary1fe2x6ktaspx
[19] Microsoft Arrays (C++ Component Extensions) MicrosoftNew York NY USA 2012 httpmsdnmicrosoftcomen-uslibraryvstudiots4c4dw6(v=vs110)aspx
[20] B Stroustrup ldquoEvolving a language in and for the real worldC++ 1991ndash2006rdquo in Proceedings of the 3rd ACM SIGPLANHistory of Programming Languages Conference (HOPL-III rsquo07)June 2007
[21] Microsoft Memory Limits for Windows Releases MicrosoftNew York NY USA 2012 httpmsdnmicrosoftcomen-uslibraryaa36677828VS8529aspxmemory limits
[22] A Fog ldquoOptimizing software in C++rdquo 2014 httpwwwagnerorgoptimize
[23] Code Project ldquoC++ Memory Poolrdquo 2014 httpwwwcodepro-jectcomArticles15527C-Memory-Pool
Submit your manuscripts athttpwwwhindawicom
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical Problems in Engineering
Hindawi Publishing Corporationhttpwwwhindawicom
Differential EquationsInternational Journal of
Volume 2014
Applied MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Probability and StatisticsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
OptimizationJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
CombinatoricsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Operations ResearchAdvances in
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Function Spaces
Abstract and Applied AnalysisHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of Mathematics and Mathematical Sciences
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Algebra
Discrete Dynamics in Nature and Society
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Decision SciencesAdvances in
Discrete MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom
Volume 2014 Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Stochastic AnalysisInternational Journal of

12 Mathematical Problems in Engineering
processes and so on until the last level Therefore we suggestusing the concept of multiple memory structures in total FFTprocess along with the new algorithm with multiple memorystructures and suitable parallel processing technique Weexpect that it is possible to achieve higher performance fromFFT process with proper combination of parallel processingtechnique and new algorithm compared to using the newalgorithm only to create bit reversal permutation Figure 7shows such approach with four (when 119904 = 2) independentmemory structures for sample size = 16
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
Acknowledgment
This publication is financially supported by the UniversityGrants Commission Sri Lanka
References
[1] C S Burrus ldquoUnscrambling for fast DFT algorithmsrdquo IEEETransactions on Acoustics Speech and Signal Processing vol 36no 7 pp 1086ndash1087 1988
[2] A C Elster and J C Meyer ldquoA super-efficient adaptable bit-reversal algorithm for multithreaded architecturesrdquo in Pro-ceedings of the IEEE International Symposium on Parallel ampDistributed Processing (IPDPS 09) vol 1ndash5 pp 1ndash8 Rome ItalyMay 2009
[3] J W Cooley and J W Tukey ldquoAn algorithm for the machinecalculation of complex Fourier seriesrdquoMathematics of Compu-tation vol 19 no 90 pp 297ndash301 1965
[4] M L Massar R Bhagavatula M Fickus and J KovacevicldquoLocal histograms and image occlusion modelsrdquo Applied andComputational Harmonic Analysis vol 34 no 3 pp 469ndash4872013
[5] R G Lyons Understanding Digital Signal Processing PrenticeHall PTR 2004
[6] C Deyun L Zhiqiang G Ming W Lili and Y XiaoyangldquoA superresolution image reconstruction algorithm based onlandweber in electrical capacitance tomographyrdquoMathematicalProblems in Engineering vol 2013 Article ID 128172 8 pages2013
[7] Q Yang and D An ldquoEMD and wavelet transform based faultdiagnosis for wind turbine gear boxrdquo Advances in MechanicalEngineering vol 2013 Article ID 212836 9 pages 2013
[8] C S Burrus Fast Fourier Transforms Rice University HoustonTex USA 2008
[9] C van Loan Computational Frameworks for the Fast FourierTransform vol 10 of Frontiers in Applied Mathematics Societyfor Industrial and Applied Mathematics (SIAM) PhiladelphiaPa USA 1992
[10] A H Karp ldquoBit reversal on uniprocessorsrdquo SIAM Review vol38 no 1 pp 1ndash26 1996
[11] A C Elster ldquoFast bit-reversal algorithmsrdquo in Proceedings ofthe International Conference on Acoustics Speech and SignalProcessing pp 1099ndash1102 IEEE Press Glasgow UK May 1989
[12] M Rubio P Gomez and K Drouiche ldquoA new superfast bitreversal algorithmrdquo International Journal of Adaptive Controland Signal Processing vol 16 no 10 pp 703ndash707 2002
[13] B Stroustrup Programming Principles and Practice Using C++Addison-Wesley 2009
[14] B Stroustrup ldquoSoftware development for infrastructurerdquo IEEEComputer Society vol 45 no 1 Article ID 6081841 pp 47ndash582012
[15] B Stroustrup The C++ Programming Language ATampT Labs3rd edition 1997
[16] S DonovanC++ by Example ldquoUnderCrdquo Learning Edition QUECorporation 2002
[17] S Mcconnell Code Complete Microsoft Press 2nd edition2004
[18] Microsoft STL Containers Microsoft New York NY USA2012 httpmsdnmicrosoftcomen-uslibrary1fe2x6ktaspx
[19] Microsoft Arrays (C++ Component Extensions) MicrosoftNew York NY USA 2012 httpmsdnmicrosoftcomen-uslibraryvstudiots4c4dw6(v=vs110)aspx
[20] B Stroustrup ldquoEvolving a language in and for the real worldC++ 1991ndash2006rdquo in Proceedings of the 3rd ACM SIGPLANHistory of Programming Languages Conference (HOPL-III rsquo07)June 2007
[21] Microsoft Memory Limits for Windows Releases MicrosoftNew York NY USA 2012 httpmsdnmicrosoftcomen-uslibraryaa36677828VS8529aspxmemory limits
[22] A Fog ldquoOptimizing software in C++rdquo 2014 httpwwwagnerorgoptimize
[23] Code Project ldquoC++ Memory Poolrdquo 2014 httpwwwcodepro-jectcomArticles15527C-Memory-Pool
Submit your manuscripts athttpwwwhindawicom
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical Problems in Engineering
Hindawi Publishing Corporationhttpwwwhindawicom
Differential EquationsInternational Journal of
Volume 2014
Applied MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Probability and StatisticsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
OptimizationJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
CombinatoricsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Operations ResearchAdvances in
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Function Spaces
Abstract and Applied AnalysisHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of Mathematics and Mathematical Sciences
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Algebra
Discrete Dynamics in Nature and Society
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Decision SciencesAdvances in
Discrete MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom
Volume 2014 Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Stochastic AnalysisInternational Journal of

Submit your manuscripts athttpwwwhindawicom
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical Problems in Engineering
Hindawi Publishing Corporationhttpwwwhindawicom
Differential EquationsInternational Journal of
Volume 2014
Applied MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Probability and StatisticsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
OptimizationJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
CombinatoricsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Operations ResearchAdvances in
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Function Spaces
Abstract and Applied AnalysisHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of Mathematics and Mathematical Sciences
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Algebra
Discrete Dynamics in Nature and Society
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Decision SciencesAdvances in
Discrete MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom
Volume 2014 Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Stochastic AnalysisInternational Journal of


















