
Rent Problem Summary Hypothesis: Average rent is $1000 Take a sample of 100 students. From it …...
32
Rent Problem Summary •Hypothesis: Average rent is $1000 •Take a sample of 100 students. From it … –Calculate the average rent: $950 –Estimate the standard deviation of the population:$150 –Calculate standard deviation of the mean: $150/100=$15 –Calculate Z=[$950-$1000]/$15=-3 1/3 •How likely is a result this far from the mean? –Use Z table to find –Probability Z>3 1/3=.005 –Probability Z<-3 1/3=.005 –Probability Z that far from the mean
-
date post
20-Dec-2015 -
Category
Documents
-
view
214 -
download
0
Transcript of Rent Problem Summary Hypothesis: Average rent is $1000 Take a sample of 100 students. From it …...

Rent Problem Summary•Hypothesis: Average rent is $1000•Take a sample of 100 students. From it …
–Calculate the average rent: $950–Estimate the standard deviation of the population:$150–Calculate standard deviation of the mean: $150/100=$15–Calculate Z=[$950-$1000]/$15=-3 1/3
•How likely is a result this far from the mean?–Use Z table to find–Probability Z>3 1/3=.005–Probability Z<-3 1/3=.005–Probability Z that far from the mean = .005+.005=.01
•So if the hypothesis is true, getting this result is surprising.

Multivariate statistics: 2 variable• Each item (person, country, state, year) has two characteristics
– How are they related to each other?
– Why?
• Descriptive approach: Scatterplot– Approximate linear relationship. But note
– The plot might show you more complicated things, that calculating the correlation coefficient would miss.
– Humans come with very good pattern recognition built in.

• The first one you would get a positive correlation coefficient—what would you miss?
• The second one, near zero correlation. But …
• The scatter plot shows the pattern
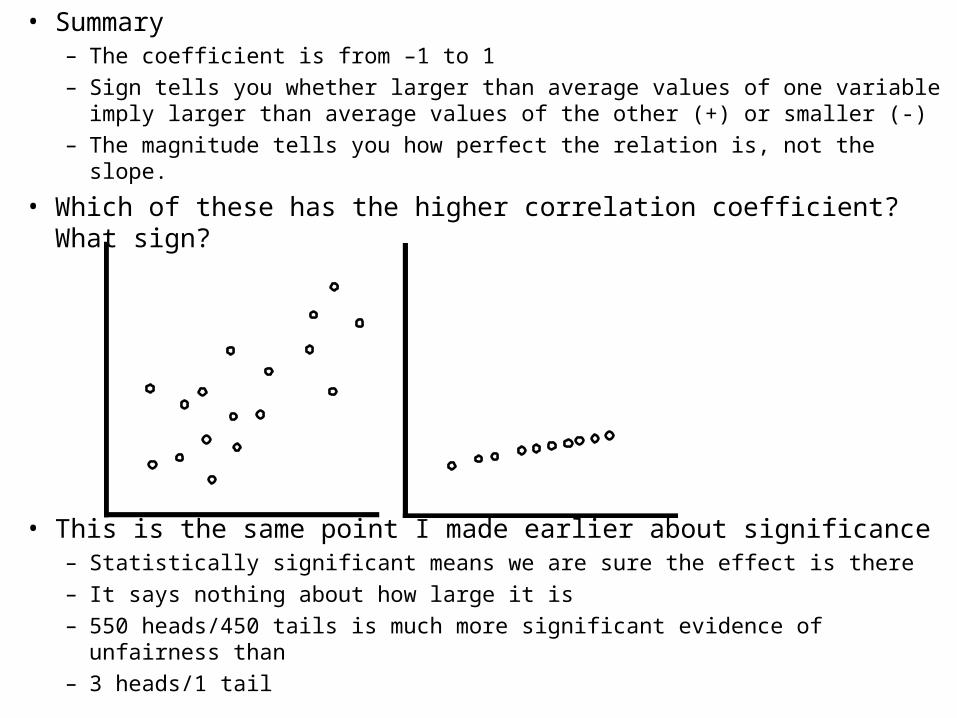
• Summary– The coefficient is from –1 to 1
– Sign tells you whether larger than average values of one variable imply larger than average values of the other (+) or smaller (-)
– The magnitude tells you how perfect the relation is, not the slope.
• Which of these has the higher correlation coefficient? What sign?
• This is the same point I made earlier about significance– Statistically significant means we are sure the effect is there
– It says nothing about how large it is
– 550 heads/450 tails is much more significant evidence of unfairness than
– 3 heads/1 tail

Mathematical Definition• For each value of the first variable, calculate how many standard deviations it is
from the mean--+ if greater than mean, - if less• For each observation (person, state, …) multiply that figure for the first variable
times that figure for the second• Average over all observations
– (except you divide by n-1 instead of by n in averaging)– for the same reason we did it earlier—sample slightly exaggerates the correlation for the
population.– I think
• Why this makes (some) sense• If above average values of X occur for the same observation as above average
values of Y, the product is positive• If below go with below, the product is still positive—negative times negative is
positive• So if the two variables move together, get a positive correlation coefficient• If they move in opposite directions, above average of one go with below average of
the other, so + times – or – times +, which gives negative• Average lots of negative numbers, get a negative correlation coefficient

Correlation need not be Causation• It might be entirely due to some third variable that causes both
– Driving an expensive car has a negligible effect on life expectancy—probably negative if it’s a sports car
– But probably correlates with life expectancy. Why?– Height has little effect on having children, but …– Number of children one has born is negatively correlated with height of adults– Because?
• Or it might be partly due to such third factors, so you don't know how strong the causal effect is
• And third factors might push the other way, reducing, eliminating, or reversing the causation– Death penalty and murder rates– If factors that make murder rates high make death penalty more likely– Either because high murder rates create pressure for death penalty– Or because the social factors that make people more willing to kill illegally also
make them more willing to kill legally.– You might have a positive correlation masking a negative causation

And Causation may not lead to correlation

Causation, Correlation and Prediction
• Correlation can be used to predict• "if the state has a death penalty, it probably has a high
murder rate"– doesn't depend on which causes which
– or whether there is a third factor causing both
• But if you have the causality wrong, you might get the prediction wrong– because you are missing other relevant evidence
– taller adults are less likely to have born children than shorter
but taller women aren't.

Correlation Summary• We have two characters, each associated with individuals in a
population– Height and weight of people– Rainfall and average temperature of years– Current Income and Lsat score
• Which could be coming from parental income and student LSAT score or• Entering LSAT and later income as a lawyer
• We want to know how the two are related– When height is above average, is weight above average? (Probably)– Do cool years have more rainfall?
• Correlation coefficient is a measure of how consistently– When one variable is above its average, the other is above its (positive
correlation)– Or when one is above, the other is below (negative)– 1 is perfect correlation--if you plot them they are on a straight line, slopes up– -1 is perfect negative correlation--straight line, slopes down– 0 is no correlation--but not necessarily no relationship.

Linear Regression• Instead of measuring how close to a line the points come (correlation
coefficient)• You try to estimate the line they come closest to• Which requires some definition of "close."
– You want to count both being too high and too low as errors– So the difference between point and line wouldn't work– Instead use the square of the difference—positive each way– Find the line that minimizes the summed square deviation.
•Unlike the correlation coefficient, this one measures the size of the effect•y= A+Bx
–A is the intercept—where the line crosses the vertical axis–B is the slope—how much the line goes up for each unit it goes out

Goodness of Fit• By convention, X (horizontal) is the independent variable, Y
(vertical) the dependent: Y=A + BX
• Simplest "prediction" is that Y always equals its average value
• How much of the departure from that does the regression explain?
•
• TSS is the sum of squared residuals from the average
€
R2 ≡TSS − SSR
TSS=
Total Sum of Squares - Sum of Squared Residuals
Total Sum of Squares
€
TSS = Y1 − Y ( )2
+ Y2 − Y ( )2+ Y3 − Y ( )
2+...
Y = Average value of Y
€
SSR = Y1 − A + BX1( )( )2
+ Y2 − A + BX2( )( )2
+ Y3 − A + BX3( )( )2+...
Because A + BX1( ) is the predicted value of Y1

• So R2 is a measure of how much of the variance about the mean is explained by the regression line. – Total variation minus variation not explained by the regression – divided by total variation
• So R2 of 0 means the regression line does no better than just assigning the mean value to every point
• R2 of 1 means the regression explains all of the variance.
• Like correlation, this is a measure of goodness of fit– In fact, R2 is the square – of the correlation coefficient r
• And B, the slope, is a measure of the strength of the relationship.
• You find A and B and by a mathematical procedure that finds the line that best fits the data
• Then calculate R2
Or rather, your computer does.

Residuals• If you plot the residuals from a regression--distance above or below
the line
• It will show you which points don't fit the pattern
• In exploratory statistics, you might want to color points in ways reflecting other characteristics– Men/women
– Blacks/whites
– Northern states/Southern states
– CEO's relatives/non-relatives
– And see if any such coloring explained the pattern
• In the book's example, Mary Starchway is both an outlier and an influential observation– Outlier because her wage is much higher than anybody else's
– Influential observation because she is far off the experience/wage regression line
– Does the first necessarily imply the second?

Limitations of Linear Regression• There might be a close relationship that isn't linear
• There are procedures analogous to linear regression for dealing with the first case– Instead of plotting Y=A+BX you might plot– Y=A+BX+CX2 for example– Giving something like that if B<0 and C>0
• The second case strongly suggests that we need more than two variables– Y is determined by X, and also by– Whatever it is that distinguishes the two lines

Multiple Regression: More than 2 variables
• Suppose you believe the murder rate depends on– The death penalty– The fraction of the population that is males 18-26– This year's unemployment rate
• You could express that as M=a+b1D+b2F+b3U– Here M is the murder rate, by state– D is the probability that a murderer will get the death penalty,
by state– F is the fraction of the state population that is male 18-26– U is the state's unemployment rate
• The regression could be cross section: All states in one year
• Or longitudinal: One state in a series of years• Or both

More Complicated Versions• We could define D as
– The fraction of murderers who are executed, or …– Executions per year per capita, or …
• Perhaps the murder rate depends on the square of D, or • Perhaps D should be treated as a binary variable instead of
continuous– States with death penalty, D=1– States without, D=0
• Perhaps murder rate in one year depends on current unemployment rate but last year's death penalty probability– In which case you use current variables for everything else– But a lagged variable for D– Meaning that the value for NY in 1990 is the death penalty
probability for NY in 1989

Running a regression means• Minimizing the sum of squared deviation of the data
from the regression's predictions– Define as the value of M predicted by the regression–
i= a+b1Di +b2Mi +b3Ui
– Here i labels the particular observation (state and year in this example)
• We are looking for the values of a, b1, b2 and b3 that minimize– The sum of squared residuals, i.e. the sum of squared
values of– (Mi- i) – summed over all i, which is to say over all states, or years,
or …
€
ˆ M
€
ˆ M
€
ˆ M

Significant Coefficients
• Regression results shows some coefficient>0– We want to know how sure we are it is true– For instance, that whites get paid more than blacks– Controlling for all other relevant factors
• We use a t test which is– Analogous to the significance tests we have done– Both in how it works and what it means– t = coefficient/its standard error– I.e. how big it is relative to how uncertain
• Look up the corresponding confidence level– On a t table--like a z table, but with one complication– Degrees of freedom

Degrees of freedom• Suppose I have only two data points
– (x1, y1) (x2,y2)– And do a simple regression: y=a+bx– How well will I fit the data?
•Perfectly•You can always draw a straight line through two points
•The result generalizes•With n parameters you can fit n data points•Whatever the relation among them is•So only fitting more points than that counts as evidence•Which is what the degrees of freedom take account of
Give me enough parameters and I’ll fit the skyline of New York

Choosing Variables• How do you decide what variables to include?
– From those that might be relevant and– That you have data on
• One approach is trial and error– Try each variable by itself, choose the one with the best R2
– Try adding each one, choose the one that increases R2 most– Repeat …– There are computer programs that will do it for you
• Problem: Out of all possible variables– Some will fit your dependent variable well by chance– And your procedure will find those ones– So if you started with thirty candidate variables– Getting a .05 result for one is not impressive

Problems or How to Cheat• All the usual ways, such as …
– Misstate the meaning of significance– Use a biased sample– Select which experiments to report– Use unreliable data
• Plus some brand new ways– Plaintiff claims aspartame causes cancer
• My regression found no significant relation• Independent variables: age, gender, use of diet drinks, aspartame
consumption
– Defense claims his prostate medicine doesn’t shorten life• My regression shows a strong correlation• Independent variables: state of residency, race, use of prostate
medicine• Dependent variable: Age at death

Collinearity problem• Significance calculation is based on
– How much better you fit the data by adding this variable– Which depends on what other variables are there– Suppose you include both temperature F and temperature C– How significant do you think either will be?
• T test is asking how many standard deviations out the coefficient is– Which depends on how precisely you know the coefficient– In my case, if you have one, the coefficient on the other could be
anything• Heating oil consumption = A +B(temp F) + C(temp C)
• Do you see why?
• The same problem exists in less extreme cases– Adding a variable that correlates closely with another– Decreases the other’s significance, because …– The new one can explain most of the same variation.

Omitted Variable Problem
• You want to prove that X (prostate medicine) causes Y (shorter life)
• You leave out a variable that correlates with both– Prostate medicine is only used by men– Men have shorter life expectancies than women– So don’t include gender in your regression
• Your independent variable X– Now seems to be predicting Y, because– X predicts gender, which predicts Y

Significance and Standard of Proof
• Book discusses wage discrimination case– Coefficient on the race effect nonzero but …– Not significant at .05 level– Footnote suggests that since it is a civil case– Perhaps .05 is too strong a requirement– What should it be?
• Would .5 do it?– “Preponderance of the evidence”– Isn’t that >.5 probability?

Statistics and the Law School• You want to raise the bar passage rate
• You have data on all students for the past ten years– Information on them when they applied– What courses they took, grades they got– Bar exam outcomes
• How might you use it?– What questions would you ask?– How could statistics answer them?– How could you use the information?

Who to admit• Bar passage rate is the dependent variable
– Independent variables are what you knew about the student before admission
• LSAT score• Undergraduate grades• Undergraduate major• Anything else?
– See which ones predict bar passage– Alter your admission policies accordingly
• Any reasons why this might not work?– Correlation is not causation– Any reasons why changing independent variables– Might not change dependent variable?

Class record• Regress bar passage rate on
– What classes student took– What grades he got on them
• Suppose you learn that– Students who took class X were less likely to pass– Students who took Y were more likely
• Would you raise bar passage rate by– Abolishing class X– Requiring class Y
• Suppose grades in class Z– Predict bar passage rates– Do well in Z, pass the bar, do badly, likely to fail– Drop students who did badly in Z?
• In each case, why might it not work?

How about Professors?• See how bar passage rate depends on
– Which courses the student took– From which professor– Take torts from Smith, pass the bar– From Jones, fail the bar
• Fire Jones, raise Smith’s pay or– If Jones has tenure– Have him teach something else
• More generally, rearrange who teaches what– On the basis of regression coefficients showing– The effect on bar passage rates

What do we need to know?• In each of these cases
– To decide whether using the regression results– Will let us improve outcomes– Whether correlation is probably causation– What additional information might we want?
•How were students assigned–To courses and to professors–Suppose X was a class failing students were assigned to–Or Y a class with very selective admissions, or …– Smith a notorious hard grader who weak students avoided

ABA Fails Statistics• ABA wants to include bar passage rate in deciding
what law schools to certify– What will the effect of doing this be?– Why is it a mistake?
To take account of bar passage, how should they do it?
•Bar passage rate depends on at least two things–Characteristics of the student–Characteristics of the law school he went to–Almost any school can get a student to pass the bar–If he is sufficiently smart and hard working–What matters is value added
–For a student with a given set of characteristics–How likely is he to pass the bar if he goes to this school

Use a Regression
• BPR=a+bLsat+c…– BPR = Bar Passage Rate– Lsat = student’s Lsat score– c … represents other relevant student characteristics
• The higher a and b, the better the school– Because the more likely to get a given student– To pass the bar
• Some schools may do well with low Lsat students, some with high– So report a, b, c …– And let the student calculate the probability that he will pass– If he goes to that school
• Bar association could decide to certify any school– That does relatively well for some– Substantial group of students– Including schools that are good for weak students

Statistics Exercises• On the syllabus, for practice
• Do the calculations with numbers
• We will discuss them next class


















