
The Near Earth Asteroid Rendezvous (NEAR) Rendezvous Burn Anomaly
date post
20-Dec-2015Category
view
223download
0
Rendezvous Points-Based Scalable Content Discovery with Load Balancing
Jun Gao Peter Steenkiste
Computer Science DepartmentCarnegie Mellon University
October 24th, 2002
NGC 2002, Boston, USA

Jun Gao Carnegie Mellon University 2
Outline
Content Discovery System (CDS) Existing solutions CDS system design Simulation evaluation Conclusions

Jun Gao Carnegie Mellon University 3
Content Discovery System (CDS)
Example: a highway monitoring service Cameras and sensors monitor
road and traffic status Users issue flexible queries
CDS enables content discovery Locate contents that match
queries
Example services Service discovery; P2P;
pub/sub; sensor networks
Snapshot from traffic.com

Jun Gao Carnegie Mellon University 4
Comparison of Existing Solutions
Searchability
Centralized
Distributed
Registrationflooding
Querybroadcasting Hash-based
Graph-basedTree-based
Scalability
Robustness
yes yes yesHierarchicalnames
Look-up
yes? no no
yes
yes
no yes yes
yes
no
Load balancing yes? no no yes?no
DesignGoals
Solutions

Jun Gao Carnegie Mellon University 5
CDS Design
Attribute-value pair based naming scheme Enable searchability
Peer-to-peer system architecture Robust distributed system
Rendezvous Points-based content discovery Improve scalability
Load Balancing Matrix Dynamic balance load

Jun Gao Carnegie Mellon University 6
Naming Scheme
Based on Attribute-Value pairs CN: {a1=v1, a2=v2,..., an=vn}
Not necessarily hierarchical Attribute can be dynamic
Searchable via subset matching Q CN Number of matches for a CN is large
2n-1
Camera ID = 5562Highway = I-279 Exit = 4City = PittsburghSpeed = 25mphRoad condition = Icy
Highway = I-279 Exit = 4City = Pittsburgh
Q1
Q2
CN1
City = PittsburghSpeed = 25mph
Jun Gao Carnegie Mellon University 7
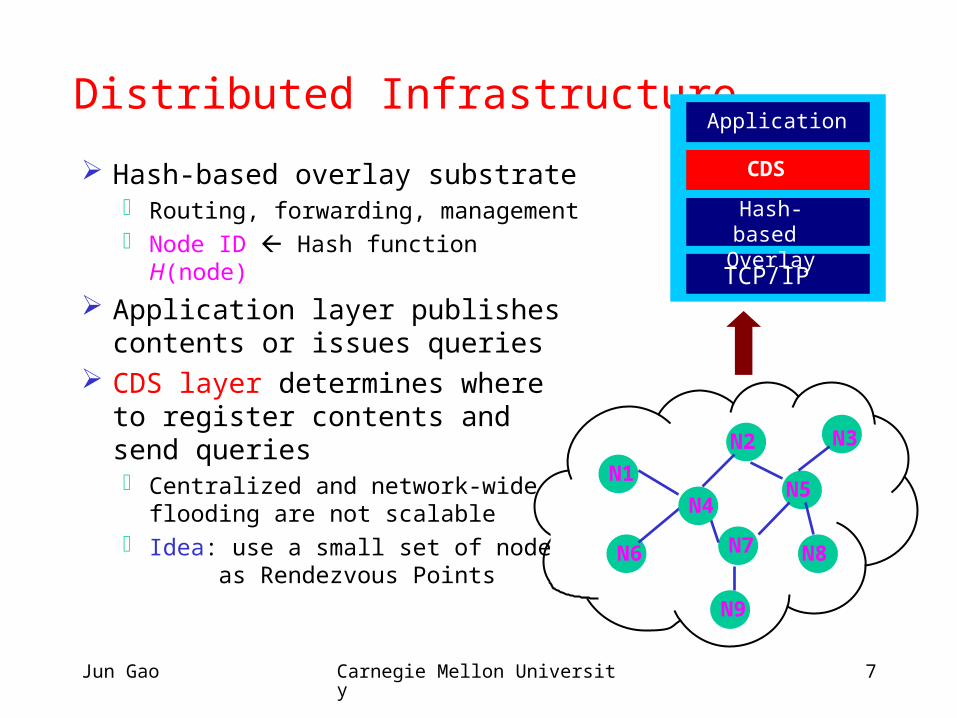
Distributed Infrastructure
Hash-based overlay substrate Routing, forwarding, management Node ID Hash function H(node)
Application layer publishes contents or issues queries
CDS layer determines where to register contents and send queries Centralized and network-wide
flooding are not scalable Idea: use a small set of nodes
as Rendezvous Points
TCP/IP
Hash-based Overlay
CDS
Application
N1
N6
N4N5
N3N2
N9
N8N7

Jun Gao Carnegie Mellon University 8
RP-based Scheme
Hash each AV-pair to get a set of RPs | RP | = n
RP node stores names that share the same pair Maintain with soft state
Query is sent directly to an RP node Use the least loaded RP RP node fully resolves
locally
N3N5
CN1
N4 N6
CN1: {a1=v1, a2=v2, a3=v3, a4=v4}
RP2
CN2
CN2: {a1=v1, a2=v2, a5=v5, a6=v6}
N2N1
RP1
Ni H(ai=vi)
N7N8
N9
?
Q:{a1=v1, a2=v2}

Jun Gao Carnegie Mellon University 9
System Properties
Efficient registration and query O(n) registration messages; n small O(m) messages for query with probing
Hashing AV-pair individually ensures subset matching Query may contain only 1 AV-pair
No inter-RP node communication for query resolution Tradeoff between CPU and Bandwidth
Load is spread across nodes Different names use different RP set

Jun Gao Carnegie Mellon University 10
Load Concentration Problem
RP node may be overloaded Some AV-pairs more popular than
others Speed=55mph vs. Speed=95mph P2P keyword follows Zipf
distribution However, many nodes are
underutilized Intuition: use a set of nodes to
share load caused by popular pairs
Challenge: accomplish load balancing in a distributed and self-adaptive fashion
10
100
1000
10000
100000
1 10 100 1000 10000
AV-pair rank
#of names
Example Zipf distribution

Jun Gao Carnegie Mellon University 11
Load Balancing Matrix (LBM)
Organize nodes into a logical matrix Each column holds a partition Rows are replicas of each
other
Node IDs are determined by: H(a1=v1, p, r) N1
(p,r)
Matrix expands itself to accommodate extra load Increase P when registration
load reaches threshold Query load R
1,1 2,1 3,1
1,2 2,2 3,2
1,3 2,3 3,3
CN1CN2 CN3 CN4 CN3 CN4
Q1Q2
Q3Q4
Q3
Q4
LBM for AV-pair: {a1=v1}
R
P

Jun Gao Carnegie Mellon University 12
Registration and Query with LBM
Determine LBM size Register with one random
column of each matrix Compute IDs locally
1,1
1,2
2,1
2,2
1,3 2,3
CN1:{a1v1, a2v2, a3v3}
0,0
P=?, R=?
P=3, R=3
LBM1
LBM2
LBM3
3,1
3,2
3,3
Q:{a1v1, a2v2}Load is balanced within an LBM
Registration
Query can be sent to the matrix of any AV-pair Use LBM with min(P)
Sent to one random node in each column
Query

Jun Gao Carnegie Mellon University 13
System Properties with LBM
Registration and query cost for one pair increases O(R) registration messages O(P) query messages Matrix size depends on current load
LBM must be kept small for efficiency Query optimization helps, e.g., large P small R Matrix shrinking mechanism E.g., May query a subset of the partitions
Load on each RP node is upper-bounded Efficient processing
Underutilized nodes are recruited as LBM expands

Jun Gao Carnegie Mellon University 14
Simulation Evaluation
Implement in an event-driven simulator Each node monitors its registration and query load Assume Chord-like underlying routing mechanism
Experiment setup 10,000 nodes in the CDS network 10,000 distinct AV-pairs (50 attributes, 200 values/attribute) Use synthetic registration and query workload
Performance metric: success rate System should maintain high success rate as load increases

Jun Gao Carnegie Mellon University 15
Workload
10
100
1000
10000
100000
1 10 100 1000 10000
Uniform
Skewed
1
10
100
1000
10000
100000
1 10 100 1000 10000
Rank of AV-pairs Rank of AV-pairs
Num
ber
of n
ames
Num
ber
of q
uerie
s
Registration load Query load

Jun Gao Carnegie Mellon University 16
Registration Success Rate Comparison
0
20
40
60
80
100
0.01 0.1 1 10
Uniform w/o LBM
Uniform w. LBM
Skewed w/o LBM
Skewed w. LBM
Avg. registration arrival rate (1000 reg/sec)
Reg
istr
atio
n su
cces
s ra
te (
%)
Threshold = 50 reg/secPoisson arrivalPmax = 10
100,000 names 1 registration every 10 secs.

Jun Gao Carnegie Mellon University 17
40
60
80
100
0.01 0.1 1 10 100
Random
Random w. LBM
With opt.
Opt. with LBM
Query Success Rate Comparison
Avg. query arrival rate (1000q/sec)
Que
ry s
ucce
ss r
ate
(%)
1 million users, 1 query every 10 secs.
Threshold = 200 q/secPoisson arrivalRmax = 10

Jun Gao Carnegie Mellon University 18
Conclusions
Proposed a distributed and scalable design to the content discovery problem
RP-based approach addresses scalability Avoid flooding
LBMs improve system throughput Balance load
Distributed algorithms Decisions are made locally


















