Remixing web data for your hacks the easy way
73
Remixing web data for your hacks the easy way YQL – the can opener of the web
-
Upload
thomas-decker -
Category
Documents
-
view
23 -
download
1
description
Remixing web data for your hacks the easy way. YQL – the can opener of the web. Hacking together systems in 24 hours is a lot of fun. But you want to spend that time thinking about the interface. And not how you get to the right data in the right format. - PowerPoint PPT Presentation
Transcript of Remixing web data for your hacks the easy way

Remixing web data for your hacks the easy wayYQL – the can opener of the web

Hacking together systems in 24 hours is a lot of fun.

But you want to spend that time thinking about the interface.

And not how you get to the right data in the right format.

The web is full of juicy and long lasting data.
http://www.flickr.com/photos/clspeace/162336973/

And there is a lot of it around.
http://www.flickr.com/photos/tudor/2981410947/

However, our attempts to get to it can be clumsy.
http://www.flickr.com/photos/lumachrome/2140368742/

What we need is an easy way to get to that data.
http://www.flickr.com/photos/careytilden/115435226/

We had a way to do that for quite a while now.
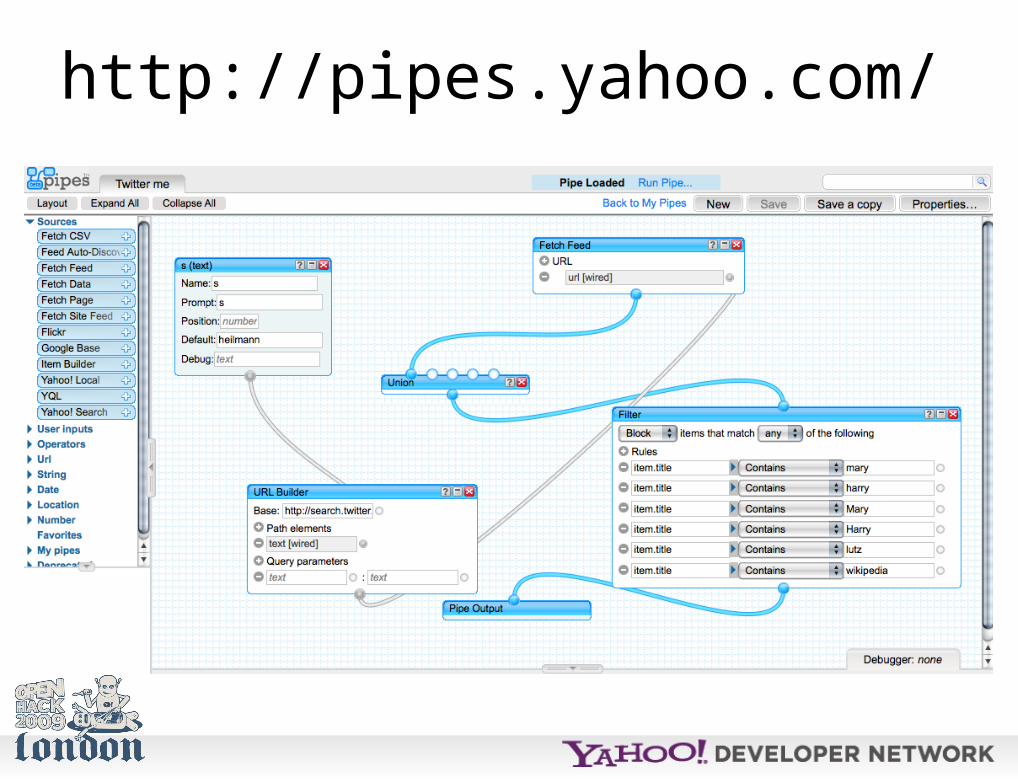
http://pipes.yahoo.com/

Pipes, however is high end technology…
http://www.flickr.com/photos/axio/2346342672/

We’re developers, not interface users.
http://www.flickr.com/photos/codepo8/2278641937/

So for a long time people asked Yahoo for a command line version of pipes.
Can we have one?

Yes, we can!

The Yahoo Query Language, or short YQL is a unified interface language to the web.
http://developer.yahoo.com/yql/

Using YQL, accessing the web and its services becomes as easy as SQL:
select {what} from {service} where {condition}

Say you want kittens in your hack (who doesn’t?)
select * from flickr.photos.search where text="kitten"

Say you want kittens in your hack (who doesn’t?)

Say you only want 5 kittens
select * from flickr.photos.search where text="kitten" limit 5

Say you only want 5 kittens

Nice, but where can you get this?

YQL is a REST API in itself, and it has two endpoints.

The public endpoint does not need any authentication.
http://query.yahooapis.com/v1/public/yql?q={query}&format={format}

The private endpoint needs oauth authentication.
http://query.yahooapis.com/v1/yql?q={query}&format={format}
http://developer.yahoo.com/yql/guide/authorization-access.html

Output formats are XML or JSON. JSON also allows for a callback parameter to use the output directly as JSON-P.
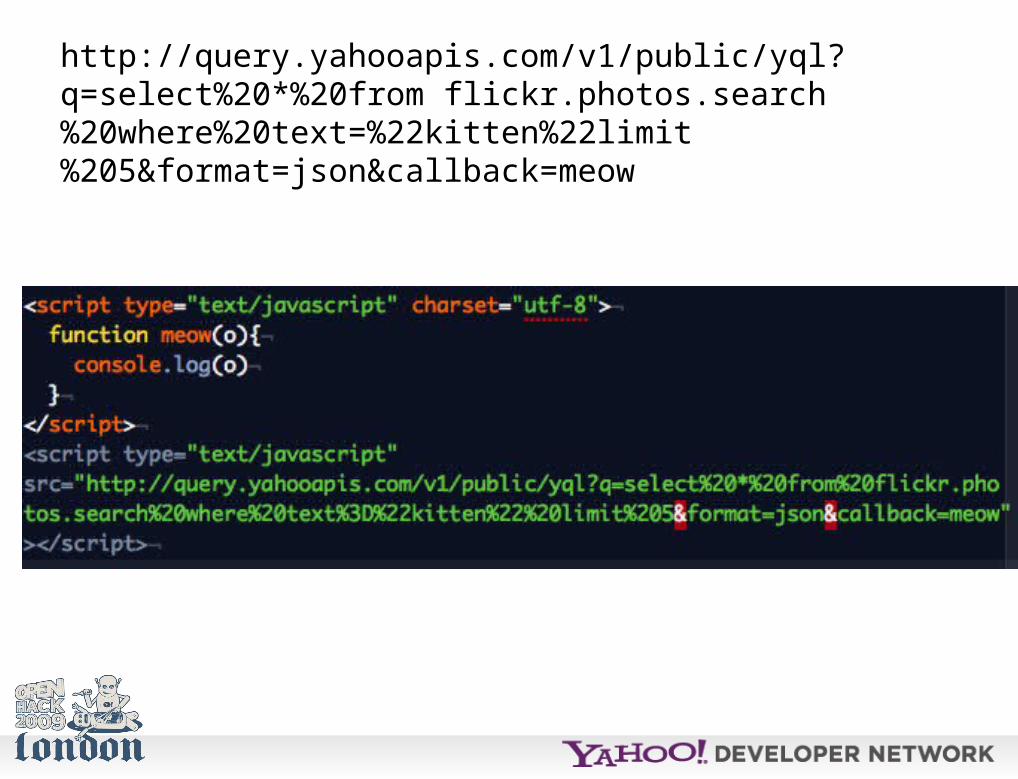
http://query.yahooapis.com/v1/public/yql?q=select%20*%20from flickr.photos.search%20where%20text=%22kitten%22limit%205&format=json&callback=meow
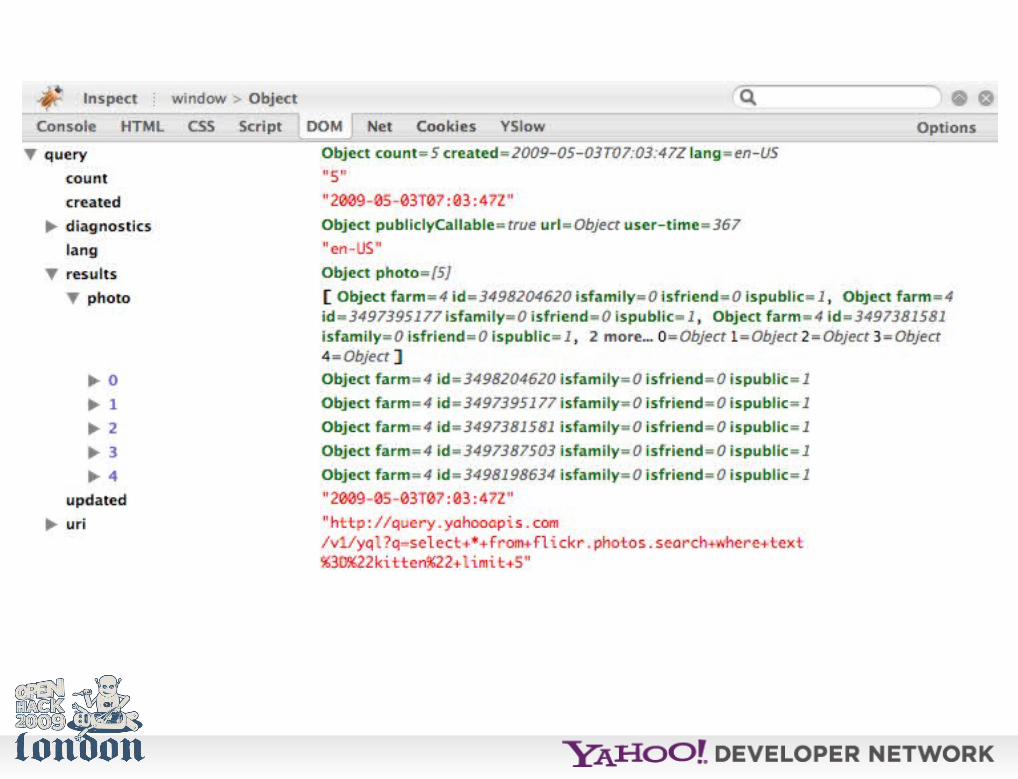

You can mix and match several web services using the in() command.

Guess what this does:
select * from flickr.photos.info where photo_id in (select id from flickr.photos.search where woe_id in (select woeid from geo.places where text='london,uk') and license=4)

Find photos in London, UK with a Creative Commons “By” license and give me all the information you have about them.

select * from flickr.photos.info where photo_id in (select id from flickr.photos.search where woe_id in (select woeid from geo.places where text='london,uk') and license=4)

Using a command like this and some out-of-the-box UI elements like Yahoo Maps and the YUI carousel, you can build something *very* quickly.
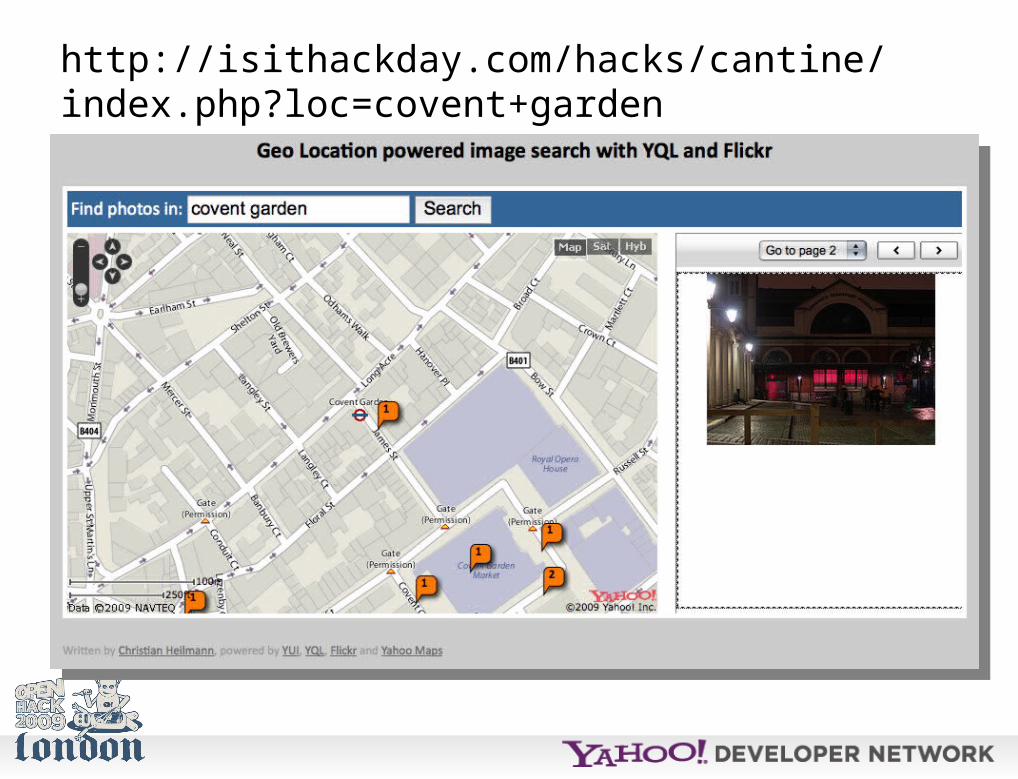
http://isithackday.com/hacks/cantine/index.php?loc=covent+garden

Instead of selecting all the information you can also limit the results:
select name,url from upcoming.venue where metro_id in (select id from upcoming.metro where search_text="stokey")

select name,url from upcoming.venue where metro_id in (select id from upcoming.metro where search_text="stokey")

The diagnostics part of the returned data shows you what happened and how long it took

Here’s what Yahoo offers you in this format:
flickr.photos.exifflickr.photos.infoflickr.photos.interestingnessflickr.photos.recentflickr.photos.searchflickr.photos.sizesflickr.placesflickr.places.infogeo.placesgeo.places.ancestorsgeo.places.belongtosgeo.places.childrengeo.places.neighborsgeo.places.parentgeo.places.siblingsgeo.placetypesgnip.activity
local.searchmusic.artist.idmusic.artist.popularmusic.artist.searchmusic.artist.similarmusic.release.artistmusic.release.idmusic.release.popularmusic.release.searchmusic.track.idmusic.track.popularmusic.track.searchmusic.video.categorymusic.video.idmusic.video.popularmusic.video.searchmusic.video.similar
mybloglog.community.findmybloglog.membermybloglog.member.contactsmybloglog.member.newwithcontactsmybloglog.member.newwithmemybloglog.members.findmybloglog.stats.findupcoming.categoryupcoming.countryupcoming.eventsupcoming.events.bestinplaceupcoming.groupsupcoming.metroupcoming.stateupcoming.userupcoming.venue

Here’s what Yahoo offers you in this format:
search.imagessearch.newssearch.siteexplorer.inlinkssearch.siteexplorer.pagessearch.spellingsearch.suggestsearch.termextractsearch.websocial.connectionssocial.contactssocial.presencesocial.profilesocial.updatesweather.forecastyahoo.identityyap.setsmallview
search.imagessearch.newssearch.siteexplorer.inlinkssearch.siteexplorer.pagessearch.spellingsearch.suggestsearch.termextractsearch.websocial.connectionssocial.contactssocial.presencesocial.profilesocial.updatesweather.forecastyahoo.identityyap.setsmallview
search.imagessearch.newssearch.siteexplorer.inlinkssearch.siteexplorer.pagessearch.spellingsearch.suggestsearch.termextractsearch.websocial.connectionssocial.contactssocial.presencesocial.profilesocial.updatesweather.forecastyahoo.identityyap.setsmallview

You want even more?
http://www.flickr.com/photos/verylastexcitingmoment/3123597774/

Alright, how about this?
atomcsvfeedhtml
jsonmicroformatsrssxml

Telegraph’s headlines anyone?select * from html where url='http://www.telegraph.co.uk/' and xpath='//h3/a'

Telegraph’s headlines anyone?

You can dynamically create YQL queries to collate several sources…

Then use cURL to pull them off the web with one single http request!

YQL caches and compresses the results for you.
Pretty easy, isn’t it?

Here’s another fun part:Anyone can be part of the YQL interface.

All we need the data provider to do is to create a schema that explains their data structure.
http://developer.yahoo.com/yql/guide/yql-opentables-chapter.html

And people do…amazonbitlydeliciousdopplretsyfriendfeedgithubGreaderguardianimdbiplocationlastfmnestorianetflix
nmmnytopensocialsearchshoppingsocialtwitterupdate.groovyweatherwesabewhitepagesyahooyelpzillow
http://github.com/spullara/yql-tables/tree/master

For example the national maritime museum:
select * from nmm.archive.search where searchterm=‘horatio nelson'
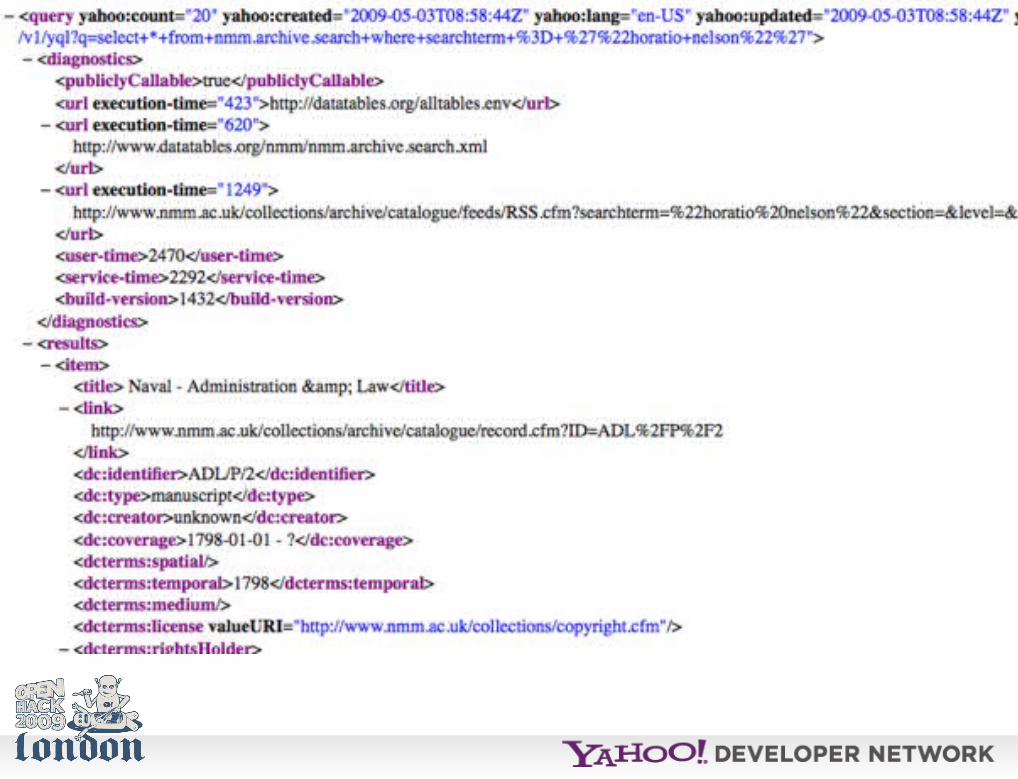
select * from nmm.archive.search where searchterm=‘horatio nelson'

That’s pretty cool – allowing anyone to be part of this interface.

The only shame is that you can’t do all the things in YQL that you can do in Pipes – for example string manipulation.

We wondered how to make this possible.
One thing we didn’t want to sacrifice is the simplicity of the language itself.

So instead of inventing an own language, we decided to piggy-back on one you already know.

YQL execute allows you to embed JavaScript in the open table schema that runs on the YQL server and converts the data for you.
http://developer.yahoo.com/yql/guide/yql-execute-chapter.html

For example you can augment an existing service to do something different.
The following example adds a rank to search results.
http://www.yqlblog.net/samples/searchrank.xml
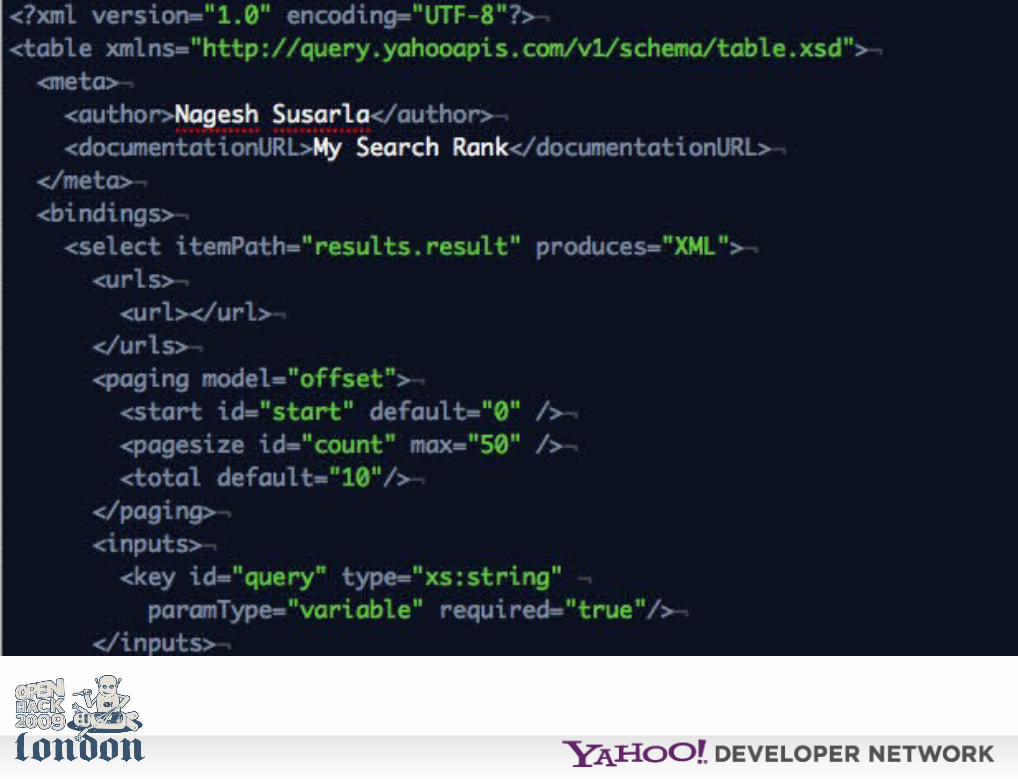
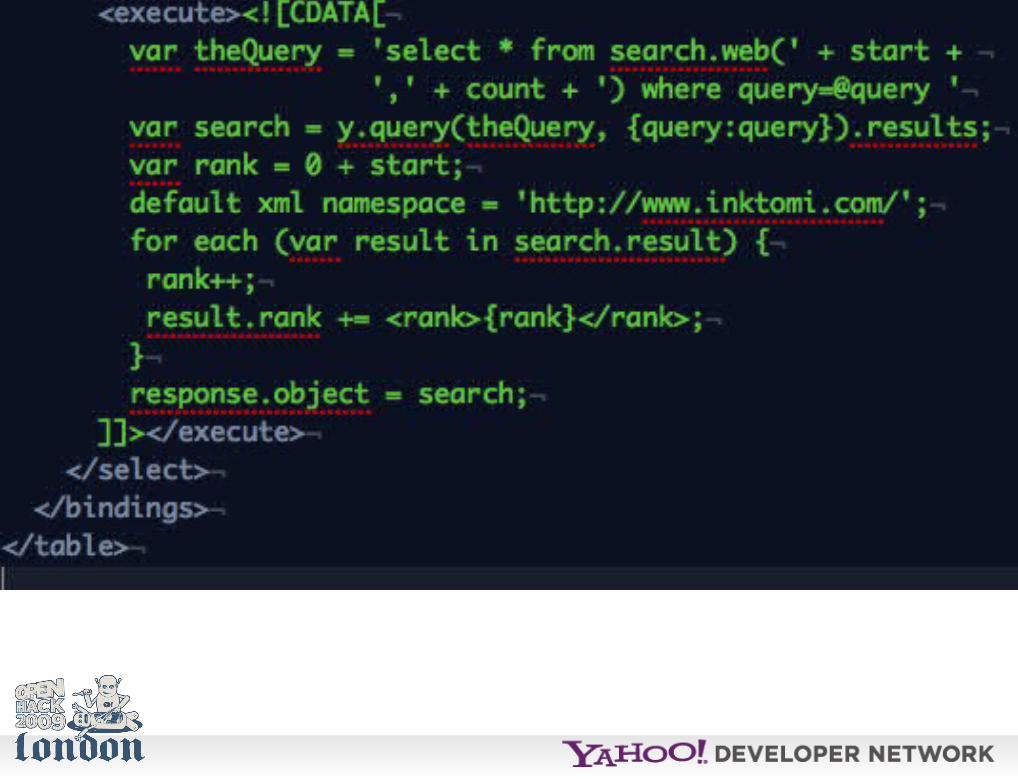

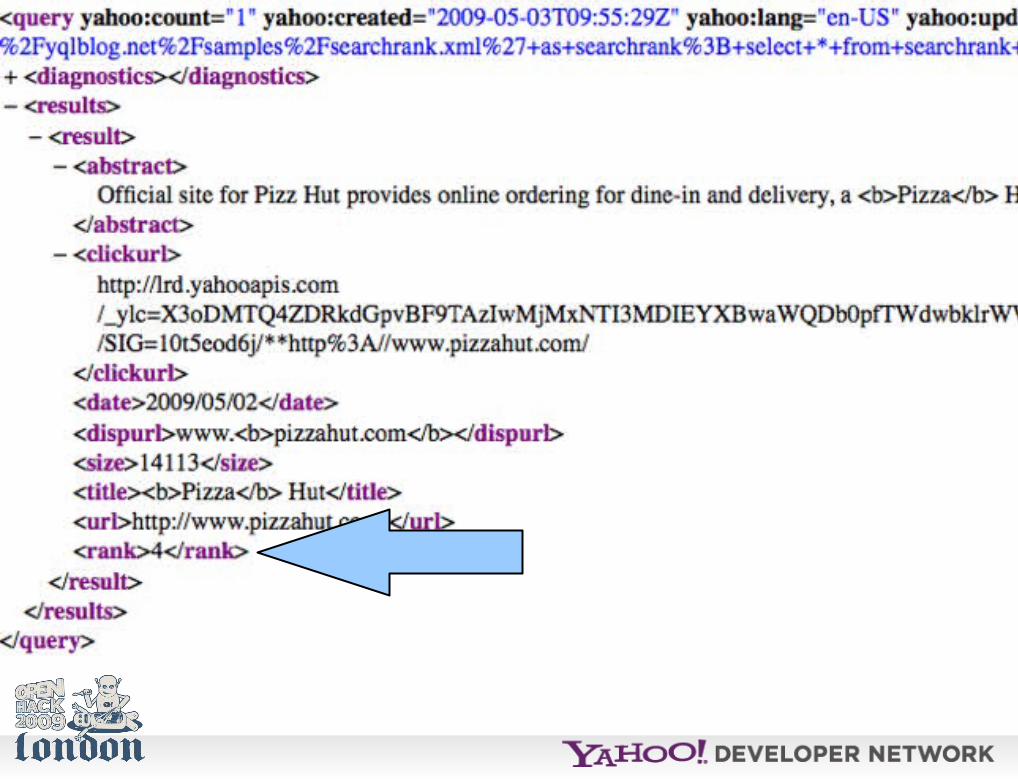
Stored as XML this can be used in a YQL query:
use 'http://yqlblog.net/samples/searchrank.xml' as searchrank; select * from searchrank where query='pizza' and dispurl like '%pizzahut%'

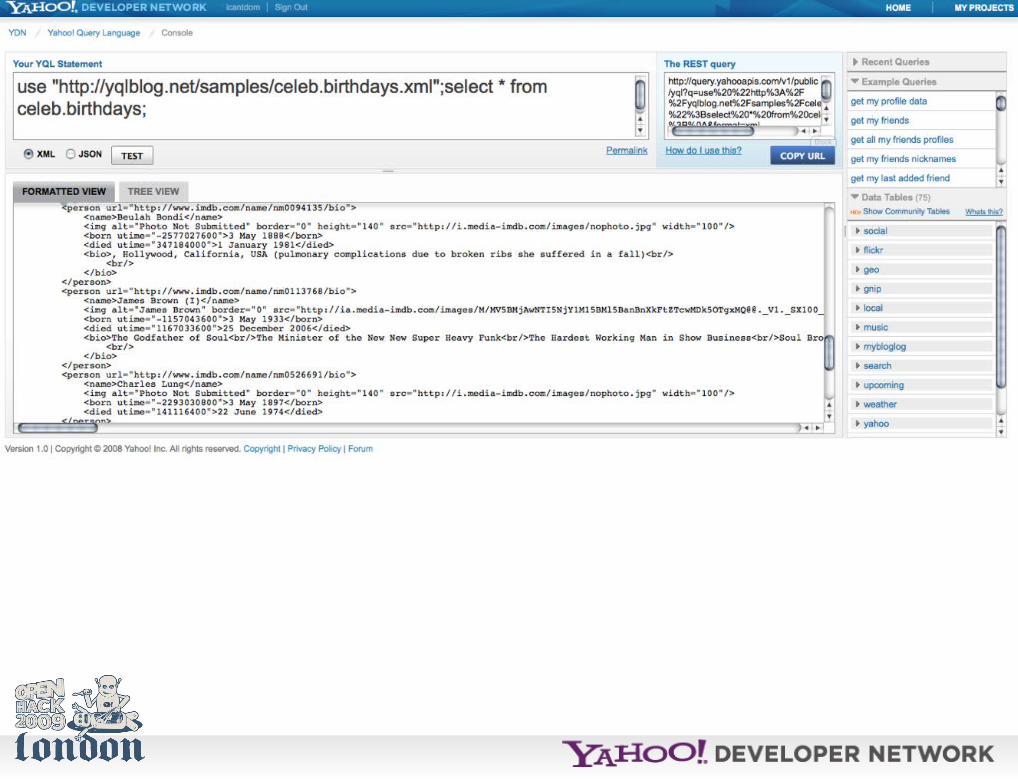
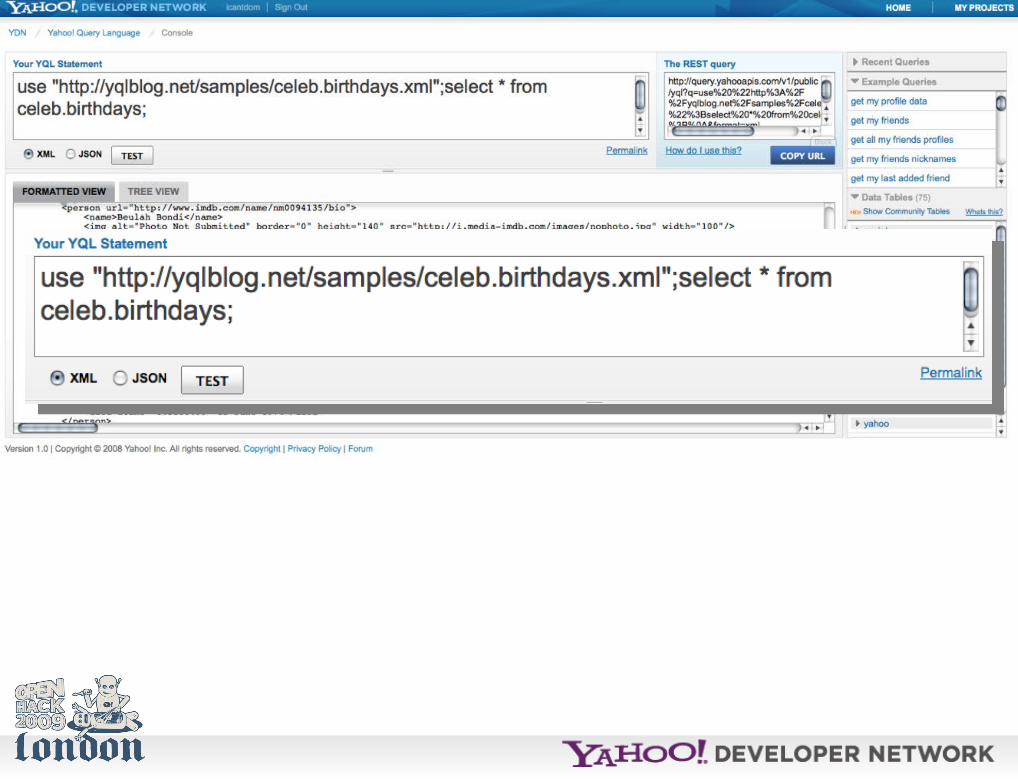
Anyways, the *easiest* way to start with YQL is to use the console.
http://developer.yahoo.com/yql/console/
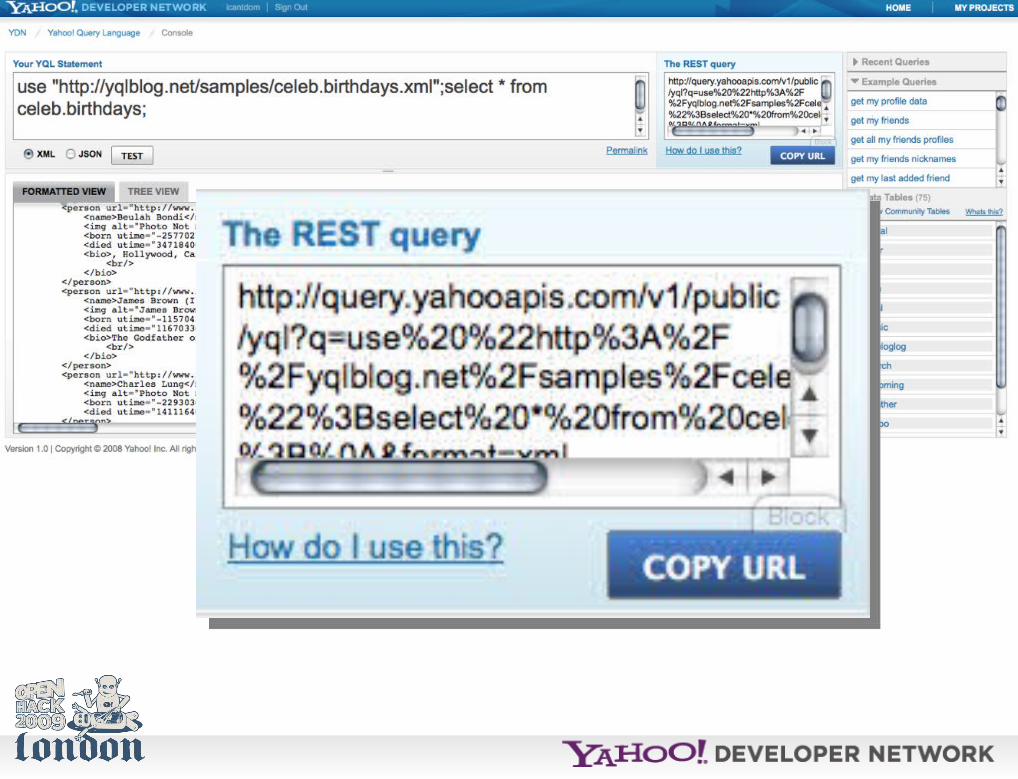
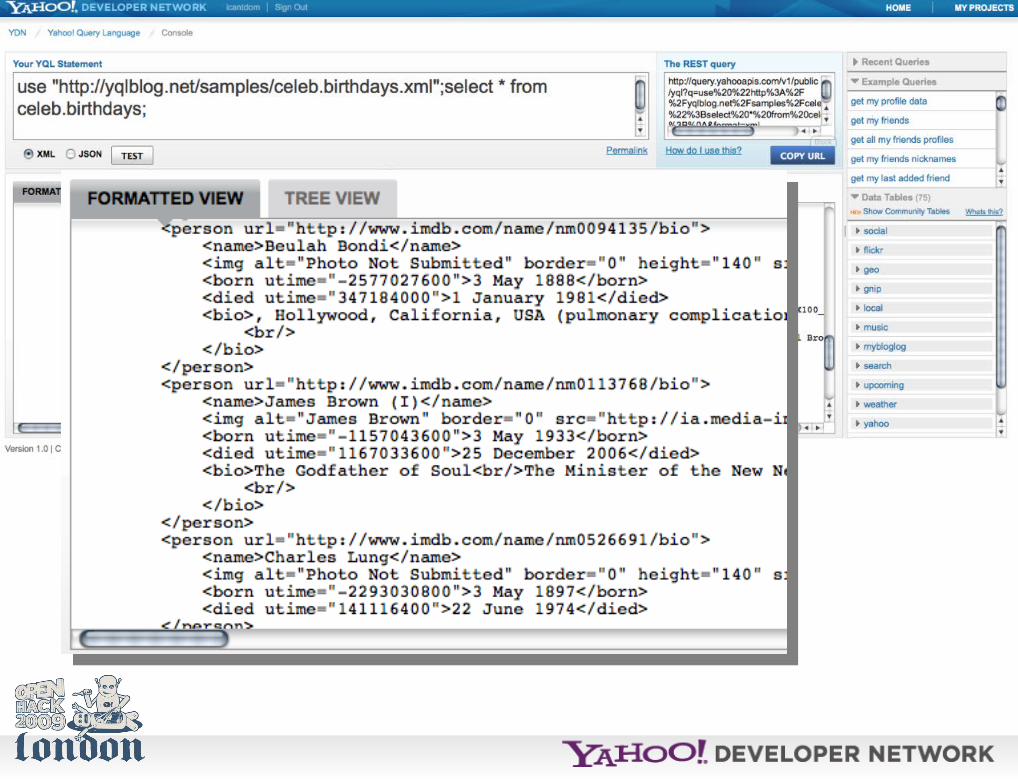
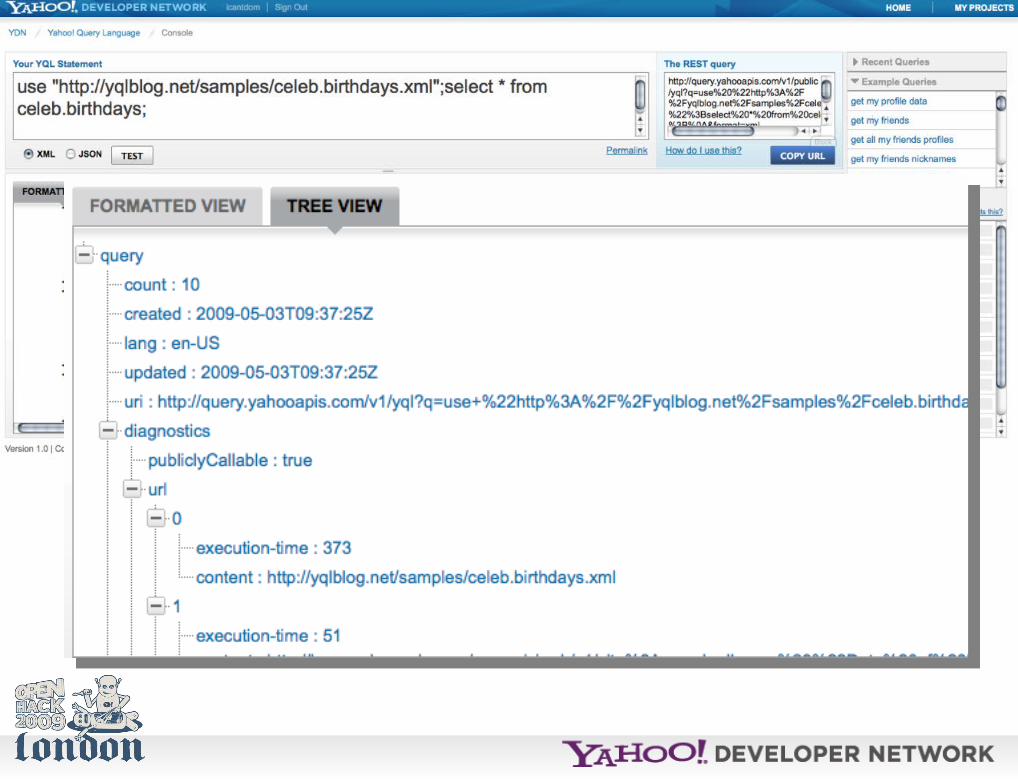
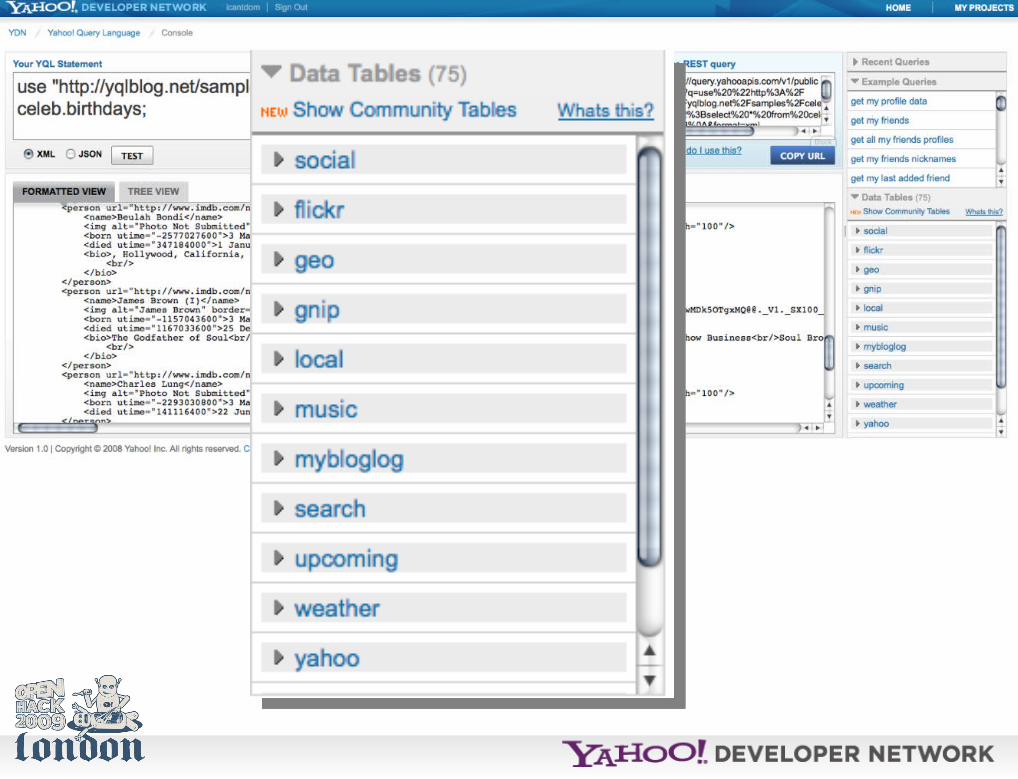
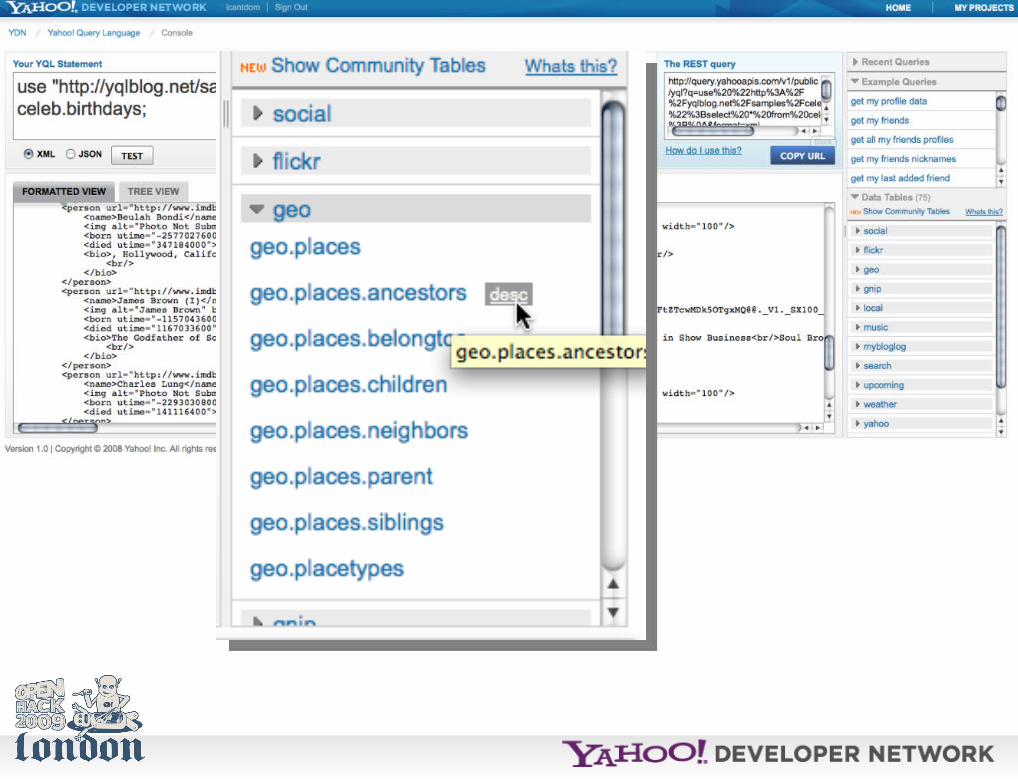


Of course, you can also spend half the hack day reading API docs

Check out some code examples on.
http://isithackday.com/hacks/ohd-london

THANKS!
Chris Heilmannhttp://twitter.com/codepo8