
Recovery-Oriented Computing Stanford ROC Updates Armando Fox.
54
Recovery-Oriented Computing Stanford ROC Updates Stanford ROC Updates Armando Fox
-
Upload
george-stanley -
Category
Documents
-
view
219 -
download
0
Transcript of Recovery-Oriented Computing Stanford ROC Updates Armando Fox.

Recovery-Oriented Computing
Stanford ROC UpdatesStanford ROC Updates
Armando Fox

2 ROC Retreat, June 16-18, 2004Emre Kıcıman
ProgressProgress
GraduationsGraduations Ben Ling (SSM, cheap-recovery session state Ben Ling (SSM, cheap-recovery session state
manager)manager) Jamie Cutler (refactoring satellite groundstation Jamie Cutler (refactoring satellite groundstation
software architecture to apply ROC techniques)software architecture to apply ROC techniques)
Andy Huang: DStore, a persistent cluster-based Andy Huang: DStore, a persistent cluster-based hash table (CHT)hash table (CHT)
Consistency model concretizedConsistency model concretized Cheap recovery exploited for fast recovery triggered Cheap recovery exploited for fast recovery triggered
by statistical monitoringby statistical monitoring Cheap recovery exploited for online repartitioningCheap recovery exploited for online repartitioning

3 ROC Retreat, June 16-18, 2004Emre Kıcıman
More progressMore progress
George Candea: Microreboots at the EJB level in George Candea: Microreboots at the EJB level in J2EE appsJ2EE apps
Shown to recover from variety of injected faultsShown to recover from variety of injected faults J2EE app session state factored out into SSM, making J2EE app session state factored out into SSM, making
the J2EE app the J2EE app crash-onlycrash-only Demo during poster sessionDemo during poster session
Emre Kiciman: Pinpoint: further exploration of Emre Kiciman: Pinpoint: further exploration of anomaly-based failure detection [in a minute]anomaly-based failure detection [in a minute]

4 ROC Retreat, June 16-18, 2004Emre Kıcıman
Fast Recovery meets Anomaly Fast Recovery meets Anomaly DetectionDetection
1.1. Use anomaly detection techniques to infer Use anomaly detection techniques to infer (possible) failures(possible) failures
2.2. Act on alarms using low-overhead “micro-Act on alarms using low-overhead “micro-recovery” mechanismsrecovery” mechanisms Microreboots in EJB appsMicroreboots in EJB apps Node- or process-level reboot in DStore or SSMNode- or process-level reboot in DStore or SSM
3.3. Occasional false positives OK since recovery is Occasional false positives OK since recovery is so cheapso cheap
These ideas will be developed at Panel tonight, These ideas will be developed at Panel tonight, and form topics for Breakouts tomorrowand form topics for Breakouts tomorrow

Recovery-Oriented Computing
Updates on PinPointUpdates on PinPoint
Emre Kıcıman and Armando Fox
{emrek, fox}@cs.stanford.edu

6 ROC Retreat, June 16-18, 2004Emre Kıcıman
What Is This Talk About?What Is This Talk About?
Overview of recent Pinpoint experimentsOverview of recent Pinpoint experiments Including observations on fault behaviorsIncluding observations on fault behaviors Comparison with other app-generic fault detectorsComparison with other app-generic fault detectors Tests of Pinpoint limitationsTests of Pinpoint limitations
Status of deployment at real sitesStatus of deployment at real sites

7 ROC Retreat, June 16-18, 2004Emre Kıcıman
Pinpoint: OverviewPinpoint: Overview
Goal: App-generic & High-level failure detectionGoal: App-generic & High-level failure detection For app-level faults, detection is significant % of MTTR For app-level faults, detection is significant % of MTTR
(75%!)(75%!)
Existing monitors: hard to build/maintain or miss high-level Existing monitors: hard to build/maintain or miss high-level faultsfaults
Approach: Monitor, aggregate, and analyze low-level Approach: Monitor, aggregate, and analyze low-level behaviors that correspond to high-level semanticsbehaviors that correspond to high-level semantics Component interactionsComponent interactions
Structure of runtime paths Structure of runtime paths
Analysis of per-node statistics (req/sec, mem usage, ...), Analysis of per-node statistics (req/sec, mem usage, ...), without without a priori thresholdsa priori thresholds
Assumption: Anomalies are likely to be faultsAssumption: Anomalies are likely to be faults Look for anomalies over time, or across peers in the cluster.Look for anomalies over time, or across peers in the cluster.

8 ROC Retreat, June 16-18, 2004Emre Kıcıman
Recap: 3 Steps to PinpointRecap: 3 Steps to Pinpoint
1.1. Observe low-level behaviors that Observe low-level behaviors that reflectreflect app-level app-level behavior behavior
Likely to change Likely to change iffiff application-behavior changes application-behavior changes App-transparent instrumentation!App-transparent instrumentation!
2.2. Model normal behavior and look for anomaliesModel normal behavior and look for anomalies Assume: most of system working most of the timeAssume: most of system working most of the time Look for anomalies over time and Look for anomalies over time and across peersacross peers No a priori app-specific info!No a priori app-specific info!
3.3. Correlate anomalous behavior to likely causesCorrelate anomalous behavior to likely causes AssumeAssume: observed connection between anomaly and cause: observed connection between anomaly and cause
Finally, notify admin or reboot componentFinally, notify admin or reboot component

9 ROC Retreat, June 16-18, 2004Emre Kıcıman
An Internet Service...An Internet Service...
Middleware
HTTPFrontends Application Components Databases

10 ROC Retreat, June 16-18, 2004Emre Kıcıman
A Failure...A Failure...
Middleware
HTTPFrontends Application Components Databases
X
• Failures behave differently than normal• Look for anomalies in patterns of internal behavior

11 ROC Retreat, June 16-18, 2004Emre Kıcıman
Patterns: Path-shapesPatterns: Path-shapes
Middleware
HTTPFrontends Application Components Databases

12 ROC Retreat, June 16-18, 2004Emre Kıcıman
Patterns: Component InteractionsPatterns: Component Interactions
Middleware
HTTPFrontends Application Components Databases

13 ROC Retreat, June 16-18, 2004Emre Kıcıman
OutlineOutline
Overview of recent Pinpoint experimentsOverview of recent Pinpoint experiments Observations on fault behaviorsObservations on fault behaviors Comparison with other app-generic fault detectors Tests of Pinpoint limitations
Status of deployment at real sites

14 ROC Retreat, June 16-18, 2004Emre Kıcıman
Compared to other anomaly-Compared to other anomaly-detection...detection...
Labeled and Unlabeled training setsLabeled and Unlabeled training sets If we know the end user saw a failure, Pinpoint can help If we know the end user saw a failure, Pinpoint can help
with with localizationlocalization But often we’re trying to catch failures that end-user-But often we’re trying to catch failures that end-user-
level detectors would level detectors would missmiss ““Ground truth” for the latter is HTML page checksums + Ground truth” for the latter is HTML page checksums +
database table snapshotsdatabase table snapshots
Current analyses are done offlineCurrent analyses are done offline Eventual goal is to move to online, with new models Eventual goal is to move to online, with new models
being trained and rotated in periodicallybeing trained and rotated in periodically
Alarms must be actionableAlarms must be actionable Microreboots (tomorrow) allows acting on alarms even Microreboots (tomorrow) allows acting on alarms even
when false positiveswhen false positives

15 ROC Retreat, June 16-18, 2004Emre Kıcıman
Fault and Error Injection BehaviorFault and Error Injection Behavior
Injected 4 types of faults and errorsInjected 4 types of faults and errors Declared and runtime exceptionsDeclared and runtime exceptions Method call omissionsMethod call omissions Source code bug injections (details on next page)Source code bug injections (details on next page)
Results ranged in severity (% of requests affected)Results ranged in severity (% of requests affected)
60% of faults caused cascades, affecting secondary 60% of faults caused cascades, affecting secondary requestsrequests
We fared most poorly on the “minor” bugsWe fared most poorly on the “minor” bugs
Fault type Num
Severe (>90%)
Major (>1%)
Minor (<1%)
Declared ex
41 20% 56% 24%
Runtime ex
41 17% 59% 24%
Call omission
41 5% 73% 22%
Src code bug
47 13% 76% 11%

16 ROC Retreat, June 16-18, 2004Emre Kıcıman
Experience w/Bug InjectionExperience w/Bug Injection
Wrote a Java code modifier to inject bugsWrote a Java code modifier to inject bugs Injects 6 kinds of bugs into code in Petstore 1.3Injects 6 kinds of bugs into code in Petstore 1.3 Limited to bugs that would not be caught by compiler, and Limited to bugs that would not be caught by compiler, and
are easy to inject -> no major structural bugsare easy to inject -> no major structural bugs Double-check fault existence by checksumming HTML outputDouble-check fault existence by checksumming HTML output
Not trivial to inject bugs that turn into failures!Not trivial to inject bugs that turn into failures! 11stst try: inject 5-10 bugs into random spots in each try: inject 5-10 bugs into random spots in each
component.component.
Ran 100 experiments, only 4 caused any changes!Ran 100 experiments, only 4 caused any changes! 22ndnd try: exhaustive enumeration of potential “bug spots” try: exhaustive enumeration of potential “bug spots”
Found total of 41 active spots out of 1000s.Found total of 41 active spots out of 1000s.
Rest is straight-line code w/no trivial bug spots, or dead Rest is straight-line code w/no trivial bug spots, or dead code.code.

17 ROC Retreat, June 16-18, 2004Emre Kıcıman
Source Code Bugs (Detail)Source Code Bugs (Detail) Loop Errors: Inverts loop conditions, injected 15.Loop Errors: Inverts loop conditions, injected 15.
while(while(bb) {stmt;} ) {stmt;} -> -> while(while(!b!b) {stmt;}) {stmt;}
Misassignment: Replaces LHS of assignment, injected 1Misassignment: Replaces LHS of assignment, injected 1 ii=f(a); =f(a); -> -> jj=f(a);=f(a);
Misinitialization: Clears a variable initialization, injected 2Misinitialization: Clears a variable initialization, injected 2 int i=int i=2020;; -> -> int i=int i=00;;
Misreference: Replaces a var reference, injected 6Misreference: Replaces a var reference, injected 6 avail=onStock-avail=onStock-OrderedOrdered;; -> -> avail=onStock-avail=onStock-onOrderonOrder;;
Off-by-one: Replaces comparison op, injected 17Off-by-one: Replaces comparison op, injected 17 if(a if(a > b) {...}> b) {...};; -> -> if(a if(a >= b) {...};>= b) {...};
Synchronization: Removes synchronization code, Synchronization: Removes synchronization code, injected 0injected 0
synchronized { stmt; }synchronized { stmt; } -> -> { stmt; }{ stmt; }

18 ROC Retreat, June 16-18, 2004Emre Kıcıman
OutlineOutline
Overview of recent Pinpoint experimentsOverview of recent Pinpoint experiments Including observations on fault behaviors Comparison with other app-generic fault detectorsComparison with other app-generic fault detectors Tests of Pinpoint limitations
Status of deployment at real sites

19 ROC Retreat, June 16-18, 2004Emre Kıcıman
Metrics: Recall and PrecisionMetrics: Recall and Precision
Recall = C/T, how much of target was Recall = C/T, how much of target was identifiedidentified
Precision = C/R, how much of results were Precision = C/R, how much of results were correctcorrect
Also, precision = 1 – false positive rateAlso, precision = 1 – false positive rate
Results (R)
Target (T)
CorrectlyIdentified (C)

20 ROC Retreat, June 16-18, 2004Emre Kıcıman
Metrics: Applying Recall and PrecisionMetrics: Applying Recall and Precision
DetectionDetection Do failures in the system cause detectable anomalies?Do failures in the system cause detectable anomalies? Recall = % of failures actually detected as anomaliesRecall = % of failures actually detected as anomalies Precision = 1 - (false positive rate); ~1.0 in our exptsPrecision = 1 - (false positive rate); ~1.0 in our expts
Identification (given a failure is detected):Identification (given a failure is detected): recall = how many actually-faulty requests are recall = how many actually-faulty requests are
returnedreturned precision = what % of requests returned are faulty = precision = what % of requests returned are faulty =
1-(false positive rate) 1-(false positive rate) using HTML page checksums as ground truthusing HTML page checksums as ground truth
Workload: PetStore 1.1 and 1.3 (significantly Workload: PetStore 1.1 and 1.3 (significantly different versions), plus RUBiSdifferent versions), plus RUBiS

21 ROC Retreat, June 16-18, 2004Emre Kıcıman
Fault Detection: Recall (All fault types)Fault Detection: Recall (All fault types)
•Minor faults were hardest to detectMinor faults were hardest to detect• especially for Component Interactionespecially for Component Interaction
22 ROC Retreat, June 16-18, 2004Emre Kıcıman
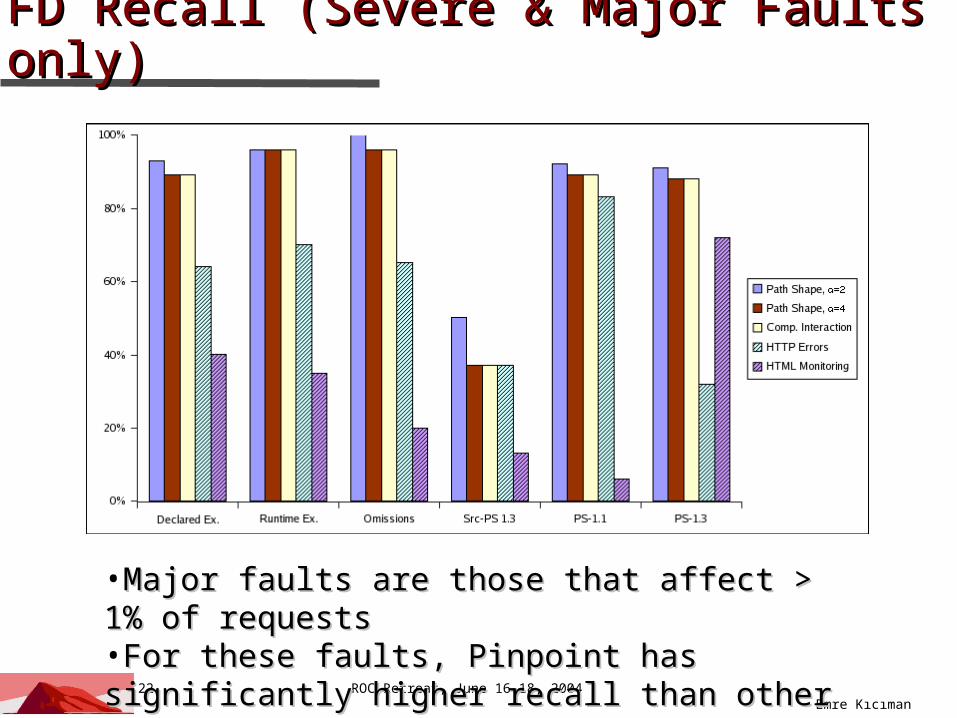
FD Recall (Severe & Major Faults only)FD Recall (Severe & Major Faults only)
•Major faults are those that affect > 1% of Major faults are those that affect > 1% of requestsrequests•For these faults, Pinpoint has significantly For these faults, Pinpoint has significantly higher recall than other low-level detectors higher recall than other low-level detectors

23 ROC Retreat, June 16-18, 2004Emre Kıcıman
Detecting Source Code BugsDetecting Source Code Bugs
Source code bugs were hardest to detectSource code bugs were hardest to detect PS-analysis, CI-analysis individually detected 7-12% of all PS-analysis, CI-analysis individually detected 7-12% of all
faults, 37% of major faultsfaults, 37% of major faults HTTP detected 10% of all faultsHTTP detected 10% of all faults We did better than HTTP logs, but that’s no excuseWe did better than HTTP logs, but that’s no excuse
Other faults: PP strictly better than HTTP and HTML Other faults: PP strictly better than HTTP and HTML det. det.
Src code bugs: complementary: together all detected Src code bugs: complementary: together all detected 15%15%

24 ROC Retreat, June 16-18, 2004Emre Kıcıman
Faulty Request IdentificationFaulty Request Identification
HTTP monitoring has perfect precision since it’s a “ground truth indicator” of a server fault
Path-shape analysis pulls more points out of the bottom left corner
Failures injected but not
detected
Failures detected, faulty
requests identified as
such
Failures not detected, but low false positives (good requests marked faulty)
Failures detected, but high rate of mis-identification of
faulty requests (false positive)

25 ROC Retreat, June 16-18, 2004Emre Kıcıman
Faulty Request IdentificationFaulty Request Identification
HTTP monitoring has perfect precision since it’s a “ground truth indicator” of a server fault
Path-shape analysis pulls more points out of the bottom left corner
26 ROC Retreat, June 16-18, 2004Emre Kıcıman
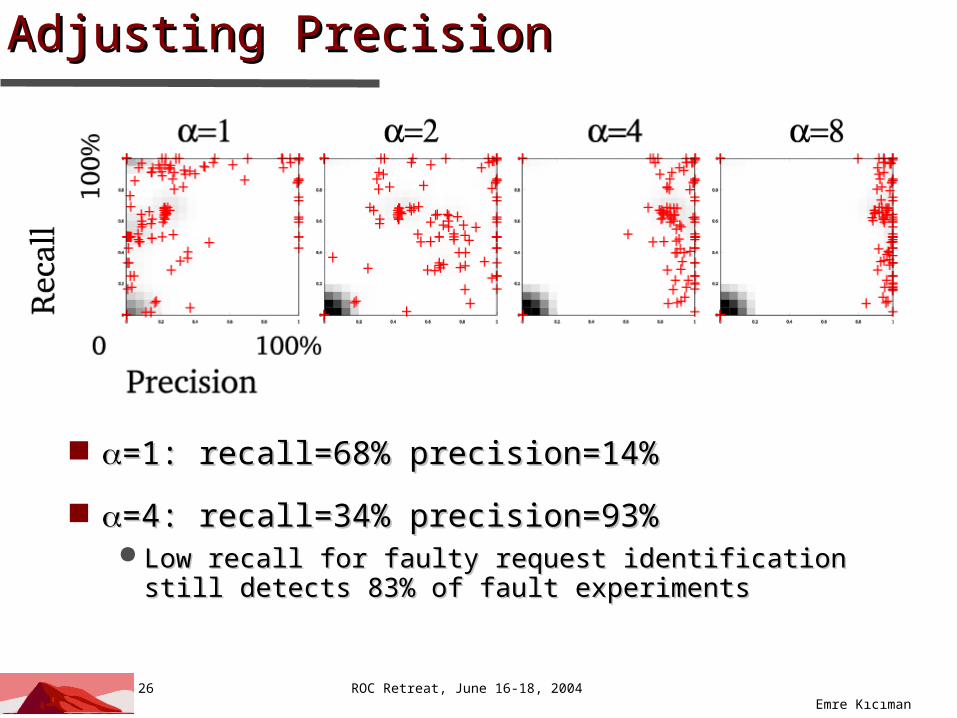
Adjusting PrecisionAdjusting Precision
=1: recall=68% precision=14%=1: recall=68% precision=14%
=4: recall=34% precision=93%=4: recall=34% precision=93% Low recall for faulty request identification still detects Low recall for faulty request identification still detects
83% of fault experiments83% of fault experiments

27 ROC Retreat, June 16-18, 2004Emre Kıcıman
OutlineOutline
Overview of recent Pinpoint experimentsOverview of recent Pinpoint experiments Including observations on fault behaviors Comparison with other app-generic fault detectors Tests of Pinpoint limitationsTests of Pinpoint limitations
Status of deployment at real sites

28 ROC Retreat, June 16-18, 2004Emre Kıcıman
OutlineOutline
Overview of recent Pinpoint experiments Including observations on fault behaviors Comparison with other app-generic fault detectors Tests of Pinpoint limitations
Status of deployment at real sitesStatus of deployment at real sites

29 ROC Retreat, June 16-18, 2004Emre Kıcıman
Status of Real-World DeploymentStatus of Real-World Deployment
Deploying parts of Pinpoint at 2 large sitesDeploying parts of Pinpoint at 2 large sites
Site 1Site 1 Instrumenting middleware to collect request paths Instrumenting middleware to collect request paths
for path-shape and component interaction analysisfor path-shape and component interaction analysis Feasability completed, instrumentation in Feasability completed, instrumentation in
progress...progress...
Site 2Site 2 Applying peer-analysis techniques developed for Applying peer-analysis techniques developed for
SSM and D-StoreSSM and D-Store Metrics (e.g., req/sec, memory usage, ...) already Metrics (e.g., req/sec, memory usage, ...) already
being collected.being collected. Beginning analysis and testing...Beginning analysis and testing...

30 ROC Retreat, June 16-18, 2004Emre Kıcıman
SummarySummary
Fault injection experiments showed range of Fault injection experiments showed range of behaviorbehavior
Cascading faults to other requests; range of severity.Cascading faults to other requests; range of severity.
Pinpoint performed better than existing low-level Pinpoint performed better than existing low-level monitorsmonitors
Detected ~90% of major component-level errors Detected ~90% of major component-level errors (exceptions, etc)(exceptions, etc)
Even in worst-case expts (src code bugs) PP provided a Even in worst-case expts (src code bugs) PP provided a complementary improvement to existing low-level complementary improvement to existing low-level monitorsmonitors
Currently, validating Pinpoint in two real-world Currently, validating Pinpoint in two real-world servicesservices

31 ROC Retreat, June 16-18, 2004Emre Kıcıman
Detail Slides

32 ROC Retreat, June 16-18, 2004Emre Kıcıman
Limitations: Independent RequestsLimitations: Independent Requests
PP assumes: request-reply w/independent PP assumes: request-reply w/independent requestsrequests
Monitored RMI-based J2EE system (ECPerf 1.1)Monitored RMI-based J2EE system (ECPerf 1.1) .. is request-reply.. is request-reply, but requests not independent, nor , but requests not independent, nor
is unit of work (UoW) well defined.is unit of work (UoW) well defined. Assume: UoW = 1 RMI call.Assume: UoW = 1 RMI call.
Most RMI calls resulted in short paths (1 comp)Most RMI calls resulted in short paths (1 comp) Injected faults do not change these short pathsInjected faults do not change these short paths When anomalies occurred, rarely in faulty path...When anomalies occurred, rarely in faulty path...
Solution? Redefine UoW as multiple RMI callsSolution? Redefine UoW as multiple RMI calls => paths capture more behavioral changes=> paths capture more behavioral changes => redefined UoW is likely app-specific=> redefined UoW is likely app-specific

33 ROC Retreat, June 16-18, 2004Emre Kıcıman
Limitations: Well-defined PeersLimitations: Well-defined Peers
PP assumes: component peer groups well-PP assumes: component peer groups well-defineddefined
But behavior can depend on contextBut behavior can depend on context
Ex. Naming server in a clusterEx. Naming server in a cluster Front-end servers mostly send lookup requestsFront-end servers mostly send lookup requests Back-end servers mostly respond to lookups.Back-end servers mostly respond to lookups.
Result: No component matches “average” Result: No component matches “average” behaviorbehavior
Both front-end and back-end naming servers Both front-end and back-end naming servers “anomalous”!“anomalous”!
Solution? Extend component-IDs to include Solution? Extend component-IDs to include logical location...logical location...

34 ROC Retreat, June 16-18, 2004Emre Kıcıman
Bonus Slides
35 ROC Retreat, June 16-18, 2004Emre Kıcıman
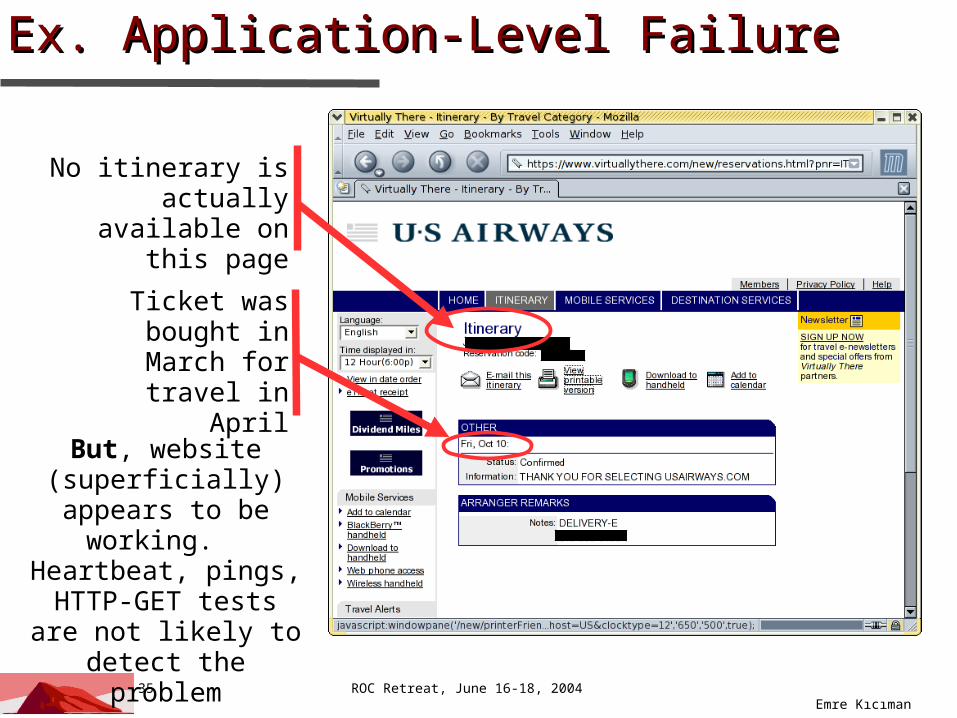
Ex. Application-Level FailureEx. Application-Level Failure
No itinerary is actually available
on this page
Ticket was bought in March for
travel in April
But, website (superficially) appears to be
working. Heartbeat, pings,
HTTP-GET tests are not likely to detect
the problem

36 ROC Retreat, June 16-18, 2004Emre Kıcıman
Application-level FailuresApplication-level Failures
Application-level failures are commonApplication-level failures are common >60% of sites have user-visible (incl. app-level) failures [BIG->60% of sites have user-visible (incl. app-level) failures [BIG-
SF]SF]
Detection is major portion of recovery timeDetection is major portion of recovery time TellMe: detecting app-level failures is 75% of recovery time TellMe: detecting app-level failures is 75% of recovery time
[CAK04][CAK04] 65% of user-visible failures mitigable by earlier detection 65% of user-visible failures mitigable by earlier detection
[OGP03][OGP03]
Existing monitoring techniques aren't good enoughExisting monitoring techniques aren't good enough Low-level monitors: pings, heartbeats, http error monitoringLow-level monitors: pings, heartbeats, http error monitoring
+ + app-generic/low maintenance, app-generic/low maintenance, - - miss high-level failures miss high-level failures High-level, app-specific testsHigh-level, app-specific tests
- - app-specific/hard to maintain, app-specific/hard to maintain, + can + can catch many app-level catch many app-level failures,failures,
- test coverage problem- test coverage problem

37 ROC Retreat, June 16-18, 2004Emre Kıcıman
Testbed and FaultloadTestbed and Faultload
Instrumented JBoss/J2EE middlewareInstrumented JBoss/J2EE middleware J2EE: state mgt, naming, etc. -> Good layer of indirection J2EE: state mgt, naming, etc. -> Good layer of indirection JBoss: open-source; millions of downloads; real JBoss: open-source; millions of downloads; real
deploymentsdeployments Track EJBs, JSPs, HTTP, RMI, JDBC, JNDITrack EJBs, JSPs, HTTP, RMI, JDBC, JNDI w/synchronous reporting: 2-40ms latency hit; 17% w/synchronous reporting: 2-40ms latency hit; 17%
throughput decrease.throughput decrease.
Testbed applicationsTestbed applications Petstore 1.3, Petstore 1.1, RUBiSPetstore 1.3, Petstore 1.1, RUBiS, ECPerf, ECPerf
Test strategy: inject faults, measure detection Test strategy: inject faults, measure detection raterate
Declared and undeclared exceptionsDeclared and undeclared exceptions Omitted calls: app not likely to handle at allOmitted calls: app not likely to handle at all Source code bugs (e.g., off-by-one errors, etc)Source code bugs (e.g., off-by-one errors, etc)

38 ROC Retreat, June 16-18, 2004Emre Kıcıman
PCFGs Model Normal Path ShapesPCFGs Model Normal Path Shapes
Probabilistic Context Free Probabilistic Context Free Grammar (PCFG)Grammar (PCFG)
Represents likely calls made by Represents likely calls made by each componenteach component
Learn probabilities of rules Learn probabilities of rules based on observed pathsbased on observed paths
Anomalous path shapesAnomalous path shapes Score a path by summing the Score a path by summing the
deviations of P(observed calls) deviations of P(observed calls) from average.from average.
Detected 90% of faults in our Detected 90% of faults in our experimentsexperiments
A B C
A B
C
Sample Paths
Learned PCFG
p=1S Ap=.5A Bp=.5A BC
p=.5B Cp=.5B $p=1C $

39 ROC Retreat, June 16-18, 2004Emre Kıcıman
Use PCFG to Score PathsUse PCFG to Score Paths
Measure difference between Measure difference between observed path and avgobserved path and avg
Score(path) = Score(path) = ∑ ∑ 1/n1/nii - P(r - P(r
ii))
Higher scores are anomalousHigher scores are anomalous
Detected 90% of faults in our Detected 90% of faults in our experimentsexperiments
A B C
A B
C
Sample Paths
Learned PCFG
p=1S Ap=.5A Bp=.5A BC
p=.5B Cp=.5B $p=1C $

40 ROC Retreat, June 16-18, 2004Emre Kıcıman
Separating Good from Bad PathsSeparating Good from Bad Paths
Use dynamic threshold to detect anomaliesUse dynamic threshold to detect anomalies
When unexpectedly many paths fall above NWhen unexpectedly many paths fall above Nthth percentilepercentile
Normal distribution Distribution with faults

41 ROC Retreat, June 16-18, 2004Emre Kıcıman
Anomalies in Component InteractionAnomalies in Component Interaction
Weighted links model component interactionWeighted links model component interaction
w0=.4w1=.3
w2=.2 w3=.1

42 ROC Retreat, June 16-18, 2004Emre Kıcıman
Scoring CI ModelsScoring CI Models
Score w/Score w/ test of goodness-of-fit:test of goodness-of-fit: Probability that same process generated bothProbability that same process generated both Makes no assumptions about shape of distributionMakes no assumptions about shape of distribution
Q=Î £n i Nwi
2
Nwi
w0=.4w1=.3
w2=.2 w3=.1
n0=30n1=10
n2=40 n3=20
Normal Pattern
Anomaly!

43 ROC Retreat, June 16-18, 2004Emre Kıcıman
Two Kinds of False PositivesTwo Kinds of False Positives
Algorithmic false positivesAlgorithmic false positives No anomaly existsNo anomaly exists But statistical technique made a mistake...But statistical technique made a mistake...
Semantic false positivesSemantic false positives Correctly found an anomalyCorrectly found an anomaly But anomaly is not a failureBut anomaly is not a failure

44 ROC Retreat, June 16-18, 2004Emre Kıcıman
Resilient Against Semantic FPResilient Against Semantic FP
Test against normal changesTest against normal changes1. Vary workload from “browse & purchase” to “only 1. Vary workload from “browse & purchase” to “only
browse”browse”
2. Minor upgrade from Petstore 1.3.1 to 1.3.22. Minor upgrade from Petstore 1.3.1 to 1.3.2 Path-shape analysis found NO differencesPath-shape analysis found NO differences Component interaction changes below thresholdComponent interaction changes below threshold
For predictable, major changes:For predictable, major changes: Consider lowering Pinpoint sensitivity until retraining Consider lowering Pinpoint sensitivity until retraining
completecomplete -> Window-of-vulnerability, but better than false-positives.-> Window-of-vulnerability, but better than false-positives.
Q: Rate of normal changes? How quickly can we Q: Rate of normal changes? How quickly can we retrain?retrain?
Minor changes every day, but only to parts of site.Minor changes every day, but only to parts of site. Training speed -> how quickly is service exercised?Training speed -> how quickly is service exercised?

45 ROC Retreat, June 16-18, 2004Emre Kıcıman
Related WorkRelated Work
Detection and Localization:Detection and Localization: Richardson: Performance failure detectionRichardson: Performance failure detection Infospect: search for logical inconsistencies in observed Infospect: search for logical inconsistencies in observed
configurationconfiguration Event/alarm correlation systems: use dependency models to Event/alarm correlation systems: use dependency models to
quiesce/collapse correlated alarms.quiesce/collapse correlated alarms.
Request TracingRequest Tracing Magpie: tracing for performance modeling/characterizationMagpie: tracing for performance modeling/characterization Mogul: discovering majority behavior in black-box distrib. Mogul: discovering majority behavior in black-box distrib.
systemssystems
Compilers & PLCompilers & PL DIDUCE: hypothesize invariants, report when they're broken DIDUCE: hypothesize invariants, report when they're broken Bug Isolation Proj.: correlate crashes w/state, across real runsBug Isolation Proj.: correlate crashes w/state, across real runs Engler: Analyze static code for patterns and anomalies -> Engler: Analyze static code for patterns and anomalies ->
bugsbugs

46 ROC Retreat, June 16-18, 2004Emre Kıcıman
ConclusionsConclusions
Monitoring path shapes and component Monitoring path shapes and component interactions..interactions..
... easy to instrument, app-generic... easy to instrument, app-generic ... are likely to change when application fails... are likely to change when application fails
Model normal pattern of behavior, look for Model normal pattern of behavior, look for anomaliesanomalies
Key assumption: most of system working most of timeKey assumption: most of system working most of time Anomaly detection detects high-level failures, and is Anomaly detection detects high-level failures, and is
deployabledeployable Resilient to (at least some) normal changes to systemResilient to (at least some) normal changes to system
Current status:Current status: Deploying in real, large Internet service.Deploying in real, large Internet service. Anomaly detection techniques for “structure-less” Anomaly detection techniques for “structure-less”
systemssystems

47 ROC Retreat, June 16-18, 2004Emre Kıcıman
More InformationMore Information
http://www.stanford.edu/~emrek/http://www.stanford.edu/~emrek/
Detecting Application-Level Failures in Component-Based Detecting Application-Level Failures in Component-Based Internet Services.Internet Services.
Emre Kiciman, Armando Fox. In submission Emre Kiciman, Armando Fox. In submission
Session State: Beyond Soft State.Session State: Beyond Soft State.
Benjamin Ling, Emre Kiciman, Armando Fox. NSDI'04Benjamin Ling, Emre Kiciman, Armando Fox. NSDI'04
Path-based Failure and Evolution ManagementPath-based Failure and Evolution Management
Chen, Accardi, Kiciman, Lloyd, Patterson, Fox, Brewer. NSDI'04Chen, Accardi, Kiciman, Lloyd, Patterson, Fox, Brewer. NSDI'04

48 ROC Retreat, June 16-18, 2004Emre Kıcıman
Localize Failures with Decision TreeLocalize Failures with Decision Tree
Search for features that occur with bad items, but Search for features that occur with bad items, but not goodnot good
Decision treesDecision trees Classification functionClassification function Each branch in tree tests a featureEach branch in tree tests a feature Leaves of tree give classificationLeaves of tree give classification
Learn decision tree to classify good/bad examplesLearn decision tree to classify good/bad examples But we won't use it for classificationBut we won't use it for classification Just look at learned classifier and extract questions as Just look at learned classifier and extract questions as
featuresfeatures

49 ROC Retreat, June 16-18, 2004Emre Kıcıman
Illustrative Decision Tree Illustrative Decision Tree

50 ROC Retreat, June 16-18, 2004Emre Kıcıman
Results: Comparing Localization RateResults: Comparing Localization Rate

51 ROC Retreat, June 16-18, 2004Emre Kıcıman
Monitoring “Structure-less” SystemsMonitoring “Structure-less” Systems
N replicated storage bricks handle read/write N replicated storage bricks handle read/write requestsrequests
No complicated interactions or requestsNo complicated interactions or requests -> Cannot do structural anomaly detection!-> Cannot do structural anomaly detection! Alternative features (performance, mem usage, etc)Alternative features (performance, mem usage, etc)
Activity statistics: How often did a brick do Activity statistics: How often did a brick do something?something?
Msgs received/sec, dropped/sec, etc.Msgs received/sec, dropped/sec, etc. Same across all peers, assuming balanced workloadSame across all peers, assuming balanced workload Use anomalies as likely failuresUse anomalies as likely failures
State statistics: What is current state of systemState statistics: What is current state of system Memory usage, queue length, etc.Memory usage, queue length, etc. Similar pattern across peers, but may not be in phaseSimilar pattern across peers, but may not be in phase Look for patterns in time-series; differences in patterns Look for patterns in time-series; differences in patterns
indicate failure at a node.indicate failure at a node.

52 ROC Retreat, June 16-18, 2004Emre Kıcıman
Surprising Patterns in Time-SeriesSurprising Patterns in Time-Series
1. Discretize time-series into string. [Keogh]1. Discretize time-series into string. [Keogh]
[0.2, 0.3, 0.4, 0.6, 0.8, 0.2] -> “aaabba”[0.2, 0.3, 0.4, 0.6, 0.8, 0.2] -> “aaabba”
2. Calculate the frequencies of short substrings in the 2. Calculate the frequencies of short substrings in the string.string.
““aa” occurs twice; “ab”, “bb”, “ba” occurs once.aa” occurs twice; “ab”, “bb”, “ba” occurs once.
3. Compare frequencies to normal, look for substrings 3. Compare frequencies to normal, look for substrings that occur much less or much more than normal.that occur much less or much more than normal.

53 ROC Retreat, June 16-18, 2004Emre Kıcıman
Inject Failures into Storage SystemInject Failures into Storage System
Inject performance failure Inject performance failure every 60s in one brickevery 60s in one brick
Slow all request my 1msSlow all request my 1ms
Pinpoint detects failures in Pinpoint detects failures in 1-2 periods1-2 periods
Does not detect anomalies Does not detect anomalies during normal behavior during normal behavior (including workload changes (including workload changes and GC)and GC)
Current issues: Too many Current issues: Too many magic numbersmagic numbers
Working on improving these Working on improving these techniques to remove or techniques to remove or automatically choose magic automatically choose magic numbersnumbers

54 ROC Retreat, June 16-18, 2004Emre Kıcıman
Responding to AnomaliesResponding to Anomalies
Want a policy for responding to anomaliesWant a policy for responding to anomalies
Cross-check for failure:Cross-check for failure: 1. If no cause is correlated with the anomaly -> not 1. If no cause is correlated with the anomaly -> not
failurefailure 2. Check user behavior for excessive reloads2. Check user behavior for excessive reloads 3. Persistent anomaly? Check for recent state changes3. Persistent anomaly? Check for recent state changes
Recovery actions:Recovery actions: 1. Reboot component or app1. Reboot component or app 2. Rollback failed request, try again.2. Rollback failed request, try again. 3. Rollback software to last known good state.3. Rollback software to last known good state. 4. Notify administrator4. Notify administrator


















