
RECENT ADVANCES IN DEEP LEARNING FOR MEDIA &...
44
1 Mark Skinner, 2016 RECENT ADVANCES IN DEEP LEARNING FOR MEDIA & ENTERTAINMENT
Transcript of RECENT ADVANCES IN DEEP LEARNING FOR MEDIA &...

1
Mark Skinner, 2016
RECENT ADVANCES IN DEEP LEARNING FOR MEDIA & ENTERTAINMENT

2
AGENDA
What is Deep Learning?
Recent advances in DL for Media & Entertainment
Applications
Hardware and Software
Q&A

3
WHAT IS DEEP LEARNING?

4
THE BIG BANG IN MACHINE LEARNING
“ Google’s AI engine also reflects how the world of computer hardware is changing. (It) depends on machines equipped with GPUs… And it depends on these chips more than the larger tech universe realizes.”
DNN GPU BIG DATA
https://developer.nvidia.com/deep-learning

5
LEVERAGING THE ECOSYSTEM
• Deep Learning solutions in practice often require huge amounts of data and many GPUs for image processing (data prep), training, and inference
• NVIDIA provides the highest performance GPU hardware for Deep Learning and provides support for nearly every major DL framework through core libraries such as CUDA, cuBLAS, and cuDNN
• Bright Computing enables dynamic cluster node re-configuration to match
diverse workloads plus rapid install of containers and custom machine images

6
TRADITIONAL MACHINE PERCEPTION
Speaker ID,
speech transcription, …
Raw data Feature extraction Result (Linear) Classifier
e.g. SVM
e.g. HMM

7
DEEP LEARNING APPROACH
LABELLED TRAINING DATA
DEEP NEURAL NETWORK “MODEL”
OBJECT CLASS PREDICTIONS
CAR
TRU
CK
DIG
GER
BACKG
RO
UN
D
TRAINING SIGNAL

8
ARTIFICIAL NEURAL NETWORK A collection of simple, trainable mathematical units that collectively
learn complex functions
Input layer Output layer
Hidden layers
Given sufficient training data an artificial neural network can approximate very complex functions mapping raw data to output decisions

9
DEEP NEURAL NETWORK (DNN)
Input Output
Raw data Low-level features Mid-level features High-level features
Typically millions of images
Billions of trainable parameters
Robust Generalizable Scalable

10
DEEP LEARNING GENERALIZES
x1
x2
x3
...
xN
Real-valued tensor Varied data types
(and multi-source)
NUMBERS
IMAGES
SOUNDS
VIDEOS
TEXT
Unstructure
d
Structured
Classification
Regression
Unsupervised learning • Clustering
• Topic extraction
• Anomaly detection
Varied tasks
Sequence prediction
Control policy learning

11
DEEP LEARNING FOR VISUAL PERCEPTION Going from strength to strength
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
2009 2010 2011 2012 2013 2014 2015 2016
IMAGENET
Accuracy Rate Traditional CV Deep Learning

12
RECENT ADVANCES IN DL APPLICATIONS

13
GPUS HELP CUT SIRI’S ERROR RATE BY HALF
“The error rate has been cut by a factor of two in all the languages, more than a factor of two in many cases” “ That’s mostly due to deep learning and the way we have optimized it”
Alex Acero, Apple’s Speech Team Head.
Apple, Aug 2016
https://news.developer.nvidia.com/gpus-help-cut-siris-error-rate-by-half/

14
DISTRIBUTED NEURAL NETWORKS WITH GPUS IN THE AWS CLOUD
Initial runs took 20 hours to train their neural network model, eventually the time was reduced to just 47 min
NETFLIX
http://techblog.netflix.com/2014/02/distributed-neural-networks-with-gpus.html

15
DL VIDEO CLASSIFICATION NVIDIA, GTC 2016
https://www.youtube.com/watch?v=Y4vx5hTYeiU

16
COGNITIVE MOVIE TRAILER IBM Watson, Sept 2016
http://m.phys.org/news/2016-09-video-cognitive-movietrailer-ibm-watson.html

17
OBJECT DETECTION A new approach to one-shot detection and localization
For each grid square predict: • Class confidence • Bounding box
relative to square
Combined bounding box regression and classification error
Deploy:
Train:
See, for example: Redmon, Divvala, Girshick, Farhadi, You Only Look Once: Unified, Real-Time Object Detection, arXiv: 1506.02640
NVIDIA, 2016

18
DL FOR SPECTROGRAM ANALYSIS Speech dialect classification, Intelligent Voice, GTC 2016
Input: Utterance in one of 20 dialects
Output: Dialect classification
“GoogLeNet” CNN
http://on-demand.gputechconf.com/gtc/2016/presentation/s6371-nigel-cannings-deep-convolution-neural-networks.pdf

19
OTHER RELEVANT APPLICATIONS
Object tracking
End-to-end learning for control
Face emotion recognition
Real-time facial manipulation in video
Unsupervised learning and synthetic data generation
Cyber security - malware detection, network anomaly detection
Your application…?

20
RECENT ADVANCES IN DL HARDWARE

21
DNN TRAINING AND INFERENCE Key operation 1: dense M x V
Key operation 2: 2D & 3D convolution Lots of Parallelism Available in a DNN

22
GPUs deliver: - cutting edge AI application accuracy - practical training times, not achievable otherwise - smaller footprint - lower power
NEURAL NETWORKS
GPUS
Inherently
Parallel
Matrix
Operations
FLOPS
Bandwidth
GPUS AND DEEP LEARNING

23
TESLA M40
0 1 2 3 4 5 6 7 8 9 10 11 12 13
GPU Server with4x TESLA M40
Dual CPU Server
13x Faster Training Caffe
Number of Days
CUDA Cores 3072
Peak SP 7 TFLOPS
GDDR5 Memory 24 GB
Bandwidth 288 GB/s
Power 250W
Reduce Training Time from 13 Days to just 1 Day
Note: Caffe benchmark with AlexNet, CPU server uses 2x E5-2680v3 12 Core 2.5GHz CPU, 128GB System Memory, Ubuntu 14.04
28 Gflop/W

24
TESLA P100 ACCELERATORS
Tesla P100 for NVLink-enabled Servers
Tesla P100 for PCIe-Based Servers
5.3 TF DP ∙ 10.6 TF SP ∙ 21 TF HP
720 GB/sec Memory Bandwidth, 16 GB
4.7 TF DP ∙ 9.3 TF SP ∙ 18.7 TF HP
Config 1: 16 GB, 720 GB/sec
Config 2: 12 GB, 540 GB/sec
https://devblogs.nvidia.com/parallelforall/inside-pascal/

25
NVIDIA DGX-1 AI supercomputer-in-a-box
170 TFLOPS performance (half precision)
8x Tesla P100 16GB
NVLink Hybrid Cube Mesh
Optimized Deep Learning Software
Dual Xeon
512 GB DDR4 Memory
7 TB SSD Deep Learning Cache
Dual 10GbE, Quad IB 100Gb
3RU – 3200W

26
TESLA M4 Highest Throughput
Hyperscale Workload Acceleration
CUDA Cores 1024
Peak SP 2.2 TFLOPS
GDDR5 Memory 4 GB
Bandwidth 88 GB/s
Form Factor PCIe Low Profile
Power 50 – 75 W
Video Processing
Image Processing
Video Transcode
Machine Learning Inference
H.264 & H.265, SD & HD
Stabilization and Enhancements
Resize, Filter, Search, Auto-Enhance

28
RECENT ADVANCES IN DL SOFTWARE

29
POWERING THE DEEP LEARNING ECOSYSTEM NVIDIA SDK accelerates every major framework
COMPUTER VISION
OBJECT DETECTION IMAGE CLASSIFICATION
SPEECH & AUDIO
VOICE RECOGNITION LANGUAGE TRANSLATION
NATURAL LANGUAGE PROCESSING
RECOMMENDATION ENGINES SENTIMENT ANALYSIS
DEEP LEARNING FRAMEWORKS
Mocha.jl
NVIDIA DEEP LEARNING SDK
developer.nvidia.com/deep-learning-software

30
0 50 100 150 200 250 300
P40
P4
1x CPU (14 cores)
Inference Execution Time (ms)
11 ms
6 ms
User Experience: Instant Response 45x Faster with Pascal + TensorRT
Faster, more responsive AI-powered services such as voice recognition, speech translation
Efficient inference on images, video, & other data in hyperscale production data centers
Based on VGG-19 from IntelCaffe Github: https://github.com/intel/caffe/tree/master/models/mkl2017_vgg_19 CPU: IntelCaffe, batch size = 4, Intel E5-2690v4, using Intel MKL 2017 | GPU: Caffe, batch size = 4, using TensorRT internal version
INTRODUCING NVIDIA TensorRT High Performance Inference Engine
260 ms

31
NVIDIA DEEPSTREAM SDK Delivering Video Analytics at Scale
Inference
Preprocess Hardware Decode
“Boy playing soccer”
Simple, high performance API for analyzing video
Decode H.264, HEVC, MPEG-2, MPEG-4, VP9
CUDA-optimized resize and scale
TensorRT
0
20
40
60
80
100
1x Tesla P4 Server +DeepStream SDK
13x E5-2650 v4 Servers
Concurr
ent
Vid
eo S
tream
s
Concurrent Video Streams Analyzed
720p30 decode | IntelCaffe using dual socket E5-2650 v4 CPU servers, Intel MKL 2017 Based on GoogLeNet optimized by Intel: https://github.com/intel/caffe/tree/master/models/mkl2017_googlenet_v2

32
TESLA PRODUCTS RECOMMENDATION
PRODUCT P100 SXM2 P100 PCIE P40 P4
Target Use Cases
• Highest DL training perf.
• Fastest time-to-solution
• Larger “Model Parallel”
DL model with 16GB x 8
• HPC DC running mix of
CPU and GPU workload
• Best throughput / $
with mix workload
• Highest inference perf.
• Simplify hyperscale DC
operations with training
and inference in the
same server
• Larger “Data Parallel”
DL model with 24GB
• Low power, low profile
optimized for scale out
deployment
• Most efficient inference
and video processing
Best Configs.
• 8 way Hybrid Cube Mesh
• Design for Volta today
• 2-4 GPU/node (HPC)
• 8 GPU/node (DL) • Up to 8 GPU/node • 1-2 GPU/node
1st Server Ship
• DGX-1 available now • OEM starting Sep’16 • OEM starting Oct’16 • OEM starting Nov’16

34
GETTING STARTED WITH DEEP LEARNING developer.nvidia.com/deep-learning

35
GPU MANAGEMENT - ROBERT STOBER, BRIGHT COMPUTING

Agenda
• NVIDIA CUDA Deployment
• Deep Learning Packages Deployment
• NVIDA Docker Images
• GPU Health Management
• Integration with Workload Manager

Bright Cluster Manager simplifies the management and use NVIDIA GPUs for
Deep Learning

NVIDIA CUDA Deployment
• Run these two commands on the head node:
# yum install cuda75-toolkit cuda75-sdk
# yum --installroot=/cm/images/default-image \
install cuda-driver
• Easily switch between multiple installed versions
$ module load cuda70/toolkit

Bright Deep Learning Goals
• Super easy deployment of DL infrastructure (~2m to install)
• Provide developer friendly environment (e.g. env modules)
• Combine DL with technology already available for HPC: • Cloud bursting to GPU enabled instances in AWS
• DL in containers
• DL in OpenStack
• DL using Spark over RDMA
• Allow DL to scale beyond single machines

Deep Learning Packages
• Installation of deep learning packages is today a time consuming, manual process.
• Caffe (machine learning framework)
• Torch (machine learning framework)
• MLPHYTHON (Python machine learning library)
• cuDNN (CUDA neural network library)
• DIGITS (machine learning user front-end)
• Theano (Python library for writing deep learning models)
• ~60 dependencies must be satisfied
• Not installable from OS repos
• Versions must work together

Deep Learning Packages Deployment
• Bright 7.3 includes GPU-accelerated versions of these common Deep Learning libraries so you can focus on the science
• Install your applications on the head node, for example:
# yum install digits
• Install dependencies into your software images, for example:
# yum --installroot=/cm/images/default-image \
install cm-ml-distdeps
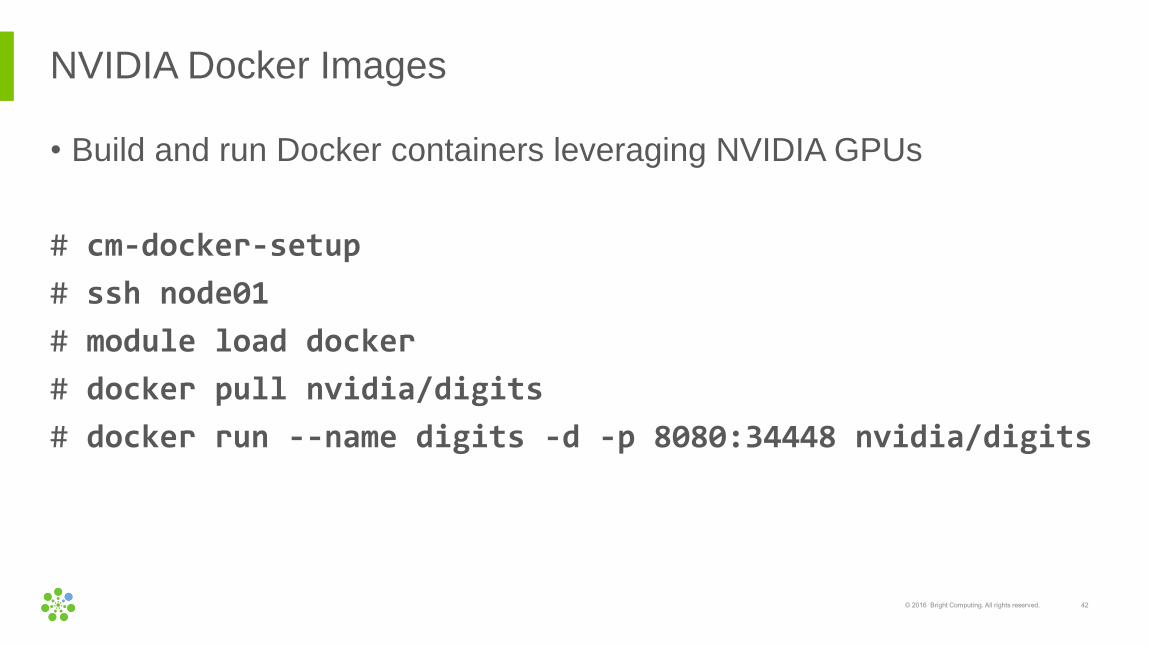
NVIDIA Docker Images
• Build and run Docker containers leveraging NVIDIA GPUs
# cm-docker-setup
# ssh node01
# module load docker
# docker pull nvidia/digits
# docker run --name digits -d -p 8080:34448 nvidia/digits


GPU Management
• Health Management
• Bright samples all the metrics provided by all NVIDIA GPUs
• Bright automatically performs health checks all NVIDIA GPUs
• Workload Manager Integration
• Bright is integrated with all the popular HPC workload managers
• Bright automatically configures GPUs within the workload manager
• User jobs are automatically directed to available GPUs
• Health checks can be designated as pre-job health checks
• Bright provides job-level metrics


Q&A


















