
Real-Time ORB Middleware: Standards, Applications, and Variations Christopher Gill...
44
Real-Time ORB Middleware: Standards, Applications, and Variations Christopher Gill [email protected] Center for Distributed Object Computing Department of Computer Science and Engineering Washington University, St. Louis, MO Research supported in part by DARPA contracts F33615-01-C-1898 (NEST); and F33615-00-C-3048 and F33615-03-C-4111 (PCES) Research conducted in collaboration with colleagues at Washington University, Vanderbilt University, University of Kansas, University of Rhode Island, Ohio University, OOMWorks, Boeing, BBN, Honeywell, and Tech-X
Transcript of Real-Time ORB Middleware: Standards, Applications, and Variations Christopher Gill...
Real-Time ORB Middleware: Standards, Applications, and Variations
Christopher [email protected]
Center for Distributed Object ComputingDepartment of Computer Science and Engineering
Washington University, St. Louis, MO
Research supported in part by DARPA contracts F33615-01-C-1898 (NEST);and F33615-00-C-3048 and F33615-03-C-4111 (PCES)
Research conducted in collaboration with colleagues at Washington University, Vanderbilt University, University of Kansas, University of Rhode Island, Ohio University, OOMWorks, Boeing, BBN, Honeywell, and Tech-X

2 - Chris Gill – 04/20/23
Main Themes
Standards enforce commonality» Specify interfaces, etc., on which applications can rely
Applications are heterogeneous» Which standards are relevant may vary from app to app» Apps may rely on different subsets of standard features
What if commonality & heterogeneity don’t match?» E.g., app needs a feature the standard doesn’t address» E.g., a needed feature may conflict with specified ones
Developing and using standards-based middleware effectively demands attention to these issues (especially if time, space, reliability are involved)

3 - Chris Gill – 04/20/23
Motivating Example: Avionics Mission Computing
In-flight collaboration between aircraft personnel» Exchange imagery and annotations over a wireless network
Trade-offs between image quality and transfer latency » Managed adaptively during download, to ensure timeliness
Why use CORBA, and for what parts of the system?» For DOC between Ada/ORBExpress server and C++/TAO client» For prioritization of OFP and image handling operations on client» For adaptive rate-based scheduling on client
low bandwidth radio link
virtual folder,images
adaptationmiddleware
transmissionmiddleware
cockpitdisplays
serverside
clientside
imageserver
Collaborative research with Boeing, BBN,
Honeywell Technology Center, supported by Boeing/AFRL contract
F33615-97-D-1155/0005 (WSOA)

4 - Chris Gill – 04/20/23
Outline: Three Illustrative Technology Studies
Real-Time CORBA 1.0» Location/language transparency, low latency,
priorities» Trade-offs in time, footprint, and features
Lightweight CCM» Component assembly, deployment,
(re-)configuration» Trade-offs in the timeliness of configuration itself
Real-Time CORBA 1.2» Pluggable dynamic scheduling, distributable threads» Trade-offs in flexibility, overhead, and mechanisms

5 - Chris Gill – 04/20/23
Technology Study I: Real-Time CORBA 1.0
Location/language transparency Low latency Static Priorities Trade-offs
» time, footprint, and features

6 - Chris Gill – 04/20/23
CORBA Location/Language Transparency
IDL provides type safety between client and server A client obtains an interoperable object reference (IOR)
» Encodes IP address, port, object ID, etc. A wire format is defined for invocation messages
» Client stubs marshal, server skeletons un-marshal messages Other details are left as ORB implementation features
» How to combine threads, sockets, event de-multiplexers, etc.» ORB developers can (and should) exploit this design
freedom
ORB ORB
Stub
Client
Skeleton
Servant
IIOPmessage
objectreference

7 - Chris Gill – 04/20/23
Exploiting Design Freedom for Low Latency
Re-use portable, type-safe, efficient mechanisms» Concurrency, communication, event demultiplexing, etc. » Available for many POSIX-like OS platforms» Also RTOS: VxWorks, LynxOS, KURT-Linux/LibeRTOS
Compose to avoid blocking, queueing, locking, etc.
E.g., ACE Framework

8 - Chris Gill – 04/20/23
Real-Time CORBA 1.0: Static Priorities
Lanes enforce priority separation between threads Set minimum (static) and additional (dyn) # of threads Set stack size, use of thread borrowing, request buffering
// Define two lanesRTCORBA::ThreadpoolLane high_priority ={10 /*Prio*/, 3 /*Static Threads*/, 0 /*Dyn Threads*/ };
RTCORBA::ThreadpoolLane low_priority ={5 /*Prio*/, 2 /*Static Threads*/, 2 /*Dyn Threads*/};
RTCORBA::ThreadpoolLanes lanes(2); lanes.length (2);lanes[0] = high_priority; lanes[1] = low_priority;
RTCORBA::ThreadpoolId pool_id = rt_orb->create_threadpool_with_lanes
(1024 * 10, // Stacksize lanes, // Thread pool lanes false, // No thread borrowing false, 0, 0); // No request buffering
// Define two lanesRTCORBA::ThreadpoolLane high_priority ={10 /*Prio*/, 3 /*Static Threads*/, 0 /*Dyn Threads*/ };
RTCORBA::ThreadpoolLane low_priority ={5 /*Prio*/, 2 /*Static Threads*/, 2 /*Dyn Threads*/};
RTCORBA::ThreadpoolLanes lanes(2); lanes.length (2);lanes[0] = high_priority; lanes[1] = low_priority;
RTCORBA::ThreadpoolId pool_id = rt_orb->create_threadpool_with_lanes
(1024 * 10, // Stacksize lanes, // Thread pool lanes false, // No thread borrowing false, 0, 0); // No request buffering
Thread Pool with Lanes
PRIORITY
10PRIORITY
5

9 - Chris Gill – 04/20/23
When Trade-Offs Impinge on a Standard
Active Damage Detection on structures (e.g., aircraft tail) Ping nodes create vibrations that are measured by sensors Computational nodes do analysis, schedule other nodes DOC middleware can help ease programming complexity Crucial trade-offs in time vs. footprint vs. features Can (and should) ORB developers stay within the standard?
12
43
Acoustic Waves (kHz Range)
Structure with Embedded or Bonded Piezoelectric
Transducers

10 - Chris Gill – 04/20/23
Design Challenges
General purpose middleware aims at supporting a wide variety of applications» Tends to support a breadth of alternative features
Extra features may impact some applications» E.g., Foot-print in memory-constrained networked
embedded systems demanding real-time assurances Need to study and select middleware features
based on application requirements Fundamental tension between
» Generality/standardization » Application specific customization

11 - Chris Gill – 04/20/23
Critical Path Analysis and Trade-offs in nORB
Simple Object Adapter
Operation lookup and dispatch
Foo()
Bar()
Skeleton code(using ACE_CDR)
Unmarshallparameters
Call to implementation
Reactor
Acceptor
ConnectionCache
ORBReactor
Acceptor
ConnectionCache
ORB
Stub code(using ACE_CDR)
Marshallparameters
Remote call
11
2
3
4Could be avoided for homogenous nodes
1)
Only a subset of GIOP messages
2)
3) Simple Life cyclemanagement
4) Hash-table vs linear search
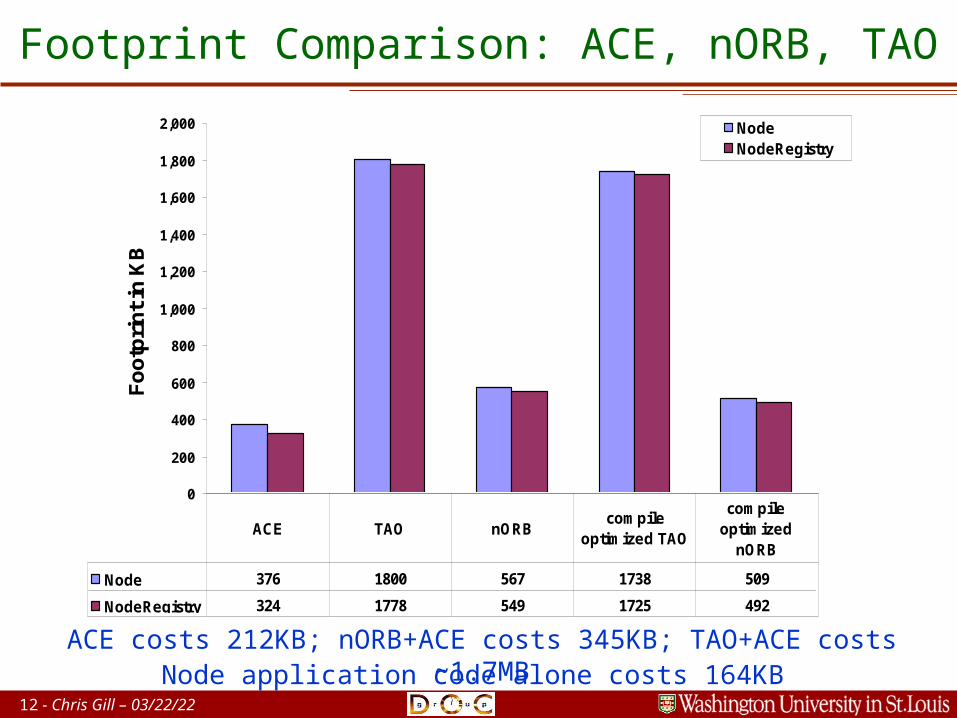
12 - Chris Gill – 04/20/23
Footprint Comparison: ACE, nORB, TAO
0
200
400
600
800
1,000
1,200
1,400
1,600
1,800
2,000F
oo
tpri
nt
in K
BNodeNodeRegistry
Node 376 1800 567 1738 509
NodeRegistry 324 1778 549 1725 492
ACE TAO nORBcompile
optimized TAO
compile optimized
nORB
ACE costs 212KB; nORB+ACE costs 345KB; TAO+ACE costs ~1.7MBNode application code alone costs 164KB

13 - Chris Gill – 04/20/23
Ping Scheduling Algorithm Convergence Time

14 - Chris Gill – 04/20/23
Technology Study I: Summary
The CORBA standard promotes DOC programming» Portable, interoperable, language/location transparent» Gives ORB developers freedom to optimize/strategize
The RT-CORBA 1.0 standard adds real-time QoS» E.g., thread pools, prioritized lanes, etc.» Here too, design freedom is crucial, e.g., for low latency
However, some application contexts raise issues» E.g., with stringent memory and RT constraints, how
crucial is strict standards compliance to developers?» Minimum CORBA, other specifications acknowledge this» Further attention to “degrees of compliance” may help

15 - Chris Gill – 04/20/23
Technology Study II: Lightweight CCM
Component assembly, deployment, re-configuration
Some applications require optimization and trade-offs in the timeliness of configuration itself
Rethink deployment/configuration lifecycle » Must fit within stringent system initialization bounds

16 - Chris Gill – 04/20/23
An Review of RT-DOC Middleware Evolution
Distributed Object Computing (DOC) Middleware» E.g., CORBA, Java RMI» Simplifies client-side programming via location (language)
independence
Real-Time DOC Middleware» E.g., Real-Time CORBA 1.0, 1.2» Enforces real-time properties between client and server
Component Middleware» E.g., CORBA Component Model (CCM), EJB/J2EE» Simplifies server programming through declarative configuration
Real-Time Component Middleware» E.g., the Component-Integrated ACE ORB (CIAO), QoS EJB» Enforces configured real-time properties within server itself» Are the configuration activities themselves real-time?
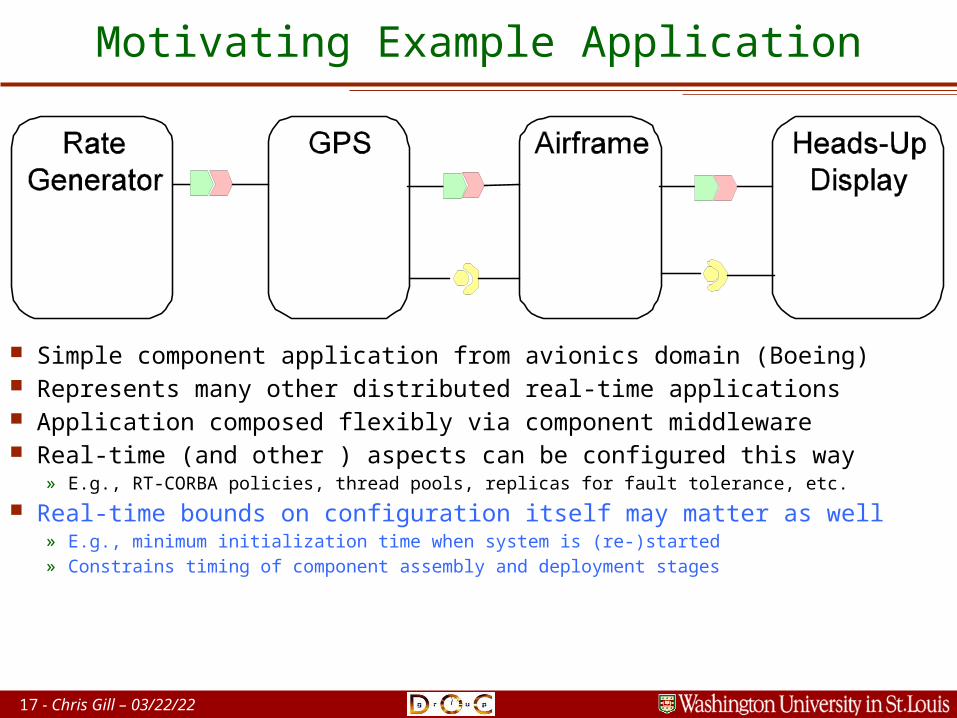
17 - Chris Gill – 04/20/23
Motivating Example Application
Simple component application from avionics domain (Boeing) Represents many other distributed real-time applications Application composed flexibly via component middleware Real-time (and other ) aspects can be configured this way
» E.g., RT-CORBA policies, thread pools, replicas for fault tolerance, etc.
Real-time bounds on configuration itself may matter as well» E.g., minimum initialization time when system is (re-)started» Constrains timing of component assembly and deployment stages

18 - Chris Gill – 04/20/23
Static vs. Dynamic Configuration
Dynamic Configuration» Component assembly & deployment
uses DLLS, XML parsing
» Problems parsing/loading time no support for .so/.dll libs on some platforms (e.g.,
VxWorks)
Static Configuration» Move as much off-line as possible » Focus on preserving only run-time flexibility that is needed» Use static linking to “load” implementations» Use run-time drivers to configure implementations at
initialization

19 - Chris Gill – 04/20/23
Static vs. Dynamic Configuration Experiments
Compared performance of static and dynamic configuration» Used example avionics domain application
Goal: identify sources of performance difference
Tests were run on a single machine» Pentium IV 2.5GHz CPU, 500MB RAM, 512KB Cache» OS was Linux 2.4.18 with KURT-Linux patches
applied Supports DLLs for dynamic configuration approach Offers good real-time predictability for experiments
» Experiments used CIAO 0.4.1 / TAO 1.4.1 / ACE 5.4.1

20 - Chris Gill – 04/20/23
Time for Application Assembly
Without RT features» msec vs. 100s of msec» 2 orders of magnitude
With RT features» Constant additional
overhead» Greater relative
cost at low orders of magnitude
Differences attributed to» Loading DLLs,
spawning processes Most expensive
» XML parsing on-line Secondary

21 - Chris Gill – 04/20/23
Component Server Creation Time
Server configuration is 2nd largest contributor to performance differences» 100s vs. 10s of msec
Static gives a baseline» Most of time was spent
hooking RT CORBA features into server
» 2 orders of magnitude less for non-RT version
Configuring RT-CORBA features

22 - Chris Gill – 04/20/23
Home Creation Time
Homes manage component instances
Configuring homes less expensive than » application assembly» component server
Loaded vs. linked homes accounts for the difference
Real-time features» Didn’t increase the total
time significantly

23 - Chris Gill – 04/20/23
CIAO vs. PRISM Configuration
CIAO’s static configuration similar to Boeing’s PRISM domain-specific component middleware» But configuration steps and flexibility/cost differ significantly» CCM (Extension Interface pattern) vs. C++ (Façade pattern) model

24 - Chris Gill – 04/20/23
CIAO vs. PRISM Configuration Experiments
Platform details» Motorola 5110-2263 VME board» MPC7410 500MHz processor w/ 512 MB RAM» VxWorks 5.4.2» Post x.4 (pre-release) version of CIAO w/ static configuration
High resolution time measurement used two tick counters» 5msec resolution: VxWorks tickGet()» 40ns resolution: VxWorks sysTimestamp()
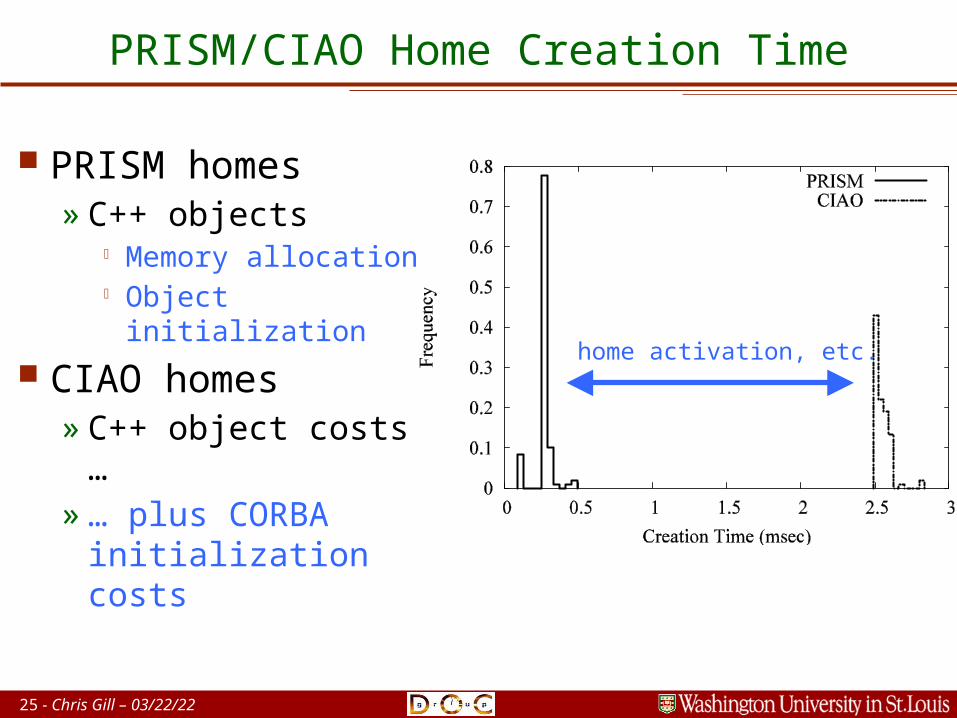
25 - Chris Gill – 04/20/23
PRISM/CIAO Home Creation Time
PRISM homes» C++ objects
Memory allocation Object
initialization
CIAO homes» C++ object costs
…» … plus CORBA
initialization costs
home activation, etc.

26 - Chris Gill – 04/20/23
PRISM/CIAO Component Creation Time
Again see C++ vs. CORBA differences
Most expensive step in static CIAO configuration
Still well bounded» for all but the
finest time scales
Bounded by 4 msec
component
activation, etc.

27 - Chris Gill – 04/20/23
PRISM/CIAO Connection Establishment Time
Least expensive configuration step
Again reflects C++ vs. CORBA differences
Trade-off is between performance and flexibility
CORBA connection
setup cost

28 - Chris Gill – 04/20/23
Technology Study II: Summary
Static approach gives real-time configuration» Avoids costs/features that hamper real-time behavior
Main costs are DLL loading, spawning processes» Concentrated in application assembly, server creation» Intermediate design point: limited on-line XML parsing?
PRISM & CIAO differ somewhat in flexibility, cost» C++ based components vs. CORBA components» Intermediate design point: mixture of object types?
Static configuration capabilities described here are available as open-source within DAnCE» Implement Deployment & Configuration specification
» http://deuce.doc.wustl.edu/Download.html

29 - Chris Gill – 04/20/23
Technology Study III: Real-Time CORBA 1.2
Distributable threads Pluggable dynamic scheduling Trade-offs in flexibility, overhead, mechanisms

30 - Chris Gill – 04/20/23
Motivation More evolution of middleware programming
model» Distributable threads are natural for certain
applications I.e., those with long-running distributed sequential activities May also help with distributed scheduling, load balancing,
etc.» Integrated with pluggable/dynamic scheduling
semantics Design and implementation goals
» Flexible on-the-fly adaptation of real-time properties» Preserve info on paths a distributable thread
traverses» Provide efficient, rigorous enforcement mechanisms

31 - Chris Gill – 04/20/23
RT-CORBA 1.2 Implementation in TAO
Implementation of Distributable Threads» Thread identity and cancellation design considerations
Give the application better control of concurrency overall OS vs. distributable thread identity issues and approach Cancellation interface and its implementation
Dynamic scheduling service framework» Flexible interface between scheduler and application» OS and middleware based prio scheduler
implementations Benchmarks
» Quantify cost of managing distributable, OS thread ids» Compare OS, middleware scheduling techniques
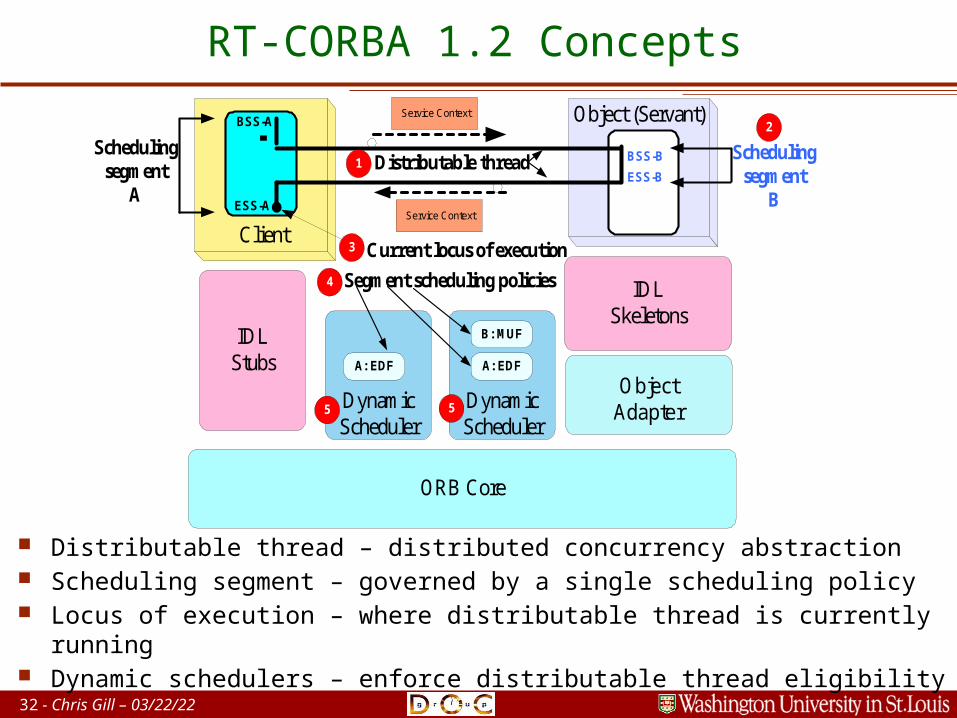
32 - Chris Gill – 04/20/23
RT-CORBA 1.2 Concepts
Distributable thread – distributed concurrency abstraction Scheduling segment – governed by a single scheduling policy Locus of execution – where distributable thread is currently
running Dynamic schedulers – enforce distributable thread eligibility
Object (Servant)
IDLStubs
IDLSkeletons
ORB Core
DynamicScheduler
BSS-A
ESS-A
Client
Service Context
Schedulingsegment
A
ObjectAdapterDynamic
Scheduler
BSS-B
ESS-B
Service Context
Schedulingsegment
B
1 Distributable thread
2
Current locus of execution3
B: MUF
A: EDFA: EDF
Segment scheduling policies4
55

33 - Chris Gill – 04/20/23
Intro to RTC2 Distributable Threads
With only 2-way CORBA invocations, distributable threads behave much like traditional OS threads» But can move (with their context) from one endsystem to another» Cross through different resource scheduling domains
Distributable threads contend with OS threads, each other» With locking, effect can span endsystems, though scheduling is local
BSS - A
BSS - B
ESS - A
ESS - B
Host 1 Host 2 Host 3
2 - WayInvocation
2 - WayInvocation
DT1
BSS - C
ESS - C
DT2
BSS - D
ESS - B
BSS - E
ESS - E
DT3

34 - Chris Gill – 04/20/23
Creating Distributable Threads
Distributable threads can be created three different ways» An application thread calling BSS outside a distributable thread» A distributable thread calling the spawn() method» A distributable thread making an asynchronous (one-way)
invocation New distributable thread inherits scheduling parameters
Host 2
BSS - A
ESS - A
1 - WayInvocation
Host 3
DT3DT4
Host 1
spawn ()DT1
DT2
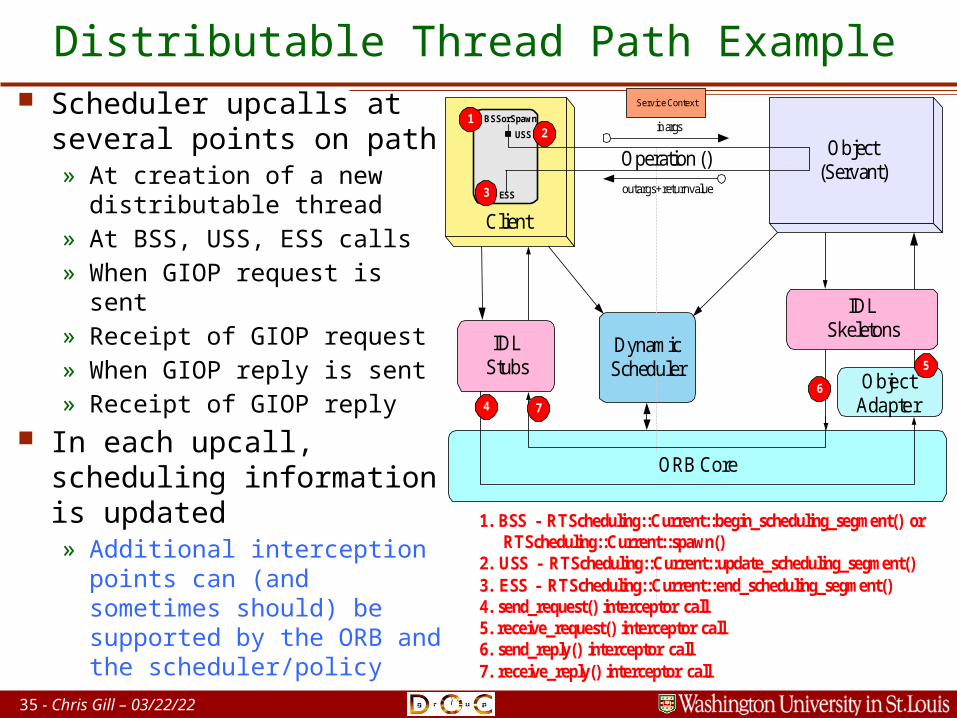
35 - Chris Gill – 04/20/23
Distributable Thread Path Example Scheduler upcalls at
several points on path» At creation of a new
distributable thread» At BSS, USS, ESS calls» When GIOP request is
sent» Receipt of GIOP request» When GIOP reply is sent» Receipt of GIOP reply
In each upcall, scheduling information is updated» Additional interception
points can (and sometimes should) be supported by the ORB and the scheduler/policy
Object(Servant)
IDLStubs
IDLSkeletons
ORB Core
DynamicScheduler
in args
out args + return value
Operation ()
BSS or Spawn
ESS
USS
Client
Service Context
12
3
4
1. BSS - RTScheduling::Current::begin_scheduling_segment() or RTScheduling::Current::spawn()2. USS - RTScheduling::Current::update_scheduling_segment()3. ESS - RTScheduling::Current::end_scheduling_segment()4. send_request() interceptor call5. receive_request() interceptor call6. send_reply() interceptor call7. receive_reply() interceptor call
7
5
6 ObjectAdapter
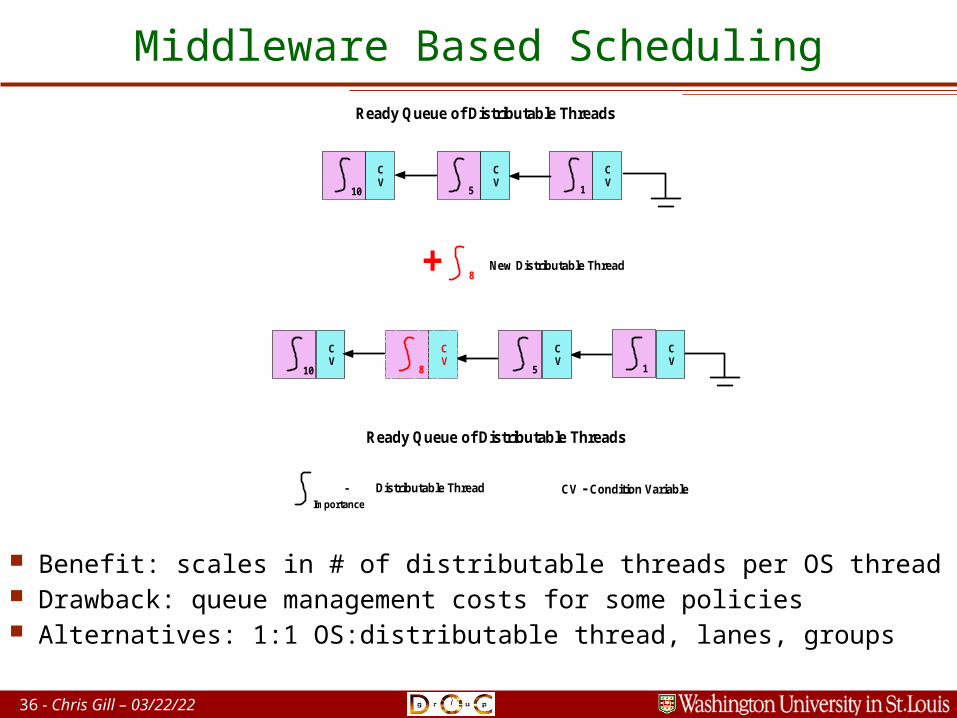
36 - Chris Gill – 04/20/23
Middleware Based Scheduling
CV
CV
1510
Ready Queue of Distributable Threads
+ 8
1510 8
New Distributable Thread
Ready Queue of Distributable Threads
CV
CV
CV
CV
CV
CV - Condition VariableImportance
- Distributable Thread
Benefit: scales in # of distributable threads per OS thread Drawback: queue management costs for some policies Alternatives: 1:1 OS:distributable thread, lanes, groups

37 - Chris Gill – 04/20/23
Simple comparison of OS and middleware scheduling
Both approaches show reasonable control at a resolution of seconds
Notice some latency in last transition in middleware approach
This OS/middleware difference is characteristic of other dynamic scheduling approaches (e.g., Group Scheduling)
Middleware/OS Scheduling Benchmark
Δ latency
OS level scheduling
middleware level scheduling
38 - Chris Gill – 04/20/23
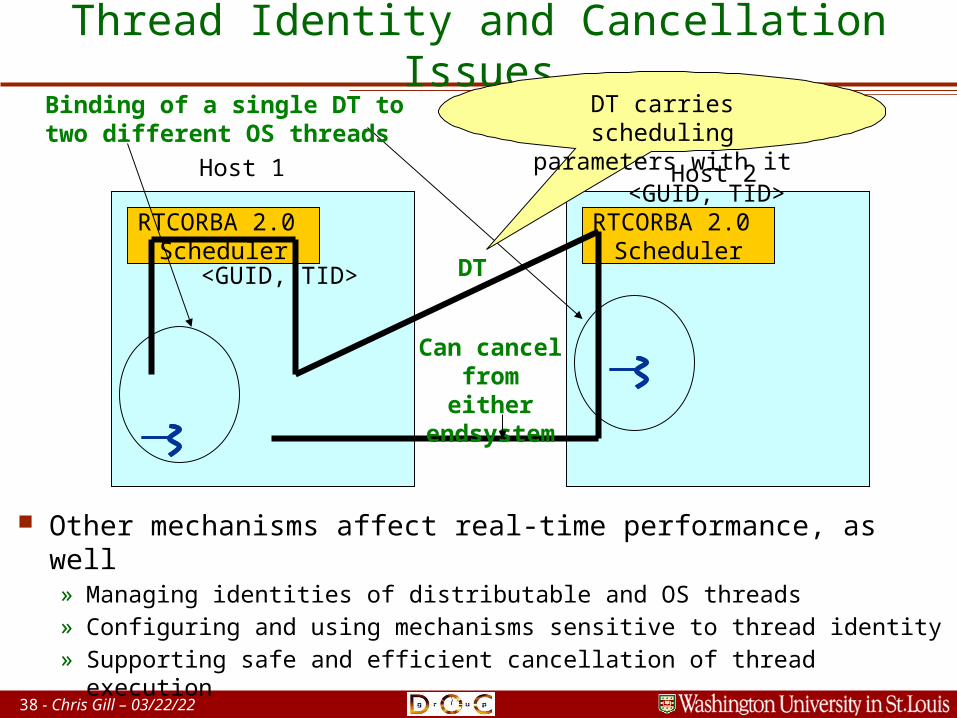
Thread Identity and Cancellation Issues
Host 1
RTCORBA 2.0 Scheduler
Host 2
RTCORBA 2.0 Scheduler
DT<GUID, TID>
<GUID, TID>
Binding of a single DT totwo different OS threads
DT carries scheduling parameters with it
Other mechanisms affect real-time performance, as well» Managing identities of distributable and OS threads» Configuring and using mechanisms sensitive to thread identity» Supporting safe and efficient cancellation of thread execution
Can cancel from either endsystem

39 - Chris Gill – 04/20/23
Thread Specific Storage (TSS) Example A distributable thread can use thread-specific
storage» Avoids locking of global data
OS provided TSS is efficient, uses OS thread id However, distributable thread may span OS threads Solution: TSS emulation based on <GUID,tid> pair What is TSS emulation cost compared to OS TSS?
Host 1 Host 2
OSThread
1
DT 1
tss_write
tss_read
OSThread
2
OSThread
1
DT 2
40 - Chris Gill – 04/20/23
TSS Emulation BenchmarksTSS Key Create:
0
500
1000
1500
2000
2500
3000
3500
4000
1 51 101 151 201 251 301 351 401 451 501Number of Keys Created
Tim
e (n
sec)
EmulatedNative OS
TSS Write/Read:
0
500
1000
1500
2000
2500
3000
1 101 201 301 401 501 601 701 801 901 1001Number of Successive Iterations
Tim
e (n
sec)
Emulated WriteEmulated ReadNative OS WriteNative OS Read
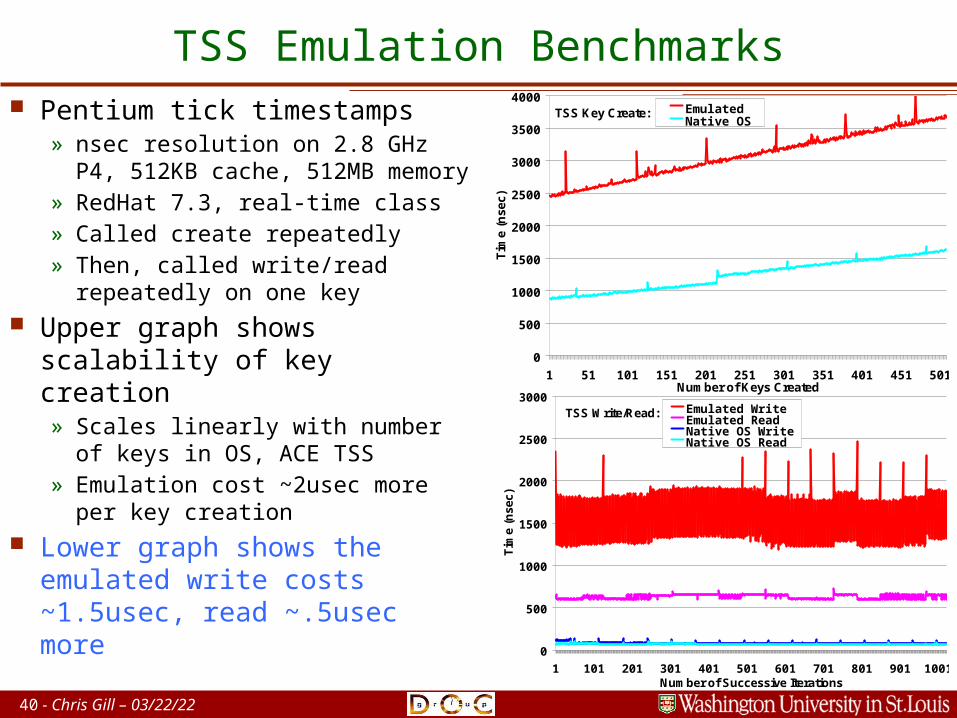
Pentium tick timestamps» nsec resolution on 2.8 GHz P4,
512KB cache, 512MB memory» RedHat 7.3, real-time class» Called create repeatedly» Then, called write/read
repeatedly on one key Upper graph shows
scalability of key creation» Scales linearly with number of
keys in OS, ACE TSS» Emulation cost ~2usec more
per key creation Lower graph shows the
emulated write costs ~1.5usec, read ~.5usec more

41 - Chris Gill – 04/20/23
Distributable Thread Cancellation
Context: distributable thread can be cancelled to save cost Problem: only safe to cancel
» on an endsystem that is in the thread’s run-time “call stack”» when thread is at a safe preemption point
Solution: cancellation is» invoked via cancel method on distributable thread instance» handled at next scheduling point (scheduler upcall)
BSS - A
cancel DT
Process thecancel at next
scheduling point
Propagatecancel
Head of DT
Host 1 Host 2 Host 3
DT cancelled

42 - Chris Gill – 04/20/23
Technology Study III: Summary
RT-CORBA 1.2 can give predictable real-time performance
Allows dynamic scheduling of distributable threads A range of thread management mechanisms matter
» must also be designed for real-time performance RT-CORBA 1.2 implementation in TAO
» open-source software, freely available on the web» http://deuce.doc.wustl.edu/Download.html

43 - Chris Gill – 04/20/23
Concluding Remarks
CORBA Developers balance ongoing trade-offs» Between what standards specify …» And what their applications need
Often many application needs are addressed well» Inter-operability, location/language transparency» Component configuration support» Prioritization, other QoS aspects as well
However, the standards don’t cover everything» Developers must exercise judgment WRT standards
When to adhere, when to augment, when to diverge from them
Sometimes, divergences are the basis for upgrading standards The key point is that it’s an evolutionary process
» Applications try to converge toward standards» Standards try to converge toward applications

44 - Chris Gill – 04/20/23
For More Information
Avionics application case study» www.cse.wustl.edu/~cdgill/PDF/RTSJ_WSOA.pdf
Small footprint real-time middleware» www.cse.wustl.edu/~cdgill/PDF/rtas04_nORB.pdf
RT-CORBA 1.2» www.cse.wustl.edu/~cdgill/PDF/JBCS_RTC1.2.pdf» www.cse.wustl.edu/~cdgill/PDF/rtas05_DTEC.pdf
Dynamic scheduling» www.cse.wustl.edu/~cdgill/PDF/dynamic.pdf» www.cse.wustl.edu/~cdgill/PDF/embedded_sched.pdf» www.cse.wustl.edu/~cdgill/PDF/rtas05_groupsched.pdf» www.cse.wustl.edu/~cdgill/PDF/rtas05_DSRM.pdf
Real-Time component configuration» www.cse.wustl.edu/~cdgill/PDF/doa04_ciao.pdf» www.cse.wustl.edu/~cdgill/PDF/rtss04_ciao.pdf


















