
RDF Storage methods and Systems Nikolaou Charalampos (A.M.: M953) Kotsifakos Alexios (A.M.: M964)...
50
RDF Storage methods and Systems Nikolaou Charalampos (A.M.: M953) Kotsifakos Alexios (A.M.: M964) Department of Informatics and Telecommunications
-
Upload
neil-brown -
Category
Documents
-
view
216 -
download
1
Transcript of RDF Storage methods and Systems Nikolaou Charalampos (A.M.: M953) Kotsifakos Alexios (A.M.: M964)...

RDF Storage methods and Systems
Nikolaou Charalampos (A.M.: M953)Kotsifakos Alexios (A.M.: M964)
Department of Informatics and Telecommunications

15/03/08 2
Presentation Outline
• RDF Triple Table
• Means of Storage
• Storage Methods
• RDF Storage Systems
• Storage Systems’ Evaluation

15/03/08 3
Storing RDF data
• RDF triple: <subject, property, object>, e.g. : <http://en.wikipedia.org/wiki/Stevie_Ray_Vaughan, performed, “Little Wing”>
• RDF database: a single table with three columns, subject, property, object

15/03/08 4
Why studying different RDF storage methods? (1/2)
• RDF triple store has the following disadvantages:– All interesting queries require many
self-joins over the rdf table:
SQL Query
SELECT p5.objFROM rdf AS p1, rdf AS p2, rdf AS p3,rdf AS p4, rdf AS p5WHERE p1.prop = ’title’ AND p1.obj ˜= ’Transaction’AND p1.subj = p2.subj AND p2.prop = ’type’AND p2.obj = ’book’ AND p3.prop = ’type’AND p3.obj = ’auth’ AND p4.prop = ’hasAuth’AND p4.subj = p2.subj AND p4.obj = p3.subjAND p5.prop = ’isnamed’ AND p5.subj = p4.obj;
RDF Triple Table
person1 isNamed ‘‘Serge Abiteboul’’person2 isNamed ‘‘Rick Hull’’person3 isNamed ‘‘Victor Vianu’’book1 hasAuthor person1book1 hasAuthor person2book1 hasAuthor person3book1 isTitled ‘‘Foundations of Databases’’

15/03/08 5
Why studying different RDF storage methods? (2/2)
- As the number of triples increases, the execution time of queries is also increased, due to memory consumption => more indexes required
- Inference at assertion time is infeasible as the number of triples scales, since for each entailment rule many more triples are stored

15/03/08 6
Triple store requirements – mapping considerations
Triple Store Requirements• Text searching• URIs• Datatypes• RDF Containers (rdf:Seq, rdf:Bag, rdf:Alt, rdf:_n)• RDF Vocabulary Description Language support (aka RDF Schema)• Ontological support, Inferencing• Triple provenance
Mapping considerations• The database schema• The particular database implementation• Non-relational databases such as ODBMS, XML• Database tuning• Database updates• Exposing the database schema

15/03/08 7
Means of storage
• Memory
• Hard Disk- Database
- File System (Native)

15/03/08 8
Storage Methods (1/2)
• Schema-oblivious (also called generic or vertical): One ternary relation is used to store any RDF/S schema or resource description graph. (Figure 1)
• Schema-aware: (also called specific or binary): One table per RDF/S schema property or class is used. (Figure 2)
• Hybrid: One ternary relation for every different property range type and a binary relation for all class instances (as in schema-aware). Property (class) instances with range values of the same type are stored in the same relation, distinguished by the property (class) id (as in schema-oblivious). (Figure 3)

15/03/08 9
Storage Methods (2/2)

15/03/08 10
Method Variations (1/2)
• Schema-oblivious– URI: stores the URIs in the table holding the triples
– ID: relies on integer identifiers to represent resources and properties in the triple table and stores them only once in a separate table

15/03/08 11
Method Variations (2/2)
• Schema-aware– ISA: exploits the object-relational features of SQL99
for representing subsumption relationships using sub-table definitions
– NOISA: stores RDF/S data using a standard relational representation as depicted in Figure 2
– Vertical Partitioning: NOISA + sort by subject + value column for each table can be optionally indexed

15/03/08 12
Extension to Schema-oblivious (1/2)
• Property Tables– Clustered Property Table: Clusters of properties that
tend to be defined together (Figure 4)
– Property-class Table: Clusters similar sets of subjects together in the same table (Figure 5)

15/03/08 13
Extension to Schema-oblivious (2/2)
Figure 4: Clustered PropertyTable Example
Figure 5: Property-class Table

15/03/08 14
Advantages – Disadvantages (1/5)
• Schema-oblivious(+) Straightforward Schema Evolution
(-) Disregards Type Information
(-) Significant storage overhead (URI)
(-) Additional join operation at the end of every query (ID)

15/03/08 15
Advantages – Disadvantages (2/5)
• Schema-aware(-) Addition/deletion of a new property requires the
addition/deletion of a table
(-) Significant overhead when managing a potentially large number of tables
(++) Subsumption is implicitly supported by the schema (ISA)
(+) Internal encoding of subsumption => efficient evaluation of taxonomic queries in secondary storage (NOISA)

15/03/08 16
Advantages – Disadvantages (3/5)
• Schema-aware (NOISA)(+) Support for multi-valued attributes(+) Support for heterogeneous records(+) Only those properties accessed by a query need to
be read(+) No clustering algorithms are needed(+) Fewer unions for one property and fast joins(-) Join is not free(-) Slower inserts

15/03/08 17
Advantages – Disadvantages (4/5)
• Hybrid(+) Schema evolution easily supported
(+) Preserves type information
(+) Internal encoding of subsumption => efficient evaluation of taxonomic queries in secondary storage (NOISA)

15/03/08 18
Advantages – Disadvantages (5/5)
• Property Tables(+) Reduce subject-subject self-joins of the triples table(+) Speed up queries that can be answered from a single
property table(-) Most queries require joins or unions to combine data
from several tables(-) RDF data tends not to be very structured (NULL)(-) Multi-valued attributes cause further complexity(-) Property clustering must be carefully done to avoid
creating too wide tables(-) Problematic queries that do not select on class type
(Property-class tables)(-) Unspecified property (clustered property tables)

15/03/08 19
Inference Support
• Precompute inferring triples (compile time)– Schema-oblivious (URI, ID)
• Compute on demand (run time)– Schema-aware (ISA, NOISA)– Hybrid
• Computation in:– Main memory (ISA)– Secondary memory (NOISA, Hybrid)

15/03/08 20
Column-Oriented DBMS
• Tuples are stored in column format instead of standard row format
• Query evaluation– Only columns relevant to a query read into memory and not entire
rows before projection occurs (wasting bandwidth)– Inserts might be slower in column-stores (especially if they are not
done in batch)
• Vertical partition uses column format for better performance
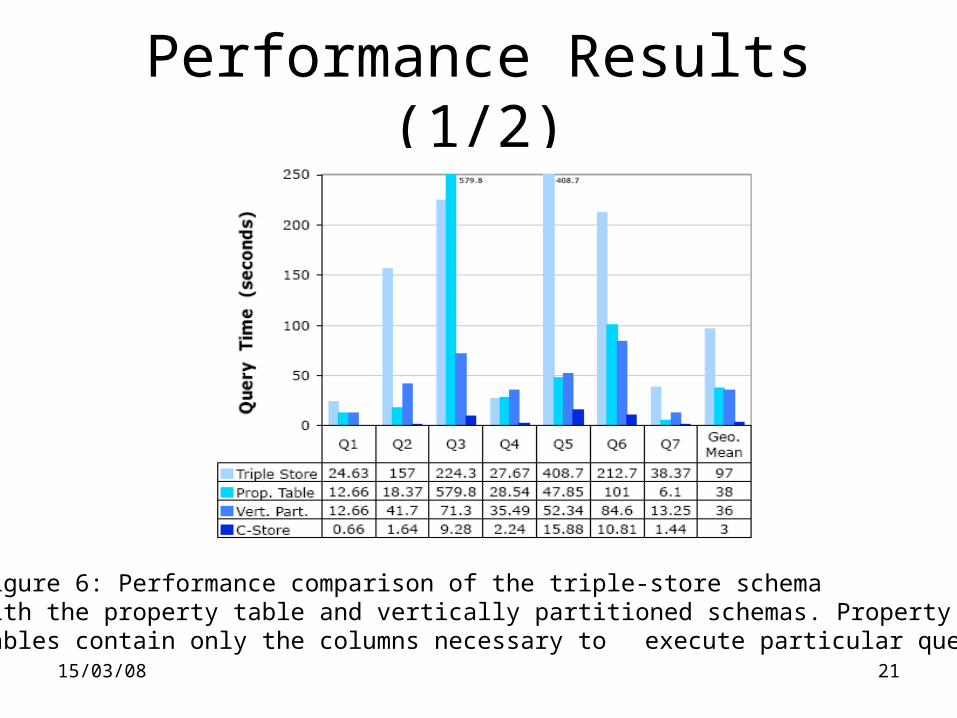
15/03/08 21
Performance Results (1/2)
Figure 6: Performance comparison of the triple-store schemawith the property table and vertically partitioned schemas. Propertytables contain only the columns necessary to execute particular query.
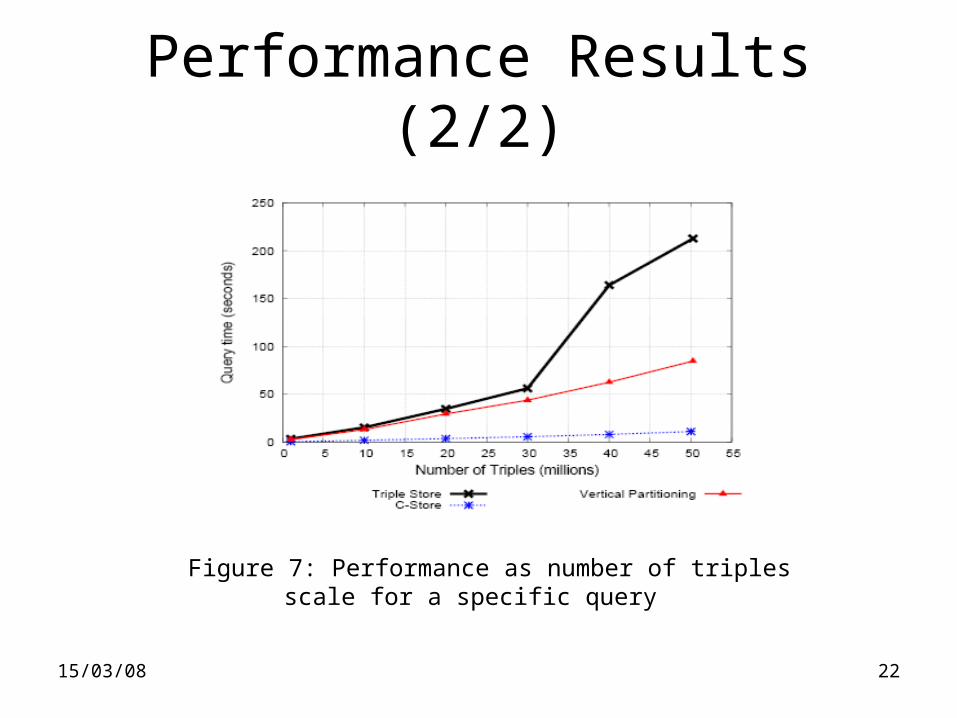
15/03/08 22
Performance Results (2/2)
Figure 7: Performance as number of triplesscale for a specific query

15/03/08 23
RDF Storage Systems
• Jena1, Jena2
• ICS-FORTH RDFSuite
• Sesame
• 3store
• RStar
• Oracle

15/03/08 24
Jena1 (1/2)
• Storage method: Schema-oblivious (ID)
• Supports multiple graphs stored in the Statement Table (one more attribute specifying the graph id)
• Supports reified statements by adding a statement id attribute to the Statement Table (does not allow multiple reified instances of any statement)
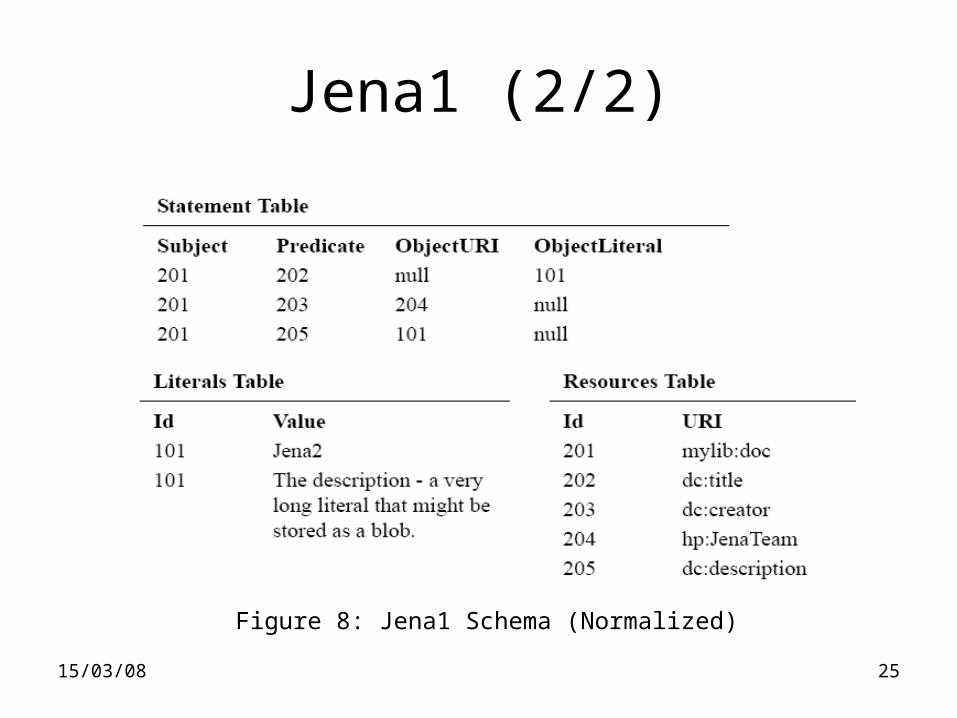
15/03/08 25
Jena1 (2/2)
Figure 8: Jena1 Schema (Normalized)

15/03/08 26
Jena2 (1/3)
• Storage method: Schema-oblivious (URI)
• Supports storage of similar graphs in multiple statement tables (one more attribute specifying the graph id)
• Supports clustered property tables and property-class table
• Reified statements are stored in property-class table (allows multiple reified instances of any statement)

15/03/08 27
Jena2 (2/3)
• Multi-valued properties may be clustered or may be stored in a separate table
• To face space consumption– Common prefixes in URIs are stored in a separate
table and the prefix itself is replaced by a db reference (prefix in cache)
– Long values are stored only once (defined by a threshold)

15/03/08 28
Jena2 (3/3)
Figure 9: Jena2 Schema (Denormalized)

15/03/08 29
Jena1 vs. Jena2
• The denormalized schema of Jena2 is faster than the normalized schema of Jena1, twice as fast for many operations
• For queries with high selectivity Jena1 and Jena2 perform about the same, but Jena2 performs better on queries which join a large number of tuples

15/03/08 30
ICS-Forth RDFSuite (1/3)• Storage method: Schema-aware (ISA)
• Core RDF/S model: Class, Property, SubClass and SubProperty tables to represent RDFS hierarchies
• Uses a Namespace table
• Uses a Type table to hold the built-in types of RDF/S (e.g. rdf:Property, rdfs:Class, etc), Literal types (e.g. integer, date), Container types (e.g. rdf:Bag)
• For each class/property there is a table in which its instances are stored
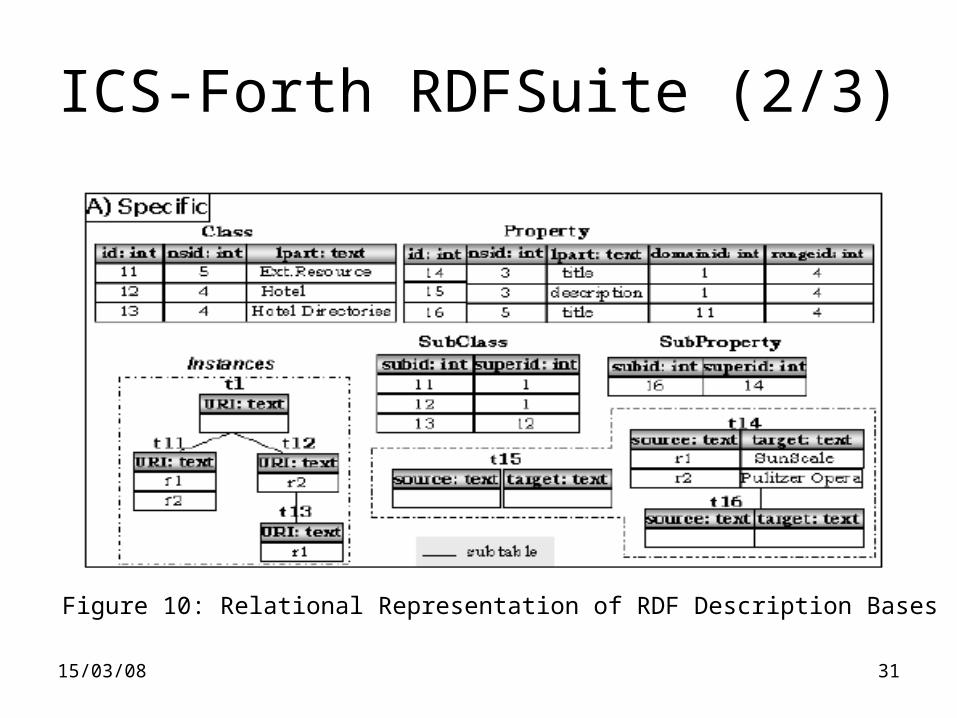
15/03/08 31
ICS-Forth RDFSuite (2/3)
Figure 10: Relational Representation of RDF Description Bases

15/03/08 32
Variations of RDFSuite (3/3)
• Construct a unified Instance table containing all instances of all classes
• Construct a unified Instance table containing all instance properties of all properties
• For every property with range a literal type, add an attribute to the class table of its domain (this is for single valued properties which are not specialized)

15/03/08 33
Sesame (1/5)
• Storage method: Schema-oblivious (ID)
• Memory, Database and File System Support
• Abandonment of object-relational backend– One table for each class/property– The semantics of subtables do not match the
semantics of rdfs:subClassOf (multiple parents)
15/03/08 34
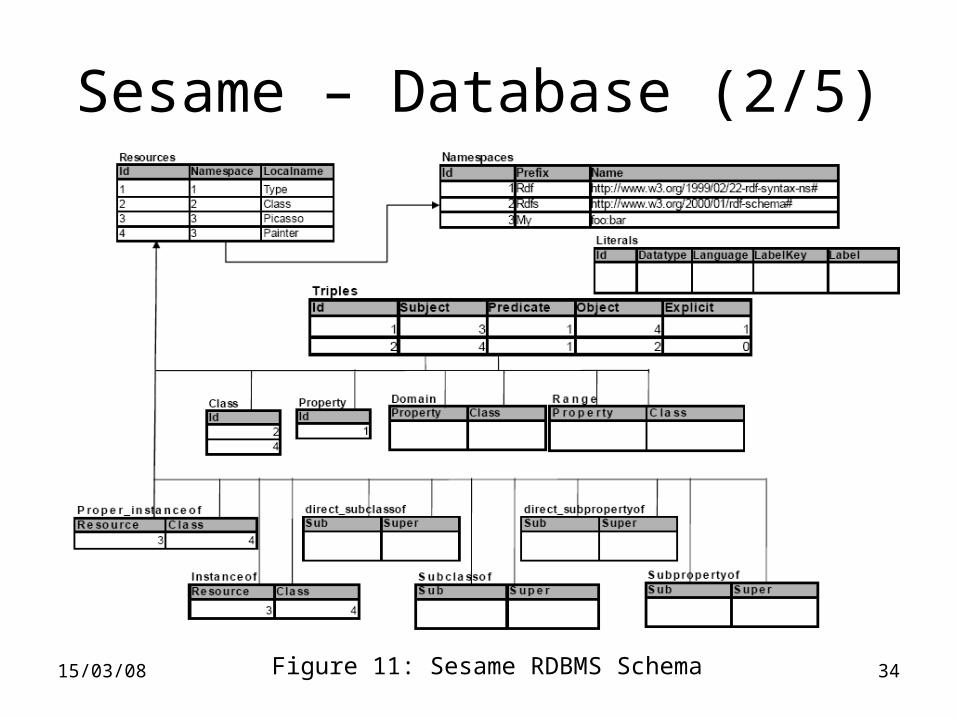
Sesame – Database (2/5)
Figure 11: Sesame RDBMS Schema
15/03/08 35
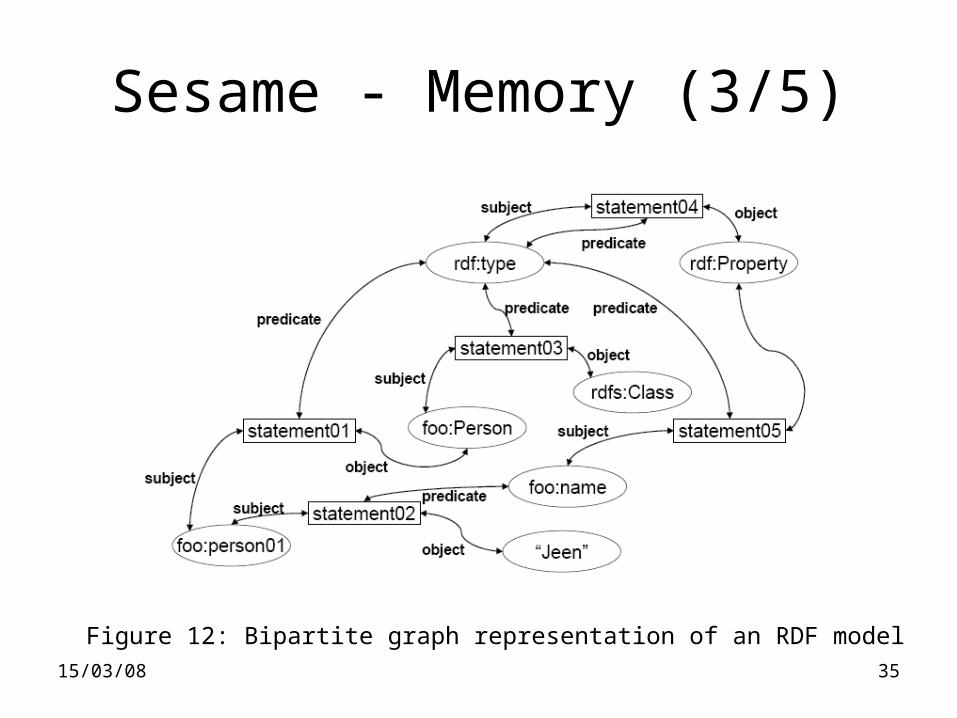
Sesame - Memory (3/5)
Figure 12: Bipartite graph representation of an RDF model

15/03/08 36
Sesame – File System (4/5)
• Read/write with Java’s I/O classes
• Stores indices (B-trees, hash tables) for quick searching
• Employs selective caching of data in memory for increasing retrieval performance

15/03/08 37
Sesame - Performance (5/5)
Figure 13: Left: first 20 min. , Right: complete upload
15/03/08 38
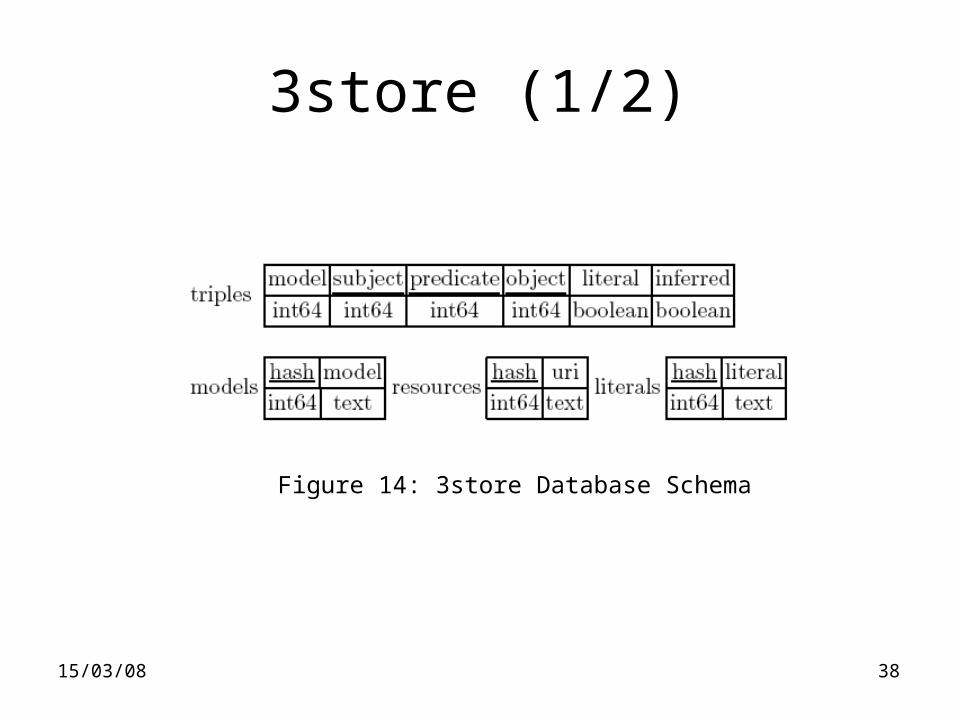
3store (1/2)
Figure 14: 3store Database Schema

15/03/08 39
3store (2/2)
• Datatypes: All datatypes are stored as strings => determination of datatype is done by conversion at runtime
• Hybrid approach for the production of entailment rules:– Those generating fewer entailments are evaluated at
assertion time with forward chaining rules– Those with greater storage cost and a lower evaluation
cost are evaluated at query time with backward chaining rules

15/03/08 40
RStar (1/2)
• Storage method: Schema-oblivious (ID)
• Core RDF/S model: Class, Property, SubClass, SubProperty and Property-Class tables to represent RDFS hierarchies
• Uses a Triples table
• Uses a Namespace table
• Uses a Type table to hold Literal types (e.g. integer, float, date, string)
• For efficient searching all property, class, resource and data names are hashed

15/03/08 41
RStar (2/2)
Figure 15: A database schema of RStar

15/03/08 42
Oracle• Storage method: Schema-oblivious (ID)
• One table for triple storage (IdTriples), one table for mapping URIs and Literals to IDs (UriMap)
• Supports user views on selective portions of the RDF data
• Supports multiple representations for the same value (canonical literal ID)
• Pre-defined datatypes are partitioned into families according to their value space (e.g. numeric family)
• To speed up query answering “subject property matrices” are used as auxiliary tables

15/03/08 43
Storage Systems’ Evaluation (1/5)
• Two storage systems based on memory(Sesame-Memory, Jena-Memory)
• Two persistent storage systems with RDBMS (Sesame-DB, Jena-DB)
• Three native RDF approach systems(Sesame-Native, Kowari, YARS)

15/03/08 44
Storage Systems’ EvaluationQuery response time (2/5)
• Sesame-DB, Jena-DB slowest systems:– Query mechanism represented by a series of join
instructions– Store most triples in a single table
• Sesame-Memory, Jena-Memory -> quick
• Native systems– Sesame-Native like Sesame-Memory (use same
query evaluation processing)– Kowari solid performance– YARS several times faster than Sesame, using index
15/03/08 45
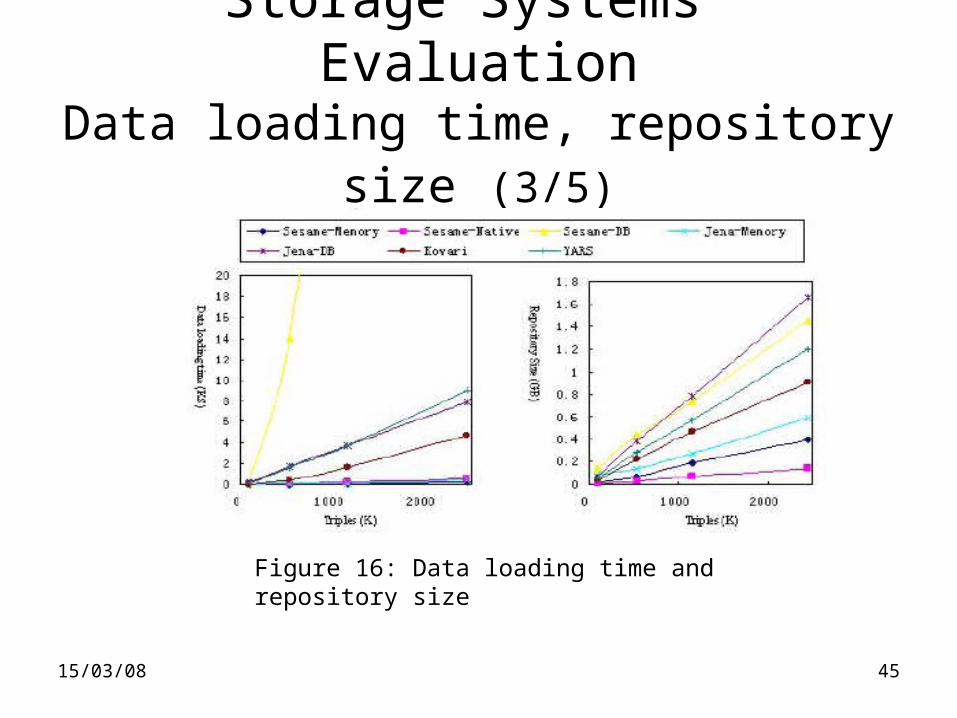
Storage Systems’ EvaluationData loading time, repository size (3/5)
Figure 16: Data loading time and repository size

15/03/08 46
Storage Systems’ EvaluationData loading time, repository size (4/5)
• Memory-based systems -> best performance
• DB-based systems -> bad scalability– Sesame-DB: a) performs duplication check, without caching
mechanism, since it employs a unique ID to RDF node mapping system, b) re-invokes its inference engine on loading RDF file
• Native systems -> nice performances– Sesame-Native, YARS use B-trees. YARS uses additional indices
=> more space– Kowari even more spaces using 64-bit storage
15/03/08 47
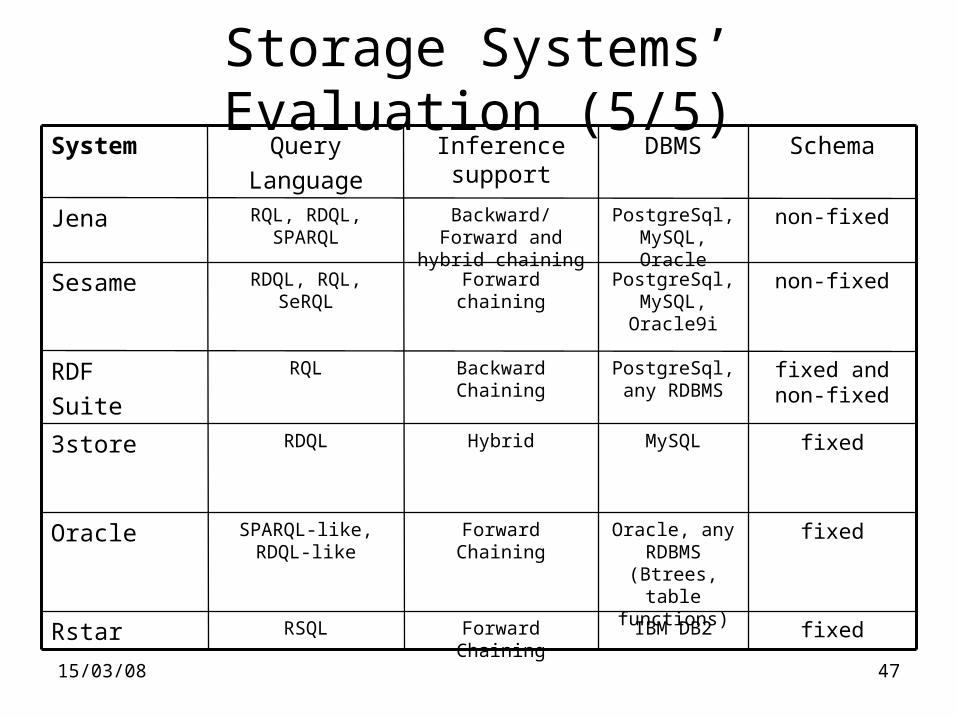
Storage Systems’ Evaluation (5/5)
fixedIBM DB2Forward ChainingRSQLRstar
fixedOracle, any RDBMS
(Btrees, table functions)
Forward ChainingSPARQL-like, RDQL-like
Oracle
fixedMySQLHybridRDQL3store
fixed and non-fixed
PostgreSql, any RDBMS
Backward ChainingRQLRDF
Suite
non-fixedPostgreSql, MySQL, Oracle9i
Forward chainingRDQL, RQL, SeRQLSesame
non-fixedPostgreSql, MySQL, Oracle
Backward/Forward and hybrid chaining
RQL, RDQL, SPARQL
Jena
SchemaDBMSInference support
Query
Language
System

15/03/08 48
Thank you!!!

15/03/08 49
References (1/2)
• Y. Theoharis, V. Christophides and G. Karvounarakis, Benchmarking Database Representations of RDF/S Stores. Fourth International Semantic Web Conference (ISWC'05), Galway, Ireland, November, 2005.
• Abadi, Daniel J., Marcus, Adam, Madden, Samuel R., and Hollenbach, Kate. Scalable Semantic Web Data Management Using Vertical Partitioning. In Proceedings of VLDB 2007.
• Stephen Harris, Nicholas Gibbins. 3store: Efficient Bulk RDF Storage, In Proceedings of the 1st International Workshop on Practical and Scalable Semantic Systems(PSSS'03).
• Jeen Broekstra, Arjohn Kampman, and Frank van Harmelen, Sesame: A Generic Architecture for Storing and Querying RDF and RDF Schema. In Proceedings of ISWC 2002.
• S. Alexaki, V. Christophides, G. Karvounarakis, D. Plexousakis, K. Tolle, The ICS-FORTH RDFSuite: Managing Voluminous RDF Description Bases, 2nd International Workshop on the Semantic Web (SemWeb'01), pp. 1-13, Hongkong, May 1, 2001.
• L. Ma, Z. Su, Y. Pan, L. Zhang, T. Liu: RStar: An RDF Storage and Query System for Enterprise Resource Management. In Proc. of the ACM CIKM 2004.

15/03/08 50
References (2/2)
• K. Wilkinson, C. Sayers, H. A. Kuno, D. Raynolds: Efficient RDF Storage and Retrieval in Jena2. In Proc. of SWDB'03 (co-located with VLDB'03).
• E. I. Chong, S. Das, G. Eadon, and J. Srinivasan. An Efficient SQL-based RDF Querying Scheme. In VLDB, pages 1216–1227, 2005.
• D. Beckett, J. Grant, SWAD-Europe: Mapping Semantic Web Data with RDBMSes, http://www.w3.org/2001/sw/Europe/reports/scalable_rdbms_mapping_report/
• J. Broekstra, “Storage, Querying and Inferencing for Semantic Web Languages”, Phd Thesis.
• Liu Baolin, H. Bo, An Evaluation of RDF Storage Systems for Large Data Applications, In Proc. of First International Conference on Semantics, Knowledge, and Grid (SKG 2005), 2005.


















