
RADEON OPEN COMPUTE PLATFORM - dotneststatic.com … · 10 | AMD FIREPRO™ SERVER GRAPHICS | AMD...
41
RADEON OPEN COMPUTE PLATFORM DMITRY KOZLOV
Transcript of RADEON OPEN COMPUTE PLATFORM - dotneststatic.com … · 10 | AMD FIREPRO™ SERVER GRAPHICS | AMD...

RADEONOPENCOMPUTEPLATFORMDMITRYKOZLOV

2 |AMDFIREPRO™SERVERGRAPHICS|AMDCONFIDENTIAL– UNDER EMBARGOUNTILMARCH31,2016AT9AMET
RADEONTECHNOLOGYGROUPPRESENTS
§ NewPathForwardforHPCandUltrascale ComputingMarkets
§ FocusedCommitmenttoMeetCustomerComputingNeeds
§ OpenFoundation ForDevelopment,DiscoveryandEducation
ROCm: Radeon Open Compute Platform

3 |AMDFIREPRO™SERVERGRAPHICS|AMDCONFIDENTIAL– UNDER EMBARGOUNTILMARCH31,2016AT9AMET
HARDWAREFORTHEROCM STAGE
1 TB/s Memory Bandwidth 13.9 TFlops Single Precision
512 GB/s Memory Bandwidth 8.19 TFlops Single Precision

4 |AMDFIREPRO™SERVERGRAPHICS|AMDCONFIDENTIAL– UNDER EMBARGOUNTILMARCH31,2016AT9AMET
ROCM PLATFORM:ANEWSTAGETOPLAY
ROCk - Headless Linux® 64-bit Kernel Driver and ROCr: HSA+ Runtime
§ Open Source from the metal up
§ Focus on overall latency to compute
§ Optimized for Node and Rack Scale Multi-GPU Compute
§ Foundation to explore GPU Compute
Announcing revolution in GPU computing

5 |AMDFIREPRO™SERVERGRAPHICS|AMDCONFIDENTIAL– UNDER EMBARGOUNTILMARCH31,2016AT9AMET
User Mode DMA
User Mode DMA
Multi-GPU Memory Management API
Multi-GPU Coarse-grain Shared Virtual MemoryLarge Memory Single Allocation
Peer to Peer Multi-GPU
Peer to Peer with RDMA
Process Concurrency & Preemption
Profiler Trace and Event Collection API
HSA Signals and Atomics
Standardized loader and Code Object Format
HCC C++ and OpenMP C/C++ compiler
Systems Management API and Tools
GCN ISA Assembler and Disassembler
Continuum IO Anaconda with NUMBA
HIP Runtime
Docker© Containerization Support
Native GCN ISA Code Generation
Large BAR
ROCmgivesyouarichfoundationforanewsound
Offline Compilation Support
Low latency dispatch
Low Overhead PCIe® data transfers
Bringing new capabilities you requested
6 |AMDFIREPRO™SERVERGRAPHICS|AMDCONFIDENTIAL– UNDER EMBARGOUNTILMARCH31,2016AT9AMET
ROCM PLATFORM:ANEWSTAGETOPLAYAnnouncing revolution in GPU computing

7 |AMDFIREPRO™SERVERGRAPHICS|AMDCONFIDENTIAL– UNDER EMBARGOUNTILMARCH31,2016AT9AMET
IT’SABOUTMAKINGPREMIUMSOUNDONTHEROCM STAGE
§ HCC is a single source ISO C++ 11/14 compiler for both the CPU and GPU
§ C++17 “Parallel Standard Template Library”
§ Built on rich compiler infrastructure CLANG/LLVM and libC++
§ Performance Optimization for Accelerators§ Low level memory placement controls: pre-fetch, discard data movement
§ Asynchronous compute kernels
§ Scratchpad memories support
HCC (Heterogeneous Compute Compiler) Mainstream Standard Languages for GPU Acceleration

8 |AMDFIREPRO™SERVERGRAPHICS|AMDCONFIDENTIAL– UNDER EMBARGOUNTILMARCH31,2016AT9AMET
IT’SABOUTMAKINGPREMIUMSOUNDONTHEROCM STAGEHCC (Heterogeneous Compute Compiler) Mainstream Standard Languages for GPU Acceleration
const float a = 100.0f;
float x[N];
float y[N];
…
for (int i = 0; i < N; i++) {
y[i] = a * x[i] + y[i];
}

9 |AMDFIREPRO™SERVERGRAPHICS|AMDCONFIDENTIAL– UNDER EMBARGOUNTILMARCH31,2016AT9AMET
IT’SABOUTMAKINGPREMIUMSOUNDONTHEROCM STAGEHCC (Heterogeneous Compute Compiler) Mainstream Standard Languages for GPU Acceleration
#include <hc.hpp>
hc::array_view<float, 1> av_x(N, x);
hc::array_view<float, 1> av_y(N, y_gpu);
// launch a GPU kernel to compute the saxpyin parallel
hc::parallel_for_each(hc::extent<1>(N), [=](index<1> i) [[hc]] {
av_y[i] = a * av_x[i] + av_y[i];
});

10 |AMDFIREPRO™SERVERGRAPHICS|AMDCONFIDENTIAL– UNDER EMBARGOUNTILMARCH31,2016AT9AMET
§ Port from CUDA to a common C++ programming model
§ HIP code runs through either CUDA NVCC or HCC
§ HiPify tools simplify porting from CUDA to HIP
§ Builds on HCC Compiler§ Host and device code can use templates, lambdas, advanced C++ features
§ C-based runtime APIs (hipMalloc, hipMemcpy, hipKernelLaunch and more)
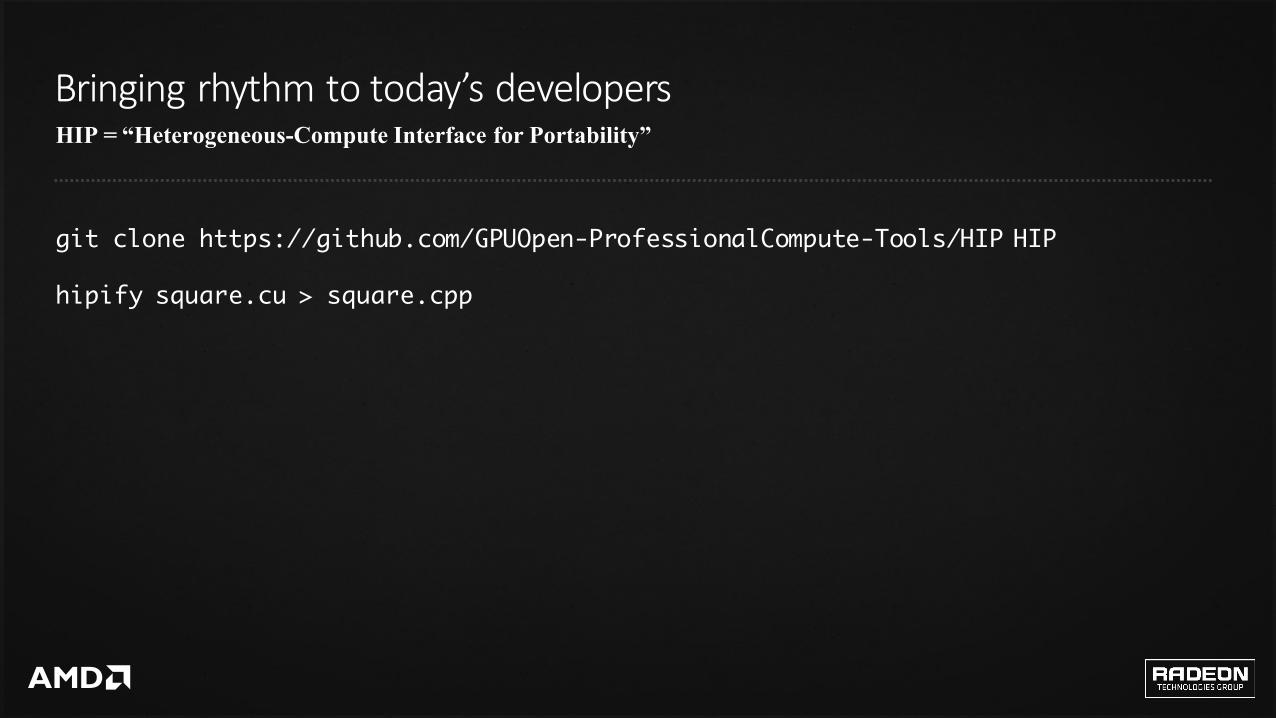
HIP = “Heterogeneous-Compute Interface for Portability”
Bringingrhythmtotoday’sdevelopers
11 |AMDFIREPRO™SERVERGRAPHICS|AMDCONFIDENTIAL– UNDER EMBARGOUNTILMARCH31,2016AT9AMET
HIP = “Heterogeneous-Compute Interface for Portability”
Bringingrhythmtotoday’sdevelopers
git clone https://github.com/GPUOpen-ProfessionalCompute-Tools/HIP HIP
hipify square.cu > square.cpp

12 |AMDFIREPRO™SERVERGRAPHICS|AMDCONFIDENTIAL– UNDER EMBARGOUNTILMARCH31,2016AT9AMET
HIP = “Heterogeneous-Compute Interface for Portability”
Bringingrhythmtotoday’sdevelopers
template <typename T>__global__ voidvector_square(T *C_d, const T *A_d, size_t N){
size_t offset = (blockIdx.x * blockDim.x + threadIdx.x);size_t stride = blockDim.x * gridDim.x ;
for (size_t i=offset; i<N; i+=stride) {C_d[i] = A_d[i] * A_d[i];
}}

13 |AMDFIREPRO™SERVERGRAPHICS|AMDCONFIDENTIAL– UNDER EMBARGOUNTILMARCH31,2016AT9AMET
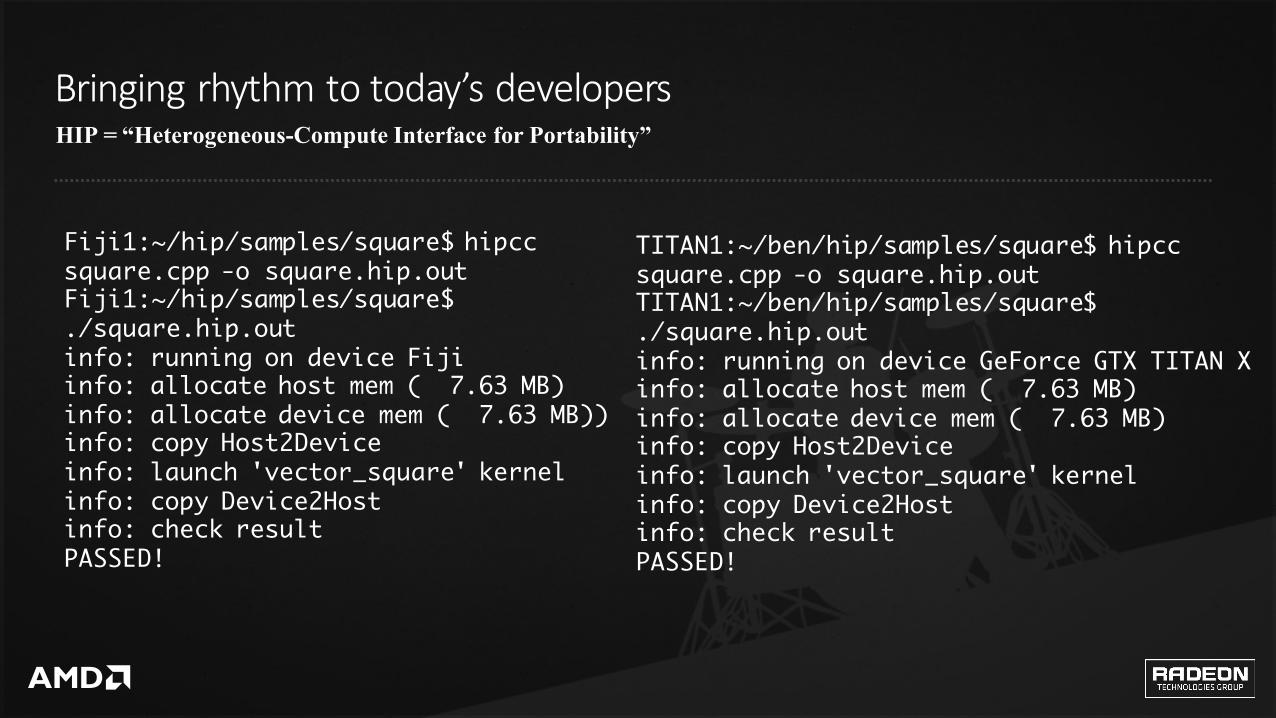
HIP = “Heterogeneous-Compute Interface for Portability”
Bringingrhythmtotoday’sdevelopers
/** Square each element in the array A and write to array C.*/template <typename T>__global__ voidvector_square(T *C_d, const T *A_d, size_t N){
size_t offset = (hipBlockIdx_x * hipBlockDim_x + hipThreadIdx_x);size_t stride = hipBlockDim_x * hipGridDim_x ;
for (size_t i=offset; i<N; i+=stride) {C_d[i] = A_d[i] * A_d[i];
}}

14 |AMDFIREPRO™SERVERGRAPHICS|AMDCONFIDENTIAL– UNDER EMBARGOUNTILMARCH31,2016AT9AMET
HIP = “Heterogeneous-Compute Interface for Portability”
Bringingrhythmtotoday’sdevelopers
CHECK(hipMalloc(&A_d, Nbytes));CHECK(hipMalloc(&C_d, Nbytes));
CHECK ( hipMemcpy(A_d, A_h, Nbytes, hipMemcpyHostToDevice));
const unsigned blocks = 512;const unsigned threadsPerBlock = 256;
hipLaunchKernel(HIP_KERNEL_NAME(vector_square), dim3(blocks), dim3(threadsPerBlock), 0, 0, C_d, A_d, N);
CHECK ( hipMemcpy(C_h, C_d, Nbytes, hipMemcpyDeviceToHost));
15 |AMDFIREPRO™SERVERGRAPHICS|AMDCONFIDENTIAL– UNDER EMBARGOUNTILMARCH31,2016AT9AMET
HIP = “Heterogeneous-Compute Interface for Portability”
Bringingrhythmtotoday’sdevelopers
Fiji1:~/hip/samples/square$ hipccsquare.cpp -o square.hip.outFiji1:~/hip/samples/square$ ./square.hip.outinfo: running on device Fijiinfo: allocate host mem ( 7.63 MB)info: allocate device mem ( 7.63 MB))info: copy Host2Deviceinfo: launch 'vector_square' kernelinfo: copy Device2Hostinfo: check resultPASSED!
TITAN1:~/ben/hip/samples/square$ hipccsquare.cpp -o square.hip.outTITAN1:~/ben/hip/samples/square$ ./square.hip.outinfo: running on device GeForce GTX TITAN Xinfo: allocate host mem ( 7.63 MB)info: allocate device mem ( 7.63 MB)info: copy Host2Deviceinfo: launch 'vector_square' kernelinfo: copy Device2Hostinfo: check resultPASSED!
16 |AMDFIREPRO™SERVERGRAPHICS|AMDCONFIDENTIAL– UNDER EMBARGOUNTILMARCH31,2016AT9AMET
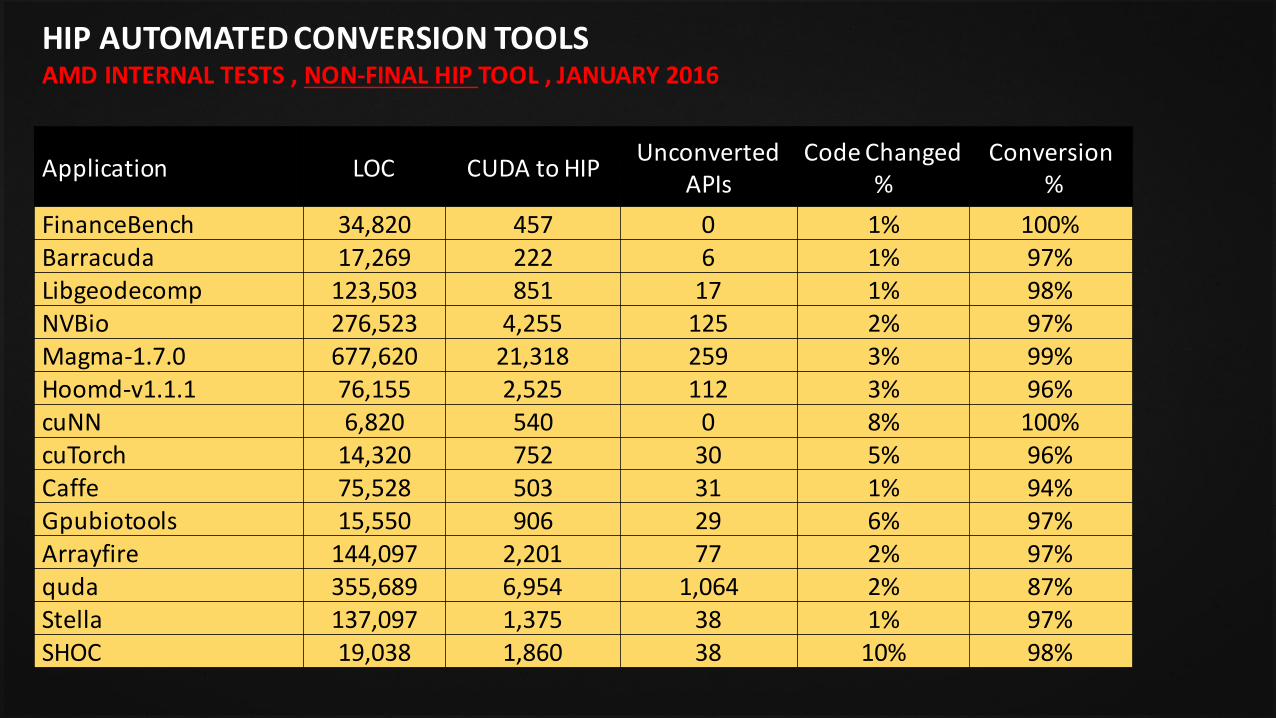
HIPAUTOMATEDCONVERSIONTOOLSAMDINTERNALTESTS,NON-FINALHIPTOOL,JANUARY2016
Application LOC CUDAto HIP UnconvertedAPIs
CodeChanged%
Conversion%
FinanceBench 34,820 457 0 1% 100%Barracuda 17,269 222 6 1% 97%Libgeodecomp 123,503 851 17 1% 98%NVBio 276,523 4,255 125 2% 97%Magma-1.7.0 677,620 21,318 259 3% 99%Hoomd-v1.1.1 76,155 2,525 112 3% 96%cuNN 6,820 540 0 8% 100%cuTorch 14,320 752 30 5% 96%Caffe 75,528 503 31 1% 94%Gpubiotools 15,550 906 29 6% 97%Arrayfire 144,097 2,201 77 2% 97%quda 355,689 6,954 1,064 2% 87%Stella 137,097 1,375 38 1% 97%SHOC 19,038 1,860 38 10% 98%

17 |AMDFIREPRO™SERVERGRAPHICS|AMDCONFIDENTIAL– UNDER EMBARGOUNTILMARCH31,2016AT9AMET
Expanding Set of Cross Platform Tools
GoingGlobal
Software LandscapeThrough 2015
Radeon Open Compute Platform(ROCm)
OpenCL
OpenCL
Catalyst
ROC Runtime+
OpenCL
CUDA
ROC Runtime+
HIP
ISO C++No GPU Acceleration
ISO C++AMD HCC Compiler
ROC Runtime+
C++ 11/14 +
PSTLImproved
PerformanceOne Code Base
Multiple PlatformsSimplest Path toGPU Acceleration
I N C R E A S I N G M A R K E T A C C E S S
C++AMD HCC Compiler
OpenCL and the OpenCL logo are trademarks of Apple Inc, used by permission by Khronos.

18 |AMDFIREPRO™SERVERGRAPHICS|AMDCONFIDENTIAL– UNDER EMBARGOUNTILMARCH31,2016AT9AMET
AMPUPTHESIGNALFocusing on Solution & Building Out Key Foundations to Support Libraries, Frameworks and Applications via GPUopen
wireless communications
security sensing
discovery medical imaging
bio-medical synthesis
learning astronomy
securitymodelling
acquisition
machine learningextraction
speech forensicsbio-it oil & gas
audioanalysisfinance

19 |AMDFIREPRO™SERVERGRAPHICS|AMDCONFIDENTIAL– UNDER EMBARGOUNTILMARCH31,2016AT9AMET
ROCKINGTHENEURALPATHWAYS
§ Supporting Key Neural Network Frameworks§ Torch 7 and Caffe
§ mlOpen§ Optimized Convolution Neural Network for NN Frameworks
§ OpenVX with Graph Optimizer § Foundation for rich Machine Learning
Instinctive Computing foundation for Machine Learning and Neural Networks

20 |AMDFIREPRO™SERVERGRAPHICS|AMDCONFIDENTIAL– UNDER EMBARGOUNTILMARCH31,2016AT9AMET
CHIMETELESCOPETHREE-DIMENSIONALMAPPINGOFTHEUNIVERSE
y Solvingoneofmostpuzzlingnewmysteriesinastronomy:FastRadioBursts(FRB)
MultiPFLOPSAMDFirePro™S9300x2cluster
“CHIMEhasatrulynoveldesign.Nomovingparts![…]Moreover,itwillhave2048antennasandamassivesoftwarecorrelatorthatallowsitto‘point’indifferentdirectionsallinsoftware.”- AstrophysicistVictoriaKaspi,GerhardHerzberg2016prizelaureate
Image:Prof.KeithVanderlinde,DunlapInstitute,UniversityofToronto.
21 |AMDFIREPRO™SERVERGRAPHICS|AMDCONFIDENTIAL– UNDER EMBARGOUNTILMARCH31,2016AT9AMET
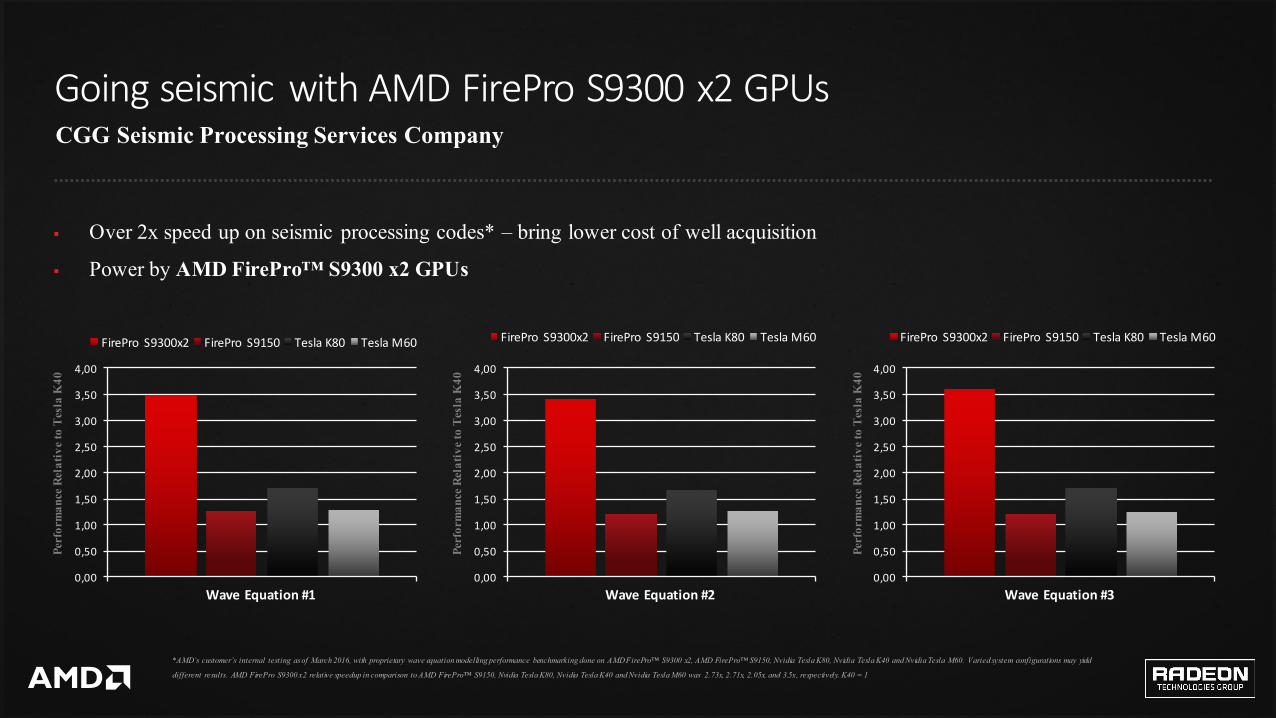
GoingseismicwithAMDFireProS9300x2GPUsCGG Seismic Processing Services Company
§ Over 2x speed up on seismic processing codes* – bring lower cost of well acquisition
§ Power by AMD FirePro™ S9300 x2 GPUs
*AMD’s customer’s internal testing as of March 2016, with proprietary wave equation modelling performance benchmarking done on AMD FirePro™ S9300 x2, AMD FirePro™ S9150, Nvidia Tesla K80, Nvidia Tesla K40 and Nvidia Tesla M60. Varied system configurations may yield
different results. AMD FirePro S9300 x2 relative speedup in comparison to AMD FirePro™ S9150, Nvidia Tesla K80, Nvidia Tesla K40 and Nvidia Tesla M60 was 2.73x, 2.71x, 2.05x, and 3.5x, respectively. K40 = 1
0,00
0,50
1,00
1,50
2,00
2,50
3,00
3,50
4,00
WaveEquation#1
FirePro S9300x2 FirePro S9150 TeslaK80 TeslaM60
Perf
orm
ance
Rel
ativ
e to
Tes
la K
40
0,00
0,50
1,00
1,50
2,00
2,50
3,00
3,50
4,00
WaveEquation#2
FirePro S9300x2 FirePro S9150 TeslaK80 TeslaM60
Perf
orm
ance
Rel
ativ
e to
Tes
la K
40
0,00
0,50
1,00
1,50
2,00
2,50
3,00
3,50
4,00
WaveEquation#3
FirePro S9300x2 FirePro S9150 TeslaK80 TeslaM60
Perf
orm
ance
Rel
ativ
e to
Tes
la K
40
22 |AMDFIREPRO™SERVERGRAPHICS|AMDCONFIDENTIAL– UNDER EMBARGOUNTILMARCH31,2016AT9AMET
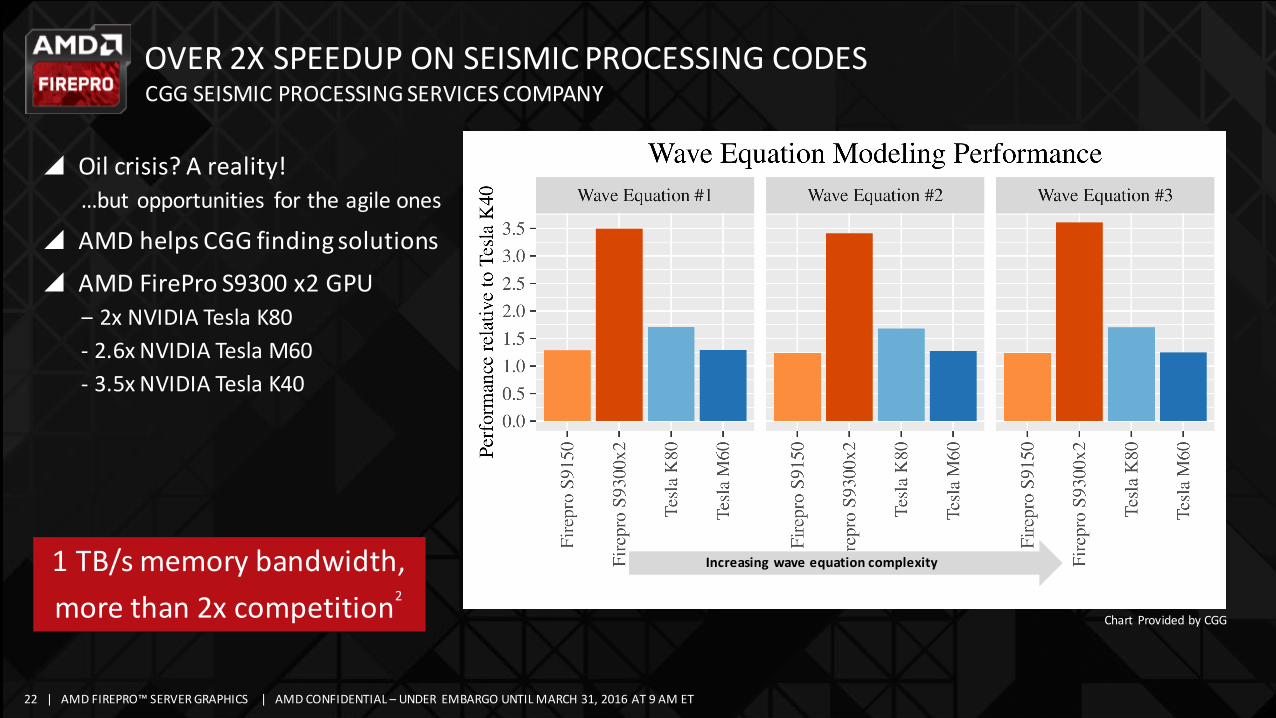
OVER2XSPEEDUPONSEISMICPROCESSINGCODESCGGSEISMICPROCESSINGSERVICESCOMPANY
Chart ProvidedbyCGG
y Oilcrisis?Areality!…butopportunities fortheagileones
y AMDhelpsCGGfindingsolutionsy AMDFireProS9300x2GPU
‒ 2xNVIDIATeslaK80- 2.6xNVIDIATeslaM60- 3.5xNVIDIATeslaK40
Increasingwaveequationcomplexity1TB/smemorybandwidth,morethan2xcompetition2
23 |AMDFIREPRO™SERVERGRAPHICS|AMDCONFIDENTIAL– UNDER EMBARGOUNTILMARCH31,2016AT9AMET
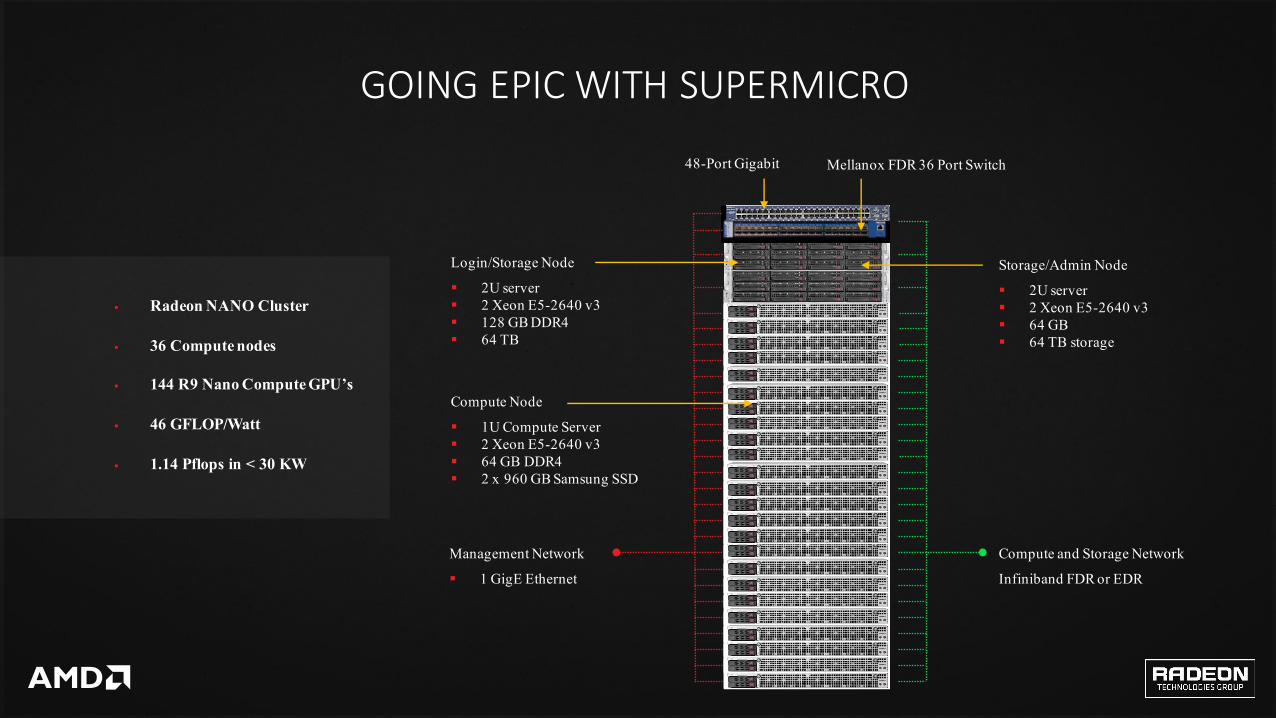
GOINGEPICWITHSUPERMICRO
Storage/Admin Node
§ 2U server § 2 Xeon E5-2640 v3§ 64 GB § 64 TB storage
Login/Storage Node
§ 2U server§ 2 Xeon E5-2640 v3§ 128 GB DDR4 § 64 TB
Mellanox FDR 36 Port Switch
Compute Node
§ 1U Compute Server§ 2 Xeon E5-2640 v3§ 64 GB DDR4 § 2 x 960 GB Samsung SSD
Compute and Storage Network
Infiniband FDR or EDR
Management Network
§ 1 GigE Ethernet
48-Port Gigabit
§ Radeon NANO Cluster
§ 36 Compute nodes
§ 144 R9 Nano Compute GPU’s
§ 46 GFLOP/Watt
§ 1.14 Pflops in < 30 KW
24 |AMDFIREPRO™SERVERGRAPHICS|AMDCONFIDENTIAL– UNDER EMBARGOUNTILMARCH31,2016AT9AMET
PLX 8747
Fiji PLX 8747 Fiji
Fiji PLX 8747 Fiji
Fiji PLX 8747 Fiji
Fiji PLX 8747 Fiji
PLX 8747
Fiji PLX 8747 Fiji
Fiji PLX 8747 Fiji
Fiji Nano
PLX 8747 Fiji
Fiji PLX 8747 Fiji
PLX 8747(x16)
x16
x16
Fiji PLX 8747 Fiji
Fiji PLX 8747 Fiji
Fiji PLX 8747 Fiji
Fiji PLX 8747 Fiji
PLX 8747(x16)
Fiji PLX 8747 Fiji
Fiji PLX 8747 Fiji
Fiji PLX 8747 Fiji
Fiji PLX 8747 Fiji
PLX 8747(x16)
x16
x16
x16
x16
x16
x16
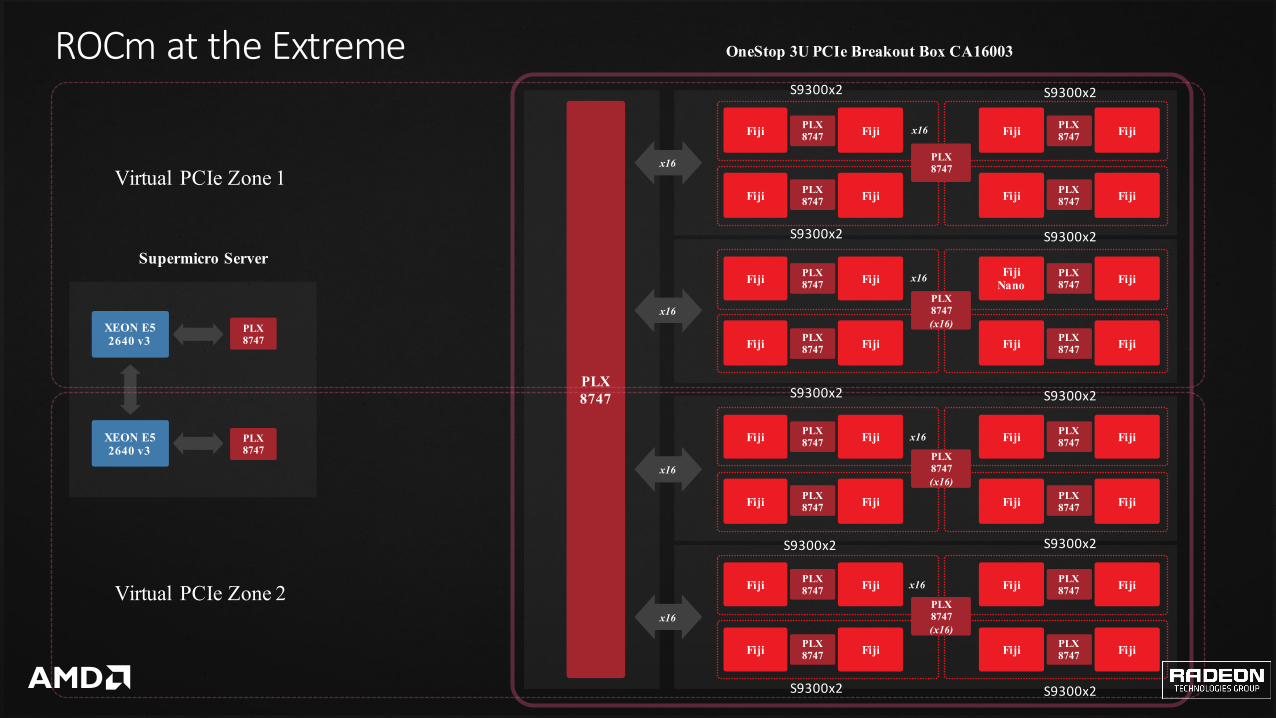
XEON E52640 v3
PLX 8747
XEON E52640 v3
PLX 8747
Supermicro Server
Virtual PCIe Zone 1
Virtual PCIe Zone 2
OneStop 3U PCIe Breakout Box CA16003ROCmattheExtremeS9300x2
S9300x2
S9300x2
S9300x2
S9300x2
S9300x2
S9300x2
S9300x2
S9300x2
S9300x2
25 |AMDFIREPRO™SERVERGRAPHICS|AMDCONFIDENTIAL– UNDER EMBARGOUNTILMARCH31,2016AT9AMET
HPCSIGNALPROCESSINGNEEDFORMAXIMUMMEMORYBANDWITHALONGWITHMAXIMUMCOMPUTEPERFORMANCE
MODELLING ANALYSIS
SENSING
ACQUISITION
DISCOVERY
SYNTHESYS
SECURITY
LEARNINGFORENSICS
ASTRONOMY
BIO-MEDICAL
EXTRACTION
BIO-IT
OIL&GAS
AUDIO SPEECH
MEDICALIMAGING
FINANCE
MACHINELEARNING
WIRELESSCOMMUNICATIONS

26 |AMDFIREPRO™SERVERGRAPHICS|AMDCONFIDENTIAL– UNDER EMBARGOUNTILMARCH31,2016AT9AMET
TheWorld’sFastestSingle-PrecisionGPUAccelerator1

27 |AMDFIREPRO™SERVERGRAPHICS|AMDCONFIDENTIAL– UNDER EMBARGOUNTILMARCH31,2016AT9AMET
AMDFIREPRO™S9300X2GPU1TB/smemorybandwidth
13.9TFLOPS32-bit
TheWorld’sFastestSingle-PrecisionGPUAccelerator1

28 |AMDFIREPRO™SERVERGRAPHICS|AMDCONFIDENTIAL– UNDER EMBARGOUNTILMARCH31,2016AT9AMET
AMDFIREPRO™S9300X2BOARDWITHAMD“FIJI”GPU
y Dual“Fiji”GPUsonsinglePCIe®x16boardy PCIe bridgeprovidesunifiedx16interfacetohosty 13.9TFLOPSpeaksingleprecisionfloatingpointy 0.8TFLOPSpeakdoubleprecisionfloatingpointy SupportforFP16floatingpoint(“halfprecision”)y 8GBHBM1
y 1TB/smemorybandwidth2
y 300WTDPy Dualslotformfactor,passivecooling
THEFIRSTDATACENTERGPUWITHHBM
Massivecomputedensityandefficiencyforsingleprecisionandhalfprecisionworkloads 14GBperGPU
2512GB/sperGPU
29 |AMDFIREPRO™SERVERGRAPHICS|AMDCONFIDENTIAL– UNDER EMBARGOUNTILMARCH31,2016AT9AMET
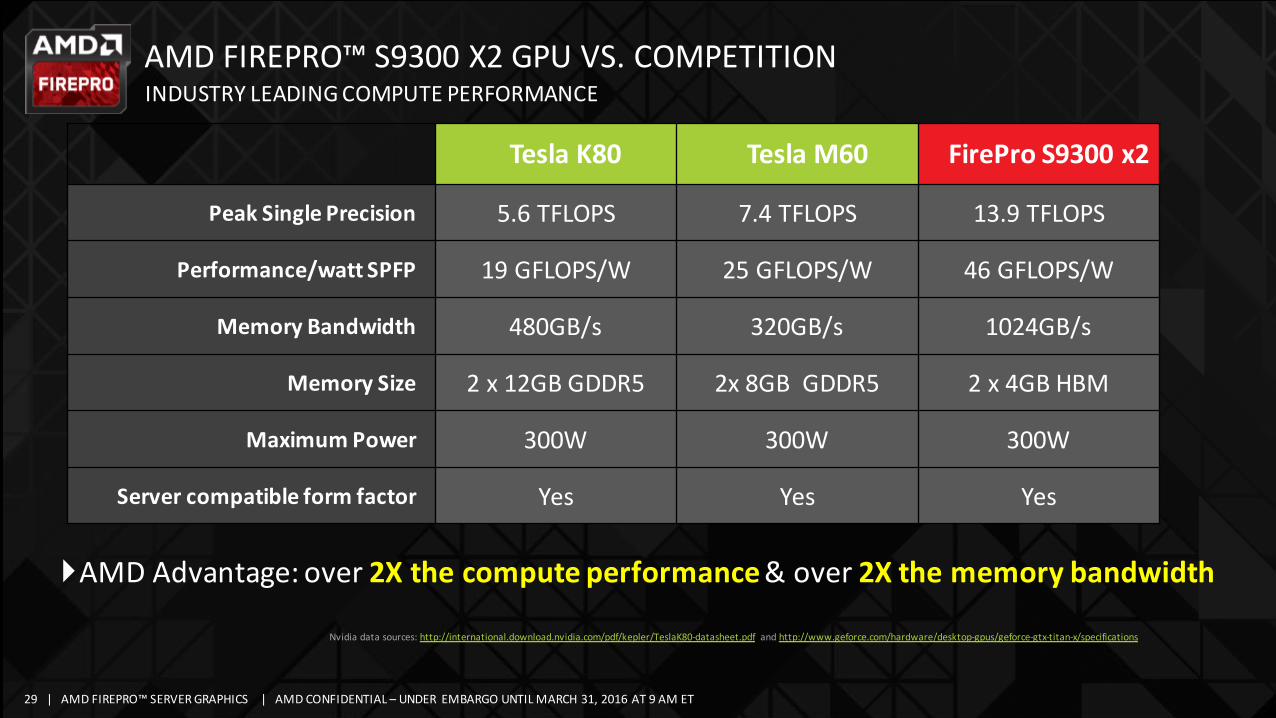
AMDFIREPRO™S9300X2GPUVS.COMPETITIONINDUSTRYLEADINGCOMPUTEPERFORMANCE
TeslaK80 TeslaM60 FirePro S9300x2
Peak SinglePrecision 5.6TFLOPS 7.4TFLOPS 13.9TFLOPS
Performance/wattSPFP 19GFLOPS/W 25GFLOPS/W 46GFLOPS/W
MemoryBandwidth 480GB/s 320GB/s 1024GB/s
MemorySize 2x12GBGDDR5 2x 8GB GDDR5 2x4GBHBM
MaximumPower 300W 300W 300W
Servercompatibleform factor Yes Yes Yes
Nvidia datasources:http://international.download.nvidia.com/pdf/kepler/TeslaK80-datasheet.pdf andhttp://www.geforce.com/hardware/desktop-gpus/geforce-gtx-titan-x/specifications
}AMDAdvantage:over2Xthecomputeperformance&over2Xthememorybandwidth

30 |AMDFIREPRO™SERVERGRAPHICS|AMDCONFIDENTIAL– UNDER EMBARGOUNTILMARCH31,2016AT9AMET
AMDFIREPRO™S-SERIESVALUEPROPFORHPC
• LargestGPUmemory• FirstwithHBM• 1TB/smemorybandwidth
Innovation
• Leadershipincomputeperformance• PowerefficiencyPerformance
Accessibility• Standardizedprogramming:OpenCL,C++• Opensourcedriverandtools• Codeportability
1,0X 1,0X
15,1X
12,7X
RelativeMemoryBandwith
RelativeFLOPS(SP)
GPUvsCPU
XeonE5-2699v3 S9300x2

31 |AMDFIREPRO™SERVERGRAPHICS|AMDCONFIDENTIAL– UNDER EMBARGOUNTILMARCH31,2016AT9AMET
AMDFIREPRO™S9300X2GPUFOCUSSEGMENTS
y DeepNeuralNetworks/MachineLearningy Geosciencey MolecularDynamicsy DataprocessingandAnalysisy DevelopmentplatformsforExascale computing

32 |AMDFIREPRO™SERVERGRAPHICS|AMDCONFIDENTIAL– UNDER EMBARGOUNTILMARCH31,2016AT9AMET
WHATTHEYARESAYING…….PURE
VIRTUALIZEDGRAPHICS
“We’reverypleasedwiththeAMDFirePro™computeclusters,”saidJean-YvesBlanc,chiefITarchitect,CGG.“We’realsoimpressedbythe1TB/smemorybandwidthoftheAMDFireProS9300x2,aboardwhichdeliversover2xtheperformanceofanyother serverGPUboardsonCGGWaveEquationModeling codes.”
“Asabelieverinopensourcesolutions forparallelcomputing andhighperformanceclusters,IapplaudAMDforitsmanycontributions andongoingefforts,”saidSimonMcIntosh-Smith,headoftheMicroelectronicsGroup,BristolUniversity.“ThecombinationoftheinnovativeROCm softwareaspartoftheGPUOpen effortswiththe1TB/smemorybandwidthofthenewAMDFirePro™S9300x2ServerGPUiscreatingexcitementthroughout theresearchandcommercialcommunities.”

33 |AMDFIREPRO™SERVERGRAPHICS|AMDCONFIDENTIAL– UNDER EMBARGOUNTILMARCH31,2016AT9AMET
y L-CSCsupercomputerinDarmstadtGermanyisusedforleadingedgeparticlephysicsresearch‒ Clusterconsistsof160nodes, eachwithfourAMDFirePro™S9150GPUs‒ Totalcomputationalpowerof3.2PetaFLOPS
y Workload‒ LatticeQuantumChromoDynamics(LQCD)computations‒ Computation requireslargesparsevectormultiplication‒ Veryhighdemandonmemorybandwidth‒ TheoreticalresultsarecorrelatedwithexperimentaldatafromFAIR(FacilityforAnti-ProtonandIonResearch)
y Considerationsinplatformdefinition‒ Performance– memorybandwidthandfloatingpointcomputation‒ Operatingcost– electricalpowerasignificantportionofTCO‒ Vendorandplatformindependent software– droveuseofOpenCL
HPCCASESTUDY– PARTICLEPHYSICSUSINGLATTICEQCD
Additionaldetailsathttp://insidehpc.com/2015/04/interview-with-dr-david-rohr/
34 |AMDFIREPRO™SERVERGRAPHICS|AMDCONFIDENTIAL– UNDER EMBARGOUNTILMARCH31,2016AT9AMET
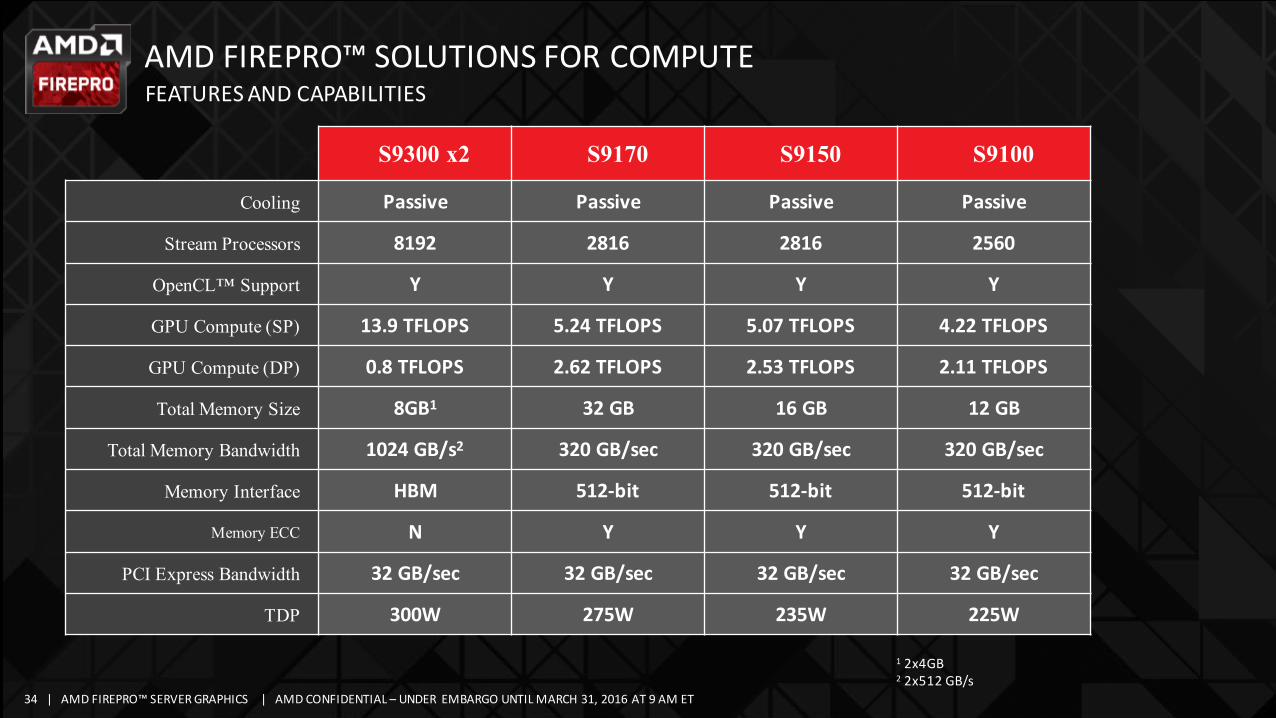
AMDFIREPRO™SOLUTIONSFORCOMPUTEFEATURESANDCAPABILITIES
S9300 x2 S9170 S9150 S9100
Cooling Passive Passive Passive Passive
Stream Processors 8192 2816 2816 2560
OpenCL™ Support Y Y Y Y
GPU Compute (SP) 13.9TFLOPS 5.24TFLOPS 5.07TFLOPS 4.22TFLOPS
GPU Compute (DP) 0.8TFLOPS 2.62TFLOPS 2.53TFLOPS 2.11TFLOPS
Total Memory Size 8GB1 32GB 16GB 12GB
Total Memory Bandwidth 1024 GB/s2 320GB/sec 320GB/sec 320GB/sec
Memory Interface HBM 512-bit 512-bit 512-bit
Memory ECC N Y Y Y
PCI Express Bandwidth 32GB/sec 32GB/sec 32GB/sec 32GB/sec
TDP 300W 275W 235W 225W
1 2x4GB2 2x512GB/s

35 |AMDFIREPRO™SERVERGRAPHICS|AMDCONFIDENTIAL– UNDER EMBARGOUNTILMARCH31,2016AT9AMET
AMDFIREPRO™GRAPHICS
y Award-winningproductsandstrongISVpartnerships
y Designedforbusinessandtechnicaluserswhodemandthehighestquality,reliabilityandapplicationperformance
y Professionalworkstationgraphics,VDIandHPCsolutionsservingmultipleenterprisemarkets– mobile,desktop,server
y ShippinginworkstationsandserversfromTier1OEMsincludingApple,Dell,HP,andLenovo

36 |AMDFIREPRO™SERVERGRAPHICS|AMDCONFIDENTIAL– UNDER EMBARGOUNTILMARCH31,2016AT9AMET
DELIVERINGTHERIGHTAMDFIREPRO™SOLUTIONS
DataCentersWorkstations
WSERIES

37 |AMDFIREPRO™SERVERGRAPHICS|AMDCONFIDENTIAL– UNDER EMBARGOUNTILMARCH31,2016AT9AMET
y GPUusedforcomputationy AlmostcompletelyLinux®OSy MultipleGPUspernode(2-16)y Multiplenodespersite(20-20,000)
y Deliverhighperformancegraphicstoremoteusersy Softwarestackincludeshypervisor,guestOS,and
remotingprotocoly MultipleGPUspernode(2-8)y Multiplenodespersite.Easilyscalable
HPC VDI
HIGHPERFORMANCECOMPUTING(HPC)ANDVIRTUALIZEDDESKTOPINFRASTRUCTURE(VDI)USECASESFORGPUSINTHEDATACENTER
HardwareRequirementsy Passivecoolingy Out-of-bandtemperaturemonitoringy Physicalsize(<10.5”)andTDP(<300W)meetserverrequirements
y Nophysicaldisplayoutputy Hardwarevirtualization

38 |AMDFIREPRO™SERVERGRAPHICS|AMDCONFIDENTIAL– UNDER EMBARGOUNTILMARCH31,2016AT9AMET
DOUBLEPRECISIONCOMPUTEPRODUCTS
y AMDFirePro™S9170GPU‒ 5.2TFLOPSsingleprecision floatingpoint‒ 2.6TFLOPSdoubleprecisionfloatingpoint‒ 32GBGDDR5graphicsmemory,withECC‒ Improvedpowerefficiency‒ 275WTDP(with235Woption)‒ Dualslotform factor,passivecooling
y AMDFirePro™S9150GPU‒ 16GBGDDR5,withECC‒ 235W
y AMDFirePro™S9100GPU‒ 12GBGDDR5,withECC‒ 225W
PERFORMANCELEADERSHIP,PROVENTECHNOLOGY
} Idealforacademicclusters,demandingdoubleprecisionandlargememory footprintworkloads

39 |AMDFIREPRO™SERVERGRAPHICS|AMDCONFIDENTIAL– UNDER EMBARGOUNTILMARCH31,2016AT9AMET
WEARELOOKINGTOBUILDOUTAWORLDWIDEBAND
§ Get started today developing with ROCm - GPUopen ROCm Getting Started http://bit.ly/1ZTlk82
§ Engage In the develop of ROCm @ GitHub RadeonOpenCompute
§ Show case your applications, libraries and tools on to ROCm via GPUOpen
How to Join the Band
“Thepowerofone,iffearlessandfocused,isformidable,butthepowerofmanyworking
togetherisbetter.”
– Gloria Macapagal Arroyo

40 |AMDFIREPRO™SERVERGRAPHICS|AMDCONFIDENTIAL– UNDER EMBARGOUNTILMARCH31,2016AT9AMET

41 |AMDFIREPRO™SERVERGRAPHICS|AMDCONFIDENTIAL– UNDER EMBARGOUNTILMARCH31,2016AT9AMET
DISCLAIMER&ATTRIBUTION
Theinformationpresentedinthisdocument isforinformationalpurposes onlyandmaycontaintechnicalinaccuracies,omissions andtypographicalerrors.
Theinformation containedhereinissubject tochangeandmayberenderedinaccurateformanyreasons, including butnotlimited toproductandroadmapchanges,component andmotherboardversion changes,newmodel and/orproductreleases, productdifferencesbetweendifferingmanufacturers,softwarechanges,BIOSflashes, firmwareupgrades,orthelike.AMDassumes noobligation toupdateorotherwisecorrectorrevisethisinformation.However,AMDreservestherighttorevisethisinformation andtomakechangesfromtimetotimetothecontenthereofwithoutobligationofAMDtonotify anypersonofsuchrevisions orchanges.
AMDMAKESNOREPRESENTATIONSORWARRANTIESWITHRESPECTTOTHECONTENTSHEREOFANDASSUMESNORESPONSIBILITYFORANYINACCURACIES,ERRORSOROMISSIONSTHATMAYAPPEARINTHISINFORMATION.
AMDSPECIFICALLYDISCLAIMSANYIMPLIEDWARRANTIESOFMERCHANTABILITYORFITNESSFORANYPARTICULARPURPOSE.INNOEVENTWILLAMD BELIABLETOANYPERSONFORANYDIRECT,INDIRECT,SPECIALOROTHERCONSEQUENTIALDAMAGESARISINGFROMTHEUSEOFANYINFORMATIONCONTAINEDHEREIN,EVENIFAMDISEXPRESSLYADVISEDOFTHEPOSSIBILITYOFSUCHDAMAGES.
ATTRIBUTION
©2016AdvancedMicroDevices,Inc.Allrightsreserved.AMD,theAMDArrowlogo,FirePro andcombinations thereofaretrademarksofAdvancedMicroDevices,Inc.intheUnitedStatesand/orotherjurisdictions.OpenCL andtheOpenCLlogoaretrademarksofApple, Inc.andused bypermission ofKhronos.PCIe andPCIExpress areregisteredtrademarksofPCI-SIGCorporation.Othernamesareforinformational purposes only andmaybetrademarksoftheirrespectiveowners.


















