
RACTICAL APPROACH FOR PROVIDING QOS IN THE INTERNET …telkamp/papers/qos-internet-ieeecomm.pdf ·...
20
- 1 - A PRACTICAL APPROACH FOR PROVIDING QOS IN THE INTERNET BACKBONE XiPeng Xiao, Redback Networks Inc. Thomas Telkamp, Global Crossing Ltd. Victoria Fineberg, Independent Consultant Cheng Chen, NEC Corp. Lionel M. Ni, Michigan State University Abstract This article proposes a practical approach for providing Quality of Service (QoS) in the Internet backbone. The approach considers not only technical but also economic factors. We first present an architecture overview of the Internet, Internet Service Provider (ISP) billing models, and how ISPs provision their networks. We then analyze causes of QoS-related problems, and propose a practical approach for providing QoS. This approach makes use of good network design, Differentiated Services (DiffServ), traffic protection, traffic engineering, and traffic management techniques. The relative importance of these techniques, and their relative positions in this integrated QoS solution, are pointed out. Although this approach largely focuses on issues within a single ISP domain, if multiple ISPs adopt such an approach (or a similar approach), inter-domain QoS can also be provided. 1. Introduction QoS is much needed for the Internet. In short, end-users need it for their real-time and mission-critical traffic, and ISPs need the value-added service to increase revenue. In this article, we present the QoS issues in the real world and propose a practical approach for providing QoS in the Internet backbone based on our experiences with a global ISP. The organization of this article is as follows. First, we present an architecture overview of the Internet, how ISPs bill their customers and how they provision their networks. Next, we examine QoS- related problems in ISP networks. This provides background information for readers to evaluate the effectiveness and practicality of any given QoS approach. We then present our approach that uses good
Transcript of RACTICAL APPROACH FOR PROVIDING QOS IN THE INTERNET …telkamp/papers/qos-internet-ieeecomm.pdf ·...

- 1 -
A PRACTICAL APPROACH FOR PROVIDING
QOS IN THE INTERNET BACKBONE
XiPeng Xiao, Redback Networks Inc.
Thomas Telkamp, Global Crossing Ltd.
Victoria Fineberg, Independent Consultant
Cheng Chen, NEC Corp.
Lionel M. Ni, Michigan State University
Abstract
This article proposes a practical approach for providing Quality of Service (QoS) in the Internet
backbone. The approach considers not only technical but also economic factors. We first present an
architecture overview of the Internet, Internet Service Provider (ISP) billing models, and how ISPs
provision their networks. We then analyze causes of QoS-related problems, and propose a practical
approach for providing QoS. This approach makes use of good network design, Differentiated Services
(DiffServ), traffic protection, traffic engineering, and traffic management techniques. The relative
importance of these techniques, and their relative positions in this integrated QoS solution, are pointed
out. Although this approach largely focuses on issues within a single ISP domain, if multiple ISPs adopt
such an approach (or a similar approach), inter-domain QoS can also be provided.
1. Introduction
QoS is much needed for the Internet. In short, end-users need it for their real-time and mission-critical
traffic, and ISPs need the value-added service to increase revenue. In this article, we present the QoS
issues in the real world and propose a practical approach for providing QoS in the Internet backbone
based on our experiences with a global ISP.
The organization of this article is as follows. First, we present an architecture overview of the
Internet, how ISPs bill their customers and how they provision their networks. Next, we examine QoS-
related problems in ISP networks. This provides background information for readers to evaluate the
effectiveness and practicality of any given QoS approach. We then present our approach that uses good

- 2 -
network design, Differentiated Services (DiffServ), a traffic protection scheme and traffic engineering
(TE) to provide QoS. At the end, the effectiveness of our approach is discussed.
1.1 Architecture Overview of the Internet
From a high level, an ISP network consists of three parts: the access network, the metro/regional
backbone and the long haul network. The architecture is shown in Fig. 1 below. The access network
connects various users (e.g., homes, corporate offices) to the ISP Points of Presence (POPs). Link
capacity in the access network is traditionally low (DS-3/E3 or lower) and is getting higher with the
introduction of metro Ethernet and other technologies. Other users collocate with their ISP in the POPs.
The metro/regional backbone distributes some traffic between POPs and backhauls other traffic to the
Super-POP where it can be sent across the long haul network to a remote POP. Link capacity in the
metro/regional backbone and the long haul network is typically high: Gigabit Ethernet (GigE), or OC-
48c/STM-16 (or higher). Data Centers (DC) may be connected to the metro/regional backbones as shown
in “POP / DC”.
•DSL•Cable•TDM•T1/E1•DS3/E3•Ethernet
•GigE•OC-48c/STM16
SuperPOP
SuperPOP
POPPOP POP /DC
POP /DC
POP /Colo
POP /Colo
SuperPOP
SuperPOP
POP /DC
POP /DC
POPPOP
POP /Colo
POP /Colo
•GigE•OC-48c/STM16
•DSL•Cable•TDM•T1/E1•DS3/E3•Ethernet
AccessNetwork
AccessNetwork
Metro / RegionalBackbone
Metro / RegionalBackbone
Long HaulNetwork
Service Provider Network
•OC-48c/STM16•OC-192c/STM64
Figure 1. Architecture overview of an ISP network
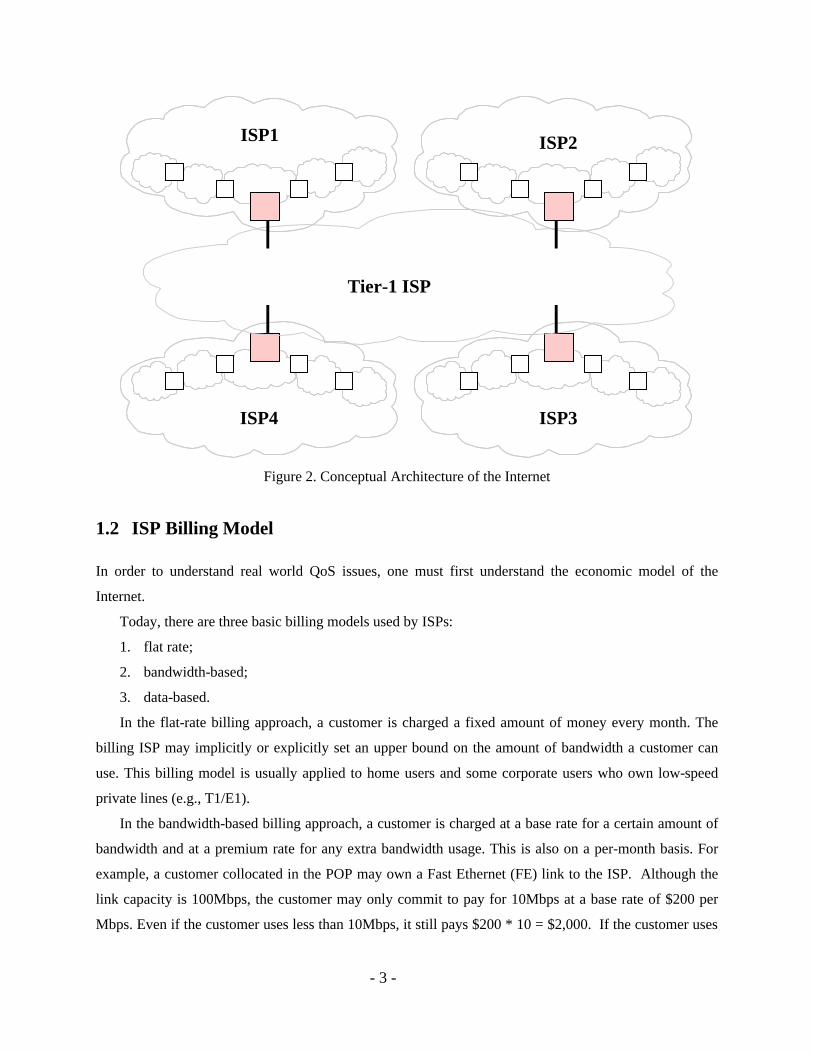
The Internet is an inter-connection of many ISP networks, as shown in Fig. 2.
- 3 -
ISP1
Tier-1 ISP
ISP3
ISP2
ISP4
Figure 2. Conceptual Architecture of the Internet
1.2 ISP Billing Model
In order to understand real world QoS issues, one must first understand the economic model of the
Internet.
Today, there are three basic billing models used by ISPs:
1. flat rate;
2. bandwidth-based;
3. data-based.
In the flat-rate billing approach, a customer is charged a fixed amount of money every month. The
billing ISP may implicitly or explicitly set an upper bound on the amount of bandwidth a customer can
use. This billing model is usually applied to home users and some corporate users who own low-speed
private lines (e.g., T1/E1).
In the bandwidth-based billing approach, a customer is charged at a base rate for a certain amount of
bandwidth and at a premium rate for any extra bandwidth usage. This is also on a per-month basis. For
example, a customer collocated in the POP may own a Fast Ethernet (FE) link to the ISP. Although the
link capacity is 100Mbps, the customer may only commit to pay for 10Mbps at a base rate of $200 per
Mbps. Even if the customer uses less than 10Mbps, it still pays $200 * 10 = $2,000. If the customer uses

- 4 -
more than 10Mbps, it pays $300 for each extra Mbps. The committed bandwidth value can be 0. Because
the base rate is lower than the premium rate, it is in the customer’s best interest to commit to
approximately as much bandwidth as it needs. The prices reflect enhanced services offered by the ISPs,
e.g., equipment hosting, some management, power supply, etc., and are decreasing over time.
Occasionally, an upper bound on bandwidth usage may also be specified and any traffic exceeding
that bound will be discarded. This model applies to customers collocated in POPs (including Internet Data
Centers) and customers with high-speed private lines, i.e., DS-3 (45Mbps) or higher.
The instant bandwidth values of a link vary in time. So which value should be used for billing and
network planning? Most often, the 95th-percentile value is used. Basically, each network port is sampled
using Simple Network Management Protocol (SNMP) at a fixed frequency, e.g. once per minute.
Assuming that the total of N bandwidth samples is collected in a month and sorted in the ascending order,
the N*95%th value is the 95th-percentile value. (For example, if there are 200,000 values all together in the
ascending order, the 190,000th value is the 95th-percentile value). All bandwidth values mentioned in this
article are the 95th-percentile values unless stated otherwise.
The data-based billing approach is similar to the bandwidth-based approach, except that customers
are charged on a per-MegaByte basis instead of on a per-Mbps basis. The usage-based billing is based on
a specific amount of MegaBytes (as opposed to the 95th percentile described for the bandwidth-based
billing) that is accurately obtained by the end of each month.
An ISP may use all three billing approaches, with different customers billed differently. In addition,
billing is generally insensitive to traffic destinations (although some ISPs do provide destination-sensitive
billing).
Note that billing is performed for both directions of traffic, sent and received. The Service Level
Agreements (SLAs) may specify that if a certain percent of the customer packets is dropped in the
network, the ISP would provide partial credits or discounts.
1.3 ISP Networks: Over-subscribed or Over-provisioned
In order to evaluate what approach is appropriate for providing QoS, one must also know how ISPs
provision their networks.
Many ISPs claim that they over-provision their networks, but it is not uncommon for users to hear
that ISP networks are over-subscribed. So what is the reality? This in fact depends on which billing
model is used.
With the flat-rate billing approach, which is typically applied to low-end customers in the access
network, ISPs do not get more revenue for sending or receiving more customer traffic. Therefore they
- 5 -
tend to oversubscribe the uplinks (i.e., links carrying customer traffic towards the backbone) in order to
maximize return on equipment investment.
With the bandwidth-based and data-based billing approaches, which are typically applied to high-end
customers in the access network and collocated customers in the POPs, the situation is different. ISPs can
get more revenue for sending and receiving more customer traffic. Therefore, they tend to over-provision
the uplinks to accommodate any customer traffic burst and growth. Over-subscription and over-
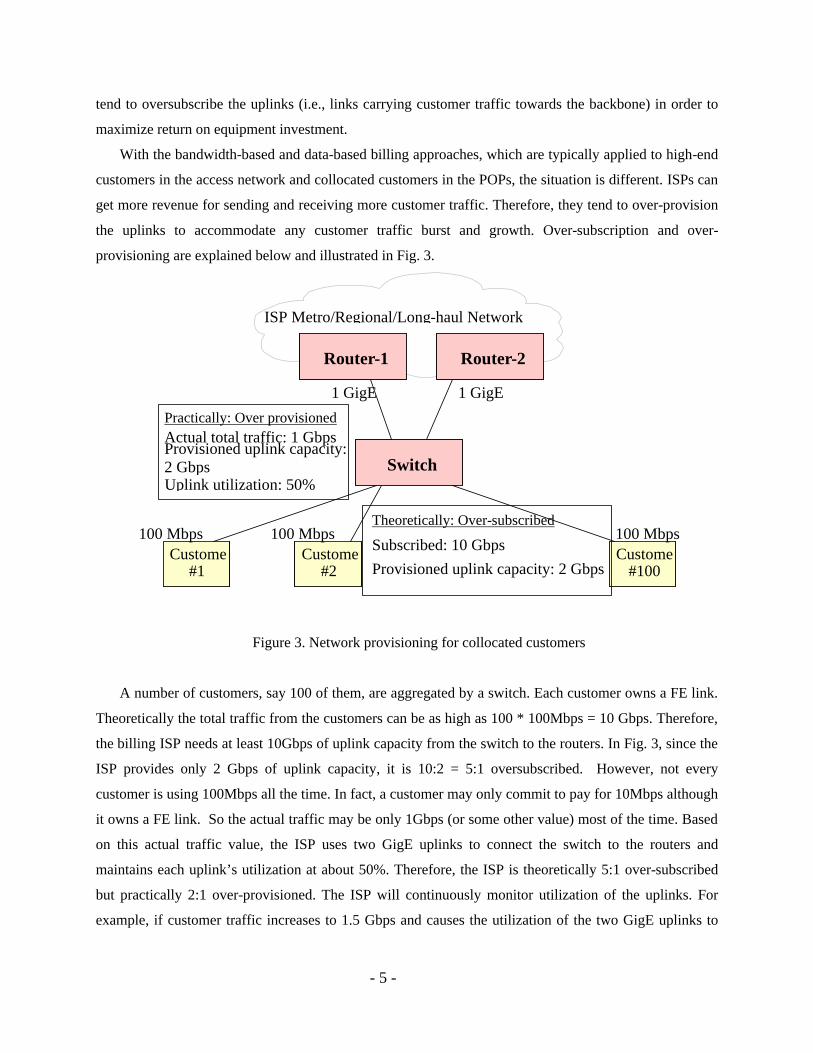
provisioning are explained below and illustrated in Fig. 3.
Switch Switch
Customer #1 Customer #1
Customer #2 Customer #2
Customer #100 Customer #100
100 Mbps (FE)
100 Mbps (FE)
100 Mbps (FE)
Theoretically: Over-subscribed
Subscribed: 10 Gbps
Provisioned uplink capacity: 2 Gbps
ISP Metro/Regional/Long-haul Network
Router - 1 Router - 1 Router - 2 Router - 2
1 GigE 1 GigE
Practically: Over provisioned Actual total traffic: 1 Gbps Provisioned uplink capacity: 2 Gbps
Uplink utilization: 50%
Figure 3. Network provisioning for collocated customers
A number of customers, say 100 of them, are aggregated by a switch. Each customer owns a FE link.
Theoretically the total traffic from the customers can be as high as 100 * 100Mbps = 10 Gbps. Therefore,
the billing ISP needs at least 10Gbps of uplink capacity from the switch to the routers. In Fig. 3, since the
ISP provides only 2 Gbps of uplink capacity, it is 10:2 = 5:1 oversubscribed. However, not every
customer is using 100Mbps all the time. In fact, a customer may only commit to pay for 10Mbps although
it owns a FE link. So the actual traffic may be only 1Gbps (or some other value) most of the time. Based
on this actual traffic value, the ISP uses two GigE uplinks to connect the switch to the routers and
maintains each uplink’s utilization at about 50%. Therefore, the ISP is theoretically 5:1 over-subscribed
but practically 2:1 over-provisioned. The ISP will continuously monitor utilization of the uplinks. For
example, if customer traffic increases to 1.5 Gbps and causes the utilization of the two GigE uplinks to

- 6 -
increase to about 75%, the ISP would add a third GigE link to keep the link utilization at about 50%, an
“ideal” link utilization at which many ISPs would like to maintain.
1.4 What Causes QoS-related Problems
Given the background information presented above, we are now ready to analyze causes of QoS
problems.
Generally speaking, QoS related problems can be divided into two categories: non-network-related
problems and network-related problems.
Causes of non-network-related problems include:
§ Overloaded data servers (e.g. Web or email) that users are trying to access;
In this case, common ways to improve QoS are to upgrade the data servers or increase the number
of data servers and use a better load-balancing scheme among the data servers.
§ Operator errors;
Configuring routers/switches is a complex and error-prone process. For example, duplicate IP
addresses can be mistakenly configured and cause routing problems.
Dealing with non-network-related problems is outside the scope of this article. But it is worth
pointing out that providing Operations Support System (OSS) for IP networks, including provisioning
tools for simplifying network device configuration, is essential to reduce operator errors.
Causes of network-related problems include:
§ Equipment problems;
Routers/switches are very complex systems with sophisticated software and hardware that are
required to process millions of packets per second. Equipment vendors are compelled to deliver
products as early as possible. It is thus no big surprise that routers/switches have hardware and
software problems. Therefore, something must be done to increase network availability,
especially for important traffic.
§ Lack of access capacity;
For economic reasons, there are always customers with slow access links (e.g. dialup modems)
and/or over-subscribed uplinks (described in Section 1.3). Technical solution for this kind of
problem is clear:
a. adding capacity;
b. classifying traffics and marking them differently for different subsequent treatment using
policing, shaping, etc. This will be further discussed in our proposed approach.

- 7 -
However, it should be pointed out that providing QoS may not make economic sense here if users
are not willing to pay for it.
§ Uneven traffic distribution that causes some links to be congested;
This is by far the most common cause of network-related QoS problems. Even though the average
link utilization of a network can be low, say 30% during a peak hour, a small number of links can
still have very high link utilization (close to 100%). Such congested links will cause long packet
delay and jitter or even packet loss. The causes of such hot spots in the network can be:
a. Unexpected events such as fiber cuts or equipment failures;
b. Traffic pattern shifts where the network topology and capacity cannot be changed as rapidly.
In the backbone, new capacity may not always available at the right place and at the right
time. As a result, the sudden success of a Web site, an unplanned broadcast of multimedia
traffic, or gradual traffic demand shift can all cause some links to become congested.
2. A Practical Approach for Providing QoS
In this section, we propose a QoS approach to address problems that are un-addressed in Section 1.4. This
approach is discussed step by step. The steps are listed in the order of decreasing importance. ISPs should
start from the first step and then add additional steps if needed. Depending on network condition, an ISP
may choose to stop at any step.
In the proposed approach, we emphasize the importance of a good network design. After a network is
carefully designed, DiffServ, a traffic protection scheme and traffic engineering can be deployed to make
the network multi-service capable and to increase the network’s survivability in emergency.
Complex schemes such as the per-flow queueing/scheduling approach (such as end-to-end RSVP) are
considered undesirable in our approach. Among many other problems, the most fundamental problem of
any complex schemes is that it is very difficult for network operators to specify the QoS-related
parameters (e.g., output rate and size of a large number of queues), and manage these schemes effectively.
The essence of DiffServ is to divide traffic into a few classes, and handle them differently (especially
under adverse network conditions e.g. caused by equipment failure) [3]. Protection schemes such as fast
reroute promptly switch traffic to an alternative path when there is a network failure to minimize packet
loss and delay. Traffic engineering is used to map traffic onto the network in such a way that congestion
caused by uneven traffic distribution is avoided or can be quickly relieved. Compared to the traditional
traffic management schemes such as policing, shaping and buffer management, Traffic engineering can
affect traffic and network performance at a much larger scale.

- 8 -
2.1 Step 1: Design the Network Right
Networks should be carefully designed, provisioned and implemented. Single points of failure,
bottlenecks under normal conditions and during router/link failure should be removed whenever possible.
Capacity should be sufficiently provisioned so that even when the most critical router/link fails, the
network with the aid of traffic engineering can still carry all the traffic. Routing, including both Interior
Gateway Protocol (IGP) and Border Gateway Protocol (BGP), and peering policy should be thoroughly
thought out and correctly implemented. Security measures should be deployed, for example to prevent
Denial of Service (DoS) attacks. Audits should be regularly performed to correct mistakes in router
configurations. ISPs should also educate their customers to upgrade their last mile circuits and TCP stacks
if applicable. These are by far the most important and useful things to do for providing QoS in the
Internet. We do not intend to present detailed network design guidelines. Many of them can be found in
[2].
In our QoS approach, good network design serves to prevent QoS-related problems from happening.
2.2 Step 2: Divide Traffic into Multiple Classes
In our proposed approach three classes of services are provided:
• Premium,
• Assured, and
• Best Effort.
Premium service provides reliable, low-delay and low-jitter service. Real-time traffic (e.g., VoIP and
video conferencing) and mission-critical traffic (e.g., financial traffic) can benefit from such a service.
Assured service provides reliable and predictable service. Non-real-time VPN traffic can benefit from it.
Best effort service is the traditional Internet service.
A customer can choose the appropriate service based on the nature of its traffic (e.g., real-time or
interactive or non-interactive). But what service an application will receive is eventually determined by
the customer’s willingness to pay. So it is possible that one customer’s email traffic receives Assured
service while another customer’s video-conferencing traffic receives Best Effort service.
Some people may think that more than three classes of traffic are needed. Two questions can be used
to help deciding how many classes are needed. First, what are the targeted applications for each traffic
class? If there is no targeted application for a traffic class, that class should be eliminated. Second, how to
distinguish different traffic classes to the end users? If a traffic class A is more expensive than class B, but
an ISP cannot clearly show that class A has better service, then A should be eliminated because

- 9 -
(eventually) nobody is going to pay for it. The second question is particularly important because answer
to the first question can be somewhat arbitrary.
In our approach, the first question has been answered in this section. The second question will be
answered in the subsequent sections.
The above discussion focuses on user traffic. Ideally, network control traffic should be separated from
user traffic and should have the highest priority. But then one more class is needed. If a network is
designed carefully, control traffic should be able to share the same class with Premium traffic.
2.3 Step 3: Protection for Premium Traffic and Traffic Engineering
Multi-Protocol Label Switching (MPLS) [4] is used in our approach for traffic protection and traffic
engineering. MPLS is an advanced forwarding scheme. It extends IP routing with respect to signaling and
path controlling. It has been deployed in many Tier-1 ISPs including AT&T and Global Crossing [5].
2.3.1 Traffic Protection
First, MPLS label switched paths (LSPs) are configured in the network. Each ingress router will have
two LSPs to the egress. One LSP is for Premium traffic to that egress and the other is shared by Assured
and Best Effort traffic. The Premium LSP will have Fast Reroute [6] enabled. The basic idea of fast
reroute is to have a patch LSP pre-configured for a link, or a router, or a segment of the path consisting of
multiple links and routers, which is to be protected. This link or router or path segment is called
“protected segment” hereon. When there is a failure in a protected segment, the router that is immediately
upstream of the protected segment (called protecting router) will detect the failure from layer-2
notification. The patch LSP will then be used to carry traffic to the end of the protected segment. This
protection can take effect within 50ms. During fast reroute, the path taken by the LSP can be sub-optimal.
To correct that, the protecting router will send a message to the ingress router of the LSP, which will then
compute a new path for the LSP and switch traffic to the new LSP. If necessary, a hot-standby LSP can be
pre-computed. This process is illustrated in Fig. 4.

- 10 -
IngressLSR
IngressLSR
LSRLSR EgressLSR
EgressLSR
LSRLSRLSRLSRLSRLSR LSRLSR
LSRLSR LSRLSR LSRLSR LSRLSR LSRLSR LSRLSR
LSRLSR LSRLSR LSRLSR LSRLSR LSRLSR
(3) Rerouted primary LSP
(1) Primary path (e.g., real-time)
Protected routerProtected segment
(2a) Patch LSP (2b) Patch LSP
MPLS Cloud
Figure 4. Fast reroute
Fast reroute is essential for Premium traffic because, when a router or a link fails, it takes IGP, e.g.
OSPF or IS-IS, seconds to converge (i.e., to propagate information and re-compute paths) in a large
network. During this time period, packets sent along an affected path will be dropped. This is
unacceptable for Premium traffic. However, fast reroute also adds considerable complexity to the
network. In the future, if IGP can converge in sub second [7], the need for fast reroute may be reduced.
A large number of LSPs may be needed if the number of routers in the network is large. In order to
increase the system’s scalability, a LSP hierarchy can be used via label stacking [8].
In our approach, traffic protection serves to provide high availability for Premium traffic.
2.3.2 Traffic Engineering
Because network topology and capacity cannot and should not be changed rapidly, uneven traffic
distribution can cause high utilization or congestion in some part of a network, even when total capacity

- 11 -
of the network is greater than total demand. Uneven traffic distribution can be caused by traffic demand
shift and/or random incidents such as fiber cut.
In our approach, each ingress router will have two LSPs to an egress. One LSP is for Premium traffic
to that egress and the other is shared by Assured and Best Effort traffics. Traffic from customers
(including other ISPs) is classified at the ingress. Classification is usually done on a per interface basis,
(i.e., per customer basis, because different customers have different incoming interfaces). Network
operators can also use multi-field (source and destination IP addresses, port numbers, and protocol ID,
etc) classification to divide traffic from the same customer into multiple classes, which can be considered
as a value-added service. In addition, the EXP fields of the different classes of packets are set
accordingly.
In order to avoid concentration of Premium traffic at every link, an upper limit is set for each link
regarding how much bandwidth can be reserved by Premium traffic. When that portion of bandwidth is
not used by Premium traffic, it can be used by other classes of traffics if that is desirable. The percentage
of the Premium traffic should be determined by policy of the ISP and the amount of demand for Premium
service. DiffServ-aware traffic engineering is done for these two sets of LSPs to avoid congestion at every
link [9][10].
A network designed this way should not have any packet loss or high latency under normal network
conditions. Even when there is a router or a link failure, the constraint-based routing algorithm in the
routers will dynamically re-compute LSPs so that congestion will only be transient. In general, the
severity of a congestion depends on the traffic patterns and the location of the congestion. It is usually
easier to reroute around a congestion when the total capacity of the network is greater than the total traffic
demand.
In our approach, traffic engineering serves two purposes: (1) to prevent (as much as possible)
congestion caused by uneven traffic distribution from happening; and (2) if congestion does happen, to
relieve it quickly; By doing traffic engineering in a DiffServ-aware manner, a third purpose is also served:
(3) to make the percentage of Premium traffic reasonably low in every link so that: (a) delay and jitter of
Premium traffic are low, and (b) if necessary, Premium traffic can preempt resources of low priority
traffic (which is not possible if all traffic is of high priority).
2.4 Step 4: Class-based Queueing and Scheduling
Based on the EXP field of the MPLS header, packets of the different classes are put into different queues.
How to configure output rate and size for these queues is a difficult task. One possible approach is
described below.

- 12 -
The arrival rate of each queue at an egress interface can be obtained by summing up the rates of all
LSPs for that class that are transiting through this interface. The rate of these LSPs can be obtained via
SNMP. Depending on the relative importance (e.g. monetary value) of each class, different weight can be
introduced. For example, the weight for Premium, Assured and Best Effort traffic can be set to 6, 3 and
1, respectively. Output rate of each queue can then be set as:
o(q) = bw * {[ w(q)*i(q) ] / [ 6*i(PQ) + 3*i(AQ) + 1*i(BQ) ]}, where
§ q = queue of interest. For the Premium queue q=PQ; for the Assured queue q=AQ; for the Best
Effort queue q=BQ;
§ bw = bandwidth of the output interface (e.g., 2.5 Gbps for an OC-48c interface);
§ o(q) = output rate of a queue “q” calculated as a fraction of the output interface bandwidth, bw;
§ w(q) = weight assumed for each queue, e.g., w(PQ) = 6, w(AQ) = 3, w(BQ) = 1;
§ i(q) = input rate of the queue of interest, where q can be PQ or AQ or BQ.
For example, for the Premium queue, the formula becomes:
o(PQ) = bw * {[ 6*i(PQ) ] / [ 6*i(PQ) + 3*i(AQ) + 1*i(BQ) ]},
And again, note that all bandwidth values are the 95th-percentile values. Also, MPLS simplifies the
above scheme, because per-(LSP, EXP) statistics can be obtained.
Because traffic grows, i(PQ), i(AQ) and i(BQ) change over time. Therefore, the output rates of these
queues should be adjusted periodically, e.g., weekly [11]. But note that adjustment of queue rates only
affects performance of traffic going through a specific interface. Compared to traffic engineering, queue
rate adjustment (and other traffic management schemes) can be considered as micro control.
From the traffic contract, the output rate of a queue, and other requirements such as maximum
allowable queueing delay, the size of the queue can then be determined as follows:
queue size = output rate of the queue * maximum allowable queueing delay.
Using the approach described above, the over-provisioning factor for the PQ, i.e., the ratio of (output
rate / input rate), is usually far greater than 1.0, depending on the relative amount of Premium, Assured
and Best Effort traffics. This is enough to guarantee that the PQ queue is empty or very short most of the
time. Therefore, the delay and jitter of the Premium traffic will be sufficiently low. Simulations have been
done to study the effect of the over-provisioning factor on delay and jitter [12, Appendix]. They
confirmed the validity of our approach.
Another alternative is to use a priority queue for Premium traffic. That is, Premium traffic will always
be sent before other traffic. In fact, this can be more effective in distinguishing Premium service from
other services. However, care must be taken to ensure that Premium traffic will not starve other traffic.

- 13 -
In our approach, queuing that considers the class of service (CoS) and scheduling are the actual
mechanisms to ensure that high priority traffic is treated preferably. It is important to prevent congestion
(if any) of low priority traffic from affecting performance of high priority traffic. This is useful when
network capacity becomes insufficient in meeting demand because of a fiber cut or other equipment
failure.
2.5 Step 5: Deploy Other Traffic Management Schemes
In this section, we discuss the applicability of policing, shaping and Random Early Detection (RED) [0].
2.5.1 Policing and shaping
When a customer signs up for Internet service, it will have a SLA with its ISP. The SLA specifies the
amount of traffic (in each class if applicable) that the customer can send/receive. Many people thought
that this means that ISPs will always do policing and/or shaping. But whether this is true or not actually
depends on how a network is provisioned, which is in turn determined by the billing model.
In the access network where the flat-rate billing model is applied, the network is generally over-
subscribed (not just theoretically but practically). Therefore, policing and shaping are useful to ensure that
no customer can consume more bandwidth than it signed up for. The policing/shaping parameters are
usually fairly static in such case. However, policing and shaping may affect performance of the access
device. In that case, an alternative is to aggregate traffic from many customers and police/shape it
collectively. Individual customer’s traffic is only policed/shaped when that customer is causing trouble
for others.
With the bandwidth-based or data-based billing models, because the ISP can increase revenue when
the customer sends/receives more traffic than the SLA specifies, there is no need for the ISP to police or
shape a customer’s traffic (but accounting will always be done), unless the customer is causing problems
for others. From Fig. 3 we can see that unused uplink capacity is usually significantly greater than the
amount that a single customer can send or receive (1Gbps vs. 100 Mbps in Fig. 3), therefore it is quite
unlikely that a customer can cause problems for others. Here, a certain degree of over-provisioning
enables the ISP to accommodate customers’ increased traffic demand at any time. In the relatively rare
case when a customer is causing problems for others or is being attacked (e.g., more than 100Mbps of
traffic was sent to a customer connected by a FE link), traffic from/to that particular customer can be
policed/shaped. Excess traffic can be marked with high drop probability or dropped immediately. With
this kind of billing model, the amount of traffic specified in a SLA is mainly for network planning
purpose.

- 14 -
In some cases, a customer may request an upper bound on the amount of money it pays for bandwidth
usage. In these cases, the ISP will need to do policing/shaping.
2.5.2 RED/WRED
RED is a buffer management scheme designed to prevent tail-drop caused by traffic burst. Backbone
routers can generally buffer traffic for up to 100ms per port. If traffic bursts over output line-rate for
longer than that, buffer will become full and all subsequent packets will be dropped. Tail-drop causes
many TCP flows to decrease and later increase their rate simultaneously and can cause oscillating
network utilization. By preventing tail-drop, RED is widely believed to be useful for enhancing network
performance.
Weighted RED (WRED) is a more advanced RED scheme. It depends on other mechanism(s) such as
classification/marking/policing to mark packets with different drop priorities. WRED will then drop them
with different probabilities (which also depends on the average queue length).
RED/WRED is useful to prevent transient burst from causing tail-drop. However, it should be noted
that it is quite difficult to set the (W)RED parameters (e.g. different drop probabilities at different queue
lengths) in a scientific way. Guidelines are yet to be developed on how to set such parameters. If a
backbone’s link utilization (time-averaged over a period of 1-5 minutes) can be maintained at 50% or
lower, there should be sufficient capacity to accommodate transient burst to avoid tail-drop. The
dependence on (W)RED can thus be reduced.
In general, traffic engineering is more effective in controlling traffic distribution in a network and has
a bigger impact on network performance, compared to traffic management schemes such as policing,
shaping, and WRED. It should be invoked for QoS purpose before traffic management schemes.
In our approach, policing, shaping and WRED are the enforcing mechanisms. They are used only
when all other techniques such as traffic engineering fail to prevent congestion from happening. In that
case, these traffic management schemes make sure that high priority traffic is treated preferably compared
to low priority traffic.
2.6 Effectiveness of Our Approach
We examine the effectiveness of our approach with respect to:
1. the effectiveness in distinguishing different classes of traffic; and
2. the effectiveness in meeting the delay and jitter requirements of applications.

- 15 -
2.6.1 Distinguishing different classes of traffic
When a link or a router fails, it takes IGP, MPLS and BGP, from seconds to minutes to re-converge.
During this period, packets will experience long delay or will be dropped. MPLS fast reroute can protect
Premium traffic during the re-converge period. Therefore network availability is better for Premium
traffic than for Assured traffic. Besides, a larger ratio of (output rate / input rate) for the Premium queue
enables Premium traffic to have lower delay and jitter.
Because Assured traffic can use 3 (or any other configured value) times more resources than Best
Effort traffic, its performance will be better than Best Effort traffic, especially when there is failure and
link utilization becomes high. Practically, an ISP that plans to offer QoS can begin with just the Premium
class and the Best Effort class. The Assured class can be added later when the need arises.
2.6.2 Meeting the delay and jitter requirements of applications
The described approach has almost fully been implemented in Global Crossing's global IP backbone.
MPLS traffic engineering has been deployed since the 2nd quarter of 1999. It turned out to be very
effective in meeting the delay and jitter requirements of applications. Generally, coast-to-coast round trip
delay in the U.S. is below 80ms and jitter is below 2ms. A snapshot of the network delay matrix is
showed in Figure 5. The hubs ams2, cdg2, cph1, fra2 and lon3 are located in Europe, the rest is in the US.
This is a very good network performance that far exceeds ITU G.114 recommendations on delay for
applications (see Table 1. Note that Figure 5 lists round-trip delay while Table 1 lists one-way delay).

- 16 -
Table 1. ITU G.114 Delay Recommendations
One-way Delay Characterization of Quality
0 – 150 ms “acceptable for most user applications”
150 – 400 ms “may impact some applications”
Above 400 ms “unacceptable for general network planning purposes”
In case of a node or link failure, traffic engineering will automatically reroute traffic and avoid any
congestion. This may increase delay slightly for some traffic because a longer path is taken, but will
prevent packet loss and maintain low jitter. Figure 6 shows the result of an simulation at a certain time in
the past, of part of the network, with (left) and without (right) traffic engineering:
• The simulator used is the NPAT package from WANDL;
Figure 5. Round-trip delay matrix of Global Crossing’s worldwide Backbone

- 17 -
• The picture shows part of Global Crossing’s network in the California Bay Area;
• Each green dot represents a router;
• Each line between two dots represents a link between the two routers. Each line has two colors,
showing its utilization in each direction. Red color (utilization 90% or higher) implies
congestion. Note that there is no congestion in the left picture and there are 2 instances of
congestion in the right picture.
3. Conclusions
Today the Internet is not perceived as reliable enough for critical missions. But this is not because of lack
of advanced mechanisms such as per-flow queueing/policing/shaping. Instead, the challenge lies in how
to manage these mechanisms effectively and make the right tradeoff between simplicity and more control.
Good network design, simplicity, high availability and protection are the keys for providing QoS in
the Internet backbone. Good network design plus a certain degree of over-provisioning not only makes a
network more robust against failure, but also prevents many network problems from happening and
eliminates the need for complex mechanisms designed to solve those problems. This keeps the network
simple and increases its availability. Three traffic classes, i.e., Premium, Assured and Best Effort, are
sufficient to meet foreseeable customer needs. Different traffic classes will be handled differently,
especially under adverse network conditions. MPLS fast reroute or other protection schemes should be
Figure 6. Network scenario with (left) and without TE

- 18 -
used to protect Premium traffic during router or link failure. When failure happens in one part of the
network, traffic engineering should be used to move traffic to other part of the network. DiffServ-aware
traffic engineering can be used to prevent concentration of high priority traffic at any link so that high
priority traffic will have low delay and jitter, and can be treated preferably at the expense of other classes
of traffic if necessary. In the backbone, traffic management schemes such as policing and shaping should
be treated as micro control and be used when traffic engineering is insufficient. Traffic management
schemes are more appropriate for the access network before the last-mile circuits and the congested
uplinks are upgraded.
4. Acknowledgement
The authors would like to thank Clarence Filsfils, Bruce Davie of Cisco Systems, Xiaowen Mang of
Photuris Inc., and Lin Hu of China Netcom for the helpful discussions.
5. Reference
1. X. Xiao and L. Ni, "Internet QoS: A Big Picture", IEEE Network Magazine, March/April, pp. 8-18, 1999.
2. Cisco technical document, “Essential IOS Features Every ISP Should Consider” http://www.cisco.com/warp/public/707/EssentialIOSfeatures_pdf.zip.
3. S. Blake, D. Black, M. Carlson, E. Davies, Z. Wang, and W. Weiss, "An Architecture for Differentiated Services", RFC 2475, Dec. 1998.
4. E. Rosen, A. Viswanathan and R.Callon, "Multiprotocol Label Switching Architecture", RFC 3031, Jan. 2001.
5. X. Xiao, A. Hannan, B. Bailey, and L. Ni, "traffic engineering with MPLS in the Internet", IEEE Network magazine, March 2000.
6. V. Sharma and F. Hellstrand, “Framework for MPLS-based Recovery”, Internet draft, < draft-ietf-mpls-recovery-frmwrk-05.txt >, May 2002.
7. C. Alaettinoglu, V. Jacobson, and H. Yu, “Towards Millisecond IGP Convergence”, Internet draft, <draft-alaettinoglu-isis-convergence-00>, Nov. 2000.
8. K. Kompella, Y. Rekher, “LSP Hierarchy with MPLS Traffic Engineering”, Internet draft <draft-ietf-mpls-lsp-hierarchy-06.txt>, May 2002.
9. D. Awduche, A. Chiu, A. Elwalid, I. Widjaja, and X. Xiao, "Overview and Principles of Internet Traffic Engineering", RFC 3272, May 2002.
10. F. Le Faucheur, T. Nadeau, T. Telkamp, D. Cooper, J. Boyle, L. Martini, L. Fang, W. Lai, J. Ash, P. Hicks, A. Chiu, W. Townsend, D. Skalecki, and M. Tatham, “Requirements for support of Diffserv-aware MPLS Traffic Engineering”, Internet draft <draft-ietf-MPLS-diff-te-reqts-04.txt>, Apr. 2002.

- 19 -
11. X. Xiao, “Providing QoS in the Internet”, Ph.D. thesis, Dept. of Computer Science, Michigan State University, May 2000 (available for download at http://www.cse.msu.edu/~xiaoxipe).
12. V. Jacobson, K. Nichols and K. Poduri, “An Expedited Forwarding PHB”, RFC 2598, June 1999.
13. S. Floyd and V. Jacobson, “Random Early Detection gateways for Congestion Avoidance”, IEEE/ACM Transactions on Networking, Vol. 1, No. 4, Aug. 1993, pp.397-413.
About the Authors
Dr. XiPeng Xiao ([email protected]) is Director of Product Management at Redback Networks, Inc. He works with network service providers and defines product requirements for Redback. Prior to Redback, he was Sr. Manager of Advanced Technology at Global Crossing. XiPeng deployed MPLS, VPN and DiffServ in Global Crossing’s network. Before joining Global Crossing, he worked for Ascend Communications on MPLS and QoS. XiPeng received his Ph.D. degree in computer science from Michigan State University. (http://www.cse.msu.edu/~xiaoxipe).
Thomas Telkamp ([email protected]) is Director of Network Architecture at Global Crossing Ltd., responsible for the planning and architecture of Global Crossing's MPLS backbone, Internet services, and Virtual Private Networks (VPN). Before joining Global Crossing in January 1999, he was at AT&T-Unisource Communications Services (now Infonet Europe) and SURFnet. He also has been working as a consultant for several companies, including DANTE and Wunderman Cato Johnson (Y&R). His current interests include network modeling and analysis, traffic engineering methods and algorithms (inter- and intradomain), MPLS technology, and Quality of Service implementations. Victoria Fineberg ([email protected]) is a Senior Member of IEEE and a licensed Professional Engineer. After graduating with Masters Degree from the University of Illinois at Urbana-Champaign in 1989, Victoria joined AT&T Bell Laboratories which later became Lucent Technologies Bell Laboratories. Victoria’s professional interests include interworking technologies, QoS, MPLS, VPN and VoIP. Presently, she works as an independent consultant. Dr. Cheng C. Chen ([email protected]) received his PhD from Florida State University in 1981. He was a faculty member at the University of South Carolina in 1980 and at Temple University from 1981 through 1982. He has extensive working experience in network engineering including AT&T Bell Laboratories from 1982 through 1989, NEC America’s Advanced Switching Laboratories from 1989 through 1994, MCI from 1994 through 1997, and again NEC America from 1997 to the present. He has published over twenty technical papers and holds two patents. He has taught telecommunications courses as an adjunct professor in SMU’s Department of Electrical Engineering since January 2000. His research areas include IP/MPLS, QoS routing, traffic engineering, ATM switch performance, PNNI network engineering, network design, and network reliability engineering. Dr. Lionel M. Ni ([email protected]) earned his B.S. degree in electrical engineering from National Taiwan University in 1973 and his Ph.D. degree in electrical engineering from Purdue University, West Lafayette, Indiana, in 1980. He is a Fellow of IEEE and a professor in the Computer Science and Engineering Department at Michigan State University. He has published over 160 technical articles in refereed journals and proceedings in the areas of high-speed networks and high-performance computer systems. He has served as an editor of many professional journals. He was program director of the NSF Microelectronic Systems Architecture Program from 1995 to 1996. He has served as program chair or

- 20 -
general chair of many professional conferences. He has received a number of awards for authoring outstanding papers and also won the Michigan State University Distinguished Faculty Award in 1994.


















