
Providing fault tolerance in extreme scale parallel applications
17
Providing fault tolerance in extreme scale parallel applications What can the HPC community learn from the Database community Huub van Dam , Abhinav Vishnu, Bert de Jong [email protected] HPCDB @ SC’11, Seattle, Friday, Nov 18, 2011
-
Upload
hjjvandam -
Category
Technology
-
view
231 -
download
2
Transcript of Providing fault tolerance in extreme scale parallel applications

Providing fault tolerance in extreme scale parallel applicationsWhat can the HPC community learn from the Database communityHuub van Dam, Abhinav Vishnu, Bert de [email protected]
HPCDB @ SC’11, Seattle, Friday, Nov 18, 2011

Outline
Intro
Hard faultError detection
Redundancy for data protection
Transactional vs. Phased updates
Fault recovery
Soft errorsCharacteristics
Read errors
Compute errors: detectable and undetectable
Optimizing algorithms vs. Step algorithms
Summary
2

PNNL is taking on extreme scale computing
The extreme scale computing initiative
Attacks a broad range of aspectsParallelization and scalability
Hybrid computing
Performance analysis, debugging, etc.
Energy efficiency and consumption
Fault tolerance
Collaborative approachAbhinav Vishnu (Computer Scientist, Global Arrays developer)
Bert de Jong (Chemist, NWChem team leader)
Huub van Dam (Chemist, NWChem developer)
NWChem was used by 2009 Gordon Bell finalist Apra et al.E. Apra, A.P. Rendell, R.J. Harrison, T. Vinod, W.A. de Jong, S.S. Xantheas, SC’09, Portland, OR, SESSION: Gordon Bell Finalists, article 66, Doi:10.1145/1654059.1654127
3

Faults are inevitable at scale
Database community realizedFaults are fact of liveBack in 1980s (e.g. J. Gray, Proc. 7th Int. Conf. Very Large Databases, Sep 9-11, 1981, 144-154; T. Haerder, A. Reuter, Computing Surveys, 1983, 15, 287-317, Doi:10.1145/289.291)
4
0
0.2
0.4
0.6
0.8
1
1 1,000 1,000,000 1,000,000,000
Pro
bab
ilit
y
Number of Cores
Prob. 1.0e-8/Core
Prob. 1.0e-7/Core
Prob. 1.0e-6/Core
Peta ScaleTera Scale Exa
Scale
Ja
gu
ar
(OR
NL
)

Different views: DB vs. HPC
5
Databases High Performance
Computing
Run for a long time Run for a limited time
Serve many queries / requests Calculate one specific thing
Entrusted with unique business
critical data
If needed calculation can be
repeated
Reliability top priority Performance top priority
Up to some 5,000 cores(Google, Yahoo, Facebook, etc.)
Up to 225,000 cores
Advanced fault tolerance
strategies
Basic checkpoint restart up to
now
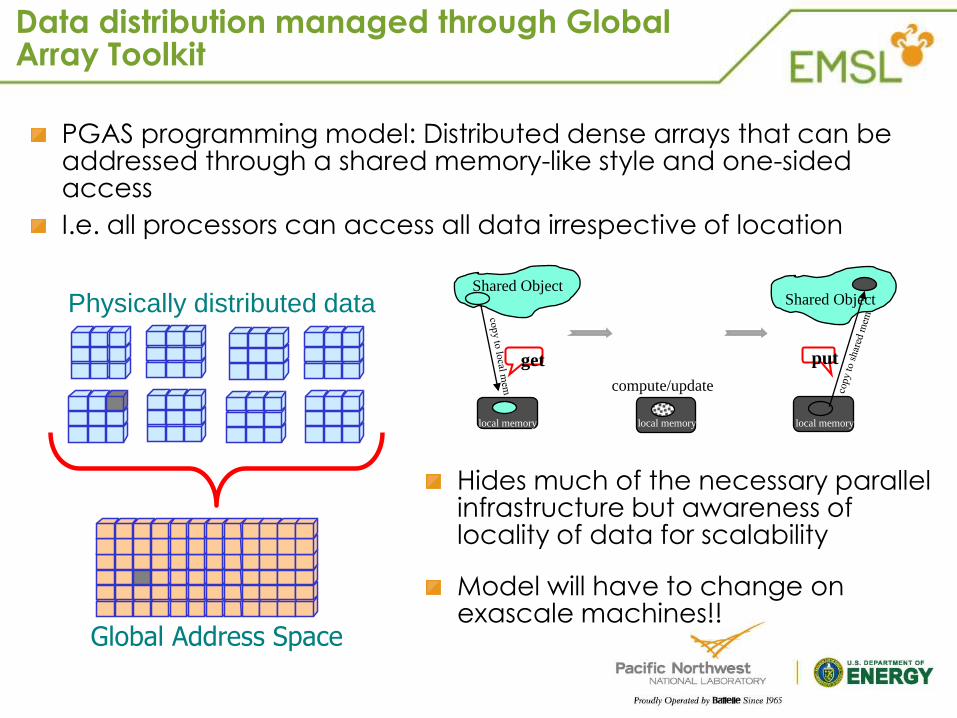
Data distribution managed through Global Array Toolkit
Physically distributed data
Global Address Space
PGAS programming model: Distributed dense arrays that can be addressed through a shared memory-like style and one-sided access
I.e. all processors can access all data irrespective of location
Hides much of the necessary parallel infrastructure but awareness of locality of data for scalability
Model will have to change on exascale machines!!
local memory
Shared Object
get
compute/update
local memory
Shared Object
local memory
put

How to handle hard faults?
Definition: A hard fault is an error that kills a process.
Examples:A power failure on a node
A process segmentation faults
Issues:How to detect a fault
How to protect against data loss
How to determine the state of the application
How to salvage the state of the application
7

Fault detection protocols
8
???
No Response
No Response
???
Node is dead
Requires
response
from remote
process,Less
Reliable
Network
Node
Ping message
RDMA Read
Reliable Notification,
Most
Reliable
Infiniband
A. Vishnu, H. van Dam, W. de Jong, P. Balaji, S.
Song, High Perf. Comp. (HiPC), 2010 Int. Conf.
on, pp.1-9, 19-22 Dec. 2010, Doi:
10.1109/HIPC.2010.5713195

Fault detection alternative
Process N only participates if valid contract in place
If contract expires N terminates itself
Manager concludes N died
M checks status of N with manager
Time to error detection increases with contract length
Communication decreases with contract length
9
Manager Proc M Proc N
Contract M
Contract N
Contract M Contract N
Contract
renewal
request
Contract
confirmation
Contract
enquiry N

How is data redundancy usedand data access orchestrated?
Proc 0 Proc 1 Proc 2 Proc 3
Working
Updating primary copy
Updating shadow copy
Done
H.J.J. van Dam, W.A. de Jong, A. Vishnu, J. Chem. Theory
Comput., 2011, 7, pp 66–75, Doi: 10.1021/ct100439u

Our approach vs. transactional
11
Our approach Transactions
Rolled into one:
a. Data transmission
b. Changing persistent
data
Separated:
a. Send data first
b. Change persistent data
only at commit
Memory efficient Stores data until commit
Three states for data
1. Available and valid
2. Available and corrupt
3. Unavailable
Two states for data
1. Available and valid
2. Unavailable
Only one update per task
allowed
Only one commit per task
allowed
M. Herlihy, J.E.B. Moss, “Transactional memory”
Proc. ISCA’93,1993, Doi:10.1145/165123.165164

What about soft errors
Soft errors are intermittent deviations from the correct platform behavior
Examples:Data as read is different from data as written
Instructions that mis-execute: i.e. Add(1,1) --> 3
Read errors can be detected using checksumsCheck all inputs to a task
Maybe also check all inputs at the end of a task
Error correction not needed if relying on duplicated persistent data
12

Mis-executing instructions
Incorrectly executed instructions can be detectedBy duplicating work and using a quorum
This is very expensive (at least factor 2, if using quorum 3)
Feasible only if used selectively
By using estimates
Requires development of bounds on (many) quantities
Much less operations than blanket duplication
Can detect only a subset of deviations
13
, ,
1
1 1 2 2 1 2 1 2
Abs Max Abs | Max Abs |
r r r r r r dr dr
i j k l
i j k l
ij kl ij ij kl kl
ij kl f f f f
M. Rebaudengo, M. Sonza Reorda, M. Torchiano, M. Violante, “Soft-Error Detection through Software Fault-Tolerance Techniques”, Proc. DFT’99, 210-218, 1999, Doi:10.1109/DFTVS.1999.802887

Impact on calculation
The soft error impact depends on algorithm type
Optimization algorithms (defined result)E.g. Minimizing the energy as a function of atom positions
Termination condition expressed as a property of the result
Designed to iteratively reduce error
Automatically removes impact of perturbations
Perturbation should not be too big
All invariants must be expressed explicitly so that they can enforced
Step algorithms (defined effort)E.g. a matrix-matrix multiplication
Termination condition independent of the result
Any error perturbs final answer
Perturbations must be actively minimized
14
A B Cij ik kj
k

Soft errors
Best candidates for soft errors resiliency are optimization algorithms
Some Step algorithms can be transformed into Optimization algorithms
Even Optimization algorithms may require rewrites to express invariants explicitly
Even Optimization algorithms may be perturbed such that recovery becomes unpractical
15

Summary
Fault tolerance in HPC is easier than in DatabasesBecause HPC algorithms make defined changes to the persistent state, so no roll back required, and re-executing tasks is no problem
Fault tolerance in HPC is harder than in DatabasesBecause all recovery has to be handled automatically without any human intervention
Reliable fault detection currently depends on hardware supported features. Is there a better way?
Our data updates are not transactional, should they be?
Soft errors are a challenge because they cannot always be detected.
Soft errors are likely manageable for Optimization algorithms
16
Question / Comments ?

17
NWChem development is funded by:
- Department of Energy: BER, ASCR, BES
- PNNL LDRD
EMSL: A national scientific user facility integrating experimental and computational resources for discovery and technological innovation


















