
Prosodic structure and tongue twister errors...
32
1 Prosodic structure and tongue twister errors 1 Karen Croot Claudia Au Amy Harper Word count (MS Word) Abstract: 188 words Manuscript excluding references: 8138 words, references 732 words, total 8870 words Address for correspondence: School of Psychology A18 University of Sydney NSW AUSTRALIA 2006 Phone: +61 2 9869 4696 Fax: +61 2 9356 5223 Email: [email protected] [email protected] [email protected]
Transcript of Prosodic structure and tongue twister errors...

1
Prosodic structure and tongue twister errors1
Karen Croot
Claudia Au
Amy Harper
Word count (MS Word)
Abstract: 188 words
Manuscript excluding references: 8138 words, references 732 words, total 8870 words
Address for correspondence:
School of Psychology A18
University of Sydney
NSW AUSTRALIA 2006
Phone: +61 2 9869 4696
Fax: +61 2 9356 5223
Email:

2
Abstract
Two experiments investigated whether segmental speech errors in tongue twister production were
associated with utterance-level prominence and prosodic phrase-initial position as described by an
autosegmental metrical model of intonational phonology. In Experiment One, 40 undergraduate
students produced words with confusable onset consonants (“tongue twister words”) in four-word
lists under prominence conditions that varied the number and location of emphatically-produced
words in the list. There was a three-way interaction between prominence condition, word position
in the list, and format (ABBA versus ABAB ordering of onset consonants). In Experiment Two, 38
undergraduate students produced tongue-twister words with and without narrow informational
focus in sentences. Onsets of tongue twister words with narrow focus were produced more
accurately than onsets in unfocussed tongue twister words. Neighbourhood density of tongue
twister words had no significant effect on error rate. Phrase-initial position yielded more errors
than non-initial position, but was confounded with format (all tongue twister words occurred in
ABBA format). Results suggest that information about utterance-level prominence and phrasing is
available at the time of segment-to-frame association, consistent with the prosody-first account of
phonological encoding proposed by Keating and Shattuck-Hufnagel (2002).

3
1. Introduction
An account of the psycholinguistic processes that occur during speech production must
specify how the segmental content and prosodic structure of an utterance are integrated to produce
the acoustic-phonetic properties of the speech signal (Shattuck-Hufnagel and Turk 1996). For
several decades, researchers have analysed speech errors as a source of information about the
subprocesses occurring within word-form and phonological encoding (Dell 1986; Stemberger 1992;
Vitevitch 2002; Wilshire 1999). Speech error studies that systematically investigate prosodic
factors may therefore inform theory about the integration of segmental and prosodic information
during speech production. To date, however, only a small number of studies have investigated the
relationship between prosodic factors and segmental errors (Frisch 2000; Goldstein, Pouplier, Chen,
Saltzman, and Byrd in press; MacKay 1971; Shattuck-Hufnagel 1983, 1992). The present paper
reports two experiments in which the segmental speech errors elicited in a tongue twister task were
influenced by prosodic organization.
1.1 Investigations of phonological encoding using segmental speech errors
Corpora of speech errors have been collected from extensive samples of naturally-occurring
speech (Shattuck-Hufnagel and Klatt 1979; Vousden, Brown, and Harley 2000), and using
laboratory techniques including the SLIPs technique (Baars, Motley, and MacKay 1975; Pouplier in
press) and tongue twister tasks (e.g. Sevald and Dell 1994; Shattuck-Hufnagel 1992; Wilshire 1998,
1999). In SLIPs experiments, participants silently read pairs of words containing a repeating
sequence of onset consonants (e.g. case tick; can tim; Pouplier in press). At some unpredictable
time, a word pair appears in which the onsets occur in reverse order (e.g. tap kip; Pouplier in press).
Participants are cued to read aloud this latter pair, and typically make a high rate of errors. In
tongue twister experiments, participants repeat or read aloud word lists, phrases or sentences
containing combinations of words (“tongue-twister words”) that systematically manipulate factors
thought to be associated with high segmental error rates in speech production.
A number of effects reliably occur across speech error studies (Stemberger 1992). For
example, higher error rates are observed on word- or syllable-initial consonants than on other
segments in a word (Dell, Juliano, and Govindjee 1993). Shattuck-Hufnagel (1992) investigated
whether word-initialness or syllable-initialness was the critical factor in a tongue twister study,
finding higher error rates on word-initial than syllable-initial consonants matched on other factors.
In a study of naturally-occurring errors that incorporated a correction for chance error rate, Vousden
et al. (2000) found an effect of syllable-initial position after word-initial effects were accounted for.

4
Many speech error effects, including initialness effects, can be described in terms of a
similarity relationship between units interacting to produce the observed error (Shattuck-Hufnagel,
1979). For example, comparatively high rates of error are observed between segments that share
phonetic features, position in a word or syllable or cluster, and/or adjacent segments (Dell 1986;
Frisch 2000; Pouplier in press; Shattuck-Hufnagel 1979). Shattuck-Hufnagel’s (1992) experiments
investigated the effect of shared lexical stress in tongue twister words, and whether there was an
interaction between initialness and stress. Sets of tongue twister words were constructed in an
orthogonal design that placed highly confusable segments (segments producing a high rate of errors
in the MIT-Arizona speech error corpus; Shattuck-Hufnagel and Klatt, 1979) at word- versus
syllable-initial position, and at the onset of stressed versus unstressed syllables. This created four
conditions: both word- and stress-position same, word-position same, stress-position same, and
neither word- nor stress-position same. The first experiment elicited the words as a list (e.g. parrot,
fad, foot peril), a second placed the words in grammatically well-formed but sometimes
semantically anomalous sentences (e.g. It’s a peril when fad takes a foot from the parrot.), a third
required participants to generate their own sentences containing the words, and a fourth replicated
the list experiment with a more powerful design.
In all Shattuck-Hufnagel’s (1992) experiments, participants made most segment interaction
errors (segments exchanging with, perseverating or anticipating a segment elsewhere in the list)
between segments that shared both word-position and stress-position. The next highest error rate
occurred between segments that were word-position same only; then between segments that were
stress-position same only. The fewest errors occurred between confusable segments that were
neither word- nor stress-position same. Shattuck-Hufnagel found no interaction between word- and
stress-position in two of the experiments (1, 1a), but a significant interaction in two other
experiments (1b, 2), one of which (Experiment 2) had a more powerful design than Experiments 1
and 1a. Frisch (2000) also found a strong interaction between word-position (word onset versus
syllable onset) and stress in tongue twisters constructed with four bisyllabic words in lists.
To account for the influence of both word-initial position and stressed-syllable-initial
position on segment interaction errors, Shattuck-Hufnagel (1992) revised her earlier “scan-copier
model” of segment-to-frame association, the process whereby segments are arranged in the correct
serial order during phonological encoding (Shattuck-Hufnagel 1979). According to the scan-copier
model, segments for words in an utterance are retrieved from long-term lexical memory and placed
into a short-term store until they can be allocated to their correct place in an organising frame that
specifies the prosodic structure of the utterance. This prosodic frame provides instructions to a
scanning mechanism about the criteria by which to select segments from the short-term store to fill
each location in the frame. Segment interaction errors occur because another segment that also

5
meets the selection criteria is selected instead of the correct segment. Because the lexical stress
value of a syllable, as well as word-initial position, contributed to error rates, Shattuck-Hufnagel
(1992) hypothesised that the organising frame must specify prominent syllables at the phrasal level,
as well as word boundaries. Each prosodic unit in the frame was hypothesised to contain one or
more syllables that are prosodically prominent at the phrasal level (Shattuck-Hufnagel 1992). This
suggests that the units of the prosodic frame are phonological words (with one prominent syllable)
or intermediate phrases (with one or more prominent syllables).
1.2 The prosodic organization of speech
In this paper we adopt the prosodic hierarchy described by Keating and Shattuck-Hufnagel
(2002) as our view of the prosodic constituents of speech. According to this view, linguistic units
are grouped into various prosodic constituents (utterances, Intonational Phrases, intermediate
phrases, phonological words, syllables) with a hierarchical structure, i.e. higher constituents (e.g.
utterances) encompass lower ones (Intonational Phrases). There are also different levels of
prosodic prominence within an utterance (Shattuck-Hufnagel and Turk 1996). A lexically-stressed
syllable is typically the most prominent syllable in a phonological word, and one of the stressed
syllables of an intermediate phrase will be accented within that phrase.
Shattuck-Hufnagel’s (1992) experiments demonstrated that prosodic information about
constituent boundaries and prominence at the level of the phonological word must be available at
the time of segment-to-frame association during phonological encoding. Questions about when
higher levels of prosodic structure become available relative to segment-to-frame allocation have
not yet been experimentally addressed. The following two experiments therefore aimed to
manipulate the prominence and initialness of confusable segments in tongue twister words in
prosodic units above the level of the phonological word. An influence of these factors on the rate
of segmental speech errors would provide evidence for the availability at the time of segment-to-
frame association of prosodic information represented above the level of the phonological word in a
prosodic hierarchy.
2. Experiment 1
To investigate experimentally the relationship between prosodic organisation and segmental
encoding, the tongue twister task is an obvious choice because it approximates connected speech
more closely than the SLIPs task (or other less frequently-reported laboratory tasks; Stemberger
1992), and provides opportunity for errors to be elicited under varying prosodic conditions.

6
Previous tongue twister studies, however, have almost never considered the prosodic organization
of the lists, phrases or sentences elicited. Wilshire (1998) reported that participants in her tasks
produced four-word list tongue twisters with a list intonation, which suggests that lists were treated
as intonational phrases or utterances. Each lexical word in a list is most likely to be produced as a
phonological word within an intermediate phrase (Fougeron, personal communication, 16 January
2007).
Our first experiment investigated whether the number and location of prominent syllables
within tongue twister lists would influence the rate of segmental errors on each word-initial
consonant. We used one-syllable content words only, so that differences in prominence between
words could not bet attributed to differences in lexical stress; information proposed to be
represented in phonological word frames for segmental spell-out (Shattuck-Hufnagel, 1992). We
elicited four prominence conditions by asking participants to emphasise one or two of the words
within each list: the first word, the last word, the first and third words, or the second and fourth
words. We used tongue twister words with confusable segments in word-initial position only, to
ensure that errors would primarily occur on word-initial segments rather than at other word
positions. This would allow a comparison between error rates on word initial segments that were
list-initial versus non-initial, with list-initial position assumed to correspond to utterance- and/or
Intonational Phrase-initial position. A main effect of prominence or list-initial position, or an
interaction between the two, would suggest that prosodic information above the level of the
phonological word was available at the time of segment-to-frame association.
Previous tongue twister experiments using four-word lists with confusable segments at
word-initial position have ordered the alliterating segments in various ways (e.g. A1A2A3A4,
A1B1B2A2, A1B1A2B2, A1B1C1D1: Sevald and Dell 1994), where A1 is the first occurrence of the first
confusable word-initial segment and A2 is the second, B1 is the first occurrence of the second
confusable word-initial segment and so on. Few studies have analysed the effect of alliteration
format, however. Wilshire (1998, 1999) found no significant difference in error rates on lists with
ABBA versus ABAB formats, but words were not matched across format conditions on factors
such as word frequency, neighbourhood density, or segment confusability that influence segmental
error rates (Dell 1990; Vitevitch 2002). Sevald and Dell (1994) found slower speech rates in the
AAAA and ABBA conditions than the ABAB and ABCD conditions in tongue twister lists
containing four different words. Pouplier (in press) argued that switching from one initial segment
order (AB) to another (BA) across pairs of words (as in SLIPS tasks, but also in ABBA tongue
twisters) is more difficult than producing a regularly alternating sequence of initial segments (as in
ABAB tongue twisters). According to the coupled oscillator model of articulatory planning
(Goldstein, Byrd, and Saltzman 2006), ABBA tongue twisters require speakers to reverse the

7
phasing of articulatory gestures for onsets across the first versus last pair of words in the list,
increasing the likelihood that the onsets will not be produced correctly. We therefore predicted
more errors on ABBA- than ABAB-format lists. The other question of interest, however, was
whether format would interact with prominence or initialness, a result that would provide further
evidence that post-lexical prosodic information is available at the time segmental errors occur
during phonological encoding.
2.1. Method
2.1.1. Participants
Forty-three native English speakers enrolled in an undergraduate psychology course
participated for optional course credit. They were screened for self-reported hearing, visual or
language impairments. One withdrew from the study, and two participants did not complete the
required number of repetitions per tongue twister when they made errors, leaving 40 participants.
2.1.2. Materials and Procedure
Tongue twisters were derived from materials created by Vitevitch (2002, Experiment 2;
Vitevitch personal communication 26 April 2005)2. Vitevitch (2002) created 20 tongue twister
lists consisting of four CVC (consonant-vowel-consonant) words in four-word lists with initial
segments selected because they were highly confusable in the MIT-Arizona corpus (Shattuck-
Hufnagel and Klatt 1979). Vitevitch’s tongue twisters manipulated neighbourhood density (10 low
and 10 high neighbourhood density lists), and contained initial consonants in an A1B1B2A2 format
(e.g. den ton tuck dial). Experiment 1 used only the 10 low neighbourhood density lists because
these yielded higher error rates in Vitevitch’s study, but we reversed the order of Words 3 and 4 in
each list to create an additional set of 10 ABAB format lists (e.g. den ton dial tuck), giving 20 lists
in total. These lists were spoken in each of four Prominence Conditions manipulating the number
and location of prominent words:
(i) first word emphasised (W1 w2 w3 w4)
(ii) fourth word emphasised (w1 w2 w3 W4)
(iii) first and third words emphasised (W1 w2 W3 w4), and
(iv) second and fourth words emphasised (w1 W2 w3 W4).
Participants were tested individually in a quiet room and took approximately 50 minutes to
complete the experiment. Written lists, metronome beat (160 beats per minute) and spoken

8
examples were presented using SuperLab experiment presentation software (Cedrus 2004) on a
laptop PC. Prior to the experiment, participants completed demonstration and practice trials to
familiarise them with the task. Each trial commenced when the participant clicked the mouse. The
metronome beat began (and continued until the end of the trial), and numerals counting down 5 to 1
appeared on the screen, after which the four-word list appeared and remained on screen until the
end of the trial. The word(s) to be accented were presented in uppercase and bold; the others in
lowercase normal font, e.g. DEN ton DIAL tuck.
The design of six practice blocks was determined by piloting various means and amounts of
practice to elicit the target prominence conditions and rate. No lists in Practice Block 1 were
tongue twisters, one list in each of Practice Blocks 2—5 was a tongue twister, and all lists in
Practice Block 6 were tongue twisters, so the blocks gradually became more difficult. Participants
were told the metronome was to indicate approximately how fast they were to speak, but they were
not required to keep in time with the metronome. In Practice Block 1, all words of each list were
presented in lowercase and no prominence condition was specified. The experimenter demonstrated
the first practice list by clicking the mouse, waiting for the countdown to finish and the list to
appear on screen, then reading the four words aloud three times in a row, at the required rate. The
participant then did the same for two practice lists. In Practice Block 2, the prominent word
appeared in uppercase and the experimenter demonstrated the procedure for three repetitions of the
first list in this block, demonstrating Prominence Condition W1 w2 w3 w4. The participant did the
same for two further lists with this prominence pattern. Participants were given feedback about rate
or required prominence at the end of a trial if either were not produced as required and were able to
correct this on subsequent productions. In Practice Blocks 3—5, the above procedure was repeated
with Prominence Conditions (ii), (iii) and (iv) respectively. In Practice Block 6, the procedure was
modified to be the identical to the experimental trials, with the spoken model presented as a sound
file. Participants were instructed to repeat the list six times at the offset of the spoken example,
imitating the prominence pattern in the model and at approximately the rate of the metronome. The
numerals 1 through 6 appeared at the bottom of the screen with each repetition to help participants
keep count. After training, participants appeared to have little difficulty producing the required
prominence conditions.
Items were presented in eight blocks of 10 tongue twister lists, with the ABBA and ABAB
lists spoken in each of the four prominence conditions by each participant, and format and
prominence condition blocked. Participants were randomly allocated to one of eight groups, with
order of prominence condition and format condition fully counterbalanced across groups. List
order within block was randomised for each participant. The experimenter monitored the prosody
and rate throughout to verify that participants were producing the tongue twisters as required, and

9
reminded participants of the required rate and prominence on the few occasions where this was
necessary. Participants took a short break at the end of each block and a longer break at the
halfway point.
2.1.3. Scoring and Analysis
Speech errors were noted in situ then transcribed in full from the recordings until all six
repetitions in a trial were heard with no further changes to the transcription (Shattuck-Hufnagel
1992). Words were scored as correct if they were produced correctly and in the correct order.
Addition, deletion or substitution of at least one of the segments, dysfluencies (e.g. “p-palm”) and
corrected segments (e.g. “p-calm”) were all scored as incorrect (Shattuck-Hufnagel 1992; Wilshire
1999). Unintelligible responses were omitted from analysis. Errors were classified as contextual if
the segment participating in the error was the confusable segment from the initial position in the
other tongue twister words.
A 4 (prominence condition) x 4 (position in list: Words 1—4) x 2 (format: ABBA, ABAB)
analysis of variance by subjects with repeated measures on all factors was carried out using SPSS
with planned contrasts performed in Excel. Alpha was set at an overall level of .05 and reduced
using the Bonferroni method to control for Type One errors on the contrasts. Degrees of freedom
were adjusted using the Greenhouse-Geisser procedure when the data did not pass a test for
sphericity. All errors were included in the analysis.
2.2. Results
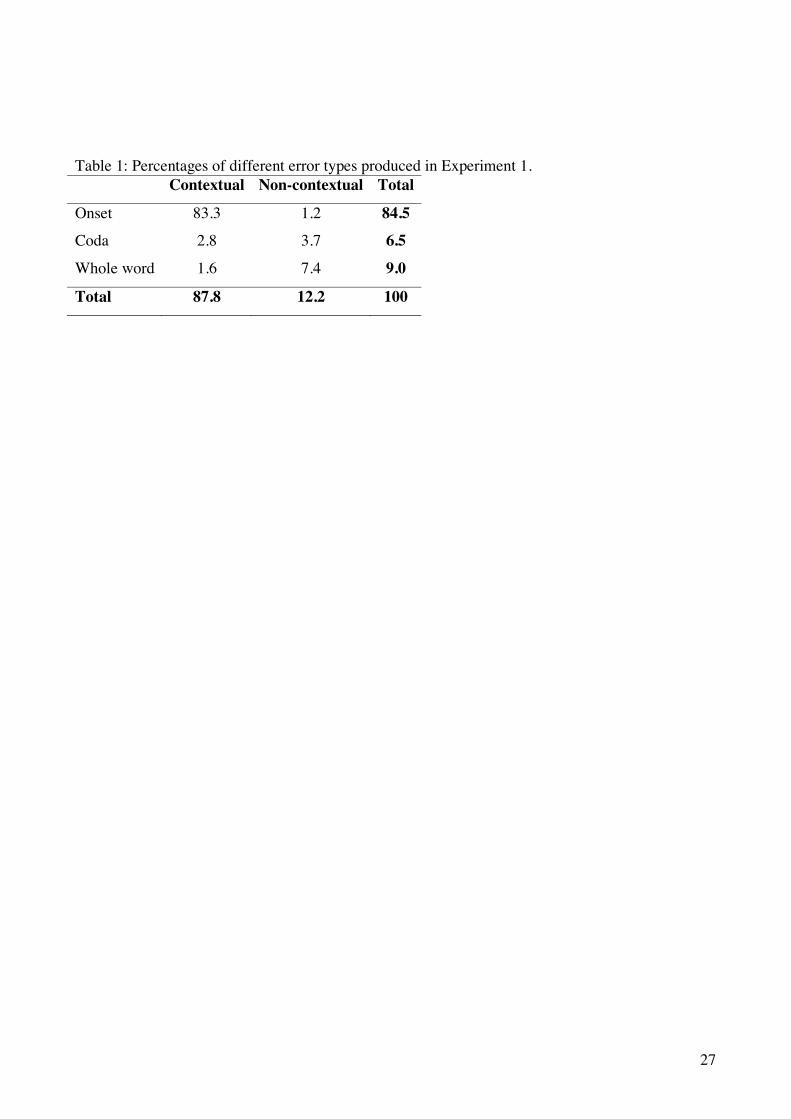
Participants made a total of 6410 errors (8.4%). The majority of errors involved word
onsets and contextual errors (Table 1). Percentage of total errors on ABAB lists was 40.3%; on
ABBA lists 59.7%.
Insert Table 1 near here
2.2.1. Effects of prominence condition, position in list and format
All main effects were significant: prominence condition (F = 5.54, d.f. = 3, 117, p = 001),
position in list (F = 64.70, d.f. = 2.02, 78.61, p < .000), and format (F = 32.67, d.f. = 1, 39, p <
.000).
All two-way interactions were significant: prominence condition X position in list (F = 6.40, d.f. =
6.64, 258.77, p < .000), prominence condition X format (F = 20.93, d.f. = 2.47, 96.35, p < .000),

10
and position in list X format (F = 11.34, d.f. = 2.46, 95.99, p < .000). Mean error rates and 95%
confidence intervals for the main effects and two-way interactions are provided in Table 2. All
these effects were overshadowed by the significant three-way interaction between prominence
condition, position in list and format (Figure 1; F = 3.31, d.f. = 6.01, 234.54, p = .004), illustrated in
Figure 1.
The following patterns are evident from visual inspection of Figure 1. Participants made
fewer errors to Word 1 in ABAB than ABBA lists, with accented Word 1 produced more accurately
in Prominence Conditions (i) and (iii), than unaccented Word 1 in Prominence Conditions (ii) and
(iv) in both formats. On Word 2, overall error rates were similar in the ABAB and ABBA lists.
Unaccented Word 2 was most error prone in Prominence Condition (ii) in both formats. Accented
Word 2 was less vulnerable to error in Prominence Condition (iv) in the ABAB lists than the
ABBA lists. Word 3 yielded the highest error rate of any position in the list in both formats, and
was more error-prone in ABBA than ABAB lists. Compared with the error rates on unaccented
Word 3 in Prominence Conditions (i) and (ii), errors were reduced on accented Word 3 in
Prominence Condition (iii) in ABAB lists. By contrast, error rates on unaccented Word 3 in
Prominence Condition (iv) were strikingly high in the ABBA lists. Finally, Word 4 was error-
prone compared with Words 1 and 2 but produced more accurately than Word 3 in both formats.
There were fewer errors on unaccented Word 4 in Prominence Condition (iii) compared to the other
prominence conditions in the ABAB lists but not the ABBA lists. By contrast, accented Word 4
was comparatively error-prone in Prominence Condition (iv) in the ABBA lists.
Insert Table 2 near here
Insert Figure 1 near here
The ABBA format yielded more errors than ABAB format, consistent with Pouplier’s (in
press) hypothesis that switching the order of onsets between the first two words of a four-word list
(AB) and the final two words (BA) involves a change in phase of articulatory gestures that makes
ABBA format more error prone than ABAB format where this reversal is not required. Rather than
pooling errors obtained as a result of potentially different articulatory requirements, post-hoc
analyses to examine effects of list-initial position were carried out for ABAB-format lists only.
2.2.2. Errors at list-initial position
Error rates to list-initial versus list-medial words matched on prominence were compared in
3 different analyses: unaccented Word 1 versus unaccented Words 2 and 3 in Prominence Condition

11
(ii), accented Word 1 versus accented Word 3 in Prominence Condition (iii), and unaccented Word
1 versus unaccented Word 3 in Prominence Condition (iv). Segment identity at the different list-
positions was also matched in the latter two comparisons. In all three comparisons, there were
fewer errors on the list-initial word than on the other word(s), and these differences were
statistically reliable (Prominence Condition (ii): F = 20.91, d.f. = 1.68, 65.61, p < .000; Prominence
Condition (iii): t = 4.01, d.f. = 39, p < .000; Prominence Condition (iv): t = 4.22, d.f. = 39, p <
.000). There was no significant difference between error rates on Word 2 and Word 3 in the first
comparison. The same error patterns were present in the first repetition of each list only, and in
repetitions 2—6 combined, thus were not due to low error rates on the first word per six repetitions
of each list alone.
2.3. Discussion
The number and location of emphatically-produced words in these tongue twister lists
influenced the number of errors made to word-initial confusable segments. Prominence condition
was a significant main effect in the full analysis of variance, and interacted with position in the list
and with format in the two- and three-way interactions. Post-hoc analyses showed fewer errors at
list-initial position on words matched for prominence and for segment identity in the ABAB lists.
We assumed that the four-word lists were typically produced as a series of four intermediate
phrases within an Intonational Phrase, and that Intonational Phrases usually also corresponded to
utterances, although it was possible that two or more lists were produced as a single utterance. The
effects of prominence condition and list-initial position would therefore suggest that prosodic
information at higher levels of prosodic organisation than the phonological word or intermediate
phrase is available at the time of segment-to-frame association during phonological encoding, when
segmental speech errors are hypothesised to arise.
The target prominence patterns across words were elicited by asking participants to read
uppercase words aloud more emphatically than lower case words. Participants practised the task
extensively before beginning, and the experimenter monitored participants’ productions and
provided feedback that was readily used to modify the emphasis after infrequent errors. It was,
however, beyond the scope of this study to analyse the prosodic phrasing of each production at the
time of transcribing the segmental speech errors, therefore we cannot be certain of the precise
prosodic organization used by participants. For example, lists in the two-accent prominence
conditions (iii) and (iv) may have been realised as two Intonational Phrases rather than one. If this
was so, the list-initial effect in the ABAB lists would suggest that information about utterance-
initial position only was available at the time of segment-to-frame association, because Word 1

12
yielded fewer error than Word 3; see Figure 1. Our results do not therefore permit the conclusion
that a full specification of prosodic information above the level of the phonological word or
intermediate phrase is available at the time of segment-to-frame association, only that at least some
higher-level prosodic information is available. A closer prosodic analysis of each rendition of each
tongue twister in a future study (feasible with a smaller corpora of speech data) would establish
precisely whether observed errors were associated with utterance- or Intonational Phrase-initial
position.
2.3.1 Effects of prominence condition, position in list and format
The significant main effect of format and the interaction between format and word position
support an account in which reversing the order of onsets across successive pairs of tongue twister
words is more difficult than repeating the same order across pairs because the former requires a
reversal of phasing of the articulatory gestures for the onsets (Pouplier, in press). The significant
three-way interaction further suggests that the number and location of prominent syllables may also
influence the stability of the articulatory coupling in a coupled oscillator model of articulatory
planning (Goldstein et al. 2006). In our results, for example, unaccented Word 3 was highly
vulnerable to error in the ABBA format lists in Prominence Condition (iv) w1 W2 w3 W4, but less
so when there was only one accented word (Prominence Conditions (i) and (ii)). By contrast,
accented Word 3 in the ABAB lists in Prominence Condition (iii) W1 w2 W3 w4 was highly
resistant to error.
As noted earlier, few experimentally controlled studies have considered the effect of
phrasal prominence on speech errors. MacKay’s (1971) participants produced four-word list tongue
twisters consisting of CV words with different onset consonants (i.e. ABCD format) and identical
codas under five prominence conditions: Word 1, Word 2, Word 3 and Word 4 emphasised
respectively, and no instruction about prominence. Unaccented onsets were more vulnerable to
error when they preceded an accented word than would be predicted by chance. In our experiment,
we similarly found that within the initial or final pair of words in the two-prominence lists there
were higher error rates to unaccented words preceding an accented word within a pair, an effect
amplified in the ABBA lists compared to the ABAB lists. Goldstein et al. (in press) elicited two-
word tongue twister lists with AB format onset consonants. Lists were repeated multiple times by
six participants and the researchers analysed the effect of first versus second word emphasised in
the list. They observed more errors on Word 1 when Word 2 was emphasised than when Word 1
was emphasised, but the main effect of prominence condition and the interaction between
prominence and position in the list were not significant. To compare our data with these, we pooled

13
errors on Words 1 and 3 and on Words 2 and 4 in the two-prominence conditions on the ABAB lists
only. We found a similar pattern of errors, but a comparatively higher error rate to the unstressed
word in the initial position in the pair (Mean error rates per word, pair-initial and accented: 5.5,
pair-initial and unaccented: 8.9, pair-final and accented: 7.1, pair-final and unaccented: 6.2). By
contrast with the materials of Goldstein et al. (in press), our lists did not control for segmental (and
thus gestural) content of the codas across items or formats, however we used a powerful design
with 40 speakers repeating 20 tongue twisters six times each per prominence condition. Further
evaluation of phrasal prominence effects on speech errors will require a sufficiently powerful
experimental design and materials controlled for segmental and gestural content.
2.3.2 Effects of list-initial position
Whereas word-initial position has been associated with high rates of segment interaction
errors in both observational and experimental studies (Dell 1986; Stemberger 1992), list-initial
position seems to have been protective against error in the ABAB quadruples in this experiment.
Initialness effects may therefore differ depending on the level of prosodic organization at which a
segment is initial. A crucial factor in explaining word-initial errors is similarity: segments interact
erroneously with other segments that are similar in one or more ways (e.g. position in word,
adjacent vowel, natural class etc.) (Dell 1986; Frisch 2000; Pouplier in press; Shattuck-Hufnagel
1979). If positional similarity is defined more narrowly, in terms of similarity of location within a
prosodic hierarchy, and there are typically fewer phrase-initial than phonological word-initial
positions within an utterance, there will be limited opportunities for phrase-initial segments to
interact with other phrase-initial segments to participate in errors. In Experiment 1, we assumed
that participants typically produced four-word lists as utterances, giving one list-initial position per
utterance – and we found fewest errors at this position.
Can the list-initial effect be explained in terms of Shattuck-Hufnagel’s (1992) revised scan
copier model? If the prosodic frame to which segments are associated specifies each segment’s
position within an utterance, Intonational and intermediate phrase, as well as phonological word,
and if segments for an entire utterance are available in the short-term store before being associated
to the frame (Keating and Shattuck-Hufnagel 2002), then there may only be one (or at most a few)
segment(s) tagged for utterance- or phrase-initial position per utterance, making these segments less
susceptible to error. There would probably, however, be several segments tagged as phonological
word-initial, accounting for higher error rates to these segments. This account would imply that
constituency within phonological words and higher level constituency have both been computed at
the time segments are allocated to prosodic structures, but the latter reduces the error-susceptibility

14
of an onset consonant whereas the former increases it, as a function of the number of competing
segments available in the short-term store.
Experiment 1 elicited speech errors using four-word tongue-twister lists read aloud
according to instructions to emphasise certain words and not others. This task differs substantially
from natural speech the meaningfulness of the utterances and the motivation for accenting words,
thus may not tell us much about the availability of prosodic information during phonological
encoding of normal connected speech. Experiment 2 was therefore designed to investigate speech
error rates on tongue twister words in sentences produced in a more naturalistic speaking task.
3. Experiment 2
Experiment 2 aimed to elicit tongue twister words in spoken sentences in a near-replication
of Shattuck-Hufnagel’s (1992) Experiment 1(a), but manipulating the location of accented words
and the initialness of segments in Intonational Phrases. Tongue twister words with highly
confusable initial segments were located in the following syntactic positions in sentences: sentence-
initial, medial in the first clause, clause-initial in the second clause, and sentence-final. These four
sentence-positions were intended to manipulate initialness within Intonational Phrases, with tongue
twister words 1 and 3 at phrase-initial positions, and tongue twister words 2 and 4 at non-phrase-
initial positions. The prominence of the tongue twister words was manipulated by asking
participants to respond to questions that would elicit a narrow informational focus on each of the
tongue twister words in turn.
We hypothesised that if higher error rates on initial segments in lexically-stressed syllables
in Shattuck-Hufnagel’s (1992) study occurred because initial segments in prosodically prominent
syllables are vulnerable to error, then we would see more errors on focussed words than unfocussed
words. Second, if initialness in prosodic constituents makes segments vulnerable to error, then we
would see higher error rates for initial compared with non-initial segments in prosodic phrases.
However, an opposite set of hypotheses can be formulated if a scan-copying procedure selects
segments on the basis of prominence or positional criteria including information about their
representation at upper levels of a prosodic hierarchy, and segmental mis-selection depends on the
similarity of the mis-selected segment to the target. If the latter account is correct, there would be
fewer errors to onsets of focussed words and Intonational Phrase-initial segments because for any
utterance there may be few or no competing segments with a similar prosodic specification to those
segments.
3.1 Method

15
3.1.1. Participants
Forty native English speakers from the same participant pool as in Experiment 1 (mean age
19.8 years; range 15—54) participated in the experiment. Two were excluded on the basis of self-
reported hearing, visual or language impairments, leaving a total of 38 speakers who completed the
study.
3.1.2. Materials and Procedure
Sentence stimuli3 were constructed using the words from all twenty of the four-word list
tongue twisters created by Vitevitch (2002, Experiment 2; Vitevitch personal communication 26
April 2005). Half the lists contained words from high density and half from low density
phonological neighbourhoods, with density conditions matched on initial segments, word
frequency, neighbourhood frequency and familiarity (Vitevitch 2002). In this experiment we used
both low and high neighbourhood density items to elicit a wider range of tongue twister words than
Experiment 1. Sentences were meaningful to allow participants to produce them naturally, and we
minimised as far as possible (while maintaining meaningfulness) the number of non-tongue-twister
words within each sentence that began with the confusable initial segments of the tongue twister
words in that sentence.
Each sentence consisted of two clauses4 presented over two lines of text in sentence case on
a PC screen, one clause per line, with a comma at the end of the first clause, the second clause
indented, and a full stop at the end of the sentence. Each clause contained two tongue twister words
separated by two syllables. Many of the tongue twister words were used as proper nouns even
when typically not in use as names (e.g. “Den” and “Tuck” in the examples below) due to the
difficulty of creating meaningful sentences with the required syntactic, segmental and syllabic
structure using the tongue twister words.
Participants read each sentence aloud to answer each of four written questions designed to
elicit a narrow informational focus on the tongue twister word that was shown in large font and
surrounded by a box, for example,
(i) Who weighs a ton or more? Den weighs a ton or more,
Tuck broke the dial.
(ii) How much does Den weigh? Den weighs a ton or more,
Tuck broke the dial.

16
(iii) Who broke the dial on the scale? Den weighs a ton or more,
Tuck broke the dial.
(iv) What did Tuck break on the scale? Den weighs a ton or more,
Tuck broke the dial.
Numbers (i) to (iv) in the above examples indicate Prominence Conditions (i) – (iv). Participants
repeated each sentence six times in succession in one of two randomised sentence orders. Error
rates did not differ across presentation order, and presentation order did not interact with
neighbourhood density, prominence condition or sentence position, so further analyses pooled
across presentation order.
Elicitation questions and tongue twister sentences were presented on a laptop PC using
SuperLab (Cedrus 2004). Responses were recorded for later transcription of errors. On each trial,
the question was displayed for 4000 ms, disappeared for 1000 ms then reappeared with the target
sentence below it. The sentence remained in view while the participant repeated it six times, then
the participant moved on to the next trial by clicking a mouse. A digital metronome (Enable
Software 2005) set at 160 beats per minute was used to standardise speech rate across participants.
Participants completed a block of 10 sentences then were encouraged to take a short break. There
were 20 sentences, each spoken in four prominence conditions, thus 80 items per participant
presented in eight blocks of 10.
Prior to the main experiment, participants worked through six demonstration items in which
a recorded voice modelled the required response and speech rate, then they completed six practice
items. The experimenter ensured they were maintaining speech rate and emphasising the required
word before they were able to proceed. At the end of each break between blocks, a further two
demonstration items were given to remind participants about the required rate and how to answer
the questions using the sentences. Participants were tested individually, taking approximately 50
minutes to complete the experiment.
3.1.3. Scoring and Analysis
Error transcription and scoring occurred as in Experiment 1, although this time dysfluencies
(e.g. “r-rice”) were scored as correct because the target segment was not replaced with the onset
used in the other tongue twister words. Errors on two sentences were removed from the corpus, one
because participants commented that they were making semantically-motivated word substitutions,
and another because they frequently pronounced the word “Gill” as “Jill” when the target segment

17
was [g]. Errors on matched sentences from opposing neighbourhood density conditions were also
removed, leaving errors from 16 sentences in the error corpus.
A 2 (prominence condition: accented, unaccented) x 4 (sentence position: Clause 1 initial,
Clause 1 medial, Clause 2 initial, Clause 2 final) x 2 (neighbourhood density: high, low) analysis of
variance by subjects with repeated measures on all factors was carried out using SPSS with planned
contrasts in Excel and control for Type I error as described for Experiment 1.
3.2. Results
Participants made 3106 errors (8.5%). Most errors involved word onsets substituted by
word onset segments elsewhere in the clause (Table 3). Error rates for the two prominence
conditions at the four sentence positions are illustrated in Figure 2.
Insert Table 3 near here
Insert Figure 2 near here
The main effect of prominence condition was significant, with fewer word-initial errors on
accented than unaccented tongue twister words (F = 31.61, d.f. = 1, 37, p < .001). The main effect
of sentence position was also significant (F = 14.73, d.f. = 2.03, 75.26, p < .001). There were more
errors on clause-initial than clause-medial position in Clause 1 (F = 14.35, d.f. = 1, 37, p = .01), and
more errors on clause-initial than clause-final position in Clause 2 (F = 20.29, d.f. = 1,37, p < .001).
There was no difference between error rates at initial positions in Clause 1 versus Clause 2, or
between error rates at clause-medial and clause final positions. There was a marginally significant
interaction between prominence condition and sentence position (F = 2.98, d.f. = 2.43, 91.52, p =
.045). There was a greater disparity between error rates on accented versus nonaccented words in
initial versus final position within Clause 2 (F = 5.44, d.f. = 1, 37, p = .025) but no disparate effect
of accent across the two sentence positions within Clause 1 (F = .96, d.f. = 1, 37, n.s.). The main
effect of neighbourhood density was not significant, and there were no significant interactions
between neighbourhood density and prominence, neighbourhood density and sentence position, or
neighbourhood density, prominence and sentence position.
3.3. Discussion
Experiment 2 investigated whether focussed tongue twister words would show more errors
than unfocussed ones. In Shattuck-Hufnagel’s (1992) experiment, syllable-initial segments in

18
lexically-stressed syllables participated in more errors than matched initial segments in unstressed
syllables. We found a significant main effect of prominence condition, but in the opposite
direction: words with narrow focus were subject to fewer segment-initial errors at all four sentence
positions in the tongue twister sentences. Thus word-initial segments at the phrasally-prominent
locations investigated in Experiment 2 did not behave the same way as the initial segments in
lexically-stressed syllables in Shattuck-Hufnagel’s (1992) study because prominence in higher
constituents was protective against segmental error. Prominence relations over larger constituents
than the phonological word must, therefore, have been computed by the time segments were ready
for association to prosodic structures to give this protective effect. If the prosodic frame specifies
accented syllables in addition to lexical stress (Keating and Shattuck-Hufnagel, 2002), then a scan-
copier would be able to narrow the search to segments marked for accent. There would be few (if
any) other onset segments of accented syllables competing for selection, whereas there would likely
be several segments tagged as initial in lexically-stressed syllables within phonological words,
leading to more segment interaction errors between stressed-syllable-initial segments than accented-
syllable-initial segments within an utterance.
Experiment 2 also found that participants made more errors to tongue twister words at
phrase-initial than -medial or -final positions. Interpretation of this finding is limited, however, by
the confound between initialness within clauses and format in this experiment, as all tongue twister
words were presented in an ABBA format (e.g. den, ton, tuck, dial). The high error rates at both
clause-initial positions may therefore have been due to the reversal of gestural phasing required at
these positions by the ABBA format over subsequent repetitions of the sentence. Many tongue
twister experiments (Frisch 2000; Goldrick and Blumstein 2006; Shattuck-Hufnagel 1992;
Vitevitch 2002) have used an ABBA format because it reliably elicits high rates of errors, however
this confound in Experiment 2, and the main and interaction effects of format in Experiment 1 urge
careful consideration of the potential consequences of different formats when designing materials
for future tongue twister studies. Our Experiment 2 should be repeated using ABAB order.
Neighbourhood density did not influence error rates in this experiment, in contrast with the
finding of Vitevitch (2002) in a tongue twister task, SLIPs task and two picture-naming tasks. We
did, however, remove four sentences from the analysis as described above, and although two were
of high density and two of low density, this may have compromised listwise differences in density
in our experiment, or listwise matching of high and low density words on frequency,
neighbourhood frequency or familiarity. Alternatively, uncontrolled effects of prosodic structure in
Vitevitch’s (1992) Experiment 2, or item difficulty due to the required phasing of gestures for all
words across the two neighbourhood density conditions in Vitevitch’s materials or ours may have
confounded the investigation of neighbourhood density in one or both studies.

19
4. General Discussion
4.1 When does prosodic structure become available during speech production?
Experiments 1 and 2 indicated that emphatic production of tongue twister words in four-
word lists, narrow informational focus in sentences, and list-initial position influence the rate of
speech errors in tongue twister production. These results provide evidence that at least some
information represented at upper levels of a prosodic hierarchy is available at the time of segment-
to-frame association during phonological encoding. Most current models of phonological encoding
have little to say, however, about how segmental information and higher-level prosodic information
are integrated during speech planning. The proposals of Levelt (1989), Levelt, Roelofs, and Meyer
(1999) and Keating and Shattuck-Hufnagel (2002) are an exception, thus they are summarised
below.
Levelt (1989: 365) acknowledged the rudimentary nature of his “rough sketch of a possible
architecture” underlying the prosodic formulation of connected speech. The key component of this
architecture is the Prosody Generator, a processing component that works incrementally from the
beginning of an utterance forward, with limited lookahead. The Prosody Generator combines
surface structure, number of syllables and lexical stress information as they become available to
build a prosodic structure which details a pattern of accented versus unaccented syllables,
Intonational Phrases and a smaller phrase he called a phonological phrase. Next the speaker’s
intonational meanings (not captured in the grammar) are consulted to determine which phrase
accents and boundary tones will apply to each phrase, and which syllables will receive prominence.
Finally, the Prosody Generator computes how the segments associated with individual words will
be combined into phonological words and structured into syllables. The outputs from the Prosody
Generator are a prosodic frame for the whole utterance that details durations, loudness, F0 and
pausing, and a string of segments tagged with their syllable position ready to be allocated to
phonological words (Keating and Shattuck-Hufnagel 2002; Levelt 1989). These are combined
during the process of phonetic encoding that specifies the articulatory gestures required for speech
and their relative timing.
In a newer, and in many ways more powerful theory, Levelt, Roelofs, and Meyer (1999)
propose that the number of syllables and location of lexical stress are only stored and retrieved in
English for the approximately 10% of words that have an atypical stress pattern (i.e., stress on other
than the first syllable). For all other words, phonological word structure, including number of
syllables and location of lexical stress, is generated incrementally and online from the segments as

20
they become available from long-term memory, using the syllabification rules of the language. A
“binding-by-checking” procedure ensures that segments are combined into words that correspond to
the target words required for the utterance, and segmental speech errors are attributed to occasional
failures in the checking procedure. Prosodic phrases are constructed according to a process
described by Levelt (1989) that depends on information about the number of syllables and location
of lexical stress that is contained in the phonological word structures. The newer theory therefore
requires that phrase-level prosodic information (prosodic phrase boundaries and locations of pitch
accents) cannot be available before phonological words are generated from segments.
Keating and Shattuck-Hufnagel (2002) argue that the theory of Levelt, Roelofs and Meyer
(1999) is unable to explain many features of connected speech. They propose instead that a
preliminary default prosodic structure for a whole utterance is initially computed on the basis of the
words in the utterance and their surface structure. This preliminary structure is progressively
modified as various other types of information required for the utterance (lexical, syntactic,
morphological, phonological and phonetic) are retrieved from long-term memory. Before any
segments are retrieved, the evolving prosodic structure contains correct Intonational and
intermediate phrase boundaries, the pitch accents and boundary tones associated with these phrases,
and the locations of phonological word boundaries and pitch accents on phonological words, taking
into account the speaker’s intonational meanings. According to Keating and Shattuck-Hufnagel,
only after all this prosodic information is available do speakers retrieve segments for all words in
the utterance and map them to this near-complete prosodic structure – at which point segmental
speech errors may occur.
The results of the present study are most consistent with the proposals of Keating and
Shattuck-Hufnagel (2002), in suggesting that information about pitch accents that realise narrow
informational focus, and prosodic constituency at upper levels of a prosodic hierarchy (e.g. the
location of utterance and/or Intonational-Phrase initial boundaries), has been computed prior to the
association of segments to the prosodic frame during phonological encoding. Our results are not
compatible with the claim that phrase-level prosodic information is generated after phonological
words are generated from segments (Levelt et al. 1999).
4.2 Why do segments at prosodically strong positions resist error?
Keating (2006) discussed the possibility raised by Frisch (2000) and Dell (2000) that initial
segments of words are highly vulnerable to error because they are less predictable than subsequent
segments, being less (or even un-) constrained by context (Fougeron and Keating 1997). The
higher a constituent is in the prosodic hierarchy, the less predictable its initial segment may be.

21
Keating suggested that the unpredictability of constituent-initial segments, and the high information
load carried by word-initial segments in word recognition, might also motivate articulatory
strengthening. In articulatory strengthening the articulators become stronger and, in the case of
consonants, form a more extreme constriction, on the initial segments of prosodic constituents.
There is also evidence that the higher the constituent the greater the strengthening (Fougeron and
Keating 1997). Articulatory strengthening also occurs on accented words (Beckman, Edwards, and
Fletcher 1992), which typically introduce new information and are less predictable than deaccented
words.
Keating (2006) hypothesised that if the unpredictability of constituent-initial segments leads
to both articulatory strengthening and segmental errors, and if initial positions of higher constituents
show greater strengthening, then constituent-initial and accented positions may also be more
vulnerable to error. Our findings, that segmental errors were reduced on accented words in
sentences, and on utterance-initial segments in several post-hoc comparisons in the ABAB lists, did
not support this prediction. We speculate that the unpredictability, and its converse, information
load, noted by Keating (2006) and Fougeron and Keating (1997) may yield the opposite effect:
because unpredictable words carry the greatest information load they may by some mechanism be
less vulnerable to error. The relatively high rate of errors on phonological word-initial segments
would still be explained with reference to the high number of positionally similar candidates
available for selection for phonological word-initial slots in the prosodic frame for an utterance.
According to the revised scan-copier model, prosodic information about lexical boundaries
and lexical stress is available along with the segments as part of the lexical representation
(Shattuck-Hufnagel 1992). How might segments in the short-term store come to be tagged for
initial position at the Intonational Phrase- and/or utterance-levels of the prosodic hierarchy, or for
accent? A phonological competition model (e.g., Sevald and Dell 1994) may be able to simulate
such effects if there was a mechanism whereby segments at informationally strong locations
received increased activation relative to other segments, reducing the likelihood of mis-selecting
those segments. Higher levels of activation cascading to the phonetic features associated with these
segments (Goldrick and Blumstein 2006), or to the motor units that articulate them (MacKay,
1971), might then further account for articulatory strengthening effects (Beckman, Edwards, and
Fletcher 1992; Fougeron and Keating 1997).
4.6 Concluding comments
These two experiments demonstrate the potential for tongue twister experiments to inform
theory about how segmental content and prosodic structure of an utterance are integrated during

22
speech planning. The significant effects of ABBA versus ABAB format in Experiment 1 urge that
future work should consider the relationship between prominence and speech errors within the
theoretical framework of a coupled oscillator model of articulatory planning. This will require
collection of kinematic data, rather than phonetic transcriptions of errors, and careful control of the
composition of entire stimuli, not just target words or segments. Finally, although previous tongue
twister studies have not always manipulated or controlled prosodic factors, especially at higher
levels of the prosodic hierarchy, it will clearly be informative to do so in future.

23
Notes
1. Many thanks to Cécile Fougeron, Patricia Keating and Marianne Pouplier for their constructive
feedback on an earlier version of this manuscript, and to Amanda White for assistance in preparing
the final version of the manuscript.
2. A copy of the tongue twister words used in this study is available on request to,
Micheal S Vitevitch, Department of Psychology, 1415 Jayhawk Blvd., University of Kansas,
Lawrence, KS 66045, USA. Email: [email protected]
3. The sentence materials are available from the first author, after tongue twister words have been
obtained as described in Note 2. Contact, Karen Croot, School of Psychology, University of
Sydney, NSW AUSTRALIA 2006. Email: [email protected]
4. With one exception, Lung wore a robe of silk, rice and gold leaf.

24
References
Baars, Bernard J., Michael T. Motley and Donald G. MacKay 1975 Output editing for lexical status from artificially elicited slips of the tongue. Journal of Verbal Learning and Verbal Behaviour 14: 382—391. Beckman, Mary E., Jan Edwards and Janet Fletcher 1992 Prosodic structure and tempo in a sonority model of articulatory dynamics. In: Gerard J. Docherty and Robert Ladd (eds.), Gesture, Segment, Prosody, 68—86. (Papers in Laboratory Phonology II.) Cambridge: Cambridge University Press. Cedrus 2004 SuperLab 2.0.4. Dell, Gary S. 1986 A spreading-activation theory of retrieval in sentence production. Psychological Review 93: 283—321. Dell, Gary S 2000 Counting, connectionism and lexical representation. In Michael B. Broe and Janet B. Pierrehumbert (eds.), Acquisition and the Lexicon, 335—348. (Papers in Laboratory Phonology V.) Cambridge: Cambridge University Press. Dell, Gary S. 1990 Effects of frequency and vocabulary type on phonological speech errors. Language and Cognitive Processes 5: 313—349. Dell, Gary S., Cornell Juliano and Anita Govindjee 1993 Structure and content in language production. Cognitive Science 17: 149—195. Enable Software 2005 Metronome. Retrieved 2005, from http://enableencore.com/encore/metronome.htm Frisch, Stefan 2000 Temporally organised lexical representations as phonological units. In Michael B. Brow and Janet B. Pierrehumbert (eds.), Acquisition and the Lexicon, 283—298. (Papers in Laboratory Phonology V.) Cambridge: Cambridge University Press. Fougeron, Cécile and Patricia A. Keating 1997 Articulatory strengthening at the edges of prosodic domains. Journal of the Acoustical Society of America 101: 3728—3740. Goldrick, Matthew and Sheila E. Blumstein 2006 Cascading activation from phonological planning to articulatory processes: Evidence from tongue twisters. Language and Cognitive Processes 21(6): 649—683. Goldstein, Louis, Dani Byrd and Elliot Saltzman 2006 The role of vocal tract gestural action units in understanding the evolution of phonology. In Michael A. Arbib (ed.), Action to Language via the Neuron System, 215—249. Cambridge: Cambridge University Press. Goldstein, Louis, Marianne Pouplier, Larissa Chen, Elliot Saltzman, and Dani Byrd In press Dynamic action units slip in speech production errors. Cognition. Keating, Patricia A 2006 Phonetic encoding of prosodic structure. In Jonathan Harrington and Marija Tabain (eds.) Speech production: Models, phonetic processes, and techniques, 167—186. (Macquarie Monographs in Cognitive Science) New York: Psychology Press.

25
Keating, Patricia and Stephanie Shattuck-Hufnagel 2002 A prosodic view of word form encoding for speech production. University of California Los Angeles Working Papers in Phonetics 101: 112—156. Levelt, Willem J. M. 1989 Speaking: From Intention to Articulation. Cambridge, Massachusetts: Massachusetts Institute of Technology Press. Levelt, Willem J. M., Ardi Roelofs and Antje S. Meyer 1999 A theory of lexical access in speech production. Behavioural and Brain Sciences, 22(1): 1—75. MacKay, Donald G. 1971 Stress pre-entry in motor systems. American Journal of Psychology, 84(1): 35—51. Pouplier, Marianne In press Tongue kinematics during utterances elicited with the SLIP technique. Language and Speech. Sevald, Christine A. and Gary S. Dell 1994 The sequential cuing effect in speech production. Cognition 53: 91—127. Shattuck-Hufnagel, Stephanie 1979 Speech errors as evidence for a serial-ordering mechanism in sentence production. In William E. Cooper and Edward C.T. Walker (eds.), Sentence Processing: Psycholinguistic Studies Presented to Merrill Garrett, 295—342. Hillsdale, New Jersey: Lawrence Erlbaum. Shattuck-Hufnagel, Stephanie 1983 Sublexical units and suprasegmental structure in speech production planning. In Peter F. MacNeilage (ed.), The Production of Speech, 109—136. New York: Springer-Verlag. Shattuck-Hufnagel, Stephanie 1992 The role of word structure in segmental serial ordering. Cognition 42: 213—259. Shattuck-Hufnagel, Stephanie and Dennis H. Klatt 1979 The limited use of distinctive features and markedness in speech production: Evidence fro speech error data. Journal of Verbal Learning and Verbal Behavior, 18:41—55. Shattuck-Hufnagel, Stefanie and Alice E. Turk 1996 A prosody tutorial for investigators of auditory sentence processing. Journal of Psycholinguistic Research, 25(2): 193—247. Stemberger, Joseph P. 1992 The reliability and replicability of naturalistic speech error data: A comparison with experimentally induced errors. In Bernard J. Baars (ed.), Experimental Slips and Human Error: Exploring the Architecture of Volition, 195—215. New York: Plenum Press. Vitevitch, Michael S. 2002 The influence of phonological similarity neighborhoods on speech production. Journal of Experimental Psychology: Learning, Memory and Cognition 28(4): 735—747. Vousden, Janet I., Gordon D.A. Brown and Trevor A. Harley 2000 Serial control of phonology in speech production: A hierarchical model. Cognitive Psychology, 41: 101—175. Wilshire, Carolyn E. 1998 Serial order in phonological encoding: An exploration of the ‘word onset effect’ using laboratory-induced errors. Cognition 68: 143—166.

26
Wilshire, Carolyn E. 1999 The ‘tongue twister’ paradigm as a technique for studying phonological encoding. Language and Speech 42(1): 57—82.
27
Table 1: Percentages of different error types produced in Experiment 1. Contextual Non-contextual Total
Onset 83.3 1.2 84.5
Coda 2.8 3.7 6.5
Whole word 1.6 7.4 9.0
Total 87.8 12.2 100

28
Table 3: Percentages of different error types produced in Experiment 2. Contextual Non-contextual Total
Onset 76 9 85
Coda 11 1 12
Whole word 3 N/A 3
Total 90 10 100

29
FIGURE CAPTIONS
Figure 1. Mean number of total errors per word at each position in the a) ABAB format and b)
ABBA format tongue twisters in Experiment 1. Participants repeated four-word lists 6 times each
under each of four prominence conditions. Bars show standard errors.
KEY: Prom Cond = Prominence Condition. W1 w2 w3 w4 = first word emphasised. w1 w2 w3 W4
= fourth word emphasised. W1 w2 W3 w4 = first and third words emphasised. w1 W2 w3 W4 =
second and fourth words emphasised.
Figure 2. Mean number of contextual errors per tongue twister word produced in sentences repeated
six times each in Experiment 2. Tongue twister words occurred at clause-initial versus non-initial
position and were accented (given narrow focus) versus unaccented.

30
Figure 1.

31
Figure 2.

Table 2. Mean number of total errors per word and 95% confidence intervals for means by prominence condition, format and position in list,
and for two-way interactions between these variables in Experiment 1. KEY: CI = Confidence Interval, W1 w2 w3 w4 = first word emphasised.
w1 w2 w3 W4 = fourth word emphasised. W1 w2 W3 w4 = first and third words emphasised. w1 W2 w3 W4 = second and fourth words
emphasised.
Prominence Condition x Position in List
Prominence Condition (i) W1 w2 w3 w4 (ii) w1 w2 w3 W4 (iii) W1 w2 W3 w4 (iv) w1 W2 w3 W4 Total
Mean CI Mean CI Mean CI Mean CI Mean CI Position in List Word 1 2.8 2.2, 3.5 4.1 3.3, 4.9 3.2 2.5, 3.9 4.6 3.9, 5.4 3.7 3.1, 4.2
Word 2 3.2 2.5, 3.9 4.9 4.0, 5.8 3.4 2.7, 4.2 3.4 2.8, 4.1 3.7 3.1, 4.3
Word 3 7.1 5.7, 8.4 7.6 6.3, 8.9 6.0 5.0, 7.0 8.9 7.5, 10.3 7.4 6.5, 8.3
Word 4 5.5 4.2, 6.8 4.8 3.7, 5.9 4.5 3.4, 5.7 6.1 4.8, 7.3 5.2 4.3, 6.2
Total 4.7 3.8, 5.6 5.3 4.4, 6.2 4.3 3.5, 5.0 5.8 4.9, 6.6 5.0 4.3, 5.7
Prominence Condition x Format Prominence Condition (i) W1 w2 w3 w4 (ii) w1 w2 w3 W4 (iii) W1 w2 W3 w4 (iv) w1 W2 w3 W4 Total
Mean CI Mean CI Mean CI Mean CI Mean CI
Format ABAB 4.4 3.6, 5.2 4.9 4.0, 5.7 2.9 2.4, 3.4 4.0 3.3, 4.7 4.0 3.5, 4.6
ABBA 4.9 3.8, 6.0 5.8 4.7, 6.9 5.7 4.6, 6.8 7.5 6.3, 8.7 6.0 5.1, 6.9
Total 4.7 3.8, 5.6 5.3 4.4, 6.2 4.3 3.5, 5.0 5.8 4.9, 6.6 5.0 4.3, 5.7
Position in List x Format
Position in List Word 1 Word 2 Word 3 Word 4 Total
Mean CI Mean CI Mean CI Mean CI Mean CI Format ABAB 2.4 2.0, 2.8 3.6 3.0, 4.2 5.7 4.8, 6.6 4.4 3.5, 5.4 4.0 3.5, 4.6
ABBA 5.0 4.1, 5.9 3.9 3.0, 4.7 9.1 7.8, 10.3 6.0 4.8, 7.2 6.0 5.1, 6.9
Total 3.7 3.1, 4.2 3.7 3.1, 4.3 7.4 6.5, 8.3 5.2 4.3, 6.2 5.0 4.3, 5.7


















