
Project Documentation for v2 - storage.googleapis.com · Project Documentation for v2.0 ......
37
Project Documentation for v2.0 Lokad.CQRS is a .NET framework and a set of guidance materials for building distributed and scalable applications to be run on-premises or deployed to Windows Azure Cloud. This project helps to design and develop decoupled systems locally and bring them to the distributed environments later. Homepage: http://code.google.com/p/lokad-cqrs/ Community: https://groups.google.com/group/lokad Primary Author: Rinat Abdullin (@abdullin), Technology Lead at Lokad Other Contributions : o Joannes Vermorel (@vermorel), Founder at Lokad o Vsevolod Parfenov (@vsevolod), Software Developer at Lokad Introduction Document Audience This document targets developers that want to learn how to use Lokad.CQRS to prototype and develop systems for Windows Azure Cloud Computing Platform with Microsoft .NET stack. It also might be helpful for .NET students who want to get guidance on building distributed and cloud systems. It is advised to be familiar with the theory behind CQRS Architecture principles (http://abdullin.com/cqrs) and also be practically familiar with development on .NET 4.0 (serialization, parallel programming, LINQ, Dependency Injection and Inversion of Control, Unit Testing). This document applies to the Lokad.CQRS v2.0 release (June 2011). We will be improving it in parallel with the samples and the framework itself. Please, make sure, that you got the latest version. Open-Source Strategy Lokad.CQRS is an open source development framework released by Lokad SAS (http://lokad.com) for the community to use. As a start-up company we’ve benefitted a lot from a large number of various frameworks like Autofac, NUnit, ScrewTurn Wiki, ProtoBuf.NET, Math.NET and many more. These frameworks, shared under a liberal license, literally saved us thousands of man hours and allowed to achieve incredible results on the field of providing statistical forecasting as a service. Building distributed systems is neither the business focus of Lokad nor it is the critical competitive advantage. So we’ve decided to share some of our work and experience to say Thank You to incredible .NET community. Hopefully this project will help somebody to save a few man-hours, avoid a few pitfalls in building cloud systems and let focus resources and people on creating amazing products and services. It helps us. Visit our Developers section for more detail on our Open-Source Strategy and list of supported projects: http://www.lokad.com/developers.ashx.
Transcript of Project Documentation for v2 - storage.googleapis.com · Project Documentation for v2.0 ......

Project Documentation for v2.0
Lokad.CQRS is a .NET framework and a set of guidance materials for building distributed and scalable
applications to be run on-premises or deployed to Windows Azure Cloud. This project helps to design and
develop decoupled systems locally and bring them to the distributed environments later.
Homepage: http://code.google.com/p/lokad-cqrs/
Community: https://groups.google.com/group/lokad Primary Author: Rinat Abdullin (@abdullin), Technology Lead at Lokad
Other Contributions:
o Joannes Vermorel (@vermorel), Founder at Lokad o Vsevolod Parfenov (@vsevolod), Software Developer at Lokad
Introduction
Document Audience This document targets developers that want to learn how to use Lokad.CQRS to prototype and develop
systems for Windows Azure Cloud Computing Platform with Microsoft .NET stack. It also might be helpful for
.NET students who want to get guidance on building distributed and cloud systems.
It is advised to be familiar with the theory behind CQRS Architecture principles (http://abdullin.com/cqrs)
and also be practically familiar with development on .NET 4.0 (serialization, parallel programming, LINQ,
Dependency Injection and Inversion of Control, Unit Testing).
This document applies to the Lokad.CQRS v2.0 release (June 2011). We will be improving it in parallel with
the samples and the framework itself. Please, make sure, that you got the latest version.
Open-Source Strategy Lokad.CQRS is an open source development framework released by Lokad SAS (http://lokad.com) for the
community to use. As a start-up company we’ve benefitted a lot from a large number of various frameworks
like Autofac, NUnit, ScrewTurn Wiki, ProtoBuf.NET, Math.NET and many more. These frameworks, shared
under a liberal license, literally saved us thousands of man hours and allowed to achieve incredible results on
the field of providing statistical forecasting as a service.
Building distributed systems is neither the business focus of Lokad nor it is the critical competitive advantage.
So we’ve decided to share some of our work and experience to say Thank You to incredible .NET community.
Hopefully this project will help somebody to save a few man-hours, avoid a few pitfalls in building cloud
systems and let focus resources and people on creating amazing products and services. It helps us.
Visit our Developers section for more detail on our Open-Source Strategy and list of supported projects:
http://www.lokad.com/developers.ashx.

Contents Introduction ........................................................................................................................................1
Document Audience .........................................................................................................................1
Open-Source Strategy .......................................................................................................................1
Project References and Cases ................................................................................................................4
Salescast .........................................................................................................................................4
Callcalc............................................................................................................................................5
Lokad Hub .......................................................................................................................................6
Public References .............................................................................................................................7
Overview ............................................................................................................................................8
Crash Course ...................................................................................................................................8
Project Structure ..............................................................................................................................9
Core Development Concepts ............................................................................................................... 10
Inversion of Control ........................................................................................................................ 10
Unit Testing ................................................................................................................................... 10
Command-Query Responsibility Segregation ..................................................................................... 10
Domain-Driven Design .................................................................................................................... 11
Cloud Computing ........................................................................................................................... 11
Messaging and Distributed Systems ..................................................................................................... 12
Message Envelopes and Serialization ................................................................................................ 13
Decide-Act-Report Model ................................................................................................................ 15
Scalability ...................................................................................................................................... 17
Entity Partitioning .......................................................................................................................... 18
Storage Blocks ................................................................................................................................... 20
Why NoSQL?.................................................................................................................................. 20
Atomic Storage .............................................................................................................................. 20
Entities vs. Singletons .................................................................................................................. 21
NuclearStorage vs. Typed Interfaces.............................................................................................. 22
Readers vs. Writers ..................................................................................................................... 23
Configuration ............................................................................................................................. 23
Streaming Storage .......................................................................................................................... 23
Optimizations ............................................................................................................................. 24
Streaming Conditions .................................................................................................................. 24

Configuration ............................................................................................................................. 25
Basics of Lokad.CQRS Application Engine and Client ............................................................................... 26
Configuring and Running Lokad.CQRS Application Engine .................................................................... 26
Configuring and Using Lokad.CQRS Application Client ......................................................................... 28
Message Directory.......................................................................................................................... 29
Using Storage Blocks....................................................................................................................... 30
Message Queues ............................................................................................................................ 30
Azure Queues............................................................................................................................. 31
In-Memory Queues ..................................................................................................................... 31
Message Dispatchers ...................................................................................................................... 31
Command Dispatcher .................................................................................................................. 31
Event Dispatcher ........................................................................................................................ 31
Routing Dispatcher ..................................................................................................................... 32
Advanced Configuration Options ......................................................................................................... 33
Configurable Message Interfaces...................................................................................................... 33
Message Context Factories .............................................................................................................. 33
Custom Envelope and Message Serialization Options.......................................................................... 35
Envelope Quarantine and Customizations ......................................................................................... 35
Custom Message Envelope Dispatchers............................................................................................. 36
Portability Scenarios ....................................................................................................................... 36
What Next?....................................................................................................................................... 37

Project References and Cases Lokad.CQRS is used and battle-tested internally at Lokad in a number of projects targeting various business
objectives, feature requirements and scalability challenges.
Below is a quick overview of these projects.
Salescast Salescast is a cloud integration engine for massive inventory optimization. It is capable of processing millions
of product references, tailored for large retail networks.
Lokad.CQRS significantly simplifies the development while preserving cloud scalability. It allows achieving less
than one hour interval between committing code and reliably deploying latest changes into production on
Windows Azure.
Features:
Multi-tenant

Tenant-specific ad-hoc integration logic.
Full audit logs.
Auto detection of 3rd party business apps.
API.
Learn more: http://www.lokad.com/salescast-sales-forecasting-software.ashx
Callcalc Callcalc is an email-based forecasting client for call centers. You send an Excel spreadsheet with call volumes
and Callcalc replies with forecasts.
Lokad.CQRS provides simple and reliable foundation for a heavily verticalized solution that tailors our raw
Forecasting API for the very specific needs of call centers.
Features:
Multi-tenant Multiple calling queues
Erlang-C staffing optimization

IMAP interface
Learn more: http://www.lokad.com/call-center-calculator-software.ashx
Lokad Hub Lokad.Hub is an internal platform unifying metered pay-as-you-go forecasting subscription offered by Lokad.
Lokad.CQRS is the key to transition a pre-cloud business app toward a decoupled and efficient design. It
provides additional reliability and allows much faster development iterations.
Features:
Multi-tenant. Full audit logs.
Flexible reporting, including ad-hoc reports and temporal queries.
Reliable failure handling.
No-downtime upgrades.

Integration with payment, Geo-Location and CRM systems.
Public References There already are a few brave souls that have tried to apply Lokad.CQRS for Windows Azure outside of our
company. Here is some feedback that was kindly shared with us.
David Pfeffer (http://twitter.com/#!/bytenik)
fivepm technolgy, inc. uses Lokad.Cqrs to drive its entire flagship Treadmarks
product. We rely on the service bus to reliably deliver messages across our cloud
application, and we use the view persistence helpers to store any view data. We
initially investigated rolling our own framework or using NServiceBus, but the
maturity of Lokad.Cqrs on the Azure platform made it an easy winner over the other
possibilities.
Chris Martin (http://twitter.com/#!/cmartinbot):
I can't thank Lokad enough for the work you guys have put in. You have literally saved
our startup thousands of man-hours!
If you want to tell us a story, use case or share a success, please, don’t hesitate to drop us a line to

Overview Lokad.CQRS is a .NET framework and guidance for designing and building distributed systems that target
cloud computing environments (like Windows Azure). Framework is written in C# but could be used in any
other .NET language.
Lokad.CQRS is designed to be non-intrusive, while guiding development away from some common pitfalls
and problems that we’ve encountered while building scalable systems for the cloud.
This project is driven by our desire to push further state of the art in the field and inspired by a set of
principles:
Messaging – way of decoupling systems by encapsulating method calls into message objects that could be sent over the networks, queued or persisted.
Domain-Driven Design – practices for design and modeling complex business domains in software. Command-Query Responsibility Segregation (CQRS) – separation between read/write
responsibilities at the class level and within the architecture. Decide-Act-Report pattern – way of modeling and designing client-driven message-based
applications with the use of messaging, intent-capturing UI, decoupled “write side” and persistent read models.
And many more.
Experience at Lokad suggests that these principles help building systems that can scale and grow in
complexity as needed, while still requiring limited development resources for further evolution and
maintenance.
In addition to that, Lokad.CQRS explicitly forces you to stick diligently to the most important principles. It is
designed this way. In return it grants limited portability - ability to run the same system under various
environments with minor changes:
Local development environments;
On-premise production deployments;
Cloud-computing deployments;
Various combinations of these items.
Crash Course From the simplest perspective, distributed systems are composed from messages, which are transported
between various components hosted somewhere (on a server, in the cloud or locally). These logical
components receive messages via message handlers, which act upon them (i.e. change database or other
data) and optionally send some more messages.
Decide-Act-Report model explains how to build feature-rich applications out of these elements, while
Domain-Driven Design helps to tackle the complexity and model the business domain.
Lokad.CQRS provides help in writing these messages, message handlers, dealing with the data, configuring
everything together with a set of technologies, and then running everything on a remote server, locally or in
the cloud.

Go to http://abdullin.com/cqrs to start learning more about
CQRS and distributed systems.
Check out Samples within the project for some practical guidance on building system with Lokad.CQRS using:
Microsoft .NET Stack
ASP.NET MVC
Project Structure Lokad.CQRS consists of the following important elements:
Storage Blocks (in Lokad.CQRS.Portable.dll)
Application Engine and Client with builders (in Lokad.CQRS.Portable.dll)
Windows Azure Extension Package (in Lokad.CQRS.Azure.dll)
Samples
Documentation and Guidance
Let’s go over these elements.

Core Development Concepts There are certain development concepts that are essential to Lokad.CQRS, understanding it properly and
successfully delivering software. These concepts will be briefly mentioned in this chapter just to ensure that
we are on the same page regarding the terminology and application scenarios.
Please, feel free to skim through this chapter, if the concepts are already familiar to you.
Inversion of Control Inversion of Control (IoC) is an approach in software development that favors removing sealed dependencies
between classes in order to make code more simple and flexible. We push control of dependency creation
outside of the class, while making this dependency explicit.
Usage of Inversion of Control generally allows creating applications that are more flexible, unit -testable,
simple and maintainable in the long run.
Often control over the dependency creation is delegated to specialized application blocks called Inversion of
Control Containers. IoC containers are really good in determining dependencies that are needed to create a
specific class and injecting them automatically. This process is often called Dependency Injection.
Continue reading: http://abdullin.com/wiki/inversion-of-control-ioc.html
Unit Testing Unit Testing in software development is a way to quickly verify that smallest blocks of software (units)
behave as expected even as the software changes and evolves.
Any program could be logically separated into distinct units (in object-oriented programming the smallest
unit usually being a class). Developers, while coding these program units, also create tests for them (code
blocks containing some assertions and expectations about units). These tests could be used to rapidly verify
behavior of the code being tested.
When some other developer introduces new units or changes something in existing units, he can run all the
tests available for the program and verify that everything is still operating as expected. Usually running unit
tests is a fast operation (less than 30 seconds), so developers are encouraged to do that often.
Continue reading: http://abdullin.com/wiki/unit-testing.html
Command-Query Responsibility Segregation Command-Query Responsibility Segregation (CQRS) is a way of designing and developing scalable and robust
enterprise solutions with rich business value.
In an oversimplified manner, CQRS separates commands (that change the data) from the queries (that read
the data). This simple decision brings along a few changes to the classical architecture with service layers
along with some positive side effects and opportunities. Instead of the RPC and Request-Reply
communications, messaging and Publish-Subscribe are used.
If we go deeper, Command-query Responsibility Separation is about development principles, patterns and the
guidance to build enterprise solution architecture on top of them.

Continue reading: http://abdullin.com/cqrs/
Domain-Driven Design Domain-Driven Design (DDD) is a way of understanding, explaining and evolving domain model in software in
such manner that:
model would focus on the most important characteristics of the problem at hand (while putting
less important things aside, for the sake of preserving the sanity of everybody); the model could evolve and still stay in sync with reality;
model would help different people with various backgrounds to work together (i.e.: users, sales
people and hard-core developers); model would let you avoid costly development mistakes (it could even help to deliver new
exciting features as a simple logical extension of what has already been implemented).
Domain-Driven Design is also a way of thinking, learning and talking about the business problem in a manner
that implementing everything would be rather simple, despite the initial complexity of the actual problem.
Continue reading: http://abdullin.com/journal/2010/11/16/key-cqrs-ingredient.html
Cloud Computing Cloud computing is all about hardware-based services (involving computing, network and storage capacities),
where:
Services are provided on-demand; customers can pay for them as they go, without the need to
invest into a datacenter. Hardware management is abstracted from the customers.
Infrastructure capacities are elastic and can easily scale up and down.
There is a powerful economic force behind this simple model: providing and consuming cloud computing
services generally allows having far more efficient resource utilization, compared to self-hosting and data
center type of hosting.
Continue reading: http://abdullin.com/wiki/cloud-computing.html

Messaging and Distributed Systems Messages are essential to building robust and distributed systems, so let’s talk a bit about them.
Message is a named data structure, which can be sent from one distributed component to another.
Components can be located on the same machine or on different sides of the Earth.
The basic example of message is an email. It has a sender, subject and one or more recipients. This email
might take some time to reach the designation. Then it gets to the inbox, where it could spend even more
time, before recipient finally gets time to read it and may be even reply.
Messages, just like emails, might take some time to reach recipient (it could be really fast but it is not
instantaneous), and they could spend some time in the message queues (analogue of inbox), before the
receiving side finally manages to get to work on this message.
The primary problem with messages and emails is their asynchronous nature. When we send email or
message, we expect the answer some time later, but we can never be sure that we will get it right away.
Direct phone calls (or direct method calls) are much better here – once you get the person on the phone, you
can talk to him in real time and get results back almost immediately.
Despite these asynchronous nature problems, messages could be better than calls for building distributed
and scalable systems.
With phone calls and method calls you:
Can get response immediately, once your call is picked up.
Must be calling, while the other side is available (greater distance you have, harder it is to negotiate
the call). More stressed the other side is, more time it will take before your call will be picked up. And this
does not guarantee, that you will get the answer (when the other side is really stressed you are likely to get: we are busy right now, call next millennia).
With messages you:
Can send a message and then get back to your work immediately.
Must organize your work in such a way, that you will not just sit idle waiting for the response.
Can send a message any time, the other side will receive and respond, as soon as it gets to the job.
More stressed the other side is, more time it takes to receive the answer. No matter what the level
of stress is, the other side will still be processing messages at its own pace without any real stress.
Since we are mostly interested in building distributed and scalable systems (which can handle stress and
delays) messages are a better fit for us, than the direct method calls in the majority of the cases. They allow
decoupling systems and evenly distributing the load. Besides, it is easy to do with messages such things like:
replaying failing messages, saving them for audit purposes, redirecting or balancing between multiple
recipients.
Note, that there are cases, where direct calls work better than messaging. For example, querying in-memory
cache does not make sense with messaging. Cache is fast and you want to have the response immediately.

Message Envelopes and Serialization Message delivery is handled by the infrastructure and messaging middleware. In order to accomplish that
task, additional information has to be associated with that message, while it travels from the sender to
recipient. This additional information is called out-of-band data and is usually represented as transport
headers sent with the messages.
Common samples of transport headers are:
Message identity – unique identifier of the message, used to detect and discard potential duplicates.
Message delivery date – time-stamp used to delay delivery of the message, till some time.
Message routing key or topic – fields used to control pub/sub and load balancing in the messaging
infrastructure. Sender’s vector clock – used to implement partial message ordering in volatile environments.
Contract information – name of the serialization format and contract, which could be used to build
message object from the binary data. Signature – to verify authenticity of the message.
While sending message data across the network or saving it into some storage, all this information is packed
along with the data into a structure called message envelope.
Message envelope is an atomic unit of transportation for messages, which includes the actual message data
and all the information needed to reach the recipients and be processed properly. Envelopes are expected to
be transparently handled by the infrastructure, while the actual application code deals with the message data
that is already deserialized into objects.
This brings us to another important topic – message serialization, contracts and their versioning.
Message serialization is the process of a way to transforming message object into a format that can be safely
persisted or sent into the wire. Message deserialization is the reverse process of rebuilding object from the
data.
In the .NET world some of the common serialization formats are:
Xml serialization – format object as XML document.
Binary serialization – encode object as a binary blob.
JSON serialization – format object into a JavaScript Object Notation.
Google Protocol Buffers – encode objects into a compact binary blob.
Given the following message class definition (message contract):
public sealed class ForecastsAvailableEvent : IDomainEvent
{
public ForecastsAvailableEvent(long solutionId, Guid syncId)
{
SyncId = syncId;
SolutionId = solutionId;
}
public long SolutionId { get; private set; }
public Guid SyncId { get; private set; }
}

This would be an example of creating new instance of message object and sending it:
int solutionId = …
Guid syncId = …
var message = new ForecastsAvailableEvent(solutionId, syncId);
sender.SendOne(message);
The messaging infrastructure will take care of serializing this object into some preconfigured data format,
adding required transport headers and sending the entire enveloper to the recipient.
If we were to use human-readable JSON serialization formats, then intercepting message envelope half-way,
would reveal us something like this:
EnvelopeId: 8f38f84b-d13a-4908-9693-49cb00c1968b
Created: 2011-06-01 00:38:01 (UTC)
0. Salescast.Context.Sync.ForecastsAvailableEvent
{
"SolutionId": 426,
"SyncId": "10a6e5d8-49cd-4b5e-8cc6-9ef50000022c"
}
The above data fragment contains all the information required for the recipient to create an instance of
ForecastsAvailableEvent and hand it over to the application code. Of course, in order to do that in a
strongly-typed fashion, the receiving side has to know about the message contract.
Message contract contains specific instructions about serializing specific members of a message object to a
data format and then deserializing it back. In the case of our sample, where we’ve used JSON serialization
format, default message contract is derived from the class structure automatically. In some other cases you
might need to specify contract with the use of attributes, like this example of class decorated for .NET
Protocol Buffers serialization format:
[ProtoContract]
public sealed class ForecastsAvailableEvent : IDomainEvent
{
public ForecastsAvailableEvent(long solutionId, Guid syncId)
{
SyncId = syncId;
SolutionId = solutionId;
}
[ProtoMember(1)] public long SolutionId { get; private set; }
[ProtoMember(2)] public Guid SyncId { get; private set; }
}
Managing contracts becomes increasingly important in the large distributed systems that are continuously
being evolved.
If we consider serialization format to be the language, then message contracts (and the meaning behind
them) are the actual verbs of this language. If two sub-systems (that could be located on the same machine
or across the globe) are to exchange messages, they need to know both the language (serialization format)
and have the same vocabularies (message contracts). Otherwise the dialogue would be impossible or flawed.

However, in any evolving system, things change rather frequently. In the software world message contracts
are changed rather frequently. Contract names change; members are added, removed or renamed to match
the intent better; new message types are added. This is similar to how every new human generation tends to
invent new words and come up with the new meanings to the old ones.
In order to avoid any misunderstandings between different generations of the software, we must ensure that
message contracts are managed explicitly. You can either define any new version of the message contract as
a completely different message, or you can update the message contract itself on all sides.
Sometimes the serialization format itself helps to simplify the evolution. For example, if you rename a
member (property or a field) in a XML-serialized message, then the receiving side will not be able to read it
unless:
It either gets the updated version of the message contract.
Or message contract on the sender side is adjusted accordingly to keep the serialization convention
as it is.
However, all serialization formats are not born equal when it comes to deal with changes. For example, one
of the major advantages of the ProtoBuf serialization format is that it precisely facilitates the contract
evolution.
Decide-Act-Report Model In the previous section we’ve maintained an analogy between messages – emails and method calls – phone
calls. In this section we will maintain this analogy, while establishing a new one – between real-world
organizations and distributed systems that could be built to support such organizations.
Let's think how some real-world organizations might function like. With some imagination you can identify 3
roles:
Managers, that run organization; they read paper reports, decide and issue orders for the workers
below them to execute. Workers, that receive orders, act upon them (where they can and have the resources) and notify
various departments about the job done. Assistants, which gather together all these notifications, mails and memos into various reports,
making them available to anybody, who has to make the decision.
Obviously, the entire iterative process of decide-act-report takes some time. It is not instantaneous, because
humans are slow. However, this somehow seems to works in the real world. Companies seem to make right
decisions that guide them through the ever-changing business world. They even manage to grow into large
organizations (with more complex structures).
In short, this structure - works. Now, take a look at the image below.

This image is a representation of distributed architecture model commonly associated with CQRS-inspired
software designs. It is just overplayed with the Decide-Act-Report (DAR) analogy from the real world.
In the software world, users are the managers, who decide, what to do in the UI. They use the latest reports
available to them in form of views (aka Read Models or Projections) in a way that makes it simple to make a
decision. User interface captures their intent in the form of command messages, which are sent to server to
order it to do some job.
Servers, then, act upon the command messages sent to them. Upon the job completion (or any other
outcome), notifications are sent to all interested parties in form of event messages published via pub/sub.
View event handlers (Projection Hosts) receive these notifications, building Views to report their data to the
user. They work even harder to keep these up-to-date, updating them upon every event message. Since
these reports are kept up-to-date, any interested party can query and an immediate result, without the need
to wait for the report to be computed.
Everything is rather straightforward, as you can see. At the same time, some of the analog ies from the real
world can still apply. For example:
There could be multiple managers, operating the same organization at the same time == multiple users can work concurrently with an application.
If there is too much work, you can hire some more workers == if there are too many commands, you
can add more servers. Actual reports can be copied and distributed around the organization, just in case manager needs
them right now == you can spread read models around the globe to keep them close to the client (or even keep them at the client).
Manager, workers and reporting assistants could be in the same building or they could be spread
across the continents, while exchanging mail between each other == distributed application with messaging can have all components as in a single process or it can spread them across the data centers.

So, again:
User - looks at views, decides and issues command messages. Command handlers - receive commands, act upon them and publish notifications (event messages)
View handlers - receive interesting notifications and update views, making them available to the
interested parties per request.
By the way, the same Decide-Act-Report model also works rather well, when you are trying to model
interactions within the aggregate root (with Event Sourcing) or within the multi-threaded responsive UI.
Scalability Once we have decoupled our system between Decide-Act-Report roles with the help of messaging, it
becomes possible to scale it in multiple directions:
Performance scalability – distributing the load between elements to handle higher performance and
reliability requirements. Development scalability – ability to distribute the development processes between various teams.
Complexity scalability – breaking down the system into a set of decoupled elements and keeping any
occasional complexity inside these elements.
While speaking about performance scaling, we have 3 options.
Scaling out the client (Decide) by load balancing – distributing the load between multiple machines,
that will still read from views and push command messages. Scaling out the domain logic (Act) by partitioning entities – putting different entities on different
machines based on some hashing function from their identity.

Scaling out the read side (Report) by replicating views to multiple storage engines (or even pushing
some views to the Content Delivery Networks around the globe)
All this is made possible (and relatively easy to achieve) by the use of messaging to decouple systems. At the
very extreme this leads to the possibility of building almost-infinitely scalable systems.
Entity Partitioning Scaling the performance of the system by replicating views and load balancing the client side – is relatively
easy. There are no real recurring race conditions. Any race conditions that could happen on the client side are
just business processes that have not been explicitly modeled in the domain.
However, you can’t just copy the command handling (Act side) between multiple machines. This creates an
opportunity for inconsistent data. Imagine that customer-5 data is located on machines A and B. Then a
message comes from the client side, telling server to rename the customer-5. You would need to somehow
update both machines, locking the data and handling potential transaction failures via the 3rd party
distributed transaction coordinator. This is not good.
Another approach of scaling out the command handling is to simply avoid any race conditions and keep write
data owned by a single process. In order to scale we will keep different data objects on different machines,
routing messages to them by a certain rule. Whenever we need to add more processing and storage
capacities – just add more machines into the mix.
Let’s establish a few terms, before we proceed further.
Entity – is some model or data, which can be uniquely identified by a key, which is called an identity. Entity
keeps the key for its lifetime. Identities are unique within the scope of the system. Two different entities can
never share the same identity.
Identities can be natural (like customer SSN) or artificial (like integral ID or GUID).
Partitioning entities (the command side or Act side) is just about putting different entities to different
partitions, based on some hashing or partitioning rule. Rule merely answers the question of “If entity’s key is
X, then it is stored on partition A”. Rule can be as simple as: “take the last digit of the identity” or more
complex, mapping some VIP entities (i.e.: customers with “Gold” status) to dedicated servers.
When command message is sent to an entity, it is automatically routed to the correct partition, based on this
rule.

Notion of partition is an important concept in building distributed systems, especially within cloud
environments. Partition borders determine the outer limit for the bounded contexts and consistency
boundaries. Transaction serializability is not supposed to cross them.
Although partition can contain multiple entities, these entities have to be considered as being in the separate
partitions. It is never known in advance if after the next repartitioning they will still be neighbors.
For more information on the theory of building distributed systems, check out the following works of Pat
Helland:
Life Beyond Distributed Transactions: An Apostate's Opinion Memories, Guesses, and Apologies
Building on Quicksand

Storage Blocks Lokad publishes Lokad.CQRS as an open source to share a few reusable blocks for building distributed
applications. These blocks have significant potential for using as stand-alone components and also as a part
of Lokad.CQRS Application Engine (to be discussed later).
Some of the most important blocks in the project deal with storage and persistence from the NoSQL
perspective.
Why NoSQL? Traditionally for the persistence in .NET world SQL databases were used. They are based on the
mathematically-proven concepts of relational model and relational algebra. SQL databases offer a wide range
of advanced features and are considered to be suitable for a wide range of application scenarios. They still
seem to be the most prominent choice in the industry for implementing persistence in .NET systems.
However, SQL databases (and relational approach in its own) may not be the most simple and fast route for
building distributed systems for the cloud. This comes from the fact that distributed environments (as
opposed to on-premises systems operating on a single machine or a tight data-center) introduce a whole
range of new factors into the picture:
High latency and eventual consistency of data.
Higher probabilities of various network, storage and node failures.
Higher deployment and maintenance complexities.
Requirement to support almost-infinite scalability scenarios (including elastic scaling).
Although SQL databases have a long history of solving these problems (and have developed highly
sophisticated set of tools and features for that), there could be a simpler approach. It requires making a step
from the relational model back to NoSQL and handling some cases explicitly.
At Lokad we believe that this approach allows developing cloud systems faster and with better efficiency.
Highly opinionated storage building blocks of Lokad.CQRS are based on some of our successes and help to
share this experience.
Each storage block consists from a set of interfaces that model interactions with some specific type of NoSQL
storage, while guiding developers to build better code. There also are various implementations of these
interfaces for each type of the storage. This separation allows coding the system once and then be capable of
switching between different storage implementations. For example, you can run same component against in-
memory storage for unit tests, on top of file system for local development and against cloud storage for the
production.
Atomic Storage Atomic storage is a set of interfaces (and implementations) modeled after the concurrency primitives and
designed for safe state persistence in distributed and cloud environments where:
Noticeable latency is expected (i.e. inserting 100000 records might take minutes).
Entities are relatively small (i.e. generally under 10MB in size). There could be multiple writers and readers (high concurrency).
Storage engine supports atomicity (i.e.: via locking or tags).

Essentially, Atomic Storage is just about persisting and retrieving some documents. In our code we don’t
care, how exactly the documents are serialized or persisted (this will depend on the configuration). But we do
care about writing scalable and distributable code. Most common use of this storage type in the CQRS world
is for Views (a la Persistent Read Models).
The most important idea behind the atomic storage is implicit atomicity of the write operations. Consider
this simplified scenario, where 2 distinct processes try to concurrently add various bonuses to the customer
document:
1. Process A reads Customer-3. It has 4 bonus points. 2. Process B reads Customer-3. It has 4 bonus points. 3. Process A adds 2 bonus points to customer (total of 6) and saves Customer-3. 4. Process B adds 1 bonus point to its retrieved copy (total of 5) and saves Customer-3.
The result is that customer has only 5 bonus points, while it should’ve had 7 (4+2+1). One way to work
around this concurrency problem is to use various explicit locks. If, however, you are writing a lot of such
code, managing locks can be tedious.
In Atomic Storage, all operations modifying documents (i.e.: Update, AddOrUpdate, TryDelete) have such
method signatures that we can write concurrency-safe code without even bothering about locks, leases, tags
or any other mechanisms for handling this sort of problems. Implementations of the storage interfaces can
use their own preferred locking mechanism for preventing (and optionally even automatically handling) race
conditions.
Document contracts for this storage are defined in the code as serializable classes:
[DataContract]
public sealed class Customer : Define.AtomicEntity
{
[DataMember] public string Name;
[DataMember] public string Address;
}
Here we are using default serialization attributes (DataContract and DataMember), which work for the
DataContractSerializer. The latter is the default serializer used by Lokad.CQRS. However, you certainly
can use different serialization format for persisting your entities.
Note, that we are using the default Define.AtomicEntity interface to mark our documents. This is the
default approach, which allows starting to work faster, but also creates dependency between Lokad.CQRS
project and your own code. The latter is not recommended for systems with complex dependencies between
the projects, since it makes harder to manage them and avoid version collisions (sometimes called as DLL
hell). By providing your own implementation of atomic strategy you can decouple document contracts from
Lokad.CQRS libraries.
Entities vs. Singletons There are two different types of documents supported and managed by the Atomic storage.
EntityDocument is a document that has a unique identity (key), which could be used to locate and manage it.
Customer is a sample of an entity; it might be identified by a customer ID.

Singleton Document is a document without an identity. Only instance of this document can exist within a
system (or sub-system). System configuration is a sample of a singleton document. It’s shared across the
system.
The difference seems to be really subtle, yet managing these types of documents internally could be
completely different story. For example, entities are scaled by partitioning, while singletons must be locked
and replicated.
To enforce this difference there are two separate sets of interfaces and methods within the Atomic storage:
dealing with singletons and managing entities.
NuclearStorage vs. Typed Interfaces Functionality behind the Atomic Storage could be leveraged via two ways.
Typed Interfaces are the default and recommended way, when you are working with the persistent read
models (views). This way involves requesting strongly-typed document reader/writer interface instances from
the factory or IoC Container. Such instance will be capable of working with a single document type only.
This provides compile-time checks, more compact code and maintenance support for managing persistent
read models. Below is a code snippet of a view handler for ReportDownloadView that requests strongly-
typed atomic storage interface IAtomicEntityWriter<Guid, ReportDownloadView> from the
constructor and uses it to manage the view.
The first parameter in the interface is the type of the key, while the second one – type of the view itself.
public sealed class ReportDownloadHandler :
ConsumerOf<ReportCreatedEvent>,
ConsumerOf<ReportDeletedEvent>
{
readonly IAtomicEntityWriter<Guid, ReportDownloadView> _writer;
public ReportDownloadHandler(IAtomicEntityWriter<Guid, ReportDownloadView> writer)
{
_writer = writer;
}
public void Consume(ReportDeletedEvent message)
{
_writer.TryDelete(message.ReportId);
}
public void Consume(ReportCreatedEvent message)
{
var view = new ReportDownloadView
{
StorageReference = message.StorageReference,
StorageContainer = message.StorageContainer,
ContentType = message.ContentType,
FileName = message.FileName,
AccountId = message.AccountId
};
_writer.AddOrUpdate(message.ReportId, view, x => { });
}
}
However, in certain scenarios this strongly-typed approach might lead to repetitive and excessive code.
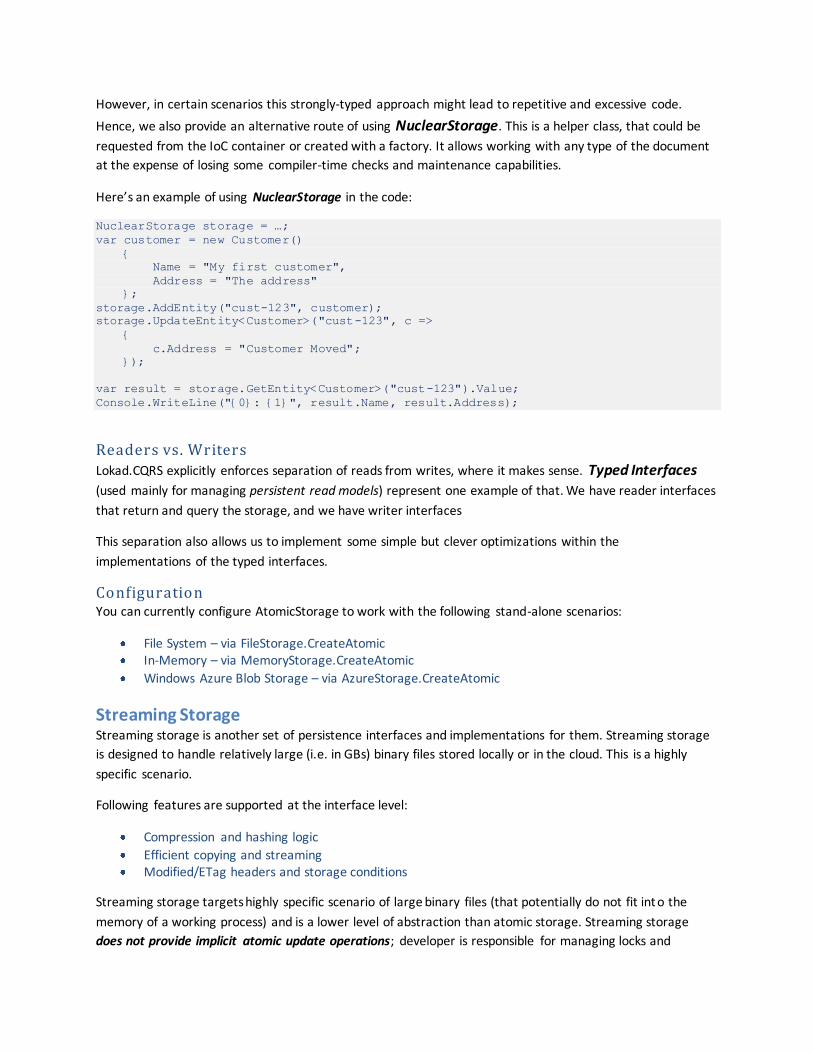
Hence, we also provide an alternative route of using NuclearStorage. This is a helper class, that could be
requested from the IoC container or created with a factory. It allows working with any type of the document
at the expense of losing some compiler-time checks and maintenance capabilities.
Here’s an example of using NuclearStorage in the code:
NuclearStorage storage = …;
var customer = new Customer()
{
Name = "My first customer",
Address = "The address"
};
storage.AddEntity("cust-123", customer);
storage.UpdateEntity<Customer>("cust-123", c =>
{
c.Address = "Customer Moved";
});
var result = storage.GetEntity<Customer>("cust-123").Value;
Console.WriteLine("{0}: {1}", result.Name, result.Address);
Readers vs. Writers
Lokad.CQRS explicitly enforces separation of reads from writes, where it makes sense. Typed Interfaces
(used mainly for managing persistent read models) represent one example of that. We have reader interfaces
that return and query the storage, and we have writer interfaces
This separation also allows us to implement some simple but clever optimizations within the
implementations of the typed interfaces.
Configuration You can currently configure AtomicStorage to work with the following stand-alone scenarios:
File System – via FileStorage.CreateAtomic In-Memory – via MemoryStorage.CreateAtomic
Windows Azure Blob Storage – via AzureStorage.CreateAtomic
Streaming Storage Streaming storage is another set of persistence interfaces and implementations for them. Streaming storage
is designed to handle relatively large (i.e. in GBs) binary files stored locally or in the cloud. This is a highly
specific scenario.
Following features are supported at the interface level:
Compression and hashing logic
Efficient copying and streaming Modified/ETag headers and storage conditions
Streaming storage targets highly specific scenario of large binary files (that potentially do not fit int o the
memory of a working process) and is a lower level of abstraction than atomic storage. Streaming storage
does not provide implicit atomic update operations; developer is responsible for managing locks and
concurrency issues. It also does not provide a uniform handling of serialization inside the interface; developer
will need to work directly with the streams.
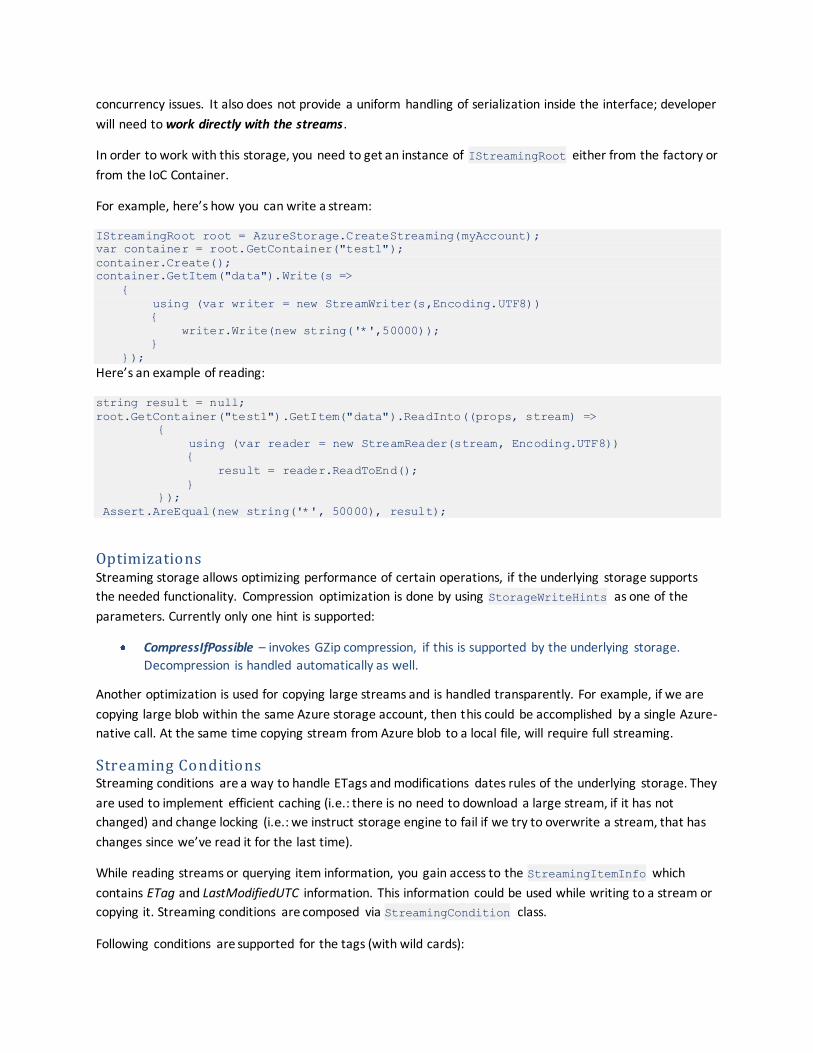
In order to work with this storage, you need to get an instance of IStreamingRoot either from the factory or
from the IoC Container.
For example, here’s how you can write a stream:
IStreamingRoot root = AzureStorage.CreateStreaming(myAccount);
var container = root.GetContainer("test1");
container.Create();
container.GetItem("data").Write(s =>
{
using (var writer = new StreamWriter(s,Encoding.UTF8))
{
writer.Write(new string('*',50000));
}
});
Here’s an example of reading:
string result = null;
root.GetContainer("test1").GetItem("data").ReadInto((props, stream) =>
{
using (var reader = new StreamReader(stream, Encoding.UTF8))
{
result = reader.ReadToEnd();
}
});
Assert.AreEqual(new string('*', 50000), result);
Optimizations Streaming storage allows optimizing performance of certain operations, if the underlying storage supports
the needed functionality. Compression optimization is done by using StorageWriteHints as one of the
parameters. Currently only one hint is supported:
CompressIfPossible – invokes GZip compression, if this is supported by the underlying storage.
Decompression is handled automatically as well.
Another optimization is used for copying large streams and is handled transparently. For example, if we are
copying large blob within the same Azure storage account, then this could be accomplished by a single Azure-
native call. At the same time copying stream from Azure blob to a local file, will require full streaming.
Streaming Conditions Streaming conditions are a way to handle ETags and modifications dates rules of the underlying storage. They
are used to implement efficient caching (i.e.: there is no need to download a large stream, if it has not
changed) and change locking (i.e.: we instruct storage engine to fail if we try to overwrite a stream, that has
changes since we’ve read it for the last time).
While reading streams or querying item information, you gain access to the StreamingItemInfo which
contains ETag and LastModifiedUTC information. This information could be used while writing to a stream or
copying it. Streaming conditions are composed via StreamingCondition class.
Following conditions are supported for the tags (with wild cards):

IfMatch
IfNoneMatch
Following conditions are supported for the modification date:
IfModifiedSince
IfUnmodifiedSince
Configuration You can currently configure Streaming Storage to work with the following stand-alone scenarios which return
an instance of IStreamingRoot:
FileStorage.CreateStreaming AzureStorage.CreateStreaming

Basics of Lokad.CQRS Application Engine and Client Lokad.CQRS framework provides a set of reusable software blocks that build upon the theoretical principles
outlined in the previous chapters. These blocks help to design and build distributed systems, while guiding
around some of the problems and technicalities that were discovered and experienced by Lokad teams.
Lokad.CQRS provides configurable .NET Application Engine. This is a light-weight stand-alone server that
could be hosted in a console process, cloud worker role or even a unit test. This Engine hosts the following
functionality:
Managing message contracts, serialization formats and transport envelopes.
Sending messages to supported queues:
o In-Memory o Azure Queues
Long-running task processes that receive messages from queues and dispatch them to the available
message handlers. Message scheduling for the delayed delivery of the messages to the recipients.
Message routing for implementing load balancing and partitioning.
Dependency Injection features for exposing additional services to the message handlers. Support for the Storage Blocks.
Special builder syntax for configuring all this functionality.
Numerous extensibility points for providing custom behaviors or introducing new features.
In addition to that, there is a .NET Application Client, offering subset of features required to build User
Interfaces and APIs. This Client is a set of helper classes that are meant to be reused in an application and
also feature configuration syntax.
Configuring and Running Lokad.CQRS Application Engine Before the engine could be started, it has to be configured via the builder syntax. This configuration happens
in the code and sets up the tasks that will be executed by the server, while it is running.
Some of these tasks are responsible for routing, receiving and dispatching messages; so the configuration has
to set up proper message contracts and serialization rules.
Storage Blocks, that were described earlier, could also be configured here. They will be made available to the
message handlers via Dependency Injection, just like the rest of the components.
In addition to that, builder syntax exposes optional hooks and extensibility points, which could be used to
modify and enhance certain parts of the system with custom behaviors. There are 3 types of the extensibility
points available from within the configuration:
Providing specific behaviors by supplying custom interface implementations, where builder syntax
accepts them. Subscribing to system events and reacting to them with the help of Reactive Extensibility framework
for .NET. Injecting custom components and implementations directly into the IoC Container used by the
Application Engine.

To simplify development and initial introduction, Application Engine is designed to self-configure itself with
the sensible defaults, where appropriate. It will also try to orchestrate tasks and adjust some settings to
achieve the best performance. Obviously, you can override and customize all this behavior.
Some of the defaults include:
Using DataContractSerializer (native to the .NET Framework) to persist messages.
Locating message contracts by scanning all loaded assemblies for classes deriving from
Define.Command and Define.Event. Locating message handlers by scanning all loaded assemblies for classes deriving from
Define.Handle<TCommand> (for command handlers) and for classes deriving from Define.Consume<TEvent> (for event handlers).
Using sensible timeout strategies for polling Azure queues, to reduce the operational costs, while still
keeping system responsive.
Here’s a sample snippet of the basic configuration for the engine to run locally, using in-memory atomic
storage and in-memory partition:
var builder = new CqrsEngineBuilder();
builder.Storage(m => m.AtomicIsInMemory());
builder.Memory(m =>
{
m.AddMemoryProcess("in");
m.AddMemorySender("in");
});
If we want to run the same code under Windows Azure using ProtoBuf for the serialization:
var account = AzureStorage.CreateConfig(storageAccount);
var builder = new CqrsEngineBuilder();
builder.Storage(m => m.AtomicIsInAzure(account));
builder.Azure(m =>
{
m.AddAzureProcess(account, "in");
m.AddAzureSender(account, "in");
});
builder.UseProtoBufSerialization();
Note, that AddAzureSender/AddMemorySender are responsible for configuring the default instance of
IMessageSender that will be available to components (i.e.: message handlers) via the dependency injection.
You need to configure only one sender, defining the default queue to which it will send messages.
Check unit tests in Lokad.CQRS sources for the samples of configuring
Application Engine and running it in memory.
This document section merely provides a high-level overview of the configuration process. Specific
configuration options will be discussed later.

In order to run Lokad.CQRS application engine, given completed builder we can do something like this:
try
{
using (var token = new CancellationTokenSource())
using (var engine = builder.Build())
{
engine.Start(token.Token);
Console.WriteLine("Press any key to stop.");
Console.ReadKey(true);
token.Cancel();
if (!token.Token.WaitHandle.WaitOne(5000))
{
Console.WriteLine("Terminating");
}
}
}
catch (Exception ex)
{
Console.WriteLine(ex.Message);
Console.ReadKey(true);
}
In this snippet we create an engine instance out of the builder and start it using cancellation token from the
Task Parallel Library of .NET 4.0. The latter allows us to gracefully shutdown all engine services later, with an
opportunity to terminate them, if shutdown takes too much time.
Configuring and Using Lokad.CQRS Application Client Lokad.CQRS Application Client is merely a set of helper classes that could be configured via builder syntax.
The latter resembles builder syntax of the Application Engine, but is more limited in features. The biggest
difference is that Application Client does not host any long-running processes and is not capable of receiving
messages.
Here’s a sample of configuration snippet for the Client that is capable of sending message to Azure queues
and accessing persistent read models (Views) stored within the Azure Storage Account:
var data = AzureStorage.CreateConfig(storageAccount);
var builder = new CqrsClientBuilder();
builder.Azure(c => c.AddAzureSender(data, "in"));
builder.Storage(s =>
{
s.AtomicIsInAzure(data);
s.StreamingIsInAzure(data);
});
var client = builder.Build()
Given this code, we can access various services provided by the client:
// read a view
var storage = client.Resolve<NuclearStorage>();
var singleton = storage.GetSingletonOrNew<UserDashboardView>();
// send a message
var sender = client.Resolve<IMessageSender>();
sender.SendOne(myMessage);
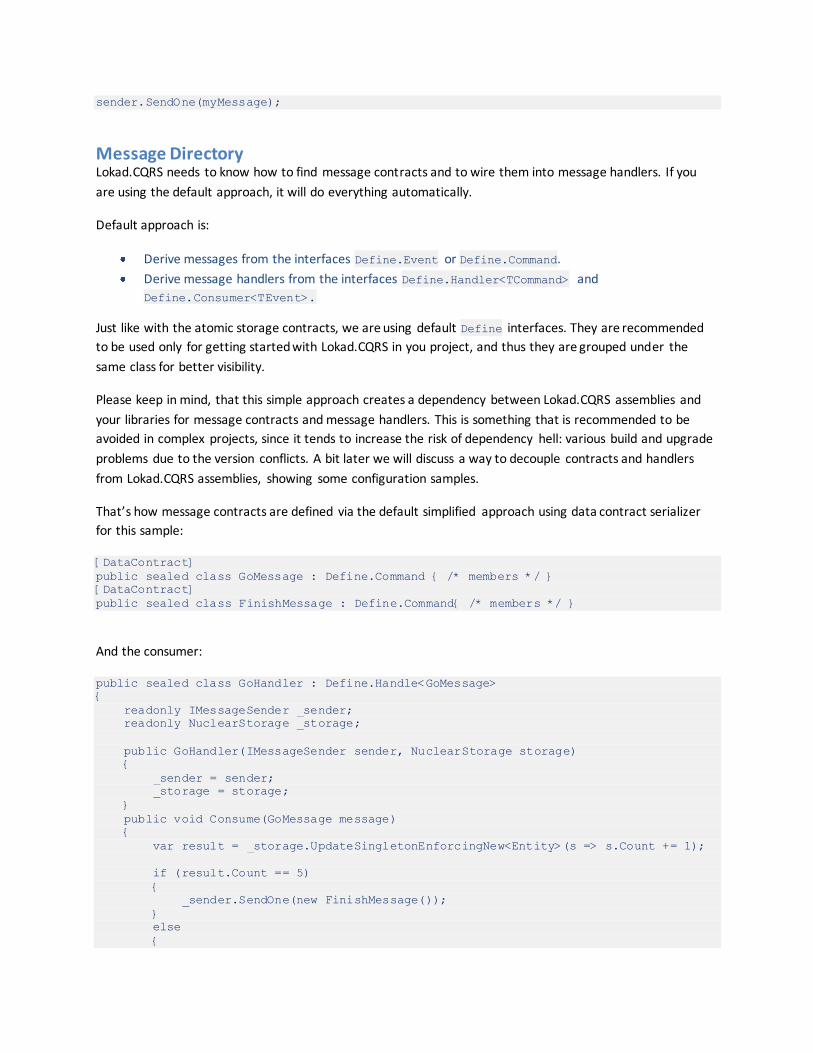
Message Directory Lokad.CQRS needs to know how to find message contracts and to wire them into message handlers. If you
are using the default approach, it will do everything automatically.
Default approach is:
Derive messages from the interfaces Define.Event or Define.Command.
Derive message handlers from the interfaces Define.Handler<TCommand> and
Define.Consumer<TEvent>.
Just like with the atomic storage contracts, we are using default Define interfaces. They are recommended
to be used only for getting started with Lokad.CQRS in you project, and thus they are grouped under the
same class for better visibility.
Please keep in mind, that this simple approach creates a dependency between Lokad.CQRS assemblies and
your libraries for message contracts and message handlers. This is something that is recommended to be
avoided in complex projects, since it tends to increase the risk of dependency hell: various build and upgrade
problems due to the version conflicts. A bit later we will discuss a way to decouple contracts and handlers
from Lokad.CQRS assemblies, showing some configuration samples.
That’s how message contracts are defined via the default simplified approach using data contract serializer
for this sample:
[DataContract]
public sealed class GoMessage : Define.Command { /* members */ }
[DataContract]
public sealed class FinishMessage : Define.Command{ /* members */ }
And the consumer:
public sealed class GoHandler : Define.Handle<GoMessage>
{
readonly IMessageSender _sender;
readonly NuclearStorage _storage;
public GoHandler(IMessageSender sender, NuclearStorage storage)
{
_sender = sender;
_storage = storage;
}
public void Consume(GoMessage message)
{
var result = _storage.UpdateSingletonEnforcingNew<Entity>(s => s.Count += 1);
if (result.Count == 5)
{
_sender.SendOne(new FinishMessage());
}
else
{

_sender.SendOne(new GoMessage());
}
}
}
Using Storage Blocks Builder syntax for both Lokad.CQRS Application Engine and Client has shortcuts to configure Storage Blocks
into the internal IoC Container. Doing so will expose associated interfaces to message handlers and other
components that might be requesting them via constructor injection.
For the Atomic Storage, you can use one of these options (with numerous overloads):
builder.Storage(m => m.AtomicIsInFiles("path-to-my-folder"));
builder.Storage(m => m.AtomicIsInAzure(myAzureAccount));
builder.Storage(m => m.AtomicIsInMemory());
You can also provide additional atomic storage configuration options or even a custom atomic factory
implementation, which will get wired to the container.
Here’s a sample of plugging in atomic storage with some non-default settings for view contract lookup and
JsonSerializer from ServiceStack.Text:
builder.Storage(s =>
{
s.AtomicIsInAzure(data, b =>
{
b.CustomSerializer(
JsonSerializer.SerializeToStream,
JsonSerializer.DeserializeFromStream);
b.WhereEntity(t =>
t.Name.EndsWith("View") &&
t.IsDefined(typeof(SerializableAttribute),false));
});
});
Streaming storage is also supported with the builder syntax. You can use one of these options to configure it:
builder.Storage(m => m.StreamingIsInFiles("path-to-my-folder"));
builder.Storage(m => m.StreamingIsInAzure(myAzureAccount));
Message Queues Lokad.CQRS Application engine can process messages coming from two different types of message queues:
In-memory message queue – configured by builder.AddMemoryProcess.
Windows Azure Cloud Queues – configured by builder.AddAzureProcess.
There are plans to add simple file-based queues and AMQP support.
Each queue implementation supports:
Volatile transactions (System.Transactions namespace).
Automatic message deduplication handled by bus.

Future messages – messages that are delivered upon the specified time, i.e. delayed messages.
Azure Queues Azure Queues implementation is built on top of Azure Storage Cloud Queues and provides native support for
a variety of scenarios. It features:
Automatic handling of message envelopes larger than 6144 bytes (or 8192 bytes in Base64 Encoding).
Queue polling scheduler that reduces number of checks, when application sits idle (to reduce Azure charges), which is configured by DecayPolicy.
Message delivery scheduler that allows delaying message delivery till certain point in time.
In-Memory Queues In-memory queues are designed to be extremely simple, non-persistent and fast-performing. They are used
in high frequency aggregation operations (where losing some messages is not an issue), internal unit tests or
when firing up Lokad.CQRS engine inside another application for various support and helper uses.
In-memory queues support message delivery scheduling as well.
Message Dispatchers Message dispatchers in Lokad.CQRS Application Engine are the “glue” that links together message envelopes
and code to handle them. It is one of the most important extensibility points in the Application Engine.
Different message handling scenarios might require different dispatch behaviors. Lokad.CQRS project
includes pre-built dispatcher implementations required to develop a system following the Decide-Act-Report
model (DAR).
Each of these dispatcher implementations could be configured in the builder syntax.
There are plans to add fourth type of the dispatcher, mapping message envelopes directly to the Aggregate
Root entities with Event Sourcing.
Command Dispatcher Command batch dispatcher dispatches incoming message envelope (with one or more command messages)
against the handlers in a single logical transaction. It enforces the rule that each message could have only one
handler.
This dispatcher is used for configuring server-side domain partitions (“Act” element of DAR):
builder.AddAzureProcess(dev, IdFor.Commands, x =>
{
x.DirectoryFilter(f => f.WhereMessagesAre<IDomainCommand>());
x.DispatchAsCommandBatch();
});
DispatchAsCommandBatch is a builder shortcut for wiring the same dispatcher manually.
Event Dispatcher Event dispatcher dispatches incoming message envelope (with exactly one message item) against available
handlers in a single logical transactions. There could be zero or more handlers.

This dispatcher is used to configure processes handling events (for example, view model denormalizers –
“Report” element of DAR):
m.AddAzureProcess(dev, IdFor.Events, x =>
{
x.DirectoryFilter(f => f.WhereMessagesAre<IDomainEvent>());
x.DispatchAsEvents();
});
DispatchAsEvents is builder shortcut for wiring this dispatcher.
Routing Dispatcher Lokad.CQRS has a default implementation of a simple rule-based router. This router could be used for
distributing the load between multiple processes or partitioning a distributed system.
Configuration might look like this for the memory process:
builder.AddMemoryRouter("in",
me => (((Message1) me.Items[0].Content).Block%2) == 0 ? "memory:do1" : "memory:do2");
Advanced Configuration Options There are some features of Lokad.CQRS that are not essential for getting started with distributed systems.
Yet, they might come in handy, if you are building complex systems or just want to provide some custom
behaviors.
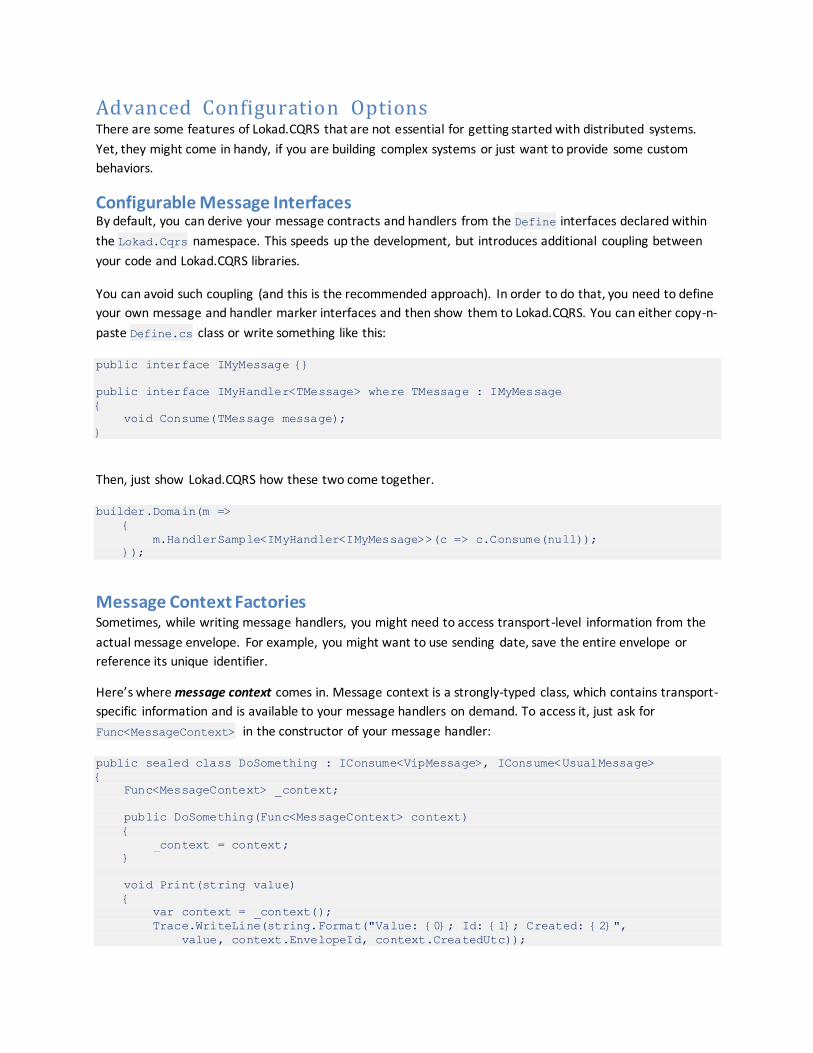
Configurable Message Interfaces By default, you can derive your message contracts and handlers from the Define interfaces declared within
the Lokad.Cqrs namespace. This speeds up the development, but introduces additional coupling between
your code and Lokad.CQRS libraries.
You can avoid such coupling (and this is the recommended approach). In order to do that, you need to define
your own message and handler marker interfaces and then show them to Lokad.CQRS. You can either copy-n-
paste Define.cs class or write something like this:
public interface IMyMessage {}
public interface IMyHandler<TMessage> where TMessage : IMyMessage
{
void Consume(TMessage message);
}
Then, just show Lokad.CQRS how these two come together.
builder.Domain(m =>
{
m.HandlerSample<IMyHandler<IMyMessage>>(c => c.Consume(null));
});
Message Context Factories Sometimes, while writing message handlers, you might need to access transport-level information from the
actual message envelope. For example, you might want to use sending date, save the entire envelope or
reference its unique identifier.
Here’s where message context comes in. Message context is a strongly-typed class, which contains transport-
specific information and is available to your message handlers on demand. To access it, just ask for
Func<MessageContext> in the constructor of your message handler:
public sealed class DoSomething : IConsume<VipMessage>, IConsume<UsualMessage>
{
Func<MessageContext> _context;
public DoSomething(Func<MessageContext> context)
{
_context = context;
}
void Print(string value)
{
var context = _context();
Trace.WriteLine(string.Format("Value: {0}; Id: {1}; Created: {2}",
value, context.EnvelopeId, context.CreatedUtc));

}
public void Consume(UsualMessage message)
{
Print(message.Word);
}
public void Consume(VipMessage message)
{
Print(message.Word);
}
}
You can also inject your own message context class, which could provide access to some additional transport
headers in a strongly-typed and uniform fashion. It is simple to do and will also allow avoiding coupling
between your handlers and Lokad.CQRS code.
First, you define your own class to hold the message context:
public sealed class MyContext
{
public readonly string MessageId;
public readonly string Token;
public readonly DateTimeOffset Created;
public MyContext(string messageId, string token, DateTimeOffset created)
{
MessageId = messageId;
Token = token;
Created = created;
}
}
And then let’s wire it in the builder syntax:
static MyContext BuildContextOnTheFly(ImmutableEnvelope envelope, ImmutableMessage
item)
{
var messageId = string.Format("[{0}]-{1}", envelope.EnvelopeId, item.Index);
var token = envelope.GetAttribute("token", "");
return new MyContext(messageId, token, envelope.CreatedOnUtc);
}
builder.Domain(m =>
{
m.HandlerSample<IMyHandler<IMyMessage>>(c => c.Consume(null));
m.ContextFactory(BuildContextOnTheFly);
});
In order to include custom transport headers to the outgoing messages, you just need to provide additional
configuration within the message sender classes:
IMessageSender sender = …;
sender.SendOne(myMessage, cb => cb.AddString("token","NeverDoThisInYourCode_SDAJ12"));

Custom Envelope and Message Serialization Options The default behavior of Lokad.CQRS is to use DataContractSerializer for serializing and deserializing both
the message envelopes and the actual message data.
This behavior can be customized to support other serialization formats, which might be desired to achieve
better performance and lower friction of managing different versions of the same contract across large
distributed system.
Custom serializers could be specified using the builder syntax for both the Client and Application Engine. For
example:
builder.Advanced.DataSerializer(t => new DataSerializerWithProtoBuf(t));
builder.Advanced.EnvelopeSerializer(new EnvelopeSerializerWithProtoBuf());
We recommend using Google Protocol Buffers for .NET (http://code.google.com/p/protobuf-net/), as
implemented by Marc Gravell. ProtoBuf is a special cross-platform binary serialization format, which was
designed by Google to handle their immense messaging needs. It is the fastest and most compact
serialization under .NET framework.
If you are using Lokad.Cqrs.Azure.dll in your project, then ProtoBuf serializers are already included and could
be plugged in via a short-cut:
builder.UseProtoBufSerialization();
Envelope Quarantine and Customizations Message envelope handling code might fail sometimes. Message envelopes might even contain data that
always causes the handler to fail.
In order to distinguish between transient failures (i.e.: something that it caused by a network outage) and
poisons (something that always fails), Lokad.CQRS features a quarantine mechanism.
Quarantine component is responsible for determining how to handle failing message envelope, and when to
give up on processing it (and how to do that).
The default implementation is a MemoryQuarantine, which works with the majority of simple cases. It
merely says that: discard message envelope, if it has caused more than 4 failures.
However, since the default behavior might not be the one desired, it can customized by implementing your
own quarantine component (that derives from IEnvelopeQuarantine) and wiring it into the engine:
m.AddAzureProcess(dev, IdFor.Events, x =>
{
x.DirectoryFilter(f => f.WhereMessagesAre<IDomainEvent>());
x.DispatchAsEvents();
x.Quarantine(c => new SalescastQuarantine(mail, c.Resolve<IStreamingRoot>()));
});

Custom Message Envelope Dispatchers Lokad.CQRS provides only a limited number of message envelope dispatchers targeting the most common
usage scenarios. However, there could be scenarios when custom dispatch behaviors are needed. For
example, you might want to route message envelopers based on content and log them for audit at the same
time.
Then the simplest way in this case is to write a custom dispatcher, and then register it in the partition.
Here’s a sample snippet that injects custom dispatcher into the publishing partition. Note, how we construct
new dispatcher instance with the services retrieved from the IoC Container.
m.AddAzureProcess(dev, IdFor.Publish, x =>
{
x.DispatcherIs((context, infos, strategy) =>
{
var log = new DomainLogWriter(sql);
var streamer = context.Resolve<IEnvelopeStreamer>();
var factory = context.Resolve<QueueWriterRegistry>();
return new MyPublishDispatcher(factory, log, PartitionCount,
streamer);
});
});
You can use following dispatcher classes (from Lokad.CQRS sources) as a sample for writing your own
message dispatcher:
DispatchCommandBatch
DispatchOneEvent
DispatchMessagesToRoute
Portability Scenarios At the moment of writing, Lokad.CQRS allows running the same application code with minimal modifications
both in Windows Azure and under local development environment outside of Azure Compute Emulator
(formerly known as Dev Fabric). Windows Azure Storage Emulator has to be running.
After we introduce support for non-Azure persistent queuing, you will be able to develop and run
applications locally, without Azure SDK, but still deploy then to the Windows Azure cloud afterwards.
You can already run Lokad.CQRS Application Engine (and systems built
with it) locally without Windows Azure SDK. However this requires use
of in-memory queues, which are not persistent across the system restarts.

What Next? Thank you for your interest in this Open-Source project and reading that far through the documentation!
You can proceed further with Lokad.CQRS by:
Downloading the latest samples and binaries: http://code.google.com/p/lokad-cqrs/
Joining discussions at Lokad community: http://groups.google.com/group/lokad
Reading a bit more about CQRS and related patterns: http://abdullin.com/cqrs
Subscribing to Lokad news: http://feeds.feedburner.com/lokad/
Lokad is planning to push forward this project by:
Porting Lokad.CQRS Maintenance Console to the open source.
Introducing storage for the event sourcing (both local and cloud scenarios) and providing message
dispatcher to handle Aggregate Roots natively. Introducing support for running Lokad.CQRS locally without Windows Azure Storage Emulator. Filling in the gaps in the documentation and updating samples.


















