
Program’Op*miza*on’and’Analysis’lu/cse467s/slides/program.pdf · Instruc*ons’(ARM7) ... "...
47
Program Op*miza*on and Analysis Chenyang Lu CSE 467S 1
Transcript of Program’Op*miza*on’and’Analysis’lu/cse467s/slides/program.pdf · Instruc*ons’(ARM7) ... "...

Program Op*miza*on and Analysis
Chenyang Lu CSE 467S
1
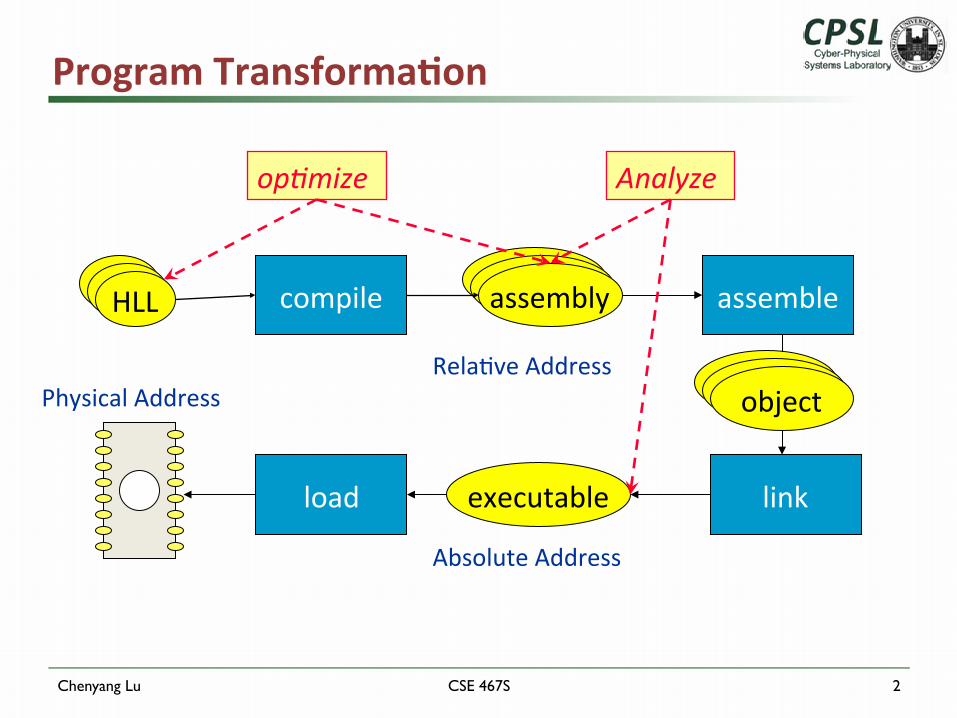
Program Transforma*on
Chenyang Lu CSE 467S 2
compile assembly assemble assembly assembly
link load
assembly assembly object
HLL HLL HLL
Rela5ve Address
Absolute Address
Physical Address
executable
op#mize Analyze

What do we need to do?
Ø Understand optimization levels (-O1, -O2, etc.) q http://gcc.gnu.org/onlinedocs/gcc/Optimize-Options.html
Ø Optimize HLL code.
Ø Analyze and optimize assembly code.
Ø Modifying compiler output requires care: q correctness;
q loss of hand-tweaked code.
Chenyang Lu CSE 467S 3

Goals Ø Optimizing for execution time. Ø Optimizing for energy/power.
Ø Optimizing for program size. Ø They may conflict with each other!
Chenyang Lu CSE 467S 4

Expression Simplifica*on
Ø Constant folding: q 8+1 = 9
Ø Algebraic: q a*b + a*c = a*(b+c)
Ø Strength reduction: q a*2 = a<<1
Chenyang Lu CSE 467S 5

Dead Code Elimina*on
Ø Dead code: #define DEBUG 0
if (DEBUG) dbg(p1);
Ø Eliminate by control flow analysis, constant folding.
Chenyang Lu CSE 467S 6
0
dbg(p1);
1
0

Func*on Call
Chenyang Lu CSE 467S 7

Instruc*ons (ARM7)
Ø Branch and link instruction: BL foo == MOV r14, r15 B foo
q r15 contains the current PC q Copies current PC to r14.
Ø To return from subroutine: MOV r15,r14
Chenyang Lu CSE 467S 8

Stack
Ø Use a stack to keep track of q parameters,
q return value,
q return address.
Ø Caller and callee access the stack in a consistent order. q Different compilers/programmers may follow different orders.
Ø Access the stack (ARM7) q r13 always points to the top of stack
q Push: STR r0, [r13, #4]!
q Pop: SUB r13, #4
Chenyang Lu CSE 467S 9

Stack Opera*ons
Ø Caller: call a function q Push parameters to stack q BL (r15 à r14; jump)
Ø Callee: receive a call q Read parameters from stack q Overwrite top of stack with return address (r14)
Ø Callee: return q Load PC with return address (on top of stack)
Ø Caller: receive a return q Pop callee’s return address from stack
Chenyang Lu CSE 467S 10

Nested func*on calls (ARM7) main() { f1(x); } void f1(int a) { f2(a); } ; f1 is called by main() LDR r0, [r13] ; load parameter into r0 from stack STR r14, [r13] ; store f1’s return addr. ; f1 calls f2() STR r0, [r13, #4]! ; push parameter for f2 to stack BL f2 ; branch and link to f2 ; return from f2() SUB r13, #4 ; pop f2’s parameter off stack ; f1 returns to main() LDR r15, [r13] ; restore register and return
Chenyang Lu CSE 467S 11

Func*on Inlining int foo(a,b,c) { return a + b -‐ c;} z = foo(w,x,y);
ð z = w + x -‐ y;
Ø Improve performance by eliminating function call overhead.
Ø May increase code size, but not always…
Ø Affect instruction cache behavior.
Chenyang Lu CSE 467S 12

Op*miza*on: Inlining
Chenyang Lu 13
• Inlining improves performance and reduces code size. • Why?
App Code size Code reduction
Data size
CPU reduction inlined noninlined
Surge 14794 16984 12% 1188 15% Maté 25040 27458 9% 1710 34% TinyDB 64910 71724 10% 2894 30%

Loops
Chenyang Lu CSE 467S 14

Loop Unrolling
Ø Reduces loop overhead
for (i=0; i<4; i++) a[i] = b[i] * c[i]; ð for (i=0; i<4; i+=2) { a[i] = b[i] * c[]; a[i+1] = b[i+1] * c[i+1]; }
Chenyang Lu CSE 467S 15

Loop Overhead on ARM7
; loop initiation code MOV r0, #0 ; use r0 for loop counter MOV r8, #0 ; use separate index for arrays LDR r1, #4 ; buffer size MOV r2, #0 ; use r2 for f ADR r3, c ; load r3 with base of c[ ] ADR r5, x ; load r5 with base of x[ ]
; loop; L: LDR r4, [r3, r8] ; get c[i] LDR r6, [r5, r8] ; get x[i] MUL r4, r4, r6 ; compute c[i]x[i] ADD r2, r2, r4 ; add into sum ADD r8, r8, #4 ; add one word to array index ADD r0, r0, #1 ; add 1 to i CMP r0, r1 ; exit? BLT L ; if i < 4, continue
Chenyang Lu CSE 467S 16

Loop Fusion
Combines multiple loops: for (i=0; i<N; i++) a[i] = b[i] * 5; for (j=0; j<N; j++) w[j] = c[j] * d[j]; ð for (i=0; i<N; i++) { a[i] = b[i] * 5; w[i] = c[i] * d[i];
}
Necessary conditions Ø Loops share a same index
Ø No dependencies between two loops
Chenyang Lu CSE 467S 17

Code Mo*on
for (i=0; i<N*M; i++) z[i] = a[i] + b[i];
Chenyang Lu CSE 467S 18
i<N*M
i=0;
z[i] = a[i] + b[i];
i = i+1;
N
Y
i<X
i=0; X = N*M

Array
Chenyang Lu CSE 467S 19

One-‐Dimensional Array
Ø C array name points to 0th element:
Chenyang Lu CSE 467S 20
a[0]
a[1]
a[2]
a a[i] = *(a + i)

Two-‐Dimensional Array
Ø Row-major layout:
Chenyang Lu CSE 467S 21
a[0,0]
a[0,1]
a[1,0]
a[1,1] a[i][j] = *(a + i*M + j)
...
M
...
N

Chenyang Lu CSE 467S 22
for (i=0; i<N; i++) for (j=0; j<M; j++) z[i][j] = b[i][j];
zptr = z; bptr = b; for (i=0; i<N; i++)
for (j=0; j<M; j++) { zind = i*M+j; bind = i*M+j; *(zptr+zind)=*(bptr+bind) }
zptr = z; bptr = b; for (i=0; i<N; i++)
for (j=0; j<M; j++) { zbind = i*M+j; *(zptr+zbind)=*(bptr+zbind); }
zptr = z; bptr = b; zbind = 0; for (i=0; i<N; i++)
for (j=0; j<M; j++) { *(zptr+zbind)=*(bptr+zbind);
zbind++; }
induction variable elimination
strength reduction

Cache Analysis
Ø Loops use large quan55es of data (arrays) à cache conflicts
Chenyang Lu CSE 467S 23

Direct-‐Mapped Cache
Chenyang Lu CSE 467S 24
valid
=
tag index offset
hit value
tag data 1 0xabcd byte byte byte ...
byte
cache block

Array Conflicts in Cache
Chenyang Lu CSE 467S 25
a[0,0]
b[0,0]
main memory cache
1024 4099
...
1024
4099
for (i=0; i<N; i++) for (j=0; j<M; j++)
a[i][j] = a[i][j] + b[i][j];
256

Array Conflicts
Ø Array elements conflict because they are in the same line. Ø Solu5on: move one array.
Chenyang Lu CSE 467S 26

Sta*c Cache Locking
Ø Lock instructions in cache before execution. Ø Predictable execution time.
Ø Similarly, lock code and data in memory to avoid paging.
Chenyang Lu CSE 467S 27

Register Alloca*on
Ø Fit current variables in registers.
Ø Load once, use many times. ü Reduce number of cache/memory accesses. ü Improve performance.
ü Reduce energy consumption.
Chenyang Lu CSE 467S 28

Register Life*me Graph
1. w = a + b; 2. x = c + w; 3. y = c + d; 4. z = a - b;
abcdwxyz
1 2 3 4
Chenyang Lu CSE 467S 29
no. of needed register = 5

ATer Rescheduling…
1. w = a + b; 2. z = a - b; 3. x = c + w; 4. y = c + d;
abcdwxyz
1 2 3 4
Chenyang Lu CSE 467S 30
no. of needed register = 4
Cannot change dependencies between instructions!

Summary: Performance Op*miza*on
Ø Use registers efficiently.
Ø Optimize loops.
Ø Optimize function calls.
Ø Optimize cache behavior: q Avoid instruction conflicts by rewriting code, rescheduling; q Move conflicting scalar/array data can be moved.
Chenyang Lu CSE 467S 31

Execu*on Time Analysis
Ø Real-time systems must meet deadlines.
Ø Need to analyze execution time.
Chenyang Lu CSE 467S 32

Execu*on Time
Ø Affected by program path and instruction timing
Ø Program path depends on input data. q Sensor readings q User input
Ø Instruction timing depends on q pipelining q cache behavior – memory can be x10 slower than cache!
Chenyang Lu CSE 467S 33
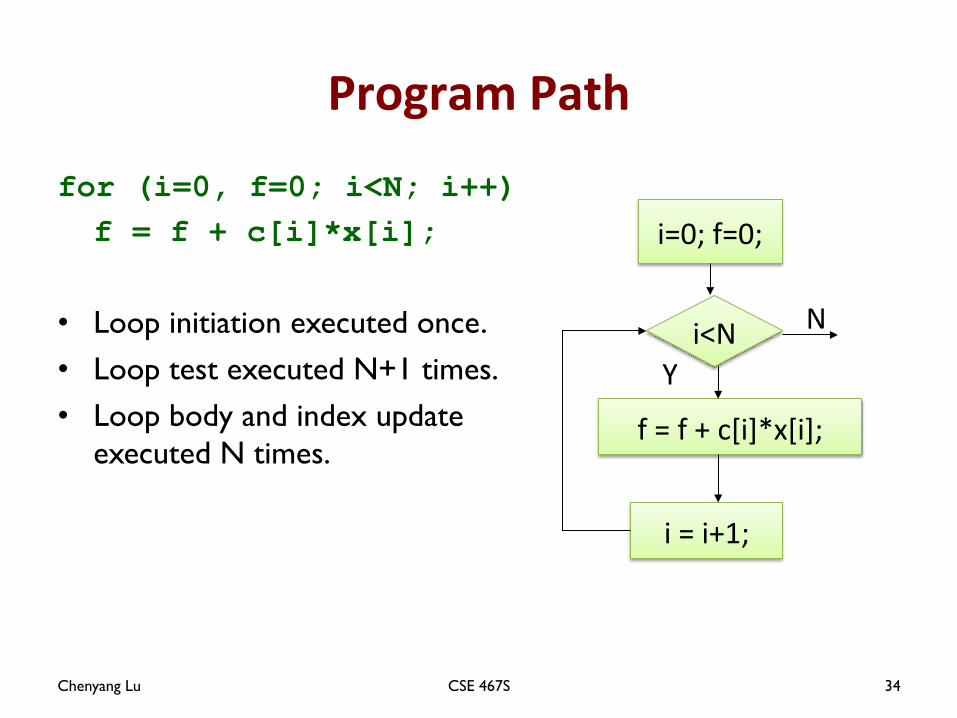
Program Path
for (i=0, f=0; i<N; i++) f = f + c[i]*x[i];
• Loop initiation executed once.
• Loop test executed N+1 times.
• Loop body and index update executed N times.
Chenyang Lu CSE 467S 34
i<N
i=0; f=0;
f = f + c[i]*x[i];
i = i+1;
N
Y

Execu*on Time Metrics
Ø Difficult to predict execution time accurately. ���
Ø Average case q For “typical” data values q Soft real-time
Ø Worst case q For any possible input set
q Hard real-time
q Longest program path may NOT lead to worst-case execution time
Chenyang Lu CSE 467S 35

Approaches
Ø Compile-time analysis: pessimistic
Ø Measurement: optimistic
Chenyang Lu CSE 467S 36

Analysis
Ø Analyze optimized assembly/binary code, not high-level language (HLL) code q HLL statement à many assembly/binary instructions
q Example: function calls
Ø Challenges q Program path depends on input data
q Pipelining, cache effects are hard to predict
q Analysis tends to be pessimistic
Chenyang Lu CSE 467S 37

Measurement
Ø CPU simulator q I/O may be hard to measure.
q May not be totally accurate.
Ø Time stamping q Requires instrumenting program.
q Timer granularity • Gettimeofday on Linux: ms • Gethrtime on Intel processors: read 64-bit clock cycle counter and return
the number of clock cycles since CPU was powered up or reset.
Ø Logic analyzer: limited logic analyzer memory depth.
Chenyang Lu CSE 467S 38

Output from a Logic Analyzer
Chenyang Lu CSE 467S 39
Timing diagram of event propagation on Mote Granularity: 50 microsecond

Trace-‐driven Analysis
Ø Record of the program path of a program.
Ø Help study cache behavior and power management policies.
Ø A useful trace q requires proper input values; q is large.
Chenyang Lu CSE 467S 40

Trace Genera*on
Ø Hardware capture q Logic analyzer
• Limited buffer space • Cannot observe on-chip cache
q Hardware assist in CPU • Pentium supports automatic tracing of branches
Ø Software q PC sampling
q Instrumentation instructions q Simulation
Chenyang Lu CSE 467S 41

Goals Ø Optimizing for execution time. Ø Optimizing for energy/power.
Ø Optimizing for program size.
Chenyang Lu CSE 467S 42

Op*mizing for Program Size
Ø Goals q Reduce memory cost;
q Reduce power consumption.
Ø Two opportunities: q Data; q Instructions.
Chenyang Lu CSE 467S 43

Reduce Data Size
Ø Reuse constants, variables, buffers in different parts of code. q Single-buffer in TinyOS.
q Pack multiple flags in one byte.
q Use shortest data type needed.
q Requires careful verification of correctness.
Ø Generate data using instructions.
Chenyang Lu CSE 467S 44
uint8_t i; for(i = 0; i < 1000; i++) { ... } // This loop will never terminate

Reduce Code Size
Ø Avoid loop unrolling.
Ø Inlining? q Size of function
q Number of calls
Ø Choose CPU with compact instructions. q Digital Signal Processors (DSP) tend to have smaller code.
Ø Some CPUs support dense instruction set q ARM Thumb, MIPS-16
Chenyang Lu CSE 467S 45

Code Compression
Ø Use sta5s5cal compression to reduce code size. Ø Decompress on-‐the-‐fly. Ø Need to handle jump addresses.
Chenyang Lu CSE 467S 46
CPU decompressor table
cache
main memory
0101101 0101101
LDR r0,[r4]

Reading
Ø Textbook 5.5, 5.6, 5.7, 5.8, 5.9.
Chenyang Lu CSE 467S 47

















