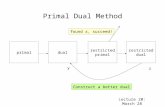
Primal-Dual Interior Point Methodseaton.math.rpi.edu/faculty/Mitchell/courses/matp...Most primal...
76
Primal-Dual Interior Point Methods John E. Mitchell http://www.rpi.edu/~mitchj RPI November, 2010 & 2018 Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 1 / 41
Transcript of Primal-Dual Interior Point Methodseaton.math.rpi.edu/faculty/Mitchell/courses/matp...Most primal...

Primal-Dual Interior Point Methods
John E. Mitchellhttp://www.rpi.edu/~mitchj
RPI
November, 2010 & 2018
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 1 / 41

Introduction
Outline
1 Introduction
2 Log barrier function
3 Primal-dual scaling and µ-complementary slackness
4 The algorithm
5 An example
6 Computational effort
7 Further reading
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 2 / 41

Introduction
Standard form
Our standard linear programming problem is
minx cT x
subject to Ax = b (P)x � 0
Here, c and x are n vectors, b is an m vector, and A is an m⇥ n matrix.The dual problem can be written
maxy ,s bT y
subject to AT y + s = c (D)s � 0
where y is an m-vector and s is the n-vector of dual slacks.
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 3 / 41

Introduction
Simplex versus interior
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 4 / 41

Introduction
Simplex versus interior
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 4 / 41

Introduction
Simplex versus interior
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 4 / 41

Introduction
Simplex versus interior
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 4 / 41

Introduction
Simplex versus interior
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 4 / 41

Introduction
Simplex versus interior
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 4 / 41

Introduction
Simplex versus interior
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 4 / 41

Introduction
Simplex versus interior
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 4 / 41

Introduction
Simplex versus interior
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 4 / 41

Introduction
Interior points
Thus, we may try to use an algorithm which cuts across the middle ofthe feasible region. Such a method is called an interior point method.
There are many different interior point algorithms; we will just considerone: a primal dual method that is close to those implemented inpackages such as CPLEX.
Notation: We will let e = [1, . . . , 1]T .
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 5 / 41

Log barrier function
Outline
1 Introduction
2 Log barrier function
3 Primal-dual scaling and µ-complementary slackness
4 The algorithm
5 An example
6 Computational effort
7 Further reading
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 6 / 41

Log barrier function
Short stepsWe may only be able to take a very small step before we violate thenonnegativity constraint.
current iterate
�c
x4 =
0Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 7 / 41

Log barrier function
Short stepsWe may only be able to take a very small step before we violate thenonnegativity constraint.
current iterate
�c
x4 =
0
updated iterate: x4 < 0
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 7 / 41

Log barrier function
Short stepsWe may only be able to take a very small step before we violate thenonnegativity constraint.
current iterate
�c
x4 =
0
updated iterate: x4 < 0optimal solution
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 7 / 41

Log barrier function
Log barrier function
In order to make the iterates more centered, we add a penalty term tothe objective of (P), giving
fµ(x) := cT
x � µnX
i=1
ln(xi)
where µ is a positive constant. Note that if xi gets close to zero thenthe function fµ(x) gets large. This gives a nonlinear program
minx cT x � µP
n
i=1 ln(xi)subject to Ax = b (P(µ))
x � 0
Given µ > 0, it can be shown that there is a unique optimal solution tothe problem (P(µ)).
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 8 / 41
- pula(xi)A . .

Log barrier function
Central pathThe central path: the solutions to (P(µ)) for different µ > 0.
optimal face
large µ
small µ
central path C
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 9 / 41

Log barrier function
Iterates following central pathMost primal dual algorithms take Newton steps towards points on Cwith µ > 0, rather than working to solve for a particular µ.
optimal face
green iterates aiming forblue target points
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 10 / 41

Log barrier function
Iterates following central pathMost primal dual algorithms take Newton steps towards points on Cwith µ > 0, rather than working to solve for a particular µ.
optimal face
green iterates aiming forblue target points
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 10 / 41

Log barrier function
Iterates following central pathMost primal dual algorithms take Newton steps towards points on Cwith µ > 0, rather than working to solve for a particular µ.
optimal face
green iterates aiming forblue target points
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 10 / 41

Log barrier function
Iterates following central pathMost primal dual algorithms take Newton steps towards points on Cwith µ > 0, rather than working to solve for a particular µ.
optimal face
green iterates aiming forblue target points
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 10 / 41

Log barrier function
Iterates following central pathMost primal dual algorithms take Newton steps towards points on Cwith µ > 0, rather than working to solve for a particular µ.
optimal face
green iterates aiming forblue target points
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 10 / 41

Log barrier function
Iterates following central pathMost primal dual algorithms take Newton steps towards points on Cwith µ > 0, rather than working to solve for a particular µ.
optimal face
green iterates aiming forblue target points
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 10 / 41

Log barrier function
Iterates following central pathMost primal dual algorithms take Newton steps towards points on Cwith µ > 0, rather than working to solve for a particular µ.
optimal face
green iterates aiming forblue target points
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 10 / 41

Log barrier function
Problem (LP1)
min �x1 � x2 + x3 + x4subject to x1 + x3 = 1 (LP1)
x2 + x4 = 2xi � 0 i = 1, ..., 4
Optimal solution: x = (1, 2, 0, 0).
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 11 / 41
a÷÷i¥¥.

Log barrier function
Log barrier function exampleFor x 2 R4 with cT x = �x1 � x2 + x3 + x4, the barrier function is
fµ(x) = �x1 � x2 + x3 + x4 � µ4X
i=1
ln(xi).
Consider two points:
xk = (0.8, 0.1, 0.2, 1.9), a somewhat central pointx = (0.95, 1.95, 0.05, 0.05), close to the optimal solution of (LP1)
fµ(xk ) fµ(x)µ = 3 11.33 13.32µ = 0.1 1.54 -2.26
Thus, for larger choices of µ, the value fµ(xk ) of the more central pointis smaller than that of fµ(x), but for smaller choices of µ the results arereversed.
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 12 / 41
¥' I I .I - .

Log barrier function
Successive minimizationRecall our nonlinear optimization problem:
minx fµ(x) := cT x � µP
n
i=1 ln(xi)subject to Ax = b (P(µ))
x � 0
The motivation for this problem is that it should be easier to get anapproximate optimal solution to (P(µ)) for a large value of µ.
This solution can help in finding approximate optimal solutions forsmaller values of µ. It provides a warm start.
The limiting solution as µ! 0 is an optimal solution to (P).
The gradient of fµ(x) is c � µX�1e. This eventually leads to a directionthat combines what is called the affine direction with a centeringdirection, as we will see later.
Notation: We will let e = [1, . . . , 1]T .Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 13 / 41
Of,61I . " i-%.
* I'....)
* text...-÷.]fit.I"i÷)

Log barrier function
Predictor-Corrector
Current commercial implementations combine affine steps withcentering and duality in predictor-corrector methods.
In addition to excellent computational performance, variants of thesemethods converge in a number of iterations that is polynomial in thesize of the problem.
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 14 / 41

Primal-dual scaling and µ-complementary slackness
Outline
1 Introduction
2 Log barrier function
3 Primal-dual scaling and µ-complementary slackness
4 The algorithm
5 An example
6 Computational effort
7 Further reading
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 15 / 41

Primal-dual scaling and µ-complementary slackness
Optimality conditions
The conditions for a point x to be optimal for (P(µ)) are closely relatedto the standard LP optimality conditions. In fact, we have the followingtheorem:
TheoremLet µ > 0. A point x > 0 is optimal for (P(µ)) if and only if there exist
vectors y and s satisfying
Ax = b (primal feasibility)AT y + s = c (dual feasibility)
xisi = µ for i = 1, . . . , n (µ� complementary slackness)
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 16 / 41
LEI"ii¥;.

Primal-dual scaling and µ-complementary slackness
Exploiting dual iterates
This theorem makes it clear that there is no particular reason to favor(P) over (D).
Typically, algorithms use iterates (x , y , s) of both primal and dualvariables.
We will assume the iterates satisfy primal and dual feasibility, and worktowards achieving µ-complementary slackness (and complementaryslackness in the limit as µ! 0).
Further, we assume x > 0 and s > 0.
(Recall: the iterates of the simplex algorithm satisfy primal feasibilityand complementary slackness, and work towards achieving dualfeasibility.)
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 17 / 41

Primal-dual scaling and µ-complementary slackness
Newton’s method for nonlinear equationsOur optimality conditions:
Ax = b (primal feasibility)AT y + s = c (dual feasibility)
xisi = µ for i = 1, . . . , n (µ� complementary slackness)
This is a system of 2n + m nonlinear equations in 2n + m unknowns.
Newton’s method:
Have current solutions (x , y , s) which satisfy Ax = b, AT y + s = c,but violate the nonlinear constraints xi si = µ 8i .Find directions dx , dy , ds.So x x + dx , y y + dy , s s + ds.The directions satisfy a linearization of the system of nonlinearequations.
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 18 / 41

Primal-dual scaling and µ-complementary slackness
Newton’s method for nonlinear equationsOur optimality conditions:
Ax = b (primal feasibility)AT y + s = c (dual feasibility)
xisi = µ for i = 1, . . . , n (µ� complementary slackness)
This is a system of 2n + m nonlinear equations in 2n + m unknowns.
Newton’s method:
Have current solutions (x , y , s) which satisfy Ax = b, AT y + s = c,but violate the nonlinear constraints xi si = µ 8i .Find directions dx , dy , ds.So x x + dx , y y + dy , s s + ds.The directions satisfy a linearization of the system of nonlinearequations.
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 18 / 41

Primal-dual scaling and µ-complementary slackness
Newton’s method for nonlinear equationsOur optimality conditions:
Ax = b (primal feasibility)AT y + s = c (dual feasibility)
xisi = µ for i = 1, . . . , n (µ� complementary slackness)
This is a system of 2n + m nonlinear equations in 2n + m unknowns.
Newton’s method:
Have current solutions (x , y , s) which satisfy Ax = b, AT y + s = c,but violate the nonlinear constraints xi si = µ 8i .Find directions dx , dy , ds.So x x + dx , y y + dy , s s + ds.The directions satisfy a linearization of the system of nonlinearequations.
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 18 / 41

Primal-dual scaling and µ-complementary slackness
Linearization
After update, ideally want
A(x + dx) = b
AT (y + dy ) + (s + ds) = c
(xi + dx
i)(si + ds
i) = µ for i = 1, . . . , n
We ignore the quadratic terms dx
ids
i.
We note that Ax = b, AT y + s = c, so the directions must satisfy
Adx = 0 (so dx in nullspace of A)AT dy + ds = 0sid
x
i+ xid
s
i= µ � xi si for i = 1, . . . , n
This is a system of 2n + m linear equations in the2n + m variables dx , dy , ds.
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 19 / 41
(tiedE)(sitdsi⇒tsid×iconity;!;.txi¥f€
I quadraticlinear i n
unknown, df,d !

Primal-dual scaling and µ-complementary slackness
Scaling matrixWe can express the solution (dx , dy , ds) to the linearized system ofequations in closed form.
To make the notation a little nicer, we introduce a scaling matrix and aprojection matrix.
Because both primal and dual iterates are available, a scaling matrixcan be used that combines the primal variables x and the dualslacks s. This matrix is
D :=
2
6666664
qx1s1
0 . . . 0
0q
x2s2
. . . ...... . . . . . . 00 . . . 0
qxn
sn
3
7777775.
We want xisi = µ for each i at optimality to (P(µ)). Then xi/si = x2i/µ.
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 20 / 41

Why a scaling m a t r i x ?
⇐"
" ÷w
current iterateMY" become, m o r e centered,+ → D-'× s , c a n take longer stop'

Primal-dual scaling and µ-complementary slackness
ProjectIt is convenient to express dx using a projection matrix.This takes a vector and projects it onto the nullspace of A, which is ascaling of A.
We define A = AD.The projection v of a vector g onto the nullspace of A can be written
v = PAg
which is calculated using the formula
PA= (I � (A)
T(A(A)
T)�1
A),
and I denotes the identity matrix.
(Aside: We assume that the rows of A are linearly independent. Underthis assumption, the projection matrix is well-defined. Note that weneed this assumption to hold in order to be able to obtain a basicfeasible solution.)
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 21 / 41

Primal-dual scaling and µ-complementary slackness
Project g
Project g onto the nullspace of A to find the direction v .
Az =b
current iterate
g
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 22 / 41

Primal-dual scaling and µ-complementary slackness
Project g
Project g onto the nullspace of A to find the direction v .
Az =b
current iterateprojection of g
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 22 / 41

Primal-dual scaling and µ-complementary slackness
Updating directions
Solving the system of 2n + m linear equations in the2n + m variables dx , dy , ds gives:
dx := �DP
ADD(s � µX
�1e)
dy := (A(D)2
AT )�1
A(D)2(s � µX�1
e)
ds := �A
Td
y
The direction dx is a combination of an affine direction DPAD
Ds and acentering direction DP
ADDX�1e.
The affine direction emphasizes improving the objective function.
The centering direction pushes the iterates back towards the middle ofthe polyhedron in order to allow longer steps on future iterations.
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 23 / 41

Primal-dual scaling and µ-complementary slackness
Updating directions
We have dx = �DPAD
D(s � µX�1e).
The multiplication by DPAD
D serves to1 DP
ADD: rescale the problem,
2 DPAD
D: project the direction in the rescaled space,3 DP
ADD: and scale back to the original space.
The dual direction dy can be calculated on the way to calculating dx .It can be shown that dx = �(D)2(s � µX�1e)� (D)2ds.
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 24 / 41

Primal-dual scaling and µ-complementary slackness
Updating directions
We have dx = �DPAD
D(s � µX�1e).
The multiplication by DPAD
D serves to1 DP
ADD: rescale the problem,
2 DPAD
D: project the direction in the rescaled space,3 DP
ADD: and scale back to the original space.
The dual direction dy can be calculated on the way to calculating dx .It can be shown that dx = �(D)2(s � µX�1e)� (D)2ds.
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 24 / 41

Primal-dual scaling and µ-complementary slackness
Updating directions
We have dx = �DPAD
D(s � µX�1e).
The multiplication by DPAD
D serves to1 DP
ADD: rescale the problem,
2 DPAD
D: project the direction in the rescaled space,3 DP
ADD: and scale back to the original space.
The dual direction dy can be calculated on the way to calculating dx .It can be shown that dx = �(D)2(s � µX�1e)� (D)2ds.
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 24 / 41

Primal-dual scaling and µ-complementary slackness
Complementary slackness
The term s � µX�1e is the gradient of the log barrier objective functionsT x � µ
Pn
i=1 ln(xi).
Note that if x is primal feasible and (y , s) is dual feasible then
sT
x = (c � AT
y)Tx = c
Tx � b
Ty .
Therefore, for a given (y , s), it is equivalent to minimize cT x or sT x .
We can say that rfµ(x) = s � µX�1e.
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 25 / 41
feeble Ex-fu? lalxi)

The algorithm
Outline
1 Introduction
2 Log barrier function
3 Primal-dual scaling and µ-complementary slackness
4 The algorithm
5 An example
6 Computational effort
7 Further reading
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 26 / 41

The algorithm
Algorithm
We have an iteration counter k .1 Initialize with x0 > 0 feasible in (P) and (y0, s0) feasible in (D)
with s0 > 0. Let k = 0.2 Let µk = ((xk )T sk )/n2. (Other scalings are possible.)3 Calculate D and Ak = AD.4 Calculate dy , ds, dx .5 Calculate primal and dual steplengths ↵P and ↵D, ensuring
xk + ↵Pdx > 0 and sk + ↵Dds > 0.6 Update xk+1 = xk + ↵Pdx , yk+1 = yk + ↵Ddy , sk+1 = sk + ↵Dds.7 Let k ! k + 1. Calculate (xk )T sk . If small enough, STOP. Else
return to Step 2.
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 27 / 41

The algorithm
Algorithm
We have an iteration counter k .1 Initialize with x0 > 0 feasible in (P) and (y0, s0) feasible in (D)
with s0 > 0. Let k = 0.2 Let µk = ((xk )T sk )/n2. (Other scalings are possible.)3 Calculate D and Ak = AD.4 Calculate dy , ds, dx .5 Calculate primal and dual steplengths ↵P and ↵D, ensuring
xk + ↵Pdx > 0 and sk + ↵Dds > 0.6 Update xk+1 = xk + ↵Pdx , yk+1 = yk + ↵Ddy , sk+1 = sk + ↵Dds.7 Let k ! k + 1. Calculate (xk )T sk . If small enough, STOP. Else
return to Step 2.
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 27 / 41
(e)" (st) = dualitygap= § x "i s"i

The algorithm
Algorithm
We have an iteration counter k .1 Initialize with x0 > 0 feasible in (P) and (y0, s0) feasible in (D)
with s0 > 0. Let k = 0.2 Let µk = ((xk )T sk )/n2. (Other scalings are possible.)3 Calculate D and Ak = AD.4 Calculate dy , ds, dx .5 Calculate primal and dual steplengths ↵P and ↵D, ensuring
xk + ↵Pdx > 0 and sk + ↵Dds > 0.6 Update xk+1 = xk + ↵Pdx , yk+1 = yk + ↵Ddy , sk+1 = sk + ↵Dds.7 Let k ! k + 1. Calculate (xk )T sk . If small enough, STOP. Else
return to Step 2.
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 27 / 41

The algorithm
Algorithm
We have an iteration counter k .1 Initialize with x0 > 0 feasible in (P) and (y0, s0) feasible in (D)
with s0 > 0. Let k = 0.2 Let µk = ((xk )T sk )/n2. (Other scalings are possible.)3 Calculate D and Ak = AD.4 Calculate dy , ds, dx .5 Calculate primal and dual steplengths ↵P and ↵D, ensuring
xk + ↵Pdx > 0 and sk + ↵Dds > 0.6 Update xk+1 = xk + ↵Pdx , yk+1 = yk + ↵Ddy , sk+1 = sk + ↵Dds.7 Let k ! k + 1. Calculate (xk )T sk . If small enough, STOP. Else
return to Step 2.
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 27 / 41

The algorithm
Algorithm
We have an iteration counter k .1 Initialize with x0 > 0 feasible in (P) and (y0, s0) feasible in (D)
with s0 > 0. Let k = 0.2 Let µk = ((xk )T sk )/n2. (Other scalings are possible.)3 Calculate D and Ak = AD.4 Calculate dy , ds, dx .5 Calculate primal and dual steplengths ↵P and ↵D, ensuring
xk + ↵Pdx > 0 and sk + ↵Dds > 0.6 Update xk+1 = xk + ↵Pdx , yk+1 = yk + ↵Ddy , sk+1 = sk + ↵Dds.7 Let k ! k + 1. Calculate (xk )T sk . If small enough, STOP. Else
return to Step 2.
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 27 / 41

The algorithm
Algorithm
We have an iteration counter k .1 Initialize with x0 > 0 feasible in (P) and (y0, s0) feasible in (D)
with s0 > 0. Let k = 0.2 Let µk = ((xk )T sk )/n2. (Other scalings are possible.)3 Calculate D and Ak = AD.4 Calculate dy , ds, dx .5 Calculate primal and dual steplengths ↵P and ↵D, ensuring
xk + ↵Pdx > 0 and sk + ↵Dds > 0.6 Update xk+1 = xk + ↵Pdx , yk+1 = yk + ↵Ddy , sk+1 = sk + ↵Dds.7 Let k ! k + 1. Calculate (xk )T sk . If small enough, STOP. Else
return to Step 2.
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 27 / 41

The algorithm
Algorithm
We have an iteration counter k .1 Initialize with x0 > 0 feasible in (P) and (y0, s0) feasible in (D)
with s0 > 0. Let k = 0.2 Let µk = ((xk )T sk )/n2. (Other scalings are possible.)3 Calculate D and Ak = AD.4 Calculate dy , ds, dx .5 Calculate primal and dual steplengths ↵P and ↵D, ensuring
xk + ↵Pdx > 0 and sk + ↵Dds > 0.6 Update xk+1 = xk + ↵Pdx , yk+1 = yk + ↵Ddy , sk+1 = sk + ↵Dds.7 Let k ! k + 1. Calculate (xk )T sk . If small enough, STOP. Else
return to Step 2.
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 27 / 41

An example
Outline
1 Introduction
2 Log barrier function
3 Primal-dual scaling and µ-complementary slackness
4 The algorithm
5 An example
6 Computational effort
7 Further reading
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 28 / 41

An example
An exampleThe problem
min �x1 � x2 + x3 + x4subject to x1 + x3 = 1 (LP1)
x2 + x4 = 2xi � 0 i = 1, ..., 4
has dual
max y1 + 2y2subject to y1 + s1 = �1
y2 + s2 = �1 (LD1)y1 + s3 = 1
y2 + s4 = 1si � 0 i = 1, . . . , 4.
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 29 / 41
×o=(O.6,1.5,0 .4 ,O-5)
y0=(-5-2)
so--(4 ,1,6,3)

An example
Initial iterateAn initial feasible point for (LP1) is x0 = (0.6, 1.5, 0.4, 0.5) and aninitial dual feasible solution is y0 = (�5,�2) giving s0 = (4, 1, 6, 3).
Note that we have x0is0
i= 2.4 for i = 1, 3 and x0
is0
i= 1.5 for i = 2, 4.
Thus, this point is not centered.
The current duality gap is 7.8, so we pick µ = 0.5 (approximately7.8/(42)). We get
D0 =
2
664
p0.15 0 0 0
0p
1.5 0 00 0
p1/15 0
0 0 0p
1/6
3
775 , s�µX�1
e =
2
664
3.170.674.752.00
3
775 ,
and A(D0)2A
T =
0.217 0
0 1.667
�.
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 30 / 41
Want x i s i y a (son. H i )
= so,-Ii,@
[ 'oo,i : ) - - a[ I {feat

An example
Calculate directions
Further,
A(D0)2(s � µX�1
e) =
0.7921.333
�
sod
y = (A(D0)2A
T )�1A(D0)2(s � µX
�1e) =
3.6540.800
�
and
ds = �A
Td
y =
2
664
�3.654�0.800�3.654�0.800
3
775
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 31 / 41

An example
Updating the iterates
Now,
dx = �(D0)2(s � µX
�1e)� (D0)2
ds
= �
2
664
0.4751.0000.3160.333
3
775 �
2
664
�0.548�1.200�0.243�0.133
3
775 =
2
664
0.0730.200�0.073�0.200
3
775 .
Taking ↵P = 2 and ↵D = 1 gives
x1 =
2
664
0.7461.9000.2540.100
3
775 , y1 =
�1.346�1.200
�, s
1 =
2
664
0.3460.2002.3462.200
3
775 .
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 32 / 41
×'=x°txpd×, y '--got* Dd',s '--sotapds

An example
Updated complementarities
The complementarity values are now
x11 s
11 = 0.26, x
12 s
12 = 0.38, x
13 s
13 = 0.60, x
14 s
14 = 0.22
and the new duality gap is 1.45.
The individual complementarities are reasonably close to the targetvalue of µ = 0.5.
The duality gap has been noticeably reduced.
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 33 / 41
= x',six... exist,
"from 7 . 8 t o 1 .45

An example
The updated iterate for the example
x3
x4
1
2
0
xk = (0.6, 1.5, 0.4, 0.5)optimalsolution
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 34 / 41

An example
The updated iterate for the example
x3
x4
1
2
0
xk = (0.6, 1.5, 0.4, 0.5)
xk+1 = (0.746, 1.900, 0.254, 0.100)optimalsolution
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 34 / 41

An example
Complementarities
Want all xisi to be the same to be on the central path.
x3s3
x4s4
2
2
0
C
xksk = (2.4, 1.5, 2.4, 1.5)
optimalsolution
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 35 / 41
O
O

An example
Complementarities
Want all xisi to be the same to be on the central path.
x3s3
x4s4
2
2
0
C
xksk = (2.4, 1.5, 2.4, 1.5)
target: µ = 0.5optimalsolution
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 35 / 41

An example
Complementarities
Want all xisi to be the same to be on the central path.
x3s3
x4s4
2
2
0
C
xksk = (2.4, 1.5, 2.4, 1.5)
target: µ = 0.5
xk+1sk+1 = (0.26, 0.38, 0.60, 0.22)optimalsolution
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 35 / 41

Computational effort
Outline
1 Introduction
2 Log barrier function
3 Primal-dual scaling and µ-complementary slackness
4 The algorithm
5 An example
6 Computational effort
7 Further reading
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 36 / 41

Computational effort
Computational effort
Each iteration requires a lot of work.
The major effort at each iteration is in calculating the projections.
It is not necessary calculate the inverse (A(D)2AT )�1 explicitly.Gaussian elimination can be used instead.
It seems that an interior point method will solve almost any problem inat most 40 iterations. The number of iterations required grows veryslowly as the size of the problem increases.
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 37 / 41

Computational effort
Comparison with simplex
By contrast, the simplex algorithm seems to need approximately 1.5m
iterations to solve a problem with m constraints.
The work required at each iteration of an interior point method is farlarger than the amount of work needed to compute a simplex pivot, sothere is a trade-off:
an interior point algorithm needs far fewer iterations, but it
takes considerably more time per iteration, when compared to
the simplex algorithm.
Commercial implementations of interior point methods use algorithmsthat are similar to the one presented, but they have some moremodifications to make them faster.
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 38 / 41

Further reading
Outline
1 Introduction
2 Log barrier function
3 Primal-dual scaling and µ-complementary slackness
4 The algorithm
5 An example
6 Computational effort
7 Further reading
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 39 / 41

Further reading
Further reading
Textbooks include [BV04, LY08, RTV05, Van08, Wri96].
Current computational results indicate that interior point methodsoutperform the simplex algorithm on large problems.
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 40 / 41

Further reading
TextbooksS. P. Boyd and L. Vandenberghe.Convex Optimization.Cambridge University Press, Cambridge, UK, 2004.
D. G. Luenberger and Y. Ye.Linear and Nonlinear Programming.Springer, 3rd edition, 2008.
C. Roos, T. Terlaky, and J.-Ph. Vial.Interior Point Methods for Linear Optimization.Springer, 2nd edition, 2005.
R. J. Vanderbei.Linear Programming: Foundations and Extensions.Springer, 3rd edition, 2008.
S. J. Wright.Primal-dual interior point methods.SIAM, Philadelphia, 1996.
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 41 / 41

Further reading
TextbooksS. P. Boyd and L. Vandenberghe.Convex Optimization.Cambridge University Press, Cambridge, UK, 2004.
D. G. Luenberger and Y. Ye.Linear and Nonlinear Programming.Springer, 3rd edition, 2008.
C. Roos, T. Terlaky, and J.-Ph. Vial.Interior Point Methods for Linear Optimization.Springer, 2nd edition, 2005.
R. J. Vanderbei.Linear Programming: Foundations and Extensions.Springer, 3rd edition, 2008.
S. J. Wright.Primal-dual interior point methods.SIAM, Philadelphia, 1996.
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 41 / 41

Further reading
TextbooksS. P. Boyd and L. Vandenberghe.Convex Optimization.Cambridge University Press, Cambridge, UK, 2004.
D. G. Luenberger and Y. Ye.Linear and Nonlinear Programming.Springer, 3rd edition, 2008.
C. Roos, T. Terlaky, and J.-Ph. Vial.Interior Point Methods for Linear Optimization.Springer, 2nd edition, 2005.
R. J. Vanderbei.Linear Programming: Foundations and Extensions.Springer, 3rd edition, 2008.
S. J. Wright.Primal-dual interior point methods.SIAM, Philadelphia, 1996.
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 41 / 41

Further reading
TextbooksS. P. Boyd and L. Vandenberghe.Convex Optimization.Cambridge University Press, Cambridge, UK, 2004.
D. G. Luenberger and Y. Ye.Linear and Nonlinear Programming.Springer, 3rd edition, 2008.
C. Roos, T. Terlaky, and J.-Ph. Vial.Interior Point Methods for Linear Optimization.Springer, 2nd edition, 2005.
R. J. Vanderbei.Linear Programming: Foundations and Extensions.Springer, 3rd edition, 2008.
S. J. Wright.Primal-dual interior point methods.SIAM, Philadelphia, 1996.
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 41 / 41

Further reading
TextbooksS. P. Boyd and L. Vandenberghe.Convex Optimization.Cambridge University Press, Cambridge, UK, 2004.
D. G. Luenberger and Y. Ye.Linear and Nonlinear Programming.Springer, 3rd edition, 2008.
C. Roos, T. Terlaky, and J.-Ph. Vial.Interior Point Methods for Linear Optimization.Springer, 2nd edition, 2005.
R. J. Vanderbei.Linear Programming: Foundations and Extensions.Springer, 3rd edition, 2008.
S. J. Wright.Primal-dual interior point methods.SIAM, Philadelphia, 1996.
Mitchell (RPI) Primal-Dual Methods November, 2010 & 2018 41 / 41